
Redes neurais em trading: Transformer eficiente em parâmetros com atenção segmentada (Conclusão)

Introdução
No artigo anterior statie, conhecemos os aspectos teóricos do framework PSformer, que introduz duas inovações fundamentais na arquitetura do Transformer padrão: o mecanismo de compartilhamento de parâmetros (Parameter Shared — PS) e a atenção a segmentos espaço-temporais (SegAtt).
Relembrando, os autores do framework PSformer propuseram um codificador baseado na arquitetura Transformer com uma estrutura de atenção segmentada em dois níveis. Cada nível inclui um bloco com parâmetros compartilhados, composto por três camadas totalmente conectadas com conexões residuais. Essa arquitetura permite reduzir o número total de parâmetros, mantendo a eficácia da troca de informações dentro do modelo.
Para a divisão dos segmentos, é utilizado o método de patching, em que séries temporais de variáveis são divididas em patches. Patches com a mesma posição em diferentes variáveis são agrupados em segmentos, representando uma expansão espacial do patch de uma variável. Essa segmentação permite estruturar eficientemente uma série temporal multidimensional em diversos segmentos.
Dentro de cada segmento, a atenção foca na identificação de conexões espaço-temporais locais, enquanto a integração de informações entre os segmentos melhora a qualidade geral das previsões.
Além disso, o uso de métodos otimização-SAM no framework PSformer ajuda a reduzir a chance de sobreajuste, mantendo sua eficiência
Os resultados de experimentos extensivos realizados pelos autores do framework com diversos conjuntos de dados para previsão de séries temporais de longo prazo confirmam o alto desempenho do PSformer. Em 6 das 8 tarefas principais de previsão de séries temporais, essa arquitetura apresentou resultados competitivos ou superiores em comparação com modelos de ponta atuais.
A visualização original do framework PSformer está apresentada abaixo.
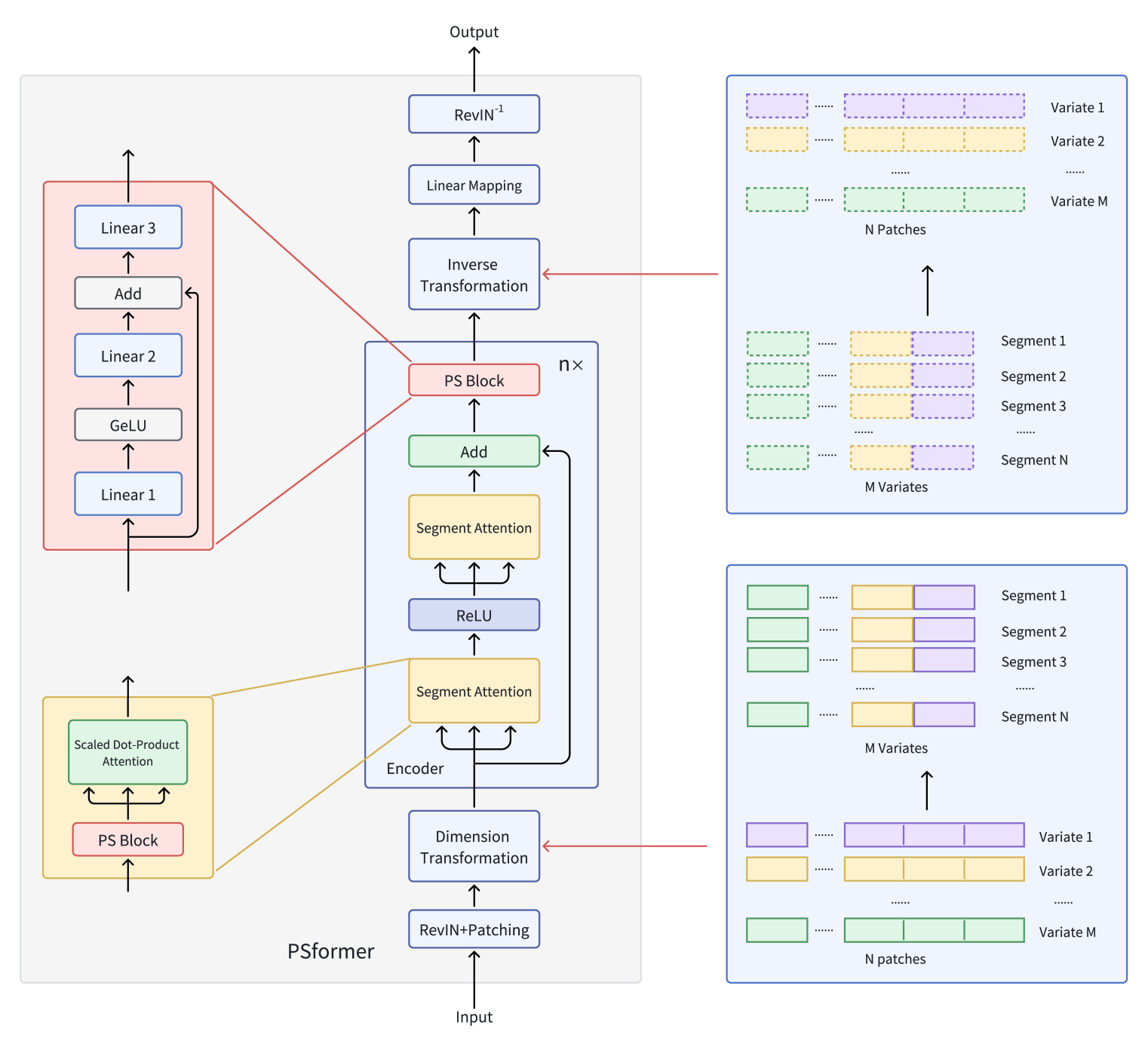
No artigo anterior, já iniciamos a implementação das abordagens propostas usando MQL5. E analisamos os algoritmos dos métodos da classe CNeuronPSBlock, na qual foi configurado o funcional do bloco de compartilhamento de parâmetros. Continuamos agora esse trabalho passando para a construção do funcional do codificador.
Criando o objeto Codificador PSformer
Antes de começarmos a implementar os algoritmos no código, vamos discuti-los brevemente. Conforme apresentado pelos autores do framework, os dados brutos passam inicialmente pelo módulo RevIn. Como você sabe, o módulo RevIn inclui 2 blocos. Na entrada do modelo, ele normaliza os dados brutos, e na saída, devolve aos resultados do modelo os parâmetros de distribuição que haviam sido removidos. Isso ajuda a alinhar os resultados do modelo com a distribuição original dos dados. O que é, sem dúvida, muito importante ao lidar com tarefas de previsão dos próximos valores de uma série temporal.
Neste artigo, assim como antes, vamos usar apenas a normalização dos dados brutos na entrada do modelo, realizada por uma camada separada de normalização em lote. E isso porque nosso objetivo final não é prever os próximos valores da série temporal, mas sim treinar uma política lucrativa para o Ator. Sabemos que os modelos funcionam melhor com dados normalizados, por isso aplicamos a normalização aos dados brutos. Pela mesma razão, é lógico fornecer ao Ator os dados já normalizados provenientes do estado oculto do codificador. Assim, quando o codificador do ambiente é treinado junto com o Ator, o bloco de mapeamento linear e o RevIn reverso tornam-se desnecessários.
Claro, vamos precisar do bloco de mapeamento e do módulo reverso do RevIn em treinamentos por etapas, quando primeiro treinamos o codificador do estado do ambiente para prever os estados futuros da série temporal analisada, e só depois treinamos separadamente os modelos do Ator e do Crítico. Mas mesmo nesse caso, é melhor fornecer ao Ator o estado oculto do codificador, pois ele contém uma representação mais compacta e normalizada dos dados brutos.
O treinamento por etapas das redes tem vantagens e desvantagens. Entre as vantagens, podemos destacar a universalidade do modelo de codificador. Afinal, ele é treinado diretamente nos dados brutos, sem ligação com uma tarefa específica. Isso permite usá-lo para buscar soluções para diferentes tarefas com base nos mesmos dados.
Por outro lado, o que é universal muitas vezes não é a melhor escolha para uma tarefa específica, pois pode não levar em conta certas particularidades.
Além disso, dois estágios de treinamento podem, no total, ser mais custosos do que treinar todos os modelos simultaneamente.
Considerando tudo isso, optamos por treinar os modelos simultaneamente, reduzindo a arquitetura do codificador.
Após a normalização dos dados brutos, o framework PSformer aplica o módulo de patching e transformação dos dados. Os autores do framework descreveram uma transformação relativamente complexa. Vamos tentar entendê-la melhor.
Na entrada do modelo é fornecida uma série temporal multimodal. Por ora, vamos ignorar a normalização e focar apenas na transformação dos dados.
Primeiramente, a série temporal multimodal é dividida em M sequências unitárias e, em seguida, cada sequência unitária é segmentada em N patches de mesmo comprimento P. Depois disso, os patches com as mesmas marcações temporais são agrupados em segmentos. Dessa forma, obtemos N patches com dimensão M×P.
No nosso caso, os dados brutos são apresentados como uma sequência de descrições históricas de barras, até a profundidade dos dados analisados. Em outras palavras, nosso buffer de dados brutos contém M elementos com a descrição de uma barra. Em seguida, vêm M elementos da descrição de outra barra, e assim por diante. Portanto, para formar um segmento, basta pegarmos P descrições sequenciais de barras. É evidente que, para isso, não há necessidade de transformar os dados de nenhuma forma específica.
Na sequência, os autores do PSformer mencionam a transformação dos dados brutos para a dimensão (M×P)×N. Para isso, basta transpor o tensor dos dados brutos.
Assim, o bloco de patching e transformação dos dados brutos no PSformer, no nosso caso, é reduzido a uma única camada de transposição.
Outro ponto que devemos discutir é a abordagem para criação das camadas sequenciais do Codificador PSformer. Aqui temos 2 alternativas. Podemos usar a abordagem básica e definir manualmente a quantidade necessária de camadas ao descrever a arquitetura do modelo, ou criar um objeto que gere automaticamente a quantidade desejada de camadas internas.
Na primeira alternativa, o processo de descrição da arquitetura do modelo se torna mais complexo, mas a criação do objeto do Codificador é simplificada. Contudo, esse modelo permite controle mais flexível sobre a arquitetura das camadas sequenciais do Codificador.
Na segunda alternativa, o processo de descrição da arquitetura do modelo é simplificado, mas o algoritmo do nosso Codificador se torna mais complexo. E, nesse tipo de implementação, todas as camadas internas do Codificador terão a mesma arquitetura.
É evidente que a primeira alternativa é mais adequada para modelos com poucas camadas no Codificador. Já a segunda se torna relevante em modelos mais profundos.
Para tomar uma decisão sobre essa questão, recorremos ao estudo original dos autores sobre o impacto da quantidade de camadas do Codificador na qualidade da previsão dos valores futuros da série temporal. Os autores do framework PSformer realizaram esse experimento com dados dos conjuntos padronizados de séries temporais ETTh1 e ETTm1. Esses dados são provenientes de transformadores elétricos. Cada ponto da série possui 8 características, incluindo data, temperatura do óleo e 6 diferentes tipos de características da carga externa. ETTh1 contém dados com intervalo de uma hora, enquanto o ETTm1 possui dados com intervalo de um minuto. Os resultados da pesquisa dos autores estão apresentados na tabela abaixo.

Como pode ser observado nas informações apresentadas, para o conjunto de dados com intervalo de uma hora, que apresenta menor nível de aleatoriedade, os melhores resultados foram obtidos com uma única camada no Codificador. Já para os dados mais ruidosos, coletados com intervalo de um minuto, o desempenho ideal foi alcançado com 3 camadas no Codificador. Portanto, não esperamos construir modelos com grande quantidade de camadas no Codificador. Assim, optamos pela primeira alternativa de implementação, com uma estrutura mais simples para o novo objeto e com definição individual dos parâmetros de cada camada do Codificador na descrição da arquitetura do modelo.
A estrutura completa do novo objeto CNeuronPSformer é apresentada abaixo.
class CNeuronPSformer : public CNeuronBaseSAMOCL { protected: CNeuronTransposeOCL acTranspose[2]; CNeuronPSBlock acPSBlocks[3]; CNeuronRelativeSelfAttention acAttention[2]; CNeuronBaseOCL cResidual; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronPSformer(void) {}; ~CNeuronPSformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronPSformer; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Como já mencionado, o framework PSformer utiliza abordagens de otimização-SAM. Por esse motivo, nossa nova classe herda o funcional básico da camada totalmente conectada correspondente.
Além disso, incluímos na estrutura do CNeuronPSformer duas camadas de transposição de dados, que assumem o papel de transformar e reverter os dados.
Também podemos observar na estrutura da nova classe três blocos de compartilhamento de parâmetros e dois módulos de atenção relativa, aos quais adicionamos anteriormente o funcional de otimização-SAM. E este é, talvez, o nosso maior afastamento em relação ao algoritmo original do PSformer.
O fato é que os autores do framework PSformer utilizaram o bloco de compartilhamento de parâmetros para formar as entidades Query, Key e Value. Nesse caso, são utilizadas matrizes de parâmetros de tamanho N×N no bloco PS. Isso indica que o mesmo tensor é utilizado como base para todas as entidades.
Na nossa implementação, optamos por uma arquitetura um pouco mais complexa para o Codificador. O bloco PS se responsabiliza apenas pela preparação preliminar dos dados, enquanto a análise das dependências é realizada em um bloco de atenção relativa mais sofisticado.
Todos os objetos internos são declarados de forma estática, o que nos permite deixar o construtor e o destrutor da classe vazios. A inicialização de todos os objetos declarados e herdados é feita no método Init. Nos parâmetros desse método, recebemos as constantes principais que permitem definir de forma clara a arquitetura da camada sendo criada. Entre elas:
- window — tamanho do vetor de descrição de um elemento da sequência;
- units_count — profundidade do histórico analisado (número de elementos na sequência);
- segments — quantidade de segmentos criados;
- rho — coeficiente da área de suavização.
bool CNeuronPSformer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, ENUM_OPTIMIZATION optimization_type, uint batch) { if(units_count % segments > 0) return false;
No corpo do método de inicialização, organizamos um bloco de verificação, no qual conferimos se a sequência analisada é múltipla da quantidade de segmentos a serem criados. Em seguida, chamamos o método homônimo da classe pai, onde já estão implementados os demais pontos de verificação das constantes recebidas e a inicialização dos objetos herdados.
if(!CNeuronBaseSAMOCL::Init(numOutputs, myIndex, open_cl, window * units_count, rho, optimization_type, batch)) return false;
Depois disso, definimos o tamanho de um segmento.
uint count = Neurons() / segments;
E passamos para o bloco de inicialização dos novos objetos internos declarados. O primeiro a ser inicializado é a camada de transposição dos dados brutos. Como número de linhas da matriz a ser transposta, indicamos a quantidade de segmentos, e o tamanho da linha é igualado ao número total de elementos em um segmento.
if(!acTranspose[0].Init(0, 0, OpenCL, segments, count, optimization, iBatch)) return false; acTranspose[0].SetActivationFunction(None);
Neste ponto, indicamos explicitamente a ausência de uma função de ativação.
Vale destacar que indicar uma função de ativação para a camada de transposição de dados não é obrigatório. Isso porque o algoritmo de propagação para frente da camada de transposição já prevê a sincronização da função de ativação com o objeto dos dados brutos.
O passo seguinte é inicializar o primeiro bloco de compartilhamento de parâmetros. Para isso, utilizamos o método de inicialização explícita do objeto.
if(!acPSBlocks[0].Init(0, 1, OpenCL, segments, segments, units_count / segments, 1, fRho, optimization, iBatch)) return false;
Depois, organizamos um laço no qual inicializamos os módulos de atenção e os blocos restantes de compartilhamento de parâmetros.
for(int i = 0; i < 2; i++) { if(!acAttention[i].Init(0, i + 2, OpenCL, segments, segments, units_count / segments, 2, optimization, iBatch)) return false; if(!acPSBlocks[i + 1].InitPS((CNeuronPSBlock*)acPSBlocks[0].AsObject())) return false; }
Observe que os blocos restantes de compartilhamento de parâmetros são inicializados com base no primeiro bloco-PS, copiando o ponteiro para os buffers comuns de parâmetros e seus momentos.
Em seguida, inicializamos a camada de armazenamento das conexões residuais. Aqui usamos a camada totalmente conectada básica, já que utilizaremos apenas seus buffers de dados para armazenar os resultados intermediários dos cálculos.
if(!cResidual.Init(0, 4, OpenCL, acAttention[1].Neurons(), optimization, iBatch)) return false; if(!cResidual.SetGradient(acAttention[1].getGradient(), true)) return false; cResidual.SetActivationFunction((ENUM_ACTIVATION)acAttention[1].Activation());
E, para reduzir as operações de cópia de dados, substituímos o buffer de gradientes de erro dessa camada pelo buffer correspondente ao do último módulo de atenção. Também sincronizamos obrigatoriamente as funções de ativação das duas camadas.
Por fim, inicializamos a camada de transposição reversa dos dados.
if(!acTranspose[1].Init(0, 5, OpenCL, count, segments, optimization, iBatch)) return false; acTranspose[1].SetActivationFunction((ENUM_ACTIVATION)acPSBlocks[2].Activation());
E substituímos os buffers do nosso objeto pelos equivalentes da última camada interna de transposição de dados.
if(!SetOutput(acTranspose[1].getOutput(), true) || !SetGradient(acTranspose[1].getGradient(), true)) return false; //--- return true; }
Depois disso, encerramos a execução do método de inicialização do novo objeto, mas antes retornamos o resultado lógico da execução das operações ao programa que o chamou.
A próxima etapa do nosso trabalho é a construção dos algoritmos de propagação para frente, que implementamos no método feedForward. A construção desse método não apresenta grande complexidade, já que o funcional principal está encapsulado nos objetos internos do nosso classe, implementados anteriormente.
Nos parâmetros do método, recebemos um ponteiro para o objeto dos dados brutos, que é imediatamente passado para o método homônimo da camada interna de transposição, para a transformação inicial.
bool CNeuronPSformer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Dimension Transformation if(!acTranspose[0].FeedForward(NeuronOCL)) return false;
Em seguida, organizamos um laço para percorrer sequencialmente os dois blocos de atenção aos segmentos.
//--- Segment Attention CObject* prev = acTranspose[0].AsObject(); for(int i = 0; i < 2; i++) { if(!acPSBlocks[i].FeedForward(prev)) return false; if(!acAttention[i].FeedForward(acPSBlocks[i].AsObject())) return false; prev = acAttention[i].AsObject(); }
No corpo do laço, chamamos em sequência os métodos dos blocos de compartilhamento de parâmetros e dos módulos de atenção relativa.
Após a execução bem-sucedida de todas as iterações do laço, adicionamos as conexões residuais dos dados brutos, salvando os resultados no buffer da camada interna cResidual.
//--- Residual Add if(!SumAndNormilize(acTranspose[0].getOutput(), acAttention[1].getOutput(), cResidual.getOutput(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false;
Mas atenção: para as conexões residuais, usamos os dados brutos já transformados ,ou seja, após a camada de transposição de dados brutos. Somente assim conseguimos preservar a estrutura necessária para realizar corretamente as conexões residuais.
Os resultados obtidos são então processados pelo último bloco de compartilhamento de parâmetros.
//--- PS Block if(!acPSBlocks[2].FeedForward(cResidual.AsObject())) return false;
E realizamos a transformação reversa dos dados.
//--- Inverse Transformation if(!acTranspose[1].FeedForward(acPSBlocks[2].AsObject())) return false; //--- return true; }
Graças à substituição dos ponteiros dos buffers de dados dos interfaces do nosso objeto pelos equivalentes do último bloco de transposição, o resultado da transposição reversa dos dados é escrito diretamente nos buffers de interface, eliminando a necessidade de cópia adicional de dados. Assim, após o transpôr dos resultados dos objetos internos, simplesmente encerramos a execução do método de propagação para frente, retornando o resultado lógico da operação para o programa que o chamou.
Concluído o trabalho com o método de propagação para frente, passamos à organização dos processos de propagação reversa, realizada nos métodos calcInputGradients e updateInputWeights. O primeiro distribui os gradientes de erro, e o segundo atualiza os parâmetros do modelo.
Nos parâmetros do método calcInputGradients, recebemos um ponteiro para o objeto dos dados brutos, no qual devemos registrar o gradiente de erro conforme a influência dos dados brutos sobre o resultado final.
bool CNeuronPSformer::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
No corpo do método, imediatamente verificamos a validade do ponteiro recebido, pois caso contrário todas as operações seguintes seriam inválidas. Após essa verificação bem-sucedida, transmitimos o gradiente de erro entre as camadas internas do nosso objeto em ordem inversa à propagação para frente.
if(!acPSBlocks[2].calcHiddenGradients(acTranspose[1].AsObject())) return false; //--- if(!cResidual.calcHiddenGradients(acPSBlocks[2].AsObject())) return false; //--- if(!acPSBlocks[1].calcHiddenGradients(acAttention[1].AsObject())) return false; if(!acAttention[0].calcHiddenGradients(acPSBlocks[1].AsObject())) return false; if(!acPSBlocks[0].calcHiddenGradients(acAttention[0].AsObject())) return false; //--- if(!acTranspose[0].calcHiddenGradients(acPSBlocks[0].AsObject())) return false;
Ao chegar à camada de transformação dos dados brutos, devemos adicionar o gradiente de erro pela via das conexões residuais. E aqui temos duas possibilidades, dependendo da função de ativação do objeto dos dados brutos. Se não houver função de ativação, simplesmente somamos os valores dos dois buffers de dados.
if(acTranspose[0].Activation() == None) { if(!SumAndNormilize(acTranspose[0].getGradient(), cResidual.getGradient(), acTranspose[0].getGradient(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false; }
Caso contrário, é necessário primeiro ajustar o gradiente de erro pela derivada da função de ativação correspondente e só então realizar a soma dos dados.
else { if(!DeActivation(acTranspose[0].getOutput(), cResidual.getGradient(), acTranspose[0].getPrevOutput(), acTranspose[0].Activation()) || !SumAndNormilize(acTranspose[0].getGradient(), acTranspose[0].getPrevOutput(), acTranspose[0].getGradient(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false; }
Ao final do método, nos resta transmitir o gradiente de erro ao nível dos dados brutos por meio da transformação reversa, encerrando a execução do método e retornando o resultado lógico da operação ao programa chamador.
if(!NeuronOCL.calcHiddenGradients(acTranspose[0].AsObject())) return false; //--- return true; }
Para concluir as operações de propagação reversa, ainda precisamos atualizar os parâmetros do modelo no sentido de reduzir o erro de previsão. Aqui, devemos lembrar que usamos abordagens otimização-SAM para ajustar os parâmetros do modelo. Como discutido anteriormente, durante a execução do algoritmo otimização-SAM, realizamos uma nova propagação para frente com os parâmetros do modelo ajustados. Isso altera os valores no buffer de resultados, o que não é crítico para o funcionamento da camada atual, mas pode distorcer o processo de ajuste dos parâmetros da próxima camada. Por isso, atualizamos os parâmetros das camadas internas na ordem inversa à propagação para frente. Isso nos permite ajustar os parâmetros das camadas internas antes que os valores do buffer de resultados da camada anterior sejam alterados.
bool CNeuronPSformer::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!acPSBlocks[2].UpdateInputWeights(cResidual.AsObject())) return false; //--- CObject* prev = acAttention[0].AsObject(); for(int i = 1; i >= 0; i--) { if(!acAttention[i].UpdateInputWeights(acPSBlocks[i].AsObject())) return false; if(!acPSBlocks[i].UpdateInputWeights(prev)) return false; prev = acTranspose[0].AsObject(); } //--- return true; }
Vale a pena comentar brevemente sobre os métodos de manipulação de arquivos. É bastante evidente que, ao utilizarmos três blocos de compartilhamento de parâmetros, não há necessidade de salvar os mesmos dados três vezes. Basta salvá-los uma única vez. Nesse caso, o método de salvamento do objeto Save assumirá o seguinte formato.
Nos parâmetros do método, recebemos o handle do arquivo onde os dados serão salvos, e ele é imediatamente passado ao método homônimo da classe pai.
bool CNeuronPSformer::Save(const int file_handle) { if(!CNeuronBaseSAMOCL::Save(file_handle)) return false;
Em seguida, salvamos uma única vez o bloco de compartilhamento de parâmetros.
if(!acPSBlocks[0].Save(file_handle)) return false;
Depois disso, organizamos um laço para salvar os módulos de atenção e as camadas de transposição de dados.
for(int i = 0; i < 2; i++) if(!acTranspose[i].Save(file_handle) || !acAttention[i].Save(file_handle)) return false; //--- return true; }
Após a execução bem-sucedida de todas as iterações do laço, basta retornar o resultado lógico da operação ao programa chamador e encerrar o método.
Observe que, ao salvar os dados, não apenas reduzimos a quantidade de blocos de compartilhamento de parâmetros, como também omitimos a camada de conexões residuais. Essa camada não possui parâmetros treináveis. Portanto, ao salvar o objeto dessa forma, não estamos perdendo nenhuma informação.
Ainda assim, ao restaurar um objeto previamente salvo, devemos reconstituir a estrutura e a funcionalidade de todos os objetos, inclusive os que foram omitidos no momento do salvamento. Por isso, vamos analisar com mais detalhe o método de restauração da funcionalidade do objeto Load.
Nos parâmetros do método, recebemos o handle do arquivo com os dados salvos anteriormente. E imediatamente passamos esse handle para o método homônimo da classe pai, onde já está implementado o algoritmo de restauração da funcionalidade dos objetos herdados.
bool CNeuronPSformer::Load(const int file_handle) { if(!CNeuronBaseSAMOCL::Load(file_handle)) return false;
Depois, restauramos os objetos salvos respeitando rigorosamente a ordem em que foram armazenados.
if(!LoadInsideLayer(file_handle, acPSBlocks[0].AsObject())) return false; for(int i = 0; i < 2; i++) if(!LoadInsideLayer(file_handle, acTranspose[i].AsObject()) || !LoadInsideLayer(file_handle, acAttention[i].AsObject())) return false;
Após carregar os objetos previamente salvos, resta restaurar a funcionalidade dos elementos omitidos no salvamento. Começamos pelos blocos de compartilhamento de parâmetros. Um deles foi carregado do arquivo, e os demais são inicializados com base nesse primeiro, copiando os ponteiros para os buffers compartilhados de parâmetros e seus momentos.
for(int i = 1; i < 3; i++) if(!acPSBlocks[i].InitPS((CNeuronPSBlock*)acPSBlocks[0].AsObject())) return false;
Em seguida, inicializamos a camada de armazenamento dos resultados das conexões residuais. Seu tamanho é igual ao do tensor de resultados do último módulo de atenção relativa.
if(!cResidual.Init(0, 4, OpenCL, acAttention[1].Neurons(), optimization, iBatch)) return false; if(!cResidual.SetGradient(acAttention[1].getGradient(), true)) return false; cResidual.SetActivationFunction((ENUM_ACTIVATION)acAttention[1].Activation());
Não nos esquecemos de substituir o ponteiro para o buffer de gradientes de erro, o que evita operações desnecessárias de cópia de dados. E logo sincronizamos as funções de ativação.
Depois disso, realizamos a substituição dos ponteiros dos buffers de interface do nosso objeto pelos equivalentes da última camada de transposição de dados.
if(!SetOutput(acTranspose[1].getOutput(), true) || !SetGradient(acTranspose[1].getGradient(), true)) return false; //--- return true; }
Finalizamos a execução do método retornando o resultado lógico da operação ao programa que o chamou.
Com isso, encerramos o trabalho com o objeto codificador CNeuronPSformer. O código completo dessa classe e de todos os seus métodos pode ser encontrado no anexo.
Arquitetura dos modelos
Depois de implementarmos os objetos com base nas abordagens propostas pelos autores do framework PSformer, passamos à descrição da arquitetura dos modelos a serem treinados. O principal foco está no Codificador do estado do ambiente, onde aplicamos as abordagens descritas.
A arquitetura do Codificador do estado do ambiente é definida no método CreateEncoderDescriptions. Nos parâmetros desse método, recebemos um ponteiro para o objeto de array dinâmico onde será registrada a descrição da arquitetura do modelo.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
No corpo do método, verificamos a validade do pointeiro recebido e, se necessário, criamos uma nova instância do array dinâmico.
Como antes, usamos uma camada totalmente conectada básica para os dados brutos. Seu tamanho deve ser suficiente para compor o tensor completo dos dados históricos até a profundidade de análise desejada.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Logo após, inserimos uma camada de normalização em lote, que realiza o processamento inicial dos dados “crus”.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os dados brutos normalizados são enviados para o codificador PSformer. Neste artigo, utilizamos 3 camadas sequenciais do codificador PSformer com arquitetura idêntica. Para gerar a descrição da quantidade necessária de camadas, criamos um laço com número de iterações igual à profundidade do codificador. Em cada iteração do laço, criamos a descrição de um objeto CNeuronPSformer.
//--- layer 2 - 4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPSformer; descr.window = BarDescr; descr.count = HistoryBars; descr.window_out = Segments; descr.probability = Rho; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } }
Após o codificador PSformer, utilizamos um bloco de mapeamento, que inclui uma camada convolucional e uma camada totalmente conectada. Todas as camadas neurais utilizadas foram adaptadas ao uso de otimização-SAM.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = int(LatentCount / descr.count); descr.probability = Rho; descr.activation = GELU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.probability = Rho; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Após a geração completa da descrição da arquitetura do Codificador do estado do ambiente, encerramos a execução do método, retornando previamente o resultado lógico da operação ao programa chamador.
O código completo do método de descrição da arquitetura do Codificador do estado do ambiente pode ser consultado no anexo. Também estão incluídas as arquiteturas dos modelos do Ator e do Crítico, trazidas das publicações anteriores sem alterações.
Além disso, transferimos sem modificações os programas de interação com o ambiente e de treinamento dos modelos. O código completo dessas rotinas está disponível para estudo no anexo. Agora passamos à etapa final do nosso trabalho, que é a verificação da eficácia das abordagens implementadas com dados históricos reais.
Testes
Conduzimos um extenso trabalho de implementação das abordagens propostas pelos autores do framework PSformer, utilizando MQL5. E agora chegamos à parte mais empolgante do projeto, avaliar a eficácia das abordagens implementadas com dados históricos reais.
Aqui, é importante destacar que estamos avaliando a eficácia das “abordagens implementadas”, e não apenas das “propostas”. Isso porque em nossa implementação, realizamos algumas modificações em relação ao framework original.
Treinamos os modelos com dados históricos de todo o ano de 2023 do ativo financeiro EURUSD, no time frame H1. Como de costume, os parâmetros de todos os indicadores analisados foram utilizados em seus valores padrão.
Como já foi mencionado, os modelos do Codificador do estado do ambiente, Ator e Crítico são treinados simultaneamente. Para o treinamento inicial, utilizamos o conjunto de dados de treinamento gerado com as versões anteriores dos modelos. E, à medida que o treinamento avançava, atualizávamos periodicamente esse conjunto.
Após algumas iterações de treinamento e atualizações do conjunto de dados, conseguimos obter uma política capaz de gerar lucro tanto na base de treinamento quanto na base de testes.
O teste da política do Ator foi realizado com dados históricos de janeiro de 2024, mantendo os demais parâmetros inalterados. Os resultados do teste são apresentados abaixo.
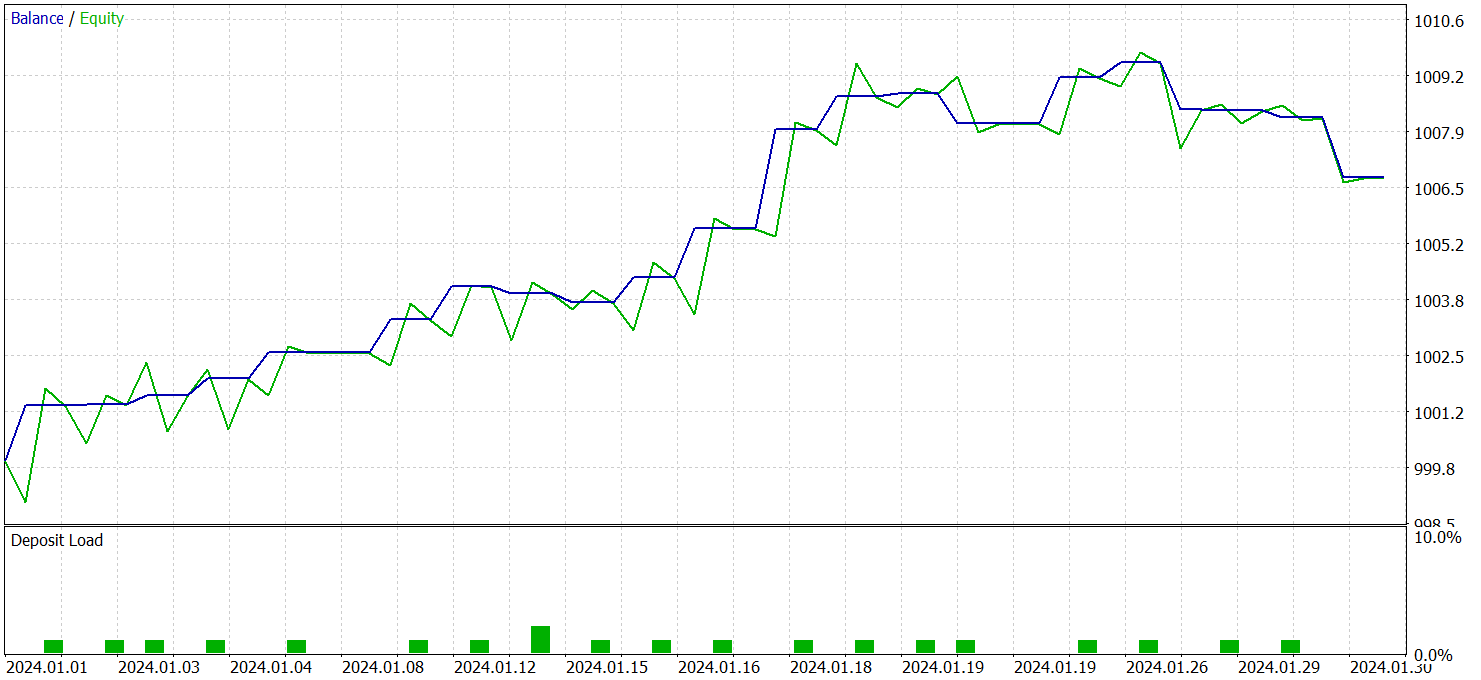

Durante o período de testes, o modelo realizou 21 operações, o que corresponde a cerca de 1 operação por dia útil de negociação. Dessas, 14 foram encerradas com lucro, representando mais de 66%. Além disso, o lucro médio das operações positivas foi 38% maior que a perda média das operações negativas.
Chama atenção o gráfico de saldo, no qual se observa uma tendência clara de crescimento nas duas primeiras décadas do mês.
No geral, os resultados obtidos indicam um bom potencial. Com melhorias adequadas e treinamento adicional sobre um conjunto maior de dados, o modelo pode ser utilizado em operações reais de trading.
Considerações finais
Conhecemos o framework PSformer, que se destaca pela alta precisão na previsão de séries temporais e pelo uso eficiente dos recursos computacionais. Os elementos arquitetônicos centrais do PSformer são o bloco de compartilhamento de parâmetros (PS) e o mecanismo de atenção a segmentos espaço-temporais (SegAtt). Esses componentes proporcionam uma modelagem eficiente tanto de dependências locais quanto globais nas séries temporais, ao mesmo tempo que reduzem a quantidade de parâmetros sem comprometer a qualidade das previsões.
Implementamos nossa própria visão das abordagens propostas, utilizando MQL5. Em seguida, treinamos modelos baseando-se nessas implementações. Os resultados obtidos com dados históricos fora da amostra de treinamento evidenciam o potencial dos modelos treinados.
Links
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos com Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento dos modelos |
| 4 | StudyEncoder.mq5 | Expert Advisor | EA para treinamento do Codificador |
| 5 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca com código OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16483
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Quando compilo o arquivo Research.mq5, recebo este erro
e quando eu compilo o arquivo ResearchRealORL.mq5, recebo este erro
e quando compilo o arquivo Study.mq5, recebo este erro
Quase o mesmo erro se repete, o que eu fiz de errado?
e quando compilo o arquivo Test.mq5, recebo este erro
Estou recebendo erros do arquivo math.math/mqh. Se houver alguma solução para isso, ficarei muito grato.