
Нейросети в трейдинге: Параметроэффективный Transformer с сегментированным вниманием (PSformer)

Введение
Прогнозирование многомерных временных рядов — важная задача глубокого обучения моделей, имеющая прикладное значение в различных областях, включая метеорологию, энергетику, выявление аномалий и финансовый анализ. С развитием методов искусственного интеллекта были предприняты значительные усилия для создания инновационных моделей, которые способствуют улучшению качества прогнозирования. Особенно привлекают внимание модели на основе архитектуры Transformer, которые доказали свою эффективность в области обработки естественного языка и компьютерного зрения. Кроме того, предварительно обученные модели большого размера, основанные на архитектуре Transformer, показали свои преимущества в прогнозировании временных рядов, подтверждая, что увеличение числа параметров и объема обучающих данных может значительно улучшить возможности модели.
С другой стороны, множество простых линейных моделей так же демонстрируют конкурентоспособные результаты по сравнению с более сложными моделями на основе архитектуры Transformer. Вероятно, ключом их успеха в прогнозировании временных рядов является низкая сложность моделей, что снижает вероятность переобучения на шумных или несущественных данных. Таким образом, даже при ограниченном объеме данных, эти модели способны эффективно фиксировать надежные представления информации.
Для преодоления ограничений, связанных с моделированием долгосрочных зависимостей и улавливанием сложных временных связей PatchTST обрабатывает данные, используя коммутационные методы для извлечения локальной семантики, что обеспечивает выдающуюся производительность. Однако он использует конструкции, независимые от каналов, и имеет значительный потенциал для дальнейшего улучшения эффективности моделирования. Кроме того, уникальные задачи моделирования многомерных временных рядов, где временные и пространственные измерения существенно отличаются от других типов данных, предоставляют множество неиспользованных возможностей.
Один из способов уменьшения сложности моделей в глубоком обучении — это использование подхода совместного использования параметров (PS), который позволяет значительно сократить количество параметров модели и увеличить эффективность вычислений. В сверточных сетях фильтры делят веса между пространственными позициями, выявляя локальные признаки с меньшим числом параметров. Подобным образом модели LSTM используют общие матрицы весов для временных шагов, управляя памятью и регулируя поток информации. В обработке естественного языка возможности совместного использования параметров расширяются, благодаря общим весам между слоями Transformer, что уменьшает избыточность параметров, сохраняя при этом производительность.
В многозадачном обучении применяется метод Task Adaptive Parameter Sharing (TAPS) — выборочная точная настройка уровней, специфичных для задачи, что позволяет максимизировать общий доступ к параметрам между задачами и достигать эффективного обучения с минимальными изменениями, специфичными для задачи. Исследования указывают на потенциал совместного использования параметров для уменьшения размеров модели, улучшения обобщающей способности и снижения риска переобучения при решении разнообразных задач.
Авторы работы "PSformer: Parameter-efficient Transformer with Segment Attention for Time Series Forecasting" исследуют инновационные разработки модели на основе Transformer для решения задач прогнозирования многомерных временных рядов с учетом концепции совместного использования параметров.
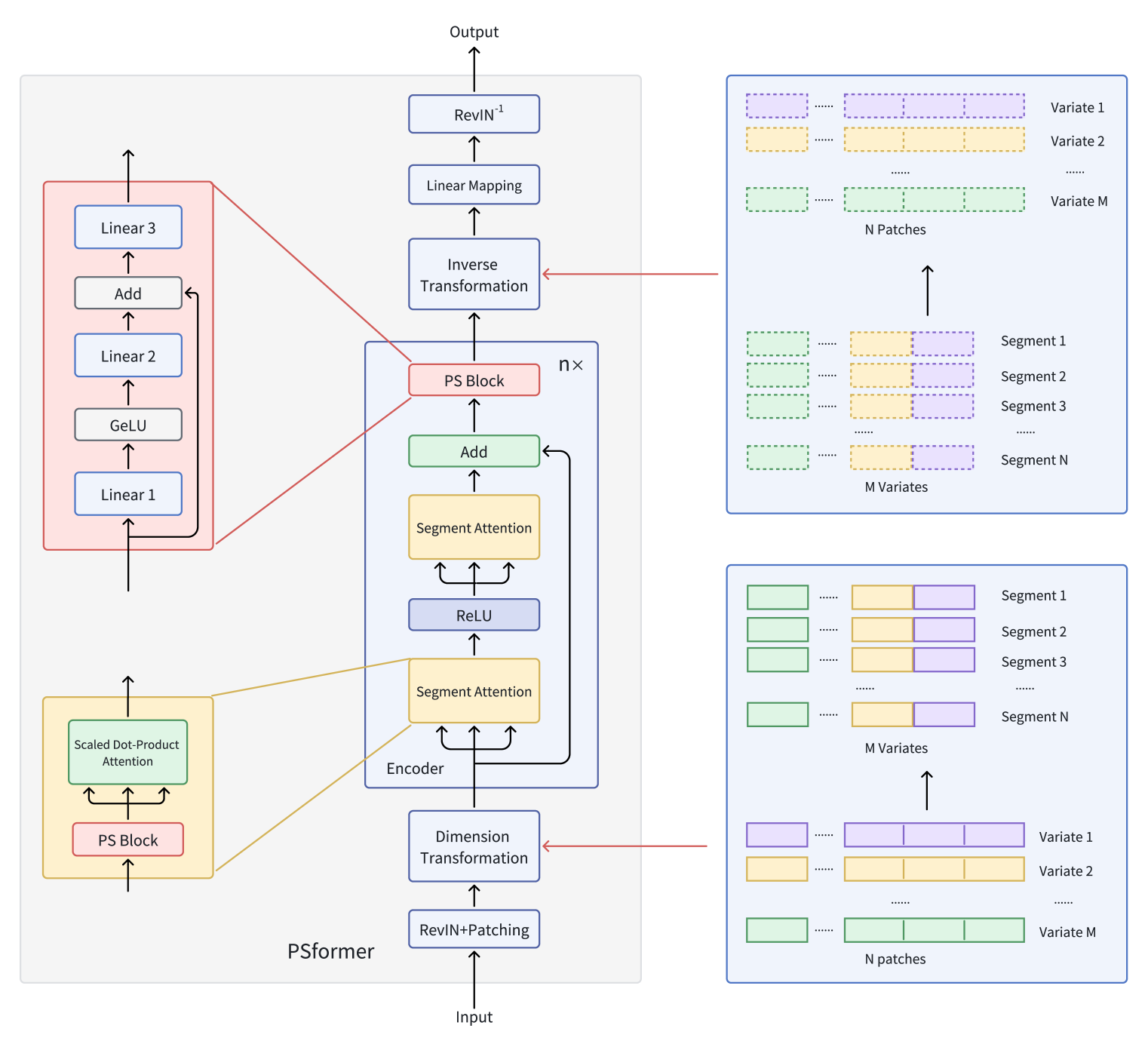
Они предлагают модель энкодера на основе архитектуры Transformer с двухуровневой структурой внимания по сегментам, где каждый уровень модели включает блок с общими параметрами. Этот блок содержит три полносвязных слоя с остаточным соединением, что позволяет поддерживать общее число параметров на низком уровне, обеспечивая эффективный обмен информацией между частями модели. Для фокусировки внимания на сегментах применяется метод патчинга, который разделяет ряды переменных на отдельные патчи. Затем патчи, находящиеся в одинаковом положении по разным переменным, объединяются в сегменты. В итоге, каждый сегмент является пространственным расширением патча одной переменной, что позволяет разделить многомерный временной ряд на несколько сегментов.
Внимание внутри каждого сегмента направлено на улучшение выявления локальных пространственно-временных связей, а интеграция информации между сегментами способствует повышению общей точности прогнозов. Внедрение метода оптимизации SAM позволяет авторам фреймворка дополнительно уменьшить переобучение, не теряя в эффективности обучения. Обширные эксперименты, проведенные создателями PSformer на данных для долгосрочного прогнозирования временных рядов, демонстрируют высокую эффективность предложенной архитектуры. PSformer показывает конкурентоспособные результаты по сравнению с передовыми моделями, достигая лучших показателей в 6 из 8 ключевых задач прогнозирования временных рядов.
Алгоритм PSformer
Многомерный временной ряд X ∈ RM×L содержит M переменных и окно ретроспективного анализа равно L. Длина последовательности L равномерно разделяется на N не перекрывающихся патчей размером P. Тогда P(i) из M переменных образует i-й сегмент, обозначающий поперечный участок длины C (C=M×P).
Ключевыми компонентами предложенного фреймворка PSformer являются внимание к сегментам (SegAtt) и блок совместного использования параметров (PS). Энкодер PSformer служит основой модели и содержит как модуль внимания к сегментам, так и блок PS. Блок PS предоставляет параметры для всех слоев в Энкодере, используя технику совместного использования параметров.
Аналогично другим архитектурам прогнозирования временных рядов, авторы PSformer используют метод RevIN, который эффективно устраняет проблему сдвига распределения.
Пространственно-временное внимание сегмента (SegAtt) объединяет патчи из разных каналов в одном и том же положении в сегмент и устанавливает пространственно-временные отношения между разными сегментами. В частности, исходные временные ряды X ∈ RM×L сначала делятся на патчи, где L=P×N, а затем преобразовываются в X ∈ R(M×P)×N, путем слияния измерений M и P. Таким образом исходные данные приобретают вид X ∈ RC×N (C=M×P), способствуя последующему кросс-канальному слиянию информации.
В этом преображенном пространстве исходные данные обрабатываются двумя последовательными модулями, имеющими одинаковую архитектуру и разделенными ReLU. Каждый такой модуль содержит блок совместного использования параметров и, уже знакомый нам, Self-Attention. В то время как вычисление матриц 𝑸uery ∈ RC×N, 𝑲ey ∈ RC×N и 𝑽alue ∈ RC×N включает в себя нелинейные преобразования исходных данных Xin по сегментам в N размерность, масштабируемое внимание в виде скалярного произведения, в первую очередь, распределяет внимание по всей C размерности, что позволяет модели сосредоточиться на зависимостях между пространственно-временными сегментами по каналам и времени.
Этот механизм обеспечивает интеграцию информации из различных сегментов посредством вычисления Q, K и V. Он также фиксирует локальные пространственно-временные зависимости внутри отдельных сегментов, уделяя внимание внутренней структуре каждого сегмента. Кроме того, он фиксирует долгосрочные зависимости между сегментами на больших временных шагах. Конечным результатом является Xout ∈ RC×N, завершая процесс внимания.
В PSformer предлагается внедрение нового блока Parameter Shared Block (PS Block), который состоит из 3 полносвязных слоев с остаточным соединением. В частности, используется 3 обучаемых линейных отображения Wj ∈ RN×N с j ∈ {1, 2, 3}. Результаты работы первых двух слоев вычисляются следующим образом:
![]()
Здесь можно заметить структуру, аналогичную блоку FeedForward с остаточными соединениями. Этот промежуточный результат 𝑿out затем используется в качестве исходных данных для третьего преобразования:
![]()
Таким образом, блок PS в целом может быть выражен следующим образом:
![]()
Структура блока PS позволяет выполнять нелинейные преобразования с сохранением траектории линейного преобразования. Несмотря на то, что 3 слоя в блоке PS имеют разные параметры, весь блок PS повторно используется в разных позициях энкодера PSformer, гарантируя, что одни и те же параметры блока 𝑾S являются общими для всех этих позиций. В частности, блок PS использует общие параметры в 3 частях каждого энкодера PSformer, включая 2 модуля простанственно-временного внимания к сегментам и последний блок PS. Эта стратегия совместного использования параметров уменьшает их общее количество, сохраняя при этом выразительность модели.
Двухступенчатый механизм SegAtt можно сравнить с FeedForward блоком в ванильном Transformer, где MLP заменяется операциями внимания. К тому же, между исходными данными и результатом добавляются остаточные соединения, после чего результат передается в конечный блок PS.
Затем применяется преобразование размерности, чтобы получить 𝑿out ∈ RM×L, где C=M×P и L=P×N.
После прохождения через n слоев энкодера PSformer, осуществляется финальная трансформация данных на горизонт планирования F.
![]()
где 𝑿pred ∈ RM×F и 𝑾F ∈ RL×F — линейное отображение.
Авторская визуализация фреймворка PSformer представлена ниже.
Реализация средствами MQL5
После рассмотрения теоретических аспектов фреймворка PSformer, мы переходим к практической реализации своего видения предложенных подходов средствами MQL5. И для нас наибольший интерес представляет алгоритм реализации блока совместного использования параметров (PS).
Parameter Shared Block
Как уже было сказано выше, блок совместного использования параметров в авторской реализации состоит из 3 полносвязных слоев, параметры которых применяются ко всем анализируемым сегментам. И здесь нет ничего сложного для нас. Мы уже не раз в подобных случаях использовали сверточные слои с неперекрывающимися окнами анализа данных. Сложность заключается в другом — механизме совместного использования параметров в нескольких блоках.
С одной стороны, мы конечно можем использовать один и тот же блок несколько раз в рамках одного слоя. Но в таком случае, мы сталкиваемся с проблемой сохранения данных для осуществления операций обратного прохода. Ведь при повторном использовании объекта для осуществления операций прямого прохода, в буфере результатов мы сохраним новые данные, которые заменят результаты предыдущего вызова метода прямого прохода. При обычном алгоритме использования нейронного слоя в этом нет ничего страшного, так как мы постоянно чередуем прямой и обратный проходы. И после выполнения операций очередного обратного прохода, мы можем безболезненно заменить результаты предыдущего прямого прохода. Ведь они нам уже не нужны. Но в случае нарушения чередований прямого и обратного проходов, возникает вопрос сохранения всех данных, необходимых для корректного выполнения функционала очередного обратного прохода.
Стоит добавить, в подобной реализации нам необходимо сохранять не только результаты на выходе блока, но и все промежуточные значения. Или повторно их вычислять, что усложнит вычислительную сложность модели. Кроме того, необходим механизм синхронизации буферов на отдельных участках, чтобы корректно провести градиент ошибки.
Очевидно, что реализация указанных требований потребует внесения изменений в наши интерфейсы обмена данными между нейронными слоями. А это повлечет более глобальные изменения в функционале нашей библиотеки.
Второй вариант, это найти механизм полноценного совместного использования одного буфера параметров несколькими одинаковыми нейронными слоями. И надо сказать, что данный вариант так же не лишен "подводных камней".
Напомню, что при рассмотрении фреймворка Deep Deterministic Policy Gradien мы уже реализовывали алгоритм мягкого обновления параметров целевой модели. Однако копирование параметров, после каждого их обновления, довольно затратно. Поэтому нам желательно осуществить подмену буферов на матрицы параметров в объектах их совместного использования.
Здесь же, помимо самой матрицы параметров, нам необходимо организовать совместное использование буферов моментов, используемых в процессе обновления параметров. Ведь использование отдельных буферов моментов на различных этапах способно сместить вектор обновления параметров в сторону одного из внутренних слоев.
Есть еще один момент, о котором мы просто обязаны сказать. При подобной реализации мы сталкиваемся с ситуацией, когда параметры слоя при выполнении операций обратного прохода отличаются от используемых при прямом проходе. Это, конечно, может показаться странным, но давайте разберем простой пример из 2 последовательных слоев с совместным использованием параметров. При прямом проходе оба слоя используют параметры W и на выходе получаем O1 и O2, соответственно. При распределении градиентов ошибки на уровне результатов каждого слоя мы имеем отклонение G1 и G2, соответственно. К процессу распределения градиентов ошибки у нас вопросов нет. На данном этапе параметры модели остаются без изменений, и все градиенты ошибки соответствуют параметрам прямого прохода W. Но как только мы скорректируем параметры одного из слоев, например второго, то получим скорректированные параметры W'. И тут же сталкиваемся с проблемой несоответствия градиентов ошибки и параметров. Очевидно, что прямое использование несоответствующего градиента ошибки может исказить процесс обучения.
Одним из вариантов решения указанной проблемы является определение целевых значений для конкретного слоя на основании результатов последнего прямого прохода и градиента ошибки, с последующим выполнением операций прямого прохода с текущими параметрами и вычисление корректного градиента ошибки. Не напоминает ли вам это алгоритм SAM-оптимизации, с которым мы познакомились в предыдущих статьях? Ведь если мы добавим в представленный выше алгоритм решения проблемы корректировку параметров перед выполнением повторного прямого прохода, то получим полный алгоритм SAM-оптимизации.
Именно SAM-оптимизацию предлагают использовать авторы фреймворка PSformer. И это позволяет нам принять риски использования несоответствующих градиентов ошибки, так как они пересчитываются перед обновлением параметров. Однако, в другом случае, это может стать серьёзной проблемой.
С учетом всего вышесказанного, было принято решение использовать второй вариант реализации совместного использования параметров.
Как уже было сказано выше, блок PS использует 3 полносвязных слоя, которые мы заменим сверточными. Поэтому реализацию алгоритма совместного использования параметров мы начнем именно с объекта сверточного слоя CNeuronConvSAMOCL.
Здесь стоит отметить, что в сверточном слое совместного использования параметров мы подменяем лишь указатели на буферы параметров и моментов. В то же время, остальные буферы и значения внутренних переменных должны соответствовать размерности матрицы параметров. Очевидно, что в данном случае нам предстоит изменить метод инициализации объекта. Но вначале мы создадим 2 вспомогательных метода InitBufferLike и ReplaceBuffer.
Первый метод создает новый буфер, заполненный нулевыми значениями по представленному образцу. Его алгоритм довольно прост. В параметрах мы получаем 2 указателя на объекты буферов данных. Вначале мы проверяем актуальность указателя на буфер-образец (master). Наличие актуального указателя на данный буфер критично для выполнения дальнейших операций. Поэтому, в случае получения отрицательного результата, мы завершаем работу метода с результатом false.
bool CNeuronConvSAMOCL::InitBufferLike(CBufferFloat *&buffer, CBufferFloat *master) { if(!master) return false;
После успешного прохождения первой точки контроля, мы проверяем актуальность указателя на создаваемый буфер. Но здесь, в случае получения отрицательного результата, мы просто создаем новый экземпляр объекта.
if(!buffer) { buffer = new CBufferFloat(); if(!buffer) return false; }
И не забываем проверить корректность создания нового буфера.
Далее мы инициализируем буфер требуемого размера нулевыми значениями.
if(!buffer.BufferInit(master.Total(), 0)) return false;
И создаем его копию в OpenCL-контексте.
if(!buffer.BufferCreate(master.GetOpenCL())) return false; //--- return true; }
После чего, завершаем работу метода, предварительно вернув логический результат выполнения операций вызывающей программе.
Второй метод ReplaceBuffer выполняет операцию подмены указателя на указанный буфер. На первый взгляд, для присвоения указателя на объект внутренней переменной нам не нужен целый метод. Однако в теле метода мы проверяем и, при необходимости, удаляем излишние буфера данных. Что позволяет нам более эффективно использовать память, как оперативную, так и OpenCL-контекста.
void CNeuronConvSAMOCL::ReplaceBuffer(CBufferFloat *&buffer, CBufferFloat *master) { if(buffer==master) return; if(!!buffer) { buffer.BufferFree(); delete buffer; } //--- buffer = master; }
После создания вспомогательных методов мы переходим к построению нового алгоритма инициализации объекта сверточного слоя по образу с копированием указателей на буферы параметров объекта-образа InitPS. В параметрах метода, вместо целого ряда констант, определяющих архитектуру объекта, мы получаем лишь указатель на объект-образ, по образцу и подобию которого нам предстоит создать новый объект.
bool CNeuronConvSAMOCL::InitPS(CNeuronConvSAMOCL *master) { if(!master || master.Type() != Type() ) return false;
В теле метода мы проверяем корректность полученного указателя и соответствие типов объектов.
Далее мы не стали выстраивать целый ряд методов родительского класса, а просто перенесли значения всех унаследованных параметров из объекта-образа.
alpha = master.alpha; iBatch = master.iBatch; t = master.t; m_myIndex = master.m_myIndex; activation = master.activation; optimization = master.optimization; iWindow = master.iWindow; iStep = master.iStep; iWindowOut = master.iWindowOut; iVariables = master.iVariables; bTrain = master.bTrain; fRho = master.fRho;
Далее, мы создаем буферы результатов и градиентов ошибки по подобию аналогичных буферов объекта-образца.
if(!InitBufferLike(Output, master.Output)) return false; if(!!master.getPrevOutput()) if(!InitBufferLike(PrevOutput, master.getPrevOutput())) return false; if(!InitBufferLike(Gradient, master.Gradient)) return false;
После чего, перенесем указатели сначала на буферы весовых параметров и их моментов, унаследованных от базового полносвязного слоя.
ReplaceBuffer(Weights, master.Weights); ReplaceBuffer(DeltaWeights, master.DeltaWeights); ReplaceBuffer(FirstMomentum, master.FirstMomentum); ReplaceBuffer(SecondMomentum, master.SecondMomentum);
Аналогичную операцию повторим для буферов параметров сверточного слоя и их моментов.
ReplaceBuffer(WeightsConv, master.WeightsConv); ReplaceBuffer(DeltaWeightsConv, master.DeltaWeightsConv); ReplaceBuffer(FirstMomentumConv, master.FirstMomentumConv); ReplaceBuffer(SecondMomentumConv, master.SecondMomentumConv);
Далее нам остается создать буферы скорректированных параметров. Однако стоит помнить, что оба буфера скорректированных параметров могут не создаваться при определенных условиях. Буфер скорректированных параметров полносвязного слоя создается только при наличии исходящих связей. Поэтому мы сначала проверяем размер данного буфера в объете-образе. И создаем аналогичный буфер только при необходимости.
if(master.cWeightsSAM.Total() > 0) { CBufferFloat *buf = GetPointer(cWeightsSAM); if(!InitBufferLike(buf, GetPointer(master.cWeightsSAM))) return false; }
В противном случае, мы очищаем данный буфер, снижая потребление памяти.
else
{
cWeightsSAM.BufferFree();
cWeightsSAM.Clear();
}
Буфер скорректированных параметров входящих связей создается при наличии коэффициента области размытия больше "0".
if(fRho > 0) { CBufferFloat *buf = GetPointer(cWeightsSAMConv); if(!InitBufferLike(buf, GetPointer(master.cWeightsSAMConv))) return false; }
Иначе, мы просто очищаем данный буфер.
else
{
cWeightsSAMConv.BufferFree();
cWeightsSAMConv.Clear();
}
Конечно, технически, вместо коэффициента размытия, мы могли проверить размер буфера скорректированных параметров входящих связей объекта-образа. Как это было сделано для буфера скорректированных параметров исходящих связей. Но мы знаем, что при коэффициенте размытия больше "0", данный буфер должен быть. И таким образом мы включаем дополнительный контроль. Ведь при попытке создания буфера нулевой длины, мы получим ошибку и остановим процесс инициализации. Это поможет исключить более серьёзные ошибки в последующем.
В завершение метода инициализации, мы перенесем все объекты в единый OpenCL-контекст и завершим работу метода, вернув логический результат выполнения операций вызывающей программе.
SetOpenCL(master.OpenCL); //--- return true; }
После внесения изменений в объект сверточного слоя, мы переходим к следующему этапу нашей работы. И на данном этапе мы создадим непосредственно блок совместного использования параметров (PS). Для этого мы создадим новый объект CNeuronPSBlock. Как было сказано в теоретической части, блок совместного использования параметров состоит из 3 последовательных слоев линейного преобразования данных. При этом каждый слой имеет квадратную матрицу параметров, что свидетельствует о сохранении размерностей тензоров на входе и выходе как блока в целом, так и внутренних слоев. Между первыми двумя слоями создается нелинейность с помощью функции активации GELU. А после второго слоя добавляется остаточная связь с исходными данными.
Для реализации предложенного алгоритма, мы создадим в теле нашего нового объекта 2 внутренних сверточных слоя, а в качестве последнего сверточного слоя будем использовать непосредственно структуру нашего класса, базовый функционал которого мы унаследуем от сверточного слоя. А так как в процессе обучения мы будем использовать SAM-оптимизацию, то и при построении архитектуры объекта будем использовать соответствующие сверточоные слои. Структура нового класса представлена ниже.
class CNeuronPSBlock : public CNeuronConvSAMOCL { protected: CNeuronConvSAMOCL acConvolution[2]; CNeuronBaseOCL cResidual; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronPSBlock(void) {}; ~CNeuronPSBlock(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint units_count, uint variables, float rho, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool InitPS(CNeuronPSBlock *master); //--- virtual int Type(void) const { return defNeuronPSBlock; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Как можно заметить, в представленной структуре нового объекта объявляется 2 метода инициализации. И это не случайно. Первый метод инициализации Init является базовым средством инициализации объекта, архитектура которого однозначно задана в параметрах метода. Второй метод InitPS, аналогично одноименному методу сверточного слоя, создает новый объект по образу и подобию получаемого в параметрах объекта-образца. И при инициализации нового объекта копируются указатели на буферы параметров и их моментов. Предлагаю детальнее рассмотреть алгоритм построения указанных методов.
Как уже было сказано выше, в параметрах метода Init мы получаем ряд констант, которые позволяют однозначно определить архитектуру создаваемого объекта.
bool CNeuronPSBlock::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint units_count, uint variables, float rho, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronConvSAMOCL::Init(numOutputs, myIndex, open_cl, window, window, window_out, units_count, variables, rho, optimization_type, batch)) return false;
И в теле метода мы сразу передаем все полученные параметры в одноименный метод родительского класса. Как вы знаете, в методе родительского класса уже организованы необходимые точки контроля полученных параметров и алгоритмы инициализации унаследованных объектов.
Как уже было сказано выше, все сверточные слои внутри блока совместного использования параметров имеют одинаковые размерности. Поэтому, при инициализации первого вложенного сверточного слоя, мы передаем такие же параметры.
if(!acConvolution[0].Init(0, 0, OpenCL, iWindow, iWindow, iWindowOut, units_count, iVariables, fRho, optimization, iBatch)) return false; acConvolution[0].SetActivationFunction(GELU);
И добавляем предложенную авторами фреймворка функцию активации.
Однако мы оставляем пользователю возможность изменения размерностей тензора на выходе блока. Поэтому, при инициализации второго вложенного сверточного слоя, за которым подразумевается добавление остаточных связей, с целью получения размерности результатов равной исходным данным, мы поменяем местами параметры окна анализируемых данных и количества фильтров.
if(!acConvolution[1].Init(0, 1, OpenCL, iWindowOut, iWindowOut, iWindow, units_count, iVariables, fRho, optimization, iBatch)) return false; acConvolution[1].SetActivationFunction(None);
Здесь мы не используем функцию активации.
Далее мы добавим базовый нейронный слой для сохранения данных остаточных связей. Его размер соответствует буферу результатов второго вложенного сверточного слоя.
if(!cResidual.Init(0, 2, OpenCL, acConvolution[1].Neurons(), optimization, iBatch)) return false; if(!cResidual.SetGradient(acConvolution[1].getGradient(), true)) return false; cResidual.SetActivationFunction(None);
И сразу осуществим подмену буфера градиентов ошибки, что позволит нам сократить операции копирования данных в процессе обратного прохода.
Теперь нам остается явным образом отключить функцию активации нашего блока совместного использования параметров и завершить работу метода, передав логический результат выполнения операций вызывающей программе.
SetActivationFunction(None); //--- return true; }
Алгоритм второго метода инициализации выглядит немного проще. В параметрах метода мы получаем указатель на объект-образец и сразу передаем его в одноименный метод родительского класса.
Здесь стоит обратить внимание на различие типов получаемых параметров в текущем методе и родительского класса. Поэтому мы явным образом указываем тип передаваемого объекта.
bool CNeuronPSBlock::InitPS(CNeuronPSBlock *master) { if(!CNeuronConvSAMOCL::InitPS((CNeuronConvSAMOCL*)master)) return false;
В теле родительского класса уже организованы необходимые точки контроля. А так же копирование констант, создание новых буферов и сохранение указателей на буферы параметров и их моментов.
Далее мы организуем цикл, в котором вызовем одноименные методы для вложенных сверточных слоев с копированием данных из соответствующих объектов-образцов.
for(int i = 0; i < 2; i++) if(!acConvolution[i].InitPS(master.acConvolution[i].AsObject())) return false;
Слой сохранения результатов остаточных связей не содержит обучаемых параметров, а его размер равен буферу результатов второго вложенного сверточного слоя. Поэтому алгоритм инициализации данного объекта мы полностью перенесли из метода основной инициализации.
if(!cResidual.Init(0, 2, OpenCL, acConvolution[1].Neurons(), optimization, iBatch)) return false; if(!cResidual.SetGradient(acConvolution[1].getGradient(), true)) return false; cResidual.SetActivationFunction(None); //--- return true; }
И не забываем про подмену указателей на буфер градиентов ошибки.
После рассмотрения методов инициализации объекта, которых в данном случае два, мы переходим к построению алгоритмов прямого прохода. Здесь все довольно банально. В параметрах метода мы получаем указатель на объект исходных данных, который сразу передаем в одноименный метод первого внутреннего сверточного слоя.
bool CNeuronPSBlock::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!acConvolution[0].FeedForward(NeuronOCL)) return false;
Результаты мы по цепочке передаем в следующий сверточный слой. После чего, суммируем полученные значения с исходными данными. Сумму значений сохраняем в буфере слоя остаточных связей.
if(!acConvolution[1].FeedForward(acConvolution[0].AsObject())) return false; if(!SumAndNormilize(NeuronOCL.getOutput(), acConvolution[1].getOutput(), cResidual.getOutput(), iWindow, true, 0, 0, 0, 1)) return false;
Здесь стоит обратить внимание, что в отличие от авторского алгоритма, тензор остаточных связей мы нормализуем. И только затем передаем в последний сверточный слой, функционал которого выполняется средствами унаследованного от родительского класса функционала.
if(!CNeuronConvSAMOCL::feedForward(cResidual.AsObject())) return false; //--- return true; }
И завершаем работу метода, вернув логический результат выполнения операций вызывающей программе.
Метод распределения градиентов ошибки calcInputGradients так же прост, но не лишен своих нюансов. В параметрах метода мы получаем указатель на объект нейронного слоя с исходными данными, в который нам и предстоит передать градиент ошибки.
bool CNeuronPSBlock::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В теле метода мы сразу проверяем актуальность полученного указателя, так как, в противном случае, дальнейшие операции не имеют смысла.
Далее мы последовательно проводим градиенты через все сверточные слои в обратном порядке.
if(!CNeuronConvSAMOCL::calcInputGradients(cResidual.AsObject())) return false; if(!acConvolution[0].calcHiddenGradients(acConvolution[1].AsObject())) return false; if(!NeuronOCL.calcHiddenGradients(acConvolution[0].AsObject())) return false;
Обратите внимание, что в представленном коде отсутствует передача градиента ошибки от объекта остаточных связей ко второму внутреннему сверточному слою. Однако, благодаря организованной нами ранее подмене указателей буферов данных, передача информации осуществляется в полном объеме.
После передачи градиента ошибки на уровень исходных данных от магистрали сверточных слоев, нам необходимо добавить градиент ошибки по магистрали остаточных связей. И здесь есть 2 пути развития событий, в зависимости от функции активации объекта исходных данных.
Я хочу напомнить, что в объект остаточных связей мы передаем градиент ошибки без корректировки на производную функции активации. Мы явным образом указывали отсутствие таковой для данного объекта.
Поэтому, при условии отсутствия функции активации у объекта исходных данных, нам достаточно сложить соответствующие значения двух буферов.
if(NeuronOCL.Activation() == None) { if(!SumAndNormilize(NeuronOCL.getGradient(), cResidual.getGradient(), NeuronOCL.getGradient(), iWindow, false, 0, 0, 0, 1)) return false; }
В противном случае, мы сначала скорректируем полученный градиент ошибки на производную функции активации исходных данных в свободный буфер. А затем, суммируем полученные результаты с ранее накопленными в буфере объекта исходных данных.
else { if(!DeActivation(NeuronOCL.getOutput(), cResidual.getGradient(), cResidual.getPrevOutput(), NeuronOCL.Activation()) || !SumAndNormilize(NeuronOCL.getGradient(), cResidual.getPrevOutput(), NeuronOCL.getGradient(), iWindow, false, 0, 0, 0, 1)) return false; } //--- return true; }
После чего завершаем работу метода.
Пару слов надо сказать и о методе обновления параметров блока updateInputWeights. Здесь нет сложностей построения алгоритма — достаточно вызвать одноименные методы родительского класса и вложенных объектов, содержащих обучаемые параметры.
bool CNeuronPSBlock::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!CNeuronConvSAMOCL::updateInputWeights(cResidual.AsObject())) return false; if(!acConvolution[1].UpdateInputWeights(acConvolution[0].AsObject())) return false; if(!acConvolution[0].UpdateInputWeights(NeuronOCL)) return false; //--- return true; }
Однако, использование подходов SAM-оптимизации накладывает строгие ограничения на последовательность выполнения операций. Дело в том, что в процессе выполнения SAM-оптимизации мы осуществляем повторный прямой проход со скорректированными параметрами. В результате чего, изменяем данные в буфере результатов. Это не критично для оптимизации параметров текущего слоя, но сказывается на обновлении параметров последующего слоя. Ведь он использует результаты прямого прохода предшествующего слоя для корректировки своих параметров. Поэтому, в данном случае, нам важно проводить корректировку параметров в обратной последовательности внутренних объектов. Это позволит скорректировать параметры слоя до изменения значений в буфере результатов предыдущего объекта.
На этом мы завершаем рассмотрение алгоритмов блока совместного использования параметров CNeuronPSBlock. С полным кодом данного класса и всех его методов вы можете ознакомиться самостоятельно во вложении.
Наша работа еще не завершена, но объем статьи практически исчерпан. Поэтому мы сделаем небольшой перерыв и продолжим начатую работу в следующей статье.
Заключение
В данной статье мы познакомились с фреймворком PSformer, авторы которого отмечают высокую точность прогнозирования временных рядов и эффективность в использовании вычислительных ресурсов. Основные архитектурные особенности PSformer — блок совместного использования параметров (PS) и внимание к пространственно-временным сегментам (SegAtt). Их использование позволяет эффективно моделировать локальные и глобальные зависимости временных рядов и сократить число параметров без потери качества прогнозов.
В практической части статьи мы начали реализацию собственного видения предложенных подходов средствами MQL5. Однако наша работа еще не завершена. И в следующей статье мы продолжим начатую работу, а также оценим эффективность предложенных подходов для решения наших задач на реальных исторических данных.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
I observed that the second parameter 'SecondInput' is unused, as CNeuronBaseOCL's feedForward method with two parameters internally calls the single-parameter version. Can you verify if this is a bug?
class CNeuronBaseOCL : public CObject
{
...
virtual bool feedForward(CNeuronBaseOCL *NeuronOCL);
virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { return feedForward(NeuronOCL); }
..
}
Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder),LatentLayer); ??
Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount)); ??