
Neuronale Netze im Handel: Parametereffizienter Transformer mit segmentierter Aufmerksamkeit (letzter Teil)

Einführung
Im vorigen Artikel haben wir die theoretischen Aspekte der PSformer untersucht, die zwei wichtige Neuerungen in der Architektur des einfachen Transformers einführt: den Mechanismus der gemeinsamen Nutzung von Parametern (PS) und die räumlich-zeitliche segmentierte Aufmerksamkeit (SegAtt).
Die Autoren von PSformer haben einen Encoder vorgeschlagen, der auf der Architektur des Transformers basiert und eine zweistufige segmentierte Aufmerksamkeitsstruktur aufweist. Jede Ebene umfasst einen Block zur gemeinsamen Nutzung von Parametern, der aus drei vollständig verbundenen Schichten mit Residualverbindungen besteht. Durch diese Architektur wird die Gesamtzahl der Parameter reduziert und gleichzeitig ein effektiver Informationsaustausch innerhalb des Modells gewährleistet.
Die Segmente werden mit einer Patching-Methode erzeugt, bei der die Zeitreihenvariablen in Patches unterteilt werden. Patches mit derselben Position in verschiedenen Variablen werden zu Segmenten zusammengefasst, die eine räumliche Ausdehnung eines Patch mit einer einzigen Variable darstellen. Diese Segmentierung ermöglicht eine effiziente Organisation von mehrdimensionalen Zeitreihen in mehrere Segmente.
Innerhalb jedes Segments liegt der Schwerpunkt auf der Ermittlung lokaler räumlich-zeitlicher Beziehungen, während die Integration von Informationen zwischen den Segmenten die Gesamtqualität der Vorhersage verbessert.
Darüber hinaus trägt die Verwendung der Optimierungsmethoden von SAM im Rahmen von PSformer dazu bei, das Risiko einer Überanpassung zu verringern, ohne die Leistung zu beeinträchtigen.
Umfangreiche Experimente, die von den Autoren an verschiedenen Datensätzen für langfristige Zeitreihenprognosen durchgeführt wurden, bestätigen die hohe Leistungsfähigkeit von PSformer. In 6 von 8 wichtigen Vorhersageaufgaben erzielte diese Architektur konkurrenzfähige oder überlegene Ergebnisse im Vergleich zu den modernsten Modellen.
Die Originalvisualisierung des Rahmens von PSformer finden Sie unten.
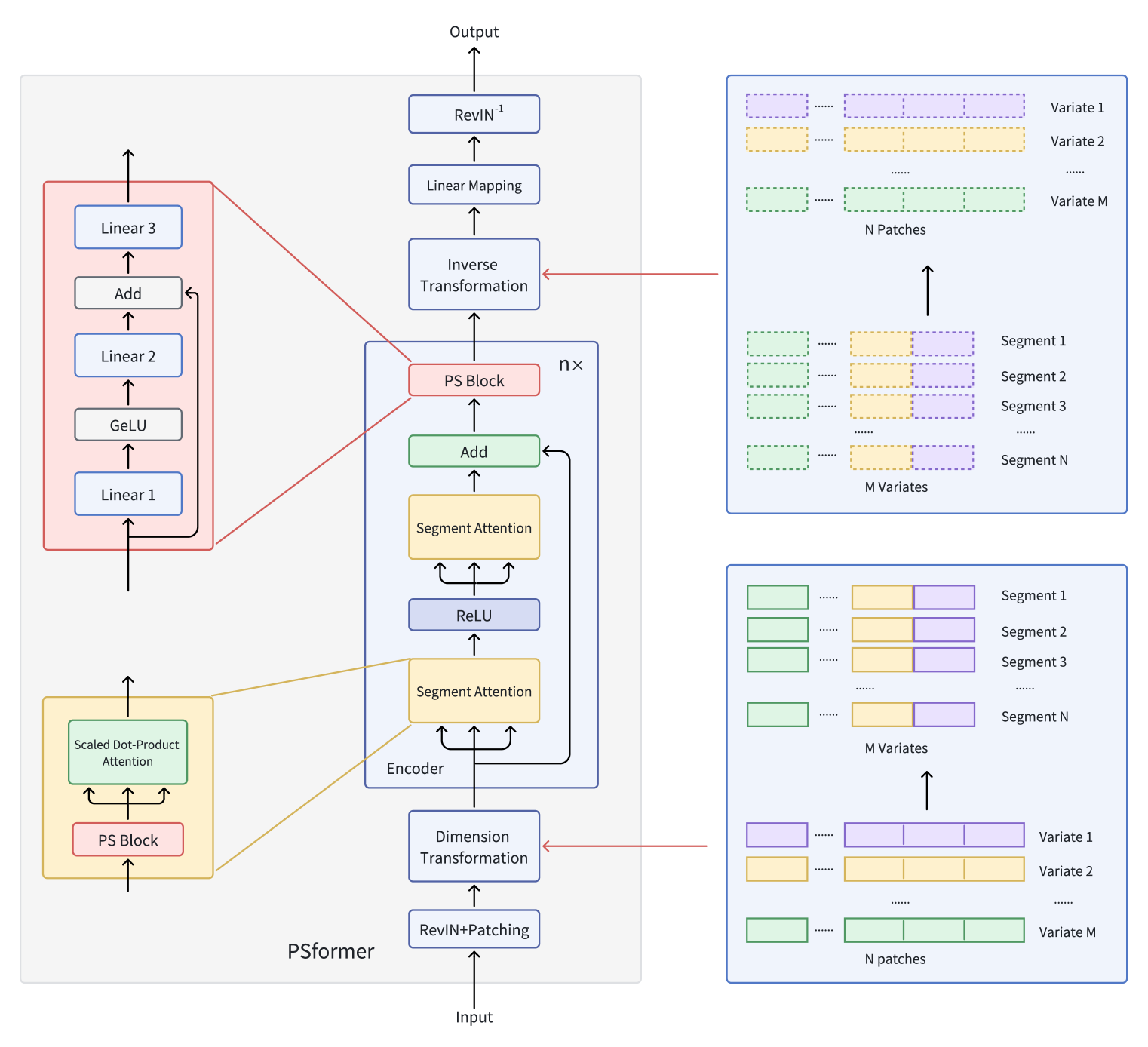
Im vorigen Artikel haben wir damit begonnen, die vorgeschlagenen Ansätze mit MQL5 zu implementieren. Wir haben die Algorithmen der Methoden der Klasse CNeuronPSBlock untersucht, die die Funktionalität des Parameter-Sharing-Blocks implementieren. Wir setzen nun unsere Arbeit fort und beginnen mit dem Aufbau der Encoder-Funktionalität.
Erstellen des PSformer-Encoder-Objekts
Bevor wir uns der Code-Implementierung zuwenden, wollen wir kurz auf die Algorithmen eingehen. Nach Angaben der Autoren des Frameworks durchlaufen die Eingabedaten zunächst RevIn. Wie Sie wissen, besteht das Modul RevIn aus zwei Blöcken. Bei der Modelleingabe werden die Rohdaten normalisiert; bei der Ausgabe werden die zuvor extrahierten Verteilungsparameter wieder in die Modellergebnisse eingesetzt. Dies trägt dazu bei, die Ausgabeverteilung des Modells an die der Originaldaten anzugleichen. Dies ist zweifellos ein wichtiger Faktor bei der Vorhersage künftiger Werte einer Zeitreihe.
In diesem Artikel werden wir wie bisher nur die Normalisierung der Eingabedaten verwenden, die als separate Batch-Normalisierungsschicht implementiert ist. Der Grund dafür ist, dass unser Ziel nicht die Vorhersage zukünftiger Zeitreihenwerte ist, sondern das Training einer profitablen Politik des Akteurs. Da Modelle im Allgemeinen mit normalisierten Daten besser funktionieren, werden die Eingabedaten normalisiert. Aus demselben Grund ist es logisch, normalisierte Daten aus dem verborgenen Zustand des Encoders an den Akteur weiterzugeben. Wenn also der Encoder zusammen mit dem Akteur in der Umgebung trainiert wird, werden sowohl der lineare Mapping-Block als auch das umgekehrten Modul RevIn überflüssig.
Natürlich werden der Mapping-Block und das umgekehrten Modul RevIn für ein gestuftes Training benötigt, bei dem zunächst der Encoder des Umgebungszustands trainiert wird, um die nachfolgenden Zustände der analysierten Zeitreihe vorherzusagen, und erst dann die Modelle von Akteur und Kritiker separat trainiert werden. Selbst in diesem Fall ist es jedoch vorzuziehen, den verborgenen Zustand des Encoders, der eine kompaktere und normalisierte Darstellung der ursprünglichen Daten enthält, an den Akteur weiterzugeben.
Die stufenweise Ausbildung hat sowohl Vorteile als auch Nachteile. Der Hauptvorteil ist die Universalität des Encoders, da er auf Rohdaten trainiert wird, ohne an eine bestimmte Aufgabe gebunden zu sein. Dadurch ist es möglich, den Kodierer für die Lösung verschiedener Probleme auf demselben Datensatz wiederzuverwenden.
Andererseits ist ein universelles Modell nicht immer optimal für eine bestimmte Aufgabe, da es bestimmte domänenspezifische Nuancen nicht erfassen kann.
Außerdem können zwei getrennte Trainingsschritte insgesamt rechenintensiver sein als das gleichzeitige Training aller Modelle.
In Anbetracht dieser Faktoren haben wir uns für ein gleichzeitiges Training der Modelle und eine Reduzierung der Architektur des Encoder entschieden.
Nach der Normalisierung der Daten wendet der Rahmen PSformer ein Patching- und Datenumwandlungsmodul an. Die Autoren beschreiben einen recht komplexen Transformationsprozess. Versuchen wir, es aufzuschlüsseln.
Das Modell erhält eine multimodale Zeitreihe als Eingabe. Lassen wir die Normalisierung vorerst beiseite und konzentrieren wir uns ausschließlich auf den Transformationsprozess.
Zunächst wird die multimodale Zeitreihe in M univariate Sequenzen unterteilt. Jede univariate Sequenz wird dann in N gleiche Patches der Länge P aufgeteilt. Als Nächstes werden Patches mit identischen Zeitindizes zu Segmenten zusammengefasst. Daraus ergeben sich N Patches der Größe M×P.
In unserem Fall handelt es sich bei den Rohdaten um eine sequentielle Beschreibung historischer Balken über die Tiefe des analysierten Datensatzes. Mit anderen Worten: Unser Rohdatenpuffer enthält M beschreibende Elemente für einen Balken. Darauf folgen M Elemente für den nächsten Balken und so weiter. Um ein Segment zu bilden, müssen wir also einfach P aufeinanderfolgende Balkenbeschreibungen nehmen. Hierfür ist natürlich keine zusätzliche Datentransformation erforderlich.
Die Autoren von PSformer beschreiben dann die Umwandlung der Rohdaten in (M×P)×N. Bei unserer Implementierung kann dies einfach durch Transposition des Eingabedatentensensors erreicht werden.
In unserem Fall wird der Patching- und Transformationsblock PSformer also effektiv auf eine einzige Transpositionsschicht reduziert.
Eine weitere wichtige Frage ist, wie die sequentiellen Encoderschichten von PSformer aufgebaut werden können. Es gibt zwei Möglichkeiten. Wir verwenden den Basisansatz und geben die gewünschte Anzahl von Schichten direkt in der Beschreibung der Modellarchitektur an oder wir erstellen ein Objekt, das die erforderliche Anzahl interner Schichten erzeugt.
Der erste Ansatz erschwert die Beschreibung der Architektur, vereinfacht aber die Erstellung des Objekts des Encoders. Er bietet außerdem Flexibilität bei der Konfiguration der sequenziellen Ebenen des Encoders.
Der zweite Ansatz vereinfacht die Beschreibung der Architektur, verkompliziert aber die Implementierung des Encoders, da alle internen Schichten die gleiche Architektur haben.
Für Modelle mit einer geringen Anzahl der Schichten des Encoders ist die erste Option eindeutig vorzuziehen. Die zweite eignet sich eher für tiefere Modelle.
Zur Entscheidungsfindung verweisen wir auf die ursprüngliche Studie, in der untersucht wurde, wie sich die Anzahl der Encoder-Schichten auf die Vorhersagegenauigkeit auswirkt. Die Autoren von PSformer führten das Experiment mit den Standard-Zeitreihendatensätzen ETTh1 und ETTm1 durch, die Daten von elektrischen Transformern enthalten. Jeder Datenpunkt enthält acht Merkmale wie Datum, Öltemperatur und sechs Arten von externen Lastmerkmalen. ETTh1 hat stündliche Intervalle, während ETTm1 Minutenintervalle hat. Die Testergebnisse sind in der Tabelle aufgeführt.

Aus den präsentierten Daten geht hervor, dass für den weniger chaotischen stündlichen Datensatz die besten Ergebnisse mit einem einzigen Encoder-Layer erzielt wurden. Für den verrauschten Minutendatensatz erwiesen sich drei Encoder-Ebenen als optimal. Folglich rechnen wir nicht damit, Modelle mit einer großen Anzahl von Encoder-Schichten zu erstellen. Daher wählen wir den ersten Implementierungsansatz mit einer einfacheren Encoder-Objektstruktur und einer expliziten Parameterspezifikation für jede Encoder-Ebene in der Modellarchitekturbeschreibung.
Die vollständige Struktur des neuen Objekts CNeuronPSformer ist unten dargestellt.
class CNeuronPSformer : public CNeuronBaseSAMOCL { protected: CNeuronTransposeOCL acTranspose[2]; CNeuronPSBlock acPSBlocks[3]; CNeuronRelativeSelfAttention acAttention[2]; CNeuronBaseOCL cResidual; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronPSformer(void) {}; ~CNeuronPSformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronPSformer; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Wie bereits erwähnt, beinhaltet der Rahmen von PSformer die Optimierungstechniken von SAM. Daher erbt unsere neue Klasse die Basisfunktionalität von der entsprechenden vollständig verbundenen Schicht.
Darüber hinaus enthält die Struktur CNeuronPSformer zwei Datentranspositionsschichten, die die Vorwärts- und Rückwärtstransformation von Daten durchführen.
Die neue Klassenstruktur enthält auch drei Blöcke für die gemeinsame Nutzung von Parametern und zwei Module für relative Aufmerksamkeit, in die wir zuvor die Optimierungsfunktionalität von SAM integriert haben. Dies ist vielleicht unsere größte Abweichung vom ursprünglichen Algorithmus PSformer.
Die Autoren von PSformer haben den Parameter-Sharing-Block verwendet, um die Entitäten Query (Abfrage), Key (Schlüssel) und Value (Wert) zu erzeugen. Im Block PS haben die Parametermatrizen eine Größe von N×N. Dies bedeutet, dass derselbe Tensor für alle drei Einheiten verwendet wird.
In unserer Implementierung haben wir die Architektur des Encoders leicht verkompliziert. Der Block von PS dient lediglich der vorläufigen Datenaufbereitung, während die Abhängigkeitsanalyse im fortgeschritteneren Block für relative Aufmerksamkeit durchgeführt wird.
Alle internen Objekte werden als statisch deklariert, sodass wir den Konstruktor und Destruktor der Klasse leer lassen können. Die Initialisierung aller deklarierten und geerbten Objekte wird in der Methode Init durchgeführt. Zu den Parametern dieser Methode gehören Schlüsselkonstanten, die die Architektur der zu erstellenden Schicht vollständig definieren, nämlich:
- window - die Größe des Vektors, der ein Sequenzelement beschreibt
- units_count - die Tiefe der historischen Daten (Sequenzlänge)
- segments - die Anzahl der erzeugten Segmente
- rho - der Koeffizient für den Unschärfebereich
bool CNeuronPSformer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, ENUM_OPTIMIZATION optimization_type, uint batch) { if(units_count % segments > 0) return false;
Bei der Initialisierungsmethode wird zunächst ein Kontrollblock eingerichtet, um zu überprüfen, ob die Sequenzlänge durch die Anzahl der Segmente teilbar ist. Anschließend rufen wir die gleichnamige Methode der Elternklasse auf, die die weitere Validierung der Konstanten und die Initialisierung der geerbten Objekte vornimmt.
if(!CNeuronBaseSAMOCL::Init(numOutputs, myIndex, open_cl, window * units_count, rho, optimization_type, batch)) return false;
Als Nächstes bestimmen wir die Größe eines einzelnen Segments.
uint count = Neurons() / segments;
Dann fahren wir mit der Initialisierung der neu deklarierten internen Objekte fort. Zunächst wird die Schicht für die Umsetzung der Eingangsdaten initialisiert. Die Anzahl der Zeilen in der transponierten Matrix wird auf die Anzahl der Segmente festgelegt, während die Zeilengröße auf die Gesamtzahl der Elemente in einem Segment festgelegt wird.
if(!acTranspose[0].Init(0, 0, OpenCL, segments, count, optimization, iBatch)) return false; acTranspose[0].SetActivationFunction(None);
Für diese Schicht ist keine Aktivierungsfunktion angegeben.
Während die Angabe einer Aktivierungsfunktion für eine Transpositionsschicht nicht erforderlich ist, bietet der Algorithmus für den Vorwärtsdurchlauf für diese Schicht bei Bedarf eine Synchronisierung mit der Aktivierungsfunktion des Quelldatenobjekts.
Als Nächstes wird der erste Block zur gemeinsamen Nutzung von Parametern initialisiert. Hierfür verwenden wir eine explizite Objektinitialisierungsmethode.
if(!acPSBlocks[0].Init(0, 1, OpenCL, segments, segments, units_count / segments, 1, fRho, optimization, iBatch)) return false;
Anschließend erstellen wir eine Schleife zur Initialisierung der Aufmerksamkeitsmodule und der übrigen Blöcke zur gemeinsamen Nutzung von Parametern.
for(int i = 0; i < 2; i++) { if(!acAttention[i].Init(0, i + 2, OpenCL, segments, segments, units_count / segments, 2, optimization, iBatch)) return false; if(!acPSBlocks[i + 1].InitPS((CNeuronPSBlock*)acPSBlocks[0].AsObject())) return false; }
Die verbleibenden Blöcke zur gemeinsamen Nutzung von Parametern werden auf dieselbe Weise initialisiert wie der erste Block von PS, wobei die Zeiger auf die gemeinsam genutzten Parameterpuffer und ihre Momente entsprechend kopiert werden.
Als Nächstes wird die Aufzeichnungsschicht der Residualverbindungen initialisiert. Hier verwenden wir eine standardmäßige voll vernetzte Schicht, da wir ihre Datenpuffer nur für die Speicherung von Zwischenergebnissen benötigen.
if(!cResidual.Init(0, 4, OpenCL, acAttention[1].Neurons(), optimization, iBatch)) return false; if(!cResidual.SetGradient(acAttention[1].getGradient(), true)) return false; cResidual.SetActivationFunction((ENUM_ACTIVATION)acAttention[1].Activation());
Um das Kopieren von Daten zu reduzieren, ersetzen wir den Gradientenpuffer dieser Schicht durch den des letzten Aufmerksamkeitsmoduls. Stellen Sie sicher, dass ihre Aktivierungsfunktionen synchronisiert sind.
Schließlich initialisieren wir die Ebene der umgekehrten Transposition.
if(!acTranspose[1].Init(0, 5, OpenCL, count, segments, optimization, iBatch)) return false; acTranspose[1].SetActivationFunction((ENUM_ACTIVATION)acPSBlocks[2].Activation());
Außerdem ersetzen wir die Schnittstellendatenpuffer unseres Objekts durch die entsprechenden Puffer der endgültigen Transpositionsebene.
if(!SetOutput(acTranspose[1].getOutput(), true) || !SetGradient(acTranspose[1].getGradient(), true)) return false; //--- return true; }
Danach ist die Initialisierungsmethode abgeschlossen und gibt ein logisches Ergebnis an den Aufrufer zurück.
Der nächste Schritt ist der Aufbau der Algorithmen der Vorwärtsdurchläufe, die in der Methode feedForward implementiert sind. Diese Methode sollte relativ übersichtlich sein, da die Hauptfunktionalität in den zuvor implementierten internen Objekten liegt.
Die Methode erhält einen Zeiger auf das Quelldatenobjekt, das sofort an die interne Transpositionsebene zur anfänglichen Transformation übergeben wird.
bool CNeuronPSformer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Dimension Transformation if(!acTranspose[0].FeedForward(NeuronOCL)) return false;
Anschließend durchlaufen wir zwei Segment-Aufmerksamkeitsblöcke.
//--- Segment Attention CObject* prev = acTranspose[0].AsObject(); for(int i = 0; i < 2; i++) { if(!acPSBlocks[i].FeedForward(prev)) return false; if(!acAttention[i].FeedForward(acPSBlocks[i].AsObject())) return false; prev = acAttention[i].AsObject(); }
Innerhalb jeder Schleifeniteration rufen wir nacheinander die Methoden des Blocks für die gemeinsame Nutzung von Parametern und des Moduls für relative Aufmerksamkeit auf.
Nachdem alle Iterationen der Schleife erfolgreich abgeschlossen wurden, addieren wir die Residualverbindungen zu den Rohdaten und speichern die Ergebnisse in unserem Innenschichtpuffer cResidual.
//--- Residual Add if(!SumAndNormilize(acTranspose[0].getOutput(), acAttention[1].getOutput(), cResidual.getOutput(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false;
Beachten Sie jedoch, dass wir für die Residualverbindungen die Rohdaten nach der Transformation, , d. h. nach der Transpositionsebene, verwenden. Dadurch wird sichergestellt, dass die Datenstruktur bei verbleibenden Verbindungen erhalten bleibt.
Die resultierenden Daten werden dann durch den letzten Block zur gemeinsamen Nutzung von Parametern geleitet.
//--- PS Block if(!acPSBlocks[2].FeedForward(cResidual.AsObject())) return false;
Anschließend führen wir die umgekehrte Datentransformation durch.
//--- Inverse Transformation if(!acTranspose[1].FeedForward(acPSBlocks[2].AsObject())) return false; //--- return true; }
Dank der gemeinsamen Pufferzeiger zwischen den Schnittstellen unseres Objekts und der endgültigen Transpositionsebene werden die Ergebnisse der Rücktransformation direkt in die Schnittstellenpuffer geschrieben, sodass kein zusätzliches Kopieren von Daten erforderlich ist. Nach der Rücktransformation gibt die Vorwärtsdurchlauf-Methode also einfach ein boolsches Ergebnis an den Aufrufer zurück.
Sobald der Vorwärtsdurchlauf abgeschlossen ist, gehen wir zum Rückwärtsdurchlauf über, der durch die Methoden calcInputGradients und updateInputWeights implementiert wird. Die erste Methode verteilt die Fehlergradienten, während die zweite die Modellparameter aktualisiert.
Die Methode calcInputGradients erhält einen Zeiger auf das Quelldatenobjekt, in das wir den Fehlergradienten übergeben müssen, der die Auswirkungen der Eingabedaten auf das Endergebnis widerspiegelt.
bool CNeuronPSformer::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Zunächst prüfen wir die Gültigkeit des empfangenen Zeigers - ist er ungültig, ist eine weitere Bearbeitung sinnlos. Wenn diese Prüfung bestanden ist, werden die Fehlergradienten in umgekehrter Reihenfolge des Vorwärtsdurchlaufs durch die internen Schichten unseres Objekts zurückverfolgt.
if(!acPSBlocks[2].calcHiddenGradients(acTranspose[1].AsObject())) return false; //--- if(!cResidual.calcHiddenGradients(acPSBlocks[2].AsObject())) return false; //--- if(!acPSBlocks[1].calcHiddenGradients(acAttention[1].AsObject())) return false; if(!acAttention[0].calcHiddenGradients(acPSBlocks[1].AsObject())) return false; if(!acPSBlocks[0].calcHiddenGradients(acAttention[0].AsObject())) return false; //--- if(!acTranspose[0].calcHiddenGradients(acPSBlocks[0].AsObject())) return false;
Nach Erreichen der Eingangsdaten-Transformationsschicht müssen wir den Residualverbindungsgradienten hinzufügen. Dies kann auf zwei Arten geschehen, je nach Aktivierungsfunktion des Quelldatenobjekts. Wenn keine Aktivierungsfunktion vorhanden ist, werden einfach die Werte aus den beiden Datenpuffern addiert.
if(acTranspose[0].Activation() == None) { if(!SumAndNormilize(acTranspose[0].getGradient(), cResidual.getGradient(), acTranspose[0].getGradient(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false; }
Wenn eine Aktivierungsfunktion vorhanden ist, passen wir zunächst den Fehlergradienten um die Ableitung der Aktivierungsfunktion an, bevor wir die Daten addieren.
else { if(!DeActivation(acTranspose[0].getOutput(), cResidual.getGradient(), acTranspose[0].getPrevOutput(), acTranspose[0].Activation()) || !SumAndNormilize(acTranspose[0].getGradient(), acTranspose[0].getPrevOutput(), acTranspose[0].getGradient(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false; }
Am Ende der Methode führen wir die Rücktransformation durch, um den Fehlergradienten auf die Eingabestufe zu übertragen, und geben dann das boolsche Ergebnis an das aufrufende Programm zurück.
if(!NeuronOCL.calcHiddenGradients(acTranspose[0].AsObject())) return false; //--- return true; }
Um den Rückwärtsdurchlauf abzuschließen, müssen wir die Modellparameter aktualisieren, um den Vorhersagefehler zu verringern. Erinnern Sie sich, dass wir Optimierungstechniken von SAM für die Aktualisierung der Parameter verwenden. Wie bereits erwähnt, erfordert SAM einen zweiten Vorwärtsdurchlauf mit gestörten Modellparametern, wodurch sich die Pufferwerte ändern. Dies hat zwar keine Auswirkungen auf die Operationen der aktuellen Ebene, kann aber die Aktualisierung der Parameter in den nachfolgenden Ebenen verzerren. Daher aktualisieren wir die internen Schichten in der umgekehrter Reihenfolge der Vorwärtsdurchlaufs. Dadurch können die Parameter jeder Schicht angepasst werden, bevor die Pufferwerte der vorangegangenen Schichten geändert werden.
bool CNeuronPSformer::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!acPSBlocks[2].UpdateInputWeights(cResidual.AsObject())) return false; //--- CObject* prev = acAttention[0].AsObject(); for(int i = 1; i >= 0; i--) { if(!acAttention[i].UpdateInputWeights(acPSBlocks[i].AsObject())) return false; if(!acPSBlocks[i].UpdateInputWeights(prev)) return false; prev = acTranspose[0].AsObject(); } //--- return true; }
Ein paar Worte zu den Dateiverarbeitungsmethoden. Da wir drei Blöcke zur gemeinsamen Nutzung von Parametern verwenden, brauchen wir dieselben Parameter nicht dreimal zu speichern. Es genügt, sie einmal zu speichern. Dementsprechend haben wir die folgende Methode Save.
Die Methode erhält ein Dateihandle, das zunächst an die Save-Methode der übergeordneten Klasse übergeben wird.
bool CNeuronPSformer::Save(const int file_handle) { if(!CNeuronBaseSAMOCL::Save(file_handle)) return false;
Anschließend speichern wir den Parameter-Sharing-Block einmal.
if(!acPSBlocks[0].Save(file_handle)) return false;
Als Nächstes wird eine Schleife zum Speichern der Aufmerksamkeitsmodule und der Transpositionsschichten erstellt.
for(int i = 0; i < 2; i++) if(!acTranspose[i].Save(file_handle) || !acAttention[i].Save(file_handle)) return false; //--- return true; }
Nach Abschluss der Schleife geben wir das boolsche Ergebnis an den Aufrufer zurück und beenden die Methode.
Beachten Sie, dass wir beim Speichern auch die residuale Verbindungsschicht weglassen. Es gibt keine trainierbaren Parameter. Daher gehen bei diesem Prozess keine Informationen verloren.
Bei der Wiederherstellung eines zuvor gespeicherten Objekts müssen wir jedoch auch die Struktur und Funktionalität aller Objekte wiederherstellen. Einschließlich derjenigen, die beim Speichern übersprungen wurden. Daher schlage ich vor, sich die Methode Load, die die Objektfunktionalität wiederherstellt, genauer anzusehen.
In den Methodenparametern erhalten wir das Dateihandle mit den zuvor gespeicherten Daten. Wir übergeben das erhaltene Handle sofort an die Load-Methode der übergeordneten Klasse, die die geerbten Objekte wiederherstellt.
bool CNeuronPSformer::Load(const int file_handle) { if(!CNeuronBaseSAMOCL::Load(file_handle)) return false;
Anschließend stellen wir die gespeicherten Objekte in genau der Reihenfolge wieder her, in der sie gespeichert wurden.
if(!LoadInsideLayer(file_handle, acPSBlocks[0].AsObject())) return false; for(int i = 0; i < 2; i++) if(!LoadInsideLayer(file_handle, acTranspose[i].AsObject()) || !LoadInsideLayer(file_handle, acAttention[i].AsObject())) return false;
Dann müssen wir die Funktionsweeise der beim Speichern fehlenden Objekte wiederherstellen. Zunächst werden die Blöcke zur gemeinsamen Nutzung von Parametern wiederhergestellt. Einer wird aus der Datei geladen, und die anderen werden auf der Grundlage des geladenen Blocks und durch Kopieren von Zeigern auf die gemeinsamen Parameterpuffer und ihre Momente initialisiert.
for(int i = 1; i < 3; i++) if(!acPSBlocks[i].InitPS((CNeuronPSBlock*)acPSBlocks[0].AsObject())) return false;
Wir initialisieren auch die Aufzeichnungsschicht für die Residualverbindung. Seine Größe entspricht dem Ausgangstensor des endgültigen relativen Aufmerksamkeitsmoduls.
if(!cResidual.Init(0, 4, OpenCL, acAttention[1].Neurons(), optimization, iBatch)) return false; if(!cResidual.SetGradient(acAttention[1].getGradient(), true)) return false; cResidual.SetActivationFunction((ENUM_ACTIVATION)acAttention[1].Activation());
Wir ersetzen den Zeiger des Gradientenpuffers, um unnötige Kopiervorgänge zu vermeiden und die Aktivierungsfunktionen zu synchronisieren.
Schließlich ersetzen wir die Schnittstellenpuffer unseres Objekts durch die der letzten Transpositionsebene.
if(!SetOutput(acTranspose[1].getOutput(), true) || !SetGradient(acTranspose[1].getGradient(), true)) return false; //--- return true; }
Die Methode schließt mit der Rückgabe des logischen Ergebnisses der Operation an den Aufrufer ab.
An diesem Punkt ist unsere Arbeit an dem Encoder-Objekt CNeuronPSformer abgeschlossen. Den vollständigen Code dieser Klasse und alle ihre Methoden finden Sie im Anhang.
Modell der Architektur
Nachdem wir Objekte konstruiert haben, die die von den Autoren des Rahmens von PSformer vorgeschlagenen Ansätze implementieren, gehen wir zur Beschreibung der Architektur der trainierbaren Modelle über. Zunächst interessieren wir uns für den Umweltzustand Encoder, in den wir die vorgeschlagenen Ansätze implementieren.
Die Architektur des Environmental State Encoders wird in der Methode CreateEncoderDescriptions definiert. In den Methodenparametern übergeben wir einen Zeiger auf ein dynamisches Array-Objekt zur Aufzeichnung der Beschreibung der Modellarchitektur.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
Im Methodenrumpf prüfen wir die Relevanz des empfangenen Zeigers und erstellen gegebenenfalls eine neue Instanz des dynamischen Arrays.
Wie zuvor ist die Rohdatenschicht eine Standardschicht mit vollständiger Verknüpfung. Seine Größe muss ausreichen, um den gesamten Tensor der historischen Daten für die angegebene Analysetiefe zu erfassen.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Darauf folgt eine Batch-Normalisierungsschicht zur ersten Vorverarbeitung der Rohdaten.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Die normalisierten Daten werden dann an den Encoder von PSformer weitergeleitet. In diesem Artikel verwenden wir drei sequenzielle PSformer-Encoderschichten mit identischer Architektur. Um die erforderliche Anzahl von Encoderschichten festzulegen, verwenden wir eine Schleife, deren Iterationszahl der gewünschten Encodertiefe entspricht. Im Hauptteil der Schleife wird bei jeder Iteration eine Beschreibung eines Objekts von CNeuronPSformer erstellt.
//--- layer 2 - 4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPSformer; descr.window = BarDescr; descr.count = HistoryBars; descr.window_out = Segments; descr.probability = Rho; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } }
Nach dem PSformer-Encoder folgt ein Mapping-Block, der aus einer Faltungsschicht und einer vollverknüpften Schicht besteht. Alle neuronalen Schichten sind für die Optimierung von SAM angepasst.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = int(LatentCount / descr.count); descr.probability = Rho; descr.activation = GELU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.probability = Rho; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Sobald die Architekturbeschreibung für den Environment State Encoder abgeschlossen ist, geben wir das boolsche Ergebnis an den Aufrufer zurück und beenden die Methode.
Der vollständige Code für diese Methode, der die Encoder-Architektur beschreibt, ist im Anhang enthalten, zusammen mit den unveränderten Modell-Architekturen von Akteur und Kritiker aus früheren Artikeln.
Wir haben auch die Programme zur Interaktion mit der Umwelt und zur Modellschulung unverändert übernommen. Sie sind auch in der Anlage verfügbar. Wir gehen nun zum letzten Schritt über - der Bewertung der Effektivität der implementierten Techniken an realen historischen Daten.
Tests
Wir haben viel Arbeit investiert, um die von den Autoren des Rahmens von PSformer vorgeschlagenen Ansätze mit MQL5 zu implementieren. Jetzt kommt die spannendste Phase - die Bewertung ihrer Wirksamkeit anhand von historischen Daten aus der realen Welt.
Es ist wichtig zu betonen, dass es sich hier um eine Bewertung der von uns implementierten Techniken handelt und nicht nur um die von den ursprünglichen Autoren vorgeschlagenen. Da unsere Implementierung gewisse Abweichungen vom ursprünglichen Rahmen von PSformer aufweist.
Wir haben die Modelle mit historischen EURUSD-Daten für das gesamte Jahr 2023 im H1-Zeitrahmen trainiert. Wie immer wurden alle Indikatorparameter auf ihre Standardwerte gesetzt.
Wie bereits erwähnt, wurden der Umgebungszustandscodierer, der Akteur und das kritische Modell gleichzeitig trainiert. Für das anfängliche Training verwendeten wir einen Datensatz, der bei der Arbeit mit früheren Modellen gesammelt wurde, und aktualisierten ihn regelmäßig, während das Training fortschritt.
Nach mehreren Iterationen des Modelltrainings und der Aktualisierung der Datensätze haben wir eine Strategie entwickelt, die sowohl in den Trainings- als auch in den Testdatensätzen Gewinne erzielt.
Die trainierte Politik des Akteurs wurde an historischen EURUSD-Daten vom Januar 2024 getestet, wobei alle anderen Parameter unverändert blieben. Die Testergebnisse sind wie folgt:
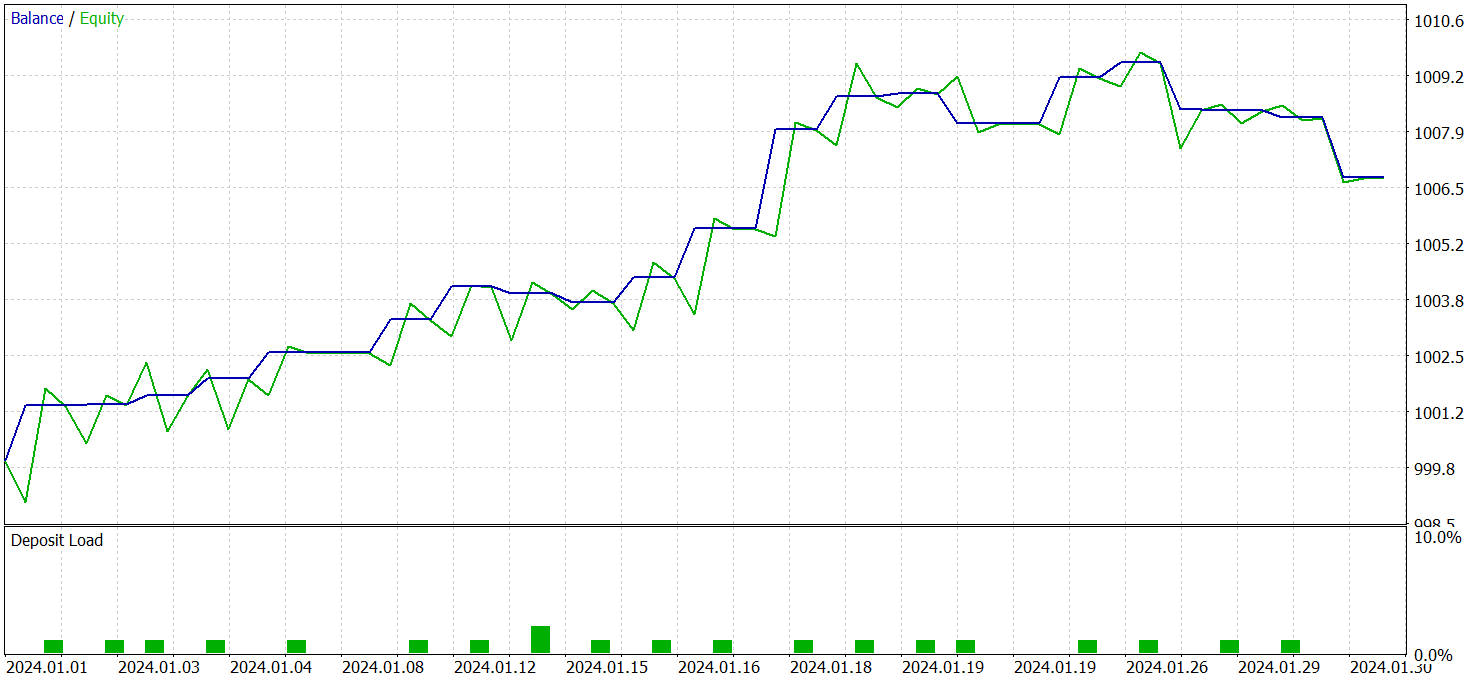
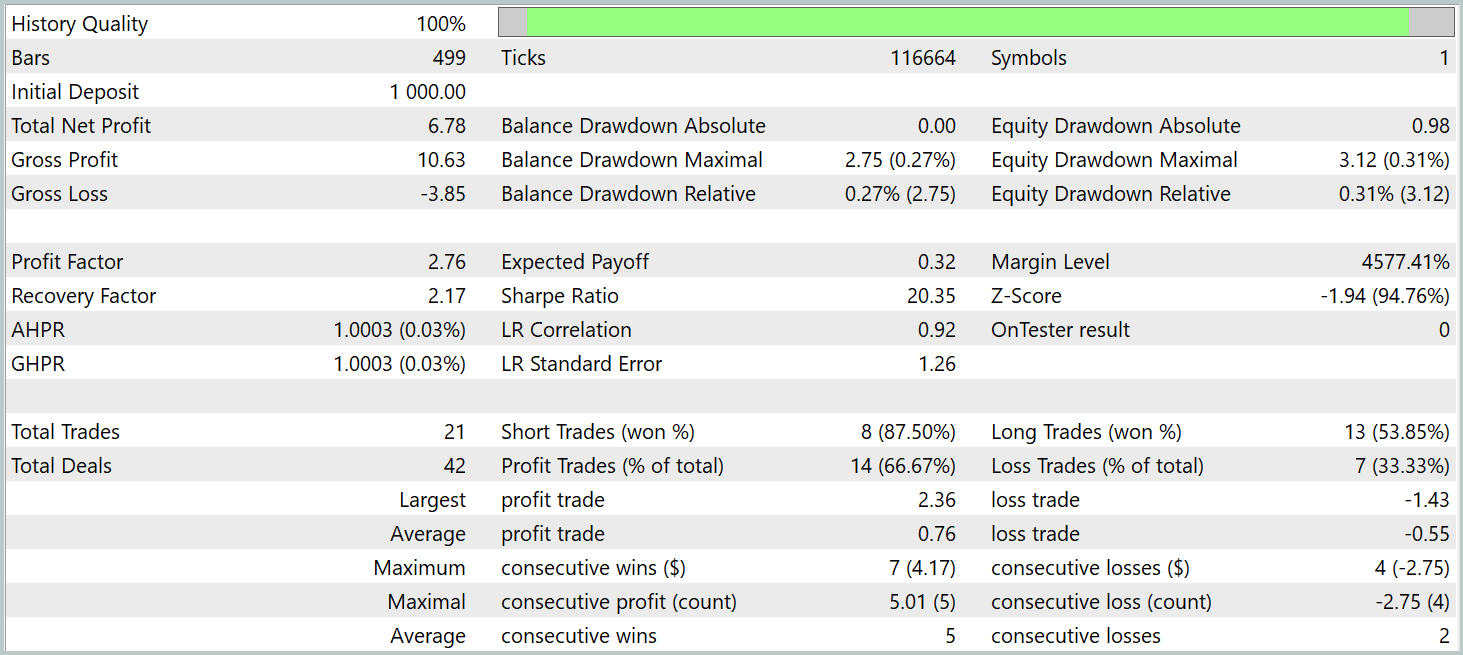
Während des Testzeitraums führte das Modell 21 Handelsgeschäfte aus, d. h. im Durchschnitt etwa ein Handelsgeschäft pro Handelstag. Davon waren 14 mit Gewinn, was mehr als 66 % ist. Der durchschnittliche Gewinn überstieg den durchschnittlichen Verlust um 38 %.
Die Saldenkurve zeigt einen klaren Aufwärtstrend in den ersten beiden Jahrzehnten des Monats.
Insgesamt zeigen die Ergebnisse ein vielversprechendes Potenzial. Bei weiterer Verfeinerung und zusätzlichem Training auf einem größeren Datensatz könnte das Modell für den Live-Handel eingesetzt werden.
Schlussfolgerung
Wir haben den Rahmen PSformer erforscht, der für seine hohe Genauigkeit bei Zeitreihenprognosen und seine effiziente Nutzung von Rechenressourcen bekannt ist. Zu den wichtigsten architektonischen Elementen von PSformer gehören der Parameter-Sharing-Block (PS) und der Mechanismus der räumlich-zeitlich segmentierten Aufmerksamkeit (SegAtt). Diese Elemente ermöglichen eine wirksame Modellierung sowohl lokaler als auch globaler Zeitreihenabhängigkeiten bei gleichzeitiger Verringerung der Anzahl der Parameter ohne Einbußen bei der Prognosequalität.
Wir haben unsere eigene Interpretation der vorgeschlagenen Ansätze in MQL5 implementiert. Wir haben mit diesen Methoden Modelle trainiert und sie an historischen Daten außerhalb des Trainingssatzes getestet. Die Ergebnisse zeigen ein deutliches Potenzial für die trainierten Modelle.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor zum Sammeln von Beispielen |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor für das Sammeln von Beispielen nach der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Modellausbildung Expert Advisor |
| 4 | StudyEncoder.mq5 | Expert Advisor | Expert Advisor für das Training des Encoders |
| 5 | Test.mq5 | Expert Advisor | Modellprüfung Expert Advisor |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Bibliothek | OpenCL-Programmcode-Bibliothek |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16483
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn ich die Datei Research.mq5 kompiliere, erhalte ich diesen Fehler
und wenn ich die Datei ResearchRealORL.mq5 kompiliere, erhalte ich diese Fehlermeldung
und wenn ich die Datei Study.mq5 kompiliere, erhalte ich diesen Fehler
Fast der gleiche Fehler wiederholt, was habe ich falsch gemacht?
und wenn ich die Datei Test.mq5 kompiliere, erhalte ich diesen Fehler
Ich habe Fehler in der Datei math.math/mqh erhalten. Wenn es irgendwelche Lösungen für dieses Problem gibt, wäre ich sehr dankbar.