
Машинное обучение и Data Science (Часть 12): Можно ли выигрывать на рынке с помощью самообучающихся нейронных сетей?

«Я не утверждаю, что нейронные сети — это просто. Нужно быть экспертом, чтобы заставить их работать. Но у этого опыта гораздо более широкое применение. Те усилия, которые раньше уходили на разработку функций, теперь направлены на разработку архитектуры, функции потерь и схемы оптимизации. Ручной труд переходит на более высокий уровень абстракции».
Стефано Соатто
Введение
Если вы занимаетесь алгоритмической торговлей, вы скорее всего слышали о нейронных сетях. Кажется, вот он, путь к созданию святого грааля. Однако в этом я не уверен, потому что для получения прибыльной системы требуется больше, чем просто добавить в торгового робота нейросеть. Более того, нужно четко понимать, во что вы ввязываетесь при использовании нейронных сетей, потому что иногда успех или неудача, т.е. прибыли или убыток, зависят от мельчайших деталей.

Лично я думаю, что нейронные сети не помогут тем, кто не хочет марать руки. Ведь с ними постоянно нужно тратить время на анализ ошибок модели, предварительную обработку и масштабирование входных данных, и многое другое, о чем мы поговорим в этой статье.
Давайте начнем эту статью с определения искусственной нейронной сети.
Что такое искусственная нейронная сеть?
Простыми словами, искусственная нейронная сеть представляет собой вычислительную систему, вдохновленные биологическими нейронными сетями живого мозга. Об основных компонентах нейросетей мы говорили в предыдущей статье из этой серии.
В предыдущих статьях я объяснял основные вещи, касающиеся нейронной сети с прямой связью. В этой статье мы рассмотрим прямой и обратный проходы, а также обучение и тестирование нейронных сетей. Мы создадим торгового робота на основе всего, о чем говорилось, и посмотрим, как работает наш торговый робот.
Если говорить о многослойном перцептроне, все нейроны/узлы текущего слоя связаны между собой с узлами второго слоя и так далее для всех слоев от входа до выхода. Благодаря этому нейронная сеть может выявлять сложные отношения в наборах данных. Чем больше у вас слоев, тем больше ваша модель способна понимать сложные отношения в наборах данных. Однако платой за это является высокая вычислительная цена, которая вовсе не гарантирует точность модели, особенно если модель слишком сложна, а задача проста.
Зачастую одного скрытого слоя достаточно для большинства задач, которые люди пытаются решить с помощью сложных нейронных сетей. Мы в статье будем работать с однослойной нейронной сетью.
Прямой проход
Операции, связанные с прямым проходом сети, просты, их можно реализовать в нескольких строках кода. Для создания по-настоящему гибких сетей стоит изучить операции с матрицами и векторами, потому что они являются строительным блоком нейронных сетей и многих алгоритмов машинного обучения, которые мы обсуждаем в этой серии.
Важный момент: при работе надо понимать тип проблемы, которую вы пытаетесь решить с помощью нейронной сети, потому что для разных задач требуются разные типы сетей с разными конфигурациями и разными выходными данными.
Основные типы задач:
- Задачи регрессии
- Задачи классификации
В задачах регрессии мы пытаемся предсказать непрерывные переменные. Применительно к трейдингу, здесь мы пытаемся предсказать следующую ценовую точку, к которой пойдет рынок. Если вы не знакомы с линейной регрессией, рекомендую почитать о ней здесь.
Задачи такого вида решают регрессионные нейросети.
2. Задачи классификации
В задачах классификации мы стараемся предсказать результаты на дискретных переменных. Применительно к трейдингу мы могли бы предсказывать сигналы. Скажем, сигнал 0 означает, что рынок движется вниз, а сигнал 1 — что рынок движется вверх.
Задачи такого рода решаются нейронными сетями классификации или нейронными сетями распознавания образов, в MATLAB они называются patternnet.
В этой статье мы будем работать с задачей регрессии, пытаясь предсказать следующую цену, к которой пойдет рынок.
matrix CRegNeuralNets::ForwardPass(vector &input_v) { matrix INPUT = this.matrix_utils.VectorToMatrix(input_v); matrix OUTPUT; OUTPUT = W.MatMul(INPUT); //Weight X Inputs OUTPUT = OUTPUT + B; //Outputs + Bias OUTPUT.Activation(OUTPUT, ENUM_ACTIVATION_FUNCTION(A_FX)); //Activation Function return (OUTPUT); }
Эта функция прямого прохода должна быть понятна, но самое важное, на что следует обратить пристальное внимание, — это размер матрицы на каждом шаге, чтобы все работало как надо.
matrix INPUT = this.matrix_utils.VectorToMatrix(input_v);
Эту часть стоит пояснить. Поскольку функция VectorToMatrix принимает на вход вектор, входные данные должны быть в матричной форме, потому что дальше мы будем использовать матричные операции.
Помните, что:
- Первая матрица на входе в нейросеть это матрица nx1
- Матрица весов представляет собой HN x n где HN — количество узлов в текущем скрытом слое, а n — количество входов из предыдущего слоя или количество строк входной матрицы.
- Матрица смещения имеет тот же размер, что и выходные данные слоя.
Это очень важно помнить. Запомните эти пункты, чтобы не разбираться во всем этом самостоятельно.
Давайте посмотрим на архитектуру нейронной сети, над которой мы работаем, чтобы вы четко понимали, чем мы здесь занимаемся.
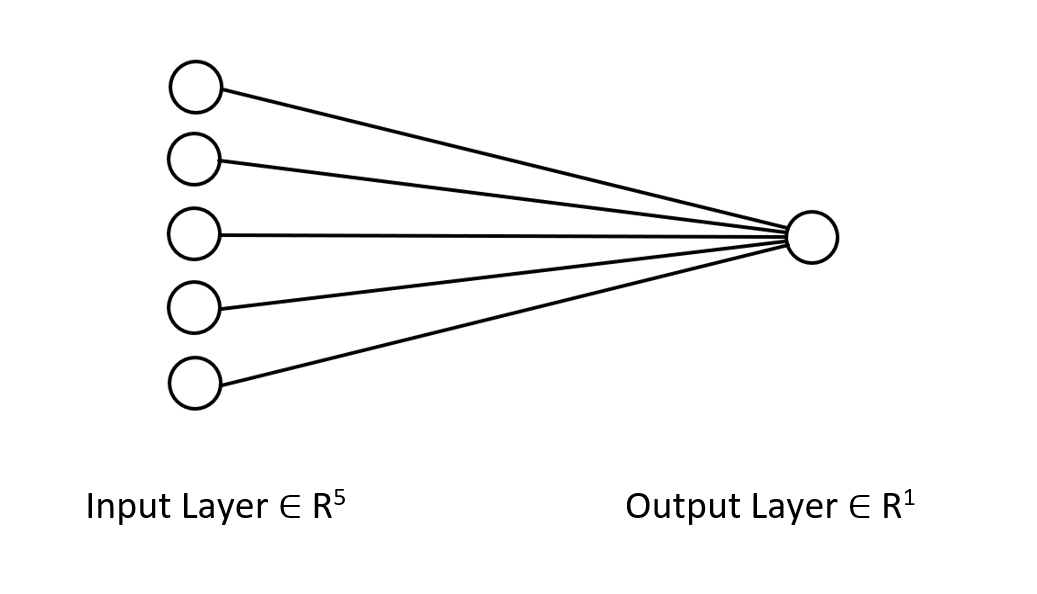
В этой нейросети только один слой, поэтому в функции прямого прохода, показанной выше, нет циклов. При этом, если следовать тому же матричному подходу и использовать соответствующие размеры, вы сможете реализовать архитектуру любой сложности.
Итак, выше показан прямой проход с матрицей W. Давайте теперь посмотрим, как найти веса для нашей модели.
Генерация весов
Генерация подходящих весов для нейронной сети — это не просто инициализация случайных значений. Я узнал на горьком опыте, что неправильный подход вызывает всевозможные проблемы с обратным распространением, которые заставляют усомниться в этом сложном коде и заниматься его отладкой.
Если инициализировать веса неправильно, весь процесс обучения можно сделать излишне трудоемким и долгим. Сеть может застрять на локальных минимумах и очень медленно сходиться.
На первом шаге мы выбираем случайные значения, я предпочитаю использовать случайное состояние 42.
this.W = matrix_utils.Random(0.0, 1.0,1,m_inputs, RANDOM_STATE);
Большинство людей останавливаются на этом шаге — генерируют веса и думают, что это все. После выбора случайных величин нужно инициализировать веса, используя Glorot или Инициализацию Ге (He Initialization).
Инициализация Xavier/Glorot лучше всего работает с сигмовидными и тангенциальными функциями активации, в то время как инициализация Ге работает с RELU и его вариантами.
Инициализация Ге (He)
![]()
где: n — это количество входов в узел.
Таким образом, после инициализации весов у нас идет нормализация.
this.W = matrix_utils.Random(0.0, 1.0,1,m_inputs, RANDOM_STATE); this.W = this.W * 1/sqrt(m_inputs); //He initialization
Поскольку эта нейронная сеть имеет один слой, у нас только одна матрица для переноса весов.
Функции активации нейронов
Это нейронная сеть регрессионного типа, а функции активации этой сети являются просто вариантами функции активации регрессии. RELU:
enum activation { AF_ELU_ = AF_ELU, AF_EXP_ = AF_EXP, AF_GELU_ = AF_GELU, AF_LINEAR_ = AF_LINEAR, AF_LRELU_ = AF_LRELU, AF_RELU_ = AF_RELU, AF_SELU_ = AF_SELU, AF_TRELU_ = AF_TRELU, AF_SOFTPLUS_ = AF_SOFTPLUS };
Эти функции активации, выделенные красным, в числе других доступны в стандартной библиотекой (Документация).
Функции потерь
Функции потерь для этой регрессионной нейронной сети:
enum loss { LOSS_MSE_ = LOSS_MSE, LOSS_MAE_ = LOSS_MAE, LOSS_MSLE_ = LOSS_MSLE, LOSS_HUBER_ = LOSS_HUBER };
В стандартной библиотеке есть и другие функции активации, подробнее о которых можно почитать в документации.
Обратный проход с использованием дельта-правила
Дельта-правило — это правило обучения градиентного спуска для обновления весов входных данных искусственных нейронов в однослойной нейронной сети. Это частный случай более общего алгоритма обратного распространения. Для нейрона j с активационной функцией g(x), дельта-правило веса Wji на позиции i для нейрона j будет таким:
![]()
Где:
![]() это небольшая константа, называемая скоростью обучения
это небольшая константа, называемая скоростью обучения
![]() является производной от g
является производной от g
g(x) — это функция активации нейрона
![]() целевой результат
целевой результат
![]() фактический результат
фактический результат
![]() i-ый вход
i-ый вход
Отлично, теперь у нас есть формула, так что нам просто нужно ее реализовать, верно? Нет.
Проблема с этой формулой в том, что как бы просто она ни выглядела, она очень сложна при преобразовании ее в код и требует пары циклов for. Такая практика в нейронных сетях может свести с ума. Правильная формула, которая нам нужна, это та, которая использует матричные операции. Вот она:
![]()
Где:
![]() — изменение матрицы весов
— изменение матрицы весов
![]() — производная функции потерь
— производная функции потерь
![]() — поэлементное умножение матриц/Адамарово произведение
— поэлементное умножение матриц/Адамарово произведение
![]() — производная матрицы активации нейронов
— производная матрицы активации нейронов
![]() — матрица входных значений.
— матрица входных значений.
Размер матрицы L всегда равен размеру матрицы O, а результирующая матрица в правой части должна иметь тот же размер, что и матрица W. Так и только так.
Давайте посмотрим, как это выглядит при переносе формулы в код.
for (ulong iter=0; iter<m_rows; iter++) { OUTPUT = ForwardPass(m_x_matrix.Row(iter)); //forward pass pred = matrix_utils.MatrixToVector(OUTPUT); actual[0] = m_y_vector[iter]; preds[iter] = pred[0]; actuals[iter] = actual[0]; //--- INPUT = matrix_utils.VectorToMatrix(m_x_matrix.Row(iter)); vector loss_v = pred.LossGradient(actual, ENUM_LOSS_FUNCTION(L_FX)); LOSS_DX.Col(loss_v, 0); OUTPUT.Derivative(OUTPUT, ENUM_ACTIVATION_FUNCTION(A_FX)); OUTPUT = LOSS_DX * OUTPUT; INPUT = INPUT.Transpose(); DX_W = OUTPUT.MatMul(INPUT); this.W -= (alpha * DX_W); //Weights update by gradient descent }
Преимущество использования для машинного обучения библиотеки матриц от MQL5 вместо массивов заключается в том, что нам не нужно производить никаких расчетов, я имею в виду, что не нужно самостоятельно считать производные функции потерь, производные функции активации — вообще ничего.
Чтобы обучить модель, нужно учесть две вещи: по крайней мере на данный момент эпохи и скорость обучения обозначаются как альфа. Если вы читали предыдущую статью из этой серии, в которой мы говорили о градиентном спуске, вы понимаете, о чем я говорю.
Эпохи. Одна эпоха — это когда весь набор данных полностью проходит цикл вперед и назад по сети. Простыми словами, это когда сеть увидела все данные. Чем больше количество эпох, тем больше времени требуется для обучения нейронной сети и тем лучше она может быть обучена.
Альфа — это размер шага, с которым алгоритм градиентного спуска движется к глобальному и локальному минимуму. Альфа обычно представляет собой небольшое значение от 0,1 до 0,00001. Чем больше это значение, тем быстрее сходится сеть, но тем выше риск пройти мимо локального минимума.
Ниже приведен полный код этого дельта-правила:
for (ulong epoch=0; epoch<epochs && !IsStopped(); epoch++) { for (ulong iter=0; iter<m_rows; iter++) { OUTPUT = ForwardPass(m_x_matrix.Row(iter)); pred = matrix_utils.MatrixToVector(OUTPUT); actual[0] = m_y_vector[iter]; preds[iter] = pred[0]; actuals[iter] = actual[0]; //--- INPUT = matrix_utils.VectorToMatrix(m_x_matrix.Row(iter)); vector loss_v = pred.LossGradient(actual, ENUM_LOSS_FUNCTION(L_FX)); LOSS_DX.Col(loss_v, 0); OUTPUT.Derivative(OUTPUT, ENUM_ACTIVATION_FUNCTION(A_FX)); OUTPUT = LOSS_DX * OUTPUT; INPUT = INPUT.Transpose(); DX_W = OUTPUT.MatMul(INPUT); this.W -= (alpha * DX_W); } printf("[ %d/%d ] Loss = %.8f | accuracy %.3f ",epoch+1,epochs,preds.Loss(actuals,ENUM_LOSS_FUNCTION(L_FX)),metrics.r_squared(actuals, preds)); }
Теперь все готово. Пришло время обучить нейронную сеть понимать небольшую закономерность в наборе данных.
#include <MALE5\Neural Networks\selftrain NN.mqh> #include <MALE5\matrix_utils.mqh> CRegNeuralNets *nn; CMatrixutils matrix_utils; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- matrix Matrix = { {1,2,3}, {2,3,5}, {3,4,7}, {4,5,9}, {5,6,11} }; matrix x_matrix; vector y_vector; matrix_utils.XandYSplitMatrices(Matrix,x_matrix,y_vector); nn = new CRegNeuralNets(x_matrix,y_vector,0.01,100, AF_RELU_, LOSS_MSE_); //Training the Network //--- return(INIT_SUCCEEDED); }
Функция XandYSplitMatrices разбивает матрицу на матрицу x и вектор y.
| X Matrix | Y Vector |
|---|---|
| { {1, 2}, {2, 3}, {3, 4}, {4, 5}, {5, 6} } | {3}, {5}, {7}, {9}, {11} |
Результаты обучения:
CS 0 20:30:00.878 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [1/100] Loss = 56.22401001 | accuracy -6.028 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [2/100] Loss = 2.81560904 | accuracy 0.648 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [3/100] Loss = 0.11757813 | accuracy 0.985 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [4/100] Loss = 0.01186759 | accuracy 0.999 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [5/100] Loss = 0.00127888 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [6/100] Loss = 0.00197030 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [7/100] Loss = 0.00173890 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [8/100] Loss = 0.00178597 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [9/100] Loss = 0.00177543 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [10/100] Loss = 0.00177774 | accuracy 1.000 … … … CS 0 20:30:00.883 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [100/100] Loss = 0.00177732 | accuracy 1.000
Всего после 5 эпох точность нейронной сети составила 100%. Это хорошо, потому что эта задача очень простая, и более быстрого обучение было ожидаемо.
Теперь, когда эта нейронная сеть обучена, давайте протестируем ее на новых значениях {7,8}. Мы с вами знаем, что результат равен 15.
vector new_data = {7,8}; Print("Test "); Print(new_data," pred = ",nn.ForwardPass(new_data));
Выводимая информация:
CS 0 20:37:36.331 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) Test CS 0 20:37:36.331 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [7,8] pred = [[14.96557787153696]]
Мы получили близкое значение 14,97. 15 — это просто значение double, f здесь мы получили дополнительные значения, но при округлении до 1 значащей цифры на выходе получится 15. Это свидетельствует о том, что наша нейронная сеть теперь способна учиться сама по себе. Отлично.
Давайте дадим этой модели реальный набор данных и посмотрим, что она сделает.
Я использовал данные по акциям Tesla и Apple в качестве независимых переменных для предсказания индекса NASDAQ (NAS 100). Я как-то прочитал в интернете статью на CNBC о том, что акции шести технологических компаний составляют половину стоимости NASDAQ. Две из них это Apple и Tesla. В этом примере я буду использовать эти две акции в качестве независимых переменных для обучения нейронной сети.
input string symbol_x = "Apple_Inc_(AAPL.O)"; input string symbol_x2 = "Tesco_(TSCO.L)"; input ENUM_COPY_RATES copy_rates_x = COPY_RATES_OPEN; input int n_samples = 100; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { matrix x_matrix(n_samples,2); vector y_vector; vector x_vector; //--- x_vector.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 0); x_vector.CopyRates(symbol_x2, PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 1); y_vector.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_CLOSE,0,n_samples); nn = new CRegNeuralNets(x_matrix,y_vector,0.01,1000, AF_RELU_, LOSS_MSE_);
Название символов в symbol_x и symbol_x2 у вашего брокера может отличаться. Не забудьте изменить эти переменные и добавить символы в обзор рынка перед запуском тестового советника. Символ y — текущий символ графика. Советник нужно запускать на графике NASDAQ.
После запуска скрипта вот что получилось в журнале:
CS 0 21:29:20.698 Self Trained NN EA (NAS100,M30) [ 1/1000 ] Loss = 353809311769.08959961 | accuracy -27061631.733 CS 0 21:29:20.698 Self Trained NN EA (NAS100,M30) [ 2/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 3/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 4/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 5/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 6/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 .... .... CS 0 21:29:20.886 Self Trained NN EA (NAS100,M30) [ 1000/1000 ] Loss = 149221473.48209998 | accuracy -11412.427
Что?! И это мы получили после всего того, что сделали. Подобные вещи часто происходят в нейронных сетях, поэтому очень важно иметь четкое понимать, как работает нейросеть, независимо от того, какой фреймворк или библиотеку Python вы используете.
Нормализация и масштабирование данных
Не устану повторять, насколько это важно. Хотя не все выборки дают лучшие результаты при нормализации, например, если нормализовать этот простой датасет, который мы использовали сначала для проверки работоспособности нейросети, результаты будут ужасными. Нейросеть будет возвращать значения хуже — я проверял.
Существует множество методов нормализации. Три наиболее часто используемых из них:
Min-Max Scaler
Это метод нормализации, который масштабирует значения числового признака до фиксированного диапазона [0, 1]. Вот так выглядит ее формула:
x_norm = (x -x_min) / (x_max - x_min)
где:
x — исходное значение функции
x_min — минимальное значение функции
x_max — максимальное значение функции
x_norm — новое нормализованное значение признака
Для выбора метода нормализации и нормализации данных необходимо импортировать библиотеку предобработки. Include-файл приложен в конце статьи.
Я решил добавить возможность нормализации данных в нашу библиотеку нейронных сетей.
CRegNeuralNets::CRegNeuralNets(matrix &xmatrix, vector &yvector,double alpha, uint epochs, activation ACTIVATION_FUNCTION, loss LOSS_FUNCTION, norm_technique NORM_METHOD)
Тут можно выбрать подходящий метод нормализации в norm_technique:
enum norm_technique { NORM_MIN_MAX_SCALER, //Min max scaler NORM_MEAN_NORM, //Mean normalization NORM_STANDARDIZATION, //standardization NORM_NONE //Do not normalize. };
После добавления нормализации я смог получить приемлемую точность.
nn = new CRegNeuralNets(x_matrix,y_vector,0.01,1000, AF_RELU_, LOSS_MSE_,NORM_MIN_MAX_SCALER);
Выводимая информация:
CS 0 22:40:56.457 Self Trained NN EA (NAS100,M30) [ 1/1000 ] Loss = 0.19379434 | accuracy -0.581 CS 0 22:40:56.457 Self Trained NN EA (NAS100,M30) [ 2/1000 ] Loss = 0.07735744 | accuracy 0.369 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 3/1000 ] Loss = 0.04761891 | accuracy 0.611 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 4/1000 ] Loss = 0.03559318 | accuracy 0.710 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 5/1000 ] Loss = 0.02937830 | accuracy 0.760 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 6/1000 ] Loss = 0.02582918 | accuracy 0.789 CS 0 22:40:56.459 Self Trained NN EA (NAS100,M30) [ 7/1000 ] Loss = 0.02372224 | accuracy 0.806 CS 0 22:40:56.459 Self Trained NN EA (NAS100,M30) [ 8/1000 ] Loss = 0.02245222 | accuracy 0.817 CS 0 22:40:56.460 Self Trained NN EA (NAS100,M30) [ 9/1000 ] Loss = 0.02168207 | accuracy 0.823 CS 0 22:40:56.460 Self Trained NN EA (NAS100,M30 CS 0 22:40:56.623 Self Trained NN EA (NAS100,M30) [ 1000/1000 ] Loss = 0.02046533 | accuracy 0.833
Также должен признать, что я не получил желаемых результатов на часовом таймфрейме. Нейросеть работала точнее на 30-минутном графике, но я не стал разбираться, в чем причина.
Итак, точность тренировочных данных составляет 82,3%. Это хорошая точность. Теперь создадим простую торговую стратегию, которая будет использовать нашу сеть для открытия сделок.
Текущий подход, который я использовал для сбора данных в функции OnInit ненадежен. Я создам функцию для обучения сетей и размещу ее в функции Init. Наша сеть будет обучаться только один раз в жизни. Однако вы можете этот момент поменять при желании — это необязательно условие.
void OnTick() { //--- if (!train_nn) TrainNetwork(); //Train the network only once train_nn = true; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void TrainNetwork() { matrix x_matrix(n_samples,2); vector y_vector; vector x_vector; x_vector.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 0); x_vector.CopyRates(symbol_x2, PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 1); y_vector.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_CLOSE,0,n_samples); nn = new CRegNeuralNets(x_matrix,y_vector,0.01,1000, AF_RELU_, LOSS_MSE_,NORM_MIN_MAX_SCALER); }
Кажется, что в этой функции обучения есть все, что нам нужно, чтобы выйти на рынок. Однако, она все же не надежна. Я запустил тестирование на дневном таймфрейме и получил точность -77%, на таймфрейме H4 он выдал точность -11234 или что-то в этом роде. При увеличении данных и тренировке на различных обучающих выборках нейронная сеть не соответствовала точности обучения, которую давала ранее.
Есть множество причин для этого, одна из них заключается в том, что разные проблемы требуют разных архитектур. Я предполагаю, что некоторые рыночные модели на разных таймфреймах могут быть слишком сложными для однослойной нейронной сети, а правило дельты предназначено именно для такой. Пока мы не можем это исправить, поэтому я продолжу с тем таймфреймом на котором у нас есть приемлемый результат. Тем не менее, мы можем кое-что сделать, чтобы улучшить результаты и немного исправить это непоследовательное поведение. Можно разделить данные со случайным состоянием.
Это важнее, чем вы можете подумать
Если вы до этого работали с Python в области машинного обучения, вы, вероятно, встречали функцию train_test_split от sklearn.
Цель разделения выборки на обучающие и тестовые данные состоит не только в том, чтобы поделить данные, но и в том, чтобы рандомизировать датасет, чтобы он не находился в исходном порядке. Я объясню. Поскольку нейросети и другие алгоритмы машинного обучения стремятся понять закономерности в данных, наличие данных в том же порядке, из которого они были извлечены, может быть плохо — моделям легче понять закономерности, когда данные представлены в том же порядке. Это не лучший способ обучения моделей, потому что для нас важно не расположение данных, а сами закономерности.
void TrainNetwork() { //--- collecting the data matrix Matrix(n_samples,3); vector y_vector; vector x_vector; x_vector.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,n_samples); Matrix.Col(x_vector, 0); x_vector.CopyRates(symbol_x2, PERIOD_CURRENT,copy_rates_x,0,n_samples); Matrix.Col(x_vector, 1); y_vector.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_CLOSE,0,n_samples); Matrix.Col(y_vector, 2); //--- matrix x_train, x_test; vector y_train, y_test; matrix_utils.TrainTestSplitMatrices(Matrix, x_train, y_train, x_test, y_test, 0.7, 42); nn = new CRegNeuralNets(x_train,y_train,0.01,1000, AF_RELU_, LOSS_MSE_,NORM_MIN_MAX_SCALER); vector test_pred = nn.ForwardPass(x_test); printf("Testing Accuracy =%.3f",metrics.r_squared(y_test, test_pred)); }
После сбора обучающих данных мы ввели функцию TrainTestSplitMatrices с random state 42.
void TrainTestSplitMatrices(matrix &matrix_,matrix &x_train,vector &y_train,matrix &x_test, vector &y_test,double train_size=0.7,int random_state=-1)
Прогнозирование рынка в реальном времени
Чтобы делать прогнозы в реальном времени, в функции Ontick должен быть код для сбора данных и размещения их во входной вектор функции прямого прохода нейронной сети.
void OnTick() { //--- if (!train_nn) TrainNetwork(); //Train the network only once train_nn = true; vector x1, x2; x1.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,1); //only the current candle x2.CopyRates(symbol_x2,PERIOD_CURRENT,copy_rates_x,0,1); //only the current candle vector inputs = {x1[0], x2[0]}; //current values of x1 and x2 instruments | Apple & Tesla matrix OUT = nn.ForwardPass(inputs); //Predicted Nasdaq value double pred = OUT[0][0]; Comment("pred ",OUT); }
Теперь наша нейронная сеть может делать прогнозы. Попробуем использовать ее в торговле. Для этого создадим стратегию.
Логика торговли
Торговая логика проста: если предсказанная нейронной сетью цена выше текущей, открываем сделку на покупку с тейк-профитом на уровне спрогнозированной цены, умноженной на значение входного параметра take profit. И наоборот для сделок на продажу. В каждой сделке ставится стоп-лосс, равный количеству пунктов тейк-профита, помноженных на значение параметра stop loss. Как это выглядит в MetaEditor.
stops_level = (int)SymbolInfoInteger(Symbol(),SYMBOL_TRADE_STOPS_LEVEL); Lots = SymbolInfoDouble(Symbol(),SYMBOL_VOLUME_MIN); spread = (double)SymbolInfoInteger(Symbol(), SYMBOL_SPREAD); MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (MathAbs(pred - ticks.ask) + spread > stops_level) { if (pred > ticks.ask && !PosExist(POSITION_TYPE_BUY)) { target_gap = pred - ticks.bid; m_trade.Buy(Lots, Symbol(), ticks.ask, ticks.bid - ((target_gap*stop_loss) * Point()) , ticks.bid + ((target_gap*take_profit) * Point()),"Self Train NN | Buy"); } if (pred < ticks.bid && !PosExist(POSITION_TYPE_SELL)) { target_gap = ticks.ask - pred; m_trade.Sell(Lots, Symbol(), ticks.bid, ticks.ask + ((target_gap*stop_loss) * Point()), ticks.ask - ((target_gap*take_profit) * Point()), "Self Train NN | Sell"); } }
Такая логика. Посмотрим, как советник работает в МТ5.
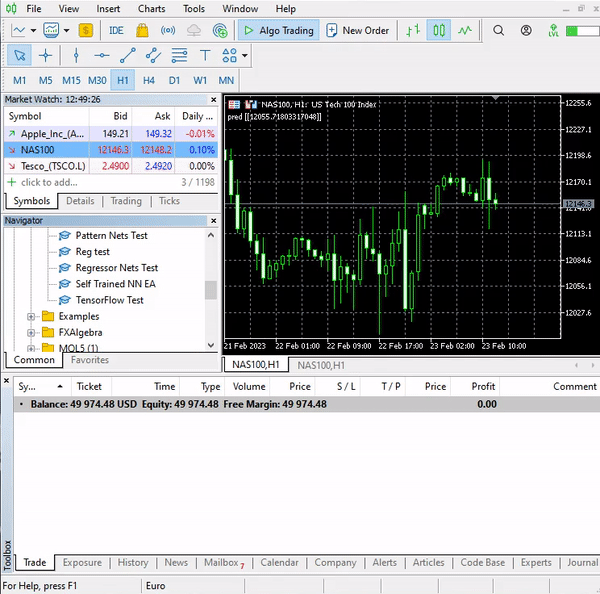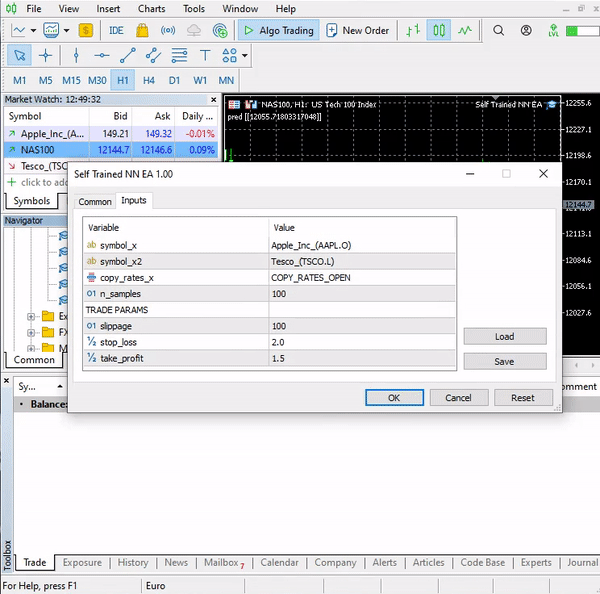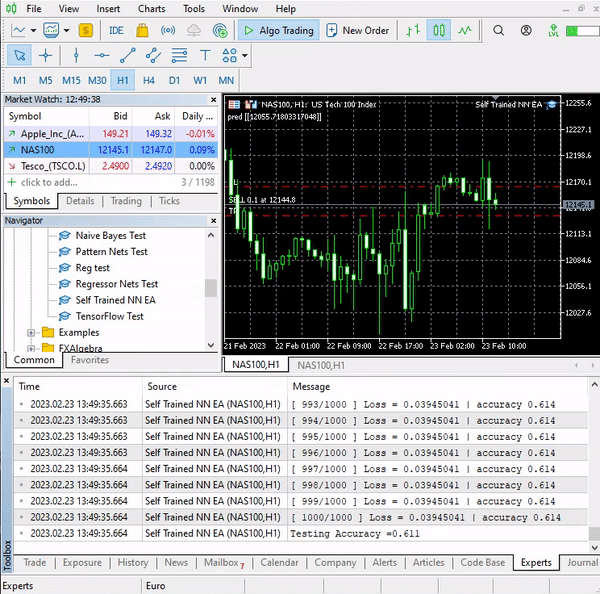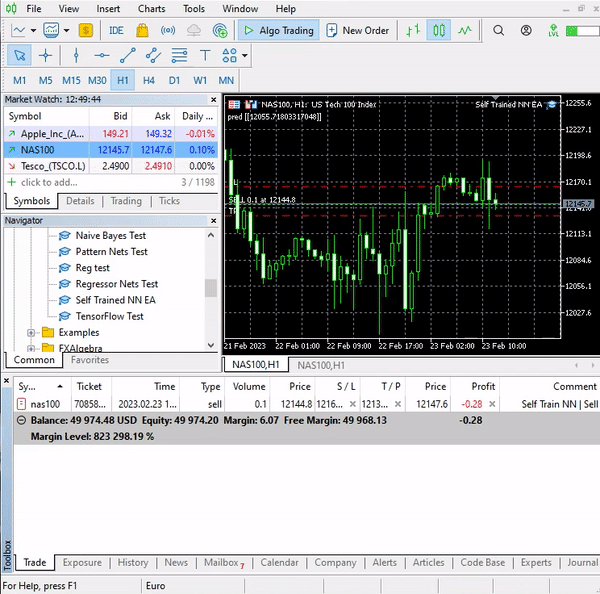
Этот простой советник может совершать сделки самостоятельно. Пока мы не можем оценить его работу — слишком рано. Перейдем в тестер стратегий.
Результаты тестера стратегий
Могут быть сложности с запуском алгоритмов машинного обучения в тестере стратегий, потому нужно убедиться, что алгоритмы работают гладко и быстрою. Ну и конечно, нужно убедиться, что советник генерирует прибыль.
Я запускал тесты с 2023.01.01 по 2023.02.23 на четырехчасовом графике на основе реальных тиков. Тестировались последние тики, так как подозреваю, что такой тест будет намного лучшего качества по сравнению тестированием на старых данных.
Мы настроили функцию, которая обучает нашу модель, на запуск на самом первом тике жизненного цикла тестирования, поэтому процесс обучения и тестирования модели был выполнен мгновенно. Посмотрим, как работает модель, а потом проверим графики и все, что предоставляет тестер стратегий.
CS 0 15:50:47.676 Tester NAS100,H4 (Pepperstone-Demo): generating based on real ticks CS 0 15:50:47.677 Tester NAS100,H4: testing of Experts\Advisors\Self Trained NN EA.ex5 from 2023.01.01 00:00 to 2023.02.23 00:00 started with inputs: CS 0 15:50:47.677 Tester symbol_x=Apple_Inc_(AAPL.O) CS 0 15:50:47.677 Tester symbol_x2=Tesco_(TSCO.L) CS 0 15:50:47.677 Tester copy_rates_x=1 CS 0 15:50:47.677 Tester n_samples=200 CS 0 15:50:47.677 Tester = CS 0 15:50:47.677 Tester slippage=100 CS 0 15:50:47.677 Tester stop_loss=2.0 CS 0 15:50:47.677 Tester take_profit=2.0 CS 3 15:50:49.209 Ticks NAS100 : 2023.02.21 23:59 - real ticks absent for 2 minutes out of 1379 total minute bars within a day CS 0 15:50:51.466 History Tesco_(TSCO.L),H4: history begins from 2022.01.04 08:00 CS 0 15:50:51.467 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 1/1000 ] Loss = 0.14025037 | accuracy -1.524 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 2/1000 ] Loss = 0.05244676 | accuracy 0.056 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 3/1000 ] Loss = 0.04488896 | accuracy 0.192 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 4/1000 ] Loss = 0.04114715 | accuracy 0.259 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 5/1000 ] Loss = 0.03877407 | accuracy 0.302 CS 0 15:50:51.469 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 6/1000 ] Loss = 0.03725228 | accuracy 0.329 CS 0 15:50:51.469 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 7/1000 ] Loss = 0.03627591 | accuracy 0.347 CS 0 15:50:51.469 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 8/1000 ] Loss = 0.03564933 | accuracy 0.358 CS 0 15:50:51.470 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 9/1000 ] Loss = 0.03524708 | accuracy 0.366 CS 0 15:50:51.470 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 10/1000 ] Loss = 0.03498872 | accuracy 0.370 CS 0 15:50:51.662 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 1000/1000 ] Loss = 0.03452066 | accuracy 0.379 CS 0 15:50:51.662 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 Testing Accuracy =0.717
Точность обучения составила 37,9%, но точность тестирования оказалась 71,7%. Как так?
Подозреваю, дело в качестве обучения. Всегда нужно следите за тем, чтобы данные для обучения и тестирования имели достойное качество, а каждый пропуск данных может иметь последствия. Поскольку мы проверяем результаты в тестере стратегий, мы должны быть уверены, что результаты тестирования на истории получены от хорошей модели, для построения которой мы приложили много усилий.
По окончании работы тестера стратегий результаты не удивили, большинство сделок, открытых этим советником, завершились с убытком в размере 78,27%.
Поскольку мы не оптимизировали стоп-лосс и тейк-профит, думаю, можно оптимизировать эти значения и другие параметры.
Я провел короткую оптимизацию и подобрал следующие значения: copy_rates_x: COPY_RATES_LOW, n_samples: 2950, Slippage: 1, Stop loss: 7.4, Take profit: 5.0.
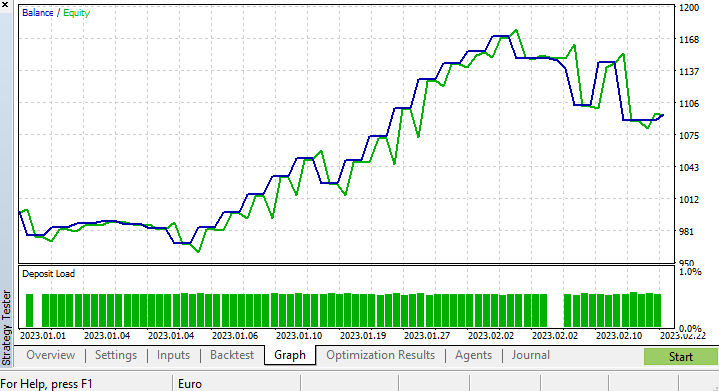
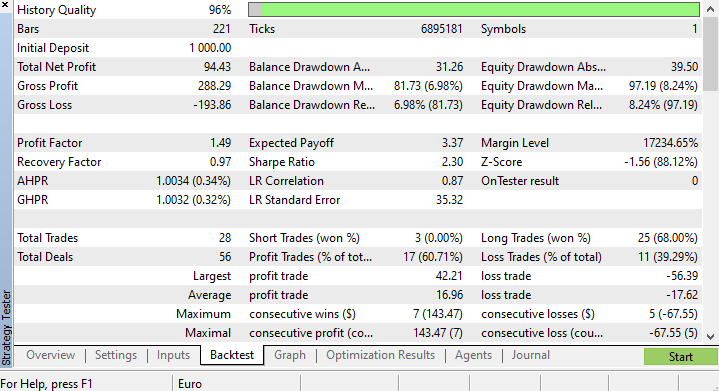
На этот раз модель показала точность обучения 61,5% и точность тестирования 63,5% в начале в тестере стратегий. Кажется приемлемым.
CS 0 17:11:52.100 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 1000/1000 ] Loss = 0.05890808 | accuracy 0.615 CS 0 17:11:52.101 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 Testing Accuracy =0.635
Заключительные мысли
Дельта-правило используется для однослойных нейронных сетей регрессионного типа. Несмотря на то, что это однослойная нейронная сеть, мы на ее примере посмотрели, как можно улучшить сеть, когда дела идут не очень хорошо. Однослойная нейронная сеть — это просто комбинация моделей линейной регрессии, работающих вместе как команда для решения задачи. Например:
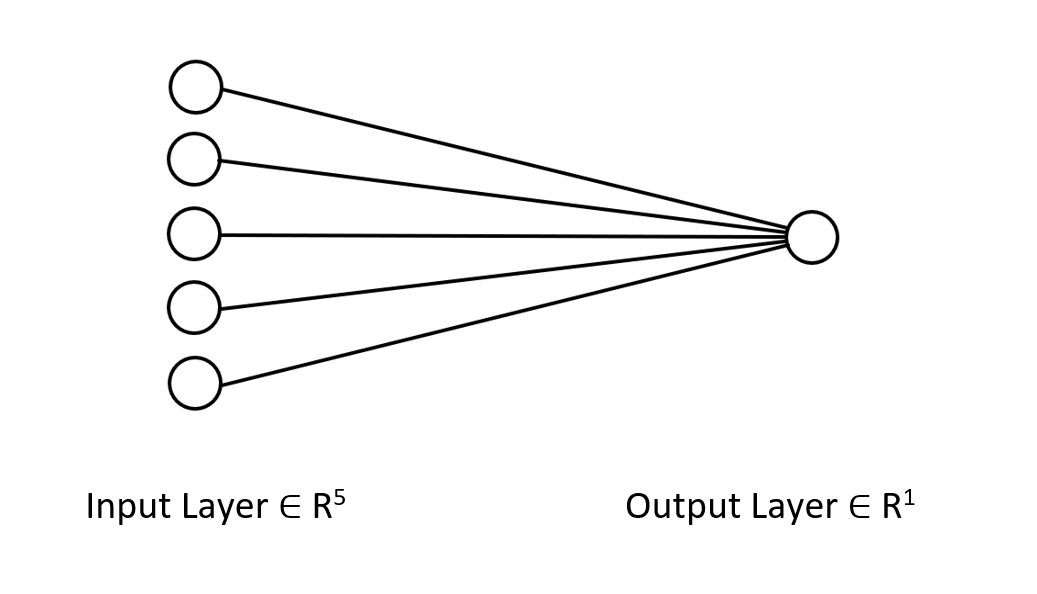
На это можно взглянуть с другой стороны - как 5 моделей линейной регрессии, работающих над одной и той же проблемой. Стоит отметить, что эта нейронная сеть не способна понимать сложные закономерности в переменных, поэтому не удивляйтесь результатам. Как было сказано ранее, дельта-правило является строительным блоком общего алгоритма обратного распространения, который используется для гораздо более сложных нейронных сетей в глубоком обучении.
Я построил нейронную сеть, которая не лишена ошибок, чтобы показать один момент: хотя нейронные сети способны изучать шаблоны, нужно обращать внимание на мелкие детали, чтобы сеть работала правильно и давала желаемые результаты.
Всем удачи!
Следите за разработкой этой библиотеки и других моделей машинного обучения в гитхабе: https://github.com/MegaJoctan/MALE5
Приложенные файлы:
| Файл | Содержание и использование |
|---|---|
| metrics.mqh | Содержит функции для измерения точности моделей нейронных сетей. |
| preprocessing.mqh | Содержит функции для масштабирования и подготовки данных для моделей нейронных сетей. |
| matrix_utils.mqh | Дополнительные функции для работы с матрицами |
| selftrain NN.mqh | Основной включаемый файл, содержащий самообучающиеся нейронные сети. |
| Self Train NN EA.mq5 | Советник для тестирования самообучающихся нейронных сетей |
Статьи по теме:
-
Работа с матрицами, расширение функционала Стандартной библиотеки матриц и векторов
-
Машинное обучение и Data Science — Нейросети (Часть 02): Архитектура нейронных сетей с прямой связью
-
Машинное обучение и Data Science — Нейросети (Часть 01): Разбираем нейронные сети с прямой связью
-
Машинное обучение и Data Science (Часть 06): Градиентный спуск
Внимание: все содержание настоящей статьи предназначено только для целей обучения и не предназначена для других целей. Трейдинг — рискованное занятие, и вы должны осознавать все связанные с ним риски. Автор не несет ответственности за любые убытки или потери в результате использования моделей, обсуждаемых в этой статье. Никогда не рискуйте деньгами большими, чем вы можете себе позволить потерять без ущерба для себя!
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/12209
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Хорошее демо, демонстрирующее возможность самообучения (настройки) ML советника.
Это все еще ранние дни MQL ML. Надеюсь, со временем все больше и больше людей будут использовать MALE5. С нетерпением ждем ее зрелости.
Как сохранить и загрузить сеть?