Машинное обучение и Data Science — Нейросети (Часть 01): Разбираем нейронные сети с прямой связью

"... устал от того, что я слишком много знаю и слишком мало понимаю."
― Ян Карон, "Дом Холли-Спрингс"
Введение
Нейронные сети выглядят как модная новая вещь, предлагающая способ приблизиться к Святому Граалю в трейдинге. Программы на основе нейронных сетей впечатляют, поскольку, кажется, что они хорошо предсказывают движения рынка, да и в целом хороши для любой поставленной задачи. Я тоже считаю, что у них есть огромный потенциал, если говорить о прогнозировании или классификации на основе неподготовленных новых данных.
Какими бы хорошими они ни были, создавать и оптимизировать их должны люди, хорошо понимающие, что они делают. Надо понимать, что не только многослойный перцептрон должен иметь правильную архитектуру, но и сам тип решаемой проблемы должен предполагать использование нейросетей, а не просто модели линейной или логистической регрессии или любого другого метода машинного обучения.
Нейронные сети — очень широкая тема, как и машинное обучение в целом, поэтому я решил начать отдельную подсерию. Рассмотрение других аспектов машинного обучения продолжим в другой ветки этой серии.
В этой статье рассмотрим основы нейронных сетей и разберем некоторые из основных вопросов, которые, как мне кажется, важно понять энтузиастам машинного обучения, чтобы освоить эту область.

Что такое искусственная нейронная сеть?
Искусственные нейронные сети (ИНС, нейронные сети, нейросети) представляют собой вычислительные системы, вдохновленные биологическими нейронными сетями живого мозга.
Многослойный перцептрон и глубокая нейронная сеть
В обсуждениях нейронных сетей часто можно встретить термин Многослойный перцептрон (MLP). Это наиболее распространенный тип нейронной сети. Многослойный перцептрон — это сеть, состоящая из входного, скрытого и выходного слоя. Из-за простоты им требуется короткое время обучения, чтобы изучить представление данных и получить результат.
Области применения:
Многослойный перцептрон обычно используется для данных, которые не являются линейно разделимыми, такими как регрессионный анализ. Благодаря своей простоте они больше всего подходят для решения сложных задач классификации и прогнозного моделирования. Они используются для машинного перевода, прогнозирования погоды, выявления мошенничества, прогнозов фондового рынка, прогнозов кредитного рейтинга и многих других аспектов, о которых только можно подумать.
Глубокие нейронные сети, наоборот, имеют общую структуру, но содержат слишком много скрытых слоев. Если ваша сеть имеет более трех (3) скрытых слоев, считайте ее глубокой нейронной сетью. Из-за своей сложной природы они требуют длительных периодов обучения сети на входных данных, кроме того, для них требуются мощные компьютеры со специализированными блоками обработки, такими как тензорные процессоры (TPU) и процессоры глубокого обучения.
Области применения:
Глубокие нейросети являются мощными алгоритмами благодаря глубине уровней, поэтому они обычно используются для решения сложных вычислительных задач. Одной из таких задач является компьютерное зрение.
Таблица различий:
| Многослойный перцептрон | Глубокая нейросеть |
|---|---|
| Небольшое количество скрытых слоев | Большое количество скрытых слоев |
| Быстрое обучение | Продолжительные периоды обучения |
| Достаточно оборудования с GPU | Требует оборудования с TPU |
Теперь давайте рассмотрим типы нейронных сетей.
Существует много типов нейронных сетей, они делятся на три основных класса:
- Нейронные сети с прямой связью
- Сверточные нейронные сети
- Рекуррентные нейронные сети
01: Нейронная сеть с прямой связью
Это один из самых простых типов нейронных сетей. Здесь данные проходят через различные входные узлы, пока не достигнут выходного узла. В отличие от метода обратного распространения, здесь данные передаются только в одном направлении.
Проще говоря, обратное распространение выполняет те же процессы в нейронной сети, что и прямой проход, когда данные передаются от входного слоя к выходному слою, за исключением того, что при обратном распространении после того, как выход сети достигает выходного слоя, он получает реальное значение класса. Сравнивая его с предсказанным значением, модель видит, насколько неправильными или правильными были сделанные ею предсказания. Если предсказания неверны, данные передаются обратно в сеть, а параметры обновляются для корректировки предсказания. Это алгоритм самообучения.
02: Рекуррентная нейронная сеть
Рекуррентная нейронная сеть — это тип искусственной нейронной сети, в которой выходные данные определенного слоя сохраняются и возвращаются во входной слой. Это помогает предсказать результат слоя.
Рекуррентные нейронные сети используются для решения задач, связанных с:
- Данными временного ряда
- Текстовыми данными
- Аудиоданными
Наиболее распространенное использование в текстовых данных — это рекомендации следующих слов для ИИ, например: Как + у + тебя + ...

03: Сверточная нейронная сеть
Сверточные нейросети используются очень часто. Например, в проектах по обработке изображений и видео.
Так, искусственный интеллект (ИИ) для обнаружения и классификации изображений состоит из сверточных нейронных сетей.

Источник изображения: analyticsvidhya.com
Мы рассмотрели типы нейронных сетей, теперь сосредоточимся на основной теме этой статьи Нейронные сети с прямой связью.
Нейросети с прямой связью
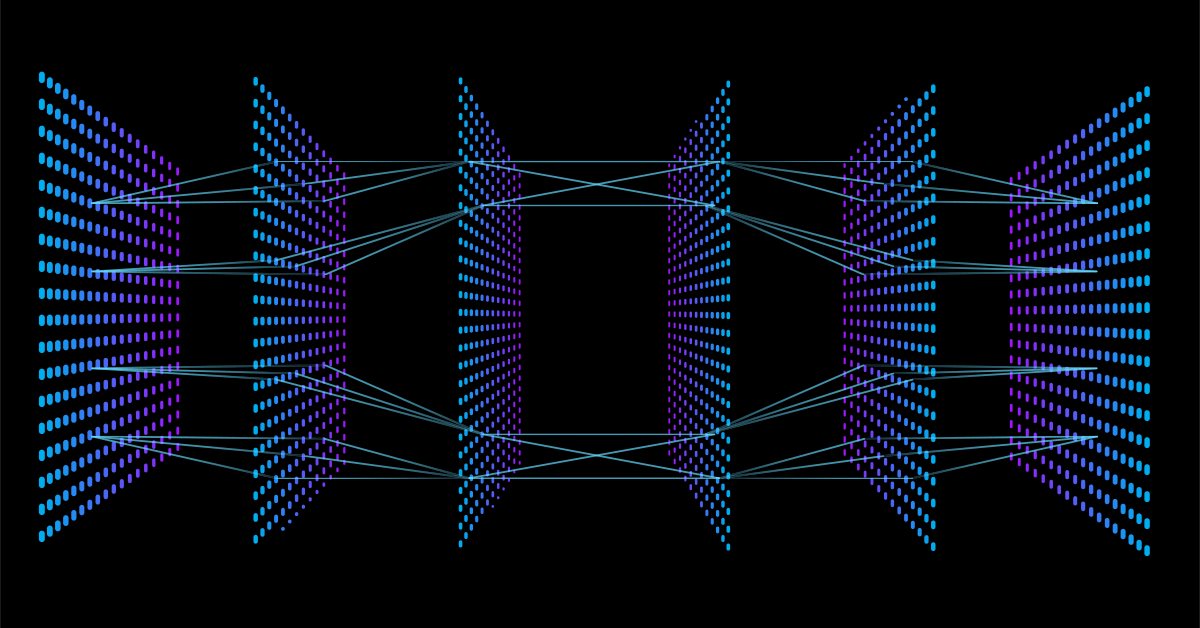
В отличие от других, более сложных типов нейронных сетей, здесь нет обратного распространения, то есть данные передаются только в одном направлении в этом типе нейронной сети. Нейронная сеть с прямой связью может иметь один или несколько скрытых слоев.
На схеме ниже показано, как работает эта нейросеть.

Входной слой
На схеме нейронной сети видно, что есть входной слой. По своей сути входной слой — это просто представление данных. Во входном слое расчеты не выполняются.
Скрытый слой
На скрытом уровне выполняется большая часть работы нейронной сети.
Чтобы лучше понять принцип работы, давайте разберем узел второго скрытого слоя.

Задействованные процессы:
- Нахождение скалярного произведения входных данных и их соответствующих весов
- Прибавление полученного скалярного произведения к смещению
- Передача результата второго действия в функцию активации
Что такое смещение?
Смещение позволяет сдвигать линейную регрессию вверх и вниз, чтобы лучше соответствовать линии прогноза данным. Это то же самое, что Intercept в линейной регрессии.
Этот параметр будет лучше объяснен в разделе Многослойный перцептрон с одним узлом в скрытом слое.
Также важность смещения хорошо объясняется в этой ветке.
Что такое весовые коэффициенты?
Весовые коэффициенты, или веса, отражают, насколько важны входные данные. Они выступают в роли коэффициентов уравнения, которое вы пытаетесь решить. Отрицательные веса уменьшают значение выходных данных и наоборот. Когда нейронная сеть обучается на наборе данных, она инициализируется с набором весов. Затем эти веса оптимизируются в течение периода обучения, и получается оптимальное значение весов.
Что такое функция активации?
Функция активации — это не что иное, как математическая функция, которая принимает входные данные и производит выходной сигнал.
Типы функций активации
Существует много функций активации с их вариантами, но вот наиболее часто используемые:
- Relu
- Сигмоид
- TanH
- Softmax
Очень важно знать, какую функцию активации использовать и где. При этом сколько раз я встречал в Интернете статьи, предлагающие использовать функцию активации там, где это неуместно. Давайте рассмотрим типы более подробно.
01: RELU
RELU означает "Выпрямленная функция линейной активации".
Это наиболее часто используемая функция активации в нейронных сетях. Она проще других, его легко написать в коде и легко интерпретировать вывод, поэтому она так популярна. Эта функция выводит данные напрямую, если входной слоя является положительным числом; в противном случае выводит ноль.
Логика такая
if x < 0 : return 0
else return x
Эту функцию лучше использовать при решении задач регрессии.

Выходные значения находятся в диапазоне от нуля до положительной бесконечности.
На MQL5 код функции будет таким:
double CNeuralNets::Relu(double z) { if (z < 0) return(0); else return(z); }
RELU решает проблему исчезающего градиента, от которой страдают функции сигмоида и TanH (подробнее познакомимся с ними в статье об обратном распространении).
02: Сигмоид
Звучит знакомо? Помните статью о логистической регрессии?
Формула сигмоида такая:
![]()
Эта функция лучше подходит для использования в задачах классификации, особенно при классификации только одного или двух классов.
Выходные значения находятся в диапазоне от нуля до единицы (вероятность).

Например, ваша сеть имеет два узла на выходе. Первый узел для кошки, а второй для собаки. Если выход первого узла больше 0,5, это будет означать кошку. И наоборот — собаку.
На MQL5 код функции будет таким:
double CNeuralNets::Sigmoid(double z) { return(1.0/(1.0+MathPow(e,-z))); }
03: TanH
Функция гиперболического тангенса.
Данная функция задается формулой:

Ее график выглядит следующим образом:

Эта функция активации похожа на сигмовидную, но лучше.
Ее выходные значения лежат в диапазоне от -1 до 1.
Эта функция подходит для использования в нейронных сетях мультиклассовой классификации.
Ее MQL5-код представлен ниже:
double CNeuralNets::tanh(double z) { return((MathPow(e,z) - MathPow(e,-z))/(MathPow(e,z) + MathPow(e,-z))); }
04: SoftMax
Кто-то однажды спросил, почему нет графика функции SoftMax. В отличие от других функций активации, SoftMax не используется в скрытых слоях, а только в выходном слое, и ее следует использовать только тогда, когда вы хотите преобразовать выходные данные мультиклассовой нейронной сети в термины вероятности.
Функция SoftMax предсказывает полиномиальное распределение вероятностей.

Например, выходы регрессионной нейронной сети: [1,3,2]. Если применить функцию SoftMax к этому выходному значению, выход теперь станет [0,09003, 0,665240, 0,244728].
Выходные значения этой функции находится в диапазоне от 0 до 1.
На MQL5 код функции будет таким:
void CNeuralNets::SoftMax(double &Nodes[]) { double TempArr[]; ArrayCopy(TempArr,Nodes); ArrayFree(Nodes); double proba = 0, sum=0; for (int j=0; j<ArraySize(TempArr); j++) sum += MathPow(e,TempArr[j]); for (int i=0; i<ArraySize(TempArr); i++) { proba = MathPow(e,TempArr[i])/sum; Nodes[i] = proba; } ArrayFree(TempArr); }
Теперь, когда мы понимаем, из чего состоит один нейрон скрытого слоя, давайте напишем его код.
void CNeuralNets::Neuron(int HLnodes, double bias, double &Weights[], double &Inputs[], double &Outputs[] ) { ArrayResize(Outputs,HLnodes); for (int i=0, w=0; i<HLnodes; i++) { double dot_prod = 0; for(int j=0; j<ArraySize(Inputs); j++, w++) { if (m_debug) printf("i %d w %d = input %.2f x weight %.2f",i,w,Inputs[j],Weights[w]); dot_prod += Inputs[j]*Weights[w]; } Outputs[i] = ActivationFx(dot_prod+bias); } }
Внутри функции ActivationFx() можно выбрать, для какой функции активации была выбрана функция при вызове конструктора NeuralNets.
double CNeuralNets::ActivationFx(double Q) { switch(A_fx) { case SIGMOID: return(Sigmoid(Q)); break; case TANH: return(tanh(Q)); break; case RELU: return(Relu(Q)); break; default: Print("Unknown Activation Function"); break; } return(0); }
Дополнительные пояснения к коду:
Функция Neuron() — это не просто одиночный узел внутри скрытого слоя, все операции скрытого слоя выполняются внутри этой одной функции. Узлы во всех скрытых слоях будут иметь тот же размер, что и входной узел, вплоть до конечного выходного узла. Я выбрал эту структуру, потому что собираюсь выполнить классификацию с использованием этой нейронной сети в случайно сгенерированном наборе данных.
Следующая далее функция FeedForwardMLP() — это структура NxN, т.е. если у вас три входных узла, и вы выбираете три скрытых слоя, на каждом скрытом слое будет по три скрытых узла. Посмотрите на рисунок:

Далее показана функция FeedForwardMLP():
void CNeuralNets::FeedForwardMLP(int HiddenLayers, double &MLPInputs[], double &MLPWeights[], double &bias[], double &MLPOutput[]) { double L_weights[], L_inputs[], L_Out[]; ArrayCopy(L_inputs,MLPInputs); int HLnodes = ArraySize(MLPInputs); int no_weights = HLnodes*ArraySize(L_inputs); int weight_start = 0; for (int i=0; i<HiddenLayers; i++) { if (m_debug) printf("<< Hidden Layer %d >>",i+1); ArrayCopy(L_weights,MLPWeights,0,weight_start,no_weights); Neuron(HLnodes,bias[i],L_weights,L_inputs,L_Out); ArrayCopy(L_inputs,L_Out); ArrayFree(L_Out); ArrayFree(L_weights); weight_start += no_weights; } if (use_softmax) SoftMax(L_inputs); ArrayCopy(MLPOutput,L_inputs); if (m_debug) { Print("\nFinal MLP output(s)"); ArrayPrint(MLPOutput,5); } }
Операции по поиску скалярного произведения в нейронной сети можно было бы выполнять с помощью матричных операций. Но для того, чтобы в этой первой статье все было понятно всем, я выбрал метод цикла. Умножение матриц в следующий раз будем использовать в следующий раз.
Мы познакомились с архитектурой, которую я выбрал по умолчанию для построения нашей библиотеки. Теперь возникает вопрос об архитектуре(ах) нейронных сетей.
Если открыть Google и поискать изображения нейронной сети, будут предложены тысячи, если не десятки тысяч изображений с различными структурами нейронных сетей, например, такими:

Вопрос на миллион долларов: какая архитектура нейронной сети лучшая?
«Никто так не далек от истины как тот, кто знает ответы на все вопросы".
Давайте разберем и поймем, что необходимо, а что нет.
Входной слойКоличество входных данных, составляющих этот слой, должно быть равно количеству признаков (столбцов в наборе данных).
Выходной слой
Определение размера (количества нейронов) определяется классами в наборе данных для классификационной нейронной сети. Для задач типа регрессии количество нейронов определяется выбранной конфигурацией модели. Одного выходного слоя для регрессора часто бывает более чем достаточно.
Скрытые слои
Если задача не очень сложная, одного или двух скрытых слоев бывает более чем достаточно. На самом деле двух скрытых слоев достаточно для подавляющего большинства проблем. Но сколько узлов должно быть в каждом скрытом слое? Я не уверен в этом, но я думаю, что это зависит от производительности. Это разработчик должен изучить и попробовать разные узлы, чтобы понять, что лучше всего подходит для определенного типа задач. Прежде чем поиграть с узлами, нужно разобраться с другими типами нейронных сетей, которые мы обсуждали ранее.
Есть прекрасная ветка на эту тему на stats.stackexchange.com (прикладываю здесь ссылку).
Я думаю, что такое же количество узлов, как и входной слой для всех скрытых слоев, идеально подходит для нейронной сети с прямой связью. Это конфигурация, с которой я работаю в большинстве случаев.
Многослойный перцептрон с одним узлом и одним скрытым слоем — линейная модель
Если обратить внимание на операции, выполняемые внутри одного узла скрытого слоя нейронной сети, можно заметите следующее:
Q = wi * Ii + b
А вот уравнение линейной регрессии:
Y = mi * xi + c
Заметили сходство? Теоретически это одно и то же, эта операция является линейной регрессией, что возвращает нас к важности смещения скрытого слоя. Смещение является константой для линейной модели, добавляющей гибкости нашей модели для соответствия заданному набору данных. Без него все модели будут проходить между осями x и y в точке нуля (0).

При обучении нейронной сети веса и смещения будут обновляться. Параметры, которые дают меньше ошибок для нашей модели, будут сохранены и запомнены в наборе данных для тестирования.
Теперь давайте построим модель многослойного перцептрона для классификации двух классов. Это поможет лучше понять использование. Но перед этим сгенерируем случайный набор данных с размеченными данными, с которыми будет работать наша нейронная сеть. Приведенная ниже функция создает случайный набор данных: второй набор умножается на 5, а первый умножается на 2 только для получения данных в разных масштабах.
void MakeBlobs(int size=10) { ArrayResize(data_blobs,size); for (int i=0; i<size; i++) { data_blobs[i].sample_1 = (i+1)*(2); data_blobs[i].sample_2 = (i+1)*(5); data_blobs[i].class_ = (int)round(nn.MathRandom(0,1)); } }
На выходе получился вот такой набор данных:
QK 0 18:27:57.298 TestScript (EURUSD,M1) CNeural Nets Initialized activation = SIGMOID UseSoftMax = No IR 0 18:27:57.298 TestScript (EURUSD,M1) [sample_1] [sample_2] [class_] LH 0 18:27:57.298 TestScript (EURUSD,M1) [0] 2.0000 5.0000 0 GG 0 18:27:57.298 TestScript (EURUSD,M1) [1] 4.0000 10.0000 0 NL 0 18:27:57.298 TestScript (EURUSD,M1) [2] 6.0000 15.0000 1 HJ 0 18:27:57.298 TestScript (EURUSD,M1) [3] 8.0000 20.0000 0 HQ 0 18:27:57.298 TestScript (EURUSD,M1) [4] 10.0000 25.0000 1 OH 0 18:27:57.298 TestScript (EURUSD,M1) [5] 12.0000 30.0000 1 JF 0 18:27:57.298 TestScript (EURUSD,M1) [6] 14.0000 35.0000 0 DL 0 18:27:57.298 TestScript (EURUSD,M1) [7] 16.0000 40.0000 1 QK 0 18:27:57.298 TestScript (EURUSD,M1) [8] 18.0000 45.0000 0 QQ 0 18:27:57.298 TestScript (EURUSD,M1) [9] 20.0000 50.0000 0
Следующая часть — сгенерировать случайные значения весовых коэффициентов и смещения.
generate_weights(weights,ArraySize(Inputs));
generate_bias(biases);
Вот результат:
RG 0 18:27:57.298 TestScript (EURUSD,M1) weights QS 0 18:27:57.298 TestScript (EURUSD,M1) 0.7084 -0.3984 0.6182 0.6655 -0.3276 0.8846 0.5137 0.9371 NL 0 18:27:57.298 TestScript (EURUSD,M1) biases DD 0 18:27:57.298 TestScript (EURUSD,M1) -0.5902 0.7384
Теперь давайте посмотрим все операции в основной функции нашего скрипта:
#include "NeuralNets.mqh"; CNeuralNets *nn; input int batch_size =10; input int hidden_layers =2; data data_blobs[]; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- nn = new CNeuralNets(SIGMOID); MakeBlobs(batch_size); ArrayPrint(data_blobs); double Inputs[],OutPuts[]; ArrayResize(Inputs,2); ArrayResize(OutPuts,2); double weights[], biases[]; generate_weights(weights,ArraySize(Inputs)); generate_bias(biases); Print("weights"); ArrayPrint(weights); Print("biases"); ArrayPrint(biases); for (int i=0; i<batch_size; i++) { Print("Dataset Iteration ",i); Inputs[0] = data_blobs[i].sample_1; Inputs[1]= data_blobs[i].sample_2; nn.FeedForwardMLP(hidden_layers,Inputs,weights,biases,OutPuts); } delete(nn); }
На что следует обратить внимание:
- Количество смещений совпадает с количеством скрытых слоев.
- Общее количество весов = квадрат количества входов, умноженный на количество скрытых слоев. Это стало возможным благодаря тому, что наша сеть имеет то же количество узлов, что и входной слой/предыдущий слой сети (все слои имеют одинаковое количество узлов от входа до выхода).
- Следуя тому же принципу, скажем, если у вас есть 3 входных узла, все скрытые слои будут иметь 3 узла, кроме последнего слоя. Посмотрим, что же будет происходить с этим слоем.
Глядя на случайно сгенерированный набор данных, можно увидеть два входных объекта/столбца в наборе данных. Поэтому я решил добавить два скрытых слоя. Вот краткий обзор логов того, как наша модель будет выполнять вычисления (чтобы не получать такие логи, установите в коде режим отладки debug mode в значение false).
NL 0 18:27:57.298 TestScript (EURUSD,M1) Dataset Iteration 0 EJ 0 18:27:57.298 TestScript (EURUSD,M1) << Hidden Layer 1 >> GO 0 18:27:57.298 TestScript (EURUSD,M1) NS 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 1 EI 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 0 = input 2.00000 x weight 0.70837 FQ 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 1 = input 5.00000 x weight -0.39838 QP 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product -0.57513 + bias -0.590 = -1.16534 RH 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.23770 CQ 0 18:27:57.298 TestScript (EURUSD,M1) OE 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 2 CO 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 2 = input 2.00000 x weight 0.61823 FI 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 3 = input 5.00000 x weight 0.66553 PN 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product 4.56409 + bias -0.590 = 3.97388 GM 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.98155 DI 0 18:27:57.298 TestScript (EURUSD,M1) << Hidden Layer 2 >> GL 0 18:27:57.298 TestScript (EURUSD,M1) NF 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 1 FH 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 0 = input 0.23770 x weight -0.32764 ID 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 1 = input 0.98155 x weight 0.88464 QO 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product 0.79044 + bias 0.738 = 1.52884 RK 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.82184 QG 0 18:27:57.298 TestScript (EURUSD,M1) IH 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 2 DQ 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 2 = input 0.23770 x weight 0.51367 CJ 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 3 = input 0.98155 x weight 0.93713 QJ 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product 1.04194 + bias 0.738 = 1.78034 JP 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.85574 EI 0 18:27:57.298 TestScript (EURUSD,M1) GS 0 18:27:57.298 TestScript (EURUSD,M1) Final MLP output(s) OF 0 18:27:57.298 TestScript (EURUSD,M1) 0.82184 0.85574 CN 0 18:27:57.298 TestScript (EURUSD,M1) Dataset Iteration 1 KH 0 18:27:57.298 TestScript (EURUSD,M1) << Hidden Layer 1 >> EM 0 18:27:57.298 TestScript (EURUSD,M1) DQ 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 1 QH 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 0 = input 4.00000 x weight 0.70837 PD 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 1 = input 10.00000 x weight -0.39838 HR 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product -1.15027 + bias -0.590 = -1.74048 DJ 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.14925 OP 0 18:27:57.298 TestScript (EURUSD,M1) CK 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 2 MN 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 2 = input 4.00000 x weight 0.61823 NH 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 3 = input 10.00000 x weight 0.66553 HI 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product 9.12817 + bias -0.590 = 8.53796 FO 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.99980 RG 0 18:27:57.298 TestScript (EURUSD,M1) << Hidden Layer 2 >> IR 0 18:27:57.298 TestScript (EURUSD,M1) PD 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 1 RN 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 0 = input 0.14925 x weight -0.32764 HF 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 1 = input 0.99980 x weight 0.88464 EM 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product 0.83557 + bias 0.738 = 1.57397 EL 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.82835 KE 0 18:27:57.298 TestScript (EURUSD,M1) GN 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 2 LS 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 2 = input 0.14925 x weight 0.51367 FL 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 3 = input 0.99980 x weight 0.93713 KH 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product 1.01362 + bias 0.738 = 1.75202 IR 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.85221 OH 0 18:27:57.298 TestScript (EURUSD,M1) IM 0 18:27:57.298 TestScript (EURUSD,M1) Final MLP output(s) MH 0 18:27:57.298 TestScript (EURUSD,M1) 0.82835 0.85221
Теперь обратите внимание на окончательные результаты многослойного перцептрона по всем итерациям. Можно заметить странное поведение, когда выходные данные имеют одинаковые значения. Есть несколько причин этой проблемы. Судя по этому обсуждению, одна из них в использовании неправильной функции активации в выходном слое. Здесь на помощь приходит функция активации SoftMax.
Насколько я понимаю, сигмоидальная функция возвращает вероятности только тогда, когда в выходном слое есть один узел, который должен классифицировать один класс. В этом случае вам понадобится вывод из сигмоидальной функции, которая подскажет, принадлежит ли что-то к определенному классу или нет. Но это совсем другая история. Если сложить выходные данные конечных узлов, получим единицу (1) в большинстве случаев. То есть понятно, что они не являются вероятностями, потому что вероятность не может превышать значение1.
Если к последнему слою применить функцию SoftMax, результаты будут такими:
First Iteration outputs [0.4915 0.5085] , Second Iteration Outputs [0.4940 0.5060]
Результат можно интерпретировать как [Вероятность принадлежности к классу 0 Вероятность принадлежности к классу 1] в таком случае.
По крайней мере, теперь у нас есть вероятности, на которые можно положиться при интерпретации чего-то значимого из нашей сети.
Заключительные мысли
Мы еще не закончили работу с нейронной сетью с прямой связью, но, по крайней мере, на данный момент у вас есть понимание теории и самых важных вещей, которые помогут освоить нейронные сети в MQL5. Разработанная нейронная сеть с прямой связью предназначена для целей классификации, поэтому подходящие функции активации — сигмовидными и TanH в зависимости от набора данных и классов, которые нужно выделить в этом наборе данных. В ней нельзя изменить выходной слой, чтобы он возвращал что-то, с чем можно поиграться, как и узла в скрытых слоях. Ведение матриц поможет сделать все эти операции динамичными, чтобы можно было построить стандартную нейронную сеть для любой задачи. Такова цель этой серии статей, так что следите за публикациями.
Также важно знать, когда можно использовать нейронную сеть, потому что не все задачи должны решаться нейронными сетями. Если задачу можно решить с помощью линейной регрессии, линейная модель может дать даже лучшие результаты. Это один из моментов, о которых следует помнить.
Репозиторий GitHub: https://github.com/MegaJoctan/NeuralNetworks-MQL5
Дополнительная литература
-
Neural Networks for Pattern Recognition (Advanced Texts in Econometrics)
-
Neural Networks: Tricks of the Trade (Lecture Notes in Computer Science, 7700)
-
Deep Learning (Adaptive Computation and Machine Learning series)
Статьи:
-
Машинное обучение и Data Science (Часть 01): Линейная регрессия
-
Машинное обучение и Data Science (Часть 02): Логистическая регрессия
-
Машинное обучение и Data Science (Часть 03): Матричная регрессия
-
Машинное обучение и Data Science (Часть 06): Градиентный спуск
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/11275
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Разработка торгового советника с нуля (Часть 29): Говорящая платформа
Разработка торгового советника с нуля (Часть 29): Говорящая платформа
 Нейросети — это просто (Часть 31): Эволюционные алгоритмы
Нейросети — это просто (Часть 31): Эволюционные алгоритмы
 Разработка торгового советника с нуля (Часть 28): Навстречу будущему (III)
Разработка торгового советника с нуля (Часть 28): Навстречу будущему (III)
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
...
Не могли бы вы объяснить это? Или привести несколько примеров?
Разница между оптимизацией в тестере стратегий и оптимизацией параметров нейронной сети заключается в цели, в тестере стратегий мы склонны фокусироваться на параметрах, которые обеспечивают наиболее прибыльные результаты или, по крайней мере, результаты торговли, которые мы хотим, это не обязательно означает, что нейронная сеть имеет хорошую модель, которая привела к таким результатам
Некоторые люди предпочитают использовать веса и смещение в качестве входных параметров систем на основе нейронных сетей(грубо говоря, Feed forward), но я думаю, что оптимизация с помощью тестера стратегий - это, по сути, поиск случайных значений лучших результатов(поиск оптимальных звучит как зависимость от удачи), в то время как если бы мы оптимизировали с помощью стохастического градиентного спуска, мы бы двигались к модели с наименьшими ошибками в прогнозах на каждом шаге
Разница между оптимизацией в тестере стратегий и оптимизацией параметров нейронной сети заключается в цели: в тестере стратегий мы, как правило, фокусируемся на параметрах, которые обеспечивают наиболее прибыльные результаты или, по крайней мере, желаемые результаты торговли, но это не обязательно означает, что нейронная сеть имеет хорошую модель, которая привела к таким результатам
Некоторые люди предпочитают использовать веса и смещение в качестве входных параметров систем на основе нейронных сетей(грубо говоря, Feed forward), но я думаю, что оптимизация с помощью тестера стратегий - это, по сути, поиск случайных значений лучших результатов(поиск оптимальных звучит как зависимость от удачи), в то время как если бы мы оптимизировали с помощью стохастического градиентного спуска, мы бы двигались к модели с наименьшими ошибками в прогнозах на каждом шаге
Спасибо за ответ.
Я понял вашу мысль.
Почему вы начали с первой части?
старая статья:
НАУКА О ДАННЫХ И МАШИННОЕ ОБУЧЕНИЕ (ЧАСТЬ 01): ЛИНЕЙНАЯ РЕГРЕССИЯ
https://www.mql5.com/ru/articles/10459
Почему вы начали с первой части?
старая статья:
НАУКА О ДАННЫХ И МАШИННОЕ ОБУЧЕНИЕ (ЧАСТЬ 01): ЛИНЕЙНАЯ РЕГРЕССИЯ
https://www.mql5.com/ru/articles/10459
Что вы имеете в виду?
Почему вы начали с первой части?
старая статья:
НАУКА О ДАННЫХ И МАШИННОЕ ОБУЧЕНИЕ (ЧАСТЬ 01): ЛИНЕЙНАЯ РЕГРЕССИЯ
https://www.mql5.com/ru/articles/10459