
Aprendizaje automático y Data Science (Parte 12): ¿Es posible tener éxito en el mercado usando redes neuronales de autoaprendizaje?

«No estoy afirmando que las redes neuronales sean algo sencillo, hace falta ser un experto para hacer que funcionen, pero esta experiencia tiene una aplicación mucho más amplia. El esfuerzo que antes se dedicaba a desarrollar las funciones, ahora se dedica a desarrollar la arquitectura, la función de pérdida y el esquema de optimización. El trabajo manual está pasando a un nivel de abstracción superior».
Stefano Soatto
Introducción
Si le gusta el trading algorítmico, probablemente haya oído hablar de las redes neuronales: esta parece ser la forma de crear el Santo Grial. Sin embargo, no estoy tan seguro de ello, porque hace falta algo más que añadir una red neuronal a un robot comercial para conseguir un sistema rentable. Además, debemos tener claro en qué nos estamos metiendo cuando utilizamos redes neuronales, porque a veces el éxito o el fracaso, es decir, los beneficios o las pérdidas, dependen de los más mínimos detalles.

Personalmente, no creo que las redes neuronales ayuden a quienes no quieren esforzarse. Al fin y al cabo, al trabajar con ellas hay que dedicar constantemente tiempo a analizar los errores del modelo, preprocesar y escalar los datos de entrada, y mucho más sobre lo que hablaremos hoy.
Empezaremos este artículo definiendo una red neuronal artificial.
¿Qué es una red neuronal artificial?
En términos sencillos, una red neuronal artificial es un sistema informático inspirado en las redes neuronales biológicas de un cerebro vivo. Ya hablamos de los componentes básicos de las redes neuronales en un artículo anterior de esta serie.
En materiales anteriores hemos explicado lo básico sobre la red neuronal de conexión directa. En este artículo veremos las pasadas directa e inversa, así como el entrenamiento y las pruebas de las redes neuronales. Además, crearemos un robot comercial basado en todo lo que hemos mencionado y veremos cómo funciona nuestro robot comercial.
En el caso de los perceptrones multicapa, todas las neuronas/nodos de la capa actual están vinculados a nodos de la segunda capa, y así sucesivamente para todas las capas desde la entrada hasta la salida. Esto permite a la red neuronal identificar relaciones complejas en los conjuntos de datos. Cuantas más capas tenga, más capaz será su modelo de comprender las relaciones complejas de los conjuntos de datos, sin embargo, el precio que hay que pagar por ello es un elevado coste computacional que no garantiza en absoluto la precisión del modelo, sobre todo si éste es demasiado complejo y la tarea es sencilla.
A menudo, una sola capa oculta resulta suficiente para la mayoría de las tareas que se intentan resolver con redes neuronales complejas. En este artículo, trabajaremos con una red neuronal de una sola capa.
Pasada directa
Las operaciones asociadas a la pasada directa por la red son sencillas y pueden implementarse en unas pocas líneas de código. Para crear redes realmente ágiles, merece la pena explorar las operaciones con matrices y vectores, ya que suponen los componentes básicos de las redes neuronales y de muchos de los algoritmos de aprendizaje automático que analizamos en esta serie.
Lo importante es comprender el tipo de problema que estamos intentando resolver con una red neuronal, porque distintos problemas requerirán distintos tipos de redes con diferentes configuraciones y distintos datos de salida.
Los principales tipos de tareas son:
- Tareas de regresión
- Tareas de la clasificación
En los problemas de regresión, intentamos predecir variables continuas. Aplicado al trading, intentamos predecir el siguiente punto de precio hacia el que se dirigirá el mercado. Si no está familiarizado con la regresión lineal, le recomiendo que lea sobre ella aquí.
Este tipo de problema se resuelve mediante redes neuronales de regresión.
2. Tareas de clasificación
En los problemas de clasificación, tratamos de predecir resultados sobre variables discretas. Aplicado al trading, podríamos predecir señales. Digamos que una señal 0 indica que el mercado se mueve a la baja y una señal 1 indica que el mercado se mueve al alza.
Estas tareas se resuelven usando redes neuronales de clasificación o redes neuronales de reconocimiento de patrones, que en MATLAB se denominan patternnet.
En este artículo trabajaremos con el problema de la regresión, tratando de predecir el próximo precio al que llegará el mercado.
matrix CRegNeuralNets::ForwardPass(vector &input_v) { matrix INPUT = this.matrix_utils.VectorToMatrix(input_v); matrix OUTPUT; OUTPUT = W.MatMul(INPUT); //Weight X Inputs OUTPUT = OUTPUT + B; //Outputs + Bias OUTPUT.Activation(OUTPUT, ENUM_ACTIVATION_FUNCTION(A_FX)); //Activation Function return (OUTPUT); }
Esta función directa debería estar clara, pero lo más importante es prestar mucha atención al tamaño de la matriz en cada paso, para que todo funcione como es debido.
matrix INPUT = this.matrix_utils.VectorToMatrix(input_v);
Vale la pena aclarar esta parte. Como la función VectorToMatrix toma un vector como entrada, los datos de entrada deberán estar en forma de matriz, porque a continuación utilizaremos operaciones matriciales.
Recuerde:
- La primera matriz de entrada a la red neuronal será una matriz nx1
- La matriz de pesos es HN x n, donde HN es el número de nodos de la capa oculta actual, mientras que n es el número de entradas de la capa anterior o el número de filas de la matriz de entrada.
- La matriz de desplazamiento tendrá el mismo tamaño que la salida de la capa.
Es muy importante no olvidarlo. Recuerde estos puntos para no tener que resolver todo por sí mismo.
Veamos la arquitectura de la red neuronal en la que estamos trabajando, para que pueda entender claramente lo que estamos haciendo aquí.
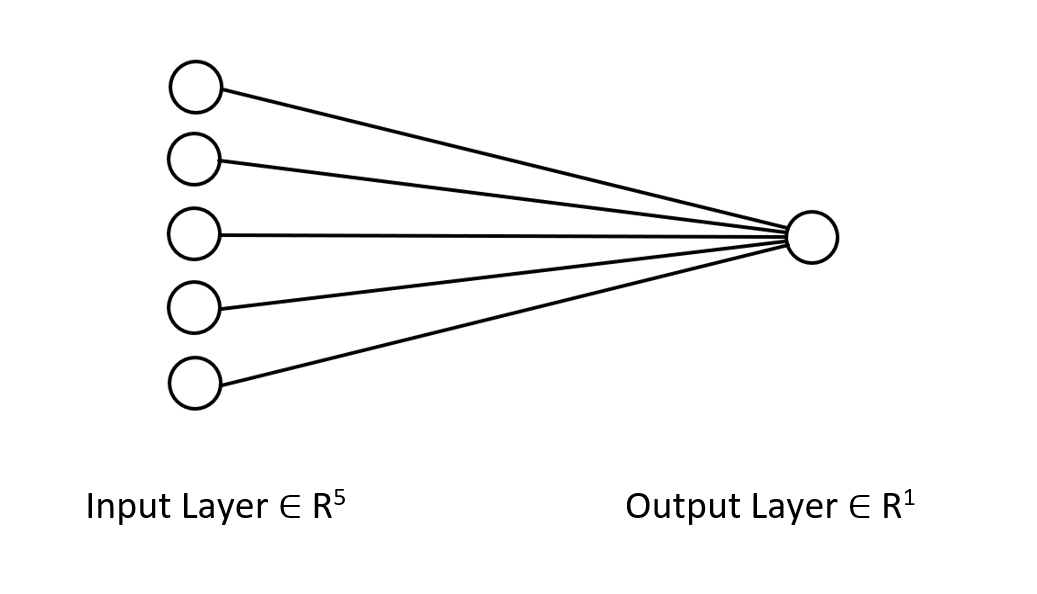
Esta red neuronal solo tiene una capa, por lo que no hay ciclos en la función de pasada directa mostrada anteriormente. Si seguimos el mismo planteamiento matricial y utilizamos las dimensiones adecuadas, podremos implementar una arquitectura de cualquier complejidad.
Bien, ya hemos mostrado más arriba una pasada directa con una matriz W. Veamos ahora cómo encontrar los pesos para nuestro modelo.
Generación de pesos
Generar los pesos adecuados para una red neuronal no consiste solo en inicializar valores aleatorios. La amarga experiencia me ha enseñado que el enfoque equivocado provoca todo tipo de problemas de propagación inversa del error que te hacen cuestionar este complejo código y ocuparte de depurarlo.
Si inicializamos los pesos de forma incorrecta, todo el proceso de entrenamiento podría hacerse innecesariamente largo y laborioso. La red puede atascarse en mínimos locales y tardar mucho tiempo en converger.
En el primer paso, seleccionaremos valores aleatorios: yo prefiero usar el estado aleatorio 42.
this.W = matrix_utils.Random(0.0, 1.0,1,m_inputs, RANDOM_STATE);
La mayoría de la gente se detiene en este paso: genera los pesos y piensa que ya está todo hecho. Una vez seleccionadas las variables aleatorias, deberemos inicializar los pesos con la inicialización de Glorot o de He (He Initialization).
La inicialización Xavier/Glorot funciona mejor con las funciones de activación sigmoidea y tangencial, mientras que la inicialización de He funciona mejor con RELU y sus variantes.
Inicialización de He
![]()
donde: n es el número de entradas al nodo.
Así, tras inicializar las escalas, tendremos la normalización.
this.W = matrix_utils.Random(0.0, 1.0,1,m_inputs, RANDOM_STATE); this.W = this.W * 1/sqrt(m_inputs); //He initialization
Como esta red neuronal tiene una sola capa, solo tendremos una matriz para cargar los pesos.
Funciones de activación de neuronas
Esta red neuronal es de tipo regresivo, y las funciones de activación en ella son simplemente variantes de la función de activación de regresión. RELU:
enum activation { AF_ELU_ = AF_ELU, AF_EXP_ = AF_EXP, AF_GELU_ = AF_GELU, AF_LINEAR_ = AF_LINEAR, AF_LRELU_ = AF_LRELU, AF_RELU_ = AF_RELU, AF_SELU_ = AF_SELU, AF_TRELU_ = AF_TRELU, AF_SOFTPLUS_ = AF_SOFTPLUS };
Estas funciones de activación, resaltadas en rojo, se encuentran entre otras disponibles en la biblioteca estándar (Documentación).
Funciones de pérdida
Funciones de pérdida para esta red neuronal de regresión:
enum loss { LOSS_MSE_ = LOSS_MSE, LOSS_MAE_ = LOSS_MAE, LOSS_MSLE_ = LOSS_MSLE, LOSS_HUBER_ = LOSS_HUBER };
Existen otras funciones de activación en la biblioteca estándar, para más información, podrá consultar la documentación.
La pasada inversa utilizando la regla delta
La regla delta es una regla de aprendizaje por descenso de gradiente para actualizar los pesos de entrada de las neuronas artificiales en una red neuronal de una sola capa. Se trata de un caso especial del algoritmo más general de propagación inversa del error. Para la neurona j con función de activación g(x), la regla delta del peso Wji en la posición i para la neurona j será la siguiente:
![]()
Donde:
![]() es una pequeña constante denominada tasa de aprendizaje
es una pequeña constante denominada tasa de aprendizaje
![]() es la derivada de g
es la derivada de g
g(x) es la función de activación de la neurona
![]() resultado objetivo
resultado objetivo
![]() resultado real
resultado real
![]() i-ésima entrada
i-ésima entrada
Genial, ya tenemos una fórmula, así que solo nos falta aplicarla, ¿no? Pues no.
El problema de esta fórmula es que, por sencilla que parezca, resulta muy complicada tras convertirla a código y requiere un par de bucles «for». Este tipo de práctica en las redes neuronales puede sacarlo a uno de quicio. La fórmula correcta que necesitamos es una que use operaciones matriciales. Aquí la tenemos:
![]()
Donde:
![]() - cambio de la matriz de pesos
- cambio de la matriz de pesos
![]() - derivada de la función de pérdida
- derivada de la función de pérdida
![]() - multiplicación de matrices por elementos/producto de Adamar
- multiplicación de matrices por elementos/producto de Adamar
![]() - derivada de la matriz de activación neuronal
- derivada de la matriz de activación neuronal
![]() - matriz de valores de entrada.
- matriz de valores de entrada.
El tamaño de la matriz L es siempre igual al tamaño de la matriz O, y la matriz resultante en el lado derecho deberá tener el mismo tamaño que la matriz W. Solo puede ser así.
Veamos qué aspecto tiene todo esto al convertir la fórmula a código.
for (ulong iter=0; iter<m_rows; iter++) { OUTPUT = ForwardPass(m_x_matrix.Row(iter)); //forward pass pred = matrix_utils.MatrixToVector(OUTPUT); actual[0] = m_y_vector[iter]; preds[iter] = pred[0]; actuals[iter] = actual[0]; //--- INPUT = matrix_utils.VectorToMatrix(m_x_matrix.Row(iter)); vector loss_v = pred.LossGradient(actual, ENUM_LOSS_FUNCTION(L_FX)); LOSS_DX.Col(loss_v, 0); OUTPUT.Derivative(OUTPUT, ENUM_ACTIVATION_FUNCTION(A_FX)); OUTPUT = LOSS_DX * OUTPUT; INPUT = INPUT.Transpose(); DX_W = OUTPUT.MatMul(INPUT); this.W -= (alpha * DX_W); //Weights update by gradient descent }
La ventaja de usar la biblioteca de matrices de MQL5 en lugar de matrices para el aprendizaje automático es que no tenemos que hacer ningún cálculo, es decir, no tenemos que calcular las derivadas de las funciones de pérdida, las derivadas de la función de activación: nada en absoluto.
Para entrenar el modelo, debemos considerar dos cosas: al menos por ahora, las épocas y la tasa de aprendizaje se denotan como alfa. Si ha leído el artículo anterior de esta serie, en el que hablábamos del descenso de gradiente, ya sabrá de qué estamos hablando.
Épocas. Una época es cuando todo el conjunto de datos pasa el ciclo completo hacia delante y hacia atrás por la red. En pocas palabras: es cuando la red ha visto todos los datos. Cuanto mayor sea el número de épocas, más tiempo se tardará en entrenar una red neuronal y mejor se podrá entrenar.
Alfa será el tamaño del paso con el que el algoritmo de descenso de gradiente se moverá hacia los mínimos global y local. Alfa suele ser un valor pequeño de entre 0,1 y 0,00001. Cuanto mayor sea el valor, más rápido convergerá la red, pero mayor será el riesgo de pasar el mínimo local.
A continuación le mostramos el código completo de esta regla delta:
for (ulong epoch=0; epoch<epochs && !IsStopped(); epoch++) { for (ulong iter=0; iter<m_rows; iter++) { OUTPUT = ForwardPass(m_x_matrix.Row(iter)); pred = matrix_utils.MatrixToVector(OUTPUT); actual[0] = m_y_vector[iter]; preds[iter] = pred[0]; actuals[iter] = actual[0]; //--- INPUT = matrix_utils.VectorToMatrix(m_x_matrix.Row(iter)); vector loss_v = pred.LossGradient(actual, ENUM_LOSS_FUNCTION(L_FX)); LOSS_DX.Col(loss_v, 0); OUTPUT.Derivative(OUTPUT, ENUM_ACTIVATION_FUNCTION(A_FX)); OUTPUT = LOSS_DX * OUTPUT; INPUT = INPUT.Transpose(); DX_W = OUTPUT.MatMul(INPUT); this.W -= (alpha * DX_W); } printf("[ %d/%d ] Loss = %.8f | accuracy %.3f ",epoch+1,epochs,preds.Loss(actuals,ENUM_LOSS_FUNCTION(L_FX)),metrics.r_squared(actuals, preds)); }
Ahora ya está todo listo. Es momento de entrenar la red neuronal para que comprenda un pequeño patrón en el conjunto de datos.
#include <MALE5\Neural Networks\selftrain NN.mqh> #include <MALE5\matrix_utils.mqh> CRegNeuralNets *nn; CMatrixutils matrix_utils; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- matrix Matrix = { {1,2,3}, {2,3,5}, {3,4,7}, {4,5,9}, {5,6,11} }; matrix x_matrix; vector y_vector; matrix_utils.XandYSplitMatrices(Matrix,x_matrix,y_vector); nn = new CRegNeuralNets(x_matrix,y_vector,0.01,100, AF_RELU_, LOSS_MSE_); //Training the Network //--- return(INIT_SUCCEEDED); }
La función XyYSplitMatrices divide la matriz en una matriz x y un vector y.
| X Matrix | Y Vector |
|---|---|
| { {1, 2}, {2, 3}, {3, 4}, {4, 5}, {5, 6} } | {3}, {5}, {7}, {9}, {11} |
Resultados del entrenamiento:
CS 0 20:30:00.878 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [1/100] Loss = 56.22401001 | accuracy -6.028 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [2/100] Loss = 2.81560904 | accuracy 0.648 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [3/100] Loss = 0.11757813 | accuracy 0.985 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [4/100] Loss = 0.01186759 | accuracy 0.999 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [5/100] Loss = 0.00127888 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [6/100] Loss = 0.00197030 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [7/100] Loss = 0.00173890 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [8/100] Loss = 0.00178597 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [9/100] Loss = 0.00177543 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [10/100] Loss = 0.00177774 | accuracy 1.000 … … … CS 0 20:30:00.883 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [100/100] Loss = 0.00177732 | accuracy 1.000
Tras solo 5 épocas, la precisión de la red neuronal ha alcanzado el 100%. Esto es bueno, porque esta tarea es muy sencilla, y esperábamos un aprendizaje más rápido.
Ahora que esta red neuronal ya ha sido entrenada, vamos a probarla con los nuevos valores {7,8}. Usted y yo sabemos que el resultado es 15.
vector new_data = {7,8}; Print("Test "); Print(new_data," pred = ",nn.ForwardPass(new_data));
Información mostrada:
CS 0 20:37:36.331 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) Test CS 0 20:37:36.331 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [7,8] pred = [[14.96557787153696]]
Hemos obtenido un valor cercano a 14.97. 15 es solo un valor double, f, aquí tenemos valores adicionales, pero cuando se redondea a 1 dígito significativo en la salida obtendremos 15. Esto indica que nuestra red neuronal ya es capaz de aprender por sí misma. Excelente.
Vamos a darle a este modelo un conjunto de datos reales y ver qué hace.
Hemos usado los datos de las acciones de Tesla y Apple como variables independientes para predecir el índice NASDAQ (NAS 100). Una vez leí un artículo en CNBC online que decía que las acciones de estas seis empresas tecnológicas suponen la mitad del valor del NASDAQ. Dos de ellas son Apple y Tesla. En este ejemplo, usaremos estas dos acciones como variables independientes para entrenar la red neuronal.
input string symbol_x = "Apple_Inc_(AAPL.O)"; input string symbol_x2 = "Tesco_(TSCO.L)"; input ENUM_COPY_RATES copy_rates_x = COPY_RATES_OPEN; input int n_samples = 100; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { matrix x_matrix(n_samples,2); vector y_vector; vector x_vector; //--- x_vector.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 0); x_vector.CopyRates(symbol_x2, PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 1); y_vector.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_CLOSE,0,n_samples); nn = new CRegNeuralNets(x_matrix,y_vector,0.01,1000, AF_RELU_, LOSS_MSE_);
El nombre de los símbolos en symbol_x y symbol_x2 puede ser diferente en su bróker. Recuerde cambiar estas variables y añadir los símbolos a la observación del mercado antes de ejecutar el asesor de prueba. El símbolo «y» será el símbolo del gráfico actual. El asesor deberá ejecutarse en el gráfico NASDAQ.
Tras ejecutar el script, esto es lo que mostrará el diario de registro:
CS 0 21:29:20.698 Self Trained NN EA (NAS100,M30) [ 1/1000 ] Loss = 353809311769.08959961 | accuracy -27061631.733 CS 0 21:29:20.698 Self Trained NN EA (NAS100,M30) [ 2/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 3/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 4/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 5/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 6/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 .... .... CS 0 21:29:20.886 Self Trained NN EA (NAS100,M30) [ 1000/1000 ] Loss = 149221473.48209998 | accuracy -11412.427
¡¿Cómo?! Y ese es el resultado después de todo el esfuerzo aplicado. Este tipo de cosas ocurren a menudo en las redes neuronales, por lo que resulta importante tener una comprensión clara de cómo funciona una red neuronal, independientemente del marco de trabajo o la biblioteca Python que utilicemos.
Normalización y escalado de datos
Nunca me cansaré de repetir lo importante que es este punto. Aunque, eso sí, no todas las muestras ofrecen los mejores resultados al normalizarse, por ejemplo, si normalizamos este sencillo conjunto de datos que usamos en primer lugar para probar el rendimiento de la red neuronal, los resultados serían terribles. La red neuronal devolverá valores peores, lo he comprobado.
Existen muchos métodos de normalización, pero los tres más utilizados son:
Min-Max Scaler
Se trata de un método de normalización que escala los valores numéricos de las características a un intervalo fijo [0, 1]. Su fórmula es como sigue:
x_norm = (x -x_min) / (x_max - x_min)
donde:
x — valor inicial de la función
x_min — valor mínimo de la función
x_max — valor máximo de la función
x_norm — nuevo valor normalizado de la característica
Para seleccionar la normalización y el método de normalización de los datos, deberemos importar la biblioteca de preprocesamiento. Al final del artículo adjuntamos un archivo Include.
Hemos decidido añadir a nuestra biblioteca de redes neuronales la posibilidad de normalizar datos.
CRegNeuralNets::CRegNeuralNets(matrix &xmatrix, vector &yvector,double alpha, uint epochs, activation ACTIVATION_FUNCTION, loss LOSS_FUNCTION, norm_technique NORM_METHOD)
Allí podremos seleccionar el método de normalización adecuado en norm_technique:
enum norm_technique { NORM_MIN_MAX_SCALER, //Min max scaler NORM_MEAN_NORM, //Mean normalization NORM_STANDARDIZATION, //standardization NORM_NONE //Do not normalize. };
Tras añadir la normalización, podremos obtener una precisión aceptable.
nn = new CRegNeuralNets(x_matrix,y_vector,0.01,1000, AF_RELU_, LOSS_MSE_,NORM_MIN_MAX_SCALER);
Información mostrada:
CS 0 22:40:56.457 Self Trained NN EA (NAS100,M30) [ 1/1000 ] Loss = 0.19379434 | accuracy -0.581 CS 0 22:40:56.457 Self Trained NN EA (NAS100,M30) [ 2/1000 ] Loss = 0.07735744 | accuracy 0.369 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 3/1000 ] Loss = 0.04761891 | accuracy 0.611 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 4/1000 ] Loss = 0.03559318 | accuracy 0.710 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 5/1000 ] Loss = 0.02937830 | accuracy 0.760 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 6/1000 ] Loss = 0.02582918 | accuracy 0.789 CS 0 22:40:56.459 Self Trained NN EA (NAS100,M30) [ 7/1000 ] Loss = 0.02372224 | accuracy 0.806 CS 0 22:40:56.459 Self Trained NN EA (NAS100,M30) [ 8/1000 ] Loss = 0.02245222 | accuracy 0.817 CS 0 22:40:56.460 Self Trained NN EA (NAS100,M30) [ 9/1000 ] Loss = 0.02168207 | accuracy 0.823 CS 0 22:40:56.460 Self Trained NN EA (NAS100,M30 CS 0 22:40:56.623 Self Trained NN EA (NAS100,M30) [ 1000/1000 ] Loss = 0.02046533 | accuracy 0.833
También debo admitir que no he obtenido los resultados que quería en el marco temporal de una hora. La red neuronal ha funcionado con más precisión en el gráfico de 30 minutos, pero no me he molestado en averiguar el motivo.
Así, la precisión de los datos de entrenamiento es del 82,3%, lo cual supone una buena precisión. Ahora vamos a crear una estrategia comercial sencilla, que nuestra red utilizará para abrir operaciones.
El enfoque actual que hemos utilizado para recopilar los datos en la función OnInit no es fiable. Así que crearemos una función para entrenar las redes y la colocaremos en la función Init. Nuestra red solo se formará una vez en la vida. No obstante, podremos modificar este punto si lo deseamos; no es necesariamente una condición.
void OnTick() { //--- if (!train_nn) TrainNetwork(); //Train the network only once train_nn = true; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void TrainNetwork() { matrix x_matrix(n_samples,2); vector y_vector; vector x_vector; x_vector.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 0); x_vector.CopyRates(symbol_x2, PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 1); y_vector.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_CLOSE,0,n_samples); nn = new CRegNeuralNets(x_matrix,y_vector,0.01,1000, AF_RELU_, LOSS_MSE_,NORM_MIN_MAX_SCALER); }
Esta función de entrenamiento parece tener todo lo que necesitamos para salir al mercado. No obstante, sigue sin ser fiable. Hemos una prueba en el marco temporal de días y hemos obtenido una precisión de -77%, en el marco temporal H4 nos ha dado una precisión de -11234, o algo así. Con más datos y entrenando con muestras de entrenamiento diferentes, la red neuronal no ha igualado la precisión de aprendizaje que había ofrecido anteriormente.
Hay muchas razones para ello, una sería que la presencia de problemas diferentes requiere arquitecturas diferentes. Supongo que algunos patrones de mercado en diferentes marcos temporales pueden resultar demasiado complejos para una red neuronal de una sola capa, y la regla delta está diseñada precisamente para eso. Aún no podemos arreglar este problema, así que seguiremos con el marco temporal en el que hemos tenido un resultado aceptable. Sin embargo, hay algo que podemos hacer para mejorar los resultados y corregir un poco este comportamiento incoherente. Podemos dividir los datos con un estado aleatorio.
Esto es más importante de lo que parece
Si usted ha trabajado antes con Python en aprendizaje automático, probablemente se haya encontrado con la función train_test_split de sklearn.
El objetivo de dividir la muestra en datos de entrenamiento y datos de prueba no consiste solo en dividir los datos, sino también en aleatorizar el conjunto de datos para que no estén en el orden original. Me explico. Como las redes neuronales y otros algoritmos de aprendizaje automático buscan entender patrones en los datos, tener los datos en el mismo orden en el que se han extraído puede resultar negativo: es más fácil para los modelos entender patrones cuando los datos se presentan en el mismo orden. En realidad, no es la mejor forma de entrenar modelos, porque lo que nos importa no es la ubicación de los datos, sino los patrones en sí.
void TrainNetwork() { //--- collecting the data matrix Matrix(n_samples,3); vector y_vector; vector x_vector; x_vector.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,n_samples); Matrix.Col(x_vector, 0); x_vector.CopyRates(symbol_x2, PERIOD_CURRENT,copy_rates_x,0,n_samples); Matrix.Col(x_vector, 1); y_vector.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_CLOSE,0,n_samples); Matrix.Col(y_vector, 2); //--- matrix x_train, x_test; vector y_train, y_test; matrix_utils.TrainTestSplitMatrices(Matrix, x_train, y_train, x_test, y_test, 0.7, 42); nn = new CRegNeuralNets(x_train,y_train,0.01,1000, AF_RELU_, LOSS_MSE_,NORM_MIN_MAX_SCALER); vector test_pred = nn.ForwardPass(x_test); printf("Testing Accuracy =%.3f",metrics.r_squared(y_test, test_pred)); }
Tras recopilar los datos de entrenamiento, introduciremos la función TrainTestSplitMatrices con random state 42.
void TrainTestSplitMatrices(matrix &matrix_,matrix &x_train,vector &y_train,matrix &x_test, vector &y_test,double train_size=0.7,int random_state=-1)
Previsiones de mercado en tiempo real
Para hacer predicciones en tiempo real, la función Ontick debe tener un código que recopile los datos y los coloque en el vector de entrada de la función de pasada directa de la red neuronal.
void OnTick() { //--- if (!train_nn) TrainNetwork(); //Train the network only once train_nn = true; vector x1, x2; x1.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,1); //only the current candle x2.CopyRates(symbol_x2,PERIOD_CURRENT,copy_rates_x,0,1); //only the current candle vector inputs = {x1[0], x2[0]}; //current values of x1 and x2 instruments | Apple & Tesla matrix OUT = nn.ForwardPass(inputs); //Predicted Nasdaq value double pred = OUT[0][0]; Comment("pred ",OUT); }
Nuestra red neuronal ya puede realizar predicciones. Intentaremos utilizarla en el trading. Para ello, crearemos una estrategia.
Lógica comercial
La lógica comercial es sencilla: si el precio pronosticado por la red neuronal es superior al precio actual, se abrirá una transacción de compra con un Take Profit al nivel del precio pronosticado, multiplicado por el valor del parámetro de entrada de Take Profit. Y viceversa para las transacciones de venta. Cada transacción tiene un Stop Loss igual al número de puntos de Take Profit multiplicado por el valor del Stop Loss. Qué aspecto tiene esto en el MetaEditor.
stops_level = (int)SymbolInfoInteger(Symbol(),SYMBOL_TRADE_STOPS_LEVEL); Lots = SymbolInfoDouble(Symbol(),SYMBOL_VOLUME_MIN); spread = (double)SymbolInfoInteger(Symbol(), SYMBOL_SPREAD); MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (MathAbs(pred - ticks.ask) + spread > stops_level) { if (pred > ticks.ask && !PosExist(POSITION_TYPE_BUY)) { target_gap = pred - ticks.bid; m_trade.Buy(Lots, Symbol(), ticks.ask, ticks.bid - ((target_gap*stop_loss) * Point()) , ticks.bid + ((target_gap*take_profit) * Point()),"Self Train NN | Buy"); } if (pred < ticks.bid && !PosExist(POSITION_TYPE_SELL)) { target_gap = ticks.ask - pred; m_trade.Sell(Lots, Symbol(), ticks.bid, ticks.ask + ((target_gap*stop_loss) * Point()), ticks.ask - ((target_gap*take_profit) * Point()), "Self Train NN | Sell"); } }
Esa es la lógica. Veamos cómo funciona el asesor en MT5.
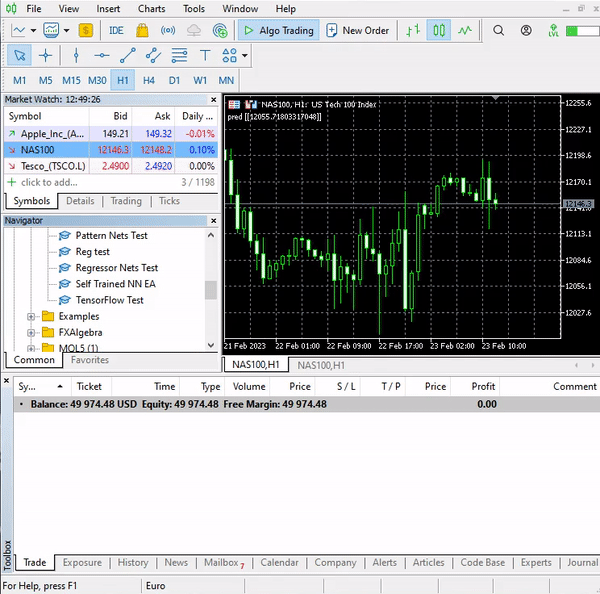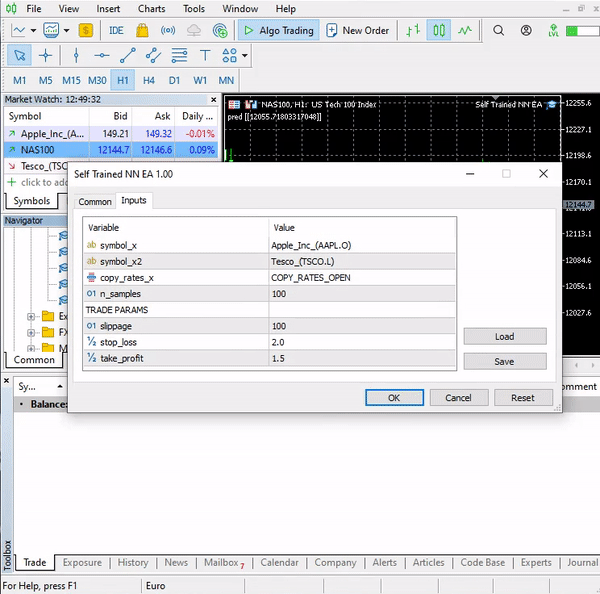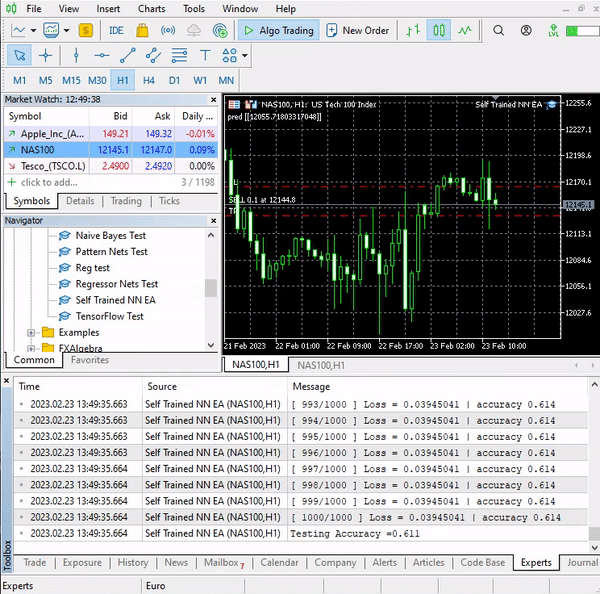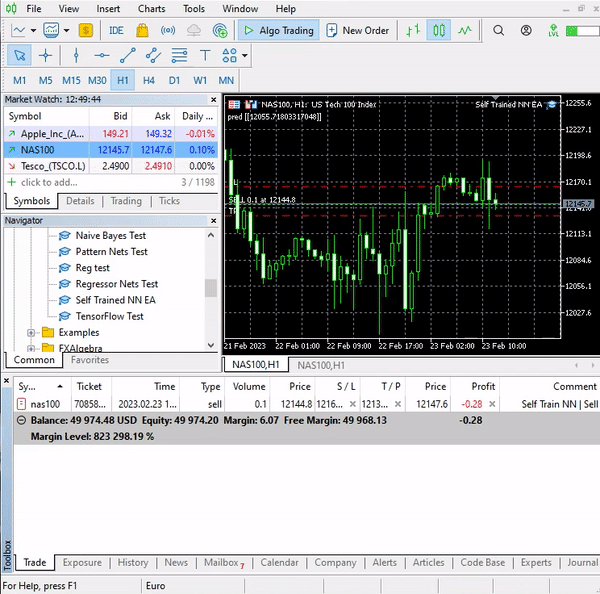
Este sencillo asesor puede realizar operaciones por sí mismo. Por el momento, no podemos valorar su trabajo, es demasiado pronto. Vamos a pasar al simulador de estrategias.
Resultados del simulador de estrategias
Al ejecutar los algoritmos de aprendizaje automático en el simulador de estrategias, pueden surgir complicaciones, así que asegúrese de que los algoritmos se ejecutan sin problemas y con rapidez. Y, por supuesto, también deberá asegurarse de que el asesor genere beneficios.
Hemos realizado pruebas desde el 2023.01.01 hasta el 2023.02.23 en un gráfico de cuatro horas basado en ticks reales. Hemos puesto a prueba los ticks más recientes, pues sospecho que una prueba de este tipo será de mucha mejor calidad en comparación con las pruebas realizadas con datos antiguos.
Hemos configurado la función que entrena nuestro modelo para que se ejecute en el primer tick del ciclo de vida de la prueba, de forma que el proceso de entrenamiento y prueba del modelo resulte instantáneo. Vamos a ver cómo funciona el modelo: después comprobaremos los gráficos y todo lo que nos ofrece el simulador de estrategias.
CS 0 15:50:47.676 Tester NAS100,H4 (Pepperstone-Demo): generating based on real ticks CS 0 15:50:47.677 Tester NAS100,H4: testing of Experts\Advisors\Self Trained NN EA.ex5 from 2023.01.01 00:00 to 2023.02.23 00:00 started with inputs: CS 0 15:50:47.677 Tester symbol_x=Apple_Inc_(AAPL.O) CS 0 15:50:47.677 Tester symbol_x2=Tesco_(TSCO.L) CS 0 15:50:47.677 Tester copy_rates_x=1 CS 0 15:50:47.677 Tester n_samples=200 CS 0 15:50:47.677 Tester = CS 0 15:50:47.677 Tester slippage=100 CS 0 15:50:47.677 Tester stop_loss=2.0 CS 0 15:50:47.677 Tester take_profit=2.0 CS 3 15:50:49.209 Ticks NAS100 : 2023.02.21 23:59 - real ticks absent for 2 minutes out of 1379 total minute bars within a day CS 0 15:50:51.466 History Tesco_(TSCO.L),H4: history begins from 2022.01.04 08:00 CS 0 15:50:51.467 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 1/1000 ] Loss = 0.14025037 | accuracy -1.524 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 2/1000 ] Loss = 0.05244676 | accuracy 0.056 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 3/1000 ] Loss = 0.04488896 | accuracy 0.192 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 4/1000 ] Loss = 0.04114715 | accuracy 0.259 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 5/1000 ] Loss = 0.03877407 | accuracy 0.302 CS 0 15:50:51.469 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 6/1000 ] Loss = 0.03725228 | accuracy 0.329 CS 0 15:50:51.469 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 7/1000 ] Loss = 0.03627591 | accuracy 0.347 CS 0 15:50:51.469 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 8/1000 ] Loss = 0.03564933 | accuracy 0.358 CS 0 15:50:51.470 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 9/1000 ] Loss = 0.03524708 | accuracy 0.366 CS 0 15:50:51.470 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 10/1000 ] Loss = 0.03498872 | accuracy 0.370 CS 0 15:50:51.662 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 1000/1000 ] Loss = 0.03452066 | accuracy 0.379 CS 0 15:50:51.662 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 Testing Accuracy =0.717
La precisión del entrenamiento ha sido del 37,9%, pero la de las pruebas ha sido del 71,7%. ¿Por qué?
Sospecho que el problema se oculta en la calidad de la formación. Siempre hay que asegurarse de que los datos para la formación y las pruebas sean de calidad decente, pues cualquier omisión en los datos puede tener consecuencias negativas. Como estamos probando los resultados en el simulador de estrategias, debemos estar seguros de que los resultados de la prueba histórica procedan de un buen modelo en cuya construcción hayamos invertido mucho esfuerzo.
Una vez finalizado el funcionamiento del simulador de estrategias, vemos que los resultados no son sorprendentes: la mayoría de las transacciones abiertas por este asesor han terminado con una pérdida del 78,27%.
Como no hemos optimizado el Stop Loss y el Take Profit, creo que podemos optimizar estos valores y otros parámetros y ver qué ocurre.
Bien, hemos realizado una pequeña optimización y seleccionado los siguientes valores: copy_rates_x: COPY_RATES_LOW, n_samples: 2950, Slippage: 1, Stop loss: 7.4, Take profit: 5.0.
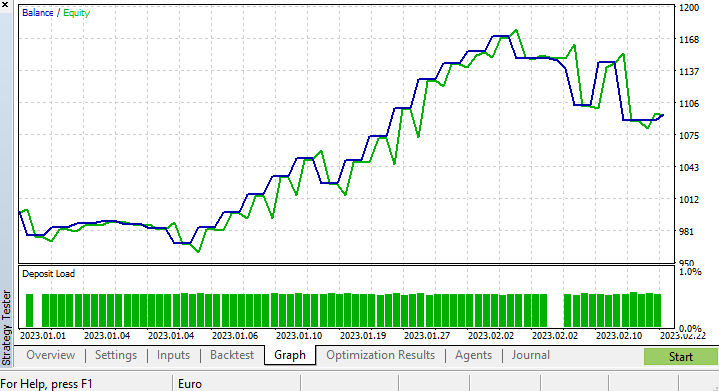
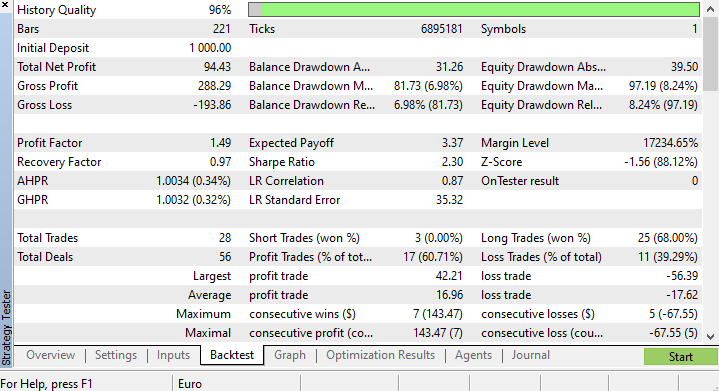
Esta vez, el modelo ha mostrado una precisión de aprendizaje del 61,5% y una precisión de prueba del 63,5% al inicio del funcionamiento del simulador de estrategias. Parece aceptable.
CS 0 17:11:52.100 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 1000/1000 ] Loss = 0.05890808 | accuracy 0.615 CS 0 17:11:52.101 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 Testing Accuracy =0.635
Reflexiones finales
La regla delta se usa para las redes neuronales monocapa regresivas. Aunque se trata de una red neuronal monocapa, la hemos usado como ejemplo para ver cómo se puede mejorar la red cuando las cosas no van bien. Una red neuronal monocapa no es más que una combinación de modelos de regresión lineal que trabajan en equipo para resolver una tarea. Por ejemplo:
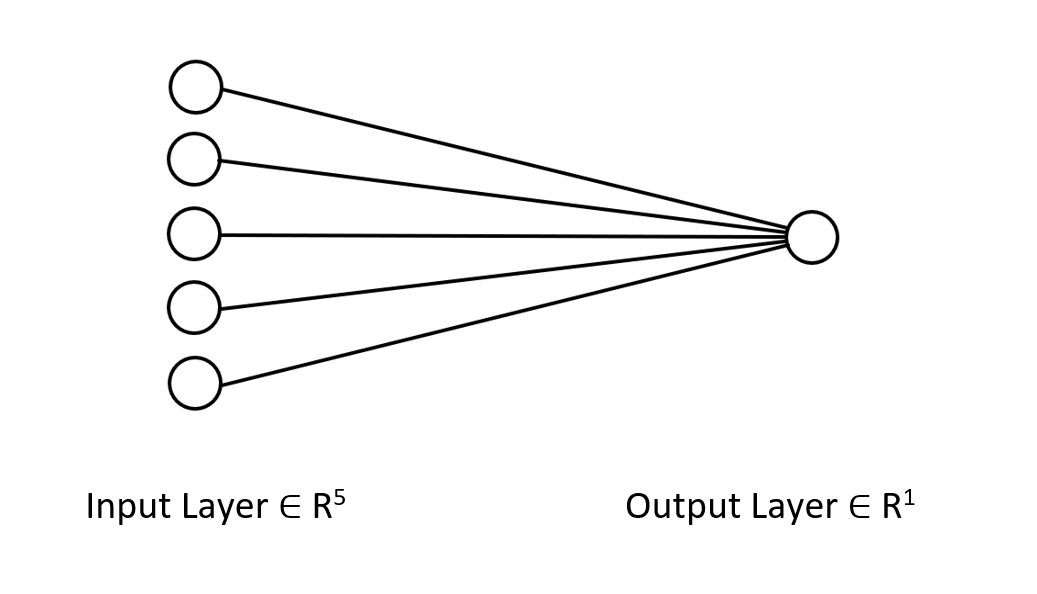
Podemos ver esto desde otra perspectiva: como 5 modelos de regresión lineal trabajando sobre el mismo problema. Cabe señalar que esta red neuronal no es capaz de entender patrones complejos en las variables, así que no se sorprenda por los resultados. Como ya hemos dicho, la regla delta es el componente básico del algoritmo general de propagación inversa del error que se utiliza para redes neuronales mucho más complejas en el aprendizaje profundo.
Hoy hemos construido una red neuronal no está exenta de errores para mostrar una idea concreta: aunque las redes neuronales son capaces de aprender patrones, debemos prestar atención a los pequeños detalles para que la red funcione correctamente y ofrezca los resultados deseados.
¡Buena suerte a todos!
Siga el desarrollo de esta biblioteca y otros modelos de aprendizaje automático en githab: https://github.com/MegaJoctan/MALE5
Archivos adjuntos:
| Archivo | Contenido y uso |
|---|---|
| metrics.mqh | Contiene funciones para medir la precisión de los modelos de redes neuronales. |
| preprocessing.mqh | Contiene funciones de escalado y preparación de datos para modelos de redes neuronales. |
| matrix_utils.mqh | Funciones adicionales para trabajar con matrices |
| selftrain NN.mqh | Archivo de inclusión básico con las redes neuronales de autoaprendizaje. |
| Self Train NN EA.mq5 | Asesor para poner a prueba las redes neuronales de autoaprendizaje |
Artículos relacionados:
Nota: todo el contenido de este artículo tiene fines exclusivamente ilustrativos. El trading es un negocio arriesgado y debe ser consciente de todos los riesgos que conlleva. El autor no se hace responsable de eventuales pérdidas o daños derivados de la utilización de los modelos expuestos en este artículo. ¡Nunca arriesgue más dinero del que pueda permitirse perder sin perjuicio para sí mismo!
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/12209
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Una buena demo para mostrar la posibilidad de auto-entrenamiento (tuning) ML EA.
Esto es todavía los primeros días de MQL ML. Esperemos que con el paso del tiempo, más y más personas utilizarán MALE5. Esperamos con interés su madurez.
¿Cómo se guarda y se carga la red?