
Ciência de Dados e Aprendizado de Máquina (Parte 12): É possível ter sucesso no mercado com redes neurais de autoaprendizagem?

“Não estou dizendo que as redes neurais são fáceis. É preciso ser um especialista para fazê-las funcionar. Mas essa experiência tem uma aplicação muito mais ampla. Os esforços que costumavam ser direcionados para o desenvolvimento de recursos agora estão focados na arquitetura, função de perda e esquema de otimização. O trabalho manual está sendo elevado para um nível mais abstrato.”
Stefano Soatto
Introdução
Se você gosta de negociação algorítmica, provavelmente já ouviu falar de redes neurais. Parece ser a maneira de encontrar o Santo Graal. No entanto, não tenho certeza disso, pois ter um sistema lucrativo requer mais do que simplesmente adicionar uma rede neural ao robô de negociação. Além disso, é preciso ter clareza sobre o que está envolvido ao usar redes neurais, pois às vezes o sucesso ou o fracasso, ou seja, o lucro ou o prejuízo, depende dos mínimos detalhes.

Na minha opinião, as redes neurais não serão úteis para aqueles que não desejam se envolver profundamente. Afinal, com elas, é necessário gastar tempo constantemente analisando erros do modelo, realizando o pré-processamento e escalonamento dos dados de entrada, entre muitas outras coisas que abordaremos neste artigo.
Vamos começar este artigo definindo uma rede neural artificial.
O que é uma rede neural artificial?
Em termos simples, uma rede neural artificial é um sistema computacional inspirado nas redes neurais biológicas do cérebro vivo. No artigo anterior abordei os principais elementos das redes neuronais desta série.
Em artigos anteriores, expliquei os aspectos básicos de uma rede neural de propagação direta. Neste artigo, analisaremos a propagação e retropropagação, bem como o treinamento e o teste de redes neurais. Criaremos um robô de negociação com base em tudo quanto discutido e veremos como nosso robô de negociação funciona.
No caso de um perceptron multicamada, todos os neurônios/nós da camada atual estão conectados aos nós da segunda camada e assim por diante, abrangendo todas as camadas desde a entrada até a saída. Isso permite que a rede neural identifique relações complexas nos conjuntos de dados. Quanto mais camadas você tiver, maior será a capacidade do seu modelo em compreender relações complexas nos conjuntos de dados. No entanto, isso vem com um alto custo computacional, sem garantir a precisão do modelo, especialmente se o modelo for muito complexo e a tarefa for simples.
Na maioria das vezes, uma única camada oculta é suficiente para resolver a maioria dos problemas por meio de redes neurais complexas. Neste artigo, trabalharemos com uma rede neural de camada única.
Propagação
As operações associadas à propagação pela rede são simples e podem ser implementadas em poucas linhas de código. Para criar redes verdadeiramente flexíveis, é importante aprender sobre o manuseio de matrizes e vetores, porque eles são o bloco de construção das redes neurais e de muitos dos algoritmos de aprendizado de máquina que discutimos nesta série.
Um ponto importante a ser ressaltado é entender o tipo de problema que se está tentando resolver com uma rede neural, pois problemas diferentes exigem tipos diferentes de redes com configurações diferentes e saídas diferentes.
Principais tipos de tarefas:
- Tarefas de regressão
- Tarefas de classificação
Quando tratamos de problemas de regressão, estamos tentando prever variáveis contínuas. Quando aplicado à negociação, estamos tentando prever o próximo ponto de preço para o qual o mercado irá. Se você não estiver familiarizado com a regressão linear, recomendo que leia sobre ela aqui.
As tarefas desse tipo são resolvidas por regressão de rede neural.
2. Tarefas da classificação
Em problemas de classificação, tentamos prever resultados em variáveis discretas. Quando aplicado à negociação, podemos prever sinais. Vamos supor que um sinal de 0 indique que o mercado está se movendo para baixo, e um sinal de 1 indique que o mercado está se movendo para cima.
Essas tarefas são resolvidas por redes neurais de classificação ou redes neurais de reconhecimento de padrões, que no MATLAB são chamadas de patternnet.
Neste artigo, trabalharemos com um problema de regressão, e tentaremos prever o próximo preço para o qual o mercado se moverá.
matrix CRegNeuralNets::ForwardPass(vector &input_v) { matrix INPUT = this.matrix_utils.VectorToMatrix(input_v); matrix OUTPUT; OUTPUT = W.MatMul(INPUT); //Weight X Inputs OUTPUT = OUTPUT + B; //Outputs + Bias OUTPUT.Activation(OUTPUT, ENUM_ACTIVATION_FUNCTION(A_FX)); //Activation Function return (OUTPUT); }
Essa função de propagação deve ser óbvia, mas o mais importante é prestar muita atenção ao tamanho da matriz em cada etapa, para que tudo funcione como deveria.
matrix INPUT = this.matrix_utils.VectorToMatrix(input_v);
É importante explicar essa parte. Como a função VectorToMatrix recebe um vetor como entrada, os dados de entrada devem estar em forma matricial, pois usaremos operações matriciais em seguida.
Lembre-se disso:
- A primeira matriz de entrada para a rede neural é uma matriz nx1
- A matriz de peso é HN x n, em que HN é o número de nós na camada oculta atual e n é o número de entradas da camada anterior ou o número de linhas da matriz de entrada.
- A matriz de deslocamento tem o mesmo tamanho que as saídas da camada.
É muito importante lembrar disso. Lembre-se desses pontos para não ter de adivinhar tudo por conta própria.
Vamos dar uma olhada na arquitetura da rede neural em que estamos trabalhando para que você entenda claramente o que estamos fazendo aqui.
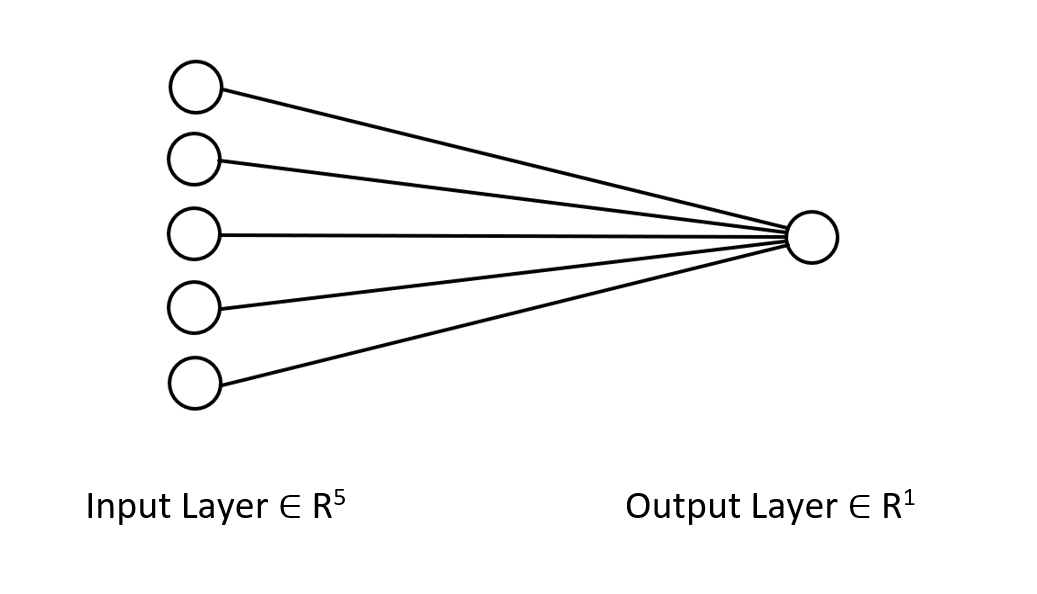
Essa rede neural tem apenas uma camada, por isso não há laços na função de propagação mostrada acima. Assim, é possível implementar uma arquitetura de qualquer complexidade se você seguir a mesma abordagem matricial e usar as dimensões apropriadas.
Bem, acima é mostrada a propagação com a matriz W. Vamos ver agora como encontrar os pesos para o nosso modelo.
Geração de pesos
Gerar pesos adequados para uma rede neural vai além de apenas inicializar valores aleatórios. Aprendi da pior forma que uma abordagem errada pode causar diversos problemas de retropropagação, levando a questionamentos e depuração de um código complexo.
Se os pesos não forem inicializados corretamente, todo o processo de treinamento pode se tornar demorado. A rede pode ficar presa em mínimos locais e convergir muito lentamente.
Na primeira etapa, escolhemos valores aleatórios e eu prefiro usar o estado aleatório 42.
this.W = matrix_utils.Random(0.0, 1.0,1,m_inputs, RANDOM_STATE);
A maioria das pessoas para por aqui, gera os pesos e acredita que é só isso. Após escolher as variáveis aleatórias, é necessário inicializar os pesos usando a inicialização de Glorot ou He.
A inicialização de Xavier/Glorot funciona melhor com funções de ativação sigmoides e tangentes, enquanto a inicialização de He funciona melhor com a função ReLU e suas variantes.
Inicialização Ge (He)
![]()
onde: n é o número de entradas para o nó.
Assim, após a inicialização dos pesos, fazemos a normalização.
this.W = matrix_utils.Random(0.0, 1.0,1,m_inputs, RANDOM_STATE); this.W = this.W * 1/sqrt(m_inputs); //He initialization
Como essa rede neural possui apenas uma camada, temos apenas uma matriz para carregar os pesos.
Funções de ativação dos neurônios
Essa rede neural é baseada em regressão e as funções de ativação utilizadas são variantes da função de ativação de regressão RELU:
enum activation { AF_ELU_ = AF_ELU, AF_EXP_ = AF_EXP, AF_GELU_ = AF_GELU, AF_LINEAR_ = AF_LINEAR, AF_LRELU_ = AF_LRELU, AF_RELU_ = AF_RELU, AF_SELU_ = AF_SELU, AF_TRELU_ = AF_TRELU, AF_SOFTPLUS_ = AF_SOFTPLUS };
Essas funções de ativação destacadas em vermelho estão disponíveis entre outras na biblioteca padrão (Documentação).
Funções de perda
Essas são as funções de perda para essa rede neural com regressão:
enum loss { LOSS_MSE_ = LOSS_MSE, LOSS_MAE_ = LOSS_MAE, LOSS_MSLE_ = LOSS_MSLE, LOSS_HUBER_ = LOSS_HUBER };
Existem outras funções de ativação na biblioteca padrão, você pode ler mais sobre elas na documentação.
Retropropagação usando a regra delta
A regra delta é uma regra de aprendizado de gradiente descendente para atualizar os pesos de entrada de neurônios artificiais em uma rede neural de camada única. É um caso especial do algoritmo de retropropagação mais geral. Para o neurônio j com função de ativação g(x), a regra delta do peso Wji na posição i para o neurônio j é:
![]()
Onde:
![]() — pequena constante chamada taxa de aprendizado
— pequena constante chamada taxa de aprendizado
![]() — derivada de g
— derivada de g
g(x) — função de ativação do neurônio
![]() — resultado alvo
— resultado alvo
![]() — resultado atual
— resultado atual
![]() — i-ésima entrada
— i-ésima entrada
Ótimo, já temos uma fórmula, agora é só implementá-la, certo? Não.
O problema com essa fórmula é que, por mais simples que pareça, é muito difícil de converter em código e requer alguns laços for. Esse tipo de prática em redes neurais pode deixá-lo louco. A fórmula correta de que precisamos é aquela que usa operações matriciais. Aqui está ela:
![]()
Onde:
![]() — alteração da matriz de pesos
— alteração da matriz de pesos
![]() — derivada da função de perda
— derivada da função de perda
![]() — multiplicação da matriz/produto Adamar elemento a elemento
— multiplicação da matriz/produto Adamar elemento a elemento
![]() — derivada da matriz de ativação neuronal
— derivada da matriz de ativação neuronal
![]() — matriz de valores de entrada.
— matriz de valores de entrada.
O tamanho da matriz L é sempre igual ao tamanho da matriz O, e a matriz resultante no lado direito deve ter o mesmo tamanho da matriz W. Assim e somente assim.
Vejamos como isso se apresenta ao transferir a fórmula para o código.
for (ulong iter=0; iter<m_rows; iter++) { OUTPUT = ForwardPass(m_x_matrix.Row(iter)); //forward pass pred = matrix_utils.MatrixToVector(OUTPUT); actual[0] = m_y_vector[iter]; preds[iter] = pred[0]; actuals[iter] = actual[0]; //--- INPUT = matrix_utils.VectorToMatrix(m_x_matrix.Row(iter)); vector loss_v = pred.LossGradient(actual, ENUM_LOSS_FUNCTION(L_FX)); LOSS_DX.Col(loss_v, 0); OUTPUT.Derivative(OUTPUT, ENUM_ACTIVATION_FUNCTION(A_FX)); OUTPUT = LOSS_DX * OUTPUT; INPUT = INPUT.Transpose(); DX_W = OUTPUT.MatMul(INPUT); this.W -= (alpha * DX_W); //Weights update by gradient descent }
A vantagem de empregar a biblioteca de matrizes do MQL5 para aprendizado de máquina em vez de arrays reside no fato de que não precisamos efetuar qualquer cálculo manualmente, isto é, não precisamos calcular por nós mesmos as derivadas das funções de perda ou as derivadas da função de ativação. De fato, não precisamos fazer nada disso.
Para o treinamento de um modelo, duas coisas devem ser levadas em consideração: no momento, as épocas e as taxas de aprendizado são denominadas de alfa. Se você leu o artigo anterior desta série onde discutimos o gradiente descendente, entenderá do que estou falando.
Épocas. Uma época é quando todo o conjunto de dados passa totalmente pela rede, indo e voltando. Em termos simples, é quando a rede já processou todos os dados. Quanto mais épocas, mais tempo necessário para treinar a rede neural e potencialmente melhor será o seu treinamento.
Alphaé o tamanho do passo que o algoritmo de descida do gradiente usa para se aproximar do mínimo global e local. Alpha é geralmente um valor pequeno, variando de 0,1 a 0,00001. Quanto maior esse valor, mais rápida será a convergência da rede, porém aumenta o risco de ultrapassar o mínimo local.
Abaixo está o código completo para esta regra delta:
for (ulong epoch=0; epoch<epochs && !IsStopped(); epoch++) { for (ulong iter=0; iter<m_rows; iter++) { OUTPUT = ForwardPass(m_x_matrix.Row(iter)); pred = matrix_utils.MatrixToVector(OUTPUT); actual[0] = m_y_vector[iter]; preds[iter] = pred[0]; actuals[iter] = actual[0]; //--- INPUT = matrix_utils.VectorToMatrix(m_x_matrix.Row(iter)); vector loss_v = pred.LossGradient(actual, ENUM_LOSS_FUNCTION(L_FX)); LOSS_DX.Col(loss_v, 0); OUTPUT.Derivative(OUTPUT, ENUM_ACTIVATION_FUNCTION(A_FX)); OUTPUT = LOSS_DX * OUTPUT; INPUT = INPUT.Transpose(); DX_W = OUTPUT.MatMul(INPUT); this.W -= (alpha * DX_W); } printf("[ %d/%d ] Loss = %.8f | accuracy %.3f ",epoch+1,epochs,preds.Loss(actuals,ENUM_LOSS_FUNCTION(L_FX)),metrics.r_squared(actuals, preds)); }
Agora está tudo pronto. É hora de treinar a rede neural para entender um pequeno padrão no conjunto de dados.
#include <MALE5\Neural Networks\selftrain NN.mqh> #include <MALE5\matrix_utils.mqh> CRegNeuralNets *nn; CMatrixutils matrix_utils; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- matrix Matrix = { {1,2,3}, {2,3,5}, {3,4,7}, {4,5,9}, {5,6,11} }; matrix x_matrix; vector y_vector; matrix_utils.XandYSplitMatrices(Matrix,x_matrix,y_vector); nn = new CRegNeuralNets(x_matrix,y_vector,0.01,100, AF_RELU_, LOSS_MSE_); //Training the Network //--- return(INIT_SUCCEEDED); }
A função XandYSplitMatrices divide uma matriz em uma matriz x e um vetor y.
| X Matrix | Y Vector |
|---|---|
| { {1, 2}, {2, 3}, {3, 4}, {4, 5}, {5, 6} } | {3}, {5}, {7}, {9}, {11} |
Resultados do aprendizado:
CS 0 20:30:00.878 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [1/100] Loss = 56.22401001 | accuracy -6.028 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [2/100] Loss = 2.81560904 | accuracy 0.648 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [3/100] Loss = 0.11757813 | accuracy 0.985 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [4/100] Loss = 0.01186759 | accuracy 0.999 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [5/100] Loss = 0.00127888 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [6/100] Loss = 0.00197030 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [7/100] Loss = 0.00173890 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [8/100] Loss = 0.00178597 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [9/100] Loss = 0.00177543 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [10/100] Loss = 0.00177774 | accuracy 1.000 … … … CS 0 20:30:00.883 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [100/100] Loss = 0.00177732 | accuracy 1.000
Após apenas 5 épocas, a precisão da rede neural foi de 100%. Isso é bom, pois essa tarefa é muito simples, e esperava-se um aprendizado mais rápido.
Agora que essa rede neural foi treinada, vamos testá-la com os novos valores {7,8}. Você e eu sabemos que o resultado é 15.
vector new_data = {7,8}; Print("Test "); Print(new_data," pred = ",nn.ForwardPass(new_data));
Resultado:
CS 0 20:37:36.331 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) Test CS 0 20:37:36.331 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [7,8] pred = [[14.96557787153696]]
Alcançamos um valor próximo de 14,97. 15 é somente um valor double, f, aqui obtivemos valores adicionais, porém ao arredondar para um dígito significativo, o resultado será 15. Isto evidencia que a nossa rede neural agora é capaz de aprender de forma autônoma. Ótimo.
Vamos alimentar este modelo com um conjunto real de dados e observar o que ele consegue fazer.
Utilizei dados das ações da Tesla e da Apple como variáveis independentes para a previsão do índice NASDAQ (NAS 100). Em uma ocasião, li um artigo na CNBC afirmando que as ações de seis empresas tecnológicas representam metade do valor do NASDAQ. Dentre elas, estão Apple e Tesla. Neste exemplo, usarei estas duas ações como variáveis independentes para o treinamento da rede neural.
input string symbol_x = "Apple_Inc_(AAPL.O)"; input string symbol_x2 = "Tesco_(TSCO.L)"; input ENUM_COPY_RATES copy_rates_x = COPY_RATES_OPEN; input int n_samples = 100; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { matrix x_matrix(n_samples,2); vector y_vector; vector x_vector; //--- x_vector.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 0); x_vector.CopyRates(symbol_x2, PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 1); y_vector.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_CLOSE,0,n_samples); nn = new CRegNeuralNets(x_matrix,y_vector,0.01,1000, AF_RELU_, LOSS_MSE_);
Os nomes dos símbolos em symbol_x e symbol_x2 podem variar de acordo com o seu corretor. Lembre-se de alterar essas variáveis e incluir os símbolos na visualização de mercado antes de iniciar o Expert Advisor de teste. O símbolo y corresponde ao símbolo atual do gráfico. O Expert Advisor deve ser executado no gráfico NASDAQ.
Após executar o script, isso foi o que se registrou no log:
CS 0 21:29:20.698 Self Trained NN EA (NAS100,M30) [ 1/1000 ] Loss = 353809311769.08959961 | accuracy -27061631.733 CS 0 21:29:20.698 Self Trained NN EA (NAS100,M30) [ 2/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 3/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 4/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 5/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 6/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 .... .... CS 0 21:29:20.886 Self Trained NN EA (NAS100,M30) [ 1000/1000 ] Loss = 149221473.48209998 | accuracy -11412.427
O que?! E isso é o resultado após todo o esforço aplicado. Este tipo de situação ocorre frequentemente em redes neurais, por isso é crucial ter uma compreensão clara de como uma rede neural opera, independente da estrutura ou biblioteca Python que esteja em uso.
Normalização e escalonamento de dados
Não me canso de enfatizar a importância desta etapa. Embora nem todos os conjuntos de dados produzam os melhores resultados quando normalizados - por exemplo, se normalizarmos o conjunto de dados simples que utilizamos inicialmente para verificar o desempenho da rede neural, os resultados serão desastrosos. A rede neural retornará valores piores - eu verifiquei.
Existem diversos métodos de normalização. Os três mais frequentemente utilizados são:
Min-Max Scaler
Este é um método de normalização que escala os valores de um atributo numérico para um intervalo fixo [0, 1]. Sua fórmula é a seguinte:
x_norm = (x -x_min) / (x_max - x_min)
onde:
x — valor original do atributo
x_min — valor mínimo do atributo
x_max — valor máximo do atributo
x_norm — novo valor normalizado do atributo
Para selecionar o método de normalização e normalizar os dados, precisamos importar a biblioteca de pré-processamento. O arquivo de inclusão está anexado no final deste artigo.
Decidi adicionar a funcionalidade de normalização de dados à nossa biblioteca de redes neurais.
CRegNeuralNets::CRegNeuralNets(matrix &xmatrix, vector &yvector,double alpha, uint epochs, activation ACTIVATION_FUNCTION, loss LOSS_FUNCTION, norm_technique NORM_METHOD)
Aqui é possível escolher o método de normalização apropriado em norm_technique:
enum norm_technique { NORM_MIN_MAX_SCALER, //Min max scaler NORM_MEAN_NORM, //Mean normalization NORM_STANDARDIZATION, //standardization NORM_NONE //Do not normalize. };
Depois de adicionar a normalização, consegui obter uma precisão aceitável.
nn = new CRegNeuralNets(x_matrix,y_vector,0.01,1000, AF_RELU_, LOSS_MSE_,NORM_MIN_MAX_SCALER);
Resultado:
CS 0 22:40:56.457 Self Trained NN EA (NAS100,M30) [ 1/1000 ] Loss = 0.19379434 | accuracy -0.581 CS 0 22:40:56.457 Self Trained NN EA (NAS100,M30) [ 2/1000 ] Loss = 0.07735744 | accuracy 0.369 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 3/1000 ] Loss = 0.04761891 | accuracy 0.611 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 4/1000 ] Loss = 0.03559318 | accuracy 0.710 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 5/1000 ] Loss = 0.02937830 | accuracy 0.760 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 6/1000 ] Loss = 0.02582918 | accuracy 0.789 CS 0 22:40:56.459 Self Trained NN EA (NAS100,M30) [ 7/1000 ] Loss = 0.02372224 | accuracy 0.806 CS 0 22:40:56.459 Self Trained NN EA (NAS100,M30) [ 8/1000 ] Loss = 0.02245222 | accuracy 0.817 CS 0 22:40:56.460 Self Trained NN EA (NAS100,M30) [ 9/1000 ] Loss = 0.02168207 | accuracy 0.823 CS 0 22:40:56.460 Self Trained NN EA (NAS100,M30 CS 0 22:40:56.623 Self Trained NN EA (NAS100,M30) [ 1000/1000 ] Loss = 0.02046533 | accuracy 0.833
Também devo admitir que não alcancei os resultados desejados no intervalo de uma hora. A rede neural funcionou com mais precisão em um gráfico de 30 minutos, mas não investiguei a razão disso.
Portanto, a precisão dos dados de treinamento é de 82,3%. Esta é uma boa precisão. Agora, vamos criar uma estratégia de negociação simples que utilizará nossa rede para abrir negociações.
A abordagem atual que utilizei para coletar dados na função OnInit não é confiável. Vou criar uma função para treinar as redes e colocá-la na função Init. Nossa rede será treinada apenas uma vez. No entanto, você pode alterar essa dinâmica se desejar - não é uma condição obrigatória.
void OnTick() { //--- if (!train_nn) TrainNetwork(); //Train the network only once train_nn = true; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void TrainNetwork() { matrix x_matrix(n_samples,2); vector y_vector; vector x_vector; x_vector.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 0); x_vector.CopyRates(symbol_x2, PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 1); y_vector.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_CLOSE,0,n_samples); nn = new CRegNeuralNets(x_matrix,y_vector,0.01,1000, AF_RELU_, LOSS_MSE_,NORM_MIN_MAX_SCALER); }
Esse recurso de aprendizado parece ter tudo o que precisamos para entrar no mercado. Ainda assim, não é confiável. Fiz o teste no período diário e obtive uma precisão de -77%, no período de 4 horas obtive uma precisão de -11234 ou algo do tipo. Ao aumentar os dados e treinar em diferentes amostras de treinamento, a rede neural não conseguiu reproduzir a precisão de treinamento fornecida anteriormente.
Há várias razões para isso, uma delas é que problemas diferentes requerem arquiteturas diferentes. Suponho que alguns padrões de mercado em diferentes prazos possam ser muito complexos para uma rede neural de camada única, e a regra delta foi projetada justamente para isso. Ainda não podemos resolver isso, então continuarei com o prazo que proporciona um resultado aceitável. No entanto, há algumas coisas que podemos fazer para melhorar os resultados e corrigir um pouco essa inconsistência. Podemos dividir os dados de maneira aleatória.
É mais importante do pode parecer
Se você já trabalhou com Python no área de aprendizado de máquina, é provável que já tenha encontrado a função train_test_split do sklearn.
O objetivo de dividir a amostra em dados de treinamento e teste não é somente para segmentar os dados, mas também para randomizar o conjunto de dados de forma que não permaneça na ordem original. Permita-me explicar. Como as redes neurais e outros algoritmos de aprendizado de máquina buscam entender os padrões nos dados, ter os dados na ordem em que foram extraídos pode ser problemático, já que os modelos tendem a compreender mais facilmente os padrões quando os dados são apresentados na mesma ordem. Esta, no entanto, não é a melhor forma de treinar modelos, já que, para nós, não é a disposição dos dados que importa, mas os padrões intrínsecos.
void TrainNetwork() { //--- collecting the data matrix Matrix(n_samples,3); vector y_vector; vector x_vector; x_vector.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,n_samples); Matrix.Col(x_vector, 0); x_vector.CopyRates(symbol_x2, PERIOD_CURRENT,copy_rates_x,0,n_samples); Matrix.Col(x_vector, 1); y_vector.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_CLOSE,0,n_samples); Matrix.Col(y_vector, 2); //--- matrix x_train, x_test; vector y_train, y_test; matrix_utils.TrainTestSplitMatrices(Matrix, x_train, y_train, x_test, y_test, 0.7, 42); nn = new CRegNeuralNets(x_train,y_train,0.01,1000, AF_RELU_, LOSS_MSE_,NORM_MIN_MAX_SCALER); vector test_pred = nn.ForwardPass(x_test); printf("Testing Accuracy =%.3f",metrics.r_squared(y_test, test_pred)); }
Depois de coletar os dados de treinamento, incluímos a função TrainTestSplitMatrices com um estado aleatório de 42.
void TrainTestSplitMatrices(matrix &matrix_,matrix &x_train,vector &y_train,matrix &x_test, vector &y_test,double train_size=0.7,int random_state=-1)
Previsão de mercado em tempo real
Para fazer previsões em tempo real, a função Ontick deve ter o código para coletar dados e colocá-los no vetor de entrada da função de propagação da rede neural.
void OnTick() { //--- if (!train_nn) TrainNetwork(); //Train the network only once train_nn = true; vector x1, x2; x1.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,1); //only the current candle x2.CopyRates(symbol_x2,PERIOD_CURRENT,copy_rates_x,0,1); //only the current candle vector inputs = {x1[0], x2[0]}; //current values of x1 and x2 instruments | Apple & Tesla matrix OUT = nn.ForwardPass(inputs); //Predicted Nasdaq value double pred = OUT[0][0]; Comment("pred ",OUT); }
Agora nossa rede neural pode fazer previsões. Vamos tentar aplicá-la na negociação. Para fazer isso, vamos criar uma estratégia.
Lógica de negociação
A lógica de negociação é simples: se o preço previsto pela rede neural for maior que o atual, abrimos uma negociação de compra com take profit no nível do preço previsto multiplicado pelo valor do parâmetro de entrada 'take profit'. E fazemos o oposto para negociações de venda. Colocamos um stop loss em cada negociação igual ao número de pontos de take profit multiplicado pelo valor do parâmetro 'stop loss'. Assim fica no MetaEditor.
stops_level = (int)SymbolInfoInteger(Symbol(),SYMBOL_TRADE_STOPS_LEVEL); Lots = SymbolInfoDouble(Symbol(),SYMBOL_VOLUME_MIN); spread = (double)SymbolInfoInteger(Symbol(), SYMBOL_SPREAD); MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (MathAbs(pred - ticks.ask) + spread > stops_level) { if (pred > ticks.ask && !PosExist(POSITION_TYPE_BUY)) { target_gap = pred - ticks.bid; m_trade.Buy(Lots, Symbol(), ticks.ask, ticks.bid - ((target_gap*stop_loss) * Point()) , ticks.bid + ((target_gap*take_profit) * Point()),"Self Train NN | Buy"); } if (pred < ticks.bid && !PosExist(POSITION_TYPE_SELL)) { target_gap = ticks.ask - pred; m_trade.Sell(Lots, Symbol(), ticks.bid, ticks.ask + ((target_gap*stop_loss) * Point()), ticks.ask - ((target_gap*take_profit) * Point()), "Self Train NN | Sell"); } }
Essa é a lógica por trás. Agora, vamos ver como funciona o EA no MT5.
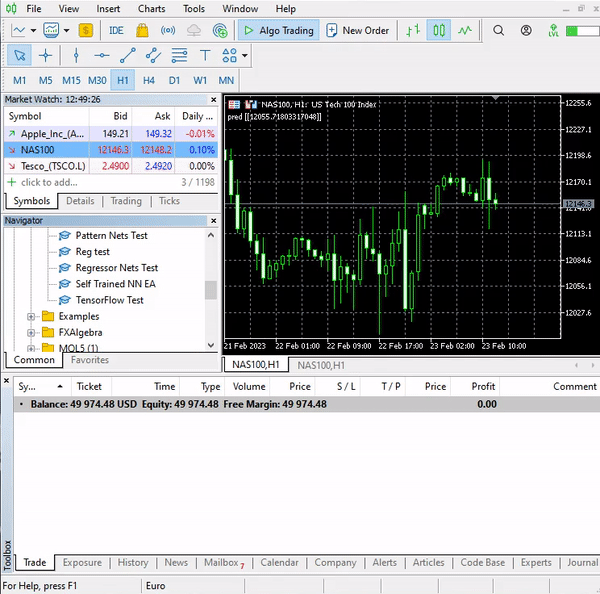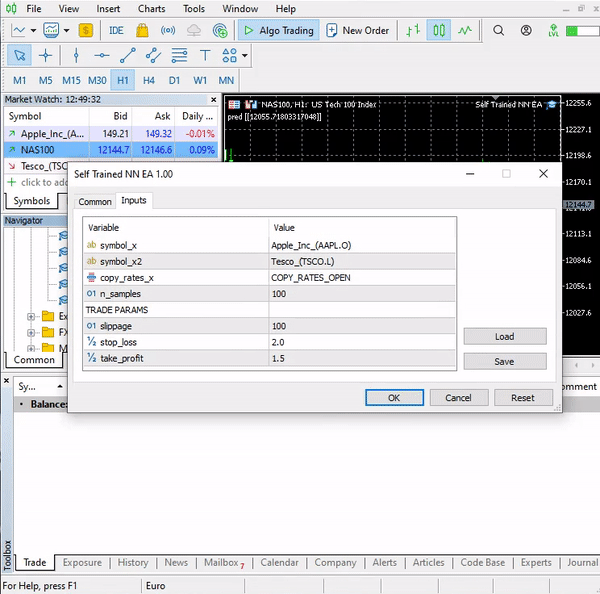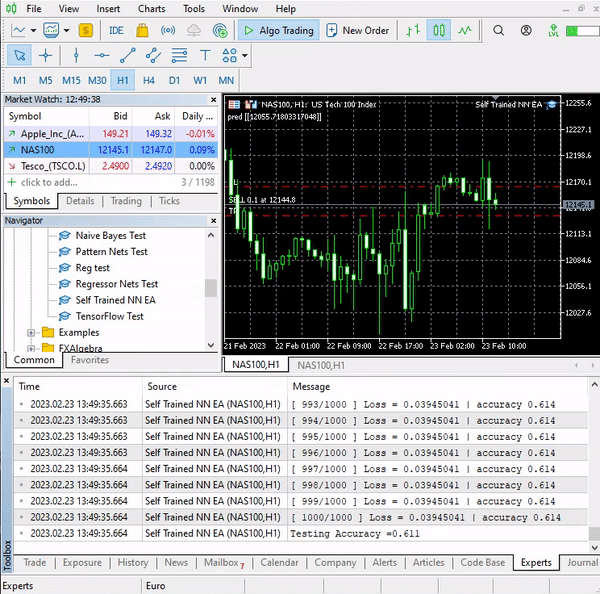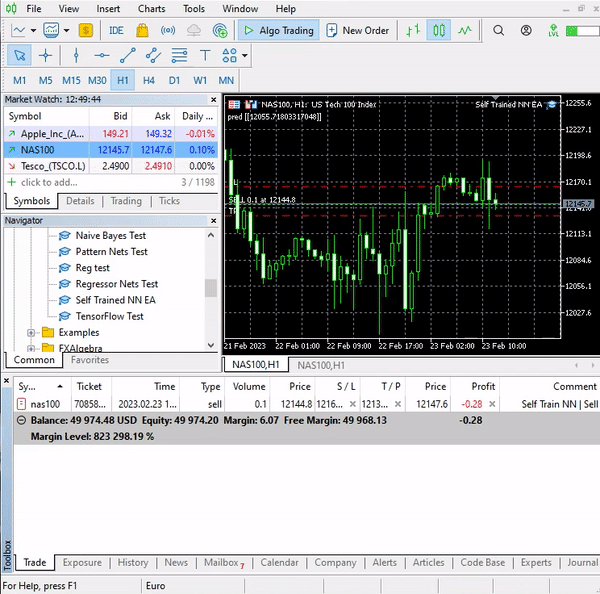
Este simples Expert Advisor pode fazer operações por conta própria, embora não possamos avaliar seu trabalho, pois é muito cedo. Vamos ao testador de estratégia.
Resultados do testador de estratégia
Executar algoritmos de aprendizado de máquina no testador de estratégia pode apresentar desafios, portanto, é essencial garantir que os algoritmos funcionem de forma rápida e fluida. E, naturalmente, é preciso assegurar que o EA gere lucro.
Realizei testes de 01/01/2023 a 23/02/2023 em um gráfico de quatro horas baseado em ticks reais. Os últimos ticks foram testados pois suspeito que tal teste oferecerá uma qualidade superior em comparação com o teste utilizando dados mais antigos.
Configuramos a função que treina o nosso modelo para ser executada no primeiro tick do ciclo de vida do teste, assim o processo de treinamento e teste do modelo foi concluído instantaneamente. Vamos analisar o desempenho do modelo e, em seguida, verificar os gráficos e todas as informações que o testador de estratégia proporciona.
CS 0 15:50:47.676 Tester NAS100,H4 (Pepperstone-Demo): generating based on real ticks CS 0 15:50:47.677 Tester NAS100,H4: testing of Experts\Advisors\Self Trained NN EA.ex5 from 2023.01.01 00:00 to 2023.02.23 00:00 started with inputs: CS 0 15:50:47.677 Tester symbol_x=Apple_Inc_(AAPL.O) CS 0 15:50:47.677 Tester symbol_x2=Tesco_(TSCO.L) CS 0 15:50:47.677 Tester copy_rates_x=1 CS 0 15:50:47.677 Tester n_samples=200 CS 0 15:50:47.677 Tester = CS 0 15:50:47.677 Tester slippage=100 CS 0 15:50:47.677 Tester stop_loss=2.0 CS 0 15:50:47.677 Tester take_profit=2.0 CS 3 15:50:49.209 Ticks NAS100 : 2023.02.21 23:59 - real ticks absent for 2 minutes out of 1379 total minute bars within a day CS 0 15:50:51.466 History Tesco_(TSCO.L),H4: history begins from 2022.01.04 08:00 CS 0 15:50:51.467 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 1/1000 ] Loss = 0.14025037 | accuracy -1.524 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 2/1000 ] Loss = 0.05244676 | accuracy 0.056 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 3/1000 ] Loss = 0.04488896 | accuracy 0.192 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 4/1000 ] Loss = 0.04114715 | accuracy 0.259 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 5/1000 ] Loss = 0.03877407 | accuracy 0.302 CS 0 15:50:51.469 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 6/1000 ] Loss = 0.03725228 | accuracy 0.329 CS 0 15:50:51.469 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 7/1000 ] Loss = 0.03627591 | accuracy 0.347 CS 0 15:50:51.469 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 8/1000 ] Loss = 0.03564933 | accuracy 0.358 CS 0 15:50:51.470 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 9/1000 ] Loss = 0.03524708 | accuracy 0.366 CS 0 15:50:51.470 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 10/1000 ] Loss = 0.03498872 | accuracy 0.370 CS 0 15:50:51.662 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 1000/1000 ] Loss = 0.03452066 | accuracy 0.379 CS 0 15:50:51.662 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 Testing Accuracy =0.717
A precisão do treinamento foi de 37,9%, mas a precisão do teste atingiu 71,7%. Como isso é possível?
Suspeito que esteja relacionado à qualidade do aprendizado. É sempre importante garantir que os dados para treinamento e teste sejam de boa qualidade, e qualquer lacuna nos dados pode ter repercussões. Como estamos testando os resultados no testador de estratégia, precisamos ter certeza de que os resultados do backtest provêm de um bom modelo, no qual empenhamos grandes esforços para construir.
No final do testador de estratégia, os resultados não foram surpreendentes: a maioria das negociações abertas por este EA resultou em uma perda de 78,27%.
Como não otimizamos stop loss e take profit, acredito que seja possível otimizar esses valores, entre outros parâmetros.
Fiz uma otimização breve e obtive os seguintes valores: copy_rates_x: COPY_RATES_LOW, n_samples: 2950, Slippage: 1, Stop loss: 7.4, Take profit: 5.0.
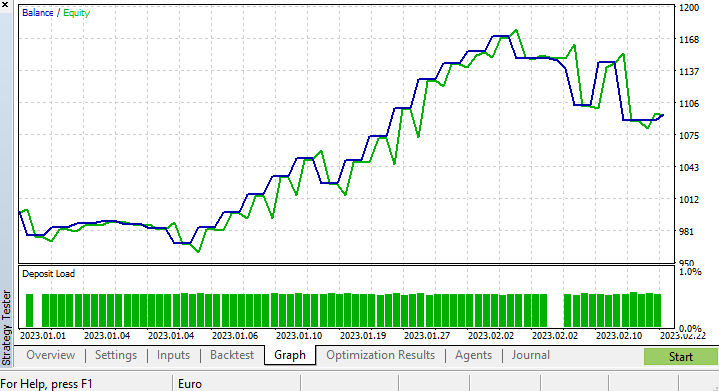
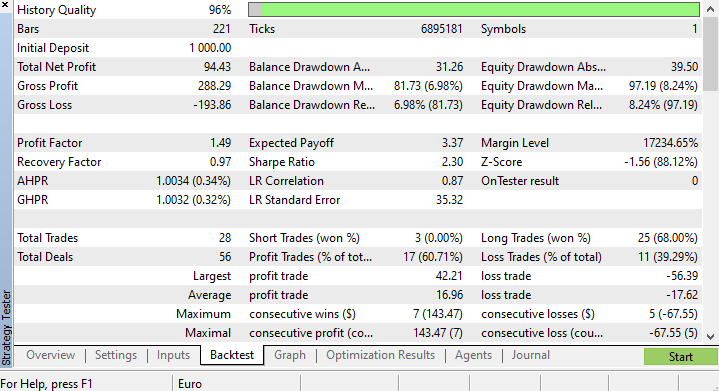
Desta vez, o modelo apresentou uma precisão de treinamento de 61,5% e uma precisão de teste de 63,5% no início do testador de estratégia. Parece aceitável.
CS 0 17:11:52.100 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 1000/1000 ] Loss = 0.05890808 | accuracy 0.615 CS 0 17:11:52.101 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 Testing Accuracy =0.635
Reflexões finais
A regra delta é aplicada na regressão de redes neurais de camada única. Apesar de ser uma rede neural de camada única, por meio dela, demonstramos como aprimorar a rede mesmo quando as coisas não estão indo tão bem. Uma rede neural de camada única nada mais é do que uma combinação de modelos de regressão linear atuando conjuntamente para resolver um problema. Por exemplo:
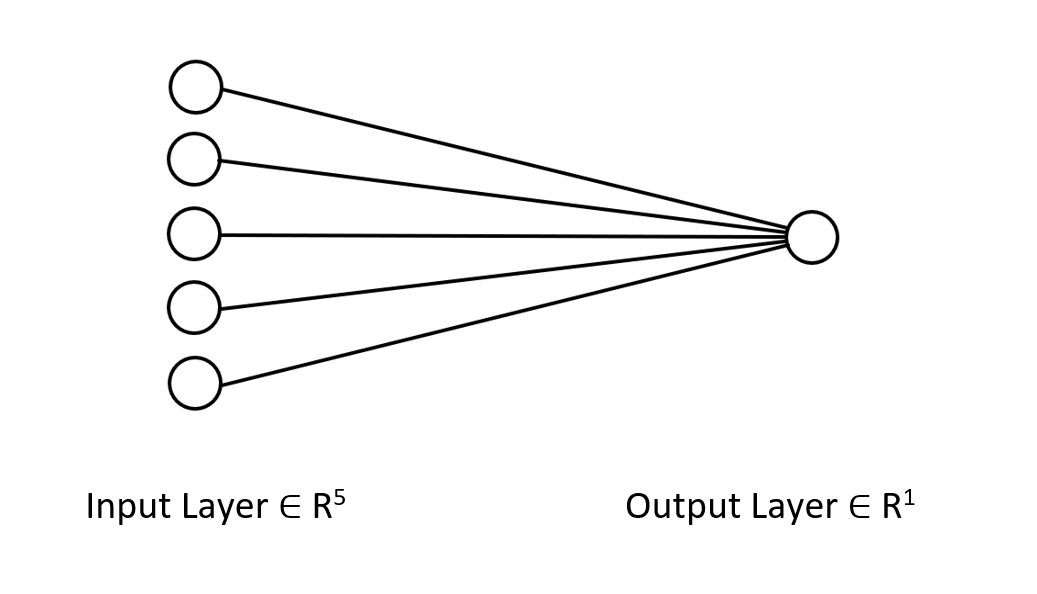
Podemos encarar isso de outra maneira, isto é, como 5 modelos de regressão linear trabalhando na mesma questão. É importante ressaltar que essa rede neural não é capaz de entender padrões complexos nas variáveis, portanto não se surpreenda com os resultados. Como mencionado anteriormente, a regra delta é o componente fundamental do algoritmo geral de retropropagação, utilizado em redes neurais bem mais complexas no aprendizado profundo.
Construí uma rede neural que não é isenta de erros para mostrar um ponto: apesar das redes neurais serem capazes de aprender padrões, é crucial prestar atenção aos detalhes sutis para que a rede funcione corretamente e produza os resultados esperados.
Boa sorte a todos!
Acompanhe o desenvolvimento desta biblioteca e outros modelos de aprendizado de máquina no github:https://github.com/MegaJoctan/MALE5
Arquivos anexados:
| Arquivo | Conteúdo e uso |
|---|---|
| metrics.mqh | Contém funções para medir a precisão dos modelos de rede neural. |
| preprocessing.mqh | Contém funções para dimensionar e preparar dados para modelos de rede neural. |
| matrix_utils.mqh | Funções adicionais para trabalhar com matrizes. |
| autotreinamento NN.mqh | O arquivo de inclusão principal contendo redes neurais de autoaprendizado. |
| Self Train NN EA.mq5 | Advisor para testar redes neurais de autoaprendizado. |
Artigos relacionados:
-
Matrix Utils, estendendo as matrizes e a funcionalidade da biblioteca padrão de vetores
-
Ciência de Dados e Aprendizado de Máquina (Parte 06): Gradiente descendente
Atenção: Todo o conteúdo deste artigo é apenas para fins educacionais e não se destina a outros fins. Negociar é uma atividade arriscada e você deve estar ciente de todos os riscos envolvidos. O autor não se responsabiliza por quaisquer perdas ou danos decorrentes do uso dos modelos discutidos neste artigo. Nunca arrisque mais dinheiro do que você pode perder sem se prejudicar!
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/12209
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Uma boa demonstração para mostrar a possibilidade de autotreinamento (ajuste) do ML EA.
Ainda estamos nos primeiros dias do MQL ML. Esperamos que, com o passar do tempo, mais e mais pessoas usem o MALE5. Estou ansioso por sua maturidade.
Como você salva e carrega a rede?