
Кросс-валидация и основы причинно-следственного вывода в моделях CatBoost, экспорт в ONNX формат
Введение
Предыдущие статьи описывали разные оригинальные способы применения алгоритмов машинного обучения для создания торговых систем. Какие-то оказались довольно удачными, другие (в основном из ранних публикаций) сильно переобучались. Таким образом, последовательность моих статей отражает эволюцию понимания: на что же на самом деле машинное обучение способно, а на что нет. Речь, конечно же, идет о классификации временных рядов.
Например, в предыдущей статье "Метамодели в машинном обучении" был продемонстрирован алгоритм поиска закономерностей посредством взаимодействия двух классификаторов. Такой нетривиальный способ был выбран из-за того, что алгоритмы МО умеют хорошо обобщать и предсказывать, но являются "ленивыми" в отношении поиска причинно-следственных связей. То есть они обобщают обучающие примеры, в которых уже может быть заложена причинно-следственная связь, сохраняющаяся на новых данных, но эта связь также может оказаться ассоциативной, то есть сиюминутной и ненадежной.
Модель не понимает, с какими связями имеет дело, для нее все обучающие данные - это просто обучающие данные. И это большая проблема для новичков, пытающихся обучить ее прибыльно торговать на новых данных. Поэтому в прошлой статье была сделана попытка научить алгоритм анализировать свои собственные ошибки, чтобы на их основе отделить статистически значимые предсказания от случайных.
Текущая статья является развитием предыдущей темы и следующим шагом на пути к созданию самообучающегося алгоритма, который способен искать закономерности в данных, минимизируя подгонку под обучающие данные. Ведь мы хотим получить реальный эффект от применения машинного обучения, чтобы оно не только обобщало обучающие примеры, но и само определяло наличие в них причинно-следственных связей.
ИНЬ (теория)
В этом разделе будет некоторое количество субъективных рассуждений, основанных на толике опыта, полученного в результате попыток создания "Искусственного интеллекта" на Форексе. Потому что это пока не любовь, но все еще опыт.
Так же как наши выводы часто ошибочны и нуждаются в проверке, так и результаты предсказаний моделей машинного обучения должны быть перепроверены. Если процесс перепроверки зациклить на самом себе, получается самоконтроль. Самоконтроль модели машинного обучения сводится к проверке ее прогнозов на предмет ошибок много раз в разных, но похожих ситуациях. Если модель в среднем мало ошибается, значит она не переобучена, если же ошибается часто, значит с ней что-то не так.
Если мы обучаем модель один раз на выбранных данных, то она не может провести самоконтроль. Если мы обучаем модель много раз на случайных подвыборках, а затем проверяем качество предсказания на каждой и суммируем все ошибки, то получаем относительно достоверную картину случаев, где она на самом деле часто ошибается и случаев, которые часто угадывает. Эти случаи можно разделить на две группы, сепарировать друг от друга. Это аналог проведения волк-форвард валидации или кросс-валидации, но с дополнительными элементами. Только таким образом можно добиться самоконтроля и получить более робастную модель.
Поэтому необходимо провести кросс-валидацию на тренировочном датасете, сравнить предсказания модели с обучающими метками и усреднить результаты по всем фолдам. Те примеры, которые в среднем были предсказаны неверно, следует удалить из финальной обучающей выборки как ошибочные. Еще следует обучить вторую модель уже на всех данных, которая отличает хорошо предсказуемые случаи от плохо предсказуемых, позволяя наиболее полно охватить все возможные исходы.
Когда плохие обучающие примеры удалены, основная модель будет иметь небольшую ошибку классификации, но будет плохо предсказывать в тех случаях, которые были удалены как сложно предсказуемые. У нее будет высокая точность, но небольшая полнота. Если теперь добавить второй классификатор и научить его разрешать торговлю первой модели только в тех случаях, которые первая модель научилась классифицировать хорошо, то он должен улучшить результаты всей ТС, поскольку обладает более низкой точностью, но большей полнотой.
Получается, что ошибки первой модели как бы переносятся во второй классификатор, но никуда не исчезают, поэтому теперь уже он будет чаще неверно предсказывать. Но за счет того, что он не предсказывает непосредственно направление сделки и охват данных больше, такие предсказания все же имеют ценность.
Будем считать, что двух моделей достаточно, чтобы своими положительными результатами компенсировать ошибки обучения.
Так, методом исключения плохих обучающих примеров, мы будем искать ситуации, которые в среднем приносят прибыль. И мы будем пытаться не торговать в тех местах, которые в среднем приводят к убыткам.
Ядро алгоритма
Функция "мета лернер" является ядром алгоритма и делает все вышесказанное, поэтому ее следует разобрать более подробно. Остальные функции являются вспомогательными.
def meta_learner(folds_number: int, iter: int, depth: int, l_rate: float) -> pd.DataFrame: dataset = get_labels(get_prices()) data = dataset[(dataset.index < FORWARD) & (dataset.index > BACKWARD)].copy() X = data[data.columns[1:-2]] y = data['labels'] B_S_B = pd.DatetimeIndex([]) # learn meta model with CV method meta_model = CatBoostClassifier(iterations = iter, max_depth = depth, learning_rate=l_rate, verbose = False) predicted = cross_val_predict(meta_model, X, y, method='predict_proba', cv=folds_number) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = [x[0] < 0.5 for x in predicted] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # select bad samples (bad labels indices) diff_negatives = coreset['labels'] != coreset['labels_pred'] B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index) to_mark = B_S_B.value_counts() marked_idx = to_mark.index data.loc[data.index.isin(marked_idx), 'meta_labels'] = 0.0 return data[data.columns[1:]]
На вход она принимает:
- количество фолдов для кросс-валидации
- количество итераций обучения для базового лернера
- глубину дерева базового лернера
- шаг градиента
Эти параметры влияют на итоговый результат и должны подбираться эмпирически, либо по сетке.
Функция cross_val_predict пакета scikit learn возвращает оценки кросс-валидации для каждого обучающего примера, после чего эти оценки сравниваются с исходными метками. Если предсказания неверны, они заносятся в книгу плохих примеров, на основе которой затем формируются "мета метки" для второго классификатора.
Функция возвращает переданный ей датафрейм, с добавочными "мета метками". Этот датафрейм затем используется для обучения финальных моделей, как показано в листинге.
# features for model\meta models. We learn main model only on filtered labels X, X_meta = dataset[dataset['meta_labels']==1], dataset[dataset.columns[:-2]] X = X[X.columns[:-2]] # labels for model\meta models y, y_meta = dataset[dataset['meta_labels']==1], dataset[dataset.columns[-1]] y = y[y.columns[-2]]
Выше в коде отмечено, что первая модель обучается только на тех строках, мета метки которых соответствуют единице, то есть помечены как хорошие обучающие примеры. Тогда как второй классификатор обучается на всем датасете полностью.
И дальше уже просто обучаются два классификатора. Один прогнозирует вероятности на покупку и продажу, а второй стоит торговать или не стоит.
Здесь каждая модель тоже имеет свои параметры обучения, которые не вынесены в гиперпараметры. Их можно настроить отдельно, но я сознательно выбрал небольшое количество итераций, равное 100, чтобы модели не переобучались и на этом финальном этапе. Можно изменять относительные размеры трейн и тест выборок, что тоже будет немного влиять на финальные результаты. В целом, первой модели обучаться достаточно просто, поскольку она обучается только на примерах, которые хорошо классифицируются, поэтому большая сложность модели не требуется. У второй модели более сложная задача, поэтому сложность модели можно увеличить.
# train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.5, test_size=0.5, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.5, test_size=0.5, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU') meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False)
Гиперпараметры алгоритма
Перед началом обучения следует правильно настроить все входные параметры, которые также влияют на итоговый результат.
export_path = '/Users/dmitrievsky/Library/Application Support/MetaTrader 5/\ Bottles/metatrader5/drive_c/Program Files/MetaTrader 5/MQL5/Include/'
# GLOBALS SYMBOL = 'EURUSD' MARKUP = 0.00015 PERIODS = [i for i in range(10, 50, 10)] BACKWARD = datetime(2015, 1, 1) FORWARD = datetime(2022, 1, 1)
- Путь до "Include" папки терминала, для сохранения обученных моделей
- Тикер символа
- Средний маркап в пунктах, включая спред, комиссии и проскальзывания
- Периоды скользящих средних, по которым считаются ценовые приращения. Они являются признаками для обучения модели.
- Диапазон дат для обучения. Слева и справа от этого диапазона остается история вне обучения (ООС), для тестов на новых данных.
def get_labels(dataset, min= 3, max= 25) -> pd.DataFrame:
Эта функция имеет аргументы min и max, для случайного семплинга сделок. Каждая новая сделка будет иметь случайную продолжительность в барах. Если выставить одинаковые значения, то все сделки будут иметь фиксированную продолжительность.
Вспомогательные функции и библиотеки
Перед началом работы следует убедиться, что все необходимые пакеты установлены и импортируются
import numpy as np import pandas as pd import random import math from datetime import datetime import matplotlib.pyplot as put from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.model_selection import cross_val_predict
Дальше следует экспортировать котировки из терминала MetaTrader 5. Выбрать необходимый символ, тайм фрейм и глубину истории. И сохранить их в подкаталог /files вашего Python проекта.
def get_prices() -> pd.DataFrame: p = pd.read_csv('files/EURUSD_H1.csv', delim_whitespace=True) pFixed = pd.DataFrame(columns=['time', 'close']) pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>'] pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed') pFixed['close'] = p['<CLOSE>'] pFixed.set_index('time', inplace=True) pFixed.index = pd.to_datetime(pFixed.index, unit='s') pFixed = pFixed.dropna() pFixedC = pFixed.copy() count = 0 for i in PERIODS: pFixed[str(count)] = pFixedC.rolling(i).mean() - pFixedC count += 1 return pFixed.dropna()
Выделенным показано, откуда бот получает котировки и каким образом создает признаки: посредством вычитания цен закрытия из скользящего среднего, заданного в списке PERIODS как гиперпараметр.
После этого сформированный датасет передается в следующую функцию для разметки меток (или целевых).
def get_labels(dataset, min= 3, max= 25) -> pd.DataFrame: labels = [] meta_labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'][i] future_pr = dataset['close'][i + rand] if future_pr < curr_pr: labels.append(1.0) if future_pr + MARKUP < curr_pr: meta_labels.append(1.0) else: meta_labels.append(0.0) elif future_pr > curr_pr: labels.append(0.0) if future_pr - MARKUP > curr_pr: meta_labels.append(1.0) else: meta_labels.append(0.0) else: labels.append(2.0) meta_labels.append(0.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset['meta_labels'] = meta_labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2.0].index) return dataset
Эта функция возвращает тот же самый датафрейм, но с дополнительными колонками "labels" и "meta labels".
Функция тестера была значительно ускорена, теперь можно загружать большие датасеты и не переживать, что тестер будет работать слишком медленно:
def tester(dataset: pd.DataFrame, plot= False): last_deal = int(2) last_price = 0.0 report = [0.0] chart = [0.0] line = 0 line2 = 0 indexes = pd.DatetimeIndex(dataset.index) labels = dataset['labels'].to_numpy() metalabels = dataset['meta_labels'].to_numpy() close = dataset['close'].to_numpy() for i in range(dataset.shape[0]): if indexes[i] <= FORWARD: line = len(report) if indexes[i] <= BACKWARD: line2 = len(report) pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta==1: last_price = pr last_deal = 0 if pred <= 0.5 else 1 continue if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 report.append(report[-1] - MARKUP + (pr - last_price)) chart.append(chart[-1] + (pr - last_price)) continue if last_deal == 1 and pred < 0.5 and pred_meta==1: last_deal = 2 report.append(report[-1] - MARKUP + (last_price - pr)) chart.append(chart[-1] + (pr - last_price)) y = np.array(report).reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = lr.coef_ if l >= 0: l = 1 else: l = -1 if(plot): plt.plot(report) plt.plot(chart) plt.axvline(x = line, color='purple', ls=':', lw=1, label='OOS') plt.axvline(x = line2, color='red', ls=':', lw=1, label='OOS2') plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l,".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
Вспомогательная функция тестирования уже обученных моделей теперь имеет более лаконичный вид. Она принимает на вход список моделей, рассчитывает вероятности классов и передает их в тестер точно так же, если бы это был готовый датафрейм с признаками и метками для тестирования. Поэтому сам тестер работает как с исходными обучающими датафреймами, так и со сформированными в результате получения прогнозов уже обученных моделей.
def test_model(result: list, plt= False): pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] pr_tst['labels'] = result[0].predict_proba(X)[:,1] pr_tst['meta_labels'] = result[1].predict_proba(X)[:,1] pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(pr_tst, plot=plt)
ЯНЬ (практика)
После настройки гиперпараметров, переходим непосредственно к обучению моделей, которое выполняется в цикле.
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learner(folds_number= 5, iter= 150, depth= 5, l_rate= 0.01)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
Здесь мы обучим 25 моделей, после чего протестируем их и займемся экспортом в терминал MetaTrader5.
Сильнее всего на результаты обучения влияют выделенные параметры, а также диапазон дат для обучения и тестирования, и продолжительность сделок. С этими параметрами следует экспериментировать.
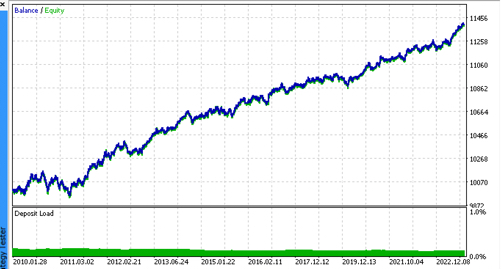
Посмотрим на топ 5 лучших моделей по версии R^2, с учетом новых данных. Горизонтальными линиями на графиках показаны ООС слева и справа.
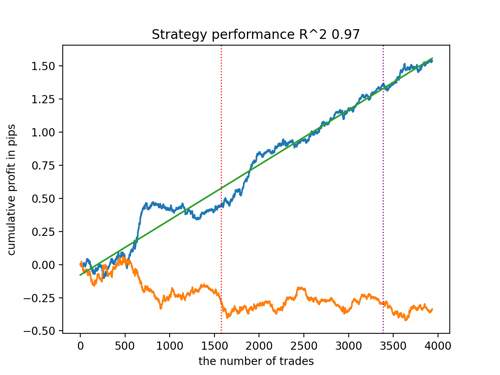
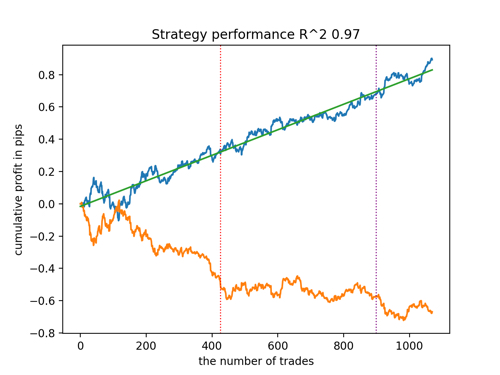
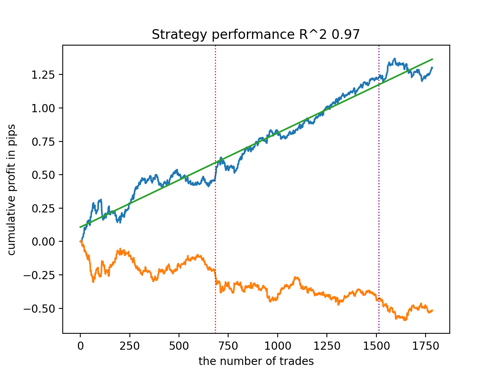
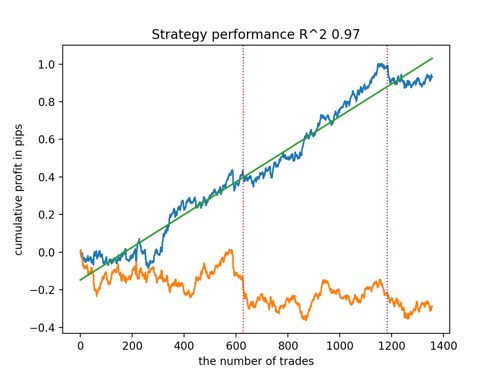
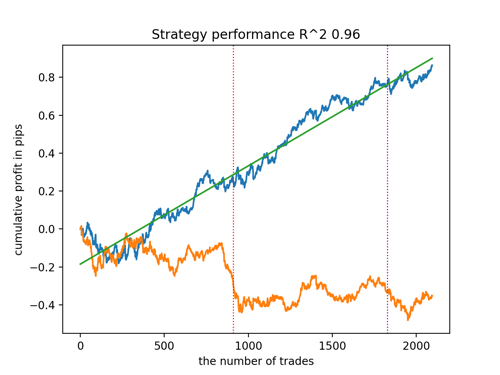
Синим цветом изображен график баланса, а оранжевым - график котировок. Видно, что все модели отличаются друг от друга. Это связано со случайным семплингом сделок, а также заложенной в каждую модель рандомизацией. Тем не менее, эти модели уже не выглядят как тестерные граали и достаточно уверенно работают на ООС. Кроме этого можно сравнить количество сделок, прибыль в пунктах и общий вид кривых. Конечно, первая и вторая модели выгодно отличаются, поэтому экспортируем их в терминал.
Следует иметь в виду, что меняя параметры обучения и делая несколько перезапусков, вы будете получать уникальное поведение, графики почти никогда не будут идентичными, но значительная их часть (что важно) будет неплохо показывать на ООС.
Экспорт модели в ONNX формат
В предыдущих статьях я использовал парсинг моделей с языка cpp на язык MQL. Сейчас терминал MetaTrader 5 поддерживает импорт моделей в формат ONNX. Это достаточно удобно, потому что можно писать меньше кода и переносить практически любые модели, обученные на языке Python.
Алгоритм CatBoost имеет собственный метод экспорта моделей в формат ONNX. Давайте рассмотрим процесс экспорта более подробно.
На выходе у нас имеются две модели CatBoost и функция, формирующая признаки в виде приращений. Поскольку функция достаточно простая, мы просто перенесем ее в код бота, тогда как модели будут экспортированы в файлы ONNX.
def export_model_to_ONNX(model, model_number): model[1].save_model( export_path +'catmodel' + str(model_number) +'.onnx', format="onnx", export_parameters={ 'onnx_domain': 'ai.catboost', 'onnx_model_version': 1, 'onnx_doc_string': 'test model for BinaryClassification', 'onnx_graph_name': 'CatBoostModel_for_BinaryClassification' }, pool=None) model[2].save_model( export_path + 'catmodel_m' + str(model_number) +'.onnx', format="onnx", export_parameters={ 'onnx_domain': 'ai.catboost', 'onnx_model_version': 1, 'onnx_doc_string': 'test model for BinaryClassification', 'onnx_graph_name': 'CatBoostModel_for_BinaryClassification' }, pool=None) code = '#include <Math\Stat\Math.mqh>' code += '\n' code += '#resource "catmodel'+str(model_number)+'.onnx" as uchar ExtModel[]' code += '\n' code += '#resource "catmodel_m'+str(model_number)+'.onnx" as uchar ExtModel2[]' code += '\n' code += 'int Periods' + '[' + str(len(PERIODS)) + \ '] = {' + ','.join(map(str, PERIODS)) + '};' code += '\n\n' # get features code += 'void fill_arays' + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods''[i],pr);\n' code += ' ret[0] = MathMean(pr) - pr[Periods[i]-1];\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' file = open(export_path + str(SYMBOL) + ' ONNX include' + str(model_number) + '.mqh', "w") file.write(code) file.close() print('The file ' + 'ONNX include' + '.mqh ' + 'has been written to disk')
В функцию экспорта передается список моделей, каждая из которых сохраняется в ONNX, с необязательными параметрами экспорта. Весь этот код сохраняет модели в папку Include терминала, а также формирует .mqh файл, который выглядит примерно следующим образом:
#resource "catmodel.onnx" as uchar ExtModel[] #resource "catmodel_m.onnx" as uchar ExtModel2[] #include <Math\Stat\Math.mqh> int Periods[4] = {10,20,30,40}; void fill_arays( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(Periods)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,Periods[i],pr); ret[0] = MathMean(pr) - pr[Periods[i]-1]; ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
Далее следует подключить его к боту. Каждый файл имеет уникальное имя, которое задается через тикер символа и порядковый номер модели в конце. Поэтому можно хранить коллекцию таких уже обученных моделей на диске, или же подключать к боту сразу несколько. Я ограничусь одним файлом в демонстрационных целях.
#include <EURUSD ONNX include1.mqh> В функции нужно правильно инициализировать модели, как показано ниже. Самое важное - это правильно задать размерности входных и выходных данных. Наши модели имеют вектор признаков переменной длины, в зависимости от количества признаков, которые заданы в списке PERIODS или экспортированном массиве, поэтому определяем размерность входного вектора как показано ниже. Обе модели принимают на вход одинаковое количество признаков.
Размерность выходного вектора может вызвать некоторую путаницу.
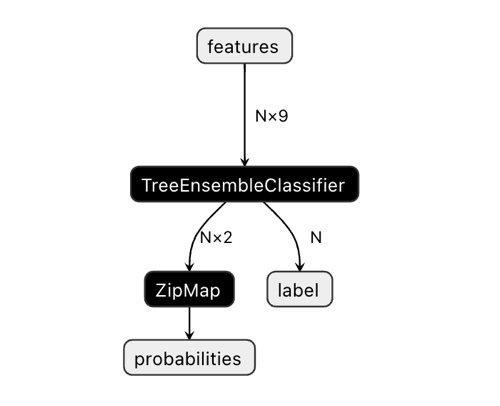

В приложении Netron видно, что модель имеет два выхода. Первый представляет собой единичный тензор с метками классов, который определен ниже в коде как нулевой выход или выход с нулевым индексом. Но его нельзя использовать для получения предсказаний, поскольку есть известные проблемы, описанные в документации CatBoost:
"The label is inferred incorrectly for binary classification. This is a known bug in the onnxruntime implementation. Ignore the value of this parameter in case of binary classification."
Соответственно мы должны использовать второй выход "probabilities", но мне не удалось корректно его задать в коде MQL, поэтому я его просто не определил. Тем не менее, он определился сам и все работает. Не знаю с чем это связано.
Поэтому для получения вероятностей классов в боте используется второй выход.
const long ExtInputShape [] = {1, ArraySize(Periods)};
int OnInit() { ExtHandle = OnnxCreateFromBuffer(ExtModel, ONNX_DEFAULT); ExtHandle2 = OnnxCreateFromBuffer(ExtModel2, ONNX_DEFAULT); if(ExtHandle == INVALID_HANDLE || ExtHandle2 == INVALID_HANDLE) { Print("OnnxCreateFromBuffer error ", GetLastError()); return(INIT_FAILED); } if(!OnnxSetInputShape(ExtHandle, 0, ExtInputShape)) { Print("OnnxSetInputShape failed, error ", GetLastError()); OnnxRelease(ExtHandle); return(-1); } if(!OnnxSetInputShape(ExtHandle2, 0, ExtInputShape)) { Print("OnnxSetInputShape failed, error ", GetLastError()); OnnxRelease(ExtHandle2); return(-1); } const long output_shape[] = {1}; if(!OnnxSetOutputShape(ExtHandle, 0, output_shape)) { Print("OnnxSetOutputShape error ", GetLastError()); return(INIT_FAILED); } if(!OnnxSetOutputShape(ExtHandle2, 0, output_shape)) { Print("OnnxSetOutputShape error ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); }
А получение сигналов моделей реализовано таким образом. Здесь мы объявляем массив признаков (features) и заполняем его через функцию fill_arrays(), которая находится в экспортированном .mqh файле.
Далее я объявил еще один массив f, чтобы инвертировать порядок значений массива features, и подал его на выполнение в Onnx Runtime. Первый выход в виде вектора нужно просто передать, но мы его не будем использовать. А в качестве второго выхода передается массив структур.
Модели (основная и мета) выполняются и возвращают предсказанные значения в массив tensor. Я беру из него вероятности второго класса.
void OnTick() { if(!isNewBar()) return; double features[]; fill_arays(features); double f[ArraySize(Periods)]; int k = ArraySize(Periods) - 1; for(int i = 0; i < ArraySize(Periods); i++) { f[i] = features[i]; k--; } static vector out(1), out_meta(1); struct output { long label[]; float tensor[]; }; output out2[], out2_meta[]; OnnxRun(ExtHandle, ONNX_DEBUG_LOGS, f, out, out2); OnnxRun(ExtHandle2, ONNX_DEBUG_LOGS, f, out_meta, out2_meta); double sig = out2[0].tensor[1]; double meta_sig = out2_meta[0].tensor[1];
Остальной код бота вам должен быть знаком из предыдущей статьи. Там мы проверяем разрешающий сигнал meta_sig. Если он больше 0.5, то дано добро на открытие и закрытие сделок, в зависимости от направления, заданного сигналом sig первой модели.
if(meta_sig > 0.5) if(count_market_orders(0) || count_market_orders(1)) for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(SymbolInfoInteger(_Symbol, SYMBOL_TRADE_FREEZE_LEVEL) < MathAbs(Bid - OrderOpenPrice())) { int res = -1; do { res = OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red); Sleep(50); } while (res == -1); } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(SymbolInfoInteger(_Symbol, SYMBOL_TRADE_FREEZE_LEVEL) < MathAbs(Bid - OrderOpenPrice())) { int res = -1; do { res = OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red); Sleep(50); } while (res == -1); } } if(meta_sig > 0.5) if(countOrders() < max_orders && CheckMoneyForTrade(_Symbol, LotsOptimized(meta_sig), ORDER_TYPE_BUY)) { double l = LotsOptimized(meta_sig); if(sig < 0.5) { int res = -1; do { double stop = Bid - stoploss * _Point; double take = Ask + takeprofit * _Point; res = OrderSend(Symbol(), OP_BUY, l, Ask, 0, stop, take, comment, OrderMagic); Sleep(50); } while (res == -1); } else { if(sig > 0.5) { int res = -1; do { double stop = Ask + stoploss * _Point; double take = Bid - takeprofit * _Point; res = OrderSend(Symbol(), OP_SELL, l, Bid, 0, stop, take, comment, OrderMagic); Sleep(50); } while (res == -1); } } }
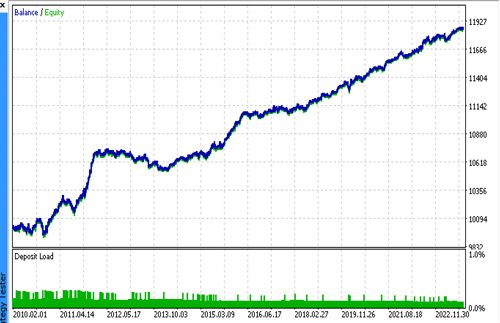
Финальные тесты
Последовательно подключим 2 файла с понравившимися моделями и убедимся, что результаты кастомного тестера полностью совпадают с результатами тестера MetaTrader 5.
Дополнительно уже в оптимизаторе MetaTrader 5 можно проверить ботов на реальных тиках, оптимизировать стоп лосс и тейк профит, подобрать размер лота и добавить больше сделок.
Финальное слово
Я не знаю есть ли научное обоснование у такого подхода к классификации временных рядов для задач трейдинга. Он был придуман методом проб и ошибок и показался мне достаточно интересным и перспективным.
Настоящим небольшим исследованием я хотел подчеркнуть, что иногда модели машинного обучения следует обучать иным образом, не так как кажется очевидным. Большую роль играет не выбор конкретной архитектуры, что тоже конечно важно, а способ применения этих моделей. В то же время, статистический подход к анализу результатов обучения выходит на первый план, будь это полностью автоматическое подобие "трейдера и исследователя", представленное в этой статье, или более простые алгоритмы, требующие экспертного вмешательства "Учителя".
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Странно... вроде 1 к 1 копируется.
Именно так, а отклик модели другой
k-- артефакт, да, можно удалить
Именно так, а отклик модели другой
k-- артефакт, да, можно удалить
Увидел, что серийность задана для featurs. Наверное потому и разный результат.
Странно... вроде 1 к 1 копируется. features динамический, а f статический, но вряд ли это причина отличий.
UPD: в примерах из справки по OnnxRun фичи в матрице передаются, а у вас массивом, может в этом причина? Странно, что справка не пишет, как надо.
В качестве input/output значений в ONNX модели можно передавать только массивы, вектора или матрицы (далее Данные).
C вектором вроде тоже неправильный отклик был. Надо перепроверять, но пока и так работает.
https://www.mql5.com/ru/docs/onnx/onnx_types_autoconversion
Отличная статья. Слышал про идею использовать 2 нейронки: одну для прогнозирования направления, другую - для прогнозирования вероятности правильного прогноза первой. И поэтому возник вопрос: выбрали градиентный бустинг, потому, что он лучше, нейросетей в данной области?
Спасибо. Сравнивал результаты простых MLP, RNN, LSTM с бустингом на своих датасетах. Сильной разницы не увидел, иногда бустинг даже был лучше. И бустинг гораздо быстрее обучается, и не нужно сильно заморачиваться с архитектурой. Не могу сказать, что он однозначно лучше, потому что НС - понятие растяжимое, можно же собрать очень много разных вариантов НС. Наверное из-за простоты выбрал, в этом плане лучше.