
Машинное обучение в однонаправленной трендовой торговле на примере золота
Введение
На протяжении последнего времени мы изучали создание симметричных торговых систем через призму бинарной классификации. Мы исходили из предположения, что сделки на покупку и продажу могут быть хорошо разделимы в пространстве признаков, то есть, существует некоторая разделяющая граница (гиперплоскость), позволяющая алгоритму машинного обучения одинаково хорошо предсказывать как длинные, так и короткие позиции.
На практике это не всегда выполняется, особенно для трендовых торговых инструментов, таких как некоторые металлы и индексы, а также криптовалюты. В ситуациях, когда актив имеет четко выраженный однонаправленный тренд, торговые системы, предполагающие покупки и продажи, могут быть слишком рискованными, и общее распределение таких сделок может оказаться сильно несимметричным, что приведет к неправильной классификации с большим количеством ошибок.
В таком случае, разнонаправленная торговая система может оказаться неэффективной, и лучше было бы сконцентрироваться на торговле в каком-нибудь одном направлении. Данная статья призвана пролить свет на возможности машинного обучения для создания таких однонаправленных стратегий.
Я предлагаю переосмыслить подходы причинно-следственного вывода и адаптировать их для задачи однонаправленной торговли.
За основу возьмем материалы из прошлых статей:
- Кросс-валидация и основы причинно-следственного вывода
- Причинно-следственный вывод в задачах классификации временных рядов
- Быстрый тестер торговых стратегий на Python
Настоятельно рекомендую ознакомиться с этими статьями, для более полного понимания идеи причинно-следственного вывода и тестирования.
Создание сэмплера сделок в заданном направлении
Поскольку раньше мы одновременно размечали сделки на покупку и на продажу, нам необходимо модифицировать разметчик сделок таким образом, чтобы он размечал сделки только для выбранного направления. Ниже приведен пример такого сэмплера, который будет использован в данной статье:
@njit def calculate_labels_one_direction(close_data, markup, min, max, direction): labels = [] for i in range(len(close_data) - max): rand = random.randint(min, max) curr_pr = close_data[i] future_pr = close_data[i + rand] if direction == "sell": if (future_pr + markup) < curr_pr: labels.append(1.0) else: labels.append(0.0) if direction == "buy": if (future_pr - markup) > curr_pr: labels.append(1.0) else: labels.append(0.0) return labels def get_labels_one_direction(dataset, markup, min = 1, max = 15, direction = 'buy') -> pd.DataFrame: close_data = dataset['close'].values labels = calculate_labels_one_direction(close_data, markup, min, max, direction) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
Появился новый параметр 'direction', с помощью которого можно задавать необходимое направление для разметки сделок, на покупку или на продажу. Теперь класс с меткой '1' указывает на то, что существует сделка для выбранного направления, а класс с меткой '0' указывает на то, что в данный момент времени лучше не открывать сделку. Также в параметрах задается случайная продолжительность сделки в диапазоне {min, max}, которая измеряется в количестве прошедших баров с момента открытия сделки. Это простой сэмплер, который оказался достаточно эффективным для данного типа стратегий.
Модификация кастомного тестера стратегий
Теперь требуется другая логика тестирования для однонаправленных стратегий, поэтому необходимо изменить сам тестер стратегий, чтобы он ей соответствовал. В модуль 'tester_lib.py' добавлены функции для однонаправленного тестирования. Давайте подробно их рассмотрим.
Функция process_data_one_direction() обрабатывает данные для торговли в одном направлении:
@jit(nopython=True) def process_data_one_direction(close, labels, metalabels, stop, take, markup, forward, backward, direction): last_deal = 2 last_price = 0.0 report = [0.0] chart = [0.0] line_f = 0 line_b = 0 for i in range(len(close)): line_f = len(report) if i <= forward else line_f line_b = len(report) if i <= backward else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 2 if pred < 0.5 else 1 continue if last_deal == 1 and direction == 'buy': if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and direction == 'sell': if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 1 and pred < 0.5 and direction == 'buy': last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and direction == 'sell': last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue return np.array(report), np.array(chart), line_f, line_b
Основное отличие от базовой функции состоит в том, что теперь используются флаги с явным указанием на то, какой тип сделок будет использован в тестере: на покупку или на продажу. Функция очень быстрая за счет ускорения посредством Numba, и выполняет проход по истории котировок, рассчитывая прибыль от каждой сделки. Обратите внимание, что тестер умеет закрывать сделки как по сигналам модели, так и по стоп-лосс и тейк-профит, в зависимости от того, какое условие сработало раньше. Это позволяет отбирать модели уже на этапе обучения, с учетом приемлемых для вас рисков.
Функция tester_one_direction() обрабатывает размеченный датасет, который содержит цены и метки и передает эти данные в функцию process_data_one_direction(), затем забирает результат для последующей отрисовки на графике.
def tester_one_direction(*args): ''' This is a fast strategy tester based on numba List of parameters: dataset: must contain first column as 'close' and last columns with "labels" and "meta_labels" stop: stop loss value take: take profit value forward: forward time interval backward: backward time interval markup: markup value direction: buy/sell plot: false/true ''' dataset, stop, take, forward, backward, markup, direction, plot = args forw = dataset.index.get_indexer([forward], method='nearest')[0] backw = dataset.index.get_indexer([backward], method='nearest')[0] close = dataset['close'].to_numpy() labels = dataset['labels'].to_numpy() metalabels = dataset['meta_labels'].to_numpy() report, chart, line_f, line_b = process_data_one_direction(close, labels, metalabels, stop, take, markup, forw, backw, direction) y = report.reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = 1 if lr.coef_[0][0] >= 0 else -1 if plot: plt.plot(report) plt.axvline(x=line_f, color='purple', ls=':', lw=1, label='OOS') plt.axvline(x=line_b, color='red', ls=':', lw=1, label='OOS2') plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l, ".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
Функция test_model_one_direction() получает предсказания модели на выбранных данных. Эти предсказания передаются в функцию tester_one_direction() для вывода результата тестирования этой модели.
def test_model_one_direction(dataset: pd.DataFrame, result: list, stop: float, take: float, forward: float, backward: float, markup: float, direction: str, plt = False): ext_dataset = dataset.copy() X = ext_dataset[ext_dataset.columns[1:]] ext_dataset['labels'] = result[0].predict_proba(X)[:,1] ext_dataset['meta_labels'] = result[1].predict_proba(X)[:,1] ext_dataset['labels'] = ext_dataset['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) ext_dataset['meta_labels'] = ext_dataset['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester_one_direction(ext_dataset, stop, take, forward, backward, markup, direction, plt)
Мета-лернер как сердце торговой системы
Давайте рассмотрим первый мета-лернер из статьи про кросс-валидацию и я постараюсь дать логичное объяснение, почему он лучше работает в случае однонаправленных стратегий, нежели в случае разнонаправленных.
def meta_learner(folds_number: int, iter: int, depth: int, l_rate: float) -> pd.DataFrame: dataset = get_labels_one_direction(get_features(get_prices()), markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() X = data[data.columns[1:-2]] y = data['labels'] B_S_B = pd.DatetimeIndex([]) # learn meta model with CV method meta_model = CatBoostClassifier(iterations = iter, max_depth = depth, learning_rate=l_rate, verbose = False) cv = StratifiedKFold(n_splits=folds_number, shuffle=False) predicted = cross_val_predict(meta_model, X, y, method='predict_proba', cv=cv) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = [x[0] < 0.5 for x in predicted] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # select bad samples (bad labels indices) diff_negatives = coreset['labels'] != coreset['labels_pred'] B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index) to_mark = B_S_B.value_counts() marked_idx = to_mark.index data['meta_labels'] = 1.0 data.loc[data.index.isin(marked_idx), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx), 'labels'] = 0.0 return data[data.columns[:]]
Для наглядности, ниже представлена схема функции мета-лернера в виде ключевых блоков, отвечающих за разный функционал.
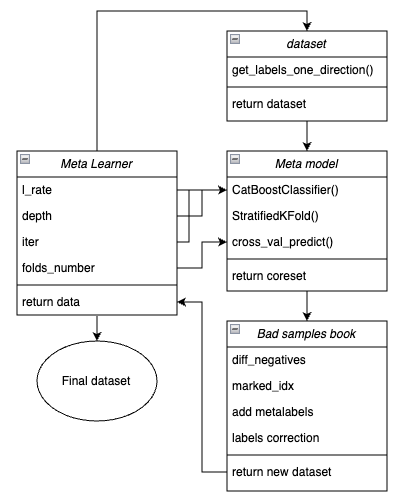
Рис 1. схематичное представление функции meta_learner()
Следует напомнить, что мета-лернер является передаточной шестерней между исходными данными и финальной моделью. Он берет на себя основную нагрузку по эффективному препроцессингу, создавая мета-метки ('meta labels') посредством мета-модели. Уникальность разработанной мной функции заключается в том, что она создает очищенные и хорошо подготовленные датасеты, благодаря которым получаются робастные модели и торговые системы.
Входные параметры функции:
- l_rate (learning rate) — это шаг градиента для мета-модели или классификатора CatBoost. Задается в диапазоне от {0.01, 0.5}. Алгоритм чувствителен к этому параметру.
- depth отвечает за глубину деревьев принятия решений, которые строятся на каждой итерации обучения классификатора CatBoost. Рекомендуемый диапазон значений {1, 6}
- iter — количество итераций обучения, рекомендуется в диапазоне {5, 25}
- folds_number — количество фолдов для кросс-валидации. Обычно достаточно {5, 15} фолдов.
Механизм работы функции:
- Создается датасет с признаками и метками. В качестве сэмплера используется функция get_labels_one_direction(), описанная ранее.
- На этих данных обучается мета-лернер c заданными параметрами в режиме кросс-валидации посредством функции StratifiedKFold(). Функция разделяет обучающие данные на несколько фолдов с учетом баланса классов. На каждом фолде происходит обучение мета-модели, а затем сохраняются все предсказания. Это необходимо для того, чтобы получить несмещенную оценку ошибок модели на обучающих данных. Эти предсказания будут использоваться для сравнения с исходными метками.
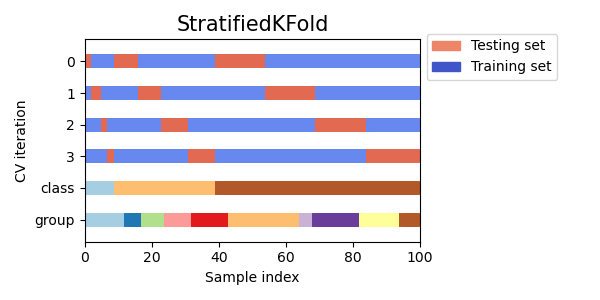
Рис 2. Схема разделения данных на фолды функцией StratifiedKFold()
- Создается отдельный датасет coreset, в который записываются как оригинальные, так и предсказанные посредством кросс-валидации метки.
- Создается отдельная переменная diff_negatives, хранящая бинарные флаги совпадений исходных и предсказанных меток.
- Создается книга плохих примеров B_S_B (Bad Samples Book), в которую записываются временные индексы тех строк датасета, для которых предсказания не совпали с исходными метками.
- Определяются уникальные индексы неправильно предсказанных примеров по всем фолдам.
- Создается дополнительный столбец 'meta_labels' в исходном датасете и всем наблюдениям назначается '1' (можно торговать).
- Для всех примеров, которые были неправильно предсказаны в процессе кросс-валидации назначается '0' в столбце 'meta_labels' (не торговать).
- Для всех неправильно предсказанных примеров, в столбце 'labels', который содержит метки для основной модели, также присваиваются метки '0' (не торговать).
- Функция возвращает модифицированный датасет.
Более надежный причинно-следственный вывод
В предыдущем разделе рассмотрен базовый мета-лернер, на примере которого легче объяснить основную концепцию. В этом разделе мы несколько усложним подход и рассмотрим непосредственно сам процесс причинно-следственного вывода. Я адаптировал функцию причинно-следственного вывода из статьи по ссылке для случая однонаправленной торговли. Она является более продвинутой и снабжена более гибким функционалом.
def meta_learners(models_number: int, iterations: int, depth: int, bad_samples_fraction: float): dataset = get_labels_one_direction(get_features(get_prices()), markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() X = data[data.columns[1:-2]] y = data['labels'] BAD_WAIT = pd.DatetimeIndex([]) BAD_TRADE = pd.DatetimeIndex([]) for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # learn debias model with train and validation subsets meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) coreset_w = coreset[coreset['labels']==0] coreset_t = coreset[coreset['labels']==1] diff_negatives_w = coreset_w['labels'] != coreset_w['labels_pred'] diff_negatives_t = coreset_t['labels'] != coreset_t['labels_pred'] BAD_WAIT = BAD_WAIT.append(diff_negatives_w[diff_negatives_w == True].index) BAD_TRADE = BAD_TRADE.append(diff_negatives_t[diff_negatives_t == True].index) to_mark_w = BAD_WAIT.value_counts() to_mark_t = BAD_TRADE.value_counts() marked_idx_w = to_mark_w[to_mark_w > to_mark_w.mean() * bad_samples_fraction].index marked_idx_t = to_mark_t[to_mark_t > to_mark_t.mean() * bad_samples_fraction].index data['meta_labels'] = 1.0 data.loc[data.index.isin(marked_idx_w), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_t), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_t), 'labels'] = 0.0 return data[data.columns[:]]
Ниже представлена схема функции мета-лернера в виде ключевых блоков, отвечающих за разный функционал.
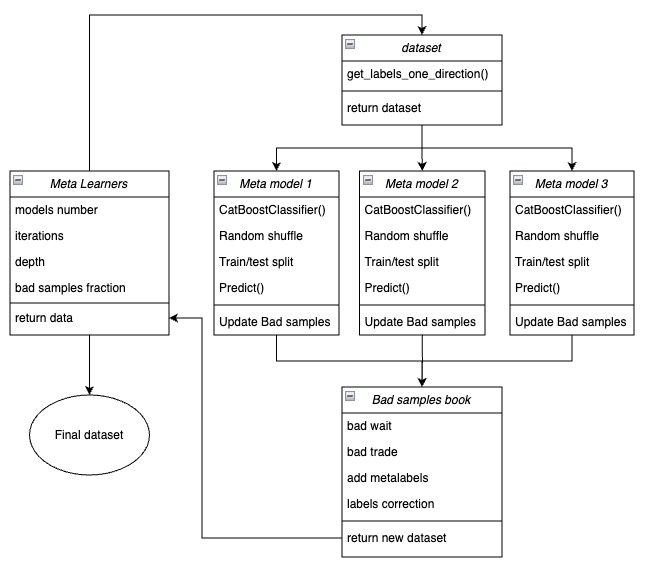
Рис 3. схематичное представление функции meta_learners()
Отличительной особенностью данной функции является то, что она имеет несколько "голов" мета-моделей, которые обучаются на случайных подвыборках исходного датасета, которые выбираются методом бутстрэпа с возвращением. Этот метод позволяет делать многократную генерацию подвыборок из исходного датасета. На этом множестве псевдовыборок можно оценить статистические и вероятностные характеристики.
Например, нас интересует среднее значение того, насколько хорошо данный конкретный пример, взятый из генеральной совокупности, предсказывается, если бы мы обучали модели на разных подвыборках этой совокупности. Это даст нам менее смещенное представление о каждом из примеров совокупности, которые затем можно разметить, как плохие или хорошие примеры с большей степенью уверенности.
Входные параметры функции:
- models number — колчество мета-моделей, которые задействуются в алгоритме. Рекомендуемый диапазон значений {5, 100}
- iterations — количество итераций обучения для каждой модели. Рекомендуемый диапазон значений {15, 35}
- depth — глубина деревьев принятия решений, которые строятся на каждой итерации обучения классификатора CatBoost. Рекомендуемый диапазон значений {1, 6}
- bad samples fraction — количество примеров, которые будут размечены как "плохие". Рекомендуемый диапазон значений {0.4, 0.9}
Механизм работы функции:
- Создается датасет с признаками и метками заданного направления торговли.
- В цикле обучается каждая из мета-моделей на случайно выбранных тренировочных и валидационных данных методом бутстрэп.
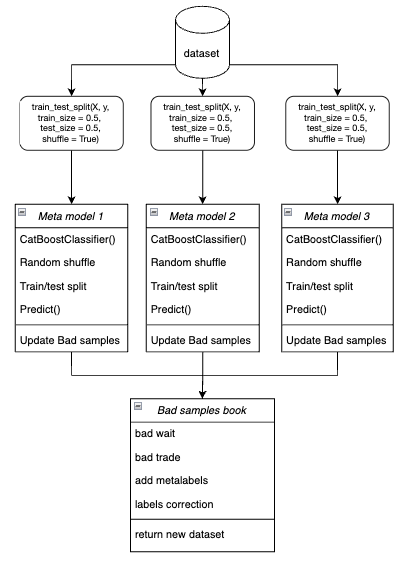
Рис 4. схематичное представление бутсрэп семплирования
- Для каждой модели сравниваются ее предсказания с истинными метками. Индексы неправильно классифицированных случаев сохраняются в книге плохих примеров.
- Определяется среднее количество неправильно предсказанных индексов по всем проходам.
- Индексы, которым принадлежит наибольшее количество неправильно предсказанных меток, и которые превышают среднее умноженное на порог, добавляются в колонку "meta_labels" как нули (запрет торговли).
- Метки 'labels' зануляются по тому же принципу.
Философия, лежащая в основе использования мета-лернера для однонаправленной торговли:
- Код мета-лернера решает задачу фильтрации "плохих" сигналов в размеченном датасете.
- Упрощение задачи классификации. Признаки оптимизируется только под один тип паттернов (например, продолжение тренда).
- В тренде даже при балансе классов (50% покупок/ 50% продаж) сохраняется асимметрия. Покупки по тренду имеют более устойчивые паттерны, тогда как продажи против тренда часто связаны с шумовыми событиями (коррекции, ложные развороты), которые сложно предсказать.
- Для продаж в растущем тренде большинство сигналов изначально ложные (False positives), что приводит к ошибкам классификации. Соответственно, в случае разнонаправленной торговли, сделки на покупку и продажу имеют разную природу и их нельзя сравнивать.
- В однонаправленной системе ошибки связаны только с ложными входами в сделку по тренду (например, вход перед коррекцией). Мета-лернер эффективно находит такие случаи, так как они имеют четкие признаки (например, перекупленность). В разнонаправленной системе ошибки включают ложные покупки и продажи, которые могут иметь похожие паттерны. Мета-лернер не может надежно отделить "шум" от реальных сигналов, так как признаки для покупок/продаж смешаны.
- В одноноправленной системе модель фокусируется на одном типе нестационарности (например, усиление тренда) и признаки адаптируются под текущую фазу рынка.
- В разнонаправленной системе существует две нестационарности (тренд + коррекции), что требует вдвое больше данных и сложнее для обобщения.
Итог:
- Упрощается задача классификации — достаточно правильно предсказать один класс вместо двух.
- Снижается шум — финальная мета-модель фильтрует только один тип ошибок.
- Улучшается кросс-валидация — стратификация работает корректно.
- Учитывается нестационарность тренда — модель адаптируется только к одной рыночной фазе.
Важная особенность мета-лернеров:
Мета-лернеры не стоит путать с финальной мета-моделью, которая обучается на метках, подготовленных мета-лернерами. Мета-лернеры не являются финальными моделями и используются только на этапе препроцессинга. В качестве базовых лернеров можно использовать любые алгоритмы бинарной классификации, включая логистическую регрессию, нейронные сети, "деревянные" модели и прочие экзотические модели. Кроме этого, можно использовать регрессионные модели при небольших модификациях кода, что выходит за рамки данной статьи и может быть рассмотрено в последующих. Для удобства я использую бинарный классификатор CatBoost, потому что привык с ним работать.
Особенности, связанные с признаками для обучения
Выше уже было упомянуто, что торговля в одном направлении упрощает задачу классификации. Признаки оптимизируются только под один тип паттернов (например, на покупку), поэтому нет необходимости в симметричных признаках. Симметричными признаками можно назвать как исходный временной ряд с разными временными лагами, значениям которого соответствуют сделки на покупку и на продажу, так и разного рода производные (ценовые приращения) и другие осцилляторы. К несимметричным признакам можно отнести волатильность в разных временных окнах, поскольку она отражает только темп изменения цен, но не их направление. В данном проекте будет использоваться волатильность с разными окнами, заданными в переменной 'periods'.
Вот полный код, который реализует создание признаков:
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
А периоды скользящих окон для расчета таких признаков заданы в словаре. Их можно произвольно менять и смотреть на производительность моделей.
hyper_params = {
'periods': [i for i in range(5, 300, 30)],
}
В этом примере мы создаем 10 признаков, первый из которых имеет период 5, а каждый последующий период увеличивается на 30, и так до 300:
>>> [i for i in range(5, 300, 30)] [5, 35, 65, 95, 125, 155, 185, 215, 245, 275]
Обучение и тестирование однонаправленных моделей
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.25,
'stop_loss': 10.0000,
'take_profit': 5.0000,
'direction': 'buy',
'periods': [i for i in range(5, 300, 30)],
'backward': datetime(2020, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
}
models = []
for i in range(10):
print('Learn ' + str(i) + ' model')
models.append(fit_final_models(meta_learner(5, 15, 3, 0.1)))
# models.append(fit_final_models(meta_learners(25, 15, 3, 0.8))) Сначала протестируем первый мета-лернер, а второй будет закоментирован. Выберем направление торговли на покупку в качестве предпочтительного, потому что на золоте сейчас растущий тренд. Обучение будет происходить с начала 2020 года до 2024. А тестовый период выбран с начала 2024 до 1 апреля 2025 года.
Мета-лернер имеет следующие настройки:
- 5 фолдов для кросс-валидации
- 15 итераций обучения для алгоритма CatBoost
- глубина дерева для каждой итерации составляет 3
- темп обучения 0.1
Так выглядит лучшая модель в тестере стратегий для направления 'buy':
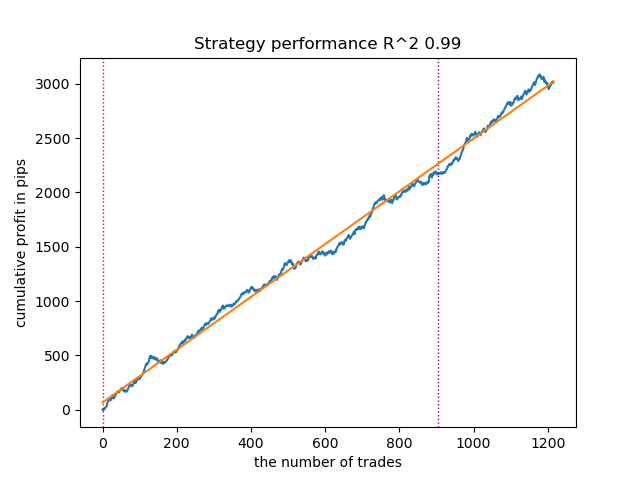
Рис 5. результаты тестирования возможностей функции meta_learner() в направлении покупок
Для сравнения, так выглядит лучшая модель для направления "sell":
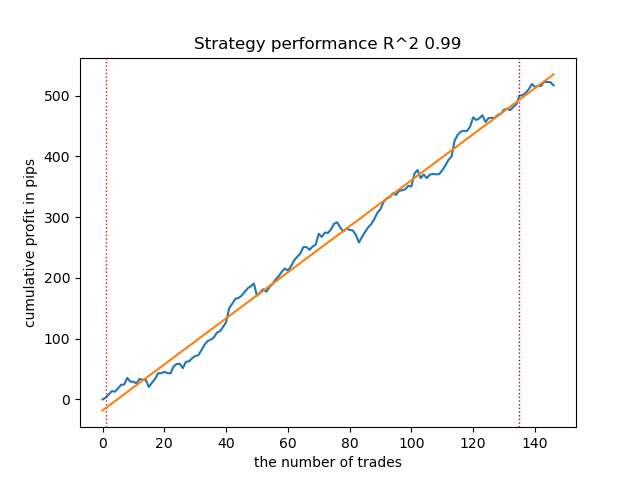
Рис 6. результаты тестирования возможностей функции meta_learner() в направлении продаж
Алгоритм научился предсказывать сделки как в направлении покупок, так и в направлении продаж. Но для продаж сделок получилось гораздо меньше, что естественно для растущего трендового рынка. Мета-модель сработала достаточно эффективно даже без подбора ее гиперпараметров, что отражено на участке как обучения, так и форвард-тестирования.
Теперь давайте рассмотрим более продвинутый мета-лернер. Проделаем аналогичные манипуляции для функции meta_learners(). Раскоментируем ее и закоментируем предыдущую:
models = [] for i in range(10): print('Learn ' + str(i) + ' model') # models.append(fit_final_models(meta_learner(5, 15, 3, 0.1))) models.append(fit_final_models(meta_learners(25, 15, 3, 0.8)))
Мета-лернер имеет следующие настройки:
- 25 "голов" или мета-моделей
- 15 итераций обучения для алгоритма CatBoost для каждой из моделей
- глубина дерева для каждой итерации составляет 3
- 0.8 для параметра "bad_samples_fraction", который определяет процент оставленных плохих примеров в обучающем датасете. 0.1 будет соответствовать очень сильной фильтрации, а 0.9 отфильтрует мало плохих примеров.
Так выглядит лучшая модель в тестере стратегий для направления 'buy':
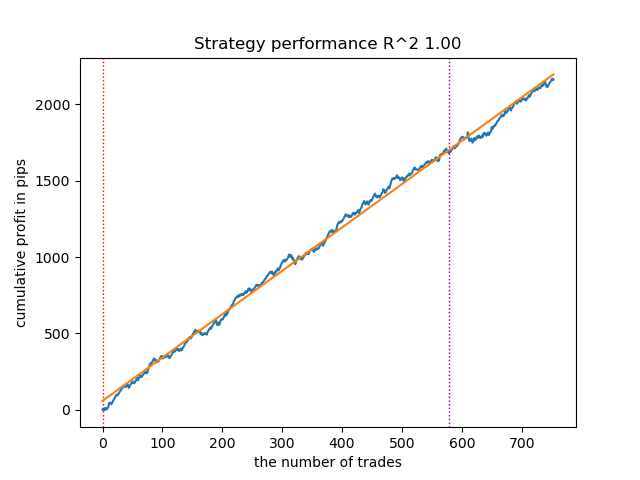
Рис 7. результаты тестирования возможностей функции meta_learners() в направлении покупок
Для сравнения, так выглядит лучшая модель для направления "sell":
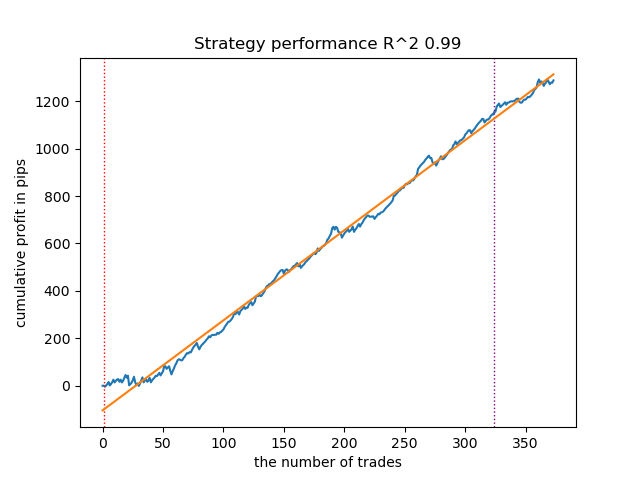
Рис 8. результаты тестирования возможностей функции meta_learners() в направлении продаж
Более продвинутая функция мета-лернеров показала более красивые кривые. Баланс для сделок на покупку и продажу сохранился. Очевидно, что наилучшей стратегией является стратегия на покупку. После того, как модели обучены и выбрана лучшая модель, их можно экспортировать в терминал Meta Trader 5. Можно использовать обе стратегии, но поскольку стратегия с открытием коротких позиций менее эффективна, выберем только стратегию для длинных позиций.
Ниже представлена таблица зависимостей результатов обучения от параметров продвинутого мета-лернера:
| Название параметра: | Влияние на качество фильтрации: |
|---|---|
| models_number: int | Чем больше "голов" или мета-моделей, тем менее смещенная оценка плохих примеров. Размер обучающего датасета влияет на выбор количества моделей. Чем длиннее история, тем больше моделей может понадобиться. Нужно экспериментировать, варьируя этот параметр в диапазоне от 5 до 100. |
| iterations: int | Сильно влияет на скорость фильтрации. Чем больше итераций обучения каждого мета-лернера, тем медленнее. Небольшие значения могут привести к недообучению, что может привести к более сильной фильтрации и небольшому количеству сделок на выходе. Рекомендуется устанавливать в диапазоне от 5 до 50. |
| depth: int | Глубина дерева задается в диапазоне от 1 до 6. На каждой итерации алгоритм достраивает дерево заданной глубины. Я использую глубину 3, но вы можете экспериментировать с этим параметром. |
| bad_samples_fraction: float | Влияет на финальный отбор плохих примеров и на количество сделок. 0.9 соответствует "мягкой" фильтрации и большому количеству сделок на выходе. 0.5 соответствует "жесткой" фильтрации и, как следствие, небольшому количеству сделок на выходе. |
Финальные штрихи: экспорт моделей и создание торгующего советника
Экспорт моделей происходит точно таким же способом, который используется в других статьях. Для этого нужно выбрать понравившуюся модель в отсортированном списке моделей и вызвать функцию экспорта.
models.sort(key=lambda x: x[0]) data = get_features(get_prices()) test_model_one_direction(data, models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], hyper_params['direction'], plt=True) export_model_to_ONNX(models[-1], 0)
Логика торгового бота изменена таим образом, что он будет торговать только в одном направлении, в зависимости от модели, которую вы экспортировали.
input bool direction = true; //True = Buy, False = Sell
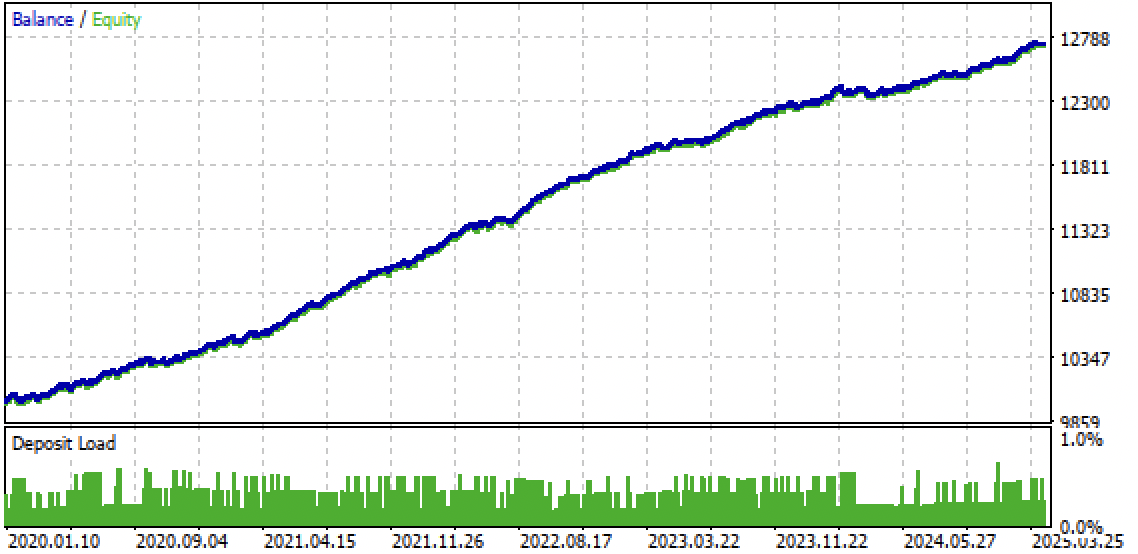
Рис 9. тестирование бота в терминале Meta Trader 5
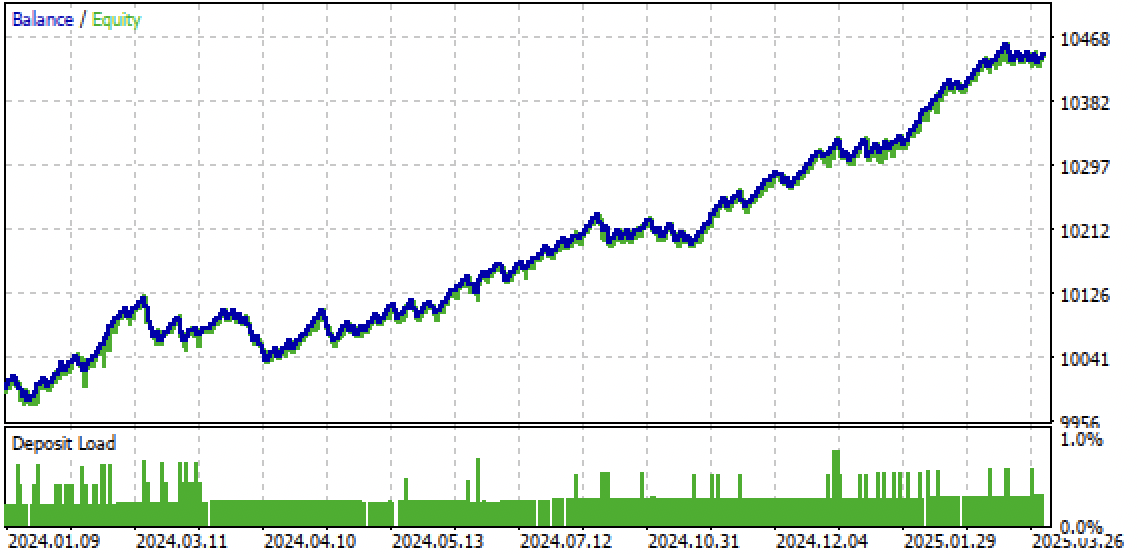
Рис 10. тестирование только на forward периоде с начала 2024г
Заключение
Идея однонаправленных стратегий с использованием машинного обучения показалась мне любопытной, поэтому я провел ряд экспериментов, включая подход, предложенный в данной статье. Он не является единственно возможным, но неплохо справляется с поставленной задачей. Такие трендозависимые стратегии могут показывать хорошую эффективность в том случае, если тренд будет продолжаться. Поэтому важно наблюдать за глобальными изменениями тренда и подстраивать такие системы под текущую рыночную ситуацию.
Архив Python files.zip содержит следующие файлы для разработки в среде Python:
| Имя файла | Описание |
|---|---|
| causal one direction.py | Основной скрипт для обучения моделей |
| labeling_lib.py | Обновленный модуль с разметчиками сделок |
| tester_lib.py | Обновленный кастомный тестер стратегий, основанных на машинном обучении |
| XAUUSD_H1.csv | Файл с котировками, экспортированный из терминала MetaTrader 5 |
Архив MQL5 files.zip cодержит файлы для терминала MetaTrader 5:
| Имя файла | Описание |
|---|---|
| one direction.ex5 | Скомпилированный бот из данной статьи |
| one direction.mq5 | Исходник бота из статьи |
| папка Include//Trend following | Расположены модели ONNX и заголовочный файл для подключения к боту |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования