
Исследуем регрессионные модели для причинно-следственного вывода и трейдинга
Введение
На протяжении ряда статей мы исследовали различные способы классификации временных рядов, но при этом не затрагивали регрессионные модели. Регрессионные модели, в отличие от бинарной классификации, позволяют предсказывать не вероятность принадлежности наблюдения к тому или иному классу, а непрерывные значения, что расширяет возможности их применения для создания автоматических торговых систем.
Бинарная классификация представляет собой фундаментальную задачу машинного обучения, целью которой является классификация входных данных по одной из двух различных категорий или классов. В контексте торгового бота на Форекс это обычно означает прогнозирование сигнала "купить" (представленного как 0) или "продать" (представленного как 1). Такой подход упрощает сложную динамику рынка до простого направленного решения.
Наиболее существенным внутренним ограничением бинарной классификации для количественной торговли является ее неспособность количественно оценить величину или интенсивность прогнозируемого движения цены. Бинарный классификатор лишь утверждает, будет ли цена двигаться вверх или вниз, не предоставляя никакой информации о том, насколько она, как ожидается, изменится. Отсутствие такой детализации принципиально ограничивает сложность торговых решений.
Точность предсказаний классификатора сама по себе не учитывает величину изменения, и поэтому не очень полезна для торговли. Этот аспект является ключевым, поскольку он подчеркивает, что высокая точность определения направления (например, прогнозирование правильного направления в 70% случаев) не автоматически приводит к прибыльности торговли.
Существует важное наблюдение, что высокая точность определения направления не гарантирует прибыльности. Например, можно быть правым в 30% случаев и быть прибыльным, или быть правым в 70% случаев и быть убыточным. Это демонстрирует, что чистый результат торговой стратегии определяется величиной прибыли по выигрышным сделкам по сравнению с величиной убытков по проигрышным сделкам, а не просто процентом выигрышей.
Модель бинарной классификации, рассматривая все правильные направленные прогнозы одинаково, независимо от фактического колебания цены, не может различать небольшое, незначительное движение цены и существенное, высокоприбыльное. Это может привести к сценарию, когда множество небольших выигрышных сделок сводятся на нет несколькими крупными убыточными сделками, или наоборот, что приводит к общему отрицательному финансовому результату (PnL), несмотря на кажущуюся высокую точность.
Отсутствие количественной оценки движения цены означает, что торговый бот не может расставить приоритеты для сделок с более высокой ожидаемой прибылью или избежать сделок, где потенциальный убыток значительно перевешивает потенциальную прибыль, даже если направление прогнозируется правильно. Без информации о величине, бот работает со слепым пятном относительно фактического финансового воздействия своих решений, что приводит к субоптимальным или даже отрицательным кумулятивным доходам, несмотря на высокий процент выигрышей на основе направления.
Модификация функции разметки
Предположим следующий сценарий: имеется финансовый временной ряд, который требуется предсказать по набору признаков. В случае бинарной классификации можно определить направление будущей сделки (покупка или продажа), и эти метки всегда фиксированы. Мы не можем разметить их иным образом, чтобы получить более точную оценку величины будущих ценовых отклонений. Сделки получаются равнозначными вне зависимости от того, насколько действительно изменилась цена.
Теперь представим, что мы можем прогнозировать не только направление сделки, но и величину будущего изменения. Это позволит более тонко настроить торговую систему путем создания дополнительных фильтров, которые помогут определить только значимые для торговли прогнозируемые ценовые колебания и исключить незначительные.
Чтобы обучить регрессионную модель, необходимо подготовить признаки и целевые для ее обучения. Признаки могут быть общими для классификатора и регрессора, тогда как целевые будут отличаться.
Напишем простую функцию, которая реализует разметку примеров для регрессионной модели:
@njit def calculate_labels_r(close_data, min_val, max_val): labels = [] for i in range(len(close_data) - max_val): rand = random.randint(min_val, max_val) labels.append(close_data[i + rand] - close_data[i]) return labels def get_labels_r(dataset, min = 1, max = 15) -> pd.DataFrame: # Extract closing prices from the dataset close_data = dataset['close'].values labels = calculate_labels_r(close_data, min, max) # Trim the dataset to match the length of calculated labels dataset = dataset.iloc[:len(labels)].copy() # Add the calculated labels as a new column dataset['labels'] = labels # Remove rows with NaN values (potentially introduced in 'calculate_labels') dataset = dataset.dropna() return dataset
Основное отличие от разметки для бинарной классификации заключается в том, что теперь мы определяем изменения цен (вычитаем из будущей цены настоящую) вместо того, чтобы просто определять направление (покупка или продажа). Код ускорен посредством Numba, поэтому разметка целевых происходит очень быстро.
Вышеприведенная функция учитывает разницу только между случайно выбранной будущей ценой в диапазоне {min_val; max_val} и текущей. Это может быть не совсем корректно, поскольку не учтены промежуточные отклонения, которые могут быть значительными. Я предлагаю еще одну модификацию функции расчета отклонений, которая представлена ниже.
@njit def calculate_labels_mean_r(close_data, min_val, max_val): labels = [] for i in range(len(close_data) - max_val): # Вычисляем среднее значение цен в окне от min_val до max_val future_prices = close_data[i + min_val : i + max_val + 1] mean_future_price = np.mean(future_prices) # Вычисляем разницу между средним будущим значением и текущей ценой labels.append(mean_future_price - close_data[i]) return labels def get_labels_r(dataset, min = 1, max = 15) -> pd.DataFrame: # Extract closing prices from the dataset close_data = dataset['close'].values # Calculate buy/hold labels based on future price movements labels = calculate_labels_mean_r(close_data, min, max) # Trim the dataset to match the length of calculated labels dataset = dataset.iloc[:len(labels)].copy() # Add the calculated labels as a new column dataset['labels'] = labels # Remove rows with NaN values (potentially introduced in 'calculate_labels') dataset = dataset.dropna() return dataset
Теперь функция учитывает все отклонения в заданном интервале, вычисляя среднее значение. После этого вычисляется разница между средним значением будущих цен и текущей ценой. Соответственно, функция get_labels_r() теперь вызывает функцию-разметчик calculate_labels_mean_r(), а не calculate_labels_r(), как раньше. Вы можете экспериментировать, вызывая разные функции-разметчики.
Добавление системы причинно-следственного вывода
Для более аккуратных предсказаний используем алгоритм аналогичный тому, что был описан в статье про причинно-следственный вывод. Основным отличием будет являться то, что используется регрессор, а не классификатор.
def meta_learners(data, models_number: int, iterations: int, depth: int): data = data.copy() data = data[(data.index < hyper_params['forward']) & (data.index > hyper_params['backward'])].copy() X = data[data.columns[1:-1]] y = data['labels'] data['meta_labels'] = 0 for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # fit debias model with train and validation subsets meta_m = CatBoostRegressor(iterations = iterations, depth = depth, verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict(X) data['meta_labels'] += abs(coreset['labels'] - coreset['labels_pred']) data['meta_labels'] = data['meta_labels'] / models_number return data
Функция обучает несколько регрессоров на случайных подмножествах данных из исходного датасета, а затем сравнивает фактические целевые с предсказанными. Таким образом, мета-модель будет предсказывать не 0 или 1 (торговать или не торговать), а усредненные значения отклонений прогнозов от фактических. Так мы сможем фильтровать прогнозы, которые сильно отклоняются от ожидаемых значений.
Обучение и тестирование обученных моделей
Для тестирования регрессионных моделей тестер был модифицирован и имеет суффикс "r". Настало время обучить несколько моделей. В данной статье я обучу 10 моделей и выберу из них наиболее понравившуюся.
hyper_params = {
'symbol': 'EURUSD_H1',
'export_path': '/Users/dmitrievsky/drive_c/Program Files/MetaTrader 5/MQL5/Include/Trend following/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.00500,
'take_profit': 0.00200,
'periods': [i for i in range(5, 100, 30)],
'backward': datetime(2010, 1, 1),
'forward': datetime(2024, 1, 1),
}
models = []
for i in range(10):
print('Learn ' + str(i) + ' model')
data = get_labels_r(get_features(get_prices()), min=1, max=15)
dataset = meta_learners(data=data, models_number=5, iterations=15, depth=3)
models.append(fit_final_models(dataset, tol=3e-2)) Здесь следует заострить внимание на параметре tol, который передается в функцию обучения финальных моделей. Поскольку мы хотим сделать основную модель максимально надежной, то нет смысла обучать ее на всех примерах. Мы будем обучать ее только на тех примерах, предсказания которых отклоняются от фактических меньше, чем на величину tol.
Поскольку отклонения от предсказаний считаются фактически в пунктах, то tol=3e-2 будет означать максимальную разницу 0.03 или 300 4-х значных пунктов. Она может показаться слишком большой в качестве фильтра, но стоит учесть, что это разница в абсолютных значениях, так как предсказания могут быть как положительными, так и отрицательными. Вы можете экспериментировать с этим параметром. Ниже приведена сама функция.
def fit_final_models(dataset, tol=1e-2) -> list: # features for model\meta models. We learn main model only on filtered labels X = dataset[dataset['meta_labels'] < tol] X, X_meta = X[X.columns[1:-2]], dataset[dataset.columns[1:-2]] # labels for model\meta models y = dataset[dataset['meta_labels'] < tol] y, y_meta = y[y.columns[-2]], dataset[dataset.columns[-1]] # fit main model with train and validation subsets model = RandomForestRegressor(n_estimators=50, max_depth=10) model.fit(X, y) # fit meta model with train and validation subsets meta_model = RandomForestRegressor(n_estimators=50, max_depth=10) meta_model.fit(X_meta, y_meta) data = get_features(get_prices()) R2 = test_model_r(data, [model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], plt=False) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) result = [R2, model, meta_model] return result
Теперь отсортируем модели и вызовем функцию кастомного тестера:
models.sort(key=lambda x: x[0]) data = get_features(get_prices()) test_model_r(data, models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], plt=True)
Модель переобучена и плохо работает на новых данных:
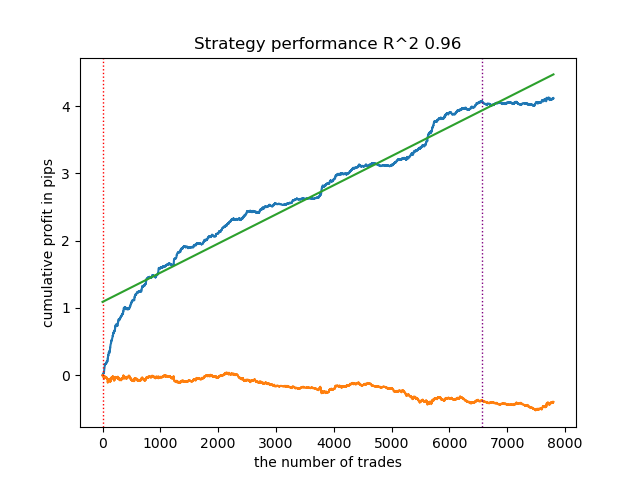
Рис 1. тестирование модели с базовой разметкой
Проведем точно такие же манипуляции, но за основу возьмем разметчик сделок calculate_labels_mean_r(), который считает средние будущие цены.
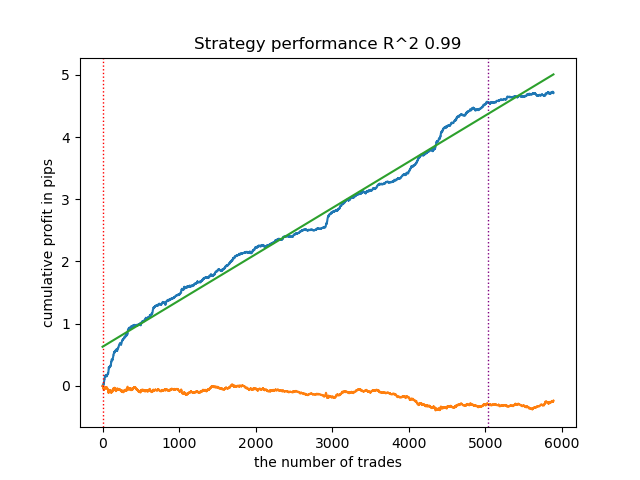
Рис 2. тестирование модели с усредненной разметкой
Второй разметчик сделок, в среднем, показывает более стабильные результаты на новых данных. Видимо это связано с тем, что учитывается среднее значение будущих цен.
В кастомном тестере не добавлена возможность определения порогов для основной регрессионной модели, поэтому он просто разделяет предсказания моделей на положительные и отрицательные, значит, сигналы являются все еще достаточно грубыми. Но мы исправим это уже непосредственно в терминале Meta Trader 5.
Экспорт моделей в терминал Meta Trader 5
Теперь нам нужно экспортировать модели в терминал в формате ONNX и произвести настройку торговой системы. Функция экспорта выглядит привычным образом:
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
Следует учесть, что мне не удалось подключить регрессионные модели CatBoost в формате ONNX к терминалу, поэтому я использовал случайный лес.
Размерность входного тензора настраивается автоматически в зависимости от гиперпараметров (количества признаков), которые задаются перед началом обучения. Далее модели конвертируются в формат ONNX с помощью функции convert_sklearn() и сохраняются на диск в директорию, указанную вами в гиперпараметрах.
def export_model_to_ONNX(**kwargs): model = kwargs.get('model') symbol = kwargs.get('symbol') periods = kwargs.get('periods') periods_meta = kwargs.get('periods_meta') model_number = kwargs.get('model_number') export_path = kwargs.get('export_path') initial_type = [('float_input', FloatTensorType([None, len(hyper_params['periods'])]))] onnx_model = convert_sklearn(model[1], initial_types=initial_type) # save main model to ONNX with open(export_path +'catmodel ' + symbol + ' ' + str(model_number) +'.onnx', "wb") as f: f.write(onnx_model.SerializeToString()) onnx_model_meta = convert_sklearn(model[2], initial_types=initial_type) # save meta model to ONNX with open(export_path +'catmodel_m ' + symbol + ' ' + str(model_number) +'.onnx', "wb") as f: f.write(onnx_model_meta.SerializeToString()) code = '#include <Math\Stat\Math.mqh>' code += '\n' code += '#resource "catmodel '+ symbol + ' '+str(model_number)+'.onnx" as uchar ExtModel_' + symbol + '_' + str(model_number) + '[]' code += '\n' code += '#resource "catmodel_m '+ symbol + ' '+str(model_number)+'.onnx" as uchar ExtModel2_' + symbol + '_' + str(model_number) + '[]' code += '\n\n' code += 'int Periods' + symbol + '_' + str(model_number) + '[' + str(len(periods)) + \ '] = {' + ','.join(map(str, periods)) + '};' code += '\n' code += 'int Periods_m' + symbol + '_' + str(model_number) + '[' + str(len(periods_meta)) + \ '] = {' + ','.join(map(str, periods_meta)) + '};' code += '\n\n' # get features code += 'void fill_arays' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'+ symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathStandardDeviation(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' # get features code += 'void fill_arays_m' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods_m' + symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods_m' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathStandardDeviation(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' file = open(export_path + str(symbol) + ' ONNX include' + ' ' + str(model_number) + '.mqh', "w") file.write(code) file.close() print('The file ' + 'ONNX include' + '.mqh ' + 'has been written to disk')
Настройка порогов в терминале Meta Trader 5
Теперь, когда мы получили две регрессионные модели вместо двух классифиаторов, у нас появляется возможность установки конкретных числовых порогов.
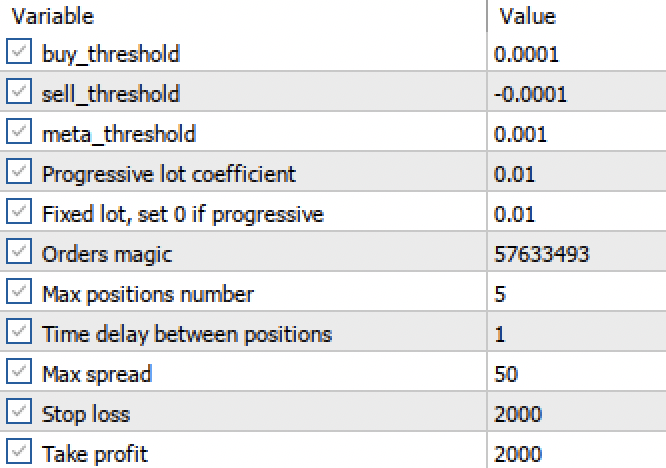
Рис 3. настройка порогов активации сигналов в терминале
- Пороги buy_threshhold и sell_threshhold отвечают за фильтрацию сигналов основной регрессионной модели. Если сигнал ниже этого порога, то сделки не открываются. Например, если прогнозируемое ценовое изменение менее 10 пунктов, то открывать такую сделку не имеет большого смысла, поскольку она не покроет спред и комиссию.
- Порог meta_threshhold фильтрует сигналы основной модели на основе причинно-следственного вывода, описанного ранее. Он проверяет насколько прогноз, вероятно, отличается от будущего фактического изменения. Если разница слишком велика, то сделки тоже не будут открыты.
Теперь проверим нашу модель в тестере Meta Trader 5 c заданными порогами:
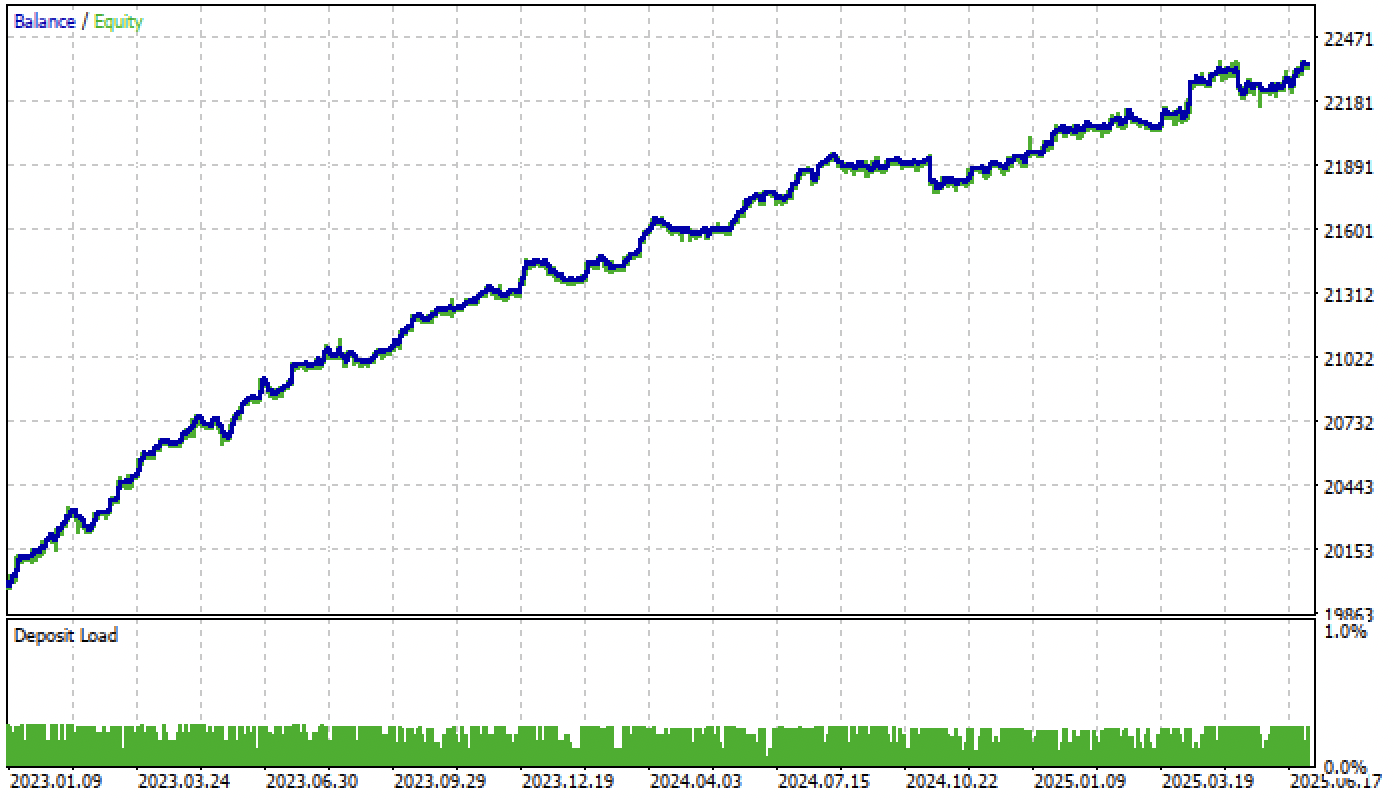
Рис 4. тестирование модели с заданными порогами
Напомню, что форвард-период начинается на начала 2024 года и теперь модель его проходит достаточно стабильно. Это подчеркивает важность правильного определения и настройки порогов. Вы можете оптимизировать значения порогов самостоятельно.
Разнообразие моделей может быть велико, в зависимости от типа признаков (в данной статье обе модели обучаются на стандартных отклонениях), а также от параметров самих моделей. Например, была обучена еще одна модель с другими параметрами, которая хорошо показала себя на новых данных даже без настройки порогов.
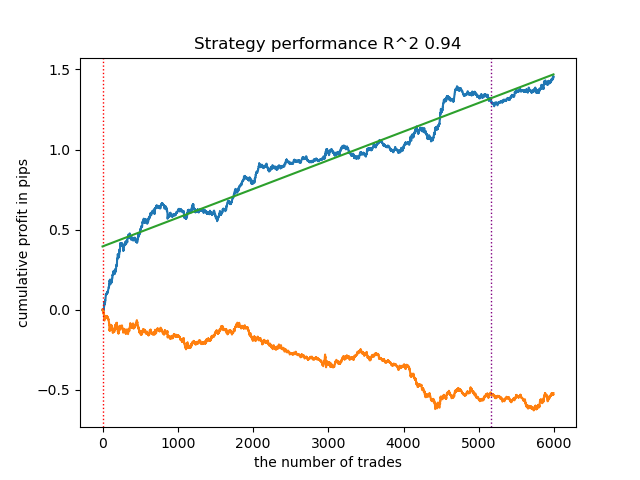
Рис 5. обучение и тестирование другой модели, с другими параметрами обучения
А после настройки порогов, модель показала устойчивый рост с начала 2024 года.
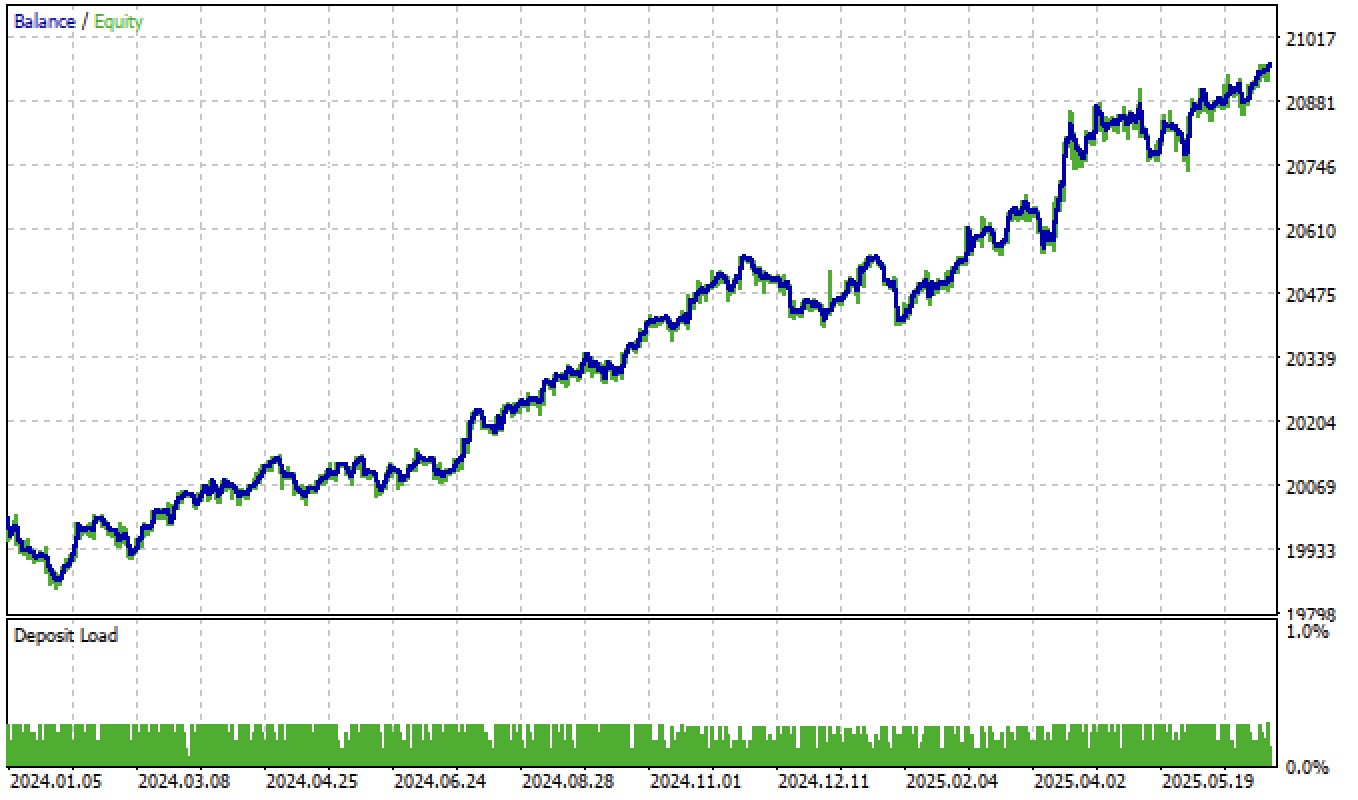
Рис 6. тестирование модели в терминале после настройки порогов
Тестирование моделей на основе второго разметчика сделок и фильтрации по порогам дает еще более интересные и аккуратные результаты:
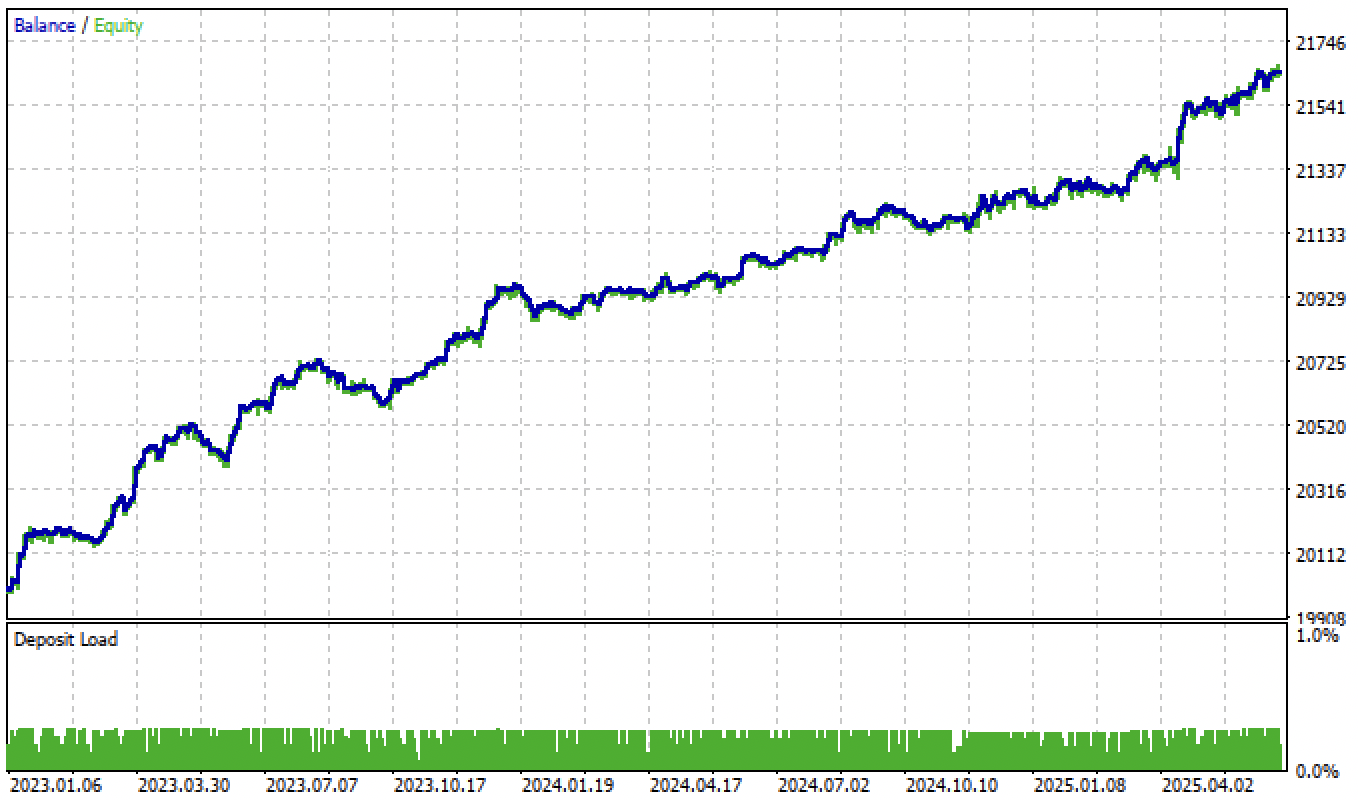
Рис 7. тестирование модели на основе усредненного разметчика сделок и tol = 1e-2
Если изменить параметр tol при обучении с 1e-2 до 1e-3, то результаты окажутся еще лучше:
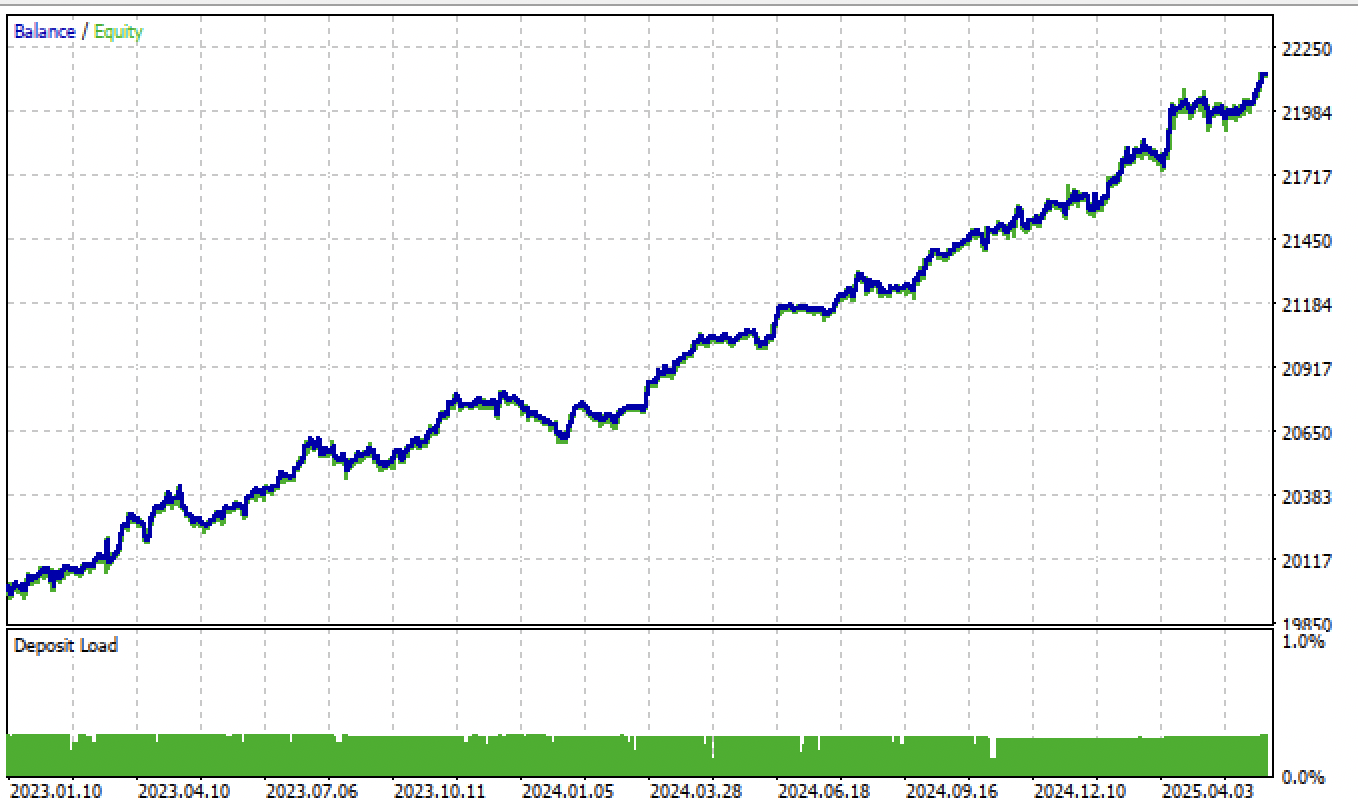
Рис 8. тестирование модели на основе усредненного разметчика сделок и tol = 1e-3
Дополнительная информация
Для экспорта моделей необходимо установить и импортировать пакет skl2onnx:
from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Также изменен код запуска ONNX моделей в коде торгового бота, чтобы он корректно обрабатывал новые регрессионные модели:
vectorf y_main(1), y_meta(1); OnnxRun(ExtHandle, ONNX_DEBUG_LOGS, f, y_main); OnnxRun(ExtHandle2, ONNX_DEBUG_LOGS, f_m, y_meta); float sig = y_main[0]; float meta_sig = y_meta[0];
Добавлены новые "input" переменные для корректировки и оптимизации порогов:
input double buy_threshold = 0.00001; input double sell_threshold = -0.00001; input double meta_threshold = 0.001;
Доступ к именам ONNX моделей теперь осуществляется через директивы #define, это упрощает подключение моделей с другими именами:
#define model ExtModel_EURUSD_H1_0 #define model_m ExtModel2_EURUSD_H1_0 #define periods PeriodsEURUSD_H1_0 #define periods_m Periods_mEURUSD_H1_0 #define fill_arrays fill_araysEURUSD_H1_0 #define fill_arrays_m fill_arays_mEURUSD_H1_0
Торговые сигналы формируются при срабатывании условий в зависимости от порогов:
if((Ask-Bid < max_spread*_Point) && MathAbs(meta_sig) < meta_threshold && AllowTrade(OrderMagic)) if(countOrders(OrderMagic) < max_orders && CheckMoneyForTrade(_Symbol, LotsOptimized(), ORDER_TYPE_BUY)) { double l = LotsOptimized(); if(sig > buy_threshold && Allow_Buy) { int res = -1; do { double stop = Bid - stoploss * _Point; double take = Ask + takeprofit * _Point; res = mytrade.PositionOpen(_Symbol, ORDER_TYPE_BUY, l, Ask, stop, take, bot_comment); Sleep(50); } while(res == -1); } else { if(sig < sell_threshold && Allow_Sell) { int res = -1; do { double stop = Ask + stoploss * _Point; double take = Bid - takeprofit * _Point; res = mytrade.PositionOpen(_Symbol, ORDER_TYPE_SELL, l, Bid, stop, take, bot_comment); Sleep(50); } while(res == -1); } } }
Модифицированный тестер стратегий и функция экспорта моделей добавлены в соответствующие модули и прикреплены к статье.
Заключение
В этой статье я описал возможный, но не единственный способ построения торговых систем на базе регрессионных моделей. Такой подход позволяет более тонко настраивать ботов, основанных на машинном обучении. Также он позволяет превращать заведомо убыточные модели в прибыльные через настройку порогов. Вы можете использовать любые признаки и/или разметчики сделок, а также проверять этот алгоритм на других торговых инструментах и других временных масштабах.
Архив Python files.zip содержит следующие файлы для разработки в среде Python:
| Имя файла | Описание |
|---|---|
| causal regression.py | Основной скрипт для обучения моделей |
| labeling_lib.py | Обновленный модуль с разметчиками сделок |
| tester_lib.py | Обновленный кастомный тестер стратегий, основанных на машинном обучении |
| export_lib.py | Модуль для экспорта моделей в терминал |
| EURUSD_H1.csv | Файл с котировками, экспортированный из терминала MetaTrader 5 |
Архив MQL5 files.zip cодержит файлы для терминала MetaTrader 5:
| Имя файла | Описание |
|---|---|
| regression trader.ex5 | Скомпилированный бот из данной статьи |
| regression trader.mq5 | Исходник бота из статьи |
| папка Include//Trend following | Расположены модели ONNX и заголовочный файл для подключения к боту |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
I use causal_regression_orig.py to produce ea header file, then compile ea.
The result is test_result pic in below.
There are so less trades than the one you posted.
So what’s the difference between these.
А в python tester много сделок? Если да, то нужно перенастроить пороги открытия сделок в mql5 программе, может быть они слишком большие.
This is the python tester result, I use the same code as you attached in this post. I checked in mt5 tester config panel, the buy_threshold and sell_threshold is both 0.0001 and -0.0001, same as the setting in this post.
I checked the code, and didnot know what is the difference between this.
This is the python tester result, I use the same code as you attached in this post. I checked in mt5 tester config panel, the buy_threshold and sell_threshold is both 0.0001 and -0.0001, same as the setting in this post.
I checked the code, and didnot know what is the difference between this.
Приветствую Максим, большое спасибо за то, что делишься с нами.
Вопрос. После расчета ONNX по новому тикеру и помещения его в папку Trend Following как убедиться что советник начал использовать обученные данные именно по новому тикеру? По другим тикерам, даже если удалить ONNX_EURUSD и поместить другой, советник ведет себя идентично. Нужно ли что-то менять в советнике MQL5 при смене тикера?
Приветствую Максим, большое спасибо за то, что делишься с нами.
Вопрос. После расчета ONNX по новому тикеру и помещения его в папку Trend Following как убедиться что советник начал использовать обученные данные именно по новому тикеру? По другим тикерам, даже если удалить ONNX_EURUSD и поместить другой, советник ведет себя идентично. Нужно ли что-то менять в советнике MQL5 при смене тикера?
Привет, в коде эксперта нужно подключить .mqh файл с новым тикером
То есть изменить выделенное на другой файл с другим именем, который был сгенерирован python скриптом.