Artigos sobre aprendizado de máquina na negociação
Criação de robôs de negociação baseados em IA: integração nativa com Python, matrizes e vetores, bibliotecas matemáticas e estatísticas e muito mais.
Descubra como usar o aprendizado de máquina no trading. Neurônios, perceptrons, redes convolutivas e recorrentes, modelos preditivos - comece com o básico e aprenda a desenvolver sua própria IA. Você aprenderá como treinar e aplicar redes neurais à negociação algorítmica nos mercados financeiros.
Novo artigo

Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se

Criação de uma estratégia de retorno à média com base em aprendizado de máquina
Neste artigo, é proposto um novo método para criar sistemas de trading baseados em aprendizado de máquina, utilizando clusterização e anotação de trades para estratégias de retorno à média.

Funcionalidades do assistente MQL5 que você precisa conhecer (Parte 08): Perceptrons
Os perceptrons, redes com uma única camada oculta, podem ser um bom suporte para aqueles familiarizados com os fundamentos do trading automático e que desejam mergulhar nas redes neurais. Vamos examinar passo a passo como eles podem ser implementados no conjunto de classes de sinais, que faz parte das classes do Assistente MQL5 para EAs.

Redes neurais em trading: Modelos bidimensionais do espaço de conexões (Chimera)
Descubra o inovador framework Chimera, um modelo bidimensional do espaço de estados que utiliza redes neurais para analisar séries temporais multidimensionais. Esse método oferece alta precisão com baixo custo computacional, superando abordagens tradicionais e arquiteturas do tipo Transformer.

Anotação de dados na análise de série temporal (Parte 2): Criação de conjuntos de dados com rótulos de tendência usando Python
Esta série de artigos apresenta várias técnicas destinadas a rotular séries temporais, técnicas essas que podem criar dados adequados à maioria dos modelos de inteligência artificial (IA). A rotulação de dados (ou anotação de dados) direcionada pode tornar o modelo de IA treinado mais alinhado aos objetivos e tarefas do usuário, melhorar a precisão do modelo e até mesmo ajudar o modelo a dar um salto qualitativo!

Gerente de risco profissional remoto para Forex em Python
Criamos um gerente de risco profissional remoto para Forex em Python e o implantamos em um servidor, passo a passo. Ao longo do artigo, veremos como gerenciar riscos no Forex de maneira programada e como evitar a perda total do depósito.
Algoritmos de otimização populacionais: algoritmo genético binário (Binary Genetic Algorithm, BGA). Parte II
Neste artigo, vamos considerar o algoritmo genético binário (BGA), que modela os processos naturais que ocorrem no material genético dos seres vivos na natureza.

Funções de ativação de neurônios durante o aprendizado: chave para uma convergência rápida?
Este trabalho apresenta uma análise da interação entre diferentes funções de ativação e algoritmos de otimização no contexto do treinamento de redes neurais. A atenção principal está voltada para a comparação entre o ADAM clássico e sua versão populacional ao lidar com uma ampla gama de funções de ativação, incluindo as funções oscilatórias ACON e Snake. Mediante uma arquitetura MLP minimalista (1-1-1) e um único exemplo de treino, isola-se a influência das funções de ativação no processo de otimização, eliminando interferências de outros fatores. Propomos um método de controle dos pesos da rede por meio dos limites das funções de ativação e um mecanismo de reflexão de pesos, permitindo evitar problemas de saturação e estagnação no aprendizado.

Algoritmos de otimização populacional: Busca em sistema carregado (Charged System Search, CSS)
Neste artigo, vamos explorar outro algoritmo de otimização inspirado pela natureza inanimada, a busca em sistema carregado (CSS). O objetivo deste artigo é apresentar um novo algoritmo de otimização baseado nos princípios da física e mecânica.

Algoritmos de otimização populacionais: algoritmo genético binário (Binary Genetic Algorithm, BGA). Parte I
Neste artigo, vamos realizar um estudo sobre vários métodos aplicados em algoritmos genéticos binários e outros algoritmos populacionais. Vamos examinar os componentes principais do algoritmo, como seleção, crossover e mutação, bem como seu impacto no processo de otimização. Além disso, vamos explorar as formas de representação de informações e seu impacto nos resultados de otimização.

Redes neurais de maneira fácil (Parte 54): usando o codificador aleatório para exploração eficiente (RE3)
A cada vez que consideramos métodos de aprendizado por reforço, nos deparamos com a questão da exploração eficiente do ambiente. A solução deste problema frequentemente leva à complexificação do algoritmo e ao treinamento de modelos adicionais. Neste artigo, vamos considerar uma abordagem alternativa para resolver esse problema.

Redes neurais em trading: Modelo multidimensional de ponta a ponta para previsão de séries temporais (Componentes principais)
Apresentamos a nova implementação dos principais componentes do framework GinAR, um algoritmo adaptativo para trabalhar com séries temporais baseadas em grafos. Neste artigo, analisamos passo a passo a arquitetura e os algoritmos de propagação para frente e de retropropagação do erro.
Experimentos com redes neurais (Parte 7): Transferência de indicadores
Desta vez, veremos exemplos de passagem de indicadores ao perceptron. Abordaremos conceitos gerais, um Expert Advisor simples pronto, os resultados de sua otimização e testes forward.

O Problema da Discordância: Mergulhando Mais Fundo na Complexidade da Explicabilidade em IA
Neste artigo, exploramos o desafio de entender como a IA funciona. Modelos de IA frequentemente tomam decisões de maneiras que são difíceis de explicar, levando ao que é conhecido como o "problema da discordância". Esta questão é fundamental para tornar a IA mais transparente e confiável.

Redes neurais de maneira fácil (Parte 65): aprendizado supervisionado ponderado por distância (DWSL)
Neste artigo, convido você a conhecer um algoritmo interessante que se situa na interseção entre os métodos de aprendizado supervisionado e de reforço.

ADAM Populacional (estimativa adaptativa de momentos)
Este artigo apresenta a transformação do conhecido e popular método de otimização por gradiente ADAM em um algoritmo populacional e sua modificação com a introdução de indivíduos híbridos. A nova abordagem permite criar agentes que combinam elementos de soluções bem-sucedidas usando uma distribuição probabilística. A principal inovação é a formação de indivíduos híbridos populacionais, que acumulam de forma adaptativa informações das soluções mais promissoras, aumentando a eficácia da busca em espaços multidimensionais complexos.

Previsão baseada em aprendizado profundo e abertura de ordens com o pacote MetaTrader 5 python e arquivo de modelo ONNX
O projeto envolve o uso de Python para previsão em mercados financeiros baseada em aprendizado profundo. Nós exploraremos as nuances do teste de desempenho do modelo usando indicadores-chave como erro absoluto médio (MAE), erro quadrático médio (MSE) e R-quadrado (R2), além de aprender a integrar tudo isso em um arquivo executável. Também criaremos um arquivo de modelo ONNX e um EA (Expert Advisor).
Teoria das Categorias em MQL5 (Parte 22): Outra Perspectiva sobre Médias Móveis
Neste artigo, tentaremos simplificar a descrição dos conceitos discutidos nesta série, focando apenas em um indicador, o mais comum e, provavelmente, o mais fácil de entender. Estamos falando da média móvel. Também examinaremos o significado e as possíveis aplicações das transformações naturais verticais.

Anotação de dados na análise de série temporal (Parte 4): Decomposição da interpretabilidade usando anotação de dados
Esta série de artigos apresenta várias técnicas destinadas a rotular séries temporais, técnicas essas que podem criar dados adequados à maioria dos modelos de inteligência artificial (IA). A rotulação de dados (ou anotação de dados) direcionada pode tornar o modelo de IA treinado mais alinhado aos objetivos e tarefas do usuário, melhorar a precisão do modelo e até mesmo ajudar o modelo a dar um salto qualitativo!

Algoritmos de otimização populacionais: Algoritmo de evolução da mente (Mind Evolutionary Computation, MEC)
Este artigo discute um algoritmo da família MEC, denominado algoritmo simples de evolução da mente (Simple MEC, SMEC). O algoritmo se destaca pela beleza da ideia subjacente e pela simplicidade de implementação.

Redes neurais em trading: Representação linear por partes de séries temporais
Este artigo é um pouco diferente dos trabalhos anteriores desta série. Nele, discutiremos uma representação alternativa de séries temporais. A representação linear por partes de séries temporais é um método de aproximação de séries temporais usando funções lineares em pequenos intervalos.

Algoritmo de Otimização Aritmética (AOA): O caminho do AOA até o SOA (Simple Optimization Algorithm)
Neste artigo, apresentamos o Algoritmo de Otimização Aritmética (Arithmetic Optimization Algorithm, AOA), que se baseia em operações aritméticas simples: adição, subtração, multiplicação e divisão. Essas operações matemáticas básicas são fundamentais para a busca de soluções ótimas em diversas tarefas.

Teoria das Categorias em MQL5 (Parte 17): funtores e monoides
Este é o último artigo da série dedicada a funtores. Nele, reconsideramos monoides como uma categoria. Os monoides, que já apresentamos nesta série, são usados aqui para ajudar na definição do tamanho da posição juntamente com perceptrons multicamadas.

Teoria das Categorias em MQL5 (Parte 15): Funtores com grafos
Este artigo continua a série sobre a implementação da teoria de categorias no MQL5, ele aborda os funtores como uma ponte entre grafos e conjuntos. Nesse escopo, voltaremos a analisar os dados de calendário e, apesar de suas limitações no uso do testador de estratégias, justificaremos o uso de funtores na previsão de volatilidade mediante correlação.

Agrupamento de séries temporais na inferência causal
Os algoritmos de agrupamento em aprendizado de máquina são ferramentas importantes de aprendizado não supervisionado que permitem dividir os dados brutos em grupos com características semelhantes. Com esses grupos, é possível, por exemplo, realizar análise de mercado para um cluster específico, identificar os clusters mais resilientes em novos conjuntos de dados e também realizar inferências causais. Este artigo apresenta um método original para o agrupamento de séries temporais, utilizando a linguagem Python.

Teoria das Categorias em MQL5 (Parte 2)
A Teoria das Categorias é um ramo diverso da Matemática e em expansão, sendo uma área relativamente recente na comunidade MQL5. Esta série de artigos visa introduzir e examinar alguns de seus conceitos com o objetivo geral de estabelecer uma biblioteca aberta que atraia comentários e discussões enquanto esperamos promover o uso deste campo notável no desenvolvimento da estratégia dos traders.

Redes neurais de maneira fácil (Parte 67): Aprendendo com experiências passadas para resolver novos problemas
Neste artigo, continuaremos a falar sobre métodos de coleta de dados em uma amostra de treinamento. É claro que o processo de aprendizado requer constante interação com o ambiente. Mas as situações podem variar.

Redes neurais em trading: modelo multivariado de ponta a ponta para previsão de séries temporais (GinAR)
Apresentamos uma abordagem inovadora para a previsão de séries temporais com dados ausentes baseada no framework GinAR. O artigo descreve a implementação dos principais componentes em OpenCL, garantindo, assim, alto desempenho. Em nossa próxima publicação, analisaremos em detalhes a integração dessas soluções ao MQL5. Isso permitirá compreender como aplicar o método no trading prático.

Funcionalidades do assistente MQL5 que você precisa conhecer (Parte 09): Combinação de agrupamento k-médias com ondas fractais
O agrupamento k-médias é uma abordagem para agrupar pontos de dados em um processo que inicialmente se concentra na representação macro do conjunto de dados, onde são aplicados centroides de cluster criados aleatoriamente. Com o tempo, esses centroides são ajustados e escalonados para representar melhor o conjunto de dados. Este artigo examina essa abordagem de agrupamento e algumas de suas aplicações.

Rede neural na prática: O primeiro neurônio
Neste artigo começamos a de fato criar algo que muitos ficam admirados em ver funcionando. Um simples e singelo neurônio que conseguiremos programar com muito pouco código em MQL5.O neurônio funcionou perfeitamente nos testes que fiz. Bem, vamos voltar um pouco, nesta mesma série sobre redes neurais, para que você possa entender do que estou falando.
Filtragem de Sazonalidade e Período de Tempo para Modelos de Deep Learning ONNX com Python para EA
Podemos nos beneficiar da sazonalidade ao criar modelos de Deep Learning com Python? A filtragem de dados para os modelos ONNX ajuda a obter melhores resultados? Qual período de tempo devemos usar? Cobriremos tudo isso neste artigo.

Fatorando Matrizes — Uma modelagem mais prática
Muito provavelmente você não tenha se dado conta, que a modelagem das matrizes estava um tanto quanto estranha. Já que não havia a indicação de linhas e colunas, mas apenas indicações de colunas. O que é muito estranho, quando se está lendo um código, que faz fatorações de matrizes. E se você estava esperando ver linhas e colunas sendo indicadas. Pode acabar ficando bastante confuso, no momento de tentar implementar a fatoração. Além do mais, aquela forma de modelar as matrizes, não é nem de longe a melhor maneira. Isto por que, quando modelamos matrizes daquela maneira, passamos a ter uma certa limitação, que nos obriga a usar outras técnicas, ou funções, que não seriam de fato necessárias. Isto quando a modelagem é feita de uma maneira um pouco mais adequada.

Arbitragem de swap no Forex: Montando uma carteira sintética e criando um fluxo estável de swaps
Quer saber como lucrar com a diferença entre taxas de juros? Neste artigo, veremos como usar a arbitragem de swap no Forex para obter uma renda estável todas as noites, criando uma carteira resistente às oscilações do mercado.

Algoritmos de otimização populacional: sistema imune micro-artificial (Micro Artificial Immune System, Micro-AIS)
Este artigo fala sobre um método de otimização baseado nos princípios de funcionamento do sistema imunológico do organismo — Micro Artificial Immune System (Micro-AIS) — uma modificação do AIS. O Micro-AIS utiliza um modelo mais simples do sistema imunológico e operações mais simples de processamento de informações imunológicas. O artigo também aborda as vantagens e desvantagens do Micro-AIS em comparação com o AIS tradicional.

Redes neurais de maneira fácil (Parte 64): Método de clonagem de comportamento ponderada conservadora (CWBC)
Pelo resultado dos testes realizados em artigos anteriores, concluímos que a qualidade da estratégia treinada depende muito da amostra de treinamento utilizada. Neste artigo, apresento a vocês um método simples e eficaz para selecionar trajetórias com o objetivo de treinar modelos.
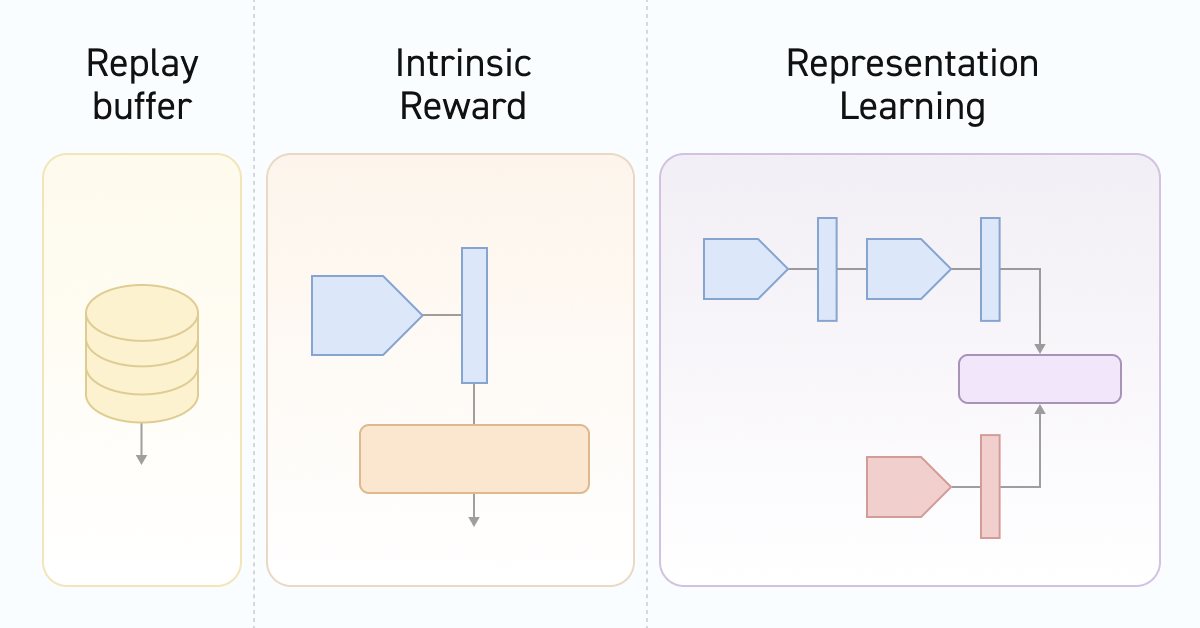
Redes neurais de maneira fácil (Parte 55): Controle interno contrastivo (CIC)
O aprendizado contrastivo é um método de aprendizado de representação sem supervisão. Seu objetivo é ensinar o modelo a identificar semelhanças e diferenças nos conjuntos de dados. Neste artigo, discutiremos o uso de abordagens de aprendizado contrastivo para explorar diferentes habilidades do Ator.

Rede neural na prática: Pseudo Inversa (I)
Aqui, vamos começar a ver como podermos implementar, usando MQL5 puro, o cálculo de pseudo inversa. Apesar do código que será visto, será de fato bem mais complicado, para os iniciantes, do que eu de fato gostaria de apresentar. Ainda estou pensando em como o explicar de forma simples. Veja isto como uma oportunidade de estudar um o código pouco comum. Então vá com calma. Sem pressa e correria. Mesmo que ele não vise ser eficiente e de rápida execução. O objetivo é ser o mais didático possível.

Data Science e Machine Learning (Parte 22): Aproveitando Redes Neurais Autoencoders para Operações Mais Inteligentes, Movendo-se do Ruído para o Sinal
No mundo acelerado dos mercados financeiros, separar sinais significativos do ruído é crucial para o sucesso nas operações de trading. Ao empregar arquiteturas sofisticadas de redes neurais, os autoencoders se destacam ao descobrir padrões ocultos dentro dos dados de mercado, transformando entradas ruidosas em insights acionáveis. Neste artigo, exploramos como os autoencoders estão revolucionando as práticas de trading, oferecendo aos traders uma ferramenta poderosa para melhorar a tomada de decisões e ganhar uma vantagem competitiva nos mercados dinâmicos de hoje.

Determinação de taxas de câmbio justas com base na PPC usando dados do FMI
Criação, em Python, de um sistema de análise de taxas de câmbio baseado na paridade do poder de compra (PPC). O autor desenvolveu um algoritmo com 5 métodos de cálculo de taxas justas, utilizando dados do FMI. Trata-se de um guia prático de análise fundamentalista de moedas, processamento de dados econômicos e integração com sistemas de trading. Código completo de fonte aberta.

Redes neurais de maneira fácil (Parte 60): transformador de decisões on-line (ODT)
As últimas 2 partes foram dedicadas ao método transformador de decisões (DT), que modela sequências de ações no contexto de um modelo autorregressivo de recompensas desejadas. Neste artigo, vamos considerar outro algoritmo de otimização deste método.

O escore de propensão na inferência causalidade
O artigo examina o tema de pareamento na inferência causal. O pareamento é utilizado para comparar observações semelhantes em um conjunto de dados. Isso é necessário para determinar corretamente os efeitos causais e eliminar o viés. O autor explica como isso ajuda na construção de sistemas de negociação baseados em aprendizado de máquina, que se tornam mais estáveis em novos dados nos quais não foram treinados. O escore de propensão desempenha um papel central e é amplamente utilizado na inferência causal.