
Redes neurais de maneira fácil (Parte 97): Treinamento do modelo usando o MSFformer

Introdução
No artigo anterior, construímos os principais módulos do modelo MSFformer: CSCM e Skip-PAM. No módulo CSCM, ocorre a construção da árvore de características da série temporal analisada. E o Skip-PAM extrai informações das séries temporais em múltiplas escalas por meio de um mecanismo de atenção baseado na árvore de características temporais. Neste artigo, continuaremos o trabalho iniciado: treinaremos o modelo e avaliaremos sua eficiência em dados reais no testador de estratégias do MetaTrader 5.
1. Arquitetura dos modelos
Antes de começarmos o treinamento dos modelos, precisamos realizar uma série de preparações. Primeiro, devemos definir a arquitetura dos modelos. O método MSFformer foi desenvolvido para tarefas de previsão de séries temporais. Assim, o incorporaremos no modelo Codificador do estado do ambiente, junto com outros métodos semelhantes.
1.1 Arquitetura do Codificador do estado do ambiente
A arquitetura do Codificador do estado do ambiente é definida no método CreateEncoderDescriptions. Esse método recebe como parâmetros um ponteiro para um objeto de matriz dinâmica, no qual iremos registrar a arquitetura do modelo.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
No corpo do método, verificamos a validade do ponteiro recebido e, se necessário, criamos uma nova instância da matriz dinâmica.
Em seguida, descrevemos diretamente a arquitetura do modelo. Na entrada do Codificador, fornecemos dados brutos que descrevem o estado atual do ambiente. Como de costume, usamos um objeto de camada totalmente conectada básica sem função de ativação como a camada de dados de entrada. Sua aplicação é desnecessária neste caso, pois os dados brutos recebidos serão gravados diretamente no buffer de resultados dessa camada.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
É importante notar que o tamanho da camada de dados de entrada criada deve corresponder exatamente ao tamanho do tensor de descrição do estado do ambiente. Além disso, a descrição do estado do ambiente deve ser idêntica em todas as etapas de treinamento e uso do modelo. Portanto, para facilitar a sincronização dos parâmetros dos programas usados no processo de treinamento e uso dos modelos, extraímos para constantes 2 parâmetros: o número de elementos que descrevem uma única barra (BarDescr) e a profundidade do histórico analisado (HistoryBars). Usaremos o produto dessas constantes para definir o tamanho da camada de dados de entrada criada.
Como já mencionado, planejamos fornecer ao modelo dados brutos (não processados). Por um lado, isso nos permite não nos preocupar com a sincronização dos blocos de preparação de dados nos programas de treinamento e uso do modelo. Essa é uma boa notícia.
Por outro lado, o uso de dados não processados geralmente reduz a eficácia do treinamento dos modelos. Isso ocorre devido às grandes diferenças nos indicadores estatísticos dos vários elementos presentes nos dados brutos utilizados. Para minimizar o impacto desse fator, realizaremos o pré-processamento dos dados brutos diretamente em nosso modelo. Esse funcional será realizado pela camada de normalização em lotes. Seu algoritmo é projetado para que os dados de saída tenham um valor médio próximo de "0" e uma variância unitária.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os dados brutos preparados, já normalizados da série temporal, são alimentados no módulo de extração de características CSCM.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCSCMOCL; descr.count = HistoryBars; descr.window = BarDescr;
Note que extrairemos as características dentro das séries temporais unitárias. Aqui, especificamos o comprimento da sequência igual à profundidade do histórico analisado, e o número de sequências unitárias é igual ao tamanho do vetor que descreve uma única barra. No entanto, ao compor o tensor de descrição do estado do ambiente em trabalhos anteriores, geralmente montamos uma matriz de dados onde as linhas correspondem às barras analisadas e as colunas às características. Portanto, especificamos nos parâmetros do CSCM a necessidade de transpor os dados previamente.
descr.step = int(true);
As características serão extraídas em 3 níveis, com tamanhos de janela de análise de 6, 5 e 4 barras.
{
int temp[] = {6, 5, 4};
if(!ArrayCopy(descr.windows, temp))
return false;
}
Não utilizamos função de ativação, e os parâmetros do modelo serão otimizados utilizando o método Adam.
descr.step = int(true); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, conforme o algoritmo do método MSFformer, vem o módulo Skip-PAM. Adicionaremos 3 camadas sequenciais de Skip-PAM com a mesma configuração em nossa implementação.
//--- layer 3 - 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSPyrAttentionMLKV; descr.count = HistoryBars; descr.window = BarDescr;
Aqui, especificamos o mesmo tamanho de sequência analisada, mas neste caso, trabalhamos com uma sequência multimodal.
O tamanho do vetor interno que descreve as entidades Query, Key e Value será de 32 elementos. Além disso, o número de cabeças de atenção para o tensor Key-Value será metade disso.
descr.window_out = 32; { int temp[] = {8, 4}; if(!ArrayCopy(descr.heads, temp)) return false; } descr.layers = 3; descr.activation = None; descr.optimization = ADAM; for(int l = 0; l < 3; l++) if(!encoder.Add(descr)) { delete descr; return false; }
A pirâmide de atenção de cada Skip-PAM conterá 3 níveis. Usamos também o método Adam para otimizar os parâmetros do modelo.
Na saída do módulo Skip-PAM, obtemos um tensor cujo tamanho corresponde aos dados brutos. No entanto, seu conteúdo foi ajustado com base nas dependências entre os elementos da sequência analisada. Em seguida, construiremos trajetórias preditivas para a continuação da série temporal multimodal dos dados brutos. Planejamos construir trajetórias preditivas separadas para cada série unitária na sequência multimodal analisada. Para isso, primeiro transporemos o tensor de dados obtido do módulo Skip-PAM.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, usaremos 2 camadas convolucionais sequenciais que atuarão como um MLP para as sequências unitárias individuais.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; descr.window_out = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = LatentCount; descr.step = LatentCount; descr.window_out = NForecast; descr.optimization = ADAM; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Note que, para fazer a semelhança de um MLP nas camadas convolucionais apresentadas acima, especificamos o tamanho da janela analisada e seu passo como iguais. No primeiro caso, no nível da profundidade da sequência analisada. E no segundo caso, igual ao número de filtros da camada anterior. O número de blocos de convolução será igual ao número de sequências unitárias analisadas. Para criar a não linearidade entre as camadas convolucionais, utilizamos a função de ativação LReLU.
Para a segunda camada convolucional, definimos o número de filtros igual ao tamanho da sequência prevista. Que, em nosso caso, é especificado pela constante NForecast.
Além disso, para a segunda camada convolucional, usamos a função de ativação tangente hiperbólica (TANH). Vale destacar que a escolha dessa função de ativação não é por acaso. Como você deve lembrar, na entrada do modelo, para o pré-processamento dos dados brutos, utilizamos uma camada de normalização em lotes que ajusta os dados a uma variância unitária e uma média próxima de "0". Conforme a regra das "3 sigmas", cerca de 2/3 dos valores de uma variável aleatória normalmente distribuída estão dentro de 1 desvio padrão da média. Portanto, o uso da tangente hiperbólica com intervalo de valores (-1, 1) como função de ativação cobre 68% dos valores da variável analisada e filtra "valores atípicos" que estão além de um desvio padrão da média.
É importante compreender que nosso objetivo não é aprender e prever todas as flutuações da série temporal analisada, pois ela é cheia de diversos ruídos. Precisamos apenas de uma previsão com precisão suficiente para construir uma estratégia de negociação lucrativa.
Em seguida, com a camada de transposição de dados, retornamos os valores previstos ao formato dos dados brutos.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
E a eles adicionamos os indicadores estatísticos que extraímos anteriormente na camada de normalização em lotes.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr*NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers=1; if(!encoder.Add(descr)) { delete descr; return false; }
Com isso, podemos considerar concluída a arquitetura do modelo do Codificador do estado do ambiente. De fato, nesse formato, ela já está de acordo com o modelo apresentado pelos autores do método MSFformer. Porém, adicionaremos um toque final. Em trabalhos anteriores, já mencionamos que a abordagem de previsão direta pressupõe a independência de etapas individuais na sequência prevista. Isso, como você deve entender, contradiz a natureza de uma série temporal. Portanto, utilizaremos as técnicas do método FreDF para alinhar os passos individuais na sequência de previsão da série temporal que construímos.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Nesse formato, a arquitetura do Codificador tem uma forma mais completa. Espero que meus comentários tenham ajudado você a entender a lógica que incorporamos no modelo construído.
Neste ponto, descrevemos a arquitetura do modelo de previsão do movimento futuro dos preços e poderíamos prosseguir para o treinamento do modelo. Mas nosso objetivo vai além de apenas prever a série temporal. Queremos treinar um modelo capaz de executar operações no mercado financeiro e gerar lucro. Isso significa que ainda precisamos criar o modelo do Ator, que gerará ações de negociação e as executará em nosso nome, e o modelo do Crítico, que avaliará as operações geradas pelo Ator e nos ajudará a desenvolver uma estratégia de negociação lucrativa.
1.2 Arquiteturas do Ator e do Crítico
A descrição das arquiteturas dos modelos Ator e Crítico será criada no método CreateDescriptions. Esse método recebe como parâmetros dois ponteiros para matrizes dinâmicas, nas quais registraremos as soluções arquitetônicas desenvolvidas.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Como no caso anterior, no corpo do método, primeiro verificamos a validade dos ponteiros recebidos e, se necessário, criamos novas instâncias de objetos de matrizes dinâmicas. Em seguida, passamos para a descrição direta das arquiteturas dos modelos que estamos criando.
Primeiro, vamos construir o modelo Ator. Mas antes de descrever a solução arquitetônica, vamos discutir um pouco os objetivos que temos para o modelo do Ator. É claro que seu objetivo principal é gerar ações ótimas para realizar uma operação de negociação. Mas como o modelo deve fazer isso? Evidentemente, o Ator deve analisar o movimento de preço previsto, que será gerado pelo Codificador do estado do ambiente, e determinar a direção da negociação. Depois, precisa considerar o estado atual da conta e determinar nossas possibilidades. Com base na análise conjunta, o Ator determina o volume da operação, os riscos e as metas em forma de stop-loss e take-profit. É exatamente nessa lógica que descreveremos a arquitetura do Ator.
Na entrada do modelo, primeiro fornecemos um vetor que descreve o estado da conta.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Esse vetor será processado por uma camada totalmente conectada.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Em seguida, adicionaremos um bloco de atenção cruzada com nove camadas aninhadas, no qual correlacionaremos o estado atual da conta com o movimento de preço previsto.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); } { int temp[] = {8, 4}; ArrayCopy(descr.heads, temp); } descr.layers = 9; descr.step = 1; descr.window_out = 32; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Assim como no Codificador do estado do ambiente, utilizamos:
- Um vetor de descrição das entidades internas com 32 elementos;
- O número de cabeças de atenção no tensor Key-Value é metade do tamanho do tensor Query.
Cada tensor Key-Value opera apenas em uma camada aninhada.
Depois, analisamos os dados processados usando um MLP de 3 camadas.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
E na saída do modelo, geramos um vetor de ações com uma cabeça estocástica.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Lembrando que a cabeça estocástica criada por nós gera ações "aleatórias" para o Ator. A região permitida para esses valores aleatórios é estritamente limitada pelos parâmetros da distribuição normal, como a média e o desvio padrão, que são aprendidos pela camada anterior. Assim, em condições ideais, quando uma ação pode ser definida com clareza, a variância da distribuição da variável aleatória gerada se aproxima de "0". Consequentemente, a saída do Ator se aproxima do valor médio aprendido. À medida que a incerteza aumenta, a variância das ações geradas também aumenta. Como resultado, obtemos ações aleatórias na saída do Ator. Portanto, ao utilizar uma política estocástica, é importante dedicar atenção especial ao processo de teste do modelo treinado. Em condições iguais, a política treinada deve gerar resultados consistentes. Uma grande divergência em dois testes consecutivos pode indicar que o modelo ainda não foi suficientemente treinado.
E, naturalmente, as ações geradas pelo Ator devem ser coerentes entre si. O nível de stop-loss deve estar alinhado com o risco permitido, dado o volume da operação. Além disso, procuramos evitar operações em direções opostas. A coerência das ações do Ator será garantida pelo uso da camada FreDF.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
O modelo Crítico possui uma arquitetura semelhante, mas substituímos o vetor de descrição do estado da conta, fornecido na entrada do Ator, pelo tensor de ações gerado pelo Ator no estado do ambiente analisado. A ausência de dados sobre o estado da conta na entrada do Crítico pode ser facilmente explicada. Afinal, o lucro ou prejuízo depende não do volume de fundos na conta, mas do volume e da direção da posição aberta.
Para uma compreensão mais detalhada da arquitetura do Crítico, recomendo que você a estude de forma independente. O código completo de todos os programas utilizados na preparação deste artigo está disponível em anexo.
2. EAs de treinamento de modelos
Após descrevermos a arquitetura dos modelos que queremos treinar, proponho que discutamos os programas que serão usados para o treinamento. Neste caso, utilizaremos dois EAs:
- StudyEncoder.mq5 — EA para treinar o Codificador do estado do ambiente.
- Study.mq5 — treinamento da política do Ator.
2.1 Programa de treinamento do Codificador
No contexto do "StudyEncoder.mq5", treinaremos o modelo do Codificador para prever o movimento futuro dos preços e os valores dos indicadores analisados. Não se surpreenda se gastarmos recursos na previsão de indicadores que possam parecer desnecessários à primeira vista. Estamos acostumados a usar indicadores para identificar zonas de sobrecompra e sobrevenda, medir a força de uma tendência e localizar pontos de reversão de preços. Contudo, a construção de indicadores geralmente envolve o uso de diversos filtros digitais, projetados para minimizar o ruído inerente aos dados brutos de movimento de preço. Isso torna os valores dos indicadores mais suaves e, frequentemente, mais previsíveis. Portanto, ao prever os valores futuros dos indicadores, estamos, de certa forma, tentando refinar e validar nossas previsões de movimento de preço.
No método de inicialização do "StudyEncoder.mq5", começamos carregando os dados do conjunto de treinamento, sobre os quais discutiremos mais adiante.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Em seguida, tentamos carregar o modelo pré-treinado do Codificador do estado do ambiente. Entendemos que nem sempre será necessário treinar um modelo completamente novo, iniciado com parâmetros aleatórios. Na maioria das vezes, precisaremos continuar o treinamento de um modelo que não atingiu os resultados desejados durante o treinamento inicial.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { Print("Create new model"); CArrayObj *encoder = new CArrayObj(); if(!CreateEncoderDescriptions(encoder)) { delete encoder; return INIT_FAILED; } if(!Encoder.Create(encoder)) { delete encoder; return INIT_FAILED; } delete encoder; }
Se, por qualquer motivo, não conseguirmos carregar o modelo pré-treinado, chamamos o método CreateEncoderDescriptions para gerar a arquitetura de um novo modelo. Em seguida, inicializamos o novo modelo com a arquitetura especificada e parâmetros aleatórios.
//--- Encoder.getResults(Result); if(Result.Total() != NForecast * BarDescr) { PrintFormat("The scope of the Encoder does not match the forecast state count (%d <> %d)", NForecast * BarDescr, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
O próximo passo é fazer um pequeno bloco de controle da arquitetura do modelo, no qual verificaremos os tamanhos da camada de dados brutos e do tensor de resultados. Claro, entendemos que, ao criar um novo modelo, desvios são praticamente impossíveis. Afinal, usamos as mesmas constantes que anteriormente definiram os tamanhos das camadas na descrição da arquitetura do modelo para essas verificações. Este bloco de controle visa principalmente identificar casos em que modelos pré-treinados carregados não correspondem ao conjunto de dados de treinamento utilizado.
Após passar com sucesso pelo bloco de controle, basta gerar um evento personalizado para iniciar o processo de treinamento do modelo e finalizar a execução do método de inicialização do EA.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
O processo real de treinamento do modelo é estruturado no método Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
No corpo do método, começamos gerando um vetor de probabilidades para a seleção de trajetórias a partir do conjunto de treinamento. O algoritmo é configurado para atribuir uma probabilidade maior às passagens com a maior rentabilidade É claro que isso é mais relevante para o treinamento da política do Ator, já que o modelo do Codificador do estado da conta não analisa nem o saldo atual nem as posições abertas. Ele trabalha exclusivamente com indicadores e movimentos de preço analisados. Mesmo assim, mantivemos essa funcionalidade para preservar a consistência arquitetônica entre todas as soluções de programa utilizadas.
Em seguida, declaramos as variáveis locais necessárias.
vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
E criamos o ciclo de treinamento do modelo. O número de iterações de treinamento é especificado nos parâmetros externos do programa.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; }
No corpo do loop, selecionamos aleatoriamente uma trajetória e um estado correspondente do conjunto de treinamento. Verificamos se o estado selecionado possui dados armazenados, e então transferimos as informações da amostra de treinamento para o buffer de dados.
state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum()==0) { iter--; continue; } bState.AssignArray(state);
Com os dados preparados, realizamos a propagação para frente do modelo treinado.
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
No entanto, não carregamos os valores previstos obtidos. Neste estágio, nosso interesse não está tanto nos resultados da previsão, mas sim no desvio em relação aos valores reais subsequentes, que estão armazenados no conjunto de treinamento. Assim, carregamos os estados subsequentes da amostra de treinamento.
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
E preparamos os valores reais com os quais vamos comparar as previsões obtidas. Esses dados são fornecidos como parâmetros para o método de propagação reversa do modelo, onde ocorre a otimização dos parâmetros com o objetivo de minimizar o erro de previsão.
if(!Encoder.backProp(Result,(CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Após a execução bem-sucedida das propagações para frente e reversa, basta informar o usuário sobre o progresso do treinamento e avançar para a próxima iteração do laço.
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Devo admitir que o processo de treinamento foi estruturado de maneira extremamente simples e sem complicações desnecessárias. A duração do treinamento é determinada apenas pelo número de iterações de treinamento, que o usuário define nos parâmetros externos ao iniciar o EA. A saída antecipada do processo de treinamento só é possível em caso de erro ou encerramento forçado do programa pelo usuário no terminal.
Após a conclusão do processo de treinamento, limpamos o campo de comentários no gráfico do programa, onde anteriormente exibíamos informações sobre o progresso.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
Os resultados do treinamento são registrados no diário do MetaTrader 5, e iniciamos o encerramento da execução do programa. O modelo treinado é salvo no método OnDeinit. Você pode encontrar o código completo do EA no anexo.
2.2 Algoritmo de treinamento do Ator
O segundo EA, "Study.mq5", é projetado para treinar a política do Ator. Além disso, dentro deste programa, também ocorre o treinamento do modelo do Crítico.
É importante mencionar que o papel do Crítico é bastante específico — ele precisa orientar o Ator a agir na direção correta. No entanto, o próprio Crítico não é usado no processo de execução do modelo. Em outras palavras, por mais paradoxal que pareça, treinamos o Crítico apenas para treinar o Ator.
A estrutura do EA para o treinamento do Ator é semelhante ao programa de treinamento do Codificador discutido anteriormente. Nesta parte do artigo, focaremos apenas no método de treinamento Train.
Assim como na aplicação mencionada antes, no corpo do método, começamos gerando um vetor de probabilidades para a seleção de trajetórias do conjunto de treinamento e declarando as variáveis locais necessárias.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
Em seguida, iniciamos o ciclo de treinamento, no qual amostramos uma trajetória do conjunto de treinamento e o estado correspondente.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i <= 0) { iter--; continue; } state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum()==0) { iter--; continue; } bState.AssignArray(state);
Neste ponto, codificamos a etiqueta de data/hora, representando-a como um vetor de harmônicos sinusoidais de diferentes frequências.
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Com os dados coletados, usamos essa informação para gerar previsões do movimento futuro do preço. Essa operação é realizada por meio da chamada ao método de propagação para frente do Codificador previamente treinado.
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false,(CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Como mencionado antes, para treinar o Ator, precisamos primeiro treinar o Crítico. Extraímos as ações realizadas pelo Ator durante a coleta do conjunto de treinamento.
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); if(bActions.GetIndex() >= 0) bActions.BufferWrite();
E as fornecemos como entrada para o modelo do Crítico junto com o estado previsto do ambiente.
Critic.TrainMode(true); if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Vale destacar que, para o Crítico, fornecemos o estado latente do Codificador em vez dos dados de previsão do movimento futuro do preço e dos indicadores futuros gerados na saída do modelo. Isso ocorre porque, na saída do Codificador, adicionamos parâmetros estatísticos da série temporal original às previsões. Assim, antes de processar esses dados no modelo do Crítico, precisaríamos normalizá-los. Em vez disso, usamos o estado latente do Codificador, onde os valores previstos são mantidos sem os desvios característicos dos dados brutos.
Com a propagação para frente concluída, o Crítico gera uma avaliação das ações do Ator. Inicialmente, essa avaliação estará longe do verdadeiro retorno obtido pelo Ator durante a interação com o ambiente. Extraímos do conjunto de treinamento a recompensa real recebida pela ação realizada.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
E executamos a propagação reversa do Crítico para minimizar o erro na avaliação das ações.
O próximo passo é treinar a política do Ator. Para realizar a propagação para frente, precisamos primeiro preparar o tensor que descreve o estado da conta, extraído do conjunto de treinamento.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Depois, realizamos a propagação para frente do modelo, passando como parâmetros o vetor de descrição do estado da conta e o estado latente do Codificador.
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Naturalmente, como resultado da propagação para frente, o Ator gera um vetor de ações. Esse vetor, juntamente com o estado latente do Codificador, é fornecido como entrada ao Crítico.
Critic.TrainMode(false); if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
É importante destacar que, nesta etapa, desativamos o modo de treinamento do Crítico. Isso ocorre porque, neste caso, o modelo do Crítico será usado apenas para fornecer o gradiente de erro ao Ator.
A otimização dos parâmetros do Ator será realizada, por assim dizer, em duas direções. Primeiro, assumimos que em nosso conjunto de treinamento existem passagens bem-sucedidas, nas quais foi obtido lucro durante o período de aprendizado. Usaremos essas passagens como referência e, por meio de métodos de aprendizado supervisionado, ajustaremos a política do nosso Ator para se alinhar com essas ações.
if(Buffer[tr].States[0].rewards[0] > 0) if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Por outro lado, sabemos que haverá significativamente mais passagens com prejuízo do que com lucro. E, obviamente, não ignoraremos as informações que elas contêm. Concordemos que, no processo de treinamento da política do Ator, as passagens com prejuízo são tão úteis quanto as lucrativas. Se ajustamos a política do Ator com base nas passagens lucrativas, precisamos usar as passagens com prejuízo como um ponto de referência. Mas até que ponto e em que direção? Além disso, até mesmo em passagens com prejuízo, pode haver negociações que resultaram em lucro, e é desejável preservar essa informação. É aqui que o papel do Crítico no processo de treinamento da política do Ator se torna evidente.
A ideia é que, durante o treinamento do Crítico, seus parâmetros sejam ajustados para otimizar uma função que relaciona as ações do Ator, o estado do ambiente e o retorno obtido. Assim, se mantivermos o estado do ambiente constante e nos movemos na direção de maximizar o retorno, o gradiente do erro indicará a direção na qual o Agente deve ajustar suas ações para aumentar a recompensa esperada. É essa propriedade que aproveitamos.
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); }
Extraímos a avaliação atual das ações feita pelo Crítico. Aumentamos a previsão de lucro em 1% e, da mesma forma, reduzimos a previsão de prejuízo em 1%. Esses serão os nossos valores-alvo para este estágio. Passamos esses valores para a operação de propagação reversa do Crítico e, em seguida, do Ator.
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Lembro que, nesta etapa, desativamos o modo de treinamento do Crítico. Portanto, ele é usado apenas para transmitir o gradiente de erro ao Ator. Essa propagação reversa não ajusta os parâmetros do Crítico. O Ator, por outro lado, ajusta os parâmetros do modelo na direção de maximizar o retorno esperado.
Depois disso, só nos resta informar o usuário sobre o progresso do treinamento dos modelos e seguir para a próxima iteração do loop.
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Quando o processo de treinamento termina, limpamos o campo de comentários no gráfico do instrumento. Os resultados do treinamento são registrados no diário, e iniciamos o processo de finalização da execução do programa.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Com isso, concluímos a explicação dos algoritmos dos programas de treinamento de modelos. O código completo de todas as aplicações usadas na preparação deste artigo está disponível para consulta no anexo.
3. Coleta do conjunto de treinamento
O próximo passo, não menos importante, é a coleta de dados para o conjunto de treinamento. Vale mencionar que, para obter dados reais sobre a interação com o ambiente, usamos o testador de estratégias MetaTrader 5. Nele, realizamos simulações em dados históricos, e os resultados obtidos são gravados em um arquivo que compõe o conjunto de treinamento.
E é natural que, antes de começar o treinamento, surja a questão de onde conseguir passagens bem-sucedidas para o conjunto de treinamento. Devo dizer que existem algumas opções. Talvez a mais óbvia seja pegar o histórico e manualmente "lançar" negociações ideais. Sem dúvida, essa abordagem é válida. Mas é um trabalho manual. E, à medida que o conjunto de treinamento cresce, os custos de trabalho aumentam exponencialmente, assim como o tempo necessário para preparar o conjunto de treinamento. Além disso, o uso de trabalho manual inevitavelmente leva a erros atribuídos ao "fator humano". Eu, em meu trabalho, utilizo o framework Real-ORL para a coleta de dados primários, que já foi descrito em detalhes nesta série de artigos. O código do programa também está disponível no anexo, então não entraremos em detalhes aqui.
A coleção inicial do conjunto de treinamento oferece ao modelo uma primeira impressão do ambiente. Mas o mundo dos mercados financeiros é tão multifacetado que nenhum conjunto de treinamento pode replicá-lo completamente. Além disso, as correlações que o modelo constrói entre os indicadores analisados e as negociações lucrativas podem ser falsas ou incompletas, pois a amostra de treinamento apresentada pode não conter exemplos que revelem essas discrepâncias. Por isso, durante o treinamento, será necessário refinar o conjunto de treinamento. Desta vez, a abordagem para coletar informações adicionais será diferente.
A questão é que, neste estágio, precisamos otimizar a política aprendida do Ator. Para isso, precisamos de dados suficientemente próximos da trajetória da política atual do Ator, que permitam entender a direção do vetor de mudança na recompensa ao desviar ligeiramente as ações da política atual. Com essas informações, podemos aumentar a lucratividade da política atual, movendo-nos na direção que maximiza a recompensa.
Aqui também há opções. Os métodos podem variar dependendo de vários fatores, incluindo a arquitetura do modelo. Por exemplo, ao usar uma política estocástica, podemos simplesmente executar várias passagens do Ator com a política atual no testador de estratégias. A cabeça estocástica fará o trabalho por nós. A dispersão das ações aleatórias do Ator cobrirá o espaço de ações que nos interessa, permitindo que o modelo seja refinado com os dados atualizados. No caso de uma política estrita do Ator, em que o modelo estabelece ligações diretas entre o estado do ambiente e a ação, podemos adicionar algum ruído às ações do Agente para criar uma nuvem de ações ao redor da política atual do Ator.
Em ambos os casos, o modo de otimização lenta do testador de estratégias é útil para coletar dados adicionais para o conjunto de treinamento.
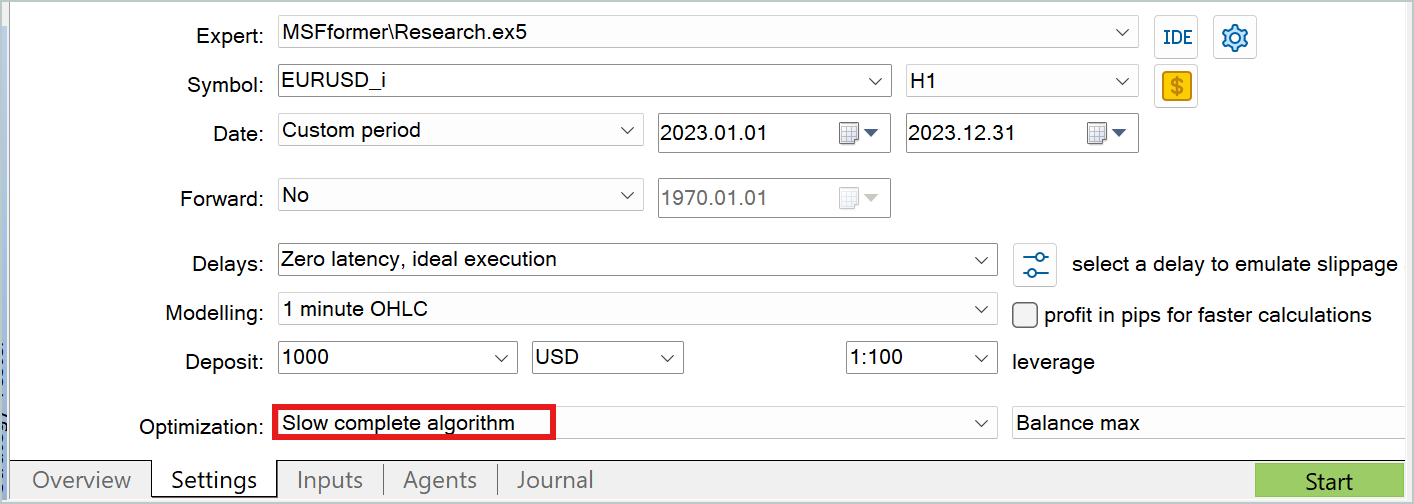
Permitam-me não entrar em detalhes sobre os programas de interação com o ambiente, pois já foram discutidos repetidamente nesta série de artigos. O código completo de todas as aplicações usadas na preparação deste artigo está disponível no anexo. Lá, você também encontrará o código dos programas de interação com o ambiente para sua consulta independente.
4. Treinamento e Teste dos Modelos
Após revisar os algoritmos de todos os programas usados no treinamento dos modelos, passamos agora ao processo em si. Treinaremos os modelos apresentados em dados históricos reais do instrumento EURUSD no timeframe H1. Como período de treinamento, utilizamos todo o ano de 2023.
Nesse intervalo histórico, coletamos o conjunto de treinamento inicial, conforme discutido anteriormente. E usamos esse conjunto para treinar o Codificador do estado do ambiente. Como mencionado, o modelo do Codificador utiliza apenas dados históricos de movimento de preço e os valores dos indicadores analisados durante o treinamento. É evidente que esses dados são idênticos para todas as passagens em um intervalo histórico fixo. Portanto, neste estágio, não há necessidade de refinar o conjunto de treinamento. Assim, treinamos o modelo do Codificador no conjunto inicial até que obtenhamos o resultado desejado.
Durante o treinamento, monitoramos o erro de previsão. Interrompemos o treinamento quando o erro deixa de diminuir e suas variações permanecem dentro de um intervalo estreito.
Claro, estamos curiosos para ver o que a modelo aprendeu. Apesar de nosso objetivo principal ser treinar uma política lucrativa para o Ator. Ainda assim, não resisti à curiosidade e comparei as mudanças previstas com as mudanças reais de preço em um conjunto de dados aleatoriamente selecionado do conjunto de treinamento.
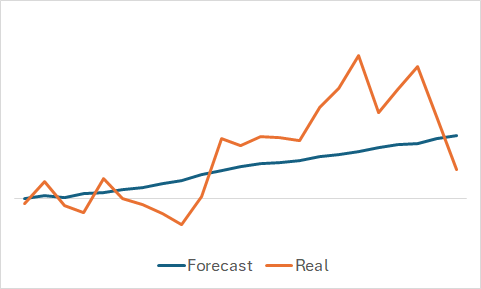
Como pode ser visto no gráfico, o modelo conseguiu captar a tendência principal do movimento de preço futuro.
O gráfico relativamente suave do movimento de preço previsto, com pequenas flutuações, pode levantar a suspeita de que o modelo captou uma tendência geral do conjunto de treinamento. E, possivelmente, repetirá esse padrão para todos os estados, independentemente dos dados reais. Para confirmar ou refutar essa hipótese, selecionamos outro estado do conjunto de treinamento e fazemos uma comparação semelhante entre o movimento de preço previsto e o real.
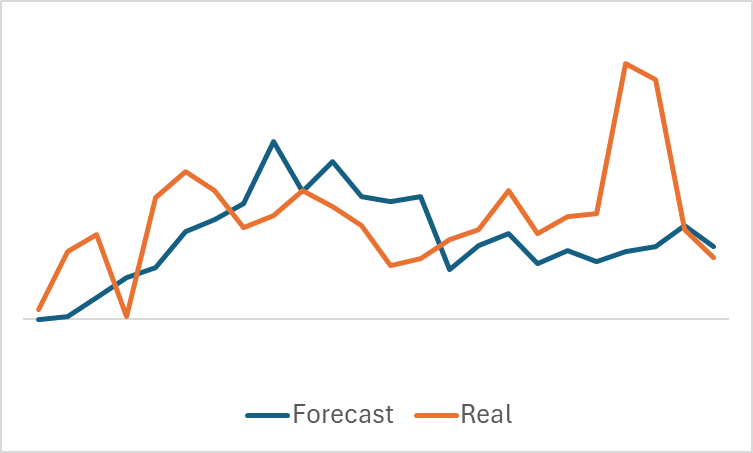
Aqui, observamos flutuações mais significativas nos valores previstos do movimento de preço. No entanto, essas previsões ainda permanecem razoavelmente próximas dos dados reais.
Depois de treinar o Codificador do estado do ambiente, passamos para a segunda etapa — o treinamento da política do Ator. Este processo é iterativo. A primeira iteração de treinamento é realizada com os dados do conjunto de treinamento inicial. Nessa etapa, damos ao modelo uma primeira noção do ambiente. E, graças às passagens lucrativas que conseguimos coletar usando o método Real-ORL, estabelecemos a base para nossa futura política.
Durante o treinamento dos modelos, assim como na primeira etapa, usamos o erro dos modelos como referência. E, nesta fase inicial, recomendo prestar atenção especial aos valores do erro do Crítico. Sim, precisamos de uma política do Ator que seja capaz de gerar lucro. Mas lembre-se do que discutimos anteriormente: para treinar o Ator, precisamos primeiro treinar o Crítico. Construir as dependências corretas dentro do Crítico é o que nos ajudará a ajustar a política do Ator na direção certa.
Quando o erro do Crítico estabilizar em um nível constante sem sinais de redução adicional, é necessário usar o testador de estratégias para coletar mais dados com o EA "Research.mq5", que recomendo executar no modo de otimização lenta.
Em seguida, realizamos o refinamento dos modelos do Ator e do Crítico. No início do processo de refinamento, pode-se observar um aumento temporário no erro de ambos os modelos, causado pelo processamento dos novos dados. No entanto, em breve você notará uma redução gradual do erro, atingindo novos mínimos.
Assim, repetimos as iterações de refinamento do conjunto de treinamento e o ajuste dos modelos.
Também quero lembrar que a arquitetura apresentada do Ator utiliza uma cabeça estocástica, o que implica alguma aleatoriedade nas ações. Portanto, ao testar a política treinada do Ator, é recomendado realizar várias passagens no intervalo de teste. Podemos considerar que a política do Ator foi treinada adequadamente se os desvios entre essas passagens forem insignificantes.
Para preparar este artigo, o teste do modelo treinado foi realizado em dados históricos de janeiro de 2024. Esse intervalo não fazia parte do conjunto de treinamento, o que significa que os dados são novos para o modelo. A proximidade entre os períodos de treinamento e teste garante a comparabilidade dos dados.
O processo de treinamento resultou em um modelo capaz de gerar lucro tanto no conjunto de treinamento quanto no período de teste.
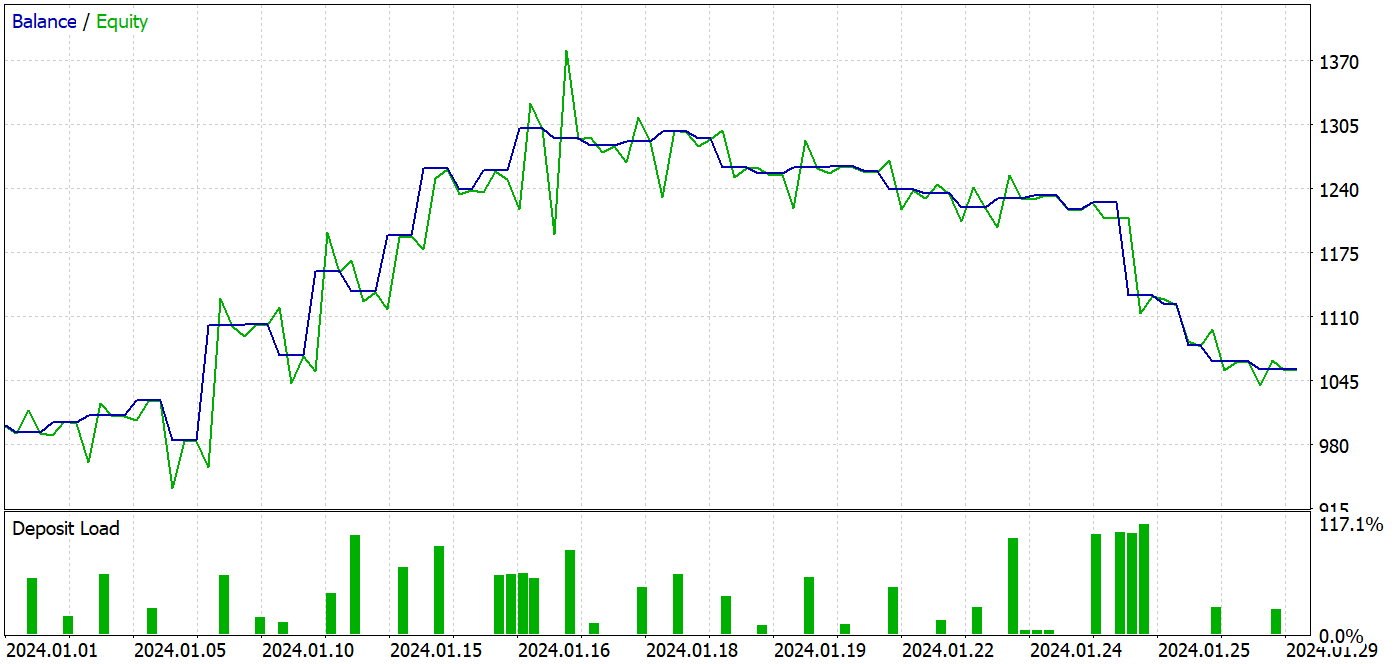
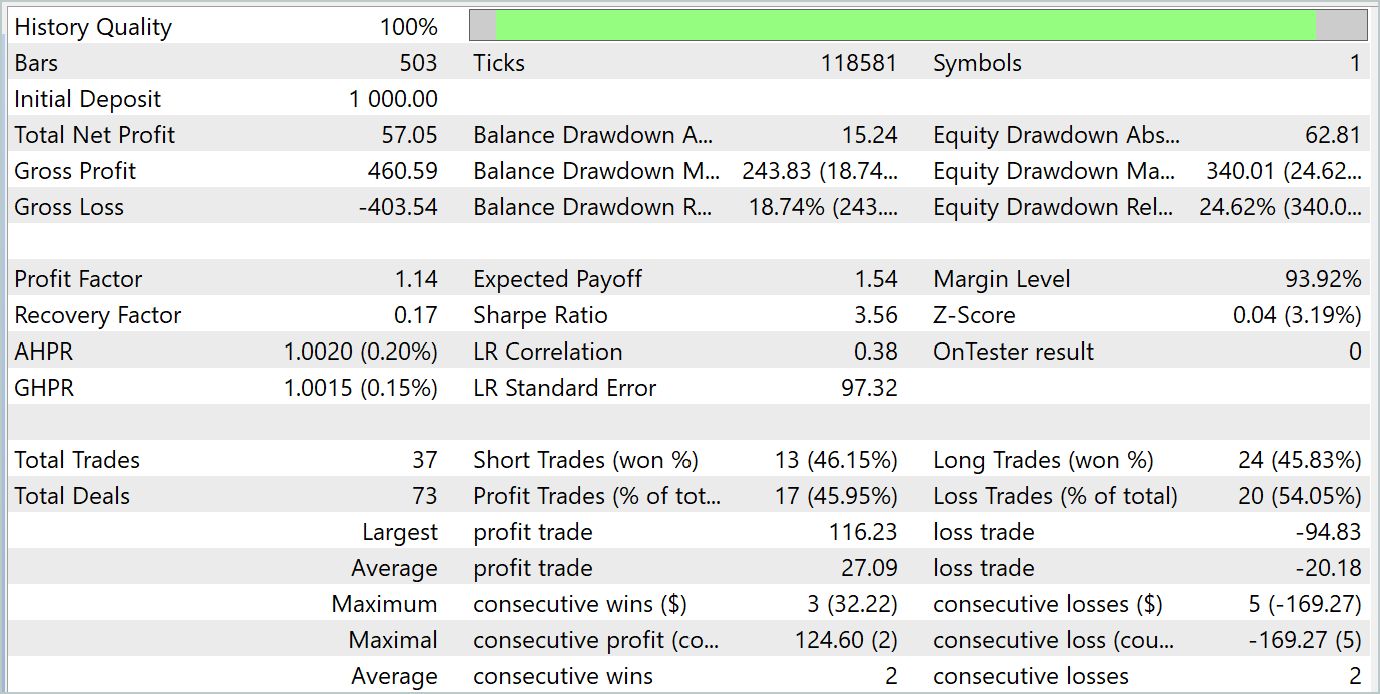
Durante o período de teste, o modelo realizou 37 operações, das quais 17 foram fechadas com lucro, representando quase 46%. É interessante observar que a proporção de operações lucrativas foi praticamente igual entre posições longas e curtas, com uma diferença de apenas 0,32%, o que pode ser considerado uma margem de erro devido ao número limitado de operações. O lucro máximo e o lucro médio por operação foram superiores às perdas correspondentes, o que permitiu ao modelo encerrar o período de teste com lucro. O fator de lucro foi de 1,14. No entanto, é preocupante que o lucro tenha sido obtido apenas na primeira metade do mês. Posteriormente, o saldo apresentou um movimento lateral, e a última semana foi marcada por uma perda.
Considerações finais
Nesta artigo, realizamos o treinamento e teste do modelo utilizando abordagens baseadas no método MSFformer. Os resultados dos testes foram promissores, indicando o potencial das abordagens propostas. Contudo, a queda no saldo na última semana do período de teste sugere que etapas adicionais de treinamento podem ser necessárias.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA de coleta de exemplos com o método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para o treinamento dos Modelos |
| 4 | StudyEncoder.mq5 | Expert Advisor | EA para o treinamento do Codificador |
| 5 | Test.mq5 | Expert Advisor | EA para testar o modelo |
| 6 | Trajectory.mqh | Biblioteca de classes | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classes | Biblioteca de classes para a criação de redes neurais |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código em OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/15171
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso