Redes neurais em trading: Superpoint Transformer (SPFormer)

Introdução
A segmentação de objetos é uma tarefa complexa de compreensão de cena, cujo objetivo não é apenas detectar objetos em uma nuvem de pontos esparsa, mas também fornecer uma máscara clara para cada objeto.
Os métodos modernos podem ser divididos em dois grupos:
- Baseados em suposições;
- Baseados em agrupamento.
Os métodos baseados em suposições tratam a segmentação de objetos 3D como um pipeline descendente. Primeiro, eles geram regiões candidatas e, em seguida, determinam as máscaras dos objetos nessas regiões. No entanto, esses métodos geralmente são ineficientes devido à esparsidade das nuvens de pontos. Em espaços 3D, o retângulo delimitador tem um alto grau de liberdade, o que aumenta a complexidade da aproximação. Além disso, os pontos geralmente existem apenas em partes da superfície do objeto, tornando os centros geométricos dos objetos difíceis de detectar. Propostas de regiões de baixa qualidade impactam a correspondência bipartida baseada em blocos, reduzindo ainda mais o desempenho do modelo.
Por outro lado, os métodos baseados em agrupamento utilizam um pipeline ascendente. Eles aprendem rótulos semânticos de pontos e deslocamento do centro de instâncias. Depois, utilizam os pontos deslocados e as previsões semânticas para agregar as instâncias. No entanto, esses métodos também possuem desvantagens. Eles dependem dos resultados da segmentação semântica, o que pode levar a previsões incorretas. Além disso, a etapa intermediária de agregação de dados aumenta o tempo de treinamento e inferência.
Para minimizar o impacto dessas limitações e aproveitar as vantagens de ambas as abordagens, os autores do estudo "Superpoint Transformer for 3D Scene Instance Segmentation" propuseram um novo método de segmentação de objetos 3D em duas etapas baseado no Superpoint Transformer (SPFormer). O SPFormer agrupa objetos potenciais ascendentes a partir de nuvens de pontos em superpoints e propõe instâncias por meio de vetores de consulta em um pipeline descendente.
Na etapa de agrupamento ascendente, uma 3D U-Net esparsa é utilizada para extrair objetos de baixo para cima, ponto a ponto. Um simples layer de pooling de pontos é proposto para agrupar objetos pontuais potenciais em superpoints. Os superpoints utilizam padrões geométricos para representar pontos vizinhos homogêneos. Os objetos potenciais obtidos permitem evitar a supervisão de objetos por meio de rótulos semânticos indiretos e rótulos de distância ao centro. Os autores do método consideram os superpoints como uma representação intermediária potencial da cena 3D e utilizam diretamente os rótulos das instâncias para treinar todo o modelo.
Na etapa de proposta descendente, é sugerido um novo decodificador Transformer com consultas. Os autores do método utilizam vetores de consulta treináveis para prever instâncias com base em funções potenciais de superpoint em um pipeline descendente. O vetor de consulta treinável pode capturar informações sobre a instância por meio do mecanismo de atenção cruzada aos superpoints. Com a ajuda dos vetores de consulta, que carregam informações sobre a instância e a função superpoint, o decodificador de consultas gera diretamente previsões de classe, estimativas e máscaras de instância. Além disso, com a correspondência bipartida baseada em máscaras de superpoint, o SPFormer pode realizar treinamento de ponta a ponta sem a etapa trabalhosa de agregação. O SPFormer também não requer pós-processamento, o que melhora ainda mais a velocidade do modelo.
1. Algoritmo SPFormer
A arquitetura do modelo SPFormer, proposta pelos autores, é logicamente dividida em blocos. Inicialmente, uma 3D U-Net esparsa é utilizada para extrair objetos pontuais ascendentes. Suponha que a nuvem de pontos original contenha N pontos. Cada ponto possui cores RGB e coordenadas XYZ. Os autores propõem voxelizar a nuvem de pontos para regularizar os dados brutos e utilizam um backbone no estilo U-Net, composto por convolução esparsa para extrair características pontuais P′. Ao contrário dos métodos baseados em agrupamento, a abordagem proposta não adiciona um ramo semântico extra.
Para criar um framework abrangente, os autores do SPFormer inserem diretamente as funções de pontos P' na camada de pooling de superpoint, com base em pontos previamente calculados. A camada de pooling Superpoint simplesmente obtém os objetos S por meio da média dos pontos dentro de cada Superpoint. Vale ressaltar que a camada de pooling Superpoint reduz de forma confiável a discretização da nuvem de pontos original, o que diminui significativamente os custos computacionais do processamento subsequente e otimiza as capacidades de representação de todo o modelo.
O decodificador de consultas consiste em dois ramos: Instance e Mask. No ramo de mascaramento, um perceptron multicamadas (MLP) é responsável por extrair características que auxiliam na geração da máscara 𝐒mask. O ramo Instance consiste em várias camadas do decodificador Transformer. Essas camadas decodificam vetores de consulta treináveis por meio da atenção cruzada aos superpoints.
Suponha que existam K vetores de consulta treináveis. Definimos previamente as propriedades dos vetores de consulta para cada camada do decodificador Transformer como Zl.
Devido à desordem e à incerteza quantitativa dos superpoints, os autores introduziram uma estrutura Transformer para lidar com dados de entrada de comprimento variável. As características potenciais dos superpoints e os vetores de consulta treináveis são usados como dados de entrada para o decodificador Transformer. A arquitetura detalhada da camada modificada do decodificador Transformer é ilustrada na figura abaixo.
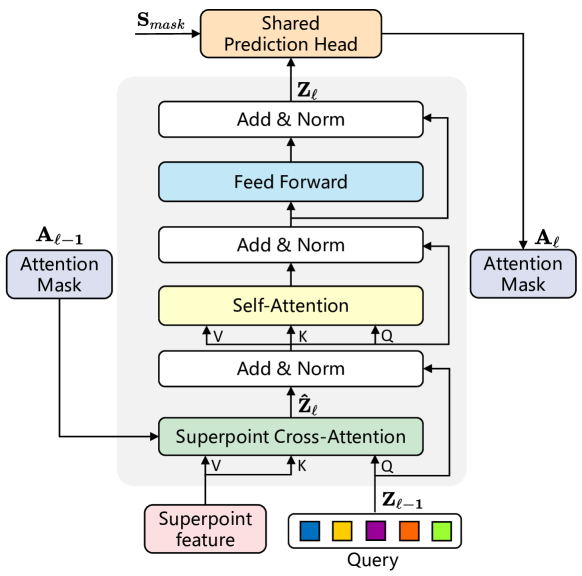
Os vetores de consulta são inicializados aleatoriamente antes do treinamento, e as informações sobre cada instância da nuvem de pontos só podem ser obtidas por meio da atenção cruzada aos superpoints. Portanto, a camada de decodificação do Transformer proposta inverte a ordem da camada Self-Attention e da camada Cross-Attention em relação ao decodificador padrão do Transformer. Além disso, como os dados de entrada são características potenciais dos Superpoints, os autores do método removem a codificação posicional.
Para capturar informações contextuais por meio do mecanismo de atenção cruzada ao Superpoint, são aplicadas máscaras de atenção Aij, que consideram o impacto do superpoint j na consulta i. Considerando as máscaras previstas dos Superpoints pela ramificação Mask Ml, as máscaras de atenção Superpoint Al são determinadas por um filtro limiar τ. Por experimentação, os autores do método definiram τ como 0,5.
Com a sobreposição das camadas do decodificador Transformer, as máscaras de atenção Superpoint Al restringem adaptativamente a atenção cruzada dentro da instância em primeiro plano.
Com a ajuda dos vetores de consulta Zl da ramificação Instance, os autores do método utilizam dois MLPs independentes para prever e classificar cada vetor de consulta e avaliar a qualidade das propostas. Em particular, eles adicionam uma previsão com probabilidade de “sem objeto” para atribuir uma confiabilidade razoável às propostas por meio da correspondência bipartida, tratando outras propostas como previsões negativas.
Além disso, o ranqueamento das propostas afeta significativamente os resultados da segmentação de instâncias. Na prática, a maioria das propostas será considerada como fundo devido ao estilo de correspondência um-para-um, o que leva a uma inconsistência na classificação de qualidade das propostas. Dessa forma, os autores do método desenvolveram uma ramificação de avaliação que estima a qualidade da previsão das máscaras dos Superpoints, permitindo corrigir esse viés.
Dado que os modelos baseados na arquitetura Transformer possuem uma convergência mais lenta, os autores alimentam cada saída da camada do decodificador Transformer para uma camada de previsão compartilhada para a geração de propostas. Durante o treinamento, eles atribuem uma confiança real a todas as saídas da camada de previsão compartilhada, independentemente da camada de entrada. Isso melhora o desempenho do modelo e aperfeiçoa a funcionalidade dos vetores de consulta, que são atualizados camada a camada.
Durante a inferência, ao receber uma nuvem de pontos original, o SPFormer prevê diretamente K objetos com classificação e suas respectivas máscaras superpoint. Os autores do método também obtêm a pontuação da máscara calculando a média da probabilidade dos superpoints acima de 0,5 em cada máscara. O SPFormer não utiliza supressão não máxima na pós-processamento, o que garante sua alta velocidade de inferência.
A visualização do método SPFormer feita pelos autores está apresentada abaixo.
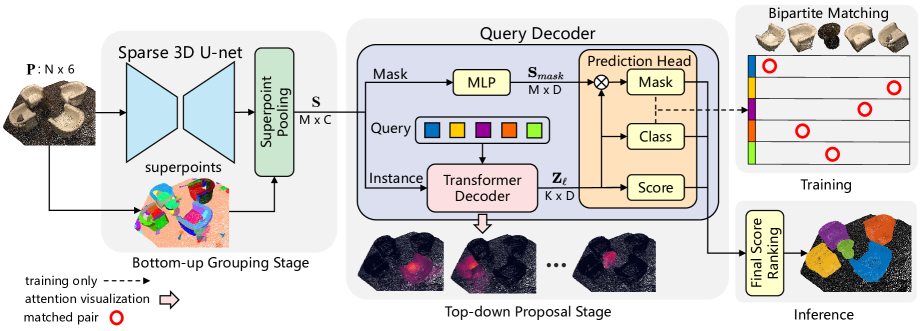
2. Implementação em MQL5
Após analisarmos os aspectos teóricos do método SPFormer, como de costume, passamos à parte prática do nosso artigo, onde implementamos nossa visão dos métodos propostos utilizando MQL5. E vale dizer que, hoje, teremos um grande volume de trabalho pela frente. Portanto, vamos direto ao ponto.
2.1 Expansão do programa OpenCL
Começamos nosso trabalho modernizando nosso programa OpenCL. Os autores do método SPFormer propuseram um novo algoritmo de mascaramento baseado em máscaras preditivas de objetos. A essência desse algoritmo está na correspondência de consultas individuais apenas com os Superpoints relevantes. Isso difere significativamente da abordagem anterior baseada na posição dos dados de entrada, conforme utilizada no Transformer vanilla. Assim, precisamos desenvolver novos kernels para Cross-Attention e propagação reversa. Primeiro, implementamos o kernel de propagação para frente MHMaskAttentionOut, cujo algoritmo será amplamente baseado no kernel do método vanilla. No entanto, faremos alterações para incorporar o novo algoritmo de mascaramento.
Nos parâmetros do kernel, assim como antes, recebemos ponteiros para os buffers globais das entidades Query, Key e Value, cujos valores foram gerados previamente. Também são especificados ponteiros para os buffers dos coeficientes de atenção e dos resultados. Além disso, adicionamos um ponteiro para o buffer global de mascaramento e um valor limiar para a máscara.
__kernel void MHMaskAttentionOut(__global const float *q, ///<[in] Matrix of Querys __global const float *kv, ///<[in] Matrix of Keys __global float *score, ///<[out] Matrix of Scores __global const float *mask, ///<[in] Mask Matrix __global float *out, ///<[out] Matrix of attention const int dimension, ///< Dimension of Key const int heads_kv, const float mask_level ) { //--- init const int q_id = get_global_id(0); const int k = get_global_id(1); const int h = get_global_id(2); const int qunits = get_global_size(0); const int kunits = get_global_size(1); const int heads = get_global_size(2);
Assim como antes, planejamos chamar o kernel em um espaço tridimensional de tarefas (Query, Key, Heads). Ao mesmo tempo, criaremos grupos de trabalho locais, permitindo que os diferentes threads compartilhem dados dentro de cada Query, no contexto das cabeças de atenção. No corpo do método, identificamos imediatamente o thread atual no espaço de tarefas e determinamos os parâmetros correspondentes.
Na próxima etapa, definimos os deslocamentos nos buffers de dados e armazenamos os valores obtidos em variáveis locais.
const int h_kv = h % heads_kv; const int shift_q = dimension * (q_id * heads + h); const int shift_k = dimension * (2 * heads_kv * k + h_kv); const int shift_v = dimension * (2 * heads_kv * k + heads_kv + h_kv); const int shift_s = kunits * (q_id * heads + h) + k;
Em seguida, calculamos a máscara relevante para o thread atual e outras constantes auxiliares.
const bool b_mask = (mask[shift_s] < mask_level); const uint ls = min((uint)get_local_size(1), (uint)LOCAL_ARRAY_SIZE); float koef = sqrt((float)dimension); if(koef < 1) koef = 1;
Criamos também um array na memória local para a troca de dados entre os threads dentro do grupo de trabalho.
__local float temp[LOCAL_ARRAY_SIZE];
Posteriormente, primeiro determinamos a soma dos valores exponenciais dos coeficientes de dependência dentro de um único Query. Para isso, estruturamos um laço para calcular sequencialmente as somas individuais e armazená-las no array local de dados.
//--- sum of exp uint count = 0; if(k < ls) { temp[k] = 0; do { if(b_mask || q_id >= (count * ls + k)) if((count * ls) < (kunits - k)) { float sum = 0; int sh_k = 2 * dimension * heads_kv * count * ls; for(int d = 0; d < dimension; d++) sum = q[shift_q + d] * kv[shift_k + d + sh_k]; sum = exp(sum / koef); if(isnan(sum)) sum = 0; temp[k] = temp[k] + sum; } count++; } while((count * ls + k) < kunits); } barrier(CLK_LOCAL_MEM_FENCE);
Depois, somamos todos os valores do array local.
do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Vale ressaltar que, ao somar localmente, levamos em consideração a máscara. Agora podemos calcular os valores normalizados dos coeficientes de atenção considerando o mascaramento.
//--- score float sum = temp[0]; float sc = 0; if(b_mask || q_id >= (count * ls + k)) if(sum != 0) { for(int d = 0; d < dimension; d++) sc = q[shift_q + d] * kv[shift_k + d]; sc = exp(sc / koef) / sum; if(isnan(sc)) sc = 0; } score[shift_s] = sc; barrier(CLK_LOCAL_MEM_FENCE);
Durante o cálculo dos coeficientes de atenção, zeramos os valores dos elementos mascarados. Assim, podemos utilizar o algoritmo vanilla para calcular os resultados do bloco Cross-Attention.
for(int d = 0; d < dimension; d++) { uint count = 0; if(k < ls) do { if((count * ls) < (kunits - k)) { float sum = kv[shift_v + d] * (count == 0 ? sc : score[shift_s + count * ls]); if(isnan(sum)) sum = 0; temp[k] = (count > 0 ? temp[k] : 0) + sum; } count++; } while((count * ls + k) < kunits); barrier(CLK_LOCAL_MEM_FENCE); //--- count = min(ls, (uint)kunits); do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- out[shift_q + d] = temp[0]; } }
A modernização do kernel de propagação reversa MHMaskAttentionInsideGradients é menos abrangente. Pode ser considerada uma modificação pontual. Isso ocorre porque a anulação dos coeficientes de dependência na propagação para frente nos permite usar o algoritmo vanilla para distribuir o gradiente do erro às entidades Query, Key e Value. No entanto, isso não nos permite propagar o gradiente do erro até a máscara. Portanto, ao algoritmo vanilla, adicionamos o gradiente de ajuste da máscara.
__kernel void MHMaskAttentionInsideGradients(__global const float *q, __global float *q_g, __global const float *kv, __global float *kv_g, __global const float *mask, __global float *mask_g, __global const float *scores, __global const float *gradient, const int kunits, const int heads_kv, const float mask_level ) { ........ ........ //--- Mask's gradient for(int k = q_id; k < kunits; k += qunits) { float m = mask[shift_s + k]; if(m < mask_level) mask_g[shift_s + k] = 0; else mask_g[shift_s + k] = 1 - m; } }
Vale destacar que buscamos normalizar as etiquetas de mascaramento para "1". E para as máscaras irrelevantes, zeramos o gradiente do erro, pois elas não influenciaram no resultado do modelo.
Com isso, concluímos nosso trabalho com o programa OpenCL. O código completo dos novos kernels pode ser encontrado no anexo.
2.2 Criação da classe do método SPFormer
Após finalizar a modernização do programa OpenCL, passamos a trabalhar na parte principal do código. Aqui, criaremos a nova classe CNeuronSPFormer, que herdará a funcionalidade base da camada totalmente conectada CNeuronBaseOCL. O escopo das modificações é tão grande que optei por não herdar os blocos de atenção cruzada anteriormente criados. A estrutura da nova classe é apresentada abaixo.
class CNeuronSPFormer : public CNeuronBaseOCL { protected: uint iWindow; uint iUnits; uint iHeads; uint iSPWindow; uint iSPUnits; uint iSPHeads; uint iWindowKey; uint iLayers; uint iLayersSP; //--- CLayer cSuperPoints; CLayer cQuery; CLayer cSPKeyValue; CLayer cMask; CArrayInt cScores; CLayer cMHCrossAttentionOut; CLayer cCrossAttentionOut; CLayer cResidual; CLayer cQKeyValue; CLayer cMHSelfAttentionOut; CLayer cSelfAttentionOut; CLayer cFeedForward; CBufferFloat cTempSP; CBufferFloat cTempQ; CBufferFloat cTempSelfKV; CBufferFloat cTempCrossKV; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *kv, const int scores, CNeuronBaseOCL *out, CNeuronBaseOCL *mask, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension, const float mask_level = 0.5f); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *kv, const int scores, CNeuronBaseOCL *out, CNeuronBaseOCL *mask, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension, const float mask_level = 0.5f); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSPFormer(void) {}; ~CNeuronSPFormer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSPFormer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Na estrutura da classe apresentada, observamos um grande número de variáveis e objetos aninhados, cujos nomes são semelhantes aos utilizados anteriormente na implementação das diferentes classes de atenção. Isso não é surpreendente. Vamos conhecer melhor o funcionamento de cada objeto durante a implementação.
Vale destacar que todos os objetos internos são declarados como estáticos, permitindo que o construtor e o destrutor da classe permaneçam vazios. A inicialização de todos os objetos herdados e declarados ocorre no método Init. Como você sabe, nos parâmetros desse método, recebemos as principais constantes que determinam a arquitetura do objeto a ser criado.
bool CNeuronSPFormer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
No corpo do método, chamamos imediatamente o método homônimo da classe pai, que é responsável pela inicialização dos objetos e variáveis herdadas.
Depois, armazenamos diretamente as constantes recebidas nas variáveis internas da classe.
iWindow = window; iUnits = units_count; iHeads = heads; iSPUnits = units_sp; iSPWindow = window_sp; iSPHeads = heads_sp; iWindowKey = window_key; iLayers = MathMax(layers, 1); iLayersSP = MathMax(layers_to_sp, 1);
O próximo passo é inicializar um pequeno MLP para gerar os vetores de consulta treináveis.
//--- Init Querys CNeuronBaseOCL *base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(iWindow * iUnits, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *buf = base.getOutput(); if(!buf || !buf.BufferInit(1, 1) || !buf.BufferWrite()) return false; if(!cQuery.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base.Init(0, 1, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cQuery.Add(base)) return false;
Em seguida, criamos o bloco de extração de Superpoint. Aqui, geramos um bloco composto por quatro camadas neurais sequenciais, cuja arquitetura é adaptada ao tamanho da sequência de entrada. Se o comprimento da sequência na entrada da camada for múltiplo de 2, utilizamos um bloco convolucional com conexão residual, que reduz o tamanho da sequência pela metade.
//--- Init SuperPoints for(int r = 0; r < 4; r++) { if(iSPUnits % 2 == 0) { iSPUnits /= 2; CResidualConv *residual = new CResidualConv(); if(!residual) return false; if(!residual.Init(0, r+2, OpenCL, 2*iSPWindow, iSPWindow, iSPUnits, optimization, iBatch)) return false; if(!cSuperPoints.Add(residual)) return false; }
Caso contrário, usamos uma simples camada convolucional, que analisa dois elementos vizinhos da sequência com um passo de um elemento. Assim, o comprimento da sequência é reduzido em 1.
else { iSPUnits--; CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv.Init(0, r+2, OpenCL, 2*iSPWindow, iSPWindow, iSPWindow, iSPUnits, 1, optimization, iBatch)) return false; if(!cSuperPoints.Add(conv)) return false; } }
Neste estágio, concluímos a inicialização dos objetos de pré-processamento dos dados. Agora, passamos para a inicialização das camadas internas do decodificador modificado Transformer. Para isso, criamos variáveis locais para armazenar temporariamente os ponteiros dos objetos e estruturamos um laço com um número de iterações correspondente à quantidade especificada de camadas internas do decodificador.
CNeuronConvOCL *conv = NULL; CNeuronTransposeOCL *transp = NULL; for(uint l = 0; l < iLayers; l++) { //--- Cross Attention //--- Query conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 6, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false; //--- Key-Value if(l % iLayersSP == 0) { conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 7, OpenCL, iSPWindow, iSPWindow, iWindowKey * iSPHeads, iSPUnits, 1, optimization, iBatch)) return false; if(!cSPKeyValue.Add(conv)) return false; }
Primeiro, inicializamos as camadas internas para a geração das entidades Query, Key e Value. O tensor Key-Value é gerado apenas quando necessário.
Em seguida, adicionamos a camada de geração de máscaras. Para isso, utilizamos uma camada convolucional, que gera os coeficientes de mascaramento para todas as consultas de cada elemento da sequência Superpoint. E, como estamos empregando um algoritmo de atenção multi-head, também geramos os coeficientes para cada cabeça de atenção. Para normalizar os valores, utilizamos a função de ativação sigmoide.
//--- Mask conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 8, OpenCL, iSPWindow, iSPWindow, iUnits * iHeads, iSPUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(SIGMOID); if(!cMask.Add(conv)) return false;
Aqui, é importante notar que, ao realizar a atenção cruzada, precisaremos dos coeficientes de atenção das consultas para os Superpoints. Portanto, realizamos a transposição do tensor de mascaramento obtido.
transp = new CNeuronTransposeOCL(); if(!transp) return false; if(!transp.Init(0, l * 14 + 9, OpenCL, iSPUnits, iUnits * iHeads, optimization, iBatch)) return false; if(!cMask.Add(transp)) return false;
O próximo passo é preparar os objetos para armazenar os resultados da atenção cruzada. Primeiro, para a atenção multi-head.
//--- MH Cross Attention out base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 10, OpenCL, iWindow * iUnits * iHeads, optimization, iBatch)) return false; if(!cMHCrossAttentionOut.Add(base)) return false;
Depois, para os valores comprimidos.
//--- Cross Attention out conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 11, OpenCL, iWindow * iHeads, iWindow * iHeads, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cCrossAttentionOut.Add(conv)) return false;
Também adicionamos uma camada para somar com os dados de entrada.
//--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 12, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false;
Em seguida, temos o bloco Self-Attention. Aqui, também geramos as entidades Query, Key e Value, mas agora com base nos resultados da atenção cruzada.
//--- Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l*14+13, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false; //--- Key-Value if(l % iLayersSP == 0) { conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l*14+14, OpenCL, iWindow, iWindow, iWindowKey * iSPHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQKeyValue.Add(conv)) return false; }
Adicionamos os objetos para armazenar os resultados da atenção multi-head e os valores comprimidos.
//--- MH Attention out base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 15, OpenCL, iWindow * iUnits * iHeads, optimization, iBatch)) return false; if(!cMHSelfAttentionOut.Add(base)) return false; //--- Attention out conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 16, OpenCL, iWindow * iHeads, iWindow * iHeads, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cSelfAttentionOut.Add(conv)) return false;
Adicionamos ainda uma camada de soma com os resultados da atenção cruzada.
//--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 17, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false;
E incluímos o bloco FeedForward com conexão residual.
//--- FeedForward conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 18, OpenCL, iWindow, iWindow, iWindow * 4, iUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(LReLU); if(!cFeedForward.Add(conv)) return false; conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 19, OpenCL, iWindow * 4, iWindow * 4, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cFeedForward.Add(conv)) return false; //--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 20, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false; if(!base.SetGradient(conv.getGradient())) return false;
Vale destacar que, para evitar operações desnecessárias de cópia de dados, combinamos os buffers de gradientes de erro da última camada do bloco FeedForward e da camada de conexão residual. Realizamos a mesma operação para os buffers de resultados e os gradientes de erro de nível superior na última camada interna.
if(l == (iLayers - 1)) { if(!SetGradient(conv.getGradient())) return false; if(!SetOutput(base.getOutput())) return false; } }
É importante ressaltar que, durante a inicialização dos objetos, não criamos buffers de dados para os coeficientes de atenção. A criação desses buffers e a inicialização dos objetos internos foram delegadas a um método separado.
//--- SetOpenCL(OpenCL); //--- return true; }
Após a inicialização dos objetos internos, passamos à construção dos métodos de propagação para frente. O algoritmo dos métodos que chamam os kernels criados acima será deixado para estudo independente, pois não apresenta grande novidade. Nos concentraremos apenas no algoritmo do método de nível superior feedForward, onde estruturamos claramente a sequência de ações do SPFormer.
bool CNeuronSPFormer::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *superpoints = NeuronOCL; CNeuronBaseOCL *neuron = NULL, *inputs = NULL, *q = NULL, *kv_cross = NULL, *kv_self = NULL;
Nos parâmetros do método, recebemos um ponteiro para o objeto de dados de entrada. No corpo do método, declaramos várias variáveis locais para armazenar temporariamente os ponteiros dos objetos.
Em seguida, processamos os dados de entrada por meio do modelo de extração de Superpoint.
//--- Superpoints for(int l = 0; l < cSuperPoints.Total(); l++) { neuron = cSuperPoints[l]; if(!neuron || !neuron.FeedForward(superpoints)) return false; superpoints = neuron; }
Geramos o vetor de consultas.
//--- Query neuron = cQuery[1]; if(!neuron || !neuron.FeedForward(cQuery[0])) return false;
Com isso, a etapa preparatória está concluída, e iniciamos um laço para percorrer as camadas internas do decodificador.
inputs = neuron; for(uint l = 0; l < iLayers; l++) { //--- Cross Attentionn q = cQuery[l * 2 + 2]; if(!q || !q.FeedForward(inputs)) return false; if((l % iLayersSP) == 0) { kv_cross = cSPKeyValue[l / iLayersSP]; if(!kv_cross || !kv_cross.FeedForward(superpoints)) return false; }
Primeiro, preparamos as entidades Query, Key e Value.
Geramos as máscaras.
neuron = cMask[l * 2]; if(!neuron || !neuron.FeedForward(superpoints)) return false; neuron = cMask[l * 2 + 1]; if(!neuron || !neuron.FeedForward(cMask[l * 2])) return false;
Executamos o algoritmo de atenção cruzada levando o mascaramento em consideração.
if(!AttentionOut(q, kv_cross, cScores[l * 2], cMHCrossAttentionOut[l], neuron, iUnits, iHeads, iSPUnits, iSPHeads, iWindowKey)) return false;
Reduzimos os resultados da atenção multi-head ao tamanho do tensor de consultas.
neuron = cCrossAttentionOut[l]; if(!neuron || !neuron.FeedForward(cMHCrossAttentionOut[l])) return false;
Depois, realizamos a soma e a normalização dos dados provenientes dos dois fluxos de informação.
q = inputs; inputs = cResidual[l * 3]; if(!inputs || !SumAndNormilize(q.getOutput(), neuron.getOutput(), inputs.getOutput(), iWindow, true, 0, 0, 0, 1)) return false;
Após o bloco Cross-Attention, estruturamos o algoritmo de Self-Attention. Aqui, geramos novamente as entidades Query, Key e Value, mas agora com base nos resultados da atenção cruzada.
//--- Self-Attention q = cQuery[l * 2 + 3]; if(!q || !q.FeedForward(inputs)) return false; if((l % iLayersSP) == 0) { kv_self = cQKeyValue[l / iLayersSP]; if(!kv_self || !kv_self.FeedForward(inputs)) return false; }
Nesta etapa, não utilizamos mascaramento. Portanto, ao chamar o método de atenção, passamos NULL em vez do objeto de máscaras.
if(!AttentionOut(q, kv_self, cScores[l * 2 + 1], cMHSelfAttentionOut[l], NULL, iUnits, iHeads, iUnits, iHeads, iWindowKey)) return false;
Os resultados da atenção multi-head são reduzidos ao tamanho do tensor de consultas.
neuron = cSelfAttentionOut[l]; if(!neuron || !neuron.FeedForward(cMHSelfAttentionOut[l])) return false;
Depois, somamos ao vetor de resultados da atenção cruzada e normalizamos os dados.
q = inputs; inputs = cResidual[l * 3 + 1]; if(!inputs || !SumAndNormilize(q.getOutput(), neuron.getOutput(), inputs.getOutput(), iWindow, true, 0, 0, 0, 1)) return false;
Em seguida, de forma análoga ao Transformer vanilla, transmitimos os dados pelo bloco FeedForward. Por fim, avançamos para a próxima iteração do laço de percorrimento das camadas internas.
//--- FeedForward neuron = cFeedForward[l * 2]; if(!neuron || !neuron.FeedForward(inputs)) return false; neuron = cFeedForward[l * 2 + 1]; if(!neuron || !neuron.FeedForward(cFeedForward[l * 2])) return false; q = inputs; inputs = cResidual[l * 3 + 2]; if(!inputs || !SumAndNormilize(q.getOutput(), neuron.getOutput(), inputs.getOutput(), iWindow, true, 0, 0, 0, 1)) return false; } //--- return true; }
Observe que, antes de passar para a próxima iteração do laço, armazenamos na variável inputs o ponteiro para o último objeto da camada interna atual.
Após concluir com sucesso todas as iterações do laço de percorrimento das camadas internas do decodificador, retornamos à função chamadora o resultado lógico da execução do método.
O próximo passo é construir os métodos de propagação reversa. Nosso maior interesse está no método de distribuição do gradiente do erro para todos os elementos do modelo, de acordo com sua influência no resultado final do calcInputGradients.
bool CNeuronSPFormer::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Nos parâmetros desse método, recebemos um ponteiro para o objeto da camada neural anterior, que forneceu os dados de entrada durante a propagação para frente. Agora, precisamos transmitir a esse objeto o gradiente do erro de acordo com a influência dos dados de entrada no resultado do modelo.
No corpo do método, verificamos imediatamente a validade do ponteiro recebido, pois, caso contrário, toda a execução subsequente do método não faria sentido.
Em seguida, declaramos várias variáveis locais para armazenar temporariamente os ponteiros dos objetos.
CNeuronBaseOCL *superpoints = cSuperPoints[cSuperPoints.Total() - 1]; CNeuronBaseOCL *neuron = NULL, *inputs = NULL, *q = NULL, *kv_cross = cSPKeyValue[cSPKeyValue.Total() - 1], *kv_self = cQKeyValue[cQKeyValue.Total() - 1];
Zeramos os buffers temporários de armazenamento de dados intermediários.
if(!cTempSP.Fill(0) || !cTempSelfKV.Fill(0) || !cTempCrossKV.Fill(0)) return false;
Depois, organizamos um laço de percorrimento reverso das camadas internas do decodificador.
for(int l = int(iLayers - 1); l >= 0; l--) { //--- FeedForward neuron = cFeedForward[l * 2]; if(!neuron || !neuron.calcHiddenGradients(cFeedForward[l * 2 + 1])) return false;
Como você deve lembrar, durante a inicialização do objeto da classe, realizamos a substituição dos ponteiros dos buffers de gradientes de erro de nível superior e da camada de conexão residual pelo último bloco FeedForward. Isso nos permite iniciar a distribuição do gradiente do erro a partir do bloco FeedForward, ignorando a transferência de dados do buffer de gradientes de erro de nível superior e da camada de conexão residual para a última camada do bloco FeedForward.
Depois, propagamos o gradiente do erro até a camada de conexão residual do bloco Self-Attention.
neuron = cResidual[l * 3 + 1]; if(!neuron || !neuron.calcHiddenGradients(cFeedForward[l * 2])) return false;
A seguir, somamos o gradiente do erro proveniente dos dois fluxos de informação e o transmitimos para a camada de resultados do Self-Attention.
if(!SumAndNormilize(((CNeuronBaseOCL*)cResidual[l * 3 + 2]).getGradient(), neuron.getGradient(), ((CNeuronBaseOCL*)cSelfAttentionOut[l]).getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
Distribuímos o gradiente do erro entre as cabeças de atenção.
//--- Self-Attention neuron = cMHSelfAttentionOut[l]; if(!neuron || !neuron.calcHiddenGradients(cSelfAttentionOut[l])) return false;
Obtemos os ponteiros para os buffers das entidades Query, Key e Value do bloco Self-Attention. Se necessário, zeramos o buffer de acumulação de valores intermediários.
q = cQuery[l * 2 + 3]; if(((l + 1) % iLayersSP) == 0) { kv_self = cQKeyValue[l / iLayersSP]; if(!kv_self || !cTempSelfKV.Fill(0)) return false; }
E então transmitimos o gradiente do erro para essas entidades, de acordo com a influência dos resultados do modelo.
if(!AttentionInsideGradients(q, kv_self, cScores[l * 2 + 1], neuron, NULL, iUnits, iHeads, iUnits, iHeads, iWindowKey)) return false;
Vale lembrar que permitimos a utilização de um único tensor Key-Value para várias camadas internas do decodificador. Portanto, dependendo do índice da camada interna atual, somamos o valor obtido ao gradiente do erro previamente acumulado no buffer temporário de dados ou no buffer de gradientes da camada correspondente Key-Value.
if(iLayersSP > 1) { if((l % iLayersSP) == 0) { if(!SumAndNormilize(kv_self.getGradient(), GetPointer(cTempSelfKV), kv_self.getGradient(), iWindowKey, false, 0, 0, 0, 1)) return false; } else { if(!SumAndNormilize(kv_self.getGradient(), GetPointer(cTempSelfKV), GetPointer(cTempSelfKV), iWindowKey, false, 0, 0, 0, 1)) return false; } }
Agora, propagamos o gradiente do erro até a camada de conexão residual do bloco de atenção cruzada. Primeiro, transmitimos o gradiente do erro para a entidade Query.
inputs = cResidual[l * 3]; if(!inputs || !inputs.calcHiddenGradients(q, NULL)) return false;
Depois, se necessário, adicionamos o gradiente do erro do fluxo de informação Key-Value.
if((l % iLayersSP) == 0) { CBufferFloat *temp = inputs.getGradient(); if(!inputs.SetGradient(GetPointer(cTempQ), false)) return false; if(!inputs.calcHiddenGradients(kv_self, NULL)) return false; if(!SumAndNormilize(temp, GetPointer(cTempQ), temp, iWindow, false, 0, 0, 0, 1)) return false; if(!inputs.SetGradient(temp, false)) return false; }
A seguir, adicionamos o gradiente do erro do fluxo de conexão residual do bloco Self-Attention e transmitimos o valor obtido para o bloco de atenção cruzada.
if(!SumAndNormilize(((CNeuronBaseOCL*)cSelfAttentionOut[l]).getGradient(), inputs.getGradient(), ((CNeuronBaseOCL*)cCrossAttentionOut[l]).getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
Agora, precisamos propagar o gradiente do erro pelo bloco de Cross-Attention. Primeiro, distribuímos o gradiente do erro entre as cabeças de atenção.
//--- Cross Attention neuron = cMHCrossAttentionOut[l]; if(!neuron || !neuron.calcHiddenGradients(cCrossAttentionOut[l])) return false;
Assim como no caso do Self-Attention, obtemos ponteiros para os objetos das entidades Query, Key e Value.
q = cQuery[l * 2 + 2]; if(((l + 1) % iLayersSP) == 0) { kv_cross = cSPKeyValue[l / iLayersSP]; if(!kv_cross || !cTempCrossKV.Fill(0)) return false; }
Passamos o gradiente do erro pelo bloco de atenção. No entanto, neste caso, adicionamos um ponteiro para o objeto de mascaramento.
if(!AttentionInsideGradients(q, kv_cross, cScores[l * 2], neuron, cMask[l * 2 + 1], iUnits, iHeads, iSPUnits, iSPHeads, iWindowKey)) return false;
O gradiente do erro da entidade Query é transmitido para a camada anterior do decodificador ou para o vetor de consultas. A escolha do objeto depende da camada atual do decodificador.
inputs = (l == 0 ? cQuery[1] : cResidual[l * 3 - 1]); if(!inputs.calcHiddenGradients(q, NULL)) return false;
Também adicionamos o gradiente do erro do fluxo de informação da conexão residual.
if(!SumAndNormilize(inputs.getGradient(), ((CNeuronBaseOCL*)cCrossAttentionOut[l]).getGradient(), inputs.getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
Neste ponto, concluímos a transmissão de dados através da estrutura do vetor de consultas. No entanto, ainda precisamos propagar o gradiente do erro pela estrutura do Superpoint. Aqui, verificamos primeiro a necessidade de transmissão de dados a partir do tensor Key-Value. Se necessário, os valores obtidos são adicionados ao buffer do gradiente do erro previamente acumulado.
if((l % iLayersSP) == 0) { if(!superpoints.calcHiddenGradients(kv_cross, NULL)) return false; if(!SumAndNormilize(superpoints.getGradient(), GetPointer(cTempSP), GetPointer(cTempSP), iSPWindow, false, 0, 0, 0, 1)) return false; }
Depois, distribuímos o gradiente do erro do modelo de geração de máscaras.
neuron = cMask[l * 2]; if(!neuron || !neuron.calcHiddenGradients(cMask[l * 2 + 1]) || !DeActivation(neuron.getOutput(), neuron.getGradient(), neuron.getGradient(), neuron.Activation())) return false; if(!superpoints.calcHiddenGradients(neuron, NULL)) return false;
O valor obtido também é somado ao gradiente do erro previamente acumulado. Mas aqui é importante considerar a camada atual do decodificador.
if(l == 0) { if(!SumAndNormilize(superpoints.getGradient(), GetPointer(cTempSP), superpoints.getGradient(), iSPWindow, false, 0, 0, 0, 1)) return false; } else if(!SumAndNormilize(superpoints.getGradient(), GetPointer(cTempSP), GetPointer(cTempSP), iSPWindow, false, 0, 0, 0, 1)) return false; }
No caso da primeira camada do decodificador (ou seja, a última iteração do laço), o gradiente acumulado é armazenado no buffer da última camada do modelo Superpoint. Caso contrário, acumulamos o gradiente do erro no buffer de armazenamento temporário de dados.
E passamos para a próxima iteração do nosso laço de propagação reversa pelas camadas internas do decodificador.
Depois que o gradiente do erro percorreu todas as camadas internas do decodificador Transformer, ainda precisamos distribuí-lo pelas camadas do modelo Superpoint. Aqui, temos uma estrutura linear de modelo. Portanto, basta organizarmos um laço de propagação reversa pelas camadas desse modelo.
for(int l = cSuperPoints.Total() - 2; l >= 0; l--) { superpoints = cSuperPoints[l]; if(!superpoints || !superpoints.calcHiddenGradients(cSuperPoints[l + 1])) return false; }
Ao finalizar esse processo, transmitimos o gradiente do erro para a camada de dados de entrada do modelo Superpoint e retornamos o resultado lógico da execução do método para a função chamadora.
if(!NeuronOCL.calcHiddenGradients(superpoints, NULL)) return false; //--- return true; }
Neste estágio, concluímos a implementação do processo de distribuição do gradiente do erro para todos os objetos internos e os dados de entrada, conforme sua influência no resultado final do modelo. Agora, precisamos otimizar os parâmetros treináveis do modelo para minimizar o erro geral. Essas operações são realizadas no método updateInputWeights.
Vale mencionar que todos os parâmetros treináveis do modelo são armazenados dentro dos objetos internos da nossa classe. O algoritmo de otimização desses parâmetros já está implementado nesses objetos. Portanto, dentro do método de atualização de parâmetros, basta chamarmos sequencialmente os métodos correspondentes dos objetos internos. Sugiro que você estude esse método por conta própria. Lembro que o código completo da nossa nova classe e todos os seus parâmetros podem ser encontrados no anexo.
A arquitetura dos modelos treináveis, bem como todos os programas de treinamento e interação com o ambiente, foram completamente baseados em trabalhos anteriores. Foram feitas apenas pequenas alterações pontuais na arquitetura do modelo do Codificador. Sugiro que você as analise de forma independente. O código completo de todas as classes e programas utilizados na preparação deste artigo está incluído no anexo. Agora chegamos à etapa final do nosso trabalho — o treinamento dos modelos e a avaliação dos resultados obtidos.
3. Testes
Neste artigo, realizamos um extenso trabalho de implementação da nossa visão dos métodos propostos pelos autores do SPFormer. Agora, chegamos à fase de treinamento dos modelos e testes da política aprendida pelo Ator com dados históricos reais.
Para o treinamento dos modelos, utilizamos dados históricos reais do ativo EURUSD ao longo de todo o ano de 2023, no time frame H1. Os parâmetros de todos os indicadores analisados foram mantidos como padrão.
O algoritmo de treinamento dos modelos foi baseado em artigos anteriores, juntamente com os programas utilizados para treinamento e testes.
O teste da política treinada do Ator foi realizado no testador de estratégias do MetaTrader 5, utilizando dados históricos reais de janeiro de 2024, mantendo todos os demais parâmetros inalterados. Os resultados dos testes estão apresentados abaixo.
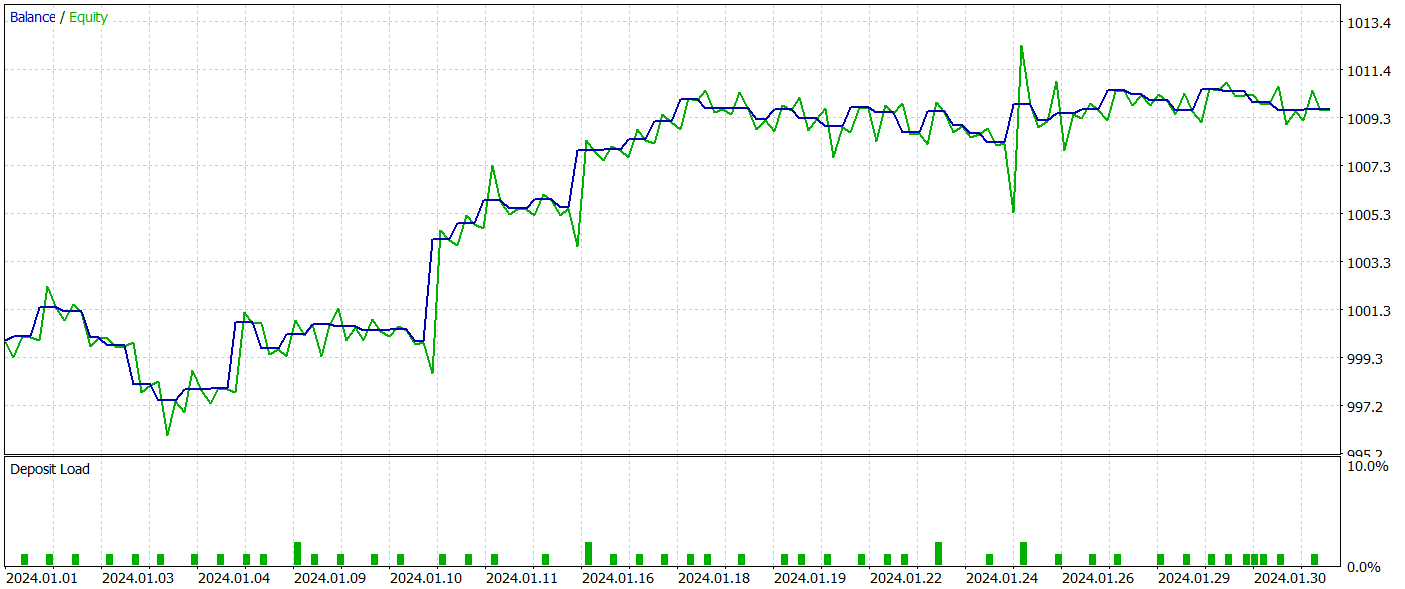
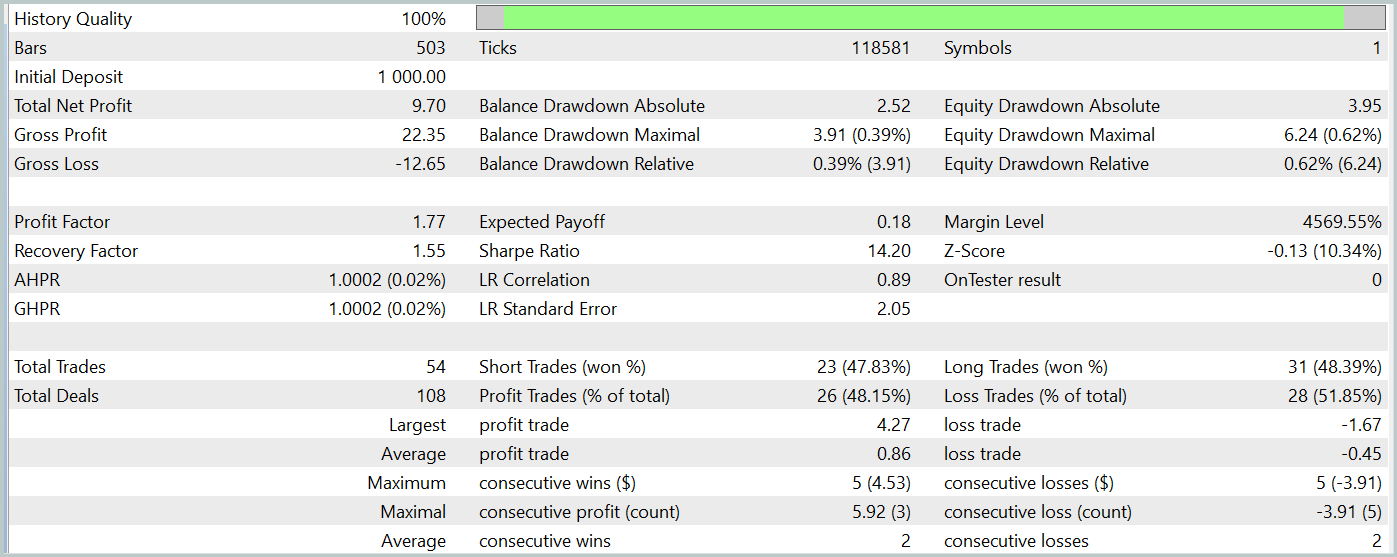
Durante o período de testes, o modelo realizou 54 operações, das quais 26 foram encerradas com lucro. Isso representa 48% de todas as operações realizadas. Além disso, a média dos trades lucrativos foi o dobro da média dos trades perdedores. Esse fator permitiu que o modelo obtivesse lucro no período de teste.
No entanto, vale ressaltar que a quantidade limitada de operações durante o período de teste não permite avaliar a estabilidade do modelo em períodos mais longos.
Considerações finais
O método SPFormer pode ser adaptado para aplicações no trading, especialmente para segmentação de dados sobre a situação atual do mercado e previsão de sinais de negociação. Diferentemente de modelos tradicionais, que frequentemente dependem de etapas intermediárias e podem perder precisão devido a ruídos nos dados, esse método poderia trabalhar diretamente com os dados Superpoint. O uso de transformadores para previsão de padrões de mercado evitaria a necessidade de processamentos intermediários complexos, aumentando tanto a precisão quanto a velocidade na tomada de decisões de trading.
Na parte prática, apresentamos nossa visão da implementação dos métodos propostos utilizando MQL5. Treinamos modelos utilizando os métodos descritos e avaliamos sua eficácia com dados históricos reais. Os resultados dos testes indicam que o modelo conseguiu obter lucro, o que sugere potencial para a aplicação desses métodos. No entanto, as implementações apresentadas no artigo são apenas demonstrativas da tecnologia. Antes de utilizar o modelo em mercados reais, é essencial realizar um treinamento em períodos mais longos e conduzir testes aprofundados.
Referências Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento de Modelos |
| 4 | Test.mq5 | Expert Advisor | EA para testar o modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/15928
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Amigo, isso é muito interessante, mas muito avançado para mim!
Obrigado por compartilhar, estou aprendendo passo a passo.