
Teoria das Categorias em MQL5 (Parte 19): Indução do quadrado de naturalidade
Introdução:
Nesta série de artigos, exploramos a aplicação da teoria das categorias para a classificação de dados discretos e, em vários exemplos, mostramos como algoritmos de trading, principalmente aqueles que gerenciam trailing stops, mas também aqueles que controlam sinais de entrada e o tamanho da posição, podem ser integrados de forma orgânica em um EA. O assistente MQL5 no IDE foi muito útil para essa tarefa, pois todo o código-fonte comum deve ser criado e testado com a ajuda dele.
Neste artigo, vamos explorar como usar os quadrados de naturalidade, um conceito que introduzimos no artigo anterior. Veremos a potencial utilidade desse recurso utilizando um exemplo de três pares de moedas que podem ser associados por operações de arbitragem. Assim, buscaremos classificar os dados de mudança de preço de um dos pares e avaliar se é possível desenvolver um algoritmo voltado para os sinais de entrada desse par.
Os quadrados de naturalidade são uma extensão das transformações naturais para um diagrama comutativo. Assim, se tivermos duas categorias separadas com mais de um funtor entre elas, poderemos avaliar a relação entre dois ou mais objetos em uma categoria de codomínio e usar essa análise não apenas para relacionar com outras categorias semelhantes, mas também para fazer previsões dentro da categoria observada se os objetos estiverem em uma série temporal.
Entendendo a configuração:
As duas categorias apresentadas neste artigo terão uma estrutura semelhante à que vimos no artigo anterior, já que haverá dois funtores entre elas. Apenas essa será a principal semelhança, visto que, agora, teremos vários objetos em ambas as categorias, enquanto no caso anterior tínhamos dois objetos na categoria de domínio e apenas quatro na categoria de codomínio.
Assim, na categoria de domínio, que contém uma série temporal, cada ponto de preço dessa série é representado como um objeto. Esses "objetos" serão associados cronologicamente por morfismos que simplesmente os incrementam em relação ao timeframe ao qual o script está associado. E como estamos trabalhando com séries temporais, isso significa que nossa categoria não é associada e, portanto, não tem cardinalidade. E novamente, como nos artigos anteriores, estamos interessados não tanto no tamanho geral e conteúdo das categorias/objetos, quanto nos morfismos e, mais especificamente, nos funtores desses objetos.
Na categoria de codomínio, temos duas séries temporais de preços para outros dois pares de moedas. Lembre-se de que para operar com base em arbitragem triangular é necessário ter pelo menos três pares de moedas. Eles podem ser mais, mas no nosso caso usamos o mínimo para manter a simplicidade relativa da implementação. Assim, na categoria de domínio, estarão as séries de preços para o primeiro par, que será USDJPY. Os outros dois pares, que serão incluídos no codomínio como séries de preços, serão EURJPY e EURUSD.
Os morfismos que associam os "objetos" de preço na segunda categoria estarão apenas dentro de uma série específica, já que, inicialmente, não temos um objeto que associa cada série.
Indução de quadrados de naturalidade:
Bem, o conceito de quadrados de naturalidade no âmbito da teoria das categorias enfatiza a propriedade comutativa, que em nosso artigo anterior foi usada para verificar a classificação. Como exemplo, pode-se considerar o diagrama abaixo, que apresenta quatro objetos da categoria de codomínio:
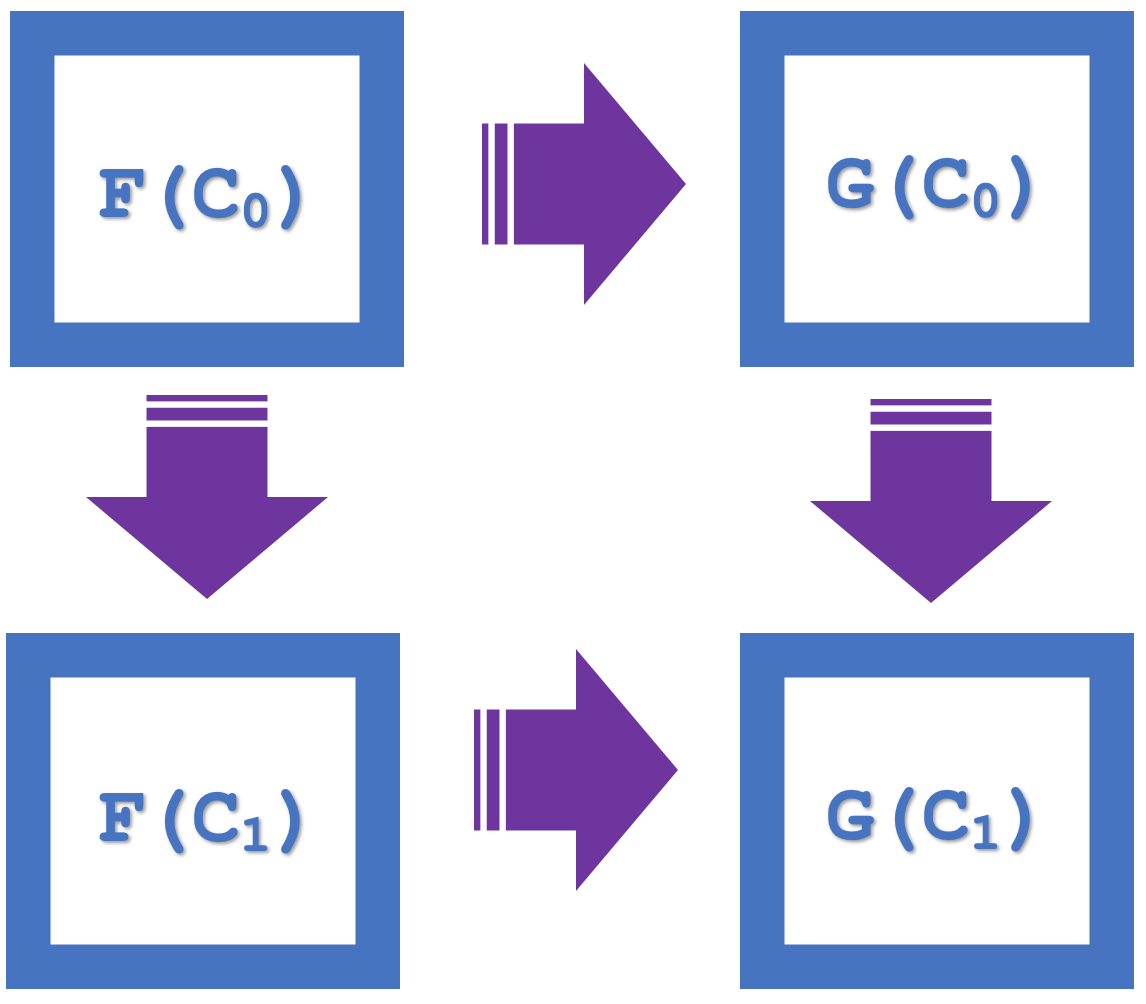
Vemos que existe comutação de F(C 0 ) para G(C 0 ) e então para G(C 1 ), equivalente a F(C 0 ) para F(C 1 ) e então para G(C 1 ).
O conceito de indução apresentado neste artigo enfatiza a possibilidade de comutar com base em séries de vários quadrados, o que simplifica o projeto e economiza recursos computacionais. Se considerarmos o diagrama abaixo, que lista n quadrados:
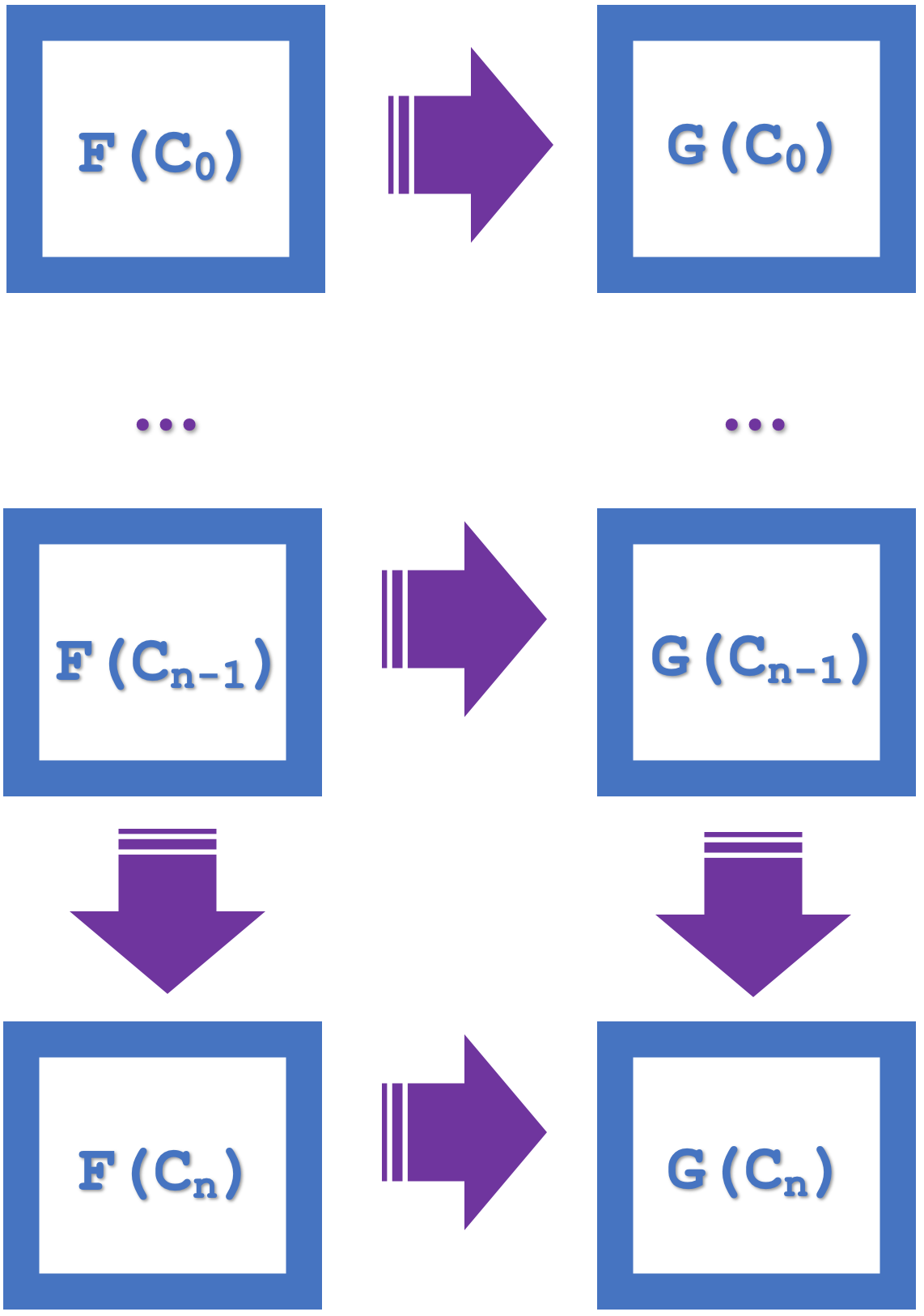
Se os pequenos quadrados de naturalidade comutam, então segue-se que o maior retângulo também comuta. Essa maior comutação implica em morfismos e funtores com passo 'n'. Assim, ambos os nossos funtores pertencerão à série USDJPY, mas se conectarão com séries diferentes, EURJPY e EURUSD. Desse modo, as transformações naturais ocorrerão de EURJPY para EURUSD. Como para a classificação usamos o quadrado de naturalidade, assim como no artigo anterior, as previsões serão para o codomínio das transformações naturais, que é EURUSD. A indução permite considerar essas previsões com base em várias barras, e não em apenas uma, como foi no artigo anterior. No artigo anterior, a tentativa de previsão baseada em várias barras exigia um grande custo computacional, pois era necessário utilizar muitas florestas aleatórias de decisão. Com a indução, agora podemos começar a classificação com um atraso de n barras.
Abaixo, temos uma representação visual desses quadrados de naturalidade como um único retângulo:
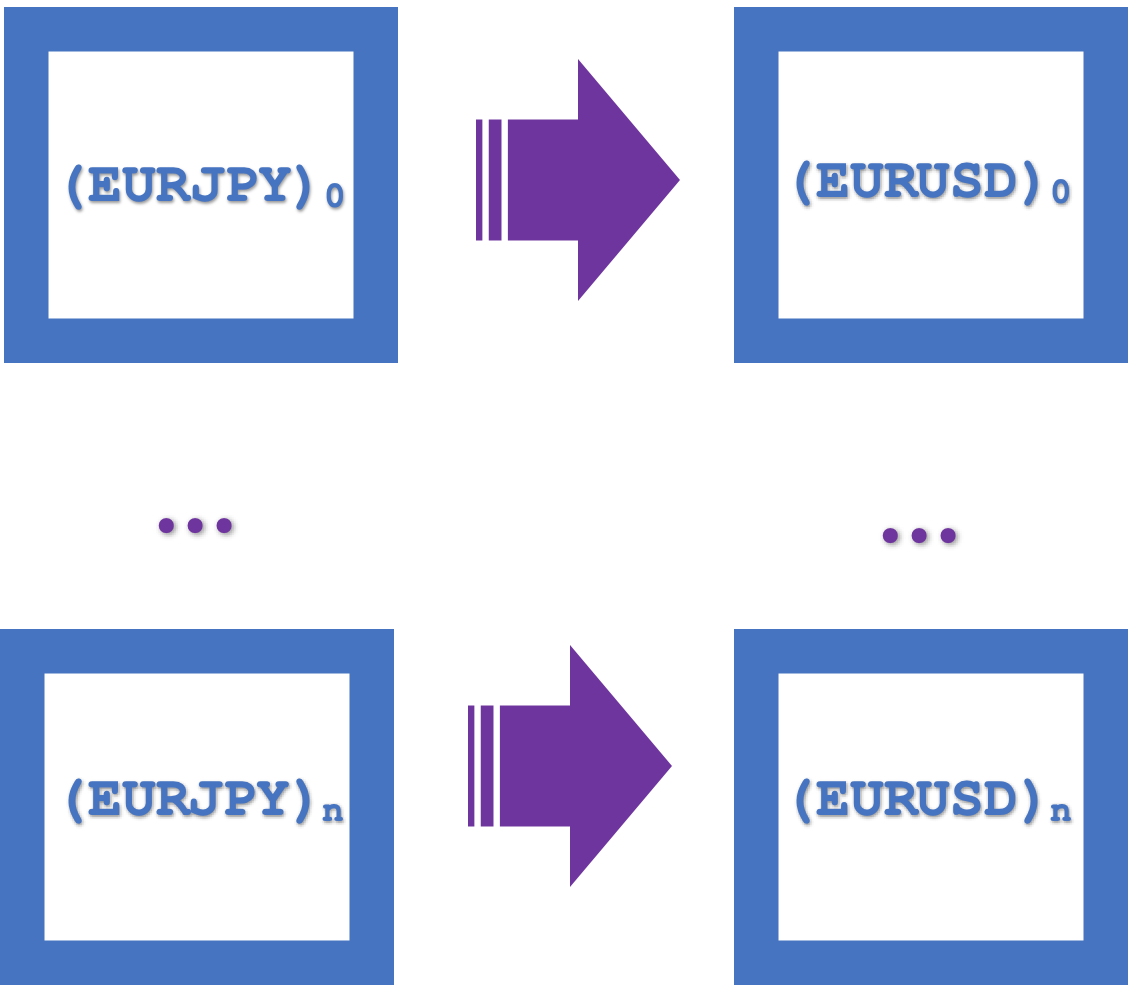
Os funtores desempenham um papel importante nisso:
Como já vimos Funtores, este parágrafo serve para enfatizar como o aplicamos ao trabalhar com quadrados de naturalidade. No artigo anterior, usamos perceptrons multicamadas para determinar o mapeamento de nossos funtores, mas neste artigo utilizamos florestas aleatórias de soluções com o mesmo propósito.
As florestas de decisão aleatória são um classificador que usa vários métodos de treinamento (florestas) para melhorar a previsão. Assim como o perceptron multicamada (MLP), ele é relativamente complexo e frequentemente referido como um método de treinamento de conjunto. Seria muito tedioso implementar isso a partir dos conceitos elementares para nossos propósitos, por isso, é bom que Alglib já tenha classes de implementação disponíveis na biblioteca MQL5 na pasta "Include\Math".
Bem, o mapeamento usando Random Decision Forests (RDFs) é definido a partir do tamanho da floresta e da atribuição de pesos às diferentes árvores e aos ramos correspondentes da mesma. Entretanto, para simplificar a descrição, podemos pensar nos RDFs como uma equipe de pequenos tomadores de decisão, em que cada tomador de decisão é uma árvore que sabe como analisar um conjunto de dados e fazer uma escolha. Todos eles recebem a mesma pergunta (dados) e cada um dá uma resposta (decisão). Depois que todas as equipes tiverem feito suas escolhas, é feita uma votação para selecionar a solução mais favorável. O mais interessante desse processo é que, embora todas as equipes (árvores) tenham recebido os mesmos dados, elas extraíram conhecimento de diferentes partes, pois a amostragem foi aleatória. As decisões baseadas nisso geralmente são inteligentes e precisas!
Eu tentei fazer minha própria implementação do zero, e esse algoritmo, embora possa ser descrito de forma simples, é bastante complexo. No entanto, isso pode ser feito usando Alglib em vários formatos. O mais simples deles requer apenas dois parâmetros de entrada: o número de florestas e o parâmetro de entrada do tipo duplo R, que define a porcentagem do conjunto de treinamento usada para construir as árvores. Para nossos propósitos, usaremos exatamente isso. Existem outros requisitos, como o número de variáveis independentes e o número de variáveis dependentes (também conhecidas como classificadores), mas eles são comuns à maioria dos modelos de aprendizado de máquina.
Implementação de scripts em MQL5:
Para codificar tudo o que é apresentado nestas séries, usamos exclusivamente o ambiente de desenvolvimento MQL5. Vale ressaltar que, além de indicadores personalizados, Expert Advisors (EAs) e scripts MQL5, nesta plataforma também é possível codificar/desenvolver serviços, bibliotecas, bases de dados e até scripts em Python.
В Neste artigo, simplesmente usamos um script para demonstrar a classificação por quadrados naturais na indução. O ideal seria termos uma instância de uma classe de sinal de um EA em vez de apenas um script, no entanto, a implementação de uma classe de sinal multimoeda, embora possível, não é tão viável quanto previsto neste artigo, por isso, em condições não otimizadas, apresentaremos as alterações previstas e reais do preço de fechamento do EURUSD e usaremos esses resultados para confirmar ou refutar nossa tese de que os quadrados de naturalidade com indução são úteis para fazer previsões.
Bem, nosso script começa com a criação de uma instância da categoria de domínio para armazenar a série de mudanças de preço de fechamento do USDJPY. Esta categoria pode ser usada para treinamento e marcada adequadamente. Embora o treinamento com ela estabeleça pesos para os funtores que se movem dela para a categoria de codomínio (nossos dois funtores), esses pesos não são críticos para nossas previsões (como mencionado no artigo anterior), mas são mencionados aqui para termos uma noção.
//create domain series (USDJPY-rates) in first category for training CCategory _c_a_train;_c_a_train.Let(); int _a_size=GetObject(_c_a_train,__currency_a,__training_start,__training_stop);
Em seguida, criamos uma instância da categoria de codomínio, que, como já mencionado, representará duas séries temporais - EURJPY e EURUSD. Como cada ponto de preço representa um objeto, precisamos garantir que "salvamos" as duas séries dentro da categoria, adicionando objetos para cada série sequencialmente. Nós os designamos como b e c.
//create 2 series (EURJPY and EURUSD rates) in second category for training CCategory _c_bc_train;_c_bc_train.Let(); int _b_trains=GetObject(_c_bc_train,__currency_b,__training_start,__training_stop); int _c_trains=GetObject(_c_bc_train,__currency_c,__training_start,__training_stop);
Assim, nossas previsões, como no artigo anterior, serão focadas nos objetos do codomínio que formam o quadrado de naturalidade. Os morfismos que conectam cada série, juntamente com as transformações naturais que conectam objetos entre séries, serão representados como RDF.
Nosso script possui um parâmetro de entrada para o número de induções, com o qual dimensionamos o quadrado e fazemos projeções além da próxima 1ª barra. Assim, nossos quadrados de naturalidade por n induções formam um único quadrado, que tomaremos pelos cantos A, B, C e D, sendo AB e CD nossas transformações e AC e BD os morfismos.
Na implementação desse mapeamento, podemos usar tanto MLP quanto RDF, digamos, para transformações e morfismos, respectivamente. Deixo para o leitor a oportunidade de explorar isso, já que vimos como o MLP pode ser usado. No entanto, avançando, precisamos preencher nossos modelos de treinamento para RDF com dados, o que é feito usando uma matriz. Quatro RDFs para cada mapeamento de AB para CD terão sua própria matriz, que é preenchida conforme listagem apresentada abaixo:
//create natural transformation, by induction across, n squares..., cpi to pmi //mapping by random forests int _training_size=fmin(_c_trains,_b_trains); int _info_ab=0,_info_bd=0,_info_ac=0,_info_cd=0; CDFReport _report_ab,_report_bd,_report_ac,_report_cd; CMatrixDouble _xy_ab;_xy_ab.Resize(_training_size,1+1); CMatrixDouble _xy_bd;_xy_bd.Resize(_training_size,1+1); CMatrixDouble _xy_ac;_xy_ac.Resize(_training_size,1+1); CMatrixDouble _xy_cd;_xy_cd.Resize(_training_size,1+1); double _a=0.0,_b=0.0,_c=0.0,_d=0.0; CElement<string> _e_a,_e_b,_e_c,_e_d; string _s_a="",_s_b="",_s_c="",_s_d=""; for(int i=0;i<_training_size-__n_inductions;i++) { _s_a="";_e_a.Let();_c_bc_train.domain[i].Get(0,_e_a);_e_a.Get(1,_s_a);_a=StringToDouble(_s_a); _s_b="";_e_b.Let();_c_bc_train.domain[i+_b_trains].Get(0,_e_b);_e_b.Get(1,_s_b);_b=StringToDouble(_s_b); _s_c="";_e_c.Let();_c_bc_train.domain[i+__n_inductions].Get(0,_e_c);_e_c.Get(1,_s_c);_c=StringToDouble(_s_c); _s_d="";_e_d.Let();_c_bc_train.domain[i+_b_trains+__n_inductions].Get(0,_e_d);_e_d.Get(1,_s_d);_d=StringToDouble(_s_d); if(i<_training_size-__n_inductions) { _xy_ab[i].Set(0,_a); _xy_ab[i].Set(1,_b); _xy_bd[i].Set(0,_b); _xy_bd[i].Set(1,_d); _xy_ac[i].Set(0,_a); _xy_ac[i].Set(1,_c); _xy_cd[i].Set(0,_c); _xy_cd[i].Set(1,_d); } }
Após os conjuntos de dados estarem prontos, podemos declarar instâncias dos modelos para cada RDF e iniciar o treinamento individual de cada um. Isso é feito conforme mostrado abaixo:
CDForest _forest; CDecisionForest _rdf_ab,_rdf_cd; CDecisionForest _rdf_ac,_rdf_bd; _forest.DFBuildRandomDecisionForest(_xy_ab,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_ab,_rdf_ab,_report_ab); _forest.DFBuildRandomDecisionForest(_xy_bd,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_bd,_rdf_bd,_report_bd); _forest.DFBuildRandomDecisionForest(_xy_ac,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_ac,_rdf_ac,_report_ac); _forest.DFBuildRandomDecisionForest(_xy_cd,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_cd,_rdf_cd,_report_cd);
Os resultados de cada treinamento, que precisamos avaliar, estão no valor inteiro do parâmetro 'info'. Assim como com o MLP, esse valor deve ser positivo. Se todos os nossos parâmetros "informacionais" forem positivos, então podemos prosseguir para o teste.
Note que os parâmetros de entrada do nosso script incluem 3 datas: a data de início do treinamento, a data de término do treinamento e a data de término do teste. Idealmente, esses valores devem ser verificados antes do uso para garantir que eles estejam em ordem crescente, na ordem em que os mencionei. Além disso, falta a data de início do teste, pois a data de término do treinamento também serve como a data de início do teste. Então, implementamos um teste direto usando a listagem fornecida abaixo:
// if(_info_ab>0 && _info_bd>0 && _info_ac>0 && _info_cd>0) { //create 2 objects (cpi and pmi) in second category for testing CCategory _c_cp_test;_c_cp_test.Let(); int _b_test=GetObject(_c_cp_test,__currency_b,__training_stop,__testing_stop); ... ... MqlRates _rates[]; ArraySetAsSeries(_rates,true); if(CopyRates(__currency_c,Period(), 0, _testing_size+__n_inductions+1, _rates)>=_testing_size+__n_inductions+1) { ArraySetAsSeries(_rates,true); for(int i=__n_inductions+_testing_size;i>__n_inductions;i--) { _s_a="";_e_a.Let();_c_cp_test.domain[i].Get(0,_e_a);_e_a.Get(1,_s_a);_a=StringToDouble(_s_a); double _x_ab[],_y_ab[]; ArrayResize(_x_ab,1); ArrayResize(_y_ab,1); ArrayInitialize(_x_ab,0.0); ArrayInitialize(_y_ab,0.0); // _x_ab[0]=_a; _forest.DFProcess(_rdf_ab,_x_ab,_y_ab); ... double _x_cd[],_y_cd[]; ArrayResize(_x_cd,1); ArrayResize(_y_cd,1); ArrayInitialize(_x_cd,0.0); ArrayInitialize(_y_cd,0.0); // _x_cd[0]=_y_ac[0]; _forest.DFProcess(_rdf_cd,_x_cd,_y_cd); double _c_forecast=0.0; if((_y_bd[0]>0.0 && _y_cd[0]>0.0)||(_y_bd[0]<0.0 && _y_cd[0]<0.0))//abd agrees with acd on currency c change { _c_forecast=0.5*(_y_bd[0]+_y_cd[0]); } double _c_actual=_rates[i-__n_inductions].close-_rates[i].close; if((_c_forecast>0.0 && _c_actual>0.0)||(_c_forecast<0.0 && _c_actual<0.0)){ _strict_match++; } else if((_c_forecast>=0.0 && _c_actual>=0.0)||(_c_forecast<=0.0 && _c_actual<=0.0)){ _generic_match++; } else { _miss++; } } // ... } }
Lembre-se de que estamos interessados na previsão da variação do EURUSD, que é representada como D em nosso quadrado. Ao verificar nossas previsões em um teste forward, registramos valores cuja direção é rigorosamente igual, valores que poderiam ser iguais, já que temos zeros envolvidos e, por fim, também registramos valores atípicos. Tudo isso é refletido na listagem fornecida acima.
Assim, para resumir nosso script, começamos com a declaração das categorias de treinamento, uma das quais é extremamente necessária para a pré-processamento de dados e treinamento. Como pares de arbitragem Forex, usamos USDJPY, EURJPY e EURUSD. Mapeamos os objetos de nossa categoria de codomínio usando RDF, que servem como morfismos nas séries e transformações naturais nas séries para construir previsões nos dados de teste, que são definidos pela data de término do treinamento e pela data de término do teste.
Resultados e análise:
Se executarmos o script fornecido no final do artigo, implementando a fonte geral acima, obteremos os seguintes logs com induções de 1 no gráfico diário do USDJPY:
2023.09.01 13:39:14.500 ct_19_r1 (USDJPY.ln,D1) void OnStart() misses: 45, strict matches: 61, & generic matches: 166, for strict pct (excl. generic): 0.58, & generic pct: 0.83, with inductions at: 1
No entanto, se aumentarmos o número de induções para 2, obteremos isto:
2023.09.01 13:39:55.073 ct_19_r1 (USDJPY.ln,D1) void OnStart() misses: 56, strict matches: 63, & generic matches: 153, for strict pct (excl. generic): 0.53, & generic pct: 0.79, with inductions at: 2
Observa-se uma pequena diminuição, embora significativa, mas ainda positiva, pois há mais correspondências exatas do que erros. Podemos criar um registro do número de entradas por correspondências e não correspondências. Isso é mostrado no gráfico abaixo:
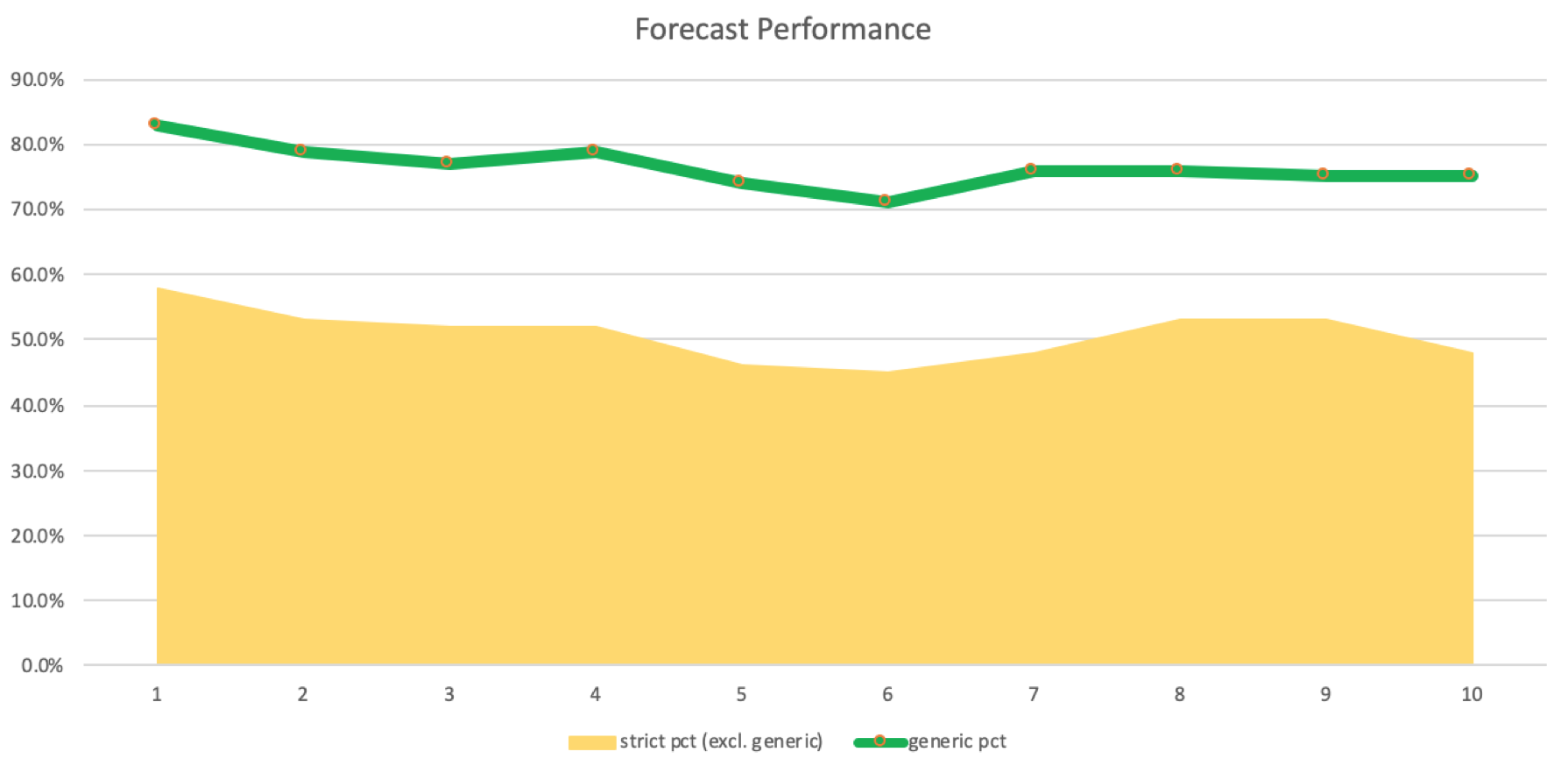
Só se pode confirmar se essas previsões e coincidências são exatas em um sistema de negociação real, realizando corridas com diferentes lags de indução para provar ou refutar sua eficácia. Com frequência, os sistemas podem ser lucrativos mesmo com uma porcentagem menor de vitórias, então não podemos afirmar com certeza que o uso de lags de indução de 5 a 8 é ideal para nosso sistema. É necessário fazer testes com um EA multimoeda para confirmar isso.
O principal problema dessa implementação é a incapacidade de o assistente MQL5 para testar os sinais como uma classe de EA. O assistente padrão inicia indicadores e buffers de preço para apenas um símbolo do gráfico. É possível contornar esse problema para colocar vários símbolos, mas para isso é necessário criar uma classe própria, herdando a classe CExpert, e fazer algumas alterações nela. Achei que isso é muito extenso para este artigo, de modo que o leitor pode explorar essa questão por conta própria.
Comparação com métodos tradicionais:
Em comparação com os métodos "tradicionais" que usam indicadores simples como médias móveis, nossa abordagem baseada na indução de quadrados de naturalidade parece complexa e, possivelmente, se apenas lermos sua descrição. No entanto, espero que, graças à abundância de bibliotecas de código (como Alglib) disponíveis online e na biblioteca MQL5, o leitor ganhe uma ideia de como é possível codificar facilmente uma abordagem ou ideia complexa à primeira vista em menos de 200 linhas. Isso permite explorar, adotar ou refutar novas ideias. O IDE MQL5 é um paraíso para os amantes do aprendizado.
As principais vantagens deste sistema são sua adaptabilidade e potencial precisão.
Aplicações reais:
Se formos investigar a aplicação prática de nosso sistema de previsão com pares de arbitragem, será somente no contexto da arbitragem dentro dos três pares. Todos sabem que cada corretora tem uma política de spread diferente para os pares no mercado Forex e, se existem oportunidades de arbitragem, é somente porque um dos três pares está com preço errado a tal ponto que a diferença excede o spread do par. Essa janela de oportunidade existia antes, mas, com o passar dos anos, à medida que a latência diminuiu para a maioria das corretoras, ela se tornou muito real. Além disso, algumas corretoras até proíbem essa prática.
Assim, se fizermos arbitragem, será em uma pseudoforma, em que "ignoramos" o spread e, em vez disso, olhamos para os preços brutos mais a previsão de nossos quadrados de naturalidade. Por exemplo, um sistema simples para entrar em uma posição longa olharia para a arbitragem do preço do terceiro par, no nosso caso EURUSD, sendo maior do que o preço de cotação atual e a previsão também indicando um aumento de preço. Lembre-se, o preço de arbitragem para o par EURUSD no nosso caso seria obtido da seguinte forma:
EURJPY / USDJPY
Incorporar tal sistema ao que tínhamos no cenário acima inevitavelmente leva a uma redução no número de trades desde a confirmação; para cada sinal, é necessário um preço de arbitragem maior ou menor para longs e shorts, respectivamente. Trabalhar com a classe de sinal de EA para criar uma instância da classe que codifique isso é a abordagem preferida e, como o suporte para multimoedas nas classes do assistente MQL5 ainda não é tão forte, podemos apenas mencioná-lo aqui e sugerir que o leitor modifique a classe de EA como acima ou tente outra abordagem que permita testar essa abordagem de multimoedas com EAs montados pelo assistente.
Reitero que testar ideias com Expert Advisors criados pelo assistente MQL5 permite não apenas compilar algo em uma unidade com menos código, mas também integrar outros sinais de saída com o que estamos trabalhando e ver se há um peso relativo entre eles que satisfaz nossos objetivos. Por exemplo, se, em vez do script fornecido no final, pudéssemos implementar várias moedas e fornecer um arquivo de sinal funcional, esse arquivo poderia ser combinado com outros arquivos de sinal da biblioteca (como Awesome Oscillator, RSI, etc.) ou mesmo com outro arquivo de sinal personalizado, para desenvolver um novo sistema de trading com resultados mais significativos ou balanceados do que apenas um arquivo de sinal.
Além da possibilidade de gerar um arquivo de sinal, a abordagem da indução de quadrados de naturalidade pode ser usada para melhorar a eficiência do gerenciamento de risco e a otimização do portfólio, se, em vez de um arquivo de sinal, codificar uma instância personalizada da classe expert money. Com essa abordagem, embora rudimentar, poderíamos, com certas limitações, posicionar nossos trades proporcionalmente ao tamanho do movimento de preço previsto.
Conclusão:
Resumindo os principais pontos desta série de artigos, examinamos como os quadrados de naturalidade, quando expandidos pela indução, simplificam o design e economizam recursos computacionais na classificação de dados e, consequentemente, na previsão do futuro.
A previsão exata de séries nunca deve ser o único e final objetivo de um sistema de trading. Muitos métodos de trading são consistentemente lucrativos com uma pequena porcentagem de vitórias, por isso nossa incapacidade de testar essas ideias como uma classe de sinais de expert é desanimadora e claramente torna os resultados obtidos aqui não conclusivos em relação ao papel e potencial da indução.
Assim, encorajam-se os leitores a testar o código fornecido em configurações que permitam suporte multimoeda de EAs, para fazer conclusões mais precisas sobre quais lags de indução funcionam e quais não.
Referências:
Wikipedia, conforme as referências gerais no artigo.
Apêndice: Snippets de código MQL5
Incluído o script (ct_19_r1.mq5), que precisa ser compilado no IDE e, em seguida, seu arquivo *.ex5 anexado a um gráfico no terminal MetaTrader 5 para execução. Pode ser executado com diferentes configurações e pares de arbitragem, além daqueles propostos por padrão. No segundo arquivo anexado, uma parte dos classes teóricas compiladas nesta fase da série é apresentada. Como sempre, ele deve ser colocado na pasta include.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/13273
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso