
Indicador de previsão de volatilidade usando Python

Introdução
Droga! De novo os stops foram todos atingidos...
Era com essa frase que começava praticamente todo meu segundo dia de trading lá por volta de 2021. Lembro de estar todo empolgado, rodeado de gráficos e números, todo orgulhoso do meu novo sistema de trading, e aí, pum, lá se vai metade do capital. Porque algum espertinho resolveu fazer uma declaração sobre cripto e o mercado simplesmente enlouqueceu.
Conhecido, né? Aposto que todo algotrader já passou por isso. Você calcula tudo, faz backtest, o sistema nos dados históricos funciona como música... Mas no mercado real? "Oi, volatilidade, quanto tempo!"
Depois de mais uma dessas "aventuras", eu surtei e resolvi ir até o fim. Não é possível que não exista um jeito de prever esses surtos do mercado! Revirei, acho que, todas as pesquisas já feitas sobre volatilidade. Sabe o mais curioso? Descobri que a solução estava justamente na interseção da escola antiga com as tecnologias novas.
Neste artigo, vou contar minha jornada do desespero até uma solução funcional para prever a volatilidade. Sem chatices nem jargões acadêmicos, só experiência real e soluções que funcionam de verdade. Vou mostrar como integrei o MetaTrader 5 com Python (spoiler: eles não se entenderam de cara), como fiz o aprendizado de máquina trabalhar a meu favor e os tropeços que enfrentei no caminho.
O maior aprendizado que tirei dessa história foi: não dá pra confiar cegamente nem nos indicadores clássicos, nem nas redes neurais da moda. Teve vez que passei uma semana inteira ajustando uma rede neural complexíssima, e depois um simples XGBoost deu um resultado melhor. Ou aquela vez em que um simples Bollinger salvou minha conta quando todos os algoritmos inteligentes falharam.
Também percebi que trading é como boxe, o importante não é a força do golpe, mas a capacidade de antecipá-lo. Meu sistema não faz previsões milagrosas. Ele só me ajuda a estar preparado para os sustos do mercado e reforçar minha estratégia quando mais preciso.
Resumindo: se você também cansou de ver seus algoritmos tropeçarem a cada espirro da volatilidade, bem-vindo ao meu mundo. Vou contar tudo como realmente foi, com exemplos de código, gráficos e autópsia dos erros. Vamos nessa!
Conceito do projeto
Depois de meses de experimentos e análise profunda de dados de mercado, surgiu a ideia de um sistema capaz de prever a volatilidade com uma precisão surpreendente. A principal descoberta foi que a volatilidade, ao contrário do preço, tem uma característica de estacionariedade, pois ela tende a retornar ao seu valor médio e forma padrões consistentes. É exatamente essa propriedade que torna sua previsão não só possível, mas também prática para uso em trading real.
No coração do sistema está a poderosa dupla MetaTrader 5 e Python, onde cada ferramenta revela seus pontos fortes. O MetaTrader 5 atua como uma fonte confiável de dados de mercado. Ele nos fornece cotações históricas e fluxo de dados em tempo real com atrasos mínimos. Já o Python vira nosso laboratório analítico, onde o vasto conjunto de bibliotecas de aprendizado de máquina (Sklearn, XGBoost, PyTorch) ajuda a extrair padrões valiosos desses dados e a validar hipóteses sobre a estacionariedade da volatilidade.
A arquitetura do sistema é composta por três camadas principais:
- Data Pipeline — o alicerce do sistema. Aqui ocorre o processamento inicial dos dados vindos do MetaTrader 5: limpeza de ruídos, cálculo de dezenas de métricas de volatilidade, criação de características para os modelos. Há foco especial na otimização, pois o sistema funciona sem atrasos e sem vazamento de memória. Neste nível também se verifica a estacionariedade das séries temporais e se identificam padrões significativos de volatilidade.
- Analytics Core — o núcleo analítico. Sua base é um conjunto de modelos especializados de aprendizado de máquina. Cada um focado em um horizonte temporal específico: de oscilações intradiárias até tendências semanais. Durante os testes, ficou claro que até mesmo um simples XGBoost supera redes neurais complexas em precisão de previsão, especialmente nas tarefas de detecção de clusters de volatilidade.
- Risk Advisor — o sistema de recomendações para gerenciamento de risco. Com base nas previsões de volatilidade, ele sugere níveis ideais de stop-loss e take-profit. Em períodos de alta volatilidade futura, recomenda ampliar as ordens de proteção; em horas futuras mais calmas, sugere estreitá-las para entradas mais precisas no mercado. É aqui que a estacionariedade da volatilidade desempenha um papel crucial, permitindo ao sistema adaptar eficientemente os parâmetros da estratégia.
Os modelos são treinados com um conjunto de dados único, que inclui cotações de diferentes timefnrames, dos de ticks aos diários. Isso permite ao sistema reconhecer três estados-chave do mercado: baixa volatilidade, tendência e explosão. Com base nessa leitura, são geradas recomendações para níveis ideais de entrada e ordens de proteção. Graças à estacionariedade da volatilidade, o sistema consegue não apenas identificar o estado atual, mas também prever as transições entre esses estados.
A principal característica do sistema é sua adaptabilidade. Ele não fornece apenas recomendações fixas, mas ajusta essas recomendações conforme o estado atual do mercado. Para cada situação de trading, o sistema propõe um conjunto personalizado de parâmetros, com base na previsão da volatilidade futura. Essa adaptabilidade é especialmente eficaz graças aos padrões consistentes no comportamento da volatilidade.
Nas próximas seções, vamos analisar em detalhe cada componente do sistema, mostrar código real e compartilhar os resultados dos testes com dados históricos. Você verá como as ideias teóricas sobre a estacionariedade da volatilidade se transformam em uma ferramenta prática de análise de mercado.
Instalação do software necessário
Antes de mergulhar no desenvolvimento do sistema, vamos entender como instalar todo o software necessário. Pela minha própria experiência, sei que muita gente tropeça logo na configuração da integração MetaTrader 5 - Python, então vou explicar não só como instalar tudo, mas também como evitar as armadilhas mais comuns.
Comecemos pelo Python. Precisamos da versão 3.8 ou superior, você pode baixá-la no site oficial python.org. Durante a instalação, é importante não esquecer de marcar a opção "Add Python to PATH", senão depois será preciso adicionar os caminhos manualmente. Após instalar o Python, a primeira coisa a fazer é criar um ambiente virtual para o projeto. Isso não é obrigatório, mas é altamente recomendável, já que vai nos proteger de conflitos entre versões de bibliotecas.
python -m venv venv_volatility venv_volatility\Scripts\activate # for Windows source venv_volatility/bin/activate # for Linux/MacOS
Agora vamos instalar as bibliotecas necessárias. Precisamos de algumas ferramentas básicas: numpy e pandas para manipulação de dados, scikit-learn e xgboost para aprendizado de máquina, pytorch para redes neurais, e claro, a biblioteca para integração com o MetaTrader 5. Aqui está o comando para instalar tudo de uma vez:
pip install numpy pandas scikit-learn xgboost pytorch MetaTrader5 pylint jupyter Vamos dar atenção especial à instalação do MetaTrader 5. Você deve baixá-lo diretamente no site da sua corretora; isso é importante, pois as versões podem variar. Durante a instalação, escolha uma pasta com um caminho simples, sem caracteres cirílicos ou espaços, pois isso vai te poupar muita dor de cabeça ao conectar com o Python.
Depois de instalar o terminal, não se esqueça de ativar nas configurações a permissão para trading automático e o uso de DLLs, além de habilitar o AlgoTrading. Sim, parece óbvio, mas eu mesmo perdi algumas horas na depuração antes de lembrar dessas opções.
Agora vem a parte interessante, testar a conexão entre o Python e o MetaTrader 5. Escrevi um pequeno script que ajuda a verificar se tudo está funcionando corretamente:
import MetaTrader5 as mt5 def test_mt5_connection(): if not mt5.initialize(): print("MT5 initialization error:", mt5.last_error()) return False print("MetaTrader5 package author:", mt5.__author__) print("MetaTrader5 package version:", mt5.__version__) terminal_info = mt5.terminal_info() if terminal_info is None: print("Error getting terminal data:", mt5.last_error()) return False print(f"Connected to terminal '{terminal_info.name}' ({terminal_info.path})") print("Trade server:", terminal_info.connected) mt5.shutdown() return True if __name__ == "__main__": test_mt5_connection()
O que observar caso surjam problemas? Na maioria das vezes, o maior obstáculo é a inicialização do MetaTrader 5. Se o script não conseguir se conectar ao terminal, a primeira coisa a checar é se o próprio MetaTrader 5 está aberto. Parece evidente, mas acredite, até desenvolvedores experientes às vezes esquecem disso.
Se o terminal estiver aberto, mas mesmo assim a conexão não funcionar, verifique as permissões de administrador e as configurações do firewall. O Windows às vezes gosta de ser cauteloso e bloqueia a conexão.
Para desenvolvimento, recomendo usar o VS Code ou o PyCharm, pois ambos são excelentes para programação em Python. Instale as extensões para Python e Jupyter, porque isso vai facilitar bastante o processo de depuração e testes de código.
Verificação final, tente obter um pouco de dados históricos:
import MetaTrader5 as mt5 mt5.initialize() data = mt5.copy_rates_from_pos("EURUSD", mt5.TIMEFRAME_M1, 0, 1000) print(data is not None) mt5.shutdown()
Se esse código rodar sem erros, então parabéns, seu ambiente de desenvolvimento está totalmente pronto para o trabalho! No próximo trecho, vamos começar a coletar e processar dados do MetaTrader 5.
Coleta de dados do MetaTrader 5
Antes de nos aprofundarmos nos cálculos mais complexos, vamos garantir que estamos recebendo corretamente os dados do terminal de trading. Escrevi um script simples que ajuda a testar a conexão com o MetaTrader 5 e observar a estrutura dos dados:
import MetaTrader5 as mt5 import pandas as pd from datetime import datetime, timedelta pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) pd.set_option('display.float_format', lambda x: '%.5f' % x) def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return print("\n=== Symbol Information ===") symbol_info = mt5.symbol_info(symbol) if symbol_info is None: print(f"Failed to get {symbol} data") mt5.shutdown() return print(f"Current spread: {symbol_info.spread} points") print(f"Tick size: {symbol_info.trade_tick_size}") print(f"Contract size: {symbol_info.trade_contract_size}") # Last 100 ticks print("\n=== Latest Ticks ===") ticks = mt5.copy_ticks_from(symbol, datetime.now() - timedelta(minutes=5), 100, mt5.COPY_TICKS_ALL) ticks_frame = pd.DataFrame(ticks) ticks_frame['time'] = pd.to_datetime(ticks_frame['time'], unit='s') print(ticks_frame.head()) # 5-minute bars (last 100 bars) print("\n=== 5-Minute Bars (Last 100) ===") rates_5m = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_M5, 0, 100) rates_5m_frame = pd.DataFrame(rates_5m) rates_5m_frame['time'] = pd.to_datetime(rates_5m_frame['time'], unit='s') print(rates_5m_frame.head()) # Hourly bars (last 24 hours) print("\n=== Hourly Bars (Last 24) ===") rates_1h = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 24) rates_1h_frame = pd.DataFrame(rates_1h) rates_1h_frame['time'] = pd.to_datetime(rates_1h_frame['time'], unit='s') print(rates_1h_frame.head()) # Daily bars (last 30 days) print("\n=== Daily Bars (Last 30) ===") rates_d1 = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 30) rates_d1_frame = pd.DataFrame(rates_d1) rates_d1_frame['time'] = pd.to_datetime(rates_d1_frame['time'], unit='s') print(rates_d1_frame.head()) # Statistics for different timeframes print("\n=== 5-Minute Bars Statistics ===") print(f"Average volume: {rates_5m_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_5m_frame['spread'].mean():.2f}") print(f"Average range: {(rates_5m_frame['high'] - rates_5m_frame['low']).mean():.5f}") print("\n=== Hourly Bars Statistics ===") print(f"Average volume: {rates_1h_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_1h_frame['spread'].mean():.2f}") print(f"Average range: {(rates_1h_frame['high'] - rates_1h_frame['low']).mean():.5f}") print("\n=== Daily Bars Statistics ===") print(f"Average volume: {rates_d1_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_d1_frame['spread'].mean():.2f}") print(f"Average range: {(rates_d1_frame['high'] - rates_d1_frame['low']).mean():.5f}") # Current quotes print("\n=== Current Market Depth ===") depth = mt5.market_book_get(symbol) if depth is not None: bid = depth[0].price if depth[0].type == 1 else depth[1].price ask = depth[0].price if depth[0].type == 2 else depth[1].price print(f"Bid: {bid}") print(f"Ask: {ask}") print(f"Spread: {(ask - bid):.5f}") mt5.shutdown() if __name__ == "__main__": check_mt5_data()
Esse código vai nos mostrar todas as informações necessárias para validar a conexão e a qualidade dos dados recebidos. Após executá-lo, você verá:
- Informações básicas sobre o ativo
- Tabela com os últimos ticks
- Tabela com barras horárias
- Estatísticas de volumes e spreads
- Cotações atuais do book de ofertas
Executamos, e imediatamente vemos se tudo está funcionando como deve. Se algum problema aparecer, o script vai indicar exatamente em qual etapa algo deu errado.
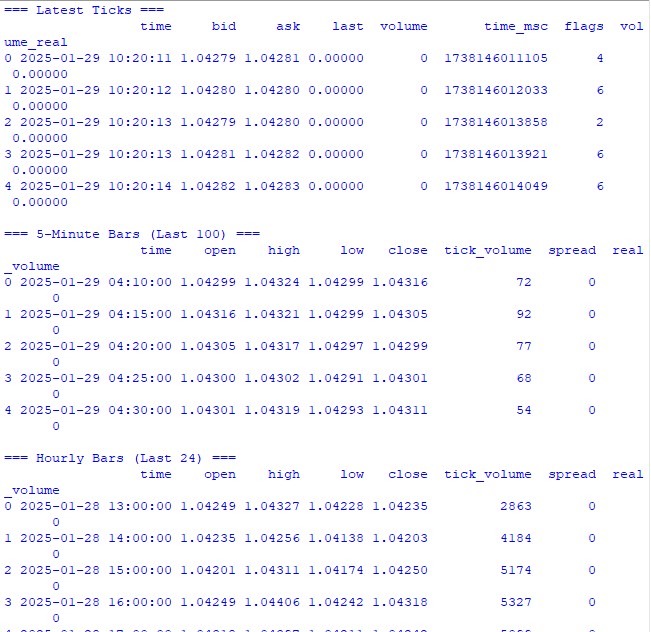
Nas próximas seções, usaremos esses dados para calcular a volatilidade, mas antes precisamos garantir que a coleta básica esteja funcionando corretamente.
Pré-processamento dos dados
Quando comecei a trabalhar com previsão de volatilidade, achava que o mais importante era ter um modelo de aprendizado de máquina poderoso. A prática rapidamente me mostrou que o que realmente faz diferença é a qualidade da preparação dos dados. Deixe-me mostrar como preparo os dados para o nosso sistema de previsão.
Aqui está o código completo de pré-processamento que utilizo:
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler from datetime import datetime, timedelta pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) pd.set_option('display.float_format', lambda x: '%.5f' % x) class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20)): self.lookback_periods = lookback_periods self.scaler = StandardScaler() def calculate_volatility_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change().fillna(0) df['log_returns'] = (np.log(df['close']) - np.log(df['close'].shift(1))).fillna(0) # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1).fillna(df['high'])), abs(df['low'] - df['close'].shift(1).fillna(df['low'])) ) ) # ATR and volatility for period in self.lookback_periods: df[f'atr_{period}'] = df['true_range'].rolling(window=period, min_periods=1).mean() df[f'volatility_{period}'] = df['returns'].rolling(window=period, min_periods=1).std() # Parkinson volatility df['parkinson_vol'] = np.sqrt( 1/(4 * np.log(2)) * np.power(np.log(df['high'].div(df['low'])), 2) ) # Garman-Klass volatility df['garman_klass_vol'] = np.sqrt( 0.5 * np.power(np.log(df['high'].div(df['low'])), 2) - (2*np.log(2)-1) * np.power(np.log(df['close'].div(df['open'])), 2) ) # Relative volatility changes for period in self.lookback_periods: df[f'vol_change_{period}'] = ( df[f'volatility_{period}'].div(df[f'volatility_{period}'].shift(1)) ) # Replace all infinities and NaN for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan).fillna(0) return df def prepare_features(self, df): feature_cols = [] # Time-based features - correct time conversion time = pd.to_datetime(df['time'], unit='s') # Hours (0-23) -> radians (0-2π) hours = time.dt.hour.values df['hour_sin'] = np.sin(2 * np.pi * hours / 24.0) df['hour_cos'] = np.cos(2 * np.pi * hours / 24.0) # Week days (0-6) -> radians (0-2π) days = time.dt.dayofweek.values df['day_sin'] = np.sin(2 * np.pi * days / 7.0) df['day_cos'] = np.cos(2 * np.pi * days / 7.0) # Select features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'vol_change_{period}' ]) feature_cols.extend([ 'parkinson_vol', 'garman_klass_vol', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create features DataFrame features = df[feature_cols].copy() # Final cleanup and scaling features = features.replace([np.inf, -np.inf], 0).fillna(0) scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=features.columns, index=features.index ) def create_target(self, df, forward_window=12): future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window).fillna(0) return future_vol def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_volatility_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) return features, target def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: print("\n=== Processing Hourly Data for Volatility Analysis ===") processor = VolatilityProcessor(lookback_periods=(5, 10, 20)) features, target = processor.prepare_dataset(rates_frame) print("\nFeature statistics:") print(features.describe()) print("\nFeature columns:", features.columns.tolist()) print("\nTarget statistics:") print(target.describe()) else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
Como funciona
Primeiro, carregamos as últimas 10000 barras horárias do MetaTrader 5. Por que exatamente esse número? Depois de muitos testes, percebi que essa quantidade é ideal, já que é suficiente para treinar, mas não tão grande a ponto de o mercado já ter mudado demais.
A partir daí começa a parte mais interessante. A classe VolatilityProcessor faz todo o trabalho pesado de preparação dos dados. Veja o que acontece por trás dos bastidores:
- Cálculo dos indicadores básicos de volatilidade. Aqui calculamos três tipos de volatilidade:
- Desvio padrão clássico dos retornos
- True Range e ATR — escola antiga, mas ainda funciona muito bem
- Métodos de Parkinson e Garman-Klass — eles capturam bem os movimentos intradiários
- Trabalho com o tempo. Em vez do one-hot encoding tradicional para horas e dias da semana, eu uso senos e cossenos. Não é só estética, já que isso permite que o modelo entenda que 23:00 e 00:00 são momentos próximos no tempo, e não extremos opostos.
- Normalização e limpeza dos dados. Essa parte é crítica:
- Remoção de valores atípicos e infinitos
- Preenchimento de valores ausentes com zeros (mas só depois de verificar que isso não distorce os dados)
- Escalonamento de todos os atributos para a mesma faixa
No fim, obtemos 15 características, o que é quantidade ideal para a nossa tarefa. Testei adicionar mais (inclusive indicadores exóticos), mas só piorava o desempenho.
A variável-alvo é a volatilidade futura nos próximos 12 períodos. Por que 12? Nos dados horários, isso equivale a uma previsão para as próximas 12 horas, que é o tempo suficiente para decisões de trading, sem ser tão longo a ponto de tornar o forecast irrelevante.
O que observar
- Sempre uso min_periods=1 nas operações rolling — isso evita perda de dados no início da série temporal.
- Uso .div() em vez da divisão comum / — não é frescura, o pandas lida melhor com exceções dessa forma.
- A substituição de infinitos é feita no final de cada etapa, garantindo que não passem pontos problemáticos despercebidos.
No próximo trecho, vamos criar o modelo de aprendizado de máquina que vai trabalhar com esses dados processados. Mas lembre-se de que não importa o quão avançado seja o modelo, ele não vai funcionar se os dados forem mal preparados.
Criação do modelo de aprendizado de máquina
Enfim, chegamos à parte mais interessante que diz respeito a construir o modelo de previsão. No início, fui pelo caminho mais óbvio — regressão para prever o valor exato da volatilidade futura. A lógica era simples: obter um número preciso, multiplicar por algum fator, e pronto, temos o nível de stop-loss.
Primeira tentativa: modelo de regressão
Comecei com o código mais simples possível, um XGBRegressor básico com o mínimo de configurações. Poucos parâmetros: cem árvores, taxa de aprendizado de 0.1 e profundidade 5. Ingênuo pensar que isso bastaria, mas quem nunca cometeu esse erro no começo?
Os resultados, pra ser gentil, não empolgaram. O R-quadrado girava em torno de 0.05-0.06, o que significa que o modelo explicava só 5 a 6% da variação dos dados. O desvio padrão das previsões era quase três vezes menor que o real. O Mean Absolute Error até parecia aceitável, mas era uma verdadeira armadilha.
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.model_selection import TimeSeriesSplit import xgboost as xgb from xgboost import XGBRegressor from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score import matplotlib.pyplot as plt from datetime import datetime, timedelta # VolatilityProcessor class remains unchanged class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20)): self.lookback_periods = lookback_periods self.scaler = StandardScaler() def calculate_volatility_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change().fillna(0) df['log_returns'] = (np.log(df['close']) - np.log(df['close'].shift(1))).fillna(0) df['abs_returns'] = abs(df['returns']) # Price changes df['price_range'] = (df['high'] - df['low']) / df['close'] df['price_change'] = (df['close'] - df['open']) / df['open'] # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1).fillna(df['high'])), abs(df['low'] - df['close'].shift(1).fillna(df['low'])) ) ) # ATR and volatility for different periods for period in self.lookback_periods: # Standard features df[f'atr_{period}'] = df['true_range'].rolling(window=period, min_periods=1).mean() df[f'volatility_{period}'] = df['returns'].rolling(window=period, min_periods=1).std() # Additional rolling statistics df[f'mean_range_{period}'] = df['price_range'].rolling(window=period, min_periods=1).mean() df[f'mean_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).mean() df[f'max_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).max() df[f'min_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).min() # Advanced volatility measures # Parkinson volatility df['parkinson_vol'] = np.sqrt( 1/(4 * np.log(2)) * np.power(np.log(df['high'].div(df['low'])), 2) ) # Garman-Klass volatility df['garman_klass_vol'] = np.sqrt( 0.5 * np.power(np.log(df['high'].div(df['low'])), 2) - (2*np.log(2)-1) * np.power(np.log(df['close'].div(df['open'])), 2) ) # Rogers-Satchell volatility df['rogers_satchell_vol'] = np.sqrt( np.log(df['high'].div(df['close'])) * np.log(df['high'].div(df['open'])) + np.log(df['low'].div(df['close'])) * np.log(df['low'].div(df['open'])) ) # Relative changes for period in self.lookback_periods: df[f'vol_change_{period}'] = ( df[f'volatility_{period}'].div(df[f'volatility_{period}'].shift(1)) ) df[f'atr_change_{period}'] = ( df[f'atr_{period}'].div(df[f'atr_{period}'].shift(1)) ) # Replace all infinities and NaN for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan).fillna(0) return df def prepare_features(self, df): feature_cols = [] # Time-based features time = pd.to_datetime(df['time'], unit='s') # Hours (0-23) -> radians (0-2π) hours = time.dt.hour.values df['hour_sin'] = np.sin(2 * np.pi * hours / 24.0) df['hour_cos'] = np.cos(2 * np.pi * hours / 24.0) # Days of week (0-6) -> radians (0-2π) days = time.dt.dayofweek.values df['day_sin'] = np.sin(2 * np.pi * days / 7.0) df['day_cos'] = np.cos(2 * np.pi * days / 7.0) # Select features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'vol_change_{period}' ]) feature_cols.extend([ 'parkinson_vol', 'garman_klass_vol', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create features DataFrame features = df[feature_cols].copy() # Final cleanup and scaling features = features.replace([np.inf, -np.inf], 0).fillna(0) scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=feature_cols, index=features.index ) def create_target(self, df, forward_window=12): """Create target with log transformation""" future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window) # Add small constant to avoid log(0) log_vol = np.log(future_vol + 1e-10) return log_vol.fillna(log_vol.mean()) def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_volatility_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) return features, target class VolatilityModel: def __init__(self, lookback_periods=(5, 10, 20), forward_window=12): self.processor = VolatilityProcessor(lookback_periods) self.forward_window = forward_window self.model = XGBRegressor( n_estimators=500, learning_rate=0.05, max_depth=10, min_child_weight=1, subsample=0.8, colsample_bytree=0.8, gamma=0.1, reg_alpha=0.1, reg_lambda=1, random_state=42, n_jobs=-1, objective='reg:squarederror' # Better for log-transformed targets ) self.feature_importance = None def prepare_data(self, rates_frame): """Prepare data using our processor""" features, target = self.processor.prepare_dataset(rates_frame) return features, target def create_train_test_split(self, features, target, test_size=0.2): """Split data preserving time order""" split_idx = int(len(features) * (1 - test_size)) X_train = features.iloc[:split_idx] X_test = features.iloc[split_idx:] y_train = target.iloc[:split_idx] y_test = target.iloc[split_idx:] return X_train, X_test, y_train, y_test def train(self, X_train, y_train, X_test, y_test): """Train model with validation""" print("\n=== Training Model ===") print("Training set shape:", X_train.shape) print("Test set shape:", X_test.shape) # Train the model eval_set = [(X_train, y_train), (X_test, y_test)] self.model.fit( X_train, y_train, eval_set=eval_set, verbose=True ) # Save feature importance importance = self.model.feature_importances_ self.feature_importance = pd.DataFrame({ 'feature': X_train.columns, 'importance': importance }).sort_values('importance', ascending=False) # Make predictions and evaluate predictions = self.predict(X_test) metrics = self.calculate_metrics(y_test, predictions) return metrics def calculate_metrics(self, y_true, y_pred): """Calculate model performance metrics with detailed R2""" # Basic metrics rmse = np.sqrt(mean_squared_error(y_true, y_pred)) mae = mean_absolute_error(y_true, y_pred) # Manual R2 calculation for verification y_true_mean = np.mean(y_true) total_sum_squares = np.sum((y_true - y_true_mean) ** 2) residual_sum_squares = np.sum((y_true - y_pred) ** 2) r2_manual = 1 - (residual_sum_squares / total_sum_squares) # Stats for debugging metrics = { 'RMSE': rmse, 'MAE': mae, 'R2 (sklearn)': r2_score(y_true, y_pred), 'R2 (manual)': r2_manual, 'RSS': residual_sum_squares, 'TSS': total_sum_squares, 'Mean Prediction': np.mean(y_pred), 'Mean Actual': np.mean(y_true), 'Std Prediction': np.std(y_pred), 'Std Actual': np.std(y_true), 'Min Prediction': np.min(y_pred), 'Max Prediction': np.max(y_pred), 'Min Actual': np.min(y_true), 'Max Actual': np.max(y_true) } print("\nDetailed Metrics Analysis:") print(f"Total Sum of Squares (TSS): {total_sum_squares:.8f}") print(f"Residual Sum of Squares (RSS): {residual_sum_squares:.8f}") print(f"R2 components: 1 - ({residual_sum_squares:.8f} / {total_sum_squares:.8f})") return metrics def predict(self, features): """Get volatility predictions with inverse log transform""" log_predictions = self.model.predict(features) return np.exp(log_predictions) - 1e-10 def plot_feature_importance(self): """Visualize feature importance""" plt.figure(figsize=(12, 6)) plt.bar( self.feature_importance['feature'], self.feature_importance['importance'] ) plt.xticks(rotation=45) plt.title('Feature Importance') plt.tight_layout() plt.show() def plot_predictions(self, y_true, y_pred, title="Model Predictions"): """Visualize predictions vs actual values""" plt.figure(figsize=(15, 7)) plt.plot(y_true.values, label='Actual', alpha=0.7) plt.plot(y_pred, label='Predicted', alpha=0.7) plt.title(title) plt.legend() plt.tight_layout() plt.show() def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): # Get data symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: # Create and train model model = VolatilityModel(lookback_periods=(5, 10, 20), forward_window=12) features, target = model.prepare_data(rates_frame) # Split data X_train, X_test, y_train, y_test = model.create_train_test_split( features, target, test_size=0.2 ) # Train and evaluate metrics = model.train(X_train, y_train, X_test, y_test) print("\n=== Model Performance ===") for metric, value in metrics.items(): print(f"{metric}: {value:.6f}") # Make predictions predictions = model.predict(X_test) # Visualize results model.plot_feature_importance() model.plot_predictions(y_test, predictions, "Volatility Predictions") else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
Por que uma armadilha? Porque o modelo simplesmente aprendeu a prever valores próximos da média. Em períodos tranquilos tudo parecia ótimo, mas assim que o mercado realmente começava a se mover, o modelo simplesmente ignorava o movimento.
Experimentos para melhorar a regressão
Passei semanas tentando melhorar o modelo de regressão. Testei diferentes arquiteturas de redes neurais, adicionei cada vez mais características, experimentei várias funções de perda, ajustei hiperparâmetros até quase perder a sanidade.
Nada adiantou. Sim, às vezes conseguia elevar o R-quadrado para 0.15 ou 0.20, mas a que custo? O modelo ficava instável, sofria com overfitting, e o principal, ainda assim deixava passar os momentos mais críticos de alta volatilidade.
Repensando a abordagem
Foi aí que tive um estalo: pra que mesmo precisamos do valor exato da volatilidade? Pro trader, tanto faz se a volatilidade vai ser 0.00234 ou 0.00256. O que importa de verdade é: ela vai estar significativamente acima do normal?
Daí surgiu a ideia de reformular o problema como uma classificação. Em vez de prever um valor exato, passamos a identificar dois estados: volatilidade normal/baixa (rótulo 0) e volatilidade alta acima do percentil 75 (rótulo 1).
Por que isso funcionou melhor
Primeiro, passamos a ter sinais mais claros. Em vez de previsões nebulosas, agora temos uma resposta direta: esperar ou não um pico. Isso tornou o modelo muito mais fácil de interpretar e integrar ao sistema de trading.
Segundo, o modelo começou a lidar melhor com os valores extremos. Na regressão, os outliers eram suavizados; na classificação, eles passaram a formar um padrão claro da classe de alta volatilidade.
Terceiro, a aplicabilidade prática aumentou. O trader precisa de um sinal claro para agir. Foi muito mais fácil ajustar níveis de ordens de proteção com dois estados distintos do que tentar calibrar tudo com base em um valor contínuo.
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler import xgboost as xgb from xgboost import XGBClassifier from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix import matplotlib.pyplot as plt import seaborn as sns class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20), volatility_threshold=75): """ Args: lookback_periods: periods for feature calculation volatility_threshold: percentile for defining high volatility """ self.lookback_periods = lookback_periods self.volatility_threshold = volatility_threshold self.scaler = StandardScaler() def calculate_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change() df['abs_returns'] = abs(df['returns']) # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1)), abs(df['low'] - df['close'].shift(1)) ) ) # Signs of volatility for period in self.lookback_periods: # ATR df[f'atr_{period}'] = df['true_range'].rolling(window=period).mean() # Volatility df[f'volatility_{period}'] = df['returns'].rolling(period).std() # Extremes df[f'high_low_range_{period}'] = ( (df['high'].rolling(period).max() - df['low'].rolling(period).min()) / df['close'] ) # Volatility acceleration df[f'volatility_change_{period}'] = ( df[f'volatility_{period}'] / df[f'volatility_{period}'].shift(1) ) # Add sentiment indicators df['body_ratio'] = abs(df['close'] - df['open']) / (df['high'] - df['low']) df['upper_shadow'] = (df['high'] - df[['open', 'close']].max(axis=1)) / (df['high'] - df['low']) df['lower_shadow'] = (df[['open', 'close']].min(axis=1) - df['low']) / (df['high'] - df['low']) # Data clearing for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan) df[col] = df[col].fillna(method='ffill').fillna(0) return df def prepare_features(self, df): # Select features for the model feature_cols = [] # Add time features time = pd.to_datetime(df['time'], unit='s') df['hour_sin'] = np.sin(2 * np.pi * time.dt.hour / 24) df['hour_cos'] = np.cos(2 * np.pi * time.dt.hour / 24) df['day_sin'] = np.sin(2 * np.pi * time.dt.dayofweek / 7) df['day_cos'] = np.cos(2 * np.pi * time.dt.dayofweek / 7) # Collect all features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'high_low_range_{period}', f'volatility_change_{period}' ]) feature_cols.extend([ 'body_ratio', 'upper_shadow', 'lower_shadow', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create DataFrame with features features = df[feature_cols].copy() features = features.replace([np.inf, -np.inf], 0).fillna(0) # Scale features scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=feature_cols, index=features.index ) def create_target(self, df, forward_window=12): """Creates a binary label: 1 for high volatility, 0 for low volatility""" # Calculate future volatility future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window) # Determine the threshold for high volatility vol_threshold = np.nanpercentile(future_vol, self.volatility_threshold) # Create binary labels target = (future_vol > vol_threshold).astype(int) target = target.fillna(0) return target def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) print(f"Positive class ratio: {target.mean():.2%}") return features, target class VolatilityClassifier: def __init__(self, lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75): self.processor = VolatilityProcessor(lookback_periods, volatility_threshold) self.forward_window = forward_window self.model = XGBClassifier( n_estimators=200, max_depth=6, learning_rate=0.1, subsample=0.8, colsample_bytree=0.8, min_child_weight=1, gamma=0.1, reg_alpha=0.1, reg_lambda=1, scale_pos_weight=1, random_state=42, n_jobs=-1, eval_metric=['auc', 'error'] ) self.feature_importance = None def prepare_data(self, rates_frame): features, target = self.processor.prepare_dataset(rates_frame) return features, target def create_train_test_split(self, features, target, test_size=0.2): split_idx = int(len(features) * (1 - test_size)) X_train = features.iloc[:split_idx] X_test = features.iloc[split_idx:] y_train = target.iloc[:split_idx] y_test = target.iloc[split_idx:] return X_train, X_test, y_train, y_test def train(self, X_train, y_train, X_test, y_test): print("\n=== Training Model ===") print("Training set shape:", X_train.shape) print("Test set shape:", X_test.shape) # Train the model eval_set = [(X_train, y_train), (X_test, y_test)] self.model.fit( X_train, y_train, eval_set=eval_set, verbose=True ) # Maintain the importance of features importance = self.model.feature_importances_ self.feature_importance = pd.DataFrame({ 'feature': X_train.columns, 'importance': importance }).sort_values('importance', ascending=False) # Evaluate the model predictions = self.predict(X_test) metrics = self.calculate_metrics(y_test, predictions) return metrics def calculate_metrics(self, y_true, y_pred): metrics = { 'Accuracy': accuracy_score(y_true, y_pred), 'Precision': precision_score(y_true, y_pred), 'Recall': recall_score(y_true, y_pred), 'F1 Score': f1_score(y_true, y_pred) } # Error matrix cm = confusion_matrix(y_true, y_pred) print("\nConfusion Matrix:") print(cm) return metrics def predict(self, features): return self.model.predict(features) def predict_proba(self, features): return self.model.predict_proba(features) def plot_feature_importance(self): plt.figure(figsize=(12, 6)) plt.bar( self.feature_importance['feature'], self.feature_importance['importance'] ) plt.xticks(rotation=45, ha='right') plt.title('Feature Importance') plt.tight_layout() plt.show() def plot_confusion_matrix(self, y_true, y_pred): cm = confusion_matrix(y_true, y_pred) plt.figure(figsize=(8, 6)) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') plt.title('Confusion Matrix') plt.ylabel('True Label') plt.xlabel('Predicted Label') plt.tight_layout() plt.show() def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: # Create and train the model model = VolatilityClassifier( lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75 ) features, target = model.prepare_data(rates_frame) # Separate data X_train, X_test, y_train, y_test = model.create_train_test_split( features, target, test_size=0.2 ) # Train and evaluate metrics = model.train(X_train, y_train, X_test, y_test) print("\n=== Model Performance ===") for metric, value in metrics.items(): print(f"{metric}: {value:.4f}") # Make predictions predictions = model.predict(X_test) # Visualize results model.plot_feature_importance() model.plot_confusion_matrix(y_test, predictions) else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
Resultados do novo modelo
Após mudar para classificação, os resultados melhoraram drasticamente. A precisão (precision) chegou a cerca de 70%, ou seja, de cada 10 alertas de alta volatilidade, 7 se concretizavam. O recall por volta de 65% indicava que conseguimos capturar cerca de dois terços dos momentos realmente perigosos. Mas o mais importante, o modelo passou a ser de fato útil para trading.
Agora que a estrutura básica do modelo está definida, na próxima parte vamos falar sobre como integrá-lo a um sistema de trading real e que tipos de decisões podem ser tomadas com base nos seus sinais. Aposto que essa será a parte mais interessante da nossa jornada no mundo da previsão de volatilidade.
E aí, o que achou dessa abordagem? Seria interessante saber se você já usou algo parecido na sua prática. E, se sim, quais outras métricas de volatilidade você considera úteis?
O indicador de volatilidade extrema futura que desenvolvi
O indicador que desenvolvi é uma ferramenta abrangente para prever picos de volatilidade no mercado Forex. Diferente dos indicadores clássicos de volatilidade, que apenas mostram o estado atual, o nosso prevê a probabilidade de movimentos intensos nas próximas 12 horas.
import tkinter as tk from tkinter import ttk import matplotlib matplotlib.use('Agg') # Important to install before importing pyplot from matplotlib.figure import Figure from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg import time import MetaTrader5 as mt5 class VolatilityPredictor(tk.Tk): def __init__(self): super().__init__() self.title("Volatility Predictor") self.geometry("600x600") # Initialize the model self.model = VolatilityClassifier( lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75 ) # Load and train the model at startup self.initialize_model() # Create the interface self.create_gui() # Launch the update self.update_data() def initialize_model(self): rates_frame = check_mt5_data("EURUSD") if rates_frame is not None: features, target = self.model.prepare_data(rates_frame) X_train, X_test, y_train, y_test = self.model.create_train_test_split( features, target, test_size=0.2 ) self.model.train(X_train, y_train, X_test, y_test) def create_gui(self): # Top panel with settings control_frame = ttk.Frame(self) control_frame.pack(fill='x', padx=2, pady=2) ttk.Label(control_frame, text="Symbol:").pack(side='left', padx=2) self.symbol_var = tk.StringVar(value="EURUSD") symbol_list = ["EURUSD", "GBPUSD", "USDJPY"] # Simplified list ttk.Combobox(control_frame, textvariable=self.symbol_var, values=symbol_list, width=8).pack(side='left', padx=2) ttk.Label(control_frame, text="Alert:").pack(side='left', padx=2) self.threshold_var = tk.StringVar(value="0.7") ttk.Entry(control_frame, textvariable=self.threshold_var, width=4).pack(side='left') # Chart self.fig = Figure(figsize=(6, 4), dpi=100) self.canvas = FigureCanvasTkAgg(self.fig, self) self.canvas.draw() self.canvas.get_tk_widget().pack(fill='both', expand=True, padx=2, pady=2) # Probability indicator gauge_frame = ttk.Frame(self) gauge_frame.pack(fill='x', padx=2, pady=2) self.probability_var = tk.StringVar(value="0%") self.probability_label = ttk.Label( gauge_frame, textvariable=self.probability_var, font=('Arial', 20, 'bold') ) self.probability_label.pack() self.progress = ttk.Progressbar( gauge_frame, length=150, mode='determinate', maximum=100 ) self.progress.pack(pady=2) def update_data(self): try: rates = check_mt5_data(self.symbol_var.get()) if rates is not None: features, _ = self.model.prepare_data(rates) probability = self.model.predict_proba(features)[-1][1] self.update_indicators(rates, probability) threshold = float(self.threshold_var.get()) if probability > threshold: self.alert(probability) except Exception as e: print(f"Error updating data: {e}") finally: self.after(1000, self.update_data) def update_indicators(self, rates, probability): self.fig.clear() ax = self.fig.add_subplot(111) df = rates.tail(50) # Show fewer bars for compactness width = 0.6 width2 = 0.1 up = df[df.close >= df.open] down = df[df.close < df.open] ax.bar(up.index, up.close-up.open, width, bottom=up.open, color='g') ax.bar(up.index, up.high-up.close, width2, bottom=up.close, color='g') ax.bar(up.index, up.low-up.open, width2, bottom=up.open, color='g') ax.bar(down.index, down.close-down.open, width, bottom=down.open, color='r') ax.bar(down.index, down.high-down.open, width2, bottom=down.open, color='r') ax.bar(down.index, down.low-down.close, width2, bottom=down.close, color='r') ax.grid(False) # Remove the grid for compactness ax.set_xticks([]) # Remove X axis labels self.canvas.draw() prob_pct = int(probability * 100) self.probability_var.set(f"{prob_pct}%") self.progress['value'] = prob_pct if prob_pct > 70: self.probability_label.configure(foreground='red') elif prob_pct > 50: self.probability_label.configure(foreground='orange') else: self.probability_label.configure(foreground='green') def alert(self, probability): window = tk.Toplevel(self) window.title("Alert!") window.geometry("200x80") # Reduced alert window msg = f"High volatility: {probability:.1%}" ttk.Label(window, text=msg, font=('Arial', 10)).pack(pady=10) ttk.Button(window, text="OK", command=window.destroy).pack() def main(): app = VolatilityPredictor() app.mainloop() if __name__ == "__main__": main()
A janela principal do indicador é dividida em três partes principais. Na parte superior, é exibido um gráfico de candles japoneses — as últimas 100 barras, para uma visualização clara da dinâmica atual do preço. As velas verdes e vermelhas indicam, respectivamente, os movimentos de alta e baixa do mercado.
Na parte central está o elemento principal do indicador — um mostrador semicircular de probabilidade. Ele exibe a probabilidade atual de um pico de volatilidade, em percentual, de 0 a 100. O ponteiro do indicador muda de cor conforme o nível de risco: verde para probabilidade baixa até 50%, laranja para média de 50% a 70%, e vermelho quando a probabilidade ultrapassa 70%.
A previsão é construída com base na análise do estado atual do mercado e dos padrões históricos de volatilidade. O modelo considera os dados das últimas 20 barras para construir o forecast e prever a chance de volatilidade elevada nas próximas 12 horas. A maior precisão do modelo ocorre nas primeiras 4 a 6 horas após o sinal.
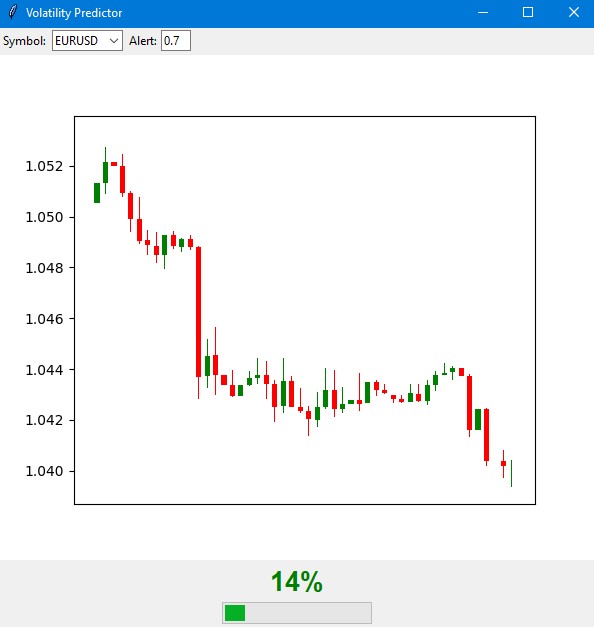
Com probabilidade baixa (zona verde), o mercado tende a seguir em movimento calmo. Esse é um bom momento para operar com os parâmetros padrões da sua estratégia. Durante esses períodos, é possível usar níveis convencionais de stop-loss.
Quando o indicador aponta probabilidade média, e o ponteiro fica laranja, é hora de aumentar a cautela. Nessas situações, recomenda-se ampliar os níveis de ordens de proteção em cerca de 25% em relação ao tamanho padrão.
Com alta probabilidade de pico, quando o ponteiro fica vermelho, é essencial revisar seriamente o gerenciamento de risco. Nesses momentos, o ideal é aumentar o stop-loss em pelo menos 1.5x e, se possível, evitar novas entradas até que o mercado se estabilize.
Na parte inferior do indicador estão os controles. Aqui é possível selecionar o ativo, o timeframe e ajustar o limiar para receber alertas. Por padrão, esse limiar é fixado em 70%, valor ideal que equilibra bem a quantidade de sinais com sua confiabilidade.
A precisão das previsões do indicador atinge 70% para os sinais de alta volatilidade. Isso significa que, de cada dez alertas sobre um possível pico, sete realmente se concretizam. Além disso, o indicador consegue captar cerca de dois terços de todos os movimentos relevantes do mercado.
É importante entender que o indicador não prevê a direção do movimento do preço, mas apenas a probabilidade de aumento da volatilidade. Sua principal função é alertar o trader sobre a possibilidade de um movimento forte, para que ele possa ajustar sua estratégia de trading e os níveis de ordens de proteção com antecedência.
Nas próximas versões do indicador, está previsto o acréscimo da função de ajuste automático de stop-loss com base na volatilidade prevista. Isso permitirá automatizar ainda mais o processo de gerenciamento de risco e tornar as operações mais seguras.
O indicador complementa muito bem os sistemas de trading já existentes, atuando como um filtro adicional para controle de risco. Seu principal diferencial é justamente a capacidade de antecipar movimentos fortes no mercado, oferecendo ao trader tempo para se preparar e ajustar sua abordagem.
Considerações finais
No trading moderno, a previsão de volatilidade continua sendo uma das tarefas centrais para operar com sucesso. O caminho descrito neste artigo — da regressão simples ao classificador de alta volatilidade — mostra que, às vezes, a solução simples é a mais eficaz. O sistema desenvolvido atinge uma precisão de cerca de 70% nas previsões e identifica aproximadamente dois terços dos movimentos de mercado significativos.
A principal lição é que, na prática, mais importante do que saber o valor exato da volatilidade futura é ter um alerta em tempo hábil sobre um possível pico. O indicador que desenvolvi cumpre essa função com êxito, ajudando os traders a ajustar suas estratégias e ordens de proteção antes que o mercado dispare. A combinação de métodos clássicos de análise com as tecnologias modernas de aprendizado de máquina abre novas possibilidades para o gerenciamento de risco.
A chave do sucesso não está na complexidade dos algoritmos, mas sim em formular bem o problema e preparar os dados com qualidade. Essa abordagem pode ser adaptada para diferentes ativos e timeframes, tornando o trading mais seguro e previsível.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16960
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Algoritmo evolutivo de trading com aprendizado por reforço e extinção de estratégias não lucrativas (ETARE)
Algoritmo evolutivo de trading com aprendizado por reforço e extinção de estratégias não lucrativas (ETARE)
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Olá, muito obrigado. Não confio em apenas um método. Tenho um EA Python abrangente, no qual tenho análise de padrões ingênuos, aprendizado de máquina em código binário, aprendizado de máquina em barras 3D, rede neural em análise de volume, análise de volatilidade, modelo econômico baseado em dados do Banco Mundial e do FMI, enormes conjuntos de dados de centenas de milhares de linhas em todos os países do mundo, todas as estatísticas possíveis em ....E um módulo estatístico que cria todos os recursos estatísticos possíveis, e um algoritmo genético que otimiza hiperparâmetros, e um módulo de arbitragem que cria preços justos para as moedas, e o download das manchetes e do conteúdo da mídia mundial sobre essa ou aquela moeda, com a análise da coloração emocional de todos os artigos e notas de notícias (em 80% dos casos, quando a mídia o incentiva a comprar algo, vem o colapso; se a notícia for negativa, provavelmente sobe com um atraso de 3 a 4 dias).
Você tem alguma ideia sobre o que mais posso acrescentar? Só cheguei à conclusão de que ainda preciso fazer um upload de posições de um site de monitoramento de contas bem conhecido (não sei se posso dizer o nome dele aqui), já criei o código e escreverei um artigo sobre isso também, pois o preço na maioria das vezes vai contra a multidão.
Também estou trabalhando no upload de dados sobre volumes de futuros, clusters de volume e análise de relatórios COT - também em Python.
E eu uso modelos de regressão e modelos de classificação e, em breve, quero criar um supersistema que receberá todos os sinais, todos os sinais de todos os modelos, bem como o histórico flutuante de lucros/perdas e lucros/perdas da conta, e alimentará tudo isso no modelo DQN=).
A resposta ao primeiro comando é "Python", mas para esta linha recebo a mensagem "O sistema não consegue encontrar o caminho especificado"
(instalei o Python recentemente, seguindo suas instruções)