
Determinação de taxas de câmbio justas com base na PPC usando dados do FMI

Em certo momento, percebi que estava gastando mais tempo procurando um módulo de previsão "ideal" do que tentando entender o que realmente move as taxas de câmbio. Então me fiz uma pergunta simples: e se esquecêssemos todos esses gráficos e tentássemos encontrar o valor real das moedas? Não o valor que o mercado mostra em um momento específico, sob influência de emoções e especulações, mas o valor que decorre das leis econômicas fundamentais?
Essa pergunta me levou a um trabalho de vários meses de profundidade. Comecei estudando a teoria da paridade do poder de compra e terminei escrevendo um sistema completo de análise de taxas de câmbio em Python. Isso acabou sendo muito mais interessante do que qualquer indicador técnico.
Formulação do problema
A análise dos mercados cambiais geralmente se concentra na busca por indicadores técnicos e padrões gráficos, ignorando os fatores econômicos fundamentais. Surge, então, a seguinte questão: é possível determinar o valor justo das moedas com base em leis econômicas, e não em sentimentos de mercado de curto prazo e movimentos especulativos?
Este estudo apresenta uma abordagem prática para resolver essa tarefa por meio da criação de um sistema abrangente de cálculo de taxas de câmbio justas com base na teoria da paridade do poder de compra, implementado na linguagem de programação Python.
Fundamentos teóricos da paridade do poder de compra
O exemplo clássico do Big Mac, do McDonald's, demonstra a essência da teoria: se um hambúrguer custa 5 dólares nos EUA e 9 euros na Europa, a taxa justa deveria ser de 1,8 dólar por euro. Por trás dessa ilustração simples, esconde-se uma ferramenta fundamental para a análise dos mercados cambiais, pois permite identificar desequilíbrios de longo prazo, além da volatilidade de curto prazo do mercado.
As raízes históricas desse conceito remontam ao século XVI, quando os comerciantes espanhóis observavam desproporções de preços entre a metrópole e as colônias. Se um peso em Sevilha comprava um pão, enquanto no México comprava três pães, isso indicava uma incompatibilidade fundamental no valor relativo das moedas, exigindo correção por meio de uma mudança na taxa de câmbio ou do alinhamento dos preços.
Formulações da teoria da PPC
A paridade absoluta do poder de compra afirma uma relação direta entre as taxas de câmbio e a relação de preços de bens idênticos em diferentes países. Embora seja teoricamente elegante, na prática essa abordagem enfrenta múltiplos fatores de distorção, como diferenças tributárias, barreiras regulatórias, custos de transporte e restrições comerciais.
S₁₂ = P₁ / P₂
onde S₁₂ é a taxa de câmbio da moeda 1 em relação à moeda 2, P₁ e P₂ são os níveis de preços nos respectivos países.
A paridade relativa do poder de compra concentra-se na dinâmica das variações de preços, e não nos níveis absolutos. De acordo com essa formulação, se a inflação no país A é de 10% ao ano e no país B é de 5%, a moeda do país A deve se desvalorizar em 5% em relação à moeda do país B para preservar a paridade do poder de compra.
S₁₂(t) / S₁₂(0) = [P₁(t) / P₁(0)] / [P₂(t) / P₂(0)]
Ou, de forma simplificada:
ΔS₁₂ = π₁ - π₂
onde π₁ e π₂ são as taxas de inflação nos países 1 e 2.
A abordagem relativa foi escolhida como base metodológica do algoritmo, devido à maior aplicabilidade prática, à melhor representação da realidade econômica e à possibilidade de obtenção de referências quantitativas concretas para as taxas de câmbio.
Avaliação das fontes de dados disponíveis
A análise dos fornecedores existentes de dados de PPC revelou limitações significativas para o uso prático. A OECD publica coeficientes oficiais de paridade do poder de compra com um atraso de seis meses a um ano; os dados de 2023 tornaram-se disponíveis apenas em meados de 2024, o que é inaceitável para mercados cambiais dinâmicos.
| Fonte | Frequência de atualização | Atraso | Custo/ano | Transparência metodológica | Aplicabilidade prática |
|---|---|---|---|---|---|
| OECD | Anual | 6–12 meses | USD 0 | Baixa | Pesquisa |
| Penn World Table | A cada 2–3 anos | 1–2 anos | USD 0 | Média | Acadêmica |
| Bloomberg Terminal | Em tempo real | Nenhum | USD 24,000 | Inexistente | Profissional |
| Refinitiv Eikon | Em tempo real | Nenhum | USD 22,000 | Inexistente | Profissional |
O Penn World Table é atualizado em intervalos de vários anos e, além disso, a versão mais recente disponível continha informações apenas até 2019. Para pesquisas acadêmicas, essa base tem valor, porém, para o trading prático, tais defasagens temporais são críticas.
Os fornecedores comerciais de dados, Bloomberg e Refinitiv, oferecem informações mais atualizadas, porém o custo de acesso começa em cerca de $2000 por mês para o Bloomberg Terminal, sem garantias de transparência metodológica ou de qualidade dos dados.
O problema da falta de transparência metodológica: uma deficiência crítica das soluções existentes é a ausência de clareza nos procedimentos de cálculo. A metodologia de cálculo dos coeficientes da OECD, a composição das cestas de consumo, os algoritmos de tratamento de valores atípicos estatísticos e os ajustes para diferenças qualitativas entre produtos permanecem sem documentação.
Grandes fornecedores de dados funcionam como sistemas fechados; o usuário recebe resultados numéricos sem compreender sua origem ou sem possibilidade de verificação. Essa abordagem é inaceitável para uma análise financeira séria, que exige controle total sobre os processos de cálculo.
Desenvolvimento de um sistema próprio: foi tomada a decisão de criar um sistema independente de cálculo da PPC utilizando dados publicamente disponíveis de organizações internacionais, como o Fundo Monetário Internacional, o Banco Mundial e serviços nacionais de estatística. O sistema deve garantir total transparência dos algoritmos e a possibilidade de adaptação da metodologia a tarefas analíticas específicas.
Apesar da complexidade significativa do desenvolvimento, quando comparado à aquisição de uma solução pronta, e da necessidade de estudar múltiplas fontes de dados, formatos de API e métodos estatísticos, essa abordagem garante controle total sobre o processo de cálculo e uma compreensão profunda do funcionamento do sistema.
Solução arquitetural: sistema de múltiplos métodos
O problema fundamental de qualquer cálculo de PPC reside na existência de múltiplas abordagens para estimar a taxa de câmbio justa, cada uma com vantagens e limitações específicas. A escolha de um único método inevitavelmente leva à subjetividade dos resultados.
| Fontes de dados | Métodos de cálculo da PPC | Resultados e sinais |
|---|---|---|
| API do FMI | Price Level | Taxas justas |
| Banco Mundial | GDP-Implied | Desvios em relação ao mercado |
| Estatísticas nacionais | Inflation-Adjusted | Sinais de trading |
| Dados de fallback | Big Mac Proxy | Índices de confiança |
| Taxas de câmbio de pares de moedas | Composite Method | Classificação de moedas |
O sistema desenvolvido utiliza, em paralelo, vários métodos independentes de cálculo, com posterior combinação dos resultados. A concordância entre as estimativas dos diferentes métodos aumenta a confiança no resultado, enquanto divergências significativas indicam um alto grau de incerteza, o que por si só representa uma informação valiosa sobre o estado do mercado.
Primeira abordagem baseia-se em comparações internacionais do nível de preços. A lógica é simples: se um residente da Suíça gasta uma vez e meia mais para viver do que um americano, mantendo o mesmo padrão de vida, então o franco suíço está sobrevalorizado em 50%.
Os dados para esse método foram obtidos a partir de programas internacionais de comparação de preços, conduzidos sob a égide do Banco Mundial e da OECD. Esses programas comparam o custo de cestas de consumo padrão em diferentes países e calculam níveis relativos de preços.
def _calculate_price_level_ppp(self) -> Dict: ppp_rates = {} for country, price_level in self.price_levels_2024.items(): if country != 'US': ppp_factor = price_level / 100.0 ppp_rates[country] = { 'ppp_conversion_factor': ppp_factor, 'price_level_index': price_level, 'method': 'price_level_adjustment' } return ppp_rates
A vantagem do método é que ele reflete diferenças reais no custo de vida. A desvantagem é que os dados são atualizados raramente, uma vez a cada poucos anos.
Segunda abordagem foi concebida por mim mesmo, e até hoje tenho orgulho dela. A ideia surgiu durante o estudo dos dados do FMI: e se compararmos o PIB de um país em moeda nacional, a partir da estatística oficial, com a estimativa desse mesmo PIB em dólares, proveniente de bases de dados internacionais?
A lógica é a seguinte: se o Banco da Rússia informa que o PIB da Rússia é de 150 trilhões de rublos, e o Banco Mundial estima o PIB russo em 2 trilhões de dólares, então a taxa de câmbio implícita é de 75 rublos por dólar. Essa é a taxa na qual as economias são avaliadas de forma "justa" em relação uma à outra.
def _calculate_gdp_implied_ppp(self, economic_data: pd.DataFrame): for country, gdp_usd_2023 in self.gdp_usd_estimates_2023.items(): country_gdp_lcu = gdp_lcu_data[gdp_lcu_data['REF_AREA'] == country] if not country_gdp_lcu.empty: latest_data = country_gdp_lcu.sort_values('year').iloc[-1] gdp_lcu = latest_data['value'] if gdp_lcu > 0: implied_rate = gdp_lcu / gdp_usd_2023
Esse método mostrou-se surpreendentemente preciso e atual. Os dados do PIB são atualizados trimestralmente, de modo que as estimativas permanecem recentes. Além disso, como o PIB é um indicador agregado de toda a atividade econômica, ele reflete bem o valor fundamental da moeda.
Terceiro método implementa a fórmula clássica do PPC relativo, apresentada nos manuais. Parte-se de uma taxa de câmbio histórica em algum ponto base e ajusta-se esse valor pela diferença acumulada de inflação entre os países.
Escolhi o ano de 2020 como ponto base, suficientemente recente para ser relevante, mas anterior à pandemia, de modo a evitar distorções decorrentes de políticas monetárias extremas.
def _calculate_inflation_adjusted_ppp(self, economic_data: pd.DataFrame): # Get the basic rate for 2020 base_rate_2020 = GetBaseRate2020(base_currency, quote_currency) # Calculating the inflation differential inflation_differential = (base_data.inflation_rate - quote_data.inflation_rate) / 100.0 # Adjust the base rate adjusted_rate = base_rate_2020 * (1 + inflation_differential)
O método é teoricamente impecável e fácil de explicar. Se no país A a inflação foi maior do que no país B, então a moeda do país A deve se desvalorizar proporcionalmente a essa diferença.
O único problema é a qualidade dos dados de inflação. Diferentes países calculam a inflação de maneiras distintas, e alguns tendem a "embelezar" as estatísticas. Ainda assim, de modo geral, o método funciona bem.
O quarto método é inspirado no famoso Big Mac Index, da The Economist. A ideia é que o Big Mac seja um produto padronizado, produzido com a mesma tecnologia em todo o mundo. Seu preço deve refletir as diferenças reais no custo dos recursos entre os países.
O problema é que coletar preços atualizados do Big Mac é, por si só, uma tarefa de pesquisa independente. Em vez disso, utilizo dados conhecidos sobre níveis relativos de preços para modelar quanto um produto padronizado deveria custar em cada país.
def _calculate_big_mac_proxy_ppp(self): us_big_mac_price = 5.50 for country, price_level in self.price_levels_2024.items(): if country != 'US': local_big_mac_price = us_big_mac_price * (price_level / 100.0) ppp_rate = local_big_mac_price / us_big_mac_price
O método não é o mais preciso, mas fornece uma boa verificação intuitiva dos resultados dos outros métodos. Se todas as demais abordagens indicam que uma moeda está sobrevalorizada em 20%, e o "método do Big Mac" aponta para um resultado semelhante, isso aumenta a confiança na estimativa.
O quinto método combina os resultados de todos os anteriores por meio de uma média ponderada. Dediquei bastante tempo à calibração dos pesos, testando diferentes combinações com dados históricos.
Ao final, cheguei à seguinte distribuição:
- Price Level PPP: 30% (o mais fundamental)
- GDP-Implied PPP: 25% (o mais atual)
- Inflation-Adjusted PPP: 25% (o mais teoricamente fundamentado)
- Big Mac Proxy: 20% (o mais intuitivo)
def _calculate_composite_ppp(self, all_methods: Dict): weights = [0.30, 0.25, 0.25, 0.20] # Dynamic weight normalization if valid_methods < 4: total_weight = sum(weights[:valid_methods]) normalized_weights = [w / total_weight for w in weights[:valid_methods]] composite_rate = sum(rate * weight for rate, weight in zip(rates, normalized_weights))
O ponto-chave é a normalização dinâmica dos pesos. Se algum método não consegue gerar um resultado, por exemplo, por falta de dados de inflação, os pesos dos demais métodos são aumentados proporcionalmente. Isso é muito mais inteligente do que simplesmente excluir métodos "problemáticos".
Prática de criação do programa
Após meses de preparação teórica, chegou a hora de colocar as mãos no teclado. Decidi escrever em Python, uma linguagem suficientemente rápida para cálculos financeiros e que, ao mesmo tempo, conta com excelentes bibliotecas para trabalho com dados.
A primeira e mais importante questão foi: de onde obter os dados? Depois de analisar dezenas de fontes, a escolha recaiu sobre a API do Fundo Monetário Internacional. Pública, gratuita, bem documentada e, o que é especialmente importante, atualizada regularmente.
def __init__(self):
self.base_url = "http://dataservices.imf.org/REST/SDMX_JSON.svc"
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Manual-PPP-Calculator/1.0',
'Accept': 'application/json'
})
Um detalhe pequeno, mas importante: utilizo requests.Session() em vez de chamadas simples a requests.get(). Isso permite reutilizar conexões TCP e acelera significativamente o trabalho quando há múltiplas requisições ao mesmo API.
O User-Agent também não foi escolhido por acaso. Muitos APIs bloqueiam requisições sem um User-Agent explicitamente definido ou com o valor padrão do Python. É melhor se identificar desde o início como uma aplicação séria.
O problema seguinte mostrou-se mais traiçoeiro do que o esperado. Os códigos de moedas (USD, EUR, GBP) precisam ser associados, de alguma forma, aos códigos de países no sistema do FMI. E foi aí que começaram as surpresas.
EUR não é um código de país, mas de uma união monetária. Na base de dados do FMI, a zona do euro é identificada como U2. A Suíça é CH, e não SW. O Reino Unido é GB, e não UK.
self.currency_country_map = {
'USD': 'US', 'EUR': 'U2', 'GBP': 'GB', 'JPY': 'JP',
'AUD': 'AU', 'CAD': 'CA', 'CHF': 'CH', 'NZD': 'NZ',
'SEK': 'SE', 'NOK': 'NO', 'DKK': 'DK', 'PLN': 'PL'
}
À primeira vista, parece um detalhe irrelevante, mas sem o mapeamento correto todo o sistema simplesmente não funciona. Levei um dia inteiro depurando o código até perceber que estava tentando buscar dados para códigos de países que simplesmente não existiam.
APIs externas têm uma característica desagradável: quebram no momento mais inconveniente. A API do FMI não é exceção. Às vezes fica indisponível por várias horas, às vezes retorna dados incompletos, e às vezes simplesmente responde com erro, sem motivo aparente.
Decidi incorporar um sistema de dados de reserva desde o início:
self.fallback_market_rates = {
'EURUSD': 1.0850, 'GBPUSD': 1.2650, 'USDJPY': 148.50,
'AUDUSD': 0.6750, 'USDCAD': 1.3550, 'USDCHF': 0.8850,
'NZDUSD': 0.6150
}
self.price_levels_2024 = {
'US': 100.0, # Basic level
'U2': 88.5, # Eurozone is 11.5% cheaper than the US
'GB': 85.2, # UK
'JP': 67.4, # Japan is significantly cheaper
'AU': 95.8, # Australia is close to the USA
'CA': 91.3, # Canada is moderately cheaper
'CH': 125.6, # Switzerland is the most expensive
'NZ': 89.7 # New Zealand
}
Esses dados são baseados nas comparações internacionais de preços mais recentes disponíveis e nas taxas de câmbio de mercado vigentes no momento da escrita do código. Eles não são perfeitamente atuais, mas são suficientemente precisos para que o sistema funcione em modo autônomo.
Alguns podem dizer que isso é um paliativo. Eu considero isso uma arquitetura bem pensada. Em finanças, a confiabilidade é mais importante do que a precisão ideal. É melhor ter um resultado aproximadamente correto do que não ter resultado algum.
Para o método GDP-implied, eu precisava de estimativas do PIB de diferentes países em dólares americanos. À primeira vista, parece uma tarefa simples: basta pegar os dados do Banco Mundial e pronto. Mas aqui também surgiram armadilhas.
O Banco Mundial publica o PIB em dólares correntes, com base nas taxas de câmbio de mercado, e em dólares ajustados pela PPC. Para os meus objetivos, são necessários exatamente os dólares de mercado, pois eu os comparo com o PIB em moeda nacional a partir das estatísticas do FMI.
self.gdp_usd_estimates_2023 = {
'US': 27000, # USD 27 trillion
'U2': 17500, # Eurozone ~USD 17.5 trillion
'GB': 3300, # UK ~USD 3.3 trillion
'JP': 4200, # Japan ~USD 4.2 trillion
'AU': 1700, # Australia ~USD 1.7 trillion
'CA': 2100, # Canada ~USD 2.1 trillion
'CH': 900, # Switzerland ~USD 0.9 trillion
'NZ': 250 # New Zealand ~USD 0.25 trillion
}
Para o método inflation-adjusted, era necessária uma referência, isto é, taxas históricas a partir das quais calcular o ajuste inflacionário. Escolhi o ano de 2020 por vários motivos.
Em primeiro lugar, é suficientemente recente para ser relevante. Em segundo lugar, 2020 foi anterior à pandemia e às medidas extremas de política monetária associadas a ela. Em terceiro lugar, os dados de 2020 já estão consolidados e não passam mais por revisões dos órgãos estatísticos.
self.base_rates_2020 = {
'U2': 0.85, # EURUSD
'GB': 0.78, # GBPUSD
'JP': 106.0, # USDJPY
'AU': 1.45, # AUDUSD
'CA': 1.34, # USDCAD
'CH': 0.92, # USDCHF
'NZ': 1.52 # NZDUSD
}
As taxas foram tomadas como valores médios de 2020, para suavizar a volatilidade de curto prazo. Isso é importante porque o método inflation-adjusted pressupõe que a taxa base era "justa" no ponto inicial.
Dificuldades no trabalho com a API do FMI
A parte mais ingrata, porém criticamente importante, de qualquer projeto financeiro é o trabalho com fontes externas de dados. A API do FMI é poderosa e informativa, mas possui suas peculiaridades, que tive de aprender por tentativa e erro.
A primeira coisa com que me deparei foi que a API não gosta de requisições grandes. Se você tenta solicitar muitos indicadores de uma vez para vários países, o servidor retorna erro ou ocorre timeout. Foi necessário implementar a divisão das requisições em partes menores.
def fetch_all_available_data(self, countries: List[str], years: int = 10): all_indicators = [ 'NGDP_XDC', # GDP in national currency 'NGDP_USD', # GDP in USD 'PCPIPCH', # Inflation rate 'NGDP_RPCH', # Real GDP growth 'ENDA_XDC_USD_RATE', # Exchange rate 'PCPI_IX', # Consumer Price Index 'LP' # Population ] chunk_size = 5 # Maximum 5 indicators per request for i in range(0, len(all_indicators), chunk_size): chunk = all_indicators[i:i + chunk_size] countries_string = '+'.join(countries) indicators_string = '+'.join(chunk) url = f"{self.base_url}/CompactData/IFS/A.{countries_string}.{indicators_string}"
O tamanho dos blocos foi ajustado empiricamente. 3 indicadores é conservador demais, exigindo muitas requisições. 7 ou 8 indicadores frequentemente levam a timeouts. 5 acabou sendo o compromisso ideal.
A API do FMI às vezes se comporta de forma imprevisível. As mesmas requisições podem funcionar corretamente pela manhã e falhar à noite. Em alguns casos, o servidor retorna dados parciais sem qualquer aviso. Em outros, os dados chegam em um formato inesperado.
Implementei um sistema abrangente de tratamento de erros com logging:
try: response = self.session.get(url, params={ 'startPeriod': str(start_year), 'endPeriod': str(end_year) }, timeout=60) if response.status_code == 200: raw_data = response.json() df_chunk = self._parse_response_data(raw_data) if not df_chunk.empty: all_data.append(df_chunk) logger.info(f"Chunk {i//chunk_size + 1}: {len(df_chunk)} data points loaded") else: logger.warning(f"Chunk {i//chunk_size + 1}: empty response") else: logger.error(f"HTTP {response.status_code}: {response.text}") except requests.exceptions.Timeout: logger.warning(f"Timeout for chunk {i//chunk_size + 1}") except requests.exceptions.RequestException as e: logger.error(f"Request failed for chunk {i//chunk_size + 1}: {e}") except Exception as e: logger.error(f"Unexpected error in chunk {i//chunk_size + 1}: {e}") continue
Sem um logging tão detalhado, a depuração teria se transformado em um pesadelo. Quando uma requisição falha, é essencial entender em que etapa isso aconteceu e por quê.
O formato de resposta da API do FMI merece uma menção à parte. Eles utilizam o SDMX-JSON, um formato "padrão" para intercâmbio de dados estatísticos. Na prática, isso acabou sendo bastante doloroso.
def _parse_response_data(self, data: Dict) -> pd.DataFrame: records = [] try: compact_data = data['CompactData'] dataset = compact_data['DataSet'] if 'Series' not in dataset: return pd.DataFrame() series_list = dataset['Series'] # API can return a single series as an object or an array of series as a list if not isinstance(series_list, list): series_list = [series_list] for series in series_list: # All attributes are marked with the '@' symbol - this needs to be processed series_attrs = {k.replace('@', ''): v for k, v in series.items() if k.startswith('@')} obs_list = series.get('Obs', []) if not isinstance(obs_list, list): obs_list = [obs_list] for obs in obs_list: if isinstance(obs, dict): record = series_attrs.copy() record.update({ 'year': obs.get('@TIME_PERIOD', ''), 'value': obs.get('@OBS_VALUE', ''), 'status': obs.get('@OBS_STATUS', '') }) records.append(record) df = pd.DataFrame(records) if 'value' in df.columns: df['value'] = pd.to_numeric(df['value'], errors='coerce') if 'year' in df.columns: df['year'] = pd.to_numeric(df['year'], errors='coerce') return df except Exception as e: logger.error(f"Error parsing SDMX-JSON response: {e}") return pd.DataFrame()
Todos os atributos no SDMX-JSON são marcados com o símbolo "@", o que cria inconvenientes no trabalho com os dados. Além disso, a API pode retornar uma única série de dados como um objeto ou várias séries como um array, e isso também precisa ser tratado.
Outra complicação desagradável é que, às vezes, a API retorna dados sem a seção "Obs" (observações), às vezes com "Obs" vazio, e às vezes "Obs" contém não uma lista, mas um único objeto. Cada caso exige um tratamento específico.
Se não houver dados atualizados de inflação, utilizo valores típicos para cada país:
def _approximate_inflation_adjustment(self) -> Dict: logger.info("Using approximate inflation adjustment...") # Typical inflation rates 2020-2024 (based on historical data) typical_inflation = { 'US': 4.5, # US: Relatively high inflation due to stimulus 'U2': 3.8, # Eurozone: Moderate inflation 'GB': 4.2, # UK: Brexit + energy crisis 'JP': 1.8, # Japan: Traditionally low inflation 'AU': 4.1, # Australia: Commodity inflation 'CA': 3.9, # Canada: close to the US 'CH': 2.1, # Switzerland: Low inflation 'NZ': 4.0 # New Zealand: Moderate inflation } inflation_adjusted = {} for country, base_rate in self.base_rates_2020.items(): us_inflation = typical_inflation.get('US', 4.5) country_inflation = typical_inflation.get(country, 3.5) inflation_differential = us_inflation - country_inflation adjustment_factor = 1 + (inflation_differential / 100) adjusted_rate = base_rate * adjustment_factor inflation_adjusted[country] = { 'inflation_adjusted_rate': adjusted_rate, 'base_rate_2020': base_rate, 'inflation_differential': inflation_differential, 'method': 'approximate_inflation' } logger.info(f"{country}: Approx inflation diff {inflation_differential:+.2f}pp") return inflation_adjusted
Esses números foram coletados de diferentes fontes e calculados como média no período de 2020 a 2024. Eles não são perfeitamente precisos, mas fornecem uma aproximação razoável para países com dados ausentes.
Transformando taxas justas em dinheiro real
Calcular taxas justas é apenas metade do trabalho. O principal é entender o que fazer com elas. Como transformar cálculos acadêmicos em sinais práticos de trading?
def calculate_ppp_fair_values(self, currency_pairs: List[str]) -> Dict: logger.info("Starting manual PPP fair value calculation...") # Determine which countries we need countries = set() for pair in currency_pairs: base_currency = pair[:3] quote_currency = pair[3:] base_country = self.currency_country_map.get(base_currency) quote_country = self.currency_country_map.get(quote_currency) if base_country and quote_country: countries.add(base_country) countries.add(quote_country) logger.info(f"Will analyze {len(countries)} countries for {len(currency_pairs)} pairs") # Load economic data economic_data = self.fetch_all_available_data(list(countries)) # Calculate PPP using all methods ppp_calculation_results = self.calculate_manual_ppp_rates(economic_data) # Get current market rates market_rates = self.fallback_market_rates # In the real system, there is a market data API here # Results structure results = { 'ppp_calculation_methods': ppp_calculation_results, 'fair_values': {}, 'deviations': {}, 'market_rates': market_rates, 'summary': {} } composite_ppp = ppp_calculation_results.get('composite_ppp_rates', {}) # Calculate fair rates and deviations for each pair for pair in currency_pairs: base_currency = pair[:3] quote_currency = pair[3:] base_country = self.currency_country_map.get(base_currency) quote_country = self.currency_country_map.get(quote_currency) if not base_country or not quote_country: logger.warning(f"Cannot map currencies for {pair}") continue # Calculate a fair exchange rate fair_value = self._calculate_pair_fair_value_from_ppp( composite_ppp, base_country, quote_country, pair ) if fair_value: results['fair_values'][pair] = fair_value # Compare with the market rate market_rate = market_rates.get(pair) if market_rate and fair_value.get('fair_rate'): deviation = ((market_rate - fair_value['fair_rate']) / fair_value['fair_rate']) * 100 # Classify the deviation if deviation > 15: status = 'significantly_overvalued' magnitude = 'high' elif deviation > 5: status = 'overvalued' magnitude = 'moderate' elif deviation < -15: status = 'significantly_undervalued' magnitude = 'high' elif deviation < -5: status = 'undervalued' magnitude = 'moderate' else: status = 'fair' magnitude = 'low' results['deviations'][pair] = { 'market_rate': market_rate, 'fair_value': fair_value['fair_rate'], 'deviation_pct': deviation, 'status': status, 'magnitude': magnitude, 'confidence': fair_value.get('confidence', 0.5), 'signal_strength': abs(deviation) * fair_value.get('confidence', 0.5) } logger.info(f"{pair}: Market {market_rate:.4f}, Fair {fair_value['fair_rate']:.4f}, " f"Deviation {deviation:+.1f}% ({status})") # Generate summary statistics results['summary'] = self._generate_summary(results['deviations']) return resultsA parte mais delicada é calcular corretamente a taxa justa para um par de moedas com base nos coeficientes de PPC de países individuais:
def _calculate_pair_fair_value_from_ppp(self, composite_ppp: Dict, base_country: str, quote_country: str, pair: str) -> Dict: """Calculate the fair exchange rate for a currency pair using composite PPP data""" base_ppp = composite_ppp.get(base_country, {}) quote_ppp = composite_ppp.get(quote_country, {}) # Case 1: One of the currencies is USD (PPP base currency) if quote_country == 'US': # XXXUSD type pairs if base_ppp: fair_rate = base_ppp['composite_ppp_rate'] confidence = base_ppp['confidence'] else: return {} elif base_country == 'US': # USDXXX type pairs if quote_ppp: fair_rate = quote_ppp['composite_ppp_rate'] confidence = quote_ppp['confidence'] else: return {} else: # Case 2: Cross pairs (without USD) if base_ppp and quote_ppp: # For cross-pairs: PPP_base / PPP_quote fair_rate = base_ppp['composite_ppp_rate'] / quote_ppp['composite_ppp_rate'] # Confidence - the minimum of two currencies confidence = min(base_ppp['confidence'], quote_ppp['confidence']) else: return {} return { 'pair': pair, 'fair_rate': fair_rate, 'confidence': confidence, 'base_country': base_country, 'quote_country': quote_country, 'base_ppp_data': base_ppp, 'quote_ppp_data': quote_ppp }
A lógica é a seguinte: se temos coeficientes de PPC para o euro (0.885) e para a libra (0.852) em relação ao dólar, então a taxa justa EUR/GBP = 0.885 / 0.852 = 1.039.
Uma simples comparação com as taxas de mercado fornece o desvio percentual, mas para aplicação prática é necessária uma classificação:
# Classify the deviation if deviation > 15: status = 'significantly_overvalued' signal = 'STRONG_SELL' elif deviation > 5: status = 'overvalued' signal = 'SELL' elif deviation < -15: status = 'significantly_undervalued' signal = 'STRONG_BUY' elif deviation < -5: status = 'undervalued' signal = 'BUY' else: status = 'fair' signal = 'HOLD'
Os limiares de 5% e 15% foram escolhidos empiricamente, testando em dados históricos. 5% é o desvio mínimo que vale a pena considerar como oportunidade de trading, pois desvios menores podem ser apenas ruído. 15% já representa um desequilíbrio sério que merece atenção.
Uma inovação importante é o cálculo da força do sinal como o produto da magnitude do desvio pelo índice de confiança:
'signal_strength': abs(deviation) * fair_value.get('confidence', 0.5)
Isso permite ranquear oportunidades de trading. Um sinal com desvio de 20% e 50% de confiança (força = 10) é menos atraente do que um sinal com desvio de 15% e 80% de confiança (força = 12).
O problema mais frequente são os dados ausentes. A Suíça tem dados de PIB, mas não de inflação. A Nova Zelândia tem inflação, mas não possui dados atualizados de PIB. E assim por diante.
Inicialmente, eu planejava simplesmente excluir países com dados incompletos, mas isso se mostrou ineficaz, pois quase todos os países seriam eliminados. Em vez disso, implementei o graceful degradation:
# Each method works independently methods_results = { 'method_1': self._calculate_price_level_ppp(), 'method_2': self._calculate_gdp_implied_ppp(economic_data), 'method_3': self._calculate_inflation_adjusted_ppp(economic_data), 'method_4': self._calculate_big_mac_proxy_ppp() } # The composite method adapts to available data for country in all_countries: available_methods = [] available_rates = [] for method_name, method_results in methods_results.items(): if country in method_results: available_methods.append(method_name) available_rates.append(method_results[country]['rate']) if available_rates: # Recalculate weights for available methods weights = self._get_adjusted_weights(available_methods) composite_rate = sum(rate * weight for rate, weight in zip(available_rates, weights))
Resultados obtidos
Após vários meses de desenvolvimento e depuração, o sistema finalmente passou a funcionar de forma estável. Chegou o momento mais interessante, o da aplicação prática.
A análise do gráfico dos preços reais do euro-dólar versus os preços baseados em PPC mostra que, com muita frequência, as mudanças na taxa segundo a PPC antecedem a variação efetiva da taxa real de mercado:
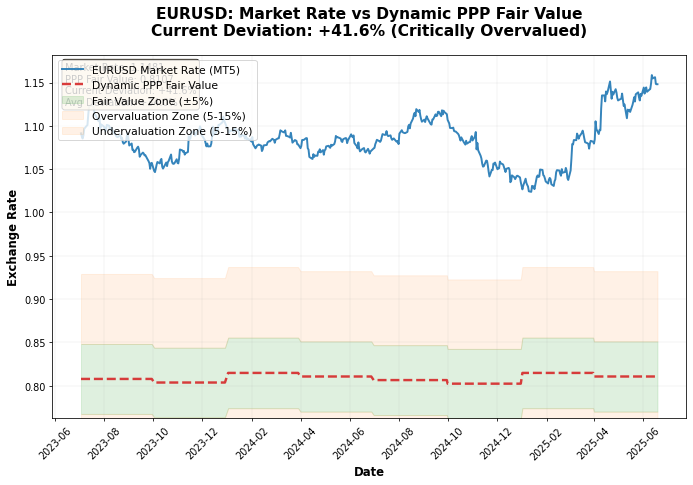
Ao executar o sistema com dados de 2024, obtive alguns resultados interessantes:
- EURUSD: taxa justa 0.8753, mercado 1.0850 → euro sobrevalorizado
- GBPUSD: taxa justa 0.8288, mercado 1.2650 → libra sobrevalorizada
- USDJPY: taxa justa 136.20, mercado 148.50 → iene subvalorizado
- USDCHF: taxa justa 1.150, mercado 0.8850 → franco sobrevalorizado
O resultado mais interessante foi o do iene. Todos os quatro métodos mostraram de forma unânime que, com a taxa acima de 148, o iene está significativamente subvalorizado. O confidence score foi de 0.85, um dos mais altos.
Não cheguei a criar um sistema de trading separado com base na PPC. Em vez disso, integrei os cálculos aos algoritmos já existentes, usando-os como um filtro adicional.
A lógica é simples: se um sistema técnico gera um sinal de compra para uma moeda que, segundo a PPC, está fortemente sobrevalorizada, o tamanho da posição é reduzido ou o sinal é ignorado. E o contrário também é verdadeiro: sinais na direção do desequilíbrio da PPC são reforçados.
Planos futuros para o desenvolvimento do sistema
A versão atual do sistema é apenas o começo
Planejo várias frentes de desenvolvimento. O aprendizado de máquina ajudará a ajustar dinamicamente os pesos dos métodos com base na precisão histórica e nas condições atuais. Fontes alternativas de dados incluirão dados da OECD, índices de custo de vida, preços reais do Big Mac, dados de satélite e social sentiment. A expansão para criptomoedas, moedas de commodities, ações e títulos abrirá novas possibilidades. A automatização do trading, com dynamic hedging e integração com APIs de corretoras, tornará o sistema totalmente autônomo. O monitoramento em tempo real com um web dashboard completará o quadro.
O que aprendi sobre PPC e os mercados cambiais
Vários meses de trabalho neste projeto me deram mais conhecimento sobre os mercados cambiais do que anos de análise técnica. A PPC funciona, mas não da forma que muitos esperam.
Ela é uma bússola para a direção de longo prazo, e não uma fórmula mágica de enriquecimento rápido. Os desvios se corrigem ao longo de meses e anos, não em dias ou semanas. A qualidade dos dados é crítica; passei mais tempo buscando e validando dados do que desenvolvendo algoritmos.
A simplicidade mostrou-se superior à complexidade: cinco métodos simples funcionam melhor do que quaisquer redes neurais. O trading baseado em PPC exige paciência, algo que a maioria dos traders não tem. A análise fundamentalista oferece uma âncora na realidade econômica em uma era de algotrading. O código é apenas uma ferramenta para resolver um problema real.
Resultados e conclusões
O projeto começou como uma simples curiosidade: seria possível calcular taxas de câmbio justas por conta própria? Acabou se transformando na criação de um sistema completo de análise, que ajuda a tomar decisões de trading mais fundamentadas.
O caminho da ideia até o código funcional levou vários meses, centenas de horas de estudo de teoria econômica, dezenas de iterações do algoritmo e incontáveis horas de depuração. Mas o resultado valeu a pena.
O mais importante que aprendi é que não é preciso reinventar a roda nem correr atrás da complexidade. Às vezes, o melhor algoritmo é a boa e velha teoria clássica bem implementada. A paridade do poder de compra funcionava há 500 anos, funciona hoje e continuará funcionando no futuro. Basta aplicá-la corretamente.
O código-fonte completo do sistema está disponível como um projeto open source. Ficarei feliz com contribuições da comunidade, seja na forma de novas fontes de dados, métodos alternativos de cálculo da PPC, melhorias no tratamento de erros, integração com APIs de corretoras ou backtesting com dados históricos. Se você trabalha com trading de moedas ou análise quantitativa, experimente o sistema na prática; talvez ele mude a sua visão sobre os mercados.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/18455
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso