
Indicador de previsión de volatilidad con Python

Introducción
¡Vaya! He vuelto a perder el equilibrio...
Esa era la frase con la que empezaba día sí día no mi negociación en el año 2021. Recuerdo que estaba sentado entre gráficos y cifras, orgulloso de mi nuevo sistema comercial, y de repente ¡zas!, y la mitad de mi depósito se había esfumado. Simplemente porque un tipo listo decidió hacer una declaración sobre las criptomonedas y el mercado se asustó.
Le suena familiar, ¿verdad? Estoy seguro de que todos los tráders algorítmicos han pasado por eso. Parece que lo has calculado y probado todo, el sistema basado en datos históricos funciona como un reloj suizo.... ¿Y en el mercado real? "¡Hola volatilidad, cuánto tiempo sin verte!"
Tras otra "aventura" de este tipo, decidí llegar al fondo del asunto. Es imposible no anticiparse de algún modo a estas rabietas del mercado. Revisé casi todas las investigaciones existentes sobre volatilidad. ¿Sabe qué es lo gracioso? Resulta que la solución estaba en la intersección de la vieja escuela y la nueva tecnología.
En este artículo, hablaremos de mi viaje desde la desesperación hasta un sistema de previsión de la volatilidad que funciona. Sin tecnicismos ni términos académicos: solo experiencia real y soluciones prácticas. Asimismo, le mostraré cómo crucé MetaTrader 5 con Python (spoiler: no se hicieron amigos de inmediato), cómo hice que el aprendizaje automático trabajara para mí y qué escollos encontré en el camino.
La principal conclusión que he sacado de toda esta historia es que no se puede confiar ciegamente ni en los indicadores clásicos ni en la moda de las neuronas. Recuerdo configurar una compleja red neuronal durante una semana, y que luego un simple XGBoost mostrase mejores resultados. O cómo una vez, un simple Bollinger salvó un depósito en el que todos los algoritmos inteligentes habían metido la pata.
También me di cuenta de que en el trading, como en el boxeo, lo principal no es la fuerza de los golpes, sino la capacidad de anticiparse a ellos. Mi sistema no hace predicciones sobrenaturales. Simplemente ayuda a estar preparado para las sorpresas del mercado y aumentar a tiempo el margen de seguridad de la estrategia comercial.
En resumen, si está cansado de que sus algoritmos tropiecen con cada cambio de la volatilidad, bienvenido a mi mundo. Se lo contaré todo tal cual, con ejemplos de código, gráficos y análisis. ¡Vamos allá!
El concepto del proyecto
Tras meses experimentando y analizando en profundidad los datos del mercado, diseñé el concepto de un sistema capaz de predecir la volatilidad con una precisión asombrosa. El descubrimiento clave fue que la volatilidad, a diferencia del precio, tiene la propiedad de la estacionariedad, pues tiende a volver a su valor medio y formar patrones estables. Precisamente esta característica hace que su previsión no solo resulte posible, sino también aplicable en la práctica en el comercio real.
El sistema se basa en una potente combinación de MetaTrader 5 y Python, donde cada herramienta revela sus puntos fuertes. MetaTrader 5 actúa como una fuente fiable de datos de mercado que nos ofrece cotizaciones históricas y un flujo de datos en tiempo real con una latencia mínima, mientras que Python se convierte en nuestro laboratorio analítico, donde un rico conjunto de bibliotecas de aprendizaje automático (Sklearn, XGBoost, PyTorch) nos ayuda a extraer valiosos patrones de estos datos y a confirmar hipótesis sobre la estacionariedad de la volatilidad.
La arquitectura del sistema consta de tres capas clave:
- Data Pipeline — base del sistema. Aquí es donde tiene lugar el procesamiento principal de los datos de MetaTrader 5: eliminación del ruido, cálculo de docenas de métricas de volatilidad, generación de características para los modelos. Hemos prestado especial atención a la optimización: el sistema funciona sin retrasos ni fugas de memoria. Este nivel también incluye la comprobación de la estacionariedad de las series temporales y la identificación de patrones de volatilidad significativos.
- Analytics Core — núcleo de análisis. Se basa en un conjunto de modelos especializados de aprendizaje automático. Cada uno está adaptado a un horizonte temporal distinto, desde las fluctuaciones intradía hasta las tendencias semanales. Las pruebas revelaron que incluso el sencillo XGBoost supera a menudo a las redes neuronales complejas en precisión de predicción, especialmente en la identificación de grupos de volatilidad.
- Risk Advisor — sistema de recomendaciones para la gestión de riesgos. Basándose en las previsiones de volatilidad, sugiere los niveles óptimos de stop-loss y take-profit. Durante los periodos de mayor volatilidad futura, recomienda ampliar las órdenes de protección, y durante las horas de calma futura, aconseja comprimirlas para una entrada más precisa en el mercado. Aquí es donde la estacionariedad de la volatilidad desempeña un papel clave, permitiendo al sistema adaptar eficazmente los parámetros comerciales.
Los modelos se entrenan con un conjunto de datos único que incluye cotizaciones de distintos marcos temporales, desde marcos de ticks hasta diarios. Esto permite al sistema reconocer tres estados clave del mercado: baja volatilidad, tendencia y explosiva. A partir de esta información, se formulan recomendaciones sobre los niveles óptimos de entrada y las órdenes de protección. Debido a la estacionariedad de la volatilidad, el sistema es capaz no solo de identificar el estado actual, sino también de pronosticar las transiciones entre estos estados.
La principal característica del sistema es su adaptabilidad. No se limita a emitir recomendaciones fijas, sino que las ajusta a las actuales condiciones del mercado. Para cada situación comercial, el sistema ofrece un conjunto individual de parámetros basados en la previsión de la volatilidad futura. Esta adaptabilidad resulta especialmente eficaz debido a la persistencia de los patrones de comportamiento de la volatilidad.
En las siguientes secciones, desglosaremos con detalle cada componente del sistema, mostraremos el código real y compartiremos los resultados de las pruebas con los datos históricos. Verá cómo los conceptos teóricos sobre la estacionariedad de la volatilidad se convierten en una herramienta práctica para el análisis del mercado.
Instalación del software necesario
Antes de sumergirnos en el desarrollo del sistema, nos familiarizaremos con la instalación de todo el software necesario. Sé por experiencia propia que muchas personas tropiezan en la etapa de configuración de MetaTrader 5 - Python, así que hoy intentaremos indicarle no solo cómo configurar todo, sino también cómo evitar los principales escollos.
Empezaremos con Python. Necesitaremos la versión 3.8 o superior, puede descargarla de la web oficial python.org. Al realizar la instalación, es importante no omitir la casilla "Add Python to PATH", de lo contrario tendrá que añadir rutas manualmente más tarde. Tras instalar Python, lo primero que haremos será crear un entorno virtual para el proyecto. Esto no es obligatorio, pero será un paso muy útil, pues nos protegerá de conflictos entre versiones de bibliotecas.
python -m venv venv_volatility venv_volatility\Scripts\activate # for Windows source venv_volatility/bin/activate # for Linux/MacOS
Ahora vamos a instalar las bibliotecas necesarias. Necesitaremos algunas herramientas básicas: numpy y pandas para trabajar con datos, scikit-learn y xgboost para el aprendizaje automático, pytorch para las redes neuronales, y por supuesto, una biblioteca para trabajar con MetaTrader 5. Este es el comando para instalar el paquete completo:
pip install numpy pandas scikit-learn xgboost pytorch MetaTrader5 pylint jupyter Nos centraremos por separado en la instalación de MetaTrader 5. Debe descargarla del sitio web de su bróker bursátil, lo cual es importante porque las versiones pueden variar. Al realizar la instalación, elija una carpeta con una ruta sencilla, sin caracteres en cirílico ni espacios: esto le ahorrará mucho estrés al establecer la comunicación con Python.
Tras instalar el terminal, no olvide permitir el comercio automático y la importación de DLL en su configuración, así como activar el AlgoTrading. Sí, suena obvio, pero yo mismo me pasé un par de horas de depuración hasta que recordé esos ajustes.
Ahora la parte más interesante, la comprobación de la conexión entre Python y MetaTrader 5. He escrito un pequeño script para asegurarme de que todo funciona como debería:
import MetaTrader5 as mt5 def test_mt5_connection(): if not mt5.initialize(): print("MT5 initialization error:", mt5.last_error()) return False print("MetaTrader5 package author:", mt5.__author__) print("MetaTrader5 package version:", mt5.__version__) terminal_info = mt5.terminal_info() if terminal_info is None: print("Error getting terminal data:", mt5.last_error()) return False print(f"Connected to terminal '{terminal_info.name}' ({terminal_info.path})") print("Trade server:", terminal_info.connected) mt5.shutdown() return True if __name__ == "__main__": test_mt5_connection()
¿Qué debemos considerar cuando surjan problemas? El escollo más frecuente es la inicialización de MetaTrader 5. Si el script no puede conectarse al terminal, compruebe primero si el propio MetaTrader 5 se está ejecutando. Parece obvio, pero créame: incluso los desarrolladores experimentados lo olvidan a veces.
Si el terminal se está ejecutando pero sigue sin haber conexión, compruebe sus derechos de administrador y los ajustes del cortafuegos. Windows a veces sobrerreacciona y bloquea la conexión.
Para el desarrollo, recomiendo utilizar VS Code o PyCharm, ambos editores son excelentes para el desarrollo de Python. Instale una extensión para Python y Jupyter: simplificará enormemente el proceso de depuración y comprobación del código.
Comprobación final: intente obtener los datos históricos:
import MetaTrader5 as mt5 mt5.initialize() data = mt5.copy_rates_from_pos("EURUSD", mt5.TIMEFRAME_M1, 0, 1000) print(data is not None) mt5.shutdown()
Si este código ha funcionado sin errores, enhorabuena, ¡su entorno de desarrollo es totalmente funcional! En la siguiente sección nos ocuparemos de la obtención y el procesamiento de datos de MetaTrader 5.
Recuperando los datos de MetaTrader 5
Antes de sumergirnos en cálculos complejos, nos aseguraremos de que estamos recibiendo correctamente los datos del terminal comercial. He escrito un sencillo script que ayudará a comprobar el funcionamiento de MetaTrader 5 y mirar la estructura de datos:
import MetaTrader5 as mt5 import pandas as pd from datetime import datetime, timedelta pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) pd.set_option('display.float_format', lambda x: '%.5f' % x) def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return print("\n=== Symbol Information ===") symbol_info = mt5.symbol_info(symbol) if symbol_info is None: print(f"Failed to get {symbol} data") mt5.shutdown() return print(f"Current spread: {symbol_info.spread} points") print(f"Tick size: {symbol_info.trade_tick_size}") print(f"Contract size: {symbol_info.trade_contract_size}") # Last 100 ticks print("\n=== Latest Ticks ===") ticks = mt5.copy_ticks_from(symbol, datetime.now() - timedelta(minutes=5), 100, mt5.COPY_TICKS_ALL) ticks_frame = pd.DataFrame(ticks) ticks_frame['time'] = pd.to_datetime(ticks_frame['time'], unit='s') print(ticks_frame.head()) # 5-minute bars (last 100 bars) print("\n=== 5-Minute Bars (Last 100) ===") rates_5m = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_M5, 0, 100) rates_5m_frame = pd.DataFrame(rates_5m) rates_5m_frame['time'] = pd.to_datetime(rates_5m_frame['time'], unit='s') print(rates_5m_frame.head()) # Hourly bars (last 24 hours) print("\n=== Hourly Bars (Last 24) ===") rates_1h = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 24) rates_1h_frame = pd.DataFrame(rates_1h) rates_1h_frame['time'] = pd.to_datetime(rates_1h_frame['time'], unit='s') print(rates_1h_frame.head()) # Daily bars (last 30 days) print("\n=== Daily Bars (Last 30) ===") rates_d1 = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 30) rates_d1_frame = pd.DataFrame(rates_d1) rates_d1_frame['time'] = pd.to_datetime(rates_d1_frame['time'], unit='s') print(rates_d1_frame.head()) # Statistics for different timeframes print("\n=== 5-Minute Bars Statistics ===") print(f"Average volume: {rates_5m_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_5m_frame['spread'].mean():.2f}") print(f"Average range: {(rates_5m_frame['high'] - rates_5m_frame['low']).mean():.5f}") print("\n=== Hourly Bars Statistics ===") print(f"Average volume: {rates_1h_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_1h_frame['spread'].mean():.2f}") print(f"Average range: {(rates_1h_frame['high'] - rates_1h_frame['low']).mean():.5f}") print("\n=== Daily Bars Statistics ===") print(f"Average volume: {rates_d1_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_d1_frame['spread'].mean():.2f}") print(f"Average range: {(rates_d1_frame['high'] - rates_d1_frame['low']).mean():.5f}") # Current quotes print("\n=== Current Market Depth ===") depth = mt5.market_book_get(symbol) if depth is not None: bid = depth[0].price if depth[0].type == 1 else depth[1].price ask = depth[0].price if depth[0].type == 2 else depth[1].price print(f"Bid: {bid}") print(f"Ask: {ask}") print(f"Spread: {(ask - bid):.5f}") mt5.shutdown() if __name__ == "__main__": check_mt5_data()
Este código emitirá toda la información que necesitamos para comprobar la corrección de la conexión y la calidad de los datos obtenidos. Una vez puesto en marcha, verá:
- La información básica sobre el instrumento comercial
- La tabla de ticks recientes
- El gráfico de barras horarias
- Las estadísticas sobre volúmenes y spreads
- Las cotizaciones actuales de la profundidad de mercado
Lo iniciamos e inmediatamente vemos si todo funciona como debería. Si hay algún problema en alguna parte, el script le mostrará exactamente en qué fase ha fallado algo.
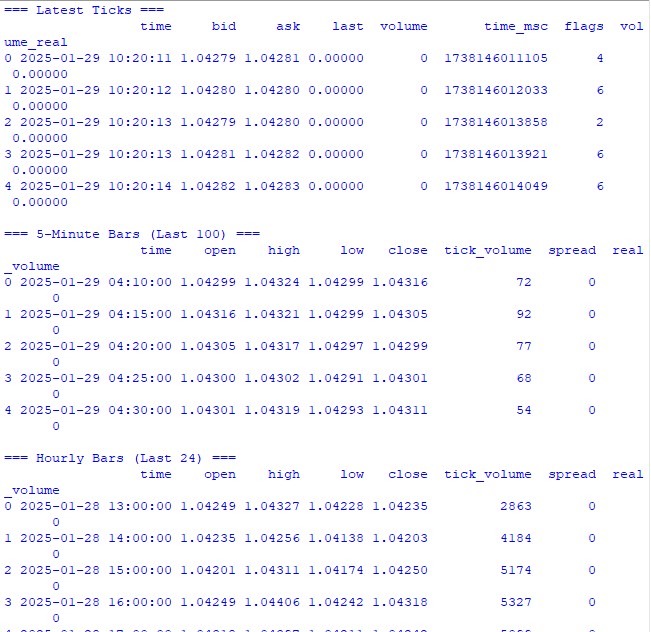
En las secciones siguientes usaremos estos datos para calcular la volatilidad, pero antes es importante asegurarse de que la adquisición de datos subyacente funcione correctamente.
Preprocesamiento de datos
Cuando empecé a trabajar con previsiones de volatilidad, pensaba que lo más importante era un modelo de aprendizaje automático atractivo. La práctica me demostró rápidamente que lo que marca la diferencia es la calidad de la preparación de los datos. Permítanme mostrarles cómo preparo los datos para nuestro sistema de previsión.
Aquí está el código de preprocesamiento completo que uso:
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler from datetime import datetime, timedelta pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) pd.set_option('display.float_format', lambda x: '%.5f' % x) class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20)): self.lookback_periods = lookback_periods self.scaler = StandardScaler() def calculate_volatility_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change().fillna(0) df['log_returns'] = (np.log(df['close']) - np.log(df['close'].shift(1))).fillna(0) # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1).fillna(df['high'])), abs(df['low'] - df['close'].shift(1).fillna(df['low'])) ) ) # ATR and volatility for period in self.lookback_periods: df[f'atr_{period}'] = df['true_range'].rolling(window=period, min_periods=1).mean() df[f'volatility_{period}'] = df['returns'].rolling(window=period, min_periods=1).std() # Parkinson volatility df['parkinson_vol'] = np.sqrt( 1/(4 * np.log(2)) * np.power(np.log(df['high'].div(df['low'])), 2) ) # Garman-Klass volatility df['garman_klass_vol'] = np.sqrt( 0.5 * np.power(np.log(df['high'].div(df['low'])), 2) - (2*np.log(2)-1) * np.power(np.log(df['close'].div(df['open'])), 2) ) # Relative volatility changes for period in self.lookback_periods: df[f'vol_change_{period}'] = ( df[f'volatility_{period}'].div(df[f'volatility_{period}'].shift(1)) ) # Replace all infinities and NaN for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan).fillna(0) return df def prepare_features(self, df): feature_cols = [] # Time-based features - correct time conversion time = pd.to_datetime(df['time'], unit='s') # Hours (0-23) -> radians (0-2π) hours = time.dt.hour.values df['hour_sin'] = np.sin(2 * np.pi * hours / 24.0) df['hour_cos'] = np.cos(2 * np.pi * hours / 24.0) # Week days (0-6) -> radians (0-2π) days = time.dt.dayofweek.values df['day_sin'] = np.sin(2 * np.pi * days / 7.0) df['day_cos'] = np.cos(2 * np.pi * days / 7.0) # Select features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'vol_change_{period}' ]) feature_cols.extend([ 'parkinson_vol', 'garman_klass_vol', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create features DataFrame features = df[feature_cols].copy() # Final cleanup and scaling features = features.replace([np.inf, -np.inf], 0).fillna(0) scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=features.columns, index=features.index ) def create_target(self, df, forward_window=12): future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window).fillna(0) return future_vol def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_volatility_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) return features, target def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: print("\n=== Processing Hourly Data for Volatility Analysis ===") processor = VolatilityProcessor(lookback_periods=(5, 10, 20)) features, target = processor.prepare_dataset(rates_frame) print("\nFeature statistics:") print(features.describe()) print("\nFeature columns:", features.columns.tolist()) print("\nTarget statistics:") print(target.describe()) else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
Cómo funciona
En primer lugar, descargamos las últimas 10.000 barras horarias de MetaTrader 5. ¿Por qué tantas? Mediante ensayo y error, he descubierto que ésta es la cantidad óptima: suficiente para aprender, pero no tanto como para que el mercado cambie mucho.
Ahora viene la parte divertida. La clase VolatilityProcessor hace todo el trabajo sucio en la preparación de los datos. Esto es lo que ocurre:
- Cálculo de los indicadores de volatilidad subyacentes. Aquí consideraremos tres tipos de volatilidad:
- Desviación típica de los rendimientos
- True Range y ATR son de la vieja escuela, pero siguen funcionando a día de hoy
- Métodos de Parkinson y Garman-Class: son buenos para captar los movimientos intradía.
- Trabajo con el tiempo. En lugar de la codificación habitual de horas y días de la semana, uso senos y cosenos. No se trata de algo vacío: así es como le decimos al modelo que las 23:00 y las 00:00 son momentos cercanos en el tiempo, no extremos opuestos del espectro.
- Normalización y limpieza de datos. Esta es la parte más importante:
- Eliminación de valores atípicos e infinitos
- Rellenado de los espacios en blanco con ceros (solo después de comprobar cuidadosamente que esto no distorsionará los datos).
- Escalado de todas las características al mismo rango
Al final tenemos 15 características, el número óptimo para nuestra tarea. Intenté añadir más (toda clase de indicadores exóticos), pero los resultados empeoraron.
La variable objetivo es la volatilidad futura durante los 12 periodos siguientes. ¿Por qué 12? Con los datos horarios, esto nos da una previsión para el siguiente medio día, suficiente para tomar decisiones comerciales, pero no tanto como para que la previsión carezca de sentido.
Qué debemos considerar
- En todas partes se utiliza min_periods=1 en las operaciones rolling, esto garantiza que los datos no se pierdan al principio de la serie temporal.
- La división mediante .div() en lugar del habitual / no es solo un capricho, pandas procesa mejor así los casos límite.
- La sustitución de los infinitos se realiza al final de cada etapa, lo cual garantiza que no se pasen por alto las zonas problemáticas.
En la siguiente sección, nos ocuparemos de construir un modelo de aprendizaje automático que trabaje con estos datos entrenados. Pero recuerde: por muy genial que sea un modelo, no salvará los datos mal preparados.
Creación de un modelo de aprendizaje automático
Así pues, hemos llegado a la parte más interesante: la creación de un modelo de predicción. Al principio, opté por la vía obvia: una regresión para predecir el valor exacto de la futura volatilidad. La lógica era sencilla: obtener una cifra concreta, multiplicarla por algún coeficiente y ahí tenemos el nivel de stop-loss.
Primer intento: modelo de regresión
Empecé con el código más simple: el XGBRegressor básico con ajustes mínimos y con pocos parámetros: un centenar de árboles, una tasa de aprendizaje de 0,1 y una profundidad de 5. Fue ingenuo pensar que sería suficiente, pero ¿quién no cometió errores así al principio del viaje?
Los resultados han sido, por decirlo suavemente, poco impresionantes. El R cuadrado oscilaba entre 0,05 y 0,06, lo que significa que el modelo solo explicaba entre el 5% y el 6% de la variación de los datos. La desviación típica de las predicciones era casi tres veces inferior a la real. Dicho esto, el Error Medio Absoluto parecía bueno, pero suponía una auténtica trampa.
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.model_selection import TimeSeriesSplit import xgboost as xgb from xgboost import XGBRegressor from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score import matplotlib.pyplot as plt from datetime import datetime, timedelta # VolatilityProcessor class remains unchanged class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20)): self.lookback_periods = lookback_periods self.scaler = StandardScaler() def calculate_volatility_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change().fillna(0) df['log_returns'] = (np.log(df['close']) - np.log(df['close'].shift(1))).fillna(0) df['abs_returns'] = abs(df['returns']) # Price changes df['price_range'] = (df['high'] - df['low']) / df['close'] df['price_change'] = (df['close'] - df['open']) / df['open'] # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1).fillna(df['high'])), abs(df['low'] - df['close'].shift(1).fillna(df['low'])) ) ) # ATR and volatility for different periods for period in self.lookback_periods: # Standard features df[f'atr_{period}'] = df['true_range'].rolling(window=period, min_periods=1).mean() df[f'volatility_{period}'] = df['returns'].rolling(window=period, min_periods=1).std() # Additional rolling statistics df[f'mean_range_{period}'] = df['price_range'].rolling(window=period, min_periods=1).mean() df[f'mean_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).mean() df[f'max_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).max() df[f'min_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).min() # Advanced volatility measures # Parkinson volatility df['parkinson_vol'] = np.sqrt( 1/(4 * np.log(2)) * np.power(np.log(df['high'].div(df['low'])), 2) ) # Garman-Klass volatility df['garman_klass_vol'] = np.sqrt( 0.5 * np.power(np.log(df['high'].div(df['low'])), 2) - (2*np.log(2)-1) * np.power(np.log(df['close'].div(df['open'])), 2) ) # Rogers-Satchell volatility df['rogers_satchell_vol'] = np.sqrt( np.log(df['high'].div(df['close'])) * np.log(df['high'].div(df['open'])) + np.log(df['low'].div(df['close'])) * np.log(df['low'].div(df['open'])) ) # Relative changes for period in self.lookback_periods: df[f'vol_change_{period}'] = ( df[f'volatility_{period}'].div(df[f'volatility_{period}'].shift(1)) ) df[f'atr_change_{period}'] = ( df[f'atr_{period}'].div(df[f'atr_{period}'].shift(1)) ) # Replace all infinities and NaN for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan).fillna(0) return df def prepare_features(self, df): feature_cols = [] # Time-based features time = pd.to_datetime(df['time'], unit='s') # Hours (0-23) -> radians (0-2π) hours = time.dt.hour.values df['hour_sin'] = np.sin(2 * np.pi * hours / 24.0) df['hour_cos'] = np.cos(2 * np.pi * hours / 24.0) # Days of week (0-6) -> radians (0-2π) days = time.dt.dayofweek.values df['day_sin'] = np.sin(2 * np.pi * days / 7.0) df['day_cos'] = np.cos(2 * np.pi * days / 7.0) # Select features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'vol_change_{period}' ]) feature_cols.extend([ 'parkinson_vol', 'garman_klass_vol', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create features DataFrame features = df[feature_cols].copy() # Final cleanup and scaling features = features.replace([np.inf, -np.inf], 0).fillna(0) scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=feature_cols, index=features.index ) def create_target(self, df, forward_window=12): """Create target with log transformation""" future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window) # Add small constant to avoid log(0) log_vol = np.log(future_vol + 1e-10) return log_vol.fillna(log_vol.mean()) def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_volatility_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) return features, target class VolatilityModel: def __init__(self, lookback_periods=(5, 10, 20), forward_window=12): self.processor = VolatilityProcessor(lookback_periods) self.forward_window = forward_window self.model = XGBRegressor( n_estimators=500, learning_rate=0.05, max_depth=10, min_child_weight=1, subsample=0.8, colsample_bytree=0.8, gamma=0.1, reg_alpha=0.1, reg_lambda=1, random_state=42, n_jobs=-1, objective='reg:squarederror' # Better for log-transformed targets ) self.feature_importance = None def prepare_data(self, rates_frame): """Prepare data using our processor""" features, target = self.processor.prepare_dataset(rates_frame) return features, target def create_train_test_split(self, features, target, test_size=0.2): """Split data preserving time order""" split_idx = int(len(features) * (1 - test_size)) X_train = features.iloc[:split_idx] X_test = features.iloc[split_idx:] y_train = target.iloc[:split_idx] y_test = target.iloc[split_idx:] return X_train, X_test, y_train, y_test def train(self, X_train, y_train, X_test, y_test): """Train model with validation""" print("\n=== Training Model ===") print("Training set shape:", X_train.shape) print("Test set shape:", X_test.shape) # Train the model eval_set = [(X_train, y_train), (X_test, y_test)] self.model.fit( X_train, y_train, eval_set=eval_set, verbose=True ) # Save feature importance importance = self.model.feature_importances_ self.feature_importance = pd.DataFrame({ 'feature': X_train.columns, 'importance': importance }).sort_values('importance', ascending=False) # Make predictions and evaluate predictions = self.predict(X_test) metrics = self.calculate_metrics(y_test, predictions) return metrics def calculate_metrics(self, y_true, y_pred): """Calculate model performance metrics with detailed R2""" # Basic metrics rmse = np.sqrt(mean_squared_error(y_true, y_pred)) mae = mean_absolute_error(y_true, y_pred) # Manual R2 calculation for verification y_true_mean = np.mean(y_true) total_sum_squares = np.sum((y_true - y_true_mean) ** 2) residual_sum_squares = np.sum((y_true - y_pred) ** 2) r2_manual = 1 - (residual_sum_squares / total_sum_squares) # Stats for debugging metrics = { 'RMSE': rmse, 'MAE': mae, 'R2 (sklearn)': r2_score(y_true, y_pred), 'R2 (manual)': r2_manual, 'RSS': residual_sum_squares, 'TSS': total_sum_squares, 'Mean Prediction': np.mean(y_pred), 'Mean Actual': np.mean(y_true), 'Std Prediction': np.std(y_pred), 'Std Actual': np.std(y_true), 'Min Prediction': np.min(y_pred), 'Max Prediction': np.max(y_pred), 'Min Actual': np.min(y_true), 'Max Actual': np.max(y_true) } print("\nDetailed Metrics Analysis:") print(f"Total Sum of Squares (TSS): {total_sum_squares:.8f}") print(f"Residual Sum of Squares (RSS): {residual_sum_squares:.8f}") print(f"R2 components: 1 - ({residual_sum_squares:.8f} / {total_sum_squares:.8f})") return metrics def predict(self, features): """Get volatility predictions with inverse log transform""" log_predictions = self.model.predict(features) return np.exp(log_predictions) - 1e-10 def plot_feature_importance(self): """Visualize feature importance""" plt.figure(figsize=(12, 6)) plt.bar( self.feature_importance['feature'], self.feature_importance['importance'] ) plt.xticks(rotation=45) plt.title('Feature Importance') plt.tight_layout() plt.show() def plot_predictions(self, y_true, y_pred, title="Model Predictions"): """Visualize predictions vs actual values""" plt.figure(figsize=(15, 7)) plt.plot(y_true.values, label='Actual', alpha=0.7) plt.plot(y_pred, label='Predicted', alpha=0.7) plt.title(title) plt.legend() plt.tight_layout() plt.show() def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): # Get data symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: # Create and train model model = VolatilityModel(lookback_periods=(5, 10, 20), forward_window=12) features, target = model.prepare_data(rates_frame) # Split data X_train, X_test, y_train, y_test = model.create_train_test_split( features, target, test_size=0.2 ) # Train and evaluate metrics = model.train(X_train, y_train, X_test, y_test) print("\n=== Model Performance ===") for metric, value in metrics.items(): print(f"{metric}: {value:.6f}") # Make predictions predictions = model.predict(X_test) # Visualize results model.plot_feature_importance() model.plot_predictions(y_test, predictions, "Volatility Predictions") else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
¿Por qué una trampa? Porque el modelo simplemente había aprendido a predecir valores cercanos a la media. En los periodos de calma todo parecía perfecto, pero en cuanto empezaba el movimiento real, el modelo fallaba con total seguridad.
Experimentos de mejora de la regresión
Pasé semanas intentando mejorar el modelo de regresión. Probé distintas arquitecturas de redes neuronales, añadí más y más características nuevas, experimenté con distintas funciones de pérdida y retorcí los hiperparámetros hasta el agotamiento.
Todo en vano. Sí, a veces era posible subir el R-cuadrado a 0,15-0,20, pero ¿a qué precio? El modelo se volvió inestable, se sobreentrenó y, lo que es más importante, siguió sin detectar los momentos más importantes de alta volatilidad.
Replanteamiento del enfoque
Y entonces caí en la cuenta: ¿para qué necesitamos un valor exacto de volatilidad? Al tráder le da igual que la volatilidad sea 0,00234 o 0,00256. Lo que importa es si será significativamente más alto de lo habitual.
Así nació la idea de reformular la tarea como una clasificación. En lugar de predecir valores concretos, empecé a definir dos estados: volatilidad normal/baja (etiqueta 0) y volatilidad alta por encima del percentil 75 (etiqueta 1).
Por qué funcionó mejor
En primer lugar, porque la señales eran más claras. En lugar de vagas predicciones, ahora había una respuesta concreta: si se espera o no un estallido de volatilidad. Este enfoque ha demostrado ser mucho más fácil de interpretar e integrar en un sistema comercial.
En segundo lugar, el modelo mejoró en el trabajo con valores extremos. En la regresión, los valores atípicos estaban "difuminados", mientras que en la clasificación formaban un patrón claro de una clase de alta volatilidad.
En tercer lugar, ha aumentado la aplicabilidad práctica. Los tráders necesitan una señal clara para actuar. Resulta mucho más fácil ajustar los niveles de las órdenes de protección a dos estados que intentar escalarlos a un continuo de valores.
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler import xgboost as xgb from xgboost import XGBClassifier from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix import matplotlib.pyplot as plt import seaborn as sns class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20), volatility_threshold=75): """ Args: lookback_periods: periods for feature calculation volatility_threshold: percentile for defining high volatility """ self.lookback_periods = lookback_periods self.volatility_threshold = volatility_threshold self.scaler = StandardScaler() def calculate_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change() df['abs_returns'] = abs(df['returns']) # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1)), abs(df['low'] - df['close'].shift(1)) ) ) # Signs of volatility for period in self.lookback_periods: # ATR df[f'atr_{period}'] = df['true_range'].rolling(window=period).mean() # Volatility df[f'volatility_{period}'] = df['returns'].rolling(period).std() # Extremes df[f'high_low_range_{period}'] = ( (df['high'].rolling(period).max() - df['low'].rolling(period).min()) / df['close'] ) # Volatility acceleration df[f'volatility_change_{period}'] = ( df[f'volatility_{period}'] / df[f'volatility_{period}'].shift(1) ) # Add sentiment indicators df['body_ratio'] = abs(df['close'] - df['open']) / (df['high'] - df['low']) df['upper_shadow'] = (df['high'] - df[['open', 'close']].max(axis=1)) / (df['high'] - df['low']) df['lower_shadow'] = (df[['open', 'close']].min(axis=1) - df['low']) / (df['high'] - df['low']) # Data clearing for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan) df[col] = df[col].fillna(method='ffill').fillna(0) return df def prepare_features(self, df): # Select features for the model feature_cols = [] # Add time features time = pd.to_datetime(df['time'], unit='s') df['hour_sin'] = np.sin(2 * np.pi * time.dt.hour / 24) df['hour_cos'] = np.cos(2 * np.pi * time.dt.hour / 24) df['day_sin'] = np.sin(2 * np.pi * time.dt.dayofweek / 7) df['day_cos'] = np.cos(2 * np.pi * time.dt.dayofweek / 7) # Collect all features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'high_low_range_{period}', f'volatility_change_{period}' ]) feature_cols.extend([ 'body_ratio', 'upper_shadow', 'lower_shadow', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create DataFrame with features features = df[feature_cols].copy() features = features.replace([np.inf, -np.inf], 0).fillna(0) # Scale features scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=feature_cols, index=features.index ) def create_target(self, df, forward_window=12): """Creates a binary label: 1 for high volatility, 0 for low volatility""" # Calculate future volatility future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window) # Determine the threshold for high volatility vol_threshold = np.nanpercentile(future_vol, self.volatility_threshold) # Create binary labels target = (future_vol > vol_threshold).astype(int) target = target.fillna(0) return target def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) print(f"Positive class ratio: {target.mean():.2%}") return features, target class VolatilityClassifier: def __init__(self, lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75): self.processor = VolatilityProcessor(lookback_periods, volatility_threshold) self.forward_window = forward_window self.model = XGBClassifier( n_estimators=200, max_depth=6, learning_rate=0.1, subsample=0.8, colsample_bytree=0.8, min_child_weight=1, gamma=0.1, reg_alpha=0.1, reg_lambda=1, scale_pos_weight=1, random_state=42, n_jobs=-1, eval_metric=['auc', 'error'] ) self.feature_importance = None def prepare_data(self, rates_frame): features, target = self.processor.prepare_dataset(rates_frame) return features, target def create_train_test_split(self, features, target, test_size=0.2): split_idx = int(len(features) * (1 - test_size)) X_train = features.iloc[:split_idx] X_test = features.iloc[split_idx:] y_train = target.iloc[:split_idx] y_test = target.iloc[split_idx:] return X_train, X_test, y_train, y_test def train(self, X_train, y_train, X_test, y_test): print("\n=== Training Model ===") print("Training set shape:", X_train.shape) print("Test set shape:", X_test.shape) # Train the model eval_set = [(X_train, y_train), (X_test, y_test)] self.model.fit( X_train, y_train, eval_set=eval_set, verbose=True ) # Maintain the importance of features importance = self.model.feature_importances_ self.feature_importance = pd.DataFrame({ 'feature': X_train.columns, 'importance': importance }).sort_values('importance', ascending=False) # Evaluate the model predictions = self.predict(X_test) metrics = self.calculate_metrics(y_test, predictions) return metrics def calculate_metrics(self, y_true, y_pred): metrics = { 'Accuracy': accuracy_score(y_true, y_pred), 'Precision': precision_score(y_true, y_pred), 'Recall': recall_score(y_true, y_pred), 'F1 Score': f1_score(y_true, y_pred) } # Error matrix cm = confusion_matrix(y_true, y_pred) print("\nConfusion Matrix:") print(cm) return metrics def predict(self, features): return self.model.predict(features) def predict_proba(self, features): return self.model.predict_proba(features) def plot_feature_importance(self): plt.figure(figsize=(12, 6)) plt.bar( self.feature_importance['feature'], self.feature_importance['importance'] ) plt.xticks(rotation=45, ha='right') plt.title('Feature Importance') plt.tight_layout() plt.show() def plot_confusion_matrix(self, y_true, y_pred): cm = confusion_matrix(y_true, y_pred) plt.figure(figsize=(8, 6)) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') plt.title('Confusion Matrix') plt.ylabel('True Label') plt.xlabel('Predicted Label') plt.tight_layout() plt.show() def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: # Create and train the model model = VolatilityClassifier( lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75 ) features, target = model.prepare_data(rates_frame) # Separate data X_train, X_test, y_train, y_test = model.create_train_test_split( features, target, test_size=0.2 ) # Train and evaluate metrics = model.train(X_train, y_train, X_test, y_test) print("\n=== Model Performance ===") for metric, value in metrics.items(): print(f"{metric}: {value:.4f}") # Make predictions predictions = model.predict(X_test) # Visualize results model.plot_feature_importance() model.plot_confusion_matrix(y_test, predictions) else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
Resultados del nuevo modelo
Los resultados mejoraron notablemente tras el paso a la clasificación. La precisión alcanzó aproximadamente el 70%, lo cual significa que de 10 señales de alta volatilidad, 7 se activaron realmente. Un recall del 65% aproximadamente indicaba que captábamos alrededor de dos tercios de todas las ocasiones de peligro. Pero lo más importante es que el modelo ha pasado a aplicarse de forma realista a la negociación.
Ahora que la estructura básica del modelo está definida, en la siguiente parte hablaremos sobre su integración en un sistema comercial real y las decisiones comerciales específicas que se pueden tomar basándose en sus señales. Estoy seguro de que ésta será la parte más interesante de nuestro viaje por el mundo de la previsión de la volatilidad.
¿Qué piensa de este planteamiento? Sería interesante saber si usted ha usado algo parecido en su práctica. Y de ser así, ¿qué otros parámetros de volatilidad le parecen útiles?
El indicador de volatilidad extrema futura que he desarrollado
El indicador desarrollado supone una herramienta compleja para predecir los estallidos de volatilidad en el mercado Forex. A diferencia de los indicadores clásicos de volatilidad, que se limitan a mostrar el estado actual, nuestro indicador predice la probabilidad de fuertes movimientos en las próximas 12 horas.
import tkinter as tk from tkinter import ttk import matplotlib matplotlib.use('Agg') # Important to install before importing pyplot from matplotlib.figure import Figure from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg import time import MetaTrader5 as mt5 class VolatilityPredictor(tk.Tk): def __init__(self): super().__init__() self.title("Volatility Predictor") self.geometry("600x600") # Initialize the model self.model = VolatilityClassifier( lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75 ) # Load and train the model at startup self.initialize_model() # Create the interface self.create_gui() # Launch the update self.update_data() def initialize_model(self): rates_frame = check_mt5_data("EURUSD") if rates_frame is not None: features, target = self.model.prepare_data(rates_frame) X_train, X_test, y_train, y_test = self.model.create_train_test_split( features, target, test_size=0.2 ) self.model.train(X_train, y_train, X_test, y_test) def create_gui(self): # Top panel with settings control_frame = ttk.Frame(self) control_frame.pack(fill='x', padx=2, pady=2) ttk.Label(control_frame, text="Symbol:").pack(side='left', padx=2) self.symbol_var = tk.StringVar(value="EURUSD") symbol_list = ["EURUSD", "GBPUSD", "USDJPY"] # Simplified list ttk.Combobox(control_frame, textvariable=self.symbol_var, values=symbol_list, width=8).pack(side='left', padx=2) ttk.Label(control_frame, text="Alert:").pack(side='left', padx=2) self.threshold_var = tk.StringVar(value="0.7") ttk.Entry(control_frame, textvariable=self.threshold_var, width=4).pack(side='left') # Chart self.fig = Figure(figsize=(6, 4), dpi=100) self.canvas = FigureCanvasTkAgg(self.fig, self) self.canvas.draw() self.canvas.get_tk_widget().pack(fill='both', expand=True, padx=2, pady=2) # Probability indicator gauge_frame = ttk.Frame(self) gauge_frame.pack(fill='x', padx=2, pady=2) self.probability_var = tk.StringVar(value="0%") self.probability_label = ttk.Label( gauge_frame, textvariable=self.probability_var, font=('Arial', 20, 'bold') ) self.probability_label.pack() self.progress = ttk.Progressbar( gauge_frame, length=150, mode='determinate', maximum=100 ) self.progress.pack(pady=2) def update_data(self): try: rates = check_mt5_data(self.symbol_var.get()) if rates is not None: features, _ = self.model.prepare_data(rates) probability = self.model.predict_proba(features)[-1][1] self.update_indicators(rates, probability) threshold = float(self.threshold_var.get()) if probability > threshold: self.alert(probability) except Exception as e: print(f"Error updating data: {e}") finally: self.after(1000, self.update_data) def update_indicators(self, rates, probability): self.fig.clear() ax = self.fig.add_subplot(111) df = rates.tail(50) # Show fewer bars for compactness width = 0.6 width2 = 0.1 up = df[df.close >= df.open] down = df[df.close < df.open] ax.bar(up.index, up.close-up.open, width, bottom=up.open, color='g') ax.bar(up.index, up.high-up.close, width2, bottom=up.close, color='g') ax.bar(up.index, up.low-up.open, width2, bottom=up.open, color='g') ax.bar(down.index, down.close-down.open, width, bottom=down.open, color='r') ax.bar(down.index, down.high-down.open, width2, bottom=down.open, color='r') ax.bar(down.index, down.low-down.close, width2, bottom=down.close, color='r') ax.grid(False) # Remove the grid for compactness ax.set_xticks([]) # Remove X axis labels self.canvas.draw() prob_pct = int(probability * 100) self.probability_var.set(f"{prob_pct}%") self.progress['value'] = prob_pct if prob_pct > 70: self.probability_label.configure(foreground='red') elif prob_pct > 50: self.probability_label.configure(foreground='orange') else: self.probability_label.configure(foreground='green') def alert(self, probability): window = tk.Toplevel(self) window.title("Alert!") window.geometry("200x80") # Reduced alert window msg = f"High volatility: {probability:.1%}" ttk.Label(window, text=msg, font=('Arial', 10)).pack(pady=10) ttk.Button(window, text="OK", command=window.destroy).pack() def main(): app = VolatilityPredictor() app.mainloop() if __name__ == "__main__": main()
La ventana principal del indicador se divide en tres partes esenciales. En la parte superior se muestra el gráfico de velas japonesas: las últimas 100 barras para visualizar la dinámica actual de precios. Las velas verdes y rojas muestran tradicionalmente los movimientos alcistas y bajistas del mercado.
En la parte central se encuentra el elemento principal del indicador: una escala de probabilidad semicircular. Esta muestra la probabilidad actual de un pico de volatilidad en porcentaje, de 0 a 100. La flecha indicadora tiene un color diferente según el nivel de riesgo: verde para una probabilidad baja de hasta el 50%, naranja para una probabilidad media de entre el 50% y el 70%, y rojo para una probabilidad alta superior al 70%.
La previsión se basa en el análisis de la situación actual del mercado y en los patrones históricos de volatilidad. El modelo considera los datos de las últimas 20 barras para elaborar una previsión y predice la probabilidad de que aumente la volatilidad en las próximas 12 horas. La mayor precisión de previsión se logra en las primeras 4-6 horas tras la señal.
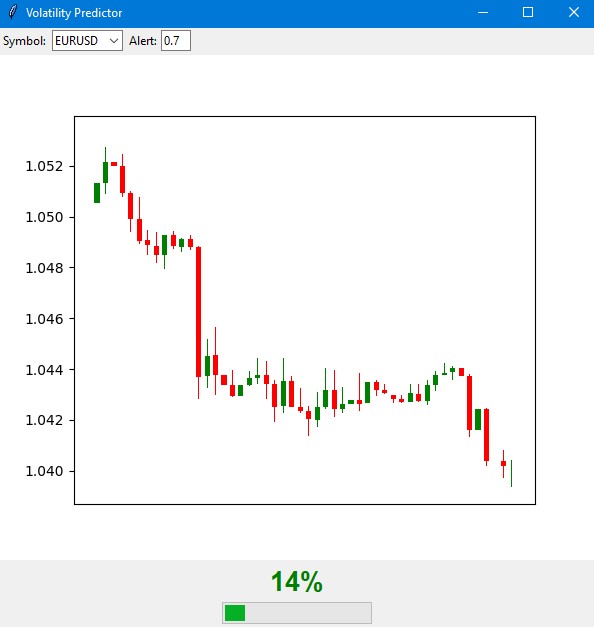
Con una probabilidad baja (zona verde), es probable que el mercado continúe su movimiento tranquilo. Este es un buen momento para trabajar en los ajustes estándar del sistema comercial. Durante esos periodos, pueden usarse los niveles normales de stop-loss.
Cuando el indicador muestra una probabilidad media y la flecha es de color naranja, debemos extremar la precaución. En tales ocasiones, se recomienda aumentar las órdenes de protección en aproximadamente una cuarta parte del tamaño estándar.
Si existe una alta probabilidad de que se produzca un pico cuando la flecha se ponga roja, deberemos reconsiderar seriamente la gestión del riesgo. En tales periodos se recomienda aumentar los stop-loss al menos una vez y media y, posiblemente, abstenerse de abrir nuevas posiciones hasta que la situación se estabilice.
El panel inferior del indicador contiene los elementos de control. Aquí podemos seleccionar el instrumento comercial, el intervalo de tiempo y establecer el umbral para recibir notificaciones. Por defecto, el umbral está fijado en el 70%, que es el valor óptimo para equilibrar el número de señales con su fiabilidad.
La precisión de las previsiones del indicador llega a un 70% para las señales de alta volatilidad. Esto significa que de cada diez advertencias de un posible aumento, siete se materializarán realmente. El indicador capta aproximadamente dos tercios de todos los movimientos significativos del mercado.
Debemos entender que el indicador no predice la dirección del movimiento de los precios, sino solo la probabilidad de que aumente la volatilidad. Su principal cometido es advertir a los tráders de posibles movimientos fuertes del mercado para que puedan ajustar con antelación su estrategia comercial y los niveles de las órdenes de protección.
En las próximas versiones del indicador tengo previsto añadir la posibilidad de ajustar automáticamente el stop-loss en función de la volatilidad prevista. Esto automatizará aún más el proceso de gestión de riesgos y hará más seguro el trading.
El indicador complementa perfectamente los sistemas comerciales existentes, funcionando como un filtro adicional para la gestión del riesgo. Su principal ventaja reside en su capacidad para advertir sobre posibles movimientos fuertes con antelación, lo que ofrece tiempo al tráder para prepararse y ajustar su estrategia.
Conclusión
En la negociación moderna, la previsión de la volatilidad sigue siendo una de las tareas clave para negociar con éxito. El camino desde un modelo de regresión simple hasta un clasificador de alta volatilidad descrito en el artículo demuestra que a veces una solución simple resulta más eficaz que una compleja. El sistema desarrollado alcanza una precisión de previsión de alrededor del 70% y capta aproximadamente dos tercios de todos los movimientos significativos del mercado.
La principal conclusión sería que lo más importante para la aplicación práctica no es el valor exacto de la volatilidad futura, sino el aviso a tiempo de su posible repunte. El indicador creado resuelve con éxito esta tarea, permitiendo a los tráders ajustar de antemano sus estrategias comerciales y los niveles de las órdenes de protección. La combinación de los métodos clásicos de análisis con las modernas tecnologías de aprendizaje automático descubre nuevas oportunidades para la gestión del riesgo de mercado.
La clave del éxito al final no reside en la complejidad de los algoritmos, sino en la correcta definición del problema y la calidad de la preparación de los datos. Este enfoque puede adaptarse a diferentes instrumentos comerciales y marcos temporales, lo que hace que la negociación sea más segura y previsible.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16960
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hola, muchas gracias. No me baso en un solo método. Tengo un EA Python integral, que incluye el análisis de patrones ingenuos, aprendizaje automático en código binario, aprendizaje automático en barras 3D, red neuronal en el análisis de volumen, análisis de volatilidad, modelo económico basado en datos del Banco Mundial y el FMI, enormes conjuntos de datos de cientos de miles de filas en todos los países del mundo, todas las estadísticas que es posible en todos....Y un módulo estadístico que construye todas las características estadísticas posibles, y un algoritmo genético que optimiza hiperparámetros, y un módulo de arbitraje que construye precios justos de divisas, y la descarga de los titulares y el contenido de los medios de comunicación del mundo en una moneda en particular, con el análisis de la coloración emocional de todos los artículos de noticias y notas (en el 80% de los casos cuando los medios de comunicación le animan a comprar algo, entonces viene el colapso, si la noticia es negativa - lo más probable es que sube con un retraso de 3-4 días).
¿Tiene alguna idea sobre qué más añadir? Sólo he llegado a la conclusión de que todavía tengo que hacer una carga de posiciones de un conocido sitio de monitoreo de cuentas (no sé si puedo decir su nombre aquí), he hecho el código, también voy a escribir un artículo sobre ello, el precio más a menudo va en contra de la multitud.
También estoy trabajando en la carga de datos sobre los volúmenes de futuros, grupos de volumen, y el análisis de los informes COT - también en Python.
Y yo uso tanto los modelos de regresión y modelos de clasificación, y pronto quiero hacer un supersistema que recibirá todas las señales, todas las señales de todos los modelos, así como flotante de ganancias / pérdidas y ganancias / pérdidas de la historia de la cuenta, y alimentar todo en DQN modelo =).
La respuesta al primer comando es "Python", pero para esta línea obtengo "El sistema no puede encontrar la ruta especificada"
(recién instalado Python, siguiendo sus instrucciones)