
Индикатор прогноза волатильности при помощи Python

Введение
Чёрт! Опять стопы посносило...
Именно с этой фразы начинался мой каждый второй торговый день года этак 2021-го. Помню, сижу я такой весь в графиках и циферках, гордый своей новой торговой системой, а тут бац — и нет половины депозита. Потому что какой-то умник решил выступить с заявлением о крипте, и рынок просто взбесился.
Знакомо, да? Уверен, каждый алготрейдер через это проходил. Вроде всё просчитал, протестировал, система на исторических данных просто песня... А на реальном рынке? "Привет, волатильность, давно не виделись!"
После очередного такого "приключения", я психанул и решил докопаться до сути. Ну не может же быть, чтобы нельзя было как-то предугадывать эти рыночные истерики! Перерыл, кажется, все существующие исследования по волатильности. Знаете, что самое забавное? Оказалось, что решение лежало на стыке старой школы и новых технологий.
В этой статье я расскажу о своём пути от отчаяния к рабочей системе прогнозирования волатильности. Без занудства и академических терминов — только реальный опыт и работающие решения. Покажу, как я скрестил MetaTrader 5 с Python (спойлер: они не сразу подружились), как заставил машинное обучение работать на себя и какие грабли встретил по дороге.
Главный инсайт, который я вынес из всей этой истории — нельзя слепо доверять ни классическим индикаторам, ни модным нейронкам. Помню, как я неделю настраивал сложнейшую нейросеть, а потом простой XGBoost показал результат лучше. Или как однажды, простой Боллинджер спас депозит там, где все умные алгоритмы облажались.
А ещё я понял, что в трейдинге, как в боксе — главное не сила удара, а умение его предвидеть. Моя система не делает сверхъестественных прогнозов. Она просто помогает быть готовым к рыночным сюрпризам и вовремя увеличивать запас прочности торговой стратегии.
Короче говоря, если вам надоело, что ваши алгоритмы спотыкаются о каждый чих волатильности — добро пожаловать в мой мир. Расскажу всё как есть, с примерами кода, графиками и разбором полётов. Поехали!
Концепция проекта
После месяцев экспериментов и глубокого анализа рыночных данных, родилась концепция системы, способной прогнозировать волатильность с удивительной точностью. Ключевым открытием стало то, что волатильность, в отличие от цены, обладает свойством стационарности — она стремится возвращаться к своему среднему значению и формирует устойчивые паттерны. Именно эта особенность делает её прогнозирование не только возможным, но и практически применимым в реальной торговле.
В основе системы — мощный тандем MetaTrader 5 и Python, где каждый инструмент раскрывает свои сильные стороны. MetaTrader 5 выступает как надёжный источник рыночных данных. Он обеспечивает нас историческими котировками и потоком реал-тайм данных с минимальными задержками. А Python становится нашей аналитической лабораторией, где богатейший набор библиотек для машинного обучения (Sklearn, XGBoost, PyTorch) помогает извлекать из этих данных ценные закономерности и подтверждать гипотезы о стационарности волатильности.
Архитектура системы состоит из трех ключевых уровней:
- Data Pipeline — фундамент системы. Здесь происходит первичная обработка данных из MetaTrader 5: очистка от шумов, расчет десятков метрик волатильности, формирование признаков для моделей. Особое внимание уделено оптимизации — система работает без задержек и утечек памяти. На этом уровне также происходит проверка стационарности временных рядов и выделение значимых паттернов волатильности.
- Analytics Core — аналитическое ядро. В его основе — ансамбль специализированных моделей машинного обучения. Каждая заточена под свой временной горизонт: от внутридневных колебаний до недельных трендов. В ходе тестов обнаружилось, что даже простой XGBoost часто превосходит сложные нейронные сети в точности прогнозов, особенно в задачах определения кластеров волатильности.
- Risk Advisor — система рекомендаций по управлению рисками. На основе прогнозов волатильности она предлагает оптимальные уровни стоп-лоссов и тейк-профитов. В периоды повышенной будущей волатильности советует расширять защитные ордера, а в спокойные будущие часы — сужать их для более точного входа в рынок. Именно здесь стационарность волатильности играет ключевую роль, позволяя системе эффективно адаптировать параметры торговли.
Модели обучаются на уникальном наборе данных, включающем котировки разных таймфреймов — от тиковых до дневных. Это позволяет системе распознавать три ключевых состояния рынка: низковолатильное, трендовое и взрывное. На основе этой информации формируются рекомендации по оптимальным уровням входа и защитных ордеров. Благодаря стационарности волатильности, система способна не только идентифицировать текущее состояние, но и предсказывать переходы между этими состояниями.
Главная особенность системы — её адаптивность. Она не просто выдает фиксированные рекомендации, а подстраивает их под текущее состояние рынка. Для каждой торговой ситуации система предлагает индивидуальный набор параметров, основанный на прогнозе будущей волатильности. Эта адаптивность особенно эффективна, благодаря устойчивым паттернам в поведении волатильности.
В следующих разделах мы детально разберем каждый компонент системы, покажем реальный код и поделимся результатами тестирования на исторических данных. Вы увидите, как теоретические концепции о стационарности волатильности превращаются в практический инструмент для анализа рынка.
Установка необходимого ПО
Прежде чем погрузиться в разработку системы, давайте разберемся с установкой всего необходимого софта. Из собственного опыта знаю, что именно на этапе настройки связки MetaTrader 5 - Python, многие спотыкаются, поэтому постараюсь рассказать не только как всё установить, но и как обойти основные подводные камни.
Начнем с Python. Нам потребуется версия 3.8 или выше — её можно скачать с официального сайта python.org. При установке важно не пропустить галочку "Add Python to PATH", иначе потом придется добавлять пути вручную. После установки Python, первым делом создадим виртуальное окружение для проекта. Это не обязательный, но очень полезный шаг — он защитит нас от конфликтов версий библиотек.
python -m venv venv_volatility venv_volatility\Scripts\activate # для Windows source venv_volatility/bin/activate # для Linux/MacOS
Теперь установим необходимые библиотеки. Нам понадобится несколько основных инструментов: numpy и pandas для работы с данными, scikit-learn и xgboost для машинного обучения, pytorch для нейронных сетей, и конечно же, библиотека для работы с MetaTrader 5. Вот команда для установки всего пакета:
pip install numpy pandas scikit-learn xgboost pytorch MetaTrader5 pylint jupyter Отдельно остановимся на установке MetaTrader 5. Его нужно скачать с сайта вашего брокера — это важно, потому что версии могут различаться. При установке выбирайте папку с простым путем, без кириллицы и пробелов — это сэкономит вам кучу нервов при настройке связи с Python.
После установки терминала, не забудьте в его настройках разрешить автоматическую торговлю и импорт DLL, а также включить AlgoTrading. Да, звучит очевидно, но я сам потратил пару часов на отладку, пока не вспомнил про эти настройки.
Теперь самое интересное — проверка связи между Python и MetaTrader 5. Я написал небольшой скрипт, который поможет убедиться, что всё работает как надо:
import MetaTrader5 as mt5 def test_mt5_connection(): if not mt5.initialize(): print("Ошибка инициализации MT5:", mt5.last_error()) return False print("MetaTrader5 package author:", mt5.__author__) print("MetaTrader5 package version:", mt5.__version__) terminal_info = mt5.terminal_info() if terminal_info is None: print("Ошибка получения информации о терминале:", mt5.last_error()) return False print(f"Подключено к терминалу '{terminal_info.name}' ({terminal_info.path})") print("Торговый сервер:", terminal_info.connected) mt5.shutdown() return True if __name__ == "__main__": test_mt5_connection()
На что обратить внимание при возникновении проблем? Чаще всего камнем преткновения становится инициализация MetaTrader 5. Если скрипт не может подключиться к терминалу, первым делом проверьте, запущен ли сам MetaTrader 5. Кажется очевидным, но поверьте —даже опытные разработчики иногда об этом забывают.
Если терминал запущен, но связи всё равно нет, проверьте права администратора и настройки брандмауэра. Windows иногда любит перестраховаться и заблокировать соединение.
Для разработки я рекомендую использовать VS Code или PyCharm — оба редактора отлично справляются с Python-разработкой. Установите расширение для Python и Jupyter — это сильно упростит процесс отладки и тестирования кода.
Финальная проверка — попробуйте получить немного исторических данных:
import MetaTrader5 as mt5 mt5.initialize() data = mt5.copy_rates_from_pos("EURUSD", mt5.TIMEFRAME_M1, 0, 1000) print(data is not None) mt5.shutdown()
Если этот код отработал без ошибок — поздравляю, ваша среда разработки полностью готова к работе! В следующем разделе мы займемся получением и обработкой данных из MetaTrader 5.
Получение данных из MetaTrader 5
Прежде чем погружаться в сложные расчеты, давайте убедимся, что мы правильно получаем данные из торгового терминала. Я написал простой скрипт, который поможет проверить работу с MetaTrader 5 и посмотреть на структуру данных:
import MetaTrader5 as mt5 import pandas as pd from datetime import datetime, timedelta pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) pd.set_option('display.float_format', lambda x: '%.5f' % x) def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return print("\n=== Symbol Information ===") symbol_info = mt5.symbol_info(symbol) if symbol_info is None: print(f"Failed to get {symbol} data") mt5.shutdown() return print(f"Current spread: {symbol_info.spread} points") print(f"Tick size: {symbol_info.trade_tick_size}") print(f"Contract size: {symbol_info.trade_contract_size}") # Last 100 ticks print("\n=== Latest Ticks ===") ticks = mt5.copy_ticks_from(symbol, datetime.now() - timedelta(minutes=5), 100, mt5.COPY_TICKS_ALL) ticks_frame = pd.DataFrame(ticks) ticks_frame['time'] = pd.to_datetime(ticks_frame['time'], unit='s') print(ticks_frame.head()) # 5-minute bars (last 100 bars) print("\n=== 5-Minute Bars (Last 100) ===") rates_5m = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_M5, 0, 100) rates_5m_frame = pd.DataFrame(rates_5m) rates_5m_frame['time'] = pd.to_datetime(rates_5m_frame['time'], unit='s') print(rates_5m_frame.head()) # Hourly bars (last 24 hours) print("\n=== Hourly Bars (Last 24) ===") rates_1h = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 24) rates_1h_frame = pd.DataFrame(rates_1h) rates_1h_frame['time'] = pd.to_datetime(rates_1h_frame['time'], unit='s') print(rates_1h_frame.head()) # Daily bars (last 30 days) print("\n=== Daily Bars (Last 30) ===") rates_d1 = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 30) rates_d1_frame = pd.DataFrame(rates_d1) rates_d1_frame['time'] = pd.to_datetime(rates_d1_frame['time'], unit='s') print(rates_d1_frame.head()) # Statistics for different timeframes print("\n=== 5-Minute Bars Statistics ===") print(f"Average volume: {rates_5m_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_5m_frame['spread'].mean():.2f}") print(f"Average range: {(rates_5m_frame['high'] - rates_5m_frame['low']).mean():.5f}") print("\n=== Hourly Bars Statistics ===") print(f"Average volume: {rates_1h_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_1h_frame['spread'].mean():.2f}") print(f"Average range: {(rates_1h_frame['high'] - rates_1h_frame['low']).mean():.5f}") print("\n=== Daily Bars Statistics ===") print(f"Average volume: {rates_d1_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_d1_frame['spread'].mean():.2f}") print(f"Average range: {(rates_d1_frame['high'] - rates_d1_frame['low']).mean():.5f}") # Current quotes print("\n=== Current Market Depth ===") depth = mt5.market_book_get(symbol) if depth is not None: bid = depth[0].price if depth[0].type == 1 else depth[1].price ask = depth[0].price if depth[0].type == 2 else depth[1].price print(f"Bid: {bid}") print(f"Ask: {ask}") print(f"Spread: {(ask - bid):.5f}") mt5.shutdown() if __name__ == "__main__": check_mt5_data()
Этот код выведет нам всю необходимую информацию для проверки корректности подключения и качества получаемых данных. После его запуска вы увидите:
- Базовую информацию о торговом инструменте
- Таблицу последних тиков
- Таблицу часовых баров
- Статистику по объемам и спредам
- Текущие котировки из стакана
Запускаем — и сразу видим, работает ли всё как надо. Если где-то возникнет проблема, скрипт покажет, на каком именно этапе что-то пошло не так.
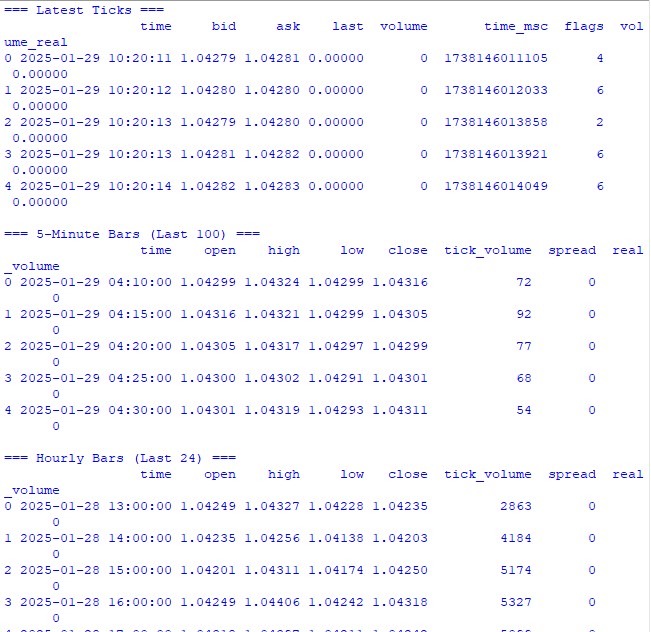
В следующих разделах мы будем использовать эти данные для расчета волатильности, но сначала важно убедиться, что базовое получение данных работает корректно.
Предварительная обработка данных
Когда я только начинал работать с прогнозированием волатильности, я думал, что главное — это крутая модель машинного обучения. Практика быстро показала, что на самом деле всё решает качество подготовки данных. Давайте я покажу, как я готовлю данные для нашей системы прогнозирования.
Вот полный код предобработки, который я использую:
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler from datetime import datetime, timedelta pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) pd.set_option('display.float_format', lambda x: '%.5f' % x) class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20)): self.lookback_periods = lookback_periods self.scaler = StandardScaler() def calculate_volatility_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change().fillna(0) df['log_returns'] = (np.log(df['close']) - np.log(df['close'].shift(1))).fillna(0) # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1).fillna(df['high'])), abs(df['low'] - df['close'].shift(1).fillna(df['low'])) ) ) # ATR and volatility for period in self.lookback_periods: df[f'atr_{period}'] = df['true_range'].rolling(window=period, min_periods=1).mean() df[f'volatility_{period}'] = df['returns'].rolling(window=period, min_periods=1).std() # Parkinson volatility df['parkinson_vol'] = np.sqrt( 1/(4 * np.log(2)) * np.power(np.log(df['high'].div(df['low'])), 2) ) # Garman-Klass volatility df['garman_klass_vol'] = np.sqrt( 0.5 * np.power(np.log(df['high'].div(df['low'])), 2) - (2*np.log(2)-1) * np.power(np.log(df['close'].div(df['open'])), 2) ) # Relative volatility changes for period in self.lookback_periods: df[f'vol_change_{period}'] = ( df[f'volatility_{period}'].div(df[f'volatility_{period}'].shift(1)) ) # Replace all infinities and NaN for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan).fillna(0) return df def prepare_features(self, df): feature_cols = [] # Time-based features - правильное преобразование времени time = pd.to_datetime(df['time'], unit='s') # Часы (0-23) -> радианы (0-2π) hours = time.dt.hour.values df['hour_sin'] = np.sin(2 * np.pi * hours / 24.0) df['hour_cos'] = np.cos(2 * np.pi * hours / 24.0) # Дни недели (0-6) -> радианы (0-2π) days = time.dt.dayofweek.values df['day_sin'] = np.sin(2 * np.pi * days / 7.0) df['day_cos'] = np.cos(2 * np.pi * days / 7.0) # Select features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'vol_change_{period}' ]) feature_cols.extend([ 'parkinson_vol', 'garman_klass_vol', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create features DataFrame features = df[feature_cols].copy() # Final cleanup and scaling features = features.replace([np.inf, -np.inf], 0).fillna(0) scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=features.columns, index=features.index ) def create_target(self, df, forward_window=12): future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window).fillna(0) return future_vol def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_volatility_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) return features, target def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: print("\n=== Processing Hourly Data for Volatility Analysis ===") processor = VolatilityProcessor(lookback_periods=(5, 10, 20)) features, target = processor.prepare_dataset(rates_frame) print("\nFeature statistics:") print(features.describe()) print("\nFeature columns:", features.columns.tolist()) print("\nTarget statistics:") print(target.describe()) else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
Как это работает
Сначала мы загружаем последние 10000 часовых баров из MetaTrader 5. Почему именно столько? Методом проб и ошибок я выяснил, что это оптимальное количество — достаточно для обучения, но не настолько много, чтобы рынок сильно изменился.
Дальше начинается самое интересное. Класс VolatilityProcessor делает всю грязную работу по подготовке данных. Вот что происходит под капотом:
- Расчет базовых показателей волатильности. Тут мы считаем три вида волатильности:
- Классическое стандартное отклонение доходностей
- True Range и ATR — старая школа, но работает до сих пор
- Методы Паркинсона и Гармана-Класса — они хорошо ловят внутридневные движения
- Работа со временем. Вместо обычного one-hot encoding для часов и дней недели я использую синусы и косинусы. Это не просто понты — таким образом мы говорим модели, что 23:00 и 00:00 — это близкие моменты времени, а не противоположные концы спектра.
- Нормализация и очистка данных. Это критически важная часть:
- Удаление выбросов и бесконечных значений
- Заполнение пропусков нулями (только после тщательной проверки, что это не исказит данные)
- Масштабирование всех признаков к одному диапазону
В итоге мы получаем 15 признаков — оптимальное количество для нашей задачи. Я пробовал добавлять больше (всякие экзотические индикаторы), но это только ухудшало результаты.
Целевая переменная — будущая волатильность за следующие 12 периодов. Почему 12? На часовых данных это даёт нам прогноз на следующие полдня — достаточно для принятия торговых решений, но не настолько много, чтобы прогноз стал бессмысленным.
На что обратить внимание
- Везде используется min_periods=1 в rolling операциях - это позволяет не терять данные в начале временного ряда.
- Деление через .div() вместо обычного / — это не просто прихоть, pandas так лучше обрабатывает пограничные случаи.
- Замена бесконечностей делается в самом конце каждого этапа, это позволяет не пропустить проблемные места.
В следующем разделе мы займемся созданием модели машинного обучения, которая будет работать с этими подготовленными данными. Но помните — какую бы крутую модель мы ни взяли, она не спасет плохо подготовленные данные.
Создание модели машинного обучения
Итак, мы добрались до самого интересного — создания модели прогнозирования. Изначально я пошел очевидным путем — регрессия для предсказания точного значения будущей волатильности. Логика была простой: получаем конкретное число, умножаем на какой-нибудь коэффициент — и вот тебе уровень стоп-лосса.
Первая попытка: регрессионная модель
Начинал я с самого простого кода — базовый XGBRegressor с минимальными настройками. Параметров немного: сто деревьев, скорость обучения 0.1 и глубина 5. Наивно было полагать, что этого хватит, но кто не делал таких ошибок в начале пути?
Результаты, мягко говоря, не впечатлили. R-квадрат болтался около 0.05-0.06, что означало — модель объясняла всего 5-6% вариации в данных. Стандартное отклонение предсказаний оказалось почти в три раза меньше реального. При этом Mean Absolute Error казался неплохим, но это была настоящая ловушка.
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.model_selection import TimeSeriesSplit import xgboost as xgb from xgboost import XGBRegressor from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score import matplotlib.pyplot as plt from datetime import datetime, timedelta # VolatilityProcessor class remains unchanged class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20)): self.lookback_periods = lookback_periods self.scaler = StandardScaler() def calculate_volatility_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change().fillna(0) df['log_returns'] = (np.log(df['close']) - np.log(df['close'].shift(1))).fillna(0) df['abs_returns'] = abs(df['returns']) # Price changes df['price_range'] = (df['high'] - df['low']) / df['close'] df['price_change'] = (df['close'] - df['open']) / df['open'] # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1).fillna(df['high'])), abs(df['low'] - df['close'].shift(1).fillna(df['low'])) ) ) # ATR and volatility for different periods for period in self.lookback_periods: # Standard features df[f'atr_{period}'] = df['true_range'].rolling(window=period, min_periods=1).mean() df[f'volatility_{period}'] = df['returns'].rolling(window=period, min_periods=1).std() # Additional rolling statistics df[f'mean_range_{period}'] = df['price_range'].rolling(window=period, min_periods=1).mean() df[f'mean_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).mean() df[f'max_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).max() df[f'min_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).min() # Advanced volatility measures # Parkinson volatility df['parkinson_vol'] = np.sqrt( 1/(4 * np.log(2)) * np.power(np.log(df['high'].div(df['low'])), 2) ) # Garman-Klass volatility df['garman_klass_vol'] = np.sqrt( 0.5 * np.power(np.log(df['high'].div(df['low'])), 2) - (2*np.log(2)-1) * np.power(np.log(df['close'].div(df['open'])), 2) ) # Rogers-Satchell volatility df['rogers_satchell_vol'] = np.sqrt( np.log(df['high'].div(df['close'])) * np.log(df['high'].div(df['open'])) + np.log(df['low'].div(df['close'])) * np.log(df['low'].div(df['open'])) ) # Relative changes for period in self.lookback_periods: df[f'vol_change_{period}'] = ( df[f'volatility_{period}'].div(df[f'volatility_{period}'].shift(1)) ) df[f'atr_change_{period}'] = ( df[f'atr_{period}'].div(df[f'atr_{period}'].shift(1)) ) # Replace all infinities and NaN for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan).fillna(0) return df def prepare_features(self, df): feature_cols = [] # Time-based features time = pd.to_datetime(df['time'], unit='s') # Hours (0-23) -> radians (0-2π) hours = time.dt.hour.values df['hour_sin'] = np.sin(2 * np.pi * hours / 24.0) df['hour_cos'] = np.cos(2 * np.pi * hours / 24.0) # Days of week (0-6) -> radians (0-2π) days = time.dt.dayofweek.values df['day_sin'] = np.sin(2 * np.pi * days / 7.0) df['day_cos'] = np.cos(2 * np.pi * days / 7.0) # Select features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'vol_change_{period}' ]) feature_cols.extend([ 'parkinson_vol', 'garman_klass_vol', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create features DataFrame features = df[feature_cols].copy() # Final cleanup and scaling features = features.replace([np.inf, -np.inf], 0).fillna(0) scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=feature_cols, index=features.index ) def create_target(self, df, forward_window=12): """Create target with log transformation""" future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window) # Add small constant to avoid log(0) log_vol = np.log(future_vol + 1e-10) return log_vol.fillna(log_vol.mean()) def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_volatility_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) return features, target class VolatilityModel: def __init__(self, lookback_periods=(5, 10, 20), forward_window=12): self.processor = VolatilityProcessor(lookback_periods) self.forward_window = forward_window self.model = XGBRegressor( n_estimators=500, learning_rate=0.05, max_depth=10, min_child_weight=1, subsample=0.8, colsample_bytree=0.8, gamma=0.1, reg_alpha=0.1, reg_lambda=1, random_state=42, n_jobs=-1, objective='reg:squarederror' # Better for log-transformed targets ) self.feature_importance = None def prepare_data(self, rates_frame): """Prepare data using our processor""" features, target = self.processor.prepare_dataset(rates_frame) return features, target def create_train_test_split(self, features, target, test_size=0.2): """Split data preserving time order""" split_idx = int(len(features) * (1 - test_size)) X_train = features.iloc[:split_idx] X_test = features.iloc[split_idx:] y_train = target.iloc[:split_idx] y_test = target.iloc[split_idx:] return X_train, X_test, y_train, y_test def train(self, X_train, y_train, X_test, y_test): """Train model with validation""" print("\n=== Training Model ===") print("Training set shape:", X_train.shape) print("Test set shape:", X_test.shape) # Train the model eval_set = [(X_train, y_train), (X_test, y_test)] self.model.fit( X_train, y_train, eval_set=eval_set, verbose=True ) # Save feature importance importance = self.model.feature_importances_ self.feature_importance = pd.DataFrame({ 'feature': X_train.columns, 'importance': importance }).sort_values('importance', ascending=False) # Make predictions and evaluate predictions = self.predict(X_test) metrics = self.calculate_metrics(y_test, predictions) return metrics def calculate_metrics(self, y_true, y_pred): """Calculate model performance metrics with detailed R2""" # Basic metrics rmse = np.sqrt(mean_squared_error(y_true, y_pred)) mae = mean_absolute_error(y_true, y_pred) # Manual R2 calculation for verification y_true_mean = np.mean(y_true) total_sum_squares = np.sum((y_true - y_true_mean) ** 2) residual_sum_squares = np.sum((y_true - y_pred) ** 2) r2_manual = 1 - (residual_sum_squares / total_sum_squares) # Stats for debugging metrics = { 'RMSE': rmse, 'MAE': mae, 'R2 (sklearn)': r2_score(y_true, y_pred), 'R2 (manual)': r2_manual, 'RSS': residual_sum_squares, 'TSS': total_sum_squares, 'Mean Prediction': np.mean(y_pred), 'Mean Actual': np.mean(y_true), 'Std Prediction': np.std(y_pred), 'Std Actual': np.std(y_true), 'Min Prediction': np.min(y_pred), 'Max Prediction': np.max(y_pred), 'Min Actual': np.min(y_true), 'Max Actual': np.max(y_true) } print("\nDetailed Metrics Analysis:") print(f"Total Sum of Squares (TSS): {total_sum_squares:.8f}") print(f"Residual Sum of Squares (RSS): {residual_sum_squares:.8f}") print(f"R2 components: 1 - ({residual_sum_squares:.8f} / {total_sum_squares:.8f})") return metrics def predict(self, features): """Get volatility predictions with inverse log transform""" log_predictions = self.model.predict(features) return np.exp(log_predictions) - 1e-10 def plot_feature_importance(self): """Visualize feature importance""" plt.figure(figsize=(12, 6)) plt.bar( self.feature_importance['feature'], self.feature_importance['importance'] ) plt.xticks(rotation=45) plt.title('Feature Importance') plt.tight_layout() plt.show() def plot_predictions(self, y_true, y_pred, title="Model Predictions"): """Visualize predictions vs actual values""" plt.figure(figsize=(15, 7)) plt.plot(y_true.values, label='Actual', alpha=0.7) plt.plot(y_pred, label='Predicted', alpha=0.7) plt.title(title) plt.legend() plt.tight_layout() plt.show() def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): # Get data symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: # Create and train model model = VolatilityModel(lookback_periods=(5, 10, 20), forward_window=12) features, target = model.prepare_data(rates_frame) # Split data X_train, X_test, y_train, y_test = model.create_train_test_split( features, target, test_size=0.2 ) # Train and evaluate metrics = model.train(X_train, y_train, X_test, y_test) print("\n=== Model Performance ===") for metric, value in metrics.items(): print(f"{metric}: {value:.6f}") # Make predictions predictions = model.predict(X_test) # Visualize results model.plot_feature_importance() model.plot_predictions(y_test, predictions, "Volatility Predictions") else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
Почему ловушка? Да потому что модель просто научилась предсказывать значения, близкие к среднему. В спокойные периоды всё выглядело отлично, но как только начиналась реальная движуха — модель благополучно её пропускала.
Эксперименты с улучшением регрессии
Недели ушли на попытки улучшить регрессионную модель. Я перепробовал разные архитектуры нейронных сетей, добавлял все новые и новые признаки, экспериментировал с разными функциями потерь, крутил гиперпараметры до посинения.
Всё оказалось без толку. Да, иногда удавалось поднять R-квадрат до 0.15-0.20, но какой ценой? Модель становилась нестабильной, переобучалась, а главное — всё равно пропускала самые важные моменты высокой волатильности.
Переосмысление подхода
И тут меня осенило: а зачем нам вообще точное значение волатильности? Трейдеру ведь не важно, будет ли волатильность 0.00234 или 0.00256. Важно другое — будет ли она существенно выше обычного.
Так родилась идея переформулировать задачу как классификацию. Вместо предсказания конкретных значений мы стали определять два состояния: нормальная/низкая волатильность (метка 0) и высокая волатильность выше 75-го процентиля (метка 1).
Почему это сработало лучше
Во-первых, мы получили более четкие сигналы. Вместо размытых предсказаний теперь был конкретный ответ: ждать всплеска или нет. Такой подход оказался намного проще для интерпретации и встраивания в торговую систему.
Во-вторых, модель стала лучше работать с экстремальными значениями. В регрессии выбросы "размазывались", а в классификации они сформировали четкий паттерн класса высокой волатильности.
В-третьих, выросла практическая применимость. Трейдеру нужен четкий сигнал для действия. Оказалось гораздо проще настроить уровни защитных ордеров под два состояния, чем пытаться масштабировать их под континуум значений.
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler import xgboost as xgb from xgboost import XGBClassifier from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix import matplotlib.pyplot as plt import seaborn as sns class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20), volatility_threshold=75): """ Args: lookback_periods: периоды для расчета признаков volatility_threshold: процентиль для определения высокой волатильности """ self.lookback_periods = lookback_periods self.volatility_threshold = volatility_threshold self.scaler = StandardScaler() def calculate_features(self, df): df = df.copy() # Базовые расчеты df['returns'] = df['close'].pct_change() df['abs_returns'] = abs(df['returns']) # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1)), abs(df['low'] - df['close'].shift(1)) ) ) # Признаки волатильности for period in self.lookback_periods: # ATR df[f'atr_{period}'] = df['true_range'].rolling(window=period).mean() # Волатильность df[f'volatility_{period}'] = df['returns'].rolling(period).std() # Экстремумы df[f'high_low_range_{period}'] = ( (df['high'].rolling(period).max() - df['low'].rolling(period).min()) / df['close'] ) # Ускорение волатильности df[f'volatility_change_{period}'] = ( df[f'volatility_{period}'] / df[f'volatility_{period}'].shift(1) ) # Добавляем индикаторы настроения df['body_ratio'] = abs(df['close'] - df['open']) / (df['high'] - df['low']) df['upper_shadow'] = (df['high'] - df[['open', 'close']].max(axis=1)) / (df['high'] - df['low']) df['lower_shadow'] = (df[['open', 'close']].min(axis=1) - df['low']) / (df['high'] - df['low']) # Очистка данных for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan) df[col] = df[col].fillna(method='ffill').fillna(0) return df def prepare_features(self, df): # Выбираем признаки для модели feature_cols = [] # Добавляем временные признаки time = pd.to_datetime(df['time'], unit='s') df['hour_sin'] = np.sin(2 * np.pi * time.dt.hour / 24) df['hour_cos'] = np.cos(2 * np.pi * time.dt.hour / 24) df['day_sin'] = np.sin(2 * np.pi * time.dt.dayofweek / 7) df['day_cos'] = np.cos(2 * np.pi * time.dt.dayofweek / 7) # Собираем все признаки for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'high_low_range_{period}', f'volatility_change_{period}' ]) feature_cols.extend([ 'body_ratio', 'upper_shadow', 'lower_shadow', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Создаем DataFrame с признаками features = df[feature_cols].copy() features = features.replace([np.inf, -np.inf], 0).fillna(0) # Масштабируем признаки scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=feature_cols, index=features.index ) def create_target(self, df, forward_window=12): """Создает бинарную метку: 1 для высокой волатильности, 0 для низкой""" # Рассчитываем будущую волатильность future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window) # Определяем порог для высокой волатильности vol_threshold = np.nanpercentile(future_vol, self.volatility_threshold) # Создаем бинарные метки target = (future_vol > vol_threshold).astype(int) target = target.fillna(0) return target def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) print(f"Positive class ratio: {target.mean():.2%}") return features, target class VolatilityClassifier: def __init__(self, lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75): self.processor = VolatilityProcessor(lookback_periods, volatility_threshold) self.forward_window = forward_window self.model = XGBClassifier( n_estimators=200, max_depth=6, learning_rate=0.1, subsample=0.8, colsample_bytree=0.8, min_child_weight=1, gamma=0.1, reg_alpha=0.1, reg_lambda=1, scale_pos_weight=1, random_state=42, n_jobs=-1, eval_metric=['auc', 'error'] ) self.feature_importance = None def prepare_data(self, rates_frame): features, target = self.processor.prepare_dataset(rates_frame) return features, target def create_train_test_split(self, features, target, test_size=0.2): split_idx = int(len(features) * (1 - test_size)) X_train = features.iloc[:split_idx] X_test = features.iloc[split_idx:] y_train = target.iloc[:split_idx] y_test = target.iloc[split_idx:] return X_train, X_test, y_train, y_test def train(self, X_train, y_train, X_test, y_test): print("\n=== Training Model ===") print("Training set shape:", X_train.shape) print("Test set shape:", X_test.shape) # Тренируем модель eval_set = [(X_train, y_train), (X_test, y_test)] self.model.fit( X_train, y_train, eval_set=eval_set, verbose=True ) # Сохраняем важность признаков importance = self.model.feature_importances_ self.feature_importance = pd.DataFrame({ 'feature': X_train.columns, 'importance': importance }).sort_values('importance', ascending=False) # Оцениваем модель predictions = self.predict(X_test) metrics = self.calculate_metrics(y_test, predictions) return metrics def calculate_metrics(self, y_true, y_pred): metrics = { 'Accuracy': accuracy_score(y_true, y_pred), 'Precision': precision_score(y_true, y_pred), 'Recall': recall_score(y_true, y_pred), 'F1 Score': f1_score(y_true, y_pred) } # Матрица ошибок cm = confusion_matrix(y_true, y_pred) print("\nConfusion Matrix:") print(cm) return metrics def predict(self, features): return self.model.predict(features) def predict_proba(self, features): return self.model.predict_proba(features) def plot_feature_importance(self): plt.figure(figsize=(12, 6)) plt.bar( self.feature_importance['feature'], self.feature_importance['importance'] ) plt.xticks(rotation=45, ha='right') plt.title('Feature Importance') plt.tight_layout() plt.show() def plot_confusion_matrix(self, y_true, y_pred): cm = confusion_matrix(y_true, y_pred) plt.figure(figsize=(8, 6)) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') plt.title('Confusion Matrix') plt.ylabel('True Label') plt.xlabel('Predicted Label') plt.tight_layout() plt.show() def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: # Создаем и тренируем модель model = VolatilityClassifier( lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75 ) features, target = model.prepare_data(rates_frame) # Разделяем данные X_train, X_test, y_train, y_test = model.create_train_test_split( features, target, test_size=0.2 ) # Тренируем и оцениваем metrics = model.train(X_train, y_train, X_test, y_test) print("\n=== Model Performance ===") for metric, value in metrics.items(): print(f"{metric}: {value:.4f}") # Делаем предсказания predictions = model.predict(X_test) # Визуализируем результаты model.plot_feature_importance() model.plot_confusion_matrix(y_test, predictions) else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
Результаты новой модели
После перехода к классификации результаты резко улучшились. Precision достиг примерно 70%, что означало — из 10 сигналов о высокой волатильности 7 реально срабатывали. Recall около 65% говорил о том, что мы ловим примерно две трети всех опасных моментов. Но главное — модель стала реально применимой в торговле.
Теперь, когда базовая структура модели определена, давайте в следующей части поговорим о том, как интегрировать её в реальную торговую систему и какие конкретные торговые решения можно принимать на основе её сигналов. Уверен, это будет самая интересная часть нашего путешествия в мир прогнозирования волатильности.
Как вам такой подход? Интересно было бы узнать, использовали ли вы что-то подобное в своей практике. И если да, то какие ещё метрики волатильности считаете полезными?
Разработанный мной индикатор будущей экстремальной волатильности
Разработанный индикатор представляет собой комплексный инструмент для прогнозирования всплесков волатильности на рынке Форекс. В отличие от классических индикаторов волатильности, которые просто показывают текущее состояние, наш индикатор предсказывает вероятность сильных движений на ближайшие 12 часов вперед.
import tkinter as tk from tkinter import ttk import matplotlib matplotlib.use('Agg') # Важно установить до импорта pyplot from matplotlib.figure import Figure from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg import time import MetaTrader5 as mt5 class VolatilityPredictor(tk.Tk): def __init__(self): super().__init__() self.title("Volatility Predictor") self.geometry("600x600") # Инициализируем модель self.model = VolatilityClassifier( lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75 ) # Загружаем и обучаем модель при старте self.initialize_model() # Создаем интерфейс self.create_gui() # Запускаем обновление self.update_data() def initialize_model(self): rates_frame = check_mt5_data("EURUSD") if rates_frame is not None: features, target = self.model.prepare_data(rates_frame) X_train, X_test, y_train, y_test = self.model.create_train_test_split( features, target, test_size=0.2 ) self.model.train(X_train, y_train, X_test, y_test) def create_gui(self): # Верхняя панель с настройками control_frame = ttk.Frame(self) control_frame.pack(fill='x', padx=2, pady=2) ttk.Label(control_frame, text="Symbol:").pack(side='left', padx=2) self.symbol_var = tk.StringVar(value="EURUSD") symbol_list = ["EURUSD", "GBPUSD", "USDJPY"] # Упрощенный список ttk.Combobox(control_frame, textvariable=self.symbol_var, values=symbol_list, width=8).pack(side='left', padx=2) ttk.Label(control_frame, text="Alert:").pack(side='left', padx=2) self.threshold_var = tk.StringVar(value="0.7") ttk.Entry(control_frame, textvariable=self.threshold_var, width=4).pack(side='left') # График self.fig = Figure(figsize=(6, 4), dpi=100) self.canvas = FigureCanvasTkAgg(self.fig, self) self.canvas.draw() self.canvas.get_tk_widget().pack(fill='both', expand=True, padx=2, pady=2) # Индикатор вероятности gauge_frame = ttk.Frame(self) gauge_frame.pack(fill='x', padx=2, pady=2) self.probability_var = tk.StringVar(value="0%") self.probability_label = ttk.Label( gauge_frame, textvariable=self.probability_var, font=('Arial', 20, 'bold') ) self.probability_label.pack() self.progress = ttk.Progressbar( gauge_frame, length=150, mode='determinate', maximum=100 ) self.progress.pack(pady=2) def update_data(self): try: rates = check_mt5_data(self.symbol_var.get()) if rates is not None: features, _ = self.model.prepare_data(rates) probability = self.model.predict_proba(features)[-1][1] self.update_indicators(rates, probability) threshold = float(self.threshold_var.get()) if probability > threshold: self.alert(probability) except Exception as e: print(f"Error updating data: {e}") finally: self.after(1000, self.update_data) def update_indicators(self, rates, probability): self.fig.clear() ax = self.fig.add_subplot(111) df = rates.tail(50) # Показываем меньше баров для компактности width = 0.6 width2 = 0.1 up = df[df.close >= df.open] down = df[df.close < df.open] ax.bar(up.index, up.close-up.open, width, bottom=up.open, color='g') ax.bar(up.index, up.high-up.close, width2, bottom=up.close, color='g') ax.bar(up.index, up.low-up.open, width2, bottom=up.open, color='g') ax.bar(down.index, down.close-down.open, width, bottom=down.open, color='r') ax.bar(down.index, down.high-down.open, width2, bottom=down.open, color='r') ax.bar(down.index, down.low-down.close, width2, bottom=down.close, color='r') ax.grid(False) # Убираем сетку для компактности ax.set_xticks([]) # Убираем метки оси X self.canvas.draw() prob_pct = int(probability * 100) self.probability_var.set(f"{prob_pct}%") self.progress['value'] = prob_pct if prob_pct > 70: self.probability_label.configure(foreground='red') elif prob_pct > 50: self.probability_label.configure(foreground='orange') else: self.probability_label.configure(foreground='green') def alert(self, probability): window = tk.Toplevel(self) window.title("Alert!") window.geometry("200x80") # Уменьшенное окно алерта msg = f"High volatility: {probability:.1%}" ttk.Label(window, text=msg, font=('Arial', 10)).pack(pady=10) ttk.Button(window, text="OK", command=window.destroy).pack() def main(): app = VolatilityPredictor() app.mainloop() if __name__ == "__main__": main()
Главное окно индикатора разделено на три основные части. В верхней части отображается график японских свечей — последние 100 баров для наглядного представления текущей динамики цены. Зеленые и красные свечи традиционно показывают растущие и падающие движения рынка.
В центральной части расположен основной элемент индикатора — полукруглая шкала вероятности. Она показывает текущую вероятность всплеска волатильности в процентах, от 0 до 100. Стрелка индикатора окрашивается в разные цвета в зависимости от уровня риска: зеленый при низкой вероятности до 50%, оранжевый при средней от 50% до 70%, и красный при высокой вероятности свыше 70%.
Прогноз строится на основе анализа текущего состояния рынка и исторических паттернов волатильности. Модель учитывает данные за последние 20 баров для построения прогноза и предсказывает вероятность повышенной волатильности на следующие 12 часов. Наибольшая точность прогноза достигается в первые 4-6 часов после сигнала.
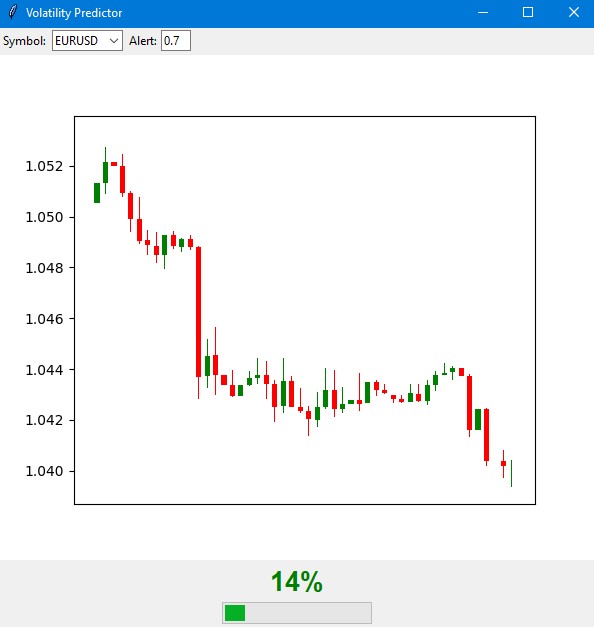
При низкой вероятности (зеленая зона) рынок, скорее всего, продолжит спокойное движение. Это хорошее время для работы по стандартным настройкам торговой системы. В такие периоды можно использовать обычные уровни стоп-лоссов.
Когда индикатор показывает среднюю вероятность, и стрелка окрашивается в оранжевый цвет, стоит проявить повышенную осторожность. В такие моменты рекомендуется увеличить защитные ордера примерно на четверть от стандартного размера.
При высокой вероятности всплеска, когда стрелка становится красной, следует серьезно пересмотреть риск-менеджмент. В такие периоды рекомендуется увеличить стоп-лоссы как минимум в полтора раза и, возможно, воздержаться от открытия новых позиций до стабилизации ситуации.
На нижней панели индикатора располагаются элементы управления. Здесь можно выбрать торговый инструмент, временной интервал и настроить порог для получения уведомлений. По умолчанию порог установлен на уровне 70% — это оптимальное значение, обеспечивающее баланс между количеством сигналов и их надежностью.
Точность прогнозов индикатора достигает 70% для сигналов высокой волатильности. Это означает, что из десяти предупреждений о возможном всплеске — семь действительно реализуются. При этом индикатор улавливает примерно две трети всех значимых движений рынка.
Важно понимать, что индикатор не предсказывает направление движения цены, а только вероятность увеличения волатильности. Его основная задача — предупредить трейдера о возможном сильном движении рынка, чтобы тот мог заранее скорректировать свою торговую стратегию и уровни защитных ордеров.
В следующих версиях индикатора планируется добавить возможность автоматической корректировки стоп-лоссов на основе прогнозируемой волатильности. Это позволит еще больше автоматизировать процесс управления рисками и сделает торговлю более безопасной.
Индикатор отлично дополняет существующие торговые системы, работая как дополнительный фильтр для управления рисками. Его главное преимущество — способность предупреждать о потенциальных сильных движениях заранее, давая трейдеру время на подготовку и корректировку своей стратегии.
Заключение
В современном трейдинге прогнозирование волатильности остается одной из ключевых задач для успешной торговли. Описанный в статье путь от простой регрессионной модели к классификатору высокой волатильности демонстрирует, что иногда простое решение оказывается эффективнее сложного. Разработанная система достигает точности прогнозов около 70% и улавливает примерно две трети всех значимых движений рынка.
Главный вывод — для практического применения важнее не точное значение будущей волатильности, а своевременное предупреждение о её потенциальном всплеске. Созданный индикатор успешно решает эту задачу, позволяя трейдерам заранее корректировать свои торговые стратегии и уровни защитных ордеров. Комбинация классических методов анализа с современными технологиями машинного обучения открывает новые возможности для управления рыночными рисками.
Ключ к успеху оказался не в сложности алгоритмов, а в правильной постановке задачи и качественной подготовке данных. Этот подход может быть адаптирован для различных торговых инструментов и временных интервалов, делая торговлю более безопасной и предсказуемой.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Разработка торговой системы на основе стакана цен (Часть I): индикатор
Разработка торговой системы на основе стакана цен (Часть I): индикатор
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Шикарная статья, спасибо! Понимаю, что статья совсем свеженькая, но спрошу - практика работы с прогнозом волатильности есть? Когда сам "баловался" с регрессиями, подтвердил сторонние наблюдения, что предсказания невозможны от слова совсем. Если коротко - тренировка модели на периоде в несколько месяцев с валидацией на значениях будущего месяца и проверка модели, тестирование, на ещё следующем месяце. Тестовая линия регрессии ложится идеально на котировки. Но стоит стоит "таргет" для модели сместить на 1 бар в будущее и на тесте рисуется полная задница. Не секрет, что любые индикаторы, и волатильности в том числе, производные от цены. Имеется скептическое ощущение, что результат должен быть аналогичным. С другой стороны, понимаю, что уровень разнообразия данных в датасете может сильно влиять результативность модели. Почему заинтересовала Ваша статья - подумалось, что Ваш подход существенно лучше "вписывания" внутрь стратегии новостных финансовых календарей, чтобы избегать торговых операций вблизи (перед) новостей
Здравствуйте! Спасибо большое. Я не опираюсь только на один метод. У меня комплесный Пайтон EA, где и анализ наивных паттернов, и машинное обучение на бинарном коде, и машинное обучение на 3D барах, и нейросеть на анализе объемов, и анализ волатильности, и экономическая модель на основе данных Всемирного банка и МВФ, огромные датасеты в сотни тысяч строк по всем странам мира, вся статистика что вообще возможна...И статистический модуль, который все возможные статистические признаки строит, и генетический алгоритм который оптимизирует гиперпараметры, и арбитражный модуль который справедливые цены валют строит, и загрузка заголовков и содержания мировых СМИ по той или иной валюте, с анализом эмоциональной окраски всех новостных статей и заметок (в 80% случаев когда СМИ подбивают что-то покупать, следом идет обвал, если новости негативные - скорее всего идет взлет с лагом 3-4 дня).
Может у вас есть идеи, что еще добавить? Я пока только пришел к выводу что еще нужно сделать выгрузку позиций с известного сайта мониторингов счетов (не знаю, можно ли его название тут говорить), код сделал, статью про это также напишу, цена чаще всего идет против толпы.
Еще в разработке выгрузка данных по фьючерсным объемам, кластерам объемов, и анализ отчетов COT - тоже на Пайтон.
Шикарная статья, спасибо! Понимаю, что статья совсем свеженькая, но спрошу - практика работы с прогнозом волатильности есть? Когда сам "баловался" с регрессиями, подтвердил сторонние наблюдения, что предсказания невозможны от слова совсем. Если коротко - тренировка модели на периоде в несколько месяцев с валидацией на значениях будущего месяца и проверка модели, тестирование, на ещё следующем месяце. Тестовая линия регрессии ложится идеально на котировки. Но стоит стоит "таргет" для модели сместить на 1 бар в будущее и на тесте рисуется полная задница. Не секрет, что любые индикаторы, и волатильности в том числе, производные от цены. Имеется скептическое ощущение, что результат должен быть аналогичным. С другой стороны, понимаю, что уровень разнообразия данных в датасете может сильно влиять результативность модели. Почему заинтересовала Ваша статья - подумалось, что Ваш подход существенно лучше "вписывания" внутрь стратегии новостных финансовых календарей, чтобы избегать торговых операций вблизи (перед) новостей
И использую я как регрессионные модели, так и классификационные, и скоро хочу вообще сделать надсистему, которая будет получать двухканально: все признаки, все сигналы всех моделей, а также плавающую прибыль / убыток и прибыль / убыток истории счета, ну и подавать это все в DQN модель=)
На первую команду ответ "Python", а на эту строчку получаю: "Системе не удаётся найти указанный путь"
(свежеустановленный Пайтон, иду по вашей инструкции)