
Erstellung eines Indikators für die Volatilitätsprognose mit Python

Einführung
Oh, Mist! Meine Stopps sind mal wieder weggeblasen worden...
Mit diesem Satz habe ich im Jahr 2021 jeden zweiten Handelstag begonnen. Ich erinnere mich, wie ich in Charts und Zahlen vertieft saß, stolz auf mein neues Handelssystem, und dann – bumm – war die Hälfte meiner Einlage weg. Weil ein kluger Kopf eine Aussage über Krypto gemacht hat und der Markt verrückt geworden ist.
Klingt vertraut, nicht wahr? Ich bin sicher, dass jeder Algo-Händler diese Erfahrung gemacht hat. Es scheint, dass ich alles berechnet und getestet habe, und das System funktioniert perfekt mit historischen Daten... Aber wie sieht es auf dem realen Markt aus? „Hallo, Volatilität, lange nicht mehr gesehen!“
Nach einem weiteren solchen „Abenteuer“ wurde ich wütend und beschloss, der Sache auf den Grund zu gehen. Es kann doch nicht sein, dass es unmöglich ist, diese Markthysterie irgendwie vorherzusehen! Ich glaube, ich habe alle vorhandenen Studien zur Volatilität durchforstet. Wissen Sie, was am lustigsten ist? Es stellte sich heraus, dass die Lösung an der Schnittstelle zwischen alten Methoden und neuen Technologien lag.
In diesem Artikel werde ich meinen Weg von der Verzweiflung zu einem funktionierenden Volatilitätsprognosesystem beschreiben. Kein langweiliges Zeug oder akademisches Fachchinesisch – nur echte Erfahrung und funktionierende Lösungen. Ich zeige Ihnen, wie ich MetaTrader 5 mit Python kombiniert habe (Spoiler: sie haben sich nicht auf Anhieb verstanden), wie ich maschinelles Lernen für mich nutzbar gemacht habe und auf welche Fallstricke ich dabei gestoßen bin.
Die wichtigste Erkenntnis, die ich aus dieser ganzen Geschichte gewonnen habe, ist, dass man weder klassischen Indikatoren noch trendigen neuronalen Netzen blind vertrauen darf. Ich erinnere mich, wie ich eine Woche damit verbracht habe, ein sehr komplexes neuronales Netz einzurichten, und dann zeigte ein einfaches XGBoost bessere Ergebnisse. Oder wie einmal ein einfacher Bollinger ein Depot rettete, wo alle intelligenten Algorithmen versagten.
Mir wurde auch klar, dass es beim Handel, wie beim Boxen, nicht auf die Wucht des Schlags ankommt, sondern auf die Fähigkeit, ihn zu antizipieren. Mein System macht keine übernatürlichen Vorhersagen. Es hilft Ihnen einfach, auf Marktüberraschungen vorbereitet zu sein und die Sicherheitsmarge Ihrer Handelsstrategie rechtzeitig zu erhöhen.
Kurz gesagt, wenn Sie es leid sind, dass Ihre Algorithmen über jedes kleine bisschen Volatilität stolpern, willkommen in meiner Welt. Ich werde Ihnen alles so erzählen, wie es ist, mit Codebeispielen, Charts und Analysen. Fangen wir an.
Projektkonzept
Nach monatelangen Experimenten und einer eingehenden Analyse der Marktdaten wurde ein Konzept für ein System entwickelt, das die Volatilität mit erstaunlicher Genauigkeit vorhersagen kann. Die wichtigste Entdeckung war, dass die Volatilität im Gegensatz zum Preis die Eigenschaft der Stationarität hat – sie neigt dazu, zu ihrem Mittelwert zurückzukehren und bildet stabile Muster. Diese Eigenschaft macht die Vorhersage nicht nur möglich, sondern auch praktisch anwendbar im realen Handel.
Das System basiert auf der leistungsstarken Kombination von MetaTrader 5 und Python, wobei jedes Tool seine Stärken ausspielt. MetaTrader 5 dient als zuverlässige Quelle für Marktdaten. Es liefert uns historische Kurse und einen Echtzeit-Datenstrom mit minimalen Verzögerungen. Und Python wird zu unserem Analyselabor, in dem ein umfangreicher Satz von Bibliotheken für maschinelles Lernen (Sklearn, XGBoost, PyTorch) dabei hilft, wertvolle Muster aus diesen Daten zu extrahieren und Hypothesen über die Stationarität der Volatilität zu bestätigen.
Die Systemarchitektur besteht aus drei Schlüsselebenen:
- Die Datenpipeline ist die Grundlage des Systems. Hier findet die primäre Verarbeitung der Daten aus MetaTrader 5 statt: Rauschunterdrückung, Berechnung von Dutzenden von Volatilitätsmetriken und die Bildung von Merkmalen für Modelle. Besonderes Augenmerk wurde auf die Optimierung gelegt – das System arbeitet ohne Verzögerungen und Speicherlecks. Auf dieser Ebene wird auch die Stationarität der Zeitreihen getestet und es werden signifikante Volatilitätsmuster ermittelt.
- Kern der Analyse. Der Kern basiert auf einem Ensemble spezialisierter maschineller Lernmodelle. Jeder ist auf seinen eigenen Zeithorizont zugeschnitten: von Intraday-Schwankungen bis zu wöchentlichen Trends. Bei den Tests stellte sich heraus, dass selbst ein einfaches XGBoost komplexe neuronale Netze bei der Vorhersagegenauigkeit oft übertrifft, insbesondere bei der Erkennung von Volatilitätsclustern.
- Risk Advisor ist ein Empfehlungssystem für das Risikomanagement. Auf der Grundlage von Volatilitätsprognosen schlägt es optimale Stop-Loss- und Take-Profit-Niveaus vor. In Zeiten erhöhter zukünftiger Volatilität wird empfohlen, die Schutzaufträge zu erweitern und in ruhigeren zukünftigen Stunden zu verengen, um einen präziseren Markteinstieg zu ermöglichen. Hier spielt die Stationarität der Volatilität eine wichtige Rolle, die es dem System ermöglicht, die Handelsparameter effektiv anzupassen.
Die Modelle werden anhand eines einzigartigen Datensatzes trainiert, der Kurse in verschiedenen Zeitrahmen enthält – von Tick bis Daily. Auf diese Weise kann das System drei wichtige Marktbedingungen erkennen: geringe Volatilität, Trend und Explosivität. Auf der Grundlage dieser Informationen werden Empfehlungen für optimale Einstiegsniveaus und Schutzaufträge ausgesprochen. Aufgrund der Stationarität der Volatilität ist das System nicht nur in der Lage, den aktuellen Zustand zu erkennen, sondern auch Übergänge zwischen diesen Zuständen vorherzusagen.
Das Hauptmerkmal des Systems ist seine Anpassungsfähigkeit. Sie gibt nicht nur feste Empfehlungen ab, sondern passt sie an die aktuelle Marktsituation an. Für jede Handelssituation bietet das System einen individuellen Satz von Parametern an, der auf der Prognose der zukünftigen Volatilität basiert. Diese Anpassungsfähigkeit ist besonders effektiv, da sich die Volatilität immer wieder ändert.
In den folgenden Abschnitten werden wir jede Systemkomponente im Detail untersuchen, den eigentlichen Code zeigen und die Ergebnisse des Backtestings mitteilen. Sie werden sehen, wie theoretische Konzepte über die Stationarität der Volatilität in ein praktisches Werkzeug für die Marktanalyse umgewandelt werden.
Installieren der erforderlichen Software
Bevor wir uns in die Systementwicklung stürzen, sollten wir einen Blick auf die Installation der gesamten erforderlichen Software werfen. Aus eigener Erfahrung weiß ich, dass die Einrichtung der MetaTrader 5-Python-Verbindung viele Leute ins Straucheln bringt. Daher werde ich versuchen, Ihnen nicht nur zu erklären, wie Sie alles installieren, sondern auch, wie Sie die wichtigsten Fallstricke vermeiden können.
Beginnen wir mit Python. Wir benötigen Version 3.8 oder höher, die von der offiziellen Website python.org heruntergeladen werden kann. Achten Sie bei der Installation darauf, dass Sie „Python zu PATH hinzufügen“ ankreuzen, sonst müssen Sie die Pfade später manuell hinzufügen. Nach der Installation von Python erstellen wir als erstes eine virtuelle Umgebung für das Projekt. Dieser Schritt ist nicht zwingend erforderlich, aber sehr nützlich – er schützt uns vor Versionskonflikten in der Bibliothek.
python -m venv venv_volatility venv_volatility\Scripts\activate # for Windows source venv_volatility/bin/activate # for Linux/MacOS
Installieren wir nun die erforderlichen Bibliotheken. Wir benötigen einige grundlegende Tools: numpy und pandas für die Arbeit mit Daten, scikit-learn und xgboost für maschinelles Lernen, pytorch für neuronale Netze und natürlich eine Bibliothek für die Arbeit mit MetaTrader 5. Hier ist der Befehl zur Installation des gesamten Pakets:
pip install numpy pandas scikit-learn xgboost pytorch MetaTrader5 pylint jupyter Werfen wir einen genaueren Blick auf die Installation von MetaTrader 5. Sie müssen es von der Website Ihres Brokers herunterladen – dies ist wichtig, da es unterschiedliche Versionen geben kann. Wählen Sie bei der Installation einen Ordner mit einem einfachen Pfad, ohne kyrillische Zeichen oder Leerzeichen – das erspart Ihnen eine Menge Ärger bei der Einrichtung der Kommunikation mit Python.
Vergessen Sie nach der Installation des Terminals nicht, in den Einstellungen den automatischen Handel und den DLL-Import zu aktivieren sowie AlgoTrading zu aktivieren. Es klingt offensichtlich, aber ich habe selbst einige Stunden mit der Fehlersuche verbracht, bis ich mich an diese Einstellungen erinnerte.
Jetzt kommt der lustige Teil – die Überprüfung der Verbindung zwischen Python und MetaTrader 5. Ich habe ein kleines Skript entwickelt, um sicherzustellen, dass alles so funktioniert, wie es sollte:
import MetaTrader5 as mt5 def test_mt5_connection(): if not mt5.initialize(): print("MT5 initialization error:", mt5.last_error()) return False print("MetaTrader5 package author:", mt5.__author__) print("MetaTrader5 package version:", mt5.__version__) terminal_info = mt5.terminal_info() if terminal_info is None: print("Error getting terminal data:", mt5.last_error()) return False print(f"Connected to terminal '{terminal_info.name}' ({terminal_info.path})") print("Trade server:", terminal_info.connected) mt5.shutdown() return True if __name__ == "__main__": test_mt5_connection()
Worauf ist zu achten, wenn Probleme auftreten? Der häufigste Stolperstein ist die Initialisierung von MetaTrader 5. Wenn das Skript keine Verbindung zum Terminal herstellen kann, überprüfen Sie zunächst, ob MetaTrader 5 selbst läuft. Es scheint offensichtlich zu sein, aber glauben Sie mir, selbst erfahrene Entwickler vergessen das manchmal.
Wenn das Terminal läuft, aber immer noch keine Verbindung zustande kommt, überprüfen Sie Ihre Administratorrechte und Firewall-Einstellungen. Windows geht manchmal lieber auf Nummer sicher und blockiert die Verbindung.
Für die Entwicklung empfehle ich VS Code oder PyCharm – beide Editoren sind hervorragend für die Python-Entwicklung geeignet. Installieren Sie die Erweiterung für Python und Jupyter – dies wird das Debuggen und Testen von Code erheblich vereinfachen.
Die letzte Prüfung besteht darin, einige historische Daten zu erhalten:
import MetaTrader5 as mt5 mt5.initialize() data = mt5.copy_rates_from_pos("EURUSD", mt5.TIMEFRAME_M1, 0, 1000) print(data is not None) mt5.shutdown()
Wenn der Code ohne Fehler läuft, ist Ihre Entwicklungsumgebung einsatzbereit! Im nächsten Abschnitt werden wir uns mit dem Empfang und der Verarbeitung von Daten aus dem MetaTrader 5 befassen.
Abrufen von Daten aus MetaTrader 5
Bevor wir uns in komplexe Berechnungen stürzen, sollten wir sicherstellen, dass wir die Daten vom Handelsterminal korrekt empfangen. Ich habe ein einfaches Skript geschrieben, mit dem Sie MetaTrader 5 testen und die Datenstruktur untersuchen können:
import MetaTrader5 as mt5 import pandas as pd from datetime import datetime, timedelta pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) pd.set_option('display.float_format', lambda x: '%.5f' % x) def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return print("\n=== Symbol Information ===") symbol_info = mt5.symbol_info(symbol) if symbol_info is None: print(f"Failed to get {symbol} data") mt5.shutdown() return print(f"Current spread: {symbol_info.spread} points") print(f"Tick size: {symbol_info.trade_tick_size}") print(f"Contract size: {symbol_info.trade_contract_size}") # Last 100 ticks print("\n=== Latest Ticks ===") ticks = mt5.copy_ticks_from(symbol, datetime.now() - timedelta(minutes=5), 100, mt5.COPY_TICKS_ALL) ticks_frame = pd.DataFrame(ticks) ticks_frame['time'] = pd.to_datetime(ticks_frame['time'], unit='s') print(ticks_frame.head()) # 5-minute bars (last 100 bars) print("\n=== 5-Minute Bars (Last 100) ===") rates_5m = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_M5, 0, 100) rates_5m_frame = pd.DataFrame(rates_5m) rates_5m_frame['time'] = pd.to_datetime(rates_5m_frame['time'], unit='s') print(rates_5m_frame.head()) # Hourly bars (last 24 hours) print("\n=== Hourly Bars (Last 24) ===") rates_1h = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 24) rates_1h_frame = pd.DataFrame(rates_1h) rates_1h_frame['time'] = pd.to_datetime(rates_1h_frame['time'], unit='s') print(rates_1h_frame.head()) # Daily bars (last 30 days) print("\n=== Daily Bars (Last 30) ===") rates_d1 = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 30) rates_d1_frame = pd.DataFrame(rates_d1) rates_d1_frame['time'] = pd.to_datetime(rates_d1_frame['time'], unit='s') print(rates_d1_frame.head()) # Statistics for different timeframes print("\n=== 5-Minute Bars Statistics ===") print(f"Average volume: {rates_5m_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_5m_frame['spread'].mean():.2f}") print(f"Average range: {(rates_5m_frame['high'] - rates_5m_frame['low']).mean():.5f}") print("\n=== Hourly Bars Statistics ===") print(f"Average volume: {rates_1h_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_1h_frame['spread'].mean():.2f}") print(f"Average range: {(rates_1h_frame['high'] - rates_1h_frame['low']).mean():.5f}") print("\n=== Daily Bars Statistics ===") print(f"Average volume: {rates_d1_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_d1_frame['spread'].mean():.2f}") print(f"Average range: {(rates_d1_frame['high'] - rates_d1_frame['low']).mean():.5f}") # Current quotes print("\n=== Current Market Depth ===") depth = mt5.market_book_get(symbol) if depth is not None: bid = depth[0].price if depth[0].type == 1 else depth[1].price ask = depth[0].price if depth[0].type == 2 else depth[1].price print(f"Bid: {bid}") print(f"Ask: {ask}") print(f"Spread: {(ask - bid):.5f}") mt5.shutdown() if __name__ == "__main__": check_mt5_data()
Dieser Code zeigt alle Informationen an, die wir benötigen, um die Gültigkeit der Verbindung und die Qualität der empfangenen Daten zu überprüfen. Sobald Sie es starten, werden Sie es sehen:
- Grundlegende Informationen über das Handelsinstrument
- Tabelle der letzten Ticks
- Tabelle der stündlichen Balken
- Statistiken über Volumen und Spreads
- Aktuelle Notierungen aus der Markttiefe
Nach dem Start sehen wir sofort, dass alles so funktioniert, wie es soll. Wenn irgendwo ein Problem auftritt, zeigt das Skript, in welchem Stadium genau etwas schief gelaufen ist.
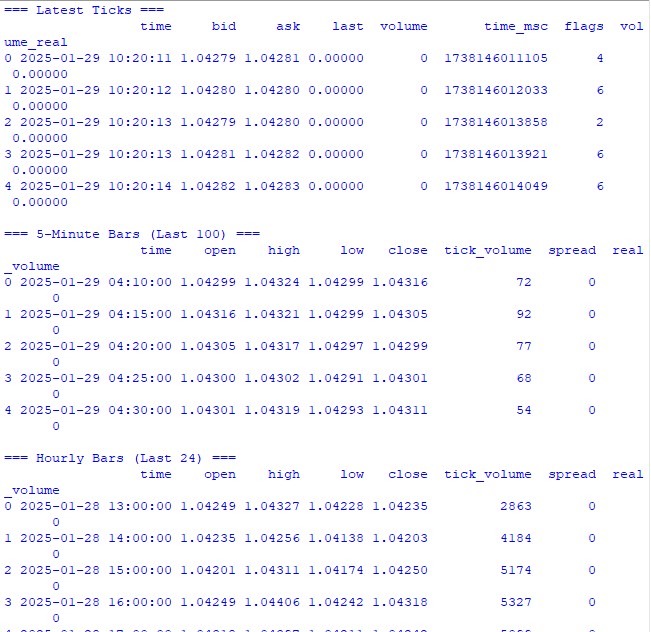
In den folgenden Abschnitten werden wir diese Daten zur Berechnung der Volatilität verwenden, aber zunächst muss sichergestellt werden, dass der zugrunde liegende Datenabruf korrekt funktioniert.
Vorverarbeitung der Daten
Als ich anfing, mich mit Volatilitätsprognosen zu beschäftigen, dachte ich, das Wichtigste sei ein cooles maschinelles Lernmodell. In der Praxis hat sich schnell gezeigt, dass die Qualität der Datenaufbereitung das Entscheidende ist. Ich möchte Ihnen zeigen, wie ich die Daten für unser Prognosesystem aufbereite.
Hier ist der vollständige Vorverarbeitungscode, den ich verwende:
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler from datetime import datetime, timedelta pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) pd.set_option('display.float_format', lambda x: '%.5f' % x) class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20)): self.lookback_periods = lookback_periods self.scaler = StandardScaler() def calculate_volatility_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change().fillna(0) df['log_returns'] = (np.log(df['close']) - np.log(df['close'].shift(1))).fillna(0) # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1).fillna(df['high'])), abs(df['low'] - df['close'].shift(1).fillna(df['low'])) ) ) # ATR and volatility for period in self.lookback_periods: df[f'atr_{period}'] = df['true_range'].rolling(window=period, min_periods=1).mean() df[f'volatility_{period}'] = df['returns'].rolling(window=period, min_periods=1).std() # Parkinson volatility df['parkinson_vol'] = np.sqrt( 1/(4 * np.log(2)) * np.power(np.log(df['high'].div(df['low'])), 2) ) # Garman-Klass volatility df['garman_klass_vol'] = np.sqrt( 0.5 * np.power(np.log(df['high'].div(df['low'])), 2) - (2*np.log(2)-1) * np.power(np.log(df['close'].div(df['open'])), 2) ) # Relative volatility changes for period in self.lookback_periods: df[f'vol_change_{period}'] = ( df[f'volatility_{period}'].div(df[f'volatility_{period}'].shift(1)) ) # Replace all infinities and NaN for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan).fillna(0) return df def prepare_features(self, df): feature_cols = [] # Time-based features - correct time conversion time = pd.to_datetime(df['time'], unit='s') # Hours (0-23) -> radians (0-2π) hours = time.dt.hour.values df['hour_sin'] = np.sin(2 * np.pi * hours / 24.0) df['hour_cos'] = np.cos(2 * np.pi * hours / 24.0) # Week days (0-6) -> radians (0-2π) days = time.dt.dayofweek.values df['day_sin'] = np.sin(2 * np.pi * days / 7.0) df['day_cos'] = np.cos(2 * np.pi * days / 7.0) # Select features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'vol_change_{period}' ]) feature_cols.extend([ 'parkinson_vol', 'garman_klass_vol', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create features DataFrame features = df[feature_cols].copy() # Final cleanup and scaling features = features.replace([np.inf, -np.inf], 0).fillna(0) scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=features.columns, index=features.index ) def create_target(self, df, forward_window=12): future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window).fillna(0) return future_vol def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_volatility_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) return features, target def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: print("\n=== Processing Hourly Data for Volatility Analysis ===") processor = VolatilityProcessor(lookback_periods=(5, 10, 20)) features, target = processor.prepare_dataset(rates_frame) print("\nFeature statistics:") print(features.describe()) print("\nFeature columns:", features.columns.tolist()) print("\nTarget statistics:") print(target.describe()) else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
Wie es funktioniert.
Zunächst laden wir die letzten 10.000 H1-Balken aus dem MetaTrader 5 herunter. Warum genau so viele? Durch Versuch und Irrtum habe ich herausgefunden, dass dies die optimale Menge ist – genug, um zu lernen, aber nicht so viel, dass sich der Markt wesentlich verändert.
Jetzt beginnt der interessanteste Teil. Die Klasse VolatilityProcessor erledigt die ganze Drecksarbeit der Datenaufbereitung. Hier sehen Sie, was unter der Haube vor sich geht:
- Berechnung der grundlegenden Volatilitätsindikatoren. Wir betrachten hier drei Arten von Volatilität:
- Klassische Standardabweichung der Renditen
- True Range und ATR sind zwar altmodisch, funktionieren aber immer noch.
- Die Parkinson- und die Harman-Klass-Methode sind gut geeignet, um Bewegungen innerhalb eines Tages zu erfassen.
- Bearbeitungszeit. Anstelle der üblichen One-Hot-Codierung von Stunden und Wochentage verwende ich Sinus und Kosinus. Dies ist nicht nur eine Angeberei – wir sagen dem Modell, dass 11:00 Uhr und 12:00 Uhr nahe beieinander liegen und nicht an entgegengesetzten Enden des Spektrums.
- Normalisierung und Bereinigung von Daten. Dies ist der entscheidende Teil:
- Entfernen von Ausreißern und unendlichen Werten
- Auffüllen von Lücken mit Nullen (nur nach sorgfältiger Prüfung, dass die Daten dadurch nicht verfälscht werden)
- Skalierung aller Merkmale auf denselben Bereich
Als Ergebnis erhalten wir 15 Merkmale – die optimale Anzahl für unsere Aufgabe. Ich habe versucht, weitere Indikatoren hinzuzufügen (alle Arten von exotischen Indikatoren), aber das hat die Ergebnisse nur verschlechtert.
Die Zielvariable ist die zukünftige Volatilität über die nächsten 12 Perioden. Warum 12? Bei stündlichen Daten erhalten wir so eine Prognose für den nächsten halben Tag – genug, um Handelsentscheidungen zu treffen, aber nicht so viel, dass die Prognose bedeutungslos wird.
Worauf ist zu achten?
- min_periods=1 wird überall bei rollierenden Operationen verwendet – dadurch gehen keine Daten am Anfang der Zeitreihe verloren.
- Die Verwendung von .div() anstelle des üblichen / ist nicht nur eine Laune; Pandas kann auf diese Weise Randfälle besser behandeln.
- Die Ersetzung von Unendlichkeiten erfolgt ganz am Ende jeder Phase, sodass wir keine Problembereiche übersehen.
Im nächsten Abschnitt werden wir ein maschinelles Lernmodell erstellen, das mit diesen aufbereiteten Daten arbeitet. Aber denken Sie daran, dass ein noch so gutes Modell schlecht aufbereitete Daten nicht speichern kann.
Erstellen eines Modells für maschinelles Lernen
Damit sind wir beim interessantesten Teil angelangt – der Erstellung eines Prognosemodells. Zunächst wählte ich den offensichtlichen Weg der Regression, um den genauen Wert der zukünftigen Volatilität vorherzusagen. Die Logik war einfach: Wir ermitteln eine bestimmte Zahl, multiplizieren sie mit einem bestimmten Verhältnis, und schon haben Sie Ihr Stop-Loss-Niveau.
Erster Versuch: Regressionsmodell
Ich habe mit dem einfachsten Code begonnen – einem einfachen XGBRegressor mit minimalen Einstellungen. Die Parameter sind gering: einhundert Bäume, Lernrate 0,1 und Tiefe 5. Es war naiv zu glauben, dass dies ausreichen würde, aber wer hat nicht schon solche Fehler am Anfang seiner Reise gemacht?
Die Ergebnisse sind, gelinde gesagt, wenig beeindruckend. Das R-Quadrat schwankte zwischen 0,05 und 0,06, was bedeutet, dass das Modell nur 5-6 % der Variation in den Daten erklärte. Die Standardabweichung der Vorhersagen erwies sich als fast dreimal kleiner als die tatsächliche Abweichung. Der mittlere absolute Fehler schien ziemlich gut zu sein, aber es war eine Falle.
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.model_selection import TimeSeriesSplit import xgboost as xgb from xgboost import XGBRegressor from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score import matplotlib.pyplot as plt from datetime import datetime, timedelta # VolatilityProcessor class remains unchanged class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20)): self.lookback_periods = lookback_periods self.scaler = StandardScaler() def calculate_volatility_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change().fillna(0) df['log_returns'] = (np.log(df['close']) - np.log(df['close'].shift(1))).fillna(0) df['abs_returns'] = abs(df['returns']) # Price changes df['price_range'] = (df['high'] - df['low']) / df['close'] df['price_change'] = (df['close'] - df['open']) / df['open'] # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1).fillna(df['high'])), abs(df['low'] - df['close'].shift(1).fillna(df['low'])) ) ) # ATR and volatility for different periods for period in self.lookback_periods: # Standard features df[f'atr_{period}'] = df['true_range'].rolling(window=period, min_periods=1).mean() df[f'volatility_{period}'] = df['returns'].rolling(window=period, min_periods=1).std() # Additional rolling statistics df[f'mean_range_{period}'] = df['price_range'].rolling(window=period, min_periods=1).mean() df[f'mean_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).mean() df[f'max_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).max() df[f'min_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).min() # Advanced volatility measures # Parkinson volatility df['parkinson_vol'] = np.sqrt( 1/(4 * np.log(2)) * np.power(np.log(df['high'].div(df['low'])), 2) ) # Garman-Klass volatility df['garman_klass_vol'] = np.sqrt( 0.5 * np.power(np.log(df['high'].div(df['low'])), 2) - (2*np.log(2)-1) * np.power(np.log(df['close'].div(df['open'])), 2) ) # Rogers-Satchell volatility df['rogers_satchell_vol'] = np.sqrt( np.log(df['high'].div(df['close'])) * np.log(df['high'].div(df['open'])) + np.log(df['low'].div(df['close'])) * np.log(df['low'].div(df['open'])) ) # Relative changes for period in self.lookback_periods: df[f'vol_change_{period}'] = ( df[f'volatility_{period}'].div(df[f'volatility_{period}'].shift(1)) ) df[f'atr_change_{period}'] = ( df[f'atr_{period}'].div(df[f'atr_{period}'].shift(1)) ) # Replace all infinities and NaN for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan).fillna(0) return df def prepare_features(self, df): feature_cols = [] # Time-based features time = pd.to_datetime(df['time'], unit='s') # Hours (0-23) -> radians (0-2π) hours = time.dt.hour.values df['hour_sin'] = np.sin(2 * np.pi * hours / 24.0) df['hour_cos'] = np.cos(2 * np.pi * hours / 24.0) # Days of week (0-6) -> radians (0-2π) days = time.dt.dayofweek.values df['day_sin'] = np.sin(2 * np.pi * days / 7.0) df['day_cos'] = np.cos(2 * np.pi * days / 7.0) # Select features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'vol_change_{period}' ]) feature_cols.extend([ 'parkinson_vol', 'garman_klass_vol', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create features DataFrame features = df[feature_cols].copy() # Final cleanup and scaling features = features.replace([np.inf, -np.inf], 0).fillna(0) scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=feature_cols, index=features.index ) def create_target(self, df, forward_window=12): """Create target with log transformation""" future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window) # Add small constant to avoid log(0) log_vol = np.log(future_vol + 1e-10) return log_vol.fillna(log_vol.mean()) def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_volatility_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) return features, target class VolatilityModel: def __init__(self, lookback_periods=(5, 10, 20), forward_window=12): self.processor = VolatilityProcessor(lookback_periods) self.forward_window = forward_window self.model = XGBRegressor( n_estimators=500, learning_rate=0.05, max_depth=10, min_child_weight=1, subsample=0.8, colsample_bytree=0.8, gamma=0.1, reg_alpha=0.1, reg_lambda=1, random_state=42, n_jobs=-1, objective='reg:squarederror' # Better for log-transformed targets ) self.feature_importance = None def prepare_data(self, rates_frame): """Prepare data using our processor""" features, target = self.processor.prepare_dataset(rates_frame) return features, target def create_train_test_split(self, features, target, test_size=0.2): """Split data preserving time order""" split_idx = int(len(features) * (1 - test_size)) X_train = features.iloc[:split_idx] X_test = features.iloc[split_idx:] y_train = target.iloc[:split_idx] y_test = target.iloc[split_idx:] return X_train, X_test, y_train, y_test def train(self, X_train, y_train, X_test, y_test): """Train model with validation""" print("\n=== Training Model ===") print("Training set shape:", X_train.shape) print("Test set shape:", X_test.shape) # Train the model eval_set = [(X_train, y_train), (X_test, y_test)] self.model.fit( X_train, y_train, eval_set=eval_set, verbose=True ) # Save feature importance importance = self.model.feature_importances_ self.feature_importance = pd.DataFrame({ 'feature': X_train.columns, 'importance': importance }).sort_values('importance', ascending=False) # Make predictions and evaluate predictions = self.predict(X_test) metrics = self.calculate_metrics(y_test, predictions) return metrics def calculate_metrics(self, y_true, y_pred): """Calculate model performance metrics with detailed R2""" # Basic metrics rmse = np.sqrt(mean_squared_error(y_true, y_pred)) mae = mean_absolute_error(y_true, y_pred) # Manual R2 calculation for verification y_true_mean = np.mean(y_true) total_sum_squares = np.sum((y_true - y_true_mean) ** 2) residual_sum_squares = np.sum((y_true - y_pred) ** 2) r2_manual = 1 - (residual_sum_squares / total_sum_squares) # Stats for debugging metrics = { 'RMSE': rmse, 'MAE': mae, 'R2 (sklearn)': r2_score(y_true, y_pred), 'R2 (manual)': r2_manual, 'RSS': residual_sum_squares, 'TSS': total_sum_squares, 'Mean Prediction': np.mean(y_pred), 'Mean Actual': np.mean(y_true), 'Std Prediction': np.std(y_pred), 'Std Actual': np.std(y_true), 'Min Prediction': np.min(y_pred), 'Max Prediction': np.max(y_pred), 'Min Actual': np.min(y_true), 'Max Actual': np.max(y_true) } print("\nDetailed Metrics Analysis:") print(f"Total Sum of Squares (TSS): {total_sum_squares:.8f}") print(f"Residual Sum of Squares (RSS): {residual_sum_squares:.8f}") print(f"R2 components: 1 - ({residual_sum_squares:.8f} / {total_sum_squares:.8f})") return metrics def predict(self, features): """Get volatility predictions with inverse log transform""" log_predictions = self.model.predict(features) return np.exp(log_predictions) - 1e-10 def plot_feature_importance(self): """Visualize feature importance""" plt.figure(figsize=(12, 6)) plt.bar( self.feature_importance['feature'], self.feature_importance['importance'] ) plt.xticks(rotation=45) plt.title('Feature Importance') plt.tight_layout() plt.show() def plot_predictions(self, y_true, y_pred, title="Model Predictions"): """Visualize predictions vs actual values""" plt.figure(figsize=(15, 7)) plt.plot(y_true.values, label='Actual', alpha=0.7) plt.plot(y_pred, label='Predicted', alpha=0.7) plt.title(title) plt.legend() plt.tight_layout() plt.show() def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): # Get data symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: # Create and train model model = VolatilityModel(lookback_periods=(5, 10, 20), forward_window=12) features, target = model.prepare_data(rates_frame) # Split data X_train, X_test, y_train, y_test = model.create_train_test_split( features, target, test_size=0.2 ) # Train and evaluate metrics = model.train(X_train, y_train, X_test, y_test) print("\n=== Model Performance ===") for metric, value in metrics.items(): print(f"{metric}: {value:.6f}") # Make predictions predictions = model.predict(X_test) # Visualize results model.plot_feature_importance() model.plot_predictions(y_test, predictions, "Volatility Predictions") else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
Warum Fallen? Das liegt daran, dass das Modell einfach gelernt hat, Werte in der Nähe des Durchschnitts vorherzusagen. In ruhigen Zeiten sah alles gut aus, aber sobald es richtig losging, verpasste es das Modell zum Glück.
Experimente zur Verbesserung der Regression
Wochenlang wurde versucht, das Regressionsmodell zu verbessern. Ich probierte verschiedene Architekturen neuronaler Netze aus, fügte immer mehr neue Funktionen hinzu, experimentierte mit verschiedenen Verlustfunktionen und veränderte die Hyperparameter, bis ich völlig erschöpft war.
Alles erwies sich als nutzlos. Manchmal ist es mir gelungen, das R-Quadrat auf 0,15-0,20 zu erhöhen, aber zu welchem Preis? Das Modell wurde instabil, überangepasst und, was am wichtigsten ist, es verfehlte immer noch die wichtigsten Momente hoher Volatilität.
Überdenken des Ansatzes
Und dann dämmerte es mir: Wozu brauchen wir überhaupt einen genauen Volatilitätswert? Einem Händler ist es egal, ob die Volatilität 0,00234 oder 0,00256 beträgt. Entscheidend ist, ob sie deutlich höher als üblich ausfallen wird.
So wurde die Idee geboren, das Problem als Klassifizierung neu zu formulieren. Anstatt bestimmte Werte vorherzusagen, begannen wir, zwei Zustände zu definieren: normale/niedrige Volatilität (Kennzeichen 0) und hohe Volatilität über dem 75. Perzentil (Kennzeichen 1).
Warum hat das besser funktioniert?
Erstens haben wir klarere Signale erhalten. Anstelle von vagen Vorhersagen gab es nun eine sichere Antwort: ob ein Anstieg zu erwarten ist oder nicht. Dieser Ansatz erwies sich als wesentlich einfacher zu interpretieren und in ein Handelssystem zu integrieren.
Zweitens ist das Modell besser im Umgang mit Extremwerten geworden. Bei der Regression wurden die Ausreißer „verwischt“, aber bei der Klassifizierung bildeten sie ein klares Muster der Klasse mit hoher Volatilität.
Drittens hat die praktische Anwendbarkeit zugenommen. Ein Händler braucht ein klares Signal, um zu handeln. Es stellte sich heraus, dass es viel einfacher war, die Höhe der Schutzanordnungen für zwei Staaten anzupassen, als zu versuchen, sie auf ein Kontinuum von Werten zu übertragen.
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler import xgboost as xgb from xgboost import XGBClassifier from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix import matplotlib.pyplot as plt import seaborn as sns class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20), volatility_threshold=75): """ Args: lookback_periods: periods for feature calculation volatility_threshold: percentile for defining high volatility """ self.lookback_periods = lookback_periods self.volatility_threshold = volatility_threshold self.scaler = StandardScaler() def calculate_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change() df['abs_returns'] = abs(df['returns']) # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1)), abs(df['low'] - df['close'].shift(1)) ) ) # Signs of volatility for period in self.lookback_periods: # ATR df[f'atr_{period}'] = df['true_range'].rolling(window=period).mean() # Volatility df[f'volatility_{period}'] = df['returns'].rolling(period).std() # Extremes df[f'high_low_range_{period}'] = ( (df['high'].rolling(period).max() - df['low'].rolling(period).min()) / df['close'] ) # Volatility acceleration df[f'volatility_change_{period}'] = ( df[f'volatility_{period}'] / df[f'volatility_{period}'].shift(1) ) # Add sentiment indicators df['body_ratio'] = abs(df['close'] - df['open']) / (df['high'] - df['low']) df['upper_shadow'] = (df['high'] - df[['open', 'close']].max(axis=1)) / (df['high'] - df['low']) df['lower_shadow'] = (df[['open', 'close']].min(axis=1) - df['low']) / (df['high'] - df['low']) # Data clearing for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan) df[col] = df[col].fillna(method='ffill').fillna(0) return df def prepare_features(self, df): # Select features for the model feature_cols = [] # Add time features time = pd.to_datetime(df['time'], unit='s') df['hour_sin'] = np.sin(2 * np.pi * time.dt.hour / 24) df['hour_cos'] = np.cos(2 * np.pi * time.dt.hour / 24) df['day_sin'] = np.sin(2 * np.pi * time.dt.dayofweek / 7) df['day_cos'] = np.cos(2 * np.pi * time.dt.dayofweek / 7) # Collect all features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'high_low_range_{period}', f'volatility_change_{period}' ]) feature_cols.extend([ 'body_ratio', 'upper_shadow', 'lower_shadow', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create DataFrame with features features = df[feature_cols].copy() features = features.replace([np.inf, -np.inf], 0).fillna(0) # Scale features scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=feature_cols, index=features.index ) def create_target(self, df, forward_window=12): """Creates a binary label: 1 for high volatility, 0 for low volatility""" # Calculate future volatility future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window) # Determine the threshold for high volatility vol_threshold = np.nanpercentile(future_vol, self.volatility_threshold) # Create binary labels target = (future_vol > vol_threshold).astype(int) target = target.fillna(0) return target def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) print(f"Positive class ratio: {target.mean():.2%}") return features, target class VolatilityClassifier: def __init__(self, lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75): self.processor = VolatilityProcessor(lookback_periods, volatility_threshold) self.forward_window = forward_window self.model = XGBClassifier( n_estimators=200, max_depth=6, learning_rate=0.1, subsample=0.8, colsample_bytree=0.8, min_child_weight=1, gamma=0.1, reg_alpha=0.1, reg_lambda=1, scale_pos_weight=1, random_state=42, n_jobs=-1, eval_metric=['auc', 'error'] ) self.feature_importance = None def prepare_data(self, rates_frame): features, target = self.processor.prepare_dataset(rates_frame) return features, target def create_train_test_split(self, features, target, test_size=0.2): split_idx = int(len(features) * (1 - test_size)) X_train = features.iloc[:split_idx] X_test = features.iloc[split_idx:] y_train = target.iloc[:split_idx] y_test = target.iloc[split_idx:] return X_train, X_test, y_train, y_test def train(self, X_train, y_train, X_test, y_test): print("\n=== Training Model ===") print("Training set shape:", X_train.shape) print("Test set shape:", X_test.shape) # Train the model eval_set = [(X_train, y_train), (X_test, y_test)] self.model.fit( X_train, y_train, eval_set=eval_set, verbose=True ) # Maintain the importance of features importance = self.model.feature_importances_ self.feature_importance = pd.DataFrame({ 'feature': X_train.columns, 'importance': importance }).sort_values('importance', ascending=False) # Evaluate the model predictions = self.predict(X_test) metrics = self.calculate_metrics(y_test, predictions) return metrics def calculate_metrics(self, y_true, y_pred): metrics = { 'Accuracy': accuracy_score(y_true, y_pred), 'Precision': precision_score(y_true, y_pred), 'Recall': recall_score(y_true, y_pred), 'F1 Score': f1_score(y_true, y_pred) } # Error matrix cm = confusion_matrix(y_true, y_pred) print("\nConfusion Matrix:") print(cm) return metrics def predict(self, features): return self.model.predict(features) def predict_proba(self, features): return self.model.predict_proba(features) def plot_feature_importance(self): plt.figure(figsize=(12, 6)) plt.bar( self.feature_importance['feature'], self.feature_importance['importance'] ) plt.xticks(rotation=45, ha='right') plt.title('Feature Importance') plt.tight_layout() plt.show() def plot_confusion_matrix(self, y_true, y_pred): cm = confusion_matrix(y_true, y_pred) plt.figure(figsize=(8, 6)) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') plt.title('Confusion Matrix') plt.ylabel('True Label') plt.xlabel('Predicted Label') plt.tight_layout() plt.show() def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: # Create and train the model model = VolatilityClassifier( lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75 ) features, target = model.prepare_data(rates_frame) # Separate data X_train, X_test, y_train, y_test = model.create_train_test_split( features, target, test_size=0.2 ) # Train and evaluate metrics = model.train(X_train, y_train, X_test, y_test) print("\n=== Model Performance ===") for metric, value in metrics.items(): print(f"{metric}: {value:.4f}") # Make predictions predictions = model.predict(X_test) # Visualize results model.plot_feature_importance() model.plot_confusion_matrix(y_test, predictions) else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
Neue Modellergebnisse
Nach der Umstellung auf die Klassifizierung verbesserten sich die Ergebnisse drastisch. Die „Präzision“ erreichte etwa 70 %, was bedeutet, dass von 10 Signalen mit hoher Volatilität 7 tatsächlich ausgelöst wurden. Ein ‚Recall‘ von etwa 65 % bedeutet, dass wir etwa zwei Drittel aller gefährlichen Momente erfasst haben. Aber die Hauptsache ist, dass das Modell im Handel wirklich anwendbar geworden ist.
Nachdem nun die Grundstruktur des Modells definiert wurde, wollen wir im nächsten Abschnitt darüber sprechen, wie es in ein reales Handelssystem integriert werden kann und welche spezifischen Handelsentscheidungen auf der Grundlage seiner Signale getroffen werden können. Ich bin sicher, dass dies der interessanteste Teil unserer Reise in die Welt der Volatilitätsprognosen sein wird.
Wie gefällt Ihnen dieser Ansatz? Es wäre interessant zu wissen, ob Sie etwas Ähnliches in Ihrer Praxis verwendet haben. Und wenn ja, welche anderen Volatilitätsmetriken halten Sie für nützlich?
Indikator für zukünftige extreme Volatilität
Der von mir entwickelte Indikator ist ein umfassendes Instrument zur Vorhersage von Volatilitätsspitzen auf dem Devisenmarkt. Im Gegensatz zu herkömmlichen Volatilitätsindikatoren, die lediglich den aktuellen Stand anzeigen, sagt unser Indikator die Wahrscheinlichkeit starker Bewegungen in den nächsten 12 Stunden voraus.
import tkinter as tk from tkinter import ttk import matplotlib matplotlib.use('Agg') # Important to install before importing pyplot from matplotlib.figure import Figure from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg import time import MetaTrader5 as mt5 class VolatilityPredictor(tk.Tk): def __init__(self): super().__init__() self.title("Volatility Predictor") self.geometry("600x600") # Initialize the model self.model = VolatilityClassifier( lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75 ) # Load and train the model at startup self.initialize_model() # Create the interface self.create_gui() # Launch the update self.update_data() def initialize_model(self): rates_frame = check_mt5_data("EURUSD") if rates_frame is not None: features, target = self.model.prepare_data(rates_frame) X_train, X_test, y_train, y_test = self.model.create_train_test_split( features, target, test_size=0.2 ) self.model.train(X_train, y_train, X_test, y_test) def create_gui(self): # Top panel with settings control_frame = ttk.Frame(self) control_frame.pack(fill='x', padx=2, pady=2) ttk.Label(control_frame, text="Symbol:").pack(side='left', padx=2) self.symbol_var = tk.StringVar(value="EURUSD") symbol_list = ["EURUSD", "GBPUSD", "USDJPY"] # Simplified list ttk.Combobox(control_frame, textvariable=self.symbol_var, values=symbol_list, width=8).pack(side='left', padx=2) ttk.Label(control_frame, text="Alert:").pack(side='left', padx=2) self.threshold_var = tk.StringVar(value="0.7") ttk.Entry(control_frame, textvariable=self.threshold_var, width=4).pack(side='left') # Chart self.fig = Figure(figsize=(6, 4), dpi=100) self.canvas = FigureCanvasTkAgg(self.fig, self) self.canvas.draw() self.canvas.get_tk_widget().pack(fill='both', expand=True, padx=2, pady=2) # Probability indicator gauge_frame = ttk.Frame(self) gauge_frame.pack(fill='x', padx=2, pady=2) self.probability_var = tk.StringVar(value="0%") self.probability_label = ttk.Label( gauge_frame, textvariable=self.probability_var, font=('Arial', 20, 'bold') ) self.probability_label.pack() self.progress = ttk.Progressbar( gauge_frame, length=150, mode='determinate', maximum=100 ) self.progress.pack(pady=2) def update_data(self): try: rates = check_mt5_data(self.symbol_var.get()) if rates is not None: features, _ = self.model.prepare_data(rates) probability = self.model.predict_proba(features)[-1][1] self.update_indicators(rates, probability) threshold = float(self.threshold_var.get()) if probability > threshold: self.alert(probability) except Exception as e: print(f"Error updating data: {e}") finally: self.after(1000, self.update_data) def update_indicators(self, rates, probability): self.fig.clear() ax = self.fig.add_subplot(111) df = rates.tail(50) # Show fewer bars for compactness width = 0.6 width2 = 0.1 up = df[df.close >= df.open] down = df[df.close < df.open] ax.bar(up.index, up.close-up.open, width, bottom=up.open, color='g') ax.bar(up.index, up.high-up.close, width2, bottom=up.close, color='g') ax.bar(up.index, up.low-up.open, width2, bottom=up.open, color='g') ax.bar(down.index, down.close-down.open, width, bottom=down.open, color='r') ax.bar(down.index, down.high-down.open, width2, bottom=down.open, color='r') ax.bar(down.index, down.low-down.close, width2, bottom=down.close, color='r') ax.grid(False) # Remove the grid for compactness ax.set_xticks([]) # Remove X axis labels self.canvas.draw() prob_pct = int(probability * 100) self.probability_var.set(f"{prob_pct}%") self.progress['value'] = prob_pct if prob_pct > 70: self.probability_label.configure(foreground='red') elif prob_pct > 50: self.probability_label.configure(foreground='orange') else: self.probability_label.configure(foreground='green') def alert(self, probability): window = tk.Toplevel(self) window.title("Alert!") window.geometry("200x80") # Reduced alert window msg = f"High volatility: {probability:.1%}" ttk.Label(window, text=msg, font=('Arial', 10)).pack(pady=10) ttk.Button(window, text="OK", command=window.destroy).pack() def main(): app = VolatilityPredictor() app.mainloop() if __name__ == "__main__": main()
Das Hauptfenster des Indikators ist in drei Hauptbereiche unterteilt. Im oberen Bereich wird ein japanisches Kerzen-Chart der letzten 100 Balken angezeigt, das die aktuelle Kursdynamik übersichtlich darstellt. Grüne und rote Kerzen zeigen traditionell steigende und fallende Marktbewegungen an.
Der zentrale Teil enthält das Hauptelement des Indikators – eine halbkreisförmige Wahrscheinlichkeitsskala. Sie zeigt die aktuelle Wahrscheinlichkeit einer Volatilitätsspitze in Prozent an, von 0 bis 100. Der Indikatorpfeil ist je nach Risikostufe unterschiedlich gefärbt: grün für eine geringe Wahrscheinlichkeit von bis zu 50 %, orange für eine mittlere Wahrscheinlichkeit von 50 % bis 70 % und rot für eine hohe Wahrscheinlichkeit von über 70 %.
Die Prognose basiert auf einer Analyse der aktuellen Marktlage und der historischen Volatilitätsmuster. Das Modell berücksichtigt die Daten der letzten 20 Balken, um eine Prognose zu erstellen, und sagt die Wahrscheinlichkeit einer erhöhten Volatilität in den nächsten 12 Stunden voraus. Die höchste Vorhersagegenauigkeit wird in den ersten 4-6 Stunden nach dem Signal erreicht.
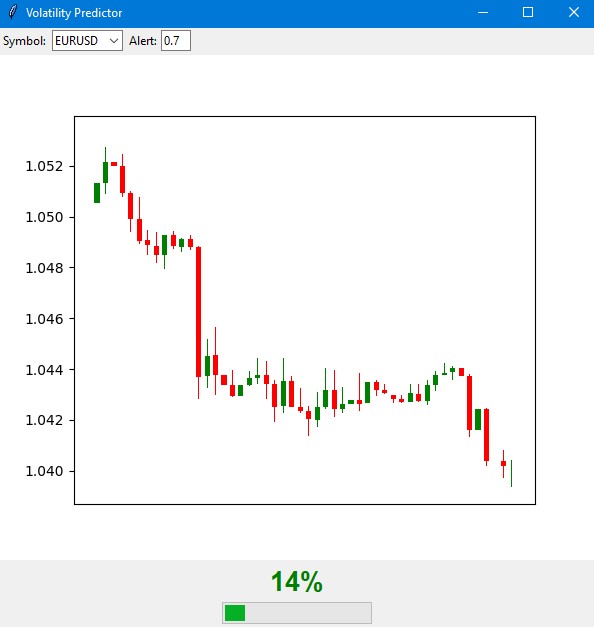
Bei geringer Wahrscheinlichkeit (grüner Bereich) wird der Markt wahrscheinlich seine ruhige Bewegung fortsetzen. Dies ist ein guter Zeitpunkt, um mit den Standardeinstellungen des Handelssystems zu arbeiten. Während dieser Zeiträume können reguläre Stop-Loss-Niveaus verwendet werden.
Wenn der Indikator eine Durchschnittswahrscheinlichkeit anzeigt und der Pfeil orangefarben ist, sollten Sie besonders vorsichtig sein. In solchen Fällen empfiehlt es sich, die Schutzanordnungen um etwa ein Viertel der Standardgröße zu erhöhen.
Wenn die Wahrscheinlichkeit eines Spikes hoch ist und der Pfeil rot wird, sollte das Risikomanagement ernsthaft überprüft werden. In solchen Phasen empfiehlt es sich, den Stop-Loss um mindestens das Anderthalbfache zu erhöhen und eventuell keine neuen Positionen zu eröffnen, bis sich die Situation stabilisiert hat.
Die Bedienelemente befinden sich auf der unteren Teil des Indikators. Hier können Sie ein Handelsinstrument und ein Zeitintervall auswählen und den Schwellenwert für den Erhalt von Benachrichtigungen festlegen. Standardmäßig ist der Schwellenwert auf 70 % eingestellt – dies ist der optimale Wert, der ein Gleichgewicht zwischen der Anzahl der Signale und ihrer Zuverlässigkeit herstellt.
Die Prognosegenauigkeit des Indikators erreicht bei Signalen mit hoher Volatilität 70 %. Das bedeutet, dass von zehn Warnungen vor einem möglichen Anstieg sieben tatsächlich eintreten. Gleichzeitig erfasst der Indikator etwa zwei Drittel aller bedeutenden Marktbewegungen.
Es ist wichtig zu verstehen, dass der Indikator nicht die Richtung der Kursbewegung vorhersagt, sondern nur die Wahrscheinlichkeit einer erhöhten Volatilität. Ihr Hauptzweck besteht darin, den Händler vor einer möglichen starken Marktbewegung zu warnen, damit er seine Handelsstrategie und die Höhe der Schutzaufträge im Voraus anpassen kann.
Für künftige Versionen des Indikators ist geplant, die Möglichkeit der automatischen Anpassung der Stop-Loss auf der Grundlage der prognostizierten Volatilität hinzuzufügen. Dies wird den Risikomanagementprozess weiter automatisieren und den Handel sicherer machen.
Der Indikator ist eine perfekte Ergänzung zu bestehenden Handelssystemen und dient als zusätzlicher Filter für das Risikomanagement. Sein Hauptvorteil ist die Fähigkeit, vor möglichen starken Bewegungen im Voraus zu warnen, was dem Händler Zeit gibt, sich vorzubereiten und seine Strategie anzupassen.
Schlussfolgerung
Im modernen Handel ist die Vorhersage der Volatilität nach wie vor eine der wichtigsten Aufgaben für den erfolgreichen Handel. Der in diesem Artikel beschriebene Weg von einem einfachen Regressionsmodell zu einem High-Volatility-Klassifikator zeigt, dass manchmal eine einfache Lösung effektiver ist als eine komplexe. Das entwickelte System erreicht eine Vorhersagegenauigkeit von etwa 70 % und erfasst etwa zwei Drittel aller bedeutenden Marktbewegungen.
Die wichtigste Schlussfolgerung ist, dass für die praktische Anwendung nicht der exakte Wert der künftigen Volatilität, sondern eine rechtzeitige Warnung vor ihrem potenziellen Anstieg wichtiger ist. Der erstellte Indikator löst dieses Problem erfolgreich und ermöglicht es den Händlern, ihre Handelsstrategien und die Höhe der Schutzaufträge im Voraus anzupassen. Die Kombination von klassischen Analysemethoden mit modernen Machine-Learning-Technologien eröffnet neue Möglichkeiten für das Marktrisikomanagement.
Es stellte sich heraus, dass der Schlüssel zum Erfolg nicht die Komplexität der Algorithmen, sondern die richtige Formulierung des Problems und eine qualitativ hochwertige Datenaufbereitung waren. Dieser Ansatz kann an verschiedene Handelsinstrumente und Zeitrahmen angepasst werden und macht den Handel sicherer und berechenbarer.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16960
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Hallo! Vielen Dank. Ich verlasse mich nicht nur auf eine Methode. Ich habe einen umfassenden Python EA, der naive Musteranalyse, maschinelles Lernen auf Binärcode, maschinelles Lernen auf 3D-Balken, neuronales Netzwerk auf Volumenanalyse, Volatilitätsanalyse, Wirtschaftsmodell basierend auf Weltbank- und IWF-Daten, riesige Datensätze mit Hunderttausenden von Zeilen über alle Länder der Welt, alle Statistiken, die auf .... möglich sind, beinhaltet.Und ein statistisches Modul, das alle möglichen statistischen Merkmale erstellt, und ein genetischer Algorithmus, der Hyperparameter optimiert, und ein Arbitragemodul, das faire Währungspreise erstellt, und das Herunterladen der Schlagzeilen und des Inhalts der weltweiten Medien zu einer bestimmten Währung, mit einer Analyse der emotionalen Färbung aller Nachrichtenartikel und -notizen (in 80 % der Fälle, wenn die Medien Sie ermutigen, etwas zu kaufen, kommt dann der Einbruch, wenn die Nachrichten negativ sind - steigt höchstwahrscheinlich mit einer Verzögerung von 3-4 Tagen).
Haben Sie irgendwelche Ideen, was man noch hinzufügen könnte? Ich bin nur zu dem Schluss gekommen, dass ich noch einen Upload von Positionen von einer bekannten Kontoüberwachungsseite (ich weiß nicht, ob ich den Namen hier sagen darf) machen muss, ich habe den Code gemacht, ich werde auch einen Artikel darüber schreiben, der Kurs geht meistens gegen die Masse.
Ich arbeite auch daran, Daten über Futures-Volumina, Volumencluster und die Analyse von COT-Berichten hochzuladen - ebenfalls in Python.
Ich verwende sowohl Regressions- als auch Klassifizierungsmodelle, und bald möchte ich ein Supersystem erstellen, das alle Vorzeichen, alle Signale aller Modelle sowie gleitende Gewinne/Verluste und Gewinne/Verluste der Kontohistorie erhält und alles in das DQN-Modell einspeist=).
Die Antwort auf den ersten Befehl ist "Python", aber für diese Zeile erhalte ich "The system cannot find the specified path"
(ich habe Python frisch installiert und bin Ihren Anweisungen gefolgt)