
Redes neurais em trading: Detecção de objetos com reconhecimento de cena (HyperDet3D)

Introdução
Nos últimos anos, a detecção de objetos tem atraído muita atenção. Nos últimos anos, a detecção de objetos tem atraído grande atenção. Baseado em representações e convolução volumétrica, o PointNet++ foca na geometria local, analisando elegantemente a nuvem de pontos bruta. Isso possibilitou seu amplo uso como rede principal em diversos modelos de detecção de objetos.
No entanto, os atributos de objetos semelhantes são ambíguos, o que reduz a qualidade do desempenho do modelo. Como consequência, o uso do modelo fica limitado ou sua arquitetura precisa ser mais complexa. Os autores do artigo "HyperDet3D: Learning a Scene-conditioned 3D Object Detector" descobriram que as informações no nível da cena fornecem conhecimento prévio para eliminar a ambiguidade na interpretação dos atributos dos objetos. Isso permite evitar resultados ilógicos na detecção de objetos no contexto da compreensão da cena.
No estudo mencionado, foi proposto o algoritmo HyperDet3D para detecção de objetos 3D em nuvens de pontos, utilizando uma estrutura baseada em hiper-rede. O HyperDet3D aprende informações condicionadas pela cena e incorpora conhecimento no nível da cena nos parâmetros da rede. Isso permite que o detector de objetos 3D se ajuste dinamicamente de acordo com diferentes tipos de dados brutos. Em particular, o conhecimento condicionado pela cena pode ser decomposto em dois níveis: informações independentes da cena e informações específicas da cena.
Para as informações independentes da cena, os autores do método propõem estudar incorporações utilizadas pela hiper-rede, que são atualizadas iterativamente à medida que diferentes cenas brutas são processadas durante o treinamento do modelo. Esse conhecimento independente da cena geralmente abstrai as características das cenas de treinamento e pode ser utilizado pelo detector durante sua operação.
Além disso, como os detectores convencionais mantêm o mesmo conjunto de parâmetros ao reconhecer objetos em diferentes cenas, os autores do HyperDet3D propõem incluir informações específicas da cena, de modo que o detector se adapte ao contexto específico durante a operação. Para isso, analisa-se quão bem a cena atual corresponde à representação geral (ou quão diferentes elas são), utilizando dados específicos como referência.
O artigo propõe a estrutura de um novo módulo chamado "atenção multicabeça condicionada pela cena" (MSA, Multi-head Scene-Conditioned Attention). O MSA permite agregar o conhecimento prévio obtido a partir das características do objeto candidato, tornando a detecção de objetos mais eficiente.
1. Algoritmo HyperDet3D
O modelo HyperDet3D é composto por três componentes principais:
- Codificador Principal;
- Camada Decodificadora de Objetos;
- Cabeça de Detecção.
A nuvem de pontos bruta de entrada é inicialmente processada pela estrutura principal, que reduz a discretização dos pontos até os candidatos a objetos e extrai suas características de forma preliminar por meio de arquiteturas hierárquicas. Os autores do método sugerem o uso da rede principal PointNet++.
Em seguida, as camadas decodificadoras de objetos refinam os potenciais atributos, incorporando o conhecimento prévio condicionado pela cena à representação no nível do objeto. Já a cabeça de detecção realiza a regressão das caixas delimitadoras com base na localização e nas características refinadas desses candidatos a objetos.
Para dotar o HyperDet3D de conhecimento sobre a metainformação no nível da cena, os autores introduzem a HyperNetwork, uma rede neural usada para parametrizar os parâmetros treináveis da rede principal. Ao contrário das redes neurais profundas convencionais, que mantêm os parâmetros fixos durante a operação, as hiper-redes permitem flexibilidade, ajustando os parâmetros de acordo com os dados brutos.
O HyperDet3D utiliza uma hiper-rede condicionada pela cena para integrar conhecimento prévio aos parâmetros da camada decodificadora do Transformer. Isso permite que a rede de detecção se adapte dinamicamente a diferentes cenas de entrada. O conceito-chave está no uso de hiper-redes condicionadas pela cena para enriquecer a representação do objeto 𝒐, dentro do conjunto de candidatos a objetos formados pelo Codificador estruturante, com conhecimento prévio parametrizado por 𝑾.
Os parâmetros gerados pelas hiper-redes condicionadas pela cena podem ser divididos em dois tipos: específicos para a cena e independentes dela.
Para obter conhecimento independente da cena, os autores propõem o treinamento de um conjunto de n vetores de incorporações independentes da cena, 𝒁a,, que são então absorvidos pela hiper-rede. A saída da hiper-rede é uma matriz de coeficientes de peso, 𝑾a, que parametriza o conhecimento independente da cena.
Como as propriedades do objeto são refinadas iterativamente por meio de várias camadas do decodificador, elas podem ser integradas sucessivamente aos resultados da hiper-rede, que abstrai o conhecimento prévio sobre diferentes cenas 3D, independentemente da cena. Dessa forma, o HyperDet3D não apenas mantém o conhecimento geral condicionado pela cena em todos os níveis do decodificador, mas também otimiza os recursos computacionais ao compartilhar informações por meio de ricas hierarquias de características.
Para adquirir conhecimento específico da cena, o modelo aprende um conjunto de incorporações 𝒁s análogo a 𝒁a. Neste caso, porém, 𝒁s deve conter informações específicas de cenas individuais. Esse efeito é alcançado por meio do uso de um bloco de atenção cruzada, no qual a incorporação da cena analisada é comparada com as incorporações aprendidas de 𝒁s. Assim, utilizando o mecanismo de atenção, o modelo mede quão bem 𝒁s corresponde à cena analisada (ou quão diferentes eles são) no espaço de incorporação.
A visualização proposta pelos autores do método HyperDet3D é apresentada a seguir.
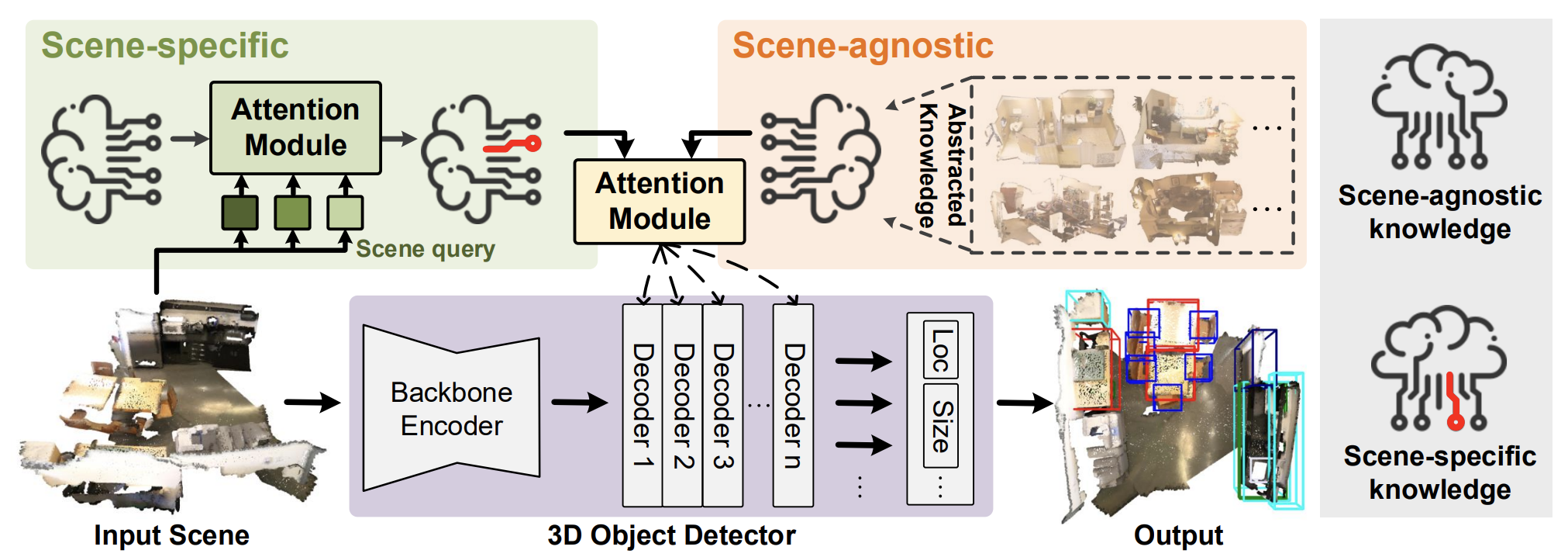
2. Implementação com MQL5
Depois de nos familiarizarmos com os aspectos teóricos do método HyperDet3D, passamos à parte prática do nosso artigo, onde implementamos nossa visão das abordagens propostas.
Desde já, podemos dizer que a implementação exigirá um volume considerável de trabalho. Por isso, dividiremos o desenvolvimento em vários blocos lógicos. Vamos "arregaçar as mangas" e começar a trabalhar.
Módulo de conhecimento específico
Inicialmente, criaremos um módulo para o aprendizado de conhecimento específico da cena. Conforme mencionado na parte teórica do artigo, o algoritmo de atenção cruzada é usado para associar a cena analisada com o conhecimento específico da cena. Assim, nossa nova classe CNeuronSceneSpecific será uma herança do bloco de atenção cruzada CNeuronMLCrossAttentionMLKV. A seguir, apresentamos a estrutura da nova classe.
class CNeuronSceneSpecific : public CNeuronMLCrossAttentionMLKV { protected: CNeuronBaseOCL cOne; CNeuronBaseOCL cSceneSpecificKnowledge; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return feedForward(NeuronOCL); } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return updateInputWeights(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSceneSpecific(void) {}; ~CNeuronSceneSpecific(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSceneSpecific; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Aqui, é importante destacar uma diferença fundamental entre nossa nova classe e sua classe-mãe. Para o correto funcionamento da classe-mãe, são necessárias duas fontes de dados: os dados analisados e o contexto. No entanto, em nossa nova classe, o contexto será representado pelos dados específicos das cenas, extraídos do conjunto de treinamento. O aprendizado dessas informações ocorrerá em dois níveis internos: cOne e cSceneSpecificKnowledge. Trata-se, essencialmente, de uma MLP de duas camadas que recebe "1" como entrada e gera um tensor de conhecimento específico da cena. Não é difícil deduzir que, durante a operação do modelo, esse tensor será estático. No entanto, no processo de treinamento, será possível "gravar" nele as informações necessárias.
Seguindo essa lógica, eliminamos dos métodos da nossa nova classe os ponteiros para o contexto externo.
Todos os objetos internos da nossa classe foram declarados como estáticos, o que permite que os construtores e destrutores da classe permaneçam vazios. A inicialização do objeto ocorre no método Init, que recebe como parâmetros as constantes principais da arquitetura do objeto que estamos criando. A funcionalidade dos parâmetros utilizados é semelhante à do método com o mesmo nome na classe mãe.
bool CNeuronSceneSpecific::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMLCrossAttentionMLKV::Init(numOutputs, myIndex, open_cl, window, window_key, heads, 16, heads_kv, units_count, units_count_kv, layers, layers_to_one_kv, optimization_type, batch)) return false;
No corpo do método, chamamos imediatamente o método de inicialização da classe-mãe, passando todos os parâmetros recebidos. Esse método verifica os parâmetros e inicializa os objetos herdados.
Em seguida, basta inicializar a MLP mencionada anteriormente, responsável pelo conhecimento específico da cena.
Vale destacar que a primeira camada contém apenas um elemento fixo. Já a segunda camada gera um conjunto de vetores de incorporações específicas do estado da cena. Para cada incorporação, definimos o tamanho do vetor como 16 elementos. O número dessas incorporações é definido nos parâmetros do método e depende da complexidade do ambiente estudado.
if(!cOne.Init(16 * units_count_kv, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = cOne.getOutput(); if(!out.BufferInit(1, 1) || !out.BufferWrite()) return false; if(!cSceneSpecificKnowledge.Init(0, 1, OpenCL, 16 * units_count_kv, optimization, iBatch)) return false; //--- return true; }
Antes de finalizar o método, retornamos um resultado lógico que indica o sucesso da operação para o programa chamador.
O método de inicialização da nossa nova classe é bastante conciso e direto. Isso não é surpreendente, pois a maior parte da funcionalidade já havia sido implementada no método da classe-mãe. Aliás, isso não se aplica apenas ao método de inicialização. O mesmo padrão pode ser observado no algoritmo do método de propagação para frente (feedForward), que possui um ponteiro para o objeto contendo os dados brutos entre seus parâmetros.
bool CNeuronSceneSpecific::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !cSceneSpecificKnowledge.FeedForward(cOne.AsObject())) return false;
Inicialmente, é preciso gerar a matriz de representações aprendidas da cena, condicionadas ao contexto. No entanto, essa operação só é executada durante o treinamento do modelo, quando os parâmetros da nossa MLP são ajustados e o tensor resultante é atualizado. Durante a operação do modelo, os dados aprendidos permanecem estáticos, não sendo necessário gerá-los novamente. Utilizamos apenas as informações previamente armazenadas.
Após isso, basta chamar o método de propagação para frente da classe-mãe, passando o conhecimento específico das representações da cena como contexto.
if(!CNeuronMLCrossAttentionMLKV::feedForward(NeuronOCL, cSceneSpecificKnowledge.getOutput())) return false; //--- return true; }
Os métodos de propagação reversa foram construídos de forma semelhante. Portanto, sugiro que eles sejam analisados de forma independente, a fim de não prolongar demasiadamente o artigo. Lembro que o código completo da classe apresentada, junto com todos os seus métodos, pode ser encontrado no anexo.
2.2 Criação do bloco MSA
E seguimos em frente, construindo um bloco de atenção multicabeça condicionada pela cena. Logicamente, herdaremos a funcionalidade principal de um dos blocos de atenção já implementados anteriormente. A estrutura da nova classe CNeuronMLMHSceneConditionAttention é apresentada a seguir.
class CNeuronMLMHSceneConditionAttention : public CNeuronMLMHAttentionMLKV { protected: CLayer cSceneAgnostic; CLayer cSceneSpecific; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMLMHSceneConditionAttention(void) {}; ~CNeuronMLMHSceneConditionAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronMLMHSceneConditionAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Na estrutura apresentada acima, podemos observar a declaração de dois novos objetos da classe CLayer. Um deles armazenará as representações da cena condicionadas pelo contexto, enquanto o outro conterá informações gerais sobre os objetos, independentemente da cena.
No entanto, é importante ressaltar que a presença desses dois objetos não limita a criação de camadas neurais internas para a identificação de objetos. Nesse caso, os objetos CLayer são utilizados como arrays dinâmicos, e o número de camadas neurais internas é definido pelo usuário durante a inicialização do novo objeto.
Todos os objetos internos foram declarados como estáticos, permitindo que os construtores e destruidores da classe permaneçam vazios. A inicialização de todos os objetos internos e herdados, como de costume, ocorre no método Init.
bool CNeuronMLMHSceneConditionAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Nos parâmetros desse método, recebemos as constantes principais que definem a arquitetura do objeto que estamos criando. No corpo do método, chamamos imediatamente o método homônimo da classe-mãe. Neste caso, no entanto, utilizamos o método da classe base de camada totalmente conectada CNeuronBaseOCL em vez da classe-mãe direta. Essa decisão se deve às diferenças significativas na estrutura e no tamanho dos objetos herdados.
Após a execução bem-sucedida do método de inicialização da classe-mãe, armazenamos as constantes da arquitetura do nosso novo modelo.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(layers, 1); iHeadsKV = fmax(heads_kv, 1); iLayersToOneKV = fmax(layers_to_one_kv, 1);
Em seguida, calculamos as dimensões dos objetos internos.
uint num_q = iWindowKey * iHeads * iUnits; //Size of Q tensor uint num_kv = 2 * iWindowKey * iHeadsKV * iUnits; //Size of KV tensor uint q_weights = (iWindow * iHeads) * iWindowKey; //Size of weights' matrix of Q tenzor uint kv_weights = 2 * (iWindow * iHeadsKV) * iWindowKey; //Size of weights' matrix of KV tenzor uint scores = iUnits * iUnits * iHeads; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits; //Size of multi-heads self-attention uint out = iWindow * iUnits; //Size of out tensore uint w0 = (iWindowKey * iHeads + 1) * iWindow; //Size W0 tensor uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
Adicionamos mais duas variáveis locais para armazenar temporariamente os ponteiros dos objetos das camadas neurais.
CNeuronBaseOCL *base = NULL; CNeuronSceneSpecific *ss = NULL;
Com isso, concluímos a preparação inicial. Em seguida, organizamos um laço com um número de iterações igual à quantidade de camadas internas especificada pelo usuário no parâmetro do método. Em cada iteração desse laço, criamos os objetos correspondentes a uma camada interna. Assim, ao final do número especificado de iterações, teremos criado um conjunto completo de objetos necessários para o funcionamento adequado das camadas neurais internas.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- Initilize Q tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Dentro desse laço, criamos imediatamente um segundo laço aninhado com duas iterações. No corpo desse laço, armazenamos os buffers de dados para registrar as informações do fluxo principal da propagação para frente, bem como os gradientes de erro para a propagação reversa. O ciclo de duas iterações permite criar uma arquitetura espelhada para os processos de propagação para frente e propagação reversa.
Primeiro, criamos o buffer para armazenar as entidades Query geradas. Em seguida, criamos o buffer para armazenar a matriz de coeficientes de peso utilizados na geração dessa entidade.
//--- Initilize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(q_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
E preste atenção: se antes sempre preenchíamos a matriz de coeficientes de peso com valores aleatórios, que eram ajustados no processo de treinamento do modelo, agora criamos um buffer com valores zerados. Isso se deve à implementação da arquitetura de hiper-redes, que será responsável por gerar essa matriz levando em consideração a cena analisada.
Repetimos operações semelhantes para a geração dos buffers de dados das entidades Key e Value. No entanto, aqui adicionamos a possibilidade de utilizar um único tensor para múltiplas camadas internas. Por isso, antes de criar os buffers de dados, verificamos a viabilidade dessa abordagem.
if(i % iLayersToOneKV == 0) { //--- Initilize KV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Tensors.Add(temp)) return false; //--- Initilize KV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(kv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Weights.Add(temp)) return false; }
Em seguida, adicionamos um buffer para registrar os coeficientes de dependência.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
E os resultados do mecanismo de atenção multicabeça.
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
Como antes, os resultados da atenção multicabeça serão escalados para corresponder ao tamanho dos dados brutos. O resultado dessa operação será armazenado no buffer de dados correspondente.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Adicionamos também os buffers para o funcionamento do bloco FeedForward.
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
Aqui, assim como no método correspondente da classe-mãe, não criamos novos buffers de dados na saída da última camada interna do bloco FeedForward, mas simplesmente armazenamos os ponteiros para os buffers do nosso próprio bloco, herdados da camada base totalmente conectada. Esses buffers são usados para a troca de dados entre as camadas do modelo. Assim, imediatamente no fluxo de operações, os dados são gravados nesses buffers, evitando transferências desnecessárias de informações entre as camadas internas e as interfaces externas.
Após a inicialização dos buffers de armazenamento dos fluxos de informações da propagação para frente e da propagação reversa, devemos inicializar as matrizes de coeficientes de peso. No entanto, para gerar as entidades Query, Key e Value, adaptadas ao estado analisado da cena, utilizaremos duas hiper-redes: uma para conhecimento prévio sobre os objetos e outra para conhecimento condicionado ao estado da cena. Assim, precisamos inicializar essas hiper-redes.
Aqui, existem diferentes abordagens de implementação. Como você sabe, as entidades Key e Value, ao contrário de Query, nem sempre são geradas em todas as camadas internas. Por isso, as alocamos em um tensor separado. Da mesma forma, poderíamos criar hiper-redes independentes para gerar as respectivas matrizes de peso. No entanto, esse não é o método mais eficiente em termos de desempenho, pois aumentaria o número de operações sequenciais. Optamos, portanto, por gerar tudo em paralelo dentro de um único modelo de hiper-rede e depois distribuir os resultados gerados nos buffers de dados correspondentes.
No entanto, devemos considerar que as entidades Key e Value não são geradas em todas as camadas internas. Assim, quando não há necessidade de gerar essas entidades, simplesmente utilizamos um modelo com um tensor de resultados de tamanho reduzido.
Faz sentido. Vamos à implementação. Primeiro, dividimos o fluxo de operações em duas direções, dependendo da necessidade de gerar o tensor Key-Value. Ambos os fluxos seguem o mesmo algoritmo, diferenciando-se apenas pelo tamanho do tensor de resultados.
if(i % iLayersToOneKV == 0) { //--- Initilize Scene-Specific layers ss = new CNeuronSceneSpecific(); if(!ss) return false; if(!ss.Init((q_weights + kv_weights), cSceneSpecific.Total(), OpenCL, iWindow, iWindowKey, 4, 2, iUnits, 100, 2, 2, optimization, iBatch)) return false; if(!cSceneSpecific.Add(ss)) return false;
Inicialmente, trabalhamos com o modelo de representação condicionada ao contexto. Aqui, criamos e inicializamos um objeto dinâmico do módulo de conhecimento específico, que implementamos anteriormente. O ponteiro para o objeto criado é armazenado no array da rede condicionada pela cena cSceneSpecific.
No entanto, há um detalhe importante a considerar. Construímos a classe do módulo de conhecimento específico com base no bloco de atenção cruzada, que recebe o estado analisado da cena como entrada e retorna um tensor de tamanho correspondente, mas enriquecido com conhecimento condicionado pelo contexto. O problema é que o tamanho do tensor de entrada provavelmente não corresponderá ao tamanho da matriz de coeficientes de peso de que precisamos. Para resolver isso, adicionamos uma camada totalmente conectada para ajustar o dimensionamento dos dados.
base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneSpecific.Total(), OpenCL, (q_weights + kv_weights), optimization, iBatch)) return false; base.SetActivationFunction(TANH); if(!cSceneSpecific.Add(base)) return false;
Essa camada de escalonamento usa a função de ativação tangente hiperbólica, cujo intervalo de valores está entre [-1, 1]. Assim, nosso conhecimento condicionado pelo contexto sobre o estado da cena funciona como um indicador da possibilidade de presença de um determinado objeto na cena analisada.
Para o modelo de conhecimento prévio independente da cena, utilizamos uma MLP de duas camadas, semelhante àquela descrita anteriormente para armazenar incorporações condicionadas ao contexto.
//--- Initilize Scene-Agnostic layers base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init((q_weights + kv_weights), cSceneAgnostic.Total(), OpenCL, 1, optimization, iBatch)) return false; temp = base.getOutput(); if(!temp.BufferInit(1, 1) || !temp.BufferWrite()) return false; if(!cSceneAgnostic.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneAgnostic.Total(), OpenCL, (q_weights + kv_weights), optimization, iBatch)) return false; if(!cSceneAgnostic.Add(base)) return false; }
Se não houver necessidade de gerar o tensor Key-Value, criamos objetos semelhantes, mas de menor tamanho.
else { //--- Initilize Scene-Specific layers ss = new CNeuronSceneSpecific(); if(!ss) return false; if(!ss.Init(q_weights, cSceneSpecific.Total(), OpenCL, iWindow, iWindowKey, 4, 2, iUnits, 100, 2, 2, optimization, iBatch)) return false; if(!cSceneSpecific.Add(ss)) return false; base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneSpecific.Total(), OpenCL, q_weights, optimization, iBatch)) return false; base.SetActivationFunction(TANH); if(!cSceneSpecific.Add(base)) return false; //--- Initilize Scene-Agnostic layers base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(q_weights, cSceneAgnostic.Total(), OpenCL, 1, optimization, iBatch)) return false; temp = base.getOutput(); if(!temp.BufferInit(1, 1) || !temp.BufferWrite()) return false; if(!cSceneAgnostic.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneAgnostic.Total(), OpenCL, q_weights, optimization, iBatch)) return false; if(!cSceneAgnostic.Add(base)) return false; }
Para a camada de escalonamento dos resultados da atenção multicabeça e o bloco FeedForward, utilizamos matrizes convencionais de parâmetros treináveis, inicializadas com valores aleatórios.
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < w0; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Também adicionamos buffers de momentos, que serão usados no processo de otimização das matrizes de parâmetros treináveis criadas. A quantidade de buffers de momentos é definida pelo método de otimização de parâmetros especificado.
//--- for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? w0 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_1 : 4 * iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_2 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } }
Após a inicialização bem-sucedida de todos os objetos mencionados, passamos para a próxima iteração do laço, onde criaremos objetos semelhantes para a camada interna subsequente.
Por fim, no encerramento do método de inicialização, inicializamos um buffer auxiliar para armazenamento temporário de dados e retornamos o resultado lógico da execução das operações ao programa chamador.
if(!Temp.BufferInit(MathMax((num_q + num_kv)*iWindow, out), 0)) return false; if(!Temp.BufferCreate(OpenCL)) return false; //--- SetOpenCL(OpenCL); //--- return true; }
A complexidade da estrutura e o grande número de objetos tornam a compreensão do algoritmo mais desafiadora. Além disso, é essencial monitorar cuidadosamente o fluxo de informações e a transferência de dados entre os objetos ao implementar os métodos de propagação para frente e de propagação reversa. Iniciamos o desenvolvimento do método de propagação para frente, o feedForward.
bool CNeuronMLMHSceneConditionAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *ss = NULL, *sa = NULL; CBufferFloat *q_weights = NULL, *kv_weights = NULL, *q = NULL, *kv = NULL;
Nos parâmetros do método, recebemos um ponteiro para o objeto que contém os dados brutos. No entanto, não realizamos uma verificação explícita da validade desse ponteiro, pois não planejamos acessá-lo diretamente nesta etapa. Em vez disso, iniciamos um pequeno processo preparatório, no qual criamos variáveis locais para armazenar temporariamente ponteiros para diferentes objetos. Em seguida, estruturamos um laço para percorrer as camadas internas do bloco.
for(uint i = 0; i < iLayers; i++) { //--- Scene-Specific ss = cSceneSpecific[i * 2]; if(!ss.FeedForward(NeuronOCL)) return false; ss = cSceneSpecific[i * 2 + 1]; if(!ss.FeedForward(cSceneSpecific[i * 2])) return false;
Dentro desse laço, primeiro geramos os coeficientes de peso para criar as entidades Query, Key e Value, utilizando as hiper-redes previamente desenvolvidas.
Inicialmente, com base na descrição do estado da cena recebida do programa chamador, geramos a matriz de parâmetros condicionados ao contexto. Como descrito anteriormente, após incorporar o conhecimento condicionado pelo contexto, escalamos o tensor de descrição da cena para corresponder ao tamanho necessário da matriz de parâmetros.
Simultaneamente, geramos a matriz de parâmetros independentes da cena.
//--- Scene-Agnostic sa = cSceneAgnostic[i * 2 + 1]; if(bTrain && !sa.FeedForward(cSceneAgnostic[i * 2])) return false;
É importante destacar que a geração da matriz de parâmetros independentes da cena ocorre apenas durante o treinamento do modelo. Durante a operação, essa matriz permanece estática, eliminando a necessidade de regenerá-la a cada execução.
Em seguida, multiplicamos as duas matrizes elemento a elemento. O resultado dessa operação nos fornece a matriz de parâmetros de peso necessária, que será distribuída nos buffers de dados previamente criados. O termo "distribuir" é empregado aqui porque geramos uma única matriz de pesos e a dividimos em duas partes. Uma parte é utilizada para formar a entidade Query, enquanto a outra é destinada às entidades Key e Value. No entanto, lembramos que essas últimas não são geradas em todas as execuções. Portanto, é necessário estruturar um fluxo condicional de operações, dependendo da necessidade de criar o tensor Key-Value.
Antes disso, realizamos uma pequena preparação adicional. Armazenamos o ponteiro do objeto de dados brutos referente à camada interna atual em uma variável local.
CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(6 * i - 4));
Aqui, salvamos o ponteiro especificamente para os dados brutos da camada interna. Isso significa que a variável recebe o ponteiro do programa externo apenas na primeira camada interna. Para as camadas subsequentes, utilizamos os resultados da camada anterior.
E armazenamos em variáveis locais os ponteiros para os buffers de dados dos coeficientes de peso e do próprio tensor de valores da entidade Query, que utilizamos em qualquer um dos dois cenários descritos anteriormente.
q_weights = QKV_Weights[i * 2]; q = QKV_Tensors[i * 2];
Caso seja necessário formar o tensor Key-Value, primeiro realizamos a multiplicação elemento a elemento entre as duas matrizes de coeficientes de peso geradas anteriormente. O resultado dessa operação é armazenado em um buffer de armazenamento temporário.
if(i % iLayersToOneKV == 0) { if(IsStopped() || !ElementMult(ss.getOutput(), sa.getOutput(), GetPointer(Temp))) return false;
Em seguida, armazenamos em variáveis locais os ponteiros para os buffers de coeficientes de peso e para os valores das entidades Key-Value.
kv_weights = KV_Weights[(i / iLayersToOneKV) * 2]; kv = KV_Tensors[(i / iLayersToOneKV) * 2];
Depois disso, distribuímos o tensor de coeficientes de peso entre dois buffers de dados distintos.
if(IsStopped() || !DeConcat(q_weights, kv_weights, GetPointer(Temp), iHeads, 2 * iHeadsKV, iWindow * iWindowKey)) return false; if(IsStopped() || !MatMul(inputs, kv_weights, kv, iUnits, iWindow, 2 * iHeadsKV * iWindowKey, 1)) return false; }
Posteriormente, formamos o tensor das entidades Key-Value por meio da multiplicação matricial entre o tensor de dados brutos da camada interna atual e a matriz de coeficientes de peso obtida.
Se não houver necessidade de gerar o tensor das entidades Key-Value, realizamos apenas a multiplicação elemento a elemento entre as duas matrizes de parâmetros, armazenando os resultados no buffer de dados correspondente. Nesse caso, nossas hiper-redes geram apenas a matriz de coeficientes de peso para a entidade Query.
else { if(IsStopped() || !ElementMult(ss.getOutput(), sa.getOutput(), q_weights)) return false; }
A formação do tensor de valores da entidade Query é realizada em qualquer cenário. Portanto, essa operação ocorre no fluxo principal do algoritmo.
if(IsStopped() || !MatMul(inputs, q_weights, q, iUnits, iWindow, iHeads * iWindowKey, 1)) return false;
Neste ponto, a implementação das hiper-redes no algoritmo de atenção é concluída. A partir daqui, seguimos para já conhecido mecanismo de Self-Attention. Primeiro, determinamos os resultados da atenção multicabeça.
//--- Score calculation and Multi-heads attention calculation CBufferFloat *temp = S_Tensors[i * 2]; CBufferFloat *out = AO_Tensors[i * 2]; if(IsStopped() || !AttentionOut(q, kv, temp, out)) return false;
Em seguida, reduzimos a dimensionalidade do tensor de resultados obtido.
//--- Attention out calculation temp = FF_Tensors[i * 6]; if(IsStopped() || !ConvolutionForward(FF_Weights[i * (optimization == SGD ? 6 : 9)], out, temp, iWindowKey * iHeads, iWindow, None)) return false;
Depois disso, somamos os resultados do bloco Self-Attention aos dados brutos e normalizamos o tensor resultante.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow, true)) return false;
Os dados passam, então, pelo bloco FeedForward.
//--- Feed Forward inputs = temp; temp = FF_Tensors[i * 6 + 1]; if(IsStopped() || !ConvolutionForward(FF_Weights[i * (optimization == SGD ? 6 : 9) + 1], inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors[i * 6 + 2]; if(IsStopped() || !ConvolutionForward(FF_Weights[i * (optimization == SGD ? 6 : 9) + 2], temp, out, 4 * iWindow, iWindow, activation)) return false;
E, por fim, realizamos outra soma e normalização dos dados.
//--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } //--- result return true; }
Repetimos essas operações para todas as camadas internas. Após completar todas as iterações do laço, retornamos ao programa chamador um valor lógico indicando o sucesso da execução do método.
Espero que, neste ponto, o funcionamento do algoritmo da nossa classe tenha ficado claro. No entanto, ainda há um detalhe importante: a distribuição do gradiente de erro no processo de propagação reversa, cujo algoritmo implementamos no método calcInputGradients.
bool CNeuronMLMHSceneConditionAttention::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
Nos parâmetros desse método, como de costume, recebemos um ponteiro para o objeto da camada anterior, ao qual devemos transmitir o gradiente de erro conforme a influência dos dados brutos no resultado final. No corpo do método, verificamos imediatamente a validade desse ponteiro. Em seguida, criamos algumas variáveis locais para armazenar temporariamente os ponteiros dos objetos.
CBufferFloat *out_grad = Gradient; CBufferFloat *kv_g = KV_Tensors[KV_Tensors.Total() - 1]; CNeuronBaseOCL *ss = NULL, *sa = NULL;
E criamos um laço para percorrer as camadas internas em ordem reversa.
for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) kv_g = KV_Tensors[(i / iLayersToOneKV) * 2 + 1];
Como você sabe, o algoritmo de distribuição do gradiente de erro é idêntico ao da propagação para frente, mas todas as operações são executadas em ordem inversa. Por isso, organizamos um laço para percorrer as camadas internas do nosso bloco no sentido inverso.
Vale lembrar que a segunda metade das operações do método de propagação para frente repetia integralmente um bloco correspondente da classe-mãe. Assim, transferimos a primeira metade do nosso método de distribuição do gradiente de erro a partir do método equivalente da classe-mãe.
Inicialmente, o gradiente de erro é distribuído através do bloco FeedForward.
//--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights[i * (optimization == SGD ? 6 : 9) + 2], out_grad, FF_Tensors[i * 6 + 1], FF_Tensors[i * 6 + 4], 4 * iWindow, iWindow, None)) return false; CBufferFloat *temp = FF_Tensors[i * 6 + 3]; if(IsStopped() || !ConvolutionInputGradients(FF_Weights[i * (optimization == SGD ? 6 : 9) + 1], FF_Tensors[i * 6 + 4], FF_Tensors[i * 6], temp, iWindow, 4 * iWindow, LReLU)) return false;
Em seguida, somamos os gradientes de erro dos dois fluxos de informação.
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
Depois disso, propagamos o gradiente de erro através do bloco Multi-Head Self-Attention.
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false; out_grad = temp; //--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights[i * (optimization == SGD ? 6 : 9)], out_grad, AO_Tensors[i * 2], AO_Tensors[i * 2 + 1], iWindowKey * iHeads, iWindow, None)) return false; //--- Passing gradient to query, key and value sa = cSceneAgnostic[i * 2 + 1]; ss = cSceneSpecific[i * 2 + 1]; if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors[i * 2], QKV_Tensors[i * 2 + 1], KV_Tensors[(i / iLayersToOneKV) * 2], kv_g, S_Tensors[i * 2], AO_Tensors[i * 2 + 1])) return false; } else { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors[i * 2], QKV_Tensors[i * 2 + 1], KV_Tensors[i / iLayersToOneKV * 2], GetPointer(Temp), S_Tensors[i * 2], AO_Tensors[i * 2 + 1])) return false; if(IsStopped() || !SumAndNormilize(kv_g, GetPointer(Temp), kv_g, iWindowKey, false, 0, 0, 0, 1)) return false; }
Aqui, é importante prestar atenção à distribuição do gradiente de erro até o tensor das entidades Key-Value. O detalhe está na coleta dos gradientes de erro de todas as camadas internas influenciadas por um determinado tensor. O algoritmo é descrito em mais detalhes no artigo que trata da implementação da classe-mãe.
Em seguida, distribuímos o gradiente de erro até o nível dos dados brutos pelo fluxo principal de informações.
CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 6 - 1); inp = FF_Tensors.At(i * 6 - 4); } if(IsStopped() || !MatMulGrad(inp, temp, QKV_Weights[i * 2], QKV_Weights[i * 2 + 1], QKV_Tensors[i * 2 + 1], iUnits, iWindow, iHeads * iWindowKey, 1)) return false; //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
Também transmitimos o gradiente de erro até as hiper-redes, conforme sua influência no resultado geral do modelo.
//--- if((i % iLayersToOneKV) == 0) { if(IsStopped() || !MatMulGrad(inp, GetPointer(Temp), KV_Weights[i / iLayersToOneKV * 2], KV_Weights[i / iLayersToOneKV * 2 + 1], KV_Tensors[i / iLayersToOneKV * 2 + 1], iUnits, iWindow, 2 * iHeadsKV * iWindowKey, 1)) return false; if(IsStopped() || !SumAndNormilize(GetPointer(Temp), temp, temp, iWindow, false, 0, 0, 0, 1)) return false; if(!Concat(QKV_Weights[i * 2 + 1], KV_Weights[i / iLayersToOneKV * 2 + 1], ss.getGradient(), iHeads, 2 * iHeadsKV, iWindow * iWindowKey)) return false; if(!ElementMultGrad(ss.getOutput(), ss.getGradient(), sa.getOutput(), sa.getGradient(), ss.getGradient(), ss.Activation(), sa.Activation())) return false; } else { if(!ElementMultGrad(ss.getOutput(), ss.getGradient(), sa.getOutput(), sa.getGradient(), QKV_Weights[i * 2 + 1], ss.Activation(), sa.Activation())) return false; } if(i > 0) out_grad = temp; }
Depois disso, seguimos para a próxima iteração do nosso laço de percorrimento das camadas internas.
Observe que, no laço do fluxo principal de operações, apenas transmitimos o gradiente de erro até o nível das hiper-redes, mas não realizamos sua propagação completa. Aqui, há alguns detalhes importantes. Primeiramente, nossa hiper-rede de conhecimento prévio, que é independente do estado da cena, possui apenas duas camadas. A primeira é estática e sempre retorna o valor "1" na saída. A segunda contém parâmetros treináveis e retorna o resultado. No fluxo principal de operações, passamos o gradiente de erro apenas para essa última camada. Transmitir o gradiente até a primeira camada seria inútil. Claro, esse é um caso específico. Se tivéssemos mais camadas na hiper-rede, seria necessário criar um algoritmo para distribuir o gradiente de erro a todos os elementos que contêm parâmetros treináveis.
O segundo detalhe se refere à construção do algoritmo da hiper-rede condicionada pelo contexto da cena. Nesta implementação, todos os parâmetros são formados com base na descrição original da cena, fornecida pelo programa chamador. Portanto, o gradiente de erro deve ser transmitido até esse nível. Para não interromper o fluxo principal de informações, decidimos isolar a distribuição do gradiente dessa hiper-rede em um laço separado. No entanto, novamente, esse é um caso específico. Se utilizássemos outra fonte para descrever a cena (por exemplo, o resultado da camada interna anterior), o gradiente de erro precisaria ser transmitido até o nível correspondente.
Retornando ao algoritmo do nosso método de distribuição do gradiente de erro, após completar as iterações do laço que percorre as camadas internas na ordem inversa, armazenamos no buffer de gradientes da camada anterior os valores que representam a influência dos dados brutos no resultado do modelo no fluxo principal de operações. Agora, precisamos adicionar a esse buffer o gradiente de erro proveniente das hiper-redes. Para isso, primeiro salvamos o ponteiro do buffer de gradientes da camada anterior em uma variável local. Em seguida, temporariamente, atribuimos ao objeto da camada um ponteiro para nosso buffer de dados auxiliar.
CBufferFloat *inp_grad = prevLayer.getGradient(); if(!prevLayer.SetGradient(GetPointer(Temp), false)) return false;
Com isso, podemos transmitir o gradiente de erro até a camada anterior sem correr o risco de perder os dados previamente armazenados. Criamos um laço para percorrer os objetos de nossa hiper-rede condicionada pelo contexto, no qual transmitimos o gradiente de erro até a camada de dados brutos. A cada iteração, adicionamos o resultado atual ao gradiente acumulado.
for(int i = int(iLayers - 2); (i >= 0 && !IsStopped()); i -= 2) { ss = cSceneSpecific[i]; if(IsStopped() || !ss.calcHiddenGradients(cSceneSpecific[i + 1])) return false; if(IsStopped() || !prevLayer.calcHiddenGradients(ss, NULL)) return false; if(IsStopped() || !SumAndNormilize(prevLayer.getGradient(), inp_grad, inp_grad, iWindow, false, 0, 0, 0, 1)) return false; }
Após a conclusão bem-sucedida do laço, restauramos no objeto da camada anterior o ponteiro do seu buffer original, agora contendo o gradiente de erro acumulado de todos os fluxos de informação.
if(!prevLayer.SetGradient(inp_grad, false)) return false; //--- return true; }
O gradiente de erro foi completamente distribuído, e retornamos ao programa chamador um valor lógico indicando o sucesso da execução do método de distribuição do gradiente. Quanto ao método de atualização dos parâmetros do modelo, sugiro que você o analise por conta própria. O código completo desta classe e de todos os seus métodos pode ser encontrado no anexo.
2.3 Construção do algoritmo completo HyperDet3D
Acima, desenvolvemos blocos individuais do algoritmo HyperDet3D. Agora, chegou o momento de unir tudo em uma estrutura única e coesa. De um lado, essa tarefa é bastante simples, mas, por outro, há alguns detalhes a serem considerados.
Neste experimento, decidi utilizar o algoritmo Pointformer, abordado no artigo anterior, substituindo o bloco de atenção global pelo módulo MSA. Essa modificação não é complexa, especialmente porque mantivemos os parâmetros de todos os métodos inalterados, incluindo o método de inicialização da classe. No entanto, todos os objetos da classe CNeuronPointFormer foram declarados como estáticos. Dessa forma, não é possível simplesmente herdá-los e modificar o tipo de alguns objetos. Portanto, criamos uma cópia da classe, na qual alteramos o tipo dos objetos necessários. A seguir, apresentamos a estrutura da nova classe.
class CNeuronHyperDet : public CNeuronPointNet2OCL { protected: CNeuronMLMHSparseAttention caLocalAttention[2]; CNeuronMLCrossAttentionMLKV caLocalGlobalAttention[2]; CNeuronMLMHSceneConditionAttention caGlobalAttention[2]; CNeuronLearnabledPE caLocalPE[2]; CNeuronLearnabledPE caGlobalPE[2]; CNeuronBaseOCL cConcatenate; CNeuronConvOCL cScale; //--- CBufferFloat *cbTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override ; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHyperDet(void) {}; ~CNeuronHyperDet(void) { delete cbTemp; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronHyperDet; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Não entraremos em detalhes sobre os algoritmos dos métodos dessa classe, pois todos eles foram gerados por meio da cópia direta dos métodos correspondentes da classe CNeuronPointFormer.
A arquitetura dos modelos, assim como todos os programas responsáveis pela interação com o ambiente e pelo treinamento das redes, também foi aproveitada do artigo anterior. Portanto, não nos aprofundaremos nesses detalhes. O código completo de todos os programas utilizados na preparação deste artigo está disponível no anexo.
3. Testes
Realizamos um extenso trabalho na implementação da nossa visão sobre os conceitos propostos pelos autores do método HyperDet3D. Agora, chegamos à parte final do artigo. Aqui, realizaremos o treinamento e os testes dos modelos que incorporam essas abordagens.
Como antes, utilizamos dados históricos reais do ativo EURUSD ao longo de todo o ano de 2023 no timeframe H1 para o treinamento dos modelos. Todos os parâmetros dos indicadores analisados foram mantidos nos valores padrão. O processo de treinamento seguiu exatamente o algoritmo descrito no artigo anterior, portanto, focaremos apenas nos resultados do teste da política do Agente, apresentados a seguir.
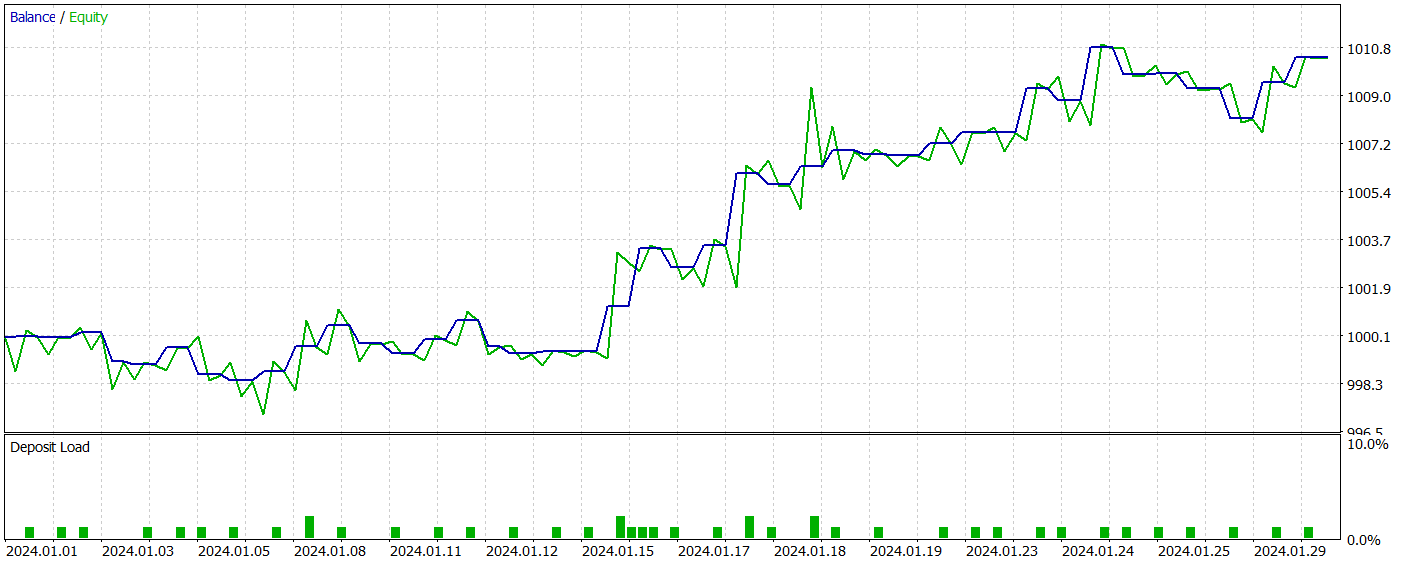
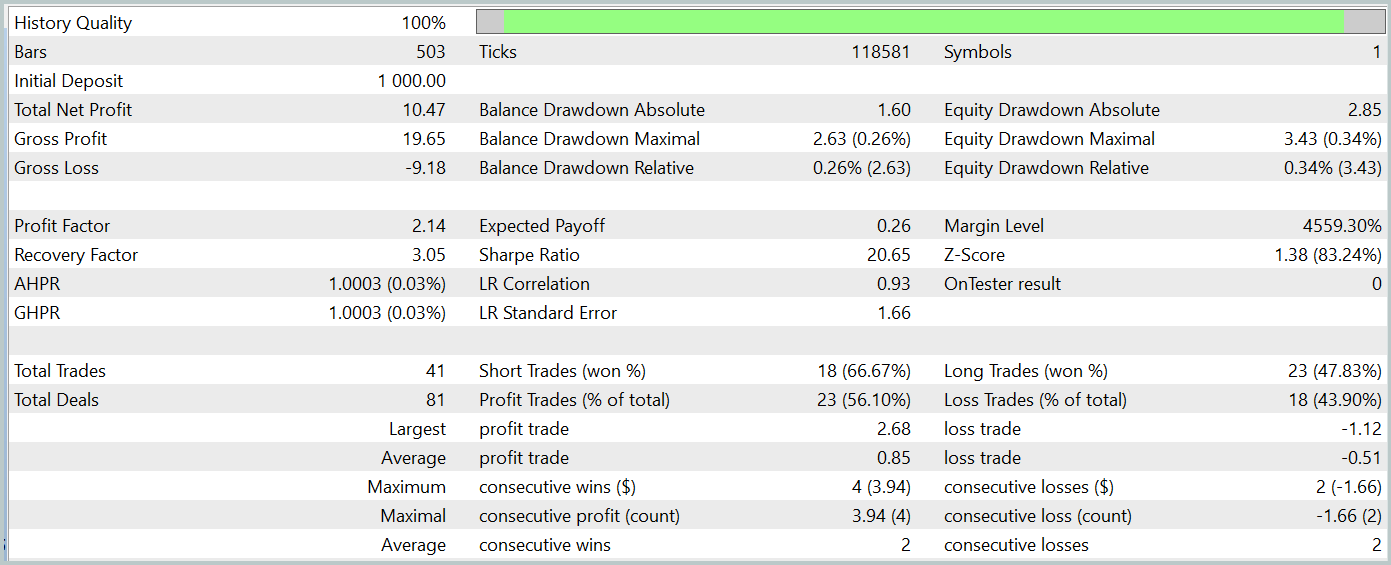
O teste da rede treinada foi realizado com dados históricos de janeiro de 2024, que não faziam parte do conjunto de treinamento. Durante esse período, a rede executou 41 operações, das quais 56% foram encerradas com lucro. A maior operação lucrativa superou a maior operação com prejuízo em um fator de 2,4, enquanto o lucro médio das operações vencedoras foi 67% superior ao das operações perdedoras. Esses fatores resultaram em um profit factor de 2,14 e um coeficiente de Sharpe de 20,65.
No geral, durante o período de teste, o modelo obteve um retorno de 1%, com um rebaixamento máximo do Equity de apenas 0,34%. O drawdown do saldo foi ainda menor. O gráfico apresenta um crescimento consistente do saldo, com uma exposição ao risco no depósito variando entre 1% e 2%.
A impressão geral dos resultados obtidos é positiva. O modelo demonstra potencial. No entanto, o curto período de teste e o número reduzido de operações não permitem concluir sobre sua estabilidade ao longo do tempo. Antes de utilizá-lo em operações reais, será necessário treiná-lo com um conjunto de dados históricos mais extenso, seguido de uma testagem abrangente.
Considerações finais
Neste artigo, exploramos o método HyperDet3D, que utiliza hiper-redes condicionadas pela cena para integrar conhecimento prévio na arquitetura Transformer. Isso permite que o modelo se adapte de maneira eficiente a diferentes cenários na tarefa de detecção de objetos, melhorando a precisão do reconhecimento por meio do ajuste dinâmico dos parâmetros do detector com base nas informações da cena. Essa abordagem torna o sistema mais versátil e poderoso.
Na parte prática deste estudo, implementamos nossa visão sobre as abordagens propostas utilizando MQL5 e as integramos à estrutura do nosso modelo. Os resultados dos testes demonstram o potencial da rede. No entanto, antes de sua aplicação prática nos mercados financeiros, ainda há um volume considerável de trabalho a ser realizado.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento de Modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criar uma rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/15859
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso