
取引におけるニューラルネットワーク:シーン認識オブジェクト検出(HyperDet3D)

はじめに
近年、オブジェクト検出は大きな注目を集めています。PointNet++は、表現学習とボリューム畳み込みに基づき、局地的な幾何情報を重視しながら、生のポイントクラウドを洗練された方法で解析します。そのため、さまざまなオブジェクト検出モデルにおいて、バックボーンネットワークとして広く採用されています。
しかし、類似オブジェクトの属性が曖昧になる場合があり、これがモデルの性能低下を招く要因となっています。その結果、モデルの適用範囲が制限されるか、アーキテクチャをより複雑にする必要が生じます。論文「HyperDet3D:Learning a Scene-conditioned 3D Object Detector」の著者は、シーンレベルの情報が、オブジェクト属性の解釈における曖昧さを解消するための事前知識として機能し、不自然な検出結果を防ぐことができると指摘しています。これにより、シーン理解の観点から、不合理な検出結果が防止されます。
この論文では、ハイパーネットワークベースのアーキテクチャを用いて、ポイントクラウドにおける3Dオブジェクト検出をおこなうHyperDet3Dアルゴリズムを提案しています。HyperDet3Dはシーン条件付きの情報を学習し、それをネットワークのパラメータに反映させることで、3Dオブジェクト検出器がさまざまな入力データに動的に適応できるようにします。具体的には、シーン条件付きの知識は「シーン不変情報」と「シーン固有情報」の2つのレベルに分けて扱います。
シーン不変の知識を捉えるために、著者はハイパーネットワークで利用される学習埋め込みを導入しており、モデルがさまざまなシーンで訓練される中で、この埋め込みが反復的に更新されます。これらのシーン不変情報は、学習データの特徴から抽象化されたものであり、推論時にも有効活用されます。
さらに、従来の検出器は異なるシーンにおいてもパラメータが固定されているのに対し、HyperDet3Dでは、推論時に検出器を特定のシーンに適応させるため、シーン固有情報の統合が提案されています。これは、特定の入力をクエリとして使用し、現在のシーンが一般的な表現とどの程度一致または乖離しているかを分析することで実現されます。
また、Multi-head Scene-Conditioned Attention (MSA)という新しいモジュール構造も導入されています。MSAは候補オブジェクトの特徴と事前知識を統合することで、より効果的なオブジェクト検出を可能にします。
1. HyperDet3Dアルゴリズム
HyperDet3Dモデルは、以下の3つの主要なコンポーネントで構成されています。
- バックボーンエンコーダ
- オブジェクトデコーダー層
- 検出ヘッド
入力されたポイントクラウドは、まずバックボーンによって処理されます。ポイントがダウンサンプリングされ、初期のオブジェクト候補が生成されると同時に、階層的なアーキテクチャによって特徴が粗く抽出されます。著者は、バックボーンネットワークとしてPointNet++を用いることを提案しています。
次に、オブジェクトデコーダ層が候補の特徴をさらに洗練させ、シーン条件付きの事前知識をオブジェクトレベルの表現に統合します。その後、検出ヘッドが、候補オブジェクトの位置と改良された特徴に基づいてバウンディングボックスの回帰をおこないます。
HyperDet3Dがシーンレベルのメタ情報を認識できるようにするために、著者はハイパーネットワークを導入しています。これは、メインネットワークの学習可能なパラメータを生成するニューラルネットワークです。従来のディープニューラルネットワークは推論時に固定されたパラメータを使用しますが、ハイパーネットワークは入力データに応じてパラメータを動的に適応させることができるため、柔軟性に優れています。
HyperDet3Dでは、Transformerデコーダ層のパラメータにシーン条件に基づく事前知識を組み込むため、シーン条件付きハイパーネットワークが使用されます。これにより、検出ネットワークは多様な入力シーンに動的に適応することが可能になります。ここでの重要なポイントは、バックボーンエンコーダによって生成された候補セットから形成されるオブジェクト表現𝒐に対して、シーン条件付きハイパーネットワークから提供される𝑾によってパラメータ化された事前知識を加えることです。
このハイパーネットワークが生成するパラメータは、シーン不変のコンポーネントとシーン固有のコンポーネントの2種類に分けられます。
まず、シーン不変の知識を得るために、著者はn個のシーン非依存の埋め込みベクトル𝒁a,を訓練し、それをハイパーネットワークに入力することを提案しています。このハイパーネットワークの出力として得られる重み行列𝑾aが、シーン不変の事前知識をパラメータ化します。
オブジェクトの特徴は複数のデコーダ層を通じて段階的に洗練されていくため、各層でこのシーン不変ハイパーネットワークの出力と融合させていくことが可能です。このネットワークは、さまざまな3Dシーンにわたって共通する事前知識を抽象化する設計になっており、すべてのデコーダレベルで一貫したシーン条件付き知識を保持できるとともに、豊富な特徴階層を通じて知識を共有することで計算リソースの節約も実現しています。
次に、シーン固有の知識を得るために、モデルは𝒁aと類似した形式のシーン固有埋め込み𝒁sを学習します。𝒁sは各シーンに固有の情報を捉えることを目的としています。これにはクロスアテンションブロックが使用され、現在のシーンの埋め込みと𝒁sとを比較することで、 両者が埋め込み空間内でどれほど一致しているか、または乖離しているかを評価します。
HyperDet3Dメソッドの公式な可視化を以下に示します。
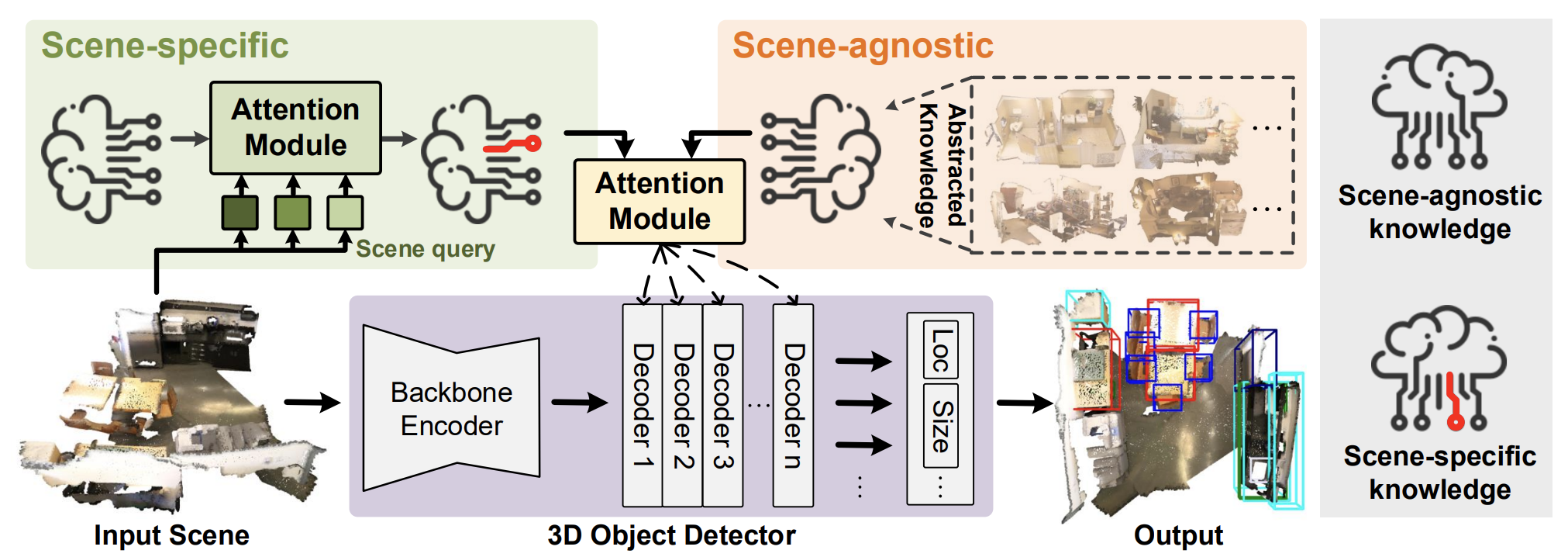
2.MQL5での実装
HyperDet3D法の理論的側面を検討した後は、提案されたアプローチに対する私たちのビジョンを実装する、この記事の実践的な部分に移りましょう。
あらかじめ言っておきますが、これからかなりの作業量が待ち受けています。これを効率的に進めるために、実装をいくつかの論理的なモジュールに分割して取り組みます。それでは、気合いを入れて始めましょう。
2.1 シーン固有の知識モジュール
まずは、シーン固有の知識を学習するためのモジュールの構築から始めます。理論セクションで説明したとおり、クロスアテンションを用いて、現在のシーンとシーン固有の知識埋め込みとを照合します。そのため、クロスアテンションブロックであるCNeuronSceneSpecificのサブクラスとして、新たにCNeuronMLCrossAttentionMLKVクラスを定義します。以下に新しいクラスの構造を示します。
class CNeuronSceneSpecific : public CNeuronMLCrossAttentionMLKV { protected: CNeuronBaseOCL cOne; CNeuronBaseOCL cSceneSpecificKnowledge; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return feedForward(NeuronOCL); } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return updateInputWeights(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSceneSpecific(void) {}; ~CNeuronSceneSpecific(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSceneSpecific; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
ここで、新しいクラスとその親クラスとの間に存在する基本的な違いのひとつを強調することが重要です。親クラスが正しく機能するためには、入力データとコンテキストという2つのデータソースが必要です。一方で、新しいクラスにおいては、コンテキストは学習済みのシーン固有データとして表現されており、これは訓練データセットから導かれたものです。このデータは、内部に定義された2つの層(cOneおよびcSceneSpecificKnowledge)を通じて学習されます。実質的には、スカラー値(1)を入力として受け取り、シーン固有の知識を表すテンソルを出力する、2層のMLPとなります。予想されるとおり、推論時にはこのテンソルは静的に保持されますが、学習時にはモデルが必要な情報をこのテンソルに「書き込む」形で更新をおこないます。
この設計思想に従い、新しいクラスでは外部コンテキストへのポインタをメソッド内から除外しています。
すべてのオブジェクトは静的に宣言されているため、クラスのコンストラクタとデストラクタは「空」のままで問題ありません。オブジェクトの初期化はInitメソッド内でおこなわれ、そのパラメータとして、オブジェクトのアーキテクチャに関する主要な定数が渡されます。これらのパラメータの機能は、親クラスにおける対応するメソッドとほぼ同様です。
bool CNeuronSceneSpecific::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMLCrossAttentionMLKV::Init(numOutputs, myIndex, open_cl, window, window_key, heads, 16, heads_kv, units_count, units_count_kv, layers, layers_to_one_kv, optimization_type, batch)) return false;
メソッド本体では、まず親クラスの初期化メソッドを呼び出し、受け取ったすべてのパラメータをそのまま渡します。この親メソッドは、パラメータの検証および継承されたコンポーネントのセットアップを担当します。
続いて、前述のシーン固有MLPの初期化をおこないます。
ここで注意すべき点として、最初の層には定数の入力(スカラー値)1つのみが含まれます。次の層では、シーン固有の知識を表現する埋め込みベクトルのセットが生成されます。各埋め込みベクトルの次元数は16で、埋め込みの総数はメソッドのパラメータによって決定されます。これは、モデル化対象となる環境の複雑さに応じて変化します。
if(!cOne.Init(16 * units_count_kv, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = cOne.getOutput(); if(!out.BufferInit(1, 1) || !out.BufferWrite()) return false; if(!cSceneSpecificKnowledge.Init(0, 1, OpenCL, 16 * units_count_kv, optimization, iBatch)) return false; //--- return true; }
メソッドを終了する前に、初期化が成功したかどうかを示すブール値を呼び出し元の関数に返します。
新しいクラスの初期化メソッドは、比較的短く簡潔な構造になっています。その理由は、主要な機能がすでに親クラス側で実装されているということです。この設計パターンは初期化メソッドに限らず、feedForwardメソッドにも当てはまります。こちらのメソッドでは、パラメータとしてソース入力データへのポインタが含まれます。
bool CNeuronSceneSpecific::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !cSceneSpecificKnowledge.FeedForward(cOne.AsObject())) return false;
メソッドの本体ではまず、学習されたシーンのコンテキスト依存表現を表す行列を生成する必要があります。ただし、この処理は、MLPのパラメータが調整され、出力テンソルが変化する「モデルの学習プロセス中」にのみ実行されます。モデルの動作時(推論時)には、これらの学習済みの値は静的であり、再計算する必要はありません。あらかじめ保存された情報を単に再利用します。
最後に、親クラスのfeedForwardメソッドを呼び出し、シーン固有の知識テンソルをコンテキスト入力として渡します。
if(!CNeuronMLCrossAttentionMLKV::feedForward(NeuronOCL, cSceneSpecificKnowledge.getOutput())) return false; //--- return true; }
バックプロパゲーションのパスメソッドも、同様の手法で構築されています。記事を簡潔に保ち、過度に長くなるのを避けるためにも、これらのメソッドについては読者ご自身で個別に学習されることをお勧めします。クラスの完全な実装およびすべてのメソッドの詳細は、添付の資料をご参照ください。
2.2 MSAブロックの構築
ここで、Multi-Head Scene-Conditioned Attention (MSA)ブロックの構築に移ります。当然ながら、以前に実装したアテンションブロックの1つからコア機能を継承します。新しいクラスCNeuronMLMHSceneConditionAttentionの構造を以下に示します。
class CNeuronMLMHSceneConditionAttention : public CNeuronMLMHAttentionMLKV { protected: CLayer cSceneAgnostic; CLayer cSceneSpecific; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMLMHSceneConditionAttention(void) {}; ~CNeuronMLMHSceneConditionAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronMLMHSceneConditionAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
この構造内で、CLayer型の2つの新しいオブジェクトの宣言に気づくでしょう。1つはシーンに依存したコンテキスト表現を格納し、もう1つはシーンに依存しない一般的なオブジェクト関連情報を保持します。
ここで重要なのは、これら2つのオブジェクトの存在によって、オブジェクト識別のためにより深くネストされたニューラル層を構築することが制限されるわけではないという点です。この場合、CLayerオブジェクトは動的配列として機能し、内部のニューラル層の数はオブジェクトの初期化時にユーザーが指定することができます。
すべての内部オブジェクトは静的として宣言されているため、コンストラクタとデストラクタを空のままにすることができます。通常どおり、すべての内部オブジェクトと継承オブジェクトの初期化はInitメソッドで実行されます。
bool CNeuronMLMHSceneConditionAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
メソッドのパラメータでは、生成されるオブジェクトのアーキテクチャを決定する主要な定数を受け取ります。そしてメソッド本体では、まず該当する祖先クラスのメソッドを直ちに呼び出します。ただし、この場合に使用するのは直接の親クラスのメソッドではなく、全結合層の基底メソッドCNeuronBaseOCLです。これは、継承されるオブジェクトの構造やサイズに大きな違いがあるためです。
祖先の初期化メソッドが正常に実行された後、新しいクラスにおけるアーキテクチャ上の定数を保存します。
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(layers, 1); iHeadsKV = fmax(heads_kv, 1); iLayersToOneKV = fmax(layers_to_one_kv, 1);
次に、内部オブジェクトの寸法を計算します。
uint num_q = iWindowKey * iHeads * iUnits; //Size of Q tensor uint num_kv = 2 * iWindowKey * iHeadsKV * iUnits; //Size of KV tensor uint q_weights = (iWindow * iHeads) * iWindowKey; //Size of weights' matrix of Q tenzor uint kv_weights = 2 * (iWindow * iHeadsKV) * iWindowKey; //Size of weights' matrix of KV tenzor uint scores = iUnits * iUnits * iHeads; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits; //Size of multi-heads self-attention uint out = iWindow * iUnits; //Size of out tensore uint w0 = (iWindowKey * iHeads + 1) * iWindow; //Size W0 tensor uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
ニューラル層オブジェクトへのポインタを一時的に保存するためのローカル変数をさらに2つ追加します。
CNeuronBaseOCL *base = NULL; CNeuronSceneSpecific *ss = NULL;
これで準備作業は終了です。次に、メソッドのパラメータでユーザーが指定した内部層の数に等しい回数のループを構築します。このループの各反復で、1つの内部層に対応するオブジェクトを生成します。したがって、指定されたループ回数がすべて完了すると、必要な数の内部ニューラル層が正常に機能するために必要なオブジェクトの完全なセットが生成されることになります。
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- Initilize Q tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
ループ本体では、2回の反復の別のネストされたループをすぐに作成します。ネストされたループの本体では、フォワードパスのメインフローデータとバックプロパゲーションパスの対応する誤差勾配を記録するためのデータバッファを保存します。この2回の反復ループにより、フィードフォワードパスとバックプロパゲーションパスのミラーアーキテクチャを作成できます。
ここではまず、生成されたQueryエンティティを記録するためのバッファを作成します。次に、このエンティティを生成するための重み行列を記録するためのバッファを作成します。
//--- Initilize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(q_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
これまでは、モデルの訓練プロセス中に調整されたランダムな値で重み行列を常に入力していたことに注意してください。今回は、ゼロ値を持つバッファを作成しました。これは、分析されたシーンを考慮してこの行列を生成するハイパーネットワークアーキテクチャの実装によるものです。
同様の操作を繰り返して、KeyとValueのエンティティデータバッファを生成します。しかし、ここでは、複数の内部層に1つのテンソルを使用する機能も追加します。したがって、データバッファを作成する前に、そのような操作の実行可能性を確認します。
if(i % iLayersToOneKV == 0) { //--- Initilize KV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Tensors.Add(temp)) return false; //--- Initilize KV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(kv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Weights.Add(temp)) return false; }
次に、依存係数を格納するバッファを追加します。
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
マルチヘッドアテンションの結果を保存するための別のバッファを追加します。
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
これまでと同様に、マルチヘッドアテンションの結果は元のデータのサイズに合わせて拡大縮小されます。この操作の結果を対応するデータバッファに書き込みます。
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
FeedForwardブロック操作バッファも追加しましょう。
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
親クラスの対応するメソッドと同様に、FeedForwardブロックの最終内部層では新たな出力バッファを作成せず、ベースとなる全結合層から継承したバッファを直接参照します。これらのバッファは層間でのデータ受け渡しに利用され、実行時には直接書き込むことで、内部・外部インターフェイス間の不要なデータ転送を回避します。
フィードフォワードおよびバックプロパゲーション用のデータバッファを初期化した後は、重み行列の初期化に進みます。ただし本実装では、現在のシーン状態に応じて調整されたQuery、Key、Value各エンティティの生成に、シーン非依存(事前知識)およびシーン依存(コンテキスト情報)の2種類のハイパーネットワークを使用します。これらのハイパーネットワークも、初期化が必要です。
この段階では、いくつかの実装方針が考えられます。ご存知のとおり、Queryとは異なり、KeyとValueは必ずしもすべての内部層で生成する必要がありません。そのため、それらは個別のテンソルに分離して割り当てます。理論上は、それぞれの重み行列に対して専用のハイパーネットワークを構築することも可能ですが、この方法は逐次処理の回数が増え、性能面では非効率です。そこで、統合されたハイパーモデルを使って必要なテンソルを並列生成し、それを適切なデータバッファへと振り分ける方式を採用しています。
加えて、KeyとValueが全ての内部層で必要となるわけではない点も考慮しています。そのような場合には、出力テンソルのサイズを抑えた軽量モデルを使用しています。
論理的ですね。それでは実装に移りましょう。まず、Key-Valueテンソルの生成が必要かどうかに応じて、処理ストリームを2つの分岐に分けます。両ストリームで実行アルゴリズム自体は同一ですが、出力テンソルのサイズが異なります。
if(i % iLayersToOneKV == 0) { //--- Initilize Scene-Specific layers ss = new CNeuronSceneSpecific(); if(!ss) return false; if(!ss.Init((q_weights + kv_weights), cSceneSpecific.Total(), OpenCL, iWindow, iWindowKey, 4, 2, iUnits, 100, 2, 2, optimization, iBatch)) return false; if(!cSceneSpecific.Add(ss)) return false;
まず、コンテキスト依存表現モデルを扱います。ここでは、先ほど実装したシーン固有の知識モジュールの動的インスタンスを作成して初期化します。この新しく作成されたオブジェクトへのポインタは、コンテキスト条件付きモデルの一部を形成するcSceneSpecific配列に格納されます。
ただし、ここで1つの重要なニュアンスに注意する必要があります。シーン固有の知識モジュールは、シーンの分析された状態を入力として受け取るクロスアテンションブロック上に構築されました。そして、コンテキスト依存の知識が強化された適切な次元のテンソルを返します。問題は、入力テンソルのサイズがターゲット重み行列の必要な次元と一致しない可能性があることです。これを解決するために、それに応じて寸法を調整する全結合スケーリング層を導入します。
base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneSpecific.Total(), OpenCL, (q_weights + kv_weights), optimization, iBatch)) return false; base.SetActivationFunction(TANH); if(!cSceneSpecific.Add(base)) return false;
このスケーリング層は、活性化関数として双曲線正接(tanh)を使用し、[-1,1]の範囲の値を出力します。その結果、シーンに関するコンテキスト条件付きの知識は、本質的にはフラグ付けメカニズムとして機能し、分析されたシーン内に特定のオブジェクトが存在する可能性または存在を示します。
シーンに依存しない事前知識モデルでは、コンテキスト条件付き埋め込みを維持するために前述したものと構造が似ている2層MLPを使用します。
//--- Initilize Scene-Agnostic layers base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init((q_weights + kv_weights), cSceneAgnostic.Total(), OpenCL, 1, optimization, iBatch)) return false; temp = base.getOutput(); if(!temp.BufferInit(1, 1) || !temp.BufferWrite()) return false; if(!cSceneAgnostic.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneAgnostic.Total(), OpenCL, (q_weights + kv_weights), optimization, iBatch)) return false; if(!cSceneAgnostic.Add(base)) return false; }
Key-Valueテンソルを生成する必要がない場合は、サイズが小さい同様のオブジェクトを作成します。
else { //--- Initilize Scene-Specific layers ss = new CNeuronSceneSpecific(); if(!ss) return false; if(!ss.Init(q_weights, cSceneSpecific.Total(), OpenCL, iWindow, iWindowKey, 4, 2, iUnits, 100, 2, 2, optimization, iBatch)) return false; if(!cSceneSpecific.Add(ss)) return false; base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneSpecific.Total(), OpenCL, q_weights, optimization, iBatch)) return false; base.SetActivationFunction(TANH); if(!cSceneSpecific.Add(base)) return false; //--- Initilize Scene-Agnostic layers base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(q_weights, cSceneAgnostic.Total(), OpenCL, 1, optimization, iBatch)) return false; temp = base.getOutput(); if(!temp.BufferInit(1, 1) || !temp.BufferWrite()) return false; if(!cSceneAgnostic.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneAgnostic.Total(), OpenCL, q_weights, optimization, iBatch)) return false; if(!cSceneAgnostic.Add(base)) return false; }
マルチヘッドアテンション結果データスケーリング層とFeedForwardブロックでは、ランダムパラメータで初期化された訓練パラメータの規則的な行列を使用します。
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < w0; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
また、作成された訓練パラメータの行列を最適化するプロセスで使用するモーメントバッファも追加します。モーメントバッファの数は、指定されたパラメータ最適化方法によって決まります。
//--- for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? w0 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_1 : 4 * iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_2 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } }
指定されたすべてのオブジェクトの初期化が正常に完了したら、ループの次の反復に進み、後続の内部層に同様のオブジェクトを作成します。
初期化メソッドの最後に、一時データを格納するための補助バッファを初期化し、操作の論理結果を呼び出し元プログラムに返します。
if(!Temp.BufferInit(MathMax((num_q + num_kv)*iWindow, out), 0)) return false; if(!Temp.BufferCreate(OpenCL)) return false; //--- SetOpenCL(OpenCL); //--- return true; }
構造が複雑でオブジェクトの数が多いため、構築されているアルゴリズムを理解するのが困難です。さらに、フィードフォワードおよびバックプロパゲーションパスメソッドの実装中に、オブジェクト間の情報の流れとデータ転送を注意深く監視する必要があります。それでは、feedForwardメソッドの構築から始めます。
bool CNeuronMLMHSceneConditionAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *ss = NULL, *sa = NULL; CBufferFloat *q_weights = NULL, *kv_weights = NULL, *q = NULL, *kv = NULL;
メソッドパラメータでは、ソースデータオブジェクトへのポインタを受け取ります。ただし、受信したインデックスの関連性のチェックはおこないません。この段階ではソースデータオブジェクトに直接アクセスする予定がないためです。ただし、少し準備作業をおこない、さまざまなオブジェクトへのポインタを一時的に保存するためのローカル変数を作成します。次に、ブロックの内部層を反復処理するループを作成します。
for(uint i = 0; i < iLayers; i++) { //--- Scene-Specific ss = cSceneSpecific[i * 2]; if(!ss.FeedForward(NeuronOCL)) return false; ss = cSceneSpecific[i * 2 + 1]; if(!ss.FeedForward(cSceneSpecific[i * 2])) return false;
ループ内では、まず、以前に定義したハイパーネットワークを使用して、Query、Key、Valueのエンティティを構築するために必要な重み係数を生成します。
まず、呼び出しプログラムから受け取ったシーン状態の説明に基づいて、コンテキスト依存パラメータの行列を生成します。前述のように、このテンソルをコンテキスト固有の知識で強化した後、必要なパラメータ行列の次元に合わせて再スケールします。
同時に、シーンに依存しないパラメータの行列を生成します。
//--- Scene-Agnostic sa = cSceneAgnostic[i * 2 + 1]; if(bTrain && !sa.FeedForward(cSceneAgnostic[i * 2])) return false;
シーンに依存しないパラメータ行列は、モデルの訓練中にのみ生成されることに注意してください。動作中、行列は静的なままです。したがって、フィードフォワードパスごとに再生成する必要はありません。
次に、2つの行列の要素ごとの乗算を実行します。結果は最終的な重み行列であり、これを以前に初期化されたデータバッファに配布します。これは単一の生成された重み行列であり、2つの部分に分割されていることに注意することが重要です。1つの部分はQueryエンティティを作成するために使用されます。2つ目の部分は、KeyとValueのエンティティに使用されます。ただし、KeyとValueは必ずしもすべての層で形成されるわけではありません。したがって、Key-Valueテンソルの生成が必要かどうかに応じて操作フローを分岐する必要があります。
その前に、少し予備的な設定をおこないます。具体的には、現在の内部層の入力データオブジェクトへのポインターをローカル変数に転送します。
CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(6 * i - 4));
ここで、内部層の入力へのポインタを保存します。つまり、外部プログラムから受信したポインターは、最初の内部層にのみ渡されます。後続のすべての層では、前の内部層からの出力を使用します。
また、重みパラメータとQueryテンソルのデータバッファへのポインターをローカル変数に格納します。これらは、2つの処理パスのどちらを実行するかに関係なく使用されます。
q_weights = QKV_Weights[i * 2]; q = QKV_Tensors[i * 2];
Key-Valueテンソルを形成する必要がある場合は、まず上記で形成された2つの重み行列の要素ごとの乗算を実行します。そして、操作の結果を一時データ保存バッファに書き込みます。
if(i % iLayersToOneKV == 0) { if(IsStopped() || !ElementMult(ss.getOutput(), sa.getOutput(), GetPointer(Temp))) return false;
重みとKey-ValueエンティティValueのバッファへのポインタをローカル変数に保存します。
kv_weights = KV_Weights[(i / iLayersToOneKV) * 2]; kv = KV_Tensors[(i / iLayersToOneKV) * 2];
次に、重みパラメータの共通テンソルを2つのデータバッファに分散します。
if(IsStopped() || !DeConcat(q_weights, kv_weights, GetPointer(Temp), iHeads, 2 * iHeadsKV, iWindow * iWindowKey)) return false; if(IsStopped() || !MatMul(inputs, kv_weights, kv, iUnits, iWindow, 2 * iHeadsKV * iWindowKey, 1)) return false; }
その後、現在の内部層の初期データテンソルと取得した重み係数の行列を行列乗算して、Key-Valueエンティティのテンソルを形成します。
Key-Valueエンティティテンソルを形成する必要がない場合は、2つのパラメータ行列の要素ごとの乗算の操作のみを実行し、その結果を対応するデータバッファに書き込みます。この場合、ハイパーネットワークはQueryエンティティの重み行列のみを形成します。
else { if(IsStopped() || !ElementMult(ss.getOutput(), sa.getOutput(), q_weights)) return false; }
QueryエンティティValueテンソルの形成は、どのような場合でも実行されます。したがって、この操作を一般的なフローで実装します。
if(IsStopped() || !MatMul(inputs, q_weights, q, iUnits, iWindow, iHeads * iWindowKey, 1)) return false;
この段階で、アテンションアルゴリズムへのハイパーネットワークの実装が完了します。次に、私たちにとってすでにおなじみの自己アテンション機構が続きます。まず、マルチヘッドアテンションの結果を決定します。
//--- Score calculation and Multi-heads attention calculation CBufferFloat *temp = S_Tensors[i * 2]; CBufferFloat *out = AO_Tensors[i * 2]; if(IsStopped() || !AttentionOut(q, kv, temp, out)) return false;
次に、結果として得られる出力テンソルの次元を削減します。
//--- Attention out calculation temp = FF_Tensors[i * 6]; if(IsStopped() || !ConvolutionForward(FF_Weights[i * (optimization == SGD ? 6 : 9)], out, temp, iWindowKey * iHeads, iWindow, None)) return false;
その後、自己アテンションブロックの結果を元のデータと合計し、結果のテンソルを正規化します。
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow, true)) return false;
次に、データはFeedForwardブロックを通過します。
//--- Feed Forward inputs = temp; temp = FF_Tensors[i * 6 + 1]; if(IsStopped() || !ConvolutionForward(FF_Weights[i * (optimization == SGD ? 6 : 9) + 1], inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors[i * 6 + 2]; if(IsStopped() || !ConvolutionForward(FF_Weights[i * (optimization == SGD ? 6 : 9) + 2], temp, out, 4 * iWindow, iWindow, activation)) return false;
次に、データを合計して正規化します。
//--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } //--- result return true; }
すべての内部層に対してこの操作を繰り返します。すべてのループ反復を完了すると、メソッド操作の実行の論理結果が呼び出し元プログラムに返されます。
この段階で、クラスのアルゴリズムがどのように機能するかを理解していただければ幸いです。ただし、バックプロパゲーションパス中の誤差勾配の分布に関連するもう1つのニュアンスがあります。そのアルゴリズムはcalcInputGradientsメソッドに実装されています。
bool CNeuronMLMHSceneConditionAttention::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
メソッドパラメータでは、通常どおり、前の層のオブジェクトへのポインタを受け取ります。このオブジェクトには、元のデータが最終結果に与える影響に応じて、誤差勾配を伝播する必要があります。メソッド本体では、受け取ったポインタの妥当性を即座に確認します。その後、オブジェクトへのポインタを一時的に保存するためのローカル変数をいくつか作成します。
CBufferFloat *out_grad = Gradient; CBufferFloat *kv_g = KV_Tensors[KV_Tensors.Total() - 1]; CNeuronBaseOCL *ss = NULL, *sa = NULL;
次に、内部層を通る逆ループを構成します。
for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) kv_g = KV_Tensors[(i / iLayersToOneKV) * 2 + 1];
ご存知のとおり、勾配バックプロパゲーションアルゴリズムはフィードフォワードパスを反映し、すべての操作が逆の順序で実行されます。このため、ブロックの内部層に逆反復ループを構築しました。
フォワードパス操作の後半では、親クラスの対応するロジックが直接複製されたことに注意してください。したがって、親クラスの対応するメソッドを再利用して、勾配バックプロパゲーションメソッドの前半を開始します。
まず、FeedForwardブロックを通じて誤差勾配を逆伝播します。
//--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights[i * (optimization == SGD ? 6 : 9) + 2], out_grad, FF_Tensors[i * 6 + 1], FF_Tensors[i * 6 + 4], 4 * iWindow, iWindow, None)) return false; CBufferFloat *temp = FF_Tensors[i * 6 + 3]; if(IsStopped() || !ConvolutionInputGradients(FF_Weights[i * (optimization == SGD ? 6 : 9) + 1], FF_Tensors[i * 6 + 4], FF_Tensors[i * 6], temp, iWindow, 4 * iWindow, LReLU)) return false;
その後、2つの情報ストリームからの誤差勾配を合計します。
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
そして、Multi-Head Self-Attentionブロックを通じて誤差勾配を伝播します。
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false; out_grad = temp; //--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights[i * (optimization == SGD ? 6 : 9)], out_grad, AO_Tensors[i * 2], AO_Tensors[i * 2 + 1], iWindowKey * iHeads, iWindow, None)) return false; //--- Passing gradient to query, key and value sa = cSceneAgnostic[i * 2 + 1]; ss = cSceneSpecific[i * 2 + 1]; if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors[i * 2], QKV_Tensors[i * 2 + 1], KV_Tensors[(i / iLayersToOneKV) * 2], kv_g, S_Tensors[i * 2], AO_Tensors[i * 2 + 1])) return false; } else { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors[i * 2], QKV_Tensors[i * 2 + 1], KV_Tensors[i / iLayersToOneKV * 2], GetPointer(Temp), S_Tensors[i * 2], AO_Tensors[i * 2 + 1])) return false; if(IsStopped() || !SumAndNormilize(kv_g, GetPointer(Temp), kv_g, iWindowKey, false, 0, 0, 0, 1)) return false; }
ここでは、誤差勾配がKey-Valueテンソルにどのように伝播されるかに特に注意を払う必要があります。重要な点は、あるテンソルによって影響を受けるすべての内部層から誤差勾配を集約するという点にあります。このアルゴリズムのより詳細な説明は、親クラスに関する記事に記載されています。
次に、メインの情報フローに沿って、入力データのレベルに誤差勾配を逆伝播します。
CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 6 - 1); inp = FF_Tensors.At(i * 6 - 4); } if(IsStopped() || !MatMulGrad(inp, temp, QKV_Weights[i * 2], QKV_Weights[i * 2 + 1], QKV_Tensors[i * 2 + 1], iUnits, iWindow, iHeads * iWindowKey, 1)) return false; //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
また、モデルの全体的な結果への影響に応じて、ハイパーネットワークに誤差勾配を伝播します。
//--- if((i % iLayersToOneKV) == 0) { if(IsStopped() || !MatMulGrad(inp, GetPointer(Temp), KV_Weights[i / iLayersToOneKV * 2], KV_Weights[i / iLayersToOneKV * 2 + 1], KV_Tensors[i / iLayersToOneKV * 2 + 1], iUnits, iWindow, 2 * iHeadsKV * iWindowKey, 1)) return false; if(IsStopped() || !SumAndNormilize(GetPointer(Temp), temp, temp, iWindow, false, 0, 0, 0, 1)) return false; if(!Concat(QKV_Weights[i * 2 + 1], KV_Weights[i / iLayersToOneKV * 2 + 1], ss.getGradient(), iHeads, 2 * iHeadsKV, iWindow * iWindowKey)) return false; if(!ElementMultGrad(ss.getOutput(), ss.getGradient(), sa.getOutput(), sa.getGradient(), ss.getGradient(), ss.Activation(), sa.Activation())) return false; } else { if(!ElementMultGrad(ss.getOutput(), ss.getGradient(), sa.getOutput(), sa.getGradient(), QKV_Weights[i * 2 + 1], ss.Activation(), sa.Activation())) return false; } if(i > 0) out_grad = temp; }
この後、内部層を通じたループの次の反復へと進みます。
ここで重要なのは、メインの操作ループにおいて、誤差勾配をハイパーネットワークに「伝播させるだけ」であり、それらを通じて「伝播はしていない」という点です。これにはいくつかのニュアンスが含まれます。まず、シーン非依存のハイパーネットワークは2層構成です。1層目は静的で、常に定数値「1」を出力します。2層目は学習可能なパラメータを持ち、実際の出力を生成します。メインの処理フローでは、誤差勾配はこの2層目にのみ伝えます。1層目は静的であり、勾配を伝播しても意味がないためです。もちろん、これはあくまで特殊なケースです。もしハイパーモデルがより多くの層で構成されている場合には、学習可能なパラメータを持つすべての層に対して、勾配のバックプロパゲーション処理を実装する必要があります。
2番目のニュアンスは、シーン依存のハイパーネットワークに関係します。この実装では、すべてのパラメータが、呼び出し元プログラムから渡されるシーン記述に基づいて生成されます。そのため、誤差勾配全体をそのレベルまでしっかりと伝播させる必要があります。メインのデータフローの整合性を維持するため、我々はこのモデルに対する勾配伝播処理を、別個のループでおこなうようにしました。繰り返しになりますが、これは実装上の特定の判断によるものです。シーン記述を他の手段(たとえば、前段の内部層の出力など)から得ていた場合には、それに応じて勾配も適切に伝播させる必要があります。
では、勾配バックプロパゲーションのアルゴリズムに戻りましょう。内部層を逆順に処理し終えた後、入力データがメインデータフローを通じてモデル出力にどのように影響を与えたかを表す勾配を、前の層の勾配バッファに格納します。次に、このバッファにハイパーネットワークによる寄与分を加算する必要があります。そのために、まず前の層の勾配バッファへのポインタをローカル変数に保存します。続いて、現在の層オブジェクトに対して、一時的に補助データバッファへのポインタを割り当てます。
CBufferFloat *inp_grad = prevLayer.getGradient(); if(!prevLayer.SetGradient(GetPointer(Temp), false)) return false;
これで、以前に保存したデータを失う心配なく、誤差勾配を前の層へと伝播させることができます。次に、コンテキスト依存のハイパーネットワークの各オブジェクトを反復処理するループを作成します。そのループ内で、誤差勾配を元のデータ層のレベルまで伝播させます。各反復において、現在の結果をそれまでに蓄積された勾配に加算していきます。
for(int i = int(iLayers - 2); (i >= 0 && !IsStopped()); i -= 2) { ss = cSceneSpecific[i]; if(IsStopped() || !ss.calcHiddenGradients(cSceneSpecific[i + 1])) return false; if(IsStopped() || !prevLayer.calcHiddenGradients(ss, NULL)) return false; if(IsStopped() || !SumAndNormilize(prevLayer.getGradient(), inp_grad, inp_grad, iWindow, false, 0, 0, 0, 1)) return false; }
ループ処理が正常に完了した後、すべての情報フローから蓄積された誤差勾配を含むバッファへのポインタを、前の層のオブジェクトに返します。
if(!prevLayer.SetGradient(inp_grad, false)) return false; //--- return true; }
誤差勾配は完全に分散され、誤差勾配分散メソッドの操作を実行した論理結果が呼び出し元プログラムに返されます。モデルパラメータを個別に更新する方法をよく理解しておくことをお勧めします。このクラスとそのすべてのメソッドの完全なコードは、添付ファイルで確認できます。
2.3 完全なHyperDet3Dアルゴリズムの構築
先ほど、HyperDet3Dアルゴリズムの各コンポーネントを個別に構築しました。ここからは、それらすべてを統合し、ひとつのまとまりある構造として完成させる段階に入ります。一見するとこれは比較的単純な作業に思えるかもしれませんが、いくつか注意すべき重要なポイントがあります。
この実験では、前回の記事で説明したPointformerアーキテクチャをベースに、統合の実装を行うことにしました。ここでの主な変更点は、グローバルアテンションブロックを、新たに構築したMSA(Multi-Scale Attention)モジュールに置き換えたことです。この処理自体は比較的簡単です。というのも、クラスの初期化メソッドを含め、すべてのメソッドパラメータは変更していないからです。しかし、ひとつ問題があります。元のCNeuronPointFormerクラスでは、すべての内部オブジェクトが静的として宣言されていました。そのため、クラスを単純に継承して内部オブジェクトの型を変更することができません。この制約を回避するために、クラスを複製し、新しい機能を組み込むために必要な内部オブジェクトの型を適切に調整します。以下に新しいクラスの構造を示します。
class CNeuronHyperDet : public CNeuronPointNet2OCL { protected: CNeuronMLMHSparseAttention caLocalAttention[2]; CNeuronMLCrossAttentionMLKV caLocalGlobalAttention[2]; CNeuronMLMHSceneConditionAttention caGlobalAttention[2]; CNeuronLearnabledPE caLocalPE[2]; CNeuronLearnabledPE caGlobalPE[2]; CNeuronBaseOCL cConcatenate; CNeuronConvOCL cScale; //--- CBufferFloat *cbTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override ; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHyperDet(void) {}; ~CNeuronHyperDet(void) { delete cbTemp; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronHyperDet; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
このクラスのメソッドはすべてCNeuronPointFormerクラスから対応するメソッドを直接コピーして作成されたため、詳しく説明しません。
モデルアーキテクチャ、およびすべてのインタラクションと訓練スクリプトも、前回の記事から流用しているため、ここでは説明しません。この記事の作成に使用されたすべてのプログラムの完全なソースコードは、添付ファイルで入手できます。
3.テスト
HyperDet3D法の提案者によるアプローチを自らの視点で解釈し、それを実装するために多くの労力を費やしてきました。いよいよこの記事の最終セクションに入り、これまでに説明した手法を組み込んだモデルの訓練およびテストをおこないます。
これまでと同様に、モデルの訓練にはEURUSDの実際の履歴データ(H1時間枠、2023年全期間)を使用します。すべてのインジケーターのパラメータはデフォルト値のままとしています。訓練プロセスそのものは、前回の記事で説明したアルゴリズムに忠実に従っています。そのため、本記事では、訓練済みのActor方策をテストした結果のみに注目し、以下にその内容を示します。
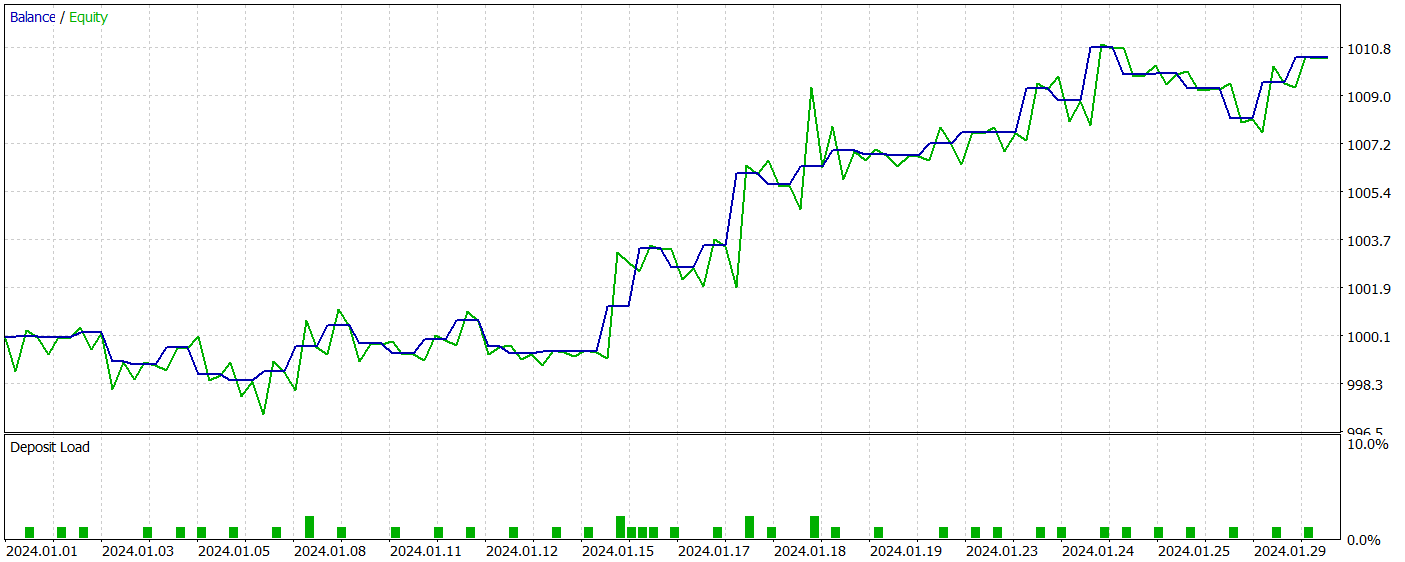
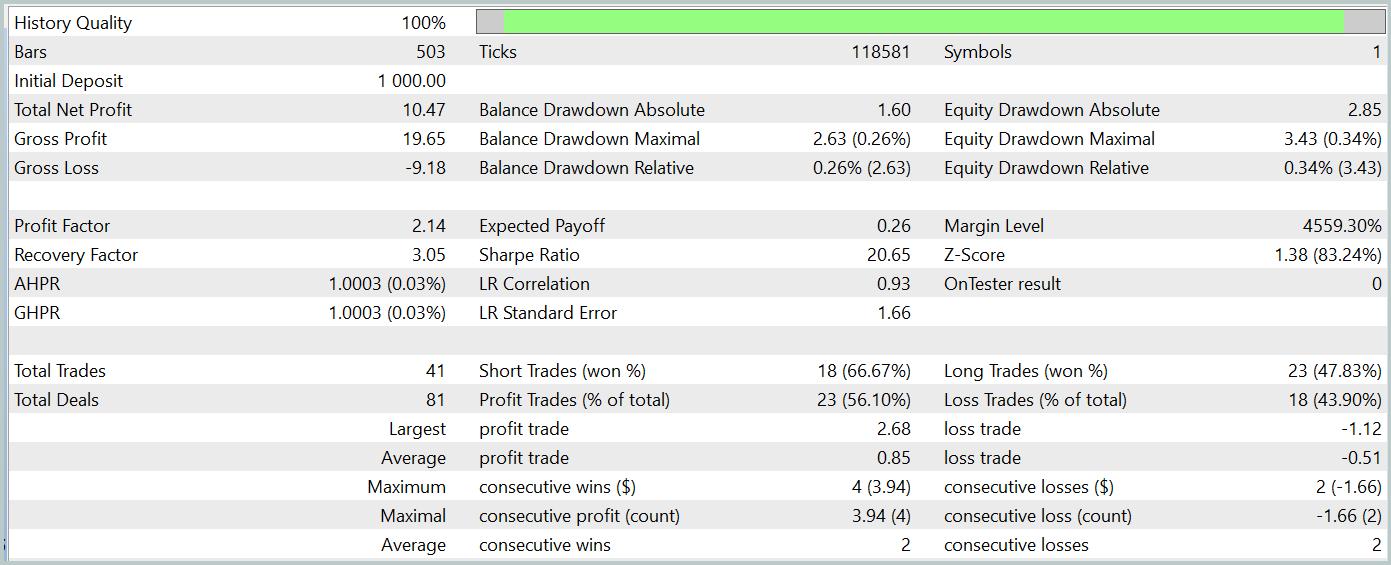
訓練済みモデルは、訓練データセットには含まれていない2024年1月の実際の履歴データを用いてテストされました。この期間中、モデルは合計41件の取引をおこない、そのうち56%が利益で終了しました。特筆すべき点として、最大の利益トレードは最大の損失トレードの2.4倍の規模であり、平均利益トレードは平均損失トレードを67%上回っていました。これらの結果から、プロフィットファクターは2.14、シャープレシオは20.65という良好な数値が得られました。
全体として、テスト期間中にモデルは1%の利益を上げており、エクイティにおける最大ドローダウンは0.34%を超えることはありませんでした。口座残高に対するドローダウンはそれよりもさらに小さく抑えられています。エクイティカーブは安定した増加傾向を示し、ポジションエクスポージャーも常に1〜2%の範囲内に収まっていました。
これらの結果から、全体的な印象としては非常に良好であり、モデルには十分な可能性が感じられます。ただし、テスト期間が短く、取引回数も限定的であることから、長期的な安定性については現時点で判断を下すことはできません。実運用に進む前には、より大規模な履歴データを用いた再訓練と、より包括的な検証が必要です。
結論
本記事では、シーン条件付きハイパーネットワークをTransformerアーキテクチャに統合し、事前知識を埋め込むことでモデルの適応性を高めるHyperDet3D手法について解説しました。この手法により、シーン情報に基づいて検出器のパラメータを動的に調整できるため、オブジェクト検出タスクにおいて多様なシーンに柔軟かつ効果的に対応できるようになります。結果として、システムはより汎用性が高く、強力なものとなります。
実装パートでは、提案された概念をMQL5上で独自に解釈・実装し、それらをカスタムモデルアーキテクチャに統合しました。テスト結果は、このモデルが持つ可能性を十分に示しています。ただし、これを実際の金融市場に応用するには、さらなる訓練や検証が不可欠です。
参考文献
この記事で使用されているプログラム
| # | ファイル名 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15859
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索