
Redes neurais em trading: Detecção Adaptativa de Anomalias de Mercado (DADA)

Introdução
Com o avanço das tecnologias e a automação dos processos, as séries temporais se tornaram parte essencial da análise dos mercados financeiros. A detecção eficaz de anomalias nos dados de mercado possibilita a identificação oportuna de potenciais ameaças, tais como variações bruscas de preço, manipulação de ativos e mudanças na liquidez. Isso é especialmente relevante para o trading algorítmico, a gestão de riscos e a avaliação da resiliência dos sistemas financeiros. Picos súbitos de volatilidade, desvios nos volumes de negociação ou correlações incomuns entre ativos podem sinalizar falhas, atividades especulativas ou até crises de mercado.
Os métodos modernos de detecção de anomalias baseados em aprendizado profundo alcançaram resultados notáveis, mas ainda apresentam limitações. Geralmente, tais abordagens exigem um treinamento separado para cada novo conjunto de dados, o que dificulta sua aplicação em condições reais. Os dados financeiros estão em constante mudança e seus padrões históricos nem sempre se repetem.
Um dos principais desafios é a diversidade estrutural dos dados entre diferentes mercados. Os algoritmos modernos normalmente utilizam autocodificadores para "memorizar" o comportamento normal do mercado, pois as anomalias são raras. No entanto, se o modelo retém informação em excesso, ele começa a considerar o ruído de mercado, reduzindo a precisão na detecção de anomalias. Por outro lado, uma compressão de dados muito forte pode levar à perda de padrões importantes. A maioria das abordagens utiliza um grau fixo de compressão, limitando a capacidade de adaptação dos modelos às diferentes condições de mercado.
Outra dificuldade está na variedade das anomalias. Muitos modelos são treinados apenas com dados normais, mas sem compreender as próprias anomalias, torna-se difícil identificá-las. Por exemplo, um salto repentino nos preços pode representar uma anomalia em um mercado, mas ser um comportamento normal em outro. Em alguns ativos, as anomalias estão ligadas a aumentos abruptos de liquidez; em outros, a correlações inesperadas. Por essa razão, o modelo pode deixar de perceber sinais importantes ou, ao contrário, gerar alertas falsos com frequência excessiva.
Para resolver esses problemas, os autores do trabalho "Towards a General Time Series Anomaly Detector with Adaptive Bottlenecks and Dual Adversarial Decoders" propuseram o novo framework DADA, que utiliza compressão adaptativa da informação e dois decodificadores independentes. Diferente dos métodos tradicionais, o DADA se ajusta de forma flexível a diferentes tipos de dados. Em vez de um nível fixo de compressão, ele aplica múltiplas variações e seleciona a mais apropriada para cada caso. Isso permite levar melhor em conta as particularidades dos dados de mercado e preservar padrões relevantes.
Na saída do modelo são utilizados dois decodificadores. Um é responsável pelos dados normais e o outro pelos anômalos. O primeiro decodificador aprende a reconstruir a série temporal, enquanto o segundo estuda exemplos de anomalias. Essa abordagem ajuda a distinguir claramente o comportamento normal das anomalias, reduzindo a probabilidade de sinais falsos.
Algoritmo DADA
As séries temporais são sequências de dados que variam ao longo do tempo. Qualquer desvio em relação ao comportamento normal dos dados pode sinalizar crises, falhas ou atividades fraudulentas. Para detectar de maneira eficaz essas anomalias, o framework DADA (Detector with Adaptive Bottlenecks and Dual Adversarial Decoders) utiliza técnicas de aprendizado profundo voltadas à análise adaptativa de séries temporais e à detecção de padrões anômalos. A principal característica do DADA é sua versatilidade. Ele não exige uma adaptação prévia a um domínio específico e pode operar com uma ampla variedade de dados brutos.
O framework DADA baseia-se na ideia de reconstrução de dados com aplicação de mascaramento, o que o torna uma ferramenta eficaz para analisar dependências temporais e identificar desvios em relação ao comportamento esperado. Esse método permite que o modelo não apenas memorize padrões nos dados, mas aprenda a compreender sua estrutura, reconstruindo trechos ausentes ou distorcidos.
O processo de treinamento envolve o trabalho com dois tipos de sequências: normais e anômalas. Diferentemente dos métodos tradicionais, que exigem a rotulação manual prévia dos dados anômalos, os autores do framework DADA adotaram uma abordagem generativa — adicionando ruído artificial às séries temporais originais. Esse método não apenas simplifica a preparação dos dados, eliminando o trabalho manual, como também torna o modelo mais universal. Ele aprende a identificar diferentes tipos de desvios: saltos bruscos, valores atípicos, mudanças de tendência, variações na volatilidade e outros padrões.
Na primeira etapa, os dados brutos são divididos em segmentos (patches), aos quais é aplicado um mascaramento aleatório. Isso é necessário para que o modelo aprenda a reconstruir as partes ausentes dos dados. Essa técnica reforça sua capacidade de detectar anomalias e padrões ocultos.
Em seguida, os segmentos são enviados ao codificador, onde são transformados em uma representação latente compacta. O codificador é treinado para identificar as características essenciais da série temporal, ignorando o ruído e detalhes irrelevantes. Essa abordagem permite que o modelo generalize melhor as informações e funcione com dados de naturezas distintas, sejam eles gráficos de preços em mercados financeiros, séries temporais de volumes de negociação ou outros indicadores.
Um dos componentes principais do modelo é o mecanismo de "gargalos adaptativos", que regula o grau de compressão da informação de acordo com a estrutura e a qualidade dos dados. Quando os dados contêm um sinal relevante, o modelo preserva mais detalhes; já quando a informação é redundante ou muito ruidosa, a compressão é intensificada, o que ajuda a reduzir o impacto das interferências e melhora a detecção de anomalias.
O módulo de gargalos adaptativos (AdaBN) altera dinamicamente o grau de compressão dos dados. Esse mecanismo é composto por um conjunto de pequenos modelos semelhantes a autocodificadores. Cada um deles possui uma representação latente de tamanho diferente:
![]()
onde DownNeti(•) realiza a compressão dos dados analisados, e UpNeti(•) — a reconstrução.
O roteador adaptativo seleciona a rota ideal com base na análise dos dados de entrada:
![]()
onde Wrouter, Wnoise — são matrizes treináveis.
Para a compressão de cada segmento, utilizam-se k rotas mais adequadas com o maior valor de R(z).
Após a codificação, as representações latentes são enviadas para dois decodificadores paralelos. Um deles é destinado à reconstrução dos dados normais e é treinado para minimizar o erro de reconstrução. O outro é voltado para a detecção de anomalias, gerando o maior desvio possível entre os valores reconstruídos e os valores originais. Esse processo adversarial permite que o modelo diferencie de forma eficiente os padrões normais dos desvios inesperados.
Durante o processo de teste e na utilização prática, o decodificador anômalo é desativado, e a avaliação é feita exclusivamente pelo decodificador normal. Se o modelo reconstrói os dados com alta precisão, isso indica que a série temporal segue um comportamento normal. Caso a reconstrução apresente erros significativos, isso aponta para uma possível anomalia.
A visualização original do framework DADA é apresentada a seguir.

Implementação com MQL5
Após analisar os aspectos teóricos do framework DADA, passamos à parte prática do nosso trabalho, na qual examinaremos uma possível implementação da nossa própria versão das abordagens propostas utilizando MQL5. O elemento-chave deste framework é o módulo de gargalos adaptativos. É precisamente com sua construção que iniciaremos o desenvolvimento.
Acredito que não fui o único a notar sua semelhança com o módulo Mixture of Experts que implementamos anteriormente. No entanto, há uma diferença importante. No objeto CNeuronMoE que construímos, pressupõe-se o uso de mini-modelos com a mesma arquitetura. Já neste caso, precisamos variar o tamanho da camada do estado latente para cada modelo, adaptando-os às diferentes características dos dados. Essa variação não pode mais ser implementada com os objetos de camadas convolucionais, como fizemos antes. Claro, poderíamos criar cada modelo separadamente e processar os dados através deles de forma sequencial. Mas isso reduziria a eficiência do uso do hardware e aumentaria os custos de treinamento e de utilização do modelo.
Para eliminar esses problemas, foi tomada a decisão de desenvolver um novo objeto de camada convolucional multi-janela. Na sua base está a ideia de usar simultaneamente várias dimensões de janelas de convolução. Isso permite que o modelo analise os dados em diferentes níveis de detalhamento, dentro de fluxos de computação paralelos. Essa abordagem torna a arquitetura mais flexível, melhora a qualidade do processamento dos dados brutos e permite um uso mais eficiente dos recursos computacionais. Em resultado, o modelo consegue se adaptar melhor às diferentes estruturas temporais dos dados de entrada, garantindo alta precisão e desempenho.
Construção dos algoritmos no lado do programa OpenCL
Como sempre, a maior parte das operações matemáticas será transferida para o contexto OpenCL. Aqui, criamos o kernel FeedForwardMultWinConv, no qual organizamos o processo de propagação para frente da nova camada.
__kernel void FeedForwardMultWinConv(__global const float *matrix_w, __global const float *matrix_i, __global float *matrix_o, __global const int *windows_in, const int inputs, const int windows_total, const int window_out, const int activation ) { const size_t i = get_global_id(0); const size_t v = get_global_id(1); const size_t outputs = get_global_size(0);
Nos parâmetros do kernel, recebemos ponteiros para 4 buffers de dados e 4 constantes que definem a estrutura dos dados de entrada e dos resultados.
É importante observar que um dos buffers globais (windows_in) contém valores inteiros. Nele são transmitidos os tamanhos das janelas de convolução. Supõe-se que no buffer de dados de entrada (matrix_i) esteja armazenada a sequência de segmentos. Dentro de cada segmento, os dados de cada janela de convolução estão dispostos de forma sequencial.
Esse kernel será chamado em um espaço bidimensional de tarefas. A dimensão do primeiro eixo indica a quantidade de valores no buffer de resultados para cada sequência unitária, enquanto a segunda dimensão indica o número total dessas sequências unitárias.
Aqui é importante esclarecer que a primeira dimensão indica exatamente a quantidade de valores no buffer de resultados, e não o número de elementos na sequência unitária. Em outras palavras, o tamanho da primeira dimensão é igual ao produto entre o número de segmentos analisados em uma sequência unitária e o número de filtros e janelas de convolução utilizados. Ao mesmo tempo, cada elemento usa a mesma quantidade de filtros, independentemente do tamanho da janela de convolução. Isso é necessário para manter a uniformidade dos formatos dos dados reconstruídos a partir da representação comprimida.
No corpo do kernel, começamos identificando o fluxo atual no espaço bidimensional de tarefas em cada uma de suas dimensões.
Em seguida, é preciso determinar o deslocamento nos buffers globais de dados até os elementos necessários. É evidente que o identificador do fluxo na primeira dimensão aponta para o elemento do buffer de resultados dentro da sequência unitária analisada. Já para calcular o deslocamento nos demais buffers de dados, é necessário realizar alguns passos adicionais.
Primeiro, determinamos a posição do elemento dentro do segmento analisado. Para isso, pegamos o resto da divisão do identificador da primeira dimensão pelo número total de elementos no buffer de resultados correspondente a um segmento.
const int id = i % (window_out * windows_total);
Depois, preparamos algumas variáveis locais para armazenar temporariamente os valores intermediários.
int step = 0; int shift_in = 0; int shift_weight = 0; int window_in = 0; int window = 0;
E em seguida, organizamos um laço que percorre todos os valores do buffer de janelas de convolução.
#pragma unroll for(int w = 0; w < windows_total; w++) { int win = windows_in[w]; step += win;
Dentro desse laço, calculamos a soma de todas as janelas de convolução, o que nos fornece o tamanho de um segmento no buffer de dados de entrada. Além disso, ainda dentro do laço, determinamos o deslocamento dentro do segmento atual até a janela de convolução necessária (shift_in), o tamanho da janela de convolução analisada (window_in) e o deslocamento no buffer de parâmetros treináveis até o início dos elementos da matriz correspondente à janela de convolução desejada (shift_weight).
if((w * window_out) < id) { shift_in = step; window_in = win; shift_weight += (win + 1) * window_out; } }
Depois disso, determinamos o número de segmentos completos até o elemento atual no buffer de resultados (steps) e adicionamos o deslocamento correspondente no buffer de dados de entrada até o segmento necessário.
int steps = (int)(i / (window_out * windows_total)); shift_in += steps * step + v * inputs;
Ao deslocamento no buffer de parâmetros treináveis, adicionamos uma correção referente ao filtro adequado. Para isso, pegamos o resto da divisão da posição do elemento analisado dentro do segmento atual do buffer de resultados, o que nos fornece o número do elemento dentro dos resultados da janela de convolução correspondente. Essencialmente, o valor obtido indica o filtro exato que precisamos. A quantidade de parâmetros treináveis em cada filtro é igual ao tamanho da janela de convolução mais o elemento bias. Assim, ao multiplicar o número do filtro pela quantidade de parâmetros treináveis, obtemos o deslocamento necessário.
shift_weight += (id % window_out) * (window_in+1);
Após a conclusão dessa etapa preparatória, organizamos um laço para calcular o valor do elemento atual e armazená-lo em uma variável local.
float sum = matrix_w[shift_weight + window_in]; #pragma unroll for(int w = 0; w < window_in; w++) if((shift_in + w) < inputs) sum += IsNaNOrInf(matrix_i[shift_in + w], 0) * matrix_w[shift_weight + w];
O valor obtido é então ajustado pela função de ativação e gravado no elemento correspondente do buffer global de resultados.
matrix_o[v * outputs + i] = Activation(sum, activation); }
Após construir o algoritmo de propagação para frente, passamos à organização dos processos de propagação reversa. Aqui, inicialmente criamos o kernel de distribuição dos gradientes de erro até o nível dos dados de entrada, chamado CalcHiddenGradientMultWinConv. A estrutura dos parâmetros desse kernel é amplamente baseada no kernel da propagação para frente. Com a diferença de que adicionamos ponteiros para os buffers correspondentes aos gradientes de erro.
__kernel void CalcHiddenGradientMultWinConv(__global const float *matrix_w, __global const float *matrix_i, __global float *matrix_ig, __global const float *matrix_og, __global const int *windows_in, const int outputs, const int windows_total, const int window_out, const int activation ) { const size_t i = get_global_id(0); const size_t v = get_global_id(1); const size_t inputs = get_global_size(0);
O funcionamento desse kernel também é organizado em um espaço bidimensional. A diferença é que, desta vez, a primeira dimensão indica o deslocamento no buffer de dados de entrada, pois é nesse nível que precisamos reunir os valores dos gradientes de erro provenientes de todos os filtros.
No corpo do kernel, como de costume, primeiro identificamos o fluxo em todas as dimensões do espaço de tarefas. Em seguida, organizamos um laço que soma todas as janelas de convolução, com o objetivo de determinar o tamanho de um segmento no buffer de dados de entrada.
int step = 0; #pragma unroll for(int w = 0; w < windows_total; w++) step += windows_in[w];
Isso nos permite identificar o número sequencial do segmento do elemento analisado e o deslocamento dentro desse segmento.
int steps = (int)(i / step); int id = i % step;
Depois, declaramos algumas variáveis locais para armazenar temporariamente os dados e organizamos outro laço, no qual determinamos o tamanho da janela de convolução analisada (window_in), o número sequencial da janela de convolução (window) e o deslocamento dentro do segmento atual até o início da janela correspondente (before).
int window = 0; int before = 0; int window_in = 0; #pragma unroll for(int w = 0; w < windows_total; w++) { window_in = windows_in[w]; if((before + window_in) >= id) break; window = w + 1; before += window_in; }
Os valores obtidos nos permitem calcular o deslocamento no buffer de resultados (shift_out) e no tensor de parâmetros (shift_weight).
int shift_weight = (before + window) * window_out + id - before; int shift_out = (steps * windows_total + window) * window_out + v * outputs;
Com isso, concluímos a parte preparatória e já dispomos de informações suficientes para somar os gradientes de erro. Organizamos então mais um laço, no qual acumulamos os valores dos gradientes de erro de todos os filtros, levando em conta os respectivos coeficientes de peso.
float sum = 0; #pragma unroll for(int w = 0; w < window_out; w++) sum += IsNaNOrInf(matrix_og[shift_out + w], 0) * matrix_w[shift_weight + w * (window_in + 1)];
O valor resultante é então ajustado pela derivada da função de ativação da camada de entrada, e o resultado é gravado no elemento correspondente do buffer global de gradientes de erro.
matrix_ig[v * inputs + i] = Deactivation(sum, matrix_i[v * inputs + i], activation); }
A terceira etapa do nosso trabalho consiste na construção do processo de distribuição do gradiente de erro até o nível dos coeficientes de peso e sua subsequente correção no sentido de minimizar o erro total do modelo. Nesta parte, implementamos o algoritmo de otimização de parâmetros Adam no kernel UpdateWeightsMultWinConvAdam.
Para garantir a correta implementação desse algoritmo, ampliamos o número de parâmetros do kernel, adicionando constantes específicas e dois buffers globais para o armazenamento dos momentos.
__kernel void UpdateWeightsMultWinConvAdam(__global float *matrix_w, __global const float *matrix_og, __global const float *matrix_i, __global float *matrix_m, __global float *matrix_v, __global const int *windows_in, const int windows_total, const int window_out, const int inputs, const int outputs, const float l, const float b1, const float b2 ) { const size_t i = get_global_id(0); // weight shift const size_t v = get_local_id(1); // variable const size_t variables = get_local_size(1);
Esse kernel também será utilizado em um espaço bidimensional de tarefas. Desta vez, a primeira dimensão indicará o elemento a ser otimizado no buffer global de parâmetros treináveis. No entanto, há aqui uma particularidade. Ao trabalhar com séries temporais multidimensionais, cada sequência unitária é analisada utilizando parâmetros treináveis compartilhados. Portanto, nesta etapa, precisamos reunir os gradientes de erro provenientes de todas as sequências unitárias. Para organizar o trabalho paralelo das diferentes sequências unitárias, elas foram distribuídas ao longo da segunda dimensão do espaço de tarefas. Entretanto, elas foram agrupadas em grupos de trabalho, o que nos permite organizar o processo de troca de dados. É justamente para esse intercâmbio de informações dentro de um grupo de trabalho que criamos um array na memória local do contexto OpenCL.
__local float temp[LOCAL_ARRAY_SIZE];
Em seguida, passamos à etapa de preparação, na qual precisamos determinar os deslocamentos dentro dos buffers de dados. Provavelmente, o cálculo mais simples que podemos fazer é o do passo no buffer de resultados (step_out). Ele é igual ao produto do número de janelas de convolução de um segmento pelo número de filtros utilizados.
int step_out = window_out * windows_total;
Para determinar os demais parâmetros, será necessário realizar alguns cálculos adicionais. Primeiro, declaramos variáveis locais destinadas ao armazenamento temporário dos resultados intermediários.
int step_in = 0; int shift_in = 0; int shift_out = 0; int window = 0; int number_w = 0;
E depois, organizamos um laço que percorre os valores do buffer global que contém os tamanhos das janelas de convolução.
#pragma unroll for(int w = 0; w < windows_total; w++) { int win = windows_in[w]; if((step_in + w)*window_out <= i && (step_in + win + w + 1)*window_out > i) { shift_in = step_in; shift_out = (step_in + w + 1) * window_out; window = win; number_w = w; } step_in += win; }
Dentro desse laço, determinamos o deslocamento até a janela de convolução necessária nos buffers de dados de entrada (shift_in) e de resultados (shift_out), o tamanho da janela de convolução (window) e seu número sequencial no buffer (number_w). Além disso, calculamos a soma de todas as janelas de convolução (step_in), o que nos indica o tamanho de um segmento. Esse mesmo valor será utilizado como o passo no buffer de dados de entrada.
É importante destacar que nem todo parâmetro treinável está associado diretamente ao buffer de dados de entrada. Pois existe também o elemento bias. E para isso, introduziremos uma flag que identifica esse tipo de elemento.
bool bias = ((i - (shift_in + number_w) * window_out) % (window + 1) == window);
Em seguida, ajustamos o deslocamento até o elemento correspondente no buffer de resultados.
int t = (i - (shift_in + number_w) * window_out) / (window + 1); shift_out += t + v * outputs;
E realizamos a mesma operação para o deslocamento no buffer global de dados de entrada.
shift_in += (i - (shift_in + number_w) * window_out) % (window + 1) + v * inputs;
Com isso, concluímos a etapa de preparação e passamos à determinação do gradiente de erro do parâmetro analisado. Para isso, organizamos um laço que coleta o gradiente de erro de todos os elementos do buffer de resultados cujos cálculos utilizaram o parâmetro que está sendo otimizado neste fluxo.
float grad = 0; int total = (inputs + step_in - 1) / step_in; #pragma unroll for(int t = 0; t < total; t++) { int sh_out = t * step_out + shift_out; if(bias && sh_out < outputs) { grad += IsNaNOrInf(matrix_og[sh_out], 0); continue; }
Para os elementos bias, simplesmente somamos os valores dos gradientes de erro, enquanto para os demais, aplicamos uma correção levando em conta o valor correspondente do dado de entrada.
int sh_in = t * step_in + shift_in; if(sh_in >= inputs) break; grad += IsNaNOrInf(matrix_og[sh_out] * matrix_i[sh_in], 0); }
Aqui é importante observar que, dentro desse laço, reunimos os valores do erro apenas no contexto de uma única sequência unitária. No entanto, como já mencionado anteriormente, o parâmetro otimizado é utilizado por todas as sequências do conjunto de séries temporais multidimensionais. Portanto, antes de iniciar a otimização do parâmetro, precisamos reunir os valores de todas as sequências unitárias que foram processadas dentro do grupo de trabalho. Para isso, em um primeiro estágio, somamos os valores individuais armazenados nos elementos do array local.
//--- sum const uint ls = min((uint)variables, (uint)LOCAL_ARRAY_SIZE); #pragma unroll for(int s = 0; s < (int)variables; s += ls) { if(v >= s && v < (s + ls)) temp[v % ls] = (i == 0 ? 0 : temp[v % ls]) + grad; barrier(CLK_LOCAL_MEM_FENCE); }
Em seguida, realizamos a soma dos valores acumulados nos elementos do array local.
uint count = ls; #pragma unroll do { count = (count + 1) / 2; if(v < ls) temp[v] += (v < count && (v + count) < ls ? temp[v + count] : 0); if(v + count < ls) temp[v + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Após obter o gradiente total de erro de todos os fluxos do grupo de trabalho, podemos atualizar o valor do parâmetro em análise. E, para essa operação, basta apenas um único fluxo.
if(v == 0) { grad = temp[0]; float mt = IsNaNOrInf(clamp(b1 * matrix_m[i] + (1 - b1) * grad, -1.0e5f, 1.0e5f), 0); float vt = IsNaNOrInf(clamp(b2 * matrix_v[i] + (1 - b2) * pow(grad, 2), 1.0e-6f, 1.0e6f), 1.0e-6f); float weight = clamp(matrix_w[i] + IsNaNOrInf(l * mt / sqrt(vt), 0), -MAX_WEIGHT, MAX_WEIGHT); matrix_w[i] = weight; matrix_m[i] = mt; matrix_v[i] = vt; } }
Com base nos resultados dessas operações, ajustamos nos buffers globais de dados tanto o valor do parâmetro otimizado quanto os respectivos momentos.
Com isso, concluímos a construção dos algoritmos do módulo convolucional multi-janela em nosso programa OpenCL. O código completo pode ser consultado no anexo.
Objeto de camada convolucional multi-janela
A próxima etapa do nosso trabalho consiste em integrar os algoritmos do módulo convolucional multi-janela, desenvolvidos anteriormente, ao programa principal. Para isso, criamos um novo objeto chamado CNeuronMultiWindowsConvOCL, no qual organizamos os processos de gerenciamento dos kernels criados no contexto OpenCL. A estrutura desse novo objeto é apresentada a seguir.
class CNeuronMultiWindowsConvOCL : public CNeuronConvOCL { protected: int aiWindows[]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronMultiWindowsConvOCL(void) { activation = SoftPlus; iWindow = -1; } ~CNeuronMultiWindowsConvOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &windows[], uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMultiWindowsConvOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual void SetOpenCL(COpenCLMy *obj); };
Na essência, o novo objeto CNeuronMultiWindowsConvOCL representa uma versão modificada da camada convolucional padrão. Portanto, é lógico utilizá-lo como classe derivada. Isso permite herdar a lógica base de funcionamento das convoluções e evitar duplicação de código.
Na estrutura apresentada, observamos o conjunto habitual de métodos virtuais sobrescritos. No entanto, a principal diferença do novo objeto está na capacidade de trabalhar simultaneamente com várias dimensões de janelas de convolução. Isso exige a criação de elementos adicionais para o armazenamento dos dados e interfaces de transferência para o contexto OpenCL. Para isso, declaramos um array adicional chamado aiWindows e realizamos modificações nos parâmetros do método de inicialização do objeto Init.
bool CNeuronMultiWindowsConvOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &windows[], uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(windows.Size() <= 0 || ArrayCopy(aiWindows, windows) < int(windows.Size())) return false;
É importante destacar que, apesar de todas as alterações realizadas no algoritmo do CNeuronMultiWindowsConvOCL, buscamos preservar ao máximo a lógica e as funcionalidades da classe base. Isso não apenas simplifica a integração do novo objeto à arquitetura existente, mas também permite o reaproveitamento dos mecanismos já testados e estáveis.
O algoritmo do método de inicialização do objeto começa verificando o tamanho do array de janelas de convolução recebido nos parâmetros e copiando seus valores para um array interno especialmente criado.
Em seguida, determinamos a soma de todas as janelas de convolução, adicionando a cada uma delas o respectivo elemento bias.
int window = 0; for(uint i = 0; i < aiWindows.Size(); i++) window += aiWindows[i] + 1;
Uma operação um tanto não óbvia, mas necessária. O fato é que, para cada janela de convolução, precisamos gerar uma matriz de pesos de tamanho (Windowi + 1) * Filters. Assim, o tamanho total do buffer de parâmetros será:
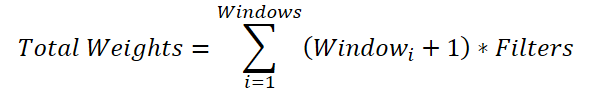
A variável comum referente à quantidade de filtros pode ser colocada fora do sinal de somatório:
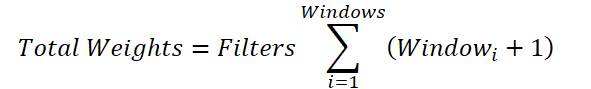
Se substituirmos a soma das janelas por um valor agregado, chegaremos à fórmula para determinar o número de parâmetros treináveis de uma única janela de convolução. No entanto, na classe base, está previsto o acréscimo de apenas um elemento bias, e não de um por cada janela de convolução necessária. Por isso, adicionamos à soma total um elemento de deslocamento para cada janela. E, em seguida, subtraímos 1 do resultado final, passando esse valor como parâmetro de janela e de passo de convolução para o método de inicialização da classe pai.
window--; if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, window, window, window_out, units_count * aiWindows.Size()*variables, 1, ADAM, batch)) return false;
Como planejamos usar os mesmos parâmetros para todas as sequências unitárias, definimos o número delas como "1". Ao mesmo tempo, aumentamos o número de elementos na sequência multiplicando-o pelo número de janelas de convolução e de sequências unitárias.
Essa abordagem nos permitiu inicializar todos os buffers de dados herdados com o tamanho adequado. Incluindo o buffer de parâmetros treináveis, que foi preenchido com valores aleatórios.
Agora, precisamos criar um buffer global de dados para transmitir o array de janelas de convolução para o contexto OpenCL. Como você pode imaginar, os valores desse buffer são definidos durante a inicialização do objeto e permanecem inalterados durante o treinamento e a utilização do modelo. Portanto, o buffer de dados é criado apenas no contexto OpenCL, enquanto no nosso objeto mantemos apenas um ponteiro para ele.
iVariables = variables; iWindow = OpenCL.AddBufferFromArray(aiWindows, 0, aiWindows.Size(), CL_MEM_READ_ONLY); if(iWindow < 0) return false; //--- return true; }
Verificamos a correção da criação do buffer global de dados por meio do identificador retornado e encerramos o método de inicialização do novo objeto, retornando previamente o resultado lógico das operações para o programa que o chamou.
Após a inicialização do novo objeto, passamos à redefinição do método de propagação para frente CNeuronMultiWindowsConvOCL::feedForward. Como você provavelmente já deduziu, aqui ocorre o enfileiramento para execução do kernel FeedForwardMultWinConv criado anteriormente. No entanto, apesar de o algoritmo ser comum para esse tipo de operação, há alguns detalhes que merecem atenção.
bool CNeuronMultiWindowsConvOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL) return false;
Nos parâmetros do método, recebemos um ponteiro para o objeto dos dados de entrada, cuja validade verificamos imediatamente.
Após a verificação bem-sucedida do bloco de controle, inicializamos os arrays correspondentes ao espaço de tarefas.
uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {Neurons() / iVariables, iVariables};
Como mencionado anteriormente, na descrição do algoritmo do kernel citado, a segunda dimensão indica o número de sequências unitárias nos dados de entrada. Já o número de fluxos na primeira dimensão é determinado pela razão entre o número total de elementos no buffer de resultados do nosso objeto e o número de sequências unitárias.
Em seguida, ocorre a transferência dos dados para os parâmetros do kernel.
ResetLastError(); int kernel = def_k_FeedForwardMultWinConv; if(!OpenCL.SetArgumentBuffer(kernel, def_k_ffmwc_matrix_i, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(kernel, def_k_ffmwc_matrix_o, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(kernel, def_k_ffmwc_matrix_w, WeightsConv.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(kernel, def_k_ffmwc_windows_in, iWindow)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Aqui, é importante observar que, como buffer das dimensões das janelas de convolução, transmitimos o identificador (handle) previamente armazenado. Já a dimensão da sequência dos dados de entrada é determinada dividindo o tamanho do buffer de entrada pelo número de sequências unitárias.
if(!OpenCL.SetArgument(kernel, def_k_ffmwc_inputs, NeuronOCL.Neurons() / iVariables)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(kernel, def_k_ffmwc_window_out, iWindowOut)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(kernel, def_k_ffmwc_windows_total, (int)aiWindows.Size())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(kernel, def_k_ffmwc_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(kernel, 2, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Após a transferência bem-sucedida de todos os parâmetros, realizamos o enfileiramento do kernel para execução e concluímos o método retornando o resultado lógico das operações para o programa que o chamou.
De forma análoga, é feito o enfileiramento dos kernels responsáveis pelos processos de propagação reversa. A única diferença é que, ao distribuir os gradientes de erro, especificamos a função de ativação da camada de entrada. E, nas operações de otimização dos parâmetros do modelo, não devemos esquecer de criar grupos de trabalho dentro da segunda dimensão do espaço de tarefas.
bool CNeuronMultiWindowsConvOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {WeightsConv.Total(), iVariables}; uint local_work_size[2] = {1, iVariables}; //--- ......... ......... ......... //--- if(!OpenCL.Execute(kernel, 2, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Com isso, encerramos a análise dos algoritmos de construção da camada convolucional multi-janela. O código completo do objeto CNeuronMultiWindowsConvOCL e de todos os seus métodos está disponível no anexo.
O volume do artigo praticamente chegou ao fim, mas nosso trabalho ainda não está concluído. Faremos uma breve pausa e continuaremos a implementação da nossa própria visão sobre as abordagens propostas pelos autores do framework DADA no próximo artigo.…
Considerações finais
Os mercados financeiros modernos caracterizam-se não apenas por enormes volumes de dados, mas também por uma elevada volatilidade. Isso torna a tarefa de detecção de anomalias especialmente desafiadora. O framework DADA propõe uma abordagem fundamentalmente nova, que combina gargalos adaptativos e dois decodificadores paralelos para uma análise mais precisa de séries temporais. Sua principal vantagem é a capacidade de se ajustar dinamicamente a diferentes estruturas de dados sem necessidade de adaptação prévia, tornando-o uma ferramenta verdadeiramente versátil.
Na parte prática do artigo, iniciamos a implementação da nossa própria visão das abordagens propostas pelos autores do framework, utilizando MQL5. No entanto, nosso trabalho ainda não terminou, e continuaremos seu desenvolvimento na próxima publicação.
Referências
- Towards a General Time Series Anomaly Detector with Adaptive Bottlenecks and Dual Adversarial Decoders
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos utilizando o método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento de modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca com o código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17549
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso