
Neuronale Netze leicht gemacht (Teil 97): Modelle mit MSFformer trainieren

Einführung
Im vorherigen Artikel haben wir die Hauptmodule des Modells MSFformer, einschließlich CSCM und Skip-PAM erstellt. Das CSCM-Modul konstruiert einen Merkmalsbaum der analysierten Zeitreihen, während Skip-PAM Informationen aus Zeitreihen auf mehreren Skalen mit Hilfe eines auf einem zeitlichen Merkmalsbaum basierenden Aufmerksamkeitsmechanismus extrahiert. In diesem Artikel werden wir diese Arbeit fortsetzen, indem wir das Modell trainieren und seine Leistung anhand von realen Daten mit dem MetaTrader 5 Strategy Tester evaluieren.
1. Modell der Architektur
Bevor wir mit dem Modelltraining fortfahren, müssen wir eine Reihe von vorbereitenden Schritten durchführen. Zuallererst müssen wir die Modellarchitektur definieren. Die Methode MSFformer wurde für Aufgaben der Zeitreihenprognose entwickelt. Dementsprechend werden wir sie in den Encoder des Environmental State Modells integrieren, zusammen mit mehreren anderen ähnlichen Methoden.
1.1 Architektur des Environmental State Encoders
Die Architektur des Environmental State Encoders wird in der Methode CreateEncoderDescriptions definiert. Diese Methode nimmt einen Zeiger auf ein dynamisches Array-Objekt als Parameter, in dem wir die Modellarchitektur angeben.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
Im Methodenrumpf prüfen wir die Relevanz des empfangenen Zeigers und erstellen gegebenenfalls eine neue Instanz des dynamischen Arrays.
Als Nächstes werden wir die Architektur des Modells definieren. Die Eingabe für den Encoder besteht aus „rohen“ Daten, die den aktuellen Zustand der Umgebung beschreiben. Wie üblich verwenden wir als Eingabeschicht eine einfache voll verbundene Schicht ohne Aktivierungsfunktion. In diesem Fall ist die Verwendung einer Aktivierungsfunktion unnötig, da die rohen Eingabedaten direkt in den Ergebnispuffer der angegebenen Schicht geschrieben werden.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Bitte beachten Sie, dass die Größe der Eingabeschicht genau den Dimensionen des Tensors zur Beschreibung des Umweltzustands entsprechen muss. Außerdem muss die Beschreibung des Umweltzustands in allen Phasen der Modellschulung und des Einsatzes identisch bleiben. Zur einfacheren Synchronisierung der Parameter in den Trainings- und Produktionsphasen werden wir zwei Konstanten definieren: BarDescr (die Anzahl der Elemente, die eine einzelne Kerze beschreiben) und HistoryBars (die Tiefe der analysierten historischen Daten). Das Produkt dieser Konstanten bestimmt die Größe der Eingabeschicht.
Wie bereits erwähnt, beabsichtigen wir, „rohe“ (unbearbeitete) Daten in das Modell einzuspeisen. Einerseits vereinfacht dieser Ansatz die Synchronisation zwischen den Datenvorverarbeitungsblöcken in den Trainings- und Betriebsprogrammen, was einen wesentlichen Vorteil darstellt.
Andererseits kann die Verwendung von unbearbeiteten Daten die Effizienz der Modellschulung oft verringern. Dies ist auf die erhebliche statistische Variabilität zwischen den verschiedenen Elementen der Eingabedaten zurückzuführen. Um dieses Problem zu entschärfen, werden wir eine erste Vorverarbeitung der Eingabedaten direkt im Modell vornehmen. Diese Aufgabe wird von einer Batch-Normalisierungsschicht übernommen. Nach dem Algorithmus dieser Schicht haben die Ausgabedaten einen Mittelwert nahe Null und eine Einheitsvarianz.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Die vorverarbeiteten Eingangsdaten der normalisierten Zeitreihen werden in das Merkmalsextraktionsmodul CSCM eingespeist.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCSCMOCL; descr.count = HistoryBars; descr.window = BarDescr;
Beachten Sie, dass die Merkmalsextraktion im Rahmen von univariaten Zeitreihen durchgeführt wird. In diesem Zusammenhang entspricht die Sequenzlänge der Tiefe der analysierten historischen Daten, während die Anzahl der univariaten Sequenzen der Größe des Vektors entspricht, der einen einzelnen Kerze beschreibt. In früheren Artikeln haben wir jedoch bei der Konstruktion des Tensors zur Beschreibung des Umweltzustands die Daten in der Regel in einer Matrix organisiert, in der die Zeilen die analysierten Balken und die Spalten die Merkmale darstellen. Daher werden wir in den Parametern des CSCM-Moduls festlegen, dass die Daten einer vorläufigen Transposition unterzogen werden sollen.
descr.step = int(true);
Wir extrahieren Merkmale in 3 Stufen mit Analysefenstern von 6, 5 und 4 Balken.
{
int temp[] = {6, 5, 4};
if(!ArrayCopy(descr.windows, temp))
return false;
}
Wir verwenden die Aktivierungsfunktion nicht. Wir werden die Modellparameter nach der Adam-Methode optimieren.
descr.step = int(true); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Als Nächstes folgt nach dem Algorithmus vom MSFformer das Modul Skip-PAM. In unserer Implementierung werden wir 3 aufeinanderfolgende Skip-PAM-Schichten mit derselben Konfiguration hinzufügen.
//--- layer 3 - 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSPyrAttentionMLKV; descr.count = HistoryBars; descr.window = BarDescr;
Hier geben wir eine ähnliche Größe der zu analysierenden Sequenz an. In diesem Fall arbeiten wir jedoch bereits mit einer multimodalen Sequenz.
Wir setzen die Größe des internen Vektors der Entitätsbeschreibungen Query, Key und Value auf 32 Elemente fest. Die Anzahl der Aufmerksamkeitsköpfe für den Key-Value-Tensor wird um den Faktor 2 geringer sein.
descr.window_out = 32; { int temp[] = {8, 4}; if(!ArrayCopy(descr.heads, temp)) return false; } descr.layers = 3; descr.activation = None; descr.optimization = ADAM; for(int l = 0; l < 3; l++) if(!encoder.Add(descr)) { delete descr; return false; }
Die Aufmerksamkeitspyramide jedes Skip-PAMs besteht aus 3 Ebenen. Auch hier verwenden wir die Adam-Methode zur Optimierung der Modellparameter.
Am Ausgang des Skip-PAM-Moduls erhalten wir einen Tensor, dessen Größe den Eingabedaten entspricht. Der Inhalt des Tensors wird durch Abhängigkeiten zwischen den Elementen der analysierten Sequenz angepasst. Als Nächstes müssen wir prädiktive Trajektorien für die Fortsetzung der multimodalen Eingangszeitreihen konstruieren. Wir werden für jede univariate Reihe in der analysierten multimodalen Sequenz separate Vorhersagetrajektorien konstruieren. Dazu transponieren wir zunächst den vom Skip-PAM-Modul erhaltenen Datentensor.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; }
Danach werden 2 aufeinanderfolgende Faltungsschichten verwendet, die die Rolle eines MLP für einzelne univariate Sequenzen übernehmen.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; descr.window_out = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = LatentCount; descr.step = LatentCount; descr.window_out = NForecast; descr.optimization = ADAM; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Bitte beachten Sie, dass wir, um die Ähnlichkeit zu MLP in den obigen Faltungsschichten zu implementieren, gleiche Größen des analysierten Fensters und seiner Stufe festlegen. Im ersten Fall ist sie gleich der Tiefe der zu analysierenden Sequenz. Im zweiten Fall ist sie gleich der Anzahl der Filter der vorherigen Schicht. Außerdem ist die Anzahl der Faltungsblöcke gleich der Anzahl der analysierten univariaten Sequenzen. Um Nichtlinearität zwischen den Faltungsschichten einzuführen, verwenden wir die Aktivierungsfunktion LReLU.
Für die zweite Faltungsschicht setzen wir die Anzahl der Filter gleich der Größe der vorhergesagten Sequenz. In unserem Fall wird sie durch die Konstante NForecast festgelegt.
Zusätzlich verwenden wir für die zweite Faltungsschicht den hyperbolischen Tangens (TANH). Dies ist eine bewusste Entscheidung. In der Eingabestufe des Modells wurden die Daten mit einer Batch-Normalisierungsschicht vorverarbeitet, um eine Einheitsvarianz und einen Mittelwert nahe Null zu gewährleisten. Nach der „Drei-Sigma-Regel“ liegen bei einer normalverteilten Zufallsvariablen etwa 2/3 der Werte innerhalb einer Standardabweichung vom Mittelwert. Die Verwendung von TANH, das einen Wertebereich von (-1, 1) hat, ermöglicht es uns daher, 68 % der Werte der analysierten Variablen zu erfassen und gleichzeitig Ausreißer herauszufiltern, die über eine Standardabweichung vom Mittelwert hinausgehen.
Es ist wichtig anzumerken, dass unser Ziel nicht darin besteht, alle Schwankungen der analysierten Zeitreihe zu erlernen und vorherzusagen, da diese ein erhebliches Rauschen enthält. Stattdessen streben wir eine Vorhersage mit ausreichender Genauigkeit an, um eine profitable Handelsstrategie zu entwickeln.
Anschließend transformieren wir die vorhergesagten Werte mithilfe einer Datentranspositionsschicht zurück in die Darstellung der ursprünglichen Daten.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Wir fügen ihnen die statistischen Variablen hinzu, die wir zuvor in der Batch-Normalisierungsschicht extrahiert haben.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr*NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers=1; if(!encoder.Add(descr)) { delete descr; return false; }
An diesem Punkt kann die Architektur des Modells vom Environmental State Encoder als vollständig angesehen werden. In seiner derzeitigen Form entspricht es dem von den Autoren der Methode MSFformer vorgestellten Modell. Wir werden jedoch eine letzte Verfeinerung hinzufügen. In unseren früheren Artikeln haben wir erörtert, dass das Paradigma der direkten Vorhersage von der Unabhängigkeit der einzelnen Schritte in der vorhergesagten Sequenz ausgeht. Wie Sie sich vorstellen können, widerspricht diese Annahme dem Wesen von Zeitreihendaten. Um dies zu erreichen, werden wir die Fortschritte nutzen, die durch die Methode FreDF eingeführt wurden, um die einzelnen Schritte innerhalb der vorhergesagten Abfolge der analysierten Zeitreihen in Einklang zu bringen.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
In dieser Form hat die Encoder-Architektur ein vollständigeres Erscheinungsbild. Ich hoffe, dass meine Ausführungen Ihnen helfen, die dem Modell zugrunde liegende Logik zu verstehen.
In diesem Stadium haben wir die Architektur des Modells zur Vorhersage der bevorstehenden Kursbewegung beschrieben und können nun zum Training des Modells übergehen. Unser Ziel geht jedoch über einfache Zeitreihenprognosen hinaus. Wir wollen ein Modell trainieren, das auf den Finanzmärkten handeln und Gewinne erzielen kann. Wir müssen also ein Modell des Akteurs (Actor) erstellen, der Handelsaktionen generiert und sie in unserem Namen durchführt. Außerdem benötigen wir ein Modell des Kritikers (Critic), das die vom Akteur (Actor) generierten Handelsoperationen bewertet und uns hilft, eine profitable Handelsstrategie zu entwickeln.
1.2 Akteur- und Kritiker-Architekturen
Mit der Methode CreateDescriptions erstellen wir die Modellbeschreibungen Akteur und Kritiker. In den Parametern erhält die angegebene Methode 2 Zeiger auf dynamische Arrays, in denen wir die Beschreibung der erstellten Architekturlösungen speichern.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Wie im vorherigen Fall beginnt der Methodenkörper mit der Überprüfung der Gültigkeit der erhaltenen Zeiger und, falls erforderlich, mit der Erstellung neuer Instanzen dynamischer Array-Objekte. Sobald dies abgeschlossen ist, gehen wir zur detaillierten Beschreibung der Architekturen für die zu entwickelnden Modelle über.
Beginnen wir mit dem Modell des Akteurs. Bevor wir uns dem Architekturentwurf zuwenden, wollen wir kurz die Ziele erörtern, die wir uns für das Modell des Akteurs gesetzt haben. Sein Hauptziel ist es, optimale Aktionen für die Ausführung von Handelsgeschäften zu entwickeln. Doch wie soll das Modell dies bewerkstelligen? Natürlich muss der Akteur zunächst die vom Environmental State Encoder vorhergesagte Kursbewegung analysieren und die Handelsrichtung bestimmen. Als Nächstes muss sie den aktuellen Stand des Kontos bewerten, um die verfügbaren Mittel einzuschätzen. Auf der Grundlage der kombinierten Analyse bestimmt der Akteur das Handelsvolumen, die damit verbundenen Risiken und die Ziele in Form von Stop-Loss- und Take-Profit-Levels. Dies ist das Paradigma, unter dem wir die Architektur des Akteurs beschreiben werden.
Die Eingabe des Modells umfasst zunächst einen Vektor, der den Kontostand darstellt.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Wir leiten sie durch eine vollständig verbundene Schicht.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Dann setzen wir einen Block für ein Kreuzaufmerksamkeit (cross-attention) aus 9 verschachtelten Schichten ein, in dem wir den aktuellen Stand des Kontos und die vorhergesagte Kursbewegung vergleichen.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); } { int temp[] = {8, 4}; ArrayCopy(descr.heads, temp); } descr.layers = 9; descr.step = 1; descr.window_out = 32; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Wie beim Environmental State Encoder verwenden wir den folgenden Aufbau:
- Die Größe des Vektors, der die internen Einheiten beschreibt, beträgt 32 Elemente;
- Die Anzahl der Aufmerksamkeitsköpfe des Key-Value-Tensors ist 2 mal geringer als die des Query-Tensors.
Jeder Key-Value-Tensor arbeitet im Rahmen von nur einer verschachtelten Schicht.
Als Nächstes analysieren wir die gewonnenen Daten mit einem 3-Schichten-MLP.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Am Ausgang des Modells wird mit Hilfe eines stochastischen Kopfes ein Vektor von Aktionen erzeugt.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Ich möchte Sie daran erinnern, dass der stochastische Kopf, den wir erstellen, „zufällige“ Aktionen für den Akteur erzeugt. Der zulässige Bereich dieser Zufallswerte ist durch die Parameter einer Normalverteilung, die durch den Mittelwert und die Standardabweichung repräsentiert werden und von der vorhergehenden Schicht gelernt wurden, streng begrenzt. Unter idealen Bedingungen, bei denen eine Handlung genau bestimmt werden kann, geht die Varianz der Verteilung für die erzeugte Handlung gegen Null. Folglich wird die Ausgabe des Akteurs dem gelernten Mittelwert sehr nahe kommen. Mit zunehmender Unsicherheit steigt auch die Varianz der erzeugten Aktionen. Infolgedessen beobachten wir zufällige Aktionen am Ausgang des Akteurs. Daher ist es bei der Anwendung einer stochastischen Politik unerlässlich, dem Testprozess des trainierten Modells größere Aufmerksamkeit zu widmen. Wenn alle anderen Faktoren gleich sind, sollte eine geschulte Politik zu konsistenten Ergebnissen führen. Signifikante Abweichungen zwischen zwei Testläufen können auf ein unzureichendes Modelltraining hinweisen.
Außerdem müssen die vom Akteur erzeugten Aktionen kohärent sein. So sollte beispielsweise das Stop-Loss-Niveau mit dem akzeptablen Risiko für das angegebene Handelsvolumen übereinstimmen. Gleichzeitig versuchen wir, widersprüchliche Handelsgeschäfte zu vermeiden. Wir werden die FreDF-Schicht verwenden, um die Konsistenz der Aktionen des Akteurs zu gewährleisten.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Das Modell des Kritikers hat eine ähnliche Architektur wie das Modell des Akteurs. Der in den Akteur eingespeiste Kontostandsvektor wird jedoch durch den Aktionstensor ersetzt, den der Akteur auf der Grundlage des analysierten Umweltzustands erzeugt. Das Fehlen von Kontostandsdaten bei der Eingabe für Kritiker ist leicht zu erklären. Der Gewinn oder Verlust, den wir beobachten, hängt nicht vom Kontostand ab, sondern vom Volumen und der Richtung der offenen Position.
Um die Architektur des Kritiker genauer zu verstehen, können Sie ihn unabhängig davon erkunden. Der vollständige Code für alle in diesem Artikel verwendeten Programme ist im Anhang enthalten.
2. Der Trainings-EA des Modells
Nachdem wir die Architekturen der Modelle beschrieben haben, wollen wir die Programme besprechen, die für ihr Training verwendet werden. In diesem Fall verwenden wir zwei Expert Advisors für das Training:
- StudyEncoder.mq5 — Environmental State Encoder Trainings-EA.
- Study.mq5 — Trainings-EA der Politik des Akteurs.
2.1 Training des Encoders
In StudyEncoder.mq5 werden wir das Encoder-Modell trainieren, um kommende Kursbewegungen und die Werte der analysierten Indikatoren vorherzusagen. Sie fragen sich vielleicht, warum wir Ressourcen für die Vorhersage scheinbar redundanter Indikatorwerte aufwenden. Dieser Ansatz ergibt sich aus der Tatsache, dass Indikatoren traditionell verwendet werden, um überkaufte und überverkaufte Zonen zu identifizieren, die Trendstärke zu bewerten und potenzielle Umkehrungen der Kursbewegung zu erkennen. Die meisten Indikatoren werden jedoch mit verschiedenen digitalen Filtern erstellt, die das Rauschen in den Rohdaten der Kursbewegung minimieren sollen. Infolgedessen sind die Indikatorwerte gleichmäßiger und oft besser vorhersehbar. Indem wir die späteren Werte dieser Indikatoren vorhersagen, wollen wir unsere Prognosen der Kursentwicklung verfeinern und bestätigen.
In der Initialisierungsmethode StudyEncoder.mq5 wird zunächst der Trainingsdatensatz geladen. Auf die Methoden der Datenerhebung werden wir später noch genauer eingehen.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Danach versuchen wir, das vortrainierte Environmental State Encoder-Modell zu laden. Wir werden nicht immer ein völlig neues Modell trainieren, das mit zufälligen Parametern initialisiert wird. Viel häufiger müssen wir ein Modell neu trainieren, wenn wir beim ersten Training nicht die gewünschten Ergebnisse erzielen konnten.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { Print("Create new model"); CArrayObj *encoder = new CArrayObj(); if(!CreateEncoderDescriptions(encoder)) { delete encoder; return INIT_FAILED; } if(!Encoder.Create(encoder)) { delete encoder; return INIT_FAILED; } delete encoder; }
Wenn das Laden eines bereits trainierten Modells aus irgendeinem Grund fehlschlägt, rufen wir die Methode CreateEncoderDescriptions auf, um die Architektur eines neuen Modells zu erstellen. Danach initialisieren wir ein neues Modell einer bestimmten Architektur mit zufälligen Parametern.
//--- Encoder.getResults(Result); if(Result.Total() != NForecast * BarDescr) { PrintFormat("The scope of the Encoder does not match the forecast state count (%d <> %d)", NForecast * BarDescr, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Der nächste Schritt ist die Implementierung eines kleinen Architekturkontrollblocks, in dem wir die Dimensionen der Eingabedatenschicht und des resultierenden Tensors überprüfen. Natürlich ist uns klar, dass Abweichungen in diesen Dimensionen bei der Erstellung eines neuen Modells fast unmöglich sind. Dies liegt daran, dass dieselben Konstanten, die zuvor zur Definition der Schichtdimensionen in der Architektur des Modells verwendet wurden, hier zur Überprüfung verwendet werden. Dieser Kontrollblock zielt eher darauf ab, Fälle zu identifizieren, in denen geladene, vorab trainierte Modelle nicht mit dem verwendeten Trainingsdatensatz übereinstimmen.
Sobald der Kontrollblock erfolgreich übergeben wurde, müssen wir nur noch ein nutzerdefiniertes Ereignis erzeugen, um den Modellbildungsprozess einzuleiten und die Initialisierungsmethode des EA abzuschließen.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Der eigentliche Prozess des Trainings von Modellen ist in der Mathode Train implementiert.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Im Hauptteil der Methode wird zunächst ein Wahrscheinlichkeitsvektor für die Auswahl von Trajektorien aus dem Trainingsdatensatz erzeugt. Der Algorithmus ist so konzipiert, dass die Trajektorien mit der höchsten Rentabilität eine höhere Wahrscheinlichkeit erhalten. Natürlich ist dieser Ansatz für das Training der Politik des Akteurs relevanter, da das Environmental State Encoder-Modell den aktuellen Saldo oder die offenen Positionen nicht analysiert. Stattdessen arbeitet es ausschließlich mit den Indikatoren und den Daten über die Kursbewegungen, die analysiert werden. Dennoch haben wir diese Funktionalität beibehalten, um einen einheitlichen architektonischen Rahmen für alle verwendeten Programme zu schaffen.
Anschließend deklarieren wir die erforderlichen lokalen Variablen
vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
und organisieren die Modelltrainingsschleife. Die Anzahl der Modelltrainingsiterationen wird in den externen Parametern des Programms angegeben.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; }
Im Schleifenkörper werden eine Trajektorie und der Zustand auf dieser Trajektorie aus dem Trainingsdatensatz ausgewählt. Es wird geprüft, ob für den ausgewählten Zustand gespeicherte Daten vorhanden sind. Dann übertragen wir die Informationen aus dem Trainingsdatensatz in den Datenpuffer.
state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum()==0) { iter--; continue; } bState.AssignArray(state);
Auf der Grundlage der vorbereiteten Daten führen wir den Vorwärtsdurchgang (feed-forward pass) des trainierten Modells durch.
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Wir laden jedoch nicht die daraus resultierenden vorhergesagten Werte. An dieser Stelle sind wir nicht so sehr an den Prognoseergebnissen interessiert als vielmehr an deren Abweichung von den tatsächlichen späteren Werten, die im Trainingsdatensatz gespeichert sind. Daher laden wir die nachfolgenden Zustände aus dem Trainingsdatensatz.
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
Wir bereiten auch die wahren Werte vor, mit denen wir die erhaltenen Prognosen vergleichen werden. Wir werden diese Daten in die Parameter der Methode des Rückwärtsdurchgangs (backpropagation) unseres Modells einspeisen. Bei dieser Methode werden die Modellparameter optimiert, um den Prognosefehler zu minimieren.
if(!Encoder.backProp(Result,(CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Nach erfolgreichem Abschluss der Vorwärts- und Rückwärtsdurchgänge unseres Modells müssen wir den Nutzer nur noch über den Fortschritt des Trainingsprozesses informieren und zur nächsten Iteration der Schleife übergehen.
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Ich muss zugeben, dass der Trainingsprozess so einfach und minimalistisch wie möglich gestaltet ist. Die Dauer des Trainings wird ausschließlich durch die Anzahl der Trainingsiterationen bestimmt, die der Nutzer beim Start des EA in den externen Parametern angibt. Ein vorzeitiger Abbruch des Trainingsprozesses ist nur im Falle eines Fehlers möglich oder wenn der Nutzer das Programm manuell im Terminal beendet.
Nach Abschluss des Trainingsprozesses löschen wir das Kommentarfeld auf dem Chart, in dem wir zuvor Informationen über den Trainingsfortschritt angezeigt hatten.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
Wir zeigen die Trainingsergebnisse im Journal des MetaTrader 5 an und initialisieren die Beendigung des laufenden Programms. Das Speichern des trainierten Modells ist in der Methode OnDeinit implementiert. Den vollständigen Code des Expert Advisors finden Sie im Anhang.
2.2 Der Trainingsalgorithmus des Akteurs
Der zweite Expert Advisor „Study.mq5“ ist für das Training der Politik des Akteurs vorgesehen. Zusätzlich wird im Rahmen dieses Programms auch das Modell des Kritikers geschult.
Es ist erwähnenswert, dass die Rolle des Kritikers sehr spezifisch ist. Sie dient dazu, den Akteur dazu anzuleiten, in die gewünschte Richtung zu handeln. Der Kritiker selbst wird jedoch während des operativen Einsatzes des Modells nicht verwendet. Mit anderen Worten: Wir schulen den Kritiker paradoxerweise nur, um den Akteur zu schulen.
Die Struktur des Akteur-Trainings EA ähnelt dem Programm, das zuvor für das Training des Encoders besprochen wurde. In diesem Artikel konzentrieren wir uns speziell auf die Methode Train zum Trainieren der Modelle.
Wie in dem früheren Programm beginnt die Methode mit der Erzeugung eines Wahrscheinlichkeitsvektors für die Auswahl von Trajektorien aus dem Trainingsdatensatz und der Deklaration der erforderlichen lokalen Variablen.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
Danach deklarieren wir eine Trainingsschleife, in deren Körper wir die Trajektorie aus dem Trainingsdatensatz und den Zustand darauf abfragen.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i <= 0) { iter--; continue; } state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum()==0) { iter--; continue; } bState.AssignArray(state);
Hier kodieren wir auch den Zeitstempel, den wir als Vektor von Sinusschwingungen verschiedener Frequenzen darstellen werden.
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Wir werden die gesammelten Daten nutzen, um Prognosewerte für die kommende Preisentwicklung zu erstellen. Dieser Vorgang wird durch den Aufruf der Vorwärtsdurchgangs-Methode des zuvor trainierten Encoders durchgeführt.
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false,(CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Wie bereits erwähnt, müssen wir, um den Akteur zu schulen, den Kritiker schulen. Wir extrahieren aus dem Trainingsdatensatz die Aktionen, die der Akteur beim Sammeln des Trainingsdatensatzes durchgeführt hat.
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); if(bActions.GetIndex() >= 0) bActions.BufferWrite();
Wir speisen die Daten zusammen mit dem vorhergesagten Zustand der Umwelt in unser Kritiker-Modell ein.
Critic.TrainMode(true); if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Es ist wichtig zu beachten, dass wir dem Kritiker nicht die vorhergesagten Kursbewegungen und die zukünftigen Indikatorwerte, die durch den Output generiert werden, sondern den verborgenen Zustand des Encoders zur Verfügung stellen. Dies ist darauf zurückzuführen, dass wir am Ausgang des Encoders statistische Parameter der ursprünglichen Zeitreihe zu den Prognosewerten hinzugefügt haben. Folglich würde die Verarbeitung solcher Daten im Kritiker-Modell zunächst eine Normalisierung erfordern. Stattdessen nehmen wir den verborgenen Zustand des Encoders, in dem die vorhergesagten Werte ohne die in den Rohdaten enthaltenen Verzerrungen enthalten sind.
Während des Vorwärtsdurchgangs erstellt der Kritiker eine Bewertung der Aktionen des Akteurs. Während der ersten Iterationen des Trainings kann diese Bewertung natürlich erheblich von den tatsächlichen Belohnungen abweichen, die der Akteur während seiner Interaktion mit der Umwelt erhält. Wir extrahieren die tatsächliche Belohnung aus dem Trainingsdatensatz, die das Ergebnis der jeweiligen Aktion widerspiegelt.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Dann führen wir den Rückwärtsdurchgang des Kritikers durch, um den Fehler bei der Bewertung von Aktionen zu minimieren.
Der nächste Schritt besteht darin, die Politik des Akteurs zu trainieren. Zur Durchführung des Vorwärtsdurchgangs muss zunächst ein Tensor erstellt werden, der den Kontostatus beschreibt, den wir aus dem Trainingsdatensatz extrahieren.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Dann führen wir einen Vorwärtsdurchgang des Modells durch, indem wir in den Parametern der Methode den Vektor der Beschreibung des Kontostandes und des versteckten Zustandes des Encoders übergeben.
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Es liegt auf der Hand, dass sich aus den Ergebnissen des Vorwärtsdurchgangs des Akteurs ein bestimmter Aktionsvektor gebildet hat. Diesen Vektor speisen wir zusammen mit dem latenten Zustand des Encoders in den Kritiker ein.
Critic.TrainMode(false); if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Bitte beachten Sie, dass wir zu diesem Zeitpunkt den Trainingsmodus des Kritikers deaktivieren. Denn in diesem Fall wird das Kritiker-Modell nur verwendet, um den Fehlergradienten an den Akteur weiterzugeben.
Wir werden die Parameter des Akteurs in zwei Richtungen optimieren. Erstens erwarten wir, dass unser Trainingsdatensatz erfolgreiche Läufe enthält, die während des Trainingszeitraums zu einem Gewinn führten. Wir werden solche Durchgänge als Benchmark verwenden und Methoden des überwachten Lernens einsetzen, um unsere Akteurs-Politik in Bezug auf solche Aktionen zu verbessern.
if(Buffer[tr].States[0].rewards[0] > 0) if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Andererseits sind wir uns darüber im Klaren, dass es deutlich weniger rentable als unrentable Pässe geben wird. Wir dürfen jedoch die Informationen, die die verlorenen Pässe liefern, nicht außer Acht lassen. In der Tat sind während des Training der Politik des Akteurs verlorene Pässe ebenso nützlich wie gewinnbringende Pässe. Während wir die Politik des Akteurs auf der Grundlage gewinnbringender Pässe anpassen, müssen wir uns von den verlustreichen Pässen trennen. Aber um wie viel und in welche Richtung? Darüber hinaus kann es auch in Verlustphasen gewinnbringende Abschlüsse geben. Und diese Informationen wollen wir aufbewahren. Hier kommt die Rolle des Kritikers im Rahmen des Trainings der Politik des Akteurs ins Spiel.
Es wird davon ausgegangen, dass während des Trainings der Kritiker seine Parameter so optimiert werden, dass sie eine Funktion widerspiegeln, die die Beziehung zwischen der Handlung des Akteurs, dem Umweltzustand und der Belohnung modelliert. Wenn wir also den Zustand der Umwelt unverändert lassen und die Belohnung maximieren wollen, gibt der Gradient des Fehlers die Richtung an, in der die Aktionen des Akteurs angepasst werden müssen, um die erwartete Belohnung zu erhöhen. Wir werden diese Eigenschaft im Trainingsprozess verwenden.
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); }
Wir entnehmen die aktuelle Bewertung der Aktionen durch den Kritiker. Dann erhöhen wir den Gewinn um 1 % und verringern den Verlust um den gleichen Betrag. Dies sind unsere Zielwerte in dieser Phase. Wir werden sie dann weitergeben, um die Operationen der Rückwärtsdurchgänge für den Kritiker und den Akteur durchzuführen.
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Ich möchte Sie daran erinnern, dass wir in diesem Stadium den Trainingsmodus für den Kritiker deaktiviert haben. Das bedeutet, dass sie nur dazu verwendet wird, den Fehlergradienten an den Akteur weiterzugeben. Bei diesem Rückwärtsdurchgang werden die Parameter des Kritikers also nicht angepasst. Der Akteur passt die Modellparameter so an, dass der erwartete Gewinn maximiert wird.
Als Nächstes müssen wir den Nutzer nur noch über den Fortschritt der Modellschulung informieren und mit der nächsten Iteration der Schleife fortfahren.
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Sobald der Trainingsprozess abgeschlossen ist, löschen wir das Kommentarfeld in der Symboltabelle. Wir geben die Trainingsergebnisse in das Protokoll aus und initialisieren den EA-Abschlussprozess.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Damit ist die Diskussion über die Algorithmen zur Modellbildung abgeschlossen. Den vollständigen Code aller hier verwendeten Programme finden Sie im Anhang.
3. Sammeln des Trainingsdatensatzes
Der nächste wichtige Schritt ist die Sammlung von Daten für den Trainingsdatensatz. Um reale Daten über die Interaktion mit der Umgebung zu erhalten, verwenden wir den MetaTrader 5 Strategietester. Hier führen wir Tests mit historischen Daten durch, und die Ergebnisse werden in einer Trainingsdatendatei gespeichert.
Bevor wir mit dem Trainingsprozess beginnen, stellt sich natürlich die Frage, woher wir erfolgreiche Läufe aus dem Trainingsdatensatz erhalten können. Es sind mehrere Optionen verfügbar. Der naheliegendste Ansatz besteht darin, die historischen Daten zu nehmen und manuell ideale Geschäfte zu „erstellen“. Dieser Ansatz ist zweifelsohne richtig, aber er ist mit manueller Arbeit verbunden. Mit zunehmender Größe des Trainingsdatensatzes wächst auch der Arbeitsaufwand und die Zeit, die für die Vorbereitung des Trainingsdatensatzes benötigt wird. Darüber hinaus führt manuelle Arbeit häufig zu verschiedenen Fehlern, die auf den „menschlichen Faktor“ zurückzuführen sind. Bei meiner Arbeit verwende ich das Real-ORL Framework zur Erhebung der Ausgangsdaten, das in dieser Artikelserie bereits ausführlich beschrieben wurde. Der entsprechende Code ist im Anhang enthalten, und wir werden hier nicht näher darauf eingehen.
Der erste Trainingsdatensatz vermittelt dem Modell ein erstes Verständnis der Umgebung. Die Finanzmärkte sind jedoch so vielschichtig, dass kein Trainingssatz sie vollständig abbilden kann. Darüber hinaus können sich die Abhängigkeiten, die das Modell zwischen den analysierten Indikatoren und den profitablen Geschäften erlernt, als falsch oder unvollständig erweisen, da dem Trainingsset möglicherweise Beispiele fehlen, die solche Diskrepanzen aufzeigen. Daher müssen wir während des Trainingsprozesses den Trainingsdatensatz verfeinern. In diesem Stadium wird der Ansatz für die Erhebung zusätzlicher Daten unterschiedlich sein.
Die Aufgabe in dieser Phase besteht darin, die erlernte Politik des Akteurs zu optimieren. Um dies zu erreichen, benötigen wir Daten, die relativ nahe am Verlauf der aktuellen Politik des Akteurs liegen, damit wir die Richtung der Belohnungsänderungen verstehen können, wenn die Aktionen von der aktuellen Politik abweichen. Mit diesen Informationen können wir die Rentabilität der aktuellen Politik erhöhen, indem wir uns in Richtung einer Maximierung der Belohnung bewegen.
Es gibt verschiedene Ansätze, um dies zu erreichen, und sie können sich je nach Faktoren wie der Modellarchitektur ändern. Bei einer stochastischen Strategie können wir zum Beispiel einfach mehrere Durchläufe des Akteurs mit der aktuellen Strategie im Strategietester durchführen. Der stochastische Kopf wird dies tun. Die Zufälligkeit der Aktionen des Akteurs deckt den Aktionsraum ab, an dem wir interessiert sind, und wir können das Modell anhand der aktualisierten Daten neu trainieren. Im Falle einer deterministischen Akteurspolitik, bei der das Modell explizite Beziehungen zwischen dem Umweltzustand und der Aktion herstellt, können wir den Aktionen des Agenten etwas Rauschen hinzufügen, um eine Wolke von Aktionen um die aktuelle Akteurspolitik herum zu erzeugen.
In beiden Fällen ist es sinnvoll, den langsamen Optimierungsmodus des Strategietesters zu verwenden, um zusätzliche Daten für den Trainingsdatensatz zu sammeln.
Ich werde nicht im Detail auf die Programme zur Interaktion mit der Umwelt eingehen. Sie wurden bereits in früheren Artikeln dieser Reihe behandelt. Der vollständige Code für alle in diesem Artikel verwendeten Programme ist in den Anhängen enthalten, einschließlich des Codes für die Interaktion mit der Umgebung für Ihre unabhängige Überprüfung.
4. Modellschulung und -prüfung
Nachdem wir die Algorithmen aller für das Modelltraining verwendeten Programme besprochen haben, gehen wir nun zum eigentlichen Prozess über. Die Modelle werden anhand echter historischer Daten für EURUSD mit dem Zeitrahmen H1 trainiert. Der Trainingszeitraum erstreckt sich über das gesamte Jahr 2023.
Die anfängliche Trainingsmenge wird, wie bereits erwähnt, in einem bestimmten historischen Intervall gesammelt. Mit diesem Datensatz trainieren wir das Modell des Environment State Encoder. Wie bereits erwähnt, verwendet der Encoder nur historische Kursbewegungsdaten und die Indikatoren, die beim Training analysiert werden. Es ist offensichtlich, dass die Daten für alle Durchgänge über dasselbe historische Datenintervall identisch sind. Daher besteht in diesem Stadium keine Notwendigkeit, den Trainingsdatensatz zu verfeinern. Wir trainieren also das Encoder-Modell mit dem anfänglichen Trainingsdatensatz, bis wir das gewünschte Ergebnis erhalten.
Während des Lernprozesses überwachen wir den Vorhersagefehler. Wir brechen den Trainingsprozess ab, wenn der Fehler nicht mehr abnimmt und seine Schwankungen in einem kleinen Bereich bleiben.
Natürlich sind wir daran interessiert, was das Modell gelernt hat. Auch wenn unser oberstes Ziel darin besteht, eine rentable Akteurspolitik zu betreiben. Ich habe trotzdem meiner Neugier gefrönt und die vorhergesagten und tatsächlichen Kursbewegungen für eine zufällig ausgewählte Teilmenge des Trainingssatzes verglichen.
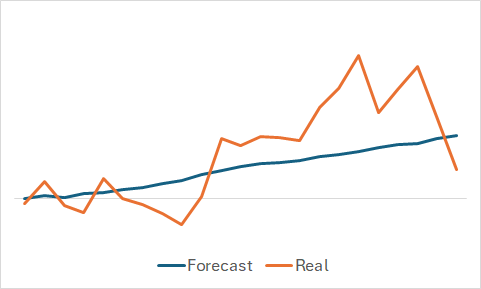
Aus dem Diagramm ist ersichtlich, dass das Modell den Haupttrend der bevorstehenden Kursbewegung erfasst hat.
Die relativ gleichmäßige vorhergesagte Preisbewegung mit geringen Schwankungen könnte zu der Annahme verleiten, dass das Modell den allgemeinen Trend des Trainingssatzes erfasst hat und unabhängig von den tatsächlichen Daten ein ähnliches Muster für alle Staaten zeigt. Um diese Annahme zu bestätigen oder zu widerlegen, nehmen wir einen anderen Zustand aus dem Trainingsdatensatz und führen einen ähnlichen Vergleich zwischen den vorhergesagten und den tatsächlichen Kursbewegungen durch.

Hier zeigen sich deutlichere Schwankungen in den vorhergesagten Werten der Preisbewegung. Sie kommen den tatsächlichen Daten jedoch noch relativ nahe.
Nach dem Training des Environmental State Encoders gehen wir zur zweiten Stufe über, um die Akteurspolitik zu trainieren. Dieser Prozess ist iterativ. Die erste Iteration des Trainings wird mit dem ersten Trainingsdatensatz durchgeführt. In diesem Stadium geben wir dem Modell ein vorläufiges Verständnis der Umwelt. Dank der mit der Methode Real-ORL gesammelten rentablen Durchläufe schaffen wir die Grundlage für unsere zukünftige Politik.
Während des Trainingsprozesses konzentrieren wir uns, wie in der ersten Phase, auf die Überwachung der Fehler der Modelle. In der Anfangsphase würde ich empfehlen, sich auf den Fehlerwert des Kritikers zu konzentrieren. Ja, wir brauchen eine Politik der Akteure, die in der Lage ist, Gewinne zu erwirtschaften, aber denken Sie an unsere frühere Diskussion: Um den Akteur zu schulen, müssen wir den Kritiker schulen. Die korrekte Festlegung von Abhängigkeiten innerhalb des Kritiker wird uns helfen, die Politik des Akteur in die richtige Richtung zu lenken.
Wenn der Fehler des Kritiker nicht mehr abnimmt und sich stabilisiert, wechseln wir zum Strategietester und sammeln zusätzliche Daten mit dem Expert Advisor Research.mq5, den ich im langsamen Optimierungsmodus empfehle.
Anschließend fahren wir mit dem weiteren Training der Modelle von Akteur und Kritiker fort. Zu Beginn des Re-Trainingsprozesses werden Sie möglicherweise einen leichten Anstieg des Fehlers für beide Modelle feststellen, der auf die Verarbeitung der neuen Daten zurückzuführen ist. Sie werden jedoch bald eine allmähliche Verringerung des Fehlers und das Erreichen neuer Minima feststellen.
Daher wiederholen wir die Iterationen zur Verfeinerung der Trainingsmenge und zum erneuten Training der Modelle.
Ich möchte Sie auch daran erinnern, dass die Architektur des Akteurs einen stochastischen Kopf verwendet, der eine gewisse Zufälligkeit in die Aktionen einbringt. Daher ist es empfehlenswert, beim Testen der trainierten Akteurs-Politik mehrere Durchläufe über einen Testzeitraum hinweg durchzuführen. Die Politik des Akteurs kann als trainiert angesehen werden, wenn die Abweichungen zwischen den Durchgängen vernachlässigbar sind.
Bei der Erstellung dieses Artikels haben wir das trainierte Modell mit historischen Daten vom Januar 2024 getestet. Dieser Zeitraum war nicht Teil des Trainingssatzes, sodass das Modell mit neuen Daten konfrontiert wurde. Die Trainings- und Testzeiträume liegen dicht beieinander, sodass wir davon ausgehen können, dass die Datensätze vergleichbar sind.
Während des Trainingsprozesses ist es mir gelungen, ein Modell zu entwickeln, das sowohl in den Trainings- als auch in den Testdatensätzen Gewinne erzielen konnte.
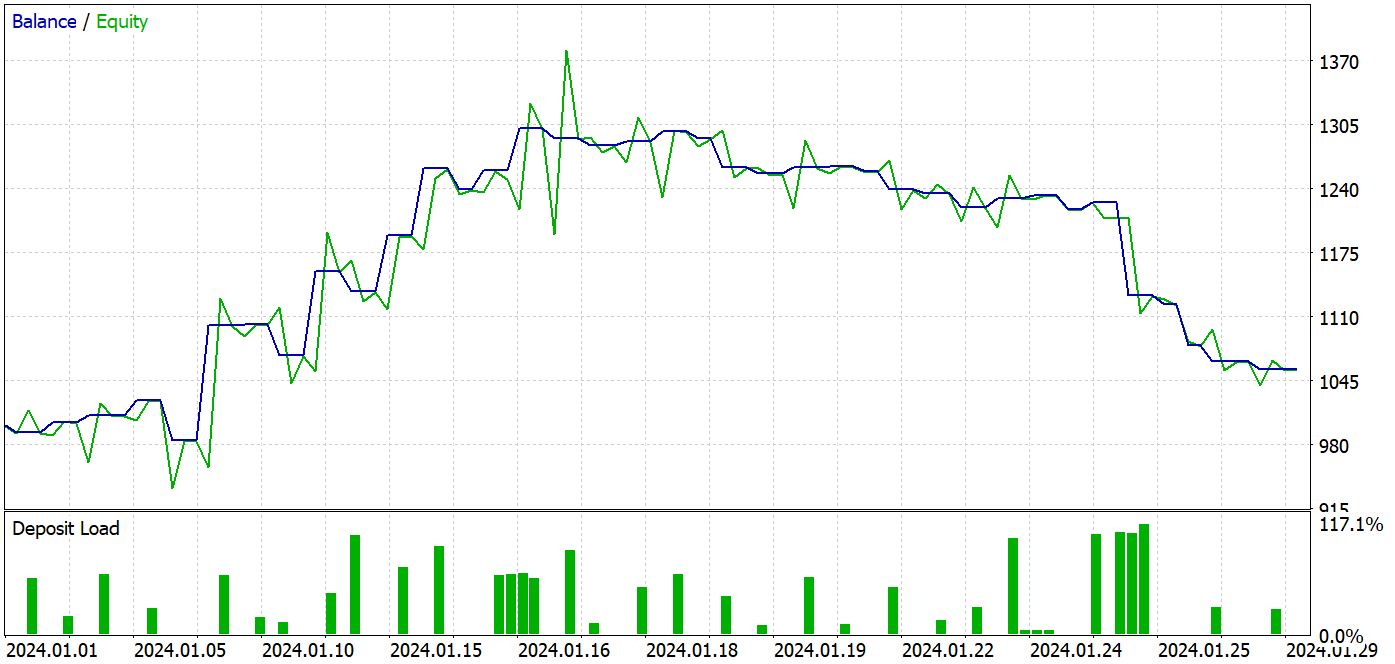
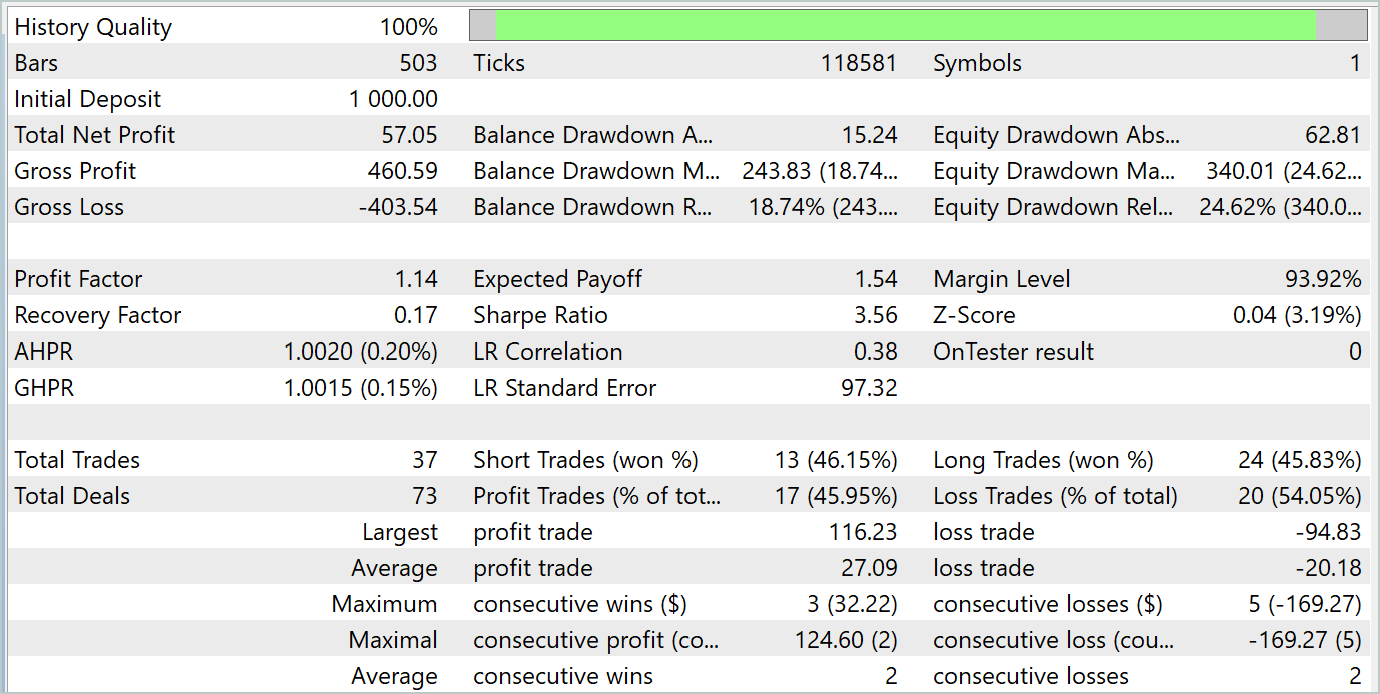
Während des Testzeitraums tätigte das Modell 37 Transaktionen, von denen 17 mit Gewinn abgeschlossen wurden. Dies waren fast 46 %. Der Anteil der gewinnbringenden Handelsgeschäfte ist bei Kauf- und Verkaufs-Positionen fast gleich. Die Differenz beträgt nur 0,32 %, was aufgrund der geringen Anzahl von Transaktionen nur ein Rechenfehler sein kann. Das Maximum und der Durchschnitt der profitablen Handelsgeschäfte sind höher als die entsprechenden Werte für die Verlustgeschäfte. Dadurch konnten wir den Testzeitraum mit einem Gewinn abschließen. Der Gewinnfaktor betrug 1,14. Bedenklich ist jedoch, dass der Gewinn in der ersten Monatshälfte erzielt wurde. Es folgt eine seitliche Bewegung des Saldos. Und die letzte Woche des Monats war durch einen Rückgang gekennzeichnet.
Schlussfolgerung
In diesem Artikel haben wir das Modell mit Ansätzen aus der Methode MSFformer trainiert und getestet. Die Testergebnisse zeigen eine gute Leistung, was darauf hindeutet, dass die vorgeschlagenen Ansätze vielversprechend sind. Bemerkenswert ist jedoch der Rückgang des Saldos in der letzten Woche des Testzeitraums, was auf die Notwendigkeit zusätzlicher Phasen des Modelltrainings hinweisen könnte.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA zum Datenabruf |
| 2 | ResearchRealORL.mq5 | EA | EA für die Erfassung von Datensätze nach der Methode Real-ORL |
| 3 | Study.mq5 | EA | Trainings-EA des Modells |
| 4 | StudyEncoder.mq5 | EA | Trainings-EA des Encoders |
| 5 | Test.mq5 | EA | Modeltest-EA |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/15171
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.