
神经网络变得简单(第 97 部分):搭配 MSFformer 训练模型

概述
在上一篇文章中,我们构建了 MSFformer 模型的主要模块,包括 CSCM 和 Skip-PAM。CSCM 模块为所分析时间序列构造一棵特征树,而 Skip-PAM 基于时间特征树的关注度机制从多个尺度的时间序列中提取信息。在本文中,我们继续这项工作,利用 MetaTrader 5 策略测试器训练模型,并评估其在真实数据上的性能。
1. 模型架构
在继续模型训练之前,我们需要完成一些准备步骤。首先且最重要的是,我们必须定义模型架构。MSFformer 方法专为时间序列预测任务而设计。相应地,我们会将其集成到环境状态编码器模型中,与其它若干种类似方法并列。
1.1环境状态编码器的架构
环境状态编码器的架构在 CreateEncoderDescriptions 方法中定义。该方法取动态数组对象的指针作为参数,于其中我们将指定模型架构。
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
在方法主体中,我们检查所收指针的相关性,并在必要时创建动态数组的新实例。
接下来,我们转到定义模型架构。编码器的输入由描述环境当前状态的 “原生” 数据组成。如常,我们使用一个基本的全连接层作为输入层,没有激活函数。在这种情况下,没必要用到激活函数,因为原生输入数据将直接写入指定层的结果缓冲区。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
请注意,输入层的大小必须与环境状态描述张量的尺寸精确匹配。甚至,在模型训练和部署的所有阶段,环境状态的描述必须保持相同。为了在训练和生产阶段更轻松地同步参数,我们将定义两个常量:BarDescr(描述单根烛条的元素数量),和 HistoryBars(所分析历史数据的深度)。这些常数的乘积将决定输入层的大小。
如上所述,我们打算将 “原生”(未经处理)数据投喂到模型之中。一方面,这种方式简化了训练和操作程序中数据预处理模块之间的同步,这是一个显著的优势。
另一方面,使用未经处理的数据往往会降低模型训练的效率。这是由于输入数据的不同元素之间的显著统计差异。为了缓解这个问题,我们将直接在模型内进行输入数据初始预处理。该任务将由批量归一化层执行。根据该层的算法,输出数据的平均值将接近于零,并且存在单位方差。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
我们将已归一化时间序列的预处理输入数据投喂到特征提取模块 CSCM 之中。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCSCMOCL; descr.count = HistoryBars; descr.window = BarDescr;
注意,特征提取将在单变量时间序列的框架内执行。在这种情况下,序列长度对应于所分析历史数据的深度,而单变量序列的数量等于描述单根烛条的向量大小。不过,在之前的文章中,在构造环境状态描述张量时,我们往往会将数据组织为一个矩阵,其中行代表所分析柱线,列对应于特征。因此,我们将在 CSCM 模块的参数中指定数据应当进行初步转置。
descr.step = int(true);
我们将提取 3 个级别的特征,分析窗口大小分别为 6、5 和 4 根柱线。
{
int temp[] = {6, 5, 4};
if(!ArrayCopy(descr.windows, temp))
return false;
}
我们未用到激活函数。我们将调用 Adam 方法优化模型参数。
descr.step = int(true); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
接下来,根据 MSFformer 方法的算法,来到 Skip-PAM 模块。在我们的实现中,我们将添加 3 个具有相同配置的连续 Skip-PAM 层。
//--- layer 3 - 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSPyrAttentionMLKV; descr.count = HistoryBars; descr.window = BarDescr;
此处,我们指定将要分析序列的相似大小。不过,在这种情况下,我们正在配以多模序列工作。
我们将描述 Query、Key 和 Value 实体的内部向量大小设置为 32 个元素。Key-Value 张量的关注度头数量将减少 2 倍。
descr.window_out = 32; { int temp[] = {8, 4}; if(!ArrayCopy(descr.heads, temp)) return false; } descr.layers = 3; descr.activation = None; descr.optimization = ADAM; for(int l = 0; l < 3; l++) if(!encoder.Add(descr)) { delete descr; return false; }
每个 Skip-PAM 的关注度金字塔将包含 3 个级别。此处我们还调用 Adam 方法优化模型参数。
在 Skip-PAM 模块的输出端,我们得到的张量其大小与输入数据相对应。张量的内容经由所分析序列元素之间的依赖关系进行调整。接下来,我们需要为多模输入时间序列的延续构造预测轨迹。我们将为所分析多模态序列中的每个单变量序列构造单独的预测轨迹。为此,我们首先转置从 Skip-PAM 模块获得的数据张量。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; }
之后,我们将用 2 个连续的卷积层,于其中为单独的单变量序列执行 MLP 的角色。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; descr.window_out = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = LatentCount; descr.step = LatentCount; descr.window_out = NForecast; descr.optimization = ADAM; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
请注意,为了在上述卷积层中实现与 MLP 的相似性,我们指定了相等大小的分析窗口、及其步长。在第一种情况下,它等于正在分析的序列的深度。在第二种情况下,它等于前一层的过滤器数量。此外,卷积模块的数量等于所分析单变量序列的数量。为了在卷积层之间引入非线性,我们调用了 LReLU 激活函数。
对于第二个卷积层,我们将滤波器的数量设置为等于所预测序列的大小。在我们的例子中,它由 NForecast 常量指定。
此外,对于第二个卷积层,我们调用双曲正切(TANH)。这个选择是经过深思熟虑的。在模型的输入阶段,我们用到一个批量归一化层,对数据进行预处理,确保单位方差和平均值接近于零。根据“3-sigma 规则”,正态分布的随机变量大约 2/3 的值位于平均值的一个标准差之内。由此,使用值范围为 (-1, 1) 的 TANH 可令我们覆盖 68% 的所分析变量值,同时过滤掉超出平均值一个标准差的异常值。
重点要注意的是,我们的意向并非学习和预测所分析时间序列的所有波动,因为它包含大量噪声。取而代之,我们瞄准的是足够准确的预测,以便构造可盈利的交易策略。
接下来,使用数据转置层,我们将预测值转换回原生数据的表示形式。
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
将我们之前在批量归一化层中提取的统计变量加到它们当中。
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr*NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers=1; if(!encoder.Add(descr)) { delete descr; return false; }
此刻,环境状态编码器模型的架构可认为是完整的。在当前形式中,它与 MSFformer 方法的作者提出的模型一致。不过,我们将加上最终的优调。在我们之前的文章中,我们讨论过直接预测的范式,假设预测序列中各个步骤的独立性。如您能想象到的,该假设与时间序列数据的固有性质相矛盾。为了解决这个问题,我们将利用 FreDF 方法带来的优势,来协调所分析时间序列的预测序列内的各个步骤。
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
以这种形式,编码器架构便有了更完整的外观。我希望我在此处给出的注释,可助您理解模型的核心逻辑。
在该阶段,我们已经描述了预测即将到来的价格走势模型的架构,并能转到训练模型。不过,我们的目标是超越简单的时间序列预测。我们希望训练一个可在金融市场进行交易,并产生利润的模型。是故,我们必须创建一个参与者模型,其将生成交易动作,并代表我们执行它们。此外,我们需要一个评论者模型,它将评估参与者生成的交易动作,并帮助我们构建可盈利的交易策略。
参与者 和 评论者 架构
我们在 CreateDescriptions 方法中创建参与者和评论者模型描述。在参数中,指定的方法接收 2 个指向动态数组的指针,我们在其中保存了已创建架构方案的描述。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
与前一种情况一样,方法主体首先验证所获取指针的有效性,并在必要时创建动态数组对象的新实例。一旦这步完成,我们将继续详细描述正在开发的模型架构。
我们从参与者模型开始。在继续架构设计之前,我们先简要讨论一下我们为参与者模型设定的意向。其主要目标是生成执行交易操作的最佳动作。但该模型应该如何实现这一点呢?显然,参与者必须首先分析环境状态编码器生成的预测价格走势,并判定交易方向。接下来,它必须评估账户的当前状态,从而估算可用资源。基于综合分析,参与者判定交易量、相关风险、及止损和止盈价位形式的目标。这是遵循我们描述参与者架构的范例。
模型的输入最初将包括一个表示账户状态的向量。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
我们经由一个全连接层传递它。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
然后我们放置一个由 9 个嵌套层组成的交叉关注度模块,在其中我们比较账户的当前状态和预测出的价格走势。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); } { int temp[] = {8, 4}; ArrayCopy(descr.heads, temp); } descr.layers = 9; descr.step = 1; descr.window_out = 32; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
与环境状态编码器一样,我们采用以下设置:
- 描述内部实体的向量大小为 32 个元素;
- Key-Value 张量的关注度头数量比 Query 张量小 2 倍。
每个 Key-Value 张量仅在一个嵌套层的框架内运行。
接下来,我们利用 3-层 MLP 分析获得的数据。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
在模型的输出处,我们使用随机头生成一个动作向量。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
我要提醒您,我们正在创建的随机头部会为参与者生成 “随机” 动作。这些随机值的允许范围严格受正态分布参数的约束,由平均值和标准差表示,这些参数学自上一层。在理想条件下,可以精确确定动作,则针对所生成动作的分布方差接近于零。因此,参与者的输出将与学到的平均值紧密匹配。随着不确定性的增加,所生成动作的差异也会增加。结果就是,我们在参与者输出中观察到随机动作。因此,当采用随机政策时,本质上要密切关注已训练模型的测试过程。在所有其它因素等同的情况下,经过训练的政策应当产生一致的结果。两次测试运行之间的显著差异也许表明模型训练不足。
甚至,参与者生成的动作必须是连贯的。举例,止损价位应与声明的交易量的可接受风险保持一致。同时,我们的靶向是避免相互矛盾的交易。我们将使用 FreDF 层来确保参与者动作的一致性。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
评论者模型的架构与参与者的架构相似。不过,投喂到参与者的账户状态向量将替换为参与者基于所分析环境状态生成的动作张量。评论者输入处没有账户状态数据很容易解释。我们观察到的盈利或亏损不取决于账户余额,而是持仓交易量和方向。
若要更详尽地理解评论者的架构,您可以独立探索它。附件中包含本文中用到的所有程序的完整代码。
2. 模型训练 EA
在讲述了模型架构之后,我们来讨论训练它们的程序。在这种情况下,我们将用到两个智能系统进行训练:
- StudyEncoder.mq5 — 环境状态编码器训练 EA。
- Study.mq5 — 参与者政策训练 EA。
2.1训练编码器
在 StudyEncoder.mq5 中,我们将训练编码器模型来预测即将到来的价格走势、及所分析指标的数值。您也许奇怪为什么我们要花费资源来预测看似多余的指标值。这种方式源于这样一个事实,即指标传统上用于识别超买和超卖区域、评估趋势强度、以及检测潜在的价格走势反转。然而,大多数指标都是利用各种数字滤波器构建的,设计用于把原生价格走势数据中固有的噪音最小化。结果就是,指标值更平滑,并且往往更好预测。通过预测这些指标的后续值,我们旨在完善和确认我们对价格走势的预测。
在 StudyEncoder.mq5 初始化方法中,我们首先加载训练数据集。我们稍后将更详细地讨论数据收集的方法。
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
之后,我们尝试加载预先训练的环境状态编码器模型。我们不会总是以随机参数初始化,来训练一个全新模型。更常见的是,如果我们在初始训练期间无法达成预期的结果,我们将需要重新训练模型。
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { Print("Create new model"); CArrayObj *encoder = new CArrayObj(); if(!CreateEncoderDescriptions(encoder)) { delete encoder; return INIT_FAILED; } if(!Encoder.Create(encoder)) { delete encoder; return INIT_FAILED; } delete encoder; }
如果出于某种原因加载预训练模型失败,我们将调用 CreateEncoderDescriptions 方法来生成新模型的架构。之后,我们用随机参数初来始化给定架构的新模型。
//--- Encoder.getResults(Result); if(Result.Total() != NForecast * BarDescr) { PrintFormat("The scope of the Encoder does not match the forecast state count (%d <> %d)", NForecast * BarDescr, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
下一步是实现一个小型架构控制模块,在其中我们验证输入数据层、和结果张量的维度。当然,我们明白,在创建新模型时,在这些维度里出现偏差几乎是不可能的。这是因为早前在定义模型架构中的层维度时,采用的相同常量会在此处进行验证。该控制模块更旨在识别加载的预训练模型、与正在使用的训练数据集不对应的情况。
一旦控制模块成功通过,我们只需生成一个用户定义事件,来启动模型训练过程,然后结束 EA 的初始化方法。
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
训练模型的实际过程在 Train 方法中实现。
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
在方法主体中,我们首先生成一个概率向量,这是为从训练数据集中选择轨迹。算法设计是为具有最高盈利能力的轨迹分配更大的概率。当然,这种方式在训练参与者政策时更相关,因为环境状态编码器模型不分析当前余额、或持仓。取而代之,它仅依据正在分析的指标和价格走势数据操作。无论如何,我们保留了该功能,以便跨所有程序中维护统一的架构框架。
在此之后,我们声明必要的局部变量。
vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
并组织模型训练循环。模型训练迭代的次数在程序的外部参数中指定。
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; }
在循环主体中,我们从训练数据集中采样一个轨迹、及其状态。我们检查所选状态是否有保存的数据。然后,我们将信息从训练数据集传送到数据缓冲区。
state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum()==0) { iter--; continue; } bState.AssignArray(state);
基于准备好的数据,我们运行已训练模型的前馈通验。
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
不过,我们不会加载生成的预测值。此刻,我们对预测结果的兴趣不大,而是对它们与存储在训练数据集中的实际后续值的偏差感兴趣。因此,我们从训练数据集加载后续状态。
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
我们还准备了真实数值,我们将其与收到的预测进行比较。我们将这些数据投喂到我们模型的反向传播方法的参数之中。模型参数经过优化,从而该方法中的预测误差最小化。
if(!Encoder.backProp(Result,(CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
模型的前馈和反向传播通验成功完成之后,我们只需通知用户训练过程的进度,然后转到循环的下一次迭代。
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
我必须承认,训练过程的设计尽可能简单明了。训练的持续时间完全由用户在启动 EA 时在外部参数中指定的训练迭代次数决定。只有在出现错误、或用户在终端中手动停止程序时,才能提前终止训练过程。
训练过程完成后,我们清除图表上的注释字段,我们之前在其中显示有关训练进度的信息。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
我们在 MetaTrader 5 日志中显示训练结果,并启动当前程序的终止。训练模型的保存是在 OnDeinit 方法中实现的。完整的智能系统代码可在附件中找到。
参与者训练算法
第二个智能系统 “Study.mq5” 专为训练参与者政策而设计。此外,评论者模型也在该程序的框架内进行训练。
值得注意的是,评论者的角色非常具体。它服务于引导参与者朝着期望的方向行动。不过,在模型的作部署期间,不会用到评论者本身。换言之,有点矛盾的是,我们训练评论者只是为了训练参与者。
参与者训练 EA 的结构类似于之前讨论过的训练变换器的程序。在本文中,我们将特别关注训练模型的 Train 方法。
与前面的程序一样,该方法首先生成一个概率向量,从训练数据集中选择轨迹,并声明必要的局部变量。
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
之后,我们声明一个训练循环,在其主体中,我们从训练数据集中采样轨迹、及其状态。
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i <= 0) { iter--; continue; } state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum()==0) { iter--; continue; } bState.AssignArray(state);
在此,我们还对时间戳进行编码,将其表示为不同频率的正弦谐波向量。
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
我们将用所收集数据为即将到来的价格走势生成预测值。该操作是调用先前训练的编码器的前馈方法来执行的。
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false,(CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
如上所述,为了训练参与者,我们需要训练评论者。我们从训练数据集中提取参与者在收集训练数据集时执行的动作。
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); if(bActions.GetIndex() >= 0) bActions.BufferWrite();
我们将数据与预测的环境状态一起投喂到评论者模型之中。
Critic.TrainMode(true); if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
重点要注意的是,替代向评论者提供输出生成的预测价格变动和未来指标值,我们为其提供编码器的隐藏状态。这是因为在编码器输出中,我们将把原始时间序列的统计参数添加到预测值之中。因此,在评论者模型中处理该类数据首先需要归一化。但是,我们替换为采用编码器的隐藏状态,其中包含预测值,没有原生数据中固有的乖离。
在前馈通验期间,评论者会针对参与者动作生成评估。自然地,在训练的初始迭代期间,该评估可能会与参与者在环境交互期间获得的实际奖励有很大偏差。我们从训练数据集中提取实际奖励,反映所采取的具体动作的成果。
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
然后,我们运行评论者反向传播通验,以便把评估动作时的误差最小化。
下一步是训练参与者政策。为了执行其前馈通验,我们首先需要准备一个描述账户状态的张量,其是我们从训练数据集中提取而来。
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
然后我们执行模型的前馈通验,在方法的参数里传递帐户状态的描述向量、和编码器的隐藏状态。
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
显然,根据参与者前馈通验的结果,已形成了确定的动作向量。我们将这个向量与编码器的潜藏状态一起投喂给评论者。
Critic.TrainMode(false); if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
请注意,目前我们将禁用评论者训练模式。因为在这种情况下,评论者模型将仅用于将误差梯度传递给参与者。
我们将从两个方向优化参与者参数。首先,我们期望我们的训练数据集包含成功的运行,这些运行在训练期间产生了利润。我们将用该类通验作为基准,并采用监督式学习方法来改进该类参与者政策执行该动作。
if(Buffer[tr].States[0].rewards[0] > 0) if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
另一方面,我们明白可盈利通验会明显少于无盈利。不过,我们不能忽视亏损通验提供的信息。事实上,训练参与者政策期间,亏损通验与可盈利通验一样有用。虽然我们基于可盈利通验调整参与者政策,但我们需要远离那些亏损的。但有多少,朝向呢?甚至,即使在亏损通验中,也许有可盈利的交易。我们希望保留这些信息。这就是评论者的在参与者政策训练当中扮演的角色。
假设在评论者训练期间,其参数经过优化后会反馈给参与者依据动作、环境状态、和奖励之间的关系进行建模的函数。因此,如果我们维持环境状态不变,并且我们的目标是最大化奖励,则误差梯度将指示调整参与者的动作的方向,以便提升预期奖励。我们将在训练过程中采用该属性。
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); }
我们提取了评论者对当前动作的评估。然后我们的盈利提升 1%,并将亏损降低相同额度。这些将是我们现阶段的目标值。然后,我们将它们传递给评论者的反向传播操作,然后是参与者。
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
我要提醒您,在该阶段,我们已经禁用了评论者的训练模式。这意味着它仅将误差梯度传播到参与者。故此,该反馈通验不会调整评论者参数。参与者调整模型参数时,朝着预期奖励最大化。
接下来,我们只需通知用户模型训练进度,并转到循环的下一次迭代。
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
训练过程完成后,我们清除品种图表上的注释字段。我们将训练结果输出到日志中,并初始化 EA 终止过程。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
针对模型训练算法的讨论到此结束。您可在附件中找到本文用到的所有程序的完整代码。
3. 收集训练数据集
下一个重要阶段是收集训练数据集的数据。为了获得与环境交互的真实数据,我们使用 MetaTrader 5 策略测试器。于此,我们依据历史数据运行测试,并将结果保存到训练数据文件当中。
自然,在开始训练过程之前,会浮现一个问题:我们从训练数据集的哪里来获得成功的运行?有若干个选项可用。最明显的方式是获取历史数据,并手动“创建”理想的交易。毋庸置疑,这种方式是有效的,但它涉及手工劳动。随着训练集的增长,那么所需的劳动力、以及准备训练数据集所需的时间也会增加。甚而,手工劳作往往导致各种错误,这些都归因于“人为因素”。在我的工作中,我使用 Real-ORL 框架来收集初始数据,这已在本系列文章中多次详述。相应的代码包含在附件之中,这里就不赘述了。
初始训练数据集为模型提供了对环境的初步理解。然而,金融市场是如此多面,以至于任何训练集都无法完全复现它们。此外,模型从所分析指标和盈利交易之间学到的依赖关系,也许是错误的、或不完整的,因为训练集也许缺乏能够揭示此类差异的示例。因此,在训练过程期间,我们需要优化训练数据集。在此阶段,收集额外数据的方式会有所不同。
在此阶段的任务是优化参与者的学习政策。为了达成这一点,我们所需的数据,要相对接近当前参与者政策轨迹,这令我们能够明白当动作偏离当前政策时奖励的变化方向。依据这些信息,我们就可以朝着回报最大化的方向前进,从而提高当前政策的盈利能力。
有多种方式可以达成该目的,且它们也许会根据模型架构等因素而变化。举例,配以随机政策,我们可以在策略测试器中简单地按照当前政策运行若干个参与者通验。随机头会这样做。参与者动作的随机性将覆盖我们感兴趣的动作空间,我们将能够使用更新的数据重新训练模型。在判定性参与者政策的情况下,模型在环境状态和动作之间建立了明确的关系,我们可以往个体的动作里添加一些干扰,从而围绕当前参与者政策创建一个云状动作集。
在这两种情况下,使用策略测试器慢速优化模式来为训练数据集收集额外的数据都很方便。
我不会详细讨论与环境交互的程序。它们已在本系列的先前文章内讲述过。附件中包含本文中用到的所有程序的完整代码,包括与环境交互的代码,供您独立审阅。
4. 模型训练和测试
在讨论过模型训练的所有程序的算法之后,我们转到过程本身。这些模型将采用 EURUSD 的真实历史数据,依据 H1 时间帧进行训练。训练周期将涵盖 2023 年全年。
如早前所述,我们按指定的历史间隔收集初始训练集。在此数据集上,我们训练环境状态编码器模型。如前所述,编码器模型仅采用历史价格走势数据,和训练期间进行分析的指标。很明显,相同历史数据间隔内的所有通验数据都是相同的。因此,在这个阶段,没有必要优调训练数据集。故此,我们在初始训练数据集上训练编码器模型,直到获得期望的结果。
在学习过程期间,我们会监控预测误差。当误差不再减少,且其波动保持在较小范围内时,我们将停止训练过程。
自然,我们对模型学到的东西感兴趣。尽管我们的最终目标是训练一个可盈利的参与者政策。我仍然放纵自己的好奇心,并针对随机选择的训练集子集,比较了预测和实际价格走势。
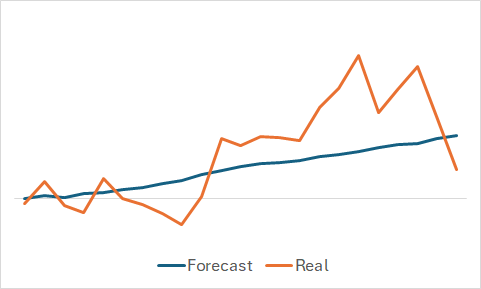
从图形中所示来讲,该模型捕捉到了即将到来的价格走势的主要趋势。
相当平滑的预测价格走势、含有轻微的波动,也许会让人相信该模型可能已经捕获了训练集的总体趋势,并且无论实际数据如何,所有状态都会显示类似的形态。为了确认或反驳这一假设,我们从训练数据集中采样另一种状态,并在预测和实际价格走势之间执行类似的比较。

在此,我们看到价格走势的预测值波动更明显。不过,它们仍与实际数据相对接近。
训练环境状态编码器之后,我们进入第二阶段,训练参与者政策。此过程是迭代的。训练的第一次迭代是在初始训练数据集上进行的。在这个阶段,我们令模型初步了解环境。幸好采用 Real-ORL 方法收集了可盈利运行,我们为未来的政策奠定了基础。
在训练过程中,与第一阶段一样,我们专注于监控模型的误差。在初始阶段,我建议关注评论者的误差值。是的,我们需要一个能够产生利润的参与者政策,但要记住我们早前的讨论:为了训练参与者,我们需要训练评论者。在评论者内正确建立依赖关系将有助于我们朝着正确的方向调整参与者的政策。
当评论者的误差停止减少,并稳定下来时,我们转到策略测试器,并运行 Research.mq5 智能系统收集额外数据,我建议在慢速优化模式下运行。
然后,我们继续对参与者和评论者模型进一步训练。在重新训练过程开始时,您也许会注意到由于处理新数据,两个模型的误差都略有增加。然而,很快您就会看到误差逐渐减少,并达到新的最小值。
因此,我们重复优化训练集的迭代,并重新训练模型。
我还要提醒您,参与者的架构使用了随机头,这为动作引入了一些随机性。因此,在测试经过训练的参与者政策时,建议在一个测试周期内运行多次通验。如果通验之间的偏差可以忽略不计,则可认为参与者的政策已训练完毕。
在准备本文时,我们在 2024 年 1 月的历史数据上测试了经过训练的模型。该区间不是训练集的一部分,如此模型遇到了新数据。训练和测试区间很接近,因此我们可以得出结论,数据集是可比的。
在训练过程中,我设法获得了一个能够在训练和测试数据集上均产生盈利的模型。
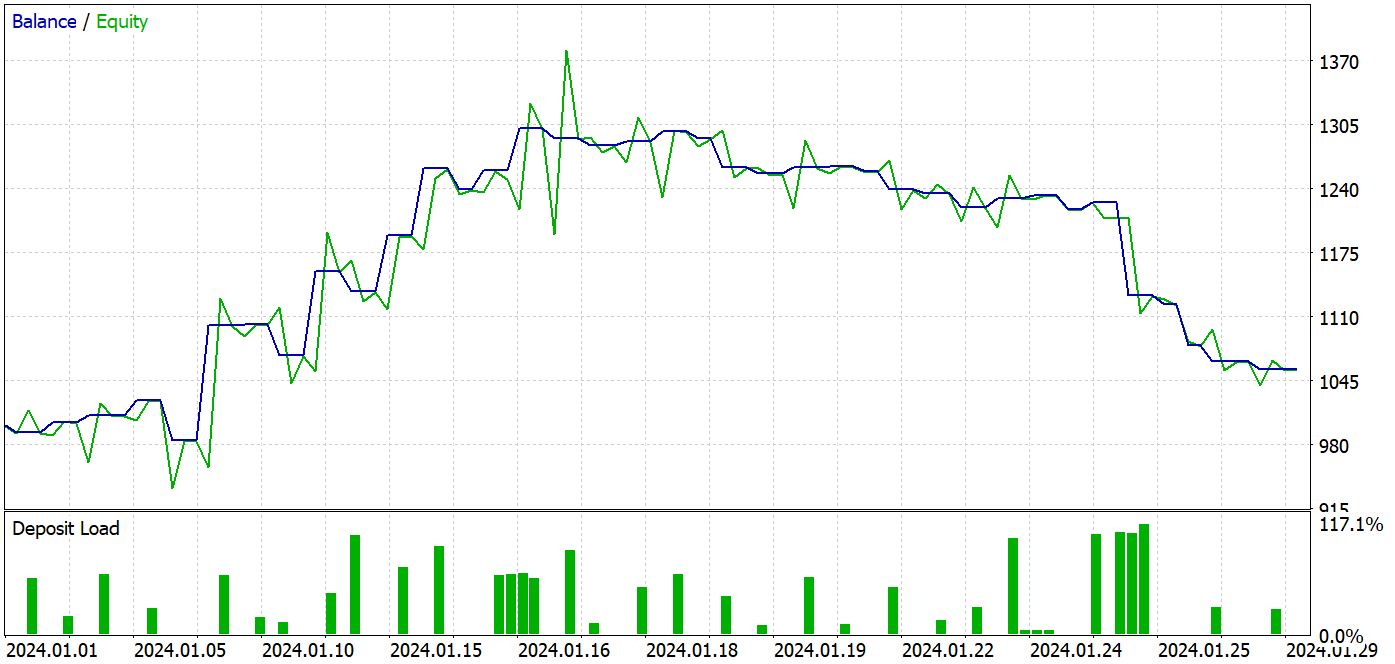
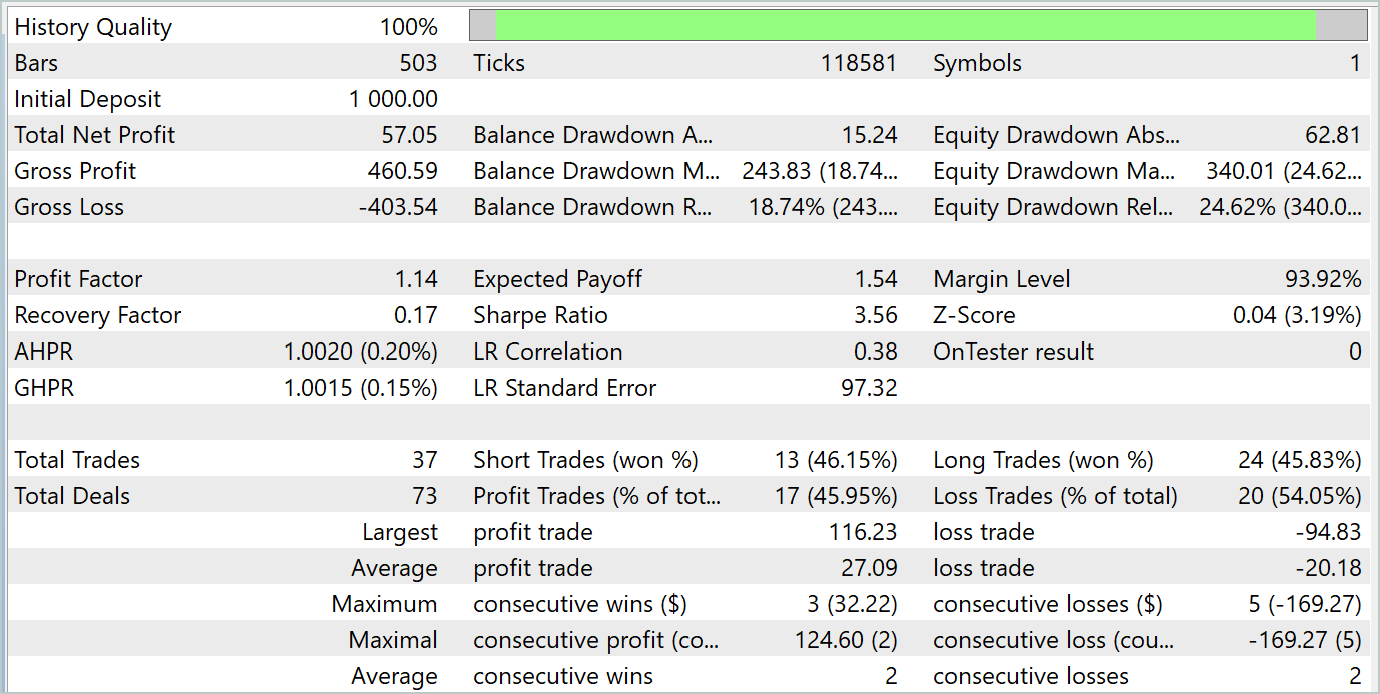
在测试期间,该模型完成了 37 笔业务,其中 17 笔以盈利了结。这相当于近 46%。多头和空头仓位之间的盈利交易份额几乎相等。相差只有 0.32%,也许只是由于交易数量少导致的计算错误。最大和平均盈利交易均高于亏损交易的相应指标。这令我们能够以盈利结束测试区间。盈利因子为 1.14。然而,令人震惊的是,盈利都是在前半个月做出的。紧随其后的是余额的横向走势。而这个月的最后一周则出现了回撤。
结束语
在本文中,我们以 MSFformer 方法的方式训练和测试了模型。测试结果表明性能良好,暗示所提议方式颇有前景。然而,测试期最后一周的余额回撤值得注意,这也许示意需要额外的模型训练阶段。
参考
文中所用程序
| # | 名称 | 类型 | 说明 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 数据集收集 EA |
| 2 | ResearchRealORL.mq5 | EA | 利用 Real-ORL 方法收集数据集的 EA |
| 3 | Study.mq5 | EA | 模型训练 EA |
| 4 | StudyEncoder.mq5 | EA | 编码器训练 EA |
| 5 | Test.mq5 | EA | 模型测试 EA |
| 6 | Trajectory.mqh | 类库 | 系统状态定义结构 |
| 7 | NeuroNet.mqh | 类库 | 创建神经网络的类库 |
| 8 | NeuroNet.cl | 代码库 | OpenCL 程序代码库 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/15171
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
