
Redes neurais em trading: Segmentação periódica adaptativa (LightGTS)

Introdução
A previsão de séries temporais há muito se tornou uma ferramenta essencial em diversas áreas, da energia e transporte à saúde e educação. No entanto, é justamente nas finanças, onde o valor de cada segundo pode ser medido em dinheiro, que a precisão da previsão se torna criticamente importante. Aqui não se perdoam erros: o menor equívoco no modelo e a estratégia passa a operar no negativo.
As abordagens tradicionais, sejam estatísticas ou baseadas em aprendizado profundo, geralmente são construídas segundo o princípio: uma tarefa, um modelo. Essas soluções funcionam bem em condições isoladas, mas na prática os mercados financeiros se comportam de forma imprevisível: mudança de volatilidade, de escalas, de ciclos e de regimes, tudo isso coloca em dúvida a eficácia de modelos rigidamente vinculados.
Nesse contexto surgem os chamados modelos fundamentais de séries temporais (Time Series Foundation Models, TSFM). Eles são treinados em enormes volumes de dados heterogêneos, apostando na universalidade e escalabilidade. Contudo, a realidade é que tais modelos exigem recursos computacionais colossais, e o ganho de precisão nem sempre justifica os custos. São dezenas de milhões de parâmetros, mas na prática a universalidade muitas vezes se perde nos detalhes.
A particularidade das séries temporais está no seu ritmo. Diferentemente do texto, onde o token é uma palavra, aqui a escala e a periodicidade são fundamentais. Alguns dados chegam uma vez por hora, outros a cada 15 minutos. Alguns contêm sazonalidade diária ou semanal, outros trimestral ou anual. Tudo isso influencia o chamado período interno, um padrão recorrente nos dados que é crítico para uma previsão de qualidade. Além disso, ao mudar a escala, o comprimento do ciclo também muda, e se o modelo não souber lidar com isso, sua capacidade de generalização cai drasticamente.
O problema é que a maioria dos modelos existentes utiliza tokenização fixa. Eles simplesmente dividem os dados em partes de mesmo comprimento, sem considerar a escala e a estrutura dos períodos. Isso faz com que alguns tokens fiquem sobrecarregados de dados, enquanto outros fiquem quase vazios. A informação se dilui, os padrões recorrentes se rompem. Isso é especialmente perceptível quando um modelo treinado em uma escala é aplicado a outra: a precisão das previsões cai, torna-se necessário aumentar o número de parâmetros e, consequentemente, crescem o tempo e o custo de treinamento.
Os autores do trabalho "LightGTS: A Lightweight General Time Series Forecasting Model" decidiram não utilizar força bruta de maneira direta, mas aplicar uma abordagem mais inteligente, explorando propriedades naturais das séries temporais: invariância de escala e periodicidade. Como resultado, surgiu o framework LightGTS, leve, eficiente e precisamente ajustado para tarefas reais de previsão de séries temporais. Sua ideia central não é combater as diferentes escalas, mas adaptar-se a elas.
Em vez de uma segmentação rígida em fragmentos de mesmo tamanho, foi proposta a tokenização periódica. O modelo divide os dados de forma adaptativa em segmentos cujo comprimento corresponde a um ciclo completo. Isso permite capturar padrões íntegros independentemente da escala, seja em gráfico diário ou em gráfico de minutos. A semântica dentro do token permanece inalterada e, consequentemente, a representação das características torna-se estável e transferível entre diferentes tarefas.
Para a previsão, o framework utiliza decodificação paralela: o último token do codificador é usado como ponto de partida e, com base nele, todos os valores futuros são gerados de uma só vez. Isso não apenas reduz o tempo e diminui o acúmulo de erros, ao contrário das abordagens autorregressivas passo a passo, como também permite explorar melhor a própria estrutura da série. O último token contém a essência de todo o histórico e está diretamente relacionado ao futuro, tornando a previsão lógica e estruturalmente fundamentada.
Adicionalmente, os autores do LightGTS abandonaram a projeção fixa de características. Em seu lugar, é utilizada uma camada flexível capaz de se adaptar a diferentes comprimentos de ciclo e a múltiplas fontes de dados. Isso é especialmente relevante em aplicações financeiras, nas quais em um mesmo portfólio podem coexistir dados horários de ações e dados diários de indicadores macroeconômicos.
Os resultados falam por si. O modelo LightGTS apresenta precisão no nível das melhores soluções da indústria e, ao mesmo tempo, possui menos de 5 milhões de parâmetros. Isso é de 10 a 100 vezes menos do que outras modelos TSFM. Consequentemente, há menos tempo de treinamento, menores custos de infraestrutura e mais chances de implementar o modelo em um sistema de trading real ou em uma plataforma analítica.
Algoritmo LightGTS
Imagine uma tarefa típica de previsão nos mercados financeiros. Temos uma série temporal multivariada, por exemplo, cotações, volumes, indicadores e outros sinais de mercado. Vamos chamá-la de Xt={xi,t-L:t}i=1,C, onde cada xi representa as observações de um canal específico ao longo dos últimos L passos de tempo. O número de canais C pode variar livremente, de um até dezenas. Essa é a nossa janela para o passado, um segmento deslizante do histórico analisado.
Nosso objetivo é olhar F passos à frente no futuro e prever os valores Ŷt={ŷi,t:t+F}i=1,C. Para avaliar a precisão durante o treinamento, também dispomos dos dados reais Yt={yi,t:t+F}i=1,C. Tudo isso se encaixa no esquema clássico de previsão.
Agora vem a parte mais interessante. O treinamento do modelo é realizado em duas etapas. Primeiro ocorre um pré-treinamento em larga escala com séries temporais heterogêneas provenientes de diferentes fontes. Podem ser dados históricos de ações, moedas, indicadores econômicos, clima, qualquer conjunto que apresente dependências temporais. Em seguida, é realizada a etapa de ajuste fino (fine-tuning) do modelo para uma tarefa específica.
Um ponto interessante: o modelo pode inclusive não ser ajustado adicionalmente, basta apenas testá-lo no conjunto de teste, caso ele tenha sido inicialmente treinado de forma suficientemente universal. Isso é especialmente importante no contexto do trading algorítmico: nem sempre há possibilidade de ajustar o modelo para cada instrumento, principalmente em tempo real.
O que torna o modelo LightGTS único? Tudo começa com a tokenização periódica, uma verdadeira régua inteligente que se adapta ao ritmo da própria série. Os autores do framework propõem dividir a sequência em patches periódicos, segmentos de dados que correspondem a um ciclo completo, por exemplo diário ou semanal. Essa operação é chamada de Adaptive Periodical Patching. Ela considera a escala e a estrutura da série temporal e forma segmentos que se encaixam perfeitamente nas repetições do comportamento do mercado.
Para descrever o método, consideremos um caso simples, uma série temporal unidimensional. Na prática, tudo é facilmente escalado para dados multidimensionais: cada canal é simplesmente processado separadamente, sem perda de estrutura.
Suponhamos que estamos trabalhando com um conjunto de séries temporais de diferentes fontes, ativos financeiros, mercados, timeframes. Cada série possui seu próprio ritmo interno, o chamado período natural. Pode ser, por exemplo, um ciclo diário de negociação, volatilidade semanal ou uma tendência sazonal. Para trabalhar de forma eficiente com essas séries, o primeiro passo é determinar o comprimento desse período, isto é, quantos pontos temporais dos dados analisados compõem um ciclo completo.
Se houver informação prévia sobre a frequência dos dados, por exemplo, se eles chegam uma vez por hora ou uma vez por minuto, determinar o comprimento do ciclo é simples: para um período diário com dados horários, isso corresponde a 24 pontos. Porém, se não houver dados sobre a frequência, recorre-se à análise espectral, incluindo a transformada rápida de Fourier (FFT), que ajuda a identificar as frequências dominantes na série. São justamente elas que refletem os padrões recorrentes, ciclos tão importantes na previsão da dinâmica do mercado.
Assim que o comprimento do ciclo, que denotaremos como P, é determinado, toda a série temporal é cuidadosamente dividida em fragmentos sequenciais e não sobrepostos exatamente de acordo com esses períodos. Cada fragmento ou patch contém P pontos e cobre completamente um ciclo. A quantidade desses patches é simplesmente L dividido por P com arredondamento para baixo, onde L é o comprimento da série original.
Esse passo, à primeira vista, parece simples, mas na prática abre para o modelo acesso a um nível completamente novo de estrutura semântica. Diferentes timeframes, frequências e fontes passam a ser interpretados em um espaço unificado e sincronizado pelo período. Isso elimina o ruído proveniente das diferenças de escala dos dados e permite que o modelo aprenda a identificar padrões que realmente se repetem de ciclo em ciclo, e não apenas a se ajustar à volatilidade local.
É exatamente essa forma de segmentação que torna possível o treinamento com fontes heterogêneas. Apesar das diferenças de frequência, todas são trazidas a uma forma comparável, na qual o período é a unidade central de informação. Isso significa que o modelo pode extrair e generalizar sinais de mercado recorrentes, algo criticamente importante para previsões confiáveis em condições reais de negociação.
Depois que a série temporal é dividida em patches cíclicos, cada um cobrindo um ciclo completo da série, é fundamental converter corretamente esses patches em uma representação vetorial. É nesse ponto que começa a magia da camada de projeção, mas, como na vida, o diabo está nos detalhes.
A solução ingênua seria utilizar uma matriz de projeção fixa que transforma cada patch em um token. O problema? Diferentes dados financeiros possuem diferentes comprimentos de ciclo: um ciclo diário em velas de um minuto corresponde a 1440 pontos, enquanto um ciclo semanal em dados horários possui apenas 120. Como resultado, o tamanho dos patches de entrada varia, e uma matriz fixa simplesmente não consegue lidar com isso: ou ela corta os dados, ou exige que tudo seja ajustado para um tamanho comum. A interpolação simples, naturalmente, ajuda, pois é possível esticar ou comprimir os dados. Porém há um inconveniente: tais operações distorcem o significado. O resultado são tokens visualmente bem alinhados, mas vazios em conteúdo real para o modelo.
Para evitar essas distorções, é introduzida a camada de projeção flexível (Flex Projection Layer). Sua tarefa não é apenas comprimir o patch para uma dimensionalidade fixa, mas fazer isso preservando a semântica dos dados. Em outras palavras, os tokens obtidos de um patch de comprimento 96 devem ser equivalentes aos que seriam gerados a partir de um patch de comprimento 144, se ambos representarem o mesmo ciclo de mercado.
Como isso funciona tecnicamente? Suponhamos que temos pesos de projeção θ treinados para um patch de comprimento P. Queremos adaptá-los para um novo patch de comprimento P′, de modo que o produto entre dados e pesos, e consequentemente os tokens, permaneça o mais próximo possível do original. A interpolação simples não é adequada aqui, pois é excessivamente grosseira. Por isso é utilizada uma transformação linear com adaptação dos pesos por meio da matriz pseudoinversa, método conhecido em métodos numéricos e na análise de regressão.
Esse mecanismo é chamado de flex-resize e resolve um problema de otimização: encontrar novos pesos θ′ que, ao transformar os novos patches, produzam um resultado o mais próximo possível do anterior, em termos da norma de Frobenius, falando em termos matemáticos. Nesse contexto também é introduzido o coeficiente δ, que considera a diferença de variâncias entre o patch original e o patch interpolado, permitindo preservar a estabilidade estatística das projeções. A fórmula final do flex-resize parece bastante complexa, mas em essência é uma maneira inteligente de tornar a matriz de pesos flexível e adaptativa.
Na implementação da Flex Projection Layer são utilizadas duas matrizes de parâmetros, uma para a entrada e outra para a saída, cada uma definida para um tamanho de patch de referência, por exemplo 96. Durante a propagação para frente do modelo (forward pass), essas matrizes são ajustadas ao comprimento necessário do patch atual por meio da transformação δ⁻¹(A)+. Após isso, os patches são facilmente projetados para o espaço latente do modelo, os tokens ficam prontos e preservam toda a estrutura do ciclo de mercado original.
Dessa forma, independentemente de o modelo analisar uma tendência semanal em velas diárias ou realizar scalping em gráficos de minutos, ele sempre trabalha com os dados em uma representação única e consistente. Isso elimina o conflito entre diferentes escalas e permite utilizar de forma eficiente pesos previamente treinados sem a necessidade de recomeçar o treinamento do zero. Em condições de mercados financeiros, onde os dados chegam de diferentes fontes e com diferentes frequências, essa flexibilidade não é luxo, mas uma necessidade.
Na arquitetura do framework LightGTS, de forma semelhante ao Transformer clássico, são utilizados Codificador e Decodificador, cada um incluindo módulos de atenção multi-head e camadas totalmente conectadas (Feed-Forward Networks). No entanto, há um detalhe fundamental: nos módulos de atenção é aplicada a codificação posicional rotacional (RoPE), que permite considerar não apenas as posições absolutas, mas também as posições relativas dos tokens. Para séries temporais, nas quais não importa apenas a ordem, mas também a distância entre os pontos, isso é especialmente relevante.
Depois que os patches periódicos são convertidos em tokens por meio da Flex Projection, forma-se a sequência de tokens 𝐗ₑ = {𝐱ₑ₁, 𝐱ₑ₂, …, 𝐱ₑₙ}, onde cada 𝐱ₑᵢ é a representação vetorial do i-ésimo patch. Ao processar essa sequência, o Codificador impõe uma estrutura posicional utilizando RoPE: os tokens não apenas registram sua posição, mas também consideram o deslocamento relativo entre si.
Especificamente, para cada token são calculados vetores de consulta (Query) e de chave (Key) por meio de matrizes treináveis 𝐖Q e 𝐖K. Em seguida, ao par de vetores (𝐱ₑᵢ, 𝐱ₑⱼ), que representam as posições i e j, é aplicada a matriz rotacional 𝐑i−j, que codifica precisamente a diferença entre suas posições. A medida de similaridade resultante entre os tokens i e j é calculada pela fórmula:
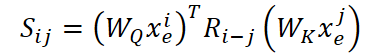
Quanto maior esse valor, maior a atenção que o token i dedica ao token j. Todos esses valores são normalizados por meio da função SoftMax e utilizados para a soma ponderada dos vetores Value, obtidos por meio de outra matriz treinável 𝐖V
É essa atenção que literalmente determina, para cada token, para quais vizinhos olhar e com qual intensidade. Após o mecanismo de atenção, cada token é adicionalmente processado por um bloco totalmente conectado, Feed-Forward Network, que extrai características latentes e enriquece a representação.
Como resultado, na saída do Codificador obtém-se um espaço latente no qual cada vetor 𝐞ⱼ contém não apenas a informação local do patch, mas também o contexto de todos os demais tokens, levando em conta suas posições relativas na série temporal. Esse mecanismo permite que o modelo compreenda a estrutura, o ritmo e os padrões recorrentes nos dados, algo crucial para séries temporais financeiras, nas quais não é apenas o ponto isolado que importa, mas também seu entorno.
Como já mencionado anteriormente, a segmentação periódica em patches ajuda a extrair ciclos recorrentes das séries temporais. Mas, para aproveitar ao máximo essa informação também na geração da previsão, o modelo aplica uma nova abordagem, a decodificação paralela periódica. Diferentemente da abordagem autorregressiva clássica, em que a previsão é construída passo a passo, aqui é utilizada uma estratégia não autorregressiva, que permite processar imediatamente todo o intervalo futuro.
A ideia central é simples, porém elegante: o último token 𝐞ₙ do espaço latente de saída do Codificador contém informação comprimida de toda a sequência anterior, incluindo sua periodicidade interna. Por isso, utilizamos exatamente esse token, clonando-o K vezes (onde K = F/P, isto é, para quantos ciclos é necessário gerar a previsão), e assim obtemos a matriz 𝐇, que servirá como entrada para o Decodificador.
No entanto, é importante considerar que a influência do último token sobre a previsão diminui à medida que avançamos no tempo. Por isso, a cada vetor clonado 𝐡ⱼ é aplicada uma função de ponderação ω(j)=1/eʲ, que reduz exponencialmente sua contribuição conforme aumenta a distância em relação ao momento atual. Os tokens ponderados ω(j)·𝐡ⱼ são enviados simultaneamente ao Decodificador, o que constitui a essência da arquitetura paralela do Decodificador.
Na saída do Decodificador obtém-se a matriz 𝐙, tokens de previsão correspondentes aos ciclos futuros. Para converter esses tokens em valores tradicionais da série temporal, o modelo utiliza a projeção inversa por meio do já conhecido mecanismo flex-resize, desta vez aplicado aos parâmetros do decodificador θd
Assim, o modelo gera todo o segmento previsto 𝐘̂ de uma só vez, sem o acúmulo de erros e atrasos característicos da previsão passo a passo. Isso não apenas acelera os cálculos, como também preserva melhor a periodicidade, pois ela foi incorporada ainda na etapa de tokenização e atravessa toda a arquitetura, do Codificador até a saída final.
Nos bastidores, o LightGTS funciona como um mecanismo de relógio: rítmico, preciso, sem custos excessivos. Graças à tokenização periódica e à decodificação paralela, o modelo evita as armadilhas clássicas de complexidade excessiva e baixa capacidade de generalização.
De acordo com a prática consolidada na área de previsão de séries temporais, os autores do framework LightGTS utilizam como função de perda o clássico erro quadrático médio (Mean Squared Error — MSE). Ele mede o desvio entre os valores previstos e os dados reais observados, atuando como critério objetivo de qualidade da previsão.
A visualização autoral do framework LightGTS é apresentada a seguir.

Implementação com MQL5
Após a análise detalhada dos aspectos teóricos do framework LightGTS, passamos à parte prática do nosso artigo. Nesta seção será apresentada nossa própria visão da implementação dos principais componentes do modelo em MQL5, considerando as particularidades das séries temporais financeiras e as limitações da plataforma.
Comecemos por um dos elementos mais fundamentais e, ao mesmo tempo, mais interessantes, o patching periódico adaptativo. É justamente com esse mecanismo que se inicia o processo de transformação da série temporal em uma estrutura adequada para processamento por um Transformer. Aqui nos deparamos com alguns desafios não triviais.
Um deles é a alteração dinâmica do tamanho do patch, já mencionada pelos autores do framework original. No artigo, é proposta uma solução elegante para essa tarefa por meio da interpolação linear dos pesos. Contudo, na prática, essa abordagem resolve apenas parte do problema.
Pois, se o tamanho do patch muda, então também muda a sua quantidade, de forma dinâmica e imprevisível. E isso já adiciona complexidade extra à arquitetura do modelo, especialmente na implementação em uma linguagem fortemente tipada como MQL5. Estruturas clássicas como laços e arrays exigem controle rigoroso de dimensões em todas as etapas, o que significa que não basta apenas adaptar a dimensionalidade dos dados de entrada, é necessário também desenvolver um mecanismo de segmentação adaptativa da série temporal em uma quantidade variável de patches, preservando sua periodicidade e coerência com o histórico de observações.
Infelizmente, as soluções arquiteturais que utilizamos não permitem empregar dimensionalidade dinâmica nos tensores de entrada ou saída durante a execução das operações. Portanto, precisamos de uma abordagem diferente, mais pragmática, que assegure tamanhos fixos de buffers mantendo a possibilidade de trabalhar com um número variável de tokens.
Uma das possíveis alternativas é criar um buffer com capacidade deliberadamente excedente, calculado para o número máximo possível de tokens. Caso o número real de tokens seja menor, as células excedentes são preenchidas com zero. Essa abordagem realmente oferece certa flexibilidade ao lidar com diferentes quantidades de patches, porém essa flexibilidade é alcançada ao custo de uso injustificado de memória, grande parte da qual permanece inutilizada.
Além disso, não se deve esquecer a vulnerabilidade central da arquitetura Transformer, a complexidade quadrática do mecanismo de atenção em relação ao comprimento da sequência. Quanto mais tokens forem fornecidos como entrada, maior será o tempo e os recursos necessários para executar os blocos de atenção. Em outras palavras, um número excessivo de tokens não é apenas ineficiente do ponto de vista de memória, mas também prejudica diretamente o desempenho computacional do modelo, especialmente em condições de tempo real ou ao processar grandes volumes de dados de mercado de alta frequência.
Surge, portanto, a necessidade de uma abordagem alternativa e mais flexível. Nesse contexto, merece atenção o conceito de LightGTS patches periódicos não sobrepostos proposto pelos autores do framework, no qual cada segmento da série temporal corresponde a um ciclo completo. Isso é bastante lógico: séries temporais frequentemente contêm componentes periódicos bem definidos, e a análise isolada de cada período permite extrair características semanticamente mais puras.
No entanto, propomos olhar para o problema sob outra perspectiva. E se abandonarmos a exigência rígida de não sobreposição dos patches? Em vez disso, podemos fixar a quantidade desejada de patches na saída e ajustar o comprimento da sobreposição entre janelas vizinhas de acordo com a periodicidade da sequência original.
Essa abordagem oferece uma série de vantagens. Em primeiro lugar, permite garantir um número constante de patches independentemente da ciclicidade original da série temporal analisada, o que é extremamente conveniente ao projetar uma arquitetura fixa. Em segundo lugar, por meio de uma sobreposição flexível, é possível assegurar cobertura completa da estrutura cíclica dos dados, sem cortá-la ou perder informações nas fronteiras das janelas. Por fim, isso possibilita um controle mais suave da resolução da representação semântica, preservando a compacidade do tensor de saída.
Em termos simples, propomos trocar a rigidez de um patch por ciclo por uma densidade de representação controlada, preservando ao mesmo tempo o volume total de informação na saída e aumentando a robustez do modelo a variações no comprimento da série de entrada.
Acredito que o conceito esteja claro. Agora é o momento de passar à implementação prática. O primeiro passo é determinar a periodicidade da série temporal analisada. Para isso, utilizaremos um método clássico e comprovado ao longo do tempo, baseado na Transformada Rápida de Fourier (Fast Fourier Transform — FFT).
A essência da abordagem é simples: analisamos o espectro de amplitudes das componentes de frequência da série temporal e identificamos a frequência que possui a maior energia. Em geral, é ela que corresponde ao ciclo dominante nos dados. O período, por sua vez, é calculado como o inverso da frequência identificada.
Por que escolhemos exatamente FFT? Em primeiro lugar, trata-se de um algoritmo rápido e eficiente mesmo ao trabalhar com grandes volumes de dados. Em segundo lugar, ele permite identificar dependências periódicas ocultas, que muitas vezes são impossíveis de detectar visualmente. Por fim, FFT é especialmente útil quando não há informação a priori sobre as características de frequência da série temporal, algo bastante comum em dados reais de trading.
E, naturalmente, um bônus adicional é a disponibilidade de uma implementação pronta de FFT em nossa biblioteca. Vale lembrar que já a utilizamos no contexto do desenvolvimento do framework FITS.
A implementação de FFT existente em nossa biblioteca retorna as partes real e imaginária do espectro, o que corresponde totalmente à forma clássica de apresentação do resultado da transformada rápida de Fourier. No entanto, por si só, essa informação ainda não responde à pergunta sobre qual frequência domina o sinal e define a estrutura das oscilações.
Para não sobrecarregar a CPU e preservar a eficiência paralela, implementamos um kernel que, diretamente no contexto OpenCL, determina a frequência dominante para cada sequência unitária. Cada thread recebe seu próprio espectro, calcula a energia de todas as componentes de frequência e seleciona aquela com maior amplitude. É como ouvir uma melodia complexa e identificar imediatamente o ritmo principal que define sua estrutura. Essa abordagem é especialmente importante ao trabalhar com séries temporais multimodais, quando cada variável pode possuir sua própria frequência característica.
O algoritmo será implementado no kernel OpenCL-MainFreq, que opera com arrays das componentes real e imaginária do espectro. Na saída, ele retorna um array contendo os índices das frequências mais pronunciadas para cada sequência.
__kernel void MainFreq(__global const float* freq_r, __global const float* freq_im, __global float *main_freq, int dimension ) { if(dimension <= 0) return; //--- size_t n = get_global_id(0); const int shift = n * dimension;
No corpo do kernel, primeiro identificamos cada thread de execução no espaço unidimensional de tarefas. O índice obtido indica o número único da sequência unitária analisada. Com base nisso, determinamos imediatamente o deslocamento nos arrays do espectro, de modo a processar exclusivamente a sua própria sequência.
Em seguida, inicializamos as variáveis para armazenar a amplitude máxima, energia, e o índice correspondente.
float max_f = 0; float max_id = 0; float energy;
Com isso, encerramos a etapa preparatória e organizamos o laço ao longo do espectro, começando pela primeira harmônica.
for(int i = 1; i < dimension; i++) { float2 freq = (float2)(freq_r[shift + i], freq_im[shift + i]); energy = ComplexAbs(freq); if(max_f < energy) { max_f = energy; max_id = i + 1; } }
A frequência zero, componente DC, é deliberadamente ignorada, pois não carrega informação sobre periodicidade e apenas reflete a componente constante do sinal.
A cada iteração formamos um número complexo a partir das partes real e imaginária. O módulo desse número representa a intensidade da frequência correspondente. Se a energia encontrada exceder o máximo atual, atualizamos os valores armazenados.
Por fim, após percorrer todo o espectro, gravamos o resultado no buffer global de dados.
main_freq[n] = max_id; }
O algoritmo funciona como um maestro experiente, que acompanha atentamente cada instrumento da orquestra e determina qual deles executa a parte principal. Não apenas identificamos a frequência, mas calculamos o período mais pronunciado do sinal, que posteriormente é utilizado para a construção adaptativa de patches no modelo. Como cada série, em condições de multimodalidade, é processada de forma independente, obtemos um sistema escalável, flexível e totalmente autônomo de determinação da periodicidade local.
Também é importante destacar que o algoritmo proposto é totalmente determinístico, não contém parâmetros treináveis e não exige custos de treinamento. Ele se baseia exclusivamente na natureza física do espectro: a avaliação da amplitude das componentes de frequência é realizada diretamente, sem recorrer a estatísticas, regressões ou pesos adaptativos. Isso torna o método transparente, confiável e especialmente conveniente na etapa de pré-processamento dos dados, quando é fundamental não introduzir distorções associadas a subtreinamento ou sobretreinamento. Em outras palavras, aqui opera matemática pura e imparcial, e não suposições probabilísticas, o que é particularmente relevante na análise de séries temporais de mercado voláteis.
A próxima etapa do nosso trabalho será a implementação direta do algoritmo de patching adaptativo com alteração dinâmica do tamanho do segmento. Contudo, como é possível imaginar, isso não pode ser explicado em poucas palavras. A implementação exige atenção a numerosos detalhes técnicos, e o tamanho do artigo atual já é considerável. Por isso, nas melhores tradições de séries com enredo envolvente, propomos fazer uma breve pausa e continuar a discussão sobre a implementação das abordagens propostas no próximo artigo.
Nele analisamos passo a passo como implementar o mecanismo de formação dinâmica de patches considerando o comprimento variável do ciclo, preservando ao mesmo tempo uma quantidade estável de tokens de saída. Também discutiremos possíveis compromissos entre a flexibilidade da arquitetura e a eficiência computacional.
Considerações finais
Neste artigo, examinamos detalhadamente os fundamentos teóricos do framework LightGTS, com foco em seus principais componentes: patching periódico, projeção flexível de tokens e o mecanismo de decodificação paralela. Analisamos como a arquitetura lida com séries temporais multimodais e se adapta a diferentes períodos sem a necessidade de recomeçar o treinamento do modelo. Foi dada atenção especial aos aspectos técnicos do cálculo da frequência dominante utilizando a transformada rápida de Fourier.
Também abordamos as limitações práticas relacionadas à alocação dinâmica de memória e ao número variável de tokens, e propusemos soluções alternativas baseadas em patches sobrepostos e comprimento fixo do vetor de saída. Essa abordagem não apenas melhora a compatibilidade com a arquitetura Transformer, como também permite utilizar os recursos de forma mais racional, evitando consumo excessivo de memória e queda de desempenho.
O material apresentado serve como base sólida para a implementação posterior da versão completa do patching adaptativo e sua integração à arquitetura preditiva. No próximo artigo continuaremos esse percurso, concentrando-nos nas implementações concretas da segmentação adaptativa da série temporal e na integração dos tokens obtidos ao modelo treinável.
Links
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | Expert Advisor | EA de treinamento offline dos modelos |
| 2 | StudyOnline.mq5 | Expert Advisor | EA de treinamento online dos modelos |
| 3 | Test.mq5 | Expert Advisor | Expert Advisor para testar o modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código de programas OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/18596
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso