
ニューラルネットワークが簡単に(第97回):MSFformerによるモデルの訓練

はじめに
前回の記事では、CSCMやSkip-PAMなど、MSFformerモデルの主要モジュールを構築しました。CSCMモジュールは分析対象の時系列データから特徴量ツリーを構築し、Skip-PAMは時間的特徴ツリーに基づくアテンションメカニズムを用いて、複数のスケールで時系列データから情報を抽出します。この記事では、MetaTrader 5のストラテジーテスターを使用してモデルを訓練し、実データを用いたパフォーマンス評価をおこないます。
1. モデルアーキテクチャ
モデルの訓練を開始する前に、いくつかの準備手順を完了する必要があります。まず最初に、モデルのアーキテクチャを定義します。MSFformerは時系列予測のために設計された手法であるため、他のいくつかの類似手法とともに、環境状態エンコーダーモデルへ統合します。
1.1 環境状態エンコーダのアーキテクチャ
環境状態エンコーダーのアーキテクチャは、CreateEncoderDescriptionsメソッド内で定義されます。このメソッドは、動的配列オブジェクトへのポインタをパラメータとして受け取り、モデルのアーキテクチャを指定します。
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
メソッド本体では、受け取ったポインタの妥当性を確認し、必要であれば動的配列の新しいインスタンスを作成します。
次に、モデルアーキテクチャの定義に進みます。エンコーダーへの入力は、環境の現在の状態を記述する「生の」データで構成されます。通常どおり、入力層には活性化関数のない基本的な全結合層を使用します。この場合、生の入力データが指定された層の結果バッファに直接書き込まれるため、活性化関数を使用する必要はありません。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
入力層のサイズは、環境状態記述テンソルの次元と正確に一致する必要があります。さらに、環境状態の記述は、モデルの訓練から運用までの全段階で一貫して同じである必要があります。訓練段階と本番段階でのパラメータ同期を容易にするため、BarDescr(1本のローソク足を表す要素の数)とHistoryBars(分析対象の履歴データの深さ)の2つの定数を定義します。これらの定数の積が入力層のサイズを決定します。
前述のとおり、「生の」(未処理の)データをそのままモデルに入力する方針です。このアプローチには、訓練プログラムと運用プログラムのデータ前処理ブロック間の同期が容易になるという大きな利点があります。
一方で、未処理のデータを使用すると、モデルの訓練効率が低下することがあります。これは、入力データ内の異なる要素間で統計的な変動が大きいためです。この問題を軽減するため、モデル内部で入力データの初期前処理をおこないます。このタスクはバッチ正規化層によって実施され、この層のアルゴリズムに従い、出力データの平均値はゼロに近づき、分散は1に調整されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
正規化された時系列の前処理された入力データを特徴量抽出モジュールCSCMに入力します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCSCMOCL; descr.count = HistoryBars; descr.window = BarDescr;
特徴量抽出は単変量時系列の枠組み内で実行されることに注意してください。この文脈において、シーケンスの長さは分析対象の履歴データの深さに対応し、単変量シーケンスの数は1本のローソク足を表すベクトルのサイズと等しくなります。ただし、これまでの記事では、環境状態記述テンソルを構築する際に、データを「行が分析対象のバー、列が特徴」に対応する行列として整理するのが一般的でした。そのため、CSCMモジュールのパラメータにおいて、データを事前に転置する必要があることを指定します。
descr.step = int(true);
分析ウィンドウサイズを6、5、4バーにして、3つのレベルで特徴量を抽出します。
{
int temp[] = {6, 5, 4};
if(!ArrayCopy(descr.windows, temp))
return false;
}
活性化関数は使用しません。Adam法を使用してモデルパラメータを最適化します。
descr.step = int(true); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
次に、MSFformerメソッドのアルゴリズムに従って、Skip-PAMモジュールが登場します。ここでの実装では、同じ構成の3つの連続したSkip-PAM層を追加します。
//--- layer 3 - 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSPyrAttentionMLKV; descr.count = HistoryBars; descr.window = BarDescr;
ここでは、分析対象のシーケンスの同様のサイズを指定します。ただし、この場合は、すでにマルチモーダルシーケンスを扱っています。
Query、Key、Valueエンティティ記述の内部ベクトルのサイズを32要素に設定します。Key-Valueテンソルのアテンションヘッドの数は2分の1になります。
descr.window_out = 32; { int temp[] = {8, 4}; if(!ArrayCopy(descr.heads, temp)) return false; } descr.layers = 3; descr.activation = None; descr.optimization = ADAM; for(int l = 0; l < 3; l++) if(!encoder.Add(descr)) { delete descr; return false; }
各Skip-PAMの注意ピラミッドには3つのレベルが含まれます。ここでも、ここでも、モデルパラメータの最適化にはAdam法を使用します。
Skip-PAMSkip-PAMモジュールの出力では、入力データに対応するサイズのテンソルが得られます。テンソルの内容は、分析されたシーケンス内の要素間の依存関係によって調整されます。次に、マルチモーダル入力時系列の続きに対する予測軌道を構築する必要があります。分析されたマルチモーダルシーケンス内の各単変量系列に対して個別の予測軌道を構築します。このため、まずSkip-PAMモジュールから得られたデータテンソルを転置します。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; }
その後、2つの連続した畳み込み層を使用します。これは、個々の単変量シーケンスに対してMLPの役割を果たします。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; descr.window_out = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = LatentCount; descr.step = LatentCount; descr.window_out = NForecast; descr.optimization = ADAM; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
上記の畳み込み層でMLPとの類似性を実装するために、分析ウィンドウとそのステップのサイズを等しく指定することに注意してください。最初のケースでは、分析対象のシーケンスの深さと等しくなります。2番目のケースでは、前の層のフィルタの数と等しくなります。また、畳み込みブロックの数は、分析される単変量シーケンスの数と等しくなります。畳み込み層間に非線形性を導入するために、LReLU活性化関数を使用します。
2番目の畳み込み層では、予測シーケンスのサイズと同じフィルタ数を設定します。このサイズはNForecast定数によって決定されます。
さらに、2番目の畳み込み層では双曲線正接(TANH)を使用します。この選択は意図的なもので、モデルの入力段階では、バッチ正規化層を使ってデータを前処理し、平均値がゼロに近く、分散が1の状態に調整しました。「3シグマルール」に基づき、正規分布するランダム変数の約2/3の値は、平均値から1標準偏差の範囲に収まります。したがって、TANHの値域(-1から1)を使用することで、分析対象となる変数の68%の値をカバーし、1標準偏差を超える外れ値をフィルタリングすることができます。
また、分析した時系列データにはノイズが多く含まれているため、私たちの目標は時系列のすべての変動を学習して予測することではありません。むしろ、十分な精度で予測をおこない、収益性のある取引戦略を構築することを目指します。
その後、データ転置層を使用して、予測された値を元のデータ形式に変換します。
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
これに、先ほどバッチ正規化層で抽出した統計変数を追加します。
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr*NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers=1; if(!encoder.Add(descr)) { delete descr; return false; }
この時点で、環境状態エンコーダーモデルのアーキテクチャは完成したと見なすことができます。現在の形態では、MSFformerメソッドの作者が提示したモデルと一致しています。しかし、最終的な改良を加えます。前回の記事で、直接予測のパラダイムが予測シーケンス内の各ステップが独立していることを前提としていると説明しました。ご想像の通り、この仮定は時系列データの本質と矛盾しています。これを解決するために、FreDFメソッドによって導入された進歩を活用し、分析した時系列の予測シーケンス内で個々のステップを調整します。
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
この形態では、エンコーダーアーキテクチャがより完成度の高いものとなっています。ここで述べたコメントが、モデルの中核にあるロジックを理解する助けとなることを願っています。
この段階では、今後の価格変動を予測するモデルのアーキテクチャを説明し、モデルの訓練に進むことができます。しかし、私たちの目標は単なる時系列予測を超えています。金融市場で取引をおこない、利益を生み出すことができるモデルを訓練したいと考えています。そのため、取引の行動を生成し、私たちの代わりに実行するActorモデルを作成する必要があります。また、Actorによって生成された取引操作を評価し、収益性の高い取引戦略の構築に役立つCriticモデルも必要です。
1.2 ActorとCriticのアーキテクチャ
CreateDescriptionsメソッドでActorおよびCriticモデルの説明を作成しましょう。パラメータでは、指定されたメソッドは動的配列への2つのポインタを受け取り、そこに作成されたアーキテクチャソリューションの説明を保存します。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
前回と同様に、メソッドの本体は取得したポインタの有効性を確認し、必要に応じて動的配列オブジェクトの新しいインスタンスを作成することから始まります。これが完了したら、開発中のモデルのアーキテクチャに関する詳細な説明に進みます。
まずはActorモデルから始めましょう。アーキテクチャ設計に進む前に、Actorモデルに設定した目標について簡単に説明します。その主な目標は、取引操作を実行するための最適な行動を生成することです。しかし、モデルはどのようにこれを達成すべきでしょうか。明らかに、Actorはまず、環境状態エンコーダーによって生成された予測価格変動を分析し、取引方向を決定する必要があります。次に、口座の現在の状態を評価し、利用可能なリソースを把握する必要があります。これらの分析を元に、Actorは取引量、関連するリスク、そしてストップロスとテイクプロフィットレベルという目標を決定します。これがActorアーキテクチャを説明するための基本的な枠組みです。
モデルの入力は、最初に口座の状態を表すベクトルが含まれます。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
それを全結合層に渡します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
次に、9層のネストされたクロスアテンションブロックを配置し、口座の現在の状態と予測される価格変動を比較します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); } { int temp[] = {8, 4}; ArrayCopy(descr.heads, temp); } descr.layers = 9; descr.step = 1; descr.window_out = 32; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
環境状態エンコーダーと同様に、次の設定を使用します。
- 内部エンティティを記述するベクトルのサイズは32要素
- Key-Valueテンソルのアテンションヘッドの数は、Queryテンソルの2分の1
各Key-Valueテンソルは、1つのネストされた層内のフレームワーク内でのみ動作します。
次に、得られたデータを3層MLPを使用して分析します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
モデルの出力では、確率的ヘッドを使用して行動のベクトルを生成します。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
ここで、作成している確率的ヘッドがActorに対して「ランダムな」行動を生成することを思い出してください。これらのランダム値の許容範囲は、前の層で学習される平均と標準偏差で表される正規分布のパラメータによって厳密に制約されます。行動を正確に決定できる理想的な条件下では、生成された行動の分布の分散はゼロに近づきます。その結果、Actorの出力は学習した平均値とほぼ一致します。不確実性が増すにつれて、生成される行動のばらつきも大きくなります。その結果、Actor出力でランダムな行動が観察されます。したがって、確率的方策を採用する場合は、訓練されたモデルのテストプロセスに細心の注意を払うことが重要です。他のすべての要因が同じであれば、訓練された方策は一貫した結果を生成するはずです。2回のテスト実行の間に大きな変動がある場合は、モデルの訓練が不十分であることを示している可能性があります。
さらに、Actorによって生成される行動は一貫している必要があります。たとえば、ストップロスレベルは、宣言された取引量に対して許容可能なリスクと一致する必要があります。同時に、矛盾した取引を避けることを目指します。FreDF層を使用して、Actorの行動の一貫性を確保します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
CriticモデルのアーキテクチャはActorのアーキテクチャに似ています。ただし、Actorに入力される口座状態ベクトルは、分析された環境状態に基づいてActorによって生成された行動テンソルに置き換えられます。Criticの入力時に口座状態データが存在しない理由は簡単に説明できます。私たちが観察する利益または損失は、口座残高ではなく、ポジションの量と方向によって決まります。
Criticのアーキテクチャをより詳細に理解するには、ご自分で調べてください。この記事で使用されているすべてのプログラムの完全なコードは添付ファイルに含まれています。
2. モデル訓練EA
モデルのアーキテクチャについて説明したので、モデルの訓練に使用されるプログラムについて説明します。この場合、2つの訓練エキスパートアドバイザー(EA)を使用します。
- StudyEncoder.mq5:環境状態エンコーダー訓練EA
- Study.mq5:Actor方策訓練EA
2.1 エンコーダーの訓練
StudyEncoder.mq5では、今後の価格変動と分析された指標の値を予測するエンコーダーモデルを訓練します。一見冗長な指標値を予測するためになぜリソースを費やすのか疑問に思うかもしれません。このアプローチは、指標が伝統的に買われ過ぎと売られ過ぎのゾーンを識別し、トレンドの強さを評価し、潜在的な価格変動の反転を検出するために使用されているという事実に由来しています。ただし、ほとんどのインジケーターは、生の価格変動データに内在するノイズを最小限に抑えるように設計されたさまざまなデジタルフィルタを使用して構築されています。その結果、指標の値はよりスムーズになり、予測しやすくなります。これらのインジケーターのその後の値を予測することで、価格変動の予測を精緻化し、確認することを目指します。
StudyEncoder.mq5初期化メソッドでは、訓練データセットを読み込むことから始めます。データ収集の方法については後ほど詳しく説明します。
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
その後、事前訓練済みの環境状態エンコーダーモデルをロードしてみます。ランダムなパラメータで初期化された完全に新しいモデルを常に訓練するわけではありません。多くの場合、最初の訓練で目的の結果が得られなかった場合、モデルを再訓練する必要があります。
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { Print("Create new model"); CArrayObj *encoder = new CArrayObj(); if(!CreateEncoderDescriptions(encoder)) { delete encoder; return INIT_FAILED; } if(!Encoder.Create(encoder)) { delete encoder; return INIT_FAILED; } delete encoder; }
何らかの理由で事前訓練済みモデルを読み込めなかったみ場合は、CreateEncoderDescriptionsメソッドを呼び出して新しいモデルのアーキテクチャを生成します。その後、ランダムなパラメータを使用して、特定のアーキテクチャの新しいモデルを初期化します。
//--- Encoder.getResults(Result); if(Result.Total() != NForecast * BarDescr) { PrintFormat("The scope of the Encoder does not match the forecast state count (%d <> %d)", NForecast * BarDescr, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
次のステップは、小さなアーキテクチャ制御ブロックを実装することです。ここでは、入力データ層の次元と結果のテンソルを検証します。もちろん、新しいモデルを作成する際には、これらの次元に偏差が生じることはほとんどありません。これは、モデルのアーキテクチャで層の次元を定義するために以前使用したのと同じ定数が、ここで検証に使用されるためです。この制御ブロックは、ロードされた事前訓練済みモデルが現在使用されている訓練データセットに適合しない場合を識別することを目的としています。
制御ブロックが正常に渡されると、モデル訓練プロセスを開始するためのユーザー定義イベントが生成され、EAの初期化メソッドが終了します。
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
モデルを訓練する実際のプロセスは、Trainメソッドで実装されます。
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
メソッド本体では、まず訓練データセットから軌跡を選択するための確率ベクトルを生成します。アルゴリズムは、収益性の高い軌跡に高い確率が割り当てられるように設計されています。もちろん、環境状態エンコーダーモデルは現在の残高やポジションを分析しないため、このアプローチは主にActorの方策を訓練する際に有効です。代わりに、分析対象となるインジケーターや価格変動データのみを基に動作します。それにもかかわらず、使用されるすべてのプログラムにおいて統一されたアーキテクチャフレームワークを維持するため、この機能を残しています。
これに続いて、必要なローカル変数を宣言します。
vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
そして、モデルの訓練ループを整理します。モデル訓練の反復回数は、プログラムの外部パラメータで指定されます。
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; }
ループ本体では、訓練データセットから1つの軌跡とその上の状態をサンプリングします。選択した状態の保存データがあるかどうかを確認します。次に、訓練データセットからデータバッファに情報を転送します。
state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum()==0) { iter--; continue; } bState.AssignArray(state);
準備されたデータに基づいて、訓練済みモデルのフィードフォワードパスを実行します。
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
ただし、結果として得られた予測値はロードしません。この時点では、予測結果そのものよりも、訓練データセットに保存されている実際の後続値との偏差に注目しています。したがって、訓練データセットから後続の状態を読み込みます。
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
また、受け取った予測と比較するための実際の値も準備します。このデータをモデルのバックプロパゲーションメソッドに入力し、予測誤差を最小限に抑えるためにモデルパラメータが最適化されます。
if(!Encoder.backProp(Result,(CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
モデルのフィードフォワードパスとバックプロパゲーションパスが正常に完了したら、訓練プロセスの進行状況をユーザーに通知し、ループの次の反復に進むだけです。
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
訓練プロセスは、可能な限りシンプルで最小限になるように設計されています。訓練の期間は、EAを起動する際にユーザーが外部パラメータで指定した訓練反復回数にのみ依存します。訓練プロセスの早期終了は、エラーが発生した場合や、ユーザーが端末でプログラムを手動で停止した場合のみ可能です。
訓練プロセスが完了した後、以前訓練の進行状況に関する情報を表示していたチャートのコメントフィールドをクリアします。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
訓練結果はMetaTrader 5操作ログに表示され、現在のプログラムの終了が初期化されます。訓練済みモデルの保存は、OnDeinitメソッドで実装されます。EAの完全なコードは、添付ファイルに記載されています。
2.2 Actor訓練アルゴリズム
2番目のEA「Study.mq5」は、Actor方策の訓練用に設計されています。さらに、Criticモデルもこのプログラム内で訓練されます。
Criticの役割は非常に特殊であることに注目すべきです。Criticは、Actorが望ましい方向に行動するように導く役割を果たします。ただし、モデルの運用時にはCritic自体は使用されません。言い換えれば、逆説的ではありますが、Actorを訓練するためだけにCriticを訓練するのです。
Actor訓練EAの構造は、以前に説明したエンコーダーの訓練プログラムと似ています。この記事では、モデルを訓練するためのTrainメソッドに特に焦点を当てます。
以前のプログラムと同様に、このメソッドは訓練データセットから軌跡を選択するための確率ベクトルを生成し、必要なローカル変数を宣言することから始まります。
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
その後、訓練ループを宣言し、その本体で訓練データセットからの軌跡とその状態をサンプリングします。
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i <= 0) { iter--; continue; } state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum()==0) { iter--; continue; } bState.AssignArray(state);
ここでは、タイムスタンプもエンコードします。これは、異なる周波数の正弦波高調波のベクトルとして表されます。
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
収集したデータを使用して、今後の価格変動の予測値を生成します。この操作は、以前に訓練されたエンコーダーのフィードフォワードメソッドを呼び出すことによって実行されます。
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false,(CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
前述のようにActorを訓練するには、Criticを訓練する必要があります。訓練データセットを収集するときにActorが実行した行動を訓練データセットから抽出します。
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); if(bActions.GetIndex() >= 0) bActions.BufferWrite();
環境の予測された状態とともにデータをCriticモデルに入力します。
Critic.TrainMode(true); if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
出力によって生成された予測価格変動や将来の指標値をそのままCriticに入力するのではなく代わりにエンコーダーの隠れ状態を提供することが重要です。これは、エンコーダーの出力において、元の時系列データの統計パラメータを予測値に追加しているためです。したがって、これらのデータをCriticモデルで処理するには、まず正規化が必要になります。しかし、その代わりに、予測値を生データ特有のバイアスなしで保持しているエンコーダーの隠れ状態を利用します。
フィードフォワードパスでは、CriticはActorの行動を評価します。当然ながら、訓練の初期段階では、この評価はActorが環境との相互作用を通じて受け取る実際の報酬と大きく乖離する可能性があります。私たちは、実際におこなわれた特定の行動の結果を反映する形で、訓練データセットから実際の報酬を抽出します。
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
次に、行動を評価する際の誤差を最小限に抑えるために、Criticバックプロパゲーションパスを実行します。
次のステップは、Actor方策の訓練です。フィードフォワードパスを実行するには、まず訓 データセットから抽出した口座の状態を記述するテンソルを準備する必要があります。
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
次に、モデルのフィードフォワードパスを実行し、口座状態とエンコーダーの隠れ状態の説明のベクトルをメソッドのパラメータに渡します。
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
明らかに、Actorのフィードフォワードパスの結果に応じて、特定の行動ベクトルが形成されています。このベクトルをエンコーダーの潜在状態とともにCriticに入力します。
Critic.TrainMode(false); if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
この時点で、Critic訓練モードは無効になっていることに注意してください。この場合、Criticismモデルは誤差勾配をActorに渡すためにのみ使用されます。
Actorのパラメータを2つの方向で最適化します。まず、訓練データセットには、訓練期間中に利益をもたらした成功した実行が含まれていると予想されます。このようなパスをベンチマークとして使用し、教師あり学習手法を使用して、このような行動に対するActor方策を改善します。
if(Buffer[tr].States[0].rewards[0] > 0) if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
一方で、利益の出るパスは、利益の出ないパスよりも大幅に少なくなることを理解しています。しかし、利益の出ないパスが提供する情報を無視することはできません。実際、Actor方策の訓練中において、利益の出ないパスも利益の出るパスと同様に重要です。利益の出るパスに基づいてActor方策を調整する一方で、損失の出るパスからは距離を取る必要があります。しかし、それをどの程度、どの方向に調整すべきでしょうか。さらに、利益の出ないパスの中にも利益を生む取引が含まれている可能性があり、その情報は保持したいと考えています。ここで、Actor方策の訓練においてCriticの役割が重要になります。
Criticの訓練では、そのパラメータがActor'sの行動、環境の状態、および報酬との関係をモデル化する関数を最適化するように調整されると仮定されます。したがって、環境の状態を変えずに報酬の最大化を目指す場合、誤差の勾配は、期待される報酬を増やすためにActorの行動をどの方向に調整すべきかを示します。この特性を訓練プロセスで活用します。
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); }
Criticの現在の行動評価を抽出します。次に、利益を1%増やし、損失を同じ額だけ減らします。これらが現段階での目標値となります。次に、それらを渡してCritic、次にActorのバックプロパゲーション操作を実行します。
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
現時点では、Criticの訓練モードは無効になっていることにご注意ください。つまり、Criticは誤差勾配をActorに伝播するためにのみ使用されます。したがって、このフィードバックバックワードパスではCriticのパラメータは調整されません。Actorは、期待される報酬が最大化されるようにモデルのパラメータを更新します。
次に、モデルの訓練の進行状況をユーザーに通知し、ループの次のイテレーションに進みます。
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
訓練プロセスが完了したら、銘柄チャートのコメントフィールドをクリアし、訓練結果をログに出力し、EA終了プロセスを初期化します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
これでモデル訓練アルゴリズムの説明は終わりです。ここで使用されているすべてのプログラムの完全なコードは添付ファイルにあります。
3. 訓練データセットの収集
次の重要な段階は、訓練データセットの収集です。環境との相互作用に関する実際のデータを取得するために、MetaTrader 5のストラテジーテスターを使用します。ここでは、過去のデータを用いてテストを実行し、その結果を訓練データファイルに保存します。
当然、訓練プロセスを開始する前に、訓練データセットから成功した実行をどのように取得するかという疑問が生じます。いくつかの方法が考えられますが、最も明白なアプローチは、過去のデータを利用し、理想的な取引を手動で「作成」することです。この方法は確かに有効ですが、多くの手作業を伴います。訓練データセットが大きくなるにつれ、作業量も増え、データ準備にかかる時間も長くなります。さらに、手作業では「ヒューマンエラー」が発生しやすくなります。私の作業では、初期データの収集にReal-ORLフレームワークを使用しています。このフレームワークについては、本連載の記事で既に詳しく説明しています。対応するコードは添付ファイルに含まれているため、ここでは詳細な説明は省略します。
初期の訓練データセットによって、モデルは環境に関する基礎的な理解を得ることができます。しかし、金融市場は非常に多様であり、どのような訓練データセットでも完全に再現することは不可能です。さらに、モデルが学習する指標と利益の関係は、必ずしも正確または完全ではない可能性があります。これは、訓練データセットにその関係性の誤りや欠落を示す十分なデータが含まれていないためです。そのため、訓練プロセスの途中でデータセットを適宜調整する必要があります。この段階では、追加データの収集方法が異なります。
この段階での目的は、Actor'sの学習済み方策を最適化することです。これを達成するには、現在のActor方策の軌道に比較的近いデータが必要になります。このデータを用いることで、行動が現在の方策から逸脱した場合に、報酬がどのように変化するかを把握できます。この情報を活用し、報酬を最大化する方向へと方策を調整することで、Actorの収益性を向上させます。
この目的を達成するためのアプローチはさまざまで、モデルのアーキテクチャなどの要因によって変化します。例えば、確率的方策を採用している場合は、現在の方策を用いてストラテジーテスターで複数のActorパスを実行することが可能です。確率的ヘッドがランダムな動作をおこなうため、探索する行動空間が広がり、収集した新しいデータを用いてモデルの訓練をおこなうことができます。一方で、決定論的Actor方策(モデルが環境状態と行動の明確な対応関係を学習する場合)では、エージェントの行動にノイズを加えることで、現在のActor方策の周囲に行動の「クラウド(分布)」を作成することができます。
どちらのケースでも、ストラテジーテスターの低速最適化モードを活用することで、追加の訓練データを効率的に収集できます。
環境との相互作用に関するプログラムの詳細な説明は、ここでは省略します。これらについては、本連載の過去の記事で既に取り上げています。本記事で使用されているすべてのプログラムの完全なコードは、添付ファイルに含まれています。また、独自に確認できるよう、環境と連携するためのコードも含まれています。
4.モデルの訓練とテスト
モデルの訓練に使用するすべてのプログラムのアルゴリズムについて説明した後、いよいよ訓練プロセスに移ります。モデルは、EURUSDのH1時間枠の実際の履歴データを使用して訓練されます。訓練期間は2023年の全期間です。
前述のとおり、指定された履歴データの期間内で初期訓練データセットを収集し、このデータセットを用いて環境状態エンコーダーモデルを訓練します。エンコーダーモデルは、過去の価格変動データと、訓練時に分析される指標のみを使用する点が特徴です。当然ながら、同じ履歴データの期間内であれば、すべてのパスでデータは同じになります。したがって、この段階では訓練データセットの改良は不要です。そのため、目標とする結果が得られるまで、初期の訓練データセットを用いてエンコーダーモデルを訓練します。
学習プロセスでは、予測誤差を常に監視し、誤差が減少しなくなり、その変動が一定の範囲内に収まった時点で訓練を終了します。
もちろん、モデルがどのような学習をしたのかには興味があります。最終的な目的は収益性の高いActor方策の訓練ですが、個人的な好奇心から、訓練セットの一部をランダムに抽出し、予測された価格変動と実際の価格変動を比較してみました。
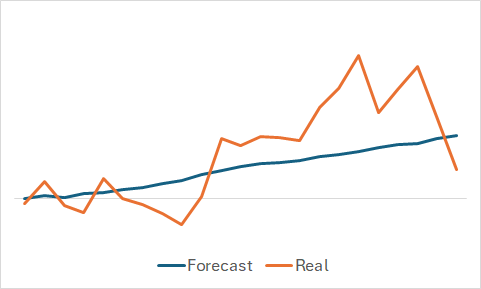
グラフから、モデルが今後の価格変動の主な傾向を捉えていることが明らかです。
わずかな変動を伴うかなり滑らかな予測価格の動きから、モデルが訓練セットの一般的な傾向を捉え、実際のデータに関係なく、すべての状態で同様のパターンを示す可能性があると考えられます。この仮定を確認または反証するために、訓練データセットから別の状態をサンプリングし、予測された価格変動と実際の価格変動の間で同様の比較を実行します。

ここでは、価格変動の予測値により大きな変動が見られますが、それでも実際のデータに比較的近い値となっています。
環境状態エンコーダーの訓練が完了した後、第2段階としてActor方策の訓練に進みます。このプロセスは反復的におこなわれます。最初の訓練は、初期のトレーニングデータセットを使用して実施され、モデルに環境の基本的な理解を与えます。Real-ORLメソッドによって収集された収益性の高い実行データを活用することで、将来の方策の基盤を築くことができます。
訓練プロセスでは、第1段階と同様に、モデルの誤差を監視することに重点を置きます。特に初期段階ではCriticの誤差値に注目することをお勧めします。もちろん、利益を生み出せるActor方策が必要ですが、以前説明したとおりActorを適切に訓練するためには、まずCriticを訓練する必要があります。Critic内の依存関係を適切に構築することで、Actor方策を正しい方向に調整しやすくなります。
Criticの誤差が減少しなくなり安定したら、戦略テスターを使用し、Research.mq5 EAを活用して追加データを収集します。この際、低速最適化モードで実行することを推奨します。
その後、ActorモデルとCriticモデルのさらなる訓練を続けます。再訓練の開始時には、新しいデータの処理により両モデルの誤差が一時的に増加することがありますが、時間が経つにつれて誤差は徐々に減少し、新たな最小値に到達します。
このようにして、訓練データセットの改良とモデルの再訓練を繰り返します。
また、Actorのアーキテクチャには確率的ヘッドが使用されており、その動作には一定のランダム性が含まれることにも留意してください。そのため、訓練済みのActor方策をテストする際は、テスト期間中に複数回の実行をおこなうことを推奨します。各実行間の結果のばらつきが無視できる程度に小さい場合、Actor方策は十分に訓練されたと判断できます。
本記事の作成にあたり、2024年1月の履歴データを使用して訓練済みモデルをテストしました。この期間は訓練データセットには含まれていなかったため、モデルにとって未知のデータとなります。訓練期間とテスト期間は近いため、両データセットは比較可能であると結論付けることができます。
訓練プロセスを通じて、訓練データセットとテストデータセットの両方で利益を生み出せるモデルを構築することに成功しました。
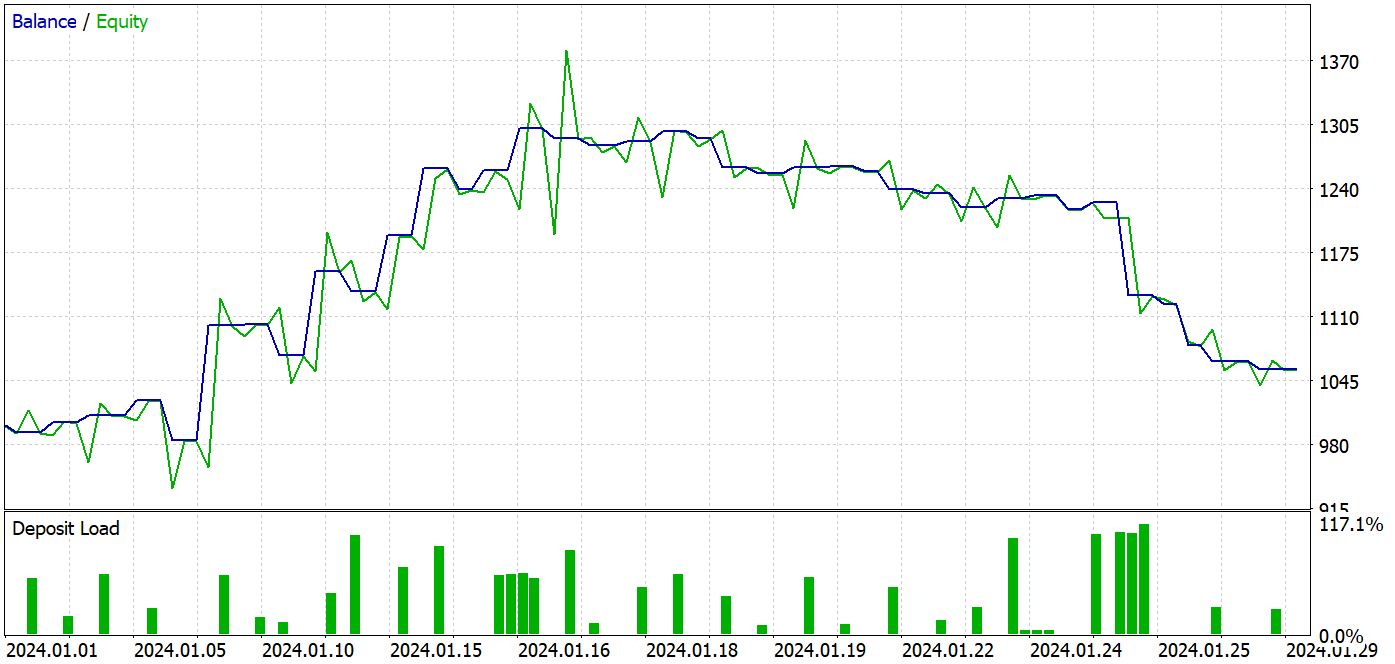
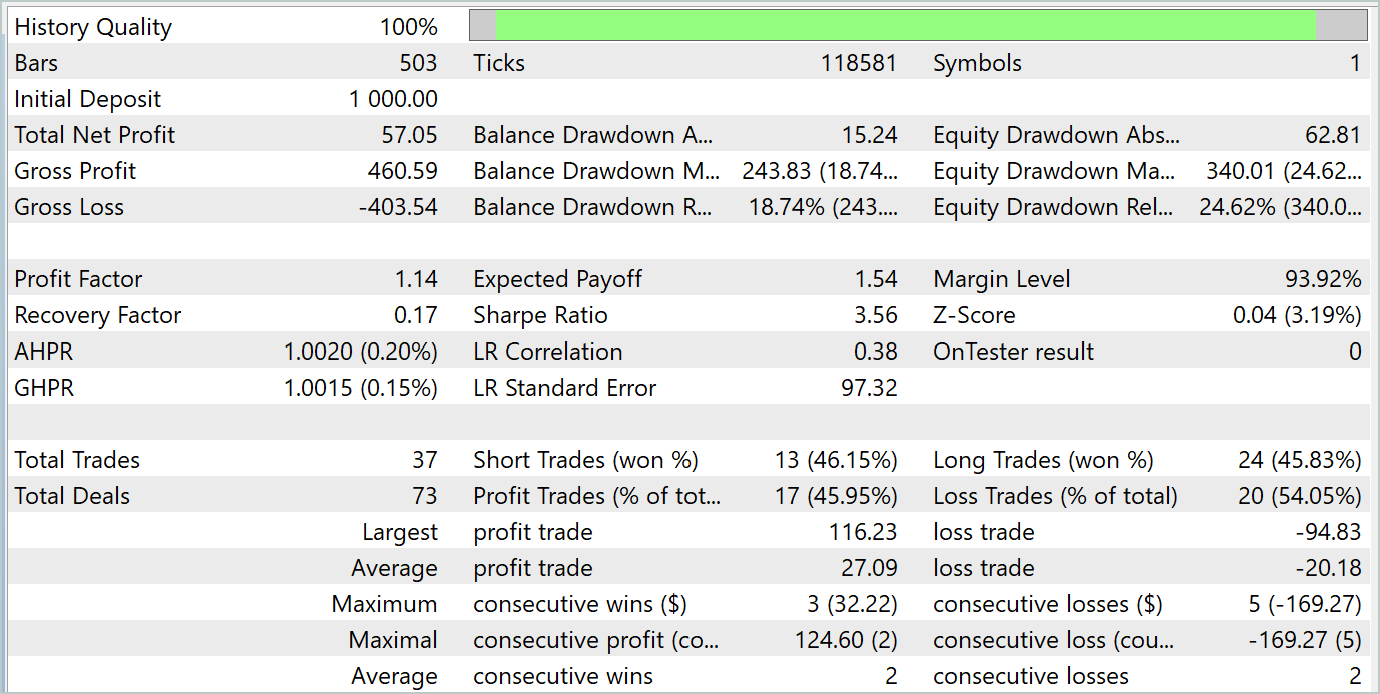
テスト期間中、モデルは37件の取引をおこない、そのうち17件が利益を出して終了しました。これは約46%に相当します。ロングポジションとショートポジションの間での利益取引の割合はほぼ同じであり、その差はわずか0.32%でした。この差は、取引数が少ないことによる計算誤差の可能性もあります。また、最大および平均の利益額は、損失額の対応する指標を上回っており、テスト期間を通じて最終的に利益を確保することができました。プロフィットファクターは1.14でした。しかし、利益の大半が月の前半に集中していた点は懸念事項です。その後、残高は横ばいとなり、月の最終週にはドローダウン(資産の減少)が発生しました。
結論
本記事では、MSFformerメソッドのアプローチを用いてモデルの訓練およびテストを実施しました。テスト結果は良好なパフォーマンスを示しており、提案されたアプローチの有望性が確認されました。しかし、テスト期間の最終週に発生した残高の減少は重要なポイントであり、追加のモデル訓練や調整の必要性を示唆している可能性があります。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | データセット収集EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を使用してデータセットを収集するためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | StudyEncoder.mq5 | EA | エンコーダー訓練EA |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15171
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索