
Redes neurais de maneira fácil (Parte 58): transformador de decisões (Decision Transformer — DT)

Introdução
No contexto desta série de artigos, já examinamos uma ampla gama de diferentes algoritmos de aprendizado por reforço. E todos eles empregam a abordagem básica:
- O Agente analisa o estado atual do ambiente.
- Realiza a ação ótima (dentro da Política aprendida — estratégia de comportamento).
- Transita para um novo estado do ambiente.
- Recebe uma recompensa do ambiente pela transição bem-sucedida para um novo estado.
Esta sequência é baseada nos princípios do processo de Markov. E presume que o ponto de partida é o estado atual do ambiente. Há só uma saída ideal deste estado e não depende do caminho anterior.
No entanto, eu gostaria de apresentar a você uma abordagem alternativa, que foi introduzida pela equipe da Google no artigo "Decision Transformer: Reinforcement Learning via Sequence Modeling" (02/06/2021). A principal "característica" deste trabalho é o mapeamento do aprendizado por reforço para modelagem de sequência de ações condicionada por um modelo autorregressivo da recompensa desejada.
1. Características do método Decision Transformer
O Decision Transformer é uma arquitetura que está transformando a perspectiva sobre o aprendizado por reforço. Diferentemente da abordagem clássica de escolha de ações pelo Agente, considera-se a tarefa de tomar decisões sequenciais no contexto da modelagem de linguagem.
Os autores do método sugerem construir as trajetórias de ações do Agente no contexto das ações realizadas anteriormente e dos estados visitados, assim como os modelos de linguagem constroem frases (sequência de palavras) no contexto do texto geral. Essa abordagem permite o uso de uma ampla gama de ferramentas de modelos de linguagem com mínimas modificações. E, em particular, tal como o modelo GPT (Generative Pre-trained Transformer).
Provavelmente, deveríamos começar com os princípios de construção das trajetórias do Agente. E, neste caso, estamos falando especificamente sobre a construção de trajetórias, e não de uma sequência de ações.
Um dos requisitos na escolha da representação da trajetória é a capacidade de usar transformadores, o que permitirá extrair padrões significativos nos dados de entrada. Entre eles, além da descrição dos estados do ambiente, estarão as ações realizadas pelo Agente e as recompensas recebidas. E aqui, os autores do método propõem uma abordagem bastante interessante para modelar recompensas. Eles querem que o modelo gere ações baseadas em recompensas desejadas futuras, e não em recompensas passadas. Afinal, nosso desejo é alcançar algum objetivo. E, em vez de fornecer a recompensa diretamente, os autores fornecem ao modelo os valores de "Return-To-Go". Isso é análogo à recompensa acumulada até o fim do episódio. Mas indicamos ao modelo não o resultado real, mas o resultado desejado.
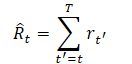
Isso leva à seguinte representação de trajetória, que é adequada para aprendizado e geração autorregressivos:
![]()
Ao testar os modelos treinados, podemos especificar a recompensa desejada (por exemplo, 1 para sucesso ou 0 para falha), bem como o estado inicial do ambiente, como informações para iniciar a geração. Após a execução da ação gerada para o estado atual, reduzimos a recompensa alvo pelo valor recebido do ambiente e repetimos o processo até alcançarmos a recompensa total desejada ou o fim do episódio.
Note que, com tal abordagem e continuando as ações após atingir o nível desejado de recompensa total em Return-To-Go, pode ser passado um valor negativo. E isso pode levar a resultados indesejáveis na forma de perdas.
Para a tomada de decisão pelo Agente, passamos as últimas K etapas de tempo para o Decision Transformer. Um total de 3*K tokens. Um para cada modalidade: return-to-go, estado e a ação que levou a esse estado. Para obter representações vetoriais dos tokens, os autores do método utilizam uma camada neural totalmente conectada treinável para cada modalidade, que projeta os dados de entrada na dimensão das representações vetoriais. Após isso, é realizada a normalização da camada. No caso da análise de estados complexos (compostos) do ambiente, é permitido o uso de um autocodificador convolucional em vez de uma camada neural totalmente conectada.
Adicionalmente, para cada etapa de tempo, é treinada uma representação vetorial do rótulo de tempo, que é adicionada a cada token. É importante saber que tal abordagem difere da representação vetorial posicional padrão em transformadores, pois uma etapa de tempo corresponde a vários tokens (no exemplo fornecido, a três). Em seguida, os tokens são processados com a ajuda do modelo GPT, que prevê futuros tokens de ações por meio de modelagem autorregressiva. Falamos mais sobre a arquitetura dos modelos GPT ao examinar métodos de aprendizado supervisionado no artigo "Uma visão sobre a GPT".
Por mais estranho que possa parecer, o processo de treinamento do modelo é construído usando métodos de aprendizado supervisionado. Primeiro, implementamos interação com o ambiente e amostramos um conjunto de trajetórias aleatórias. Nós já realizamos isso várias vezes. E então é executado um treinamento offline. Escolhemos minipacotes de tamanho K do conjunto coletado de trajetórias. A cabeça preditiva, correspondente ao token de entrada st, é treinada para prever a ação at quer seja usando a função de perda de entropia cruzada para ações discretas ou o erro quadrático médio para ações contínuas. As perdas para cada etapa de tempo são médias.
Durante a experimentação, os autores do método não encontraram evidências de que prever os próximos estados ou recompensas melhorasse a eficiência dos modelos.
A seguir, é apresentada uma visualização do método feita pelo autor.

Não vou me deter detalhadamente na arquitetura dos transformadores e no mecanismo de Self-Attention em particular, pois já foram dedicados vários artigos a isso nesta série. Sugiro passar diretamente para a parte prática e examinar a implementação do mecanismo Decision Transformer usando MQL5.
2. Implementação usando MQL5
Após uma breve imersão nos aspectos teóricos do método Decision Transformer, avançamos para sua implementação com MQL5. O primeiro desafio que enfrentamos é a implementação de incorporações para as entidades dos dados de entrada. Em tarefas semelhantes, utilizando métodos de aprendizado supervisionado, aplicamos camadas convolucionais com passos iguais à janela dos dados de entrada. No entanto, neste caso, encontramos duas dificuldades:
- O tamanho do vetor que descreve o estado do ambiente é diferente do vetor do espaço de ação. E o vetor de recompensas tem um terceiro tamanho.
- Todas as entidades contêm dados de diferentes distribuições. Para alinhar esses dados em um espaço comparável, são necessárias diferentes matrizes de incorporação.
Lembramos também que dividimos o estado do ambiente em dois blocos completamente diferentes em conteúdo e tamanho: dados históricos do movimento de preços e descrição do estado atual da conta. Isso introduz uma modalidade adicional para análise. E, à medida que novos experimentos são realizados, podem surgir dados adicionais para análise. É evidente que nessas condições não podemos usar a camada convolucional e precisamos de uma solução universal capaz de realizar a incorporação de N modalidades com tamanhos de vetores [n1, n2, n3,...,nN]. Conforme mencionado anteriormente, os autores do método utilizaram camadas totalmente conectadas treináveis para cada modalidade. Esse método é bastante universal, mas, no nosso caso, implica a renúncia à incorporação paralela de várias modalidades.
Nesta situação, a criação de um novo objeto na forma de uma camada de incorporação neural, CNeuronEmbeddingOCL, parece ser a solução mais adequada, na minha opinião. Somente essa abordagem nos permitirá estruturar o processo corretamente. No entanto, antes de criar os objetos e a funcionalidade da nova classe, ainda precisamos definir algumas de suas características arquitetônicas.
Em cada iteração da propagação, planejamos transmitir cinco vetores de dados de entrada:
- Dados históricos de movimento de preços.
- Estado da conta.
- Recompensa.
- Ação realizada no passo anterior.
- Rótulo de tempo.
Como podemos observar, a informação de diferentes modalidades varia significativamente em termos de conteúdo e volume de dados. Precisamos determinar a abordagem para transmitir os dados de entrada para a camada de incorporação. Usar uma matriz com uma linha ou coluna dedicada para cada modalidade não é viável devido aos diferentes tamanhos dos vetores de dados. Claro, é possível usar um array dinâmico de vetores. Mas essa abordagem só é viável com a implementação usando MQL5. No entanto, encontraremos dificuldades ao passar esse tipo de array para o contexto do OpenCL para realizar cálculos paralelos. Criar kernels separados para diferentes quantidades de modalidades de dados complicará o programa e impedirá que o algoritmo seja totalmente universal. E usar um kernel separado para cada modalidade leva à sua incorporação sequencial e limita a computação paralela.
Nessa situação, na minha opinião, a abordagem mais universal seria usar dois vetores (buffers). Em um método, apontamos sequencialmente todos os dados de entrada. No outro, fornecemos um "mapa de dados", na forma dos tamanhos das janelas de cada sequência. Assim, utilizando apenas dois buffers, podemos passar qualquer quantidade de modalidades com tamanhos de dados independentes para o kernel, sem alterar o algoritmo de ação dentro do kernel. Uma solução bastante universal com a possibilidade de cálculos paralelos de incorporação de todas as modalidades simultaneamente.
Além da simplicidade e universalidade, essa abordagem nos permite facilmente integrar uma nova classe com todas as camadas neurais criadas anteriormente.
A questão da transferência de dados de entrada está resolvida. Mas enfrentamos uma situação quase idêntica com as matrizes de pesos. Já foi mencionado que cada modalidade precisa de sua própria matriz de incorporação. No entanto, neste caso, temos uma vantagem: os tamanhos de incorporação de todas as modalidades são iguais. Afinal, o objetivo do processo de incorporação é tornar as diferentes modalidades comparáveis. Por isso, cada elemento dos dados de entrada tem uma quantidade igual de coeficientes de peso para a transmissão de dados para a saída da camada neural. Isso nos permite usar uma matriz comum para armazenar os coeficientes de peso das incorporações de todas as modalidades. O número de colunas da matriz corresponde ao tamanho da incorporação de uma modalidade. E o número de linhas é igual ao número total de dados de entrada. Podemos também adicionar elementos de viés bayesiano, o que nos dá uma linha adicional na matriz de coeficientes de peso para cada modalidade.
O próximo ponto construtivo que gostaria de discutir é a viabilidade de embutir toda a sequência anterior. Vamos deixar claro de imediato que não questionamos a necessidade de o Agente analisar a trajetória anterior. Afinal, essa é a base do método em questão. Mas vamos dar uma olhada mais ampla na questão. O Decision Transformer, por sua natureza, é um modelo autorregressivo que recebe K*N tokens na entrada. E em cada etapa de tempo, apenas N tokens são novos. Os outros (K-1)*N tokens são exatamente os mesmos usados na etapa de tempo anterior. Claro, nos estágios iniciais do treinamento, mesmo os dados de entrada repetidos terão incorporações diferentes devido às alterações feitas nas matrizes de incorporação. Mas esse efeito diminuirá à medida que o treinamento do modelo progredir. E durante a operação em grande escala, quando as matrizes de peso não mudam, essas variações são completamente ausentes. E faz todo sentido incorporar apenas os novos dados de entrada em cada etapa de tempo. Isso nos permitirá reduzir significativamente o consumo de recursos para a incorporação de dados durante o treinamento e a operação em grande escala do modelo.
Além disso, vamos prestar atenção a outro ponto: a codificação posicional. No contexto da nossa tarefa, a posição dos dados históricos é indicada pelo tempo de abertura da barra. Em nosso modelo de dados de entrada, previmos a codificação de um rótulo de tempo. Mas os autores do método adicionavam o token de posição à incorporação de outras modalidades. Essa solução está totalmente alinhada com a arquitetura do transformador, mas adiciona uma operação adicional na sequência de ações. Nós, por outro lado, criaremos a incorporação do rótulo de tempo e a adicionaremos como uma modalidade separada, já que a incorporação da posição pode ser realizada em paralelo com a incorporação das demais modalidades. Contudo, essa abordagem aumenta o volume dos dados analisados. E, em cada caso específico, é necessário considerar o equilíbrio entre diferentes fatores de operação do programa ao escolher o método de codificação posicional.
Após definir as principais características estruturais da nossa implementação, podemos proceder à construção do programa OpenCL. E começaremos, como sempre, pela construção do kernel de propagação. Como você entende, pretendemos obter, como resultado, uma matriz de incorporações. Cada linha desta matriz representará a incorporação de uma modalidade separada. Da mesma forma, formaremos o espaço bidimensional para as tarefas do kernel. Em uma dimensão, indicaremos o tamanho da incorporação de uma modalidade. E na outra, especificaremos a quantidade de modalidades analisadas.
Lembro que decidimos incorporar apenas as últimas modalidades na sequência. Mantemos a incorporação dos dados anteriores inalterada em relação aos resultados anteriores. Assim, na saída do nosso CNeuronEmbeddingOCL, obtemos a incorporação de toda a sequência.
Bem, nos parâmetros do kernel, passamos ponteiros para 5 buffers de dados e 1 constante, na qual indicaremos o tamanho da sequência. Neste caso, por tamanho da sequência, entendemos o número de etapas de dados históricos analisados.
Nos buffers de dados, passaremos a seguinte informação:
- inputs — contém os dados de entrada na forma de sequência de todas as modalidades (1 etapa de tempo);
- outputs — contém a sequência de incorporações de todas as modalidades até a profundidade do histórico analisado;
- weights — matriz de coeficientes de peso;
- windows — mapa de dados de entrada (tamanhos das janelas de dados de cada modalidade nos dados de entrada);
- std — vetor de desvios padrão (usado para normalização das incorporações).
__kernel void Embedding(__global float *inputs, __global float *outputs, __global float *weights, __global int *windows, __global float *std, const int stack_size ) { const int window_out = get_global_size(0); const int pos = get_local_id(0); const int emb = get_global_id(1); const int emb_total = get_global_size(1); const int shift_out = emb * window_out + pos; const int step = emb_total * window_out; const uint ls = min((uint)get_local_size(0), (uint)LOCAL_ARRAY_SIZE);
No corpo do kernel, identificamos o fluxo em ambas as dimensões e definimos as constantes de deslocamento nos buffers de dados. Em seguida, deslocamos as incorporações previamente obtidas no buffer de resultados. Note que, em cada fluxo, é realizada a transferência de apenas uma posição de incorporação. Isso permite copiar os dados em fluxos paralelos.
for(int i=stack_size-1;i>0;i--) outputs[i*step+shift_out]=outputs[(i-1)*step+shift_out];
O próximo passo é definir o deslocamento no buffer de dados de entrada até a modalidade analisada. Para isso, calcularemos o número total de elementos nas modalidades localizadas no buffer de dados de entrada antes da modalidade analisada.
int shift_in = 0; for(int i = 0; i < emb; i++) shift_in += windows[i];
Também definiremos o deslocamento no buffer da matriz de pesos, considerando o elemento bayesiano.
const int shift_weights = (shift_in + emb) * window_out;
Salvaremos em uma variável local o tamanho da janela de dados de entrada da modalidade atual e definiremos constantes para trabalhar com o array local.
const int window_in = windows[emb]; const int local_pos = (pos >= ls ? pos % (ls - 1) : pos); const int local_orders = (window_out + ls - 1) / ls; const int local_order = pos / ls;
Criaremos um array local e o preencheremos com valores zero. Aqui, estabeleceremos uma barreira para a sincronização local dos fluxos.
__local float temp[LOCAL_ARRAY_SIZE]; if(local_order == 0) temp[local_pos] = 0; barrier(CLK_LOCAL_MEM_FENCE);
Com isso, podemos considerar concluído o trabalho preparatório, e passamos diretamente para as operações de incorporação. Inicialmente, multiplicaremos o vetor de dados de entrada da modalidade analisada pelo vetor correspondente de coeficientes de peso. Assim, obtemos o elemento de incorporação desejado.
float value = weights[shift_weights + window_in]; for(int i = 0; i < window_in; i++) value += inputs[shift_in + i] * weights[shift_weights + i];
Neste caso, não usamos uma função de ativação, pois precisamos obter a projeção de cada elemento da sequência no subespaço desejado. No entanto, estamos cientes de que essa abordagem não garante a comparabilidade das incorporações de diferentes dados de entrada. Por isso, a próxima etapa será a normalização dos dados dentro da incorporação de uma modalidade específica. Dessa forma, ajustamos os dados de todas as incorporações para terem média zero e variância unitária. Lembre a fórmula de normalização.

Para isso, primeiro reuniremos, por meio de um array local, a soma de todos os elementos da incorporação analisada. E dividiremos a soma obtida pelo tamanho do vetor de incorporação. Assim, determinaremos o valor médio. E imediatamente ajustaremos o valor do elemento de incorporação atual para o valor médio. Para a sincronização dos fluxos locais, usaremos barreiras.
for(int i = 0; i < local_orders; i++) { if(i == local_order) temp[local_pos] += value; barrier(CLK_LOCAL_MEM_FENCE); } //--- int count = ls; do { count = (count + 1) / 2; if(pos < count) temp[pos] += temp[pos + count]; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- value -= temp[0] / (float)window_out; barrier(CLK_LOCAL_MEM_FENCE);
Aqui vale a pena comentar sobre a derivada das operações realizadas. Como você sabe, para propagar o gradiente do erro durante a retropropagação, utilizamos as derivadas da função de propagação. Ao somar ou subtrair uma constante de uma variável, o gradiente do erro é totalmente transmitido à variável. Contudo, a nuance desta situação é que estamos subtraindo o valor médio. Que, por sua vez, é uma função das variáveis analisadas e tem sua própria derivada. E para a distribuição precisa do gradiente de erro, é necessário passá-lo também pela derivada da função de média. Esta afirmação é válida também para o desvio padrão, que utilizaremos em seguida. No entanto, minha experiência pessoal mostra que o gradiente de erro total, passado pela derivada da função de média e variância, é significativamente menor do que o gradiente de erro na própria variável. E, com o objetivo de economizar recursos, não complicaremos agora o algoritmo com a preservação de dados intermediários e o subsequente cálculo de gradientes de erro nesta direção.
Mas voltemos ao algoritmo do nosso kernel. Nesta etapa, já ajustamos o vetor de incorporação para uma média zero. E a seguir, ajustaremos para uma variância unitária. Para isso, dividiremos todos os elementos da incorporação analisada pelo seu desvio padrão, que calculamos usando o array local.
Lembre-se de que o array local é usado para transferir dados entre os fluxos do grupo local. E a sincronização dos fluxos é realizada por meio de barreiras.
if(local_order == 0) temp[local_pos] = 0; barrier(CLK_LOCAL_MEM_FENCE); //--- for(int i = 0; i < local_orders; i++) { if(i == local_order) temp[local_pos] += pow(value,2.0f) / (float)window_out; barrier(CLK_LOCAL_MEM_FENCE); } //--- count = ls; do { count = (count + 1) / 2; if(pos < count) temp[pos] += temp[pos + count]; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- if(temp[0] > 0) value /= sqrt(temp[0]);
Agora resta-nos salvar o valor obtido no elemento correspondente do buffer de resultados. E não esqueçamos de salvar o desvio padrão calculado para a distribuição subsequente do gradiente de erro durante a retropropagação.
outputs[shift_out] = value; if(pos == 0) std[emb] = sqrt(temp[0]); }
Após a conclusão do trabalho no kernel de propagação, sugiro passarmos para a análise do algoritmo do kernel de distribuição do gradiente de erro. Já começamos a discussão sobre a distribuição do gradiente de erro através da função de normalização de dados anteriormente. E para otimizar o uso de recursos, decidiu-se simplificar o algoritmo na parte do gradiente de erro através das funções de média e variância do vetor de incorporação. Nesta fase, consideramos a média e a variância como constantes. É nesta paradigma que o algoritmo do kernel de distribuição do gradiente de erro EmbeddingHiddenGradient é construído.
Nos parâmetros do kernel, passamos 5 buffers de dados e 1 constante. Já nos familiarizamos com a constante e 3 dos buffers usados no kernel anterior. E os buffers de dados de entrada e resultados são substituídos pelos buffers dos gradientes de erro correspondentes.
__kernel void EmbeddingHiddenGradient(__global float *inputs_gradient, __global float *outputs_gradient, __global float *weights, __global int *windows, __global float *std, const int window_out ) { const int pos = get_global_id(0);
Chamaremos o kernel em um espaço unidimensional de tarefas de acordo com o número de elementos dos dados de entrada. No corpo do kernel, identificamos imediatamente o fluxo atual. No entanto, a posição do elemento no buffer de dados de entrada não nos dá uma representação clara dos elementos dependentes no buffer de resultados. Por isso, primeiro iteramos pelo buffer do mapa de dados de entrada para determinar a modalidade analisada.
int emb = -1; int count = 0; do { emb++; count += windows[emb]; } while(count <= pos);
E então, com base no índice da modalidade analisada, determinamos o deslocamento nos buffers de resultados e nos coeficientes de peso.
const int shift_out = emb * window_out; const int shift_weights = (pos + emb) * window_out;
Após determinar os deslocamentos nos buffers de dados, coletamos os gradientes de erro de todos os elementos dependentes do buffer de resultados e ajustamos esses pelo desvio padrão do vetor de incorporação antes da normalização. Lembro que seu valor foi salvo no buffer std durante a propagação.
float value = 0; for(int i = 0; i < window_out; i++) value += outputs_gradient[shift_out + i] * weights[shift_weights + i]; float s = std[emb]; if(s > 0) value /= s; //--- inputs_gradient[pos] = value; }
O valor obtido é salvo no buffer de gradientes da camada anterior.
Para concluir o trabalho com o programa OpenCL, resta-nos examinar o algoritmo dos kernels de atualização da matriz de pesos. Neste artigo, consideraremos apenas o kernel do método Adam, que uso com mais frequência. O principal diferencial deste kernel em relação aos similares já examinados reside na parte de definição dos deslocamentos nos buffers de dados. Isso é bastante esperado, já que não estamos introduzindo mudanças radicais no algoritmo do próprio método de atualização dos coeficientes de peso.
__kernel void EmbeddingUpdateWeightsAdam(__global float *weights, __global const float *gradient, __global const float *inputs, __global float *matrix_m, __global float *matrix_v, __global int *windows, __global float *std, const int window_out, const float l, const float b1, const float b2 ) { const int i = get_global_id(0);
Um número bastante grande de buffers e constantes é passado nos parâmetros do kernel. Mas todos eles já nos são familiares. O kernel será chamado em um espaço unidimensional de tarefas pelo número de elementos no buffer de coeficientes de peso.
No corpo do kernel, como de costume, identificamos o elemento do buffer analisado pelo identificador do fluxo. Depois, definimos os deslocamentos nos buffers de dados até os elementos necessários.
int emb = -1; int count = 0; int shift = 0; do { emb++; shift = count; count += (windows[emb] + 1) * window_out; } while(count <= i); const int shift_out = emb * window_out; int shift_in = shift / window_out - emb; shift = (i - shift) / window_out;
E então, ajustamos o coeficiente de peso. O processo repete completamente o que foi discutido nos artigos anteriores desta série. Salvamos o resultado e os dados necessários nos buffers correspondentes.
float weight = weights[i]; float g = gradient[shift_out] * inp / std[emb]; float mt = b1 * matrix_m[i] + (1 - b1) * g; float vt = b2 * matrix_v[i] + (1 - b2) * pow(g, 2); float delta = l * (mt / (sqrt(vt) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight)); if(delta * g > 0) weights[i] = clamp(weights[i] + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[i] = mt; matrix_v[i] = vt; }
Após a conclusão do trabalho nos kernels do programa OpenCL, retornamos ao trabalho no lado do programa principal. Agora que esclarecemos a funcionalidade da classe e da lista completa de buffers de dados necessários, podemos criar todas as condições para a chamada e manutenção dos kernels discutidos anteriormente.
Como já mencionado anteriormente, criamos uma nova classe CNeuronEmbeddingOCL baseada na classe base de camadas neurais CNeuronBaseOCL. O funcionamento principal da camada neural é herdado da classe mãe. Nosso objetivo é adicionar novas funcionalidades à classe.
Para armazenar o mapa de dados de entrada, criamos um array dinâmico a_Windows. No entanto, não criaremos um objeto de buffer separado para mantê-lo. Apenas criaremos uma variável para registrar o ponteiro para o buffer no contexto do OpenCL i_WindowsBuffer. Aqui também criaremos variáveis para registrar o tamanho de uma incorporação e a profundidade do histórico analisado — i_WindowOut e i_StackSize, respectivamente.
Para a matriz de pesos de incorporação e momentos, criaremos os buffers de dados:
- WeightsEmbedding;
- FirstMomentumEmbed;
- SecondMomentumEmbed.
No entanto, o buffer de desvios padrão é usado apenas para cálculos intermediários. Desse modo, não o criaremos no lado do programa principal. Criaremos apenas na memória do contexto do OpenCL e salvaremos seu ponteiro na variável i_STDBuffer.
O conjunto de métodos sobrescritos é bastante padrão e não nos deteremos em sua finalidade no momento.
class CNeuronEmbeddingOCL : public CNeuronBaseOCL { protected: int a_Windows[]; int i_WindowOut; int i_StackSize; int i_WindowsBuffer; int i_STDBuffer; //--- CBufferFloat WeightsEmbedding; CBufferFloat FirstMomentumEmbed; CBufferFloat SecondMomentumEmbed; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronEmbeddingOCL(void); ~CNeuronEmbeddingOCL(void); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint stack_size, uint window_out, int &windows[]); //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronEmbeddingOCL; } virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual bool Clear(void); };
No construtor da classe, inicializamos variáveis e ponteiros para os buffers com valores iniciais.
CNeuronEmbeddingOCL::CNeuronEmbeddingOCL(void) { ArrayFree(a_Windows); if(!!OpenCL) { if(i_WindowsBuffer >= 0) OpenCL.BufferFree(i_WindowsBuffer); if(i_STDBuffer >= 0) OpenCL.BufferFree(i_STDBuffer); } //-- i_WindowsBuffer = INVALID_HANDLE; i_STDBuffer = INVALID_HANDLE; i_WindowOut = 0; i_StackSize = 1; }
A iniciação do objeto da camada de incorporação é realizada no método Init. Nos parâmetros do método, além das constantes já familiares, passamos a profundidade do histórico analisado (stack_size), o tamanho do vetor de incorporação (window_out) e a "mapa de dados de entrada" (array dinâmico windows[]).
bool CNeuronEmbeddingOCL::Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl,uint stack_size, uint window_out,int &windows[]) { if(CheckPointer(open_cl) == POINTER_INVALID || window_out <= 0 || windows.Size() <= 0 || stack_size <= 0) return false; if(!!OpenCL && OpenCL != open_cl) delete OpenCL; uint numNeurons = window_out * windows.Size() * stack_size; if(!CNeuronBaseOCL::Init(numOutputs,myIndex,open_cl,numNeurons,ADAM,1)) return false;
No corpo do método, criamos o bloco de controle dos dados de entrada. Em seguida, recalculamos o tamanho do buffer de resultados como o produto do comprimento do vetor de uma incorporação pelo número de modalidades e pela profundidade do histórico analisado. Note que não há um número total de modalidades nos parâmetros externos. Mas, obtemos o "mapa de dados de entrada". O tamanho do array obtido nos indicará o número de modalidades analisadas.
A inicialização imediata do buffer de resultados, bem como de outros objetos herdados, é realizada pelo mesmo método da classe pai, o qual invocamos após a conclusão das operações preparatórias.
Após a inicialização bem-sucedida dos objetos herdados, precisaremos preparar as entidades adicionadas. Primeiro, inicializamos o buffer de pesos dos coeficientes de incorporação. Como mencionado anteriormente, este buffer é uma matriz com o número de linhas igual ao volume dos dados de entrada e colunas de acordo com o tamanho do vetor de uma única incorporação. O tamanho da incorporação é conhecido para nós. No entanto, para determinar o tamanho dos dados de entrada, precisamos somar todos os valores do "mapa de dados". E a essa soma, adicionamos uma linha de viés bayesiano para cada modalidade. Assim, obtemos o tamanho do buffer de pesos dos coeficientes de incorporação. Agora, preencheremos com valores aleatórios e transferiremos para a memória do contexto OpenCL.
uint weights = 0; ArrayCopy(a_Windows,windows); i_WindowOut = (int)window_out; i_StackSize = (int)stack_size; for(uint i = 0; i < windows.Size(); i++) weights += (windows[i] + 1) * window_out; if(!WeightsEmbedding.Reserve(weights)) return false; float k = 1.0f / sqrt((float)weights / (float)window_out); for(uint i = 0; i < weights; i++) if(!WeightsEmbedding.Add(k * (2 * GenerateWeight() - 1.0f)*WeightsMultiplier)) return false; if(!WeightsEmbedding.BufferCreate(OpenCL)) return false;
Os buffers do primeiro e segundo momentos têm um tamanho similar. Mas, os inicializamos com valores zero e os transferimos para a memória do contexto OpenCL.
if(!FirstMomentumEmbed.BufferInit(weights, 0)) return false; if(!FirstMomentumEmbed.BufferCreate(OpenCL)) return false; //--- if(!SecondMomentumEmbed.BufferInit(weights, 0)) return false; if(!SecondMomentumEmbed.BufferCreate(OpenCL)) return false;
Em seguida, criamos os buffers do mapa de dados de entrada e dos desvios padrão.
i_WindowsBuffer = OpenCL.AddBuffer(sizeof(int) * a_Windows.Size(),CL_MEM_READ_WRITE); if(i_WindowsBuffer < 0 || !OpenCL.BufferWrite(i_WindowsBuffer,a_Windows,0,0,a_Windows.Size())) return false; i_STDBuffer = OpenCL.AddBuffer(sizeof(float) * a_Windows.Size(),CL_MEM_READ_WRITE); if(i_STDBuffer<0) return false; //--- return true; }
É crucial controlar o processo de execução em cada etapa e, após a conclusão de todas as operações do método, retornar à chamada do programa um resultado lógico do trabalho do método.
Após a inicialização do objeto, devemos criar os métodos de seu principal funcional. No nosso caso, são os métodos de propagação e retropropagação. Como você já deve ter adivinhado, o trabalho principal de configurar o funcional já foi realizado no programa OpenCL. Agora, resta-nos configurar a chamada dos kernels correspondentes. Mas, antes de iniciar este trabalho, precisamos declarar as constantes para lidar com os kernels: identificadores dos kernels no programa e seus parâmetros. Como sempre, realizamos esta funcionalidade usando a diretiva #define.
#define def_k_Embedding 59 #define def_k_emb_inputs 0 #define def_k_emb_outputs 1 #define def_k_emb_weights 2 #define def_k_emb_windows 3 #define def_k_emb_std 4 #define def_k_emb_stack_size 5 //--- #define def_k_EmbeddingHiddenGradient 60 #define def_k_ehg_inputs_gradient 0 #define def_k_ehg_outputs_gradient 1 #define def_k_ehg_weights 2 #define def_k_ehg_windows 3 #define def_k_ehg_std 4 #define def_k_ehg_window_out 5 //--- #define def_k_EmbeddingUpdateWeightsAdam 61 #define def_k_euw_weights 0 #define def_k_euw_gradient 1 #define def_k_euw_inputs 2 #define def_k_euw_matrix_m 3 #define def_k_euw_matrix_v 4 #define def_k_euw_windows 5 #define def_k_euw_std 6 #define def_k_euw_window_out 7 #define def_k_euw_learning_rate 8 #define def_k_euw_b1 9 #define def_k_euw_b2 10
O enfileiramento do kernel para execução será realizado usando o método de propagação feedForward como exemplo. Nos parâmetros do método, assim como em todos os semelhantes anteriormente discutidos, recebemos um ponteiro para o objeto da camada neural anterior.
bool CNeuronEmbeddingOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false;
No corpo do método, verificamos o ponteiro recebido e o ponteiro para o objeto que trabalha com o contexto OpenCL.
Em seguida, passamos ao kernel os ponteiros para os buffers de dados e as constantes necessárias, que anteriormente foram especificadas nos parâmetros do kernel. Não esquecemos de controlar o processo de execução das operações a cada etapa.
if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_std, i_STDBuffer)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_weights, WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_windows, i_WindowsBuffer)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_Embedding, def_k_emb_stack_size, i_StackSize)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; }
Após a transferência bem-sucedida de todos os parâmetros, precisamos definir o espaço de tarefas para o kernel. Como discutimos anteriormente, o kernel será executado em um espaço de tarefas bidimensional. Na primeira dimensão, especificaremos o tamanho de uma incorporação. E na segunda, o número de modalidades para análise.
uint global_work_offset[2] = {0,0}; uint global_work_size[2] = {i_WindowOut,a_Windows.Size()};
A particularidade do kernel de incorporação é a normalização dos dados dentro do vetor de incorporação de uma modalidade. Para construir esse subprocesso, geramos a troca de dados entre os fluxos dentro de um mesmo grupo de trabalho através de um array local. E agora precisamos especificar o tamanho do grupo local, que é igual ao tamanho do vetor de incorporação. O detalhe é que, ao especificar um espaço bidimensional, precisamos indicar um grupo local bidimensional. Portanto, a segunda dimensão do grupo local é igual a 1.
uint local_work_size[2] = {i_WindowOut,1};
Ao final, chamamos o método para enfileirar o kernel e controlamos a execução das operações.
if(!OpenCL.Execute(def_k_Embedding, 2, global_work_offset, global_work_size,local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__,GetLastError()); return false; } //--- return true; }
O procedimento de chamada dos kernels de retropropagação é similar, e não detalharemos esses métodos agora. Você pode se familiarizar no anexo com o código deles, assim como o código de todas as classes e seus métodos utilizados no artigo. Mas eu gostaria de enfatizar um ponto. O Decision Transformer é um modelo autorregressivo, e a sequência de dados de entrada é de grande importância. Determinamos anteriormente que, a cada etapa de tempo, alimentávamos o modelo com apenas novos dados. Toda a profundidade do histórico analisado é copiada das operações anteriores do modelo. Essencialmente, usamos o buffer de resultados da camada CNeuronEmbeddingOCL como uma pilha de incorporações. Essa abordagem reduz os custos de processamento primário dos dados. Mas introduz a exigência de uma alimentação sequencial dos dados de entrada, tanto no processo de treinamento quanto no de operação. Ao mesmo tempo, no processo de treinamento, frequentemente utilizamos amostras aleatórias dos dados de entrada. A necessidade disso já foi discutida anteriormente várias vezes. E para eliminar a distorção dos dados devido a "saltos temporais" nos dados de entrada ou ao mudar para uma trajetória alternativa, precisamos de um método para limpar a pilha de incorporações. O método Clear foi criado para essa finalidade. O algoritmo é bastante simples: simplesmente preenchemos todo o buffer com valores zero e copiamos os dados para a memória do contexto OpenCL.
bool CNeuronEmbeddingOCL::Clear(void) { if(!Output.BufferInit(Output.Total(),0)) return false; if(!OpenCL) return true; //--- return Output.BufferWrite(); }
Com isso, sugiro concluir a discussão sobre os algoritmos dos métodos da classe CNeuronEmbeddingOCL. Você pode se familiarizar com o código completo dele e de todos os métodos no anexo.
Como resultado do trabalho realizado, temos incorporações comparáveis de várias modalidades diferentes na saída da camada CNeuronEmbeddingOCL. Isso nos permite usar os objetos do transformador criados anteriormente para implementar o método apresentado Decision Transformer. Isso significa que podemos prosseguir para trabalhar na descrição da arquitetura do modelo. Sim, neste caso, usaremos apenas um modelo - o Agente. Faz tempo que algo assim não acontecia em nossa série de artigos.
Mas antes, devo lembrar-lhes sobre o "mapa de dados de entrada". Para sua descrição, usamos um array, que anteriormente não estava presente na classe de descrição da camada neural. Vamos adicioná-lo.
class CLayerDescription : public CObject { public: /** Constructor */ CLayerDescription(void); /** Destructor */~CLayerDescription(void) {}; //--- int type; ///< Type of neurons in layer (\ref ObjectTypes) int count; ///< Number of neurons int window; ///< Size of input window int window_out; ///< Size of output window int step; ///< Step size int layers; ///< Layers count int batch; ///< Batch Size ENUM_ACTIVATION activation; ///< Type of activation function (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Type of optimization method (#ENUM_OPTIMIZATION) float probability; ///< Probability of neurons shutdown, only Dropout used int windows[]; //--- virtual bool Copy(CLayerDescription *source); //--- virtual bool operator= (CLayerDescription *source) { return Copy(source); } };
A arquitetura do modelo descrevemos no método CreateDescriptions. Nos parâmetros do método, recebe-se um ponteiro apenas para um array dinâmico de descrição da arquitetura do Ator. No array recebido, vamos salvar a descrição das camadas neurais do modelo.
bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear();
Como primeira camada, indicaremos uma camada neural totalmente conectada de dados de entrada, na qual registraremos sequencialmente todos os dados necessários para análise. Note que não dividimos os dados de entrada em buffers separados por conteúdo. Neste caso, sua separação é bastante convencional. Apenas os registramos sequencialmente. E a divisão lógica deles será realizada no nível de incorporações pelo "mapa de dados de entrada", que criaremos mais tarde.
Observe que a camada de dados de entrada contém informações apenas sobre o último estado do sistema (recompensa, estado do ambiente, estado da conta, rótulo de tempo e a última ação do Agente).
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (NRewards + BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Após a camada de dados de entrada, tradicionalmente indicaremos uma camada de normalização em lote, onde ocorre o pré-processamento dos dados. Novamente, não nos preocupamos com a natureza diversa dos dados recebidos. Afinal, essa camada realiza a normalização considerando os dados históricos de cada característica independentemente.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Isso é seguido por uma camada de normalização de lote. Aqui, indicamos a profundidade do histórico analisado, o tamanho do vetor de uma incorporação e o "mapa de dados de entrada".
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NRewards,NActions}; ArrayCopy(descr.windows,temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
Após a camada de incorporação, colocaremos um bloco de atenção esparsa defNeuronMLMHSparseAttentionOCL, que constituirá a base do nosso transformador. Devo dizer honestamente que os autores do método utilizaram o transformador original. No entanto, o uso do bloco de atenção esparsa nos permitirá aumentar significativamente a profundidade do histórico analisado com um aumento insignificante nos custos de recursos e no tempo de operação do modelo.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
E o modelo é concluído com um bloco de tomada de decisão composto por camadas totalmente conectadas e uma camada latente de autocodificador variacional na saída para criar a estocasticidade da política do Ator.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
É preciso dizer que o bloco de tomada de decisão também difere do utilizado no algoritmo DT original. Os autores do método utilizaram o decodificador do último token na sequência na saída do transformador. Nós, por outro lado, analisamos toda a sequência para tomar uma decisão ponderada.
Após definir a arquitetura do modelo, passamos a criar o EA para interagir com o ambiente e coletar dados para o treinamento do modelo no buffer de reprodução de experiências "\DT\Research.mq5". A estrutura da construção do EA repete completamente as que já examinamos anteriormente, mas vale a pena focar no método de processamento de ticks OnTick. É aqui que a sequência de dados de entrada é formada de acordo com o mapa descrito anteriormente.
No corpo do método, como antes, verificamos a ocorrência de uma nova barra e, se necessário, carregamos os dados históricos. Mas agora carregamos não toda a profundidade do histórico analisado, apenas as atualizações no tamanho do padrão de uma etapa de tempo. Isso pode ser os dados de uma única última vela fechada. Para ajustar a profundidade do carregamento de dados, introduzimos a constante NBarInPattern. Por favor, não confunda com a constante HistoryBars, que usaremos para determinar a profundidade da pilha de incorporações.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Em seguida, criamos a partir dos dados históricos um array para salvar na trajetória e o transferimos para o buffer de dados de entrada. O procedimento é completamente idêntico aos Expert Advisors discutidos anteriormente.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
O próximo passo é formar a descrição do estado da conta. A coleta de dados é realizada pelo procedimento anteriormente trabalhado. Mas os dados não são transferidos para um buffer separado, e sim para um único buffer de dados de entrada bState.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Nesse mesmo buffer, adicionamos o rótulo de tempo.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
Os dados seguintes são gerados pelas exigências do método Decision Transformer. Aqui, adicionamos ao buffer de dados de entrada a modalidade Return-To-Go. Pode ser um elemento de recompensa desejada ou um vetor de recompensa decomposta. Indicaremos 3 elementos: a mudança no saldo, a mudança no patrimônio líquido e o rebaixamento. Todos os 3 indicadores são dados em valores relativos.
//--- Return to go bState.Add(float(1-(sState.account[0] - PrevBalance) / PrevBalance)); bState.Add(float(0.1f-(sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(0);
E, para finalizar o vetor de dados de entrada, adicionamos o vetor das últimas ações do Agente. Na primeira chamada, este vetor está preenchido com valores zero.
//--- Prev action
bState.AddArray(AgentResult);
O vetor de dados de entrada está pronto, e realizamos a propagação do Agente.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) return;
O algoritmo posterior de interpretação dos resultados do modelo e realização de transações é transferido sem alterações, e não vamos nos deter nele. E você pode se familiarizar de forma independente no anexo com o código completo do Expert Advisor e todos os seus métodos. Agora, passamos à construção do processo de treinamento do modelo no Expert Advisor “\DT\Study.mq5”. O Expert Advisor também herdou muito dos trabalhos anteriores. E agora nos deteremos detalhadamente apenas no método de treinamento dos modelos, Train.
No corpo do método, primeiro determinamos o número de trajetórias salvas no buffer local de reprodução de experiências.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
E então criamos um laço pelo número de iterações de treinamento, laço esse no qual aleatoriamente selecionamos uma trajetória e um estado específico nessa trajetória. Aqui tudo como antes.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; }
As diferenças começam a seguir. Lembre-se de que falamos sobre a necessidade de alimentar a entrada do modelo com dados sequenciais. Mas escolhemos um estado aleatório na trajetória. Com o objetivo de eliminar a distorção de dados na sequência analisada, limpamos o buffer de incorporação e o vetor das últimas ações do Agente.
Actions = vector<float>::Zeros(NActions); Agent.Clear();
E então fazemos um laço aninhado, cujo número de iterações é três vezes maior que a profundidade do histórico analisado. Claro, se o tamanho da trajetória salva permitir. No corpo deste laço aninhado, realizaremos o treinamento do modelo, alimentando-o com dados da trajetória salva em uma estrita sequência de interação com o ambiente. Primeiro, carregamos no buffer os dados históricos do movimento dos preços dos indicadores.
for(int state = i; state < MathMin(Buffer[tr].Total - 1,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
Segue-se a informação sobre o estado da conta.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
E o rótulo de tempo.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
Quanto ao Return-To-Go, neste estágio, passamos a recompensa cumulativa real até o final da trajetória. Isso difere um pouco da abordagem do token similar no Expert Advisor de interação com o ambiente. Mas é exatamente isso que nos permite treinar o modelo.
//--- Return to go
State.AddArray(Buffer[tr].States[state].rewards);
E adicionaremos a ação do Agente na etapa de tempo anterior do buffer de reprodução de experiência.
//--- Prev action
State.AddArray(Actions);
O buffer de dados de entrada para uma única iteração de treinamento está pronto, e chamamos o método de propagação do Agente.
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Após a execução bem-sucedida da propagação, temos que realizar a retropropagação e ajustar os parâmetros do modelo. E aqui surge a questão dos valores-alvo, que é resolvida de forma bastante simples. Como valores-alvo, usamos as ações efetivamente realizadas pelo Agente durante a interação com o ambiente. Por mais paradoxal que pareça, isso é aprendizado supervisionado "puro". Mas onde está o aprendizado por reforço? Onde estão as otimizações de recompensa? Nem podemos usar o aprendizado supervisionado, já que as ações realizadas durante a interação com o ambiente não são ótimas.
Treinamos um modelo autorregressivo que, com base no conhecimento da trajetória percorrida e do resultado desejado, gera a ação ótima. Neste aspecto, o papel principal é desempenhado pela indicação da recompensa acumulada real no token return-to-go. Afinal, não há dúvidas de que foram precisamente as ações efetivamente realizadas que levaram às recompensas efetivamente obtidas. Consequentemente, podemos perfeitamente treinar o modelo para identificar essas ações com a recompensa recebida. E um modelo bem treinado posteriormente será capaz de gerar ações para alcançar o resultado desejado durante a operação.
Os autores do Decision Transformer sugerem usar MSE para o espaço de ações contínuo. Nós vamos complementá-lo com o método CAGrad.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Após uma retropropagação bem-sucedida, informamos o usuário sobre o estado do processo de treinamento e passamos para a próxima iteração do nosso sistema de ciclos de treinamento. E após a conclusão de todas as iterações, iniciamos o processo de finalização do trabalho do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
Você pode consultar o código completo de todos os programas usados no anexo ao artigo.
3. Teste
Acima, trabalhamos bastante para implementar o método Decision Transformer usando o MQL5. Nesta parte do nosso artigo, realizaremos o treinamento e teste do modelo. Como sempre, o treinamento e teste dos modelos são realizados com dados históricos do EURUSD no timeframe H1. Os parâmetros de todos os indicadores são usados por padrão. O período de treinamento é de 7 meses de 2023. O teste de desempenho do modelo será realizado em dados históricos de agosto de 2023.
Pelos resultados dos testes deste método, pode-se dizer que a ideia é bastante interessante. Mas, nas condições de estocasticidade do mercado, consegui alcançar o resultado desejado. Se na amostra de treinamento ainda conseguimos alcançar resultados aceitáveis, então, em novos dados, vemos o crescimento do saldo na primeira década do período de teste. Mas depois segue-se uma série de operações deficitárias. Como resultado, o modelo gerou perdas nos dados de teste. Embora observemos que a média de operações lucrativas excede a média de perdas por um pouco mais de 1,0%, isso não é suficiente. Pois a proporção de operações lucrativas é de apenas 47,76%. No final das contas, o fator de lucro está no nível de 0,92.


Considerações finais
Neste artigo, nos familiarizamos com o método Decision Transformer, que representa uma abordagem nova e inovadora para o aprendizado por reforço. Em contraste com os métodos tradicionais, o Decision Transformer modela sequências de ações no contexto de um modelo autorregressivo de recompensas desejadas. Isso permite que o Agente aprenda a tomar decisões focadas em objetivos futuros e otimize seu comportamento com base nesses objetivos.
Na parte prática do artigo, implementamos o método apresentado usando MQL5. Realizamos o treinamento e teste do modelo. No entanto, o modelo treinado não conseguiu gerar lucro ao longo de todo o período de teste. Na primeira metade da amostra de teste, o modelo gerou lucro, mas todo ele foi perdido à medida que o teste continuou. Pode-se dizer que o algoritmo tem potencial. Mas são necessários trabalhos adicionais com o modelo para alcançar o resultado desejado.
Referências
- Decision Transformer: Reinforcement Learning via Sequence Modeling
- Redes neurais de maneira fácil (Parte 57): Stochastic Marginal Actor-Critic (SMAC)
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | Expert Advisor para coleta de exemplos |
| 2 | Study.mq5 | EA | Expert Advisor para treinamento do agente |
| 3 | Test.mq5 | EA | Expert Advisor para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrição do estado do sistema |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13347
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso