
Reimaginando Estratégias Clássicas (Parte XI): Cruzamento de Médias Móveis (II)

Já abordamos anteriormente a ideia de prever cruzamentos de médias móveis, o artigo está vinculado aqui. Observamos que os cruzamentos de médias móveis são mais fáceis de prever do que as mudanças de preço diretamente. Hoje revisitaremos esse problema familiar, mas com uma abordagem totalmente diferente.
Agora queremos investigar minuciosamente quão grande é a diferença que isso faz para nossas aplicações de trading e como esse fato pode melhorar suas estratégias de trading. Os cruzamentos de médias móveis estão entre as estratégias de negociação mais antigas existentes. É desafiador construir uma estratégia lucrativa usando uma técnica tão amplamente conhecida. Ainda assim, espero mostrar neste artigo que até velhos cães podem, de fato, aprender novos truques.
Para sermos empíricos em nossas comparações, primeiro construiremos uma estratégia de trading em MQL5 para o par EURGBP usando apenas os seguintes indicadores:
- 2 Médias Móveis Exponenciais aplicadas ao Preço de Fechamento. Uma com período de 20 e a outra definida como 60.
- O oscilador Estocástico com as configurações padrão de 5,3,3 aplicado, definido para o Modo de Média Móvel Exponencial e configurado para fazer seus cálculos no modo CLOSE_CLOSE.
- O indicador Average True Range com período de 14 para definir nossos níveis de take-profit e stop-loss.
Exploraremos extensivamente os parâmetros sob os quais o backtest foi realizado mais adiante no artigo. No entanto, anotaremos métricas-chave de desempenho ao longo do backtest, como a razão de Sharpe, proporção de negociações lucrativas, lucro máximo e outras métricas de desempenho importantes.
Uma vez concluído, substituiremos cuidadosamente todas as regras clássicas de negociação por regras algorítmicas aprendidas a partir de nossos dados de mercado. Treinaremos 3 modelos de IA para aprender a prever:
- Volatilidade Futura: Isso será feito treinando um modelo de IA para prever a leitura do ATR.
- Relação entre a mudança no preço e os cruzamentos de médias móveis: Criaremos 2 estados distintos em que as médias móveis podem estar. As médias móveis só podem estar em 1 estado por vez. Isso ajudará nosso modelo de IA a focar nas mudanças críticas do indicador e no efeito médio dessas mudanças sobre os níveis futuros de preço.
- Relação entre a mudança no preço e o oscilador estocástico: Desta vez criaremos 3 estados distintos, em que o oscilador estocástico só poderá ocupar 1 por vez. Nosso modelo então aprenderá o efeito médio das mudanças críticas no oscilador estocástico.
Esses 3 modelos de IA não serão treinados em nenhum dos períodos de tempo que usaremos para nosso backtest. Nosso backtest rodará de 2022 até junho de 2024, e nossos modelos de IA serão treinados de 2011 até 2021. Cuidamos para não sobrepor o treinamento e o backtest, para tentarmos ao máximo permanecer próximos do desempenho real do modelo em dados que ele não viu.
Acredite ou não, melhoramos com sucesso todas as métricas de desempenho em geral. Nossa nova estratégia de negociação foi mais lucrativa, teve uma maior razão de Sharpe e ganhou mais da metade, 55%, de todas as operações realizadas durante o período de backtest.
Se uma estratégia tão antiga e amplamente explorada pode se tornar mais lucrativa, acredito que isso deve encorajar qualquer leitor de que suas estratégias também podem se tornar mais lucrativas, se você conseguir estruturar sua estratégia da maneira correta.
A maioria dos traders trabalha arduamente por longos períodos para criar suas estratégias de negociação e dificilmente discute suas preciosas estratégias pessoais em detalhes. Portanto, o cruzamento de médias móveis serve como um ponto neutro de discussão que todos os membros da nossa comunidade podem usar como referência. Espero fornecer-lhe uma estrutura generalizada que você possa complementar com suas próprias estratégias de negociação e, seguindo esse framework adequadamente, você deverá ver algumas melhorias em suas próprias estratégias.
Primeiros Passos
Espero fornecer-lhe uma estrutura generalizada que você possa complementar com suas próprias estratégias de negociação e, seguindo esse framework adequadamente, você deverá ver algumas melhorias em suas próprias estratégias.
Queremos implementar uma estratégia simples de cruzamento de médias móveis, então vamos começar. Importaremos primeiro a biblioteca de trade.
//+------------------------------------------------------------------+ //| EURGBP Stochastic AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
Definir variáveis globais.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double vol,bid,ask;
Criando manipuladores para nossos indicadores técnicos.
//+------------------------------------------------------------------+ //| Technical indicator handlers | //+------------------------------------------------------------------+ int slow_ma_handler,fast_ma_handler,stochastic_handler,atr_handler; double slow_ma[],fast_ma[],stochastic[],atr[];
Também fixaremos algumas de nossas variáveis como constantes.
//+------------------------------------------------------------------+ //| Constants | //+------------------------------------------------------------------+ const int slow_period = 60; const int fast_period = 20; const int atr_period = 14;
Algumas de nossas entradas devem ser controladas manualmente. Como o tamanho do lote e a largura do stop loss.
//+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input group "Money Management" input int lot_multiple = 5; //Lot size input group "Risk Management" input int atr_multiple = 5; //Stop Loss Width
Quando nosso sistema estiver carregando, chamaremos uma função especial para configurar nossos indicadores técnicos e salvar dados de mercado.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setup our technical indicators and fetch market data setup(); //--- return(INIT_SUCCEEDED); }
Caso contrário, se não estivermos mais usando o aplicativo de negociação, vamos liberar os recursos que não precisamos mais.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(fast_ma_handler); IndicatorRelease(slow_ma_handler); IndicatorRelease(atr_handler); IndicatorRelease(stochastic_handler); }
Se não tivermos posições abertas no mercado, procuraremos uma oportunidade de negociação.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated quotes update(); //--- If we have no open positions, check for a setup if(PositionsTotal() == 0) { find_setup(); } }
Essa função inicializará nossos indicadores técnicos e salvará o tamanho do lote especificado pelo usuário final.
//+------------------------------------------------------------------+ //| Setup technical market data | //+------------------------------------------------------------------+ void setup(void) { //--- Setup our indicators slow_ma_handler = iMA("EURGBP",PERIOD_D1,slow_period,0,MODE_EMA,PRICE_CLOSE); fast_ma_handler = iMA("EURGBP",PERIOD_D1,fast_period,0,MODE_EMA,PRICE_CLOSE); stochastic_handler = iStochastic("EURGBP",PERIOD_D1,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR("EURGBP",PERIOD_D1,atr_period); //--- Fetch market data vol = lot_multiple * SymbolInfoDouble("EURGBP",SYMBOL_VOLUME_MIN); }
Agora construiremos uma função para salvar cotações de preços atualizadas quando as recebermos.
//+------------------------------------------------------------------+ //| Fetch updated market data | //+------------------------------------------------------------------+ void update(void) { //--- Update our market prices bid = SymbolInfoDouble("EURGBP",SYMBOL_BID); ask = SymbolInfoDouble("EURGBP",SYMBOL_ASK); //--- Copy indicator buffers CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(slow_ma_handler,0,0,1,slow_ma); CopyBuffer(fast_ma_handler,0,0,1,fast_ma); CopyBuffer(stochastic_handler,0,0,1,stochastic); }
Essa função finalmente verificará nosso sinal de negociação. Se o sinal for encontrado, entraremos em nossas posições com stop losses e take profits definidos pelo ATR.
//+------------------------------------------------------------------+ //| Check if we have an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Can we buy? if((fast_ma[0] > slow_ma[0]) && (stochastic[0] > 80)) { Trade.Buy(vol,"EURGBP",ask,(ask - (atr[0] * atr_multiple)),(ask + (atr[0] * atr_multiple)),"EURGBP"); } //--- Can we sell? if((fast_ma[0] < slow_ma[0]) && (stochastic[0] < 20)) { Trade.Sell(vol,"EURGBP",bid,(bid + (atr[0] * atr_multiple)),(bid - (atr[0] * atr_multiple)),"EURGBP"); } } //+------------------------------------------------------------------+
Agora estamos prontos para fazer o backtest de nosso sistema de negociação. Treinaremos o algoritmo de negociação de cruzamento de médias móveis simples que acabamos de definir acima nos dados de mercado diário do EURGBP. Nosso período de backtest será do início de janeiro de 2022 até o final de junho de 2024. Definiremos o parâmetro "Forward" como falso. Os dados de mercado serão modelados usando ticks reais que nosso Terminal terá que solicitar ao nosso corretor. Isso garantirá que os resultados de nosso teste estejam reproduzindo de perto as condições de mercado que ocorreram naquele dia.
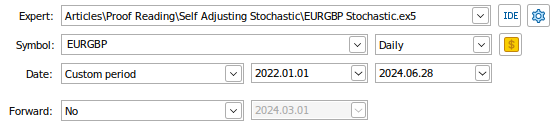
Fig1: Algumas das configurações para o nosso backtest
Fig 2: Os parâmetros restantes do nosso backtest
Os resultados do nosso backtest inicial não são animadores. Nossa estratégia de negociação estava perdendo dinheiro ao longo de todo o teste. No entanto, isso também não é surpreendente, pois já sabemos que os cruzamentos de médias móveis são sinais de negociação atrasados. A Fig 3 abaixo resume o saldo da nossa conta de negociação durante o teste.
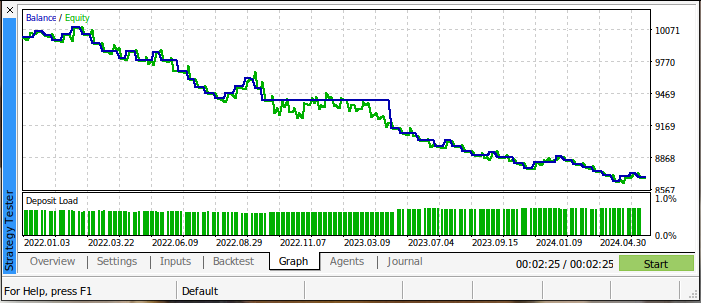
Fig 3: O saldo da nossa conta de negociação enquanto realizávamos o backtest
Nossa razão de Sharpe foi de -5,0, e perdemos 69,57% de todas as operações realizadas. Nossa perda média foi maior que nosso lucro médio. Esses são indicadores de desempenho ruins. Se usássemos esse sistema de negociação em seu estado atual, certamente perderíamos nosso dinheiro rapidamente.
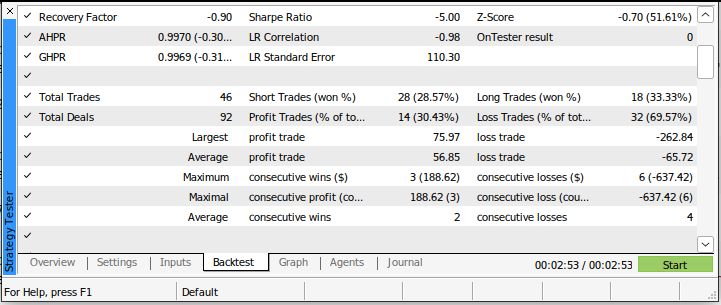
Fig 4: Os detalhes do nosso backtest usando uma abordagem clássica para negociar os mercados
Estratégias que dependem de cruzamentos de médias móveis e do oscilador estocástico já foram amplamente exploradas e dificilmente possuem qualquer vantagem material que possamos usar como traders humanos. Mas isso não significa que não exista uma vantagem material que nossos modelos de IA possam aprender. Vamos empregar uma transformação especial conhecida como "dummy encoding" para representar o estado atual dos mercados ao nosso modelo de IA.
O dummy encoding é usado quando se tem uma variável categórica não ordenada, e atribuímos uma coluna para cada valor que ela pode assumir. Por exemplo, imagine se a equipe do MQL5 permitisse que você escolhesse qual tema de cor deseja na instalação do MetaTrader 5. Suas opções seriam Vermelho, Rosa ou Azul. Podemos capturar essa informação tendo um banco de dados com 3 colunas intituladas "Vermelho", "Rosa" e "Azul", respectivamente. A coluna selecionada durante a instalação será definida como 1, enquanto as outras colunas permanecerão 0. Essa é a ideia por trás do dummy encoding.
O dummy encoding é poderoso porque, se tivéssemos escolhido uma representação diferente da informação, como 1-Vermelho, 2-Rosa e 3-Azul, nossos modelos de IA poderiam aprender interações falsas nos dados que não existem na vida real. Por exemplo, o modelo poderia aprender que 2 e meio seria a cor ideal. Portanto, o dummy encoding nos ajuda a apresentar informações categóricas aos nossos modelos de maneira que garanta que o modelo não assuma implicitamente que existe uma escala nos dados fornecidos.
Nossas médias móveis terão dois estados: o primeiro estado será ativado quando a média móvel rápida estiver acima da lenta. Caso contrário, o segundo estado será ativado. Apenas um estado pode estar ativo em qualquer momento. É impossível que o preço esteja em ambos os estados ao mesmo tempo. Da mesma forma, nosso oscilador estocástico terá 3 estados. Um estará ativo se o preço estiver acima da leitura 80 no indicador, o segundo será ativado quando o preço estiver abaixo da região 20. Caso contrário, o terceiro estado será ativado.
O estado ativo será definido como 1 e todos os outros estados serão definidos como 0. Essa transformação forçará nosso modelo a aprender a mudança média no alvo à medida que o preço transita entre os diferentes estados do nosso indicador. Isso se aproxima do que traders humanos profissionais fazem. Trading não é como engenharia, não podemos esperar precisão milimétrica. Ao contrário, os melhores traders humanos, com o tempo, aprendem o que é mais provável de acontecer em seguida. Treinar nosso modelo usando dummy encoding nos levará ao mesmo fim. Nosso modelo otimizará seus parâmetros para aprender a mudança média no preço, dado o estado atual dos indicadores técnicos.
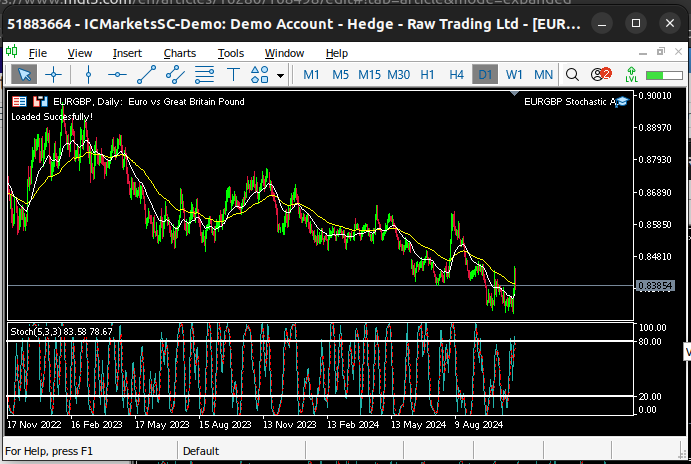
Fig 5: Visualizando o mercado diário EURGBP
O primeiro passo que daremos para construir nossos modelos de IA é buscar os dados que precisamos. É sempre uma prática recomendada buscar os mesmos dados que você usará na produção. É por isso que usaremos este script MQL5 para buscar todos os nossos dados de mercado do terminal MetaTrader 5. Diferenças inesperadas entre como os valores dos indicadores estão sendo calculados em diferentes bibliotecas podem nos deixar com resultados insatisfatórios no final do dia.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_fast_handler,ma_slow_handler,stoch_handler,atr_handler; double ma_fast[],ma_slow[],stoch[],atr[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator ma_fast_handler = iMA(Symbol(),PERIOD_CURRENT,20,0,MODE_EMA,PRICE_CLOSE); ma_slow_handler = iMA(Symbol(),PERIOD_CURRENT,60,0,MODE_EMA,PRICE_CLOSE); stoch_handler = iStochastic(Symbol(),PERIOD_CURRENT,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR(Symbol(),PERIOD_D1,14); //--- Load the indicator values CopyBuffer(ma_fast_handler,0,0,size,ma_fast); CopyBuffer(ma_slow_handler,0,0,size,ma_slow); CopyBuffer(stoch_handler,0,0,size,stoch); CopyBuffer(atr_handler,0,0,size,atr); ArraySetAsSeries(ma_fast,true); ArraySetAsSeries(ma_slow,true); ArraySetAsSeries(stoch,true); ArraySetAsSeries(atr,true); //--- File name string file_name = "Market Data " + Symbol() +" MA Stoch ATR " + " As Series.csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","MA Fast","MA Slow","Stoch Main","ATR"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), ma_fast[i], ma_slow[i], stoch[i], atr[i] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Análise Exploratória dos Dados
Agora que buscamos nossos dados de mercado do terminal, vamos começar a analisá-los.
#Import the libraries import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
Carregar os dados.
#Read in the data data = pd.read_csv("Market Data EURGBP MA Stoch ATR As Series.csv")
Vamos adicionar um alvo binário para nos ajudar a visualizar os dados.
#Let's visualize the data data["Binary Target"] = 0 data.loc[data["Close"].shift(-look_ahead) > data["Close"],"Binary Target"] = 1 data = data.iloc[:-look_ahead,:]
Escalar os dados.
#Scale the data before we start visualizing it from sklearn.preprocessing import RobustScaler scaler = RobustScaler() data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
Usaremos a biblioteca plotly para visualizar os dados.
import plotly.express as px
Vamos ver quão bem as médias móveis lenta e rápida nos ajudam a separar movimentos de mercado de alta e de baixa.
# Create a 3D scatter plot showing the ineteraction between the slow and fast moving average fig = px.scatter_3d( data, x=data.index, y='MA Slow', z='MA Fast', color='Binary Target', title="3D Scatter Plot of Time, The Slow Moving Average, and The Fast Moving Average", labels={'x': 'Time', 'y': 'MA Fast', 'z':'MA Slow'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
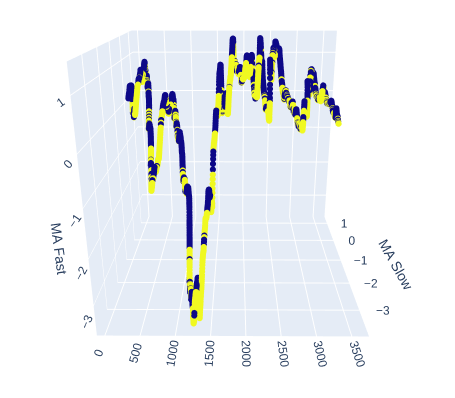
Fig 6: Visualizando a relação entre as médias móveis e o alvo
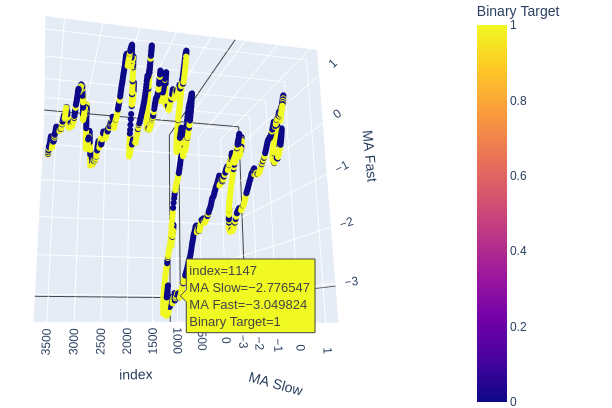
Fig 7: Nossas médias móveis parecem agrupar movimentos de preço de alta e de baixa de forma razoável
Vamos ver se talvez a volatilidade do mercado tem algum efeito sobre o alvo. Substituiremos o tempo no eixo x e, em vez disso, colocaremos o valor do ATR, enquanto as médias móveis lenta e rápida manterão suas posições.
# Create a 3D scatter plot showing the ineteraction between the slow and fast moving average and the ATR fig = px.scatter_3d( data, x='ATR', y='MA Slow', z='MA Fast', color='Binary Target', title="3D Scatter Plot of ATR, The Slow Moving Average, and The Fast Moving Average", labels={'x': 'ATR', 'y': 'MA Fast', 'z':'MA Slow'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
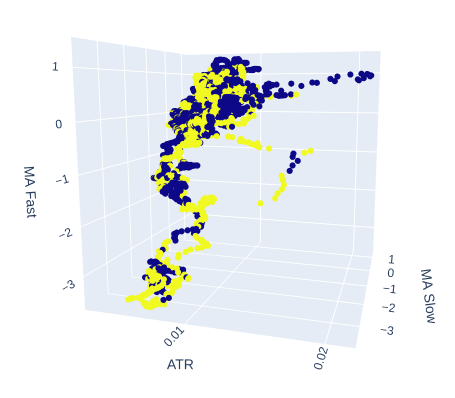
Fig 8: O ATR parece adicionar pouca clareza à nossa visão do mercado. Talvez precisemos transformar a leitura da volatilidade um pouco para que ela seja informativa.
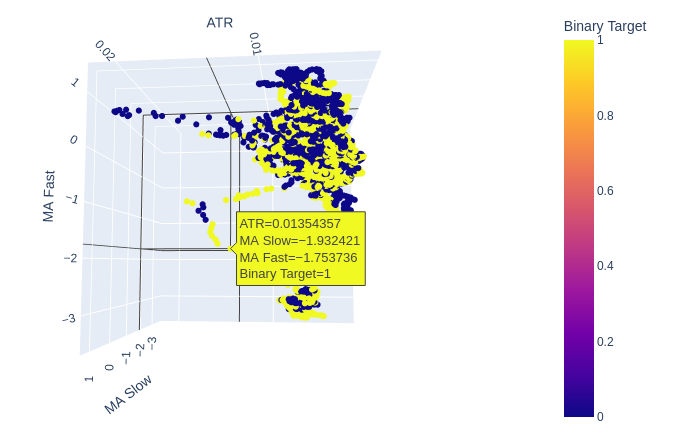
Fig 9: O ATR parece expor clusters de movimentos de preço de alta e de baixa. No entanto, os clusters são pequenos e podem não ocorrer com frequência suficiente para fazer parte de uma estratégia de negociação confiável.
As 2 médias móveis e o oscilador estocástico juntos conferem aos nossos dados de mercado uma nova estrutura como um todo.
# Creating a 3D scatter plot of the slow and fast moving average and the stochastic oscillator fig = px.scatter_3d( data, x='MA Fast', y='MA Slow', z='Stoch Main', color='Binary Target', title="3D Scatter Plot of Time, Close Price, and The Stochastic Oscilator", labels={'x': 'Time', 'y': 'Close Price', 'z': 'Stochastic Oscilator'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
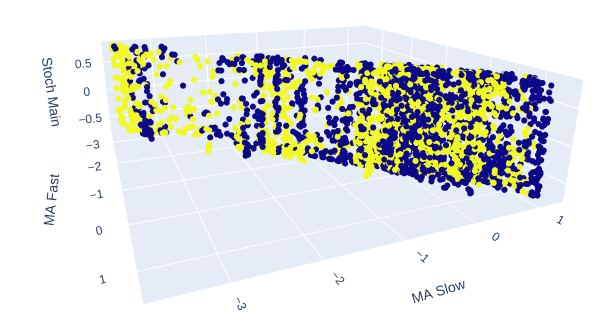
Fig 10: A leitura principal do Estocástico e as 2 médias móveis fornecem algumas zonas bem definidas de alta e de baixa
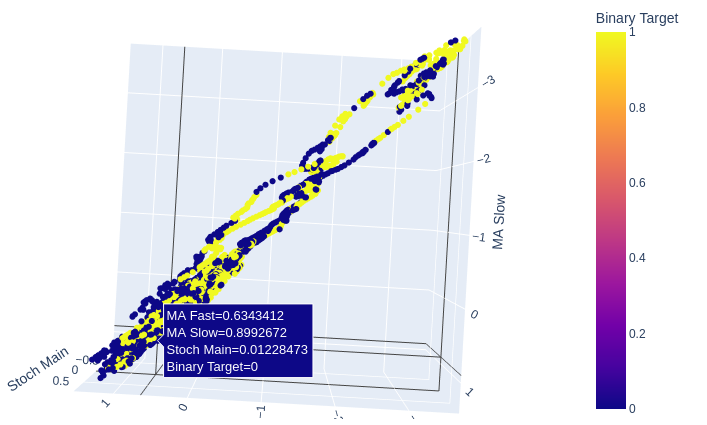
Fig 11: A relação entre as 2 médias móveis e o estocástico pode ser mais adequada para expor a ação de preço de alta do que a ação de preço de baixa
Dado que estamos usando 3 indicadores técnicos e 4 diferentes cotações de preço, nossos dados têm 7 dimensões, mas podemos visualizar no máximo 3. Podemos transformar nossos dados em apenas 2 colunas usando técnicas de redução de dimensionalidade. A Análise de Componentes Principais é uma escolha popular para resolver esse tipo de problema. Podemos usar o algoritmo para resumir todas as colunas em nosso conjunto de dados original em apenas 2 colunas.
Em seguida, criaremos um gráfico de dispersão dos 2 componentes principais e determinaremos quão bem eles expõem o alvo para nós.
# Selecting features to include in PCA features = data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow']] pca = PCA(n_components=2) pca_components = pca.fit_transform(features.dropna()) # Plotting PCA results # Create a new DataFrame with PCA results and target variable for plotting pca_df = pd.DataFrame(data=pca_components, columns=['PC1', 'PC2']) pca_df['target'] = data['Binary Target'].iloc[:len(pca_components)] # Add target column # Plot PCA results with binary target as hue fig = px.scatter( pca_df, x='PC1', y='PC2', color='target', title="2D PCA Plot of OHLC Data with Target Hue", labels={'PC1': 'Principal Component 1', 'PC2': 'Principal Component 2', 'color': 'Target'} ) # Update layout for custom size fig.update_layout( width=600, # Width of the figure in pixels height=600 # Height of the figure in pixels ) fig.show()
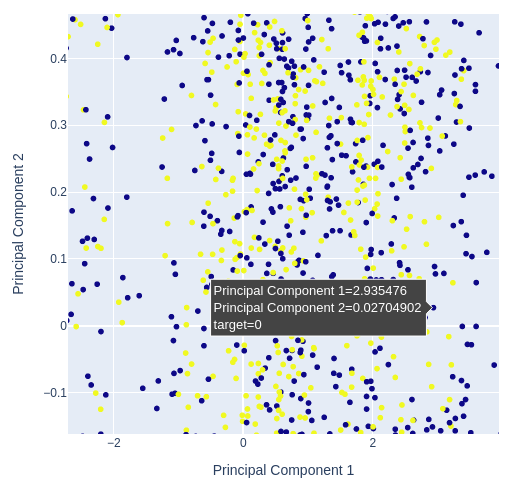
Fig 12: Ampliando uma parte aleatória do nosso gráfico de dispersão dos 2 primeiros componentes principais para ver quão bem eles separam as flutuações de preço
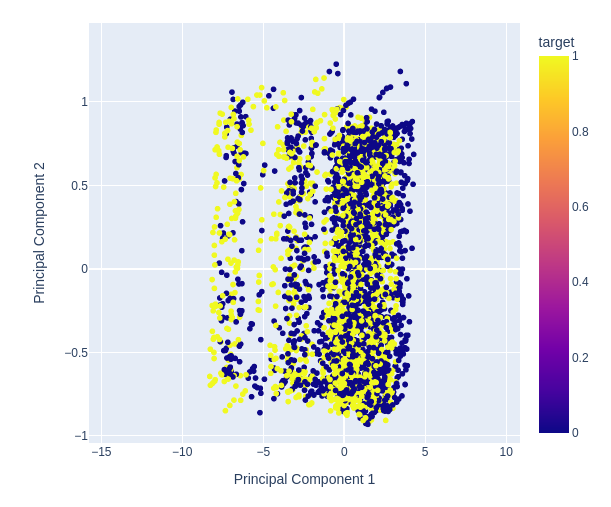
Fig 13:Visualizing our data shows us that PCA doesn't add better separation to the data set
Algoritmos de aprendizado não supervisionado como o KMeansClustering podem ser capazes de aprender padrões nos dados que não são aparentes para nós. O algoritmo criará rótulos para os dados que recebe, sem nenhuma informação sobre o alvo.
A ideia é que nosso algoritmo de clustering KMeans consiga aprender 2 classes a partir do nosso conjunto de dados que separarão bem nossas 2 classes. Infelizmente, o algoritmo KMeans não atendeu realmente às nossas expectativas. Observamos tanto ações de preço de alta quanto de baixa em ambas as classes que o algoritmo gerou a partir dos dados.
from sklearn.cluster import KMeans # Select relevant features for clustering features = data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main','ATR']] target = data['Binary Target'].iloc[:len(features)] # Ensure target matches length of features # Apply K-means clustering with 2 clusters kmeans = KMeans(n_clusters=2) clusters = kmeans.fit_predict(features) # Create a DataFrame for plotting with target and cluster labels plot_data = pd.DataFrame({ 'target': target, 'cluster': clusters }) # Plot with seaborn's catplot to compare the binary target and cluster assignments sns.catplot(x='cluster', hue='target',kind='count', data=plot_data) plt.title("Comparison of K-means Clusters with Binary Target") plt.show()
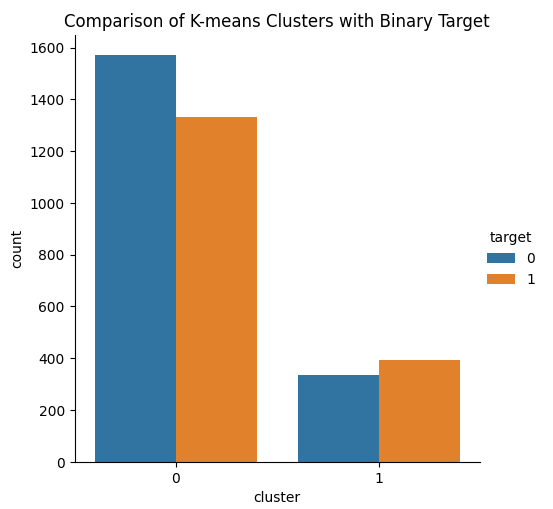
Fig 14: Visualizando os 2 clusters que nosso algoritmo KMeans aprendeu a partir dos dados de mercado
Também podemos testar relações entre as variáveis medindo a correlação de cada entrada com nosso alvo. Nenhuma de nossas entradas tem coeficientes de correlação fortes com nosso alvo. Observe que isso não refuta a existência de uma relação que possamos modelar.
#Read in the data data = pd.read_csv("Market Data EURGBP MA Stoch ATR As Series.csv") #Add targets data["ATR Target"] = data["ATR"].shift(-look_ahead) data["Target"] = data["Close"].shift(-look_ahead) - data["Close"]
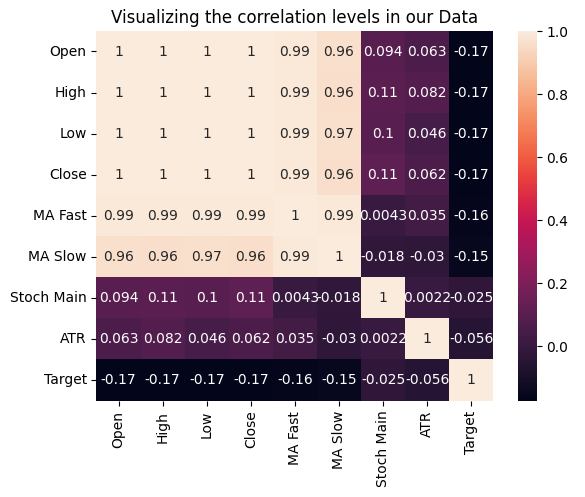
Fig 15: Visualizando os níveis de correlação em nosso conjunto de dados
Agora vamos transformar nossos dados de entrada. Temos 3 formas de usar nossos indicadores:
- A leitura atual.
- Estados de Markov.
- Diferença em relação ao seu valor passado.
Cada forma tem seu próprio conjunto de vantagens e desvantagens. A forma ideal de apresentar os dados variará dependendo de fatores como qual indicador está sendo modelado e em qual mercado o indicador está sendo aplicado. Como não há outra forma de determinar a escolha ideal, realizaremos uma busca por força bruta em todas as opções possíveis para cada indicador.
Preste atenção à coluna "Time" em nosso conjunto de dados. Observe que nossos dados vão do ano de 2010 até 2021. Isso não se sobrepõe ao período que usaremos para nosso backtest?
#Let's think of the different ways we can show the indicators to our AI Model #We can describe the indicator by its current reading #We can describe the indicator using markov states #We can describe the change in the indicator's value #Let's see which form helps our AI Model predict the future ATR value data["ATR 1"] = 0 data["ATR 2"] = 0 #Set the states data.loc[data["ATR"] > data["ATR"].shift(look_ahead),"ATR 1"] = 1 data.loc[data["ATR"] < data["ATR"].shift(look_ahead),"ATR 2"] = 1 #Set the change in the ATR data["Change in ATR"] = data["ATR"] - data["ATR"].shift(look_ahead) #We'll do the same for the stochastic data["STO 1"] = 0 data["STO 2"] = 0 data["STO 3"] = 0 #Set the states data.loc[data["Stoch Main"] > 80,"STO 1"] = 1 data.loc[data["Stoch Main"] < 20,"STO 2"] = 1 data.loc[(data["Stoch Main"] >= 20) & (data["Stoch Main"] <= 80) ,"STO 3"] = 1 #Set the change in the stochastic data["Change in STO"] = data["Stoch Main"] - data["Stoch Main"].shift(look_ahead) #Finally the moving averages data["MA 1"] = 0 data["MA 2"] = 0 #Set the states data.loc[data["MA Fast"] > data["MA Slow"],"MA 1"] = 1 data.loc[data["MA Fast"] < data["MA Slow"],"MA 2"] = 1 #Difference in the MA Height data["Change in MA"] = (data["MA Fast"] - data["MA Slow"]) - (data["MA Fast"].shift(look_ahead) - data["MA Slow"].shift(look_ahead)) #Difference in price data["Change in Close"] = data["Close"] - data["Close"].shift(look_ahead) #Clean the data data.dropna(inplace=True) data.reset_index(inplace=True,drop=True) #Drop the last 2 years of test data data = data.iloc[:((-365*2) - 18),:] data.dropna(inplace=True) data.reset_index(inplace=True,drop=True) data
Fig 16: Visualizando nossos dados de mercado após transformá-los de acordo
Vamos ver qual forma de apresentação é mais eficaz para nosso modelo aprender a mudança de preço dado a mudança em nossos indicadores. Usaremos uma árvore de regressão gradient boosting como nosso modelo de escolha.
#Let's see which method of presentation is most effective from sklearn.ensemble import GradientBoostingRegressor from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,cross_val_score
Defina os parâmetros da nossa validação cruzada de séries temporais.
tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead)Agora vamos definir um limite. Qualquer modelo que possa ser superado simplesmente usando o preço de fechamento para prever a mudança no preço não é um bom modelo.
#Our baseline accuracy forecasting the change in price using current price np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Close"]],data.loc[:,"Target"],cv=tscv))
-0.14861941262441164
Na maioria dos problemas, sempre podemos ter um desempenho melhor usando a mudança no preço, em vez de apenas a leitura atual do preço.
#Our accuracy forecasting the change in price using current change in price np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in Close"]],data.loc[:,"Target"],cv=tscv))
-0.1033528767401429
Nosso modelo pode ter um desempenho ainda melhor se fornecermos a ele o oscilador estocástico.
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Stoch Main"]],data.loc[:,"Target"],cv=tscv))
-0.09152071417994265
No entanto, isso é o melhor que podemos fazer? O que aconteceria se déssemos ao nosso modelo a mudança no oscilador estocástico em vez disso? Nossa capacidade de prever as mudanças de preço melhora!
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in STO"]],data.loc[:,"Target"],cv=tscv))
-0.07090156075020868
O que você acha que acontecerá se agora aplicarmos nossa abordagem de codificação dummy? Criamos 3 colunas para simplesmente nos dizer em qual estado o indicador está. Nossas taxas de erro diminuem. Esse resultado é muito interessante, estamos tendo um desempenho muito melhor do que um trader que está tentando prever mudanças no preço dado o preço atual ou a leitura atual do oscilador estocástico. Mas lembre-se, não sabemos se isso é verdade em todos os mercados possíveis. Estamos apenas confiantes de que isso é verdadeiro no mercado EURGBP no período diário.
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["STO 1","STO 2","STO 3"]],data.loc[:,"Target"],cv=tscv))
Vamos agora avaliar nossa precisão ao prever as mudanças de preço usando a leitura atual das duas médias móveis. Os resultados não parecem bons, nossas taxas de erro são maiores do que nossa precisão ao usar apenas o preço de fechamento para prever a mudança futura no preço. Este modelo deve ser abandonado e não serve para uso em produção.
#Our accuracy forecasting the change in price using the moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["MA Slow","MA Fast"]],data.loc[:,"Target"],cv=tscv))
Se transformarmos nossos dados para que possamos ver a mudança nos valores das médias móveis, nossos resultados melhoram. No entanto, ainda estaremos em melhor situação usando um modelo mais simples que considera apenas o preço de fechamento atual.
#Our accuracy forecasting the change in price using the change in the moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in MA"]],data.loc[:,"Target"],cv=tscv))
No entanto, se aplicarmos nossa técnica de codificação dummy aos dados de mercado, começamos a superar qualquer trader no mesmo mercado usando cotações de preço comuns no período diário. Nossas taxas de erro diminuem para novos mínimos que não tínhamos visto antes. Essa transformação é poderosa. Lembre-se de que ela ajuda o modelo a se concentrar mais nas mudanças críticas no valor do indicador, em vez de aprender o mapeamento exato de cada valor possível que nosso indicador pode assumir.
#Our accuracy forecasting the change in price using the state of moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["MA 1","MA 2"]],data.loc[:,"Target"],cv=tscv))
Para os leitores que estão aprendendo este tópico pela primeira vez, esta seção é particularmente importante. Como seres humanos, tendemos a ver padrões, mesmo quando eles não existem. O que você leu até agora pode deixá-lo com a impressão de que a codificação dummy é sempre sua melhor amiga. No entanto, esse não é o caso. Observe o que acontece enquanto tentamos otimizar nosso modelo final de IA que vai prever a leitura futura do ATR.
Não compare os resultados que você verá agora com os resultados que acabamos de discutir. As unidades do alvo mudaram. Portanto, uma comparação direta entre nossa precisão prevendo as mudanças no preço e nossa precisão prevendo o valor futuro do ATR não faz sentido na prática.
Estamos essencialmente criando um novo limite. Nossa precisão em prever o ATR usando valores anteriores do ATR é nossa nova linha de base. Qualquer técnica que resulte em maior erro não é ideal e deve ser abandonada.
#Our accuracy forecasting the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["ATR"]],data.loc[:,"ATR Target"],cv=tscv))
Até agora, hoje, observamos que nossas taxas de erro diminuíram sempre que passamos ao nosso modelo a diferença nos dados em vez dos dados em sua forma atual. No entanto, desta vez, nosso erro piorou.
#Our accuracy forecasting the ATR using the change in the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in ATR"]],data.loc[:,"ATR Target"],cv=tscv))
-0.5916640039518372
Além disso, codificamos em dummy o indicador ATR para indicar se ele estava subindo ou caindo. Nossas taxas de erro ainda eram inaceitáveis. Portanto, usaremos nosso indicador ATR como está e o Oscilador Estocástico e nossas Médias Móveis serão codificados em dummy.
#Our accuracy forecasting the ATR using the current state of the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["ATR 1","ATR 2"]],data.loc[:,"ATR Target"],cv=tscv))
Exportando para ONNX
Open Neural Network Exchange (ONNX) é um protocolo open-source que define uma representação universal para todos os modelos de aprendizado de máquina. Isso nos permite desenvolver e compartilhar modelos em qualquer linguagem, desde que essa linguagem ofereça suporte completo à API do ONNX. O ONNX nos permite exportar os modelos de IA que acabamos de desenvolver e usá-los diretamente em nossos modelos de IA para tomar decisões de negociação, em vez de usar regras fixas de negociação.
#Load the libraries we need import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Defina a forma de entrada de cada modelo.
#Define the input shapes #ATR AI initial_types_atr = [('float_input', FloatTensorType([1, 1]))] #MA AI initial_types_ma = [('float_input', FloatTensorType([1, 2]))] #STO AI initial_types_sto = [('float_input', FloatTensorType([1, 3]))]
Ajuste cada modelo com todos os dados que temos.
#ATR AI Model atr_ai = GradientBoostingRegressor().fit(data.loc[:,["ATR"]],data.loc[:,"ATR Target"]) #MA AI Model ma_ai = GradientBoostingRegressor().fit(data.loc[:,["MA 1","MA 2"]],data.loc[:,"Target"]) #Stochastic AI Model sto_ai = GradientBoostingRegressor().fit(data.loc[:,["STO 1","STO 2","STO 3"]],data.loc[:,"Target"])
Salve os modelos ONNX.
#Save the ONNX models onnx.save(convert_sklearn(atr_ai, initial_types=initial_types_atr),"EURGBP ATR.onnx") onnx.save(convert_sklearn(ma_ai, initial_types=initial_types_ma),"EURGBP MA.onnx") onnx.save(convert_sklearn(sto_ai, initial_types=initial_types_sto),"EURGBP Stoch.onnx")
Implementando em MQL5
Usaremos o mesmo algoritmo de negociação que desenvolvemos até agora. Apenas mudaremos as regras fixas que demos inicialmente e, em vez disso, permitiremos que nosso aplicativo de negociação faça suas operações sempre que nossos modelos nos derem um sinal claro. Além disso, começaremos importando os modelos ONNX que desenvolvemos.
//+------------------------------------------------------------------+ //| EURGBP Stochastic AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the AI Modules | //+------------------------------------------------------------------+ #resource "\\Files\\EURGBP MA.onnx" as const uchar ma_onnx_buffer[]; #resource "\\Files\\EURGBP ATR.onnx" as const uchar atr_onnx_buffer[]; #resource "\\Files\\EURGBP Stoch.onnx" as const uchar stoch_onnx_buffer[];
Agora, defina variáveis globais que irão armazenar as previsões do nosso modelo.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double vol,bid,ask; long atr_model,ma_model,stoch_model; vectorf atr_forecast = vectorf::Zeros(1),ma_forecast = vectorf::Zeros(1),stoch_forecast = vectorf::Zeros(1);
Também precisamos atualizar nosso procedimento de desinicialização. Nosso modelo também deve liberar os recursos que estavam sendo usados pelos nossos modelos ONNX.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(fast_ma_handler); IndicatorRelease(slow_ma_handler); IndicatorRelease(atr_handler); IndicatorRelease(stochastic_handler); OnnxRelease(atr_model); OnnxRelease(ma_model); OnnxRelease(stoch_model); }
Obter previsões de nossos modelos ONNX não é tão caro quanto treinar os modelos. No entanto, para realizar back-tests rápidos de nossos algoritmos de trading, obter uma previsão de IA em cada tick se torna caro. Nossos back-tests serão muito mais rápidos se buscarmos previsões de nossos modelos de IA a cada 5 minutos em vez disso.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated quotes update(); //--- Only on new candles static datetime time_stamp; datetime current_time = iTime(_Symbol,PERIOD_M5,0); if(time_stamp != current_time) { time_stamp = current_time; //--- If we have no open positions, check for a setup if(PositionsTotal() == 0) { find_setup(); } } }
Também precisamos atualizar a função responsável por configurar nossos indicadores técnicos. A função configurará nossos modelos de IA e validará se os modelos foram carregados corretamente.
//+------------------------------------------------------------------+ //| Setup technical market data | //+------------------------------------------------------------------+ void setup(void) { //--- Setup our indicators slow_ma_handler = iMA("EURGBP",PERIOD_D1,slow_period,0,MODE_EMA,PRICE_CLOSE); fast_ma_handler = iMA("EURGBP",PERIOD_D1,fast_period,0,MODE_EMA,PRICE_CLOSE); stochastic_handler = iStochastic("EURGBP",PERIOD_D1,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR("EURGBP",PERIOD_D1,atr_period); //--- Fetch market data vol = lot_multiple * SymbolInfoDouble("EURGBP",SYMBOL_VOLUME_MIN); //--- Create our onnx models atr_model = OnnxCreateFromBuffer(atr_onnx_buffer,ONNX_DEFAULT); ma_model = OnnxCreateFromBuffer(ma_onnx_buffer,ONNX_DEFAULT); stoch_model = OnnxCreateFromBuffer(stoch_onnx_buffer,ONNX_DEFAULT); //--- Validate our models if(atr_model == INVALID_HANDLE || ma_model == INVALID_HANDLE || stoch_model == INVALID_HANDLE) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } //--- Set the sizes of our ONNX models ulong atr_input_shape[] = {1,1}; ulong ma_input_shape[] = {1,2}; ulong sto_input_shape[] = {1,3}; if(!(OnnxSetInputShape(atr_model,0,atr_input_shape)) || !(OnnxSetInputShape(ma_model,0,ma_input_shape)) || !(OnnxSetInputShape(stoch_model,0,sto_input_shape))) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } ulong output_shape[] = {1,1}; if(!(OnnxSetOutputShape(atr_model,0,output_shape)) || !(OnnxSetOutputShape(ma_model,0,output_shape)) || !(OnnxSetOutputShape(stoch_model,0,output_shape))) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } }
Em nosso algoritmo de trading anterior simplesmente abríamos nossas posições desde que os indicadores estivessem alinhados a nosso favor. Agora, em vez disso, abriremos nossas posições se nossos modelos de IA nos derem um sinal de trading claro. Além disso, nossos níveis de take profit e stop loss serão definidos dinamicamente para níveis de volatilidade antecipados Com sorte, criamos um filtro usando IA que nos dará sinais de trading mais lucrativos.
//+------------------------------------------------------------------+ //| Check if we have an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Predict future ATR values vectorf atr_model_input = vectorf::Zeros(1); atr_model_input[0] = (float) atr[0]; //--- Predicting future price using the stochastic oscilator vectorf sto_model_input = vectorf::Zeros(3); if(stochastic[0] > 80) { sto_model_input[0] = 1; sto_model_input[1] = 0; sto_model_input[2] = 0; } else if(stochastic[0] < 20) { sto_model_input[0] = 0; sto_model_input[1] = 1; sto_model_input[2] = 0; } else { sto_model_input[0] = 0; sto_model_input[1] = 0; sto_model_input[2] = 1; } //--- Finally prepare the moving average forecast vectorf ma_inputs = vectorf::Zeros(2); if(fast_ma[0] > slow_ma[0]) { ma_inputs[0] = 1; ma_inputs[1] = 0; } else { ma_inputs[0] = 0; ma_inputs[1] = 1; } OnnxRun(stoch_model,ONNX_DEFAULT,sto_model_input,stoch_forecast); OnnxRun(atr_model,ONNX_DEFAULT,atr_model_input,atr_forecast); OnnxRun(ma_model,ONNX_DEFAULT,ma_inputs,ma_forecast); Comment("ATR Forecast: ",atr_forecast[0],"\nStochastic Forecast: ",stoch_forecast[0],"\nMA Forecast: ",ma_forecast[0]); //--- Can we buy? if((ma_forecast[0] > 0) && (stoch_forecast[0] > 0)) { Trade.Buy(vol,"EURGBP",ask,(ask - (atr[0] * atr_multiple)),(ask + (atr_forecast[0] * atr_multiple)),"EURGBP"); } //--- Can we sell? if((ma_forecast[0] < 0) && (stoch_forecast[0] < 0)) { Trade.Sell(vol,"EURGBP",bid,(bid + (atr[0] * atr_multiple)),(bid - (atr_forecast[0] * atr_multiple)),"EURGBP"); } } //+------------------------------------------------------------------+
Realizaremos nosso back-test sobre o mesmo período que usamos antes, do início de janeiro de 2022 até junho de 2024. Lembre-se de que, quando estávamos treinando nosso modelo de IA, não tínhamos nenhum dado dentro do intervalo do back-test. Faremos o teste usando o mesmo símbolo, o par EURGBP no mesmo time frame, o time frame Diário.
Fig 17: Back-testando nosso modelo de IA
Corrigiremos todos os outros parâmetros do back-test para que nossos testes sejam essencialmente idênticos. Estamos essencialmente tentando isolar a diferença feita por termos nossas decisões sendo tomadas por nossos modelos de IA.
Fig 18: Os parâmetros restantes do nosso back-test
Nossa estratégia de trading foi mais lucrativa ao longo do período de teste! Isso é uma ótima notícia porque os modelos não foram expostos aos dados que estamos usando no back-test. Portanto, podemos ter expectativas positivas ao usar este modelo para operar em uma conta real.
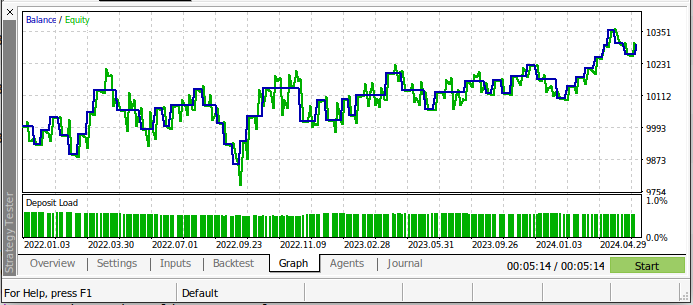
Fig 19: Os resultados do back-test do nosso modelo de IA ao longo das datas de teste
O novo modelo realizou menos trades durante o back-test, mas teve uma proporção maior de trades vencedores do que nosso antigo algoritmo de trading. Além disso, nosso Índice de Sharpe agora é positivo e apenas 44% de nossos trades foram perdedores.
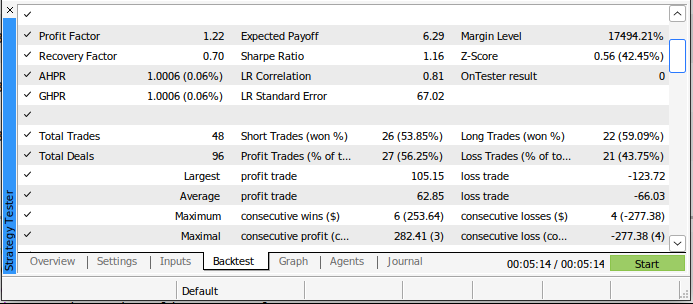
Fig 20: Resultados detalhados do back-test de nossa estratégia de trading impulsionada por IA
Conclusão
Com sorte, após ler este artigo, você concordará comigo que a IA pode realmente ser usada para melhorar nossas estratégias de trading. Mesmo a mais antiga estratégia clássica de trading pode ser reinventada usando IA e renovada para novos níveis de desempenho. Parece que o segredo está em transformar inteligentemente os dados dos indicadores para ajudar os modelos a aprender de forma eficaz. A técnica de codificação dummy que demonstramos hoje nos ajudou bastante. Mas não podemos concluir que seja a melhor escolha a se fazer em todos os mercados possíveis. É possível que a técnica de codificação dummy seja a melhor escolha que temos para um determinado grupo de mercados. No entanto, podemos concluir com confiança que o cruzamento de médias móveis pode efetivamente ser renovado usando IA.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/16280
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Obrigado, Gamu. Gosto de suas publicações e tento aprender reproduzindo suas etapas.
Estou tendo alguns problemas, espero que isso possa ajudar outras pessoas.
1) Meus testes com o EURGBP_Stochastic diário usando o script fornecido produziram apenas 2 ordens e, posteriormente, uma taxa de Sharpe de 0,02. Acredito que tenho as mesmas configurações que você, mas em duas corretoras ele produz apenas duas ordens.
2) como alerta para outros, talvez seja necessário modificar as configurações do símbolo para corresponder à sua corretora (por exemplo, EURGBP para EURGBP.i), se necessário
3) em seguida, quando tento exportar os dados, obtenho uma matriz fora do intervalo para o ATR. Acredito que isso ocorra porque não obtenho 100.000 registros na minha matriz (se eu alterá-la para 677), posso, portanto, obter um arquivo com 677 linhas. Para mim, o padrão para o número máximo de barras em um gráfico é 50.000. Se eu alterar isso para 100.000, o tamanho da minha matriz será de apenas 677, mas é possível que eu tenha uma configuração incorreta. Talvez você também possa incluir o script de extração de dados em seu download.
4) Copiei o código do seu artigo para tentar no Python e recebi um erro look_ahead not defined ----> 3 data.loc[data["Close"].shift(-look_ahead) > data["Close"], "Binary Target"] = 1
4 data = data.iloc[:-look_ahead,:]
NameError: o nome 'look_ahead' não está definido
5) Quando carreguei o notebook do Juypiter, descobri que ele precisava ter o look ahead definido #Let us forecast 20 steps into the future
look_ahead = 20 , Depois disso, usei apenas o arquivo incluído, mas estou com o seguinte erro, possivelmente relacionado ao fato de ter apenas 677 linhas.
Executei o #Scale os dados antes de começar a visualizá-los
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
o que me dá um erro que não sei como resolver
ipython-input-6-b2a044d397d0>:4: SettingWithCopyWarning: Um valor está tentando ser definido em uma cópia de uma fatia de um DataFrame. Em vez disso, tente usar .loc[row_indexer,col_indexer] = value Veja as advertências na documentação: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy data[[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
Obrigado, Gamu. Gosto de suas publicações e tento aprender reproduzindo suas etapas.
Estou tendo alguns problemas, espero que isso possa ajudar outras pessoas.
1) Meus testes com o EURGBP_Stochastic diário usando o script fornecido produziram apenas 2 ordens e, posteriormente, uma taxa de Sharpe de 0,02. Acredito que tenho as mesmas configurações que você, mas em duas corretoras ele produz apenas duas ordens.
2) como alerta para outros, talvez seja necessário modificar as configurações do símbolo para que correspondam à sua corretora (por exemplo, EURGBP para EURGBP.i), se necessário
3) em seguida, quando tento exportar os dados, obtenho uma matriz fora do intervalo para o ATR. Acredito que isso ocorra porque não obtenho 100.000 registros na minha matriz (se eu alterá-la para 677), posso, portanto, obter um arquivo com 677 linhas. Para mim, o padrão para o número máximo de barras em um gráfico é 50.000. Se eu alterar isso para 100.000, o tamanho da minha matriz será de apenas 677, mas é possível que eu tenha uma configuração incorreta. Talvez você também possa incluir o script de extração de dados em seu download.
4) Copiei o código do seu artigo para tentar no Python e recebi um erro look_ahead not defined ----> 3 data.loc[data["Close"].shift(-look_ahead) > data["Close"], "Binary Target"] = 1
4 data = data.iloc[:-look_ahead,:]
NameError: o nome 'look_ahead' não está definido
5) Quando carreguei seu notebook Juypiter, descobri que ele precisava ter o look ahead definido #Let us forecast 20 steps into the future
look_ahead = 20 , Depois disso, usei apenas o arquivo incluído, mas estou com o seguinte erro, possivelmente relacionado ao fato de ter apenas 677 linhas.
Executei o #Scale os dados antes de começar a visualizá-los
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
o que me dá um erro que não sei como resolver
ipython-input-6-b2a044d397d0>:4: SettingWithCopyWarning: Um valor está tentando ser definido em uma cópia de uma fatia de um DataFrame. Em vez disso, tente usar .loc[row_indexer,col_indexer] = value Veja as advertências na documentação: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy data[[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
E aí, Neil, acredito que você esteja bem.
Sim, sei que há muitas partes móveis. Verei se isso resolverá meus problemas.
Sim, eu sei que há muitas partes móveis, vou ver se isso resolverá meus problemas.