
ニューラルネットワークが簡単に(第58回):Decision Transformer (DT)

はじめに
本連載では、すでにかなり幅広い種類の強化学習アルゴリズムを検証してきました。どれも基本的なアプローチを採用しています。
- エージェントは環境の現状を分析します。
- (学習した方策-行動戦略の枠内で)最適な行動をとります。
- 環境の新しい状態に移行します。
- 新しい状態に完全に移行すると、環境から報酬を受け取ります。
このシーケンスはマルコフ過程の原理に基づいています。出発点は現在の環境状態であると仮定します。この状態から抜け出す最適な方法はひとつしかなく、それはそれまでの道筋に左右されません。
グーグルチームが「Decision Transformer:Reinforcement Learning via Sequence Modeling」(06.02.2021)という記事で紹介した別のアプローチを紹介したいと思います。この研究の主なハイライトは、強化学習問題を、所望の報酬の自己回帰モデルによって条件付けられた、条件付き行動シーケンスのモデリングに投影したことです。
1.Decision Transformer法の特徴
Decision Transformerは、強化学習の見方を変えるアーキテクチャです。エージェントの行動を選択する古典的なアプローチとは対照的に、言語モデリングの枠組みの中で逐次的な意思決定の問題が検討されます。
この手法の著者は、言語モデルが一般的なテキストのコンテキストでセンテンス(単語のシーケンス)を構築するのと同じように、以前に実行された行動や訪問した状態のコンテキストでエージェントの行動の軌跡を構築することを提案しています。このように問題を設定することで、GPT (Generative Pre-trained Transformer)を含め、最小限の修正で幅広い言語モデルツールを使用することができます。
エージェントの軌道を構築する原則から始める価値があるでしょう。この場合、私たちが特に話しているのは軌跡の構築についてであり、一連の行動についてではありません。
軌跡表現を選択する際の要件のひとつは、変換器を使用できることであり、これによってソースデータの重要なパターンを抽出することができます。環境条件の記述に加えて、エージェントが実行する行動と報酬があります。この手法の著者は、報酬をモデル化するための興味深いアプローチを提供しています。私たちは、モデルが過去の報酬ではなく、将来望む報酬に基づいて行動を生成することを望んでいます。結局のところ、私たちの望みは何らかの目標を達成することです。報酬を直接渡す代わりに、著者らは「Return-To-Go」のマグニチュードモデルを提供しています。これは、エピソード終了までの累積報酬に似ています。ただし、実際の結果ではなく、望まれる結果を示します。
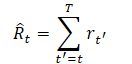
この結果、自己回帰学習と生成に適した次のような軌跡表現になります。
![]()
訓練済みモデルをテストする際には、生成のトリガーとなる情報として、望まれる報酬(例えば、成功なら1、失敗なら0)や環境の初期状態を指定することができます。現在の状態に対して生成された行動を実行した後、環境から受け取った量だけ目標報酬を減らし、希望する合計報酬を受け取るか、エピソードが完了するまでこのプロセスを繰り返します。
この方法を使用し、希望する総報酬のレベルに達した後に続行した場合、Return-To-Goに負の値が渡される可能性があることに注意してください。これによって損失が発生する可能性があります。
エージェントに決断をさせるために、最後のK時間ステップをソースデータとしてDecision Transformerに渡します。合計で3*Kのトークンが必要です。各モダリティ(Return-To-Go、状態、その状態に至った行動)に1つずつです。トークンのベクトル表現を得るために、この手法の著者は、各モダリティごとに訓練された全結合ニューラル層を使用し、ソースデータをベクトル表現の次元に投影します。層はその後正規化されます。複雑な(複合的な)環境状態を分析する場合、全結合ニューラル層の代わりに畳み込みエンコーダーを使用することが可能です。
さらに、各タイムステップごとに、タイムスタンプのベクトル表現が学習され、各トークンに追加されます。このアプローチは、トランスフォーマーにおける標準的な位置ベクトル表現とは異なります。1つの時間ステップが複数のトークン(与えられた例では3つ)に対応するからです。トークンは次に、自己回帰モデリングを用いて将来の行動トークンを予測するGPTモデルを使って処理されます。教師あり訓練法を考慮した場合のGPTモデルのアーキテクチャについては、「GPTについての一考察」という記事で詳しくお話しました。
奇妙に思われるかもしれませんが、モデルの訓練プロセスは教師あり学習の手法を用いて構築されています。まず、環境との相互作用をアレンジし、ランダムな軌道のセットをサンプリングします。すでに何度もやっています。その後、オフラインで訓練がおこなわれます。収集された軌跡のセットからKの長さのミニパッケージを選択します。st入力トークンに対応する予測ヘッドは、離散行動の場合はクロスエントロピー損失関数を使用するか、連続行動の場合は平均二乗誤差を使用して、at行動を予測することを学習します。各時間ステップの損失は平均化されます。
しかし、実験中、この手法の著者たちは、その後の状態や報酬を予測することでモデルの効率が向上することを発見しませんでした。
以下は、その方法を著者が視覚化したものです。

トランスフォーマーの構造やセルフアテンションメカニズムについては、すでに述べたとおりなので、ここでは詳しく触れません。実用的な部分に移り、MQL5を使ったDecision Transformerのメカニズムの実装を見てみましょう。
2.MQL5を使用した実装
Decision Transformer法の理論的側面について少し触れた後、MQL5を使った実装に移りましょう。最初に直面するのは、ソースデータエンティティの埋め込みを実装する問題です。教師あり学習法で同様の問題を解く場合、元データのウィンドウに等しいステップを持つ畳み込み層を使用しました。しかし、この場合、2つの困難が待ち受けています。
- 環境状態記述ベクトルのサイズは、行動空間ベクトルとは異なります。報酬ベクトルは3番目のサイズです。
- すべてのエンティティは、異なるディストリビューションからのソースデータを含んでいます。それらを単一の空間で比較可能な形にするためには、異なる埋め込み行列が必要となります。
環境の状態を、内容も大きさもまったく異なる2つのブロックに分けました。値動きの過去のデータと、口座の現在の状態の説明です。これによって、分析の方法がまたひとつ増えました。新たな実験中に、分析のための追加データが現れるかもしれません。明らかに、このような条件では畳み込み層は使えません。ベクトル サイズ [n1, n2, n3,...,nN] のN個のモダリティを埋め込むことができる別の汎用ソリューションが必要です。上述したように、この手法の著者たちは、各モダリティに対して訓練済み全結合層を使用しました。このアプローチは非常に普遍的なものですが、ここでの場合、複数のモダリティの並列処理を放棄することになります。
この場合、私の考えでは、最も最適な解決策は、ニューラル埋め込み層CNeuronEmbeddingOCLの形で新しいオブジェクトを作成することです。これが、プロセスを正しく構築できる唯一のアプローチです。しかし、新しいクラスのオブジェクトや関数を作る前に、そのアーキテクチャーの特徴をいくつか決めなければなりません。
フォワードパスの各反復で、ソースデータの5つのベクトルを送信する予定です。
- 過去の値動きデータ
- 口座状態
- 報酬
- 前のステップでとられた行動
- タイムスタンプ
このように、異なるモダリティからの情報は、その内容もデータ量も大きく異なります。ソースデータを埋め込み層に転送する技術を決めなければなりません。各モダリティに別々の行や列を持つ行列を使用することは、データベクトルのサイズが異なるため不可能です。もちろん、ベクトルの動的配列を使うこともできます。しかし、このオプションはMQL5を使った実装の枠組みの中でしかできません。しかし、このような配列を並列計算用のOpenCLコンテキストに渡すのは難しいでしょう。異なる数のソースデータモダリティに対して別々のカーネルを作成すれば、プログラムが複雑になり、アルゴリズムを完全に普遍的なものにすることはできません。個々のモダリティに対して1つのカーネルを使用することは、逐次的な埋め込みにつながり、並列計算の可能性が制限されます。
このような状況では、2つのベクトル(バッファ)を使うのが最も普遍的な解決策だと私は思います。ベクトルの1つでは、すべてのソースデータを一貫して示します。2つ目は、各シーケンスのウィンドウサイズという形で「データマップ」が提供されます。このように、たった2つのバッファを使うだけで、カーネル内部の行動のアルゴリズムを変更することなく、独立したデータサイズを持つ任意の数のモダリティをカーネルに転送することができます。これは、すべてのモダリティを同時に埋め込むための並列計算が可能な、完全に普遍的なソリューションです。
シンプルさと汎用性に加えて、このアプローチでは、新しいクラスを以前に作成したすべてのニューラル層と簡単に組み合わせることができます。
元のデータを転送することで問題を解決しました。しかし、重み行列についてもほぼ同じような状況があります。すでに述べたように、各モダリティは独自の埋め込み行列を必要とします。しかしこの場合、1つの利点があります。すべてのモダリティの埋め込みサイズが等しいということです。結局のところ、埋め込みプロセスの目的は、異なるモダリティを同等の形にすることです。したがって、ソースデータの各要素は、ニューラル層の出力にデータを転送するために、同じ数の重み付け係数を持ちます。これにより、すべてのモダリティの埋め込み重みを格納するために、1つの共通の行列を使うことができます。行列の列数は、1つのモダリティの埋め込みサイズに等しいです。行数はソースデータの総数と等しくなります。ここでベイズバイアス要素を追加することができます。これで、各モダリティの重み係数行列に1行が追加されます。
次に私が議論したい建設的な点は、直前のシーケンス全体を埋め込むことの妥当性です。私は、エージェントが以前の軌跡を分析する必要性に疑問を持っているわけではありません。結局のところ、これが検討中の方法の基本なのです。しかし、この問題をもっと広く見てみましょう。Decision Transformerの本質は自己回帰モデルです。このモデルは、K*Nトークンを入力として受け取ります。各時間ステップではNトークンだけが新しいままです。残りの(K-1)*Nトークンは、前の時間ステップで使用されたトークンを完全に繰り返します。もちろん、訓練の初期段階では、埋め込み行列に変更が加えられるため、繰り返されるソースデータでさえも異なる埋め込みがおこなわれます。しかし、この影響はモデルの訓練が進むにつれて減少していきます。重み行列が変化しない日常的な運用では、このようなズレはまったくありません。そして、各時間ステップで新しいソースデータだけを埋め込むことは、極めて論理的です。これにより、モデルの訓練時や日常的な運用時のデータ埋め込みにかかるリソースコストを大幅に削減することができます。
さらに、もう一点、ポジションコーディングに注目してみましょう。私たちのタスクでは、過去のデータの位置はバーの開始時間で示されます。ソースデータモデルにタイムスタンプエンコーディングを含めています。しかし、この方法の著者は、他のモダリティの埋め込みに位置トークンを追加しました。この解決策はトランスフォーマーのアーキテクチャと完全に一致していますが、一連の動作に追加の操作が加わります。位置の埋め込みは、他のモダリティの埋め込みと並行しておこなうことができるので、タイムスタンプの埋め込みを作成し、別のモダリティとして追加します。しかし、この方法では分析データ量が増えてしまいます。個々のケースにおいて、ポジションエンコーディングの方法を選択する際には、プログラムのさまざまな要素のバランスを考慮する必要があります。
実装の主な設計機能を定義した後、OpenCLプログラムの構築に移ることができます。いつものように、フォワードパスカーネルを作ることから始めます。結果として埋め込み行列を得たいのです。この行列の各行は、別々のモダリティの埋め込みを表します。同様に、カーネル問題の2次元空間を形成します。1次元では1つのモダリティの埋め込みサイズを示し、2次元目では分析したモダリティの数を示ます。
覚えていらっしゃるかもしれませんが、最後のモダリティだけをシーケンスに組み込むことにしています。以前のデータの埋め込みを、以前得られた結果から変更することなく転送します。同時に、CNeuronEmbeddingOCL層の出力で、シーケンス全体の埋め込みを受け取ります。
カーネルパラメータには、5つのデータバッファへのポインタと、シーケンスのサイズを示す1つの定数を渡します。この場合、シーケンスサイズとは、分析された履歴データステップの数を意味します。
データバッファには以下の情報を渡します。
- 入力:すべてのモダリティのシーケンス形式の初期データ(1時間ステップ)
- 出力:分析された履歴の深さまでのすべてのモダリティの埋め込みのシーケンス
- 重み:重み比の行列
- ウィンドウ:ソースデータマップ(ソースデータ内の各モダリティのデータウィンドウのサイズ)
- std:標準偏差のベクトル(埋め込みデータを正規化するために使用)
__kernel void Embedding(__global float *inputs, __global float *outputs, __global float *weights, __global int *windows, __global float *std, const int stack_size ) { const int window_out = get_global_size(0); const int pos = get_local_id(0); const int emb = get_global_id(1); const int emb_total = get_global_size(1); const int shift_out = emb * window_out + pos; const int step = emb_total * window_out; const uint ls = min((uint)get_local_size(0), (uint)LOCAL_ARRAY_SIZE);
カーネル本体では、両方の次元のフローを識別し、データバッファにオフセット定数を定義します。そして、先に得られた埋め込みを結果バッファにシフトします。各スレッドで転送される埋め込み位置は1つだけであることに注意してください。これにより、並列スレッドでのデータコピーをおこなうことができます。
for(int i=stack_size-1;i>0;i--) outputs[i*step+shift_out]=outputs[(i-1)*step+shift_out];
次のステップは、解析対象のモダリティに対するソースデータバッファのオフセットを決定することです。そのために、分析前のデータバッファにあるモダリティの要素の総数を数えてみましょう。
int shift_in = 0; for(int i = 0; i < emb; i++) shift_in += windows[i];
ここでは、ベイズ要素を考慮して、重み行列のバッファ内のオフセットを決定します。
const int shift_weights = (shift_in + emb) * window_out;
現在のモダリティのソースデータウィンドウのサイズをローカル変数に保存し、ローカル配列を操作するための定数を定義しましょう。
const int window_in = windows[emb]; const int local_pos = (pos >= ls ? pos % (ls - 1) : pos); const int local_orders = (window_out + ls - 1) / ls; const int local_order = pos / ls;
ローカル配列を作成し、ゼロ値で埋めます。ここでは、ローカルスレッド同期用のバリアを設定します。
__local float temp[LOCAL_ARRAY_SIZE]; if(local_order == 0) temp[local_pos] = 0; barrier(CLK_LOCAL_MEM_FENCE);
この時点で、準備作業は完了したとみなすことができるので、直接埋め込み操作に進みます。まず、分析されたモダリティの入力データのベクトルに、対応する重み比のベクトルを掛け合わせます。こうすることで、必要な埋め込み要素を得ることができます。
float value = weights[shift_weights + window_in]; for(int i = 0; i < window_in; i++) value += inputs[shift_in + i] * weights[shift_weights + i];
この場合、シーケンスの各要素の所望の部分空間への射影を得る必要があるので、活性化関数は使用しません。しかし、このようなアプローチは、異なるソースデータの埋め込みの比較可能性を保証するものではないことを認識しています。したがって、次のステップは、単一のモダリティの埋め込み内でデータを正規化することです。したがって、すべての埋め込みデータをゼロ平均単位分散にします。正規化の方程式を思い出してください。

これをおこなうには、まず、分析された埋込みの全要素の和をローカル配列を通して収集します。その結果を埋め込みベクトルのサイズで割ります。こうして平均値を決定します。そして、現在の埋め込み要素の値を平均値に調整します。ローカルスレッドの同期にはバリアを使っています。
for(int i = 0; i < local_orders; i++) { if(i == local_order) temp[local_pos] += value; barrier(CLK_LOCAL_MEM_FENCE); } //--- int count = ls; do { count = (count + 1) / 2; if(pos < count) temp[pos] += temp[pos + count]; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- value -= temp[0] / (float)window_out; barrier(CLK_LOCAL_MEM_FENCE);
ここで、実施された手術の派生物について少し述べておきます。ご存知のように、後方パス中に誤差勾配を伝播させるために前方パス関数の導関数を使用します。変数から定数を和算または減算する場合、誤差勾配をすべて変数に移します。しかし、この状況のニュアンスは、平均値を引いているということです。また、分析変数の関数として使用され、その導関数を持ちます。誤差勾配を正確に分布させるためには、平均値関数の導関数に誤差勾配を通す必要があります。これは標準偏差にも当てはまります。標準偏差は後で使います。しかし、私の個人的な経験では、平均と分散関数の微分を通過する誤差勾配の合計は、変数自体の誤差勾配よりも数倍小さいです。リソースを節約するため、中間データの保存とそれに続く誤差勾配の計算のアルゴリズムを複雑にすることはここではしません。
さて、カーネルアルゴリズムに話を戻しましょう。この段階で、埋め込みベクトルはすでに平均ゼロになっています。今こそ単位分散に減らす時です。これをおこなうには、分析した埋込みの全要素を標準偏差で割ります。標準偏差は、局所配列を使って計算します。
ローカル配列は、ローカルグループのスレッド間でデータを転送するために使われることを思い出してください。スレッドの同期はバリアを通しておこなわれます。
if(local_order == 0) temp[local_pos] = 0; barrier(CLK_LOCAL_MEM_FENCE); //--- for(int i = 0; i < local_orders; i++) { if(i == local_order) temp[local_pos] += pow(value,2.0f) / (float)window_out; barrier(CLK_LOCAL_MEM_FENCE); } //--- count = ls; do { count = (count + 1) / 2; if(pos < count) temp[pos] += temp[pos + count]; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- if(temp[0] > 0) value /= sqrt(temp[0]);
あとは、受け取った値を結果バッファの対応する要素に保存するだけです。また、計算された標準偏差を、その後のリバースパスの誤差勾配分布のために保存することも忘れないでください。
outputs[shift_out] = value; if(pos == 0) std[emb] = sqrt(temp[0]); }
フォワードパスカーネルに関する作業を終えた後、誤差勾配分布カーネルアルゴリズムの分析に移ることを提案します。データの正規化関数による誤差勾配の分布については、すでに前述したとおりです。リソースの利用を最適化するため、埋め込みベクトルの平均値と分散の関数を通して、誤差勾配の観点からアルゴリズムを単純化することにしました。この段階では、平均と分散を定数として扱います。EmbeddingHiddenGradientエラー勾配カーネルアルゴリズムが構築されたのは、このパラダイムにおいてです。
カーネルパラメータには、5つのデータバッファと1つの定数を渡します。前のカーネルで使われたバッファの定数と3については、すでに熟知しています。元のデータと結果のバッファは、対応する誤差勾配のバッファに置き換えられます。
__kernel void EmbeddingHiddenGradient(__global float *inputs_gradient, __global float *outputs_gradient, __global float *weights, __global int *windows, __global float *std, const int window_out ) { const int pos = get_global_id(0);
ソースデータの要素数に応じて、1次元のタスク空間でカーネルを呼び出します。カーネル本体では、すぐに現在のスレッドを特定します。しかし、ソースデータバッファ内の要素の位置は、結果バッファ内の従属要素の明示的なアイデアにはなりません。そのため、まず生データマップバッファを繰り返し処理し、解析するモダリティを決定します。
int emb = -1; int count = 0; do { emb++; count += windows[emb]; } while(count <= pos);
分析対象のモダリティのインデックスに基づいて、結果バッファと重みバッファのバイアスを決定します。
const int shift_out = emb * window_out; const int shift_weights = (pos + emb) * window_out;
データバッファのバイアスを決定した後、結果バッファのすべての従属要素から誤差勾配を収集し、正規化する前に埋め込みベクトルの標準偏差で調整します。その値をstdバッファに保存したことを思い出してください。
float value = 0; for(int i = 0; i < window_out; i++) value += outputs_gradient[shift_out + i] * weights[shift_weights + i]; float s = std[emb]; if(s > 0) value /= s; //--- inputs_gradient[pos] = value; }
結果の値は、前の層の勾配バッファに保存されます。
OpenCLプログラムで作業を完了するには、重み行列を更新するためのカーネルアルゴリズムを考えるだけでよくなります。この記事では、私が最もよく使うアダムメソッドのカーネルだけを見ることにします。このカーネルと先に説明した同様のカーネルとの主な違いは、データバッファのオフセットの決定にあります。これは予想通りです。重み比更新法のアルゴリズムそのものに根本的な変更を加えるわけではありません。
__kernel void EmbeddingUpdateWeightsAdam(__global float *weights, __global const float *gradient, __global const float *inputs, __global float *matrix_m, __global float *matrix_v, __global int *windows, __global float *std, const int window_out, const float l, const float b1, const float b2 ) { const int i = get_global_id(0);
かなり多くのバッファと定数がカーネルパラメータに渡されます。私たちはすでにそのすべてを知っています。カーネルは、重み比バッファの要素数に基づく一次元タスク空間で呼び出されます。
カーネル本体では、いつものように、スレッドIDによって解析対象のバッファ要素を特定します。その後、必要な要素へのデータバッファのオフセットを決定します。
int emb = -1; int count = 0; int shift = 0; do { emb++; shift = count; count += (windows[emb] + 1) * window_out; } while(count <= i); const int shift_out = emb * window_out; int shift_in = shift / window_out - emb; shift = (i - shift) / window_out;
そして、重み比を調整します。このプロセスは、以前の連載で取り上げたものと完全に同じです。結果と必要なデータを適切なバッファに保存します。
float weight = weights[i]; float g = gradient[shift_out] * inp / std[emb]; float mt = b1 * matrix_m[i] + (1 - b1) * g; float vt = b2 * matrix_v[i] + (1 - b2) * pow(g, 2); float delta = l * (mt / (sqrt(vt) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight)); if(delta * g > 0) weights[i] = clamp(weights[i] + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[i] = mt; matrix_v[i] = vt; }
OpenCLプログラムのカーネルに関する作業を終えたら、メインプログラム側の作業に戻ります。これで、クラスの機能が明確になり、必要なデータバッファの完全なリストができたので、上で説明したカーネルを呼び出して維持するための条件をすべて作ることができます。
前述のように、CNeuronBaseOCL基本クラスを基にして、新しいクラスCNeuronEmbeddingOCLクラスを作成します。ニューラル層の主な機能は親クラスから継承されます。このクラスに新しい機能を追加しなければなりません。
a_Windows動的配列を作成し、ソースデータマップを格納します。しかし、それを維持するために別のバッファオブジェクトを作ることはしません。その代わりに、i_WindowsBufferOpenCLコンテキストにバッファへのポインタを記録する変数を作りましょう。ここでは、1つの埋め込みのサイズと、分析された履歴の深さを記録する変数を作成します。それぞれ、i_WindowOutとi_StackSizeです。
埋め込み重み比とモーメントの行列のデータバッファを作成します。
- WeightsEmbedding
- FirstMomentumEmbed
- SecondMomentumEmbed
しかし、標準偏差バッファは中間計算にのみ使用されます。従って、メインプログラムの側では作成しません。OpenCLコンテキストメモリにのみ作成し、そのポインタをi_STDBuffer変数に格納します。
オーバーライドされたメソッドグループはごく標準的なものであり、その目的についてはここでは触れません。
class CNeuronEmbeddingOCL : public CNeuronBaseOCL { protected: int a_Windows[]; int i_WindowOut; int i_StackSize; int i_WindowsBuffer; int i_STDBuffer; //--- CBufferFloat WeightsEmbedding; CBufferFloat FirstMomentumEmbed; CBufferFloat SecondMomentumEmbed; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronEmbeddingOCL(void); ~CNeuronEmbeddingOCL(void); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint stack_size, uint window_out, int &windows[]); //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronEmbeddingOCL; } virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual bool Clear(void); };
クラスのコンストラクタで、変数とバッファへのポインタを初期値で初期化します。
CNeuronEmbeddingOCL::CNeuronEmbeddingOCL(void) { ArrayFree(a_Windows); if(!!OpenCL) { if(i_WindowsBuffer >= 0) OpenCL.BufferFree(i_WindowsBuffer); if(i_STDBuffer >= 0) OpenCL.BufferFree(i_STDBuffer); } //-- i_WindowsBuffer = INVALID_HANDLE; i_STDBuffer = INVALID_HANDLE; i_WindowOut = 0; i_StackSize = 1; }
埋め込み層オブジェクトの直接初期化はInitメソッドでおこなわれます。定数に加えて、分析履歴の深さ(stack_size)、埋め込みベクトルサイズ(window_out)、そしてソースデータマップ(windows[]動的配列)をメソッドのパラメータに指定します。
bool CNeuronEmbeddingOCL::Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl,uint stack_size, uint window_out,int &windows[]) { if(CheckPointer(open_cl) == POINTER_INVALID || window_out <= 0 || windows.Size() <= 0 || stack_size <= 0) return false; if(!!OpenCL && OpenCL != open_cl) delete OpenCL; uint numNeurons = window_out * windows.Size() * stack_size; if(!CNeuronBaseOCL::Init(numOutputs,myIndex,open_cl,numNeurons,ADAM,1)) return false;
メソッド本体にソースデータコントロールブロックを作成します。そして、1つの埋め込みのベクトルの長さと、モダリティの数と分析された履歴の深さの積として、結果バッファのサイズを再計算します。外部パラメータにモダリティの総数はないことに注意してください。ただし、「初期データの地図」は手に入れています。得られた配列のサイズから、解析されるモダリティの数がわかります。
結果バッファや他の継承オブジェクトの直接初期化は、親クラスの同様のメソッドでおこなわれます。準備操作が完了した後にこれを呼び出します。
継承されたオブジェクトの初期化に成功したら、追加されたエンティティを準備する必要があります。まず、埋め込み重みバッファを初期化します。上述したように、このバッファは、元データのボリュームに等しい行数と、1つの埋め込みのベクトルのサイズに等しい列数を持つ行列です。埋め込みのサイズはわかっています。しかし、ソースデータのサイズを決定するには、「データマップ」のすべての値を合計する必要があります。各モダリティの結果の合計に、ベイズバイアスを1行加えます。このようにして、埋め込み重みバッファのサイズを求めます。このメモリにランダムな値を入れ、OpenCLのコンテキストメモリに転送します。
uint weights = 0; ArrayCopy(a_Windows,windows); i_WindowOut = (int)window_out; i_StackSize = (int)stack_size; for(uint i = 0; i < windows.Size(); i++) weights += (windows[i] + 1) * window_out; if(!WeightsEmbedding.Reserve(weights)) return false; float k = 1.0f / sqrt((float)weights / (float)window_out); for(uint i = 0; i < weights; i++) if(!WeightsEmbedding.Add(k * (2 * GenerateWeight() - 1.0f)*WeightsMultiplier)) return false; if(!WeightsEmbedding.BufferCreate(OpenCL)) return false;
第1と第2のモーメントバッファは同じような大きさですが、それらをゼロ値で初期化し、OpenCLコンテキストメモリに転送します。
if(!FirstMomentumEmbed.BufferInit(weights, 0)) return false; if(!FirstMomentumEmbed.BufferCreate(OpenCL)) return false; //--- if(!SecondMomentumEmbed.BufferInit(weights, 0)) return false; if(!SecondMomentumEmbed.BufferCreate(OpenCL)) return false;
次に、生データと標準偏差マップバッファを作成します。
i_WindowsBuffer = OpenCL.AddBuffer(sizeof(int) * a_Windows.Size(),CL_MEM_READ_WRITE); if(i_WindowsBuffer < 0 || !OpenCL.BufferWrite(i_WindowsBuffer,a_Windows,0,0,a_Windows.Size())) return false; i_STDBuffer = OpenCL.AddBuffer(sizeof(float) * a_Windows.Size(),CL_MEM_READ_WRITE); if(i_STDBuffer<0) return false; //--- return true; }
各ステップで操作をおこなうプロセスを確実に管理します。メソッドのすべての操作が完了したら、メソッドの論理結果を呼び出し元のプログラムに返します。
オブジェクトを初期化した後、主な機能のメソッドを作らなければなりません。ここでの場合、これらはフォワードパスとバックワードパスです。お察しの通り、OpenCLプログラムの機能配置に関する主な作業はすでに終わっています。あとは適切なカーネルの呼び出しを整理するだけです。開始する前に、カーネルを扱うための定数(プログラム内のカーネルIDとそのパラメータ)を宣言する必要があります。いつものように、#defineディレクティブを使ってこの機能を実行します。
#define def_k_Embedding 59 #define def_k_emb_inputs 0 #define def_k_emb_outputs 1 #define def_k_emb_weights 2 #define def_k_emb_windows 3 #define def_k_emb_std 4 #define def_k_emb_stack_size 5 //--- #define def_k_EmbeddingHiddenGradient 60 #define def_k_ehg_inputs_gradient 0 #define def_k_ehg_outputs_gradient 1 #define def_k_ehg_weights 2 #define def_k_ehg_windows 3 #define def_k_ehg_std 4 #define def_k_ehg_window_out 5 //--- #define def_k_EmbeddingUpdateWeightsAdam 61 #define def_k_euw_weights 0 #define def_k_euw_gradient 1 #define def_k_euw_inputs 2 #define def_k_euw_matrix_m 3 #define def_k_euw_matrix_v 4 #define def_k_euw_windows 5 #define def_k_euw_std 6 #define def_k_euw_window_out 7 #define def_k_euw_learning_rate 8 #define def_k_euw_b1 9 #define def_k_euw_b2 10
ここでは、feedForwardダイレクトパスメソッドを例に、カーネルを実行キューに入れるプロセスのアレンジについて見ていきます。メソッドのパラメータには、これまで検討した同様のものと同様に、前のニューラル層のオブジェクトへのポインタを受け取ります。
bool CNeuronEmbeddingOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false;
メソッド本体では、受け取ったポインタと、OpenCLコンテキストで動作するオブジェクトへのポインタを確認します。
次に、データバッファへのポインタと、事前にカーネルパラメータで指定した必要な定数をカーネルに渡します。すべてのステップで操作を監視することを忘れてはなりません。
if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_std, i_STDBuffer)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_weights, WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_windows, i_WindowsBuffer)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_Embedding, def_k_emb_stack_size, i_StackSize)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; }
すべてのパラメータをうまく渡したら、カーネルのタスク空間を定義する必要があります。上述したように、カーネルは2次元のタスク空間で実行されます。1次元目では、1つの埋め込みサイズを示し、2次元目では、分析のためのモダリティの数を指定します。
uint global_work_offset[2] = {0,0}; uint global_work_size[2] = {i_WindowOut,a_Windows.Size()};
埋め込みカーネルの特徴は、あるモダリティの埋め込みベクトル内のデータを正規化することです。このサブプロセスを構築するために、同じワークグループ内のスレッド間のデータ交換を、ローカル配列を通じて組織化しました。ここで、埋め込みベクトルのサイズに等しいローカルグループのサイズを指定する必要があります。ニュアンスとしては、2次元空間を指定する場合、2次元のローカルグループを指定する必要があるということです。したがって、ローカルグループの2次元目は1です。
uint local_work_size[2] = {i_WindowOut,1};
最後に、カーネルをキューイングするメソッドを呼び出し、操作の実行プロセスを制御します。
if(!OpenCL.Execute(def_k_Embedding, 2, global_work_offset, global_work_size,local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__,GetLastError()); return false; } //--- return true; }
バックパスカーネルを呼び出す手順も同様ですが、ここでは触れません。必要なコードは添付ファイルにあります。私が注目したいのは次の点です。Decision Transformerは自己回帰モデルであり、入力データの一貫性が非常に重要です。上記では、各時間ステップで新しいデータのみをモデル入力に与えることにしました。分析された履歴の深さ全体が、過去のモデル操作からコピーされます。基本的には、CNeuronEmbeddingOCL層の結果バッファを埋め込みスタックとして使用します。このアプローチにより、一次データ処理のコストを削減することができます。しかし、訓練の過程でも作業の過程でも、一貫した初期データの供給が必要となります。同時に、訓練ではソースデータのランダムなサンプルを使用することが多いです。その必要性については、以前から何度も議論されてきました。元データの「一時的なジャンプ」の結果、あるいは代替軌道に切り替わる際のデータの破損を排除するためには、埋め込みスタックをクリアする方法が必要です。Clearメソッドは、こうした目的のために生まれました。そのアルゴリズムは非常にシンプルで、バッファ全体をゼロ値で満たし、データをOpenCLのコンテキストメモリにコピーするだけです。
bool CNeuronEmbeddingOCL::Clear(void) { if(!Output.BufferInit(Output.Total(),0)) return false; if(!OpenCL) return true; //--- return Output.BufferWrite(); }
これでCNeuronEmbeddingOCLクラスメソッドアルゴリズムの説明を終えます。全コードと全メソッドは添付ファイルにあります。
この作業の結果、いくつかの異なるモダリティの埋め込みをCNeuronEmbeddingOCL層の出力に、複数の異なるモダリティの埋め込みを比較できるようになりました。これにより、以前に作成したトランスフォーマーオブジェクトを使用して、提示されたDecision Transformerメソッドを実装することができます。つまり、モデルアーキテクチャの記述に移れるということです。この場合、使用するモデルは1つだけです。エージェントのモデルです。この連載では久しぶりの出来事です。
ただし、その前に「ソースマップ」を思い出してください。それを記述するために、これまでニューラル層記述クラスにはなかった配列を使いました。追加しましょう。
class CLayerDescription : public CObject { public: /** Constructor */ CLayerDescription(void); /** Destructor */~CLayerDescription(void) {}; //--- int type; ///< Type of neurons in layer (\ref ObjectTypes) int count; ///< Number of neurons int window; ///< Size of input window int window_out; ///< Size of output window int step; ///< Step size int layers; ///< Layers count int batch; ///< Batch Size ENUM_ACTIVATION activation; ///< Type of activation function (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Type of optimization method (#ENUM_OPTIMIZATION) float probability; ///< Probability of neurons shutdown, only Dropout used int windows[]; //--- virtual bool Copy(CLayerDescription *source); //--- virtual bool operator= (CLayerDescription *source) { return Copy(source); } };
CreateDescriptionsメソッドでモデルアーキテクチャを記述します。パラメータとして、このメソッドはActorのアーキテクチャを記述する1つの動的配列へのポインタを受け取ります。モデルのニューラル層の記述を、結果の配列に保存します。
bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear();
最初の層として、ソースデータの全結合ニューラル層を示し、そこに分析に必要なすべてのデータを順次書き込んでいきます。なお、ソースデータを内容に応じて別々のバッファに分割することはありません。この場合、その分け方はかなり恣意的です。順番に書いていくだけです。これらの論理的な分離は、後で作成する「ソースデータマップ」に従って、埋め込みレベルでおこなわれます。
ソースデータ層は、システムの最後の状態に関する情報(報酬、環境状態、アカウント状態、タイムスタンプ、および最後のエージェントの行動)のみを含んでいることに注意してください。
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (NRewards + BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
ソースデータ層に続いて、データの前処理をおこなうバッチ正規化層を示します。ここでも、得られたデータの性質の違いについては考えません。結局のところ、この層は各属性について、過去のデータとの関連で正規化を独立しておこないます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
次に一括正規化層が来ます。ここでは、分析された履歴の深さ、1つの埋め込みのベクトルのサイズ、および「ソースデータマップ」を示します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NRewards,NActions}; ArrayCopy(descr.windows,temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
埋め込み層の背後には、トランスフォーマーの基礎を形成するスパースアテンションブロックdefNeuronMLMHSparseAttentionOCLを配置します。この方法の著者はオリジナルの変圧器を使用しました。しかし、スパースアテンションブロックを使用することで、リソースコストとモデル実行時間をわずかに増加させながら、分析履歴の深さを大幅に増加させることができます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
このモデルは、全結合層の意思決定ブロックと、Actorの方策に確率性を持たせるための変分オートエンコーダの潜在層で完成します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
意思決定ブロックも、著者のDTアルゴリズムで使用されているものとは異なると言わざるを得ません。この方法の著者たちは、変圧器の出力でシーケンスの最後のトークンのデコーダを使用しました。情報に基づいた決断を下すために、一連の流れ全体を分析します。
モデルのアーキテクチャを指定した後、環境とインタラクションするためのEAを作成し、モデルを学習するためのデータを体験再生バッファ「\DT\Research.mq5」に収集します。EAの構造は先に説明したものとまったく同じですが、OnTickティック処理方法に注目する価値があります。ここで、上述のマップに従って初期データのシーケンスが形成されます。
メソッド本体では、新しいバーを開くイベントの発生を確認し、必要であれば過去のデータを読み込みます。しかし現在では、分析された履歴の深さ全体を読み込むのではなく、1つの時間ステップのパターンの大きさだけを更新しています。これは、最後に閉じたローソク足のデータである場合もあれば、それ以上である場合もあります。データ読み込みの深さを調整するために、NBarInPattern定数を導入しました。これを、埋め込みスタックの深さを決定するのに使用するHistoryBars定数と混同しないでください。
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
次に、軌跡に格納するための履歴データから配列を作成し、ソースデータバッファに転送します。手順は、先に説明したEAとまったく同じです。
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
次のステップは、口座ステータスの説明を作成することです。データ収集は、事前に適用された手順に従っておこなわれます。しかし、データは別のバッファではなく単一の元のデータのbStateバッファに転送されます。
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
同じバッファにタイムスタンプを追加します。
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
以下のデータは、Decision Transformer法の要件によってすでに生成されています。ここでは、Return-To-Goモダリティをソースデータバッファに追加します。希望する報酬の要素は1つかもしれないし、分解された報酬のベクトルかもしれません。残高の変化、エクイティの変化、ドローダウンの3つの要素を示します。3つの指標はすべて相対値で表示されています。
//--- Return to go bState.Add(float(1-(sState.account[0] - PrevBalance) / PrevBalance)); bState.Add(float(0.1f-(sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(0);
初期データのベクトルを完成させるために、エージェントの最新の行動のベクトルを追加します。初めて呼ばれたとき、このベクトルはゼロ値で満たされます。
//--- Prev action
bState.AddArray(AgentResult);
ソースデータベクトルの準備ができたので、エージェントのダイレクトパスを実行します。
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) return;
モデル結果を解釈し、取引をおこなうためのさらなるアルゴリズムは、変更されることなく移管されたので、ここでは触れません。EAの全コードと全メソッドが添付ファイルにあります。EA「\DT\Study.mq5」でモデルの訓練プロセスを構築しましょう。EAも前作から多くを受け継いでいます。ここでは、Trainモデルの訓練方法についてのみ詳しく説明します。
メソッド本体では、まずローカル経験再生バッファに保存されている軌跡の数を決定します。
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
次に、訓練の反復回数に基づいてサイクルを調整し、ランダムに1つの軌道とこの軌道上の別の状態を選択します。ここでは、すべてが以前と同じです。
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; }
違いはここから始まります。モデルの入力にシーケンシャルなデータを供給する必要性について話したことを思い出してください。それなのに、私たちは軌道上のランダムな状態なのです。分析されたシーケンスのデータ破損を排除するために、埋め込みバッファとエージェントの最後の行動のベクトルをクリアします。
Actions = vector<float>::Zeros(NActions); Agent.Clear();
もちろん、保存された軌跡のサイズがそれを可能にするならば、反復の回数は分析された軌跡の深さの3倍です。このネストされたループの本体では、保存された軌跡からの入力データを、環境との相互作用の厳密な順序で与えることによって、モデルを訓練します。まず、過去の指標の値動きデータをバッファに読み込みます。
for(int state = i; state < MathMin(Buffer[tr].Total - 1,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
以下は口座ステータスに関する情報です。
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
そしてタイムスタンプに関する情報です。
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
この段階で、実際の累積報酬をReturn-To-Goで軌跡の最後に移します。このアプローチは、環境インタラクションEAの同様のトークンとは少し異なります。しかし、これによってモデルを訓練することができます。
//--- Return to go
State.AddArray(Buffer[tr].States[state].rewards);
前のタイムステップでのエージェントの行動を経験再生バッファから追加します。
//--- Prev action
State.AddArray(Actions);
1回の訓練反復のソースデータバッファの準備ができたので、エージェントのフォワードパスメソッドを呼び出します。
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
フォワードパスが成功したら、リバースパスをおこない、モデルのパラメータを調整しなければなりません。ここで目標値の問題が生じますが、これは極めてシンプルな方法で解決されます。エージェントが環境と相互作用する際に実際に実行した行動を目標値として使用します。逆説的ですが、これは純粋な監督付き訓練です。強化学習はどこでしょうか。報酬の最適化はどこでしょうか。環境と相互作用する際の行動は最適ではないため、教師あり学習を使うこともできません。
自己回帰モデルを学習し、移動した軌跡と望ましい結果の知識に基づいて、最適な行動を生成します。この面では、実際に蓄積された報酬をReturn-To-Goトークンに表示することが主な役割を果たします。結局のところ、実際におこなわれた行動こそが、実際に受け取った報酬につながったことを疑う人はいません。従って、これらの行動を報酬で識別するモデルを簡単に訓練することができます。よく訓練されたモデルは、その後、操作中に望ましい結果を得るための行動を生成できるようになります。
意思決定トランスフォーマー著者らはMSEを使用することを提案しています。それを補うのがCAGradメソッドです。
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
リバースパスに成功すると、訓練の状態をユーザーに知らせ、学習プロセスループシステムの次の反復に移ります。すべての反復が完了したら、EA作業を終了するプロセスを開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
この記事で使用されているすべてのプログラムの完全なコードを添付ファイルでご覧ください。
3.検証
MQL5を使ってDecision Transformer法を実装するために、かなり多くの作業をおこないました。モデルを訓練し、テストする時が来ました。いつものように、モデルの訓練とテストはEURUSDH1でおこなわれます。すべての指標のパラメータがデフォルトで使用されます。訓練期間は2023年の7カ月間です。2023年8月の履歴データを用いてモデルをテストします。
この方法をテストした結果、このアイデアは非常に面白いと言えます。しかし、確率論的な市場において、何とか望ましい結果を得ることができました。訓練サンプルではまだ納得のいく結果を出すことが可能ですが、新しいデータではテスト期間の最初の10日間でバランスが悪化しているのがわかります。しかし、その後、負けトレードが続きました。その結果、このモデルはテストデータで損失を出しました。平均勝ちトレードは平均負けトレードを1.0%強上回っていますが、これだけでは十分ではありません。収益性の高い取引の割合は47.76%に過ぎません。つまり、プロフィットファクターは0.92です。


結論
今回は、強化学習の新しい革新的なアプローチである「Decision Transformer」と呼ばれる、ちょっと面白い手法を紹介しました。従来の方法とは異なり、Decision Transformerは、望まれる報酬の自己回帰モデルの文脈で行動シーケンスをモデル化します。これにより、エージェントは将来の目標に基づいた意思決定を学習し、その目標に基づいて行動を最適化することができます。
本稿の実践編では、MQL5を用いて本手法を実装し、モデルの訓練とテストをおこないました。しかし、訓練されたモデルはテスト期間を通じて利益を生み出すことができませんでした。テストサンプルの前半では、このモデルは利益を上げましたが、テストを続けるとそのすべてが失われました。このアルゴリズムには可能性があります。しかし、望ましい結果を得るためには、このモデルをさらに改良する必要があります。
リンク
- Decision Transformer:Reinforcement Learning via Sequence Modeling
- ニューラルネットワークが簡単に(第57回):Stochastic Marginal Actor-Critic (SMAC)
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Study.mq5 | EA | エージェント訓練EA |
| 3 | Test.mq5 | EA | モデルテストEA |
| 4 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造 |
| 5 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 6 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13347
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索