
Redes neuronales: así de sencillo (Parte 58): Transformador de decisión (Decision Transformer-DT)

Introducción
En esta serie de artículos, ya hemos abarcado una gama bastante amplia de diferentes algoritmos de aprendizaje por refuerzo. Y todos ellos explotan el planteamiento básico:
- El agente analizará el estado actual del entorno.
- Realizará la acción óptima (dentro de la Política aprendida - estrategia de comportamiento).
- Pasará a un nuevo estado del entorno.
- Obtendrá una recompensa del entorno por una transición perfecta a un nuevo estado.
Esta secuencia se basará en los principios del proceso de Markov. Y se asumirá que el punto de partida es el estado actual del entorno. Solo hay un camino óptimo para salir de un estado dado y no dependerá del camino anterior.
Quiero presentarles un enfoque alternativo presentado por el equipo de Google en el artículo "Decision Transformer: Reinforcement Learning via Sequence Modeling" (2.06.2021) El principal "plato fuerte" de este trabajo consiste en la proyección de una tarea de aprendizaje por refuerzo en el modelado de una secuencia condicional de acciones condicionadas a un modelo autorregresivo de recompensa deseada.
1. Características del método Decision Transformer
El Decision Transformer representa una arquitectura que está cambiando nuestra forma de ver el aprendizaje por refuerzo. En contraste con el enfoque clásico de la selección de acciones de agentes, consideraremos el problema de la toma de decisiones secuencial dentro de un marco de modelado lingüístico.
Los autores del método proponen construir trayectorias de acciones del Agente en el contexto de las acciones realizadas y los estados visitados anteriormente, del mismo modo que los modelos lingüísticos construyen frases (secuencias de palabras) en el contexto de un texto común. Esta formulación del problema permite usar una amplia gama de herramientas de modelos lingüísticos con modificaciones mínimas, en concreto, un modelo como GPT (Generative Pre-trained Transformer).
Probablemente deberíamos empezar por los principios de construcción de trayectorias de los Agentes. En este caso hablamos específicamente de construir trayectorias, no secuencias de acciones.
Uno de los requisitos para elegir una representación de trayectorias será la capacidad de usar transformadores que permitan extraer patrones significativos en los datos de origen, entre los cuales, además de la descripción de los estados del entorno, estarán las acciones realizadas por el Agente y las recompensas obtenidas por este. Y aquí los autores del método ofrecen un enfoque bastante interesante para modelizar las recompensas. Sería deseable que el modelo genere acciones basadas en las recompensas futuras deseadas en lugar de las recompensas pasadas. Al fin y al cabo, nuestro deseo es alcanzar algún objetivo, y en lugar de suministrar la recompensa directamente, los autores ofrecen modelos de magnitud Return-To-Go. Es el análogo de una recompensa acumulativa hasta el final del episodio; solo especificaremos los modelos, no el resultado real, sino el resultado deseado.
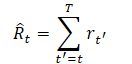
Esto conducirá a la siguiente representación de la trayectoria, que resulta adecuada para el aprendizaje y la generación autorregresiva:
![]()
Al probar modelos entrenados, podemos especificar la recompensa deseada (por ejemplo, 1 para el éxito o 0 para el fracaso) y el estado inicial del entorno como información para iniciar la generación. Después de ejecutar la acción generada para el estado actual, reduciremos la recompensa objetivo en la magnitud obtenida del entorno y repetiremos el proceso hasta obtener la recompensa total deseada o finalizar el episodio.
Tenga en cuenta que se puede transmitir un valor negativo a Return-To-Go si se adopta este enfoque y se continúa la acción tras haber alcanzado el nivel deseado de recompensa total. Y esto puede provocar resultados indeseables en forma de pérdidas.
Para la toma de decisiones del Agente, como datos de entrada transmitiremos los últimos K pasos temporales al Decision Transformer. En total, 3*K tokens. Uno para cada modalidad: el regreso a la normalidad, el estado y la acción que ha producido ese estado. Para obtener representaciones vectoriales de los tokens, los autores del método utilizan una capa neuronal totalmente conectada entrenada para cada modalidad, que proyectará los datos de origen en la dimensionalidad de las representaciones vectoriales. A continuación se realiza la normalización de las capas. En el caso del análisis de entornos complejos (compuestos), resulta aceptable utilizar un codificador convolucional en lugar de una capa neuronal totalmente conectada.
Además, se formará una representación vectorial de la marca temporal para cada paso temporal y se añadirá a cada token. Hay que decir que este enfoque se distingue de la representación vectorial posicional estándar en los transformadores, ya que un paso temporal se corresponderá con varios tokens (tres tokens en el ejemplo anterior). A continuación, los tokens se procesarán con el modelo GPT, que pronosticará los tokens de acciones futuras usando modelos autorregresivos. Hablamos con mayor detalle sobre la arquitectura de los modelos GPT al analizar los métodos para el aprendizaje supervisado en el artículo "Variaciones sobre el tema GPT".
Por extraño que pueda parecer, el proceso de entrenamiento del modelo se construye utilizando métodos de aprendizaje supervisado. Primero organizaremos el proceso de interacción con el entorno y muestrearemos un conjunto de trayectorias aleatorias. Usted y yo lo hemos hecho en más de una ocasión. Y realizaremos un entrenamiento adicional offline. Luego seleccionaremos mini paquetes con una longitud K del conjunto de trayectorias recopilado. La cabeza de predicción correspondiente al token de entrada st se entrena para predecir la acción at utilizando la función de pérdida de entropía cruzada para acciones discretas o el error cuadrático medio para acciones continuas. Las pérdidas de cada paso temporal se promediarán.
No obstante, los autores del método no han observado que la predicción de estados o recompensas posteriores mejore el rendimiento de los modelos durante los experimentos.
A continuación le mostramos la visualización del método por parte de los autores.

No voy a entrar ahora en detalles sobre la arquitectura de transformadores y el mecanismo de autoatención en particular, ya que esto ya se ha tratado en varios artículos de esta serie. Le propongo ir directamente a la parte práctica y ver la implementación del mecanismo del Decision Transformer utilizando herramientas MQL5.
2. Implementación usando MQL5
Tras una breve inmersión en los aspectos teóricos del método del Decision Transformer, pasaremos a su aplicación usando las herramientas MQL5. Y lo primero a lo que nos enfrentaremos será a la implementación de incorporaciones de entidades de datos de origen. Al resolver problemas similares en los métodos de aprendizaje supervisado, utilizamos capas convolucionales con un tamaño de paso igual a la ventana de datos de origen. Pero en este caso nos esperan 2 complejidades:
- El tamaño del vector de descripción del estado del entorno será diferente del vector del espacio de acciones, mientras que el vector de recompensas tendrá un tercer tamaño.
- Todas las entidades contendrán datos de origen de diferentes distribuciones, y para llevarlas a una forma comparable en un único espacio serán necesarias diferentes matrices de incorporación.
Aquí debemos recordar que hemos dividido el estado del entorno en 2 bloques completamente distintos en cuanto a contenido y tamaño: los datos históricos del movimiento de precios y la descripción del estado de la cuenta corriente. Lo cual añadirá otra modalidad a analizar. Y durante los nuevos experimentos, puede que se disponga de datos adicionales para su análisis. Obviamente, en tales condiciones no podemos utilizar una capa de convolución y necesitaremos otra solución universal que pueda realizar la incorporación de N modalidades con tamaños de vectores [n1, n2, n3,...,nN]. Como ya hemos indicado, los autores del método utilizaron capas totalmente conectadas entrenadas para cada modalidad. Este enfoque resulta bastante universal, pero en nuestro caso implicará un rechazo de la incorporación paralela de varias modalidades.
En este caso, la mejor solución, en mi opinión, será crear un nuevo objeto en forma de capa neuronal de incorporación CNeuronEmbeddingOCL. Solo este enfoque nos permitirá acertar con el proceso. Pero antes de crear los objetos y la funcionalidad de la nueva clase, todavía tendremos que decidir algunas de sus características arquitectónicas.
En cada iteración de la pasada directa, planeamos transmitir cinco vectores de datos de origen:
- Los datos históricos del movimiento de precios.
- El estado de la cuenta.
- La recompensa.
- La acción realizada en el paso anterior.
- La marca temporal.
Como podemos ver, la información de las distintas modalidades difiere mucho en cuanto al contenido y la cantidad de los datos, y deberemos determinar la tecnología para transferir los datos de origen a la capa de incorporación. No resultará posible utilizar una matriz con una asignación de filas o columnas distinta para cada modalidad, debido al diferente tamaño de los vectores de datos. Obviamente, podemos utilizar un array dinámico de vectores. Pero esta opción solo será posible en el marco de la implementación de MQL5. Sin embargo, tendremos dificultades a la hora de transmitir un array de este tipo al contexto OpenCL para organizar los cálculos paralelos. La creación de kernels separados para diferentes números de modalidades de datos de origen complicará el programa y no hará que el algoritmo resulte totalmente universal, mientras que el uso de un kernel para cada modalidad individual provocará la incorporación secuencial de las mismas y limitará el cálculo paralelo.
En tal situación lo más universal, en mi opinión, sería utilizar dos vectores (búferes). En uno, enumeraremos todos los datos de origen secuencialmente. Y en el segundo ofreceremos un "mapa de los datos", en forma de tamaños de ventana de cada secuencia. Así, utilizando solo dos búferes, podremos transmitir al kernel cualquier número de modalidades con tamaños de datos independientes sin cambiar el algoritmo de acción dentro del kernel, una solución bastante versátil con la posibilidad de calcular en paralelo la incorporación de todas las modalidades simultáneamente.
Además de la simplicidad y la generalidad, este enfoque nos permitirá combinar fácilmente la nueva clase con todas las capas neuronales creadas anteriormente.
Ya hemos resuelto el problema con la transmisión de los datos de origen, pero tenemos una situación casi similar con las matrices de pesos. Ya hemos dicho que cada modalidad necesita su propia matriz de incorporación. Sin embargo, en este caso tenemos una ventaja: los tamaños de incorporación de todas las modalidades son iguales, ya que, al fin y al cabo, el objetivo del proceso de incorporación es llevar las distintas modalidades a una forma comparable. Por lo tanto, cada elemento de los datos de origen tendrá el mismo número de coeficientes de peso para transmitir los datos a la salida de la capa neuronal. Esto nos permitirá utilizar una matriz común para almacenar los pesos de incorporación de todas las modalidades. El número de columnas de la matriz será igual al tamaño de la incorporación de una modalidad, mientras que el número de filas será igual al número total de datos de origen. Aquí también podemos añadir elementos de desplazamiento bayesiano, que añadirán una fila en la matriz de pesos para cada modalidad.
El siguiente punto constructivo que me gustaría tratar es la conveniencia de incorporar toda la secuencia anterior. Digamos de entrada que no estamos cuestionando la necesidad de que el Agente analice la trayectoria previa. Al fin y al cabo, esta es la base del método analizado. Pero echemos un vistazo más amplio a la cuestión. El Decision Transformer en su esencia es un modelo autorregresivo, que recibe en la entrada K*N tokens. Y en cada paso temporal, solo N tokens serán nuevos. El resto (K-1)*N repetirán completamente los tokens utilizados en el paso anterior. Obviamente, en la fase inicial de entrenamiento, incluso los datos de origen repetidos tendrán diferentes incorporaciones debido a los cambios realizados en las matrices de incorporación. Pero este impacto disminuirá a medida que entrenemos el modelo. Y en el proceso de explotación, cuando las matrices de escala no se modifican, tales desviaciones están completamente ausentes, y resultará bastante lógico incorporar solo nuevos datos de entrada en cada paso temporal. Esto nos permitirá reducir considerablemente la sobrecarga de recursos que supone la incorporación de datos durante el entrenamiento y la explotación del modelo.
Además, señalaremos otro punto: la codificación posicional. En nuestra tarea, la posición de los datos históricos viene indicada por la hora de apertura de la barra. En nuestro modelo de datos de origen, hemos previsto la codificación de una marca temporal. Pero los autores del método añadieron el token de posición a la incorporación de otras modalidades; esta solución es totalmente coherente con la arquitectura del transformador, pero añadirá una operación adicional a la secuencia de operaciones. No obstante, crearemos una incorporación de marca temporal y la añadiremos como modalidad independiente, ya que la incorporación de la posición puede realizarse en paralelo con la incorporación de las demás modalidades. Sin embargo, este enfoque aumentará la cantidad de datos a analizar. Y en cada caso concreto deberemos tener en cuenta el equilibrio de los distintos factores del funcionamiento del programa a la hora de elegir un método de codificación de la posición.
Una vez definidas las principales características de diseño de nuestra implementación, podremos pasar a construir un programa OpenCL. Y empezaremos, como siempre, construyendo el kernel de pasada directa. Como comprenderá, pretendemos obtener una matriz de incorporaciones en la salida. Cada fila de esta matriz representará la incorporación de una modalidad diferente. De la misma manera, también formaremos el espacio bidimensional de tareas del kernel. En una dimensión, indicaremos el tamaño de la incorporación de una modalidad. Y en la segunda, el número de modalidades analizadas.
Recordemos que hemos decidido incorporar solo las últimas modalidades en la secuencia. Mantendremos la incorporación de los datos anteriores sin cambios. Al hacerlo, en la salida de nuestra capa CNeuronEmbeddingOCL obtendremos la incorporación de toda la secuencia.
Así, en los parámetros del kernel transmitiremos los punteros a 5 búferes de datos y 1 constante en la que especificaremos el tamaño de la secuencia. En este caso, por tamaño de la secuencia entenderemos el número de pasos de datos históricos que se van a analizar.
En los búferes de datos, transmitiremos la siguiente información a continuación:
- inputs — contiene los datos de origen en forma de secuencia de todas las modalidades (1 paso temporal);
- outputs — contiene una secuencia de incorporaciones de todas las modalidades en la profundidad de la historia analizada;
- weights — matriz de coeficientes de peso;
- windows — mapa de los datos de origen (tamaños de las ventanas de datos de cada modalidad en los datos de origen);
- std — vector de desviaciones estándar (usado para la normalización de la incorporación).
__kernel void Embedding(__global float *inputs, __global float *outputs, __global float *weights, __global int *windows, __global float *std, const int stack_size ) { const int window_out = get_global_size(0); const int pos = get_local_id(0); const int emb = get_global_id(1); const int emb_total = get_global_size(1); const int shift_out = emb * window_out + pos; const int step = emb_total * window_out; const uint ls = min((uint)get_local_size(0), (uint)LOCAL_ARRAY_SIZE);
En el cuerpo del kernel, identificaremos el flujo en ambas dimensiones y determinaremos las constantes de desplazamiento en los búferes de datos. Después, desplazaremos las incorporaciones obtenidas anteriormente en el búfer de resultados. Tenga en cuenta que solo se trasladará una posición de incorporación aparte en cada flujo. Esto permitirá organizar el copiado de datos en flujos paralelos.
for(int i=stack_size-1;i>0;i--) outputs[i*step+shift_out]=outputs[(i-1)*step+shift_out];
A continuación, determinaremos el desplazamiento en el búfer de datos de origen hacia la modalidad analizada. Para ello, calcularemos el número total de elementos en las modalidades situados en el búfer de datos de origen antes de la analizada.
int shift_in = 0; for(int i = 0; i < emb; i++) shift_in += windows[i];
Aquí también determinamos el desplazamiento en el búfer de la matriz de pesos considerando el elemento bayesiano.
const int shift_weights = (shift_in + emb) * window_out;
Luego almacenaremos el tamaño de la ventana de datos inicial de la modalidad actual en una variable local y definiremos las constantes para trabajar con el array local.
const int window_in = windows[emb]; const int local_pos = (pos >= ls ? pos % (ls - 1) : pos); const int local_orders = (window_out + ls - 1) / ls; const int local_order = pos / ls;
Después crearemos un array local y lo rellenaremos de valores cero. Aquí estableceremos una barrera para la sincronización local de los flujos.
__local float temp[LOCAL_ARRAY_SIZE]; if(local_order == 0) temp[local_pos] = 0; barrier(CLK_LOCAL_MEM_FENCE);
Llegados a este punto, podemos dar por concluido el trabajo preparatorio y pasar directamente a las operaciones de incorporación. En primer lugar, multiplicaremos el vector de datos de origen de la modalidad analizada por el vector correspondiente de coeficientes de peso. Así obtendremos el elemento de incorporación que necesitamos.
float value = weights[shift_weights + window_in]; for(int i = 0; i < window_in; i++) value += inputs[shift_in + i] * weights[shift_weights + i];
En este caso, no utilizaremos la función de activación porque necesitamos obtener la proyección de cada elemento de la secuencia en el subespacio deseado. Sin embargo, somos conscientes de que este enfoque no garantizará la comparabilidad de las incorporaciones de los distintos datos de origen. Por lo tanto, el siguiente paso consistirá en normalizar los datos dentro de la incorporación de una única modalidad. De este modo, los datos de todas las incorporaciones tendrán una media cero y una varianza unitaria. Permítanme recordarles la fórmula de normalización.

Para ello, primero recogeremos la suma de todos los elementos de la incorporación analizada usando una matriz local. Y dividiremos la suma resultante por el tamaño del vector de incorporación. De esta forma, determinaremos el valor medio. E inmediatamente ajustaremos el valor del elemento de incorporación actual al valor medio. Para sincronizar los flujos locales, utilizaremos barreras.
for(int i = 0; i < local_orders; i++) { if(i == local_order) temp[local_pos] += value; barrier(CLK_LOCAL_MEM_FENCE); } //--- int count = ls; do { count = (count + 1) / 2; if(pos < count) temp[pos] += temp[pos + count]; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- value -= temp[0] / (float)window_out; barrier(CLK_LOCAL_MEM_FENCE);
Aquí vale la pena decir unas palabras sobre la derivada de las operaciones realizadas. Como sabemos, utilizamos las derivadas de la función de pasada directa para propagar el gradiente de error en el pasada inversa. Al sumar o restar una constante de una variable, transmitiremos todo el gradiente de error a la variable. Sin embargo, el detalle interesante de esta situación es que estaremos restando la media, que, a su vez, será una función de las variables analizadas y tendrá su derivada. Y para obtener una distribución precisa del gradiente de error, necesitaremos transmitirlo también por la derivada de la función de valor medio. Esta afirmación también será válida para la desviación típica, que utilizaremos a continuación. Pero mi experiencia personal me dice que el gradiente de error total a través de la derivada de la función de valor medio y varianza es muchas veces menor que el gradiente de error sobre la propia variable. Y para ahorrar recursos, ahora no complicaremos el algoritmo para guardar datos intermedios y luego calcular gradientes de error en esta dirección.
Pero volvamos a nuestro algoritmo del kernel. En esta fase, ya hemos llevado el vector de incorporación a la media cero. Y luego lo reduciremos a la varianza unitaria. Para ello, dividiremos todos los elementos de la incorporación analizada por su desviación estándar, que calcularemos utilizando un array local.
Recuerde que el array local se utilizará para transmitir datos entre flujos de un grupo local. Y la sincronización de los flujos se realizará mediante barreras.
if(local_order == 0) temp[local_pos] = 0; barrier(CLK_LOCAL_MEM_FENCE); //--- for(int i = 0; i < local_orders; i++) { if(i == local_order) temp[local_pos] += pow(value,2.0f) / (float)window_out; barrier(CLK_LOCAL_MEM_FENCE); } //--- count = ls; do { count = (count + 1) / 2; if(pos < count) temp[pos] += temp[pos + count]; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- if(temp[0] > 0) value /= sqrt(temp[0]);
Ahora solo tenemos que guardar el valor obtenido en el elemento correspondiente del búfer de resultados. Y tampoco nos olvidaremos de guardar la desviación estándar calculada para la posterior distribución del gradiente de error en la pasada inversa.
outputs[shift_out] = value; if(pos == 0) std[emb] = sqrt(temp[0]); }
Tras completar el trabajo sobre el kernel de pasada directa, le proponemos proceder al análisis sintáctico del algoritmo del kernel de distribución del gradiente de error. Más arriba ya hemos empezado a hablar de la distribución del gradiente de error a través de la función de normalización de datos. Y para optimizar el uso de recursos, hemos decidido simplificar el algoritmo en cuanto al gradiente de error usando las funciones de valor medio y varianza del vector de incorporación. En esta fase, trataremos el valor medio y la varianza como constantes. Precisamente sobre este paradigma se construirá el algoritmo del kernel de distribución del gradiente de error EmbeddingHiddenGradient.
En los parámetros del kernel, transmitiremos 5 búferes de datos y 1 constante. Ya hemos aprendido acerca de la constante y 3 de los búferes utilizados en el kernel anterior. Los búferes de datos de origen y los resultados, a su vez, serán sustituidos por los búferes de los gradientes de error correspondientes.
__kernel void EmbeddingHiddenGradient(__global float *inputs_gradient, __global float *outputs_gradient, __global float *weights, __global int *windows, __global float *std, const int window_out ) { const int pos = get_global_id(0);
Luego llamaremos al kernel en un espacio de tareas unidimensional según el número de elementos de los datos de origen. En el cuerpo del kernel, identificaremos directamente el flujo actual. Sin embargo, la posición de un elemento en el búfer de origen no nos ofrecerá una visión explícita de los elementos dependientes en la búfer de resultados. Por lo tanto, primero iteraremos el búfer del mapa de datos de origen para determinar la modalidad que se va a analizar.
int emb = -1; int count = 0; do { emb++; count += windows[emb]; } while(count <= pos);
Y después, según el índice de la modalidad analizada, determinaremos el desplazamiento de los búferes de resultados y los coeficientes de peso.
const int shift_out = emb * window_out; const int shift_weights = (pos + emb) * window_out;
Tras determinar los desplazamientos en los búferes de datos, recopilaremos los gradientes de error de todos los elementos dependientes del búfer de resultados y los corregiremos según la desviación estándar del vector de incorporación antes de la normalización. Le recuerdo que hemos almacenado su valor en el búfer std durante la pasada directa.
float value = 0; for(int i = 0; i < window_out; i++) value += outputs_gradient[shift_out + i] * weights[shift_weights + i]; float s = std[emb]; if(s > 0) value /= s; //--- inputs_gradient[pos] = value; }
El valor obtenido se almacenará en el búfer de gradientes de la capa anterior.
Para completar el programa OpenCL, solo nos quedará analizar el algoritmo de los kernels para actualizar la matriz de pesos. En el marco del presente artículo, solo examinaremos el kernel del método Adam, que es el que utilizamos con más frecuencia. La principal diferencia entre este kernel y otros similares analizados anteriormente radica en la determinación de los desplazamientos en los búferes de datos. Esto es de esperar, ya que no hemos introducido ningún cambio fundamental en el algoritmo del método de actualización de los coeficientes de peso.
__kernel void EmbeddingUpdateWeightsAdam(__global float *weights, __global const float *gradient, __global const float *inputs, __global float *matrix_m, __global float *matrix_v, __global int *windows, __global float *std, const int window_out, const float l, const float b1, const float b2 ) { const int i = get_global_id(0);
En los parámetros del kernel se transmitirá un gran número de búferes y constantes, pero todos ellos nos son ya familiares. El kernel se invocará en un espacio de tareas unidimensional según el número de elementos en el búfer de coeficientes de peso.
En el cuerpo del kernel, identificaremos el elemento del búfer que se va a analizar usando el identificador del flujo, como es habitual. A continuación, determinaremos los desplazamientos en los búferes de datos hacia los elementos que necesitamos.
int emb = -1; int count = 0; int shift = 0; do { emb++; shift = count; count += (windows[emb] + 1) * window_out; } while(count <= i); const int shift_out = emb * window_out; int shift_in = shift / window_out - emb; shift = (i - shift) / window_out;
Y luego organizaremos el ajuste del coeficiente de peso. El proceso resulta totalmente idéntico al descrito en los artículos anteriores de esta serie. Guardaremos el resultado y los datos necesarios en los búferes correspondientes.
float weight = weights[i]; float g = gradient[shift_out] * inp / std[emb]; float mt = b1 * matrix_m[i] + (1 - b1) * g; float vt = b2 * matrix_v[i] + (1 - b2) * pow(g, 2); float delta = l * (mt / (sqrt(vt) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight)); if(delta * g > 0) weights[i] = clamp(weights[i] + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[i] = mt; matrix_v[i] = vt; }
Cuando terminemos de trabajar en los kernels del programa OpenCL, volveremos a trabajar en la parte del programa principal. Y ahora que ya tenemos clara la funcionalidad de la clase y una lista completa de los búferes de datos necesarios, podemos crear todas las condiciones para llamar y mantener los kernels anteriormente analizados.
Como hemos mencionado antes, hemos creado una nueva clase CNeuronEmbeddingOCL basada en la clase básica de capas neuronales CNeuronBaseOCL. La funcionalidad básica del funcionamiento de la capa neuronal se heredará de la clase padre. No obstante, tendremos que añadir nuevas funciones a la clase.
Luego crearemos un array dinámico para almacenar el mapa de datos fuente a_Windows. Al hacerlo, no crearemos un objeto de búfer separado para mantenerlo. Crearemos solo una variable para registrar el puntero al búfer en el contexto OpenCL i_WindowsBuffer. Aquí también crearemos variables para registrar el tamaño de la incorporación y la profundidad de la historia analizada: i_WindowOut y i_StackSize, respectivamente.
A continuación, para la matriz de coeficientes de peso de incorporación y momentos, crearemos los búferes de datos:
- WeightsEmbedding;
- FirstMomentumEmbed;
- SecondMomentumEmbed.
Pero el búfer de desviación estándar solo se utilizará para los cálculos intermedios. Por lo tanto, no lo crearemos al margen del programa principal, lo crearemos solo en la memoria contextual OpenCL y almacenaremos el puntero al búfer en la variable i_STDBuffer.
El conjunto de métodos redefinidos es bastante estándar y no nos detendremos en su propósito ahora.
class CNeuronEmbeddingOCL : public CNeuronBaseOCL { protected: int a_Windows[]; int i_WindowOut; int i_StackSize; int i_WindowsBuffer; int i_STDBuffer; //--- CBufferFloat WeightsEmbedding; CBufferFloat FirstMomentumEmbed; CBufferFloat SecondMomentumEmbed; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronEmbeddingOCL(void); ~CNeuronEmbeddingOCL(void); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint stack_size, uint window_out, int &windows[]); //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronEmbeddingOCL; } virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual bool Clear(void); };
En el constructor de la clase, inicializaremos las variables y los punteros a los búferes con los valores iniciales.
CNeuronEmbeddingOCL::CNeuronEmbeddingOCL(void) { ArrayFree(a_Windows); if(!!OpenCL) { if(i_WindowsBuffer >= 0) OpenCL.BufferFree(i_WindowsBuffer); if(i_STDBuffer >= 0) OpenCL.BufferFree(i_STDBuffer); } //-- i_WindowsBuffer = INVALID_HANDLE; i_STDBuffer = INVALID_HANDLE; i_WindowOut = 0; i_StackSize = 1; }
El objeto de capa de incorporación se inicializará directamente en el método Init. En los parámetros del método, además de las constantes habituales, transmitiremos la profundidad de la historia analizada (stack_size), el tamaño del vector de incorporación (window_out) y el "mapa de datos de origen" (array dinámico windows[]).
bool CNeuronEmbeddingOCL::Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl,uint stack_size, uint window_out,int &windows[]) { if(CheckPointer(open_cl) == POINTER_INVALID || window_out <= 0 || windows.Size() <= 0 || stack_size <= 0) return false; if(!!OpenCL && OpenCL != open_cl) delete OpenCL; uint numNeurons = window_out * windows.Size() * stack_size; if(!CNeuronBaseOCL::Init(numOutputs,myIndex,open_cl,numNeurons,ADAM,1)) return false;
En el cuerpo del método, organizaremos el bloque inicial de control de datos. A continuación, recalcularemos el tamaño del búfer de resultados como producto de la longitud del vector de incorporación por el número de modalidades y la profundidad de la historia analizada. Tenga en cuenta que no existe un número total de modalidades en los parámetros externos, pero obtendremos un "mapa de datos de origen". El tamaño del array resultante indicará el número de modalidades que deben analizarse.
La inicialización directa del búfer de resultados, así como de otros objetos heredados, se realizará en un método similar de la clase padre, al que llamaremos una vez finalizadas las operaciones preparatorias.
Tras inicializar correctamente los objetos heredados, tendremos que preparar las entidades añadidas. Primero inicializaremos el búfer de coeficientes de peso de incorporación. Como hemos descrito antes, este búfer supondrá una matriz con un número de filas igual al volumen de los datos de origen y de columnas igual al tamaño del vector de incorporación. El tamaño de la incorporación ya lo conocemos, pero para determinar el tamaño de los datos de origen, deberemos resumir todos los valores del "mapa de datos". Y a la suma resultante, le añadiremos una línea de desplazamiento bayesiano para cada modalidad. De este modo obtendremos el tamaño del búfer de coeficientes de peso de incorporación. Ahora lo rellenaremos con valores aleatorios y lo desplazaremos a la memoria contextual OpenCL.
uint weights = 0; ArrayCopy(a_Windows,windows); i_WindowOut = (int)window_out; i_StackSize = (int)stack_size; for(uint i = 0; i < windows.Size(); i++) weights += (windows[i] + 1) * window_out; if(!WeightsEmbedding.Reserve(weights)) return false; float k = 1.0f / sqrt((float)weights / (float)window_out); for(uint i = 0; i < weights; i++) if(!WeightsEmbedding.Add(k * (2 * GenerateWeight() - 1.0f)*WeightsMultiplier)) return false; if(!WeightsEmbedding.BufferCreate(OpenCL)) return false;
El primer y el segundo búfer tendrán un tamaño similar, pero los inicializaremos con valores cero y los desplazaremos a la memoria contextual OpenCL.
if(!FirstMomentumEmbed.BufferInit(weights, 0)) return false; if(!FirstMomentumEmbed.BufferCreate(OpenCL)) return false; //--- if(!SecondMomentumEmbed.BufferInit(weights, 0)) return false; if(!SecondMomentumEmbed.BufferCreate(OpenCL)) return false;
A continuación, crearemos búferes con el mapa de datos de origen y las desviaciones estándar.
i_WindowsBuffer = OpenCL.AddBuffer(sizeof(int) * a_Windows.Size(),CL_MEM_READ_WRITE); if(i_WindowsBuffer < 0 || !OpenCL.BufferWrite(i_WindowsBuffer,a_Windows,0,0,a_Windows.Size())) return false; i_STDBuffer = OpenCL.AddBuffer(sizeof(float) * a_Windows.Size(),CL_MEM_READ_WRITE); if(i_STDBuffer<0) return false; //--- return true; }
Asegúrese de controlar el proceso de ejecución de las operaciones en cada paso y retornar el resultado lógico del método al programa que haya realizado la llamada una vez finalizadas todas las operaciones del método.
Después de inicializar el objeto, tendremos que crear los métodos de su funcionalidad principal. En nuestro caso, hablamos de los métodos de pasada directa e inversa. Como ya habrá adivinado, ya hemos realizado el trabajo principal de organización de la funcionalidad en el programa OpenCL. Ahora nos queda organizar la llamada a los kernels correspondientes. Pero antes de empezar este trabajo, necesitaremos declarar las constantes para trabajar con los kernels: los identificadores de los kernels en el programa y sus parámetros. Como siempre, implementaremos esta funcionalidad utilizando la directiva #define.
#define def_k_Embedding 59 #define def_k_emb_inputs 0 #define def_k_emb_outputs 1 #define def_k_emb_weights 2 #define def_k_emb_windows 3 #define def_k_emb_std 4 #define def_k_emb_stack_size 5 //--- #define def_k_EmbeddingHiddenGradient 60 #define def_k_ehg_inputs_gradient 0 #define def_k_ehg_outputs_gradient 1 #define def_k_ehg_weights 2 #define def_k_ehg_windows 3 #define def_k_ehg_std 4 #define def_k_ehg_window_out 5 //--- #define def_k_EmbeddingUpdateWeightsAdam 61 #define def_k_euw_weights 0 #define def_k_euw_gradient 1 #define def_k_euw_inputs 2 #define def_k_euw_matrix_m 3 #define def_k_euw_matrix_v 4 #define def_k_euw_windows 5 #define def_k_euw_std 6 #define def_k_euw_window_out 7 #define def_k_euw_learning_rate 8 #define def_k_euw_b1 9 #define def_k_euw_b2 10
Analizaremos la organización del proceso de ubicación del kernel en la cola de ejecución utilizando el método feedForward como ejemplo. En los parámetros del método, como en todos los similares comentados anteriormente, obtendremos el puntero al objeto de la capa neuronal anterior.
bool CNeuronEmbeddingOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false;
En el cuerpo del método comprobaremos el puntero obtenido y el puntero al objeto de trabajo con el contexto OpenCL.
A continuación, transmitiremos al kernel los punteros a los búferes de datos y las constantes necesarias previamente especificadas en los parámetros del kernel. No olvide comprobar el proceso de las operaciones en cada paso.
if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_std, i_STDBuffer)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_weights, WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_windows, i_WindowsBuffer)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_Embedding, def_k_emb_stack_size, i_StackSize)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; }
Tras transmitir correctamente todos los parámetros, deberemos definir el espacio de tareas para el kernel. Como hemos comentado antes, el kernel se ejecutará en un espacio de tareas bidimensional. En la primera dimensión, especificaremos el tamaño de la incorporación, mientras que en el segundo indicaremos el número de modalidades a analizar.
uint global_work_offset[2] = {0,0}; uint global_work_size[2] = {i_WindowOut,a_Windows.Size()};
Una característica de la incorporación de kernels será la normalización de los datos dentro del vector de incorporación de una modalidad. Para construir este subproceso, organizaremos el intercambio de datos entre flujos dentro del mismo grupo de trabajo a través de un array local. Y ahora tendremos que especificar el tamaño del grupo local, que será igual al tamaño del vector de incorporación. El detalle a considerar será que al especificar un espacio bidimensional, necesitaremos especificar un grupo local bidimensional. Por lo tanto, la dimensión 2 del grupo local será 1.
uint local_work_size[2] = {i_WindowOut,1};
Por último, llamaremos al método para poner en cola el kernel y supervisar el proceso de las operaciones.
if(!OpenCL.Execute(def_k_Embedding, 2, global_work_offset, global_work_size,local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__,GetLastError()); return false; } //--- return true; }
El procedimiento para llamar a los kernels de pasada inversa será similar, y no nos detendremos ahora en una revisión exhaustiva de estos métodos. Su código, así como el de todas sus clases y métodos utilizados en el artículo, se encuentra en el archivo adjunto. Y quería hacer hincapié en un punto. El Decision Transformer es un modelo autorregresivo, por lo que la coherencia de los datos de entrada es importante. Arriba hemos definido que en cada paso de tiempo suministraremos solo nuevos datos a la entrada del modelo. Toda la profundidad de la historia analizada se copiará de operaciones anteriores del modelo. Básicamente, utilizaremos el búfer de resultados de la capa CNeuronEmbeddingOCL como pila de incorporación. Este enfoque reducirá el coste del procesamiento inicial de los datos, pero introducirá como requisito necesario el suministro de datos de entrada de forma secuencial tanto en el proceso de entrenamiento como en el de explotación. Al mismo tiempo, a menudo utilizaremos muestras aleatorias de los datos de origen en el proceso de entrenamiento. Ya hemos hablado muchas veces de esta necesidad. Y para excluir la distorsión de los datos a causa de un "salto temporal" de los datos iniciales o al cambiar a una trayectoria alternativa, necesitaremos un método para limpiar la pila de incorporación. Para ello hemos creado el método Clear. Su algoritmo es bastante sencillo: simplemente rellenaremos todo el búfer con valores cero y copiaremos los datos a la memoria contextual OpenCL.
bool CNeuronEmbeddingOCL::Clear(void) { if(!Output.BufferInit(Output.Total(),0)) return false; if(!OpenCL) return true; //--- return Output.BufferWrite(); }
Aquí le propongo concluir la discusión sobre los algoritmos de los métodos de la clase CNeuronEmbeddingOCL. Podrá ver su código completo y todos los métodos en el archivo adjunto.
Como resultado de este trabajo, dispondremos de incorporaciones comparables de varias modalidades diferentes a la salida de la capa CNeuronEmbeddingOCL, lo cual nos permitirá utilizar objetos de Transformer previamente creados para implementar el método presentado Decision Transformer. Y esto significa que podremos comenzar a trabajar en la descripción de la arquitectura del modelo. Sí, en este caso solo utilizaremos un modelo, el Agente. Hacía tiempo que no teníamos uno de estos en nuestra serie de artículos.
Pero antes debo recordarle el "mapa de datos de origen". Para describirlo, utilizaremos un array que antes no estaba disponible en la clase de descripción de capas neuronales. Vamos a añadirlo.
class CLayerDescription : public CObject { public: /** Constructor */ CLayerDescription(void); /** Destructor */~CLayerDescription(void) {}; //--- int type; ///< Type of neurons in layer (\ref ObjectTypes) int count; ///< Number of neurons int window; ///< Size of input window int window_out; ///< Size of output window int step; ///< Step size int layers; ///< Layers count int batch; ///< Batch Size ENUM_ACTIVATION activation; ///< Type of activation function (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Type of optimization method (#ENUM_OPTIMIZATION) float probability; ///< Probability of neurons shutdown, only Dropout used int windows[]; //--- virtual bool Copy(CLayerDescription *source); //--- virtual bool operator= (CLayerDescription *source) { return Copy(source); } };
Ahora describiremos la arquitectura del modelo en el método CreateDescriptions. En los parámetros, el método recibirá el puntero al único array dinámico de la descripción de la arquitectura del Actor. Luego almacenaremos la descripción de las capas neuronales del modelo en el array obtenido.
bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear();
La primera capa que especificaremos será una capa neuronal totalmente conectada de datos de origen, en la que registraremos secuencialmente todos los datos necesarios para el análisis. Tenga en cuenta que no dividiremos los datos de origen en búferes separados según el contenido. En este caso, su división será más bien convencional. Simplemente los escribiremos secuencialmente. Y su separación lógica se hará a nivel de incorporación usando el "mapa de datos de origen" que crearemos más adelante.
Tenga en cuenta que la capa de datos sin procesar solo contendrá información sobre el último estado del sistema (recompensa, estado del entorno, estado de la cuenta, marca temporal y última acción del Agente).
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (NRewards + BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Después de la capa de datos de origen, especificaremos habitualmente la capa de normalización de lotes, donde se realizará el preprocesamiento de los datos. Una vez más, no pensaremos en la diferente naturaleza de los datos resultantes. De hecho, esta capa efectuará la normalización en cuanto a los datos históricos para cada característica de forma independiente.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
A esto le seguirá una capa de normalización por lotes. Aquí especificaremos la profundidad de la historia a analizar, el tamaño del vector de incorporación y el "mapa de datos de origen".
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NRewards,NActions}; ArrayCopy(descr.windows,temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
Detrás de la capa de incorporación pondremos un bloque de atención dispersa defNeuronMLMHSparseAttentionOCL, que formará la base de nuestro transformador. Debo decir sinceramente que los autores del método usaron el transformador original. Sin embargo, el uso de un bloque de atención dispersa nos permitirá aumentar significativamente la profundidad de la historia analizada, incrementando de forma insignificante el coste de recursos y el tiempo de ejecución del modelo.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Y el modelo se completará con un bloque de decisión de capas totalmente conectadas y una capa latente de autocodificador variacional en la salida para crear la estocasticidad de la política del Actor.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
Debemos decir que el bloque de decisión también es diferente al utilizado en el algoritmo DT del autor. Los autores del método utilizaron un descodificador del último token de la secuencia a la salida del transformador. Nosotros, en cambio, analizaremos la secuencia completa para tomar una decisión con conocimiento de causa.
Tras especificar la arquitectura del modelo, comenzaremos a crear un asesor para interactuar con el entorno y recoger los datos necesarios para entrenar el modelo en el búfer de reproducción de experiencias "\DT\Research.mq5". La estructura de la construcción del asesor repite al completo las que anteriormente analizadas, pero vale la pena detenerse en el método de procesamiento de ticks OnTick. Aquí se generará la secuencia de datos de origen según el mapa descrito con anterioridad.
En el cuerpo del método, como antes, comprobamos la aparición de un nuevo evento de apertura de barra y, de ser necesario, cargaremos los datos históricos, solo que ahora no estaremos cargando la profundidad de la historia analizada al completo, sino solo las actualizaciones en el tamaño del patrón de un paso temporal. Pueden ser los datos de una última vela cerrada. Para regular la profundidad de la carga de datos, hemos introducido la constante NBarInPattern. Por favor, no confunda esta con la constante HistoryBars que utilizaremos para determinar la profundidad de la pila de incorporación.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
A continuación, crearemos un array a partir de los datos históricos para su almacenamiento en la trayectoria y su transmisión al búfer de datos de origen. El procedimiento será completamente idéntico al de los asesores anteriores.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
El siguiente paso consistirá en generar una descripción del estado de la cuenta. La recogida de datos seguirá el procedimiento previamente elaborado, solo que los datos no se transferirán a un búfer aparte, sino a un único búfer de datos de origen bState.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Luego añadiremos una marca temporal al mismo búfer.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
Los siguientes datos ya estarán generados por los requisitos del método Decision Transformer. Aquí añadiremos la modalidad Return-To-Go al búfer de datos de origen. En este lugar puede encontrarse un único elemento de recompensa deseado, o podemos tener un vector de recompensa descompuesto. Especificaremos 3 elementos: la variación del balance, la variación de la equidad y la reducción. Los 3 indicadores se ofrecerán en valores relativos.
//--- Return to go bState.Add(float(1-(sState.account[0] - PrevBalance) / PrevBalance)); bState.Add(float(0.1f-(sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(0);
Y para completar el vector de datos de origen, añadiremos un vector de acciones recientes del Agente. Cuando se llame por primera vez, este vector se rellenará con valores cero.
//--- Prev action
bState.AddArray(AgentResult);
El vector de datos de origen ya está listo, así que realizaremos la pasada directa del Agente.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) return;
El algoritmo adicional para interpretar los resultados del modelo y realizar operaciones se mantendrá sin cambios, y no nos detendremos en él. Usted mismo puede leer el código completo del asesor y todos sus métodos en el archivo adjunto. Ahora pasaremos a la construcción del proceso de entrenamiento del modelo en el asesor "\DT\Study.mq5". El asesor también ha heredado mucho del trabajo anterior. Y ahora nos detendremos únicamente en el método de entrenamiento del modelo Train.
En el cuerpo del método, primero determinaremos el número de trayectorias almacenadas en el búfer local de reproducción de experiencias.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Y luego organizaremos un ciclo por el número de iteraciones de entrenamiento, en el que seleccionaremos aleatoriamente una trayectoria y un estado individual en dicha trayectoria. Aquí todo está como antes.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; }
Las diferencias comenzarán a continuación. Recuerde lo que dijimos sobre la necesidad de introducir datos coherentes en la entrada del modelo. Pero somos un estado aleatorio en una trayectoria. Para evitar la distorsión de los datos en la secuencia analizada, borraremos el búfer de incorporación y el vector de acciones recientes del Agente.
Actions = vector<float>::Zeros(NActions); Agent.Clear();
Y a continuación organizaremos un ciclo anidado cuyo número de iteraciones será 3 veces la profundidad de la historia analizada. Obviamente, si el tamaño de la trayectoria guardada lo permite. En el cuerpo de este ciclo anidado, entrenaremos el modelo suministrándole datos sobre la trayectoria almacenada en una secuencia estricta de interacción con el entorno. En primer lugar, cargaremos en el búfer los datos históricos del movimiento de precios de los indicadores.
for(int state = i; state < MathMin(Buffer[tr].Total - 1,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
A continuación vendrá la información sobre el estado de la cuenta.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Y la marca temporal.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
En cambio, en Return-To-Go, en este punto transmitiremos la recompensa acumulada real al final de la trayectoria. El enfoque del token análogo en el asesor de interacción con el entorno se distingue ligeramente. Pero eso es precisamente lo que nos permite entrenar el modelo.
//--- Return to go
State.AddArray(Buffer[tr].States[state].rewards);
Ahora añadiremos la acción del Agente en el paso de tiempo anterior desde el búfer de reproducción de experiencias.
//--- Prev action
State.AddArray(Actions);
El búfer de datos de origen para la iteración de entrenamiento está listo, así que llamaremos al método de pasada inversa del Agente.
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Después de realizar la pasada directa con éxito, deberemos realizar la pasada inversa y ajustar los parámetros del modelo. Y luego está la cuestión de los valores objetivo, que resolveremos de forma bastante sencilla. Como valores objetivo utilizaremos las acciones realmente efectuadas por el Agente al interactuar con el entorno. Paradójicamente, estamos hablando de aprendizaje supervisado "puro y duro". Pero, ¿dónde se encuentra el aprendizaje por refuerzo? ¿Dónde están las optimizaciones de las recompensas? Ni siquiera podemos usar el aprendizaje supervisado porque las acciones que se realizan al interactuar con el entorno no son óptimas.
Estamos entrenando un modelo autorregresivo que generará una acción óptima basada en el conocimiento de la trayectoria recorrida y el resultado deseado. En este aspecto, la especificación de la recompensa real acumulada en el token return-to-go desempeñará un papel fundamental. Al fin y al cabo, a nadie le cabe duda de que han sido las acciones reales realizadas las que han conducido a las recompensas reales obtenidas. Como consecuencia, podremos entrenar al modelo para que identifique estas acciones con la recompensa obtenida. Y un modelo bien entrenado será capaz posteriormente de generar acciones para producir el resultado deseado durante el proceso de explotación.
Los autores del Decision Transformer sugieren utilizar MSE para un espacio continuo de acciones. Lo complementaremos con el método CAGrad.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Tras realizar con éxito la pasada inversa, informaremos al usuario sobre el estado del proceso de entrenamiento y pasaremos a la siguiente iteración de nuestro sistema de ciclos del proceso de entrenamiento. Y cuando todas las iteraciones se hayan completado, inicializaremos el proceso de finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
El código completo de todos los programas usados en el artículo se encuentra en el archivo adjunto.
3. Simulación
Antes hemos trabajado bastante en la implementación del método Decision Transformer utilizando las herramientas MQL5. En esta parte de nuestro artículo, entrenaremos y probaremos el modelo. Como siempre, el entrenamiento y las pruebas de los modelos se realizarán usando los datos históricos de EURUSD, con el marco temporal H1. Los parámetros de todos los indicadores se utilizarán por defecto. El periodo de entrenamiento será de 7 meses de 2023. Ahora comprobaremos el rendimiento del modelo con los datos históricos de agosto de 2023.
Basándonos en los resultados de las pruebas de este método, podemos decir que la idea resulta bastante interesante. Pero en un mercado estocástico, podemos lograr el resultado deseado, si aún pueden obtenerse resultados aceptables en la muestra de entrenamiento. Luego, con los nuevos datos, podemos ver que el balance aumenta en la primera década del periodo de pruebas. Pero luego llega una serie de operaciones perdedoras. Como resultado, el modelo ha incurrido en pérdidas en los datos de prueba. Aunque que la operación media rentable supera la pérdida media en algo más del 1,0%, esto no es suficiente. Al fin y al cabo, el porcentaje de operaciones rentables es solo del 47,76%. El resultado final es un factor de beneficio de 0,92.


Conclusión
En este artículo, hemos presentado el interesante método del Decision Transformer, que supone un enfoque nuevo e innovador del aprendizaje por refuerzo. A diferencia de los métodos tradicionales, el Decision Transformer modela las secuencias de acciones en el contexto de un modelo autorregresivo de recompensas deseadas. Esto permite al Agente aprender a tomar decisiones considerando los futuros objetivos y optimizar su comportamiento en función de dichos objetivos.
En la parte práctica del artículo, hemos implementado el método presentado usando herramientas MQL5. Asimismo, hemos llevado a cabo el entrenamiento y la prueba del modelo. Sin embargo, el modelo entrenado no ha conseguido generar beneficios durante todo el periodo de prueba. El modelo ha obtenido beneficios en la primera mitad de la muestra de prueba, pero lo ha perdido todo al continuar las pruebas. Puede decirse que el algoritmo tiene potencial, pero debemos trabajar más con el modelo para obtener el resultado deseado.
Enlaces
- Decision Transformer: Reinforcement Learning via Sequence Modeling
- Redes neuronales: así de sencillo (Parte 57): Stochastic Marginal Actor-Critic (SMAC)
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mq5 | Asesor | Asesor de entrenamiento del agente |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13347
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso