
Neuronale Netze leicht gemacht (Teil 58): Decision Transformer (DT)

Einführung
In dieser Serie haben wir bereits eine ganze Reihe verschiedener Algorithmen des Reinforcement Learning (Verstärkungslernen) untersucht. Sie alle verfolgen den gleichen Ansatz:
- Der Agent analysiert den aktuellen Zustand der Umgebung.
- Ergreifen der optimalen Handlung (im Rahmen der erlernten Strategie für Politik und Verhalten).
- Wechseln in einen neuen Zustand der Umgebung.
- Erhält eine Belohnung von der Umgebung für einen vollständigen Übergang in einen neuen Zustand.
Der Ablauf basiert auf den Prinzipien des Markov-Prozesses. Es wird davon ausgegangen, dass der Ausgangspunkt der aktuelle Zustand der Umgebung ist. Es gibt nur einen optimalen Weg aus diesem Zustand heraus, und der hängt nicht vom vorherigen Weg ab.
Ich möchte einen alternativen Ansatz vorstellen, den das Google-Team in dem Artikel „Decision Transformer: Reinforcement Learning via Sequence Modeling“ (06.02.2021). Das Hauptaugenmerk dieser Arbeit liegt auf der Projektion des Verstärkungslernproblems in die Modellierung einer bedingten Handlungssequenz, die durch ein autoregressives Modell der gewünschten Belohnung bedingt ist.
1. Merkmale der Methode Decision-Transformer
Der Decision Transformer (Entscheidungstransformierer) ist eine Architektur, die die Art und Weise, wie wir das Reinforcement Learning betrachten, verändert. Im Gegensatz zum klassischen Ansatz zur Auswahl einer Agentenaktion wird das Problem der sequentiellen Entscheidungsfindung im Rahmen der Sprachmodellierung betrachtet.
Die Autoren der Methode schlagen vor, Trajektorien der Aktionen des Agenten im Kontext von zuvor durchgeführten Aktionen und besuchten Zuständen zu erstellen, so wie Sprachmodelle Sätze (eine Folge von Wörtern) im Kontext eines allgemeinen Textes erstellen. Diese Problemstellung ermöglicht die Verwendung einer breiten Palette von Sprachmodellen mit minimalen Änderungen, einschließlich GPT (Generative Pre-trained Transformer).
Es lohnt sich wahrscheinlich, mit den Grundsätzen für die Konstruktion der Flugbahnen des Agenten zu beginnen. In diesem Fall geht es speziell um die Erstellung von Trajektorien und nicht um eine Abfolge von Aktionen.
Eine der Anforderungen bei der Auswahl einer Trajektoriendarstellung ist die Fähigkeit, Transformatoren zu verwenden, die es erlauben, signifikante Muster in den Quelldaten zu extrahieren. Neben der Beschreibung der Umgebungsbedingungen wird es Aktionen und Belohnungen geben, die der Agent durchführt. Die Autoren der Methode bieten hier einen recht interessanten Ansatz zur Modellierung von Belohnungen. Wir wollen, dass das Modell Handlungen auf der Grundlage zukünftiger gewünschter Belohnungen und nicht auf der Grundlage vergangener Belohnungen entwickelt. Schließlich wollen wir ja ein Ziel erreichen. Anstatt die Belohnung direkt auszuzahlen, bieten die Autoren ein Magnituden-Modell „Return-To-Go“. Dies ist vergleichbar mit einer kumulativen Belohnung bis zum Ende der Episode. Wir geben jedoch nicht das tatsächliche, sondern das gewünschte Ergebnis an.
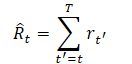
Daraus ergibt sich die folgende Trajektoriendarstellung, die für autoregressives Lernen und Generieren geeignet ist:
![]()
Beim Testen von trainierten Modellen können wir die gewünschte Belohnung (z. B. 1 für Erfolg oder 0 für Misserfolg) sowie den Anfangszustand der Umgebung als Informationen für die Generierung angeben. Nachdem wir die für den aktuellen Zustand generierte Aktion ausgeführt haben, reduzieren wir die Zielbelohnung um den von der Umgebung erhaltenen Betrag und wiederholen den Vorgang, bis die gewünschte Gesamtbelohnung erhalten oder die Episode abgeschlossen ist.
Bitte beachten Sie, dass, wenn Sie diesen Ansatz verwenden und nach Erreichen der gewünschten Gesamtbelohnung fortfahren, ein negativer Wert an Return-To-Go übergeben werden kann. Dies kann zu Verlusten führen.
Um den Agenten eine Entscheidung treffen zu lassen, übergeben wir die letzte K Zeitschritte an den Decision Transformer als Quelldaten. Insgesamt, 3*K Token. Eine für jede Modalität: Rückkehr zum Ziel, Zustand und Handlung, die zu diesem Zustand geführt hat. Um Vektorrepräsentationen der Token zu erhalten, verwenden die Autoren der Methode für jede Modalität eine trainierte und vollständig verbundene neuronale Schicht, die die Quelldaten in die Dimension der Vektordarstellungen projiziert. Die Ebene wird anschließend normalisiert. Bei der Analyse komplexer (zusammengesetzter) Umgebungszustände ist es möglich, einen Faltungscodierer anstelle einer vollständig verknüpften neuronalen Schicht zu verwenden.
Zusätzlich wird für jeden Zeitschritt eine Vektordarstellung des Zeitstempels trainiert und zu jedem Token hinzugefügt. Dieser Ansatz unterscheidet sich von der Standard-Positionsvektordarstellung in Transformatoren, da ein Zeitschritt mehreren Token entspricht (im gegebenen Beispiel sind es drei). Die Token werden dann mit dem Modell GPT verarbeitet, das zukünftige Aktionstoken mit Hilfe autoregressiver Modellierung vorhersagt. Wir haben in dem Artikel „Ein Blick auf GPT“ mehr über die Architektur von GPT-Modellen bei der Betrachtung von überwachten Trainingsmethoden gesprochen.
So seltsam es klingen mag, das Modelltraining erfolgt mit Methoden des überwachten Lernens. Zunächst arrangieren wir die Interaktion mit der Umgebung und nehmen eine Reihe von zufälligen Flugbahnen auf. Wir haben dies bereits mehrfach getan. Anschließend wird ein Offline-Training durchgeführt. Wir wählen Minipakete von K Länge aus der gesammelten Menge von Flugbahnen aus. Der Vorhersagekopf, der dem Eingabe-Token st entspricht, lernt die Vorhersage der Aktion at - entweder unter Verwendung der Kreuzentropie-Verlustfunktion für diskrete Aktionen oder unter Verwendung des mittleren quadratischen Fehlers für kontinuierliche Aktionen. Die Verluste für jeden Zeitschritt werden gemittelt.
Bei den Experimenten stellten die Autoren der Methode jedoch nicht fest, dass die Vorhersage von Folgezuständen oder Belohnungen die Effizienz der Modelle verbessert.
Im Folgenden stellt der Autor die Methode vor.

Ich werde nicht im Detail auf die Architektur der Transformatoren und den Mechanismus der Self-Attention eingehen, da diese Themen bereits zuvor behandelt worden sind. Kommen wir nun zum praktischen Teil und betrachten wir die Implementierung des Decision Transformer-Mechanismus mit MQL5.
2. Implementierung mit MQL5
Nach einem kurzen Einblick in die theoretischen Aspekte der Decision-Transformer-Methode gehen wir nun zu ihrer Implementierung mit MQL5 über. Das erste Problem, mit dem wir konfrontiert werden, ist die Implementierung der Einbettung von Quelldatenentitäten. Bei der Lösung ähnlicher Probleme in überwachten Lernmethoden haben wir Faltungsschichten mit einem Schritt verwendet, der dem Fenster der Originaldaten entspricht. In diesem Fall gibt es jedoch zwei Schwierigkeiten:
- Die Größe des Vektors zur Beschreibung des Umgebungszustands ist anders als die des Aktionsraumvektors. Der Reward-Vektor hat die dritte Größe.
- Alle Entitäten enthalten Quelldaten aus verschiedenen Verteilungen. Um sie in eine vergleichbare Form in einem einzigen Raum zu bringen, sind verschiedene Einbettungsmatrizen erforderlich.
Wir haben den Zustand des Umfelds in zwei in Inhalt und Umfang völlig unterschiedliche Blöcke unterteilt: historische Daten der Preisbewegung und eine Beschreibung des aktuellen Zustands des Kontos. Dadurch wird eine weitere Modalität für die Analyse hinzugefügt. Bei neuen Versuchen können zusätzliche Daten zur Analyse anfallen. Offensichtlich können wir unter solchen Bedingungen keine Faltungsschicht verwenden, und wir brauchen eine andere universelle Lösung, die in der Lage ist, N Modalitäten mit Vektorgrößen [n1, n2, n3,...,nN] einbetten kann. Wie bereits erwähnt, verwendeten die Autoren der Methode für jede Modalität trainierte und vollständig verbundene Schichten. Dieser Ansatz ist recht universell, aber in unserem Fall bedeutet es den Verzicht auf die parallele Verarbeitung mehrerer Modalitäten.
In diesem Fall besteht die optimale Lösung meiner Meinung nach darin, ein neues Objekt in Form einer neuronalen Einbettungsschicht CNeuronEmbeddingOCL zu erstellen. Dies ist der einzige Ansatz, der es uns ermöglicht, den Prozess richtig zu gestalten. Bevor wir jedoch Objekte und Funktionen der neuen Klasse erstellen, müssen wir noch einige ihrer architektonischen Merkmale festlegen.
Bei jeder Iteration des Vorwärtsdurchlaufs sollen fünf Vektoren von Quelldaten übertragen werden:
- Daten zur historischen Preisentwicklung.
- Status eines Kontos.
- Belohnung.
- Die im vorherigen Schritt durchgeführte Aktion.
- Zeitstempel.
Wie Sie sehen können, unterscheiden sich die Informationen aus den verschiedenen Modalitäten in Bezug auf Inhalt und Datenmenge erheblich. Wir müssen die Technologie für die Übertragung der Quelldaten in die Einbettungsschicht festlegen. Die Verwendung einer Matrix mit einer separaten Zeile oder Spalte für jede Modalität ist aufgrund der unterschiedlichen Größe der Datenvektoren nicht möglich. Wir können natürlich auch ein dynamisches Array von Vektoren verwenden. Diese Option ist jedoch nur im Rahmen der Implementierung mit MQL5 möglich. Es wird jedoch schwierig sein, ein solches Array an den OpenCL-Kontext für parallele Berechnungen zu übergeben. Die Erstellung separater Kernel für eine unterschiedliche Anzahl von Quelldatenmodalitäten verkompliziert das Programm und macht den Algorithmus nicht vollständig universell. Die Verwendung eines Kerns für jede einzelne Modalität führt zu deren sequentieller Einbettung und schränkt die Möglichkeiten des parallelen Rechnens ein.
In einer solchen Situation wäre es meiner Meinung nach die universellste Lösung, zwei Vektoren (Puffer) zu verwenden. In einem der Vektoren geben wir konsequent alle Quelldaten an. Im zweiten Fall wird eine „data map“ (Datenkarte) in Form von Fenstergrößen für jede Sequenz bereitgestellt. So können wir mit nur zwei Puffern eine beliebige Anzahl von Modalitäten mit einer unabhängigen Datengröße an den Kernel übertragen, ohne den Algorithmus der Aktionen innerhalb des Kernels zu ändern. Dies ist eine völlig universelle Lösung mit der Möglichkeit paralleler Berechnungen zur gleichzeitigen Einbettung aller Modalitäten.
Dieser Ansatz ist nicht nur einfach und vielseitig, sondern ermöglicht auch die einfache Kombination einer neuen Klasse mit allen zuvor erstellten neuronalen Schichten.
Wir haben das Problem mit der Übertragung der Originaldaten behoben. Bei den Gewichtsmatrizen ist die Situation jedoch fast ähnlich. Wie wir bereits erwähnt haben, benötigt jede Modalität ihre eigene Einbettungsmatrix. In diesem Fall haben wir jedoch einen Vorteil - die Einbettungsgrößen aller Modalitäten sind gleich. Das Ziel des Einbettungsprozesses ist es ja, verschiedene Modalitäten in eine vergleichbare Form zu bringen. Daher hat jedes Element der Quelldaten die gleiche Anzahl von Gewichtungskoeffizienten, um Daten an den Ausgang der neuronalen Schicht zu übertragen. So können wir eine gemeinsame Matrix verwenden, um die Einbettungsgewichte aller Modalitäten zu speichern. Die Anzahl der Matrixspalten ist gleich der Einbettungsgröße einer Modalität. Die Anzahl der Zeilen ist gleich der Gesamtzahl der Quelldaten. Hier können wir Bayes'sche Verzerrungselemente hinzufügen, die der Gewichtskoeffizientenmatrix für jede Modalität eine Zeile hinzufügen.
Der nächste konstruktive Punkt, auf den ich eingehen möchte, ist die Bedeutung der Einbettung der gesamten vorangegangenen Sequenz. Ich stelle nicht in Frage, dass der Bevollmächtigte die vorherige Flugbahn analysieren muss. Dies ist schließlich die Grundlage der hier betrachteten Methode. Aber lassen Sie uns das Thema etwas umfassender betrachten. Der Decision Transformer ist im Wesentlichen ein autoregressives Modell, das K*N Token als Eingabe erhält. In jedem Zeitschritt werden nur N Token neu bleiben. Der Rest (K-1)*N Token wiederholen vollständig die im vorherigen Zeitschritt verwendeten Token. Natürlich werden in der Anfangsphase des Trainings auch wiederholte Quelldaten aufgrund von Änderungen an den Einbettungsmatrizen unterschiedliche Einbettungen aufweisen. Dieser Einfluss wird jedoch mit dem Training des Modells abnehmen. Im Alltagsbetrieb, wenn sich die Gewichtsmatrizen nicht ändern, gibt es solche Abweichungen überhaupt nicht. Und es ist ganz logisch, bei jedem Zeitschritt nur neue Quelldaten einzubinden. Dadurch können wir die Ressourcenkosten für die Dateneinbettung während des Trainings und des täglichen Betriebs des Modells erheblich reduzieren.
Darüber hinaus sollten wir noch einen weiteren Punkt beachten - die Positionskodierung. In unserer Aufgabe wird die Position der historischen Daten durch die Öffnungszeit des Balkens angegeben. Wir haben die Kodierung von Zeitstempeln in unser Quelldatenmodell aufgenommen. Die Autoren der Methode fügten jedoch ein Positions-Token zur Einbettung anderer Modalitäten hinzu. Diese Lösung steht in vollem Einklang mit der Architektur des Transformators, fügt jedoch einen zusätzlichen Vorgang in die Abfolge der Aktionen ein. Wir erstellen eine Zeitstempel-Einbettung und fügen sie als separate Modalität hinzu, da die Positionseinbettung parallel zur Einbettung anderer Modalitäten erfolgen kann. Dieser Ansatz erhöht jedoch das Volumen der analysierten Daten. In jedem einzelnen Fall müssen Sie bei der Wahl einer Positionskodierungsmethode die Ausgewogenheit verschiedener Faktoren des Programms berücksichtigen.
Nachdem wir die wichtigsten Designmerkmale unserer Implementierung definiert haben, können wir mit der Erstellung eines OpenCL-Programms fortfahren. Wir beginnen, wie immer, mit dem Aufbau eines Kerns für Vorwärtsdurchgänge. Als Ergebnis wollen wir eine Einbettungsmatrix erhalten. Jede Zeile dieser Matrix steht für die Einbettung einer einzelnen Modalität. In ähnlicher Weise werden wir einen 2-dimensionalen Raum von Kernproblemen bilden. In einer Dimension geben wir die Größe der Einbettung einer Modalität an. In der zweiten Spalte geben wir die Anzahl der analysierten Modalitäten an.
Wie Sie sich vielleicht erinnern, haben wir beschlossen, nur die letzten Modalitäten in die Sequenz einzubinden. Wir übertragen die Einbettung der vorherigen Daten ohne Änderungen der zuvor erzielten Ergebnisse. Gleichzeitig erhalten wir die Einbettung der gesamten Sequenz am Ausgang unserer Schicht CNeuronEmbeddingOCL.
In den Kernelparametern übergeben wir Zeiger auf 5 Datenpuffer und 1 Konstante, in der wir die Größe der Sequenz angeben. In diesem Fall ist mit Sequenzgröße die Anzahl der analysierten historischen Datenschritte gemeint.
In den Datenpuffern werden wir die folgenden Informationen übergeben:
- inputs — Ausgangsdaten in Form einer Sequenz aller Modalitäten (1 Zeitschritt);
- outputs — Folge von Einbettungen aller Modalitäten bis zur Tiefe der analysierten Geschichte;
- weights — Matrix der Gewichtsverhältnisse;
- windows — Quelldatenkarte (Größe der Datenfenster jeder Modalität in den Quelldaten);
- std — Vektor der Standardabweichungen (wird zur Normalisierung der Einbettungen verwendet).
__kernel void Embedding(__global float *inputs, __global float *outputs, __global float *weights, __global int *windows, __global float *std, const int stack_size ) { const int window_out = get_global_size(0); const int pos = get_local_id(0); const int emb = get_global_id(1); const int emb_total = get_global_size(1); const int shift_out = emb * window_out + pos; const int step = emb_total * window_out; const uint ls = min((uint)get_local_size(0), (uint)LOCAL_ARRAY_SIZE);
Im Kernelkörper identifizieren wir den Fluss in beiden Dimensionen und definieren Offset-Konstanten in den Datenpuffern. Dann verschieben wir die zuvor erhaltenen Einbettungen in den Ergebnispuffer. Bitte beachten Sie, dass in jedem Thread nur eine einzige Einbettungsposition übertragen wird. Dadurch kann das Kopieren von Daten in parallelen Threads organisiert werden.
for(int i=stack_size-1;i>0;i--) outputs[i*step+shift_out]=outputs[(i-1)*step+shift_out];
Der nächste Schritt ist die Bestimmung des Offsets im Quelldatenpuffer zu der zu analysierenden Modalität. Dazu zählen wir die Gesamtzahl der Elemente in den Modalitäten, die sich im Quelldatenpuffer vor dem analysierten Puffer befinden.
int shift_in = 0; for(int i = 0; i < emb; i++) shift_in += windows[i];
Hier bestimmen wir den Offset im Puffer der Gewichtsmatrix unter Berücksichtigung des Bayes'schen Elements.
const int shift_weights = (shift_in + emb) * window_out;
Speichern der Größe des Quelldatenfensters der aktuellen Modalität in einer lokalen Variablen und definieren der Konstanten für die Arbeit mit dem lokalen Array.
const int window_in = windows[emb]; const int local_pos = (pos >= ls ? pos % (ls - 1) : pos); const int local_orders = (window_out + ls - 1) / ls; const int local_order = pos / ls;
Erstellen eines lokales Arrays und füllen mit Nullwerten. Hier werden wir eine Barriere für die lokale Thread-Synchronisierung einrichten.
__local float temp[LOCAL_ARRAY_SIZE]; if(local_order == 0) temp[local_pos] = 0; barrier(CLK_LOCAL_MEM_FENCE);
An diesem Punkt können die vorbereitenden Arbeiten als abgeschlossen betrachtet werden, und wir gehen direkt zu den Einbettungsoperationen über. Zunächst multiplizieren wir den Vektor der Eingangsdaten der analysierten Modalität mit dem entsprechenden Vektor der Gewichtsverhältnisse. Auf diese Weise erhalten wir das benötigte Einbettungselement.
float value = weights[shift_weights + window_in]; for(int i = 0; i < window_in; i++) value += inputs[shift_in + i] * weights[shift_weights + i];
In diesem Fall verwenden wir die Aktivierungsfunktion nicht, da wir die Projektion jedes Elements der Sequenz in den gewünschten Unterraum erhalten müssen. Wir sind uns jedoch bewusst, dass ein solcher Ansatz die Vergleichbarkeit von Einbettungen unterschiedlicher Quelldaten nicht garantiert. Daher besteht der nächste Schritt darin, die Daten innerhalb der Einbettung einer einzelnen Modalität zu normalisieren. Wir reduzieren also die Daten aller Einbettungen auf einen Mittelwert von Null und eine Einheitsvarianz. Ich möchte Sie an die Normalisierungsgleichung erinnern.

Zu diesem Zweck wird zunächst die Summe aller Elemente der analysierten Einbettung in einem lokalen Array erfasst. Wir teilen den resultierenden Betrag durch die Größe des Einbettungsvektors. Auf diese Weise können wir den Durchschnittswert ermitteln. Dann passen wir den Wert des aktuellen Einbettungselements an den Durchschnittswert an. Wir verwenden Barrieren, um lokale Threads zu synchronisieren.
for(int i = 0; i < local_orders; i++) { if(i == local_order) temp[local_pos] += value; barrier(CLK_LOCAL_MEM_FENCE); } //--- int count = ls; do { count = (count + 1) / 2; if(pos < count) temp[pos] += temp[pos + count]; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- value -= temp[0] / (float)window_out; barrier(CLK_LOCAL_MEM_FENCE);
An dieser Stelle ist es angebracht, einige Worte über die Ableitung der durchgeführten Operationen zu verlieren. Wie Sie wissen, verwenden wir Ableitungen der Vorwärtsdurchgangs-Funktion, um den Fehlergradienten während des Rückwärtsdurchgangs zu propagieren. Wenn wir eine Konstante von einer Variablen addieren oder subtrahieren, übertragen wir den gesamten Fehlergradienten auf die Variable. Der Clou an dieser Situation ist jedoch, dass wir den Durchschnittswert abziehen. Sie wird ihrerseits als Funktion der analysierten Variablen verwendet und hat ihre Ableitung. Um den Fehlergradienten genau zu verteilen, müssen wir ihn durch die Ableitung der Mittelwertfunktion leiten. Diese Aussage gilt auch für die Standardabweichung, die wir weiter verwenden werden. Meine persönliche Erfahrung zeigt jedoch, dass der Gesamtfehlergradient, der durch die Ableitung der Mittelwert- und Varianzfunktion entsteht, um ein Vielfaches geringer ist als der Fehlergradient der Variablen selbst. Um Ressourcen zu sparen, werde ich den Algorithmus für die Speicherung von Zwischendaten und die anschließende Berechnung von Fehlergradienten in dieser Richtung jetzt nicht weiter verkomplizieren.
Kehren wir nun zu unserem Kernel-Algorithmus zurück. In diesem Stadium haben wir den Einbettungsvektor bereits auf einen Mittelwert von Null gebracht. Es ist an der Zeit, sie auf die Einheitsvarianz zu reduzieren. Dazu teilen wir alle Elemente der analysierten Einbettung durch ihre Standardabweichung, die wir mithilfe eines lokalen Arrays berechnen.
Ich möchte Sie daran erinnern, dass ein lokales Array dazu dient, Daten zwischen Threads einer lokalen Gruppe zu übertragen. Die Synchronisierung von Threads erfolgt über Barrieren.
if(local_order == 0) temp[local_pos] = 0; barrier(CLK_LOCAL_MEM_FENCE); //--- for(int i = 0; i < local_orders; i++) { if(i == local_order) temp[local_pos] += pow(value,2.0f) / (float)window_out; barrier(CLK_LOCAL_MEM_FENCE); } //--- count = ls; do { count = (count + 1) / 2; if(pos < count) temp[pos] += temp[pos + count]; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- if(temp[0] > 0) value /= sqrt(temp[0]);
Jetzt müssen wir nur noch den empfangenen Wert in das entsprechende Element des Ergebnispuffers speichern. Vergessen wir auch nicht, die berechnete Standardabweichung für die spätere Verteilung des Fehlergradienten beim Umkehrdurchgang zu speichern.
outputs[shift_out] = value; if(pos == 0) std[emb] = sqrt(temp[0]); }
Nach Abschluss der Arbeiten am Vorwärtsdurchgangs-Kernel schlage ich vor, mit der Analyse des Kernel-Algorithmus für die Fehlergradientenverteilung fortzufahren. Wir haben bereits oben damit begonnen, die Verteilung des Fehlergradienten durch die Datennormalisierungsfunktion zu diskutieren. Um die Nutzung der Ressourcen zu optimieren, wurde beschlossen, den Algorithmus in Bezug auf den Fehlergradienten durch die Funktionen des Durchschnittswertes und der Streuung des Einbettungsvektors zu vereinfachen. In diesem Stadium behandeln wir den Mittelwert und die Varianz als Konstanten. Auf diesem Paradigma basiert der Algorithmus des Kernels des Fehlergradient EmbeddingHiddenGradient.
In den Kernel-Parametern übergeben wir 5 Datenpuffer und 1 Konstante. Wir haben uns bereits mit der Konstante und den 3 Puffern vertraut gemacht, die im vorherigen Kernel verwendet wurden. Die Puffer für die ursprünglichen Daten und Ergebnisse werden durch Puffer für die entsprechenden Fehlergradienten ersetzt.
__kernel void EmbeddingHiddenGradient(__global float *inputs_gradient, __global float *outputs_gradient, __global float *weights, __global int *windows, __global float *std, const int window_out ) { const int pos = get_global_id(0);
Wir werden den Kernel in einem eindimensionalen Aufgabenraum entsprechend der Anzahl der Elemente der Quelldaten aufrufen. Im Hauptteil des Kernels wird der aktuelle Thread sofort identifiziert. Die Position eines Elements im Quelldatenpuffer gibt uns jedoch keine eindeutige Vorstellung von den abhängigen Elementen im Ergebnispuffer. Daher durchlaufen wir zunächst den Puffer der Rohdatenkarte, um die zu analysierende Modalität zu bestimmen.
int emb = -1; int count = 0; do { emb++; count += windows[emb]; } while(count <= pos);
Auf der Grundlage des Index der analysierten Modalität bestimmen wir die Verzerrung in den Ergebnis- und Gewichtspuffern.
const int shift_out = emb * window_out; const int shift_weights = (pos + emb) * window_out;
Nach der Bestimmung der Verzerrungen in den Datenpuffern werden die Fehlergradienten aus allen abhängigen Elementen des Ergebnispuffers gesammelt und vor der Normalisierung um die Standardabweichung des Einbettungsvektors bereinigt. Ich möchte Sie daran erinnern, dass wir den Wert im Puffer std während der direkten Passage gespeichert haben.
float value = 0; for(int i = 0; i < window_out; i++) value += outputs_gradient[shift_out + i] * weights[shift_weights + i]; float s = std[emb]; if(s > 0) value /= s; //--- inputs_gradient[pos] = value; }
Der resultierende Wert wird im Gradientenpuffer der vorherigen Schicht gespeichert.
Um die Arbeit mit dem OpenCL-Programm abzuschließen, müssen wir nur noch den Kernel-Algorithmus zur Aktualisierung der Gewichtsmatrix berücksichtigen. In diesem Artikel werden wir nur den Kernel der Adam-Methode betrachten, die ich am häufigsten verwende. Der Hauptunterschied zwischen diesem Kernel und ähnlichen, bereits besprochenen Kerneln liegt in der Bestimmung der Offsets in den Datenpuffern. Das ist durchaus zu erwarten. Wir nehmen keine grundlegenden Änderungen am Algorithmus der Aktualisierungsmethode der Gewichtsverhältnisse selbst vor.
__kernel void EmbeddingUpdateWeightsAdam(__global float *weights, __global const float *gradient, __global const float *inputs, __global float *matrix_m, __global float *matrix_v, __global int *windows, __global float *std, const int window_out, const float l, const float b1, const float b2 ) { const int i = get_global_id(0);
In den Kernel-Parametern wird eine ziemlich große Anzahl von Puffern und Konstanten übergeben. Wir kennen sie bereits alle. Der Kernel wird in einem eindimensionalen Aufgabenraum aufgerufen, der auf der Anzahl der Elemente im Gewichtsverhältnispuffer basiert.
Im Kernelkörper identifizieren wir das zu analysierende Pufferelement wie üblich durch die Thread-ID. Danach bestimmen wir die Offsets in den Datenpuffern zu den benötigten Elementen.
int emb = -1; int count = 0; int shift = 0; do { emb++; shift = count; count += (windows[emb] + 1) * window_out; } while(count <= i); const int shift_out = emb * window_out; int shift_in = shift / window_out - emb; shift = (i - shift) / window_out;
Anschließend werden Anpassungen des Gewichtungsfaktors vorgenommen. Das Verfahren entspricht vollständig dem in den vorangegangenen Artikeln dieser Reihe beschriebenen. Speichern Sie das Ergebnis und die erforderlichen Daten in den entsprechenden Puffern.
float weight = weights[i]; float g = gradient[shift_out] * inp / std[emb]; float mt = b1 * matrix_m[i] + (1 - b1) * g; float vt = b2 * matrix_v[i] + (1 - b2) * pow(g, 2); float delta = l * (mt / (sqrt(vt) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight)); if(delta * g > 0) weights[i] = clamp(weights[i] + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[i] = mt; matrix_v[i] = vt; }
Nachdem wir die Arbeit an den Kerneln des OpenCL-Programms beendet haben, kehren wir zur Arbeit an der Seite des Hauptprogramms zurück. Da wir nun bereits Klarheit über die Klassenfunktionalität und eine vollständige Liste der erforderlichen Datenpuffer haben, können wir alle Voraussetzungen für den Aufruf und die Pflege der oben besprochenen Kernel schaffen.
Wie oben erwähnt, erstellen wir die neue Klasse CNeuronEmbeddingOCL, die auf der CNeuronBaseOCL Basisklasse der neuronalen Schichten basiert. Die Hauptfunktionen der neuronalen Schicht werden von der übergeordneten Klasse geerbt. Wir müssen der Klasse neue Funktionen hinzufügen.
Erstellen wir das dynamische Array a_Windows, um die Quelldatenkarte zu speichern. Wir werden jedoch kein separates Pufferobjekt erstellen, um es zu verwalten. Stattdessen erstellen wir eine Variable, die einen Zeiger auf den Puffer im OpenCL-Kontext i_WindowsBuffer aufzeichnet. Hier werden wir Variablen erstellen, um die Größe einer Einbettung und die Tiefe des analysierten Verlaufs zu erfassen — jeweils i_WindowOut und i_StackSize.
Wir erstellen Datenpuffer für die Matrix der Einbettungsgewichtsverhältnisse und Momente:
- WeightsEmbedding;
- FirstMomentumEmbed;
- SecondMomentumEmbed.
Der Standardabweichungspuffer wird jedoch nur für Zwischenberechnungen verwendet. Deshalb werden wir sie nicht neben dem Hauptprogramm erstellen. Erzeugen wir ihn nur im OpenCL-Kontextspeicher und speichern einen Zeiger darauf in der i_STDBuffer Variable.
Die Menge der überschriebenen Methoden ist ziemlich standardmäßig und wir werden uns jetzt nicht mit ihrem Zweck befassen.
class CNeuronEmbeddingOCL : public CNeuronBaseOCL { protected: int a_Windows[]; int i_WindowOut; int i_StackSize; int i_WindowsBuffer; int i_STDBuffer; //--- CBufferFloat WeightsEmbedding; CBufferFloat FirstMomentumEmbed; CBufferFloat SecondMomentumEmbed; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronEmbeddingOCL(void); ~CNeuronEmbeddingOCL(void); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint stack_size, uint window_out, int &windows[]); //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronEmbeddingOCL; } virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual bool Clear(void); };
Im Klassenkonstruktor initialisieren wir Variablen und Zeiger auf Puffer mit Anfangswerten.
CNeuronEmbeddingOCL::CNeuronEmbeddingOCL(void) { ArrayFree(a_Windows); if(!!OpenCL) { if(i_WindowsBuffer >= 0) OpenCL.BufferFree(i_WindowsBuffer); if(i_STDBuffer >= 0) OpenCL.BufferFree(i_STDBuffer); } //-- i_WindowsBuffer = INVALID_HANDLE; i_STDBuffer = INVALID_HANDLE; i_WindowOut = 0; i_StackSize = 1; }
Die direkte Initialisierung des Objekts der Einbettungsschicht erfolgt in der Methode Init. Zusätzlich zu den Konstanten übermitteln wir die Tiefe der analysierten Historie (stack_size), die Größe des Einbettungsvektors (window_out) und das dynamische Array der Quelldatenkarte bzw. „source data map“ (windows[]) in den Methodenparametern.
bool CNeuronEmbeddingOCL::Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl,uint stack_size, uint window_out,int &windows[]) { if(CheckPointer(open_cl) == POINTER_INVALID || window_out <= 0 || windows.Size() <= 0 || stack_size <= 0) return false; if(!!OpenCL && OpenCL != open_cl) delete OpenCL; uint numNeurons = window_out * windows.Size() * stack_size; if(!CNeuronBaseOCL::Init(numOutputs,myIndex,open_cl,numNeurons,ADAM,1)) return false;
Wir erstellen einen Block zur Kontrolle der Quelldaten im Hauptteil der Methode. Dann berechnen wir die Größe des Ergebnispuffers neu als Produkt der Länge des Vektors einer Einbettung durch die Anzahl der Modalitäten und die Tiefe der analysierten Geschichte. Beachten Sie, dass es keine Gesamtzahl von Modalitäten in den externen Parametern gibt. Aber wir erhalten die „map of initial data“ (Karte der Ausgangsdaten). Die Größe des resultierenden Arrays gibt Aufschluss über die Anzahl der zu analysierenden Modalitäten.
Die direkte Initialisierung des Ergebnispuffers sowie anderer abgeleiteten Objekte erfolgt in einer ähnlichen Methode der Elternklasse, die wir nach Abschluss der vorbereitenden Operationen aufrufen.
Nach erfolgreicher Initialisierung der abgeleiteten Objekte müssen wir die hinzugefügten Entitäten vorbereiten. Zunächst wird der Puffer für die Einbettungsgewichte initialisiert. Wie oben beschrieben, ist dieser Puffer eine Matrix mit einer Anzahl von Zeilen, die dem Volumen der Originaldaten entspricht, und Spalten, die der Größe des Vektors einer Einbettung entspricht. Wir kennen die Größe der Einbettung. Um jedoch die Größe der Quelldaten zu bestimmen, müssen wir alle Werte der Datenkarte zusammenzählen. Fügen wir zu der sich ergebenden Summe für jede Modalität eine Zeile Bayes'sche Verzerrung hinzu. Auf diese Weise erhalten wir die Größe des Puffers für das Einbettungsgewicht. Jetzt werden wir ihn mit Zufallswerten füllen und in den OpenCL-Kontextspeicher übertragen.
uint weights = 0; ArrayCopy(a_Windows,windows); i_WindowOut = (int)window_out; i_StackSize = (int)stack_size; for(uint i = 0; i < windows.Size(); i++) weights += (windows[i] + 1) * window_out; if(!WeightsEmbedding.Reserve(weights)) return false; float k = 1.0f / sqrt((float)weights / (float)window_out); for(uint i = 0; i < weights; i++) if(!WeightsEmbedding.Add(k * (2 * GenerateWeight() - 1.0f)*WeightsMultiplier)) return false; if(!WeightsEmbedding.BufferCreate(OpenCL)) return false;
Der erste und der zweite Momentpuffer haben eine ähnliche Größe. Wir initialisieren sie jedoch mit Nullwerten und übertragen sie in den OpenCL-Kontextspeicher.
if(!FirstMomentumEmbed.BufferInit(weights, 0)) return false; if(!FirstMomentumEmbed.BufferCreate(OpenCL)) return false; //--- if(!SecondMomentumEmbed.BufferInit(weights, 0)) return false; if(!SecondMomentumEmbed.BufferCreate(OpenCL)) return false;
Als Nächstes erstellen wir die Puffer für die Rohdaten und die Standardabweichungskarte.
i_WindowsBuffer = OpenCL.AddBuffer(sizeof(int) * a_Windows.Size(),CL_MEM_READ_WRITE); if(i_WindowsBuffer < 0 || !OpenCL.BufferWrite(i_WindowsBuffer,a_Windows,0,0,a_Windows.Size())) return false; i_STDBuffer = OpenCL.AddBuffer(sizeof(float) * a_Windows.Size(),CL_MEM_READ_WRITE); if(i_STDBuffer<0) return false; //--- return true; }
Wir stellen sicher, dass wir den Prozess der Durchführung von Operationen bei jedem Schritt kontrollieren. Nachdem alle Operationen der Methode abgeschlossen sind, geben wir das logische Ergebnis der Methode an das aufrufende Programm zurück.
Nach der Initialisierung des Objekts müssen wir Methoden für seine Hauptfunktionen erstellen. In unserem Fall handelt es sich um Vorwärts- und Rückwärtsdurchangsmethoden. Wie Sie vielleicht schon erraten haben, haben wir die Hauptarbeit bei der Anordnung der Funktionen im OpenCL-Programm bereits geleistet. Jetzt müssen wir nur noch den Aufruf der entsprechenden Kernel organisieren. Bevor wir beginnen, müssen wir Konstanten für die Arbeit mit Kernels deklarieren: Kernel-IDs im Programm und ihre Parameter. Wie immer verwenden wir für diese Funktion die Richtlinie #define.
#define def_k_Embedding 59 #define def_k_emb_inputs 0 #define def_k_emb_outputs 1 #define def_k_emb_weights 2 #define def_k_emb_windows 3 #define def_k_emb_std 4 #define def_k_emb_stack_size 5 //--- #define def_k_EmbeddingHiddenGradient 60 #define def_k_ehg_inputs_gradient 0 #define def_k_ehg_outputs_gradient 1 #define def_k_ehg_weights 2 #define def_k_ehg_windows 3 #define def_k_ehg_std 4 #define def_k_ehg_window_out 5 //--- #define def_k_EmbeddingUpdateWeightsAdam 61 #define def_k_euw_weights 0 #define def_k_euw_gradient 1 #define def_k_euw_inputs 2 #define def_k_euw_matrix_m 3 #define def_k_euw_matrix_v 4 #define def_k_euw_windows 5 #define def_k_euw_std 6 #define def_k_euw_window_out 7 #define def_k_euw_learning_rate 8 #define def_k_euw_b1 9 #define def_k_euw_b2 10
Wir werden den Prozess der Platzierung des Kernels in die Ausführungswarteschlange anhand des Beispiels der direkten Methode feedForward betrachten. In den Methodenparametern erhalten wir, wie in allen zuvor betrachteten ähnlichen Methoden, den Zeiger auf das Objekt der vorherigen neuronalen Schicht.
bool CNeuronEmbeddingOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !OpenCL) return false;
Im Methodenkörper werden der empfangene Zeiger und der Zeiger auf das Objekt für die Arbeit mit dem OpenCL-Kontext überprüft.
Als Nächstes übergeben wir dem Kernel Zeiger auf die Datenpuffer und die notwendigen Konstanten, die zuvor in den Kernel-Parametern angegeben wurden. Vergessen wir nicht, die Vorgänge bei jedem Schritt zu überwachen.
if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_std, i_STDBuffer)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_weights, WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Embedding, def_k_emb_windows, i_WindowsBuffer)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_Embedding, def_k_emb_stack_size, i_StackSize)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__,GetLastError(), __LINE__); return false; }
Nachdem wir alle Parameter erfolgreich übergeben haben, müssen wir den Aufgabenraum für den Kernel definieren. Wie bereits erwähnt, läuft der Kernel in einem 2-dimensionalen Aufgabenraum. In der ersten Dimension geben wir die Größe einer Einbettung an, während wir in der zweiten Dimension die Anzahl der zu analysierenden Modalitäten angeben.
uint global_work_offset[2] = {0,0}; uint global_work_size[2] = {i_WindowOut,a_Windows.Size()};
Ein Merkmal des Einbettungskerns ist die Normalisierung der Daten innerhalb des Einbettungsvektors einer Modalität. Um diesen Unterprozess aufzubauen, haben wir den Datenaustausch zwischen Threads innerhalb derselben Arbeitsgruppe über ein lokales Array organisiert. Nun müssen wir die Größe der lokalen Gruppe angeben, die gleich der Größe des Einbettungsvektors ist. Der Clou ist, dass wir bei der Angabe eines 2-dimensionalen Raums eine 2-dimensionale lokale Gruppe angeben müssen. Daher ist die 2. Dimension der lokalen Gruppe 1.
uint local_work_size[2] = {i_WindowOut,1};
Wir rufen schließlich die Methode für die Einreihung des Kernels in die Warteschlange auf und steuern den Prozess der Durchführung von Operationen.
if(!OpenCL.Execute(def_k_Embedding, 2, global_work_offset, global_work_size,local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__,GetLastError()); return false; } //--- return true; }
Das Verfahren zum Aufrufen des Kernels für den Rückwärtsdurchgang ist ähnlich, und wir werden jetzt nicht näher auf diese Methoden eingehen. Den erforderlichen Code finden Sie im Anhang. Ich möchte mich auf den folgenden Punkt konzentrieren. Decision Transformer ist ein autoregressives Modell und die Konsistenz der Eingabedaten ist von großer Bedeutung. Oben haben wir festgelegt, dass wir in jedem Zeitschritt nur neue Daten in das Modell einspeisen. Die gesamte Tiefe der analysierten Historie wird aus früheren Modelloperationen übernommen. Im Wesentlichen verwenden wir den Ergebnispuffer der CNeuronEmbeddingOCL-Schicht als Einbettungsstapel. Mit diesem Ansatz lassen sich die Kosten für die Primärdatenverarbeitung senken. Allerdings müssen die Ausgangsdaten sowohl während des Trainings als auch während des Betriebs ständig zur Verfügung stehen. Gleichzeitig verwenden wir beim Training häufig Stichproben von Quelldaten. Die Notwendigkeit dieser Maßnahme wurde bereits mehrfach erörtert. Um Datenverfälschungen infolge eines „temporären Sprungs“ in den Originaldaten oder beim Wechsel zu einer alternativen Trajektorie auszuschließen, benötigen wir eine Methode zum Leeren des Einbettungsstapels. Zu diesem Zweck wurde die Clear-Methode entwickelt. Der Algorithmus ist recht einfach: Wir füllen einfach den gesamten Puffer mit Nullwerten und kopieren die Daten in den OpenCL-Kontextspeicher.
bool CNeuronEmbeddingOCL::Clear(void) { if(!Output.BufferInit(Output.Total(),0)) return false; if(!OpenCL) return true; //--- return Output.BufferWrite(); }
Das beschließt die Diskussion über die Methodenalgorithmen der Klasse CNeuronEmbeddingOCL. Den vollständigen Code und alle Methoden finden Sie im Anhang.
Als Ergebnis dieser Arbeit haben wir vergleichbare Einbettungen mehrerer verschiedener Modalitäten am Ausgang der Schicht CNeuronEmbeddingOCL. Dies ermöglicht es uns, zuvor erstellte Transformer-Objekte zu verwenden, um die vorgestellten Entscheidungstransformator Methode zu implementieren. Das bedeutet, dass wir mit der Beschreibung der Modellarchitektur fortfahren können. In diesem Fall werden wir nur ein Modell verwenden - das des Agenten. Es ist schon eine Weile her, dass dies in unserer Artikelserie geschehen ist.
Doch zunächst muss ich Sie an die „source map“ (Quell-Karte) erinnern. Zu ihrer Beschreibung haben wir ein Array verwendet, das bisher nicht in der Beschreibungsklasse für neuronale Schichten enthalten war. Fügen wir das hinzu.
class CLayerDescription : public CObject { public: /** Constructor */ CLayerDescription(void); /** Destructor */~CLayerDescription(void) {}; //--- int type; ///< Type of neurons in layer (\ref ObjectTypes) int count; ///< Number of neurons int window; ///< Size of input window int window_out; ///< Size of output window int step; ///< Step size int layers; ///< Layers count int batch; ///< Batch Size ENUM_ACTIVATION activation; ///< Type of activation function (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Type of optimization method (#ENUM_OPTIMIZATION) float probability; ///< Probability of neurons shutdown, only Dropout used int windows[]; //--- virtual bool Copy(CLayerDescription *source); //--- virtual bool operator= (CLayerDescription *source) { return Copy(source); } };
Wir beschreiben die Modellarchitektur in der Methode CreateDescriptions. In den Parametern erhält die Methode einen Zeiger auf ein einziges dynamisches Array, das die Architektur des Actors beschreibt. Wir werden die Beschreibung der neuronalen Schichten des Modells in dem resultierenden Array speichern.
bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear();
Als erste Schicht geben wir eine vollständig verknüpfte neuronale Schicht der Quelldaten an, in die wir nacheinander alle für die Analyse erforderlichen Daten schreiben. Bitte beachten Sie, dass wir die Quelldaten nicht nach dem Inhalt in separate Puffer aufteilen. In diesem Fall ist ihre Aufteilung eher willkürlich. Wir schreiben sie einfach der Reihe nach auf. Ihre logische Trennung erfolgt auf der Ebene der Einbettung gemäß der „Quelldatenkarte“, die wir später erstellen werden.
Beachten Sie, dass die Quelldatenschicht nur Informationen über den letzten Zustand des Systems enthält (Belohnung, Umgebungszustand, Kontostatus, Zeitstempel und letzte Agentenaktion).
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (NRewards + BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Im Anschluss an die Quelldatenebene wird die Stapelnormalisierungsebene angegeben, in der die Daten vorverarbeitet werden. Auch hier denken wir nicht an die unterschiedliche Beschaffenheit der erhaltenen Daten. Schließlich führt diese Ebene die Normalisierung im Kontext der historischen Daten für jedes Attribut unabhängig durch.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Als Nächstes folgt die Ebene der Stapelnormalisierung. Hier geben wir die Tiefe der analysierten Geschichte, die Größe des Vektors einer Einbettung und die „Quelldatenkarte“ an.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NRewards,NActions}; ArrayCopy(descr.windows,temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
Hinter der Einbettungsschicht platzieren wir einen spärlichen (sparse) Aufmerksamkeitsblock defNeuronMLMHSparseAttentionOCL, der die Grundlage für unseren Transformator bildet. Die Autoren der Methode verwendeten einen originellen Transformator. Die Verwendung eines spärlichen Aufmerksamkeitsblocks ermöglicht es uns jedoch, die Tiefe des analysierten Verlaufs deutlich zu erhöhen, wobei sich die Ressourcenkosten und die Modelllaufzeit leicht erhöhen.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Das Modell wird durch einen Entscheidungsfindungsblock aus vollständig verknüpften Schichten und einer latenten Schicht eines Variations-Autoencoders am Ausgang vervollständigt, um Stochastizität in der Politik des Actors zu erzeugen.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
Auch der Entscheidungsblock unterscheidet sich von dem im DT-Algorithmus des Autors verwendeten. Die Autoren der Methode verwendeten den Decoder des letzten Tokens in der Sequenz am Ausgang des Transformators. Wir analysieren den gesamten Ablauf, um eine fundierte Entscheidung zu treffen.
Nachdem wir die Modellarchitektur festgelegt haben, erstellen wir einen EA für die Interaktion mit der Umgebung und sammeln Daten für das Training des Modells im Erfahrungswiedergabepuffer „\DT\Research.mq5“. Die EA-Struktur ist völlig identisch mit den zuvor besprochenen, aber es lohnt sich, sich auf die OnTick-Tick-Verarbeitungsmethode zu konzentrieren. Hier wird die Reihenfolge der Ausgangsdaten entsprechend der oben beschriebenen Karte gebildet.
Im Hauptteil der Methode wird geprüft, ob das Ereignis des Öffnens eines neuen Balkens eingetreten ist, und es werden gegebenenfalls historische Daten geladen. Allerdings laden wir jetzt nicht die gesamte Tiefe der analysierten Geschichte, sondern nur Aktualisierungen in der Größe des Musters eines Zeitschritts. Dies können die Daten einer letzten geschlossenen Kerze oder auch mehrere sein. Wir haben die Konstante NBarInPattern eingeführt, um die Tiefe des Datenladens zu regulieren. Bitte verwechseln Sie es nicht mit der Konstanten HistoryBars, die wir zur Bestimmung der Tiefe des Einbettungsstapels verwenden werden.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Dann erstellen wir ein Array aus den historischen Daten, um sie in der Trajektorie zu speichern, und übertragen es in den Quelldatenpuffer. Das Verfahren ist völlig identisch mit dem der zuvor besprochenen EAs.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Der nächste Schritt besteht darin, eine Beschreibung des Kontostatus zu erstellen. Die Datenerhebung erfolgt nach einem zuvor angewandten Verfahren. Die Daten werden jedoch nicht in einen separaten Puffer übertragen, sondern in den einzigen ursprünglichen Datenpuffer bState.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Fügen wir den Zeitstempel in denselben Puffer ein.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
Die folgenden Daten werden bereits durch die Anforderungen der Methode Decision-Transformer erzeugt. Hier fügen wir die Return-To-Go-Modalität in den Quelldatenpuffer ein. Es kann ein Element der gewünschten Belohnung oder ein Vektor von zerlegten Belohnungen sein. Wir werden 3 Elemente angeben: Veränderung des Saldos, Veränderung des Kapitals und den Drawdown. Alle 3 Indikatoren sind in relativen Werten angegeben.
//--- Return to go bState.Add(float(1-(sState.account[0] - PrevBalance) / PrevBalance)); bState.Add(float(0.1f-(sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(0);
Um den Vektor der Ausgangsdaten zu vervollständigen, fügen wir den Vektor der letzten Aktionen des Agenten hinzu. Beim ersten Aufruf wird dieser Vektor mit Nullwerten gefüllt.
//--- Prev action
bState.AddArray(AgentResult);
Der Quelldatenvektor ist fertig, und wir führen einen direkten Durchlauf des Agenten durch.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) return;
Der weitere Algorithmus für die Interpretation der Modellergebnisse und die Durchführung von Transaktionen wurde unverändert übernommen, sodass wir darauf nicht näher eingehen werden. Den vollständigen Code des EA und alle seine Methoden finden Sie im Anhang. Fahren wir nun mit der Erstellung des Modelltrainings in dem EA „\DT\Study.mq5“ fort. Der EA hat auch viel von früheren Arbeiten übernommen. Im Folgenden werden wir uns nur mit der Trainingsmethode für das Model Train befassen.
Im Hauptteil der Methode wird zunächst die Anzahl der Trajektorien bestimmt, die im lokalen Erfahrungswiedergabepuffer gespeichert sind.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Dann ordnen wir einen Zyklus auf der Grundlage der Anzahl der Trainingsiterationen an, in dem wir zufällig eine Trajektorie und einen separaten Zustand auf dieser Trajektorie auswählen. Hier ist alles so wie früher.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; }
Hier beginnen die Unterschiede. Erinnern Sie sich daran, dass wir über die Notwendigkeit gesprochen haben, sequenzielle Daten an den Eingang des Modells zu liefern. Aber wir sind ein zufälliger Zustand auf einer Flugbahn. Um Datenverfälschungen in der analysierten Sequenz zu vermeiden, löschen wir den Einbettungspuffer und den Vektor der letzten Aktionen des Agenten.
Actions = vector<float>::Zeros(NActions); Agent.Clear();
Dann organisieren wir eine verschachtelte Schleife, deren Anzahl der Iterationen das Dreifache der Tiefe der analysierten Geschichte beträgt, natürlich nur, wenn die Größe der gespeicherten Trajektorie dies zulässt. Im Hauptteil dieser verschachtelten Schleife trainieren wir das Modell, indem wir es mit Eingabedaten aus der gespeicherten Trajektorie in einer strikten Reihenfolge der Interaktion mit der Umgebung füttern. Zunächst laden wir die historischen Preisbewegungsdaten des Indikators in den Puffer.
for(int state = i; state < MathMin(Buffer[tr].Total - 1,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
Im Folgenden finden Sie Informationen zum Kontostand.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Und einen Zeitstempel.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
In diesem Stadium übertragen wir die tatsächliche akkumulierte Belohnung an das Ende der Flugbahn in Return-To-Go. Der Ansatz unterscheidet sich leicht von einem ähnlichen Token in der Umgebungsinteraktion EA. Aber das ist es, was uns erlaubt, das Modell zu trainieren.
//--- Return to go
State.AddArray(Buffer[tr].States[state].rewards);
Fügen wir die Aktion des Agenten im vorherigen Zeitschritt aus dem Erfahrungswiedergabepuffer hinzu.
//--- Prev action
State.AddArray(Actions);
Der Quelldatenpuffer für eine Trainingsiteration ist bereit, und wir rufen die Methode des Vorwärtsdurchgangs des Agenten auf.
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Nach dem erfolgreichen Abschluss des Vorwärtsdurchlaufs müssen wir einen Rückwärtsdurchlauf durchführen und die Modellparameter anpassen. Hier stellt sich die Frage nach den Zielwerten, die auf recht einfache Weise gelöst wird. Wir verwenden die Aktionen, die der Agent bei der Interaktion mit der Umgebung tatsächlich durchführt, als Zielwerte. Paradoxerweise handelt es sich dabei um ein rein überwachtes Training. Aber wo bleibt das Verstärkungslernen? Wo sind die Optimierungen der Belohnung? Wir können nicht einmal überwachtes Lernen verwenden, weil die Aktionen, die wir bei der Interaktion mit der Umgebung ausführen, nicht optimal sind.
Wir trainieren ein autoregressives Modell, das auf der Grundlage der Kenntnis des zurückgelegten Weges und des gewünschten Ergebnisses eine optimale Aktion generiert. Die Hauptrolle spielt dabei die Angabe der tatsächlich angesammelten Belohnung auf dem Return-to-Go-Token. Schließlich bezweifelt niemand, dass es die tatsächlich durchgeführten Handlungen waren, die zu den tatsächlich erhaltenen Belohnungen geführt haben. Daher können wir das Modell leicht trainieren, um diese Aktionen mit der erhaltenen Belohnung zu identifizieren. Ein gut trainiertes Modell ist anschließend in der Lage, Aktionen zu generieren, um das gewünschte Ergebnis während des Betriebs zu erzielen.
Die Autoren von Decision Transformer schlagen die Verwendung von MSE für einen kontinuierlichen Aktionsraum vor. Wir ergänzen sie mit dem Methode CAGrad.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Nach einem erfolgreichen Rückwärtsdurchlauf informieren wir den Nutzer über den Stand des Trainings und fahren mit der nächsten Iteration unseres Lernprozess-Schleifensystems fort. Nach Abschluss aller Iterationen leiten wir den Prozess zur Beendigung der EA-Arbeit ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
Im Anhang finden Sie den vollständigen Code aller im Artikel verwendeten Programme.
3. Test
Wir haben viel Arbeit in die Implementierung der Methode Decision-Transformer in MQL5 gesteckt. Nun ist es an der Zeit, das Modell zu trainieren und zu testen. Wie immer wird das Training und Testen der Modelle auf EURUSD H1 durchgeführt. Die Parameter aller Indikatoren werden standardmäßig verwendet. Die Trainingszeit beträgt 7 Monate im Jahr 2023. Wir werden das Modell anhand historischer Daten für August 2023 testen.
Ausgehend von den Ergebnissen des Tests dieser Methode können wir sagen, dass die Idee recht interessant ist. Aber in einem stochastischen Markt ist es mir gelungen, das gewünschte Ergebnis zu erzielen. Während mit der Trainingsstichprobe noch akzeptable Ergebnisse erzielt werden können, ist in den ersten zehn Tagen des Testzeitraums mit den neuen Daten ein Anstieg der Bilanz zu verzeichnen. Doch dann kommt eine Reihe von Verlustgeschäften. Infolgedessen führte das Modell bei den Testdaten zu Verlusten. Obwohl der durchschnittliche Gewinn den durchschnittlichen Verlust um etwas mehr als 1,0 % übersteigt, ist dies nicht ausreichend. Der Anteil der gewinnbringenden Transaktionen beträgt nur 47,76 %. Unterm Strich ergibt sich ein Gewinnfaktor von 0,92.


Schlussfolgerung
In diesem Artikel habe ich eine recht interessante Methode namens Decision Transformer vorgestellt, die einen neuen und innovativen Ansatz für das Reinforcement Learning darstellt. Im Gegensatz zu herkömmlichen Methoden modelliert der Decision Transformer Handlungssequenzen im Rahmen eines autoregressiven Modells der gewünschten Belohnungen. Dadurch kann der Agent lernen, Entscheidungen auf der Grundlage zukünftiger Ziele zu treffen und sein Verhalten auf der Grundlage dieser Ziele zu optimieren.
Im praktischen Teil des Artikels haben wir die vorgestellte Methode unter Verwendung von MQL5 implementiert und Training und Test des Modells durchgeführt. Das trainierte Modell war jedoch nicht in der Lage, während des gesamten Testzeitraums Gewinne zu erzielen. In der ersten Hälfte der Testphase hat das Modell einen Gewinn erzielt, der jedoch bei der Fortsetzung der Tests vollständig verloren ging. Der Algorithmus hat Potenzial. Es sind jedoch zusätzliche Arbeiten mit dem Modell erforderlich, um die gewünschten Ergebnisse zu erzielen.
Links
- Decision Transformer: Reinforcement Learning via Sequence Modeling
- Neuronale Netze leicht gemacht (Teil 57): Stochastic Marginal Actor-Critic (SMAC)
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Study.mq5 | Expert Advisor | Trainings-EA des Agenten |
| 3 | Test.mq5 | Expert Advisor | Test-EA des Modells |
| 4 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 5 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 6 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13347
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Verständnis von Programmierparadigmen (Teil 1): Ein verfahrenstechnischer Ansatz für die Entwicklung eines Price Action Expert Advisors
Verständnis von Programmierparadigmen (Teil 1): Ein verfahrenstechnischer Ansatz für die Entwicklung eines Price Action Expert Advisors
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.