Redes neurais de maneira fácil (Parte 55): Controle interno contrastivo (CIC)

Introdução
Nos artigos anteriores, já discutimos as vantagens de usar modelos hierárquicos. Examinamos métodos de treinamento de modelos capazes de extrair e destacar habilidades individuais do Agente. As habilidades adquiridas podem ser úteis para alcançar o objetivo final da tarefa designada. Exemplos desses algoritmos incluem DIAYN, DADS, EDL. Esses algoritmos abordam o aprendizado de habilidades de maneiras diferentes, mas todos foram usados para tarefas em espaços de ação discretos. Hoje, falaremos sobre outra abordagem para estudar habilidades do Agente e veremos sua aplicação na área de resolução de problemas em espaços de ação contínuos.
1. Componentes Principais do CIC
Na prática de aprendizado por reforço, algoritmos de treinamento prévio de Agentes usando recompensas internas auto-supervisionadas são amplamente utilizados. Tais algoritmos podem ser condicionalmente divididos em 3 categorias: baseados em competências, conhecimento e dados. Testes em Unsupervised Reinforcement Learning Benchmark demonstram que algoritmos baseados em competências são inferiores a outras categorias.
Algoritmos que utilizam competências buscam maximizar a informação mútua entre os estados observados e o vetor latente de habilidades. Essa informação mútua é avaliada por meio de um modelo Discriminador. Geralmente, um modelo classificador ou regressor é usado como Discriminador. No entanto, para alcançar precisão em tarefas de classificação e regressão, é necessário uma enorme quantidade de dados de treinamento variados. Em ambientes simples, onde o número de opções de comportamento potenciais é limitado, métodos baseados em competências demonstram sua eficácia. No entanto, em ambientes com muitas possíveis variações de comportamento, sua eficácia diminui significativamente.
Ambientes complexos implicam a presença de um grande número de habilidades diversas. E para processá-los, é necessário um Discriminador de alta capacidade. A contradição entre esta exigência e as capacidades limitadas dos Discriminadores existentes levou à criação do método Contrastive Intrinsic Control (CIC).
O Controle Intrínseco Contrastivo representa uma nova abordagem de avaliação contrastiva da densidade para aproximar a entropia condicional do Discriminador. O método opera transições entre estados e vetores de habilidades. Isso permite a aplicação de métodos poderosos de aprendizagem de representações, desde o processamento de dados visuais até a identificação de habilidades. O método proposto aumenta a estabilidade e eficácia do treinamento do Agente em ambientes diversos.
O algoritmo de Controle Intrínseco Contrastivo começa com o treinamento do Agente em um ambiente usando feedback e obtenção de trajetórias de estados e ações. Em seguida, é realizado o treinamento de representações usando Contrastive Predictive Coding (CPC), motivando o Agente a extrair características chave dos estados e ações. São formadas representações que consideram dependências entre estados consecutivos.
Um papel importante é desempenhado pela recompensa interna, determinando quais estratégias comportamentais devem ser maximizadas. No CIC, a entropia das transições entre estados é maximizada, promovendo a diversidade de comportamento do Agente. Isso permite que o Agente explore e crie diversas estratégias comportamentais.
Após a formação de habilidades e estratégias diversas, o algoritmo CIC usa o Discriminador para especificar as representações de habilidades. O Discriminador visa garantir que os estados sejam previsíveis e estáveis. Assim, o Agente aprende a "utilizar" habilidades em situações previsíveis.
A combinação da exploração motivada por recompensas internas e o uso de habilidades para ações previsíveis cria uma abordagem equilibrada para o desenvolvimento de estratégias diversas e eficazes.
Consequentemente, o algoritmo de Codificação Preditiva Contrastiva estimula o Agente a descobrir e assimilar uma ampla gama de estratégias comportamentais, garantindo ao mesmo tempo um treinamento estável. A seguir, apresenta-se uma visualização autoral do algoritmo.

Vamos nos familiarizar mais detalhadamente com o algoritmo durante a implementação.
2. Implementação com MQL5
Ao iniciar nossa implementação do algoritmo de Codificação Preditiva Contrastiva com MQL5, devemos definir alguns pontos-chave. Primeiramente, o treinamento do modelo é dividido em dois grandes estágios:
- treinamento de habilidades sem recompensa externa do ambiente;
- treinamento da política de solução de problemas com base em recompensa externa.
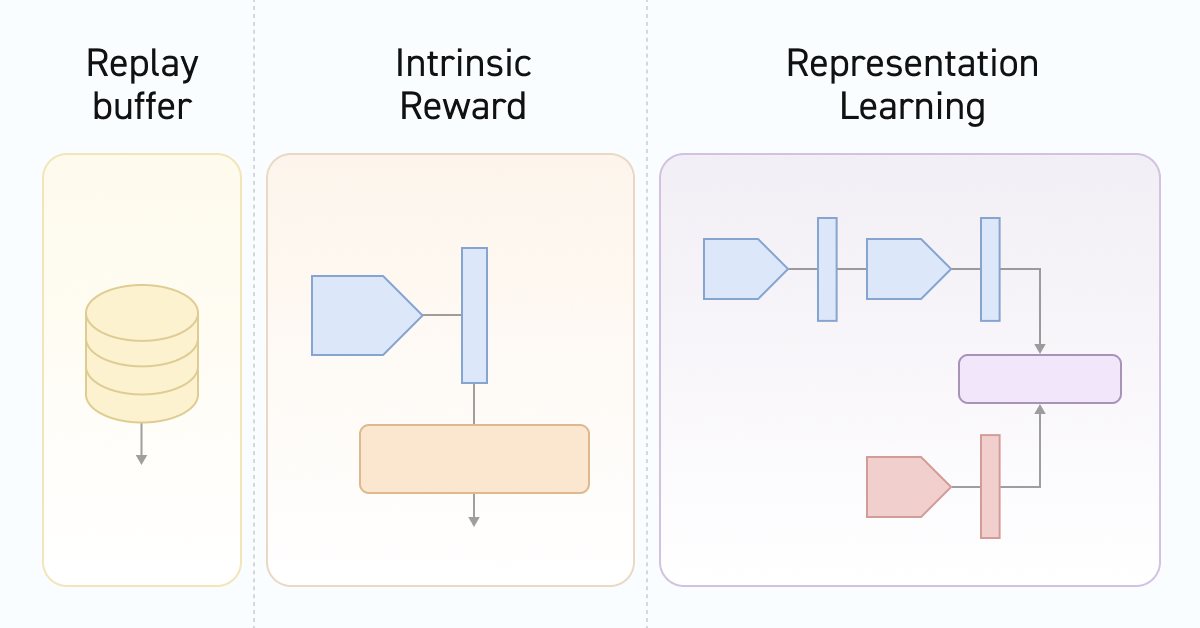
Em segundo lugar, durante o treinamento, o Discriminador aprende a correspondência entre as transições de estados e habilidades. É importante salientar que estamos lidando especificamente com a mudança de estado. Não com a recompensa externa pela transição para um novo estado. E não com a ação que levou a esse estado. Se fizermos analogias com algoritmos anteriormente analisados que lidavam com esses mesmos dados, o DIAYN, com base no estado inicial e no novo estado, o modelo identificava a habilidade. No DADS, por outro lado, com base no estado inicial e na habilidade, o Discriminador previa o próximo estado. Neste método, determinamos o erro contrastivo entre a transição (estado inicial e subsequente) e a habilidade usada pelo Agente. Assim, são formadas representações latentes dos estados e habilidades. É o Discriminador que influencia o treinamento do codificador de estados, que posteriormente é utilizado pelo Agente e pelo planejador. E isso se reflete na arquitetura dos modelos que usamos. Foi isso que nos motivou a separar o Codificador do estado do ambiente em um modelo à parte.
2.1 Descrição da arquitetura dos modelos
Assim, nós gradualmente chegamos ao método de descrever as arquiteturas dos modelos usados, CreateDescriptions. Nos parâmetros desse método, vemos ponteiros para os arrays de descrição de arquiteturas de 6 modelos, cujas funções discutiremos na descrição.
bool CreateDescriptions(CArrayObj *state_encoder, CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution, CArrayObj *descriminator, CArrayObj *skill_project ) { //--- CLayerDescription *descr; //--- if(!state_encoder) { state_encoder = new CArrayObj(); if(!state_encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } if(!skill_project) { skill_project = new CArrayObj(); if(!skill_project) return false; }
O primeiro é o modelo do codificador de estados do ambiente. Já começamos a falar sobre a funcionalidade desse modelo anteriormente. Como você sabe, o estado do ambiente é composto por 2 blocos: dados históricos e estado da conta. Ambos esses tensores serão fornecidos à entrada do nosso codificador. A arquitetura desse modelo lembrará você do bloco de pré-processamento de dados brutos anteriormente usado nos modelos dos Atores.
bool CreateDescriptions(CArrayObj *state_encoder, CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution, CArrayObj *descriminator, CArrayObj *skill_project ) { //--- CLayerDescription *descr; //--- if(!state_encoder) { state_encoder = new CArrayObj(); if(!state_encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } if(!skill_project) { skill_project = new CArrayObj(); if(!skill_project) return false; } //--- State Encoder state_encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = 8; descr.step = 8; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = NSkills; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!state_encoder.Add(descr)) { delete descr; return false; }
Em seguida, consideraremos a arquitetura do Ator. É o mesmo modelo. Apenas excluímos o bloco de pré-processamento de dados brutos, que foi separado em um Codificador próprio. Mas há um detalhe. Adicionamos mais um tensor de dados brutos, que descreve a habilidade utilizada.
E para que as políticas de comportamento do Ator ao usar diferentes habilidades sejam claramente distinguíveis, desistimos do uso de políticas estocásticas.
//--- Actor actor.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NSkills; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Como de costume, após o Ator, descrevemos a arquitetura do Crítico. E aqui devemos ponderar sobre sua funcionalidade. À primeira vista, a questão é bastante prosaica. O Crítico avalia a recompensa esperada pela transição para um novo estado. E a recompensa por uma transição específica depende da ação realizada, e não da habilidade usada. Claro, a ação é escolhida pelo Ator com base na habilidade indicada. Mas para o ambiente, é indiferente quais motivos guiaram o Agente. Ele reage à sua ação.
Por outro lado, o Crítico avalia a política do Ator e prevê a recompensa esperada pelo uso subsequente dessa política. E as políticas do Ator dependem diretamente da habilidade utilizada. Por isso, nos dados de entrada para o Crítico, precisamos fornecer o estado atual do ambiente, a habilidade usada e a ação escolhida pelo Ator. Aqui, usaremos uma abordagem já testada anteriormente. Vamos pegar o estado latente do Ator, que já leva em conta a descrição do estado do ambiente e a habilidade usada. E adicionaremos a ação escolhida pelo Ator. Assim, a arquitetura do Crítico permaneceu inalterada. Mas o identificador do estado latente do Ator mudou.
E também desistimos da decomposição da função de recompensa. Essa foi uma medida forçada. Como já mencionado, treinaremos o modelo em 2 etapas. E em cada etapa, usaremos uma função de recompensa diferente. Ficamos então com uma escolha. Usar a decomposição da recompensa e treinar 2 Críticos diferentes em cada etapa. Ou desistir da decomposição da recompensa, mas usar o mesmo Crítico em ambas as etapas. Decidimos seguir o segundo caminho.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
Em seguida, contribuímos com nossa visão para otimizar o algoritmo. O fato é que, como recompensa interna, os autores do método propõem usar a entropia das transições usando o método de partículas dos k vizinhos mais próximos, como fizemos no artigo anterior artigo. Apenas os autores usaram a distância entre as transições de um mini-lote na representação do codificador treinado. E para isso, precisaremos codificar algum lote de transições a cada iteração de atualização de parâmetros. Não podemos codificar um mini-lote uma vez e usar essa representação durante o treinamento. Afinal, após cada atualização dos parâmetros do codificador, o espaço de seus resultados mudará.
Mas sabemos que até um modelo convolucional aleatório pode nos fornecer informações suficientes para comparar dois estados. Assim sendo, para fins de recompensa interna, criaremos um modelo convolucional não treinável. E antes do treinamento, criaremos primeiro uma representação compacta de todas as transições do buffer de reprodução da experiência. Durante o treinamento, apenas codificaremos a transição em análise.
Falando de transição, neste caso, referimo-nos a 2 estados subsequentes do ambiente.
//--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 2 * (HistoryBars * BarDescr + AccountDescr); descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 512; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = 512 / 8; descr.window = 8; descr.step = 8; int prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 4; descr.window = 4; descr.step = 4; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 4; descr.window = 4; descr.step = 4; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
E então passamos para o Discriminador. É importante dizer que, neste caso, o Discriminador consistirá em 2 modelos. Um modelo, ao qual mantivemos o nome Discriminador, recebe na entrada 2 estados consecutivos do ambiente e retorna uma representação latente da transição. Note, como mencionado anteriormente, o modelo codifica especificamente a transição no ambiente sem considerar a habilidade usada e a ação realizada. Aqui, como dados de entrada, usamos os resultados do codificador para os 2 estados subsequentes.
Na saída do modelo, usamos SoftMax para normalizar os resultados obtidos.
//--- Descriminator descriminator.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NSkills; descr.optimization = ADAM; descr.activation = SIGMOID; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = 1; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
A segunda parte do Discriminador é um modelo para a representação latente da habilidade usada. A função do modelo implica que ele recebe apenas a habilidade usada na entrada. E retorna sua representação compactada em forma de tensor, semelhante à representação latente da transição (resultado do modelo Discriminador).
Os resultados desses dois modelos serão os dados para o controle interno contrastivo. Consequentemente, também usamos SoftMax na saída do modelo.
//--- Skills project skill_project.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = SIGMOID; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = 1; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- return true; }
Embora os 2 últimos modelos usem dados de entrada diferentes. Eles têm funções bastante semelhantes. Por isso, usamos soluções arquitetônicas um tanto semelhantes para ambos.
Como se pode ver, concluímos o método de descrição das soluções arquitetônicas dos modelos usados. Mas não inclui a descrição da arquitetura do planejador. Isso porque, na fase de treinamento de habilidades, não usamos o planejador. Adiantando um pouco, direi que na primeira fase de treinamento, geraremos aleatoriamente a representação das habilidades. Isso permitirá que nosso Ator aprenda melhor diferentes políticas de comportamento. Mas usaremos o planejador para treinar a política de uso de habilidades para alcançar o objetivo desejado. Portanto, o modelo do planejador foi transferido para um método separado, SchedulerDescriptions.
bool SchedulerDescriptions(CArrayObj *scheduler) { //--- Scheduller if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } scheduler.Clear(); //--- CLayerDescription *descr = NULL; //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.window = prev_count; descr.optimization = ADAM; descr.activation = SIGMOID; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
Com isso, concluímos o trabalho de descrever as soluções arquitetônicas dos modelos utilizados e passamos para a estruturação do algoritmo de seu funcionamento.
2.2 Expert Advisor para coleta de amostra de treinamento
Como antes, no treinamento do modelo, usaremos vários programas. O primeiro Expert Advisor "...\CIC\Research.mq5" será usado para coletar a amostra de treinamento. O próprio processo de coleta de dados não mudou. Só que para formar a ação do Ator, precisamos usar vários modelos consecutivamente. Mas primeiro, precisamos criá-los no método de inicialização do Expert Advisor OnInit.
No corpo deste método, como de costume, inicializamos todos os indicadores necessários.
int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
E então carregamos os modelos do Codificador e do Ator. Se não houver modelos pré-treinados, geraremos aleatórios.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *encoder = new CArrayObj(); CArrayObj *descr = new CArrayObj(); if(!CreateDescriptions(encoder,actor, descr,descr,descr,descr)) { delete encoder; delete actor; delete descr; return INIT_FAILED; } if(!Encoder.Create(encoder) || !Actor.Create(actor)) { delete encoder; delete actor; delete descr; return INIT_FAILED; } delete encoder; delete actor; delete descr; //--- }
Mas a situação com o Planejador é um pouco diferente. Afinal, precisaremos coletar dados da amostra de treinamento para ambas as fases de treinamento. E o uso do modelo do Planejador na primeira fase pode limitar um pouco o espaço de ação do Ator. No entanto, o uso de um tensor de habilidade gerado aleatoriamente é em muitos aspectos semelhante ao uso do Planejador com parâmetros aleatórios. Isso é muito mais rápido do que a propagação do modelo.
Ao mesmo tempo, na segunda fase de treinamento, é preferível usar o Planejador pré-treinado. Pois isso permitirá não apenas coletar dados na área de ações de sua política, mas também avaliar os resultados de seu treinamento.
Portanto, tentamos carregar o modelo do Planejador pré-treinado, e o resultado da operação é registrado na bandeira do uso de um vetor de habilidades aleatório.
bRandomSkills = (!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true));
Em seguida, transferimos todos os modelos usados para um único contexto OpenCL.
COpenCLMy *opcl = Encoder.GetOpenCL();
Actor.SetOpenCL(opcl);
if(!bRandomSkills)
Scheduler.SetOpenCL(opcl);
Verificamos a conformidade dos modelos.
Actor.getResults(ActorResult); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- vector<float> EncoderResults; Actor.GetLayerOutput(0,Result); Encoder.getResults(EncoderResults); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Actor doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } //--- if(!bRandomSkills) { Scheduler.GetLayerOutput(0,Result); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Scheduler doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } }
E inicializamos as variáveis.
//--- PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
A coleta de dados é realizada no método OnTick. Como antes, todas as operações são realizadas apenas no momento da abertura de um novo bar.
void OnTick() { //--- if(!IsNewBar()) return;
Aqui, primeiro coletamos dados históricos e informações sobre o estado da conta. Este processo foi transferido sem alterações dos algoritmos previamente considerados, e não vamos nos deter nisso agora. Mas vamos imediatamente proceder com a estruturação da propagação dos modelos. E o primeiro passo é a chamada do Codificador.
//--- Encoder if(!Encoder.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
Depois, verificamos a bandeira de uso do vetor de habilidades aleatórias. Se conseguimos carregar o modelo do Planejador anteriormente, então realizamos a chamada sequencial do Planejador e do Ator.
//--- Scheduler & Actor if(!bRandomSkills) { if(!Scheduler.feedForward((CNet *)GetPointer(Encoder),-1,NULL,-1) || !Actor.feedForward(GetPointer(Encoder),-1,GetPointer(Scheduler),-1)) return; }
Caso contrário, primeiro formamos um tensor de habilidades aleatórias. Não esquecemos de normalizá-lo com a função SoftMax, pois são vetores de probabilidade de uso de habilidades individuais. E só então realizamos a chamada do Ator.
else { vector<float> skills = vector<float>::Zeros(NSkills); for(int i = 0; i < NSkills; i++) skills[i] = (float)((double)MathRand() / 32767.0); skills.Activation(skills,AF_SOFTMAX); bSkills.AssignArray(skills); if(bSkills.GetIndex() >= 0 && !bSkills.BufferWrite()) return; if(!Actor.feedForward(GetPointer(Encoder),-1,(CBufferFloat *)GetPointer(bSkills))) return; }
Como resultado da propagação dos modelos, obtemos um certo tensor de ações na saída do Ator. Mas aqui é importante notar que a renúncia à política estocástica leva a associações rígidas do Ator entre os dados de entrada e a ação escolhida. E para os propósitos de explorar o ambiente, adicionaremos um pequeno ruído ao vetor de ações obtido.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- for(ulong i = 0; i < temp.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.1f; temp[i] += rnd; } temp.Clip(0.0f,1.0f); ActorResult = temp;
Só após estas operações realizamos as ações do Ator e salvamos o resultado obtido no buffer de reprodução de experiência.
Aqui vale ressaltar que mantemos o conjunto de dados anterior sem o identificador de habilidade. Pois, para fins de treinamento dos modelos a partir do ambiente, precisamos de transições e recompensas. E diferentes vetores de identificação de habilidades serão gerados durante o treinamento. Isso nos permitirá expandir significativamente a amostra de treinamento sem interação adicional com o ambiente.
O código subsequente do método, como o do Expert Advisor como um todo, permaneceu inalterado e foi transferido dos Expert Advisors anteriormente considerados. E não vamos nos aprofundar nele agora. Você pode se familiarizar com ele no anexo.
2.3 Treinamento de habilidades
A primeira fase do treinamento dos modelos — o aprendizado de habilidades é programado no Expert Advisor "...\CIC\Pretrain.mq5". Em muitos aspectos, ele é construído de forma semelhante aos Expert Advisors "Study.mq5" previamente considerados, mas levando em conta a especificidade do algoritmo Contrastive Intrinsic Control.
O algoritmo do método de inicialização do EA OnInit não difere dos métodos com o mesmo nome dos EAs parecidos analisados anteriormente. Vamos nos concentrar apenas na lista de modelos utilizados. Aqui vemos o Codificador, o Ator, 2 Críticos, um Codificador convolucional aleatório e modelos de Discriminador. Mas o alvo é apenas um modelo do Codificador.
Duas modelos do Codificador são necessárias para codificar os estados analisados e subsequentes do ambiente, que são usados pelo Discriminador.
No entanto, não usamos os modelos-alvo do Ator e dos Críticos, já que nesta fase estamos ensinando o Ator a realizar ações distinguíveis sob a influência de uma habilidade específica em um estado específico do ambiente. Não buscamos acumular recompensa interna para habilidades diferentes. Maximizamos isso em cada momento específico.
int OnInit() { //--- ....... ....... //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Descriminator.Load(FileName + "Des.nnw", temp, temp, temp, dtStudied, true) || !SkillProject.Load(FileName + "Skp.nnw", temp, temp, temp, dtStudied, true) || !Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true) || !TargetEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *encoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *descrim = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); CArrayObj *skill_poject = new CArrayObj(); if(!CreateDescriptions(encoder,actor, critic, convolution,descrim,skill_poject)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } if(!Encoder.Create(encoder) || !Actor.Create(actor) || !Critic1.Create(critic) || !Critic2.Create(critic) || !Descriminator.Create(descrim) || !SkillProject.Create(skill_poject) || !Convolution.Create(convolution)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } if(!TargetEncoder.Create(encoder)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; //--- TargetEncoder.WeightsUpdate(GetPointer(Encoder), 1.0f); } //--- OpenCL = Actor.GetOpenCL(); Encoder.SetOpenCL(OpenCL); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetEncoder.SetOpenCL(OpenCL); Descriminator.SetOpenCL(OpenCL); SkillProject.SetOpenCL(OpenCL); Convolution.SetOpenCL(OpenCL); //--- ........ ........ //--- return(INIT_SUCCEEDED); }
O treinamento direto dos modelos é realizado no método `Train`.
De forma análoga ao artigo anterior, no início do método codificamos todas as transições entre estados presentes no buffer de reprodução de experiência. O algoritmo de construção do processo é idêntico. Mas há uma especificidade. Codificamos as transições. Por isso, na entrada para o codificador aleatório, fornecemos um tensor de 2 estados consecutivos sem considerar as ações realizadas.
E segundo, nesta fase, usamos apenas a recompensa interna. Isso significa que excluímos o processamento de recompensas externas do ambiente.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- int total_states = Buffer[0].Total - 1; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total - 1; vector<float> temp; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total - 1; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- State.AddArray(Buffer[tr].States[st + 1].state); State.Add((Buffer[tr].States[st + 1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[1] / PrevBalance); State.Add((Buffer[tr].States[st + 1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st + 1].account[2]); State.Add(Buffer[tr].States[st + 1].account[3]); State.Add(Buffer[tr].States[st + 1].account[4] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[5] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[6] / PrevBalance); x = (double)Buffer[tr].States[st + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } } if(state != total_states) { state_embedding.Reshape(state,state_embedding.Cols()); total_states = state; }
Em seguida, declaramos variáveis locais.
vector<float> reward = vector<float>::Zeros(NRewards); vector<float> rewards1 = reward, rewards2 = reward; int bar = (HistoryBars - 1) * BarDescr;
E fazemos o ciclo de treinamento dos modelos. No corpo do ciclo, como antes, selecionamos aleatoriamente uma trajetória e um estado analisado do buffer de reprodução de experiência.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
Com base nos dados do estado amostrado, formamos tensores de dados de entrada para nossos modelos.
//--- State State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Aqui também formamos um tensor aleatório da habilidade usada.
//--- Skills vector<float> skills = vector<float>::Zeros(NSkills); for(int sk = 0; sk < NSkills; sk++) skills[sk] = (float)((double)MathRand() / 32767.0); skills.Activation(skills,AF_SOFTMAX); Skills.AssignArray(skills); if(Skills.GetIndex() >= 0 && !Skills.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Os dados de entrada formados são primeiramente fornecidos ao nosso Codificador.
//--- Encoder State if(!Encoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
E então realizamos a propagação do Ator.
//--- Actor if(!Actor.feedForward(GetPointer(Encoder), -1, GetPointer(Skills))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Com base no tensor de ações obtido, formamos o estado subsequente previsto. Com os dados históricos de movimento de preços, não temos problemas. Simplesmente os pegamos do buffer de reprodução de experiência. Mas para calcular o estado previsto da conta, criaremos o método `ForecastAccount`, cujo algoritmo será apresentado um pouco mais tarde.
//--- Next State TargetState.AssignArray(Buffer[tr].States[i + 1].state); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); Actor.getResults(Result); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,Result,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetAccount.AssignArray(forecast); if(TargetAccount.GetIndex() >= 0 && !TargetAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
E então realizamos a propagação do Codificador alvo para obter a representação latente do estado subsequente.
if(!TargetEncoder.feedForward(GetPointer(TargetState), 1, false, GetPointer(TargetAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Neste estágio, temos a representação latente de 2 estados subsequentes do ambiente e podemos obter o vetor de representação da transição. E imediatamente obtemos o vetor de representação da habilidade.
//--- Descriminator if(!Descriminator.feedForward(GetPointer(Encoder),-1,GetPointer(TargetEncoder),-1) || !SkillProject.feedForward(GetPointer(Skills),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
O resultado da comparação contrastante dos dois vetores obtidos serve como a primeira parte da nossa recompensa interna. A maximização dessa recompensa estimula o Ator a aprender habilidades facilmente distintas e previsíveis, que podem ser facilmente associadas a uma transição de estado específica no ambiente.
Descriminator.getResults(rewards1); SkillProject.getResults(rewards2); float norm1 = rewards1.Norm(VECTOR_NORM_P,2); float norm2 = rewards2.Norm(VECTOR_NORM_P,2); reward[0] = (rewards1 / norm1).Dot(rewards2 / norm2);
E imediatamente atualizamos os parâmetros dos modelos do Discriminador. Sem complicar desnecessariamente o algoritmo, simplesmente treinamos o modelo do Discriminador para aproximar a representação condensada da habilidade. E o modelo de projeção da habilidade para a aproximação da representação condensada da transição.
Simultaneamente, treinamos o Codificador para tal representação do estado do ambiente que poderia ser identificada com alguma habilidade. O Codificador é treinado com base nos gradientes de erro obtidos do Discriminador. De maneira similar ao Ator e ao Crítico no espaço contínuo de ações.
Result.AssignArray(rewards2); if(!Descriminator.backProp(Result,GetPointer(TargetEncoder)) || !Encoder.backPropGradient(GetPointer(Account),GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.AssignArray(rewards1); if(!SkillProject.backProp(Result,(CNet *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
A segunda componente da nossa função de recompensa interna é a penalidade pela ausência de posições abertas no momento atual. A informação sobre a presença de negociações é tirada do estado previsto da conta.
if(forecast[3] == 0.0f && forecast[4] == 0.f) reward[0] -= Buffer[tr].States[i + 1].state[bar + 6] / PrevBalance;
E a terceira componente da nossa recompensa interna é a entropia da transição, o que estimula o Ator a explorar comportamentos diversos e adquirir um grande número de habilidades. Para obter a entropia da transição, primeiro obtemos a representação condensada da transição no espaço do codificador aleatório e determinamos os k vizinhos mais próximos no método `KNNReward`.
State.AddArray(GetPointer(Account)); State.AddArray(GetPointer(TargetState)); State.AddArray(GetPointer(TargetAccount)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(rewards1); reward[0] += KNNReward(7,rewards1,state_embedding);
O resultado obtido da entropia da transição é adicionado à nossa recompensa interna.
Agora, tendo formado o valor completo da nossa recompensa interna complexa, podemos prosseguir para o treinamento dos Críticos e do Ator. A propagação do Ator já foi realizada anteriormente. Agora chamamos a propagação de ambos os críticos.
Result.AssignArray(reward); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
O Ator será treinado usando o crítico com o menor erro. Verificamos a média móvel do erro dos Críticos. E primeiro realizamos a retropropagação do Crítico com o menor erro. Depois, segue-se a retropropagação do Ator. E finaliza com a retropropagação do Crítico com o maior erro médio de previsão do custo das ações do Ator.
if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) { if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Skills), GetPointer(Gradient), -1) || !Critic2.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } } else { if(!Critic2.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Skills), GetPointer(Gradient), -1) || !Critic1.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Em seguida, atualizamos os parâmetros do Codificador alvo e informamos o usuário sobre o estado do treinamento dos modelos.
//--- Update Target Nets TargetEncoder.WeightsUpdate(GetPointer(Encoder), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Após a conclusão de todas as iterações do ciclo de treinamento, limpamos o campo de comentários do gráfico e iniciamos o fechamento do programa.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Para compor uma visão geral do treinamento, consideraremos também o método de formação do estado previsto da conta `ForecastAccount`. O método recebe como parâmetros um ponteiro para o estado anterior da conta, o tensor de ações, o valor do lucro em 1 lote de uma posição longa para a próxima barra e o carimbo de tempo da próxima barra. O tamanho do lucro em 1 lote é determinado antes da chamada do método com base na informação da vela subsequente. Essa operação é possível apenas no treinamento offline com base em dados históricos de movimento de preço.
No corpo do método, primeiro realizamos um pouco de trabalho preparatório. Aqui declaramos variáveis locais e carregamos algumas informações sobre o instrumento. É importante notar que, como não especificamos o instrumento em nenhum lugar nos dados de treinamento, usaremos os dados do instrumento do gráfico. Assim, para um processo de treinamento correto, é necessário executar o Expert Advisor de treinamento no gráfico do instrumento de interesse.
vector<float> ForecastAccount(float &prev_account[], CBufferFloat *actions,double prof_1l,float time_label) { vector<float> account; vector<float> act; double min_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); double step_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_STEP); double stops = MathMax(SymbolInfoInteger(_Symbol,SYMBOL_TRADE_STOPS_LEVEL), 1) * Point(); double margin_buy,margin_sell; if(!OrderCalcMargin(ORDER_TYPE_BUY,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_ASK),margin_buy) || !OrderCalcMargin(ORDER_TYPE_SELL,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_BID),margin_sell)) return vector<float>::Zeros(prev_account.Size());
Para conveniência, transferimos os dados recebidos nos parâmetros para vetores.
actions.GetData(act); account.Assign(prev_account);
Após isso, ajustamos as ações do agente para abrir posições apenas em uma direção, baseando-nos na diferença dos volumes declarados. E imediatamente verificamos se há fundos suficientes para realizar as operações. Em caso de falta de recursos na conta, zeramos o volume da negociação.
if(act[0] >= act[3]) { act[0] -= act[3]; act[3] = 0; if(act[0]*margin_buy >= MathMin(account[0],account[1])) act[0] = 0; } else { act[3] -= act[0]; act[0] = 0; if(act[3]*margin_sell >= MathMin(account[0],account[1])) act[3] = 0; }
Seguem-se as operações de decodificação das ações recebidas. O processo é construído de forma análoga ao algoritmo de realização de ações no Expert Advisor de coleta de dados de treinamento. Só que, em vez de realizar ações, modificamos os elementos correspondentes da descrição do estado da conta. Primeiro, consideramos os elementos de uma posição longa. Se o volume da negociação é igual a "0" ou os níveis de stops são menores que a margem mínima do instrumento, então esse conjunto de parâmetros indica o fechamento da negociação. Obviamente, se tal negociação estivesse aberta. Zeramos o tamanho da posição atual nessa direção. E somamos o lucro/prejuízo acumulado ao saldo atual.
//--- buy control if(act[0] < min_lot || (act[1] * MaxTP * Point()) <= stops || (act[2] * MaxSL * Point()) <= stops) { account[0] += account[4]; account[2] = 0; account[4] = 0; }
No caso de abrir ou manter uma posição, normalizamos o volume da negociação. E comparamos o volume obtido com o aberto anteriormente. Se a posição fosse maior que a proposta pelo Ator, então dividimos o lucro/prejuízo acumulado proporcionalmente entre os volumes proposto e a ser fechado. O lucro/prejuízo do volume a ser fechado é adicionado ao saldo. A diferença é deixada no campo de lucro acumulado. E o volume da posição é alterado para o proposto pelo Ator. Adicionalmente, ao volume acumulado, adicionamos o lucro/prejuízo da transição para o próximo estado do ambiente.
else { double buy_lot = min_lot + MathRound((double)(act[0] - min_lot) / step_lot) * step_lot; if(account[2] > buy_lot) { float koef = (float)buy_lot / account[2]; account[0] += account[4] * (1 - koef); account[4] *= koef; } account[2] = (float)buy_lot; account[4] += float(buy_lot * prof_1l); }
As operações são repetidas para posições curtas.
//--- sell control if(act[3] < min_lot || (act[4] * MaxTP * Point()) <= stops || (act[5] * MaxSL * Point()) <= stops) { account[0] += account[5]; account[3] = 0; account[5] = 0; } else { double sell_lot = min_lot + MathRound((double)(act[3] - min_lot) / step_lot) * step_lot; if(account[3] > sell_lot) { float koef = float(sell_lot / account[3]); account[0] += account[5] * (1 - koef); account[5] *= koef; } account[3] = float(sell_lot); account[5] -= float(sell_lot * prof_1l); }
O lucro acumulado de posições longas e curtas constitui o lucro acumulado da conta. E a soma do lucro acumulado mais o saldo dá o indicador de Equity.
account[6] = account[4] + account[5]; account[1] = account[0] + account[6];
A partir dos valores obtidos, formamos o vetor de descrição do estado da conta e o retornamos ao programa chamador.
vector<float> result = vector<float>::Zeros(AccountDescr); result[0] = (account[0] - prev_account[0]) / prev_account[0]; result[1] = account[1] / prev_account[0]; result[2] = (account[1] - prev_account[1]) / prev_account[1]; result[3] = account[2]; result[4] = account[3]; result[5] = account[4] / prev_account[0]; result[6] = account[5] / prev_account[0]; result[7] = account[6] / prev_account[0]; double x = (double)time_label / (double)(D'2024.01.01' - D'2023.01.01'); result[8] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_MN1); result[9] = (float)MathCos(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_W1); result[10] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_D1); result[11] = (float)MathSin(2.0 * M_PI * x); //--- return result return result; }
Após a conclusão do treinamento, todos os modelos são salvos no método de desinicialização do Expert Advisor `OnDeinit`.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- TargetEncoder.WeightsUpdate(GetPointer(Encoder), Tau); Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetEncoder.Save(FileName + "Enc.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); Critic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); Critic2.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Convolution.Save(FileName + "CNN.nnw", 0, 0, 0, TimeCurrent(), true); Descriminator.Save(FileName + "Des.nnw", 0, 0, 0, TimeCurrent(), true); SkillProject.Save(FileName + "Skp.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
Com isso, concluímos o trabalho no Expert Advisor de treinamento preliminar de habilidades do Ator sem recompensa externa. E com o código completo deste Expert Advisor, pode-se familiarizar no anexo. Você também encontrará o código completo de todos os programas usados no artigo.
2.4 EA de Ajuste Fino
O treinamento de modelos é concluído com o treinamento do Planejador, que gera um vetor de habilidades usadas e, assim, controla as ações do Ator.
A política do Planejador é treinada para maximizar a recompensa externa. E fazemos o treinamento no EA "...\\CIC\\Finetune.mq5". O EA é construído de forma semelhante ao anterior, mas há nuances. Para o funcionamento do EA, são necessários modelos previamente treinados do Codificador, do Ator e dos Críticos. Também usaremos cópias-alvo desses modelos.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true) || !TargetEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !TargetActor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { Print("No pretrained models found"); return INIT_FAILED; }
Além disso, carregamos o modelo de um codificador convolucional aleatório. Mas não carregamos os modelos do Discriminador. Nesta etapa, usamos apenas a recompensa externa. As políticas comportamentais do Ator foram aprendidas na etapa anterior. Agora, precisamos aprender a política de alto nível do Planejador.
Desse modo, após carregar os modelos pré-treinados, tentamos carregar o modelo do Planejador. E se tal modelo não for encontrado, desta vez criamos um novo modelo e o inicializamos com parâmetros aleatórios.
if(!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *descr = new CArrayObj(); if(!SchedulerDescriptions(descr) || !Scheduler.Create(descr)) { delete descr; return INIT_FAILED; } delete descr; }
Em seguida, movemos todos os modelos para um único contexto do OpenCL e desativamos o modo de treinamento do Ator e do Codificador.
OpenCL = Actor.GetOpenCL(); Encoder.SetOpenCL(OpenCL); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetEncoder.SetOpenCL(OpenCL); TargetActor.SetOpenCL(OpenCL); TargetCritic1.SetOpenCL(OpenCL); TargetCritic2.SetOpenCL(OpenCL); Scheduler.SetOpenCL(OpenCL); Convolution.SetOpenCL(OpenCL); //--- Actor.TrainMode(false); Encoder.TrainMode(false);
Ao concluir o método de inicialização, verificamos a conformidade da arquitetura dos modelos e geramos um evento de início do treinamento.
vector<float> ActorResult; Actor.getResults(ActorResult); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- vector<float> EncoderResults; Actor.GetLayerOutput(0,Result); Encoder.getResults(EncoderResults); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Actor doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } //--- Actor.GetLayerOutput(LatentLayer, Result); int latent_state = Result.Total(); Critic1.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic doesn't match latent state Actor (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; } //--- Gradient.BufferInit(AccountDescr, 0); //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
No método de desinicialização do EA, salvamos apenas os modelos dos Críticos e do Planejador.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); TargetCritic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic2.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Scheduler.Save(FileName + "Sch.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
Acho que ninguém questiona a necessidade de treinar o Planejador. Mas a questão da atualização dos parâmetros dos Críticos e da fixação dos parâmetros do Ator provavelmente merece explicação. Na etapa anterior, treinamos as políticas do Ator com base na habilidade usada. E nesta etapa, aprendemos a controlar as habilidades. Por isso, fixamos os parâmetros do Ator e treinamos o Planejador para controlá-lo.
Outra questão é sobre os Críticos. O fato é que, na etapa de treinamento das habilidades, usamos apenas a recompensa interna, que foi direcionada para aprender várias habilidades do Ator. E, claro, os Críticos estabeleceram dependências entre as ações do Ator e seu impacto na recompensa interna. Mas nesta etapa, usamos a recompensa externa. E é provável que as ações do Ator tenham um impacto completamente diferente sobre ela. Portanto, precisamos re-treinar os Críticos sob novas circunstâncias.
Aqui, também é importante dizer que, se antes usávamos nossas suposições sobre o impacto da habilidade escolhida no resultado, agora passaremos o gradiente de erro da recompensa do Crítico através do Ator até o Planejador. Mas vamos voltar ao nosso EA e olhar para o algoritmo de desenvolvimento do processo.
O treinamento dos modelos ainda é realizado no método Train. Como no EA de treinamento de habilidades discutido anteriormente, no início do método, realizamos a codificação das transições. Só que desta vez adicionamos o carregamento das recompensas externas do ambiente. E note que pegamos a recompensa apenas para uma transição específica. A recompensa acumulada será prevista usando os modelos-alvo.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); float loss = 0; //--- int total_states = Buffer[0].Total - 1; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total - 1; vector<float> temp; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states,NRewards); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total - 1; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- State.AddArray(Buffer[tr].States[st + 1].state); State.Add((Buffer[tr].States[st + 1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[1] / PrevBalance); State.Add((Buffer[tr].States[st + 1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st + 1].account[2]); State.Add(Buffer[tr].States[st + 1].account[3]); State.Add(Buffer[tr].States[st + 1].account[4] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[5] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[6] / PrevBalance); x = (double)Buffer[tr].States[st + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); temp.Assign(Buffer[tr].States[st].rewards); for(ulong r = 0; r < temp.Size(); r++) temp[r] -= Buffer[tr].States[st + 1].rewards[r] * DiscFactor; rewards.Row(temp,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } } if(state != total_states) { state_embedding.Reshape(state,state_embedding.Cols()); rewards.Reshape(state,NRewards); total_states = state; }
Em seguida, executamos um ciclo de treinamento dos modelos. No corpo do ciclo, amostramos o estado do buffer de replay de experiência.
vector<float> reward, rewards1, rewards2, target_reward; int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; } reward = vector<float>::Zeros(NRewards); rewards1 = reward; rewards2 = reward; target_reward = reward;
E preparamos os buffers de dados de entrada.
//--- State State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; if(PrevBalance == 0.0f || PrevEquity == 0.0f) continue; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Após a formação do conjunto completo de dados de entrada do estado selecionado, realizamos a propagação do Codificador.
//--- Encoder State if(!Encoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Após o Codificador, vem a propagação do Planejador, que avalia a representação latente do estado do ambiente e gera um vetor de habilidades para o Ator.
//--- Skills if(!Scheduler.feedForward(GetPointer(Encoder), -1, NULL,-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
O Ator, por sua vez, utiliza a habilidade indicada pelo Planejador e analisa a representação latente do estado do ambiente do Codificador. Com o conjunto total de dados de entrada, o Ator gera um vetor de ações.
//--- Actor if(!Actor.feedForward(GetPointer(Encoder), -1, GetPointer(Scheduler),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Usamos o vetor de ações obtido para prever o próximo estado do ambiente.
//--- Next State TargetState.AssignArray(Buffer[tr].States[i + 1].state); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); Actor.getResults(Result); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,Result,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetAccount.AssignArray(forecast); if(TargetAccount.GetIndex() >= 0 && !TargetAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
E repetimos as ações, mas já para o estado subsequente com os modelos-alvo. Dessa cadeia, excluímos o Planejador, pois supomos o uso da mesma habilidade.
if(!TargetEncoder.feedForward(GetPointer(TargetState), 1, false, GetPointer(TargetAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- Target if(!TargetActor.feedForward(GetPointer(TargetEncoder), -1, GetPointer(Scheduler),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
No entanto, para avaliar a política do Ator, precisamos de uma avaliação de suas ações pelo Crítico. E aqui usaremos a menor avaliação como previsão da recompensa futura.
//--- if(!TargetCritic1.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor)) || !TargetCritic2.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1; else target_reward = rewards2; target_reward *= DiscFactor;
A avaliação da ação atual será feita com base nos k vizinhos mais próximos da transição prevista. Para isso, usaremos um Codificador aleatório.
State.AddArray(GetPointer(TargetState)); State.AddArray(GetPointer(TargetAccount)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(rewards1); reward[0] += KNNReward(7,rewards1,state_embedding,rewards); reward += target_reward; Result.AssignArray(reward);
Combinamos a recompensa atual e prevista. Agora temos um valor-alvo para o treinamento dos modelos. Resta escolher o modelo do Crítico para atualizar os parâmetros do Planejador. Realizamos a propagação de ambos os Críticos e selecionamos a menor avaliação da ação escolhida pelo Ator.
if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic1.getResults(rewards1); Critic2.getResults(rewards2);
Como no EA anterior, realizamos a retropropagação do Crítico selecionado, do Ator, do Planejador. E por último realizamos a retropropagação do Crítico com a maior avaliação das ações do Ator.
if(rewards1.Sum() <= rewards2.Sum()) { loss = (loss * MathMin(iter,999) + (reward - rewards1).Sum()) / MathMin(iter + 1,1000); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Scheduler),-1,-1) || !Scheduler.backPropGradient() || !Critic2.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } } else { loss = (loss * MathMin(iter,999) + (reward - rewards2).Sum()) / MathMin(iter + 1,1000); if(!Critic2.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Scheduler),-1,-1) || !Scheduler.backPropGradient() || !Critic1.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Ao concluir as iterações do ciclo de treinamento, resta-nos atualizar os modelos-alvo dos Críticos e informar o usuário sobre o progresso do treinamento dos modelos.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), loss); Comment(str); ticks = GetTickCount(); } }
Após concluir todas as iterações do ciclo de treinamento dos modelos, limpamos o campo de comentários do gráfico e concluímos o trabalho do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", loss); ExpertRemove(); //--- }
Com isso, concluímos a revisão dos programas de implementação do algoritmo apresentado. Ainda não examinamos o EA de teste dos modelos treinados. Alterações semelhantes às do EA de coleta de amostra de treinamento foram feitas nele. Só que não adicionamos ruído aleatório ao vetor de ações, para avaliar a qualidade real do trabalho dos modelos treinados. Com o código completo de todos os programas usados no artigo, você pode se familiarizar independentemente no anexo.
3. Testando
O treinamento e o teste dos modelos foram realizados com dados históricos dos primeiros 5 meses de 2023. Instrumento EURUSD, timeframe H1. Como sempre, os parâmetros de todos os indicadores foram usados por padrão. É importante dizer imediatamente que o treinamento dos modelos é bastante longo. Os autores do método sugerem realizar a primeira etapa de aprendizado das habilidades por cerca de 2 milhões de iterações. Claro, o número de iterações pode ser aumentado para ambientes mais complexos. No treinamento de meu modelo, percorri este caminho em várias tentativas com coleta adicional de dados de treinamento.
Após o aprendizado das habilidades, segue-se a etapa de ajuste fino e treinamento do Planejador. Esta etapa também conta com pelo menos 100 mil iterações. Também sugiro realizar esta etapa em várias tentativas. Primeiro, inicializamos um modelo aleatório do Planejador e o treinamos em um amplo conjunto de dados. Após a primeira corrida do treinamento do Planejador, coletamos conjuntos de treinamento adicionais que incluirão exemplos da interação da política do Planejador com o ambiente. Isso permitirá ajustar sua política para melhor.
No treinamento, consegui treinar um modelo capaz de gerar lucro. No gráfico de resultados do teste apresentado, vemos uma clara tendência de crescimento da linha de saldo. Ao mesmo tempo, algumas áreas de redução de patrimônio me preocupam, o que pode indicar a necessidade de treinamento adicional do modelo. Sabemos que os mercados financeiros são ambientes bastante estocásticos e complexos. E, naturalmente, períodos de treinamento mais longos são necessários para alcançar os resultados desejados.


Conclusão
Neste artigo, nos familiarizamos com um método promissor na área de aprendizado por reforço hierárquico - "Controle Interno Contrastante" (CIC). Este método pertence à família de algoritmos baseados em recompensas internas auto-supervisionadas. Baseado nos princípios do algoritmo DIAYN, visa melhorar a extração de habilidades hierárquicas do Agente através da introdução de aprendizado contrastante.
Uma das principais características do CIC é sua capacidade de aprender habilidades diversas em ambientes complexos, onde o número de opções comportamentais potenciais pode ser bastante grande. Esta propriedade é particularmente útil na área de solução de problemas com espaço de ações contínuo. O uso do aprendizado contrastante permite orientar o Agente de forma que ele possa não apenas treinar eficazmente em vários cenários, mas também extrair conhecimentos valiosos desses cenários.
Na parte prática do nosso artigo, implementamos o algoritmo usando MQL5. Realizamos o treinamento e teste do modelo em dados históricos reais. Os resultados obtidos permitem falar sobre a eficácia potencial do método. No entanto, o estudo de um grande número de habilidades requer custos de treinamento comparáveis para o Agente.
Referências
- CIC: Contrastive Intrinsic Control for Unsupervised Skill Discovery
- Representation Learning with Contrastive Predictive Coding
- Redes neurais de maneira fácil (Parte 43): dominando habilidades sem função de recompensa
- Redes neurais de maneira fácil (Parte 44): explorando habilidades de forma dinâmica
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA para coleta de exemplos |
| 2 | Pretrain.mq5 | EA | EA para treinamento de habilidades do Ator |
| 3 | Finetune.mq5 | EA | EA para ajuste fino e treinamento do Planejador |
| 4 | Test.mq5 | EA | EA para testar o modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13212
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
A captura de tela do artigo mostra apenas posições curtas (venda).
Como posso fazer com que ela funcione nos dois sentidos? O Expert Advisor parou de aprender. O Pretrain e o Finetune saem do gráfico após a incorporação. Infelizmente. Devo começar tudo de novo?
O Expert Advisor parou de aprender. O Pretrain e o Finetune estão saindo do gráfico após a incorporação.
Quais são as mensagens no registro?
Quais são as mensagens de registro?
O Smoke voltou à vida. Notei uma coisa estranha: depois de passar a pesquisa no testador, o computador trava por um tempo. Provavelmente é por isso que eles estavam travando. Vamos continuar aprendendo.
O Smokehouse está ativo. Notei uma coisa estranha: depois de passar a pesquisa no testador, o computador trava por um tempo. Talvez seja por isso que eles voaram. Continuamos aprendendo.
Depois de passar na Pesquisa, o banco de dados de exemplos é salvo. E se ele for grande o suficiente, você poderá sentir que o computador fica mais lento ao processar o banco de dados e gravá-lo no disco. Naturalmente, se houver erros ao salvar o banco de dados, o Pretrain e o Finetune não conseguirão lê-lo e travarão.