Neuronale Netze leicht gemacht (Teil 55): Contrastive Intrinsic Control (CIC)

Einführung
In früheren Artikeln haben wir bereits die Vorteile der Verwendung hierarchischer Modelle erörtert. Wir haben Methoden für das Training von Modellen untersucht, die in der Lage sind, die individuellen Fähigkeiten des Agenten zu extrahieren und hervorzuheben. Die erworbenen Fähigkeiten können nützlich sein, um das Endziel der Aufgabe zu erreichen. Beispiele für solche Algorithmen sind DIAYN, DADS und EDL. Diese Algorithmen gehen auf unterschiedliche Weise an den Trainingsprozess heran, aber alle wurden für diskrete Aktionsraumprobleme verwendet. Heute werden wir über einen anderen Ansatz zur Untersuchung der Fähigkeiten des Agenten sprechen und seine Anwendung auf dem Gebiet der Lösung kontinuierlicher Aktionsraumprobleme betrachten.
1. Wichtigste CIC-Komponenten
Beim Verstärkungslernen werden Algorithmen für das Vorab-Training von Agenten mit selbstgesteuerten internen Belohnungen aktiv eingesetzt. Solche Algorithmen lassen sich in 3 Kategorien einteilen: solche, die auf Kompetenzen, Wissen und Daten basieren. Die Tests im Unsupervised Reinforcement Learning Benchmark zeigen, dass kompetenzbasierte Algorithmen den anderen Kategorien unterlegen sind.
Algorithmen, die Kompetenzen verwenden, streben danach, die gegenseitige Information zwischen beobachteten Zuständen und einem latenten Vektor von Fähigkeiten zu maximieren. Diese gegenseitige Information wird durch das Diskriminatormodell geschätzt. In der Regel wird ein Klassifikator oder ein Regressionsmodell als Diskriminator verwendet. Um bei Klassifizierungs- und Regressionsaufgaben Genauigkeit zu erreichen, ist jedoch eine große Menge an unterschiedlichen Trainingsdaten erforderlich. In einfachen Umgebungen, in denen die Zahl der möglichen Verhaltensweisen begrenzt ist, haben kompetenzbasierte Methoden ihre Effizienz unter Beweis gestellt. In Umgebungen mit vielen potenziellen Verhaltensoptionen ist ihre Wirksamkeit jedoch deutlich geringer.
Komplexe Umgebungen erfordern eine große Vielfalt an Fähigkeiten. Um sie zu bewältigen, brauchen wir einen Discriminator mit hoher Leistung. Der Widerspruch zwischen dieser Anforderung und den begrenzten Möglichkeiten der bestehenden Diskriminatoren führte zur Entwicklung der Methode Contrastive Intrinsic Control (CIC).
Contrastive Intrinsic Control ist ein neuer Ansatz zur kontrastiven Dichteschätzung, um die bedingte Entropie des Diskriminators zu approximieren. Die Methode behandelt Übergänge zwischen Zuständen und Fähigkeitsvektoren. Dies ermöglicht leistungsstarke Repräsentationslerntechniken von der visuellen Verarbeitung bis zur Erkennung von Fähigkeiten. Die vorgeschlagene Methode ermöglicht es, die Stabilität und Effizienz des Agententrainings in einer Vielzahl von Umgebungen zu erhöhen.
Der Algorithmus der kontrastiven intrinsischen Kontrolle beginnt mit dem Training des Agenten in der Umgebung unter Verwendung von Feedback und der Ermittlung von Trajektorien von Zuständen und Aktionen. Das Training der Repräsentation erfolgt dann mit Contrastive Predictive Coding (CPC), das den Agenten dazu motiviert, Schlüsselmerkmale aus Zuständen und Aktionen abzurufen. Es werden Darstellungen gebildet, die die Abhängigkeiten zwischen aufeinanderfolgenden Zuständen berücksichtigen.
Intrinsische Belohnungen spielen eine wichtige Rolle bei der Entscheidung, welche Verhaltensstrategien maximiert werden sollten. CIC maximiert die Entropie der Übergänge zwischen den Zuständen, was die Vielfalt des Agentenverhaltens fördert. Dies ermöglicht dem Agenten, eine Vielzahl von Verhaltensstrategien zu erforschen und zu entwickeln.
Nach der Generierung einer Vielzahl von Fähigkeiten und Strategien verwendet der CIC-Algorithmus den Discriminator, um die Repräsentationen der Fähigkeiten zu instanziieren. Der Discriminator soll dafür sorgen, dass die Zustände vorhersehbar und stabil sind. Auf diese Weise lernt der Agent, seine Fähigkeiten in vorhersehbaren Situationen „einzusetzen“.
Die Kombination aus intrinsisch motivierter Erkundung und dem Einsatz von Fähigkeiten für vorhersehbare Handlungen schafft einen ausgewogenen Ansatz für die Entwicklung vielfältiger und wirksamer Strategien.
Der Algorithmus der kontrastiven prädiktiven Kodierung ermutigt den Agenten, eine breite Palette von Verhaltensstrategien zu erkennen und zu erlernen, und gewährleistet gleichzeitig ein stabiles Lernen. Nachfolgend sehen Sie die Visualisierung des nutzerdefinierten Algorithmus.

Wir werden den Algorithmus bei der Implementierung noch genauer kennenlernen.
2. Implementierung mit MQL5
Bevor wir den Algorithmus der kontrastiven prädiktiven Kodierung mit MQL5 implementieren, sollten wir einige wichtige Punkte festlegen. Zunächst ist der Algorithmus für die Modellschulung in zwei große Stufen unterteilt:
- Fähigkeiten ohne externe Belohnung durch die Umgebung zu trainieren;
- Training einer Strategie zur Lösung einer bestimmten Aufgabe auf der Grundlage externer Belohnungen.
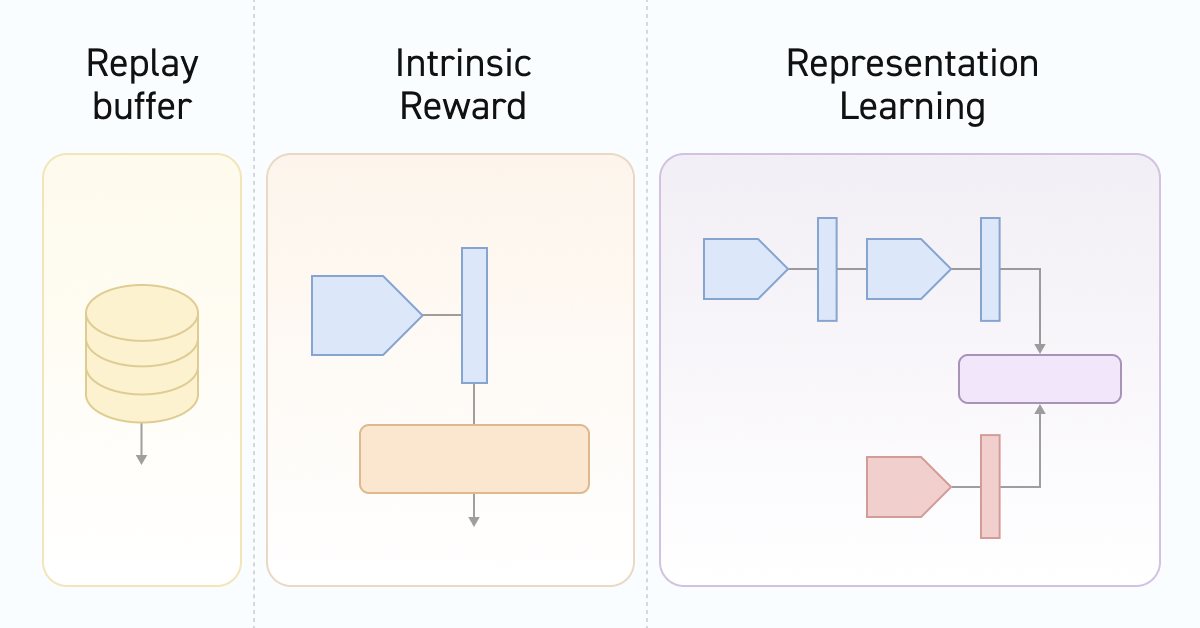
Zweitens lernt der Diskriminator während des Trainingsprozesses die Korrespondenz von Übergängen zwischen Zuständen und Fähigkeiten. Denken Sie daran, dass es sich um eine Zustandsänderung handelt und nicht um eine externe Belohnung für den Übergang zu einem neuen Zustand oder eine Handlung, die zu diesem Zustand geführt hat. Wenn wir Analogien zu den zuvor besprochenen Algorithmen ziehen, die mit denselben Daten arbeiteten, dann bestimmt DIAYN die Fähigkeit auf der Grundlage des ursprünglichen und des neuen Modellzustands. Im Gegensatz dazu sagt der Discriminator bei DADS den nächsten Zustand auf der Grundlage des Ausgangszustands und der Fähigkeiten voraus. Bei dieser Methode wird der Kontrastfehler zwischen dem Übergang (Anfangs- und Folgezustand) und der vom Agenten verwendeten Fähigkeit bestimmt. Gleichzeitig werden latente Repräsentationen von Zuständen und Fähigkeiten gebildet. Der Discriminator beeinflusst das Training des Zustandscodierers, der anschließend vom Agenten und dem Scheduler verwendet wird. Dies spiegelt sich in der Architektur der von uns verwendeten Modelle wider. Dies hat uns dazu veranlasst, den Umgebungszustandscodierer in ein separates Modell auszulagern.
2.1 Modellarchitektur
Wir nähern uns schrittweise der Methode CreateDescriptions zur Beschreibung der Architekturen der verwendeten Modelle. In den Methodenparametern sind die Zeiger auf die Architekturbeschreibungsarrays von sechs Modellen zu sehen. Ihr Zweck wird später beschrieben.
bool CreateDescriptions(CArrayObj *state_encoder, CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution, CArrayObj *descriminator, CArrayObj *skill_project ) { //--- CLayerDescription *descr; //--- if(!state_encoder) { state_encoder = new CArrayObj(); if(!state_encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } if(!skill_project) { skill_project = new CArrayObj(); if(!skill_project) return false; }
Zunächst haben wir ein Modell des Umgebungszustands-Encoders. Wir haben bereits über die Funktionalität dieses Modells gesprochen. Wie Sie wissen, besteht unser Umgebungszustand aus zwei Blöcken: historische Daten und Kontostatus. Diese beiden Tensoren werden dem Encodereingang zugeführt. Die Architektur dieses Modells erinnert an den Block zur Vorverarbeitung der Quelldaten, der zuvor in den Actor-Modellen verwendet wurde.
bool CreateDescriptions(CArrayObj *state_encoder, CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution, CArrayObj *descriminator, CArrayObj *skill_project ) { //--- CLayerDescription *descr; //--- if(!state_encoder) { state_encoder = new CArrayObj(); if(!state_encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } if(!skill_project) { skill_project = new CArrayObj(); if(!skill_project) return false; } //--- State Encoder state_encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = 8; descr.step = 8; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = NSkills; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!state_encoder.Add(descr)) { delete descr; return false; }
Als Nächstes wollen wir uns die Architektur von Actor ansehen. Es handelt sich immer noch um dasselbe Modell. Wir schließen jedoch den Block der Vorverarbeitung der Quelldaten aus, der in einem separaten Encoder untergebracht ist. Aber es gibt ein Detail. Wir fügen einen weiteren Eingangstensor hinzu, der die verwendete Fähigkeit beschreibt.
Außerdem lehnen wir die Verwendung stochastischer Strategien ab, damit die Strategien für das Verhalten des Akteurs beim Einsatz verschiedener Fähigkeiten klar getrennt werden können.
//--- Actor actor.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NSkills; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Wie üblich beschreiben wir nach dem Akteur (Actor) die Architektur des Kritikers (Critic). Es ist an der Zeit, über seine Funktionsweise nachzudenken. Auf den ersten Blick ist die Frage recht einfach. Der Kritiker schätzt die erwartete Belohnung für den Umzug in einen neuen Staat. Die Belohnung für einen bestimmten Übergang hängt von der ausgeführten Aktion ab, nicht von der verwendeten Fähigkeit. Natürlich wird die Aktion vom Akteur auf der Grundlage der angegebenen Fähigkeit ausgewählt. Aber der Umgebung ist es egal, von welchen Motiven sich der Agent leiten ließ. Sie reagiert auf den Einfluss des Agenten.
Auf der anderen Seite bewertet der Kritiker die Politik des Akteurs und sagt die erwartete Belohnung für die spätere Anwendung dieser Politik voraus. Die Politik des Akteurs hängt direkt von der verwendeten Fähigkeit ab. Daher muss der Kritiker in den Ausgangsdaten nicht den aktuellen Zustand der Umgebung, die verwendete Fähigkeit und die gewählte Aktion des Akteurs mitteilen. Hier werden wir eine Technik anwenden, die schon früher verwendet wurde. Wir nehmen den latenten Zustand des Akteurs, der bereits die Beschreibung des Umgebungszustands und die verwendete Fähigkeit berücksichtigt, und fügen die vom Akteur gewählte Aktion hinzu. Die Architektur des Kritikers ist also unverändert geblieben. Aber die latente Status-ID des Akteurs hat sich geändert.
Außerdem haben wir auf die Aufteilung der Belohnungsfunktion verzichtet. Dies ist eine notwendige Maßnahme. Wie bereits erwähnt, werden wir das Modell in zwei Stufen trainieren. In jeder Phase werden wir eine andere Belohnungsfunktion verwenden. Wir stehen vor einer Wahl. Wir können die Aufteilung der Belohnung verwenden und in jeder Phase 2 verschiedene Critics trainieren. Alternativ können wir auch auf die Aufteilung der Belohnung verzichten und in beiden Phasen denselben Critic verwenden. Ich beschloss, den zweiten Weg einzuschlagen.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
Als Nächstes haben wir unsere Vision auf die Optimierung des Algorithmus übertragen. Die Autoren der Methode schlagen vor, die Entropie der Übergänge als interne Belohnung zu verwenden, indem sie die Methode der Partikel von k nächsten Nachbarn verwenden, wie wir es im vorherigen Artikel getan haben. Der einzige Unterschied besteht darin, dass die Autoren die Übergangsdistanz aus dem Mini-Batch in der trainierten Encoder-Darstellung verwenden. Um dies zu erreichen, müssen wir bei jeder Iteration der Aktualisierung der Parameter ein bestimmtes Paket von Übergängen kodieren. Es ist nicht möglich, einen Mini-Batch einmal zu kodieren und diese Darstellung beim Training zu verwenden. Schließlich ändert sich nach jeder Aktualisierung der Encoder-Parameter auch der Raum der Ergebnisse.
Aber wir wissen, dass selbst ein zufälliges Faltungsmodell genügend Daten liefern kann, um zwei Zustände zu vergleichen. Daher werden wir ein nicht trainierbares Faltungsmodell für den Zweck der intrinsischen Belohnung erstellen. Vor dem Training wird zunächst eine komprimierte Darstellung aller Übergänge aus dem Erfahrungswiedergabepuffer erstellt. Beim Training wird nur der analysierte Übergang kodiert.
Wenn wir von einem Übergang sprechen, meinen wir zwei aufeinander folgende Umgebungszustände.
//--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 2 * (HistoryBars * BarDescr + AccountDescr); descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 512; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = 512 / 8; descr.window = 8; descr.step = 8; int prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 4; descr.window = 4; descr.step = 4; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 4; descr.window = 4; descr.step = 4; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
Kommen wir zum Discriminator. In diesem Fall besteht der Discriminator aus zwei Modellen. Ein Modell namens Discriminator nimmt zwei aufeinanderfolgende Umgebungszustände als Eingabe und liefert eine latente Darstellung des Übergangs. Wie bereits erwähnt, kodiert das Modell genau den Übergang in der Umgebung, ohne die verwendeten Fähigkeiten und die ausgeführten Handlungen zu berücksichtigen. Hier verwenden wir als Ausgangsdaten die Ergebnisse des Encoders für zwei Folgezustände.
Am Ausgang des Modells verwenden wir SoftMax, um die erhaltenen Ergebnisse zu normalisieren.
//--- Descriminator descriminator.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NSkills; descr.optimization = ADAM; descr.activation = SIGMOID; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = 1; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
Die zweite Komponente des Discriminators ist ein Modell zur Darstellung einer latenten Repräsentation der verwendeten Fähigkeit. Aus der Funktionsweise des Modells folgt, dass es nur die verwendete Fähigkeit als Input erhält und seine komprimierte Repräsentation in Form eines Tensors zurückgibt, der der latenten Repräsentation des Übergangs ähnelt (das Ergebnis des Diskriminatormodells).
Die Ergebnisse dieser beiden Modelle werden die Daten für die Gegenüberstellung der intrinsischen Kontrolle sein. Dementsprechend verwenden wir SoftMax auch am Ausgang des Modells.
//--- Skills project skill_project.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = SIGMOID; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = 1; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- return true; }
Obwohl die beiden letztgenannten Modelle unterschiedliche Ausgangsdaten verwenden, haben sie eine recht ähnliche Funktionalität. Aus diesem Grund haben wir für sie ähnliche architektonische Lösungen gewählt.
Wie Sie sehen können, haben wir die Methode zur Beschreibung der architektonischen Lösungen der verwendeten Modelle abgeschlossen. Sie beschreibt jedoch nicht die Architektur des Schedulers. In der Phase des Kompetenztrainings verwenden wir den Scheduler nicht. Ein wenig vorausschauend möchte ich sagen, dass wir in der ersten Ausbildungsphase eine zufällige Darstellung der Fähigkeiten erzeugen werden. Auf diese Weise kann unser Akteur verschiedene Verhaltensweisen besser erlernen. Aber wir werden den Planer nutzen, um die Politik des Einsatzes von Fähigkeiten zu lehren, um das gewünschte Ziel zu erreichen. Daher wurde das Scheduler-Modell in eine separate Methode SchedulerDescriptions ausgelagert.
bool SchedulerDescriptions(CArrayObj *scheduler) { //--- Scheduller if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } scheduler.Clear(); //--- CLayerDescription *descr = NULL; //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.window = prev_count; descr.optimization = ADAM; descr.activation = SIGMOID; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
Damit ist die Beschreibung der architektonischen Lösungen der verwendeten Modelle abgeschlossen, und wir gehen zur Entwicklung eines Algorithmus für deren Betrieb über.
2.2 Die Kollektion der Training-EAs
Wie bisher werden wir beim Training des Modells mehrere Programme verwenden. Wir werden den ersten EA „...\CIC\Research.mq5“ verwenden, um eine Trainingsstichprobe zu sammeln. Der Prozess der Datenerhebung selbst hat sich nicht geändert. Wir müssen konsequent mehrere Modelle verwenden, um die Aktion des Akteurs zu gestalten. Aber zuerst sollten wir sie in der Initialisierungsmethode OnInit EA erstellen.
Im Hauptteil der Methode werden wie üblich alle erforderlichen Indikatoren initialisiert.
int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Als Nächstes laden Sie die Modelle Encoder und Actor. Wenn es keine vortrainierten Modelle gibt, generieren wir zufällige Modelle.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *encoder = new CArrayObj(); CArrayObj *descr = new CArrayObj(); if(!CreateDescriptions(encoder,actor, descr,descr,descr,descr)) { delete encoder; delete actor; delete descr; return INIT_FAILED; } if(!Encoder.Create(encoder) || !Actor.Create(actor)) { delete encoder; delete actor; delete descr; return INIT_FAILED; } delete encoder; delete actor; delete descr; //--- }
Beim Scheduler liegt der Fall ein wenig anders. Für beide Trainingsstufen müssen wir Daten für Trainingsbeispiele sammeln. Die Verwendung des Scheduler-Modells in der ersten Phase kann den Handlungsspielraum des Akteurs etwas einschränken. Die Verwendung eines zufällig generierten Fähigkeitstensors ist in vielerlei Hinsicht vergleichbar mit der Verwendung eines Schedulers mit zufälligen Parametern. Gleichzeitig ist es um ein Vielfaches schneller als der direkte Durchgang des Modells.
Gleichzeitig ist es ratsam, in der zweiten Phase des Trainings einen vortrainierten Scheduler zu verwenden. Dies ermöglicht nicht nur die Erhebung von Daten im Bereich der politischen Maßnahmen, sondern auch die Bewertung der Schulungsergebnisse.
Daher versuchen wir, das vorab trainierte Scheduler-Modell zu laden, und das Ergebnis dieses Vorgangs wird in das Verwendungskennzeichen für den Zufallsfähigkeitsvektor geschrieben.
bRandomSkills = (!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true));
Als Nächstes übertragen wir alle verwendeten Modelle in einen einzigen OpenCL-Kontext.
COpenCLMy *opcl = Encoder.GetOpenCL();
Actor.SetOpenCL(opcl);
if(!bRandomSkills)
Scheduler.SetOpenCL(opcl);
Überprüfen Sie die Übereinstimmung der Modelle.
Actor.getResults(ActorResult); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- vector<float> EncoderResults; Actor.GetLayerOutput(0,Result); Encoder.getResults(EncoderResults); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Actor doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } //--- if(!bRandomSkills) { Scheduler.GetLayerOutput(0,Result); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Scheduler doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } }
Initialisieren Sie die Variablen.
//--- PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
Sammeln Sie Daten in der Methode OnTick. Wie bisher werden alle Operationen nur beim Öffnen einer neuen Bar ausgeführt.
void OnTick() { //--- if(!IsNewBar()) return;
Hier sammeln wir zunächst historische Daten und Kontodaten. Dieses Verfahren wurde ohne Änderungen aus den zuvor besprochenen Algorithmen übernommen. Ich werde mich hier nicht weiter damit befassen. Gehen wir gleich zur Gestaltung des direkten Durchgangs der Modelle über. Wir rufen zuerst den Encoder auf.
//--- Encoder if(!Encoder.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
Anschließend überprüfen wir das Flag für die Verwendung des Zufallsvektors. Wenn wir es zuvor geschafft haben, das Scheduler-Modell zu laden, dann machen wir einen sequentiellen Aufruf des Schedulers und des Actors.
//--- Scheduler & Actor if(!bRandomSkills) { if(!Scheduler.feedForward((CNet *)GetPointer(Encoder),-1,NULL,-1) || !Actor.feedForward(GetPointer(Encoder),-1,GetPointer(Scheduler),-1)) return; }
Andernfalls erzeugen wir zunächst einen zufälligen Fähigkeitstensor. Vergessen wir nicht, sie mit der SoftMax-Funktion zu normalisieren, da es sich um Vektoren von Wahrscheinlichkeiten für den Einsatz einzelner Fähigkeiten handelt. Schließlich rufen wir den Akteur auf.
else { vector<float> skills = vector<float>::Zeros(NSkills); for(int i = 0; i < NSkills; i++) skills[i] = (float)((double)MathRand() / 32767.0); skills.Activation(skills,AF_SOFTMAX); bSkills.AssignArray(skills); if(bSkills.GetIndex() >= 0 && !bSkills.BufferWrite()) return; if(!Actor.feedForward(GetPointer(Encoder),-1,(CBufferFloat *)GetPointer(bSkills))) return; }
Als Ergebnis des direkten Durchlaufs der Modelle erhalten wir einen bestimmten Aktionstensor am Ausgang des Actors. Die Ablehnung einer stochastischen Politik führt zu strengen Assoziationen des Akteurs zwischen den Ausgangsdaten und der gewählten Aktion. Zu Zwecken der Umgebungsforschung werden wir dem resultierenden Aktionsvektor ein wenig Rauschen hinzufügen.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- for(ulong i = 0; i < temp.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.1f; temp[i] += rnd; } temp.Clip(0.0f,1.0f); ActorResult = temp;
Nach diesen Vorgängen führen wir die Aktionen des Akteurs aus und speichern das Ergebnis im Wiedergabepuffer für das Erlebnis.
Denken Sie daran, dass wir denselben Datensatz ohne die Kennung der Fähigkeiten speichern. Für das Training der Modelle benötigen wir Übergänge und Belohnungen aus der Umgebung, während wir während des Trainings verschiedene Vektoren zur Identifizierung von Fähigkeiten generieren werden. Auf diese Weise können wir die Trainingsmenge ohne zusätzliche Interaktion mit der Umgebung um ein Vielfaches erweitern.
Der übrige Methodencode sowie die EA als Ganzes blieben unverändert und wurden aus früheren ähnlichen EAs übernommen. Wir werden sie jetzt nicht im Detail analysieren. Sie finden sie in der Anlage.
2.3 Ausbildung von Fertigkeiten
Die erste Stufe des Modeltrainings - das Erlernen von Fähigkeiten - ist in der EA „...\CIC\Pretrain.mq5“ angeordnet. In vielerlei Hinsicht ist er analog zu den zuvor diskutierten „Study.mq5“ EAs aufgebaut, wobei die Besonderheiten des hier betrachteten Algorithmus der Kontrastiven Intrinsischen Kontrolle berücksichtigt werden.
Der Algorithmus zur Initialisierung des OnInit EA unterscheidet sich nicht von den gleichnamigen Methoden der zuvor besprochenen ähnlichen EAs. Bleiben wir nur bei der Liste der verwendeten Modelle. Hier sehen wir die Modelle von Encoder, dem Akteur, zwei Kritiker, Zufalls-Faltungs-Encoder und dem Discriminator. Aber nur ein Encoder-Modell ist ein gezieltes Modell.
Wir benötigen zwei Encoder-Modelle, um die analysierten und nachfolgenden Umgebungszustände zu kodieren, die vom Discriminator verwendet werden.
Wir verwenden jedoch keine Zielmodelle des Akteurs und der Kritiker, da wir in diesem Stadium dem Akteur beibringen, trennbare Handlungen unter dem Einfluss einer bestimmten Fähigkeit in einem bestimmten Zustand der Umgebung auszuführen. Wir streben nicht danach, intrinsische Belohnungen für verschiedene Fähigkeiten anzuhäufen. Wir maximieren sie in jedem einzelnen Moment.
int OnInit() { //--- ....... ....... //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Descriminator.Load(FileName + "Des.nnw", temp, temp, temp, dtStudied, true) || !SkillProject.Load(FileName + "Skp.nnw", temp, temp, temp, dtStudied, true) || !Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true) || !TargetEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *encoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *descrim = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); CArrayObj *skill_poject = new CArrayObj(); if(!CreateDescriptions(encoder,actor, critic, convolution,descrim,skill_poject)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } if(!Encoder.Create(encoder) || !Actor.Create(actor) || !Critic1.Create(critic) || !Critic2.Create(critic) || !Descriminator.Create(descrim) || !SkillProject.Create(skill_poject) || !Convolution.Create(convolution)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } if(!TargetEncoder.Create(encoder)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; //--- TargetEncoder.WeightsUpdate(GetPointer(Encoder), 1.0f); } //--- OpenCL = Actor.GetOpenCL(); Encoder.SetOpenCL(OpenCL); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetEncoder.SetOpenCL(OpenCL); Descriminator.SetOpenCL(OpenCL); SkillProject.SetOpenCL(OpenCL); Convolution.SetOpenCL(OpenCL); //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Der eigentliche Prozess des Trainings von Modellen ist in der Methode Train geregelt.
Ähnlich wie im vorangegangenen Artikel kodieren wir zu Beginn der Methode alle Übergänge zwischen den im Erfahrungswiedergabepuffer verfügbaren Zuständen. Der Algorithmus für den Aufbau des Prozesses ist identisch. Sie hat jedoch ihre eigenen Nuancen. Wir codieren Übergänge. Daher geben wir einen Tensor von zwei aufeinanderfolgenden Zuständen als Eingabe für einen Zufallscodierer vor, ohne die durchgeführten Aktionen zu berücksichtigen.
Außerdem verwenden wir in dieser Phase nur interne Belohnungen. Das bedeutet, dass wir die Verarbeitung von externen Umgebungsbelohnungen ausschließen.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- int total_states = Buffer[0].Total - 1; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total - 1; vector<float> temp; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total - 1; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- State.AddArray(Buffer[tr].States[st + 1].state); State.Add((Buffer[tr].States[st + 1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[1] / PrevBalance); State.Add((Buffer[tr].States[st + 1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st + 1].account[2]); State.Add(Buffer[tr].States[st + 1].account[3]); State.Add(Buffer[tr].States[st + 1].account[4] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[5] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[6] / PrevBalance); x = (double)Buffer[tr].States[st + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } } if(state != total_states) { state_embedding.Reshape(state,state_embedding.Cols()); total_states = state; }
Als Nächstes deklarieren wir lokale Variablen.
vector<float> reward = vector<float>::Zeros(NRewards); vector<float> rewards1 = reward, rewards2 = reward; int bar = (HistoryBars - 1) * BarDescr;
Die Organisation eines Modellschulungszyklus. Im Zykluskörper wählen wir, wie zuvor, die Trajektorie und den analysierten Zustand zufällig aus dem Erfahrungswiedergabepuffer aus.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
Anhand der abgetasteten Zustandsdaten bilden wir die Anfangsdatentensoren unserer Modelle.
//--- State State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Hier bilden wir einen zufälligen Tensor der verwendeten Fähigkeit.
//--- Skills vector<float> skills = vector<float>::Zeros(NSkills); for(int sk = 0; sk < NSkills; sk++) skills[sk] = (float)((double)MathRand() / 32767.0); skills.Activation(skills,AF_SOFTMAX); Skills.AssignArray(skills); if(Skills.GetIndex() >= 0 && !Skills.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Zunächst übermitteln wir die generierten Ausgangsdaten an den Encoder-Eingang.
//--- Encoder State if(!Encoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Dann führen wir einen direkten Durchlauf des Actors durch.
//--- Actor if(!Actor.feedForward(GetPointer(Encoder), -1, GetPointer(Skills))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Auf der Grundlage des resultierenden Aktionstensors bilden wir einen vorausschauenden Folgezustand. Wir haben keine Probleme mit historischen Preisbewegungsdaten. Wir nehmen sie einfach aus dem Erfahrungswiedergabepuffer. Um den Stand des Prognosekontos zu berechnen, erstellen wir die Methode ForecastAccount, auf deren Algorithmus wir später eingehen werden.
//--- Next State TargetState.AssignArray(Buffer[tr].States[i + 1].state); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); Actor.getResults(Result); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,Result,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetAccount.AssignArray(forecast); if(TargetAccount.GetIndex() >= 0 && !TargetAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Wir führen einen direkten Durchlauf durch den Ziel-Encoder durch, um eine latente Darstellung des nachfolgenden Zustands zu erhalten.
if(!TargetEncoder.feedForward(GetPointer(TargetState), 1, false, GetPointer(TargetAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
In diesem Stadium haben wir eine latente Darstellung der beiden nachfolgenden Umgebungszustände. Wir sind in der Lage, den Vektor der Übergangsdarstellung zu erhalten. Wir erhalten hier den Repräsentationsvektor der Fähigkeiten.
//--- Descriminator if(!Descriminator.feedForward(GetPointer(Encoder),-1,GetPointer(TargetEncoder),-1) || !SkillProject.feedForward(GetPointer(Skills),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Das Ergebnis des kontrastiven Vergleichs der beiden resultierenden Vektoren dient als erster Teil unserer internen Belohnung. Die Maximierung dieser Belohnung ermutigt den Akteur, leicht trennbare und vorhersehbare Fähigkeiten zu trainieren, die sich leicht auf einzelne Zustandsübergänge in der Umgebung abbilden lassen.
Descriminator.getResults(rewards1); SkillProject.getResults(rewards2); float norm1 = rewards1.Norm(VECTOR_NORM_P,2); float norm2 = rewards2.Norm(VECTOR_NORM_P,2); reward[0] = (rewards1 / norm1).Dot(rewards2 / norm2);
Wir aktualisieren sofort die Parameter der Diskriminatormodelle. Ohne den Algorithmus weiter zu verkomplizieren, trainieren wir einfach das Discriminator-Modell, um eine komprimierte Darstellung einer Fähigkeit zu approximieren. Das Modell der Fähigkeitsprojektion wird so trainiert, dass es eine komprimierte Übergangsdarstellung annähert.
Gleichzeitig trainieren wir den Encoder, den Zustand der Umgebung so darzustellen, dass er mit einer bestimmten Fähigkeit identifiziert werden kann. Wir trainieren den Encoder auf der Grundlage der Fehlergradienten, die wir vom Discriminator erhalten, ähnlich wie bei Akteur und Kritiker in einem kontinuierlichen Raum von Aktionen.
Result.AssignArray(rewards2); if(!Descriminator.backProp(Result,GetPointer(TargetEncoder)) || !Encoder.backPropGradient(GetPointer(Account),GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.AssignArray(rewards1); if(!SkillProject.backProp(Result,(CNet *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Die zweite Komponente unserer internen Belohnungsfunktion ist eine Strafe für den Mangel an offenen Positionen zum aktuellen Zeitpunkt. Die Informationen über das Vorhandensein von Transaktionen entnehmen wir dem voraussichtlichen Stand des Kontos.
if(forecast[3] == 0.0f && forecast[4] == 0.f) reward[0] -= Buffer[tr].States[i + 1].state[bar + 6] / PrevBalance;
Die dritte Komponente unserer internen Belohnung ist die Entropie des Übergangs, die den Akteur dazu anregt, eine Vielzahl von Verhaltensweisen zu studieren und eine große Anzahl von Fähigkeiten zu beherrschen. Um die Übergangsentropie zu erhalten, erhalten wir zunächst eine komprimierte Darstellung des Übergangs im Zufallscodierer-Raum und bestimmen die k nächsten Nachbarn mit der KNNReward-Methode.
State.AddArray(GetPointer(Account)); State.AddArray(GetPointer(TargetState)); State.AddArray(GetPointer(TargetAccount)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(rewards1); reward[0] += KNNReward(7,rewards1,state_embedding);
Wir addieren das Ergebnis der Übergangsentropie zu unserer internen Belohnung.
Nachdem wir nun die volle Bedeutung unserer komplexen intrinsischen Belohnungen erkannt haben, können wir mit der Ausbildung der Kritiker und des Akteurs fortfahren. Wir haben die Vorwärtsdurchgänge des Akteurs bereits früher durchgeführt. Nun rufen wir den direkten Durchgang der beiden Kritiker auf.
Result.AssignArray(reward); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Wir trainieren den Akteur mit Hilfe eines Kritikers mit minimalem Fehler. Wir prüfen den gleitenden Durchschnittsfehler der Kritiker. Zunächst führen wir den Rückwärtsdurchlauf des Kritikers mit minimalen Fehlern durch. Danach folgt der Rückwärtsdurchgang des Akteurs. Die letzte Stufe ist der umgekehrte Durchgang des Kritikers mit dem größten durchschnittlichen Fehler bei der Vorhersage der Kosten der Handlungen des Akteurs.
if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) { if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Skills), GetPointer(Gradient), -1) || !Critic2.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } } else { if(!Critic2.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Skills), GetPointer(Gradient), -1) || !Critic1.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Als Nächstes aktualisieren wir die Parameter des Ziel-Encoders und informieren den Nutzer über den Stand des Modelltrainings.
//--- Update Target Nets TargetEncoder.WeightsUpdate(GetPointer(Encoder), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Nachdem alle Iterationen des Trainingszyklus abgeschlossen sind, löschen wir das Kommentarfeld der Tabelle und leiten den Programmabschlussprozess ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Um ein allgemeines Bild von der Ausbildung zu erhalten, betrachten wir eine andere Methode zur Erstellung des Prognosestatus des Kontos ForecastAccount. Als Parameter erhält die Methode einen Zeiger auf den vorherigen Kontostand, einen Aktionstensor, den Gewinnwert von 1 Lot einer Long-Position für den nächsten Balken und den Zeitstempel des nächsten Balkens. Die Gewinngröße pro 1 Lot wird vor dem Aufruf der Methode anhand der nachfolgenden Kerzendaten ermittelt. Dieser Vorgang ist nur mit einem Offline-Training auf der Grundlage historischer Daten über Preisbewegungen möglich.
Wir werden zunächst ein wenig Vorbereitungsarbeit im Methodenkörper leisten. Hier deklarieren wir lokale Variablen und laden einige Informationen über das Werkzeug. Da wir das Instrument in den Trainingsdaten nicht spezifiziert haben, werden wir die Daten über das Chart-Instrument verwenden. Für eine korrekte Ausbildung ist es daher notwendig, den Lern-EA auf dem erforderlichen Chart des Instruments zu starten.
vector<float> ForecastAccount(float &prev_account[], CBufferFloat *actions,double prof_1l,float time_label) { vector<float> account; vector<float> act; double min_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); double step_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_STEP); double stops = MathMax(SymbolInfoInteger(_Symbol,SYMBOL_TRADE_STOPS_LEVEL), 1) * Point(); double margin_buy,margin_sell; if(!OrderCalcMargin(ORDER_TYPE_BUY,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_ASK),margin_buy) || !OrderCalcMargin(ORDER_TYPE_SELL,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_BID),margin_sell)) return vector<float>::Zeros(prev_account.Size());
Der Einfachheit halber übertragen wir die aus den Parametern gewonnenen Daten in Vektoren.
actions.GetData(act); account.Assign(prev_account);
Danach passen wir die Aktionen des Agenten so an, dass er eine Position in nur einer Richtung eröffnet, die der Differenz der angegebenen Volumina entspricht. Anschließend prüfen wir, ob die Mittel für den Operationen ausreichen. Wenn das Konto nicht ausreichend gedeckt ist, setzen wir das Handelsvolumen auf Null zurück.
if(act[0] >= act[3]) { act[0] -= act[3]; act[3] = 0; if(act[0]*margin_buy >= MathMin(account[0],account[1])) act[0] = 0; } else { act[3] -= act[0]; act[0] = 0; if(act[3]*margin_sell >= MathMin(account[0],account[1])) act[3] = 0; }
Als Nächstes folgen die Dekodierungsoperationen der empfangenen Aktionen. Der Prozess wird in Analogie zum Algorithmus für die Durchführung von Aktionen im EA zur Sammlung von Trainingsdaten aufgebaut. Nur dass wir anstelle von Aktionen die entsprechenden Elemente der Kontostandsbeschreibung ändern. Betrachten wir zunächst die Elemente einer Kaufposition. Wenn das Volumen eines Geschäfts gleich „0“ ist oder die Stop-Levels unter der Mindestmarge für das Instrument liegen, dann zeigt dieser Parametersatz die Schließung eines Handelsgeschäfts an, sofern ein solches offen war. Wir setzen die Größe der aktuellen Position in diese Richtung zurück, während der kumulierte Gewinn/Verlust zum aktuellen Saldo addiert wird.
//--- buy control if(act[0] < min_lot || (act[1] * MaxTP * Point()) <= stops || (act[2] * MaxSL * Point()) <= stops) { account[0] += account[4]; account[2] = 0; account[4] = 0; }
Wenn wir eine Position eröffnen oder halten, normalisieren wir das Handelsvolumen und vergleichen das resultierende Volumen mit dem zuvor eröffneten. Wenn die Position größer war als die vom Akteur angebotene, dann teilen wir den kumulierten Gewinn/Verlust im Verhältnis zum angebotenen und geschlossenen Volumen. Wir addieren den Gewinn/Verlust des abgeschlossenen Volumens zum Saldo. Die Differenz belassen wir im Feld für den kumulierten Gewinn. Wir ändern das Positionsvolumen in das vom Akteur vorgeschlagene. Außerdem ändern wir den Gewinn/Verlust aus dem Übergang zum nächsten Umgebungszustand zum kumulierten Volumen.
else { double buy_lot = min_lot + MathRound((double)(act[0] - min_lot) / step_lot) * step_lot; if(account[2] > buy_lot) { float koef = (float)buy_lot / account[2]; account[0] += account[4] * (1 - koef); account[4] *= koef; } account[2] = (float)buy_lot; account[4] += float(buy_lot * prof_1l); }
Die Vorgänge werden für Verkaufspositionen wiederholt.
//--- sell control if(act[3] < min_lot || (act[4] * MaxTP * Point()) <= stops || (act[5] * MaxSL * Point()) <= stops) { account[0] += account[5]; account[3] = 0; account[5] = 0; } else { double sell_lot = min_lot + MathRound((double)(act[3] - min_lot) / step_lot) * step_lot; if(account[3] > sell_lot) { float koef = float(sell_lot / account[3]); account[0] += account[5] * (1 - koef); account[5] *= koef; } account[3] = float(sell_lot); account[5] -= float(sell_lot * prof_1l); }
Die kumulierten Gewinne aus Kauf- und Verkaufspositionen bilden den kumulierten Gewinn des Kontos. Die Summe aus kumuliertem Gewinn und Saldo ergibt den Parameter Kapital.
account[6] = account[4] + account[5]; account[1] = account[0] + account[6];
Verwenden Sie die erhaltenen Werte, um einen Vektor zu bilden, der den Zustand des Kontos beschreibt, und geben Sie ihn an das aufrufende Programm zurück.
vector<float> result = vector<float>::Zeros(AccountDescr); result[0] = (account[0] - prev_account[0]) / prev_account[0]; result[1] = account[1] / prev_account[0]; result[2] = (account[1] - prev_account[1]) / prev_account[1]; result[3] = account[2]; result[4] = account[3]; result[5] = account[4] / prev_account[0]; result[6] = account[5] / prev_account[0]; result[7] = account[6] / prev_account[0]; double x = (double)time_label / (double)(D'2024.01.01' - D'2023.01.01'); result[8] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_MN1); result[9] = (float)MathCos(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_W1); result[10] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_D1); result[11] = (float)MathSin(2.0 * M_PI * x); //--- return result return result; }
Nach Abschluss des Trainingsprozesses werden alle Modelle in der Deinitialisierungsmethode von OnDeinit EA gespeichert.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- TargetEncoder.WeightsUpdate(GetPointer(Encoder), Tau); Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetEncoder.Save(FileName + "Enc.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); Critic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); Critic2.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Convolution.Save(FileName + "CNN.nnw", 0, 0, 0, TimeCurrent(), true); Descriminator.Save(FileName + "Des.nnw", 0, 0, 0, TimeCurrent(), true); SkillProject.Save(FileName + "Skp.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
Damit ist unsere Arbeit über den EA für das vorläufige Training der Fähigkeiten des Akteurs ohne externe Belohnung abgeschlossen. Der vollständige Code des EAs befindet sich im Anhang. Dort finden Sie auch den vollständigen Code aller in diesem Artikel verwendeten Programme.
2.4 Feinabstimmung EA
Das Training des Modells endet mit dem Training des Schedulers, der einen Vektor der eingesetzten Fähigkeiten generiert und damit die Aktionen des Akteurs steuert.
Die Strategie des Planers ist auf die Maximierung der externen Belohnungen ausgerichtet. Wir gestalten das Training im EA „...\CIC\Finetune.mq5“. Der EA ist ähnlich aufgebaut wie der vorherige, aber es gibt einige Nuancen. Damit der EA funktioniert, benötigen wir vortrainierte Modelle von Encoder, Akteur und Kritiker. Wir werden auch Zielkopien der angegebenen Modelle verwenden.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true) || !TargetEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !TargetActor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { Print("No pretrained models found"); return INIT_FAILED; }
Zusätzlich laden wir ein zufälliges Faltungscodierungsmodell. Die Discriminator-Modelle werden jedoch nicht geladen. In diesem Stadium verwenden wir nur externe Belohnungen. Die Verhaltenspolitik des Akteurs wurde in der vorherigen Phase untersucht. Jetzt müssen wir die Top-Level-Policy des Schedulers lernen.
Daher versuchen wir, nach dem Laden der vortrainierten Modelle, das Scheduler-Modell zu laden. Wenn kein Modell gefunden wird, erstellen wir diesmal ein neues Modell und initialisieren es mit Zufallsparametern.
if(!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *descr = new CArrayObj(); if(!SchedulerDescriptions(descr) || !Scheduler.Create(descr)) { delete descr; return INIT_FAILED; } delete descr; }
Als Nächstes übertragen wir alle Modelle in einen einzigen OpenCL-Kontext und deaktivieren den Actor- und Encoder-Trainingsmodus.
OpenCL = Actor.GetOpenCL(); Encoder.SetOpenCL(OpenCL); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetEncoder.SetOpenCL(OpenCL); TargetActor.SetOpenCL(OpenCL); TargetCritic1.SetOpenCL(OpenCL); TargetCritic2.SetOpenCL(OpenCL); Scheduler.SetOpenCL(OpenCL); Convolution.SetOpenCL(OpenCL); //--- Actor.TrainMode(false); Encoder.TrainMode(false);
Am Ende der Initialisierungsmethode überprüfen wir die Konsistenz der Modellarchitektur und generieren das Ereignis für den Trainingsbeginn.
vector<float> ActorResult; Actor.getResults(ActorResult); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- vector<float> EncoderResults; Actor.GetLayerOutput(0,Result); Encoder.getResults(EncoderResults); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Actor doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } //--- Actor.GetLayerOutput(LatentLayer, Result); int latent_state = Result.Total(); Critic1.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic doesn't match latent state Actor (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; } //--- Gradient.BufferInit(AccountDescr, 0); //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Bei der EA-Deinitialisierungsmethode speichern wir nur die Modelle Kritiker und Scheduler.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); TargetCritic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic2.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Scheduler.Save(FileName + "Sch.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
Ich glaube nicht, dass irgendjemand die Notwendigkeit in Frage stellt, den Scheduler zu schulen. Aber das Problem der Aktualisierung der Kritiker-Parameter und der Festsetzung der Akteurs-Parameter ist wahrscheinlich erklärungsbedürftig. Im vorangegangenen Schritt haben wir die Richtlinien des Akteurs in Abhängigkeit von der verwendeten Fähigkeit trainiert. In dieser Phase lernen wir, Fähigkeiten zu verwalten. Daher legen wir die Parameter des Akteurs fest und trainieren den Scheduler, um ihn zu steuern.
Eine weitere Frage betrifft die Kritiker. In der Phase des Kompetenztrainings haben wir nur interne Belohnungen eingesetzt, die darauf abzielten, verschiedene Fähigkeiten des Akteurs zu trainieren. Natürlich haben die Kritiker Abhängigkeiten zwischen den Handlungen des Akteurs und ihren Auswirkungen auf die internen Belohnungen hergestellt. In dieser Phase setzen wir jedoch externe Belohnungen ein. Höchstwahrscheinlich haben die Handlungen des Akteurs eine ganz andere Wirkung auf ihn. Deshalb müssen wir die Kritiker für die neuen Umstände neu trainieren.
Während wir zuvor unsere Annahmen über den Einfluss der gewählten Fähigkeit auf das Ergebnis verwendet haben, werden wir nun den Gradienten des Belohnungsfehlers vom Kritiker über den Akteur an den Planer weitergeben. Aber kehren wir zu unserem EA zurück und sehen wir uns den Algorithmus zur Gestaltung des Prozesses an.
Der Modellbildungsprozess ist weiterhin in der Methode Train organisiert. Wie beim oben beschriebenen ESA für das Fertigkeitstraining kodieren wir die Übergänge zu Beginn der Methode. Dieses Mal fügen wir jedoch externe Belohnungen aus der Umgebung hinzu. Beachten Sie, dass wir die Belohnung nur für einen separaten Übergang nehmen. Wir werden die kumulative Belohnung mithilfe von Zielmodellen vorhersagen.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); float loss = 0; //--- int total_states = Buffer[0].Total - 1; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total - 1; vector<float> temp; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states,NRewards); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total - 1; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- State.AddArray(Buffer[tr].States[st + 1].state); State.Add((Buffer[tr].States[st + 1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[1] / PrevBalance); State.Add((Buffer[tr].States[st + 1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st + 1].account[2]); State.Add(Buffer[tr].States[st + 1].account[3]); State.Add(Buffer[tr].States[st + 1].account[4] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[5] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[6] / PrevBalance); x = (double)Buffer[tr].States[st + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); temp.Assign(Buffer[tr].States[st].rewards); for(ulong r = 0; r < temp.Size(); r++) temp[r] -= Buffer[tr].States[st + 1].rewards[r] * DiscFactor; rewards.Row(temp,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } } if(state != total_states) { state_embedding.Reshape(state,state_embedding.Cols()); rewards.Reshape(state,NRewards); total_states = state; }
Als Nächstes führen wir einen Modelltrainingszyklus durch. Im Hauptteil der Schleife wird der Zustand aus dem Erfahrungswiedergabepuffer abgerufen.
vector<float> reward, rewards1, rewards2, target_reward; int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; } reward = vector<float>::Zeros(NRewards); rewards1 = reward; rewards2 = reward; target_reward = reward;
Vorbereiten der Quelldatenpuffer.
//--- State State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; if(PrevBalance == 0.0f || PrevEquity == 0.0f) continue; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Nach der Generierung eines vollständigen Satzes von Ausgangsdaten für den ausgewählten Zustand führen wir einen direkten Durchlauf des Encoders durch.
//--- Encoder State if(!Encoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Auf den Encoder folgt ein Vorwärtsdurchlauf des Schedulers, der die latente Repräsentation des Umgebungszustands auswertet und einen Vektor der Fertigkeiten (skills) für den Akteur generiert.
//--- Skills if(!Scheduler.feedForward(GetPointer(Encoder), -1, NULL,-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Der Akteur wiederum nutzt die vom Scheduler vorgegebene Fähigkeit und analysiert die latente Repräsentation des Umgebungszustands vom Encoder. Auf der Grundlage der Gesamtheit der Ausgangsdaten erstellt der Akteur einen Vektor von Aktionen.
//--- Actor if(!Actor.feedForward(GetPointer(Encoder), -1, GetPointer(Scheduler),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Wir verwenden den resultierenden Aktionsvektor, um den nächsten Zustand der Umgebung vorherzusagen.
//--- Next State TargetState.AssignArray(Buffer[tr].States[i + 1].state); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); Actor.getResults(Result); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,Result,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetAccount.AssignArray(forecast); if(TargetAccount.GetIndex() >= 0 && !TargetAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Wir wiederholen die Aktionen für den nachfolgenden Zustand mit Zielmodellen. Der Scheduler ist von dieser Kette ausgeschlossen, da wir davon ausgehen, dass er dieselbe Fähigkeit besitzt.
if(!TargetEncoder.feedForward(GetPointer(TargetState), 1, false, GetPointer(TargetAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- Target if(!TargetActor.feedForward(GetPointer(TargetEncoder), -1, GetPointer(Scheduler),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Um jedoch die Politik des Akteurs zu bewerten, brauchen wir den Kritiker, der seine Handlungen bewertet. Hier wird die niedrigere Schätzung als Vorhersage einer zukünftigen Belohnung verwendet.
//--- if(!TargetCritic1.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor)) || !TargetCritic2.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1; else target_reward = rewards2; target_reward *= DiscFactor;
Wir bewerten die aktuelle Aktion auf der Grundlage der k nächsten Nachbarn des vorhergesagten Übergangs. Dazu werden wir einen Zufalls-Encoder verwenden.
State.AddArray(GetPointer(TargetState)); State.AddArray(GetPointer(TargetAccount)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(rewards1); reward[0] += KNNReward(7,rewards1,state_embedding,rewards); reward += target_reward; Result.AssignArray(reward);
Wir kombinieren die aktuelle und die prognostizierte Belohnung. Wir haben jetzt einen Zielwert für das Training der Modelle. Nun muss nur noch das kritische Modell ausgewählt werden, um die Scheduler-Parameter zu aktualisieren. Wir führen einen direkten Durchgang beider Kritiker durch und wählen die Mindestbewertung für die vom Akteurs gewählte Handlung.
if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic1.getResults(rewards1); Critic2.getResults(rewards2);
Wie im vorherigen EA führen wir einen umgekehrten Durchlauf durch den ausgewählten Kritiker, Akteur und Scheduler durch. Bei letzterem führen wir einen umgekehrten Durchgang des Kritikers mit der maximalen Bewertung der Handlungen des Akteurs durch.
if(rewards1.Sum() <= rewards2.Sum()) { loss = (loss * MathMin(iter,999) + (reward - rewards1).Sum()) / MathMin(iter + 1,1000); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Scheduler),-1,-1) || !Scheduler.backPropGradient() || !Critic2.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } } else { loss = (loss * MathMin(iter,999) + (reward - rewards2).Sum()) / MathMin(iter + 1,1000); if(!Critic2.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Scheduler),-1,-1) || !Scheduler.backPropGradient() || !Critic1.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Am Ende der Iterationen des Trainingszyklus müssen wir nur noch die Modelle der Zielkritiker aktualisieren und den Nutzer über den Fortschritt des Modelltrainings informieren.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), loss); Comment(str); ticks = GetTickCount(); } }
Nach Abschluss aller Iterationen des Modelltrainingszyklus löschen wir den Kommentarblock im Chart und leiten den Prozess der Beendigung des EA ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", loss); ExpertRemove(); //--- }
Damit sind unsere Überlegungen zu Programmen für die Implementierung des vorgestellten Algorithmus abgeschlossen. Wir haben uns den EA zum Testen trainierter Modelle noch nicht angesehen. Sie hat die gleichen Anpassungen erhalten wie die EA für die Erhebung einer Ausbildungsstichprobe. Allerdings habe ich dem Aktionsvektor kein Zufallsrauschen hinzugefügt, um die tatsächliche Qualität der trainierten Modelle zu bewerten. Der vollständige Code aller in diesem Artikel verwendeten Programme ist im Anhang verfügbar.
3. Test
Das Training und Testen der Modelle wird für die ersten 5 Monate des Jahres 2023 auf EURUSD H1 durchgeführt. Wie immer wurden die Parameter aller Indikatoren als Standardwerte verwendet. Der Prozess der Modellbildung ist recht langwierig. Die Autoren der Methode schlagen zwei Millionen Iterationen in der ersten Phase der Ausbildung von Fähigkeiten vor. Natürlich kann die Anzahl der Iterationen für komplexere Umgebungen erhöht werden. Während des Trainings meines Modells verfolgte ich diesen Weg in mehreren Ansätzen mit zusätzlicher Sammlung von Trainingsdaten.
Nach dem Training der Fertigkeiten ist es an der Zeit, die Feinabstimmung vorzunehmen und den Planer zu schulen. Auch in dieser Phase werden mindestens 100 Tausend Iterationen durchgeführt. Ich schlage außerdem vor, diese Phase in mehreren Schritten durchzuführen. Wir initialisieren zunächst ein zufälliges Scheduler-Modell und trainieren es auf einem großen Datensatz. Nach dem ersten Durchlauf des Scheduler-Trainings sammeln wir weitere Trainings-Sets, die Beispiele für die Interaktion der Scheduler-Richtlinien mit der Umgebung enthalten. Dies wird es ermöglichen, seine Politik besser zu gestalten.
Während der Schulung konnte ich ein Modell trainieren, das in der Lage ist, Gewinne zu erzielen. Das Diagramm zeigt einen klaren Aufwärtstrend in der Bilanzlinie. Gleichzeitig habe ich einige Equity-Drawdown-Zonen festgestellt, die möglicherweise auf die Notwendigkeit eines zusätzlichen Trainings des Modells hinweisen. Wir wissen, dass die Finanzmärkte ein recht stochastisches und komplexes Umfeld sind. Es ist also zu erwarten, dass längere Trainingszeiten erforderlich sind, um die gewünschten Ergebnisse zu erzielen.


Schlussfolgerung
In diesem Artikel stellen wir eine vielversprechende Methode auf dem Gebiet des hierarchischen Verstärkungslernens vor - Contrastive Internal Control (CIC, Kontrastive Intrinsische Kontrolle). Diese Methode gehört zu einer Familie von Algorithmen, die auf selbstgesteuerten intrinsischen Belohnungen basieren. Basierend auf den Prinzipien des DIAYN-Algorithmus zielt er darauf ab, die Extraktion von hierarchischen Fähigkeiten des Agenten durch die Einführung von kontrastivem Training zu verbessern.
Eines der Hauptmerkmale von CIC ist die Fähigkeit, eine Vielzahl von Fähigkeiten in komplexen Umgebungen zu erlernen, in denen die Zahl der möglichen Verhaltensweisen sehr groß sein kann. Diese Eigenschaft ist besonders nützlich bei der Lösung von Problemen mit einem kontinuierlichen Aktionsraum. Durch kontrastives Training können wir den Agenten so anleiten, dass er nicht nur effektiv in einer Vielzahl von Szenarien lernt, sondern auch wertvolles Wissen aus diesen Szenarien gewinnen kann.
Im praktischen Teil unseres Artikels haben wir den Algorithmus mit MQL5 implementiert. Das Modell wurde anhand realer historischer Daten trainiert und getestet. Die erzielten Ergebnisse weisen auf die potenzielle Effizienz der Methode hin. Die Ausbildung einer großen Anzahl von Fähigkeiten erfordert auch vergleichbare Kosten für die Ausbildung des Agenten.
Links
- CIC: Contrastive Intrinsic Control for Unsupervised Skill Discovery
- Representation Learning with Contrastive Predictive Coding
- Neuronale Netze leicht gemacht (Teil 43): Beherrschung von Fertigkeiten ohne Belohnungsfunktion
- Neuronale Netze leicht gemacht (Teil 44): Erlernen von Fertigkeiten mit Blick auf die Dynamik
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Pretrain.mq5 | Expert Advisor | Trainings-EA für die Fähigkeiten des Akteurs |
| 3 | Finetune.mq5 | Expert Advisor | Feinabstimmung des Zeitplaners und Schulung EA |
| 4 | Test.mq5 | Expert Advisor | Modeltraining-EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13212
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Der Screenshot im Artikel zeigt nur Short-Positionen (Verkaufen).
Wie kann ich es in beide Richtungen funktionieren lassen? Der Expert Advisor hat aufgehört zu lernen. Pretrain und Finetune fliegen nach dem Embedding aus dem Chart. Leider. Soll ich noch einmal ganz von vorne anfangen?
Der Expert Advisor hat aufgehört zu lernen. Pretrain und Finetune fliegen nach dem Einbetten aus dem Chart.
Wie lauten die Meldungen im Protokoll?
Wie lauten die Protokollmeldungen?
Smoke ist wieder zum Leben erwacht. Mir ist etwas Seltsames aufgefallen - nachdem ich Research im Tester durchlaufen habe, hängt der Computer eine Weile fest. Das ist wahrscheinlich der Grund, warum sie abgestürzt sind. Lasst uns weiter lernen.
Smokehouse ist lebendig. Mir ist etwas Seltsames aufgefallen - nachdem ich die Forschung im Testgerät durchlaufen habe, bleibt der Computer eine Weile hängen. Vielleicht ist das der Grund, warum sie weggeflogen sind. Wir lernen weiter.
Nachdem man die Forschung bestanden hat, wird die Datenbank mit den Beispielen gespeichert. Und wenn sie groß genug ist, kann es vorkommen, dass der Computer langsamer wird, während er die Datenbank verarbeitet und auf die Festplatte schreibt. Wenn beim Speichern der Datenbank Fehler auftreten, können Pretrain und Finetune sie natürlich nicht lesen und stürzen ab.