ニューラルネットワークが簡単に(第55回):対照的内発制御(Contrastive intrinsic control、CIC)

はじめに
以前の記事で、階層モデルを使用する利点についてすでに説明しました。個々のエージェントのスキルを抽出して強調できるモデルを訓練する方法を検討しました。獲得したスキルは、タスクの最終目標を達成するのに役立ちます。このようなアルゴリズムの例としては、DIAYN、DADS、EDLがあります。これらのアルゴリズムはさまざまな方法でスキル訓練プロセスにアプローチしますが、それらはすべて離散行動空間の問題に使用されました。今日は、エージェントのスキルを研究する別のアプローチについて説明し、連続行動空間の問題を解決する分野でのその応用について見ていきます。
1.主なCICコンポーネント
強化学習では、自己制御された内部報酬を使用したエージェントの事前訓練にアルゴリズムを積極的に使用します。このようなアルゴリズムは、コンピテンシー、知識、データに基づくアルゴリズムの3つのカテゴリに分類できます。教師なし強化学習ベンチマークのテストでは、コンピテンシーベースのアルゴリズムが他のカテゴリより劣っていることが実証されています。
コンピテンシーを使用したアルゴリズムは、観察された状態とスキルの潜在的なベクトルの間の相互情報を最大化するよう努めます。この相互情報量は、識別子(Discriminator)モデルを通じて推定されます。通常、分類子モデルまたは回帰子モデルが識別子として使用されます。ただし、分類および回帰タスクで精度を達成するには、膨大な量の多様な訓練データが必要です。潜在的な行動の数が限られている単純な環境では、コンピテンシーベースの手法が効率的であることが実証されています。しかし、多くの潜在的な行動オプションがある環境では、その有効性は大幅に低下します。
複雑な環境では、さまざまなスキルが必要です。それらに対処するには、強力な識別子が必要です。この要件と既存の識別子の制限された機能との間の矛盾により対照的内発制御(Contrastive intrinsic control、CIC)法の作成が促されました。
対照的内発制御は、識別子の条件付きエントロピーを近似するためのコントラスト密度推定への新しいアプローチです。このメソッドは、状態とスキルベクトルの間の遷移を処理します。これにより、視覚処理からスキル検出までの強力な表現学習技術が可能になります。提案手法により、さまざまな環境におけるエージェント訓練の安定性と効率性を向上させることが可能になります。
対照的内発制御アルゴリズムは、フィードバックを使用して環境内でエージェントを訓練し、状態と行動の軌跡を取得することから始まります。次に対照予測コーディング(Contrastive Predictive Coding、CPC)を使用して表現訓練が実行され、エージェントが状態と行動から主要な特徴を取得するように動機付けられます。連続する状態間の依存関係を考慮した表現が形成されます。
内発的報酬は、どの行動戦略を最大化するかを決定する上で重要な役割を果たします。CICは状態間の遷移のエントロピーを最大化し、エージェントの動作の多様性を促進します。これにより、エージェントはさまざまな行動戦略を探索し、作成することができます。
さまざまなスキルと戦略を生成した後、CICアルゴリズムは識別子を使用してスキル表現をインスタンス化します。識別子は、状態が予測可能で安定していることを保証することを目的としています。このようにして、エージェントは予測可能な状況でスキルを「使用する」ことを学びます。
内発的報酬によって動機付けられた探索と、予測可能な行動のためのスキルの使用を組み合わせることで、多様で効果的な戦略を作成するためのバランスの取れたアプローチが生まれます。
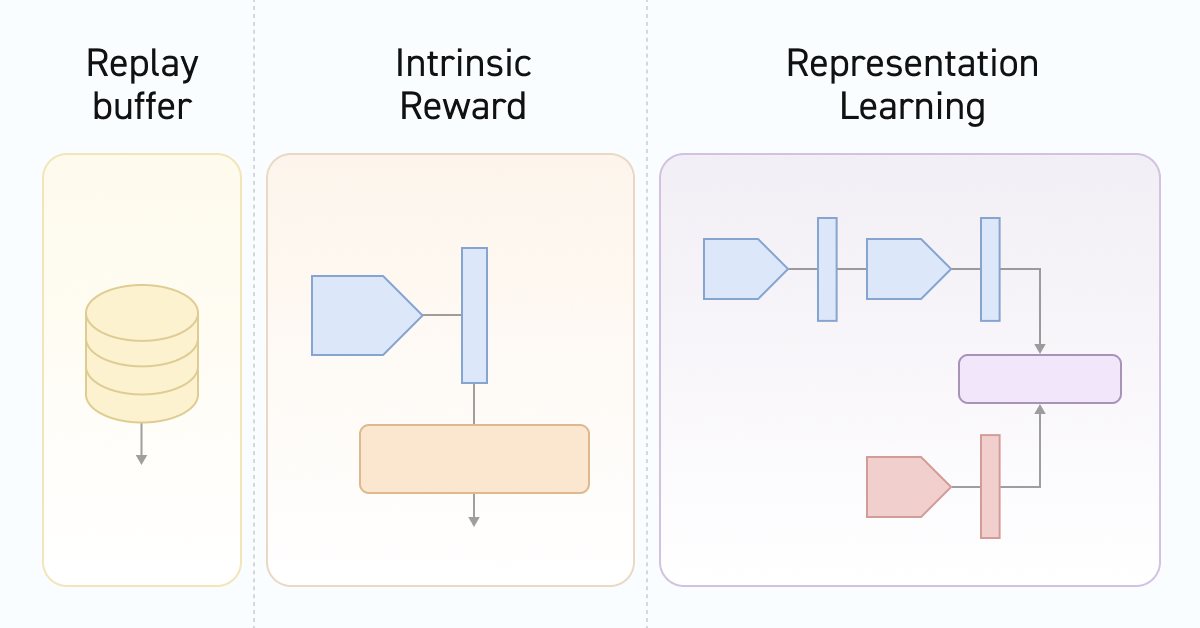
その結果、対照予測コーディングアルゴリズムは、安定した学習を確保しながら、エージェントが幅広い行動戦略を検出して学習することを促進します。以下はカスタムアルゴリズムの視覚化です。

アルゴリズムについては、実装中にさらに詳しく説明します。
2.MQL5を使用した実装
MQL5を使用して対照予測コーディングアルゴリズムを実装する前に、いくつかの重要なポイントを決定する必要があります。まず、モデル訓練アルゴリズムは2つの大きな段階に分かれています。
- 環境からの外部報酬なしでスキルを訓練する
- 外部報酬に基づいて、特定のタスクを解決するための方策を訓練する
次に、訓練プロセス中に、識別子は状態とスキル間の遷移の対応を学習します。新しい状態への遷移やその状態に至った行動に対する外部の報酬ではなく、正確に状態の変化を操作していることに留意してください。同じデータを使用して動作する前述のアルゴリズムと類推すると、DIAYNは初期モデルと新しいモデルの状態に基づいてスキルを決定します。これに対し、DADSでは、識別子が初期状態とスキルに基づいて次の状態を予測します。この方法では、遷移(初期状態とその後の状態)とエージェントが使用するスキルの間のコントラスト誤差を決定します。同時に、状態やスキルの潜在表現が形成されます。状態エンコーダの訓練に影響を与えるのは識別子であり、その後エージェントとスケジューラーによって使用されます。これは、私たちが使用するモデルのアーキテクチャに反映されています。これが、環境状態エンコーダを別のモデルに移行するきっかけとなったものです。
2.1モデルのアーキテクチャ
使用するモデルのアーキテクチャを記述するCreateDescriptionsメソッドに徐々に近づいていきます。メソッドパラメータには、6つのモデルのアーキテクチャ記述配列へのポインタが表示されます。それらの目的については後述します。
bool CreateDescriptions(CArrayObj *state_encoder, CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution, CArrayObj *descriminator, CArrayObj *skill_project ) { //--- CLayerDescription *descr; //--- if(!state_encoder) { state_encoder = new CArrayObj(); if(!state_encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } if(!skill_project) { skill_project = new CArrayObj(); if(!skill_project) return false; }
まず、環境状態エンコーダのモデルがあります。このモデルの機能についてはすでに話し始めています。ご存知のとおり、私たちの環境の状態は、過去のデータと口座のステータスという2つのブロックで構成されています。これらのテンソルの両方をエンコーダ入力に供給します。このモデルのアーキテクチャは、Actorモデルで以前に使用されていたソースデータ前処理ブロックを思い出させます。
bool CreateDescriptions(CArrayObj *state_encoder, CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution, CArrayObj *descriminator, CArrayObj *skill_project ) { //--- CLayerDescription *descr; //--- if(!state_encoder) { state_encoder = new CArrayObj(); if(!state_encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } if(!skill_project) { skill_project = new CArrayObj(); if(!skill_project) return false; } //--- State Encoder state_encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = 8; descr.step = 8; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = NSkills; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!state_encoder.Add(descr)) { delete descr; return false; }
次に、Actorのアーキテクチャを見てみましょう。まだ同じモデルです。ただし、別のエンコーダに置かれたソースデータの前処理のブロックは除きます。詳細が1つあります。使用されているスキルを記述する別の入力テンソルを追加します。
さらに、さまざまなスキルを使用するときのActorの動作の方策を明確に分離できるように、確率的方策の使用を拒否します。
//--- Actor actor.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NSkills; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
いつものように、Actorの後で、Criticのアーキテクチャについて説明します。その機能について考える時期が来ています。一見すると、質問は非常に単純です。Criticは、新しい状態に移行することで期待される報酬を見積もります。特定の遷移の報酬は、使用されたスキルではなく、実行された行動によって異なります。もちろん、行動は指定されたスキルに基づいてActorによって選択されます。しかし、環境はエージェントがどのような動機に導かれたかは気にしません。エージェントの影響に反応します。
一方、CriticはActorの方策を評価し、その後のこの方策の使用によって期待される報酬を予測します。Actorの方策は、使用されるスキルに直接依存します。したがって、初期データでは、Criticは環境の現在の状態、使用されたスキル、およびActorの選択された行動を伝える必要はありません。ここでは、以前に使用されていたテクニックを使用します。環境状態の説明と使用されるスキルがすでに考慮されているActorの潜在状態を取得し、Actorによって選択された行動を追加します。したがって、Criticのアーキテクチャは変わっていません。ただし、Actorの潜在状態IDは変更されています。
さらに、報酬関数の分解を放棄しました。これは必要な措置です。すでに述べたように、モデルを2段階で訓練します。各段階で、異なる報酬関数を使用します。私たちは選択を迫られています。報酬分解を使用して、各ステージで2つの異なるCriticを訓練する場合があります。あるいは、報酬の分解を放棄して、両方の段階で同じCriticを使用することもできます。私は2番目の道を歩むことにしました。
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
次に、アルゴリズムの最適化に私たちのビジョンを持ち込みました。この方法の著者らは、前の記事で行ったように、k個の最近傍からの粒子の方法を使用して、遷移のエントロピーを内部報酬として使用することを提案しています。唯一の違いは、著者が訓練されたエンコーダ表現でミニバッチからの遷移距離を使用したことです。これを実現するには、パラメータの更新を繰り返すたびに、遷移の特定のパッケージをエンコードする必要があります。ミニバッチを一度コーディングして、この表現を訓練で使用することはできません。結局のところ、エンコーダパラメータが更新されるたびに、その結果の空間が変化します。
しかし、ランダムな畳み込みモデルでも2つの状態を比較するのに十分なデータが得られることがわかっています。したがって、内発的報酬を目的として、訓練不可能な畳み込みモデルを作成します。訓練の前に、まず経験再生バッファからすべての遷移の圧縮表現を作成します。訓練中は、分析された遷移のみをエンコードします。
遷移とは、その後の2つの環境状態を意味します。
//--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 2 * (HistoryBars * BarDescr + AccountDescr); descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 512; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = 512 / 8; descr.window = 8; descr.step = 8; int prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 4; descr.window = 4; descr.step = 4; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 4; descr.window = 4; descr.step = 4; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
識別子に移りましょう。この場合、識別子は2つのモデルで構成されます。識別子という名前の1つのモデルは、2つの連続する環境状態を入力として受け取り、遷移の潜在的な表現を返します。上で述べたように、モデルは、使用されたスキルや実行された行動を考慮せずに、環境内の遷移を正確にエンコードします。ここでは、初期データとして、後続の2つの状態に対するエンコーダの結果を使用します。
モデルの出力では、SoftMaxを使用して、取得された結果を正規化します。
//--- Descriminator descriminator.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NSkills; descr.optimization = ADAM; descr.activation = SIGMOID; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = 1; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
識別子の2番目のコンポーネントは、使用されているスキルの潜在的な表現を表すモデルです。モデルの機能から、遷移の潜在表示(識別子モデルの結果)と同様のテンソルの形式でその圧縮表現を返す入力として使用されるスキルのみを受け取ることになります。
これら2つのモデルの結果は、内発的制御を対照するためのデータになります。したがって、モデルの出力にもSoftMaxを使用します。
//--- Skills project skill_project.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = SIGMOID; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = 1; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- return true; }
最後の2つのモデルは異なる初期データを使用しますが、機能はかなり似ています。それらにある程度似たアーキテクチャソリューションを使用したのはこのためです。
ご覧のとおり、使用されるモデルのアーキテクチャソリューションを記述する方法が完成しました。ただし、スケジューラーのアーキテクチャについては説明しません。スキル訓練の段階ではスケジューラーは使いません。少し先を見据えて、最初の訓練段階でスキルの表現をランダムに生成すると言うことにします。これにより、Actorはさまざまな動作方策をよりよく学習できるようになります。しかし、スケジューラーを使用して、目的を達成するためにスキルを使用するという方策を教えます。したがって、スケジューラーモデルは別のSchedulerDescriptionsメソッドに移動されました。
bool SchedulerDescriptions(CArrayObj *scheduler) { //--- Scheduller if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } scheduler.Clear(); //--- CLayerDescription *descr = NULL; //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.window = prev_count; descr.optimization = ADAM; descr.activation = SIGMOID; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
これで、使用するモデルのアーキテクチャソリューションを記述する作業が完了し、モデルを操作するためのアルゴリズムの構築に進みます。
2.2訓練サンプル収集EA
前と同様に、モデルの訓練中にいくつかのプログラムを使用します。最初の「...\CIC\Research.mq5」EAを使用して訓練サンプルを収集します。データ収集プロセス自体は変更されていません。Actor行動を形成するには、複数のモデルを一貫して使用する必要があります。ただし、最初にOnInitEA初期化メソッドでそれらを作成する必要があります。
メソッド本体では、いつものように、必要な指標をすべて初期化します。
int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
次に、エンコーダモデルとActorモデルを読み込みます。事前訓練されたモデルがない場合は、ランダムなモデルが生成されます。
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *encoder = new CArrayObj(); CArrayObj *descr = new CArrayObj(); if(!CreateDescriptions(encoder,actor, descr,descr,descr,descr)) { delete encoder; delete actor; delete descr; return INIT_FAILED; } if(!Encoder.Create(encoder) || !Actor.Create(actor)) { delete encoder; delete actor; delete descr; return INIT_FAILED; } delete encoder; delete actor; delete descr; //--- }
スケジューラーの場合は少し異なります。両方の訓練段階で訓練サンプルデータを収集する必要があります。最初の段階でスケジューラーモデルを使用すると、Actorの行動スペースが多少制限される可能性があります。ランダムに生成されたスキルテンソルの使用は、多くの点で、ランダムパラメータを持つスケジューラーの使用に似ています。同時に、モデルのダイレクトパスよりも何倍も高速です。
同時に、訓練の第2段階では、事前訓練されたスケジューラーを使用することをお勧めします。これにより、方策行動の分野でデータを収集するだけでなく、訓練結果を評価することも可能になります。
したがって、事前訓練されたスケジューラーモデルをロードしようとすると、操作の結果がランダムスキルベクトル使用フラグに書き込まれます。
bRandomSkills = (!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true));
次に、使用されているすべてのモデルを単一のOpenCLコンテキストに転送します。
COpenCLMy *opcl = Encoder.GetOpenCL();
Actor.SetOpenCL(opcl);
if(!bRandomSkills)
Scheduler.SetOpenCL(opcl);
機種の適合をご確認ください。
Actor.getResults(ActorResult); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- vector<float> EncoderResults; Actor.GetLayerOutput(0,Result); Encoder.getResults(EncoderResults); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Actor doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } //--- if(!bRandomSkills) { Scheduler.GetLayerOutput(0,Result); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Scheduler doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } }
変数を初期化します。
//--- PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
OnTickメソッドでデータを収集します。以前と同様に、すべての操作は新しいバーを開くときにのみ実行されます。
void OnTick() { //--- if(!IsNewBar()) return;
ここでは、まず過去のデータと口座データを収集します。このプロセスは、以前に説明したアルゴリズムから変更せずに移行されました。ここではこれについては触れません。早速、モデルのダイレクトパスの配置に移りましょう。最初にエンコーダを呼び出します。
//--- Encoder if(!Encoder.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
次に、ランダムなスキルベクトルの使用フラグを確認します。以前にスケジューラーモデルをロードできた場合は、スケジューラーとActorを連続的に呼び出します。
//--- Scheduler & Actor if(!bRandomSkills) { if(!Scheduler.feedForward((CNet *)GetPointer(Encoder),-1,NULL,-1) || !Actor.feedForward(GetPointer(Encoder),-1,GetPointer(Scheduler),-1)) return; }
それ以外の場合は、最初にランダムなスキルテンソルを生成します。これらは個々のスキルを使用する確率のベクトルであるため、SoftMax関数で正規化することを忘れないでください。最後に、Actorを呼び出します。
else { vector<float> skills = vector<float>::Zeros(NSkills); for(int i = 0; i < NSkills; i++) skills[i] = (float)((double)MathRand() / 32767.0); skills.Activation(skills,AF_SOFTMAX); bSkills.AssignArray(skills); if(bSkills.GetIndex() >= 0 && !bSkills.BufferWrite()) return; if(!Actor.feedForward(GetPointer(Encoder),-1,(CBufferFloat *)GetPointer(bSkills))) return; }
モデルをダイレクトパスした結果、Actor出力で行動の特定のテンソルが得られます。確率的方策が拒否されると、初期データと選択された行動の間のActorの厳密な関連付けがおこなわれます。環境研究の目的で、結果として得られる行動ベクトルに少しノイズを追加します。
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- for(ulong i = 0; i < temp.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.1f; temp[i] += rnd; } temp.Clip(0.0f,1.0f); ActorResult = temp;
これらの操作の後、Actorの行動を実行し、結果を経験再生バッファに保存します。
同じデータセットをスキル識別子なしで保存することに注意してください。訓練中にさまざまなスキル識別ベクトルを生成する一方で、モデルを訓練するには環境からの遷移と報酬が必要です。これにより、環境と追加に相互作用せずに訓練セットを何度も拡張できるようになります。
残りのメソッドコードとEA全体は変更されず、以前に検討された同様のEAから引き継がれました。今は詳しく分析しません。添付ファイルをご覧ください。
2.3スキル訓練
モデル訓練の最初の段階であるスキルの学習は、「...\CIC\Pretrain.mq5」EAに配置されています。多くの点で、これは、検討中の対照的内発制御lアルゴリズムの詳細を考慮しながら、前述の「Study.mq5」EAと類似して構築されています。
OnInitEAを初期化するアルゴリズムは、以前に説明した同様のEAの同じ名前のメソッドと何ら変わりません。使用されているモデルのリストのみに注目してみましょう。ここでは、エンコーダ、Actor、2つのCritics、ランダム畳み込みエンコーダおよび識別子モデルが表示されます。ただし、対象となるエンコーダモデルは1つだけです。
分析された環境状態とその後の環境状態をエンコードするには、識別子によって使用される2つのエンコーダモデルが必要です。
ただし、この段階では環境の特定の状態で特定のスキルの影響下で分離可能な行動を実行するようにActorに学習しているため、ActorとCriticのターゲットモデルは使用しません。私たちはさまざまなスキルに対する内発的報酬を蓄積しようとはしません。私たちはあらゆる瞬間においてそれを最大化します。
int OnInit() { //--- ....... ....... //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Descriminator.Load(FileName + "Des.nnw", temp, temp, temp, dtStudied, true) || !SkillProject.Load(FileName + "Skp.nnw", temp, temp, temp, dtStudied, true) || !Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true) || !TargetEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *encoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *descrim = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); CArrayObj *skill_poject = new CArrayObj(); if(!CreateDescriptions(encoder,actor, critic, convolution,descrim,skill_poject)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } if(!Encoder.Create(encoder) || !Actor.Create(actor) || !Critic1.Create(critic) || !Critic2.Create(critic) || !Descriminator.Create(descrim) || !SkillProject.Create(skill_poject) || !Convolution.Create(convolution)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } if(!TargetEncoder.Create(encoder)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; //--- TargetEncoder.WeightsUpdate(GetPointer(Encoder), 1.0f); } //--- OpenCL = Actor.GetOpenCL(); Encoder.SetOpenCL(OpenCL); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetEncoder.SetOpenCL(OpenCL); Descriminator.SetOpenCL(OpenCL); SkillProject.SetOpenCL(OpenCL); Convolution.SetOpenCL(OpenCL); //--- ........ ........ //--- return(INIT_SUCCEEDED); }
モデルを訓練する実際のプロセスは、Trainメソッドにまとめられています。
前の記事と同様に、メソッドの開始時に経験再生バッファで使用可能な状態間のすべての遷移をエンコードします。プロセスを構築するためのアルゴリズムは同じです。ただし、これには独自のニュアンスがあります。遷移をコード化します。したがって、実行される行動を考慮せずに、2つの連続する状態のテンソルをランダムエンコーダへの入力として提供します。
また、この段階では内部報酬のみを使用します。これは、外部環境報酬の処理を除外することを意味します。
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- int total_states = Buffer[0].Total - 1; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total - 1; vector<float> temp; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total - 1; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- State.AddArray(Buffer[tr].States[st + 1].state); State.Add((Buffer[tr].States[st + 1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[1] / PrevBalance); State.Add((Buffer[tr].States[st + 1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st + 1].account[2]); State.Add(Buffer[tr].States[st + 1].account[3]); State.Add(Buffer[tr].States[st + 1].account[4] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[5] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[6] / PrevBalance); x = (double)Buffer[tr].States[st + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } } if(state != total_states) { state_embedding.Reshape(state,state_embedding.Cols()); total_states = state; }
次に、ローカル変数を宣言します。
vector<float> reward = vector<float>::Zeros(NRewards); vector<float> rewards1 = reward, rewards2 = reward; int bar = (HistoryBars - 1) * BarDescr;
モデルの訓練サイクルを調整します。サイクル本体では、以前と同様に、経験再生バッファから軌跡と分析された状態をランダムに選択します。
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
サンプリングされた状態データを使用して、モデルの初期データテンソルを形成します。
//--- State State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
ここでは、使用されるスキルのランダムなテンソルを形成します。
//--- Skills vector<float> skills = vector<float>::Zeros(NSkills); for(int sk = 0; sk < NSkills; sk++) skills[sk] = (float)((double)MathRand() / 32767.0); skills.Activation(skills,AF_SOFTMAX); Skills.AssignArray(skills); if(Skills.GetIndex() >= 0 && !Skills.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
まず、生成された初期データをエンコーダ入力に送信します。
//--- Encoder State if(!Encoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
次に、Actorのダイレクトパスを実行します。
//--- Actor if(!Actor.feedForward(GetPointer(Encoder), -1, GetPointer(Skills))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
結果として得られる行動テンソルに基づいて、予測後の状態を形成します。過去の価格変動データには問題ありません。経験再生バッファからそれらを取得するだけです。予測口座のステータスを計算するために、ForecastAccountメソッドを作成します。このメソッドのアルゴリズムは後で検討します。
//--- Next State TargetState.AssignArray(Buffer[tr].States[i + 1].state); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); Actor.getResults(Result); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,Result,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetAccount.AssignArray(forecast); if(TargetAccount.GetIndex() >= 0 && !TargetAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
ターゲットエンコーダを介したダイレクトパスを実行して、後続の状態の潜在表現を取得します。
if(!TargetEncoder.feedForward(GetPointer(TargetState), 1, false, GetPointer(TargetAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
この段階では、その後の2つの環境状態の潜在的な表現が得られます。遷移表現ベクトルを取得することができます。ここでスキル表現ベクトルを取得します。
//--- Descriminator if(!Descriminator.feedForward(GetPointer(Encoder),-1,GetPointer(TargetEncoder),-1) || !SkillProject.feedForward(GetPointer(Skills),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
結果として得られる2つのベクトルの対照的な比較の結果は、内部報酬の最初の部分として機能します。この報酬を最大化すると、Actorは、環境内の個々の状態遷移に簡単に写像できる、簡単に分離可能で予測可能なスキルを訓練することが促進されます。
Descriminator.getResults(rewards1); SkillProject.getResults(rewards2); float norm1 = rewards1.Norm(VECTOR_NORM_P,2); float norm2 = rewards2.Norm(VECTOR_NORM_P,2); reward[0] = (rewards1 / norm1).Dot(rewards2 / norm2);
識別子モデルのパラメータをすぐに更新します。アルゴリズムをさらに複雑にすることなく、単純に識別子モデルを訓練して、スキルの圧縮表現を近似します。スキル投影モデルは、圧縮された遷移表現を近似するように訓練されます。
同時に、特定のスキルで識別できる方法で環境の状態を表すようにエンコーダを訓練します。行動の連続空間におけるActorやCriticと同様に、ディスクリミネーターから受け取ったエラー勾配に基づいてエンコーダを訓練します。
Result.AssignArray(rewards2); if(!Descriminator.backProp(Result,GetPointer(TargetEncoder)) || !Encoder.backPropGradient(GetPointer(Account),GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.AssignArray(rewards1); if(!SkillProject.backProp(Result,(CNet *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
内部報酬関数の2番目のコンポーネントは、現時点でポジションが不足していることに対するペナルティです。口座の予測状態からトランザクションの存在に関する情報を取得します。
if(forecast[3] == 0.0f && forecast[4] == 0.f) reward[0] -= Buffer[tr].States[i + 1].state[bar + 6] / PrevBalance;
内部報酬の3番目の要素は遷移のエントロピーです。これは、Actorがさまざまな行動を研究し、多数のスキルを習得するように刺激します。遷移エントロピーを取得するには、まずランダムエンコーダ空間で遷移の圧縮表現を取得し、KNNRewardメソッドでk個の最近傍を決定します。
State.AddArray(GetPointer(Account)); State.AddArray(GetPointer(TargetState)); State.AddArray(GetPointer(TargetAccount)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(rewards1); reward[0] += KNNReward(7,rewards1,state_embedding);
結果として得られる遷移エントロピーの結果を内部報酬に追加します。
複雑な内発的報酬の完全な意味を確立したので、次はCriticとActorの訓練に進むことができます。Actorの前方通過はすでに実行済みです。ここでは、両方のCriticのダイレクトパスを呼び出します。
Result.AssignArray(reward); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
最小限のエラーでCriticを使用してActorを訓練します。Criticsの移動平均誤差を確認します。まず、Criticのリバースパスを最小限のエラーで実行します。続いてActorのリバースパスが続きます。最後のステージは、Actorの行動のコストを予測する際の平均誤差が最も大きいCriticのリバースパスです。
if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) { if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Skills), GetPointer(Gradient), -1) || !Critic2.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } } else { if(!Critic2.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Skills), GetPointer(Gradient), -1) || !Critic1.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
次に、ターゲットエンコーダのパラメータを更新し、モデルの訓練の状態をユーザーに通知します。
//--- Update Target Nets TargetEncoder.WeightsUpdate(GetPointer(Encoder), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
すべての訓練サイクルの反復が完了したら、チャートのコメントフィールドをクリアし、プログラム終了プロセスを開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
訓練の全体像を把握するために、ForecastAccount口座の予測状態を生成する別の方法を考えてみましょう。パラメータでは、メソッドは前の口座状態へのポインタ、行動テンソル、次のバーのロングポジションの1ロットの利益値、および次のバーのタイムスタンプを受け取ります。1ロットあたりの利益サイズは、後続のローソク足データに基づいてメソッドを呼び出す前に決定されます。この操作は、価格変動の過去のデータに基づくオフライン訓練でのみ可能です。
まず、メソッド本体で少し準備作業をおこないます。ここでは、ローカル変数を宣言し、ツールに関する情報をロードします。訓練データのどこにも銘柄を指定していないため、チャート銘柄に関するデータを使用することに注意してください。したがって、正しい訓練をおこなうには、必要なインストゥルメントチャートで学習EAを起動する必要があります。
vector<float> ForecastAccount(float &prev_account[], CBufferFloat *actions,double prof_1l,float time_label) { vector<float> account; vector<float> act; double min_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); double step_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_STEP); double stops = MathMax(SymbolInfoInteger(_Symbol,SYMBOL_TRADE_STOPS_LEVEL), 1) * Point(); double margin_buy,margin_sell; if(!OrderCalcMargin(ORDER_TYPE_BUY,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_ASK),margin_buy) || !OrderCalcMargin(ORDER_TYPE_SELL,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_BID),margin_sell)) return vector<float>::Zeros(prev_account.Size());
便宜上、パラメータで取得したデータをベクトルに転送しましょう。
actions.GetData(act); account.Assign(prev_account);
この後、宣言されたボリュームの差に対して一方向のみでポジションをオープンするようにエージェントの行動を調整します。その後、運用資金が十分であるかどうかを確認します。口座の資金が不足している場合は、取引量をゼロにリセットします。
if(act[0] >= act[3]) { act[0] -= act[3]; act[3] = 0; if(act[0]*margin_buy >= MathMin(account[0],account[1])) act[0] = 0; } else { act[3] -= act[0]; act[0] = 0; if(act[3]*margin_sell >= MathMin(account[0],account[1])) act[3] = 0; }
次に、受信した行動のデコード操作がおこなわれます。このプロセスは、訓練データを収集するためにEAで行動を実行するアルゴリズムと同様に構築されます。行動を実行する代わりに、口座状態の説明の対応する要素を変更するだけです。まず、ロングポジションの要素を見ていきます。取引量が「0」に等しい場合、またはストップレベルが商品の最小証拠金未満の場合、このパラメータのセットは、取引が開かれている場合に取引が終了したことを示します。この方向で現在のポジションのサイズをリセットし、累積損益が現在の残高に追加されます。
//--- buy control if(act[0] < min_lot || (act[1] * MaxTP * Point()) <= stops || (act[2] * MaxSL * Point()) <= stops) { account[0] += account[4]; account[2] = 0; account[4] = 0; }
ポジションをオープンまたは保持する場合、取引量を正規化し、その結果得られる量を以前にオープンした量と確認します。ポジションがActorによってオファーされたポジションよりも大きかった場合、累積損益をオファーされたボリュームと決済されたボリュームに比例して分割します。決済したボリュームの損益を残高に追加します。差額は累積利益フィールドに残します。位置ボリュームをActorが提案したものに変更します。また、次の環境状態への移行による損益を累計量に加算します。
else { double buy_lot = min_lot + MathRound((double)(act[0] - min_lot) / step_lot) * step_lot; if(account[2] > buy_lot) { float koef = (float)buy_lot / account[2]; account[0] += account[4] * (1 - koef); account[4] *= koef; } account[2] = (float)buy_lot; account[4] += float(buy_lot * prof_1l); }
この操作がショートポジションに対して繰り返されます。
//--- sell control if(act[3] < min_lot || (act[4] * MaxTP * Point()) <= stops || (act[5] * MaxSL * Point()) <= stops) { account[0] += account[5]; account[3] = 0; account[5] = 0; } else { double sell_lot = min_lot + MathRound((double)(act[3] - min_lot) / step_lot) * step_lot; if(account[3] > sell_lot) { float koef = float(sell_lot / account[3]); account[0] += account[5] * (1 - koef); account[5] *= koef; } account[3] = float(sell_lot); account[5] -= float(sell_lot * prof_1l); }
ロングポジションとショートポジションからの累積利益は、口座の累積利益を構成します。累積利益と残高の合計が資本パラメータを与えます。
account[6] = account[4] + account[5]; account[1] = account[0] + account[6];
取得した値を使用して口座の状態を記述するベクトルを形成し、それを呼び出し側プログラムに返します。
vector<float> result = vector<float>::Zeros(AccountDescr); result[0] = (account[0] - prev_account[0]) / prev_account[0]; result[1] = account[1] / prev_account[0]; result[2] = (account[1] - prev_account[1]) / prev_account[1]; result[3] = account[2]; result[4] = account[3]; result[5] = account[4] / prev_account[0]; result[6] = account[5] / prev_account[0]; result[7] = account[6] / prev_account[0]; double x = (double)time_label / (double)(D'2024.01.01' - D'2023.01.01'); result[8] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_MN1); result[9] = (float)MathCos(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_W1); result[10] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_D1); result[11] = (float)MathSin(2.0 * M_PI * x); //--- return result return result; }
訓練プロセスが完了すると、すべてのモデルがOnDeinitEAの初期化解除メソッドに保存されます。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- TargetEncoder.WeightsUpdate(GetPointer(Encoder), Tau); Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetEncoder.Save(FileName + "Enc.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); Critic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); Critic2.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Convolution.Save(FileName + "CNN.nnw", 0, 0, 0, TimeCurrent(), true); Descriminator.Save(FileName + "Des.nnw", 0, 0, 0, TimeCurrent(), true); SkillProject.Save(FileName + "Skp.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
これで、外部報酬なしでActorスキルを事前訓練するためのEAでの作業は終了です。完全なEAコードは添付ファイルにあります。ここには、記事で使用されているすべてのプログラムの完全なコードもあります。
2.4EAの微調整
モデルの訓練は、スケジューラーの訓練で終了します。スケジューラーは、使用されるスキルのベクトルを生成し、それによってActorの行動を制御します。
スケジューラーの方策は、外部報酬を最大化するように訓練されています。「...\CIC\Finetune.mq5」EAで訓練を調整します。EAは以前のものと同様に構築されていますが、いくつかのニュアンスがあります。EAが機能するには、事前訓練されたエンコーダ、Actor、Criticモデルが必要です。指定されたモデルのターゲットコピーも使用します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true) || !TargetEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !TargetActor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { Print("No pretrained models found"); return INIT_FAILED; }
さらに、ランダムな畳み込みエンコーダモデルを読み込みます。ただし、識別子モデルはロードしません。この段階では、外部報酬のみを使用します。Actorの行動方策は前の段階で検討されています。次に、スケジューラーのトップレベルの方策を学習する必要があります。
したがって、事前訓練されたモデルをロードした後、スケジューラーモデルをロードしようとします。見つからない場合は、今度は新しいモデルを作成し、ランダムなパラメータで初期化します。
if(!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *descr = new CArrayObj(); if(!SchedulerDescriptions(descr) || !Scheduler.Create(descr)) { delete descr; return INIT_FAILED; } delete descr; }
次に、すべてのモデルを単一のOpenCLコンテキストに転送し、Actorとエンコーダの訓練モードを無効にします。
OpenCL = Actor.GetOpenCL(); Encoder.SetOpenCL(OpenCL); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetEncoder.SetOpenCL(OpenCL); TargetActor.SetOpenCL(OpenCL); TargetCritic1.SetOpenCL(OpenCL); TargetCritic2.SetOpenCL(OpenCL); Scheduler.SetOpenCL(OpenCL); Convolution.SetOpenCL(OpenCL); //--- Actor.TrainMode(false); Encoder.TrainMode(false);
初期化メソッドの最後に、モデルアーキテクチャの一貫性をチェックし、訓練開始イベントを生成します。
vector<float> ActorResult; Actor.getResults(ActorResult); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- vector<float> EncoderResults; Actor.GetLayerOutput(0,Result); Encoder.getResults(EncoderResults); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Actor doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } //--- Actor.GetLayerOutput(LatentLayer, Result); int latent_state = Result.Total(); Critic1.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic doesn't match latent state Actor (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; } //--- Gradient.BufferInit(AccountDescr, 0); //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
EA初期化解除方法では、CriticsモデルとSchedulerモデルのみを保存します。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); TargetCritic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic2.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Scheduler.Save(FileName + "Sch.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
スケジューラーを訓練する必要性に疑問を抱く人はいないと思います。ただし、Criticsパラメータの更新とActorパラメータの修正の問題については、おそらく説明する価値があります。前のステップでは、使用するスキルに応じてActorの方策を訓練しました。この段階では、スキルの管理方法を学びます。したがって、Actorのパラメータを修正し、それを制御するようにスケジューラーを訓練します。
もう一つの質問はCriticに関するものです。スキル訓練の段階では、Actorのさまざまなスキルを訓練することを目的とした内部報酬のみを使用しました。もちろん、CriticはActorの行動とその行動が内部報酬に与える影響との間に依存関係を構築しました。ただし、この段階では外部報酬を使用します。おそらく、Actorの行動はまったく異なる影響を与えます。したがって、新しい状況に合わせてCriticを再訓練する必要があります。
さらに、以前は選択したスキルが結果に及ぼす影響についての仮定を使用していましたが、今回は報酬誤差の勾配をCriticからActorを介してスケジューラーに渡します。しかし、EAに戻って、プロセスを調整するためのアルゴリズムを見てみましょう。
モデルの訓練プロセスは、引き続きTrainメソッド内に配置されます。上で説明したスキル訓練EAと同様に、メソッドの先頭で遷移をエンコードします。ただし、今回は環境からの外部報酬読み込みを追加します。個別の遷移ごとに報酬のみを受け取ることに注意してください。ターゲットモデルを使用して累積報酬を予測します。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); float loss = 0; //--- int total_states = Buffer[0].Total - 1; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total - 1; vector<float> temp; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states,NRewards); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total - 1; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- State.AddArray(Buffer[tr].States[st + 1].state); State.Add((Buffer[tr].States[st + 1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[1] / PrevBalance); State.Add((Buffer[tr].States[st + 1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st + 1].account[2]); State.Add(Buffer[tr].States[st + 1].account[3]); State.Add(Buffer[tr].States[st + 1].account[4] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[5] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[6] / PrevBalance); x = (double)Buffer[tr].States[st + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); temp.Assign(Buffer[tr].States[st].rewards); for(ulong r = 0; r < temp.Size(); r++) temp[r] -= Buffer[tr].States[st + 1].rewards[r] * DiscFactor; rewards.Row(temp,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } } if(state != total_states) { state_embedding.Reshape(state,state_embedding.Cols()); rewards.Reshape(state,NRewards); total_states = state; }
次に、モデルの訓練サイクルを調整します。サイクル本体では、経験再生バッファから状態をサンプリングします。
vector<float> reward, rewards1, rewards2, target_reward; int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; } reward = vector<float>::Zeros(NRewards); rewards1 = reward; rewards2 = reward; target_reward = reward;
ソースデータバッファを準備します。
//--- State State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; if(PrevBalance == 0.0f || PrevEquity == 0.0f) continue; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
選択された状態の初期データの完全なセットを生成した後、エンコーダのダイレクトパスを実行します。
//--- Encoder State if(!Encoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
エンコーダの後には、環境状態の潜在表現を評価し、Actorのスキルベクトルを生成するスケジューラーのフォワードパスが続きます。
//--- Skills if(!Scheduler.feedForward(GetPointer(Encoder), -1, NULL,-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
次に、Actorはスケジューラーによって指定されたスキルを使用し、エンコーダからの環境状態の潜在的な表現を分析します。初期データの全体に基づいて、Actorによって行動のベクトルが生成されます。
//--- Actor if(!Actor.feedForward(GetPointer(Encoder), -1, GetPointer(Scheduler),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
結果として得られる行動ベクトルを使用して、環境の次の状態を予測します。
//--- Next State TargetState.AssignArray(Buffer[tr].States[i + 1].state); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); Actor.getResults(Result); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,Result,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetAccount.AssignArray(forecast); if(TargetAccount.GetIndex() >= 0 && !TargetAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
ターゲットモデルに対して次の状態の行動を繰り返します。スケジューラーは同じスキルの使用を想定しているため、このチェーンから除外されます。
if(!TargetEncoder.feedForward(GetPointer(TargetState), 1, false, GetPointer(TargetAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- Target if(!TargetActor.feedForward(GetPointer(TargetEncoder), -1, GetPointer(Scheduler),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
ただし、Actorの方策を評価するには、その行動を評価するCriticが必要です。ここでは、将来の報酬の予測として、より低い推定値を使用します。
//--- if(!TargetCritic1.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor)) || !TargetCritic2.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1; else target_reward = rewards2; target_reward *= DiscFactor;
予測された遷移のk個の最近傍に基づいて現在の行動を評価します。これには、ランダムエンコーダを使用します。
State.AddArray(GetPointer(TargetState)); State.AddArray(GetPointer(TargetAccount)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(rewards1); reward[0] += KNNReward(7,rewards1,state_embedding,rewards); reward += target_reward; Result.AssignArray(reward);
現在の報酬と予測される報酬を組み合わせます。これで、モデルを訓練するための目標値が決まりました。残っているのは、Criticモデルを選択してスケジューラーパラメータを更新することだけです。両方のCriticのダイレクトパスを実行し、Actorが選択した行動の最小評価を選択します。
if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic1.getResults(rewards1); Critic2.getResults(rewards2);
前のEAと同様に、選択したCritic、Actor、スケジューラーを介して逆パスを実行します。後者では、Actorの行動を最大限に評価して、Criticの逆パスを実行します。
if(rewards1.Sum() <= rewards2.Sum()) { loss = (loss * MathMin(iter,999) + (reward - rewards1).Sum()) / MathMin(iter + 1,1000); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Scheduler),-1,-1) || !Scheduler.backPropGradient() || !Critic2.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } } else { loss = (loss * MathMin(iter,999) + (reward - rewards2).Sum()) / MathMin(iter + 1,1000); if(!Critic2.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Scheduler),-1,-1) || !Scheduler.backPropGradient() || !Critic1.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
訓練サイクルの反復の終了時に、ターゲットのCriticsのモデルを更新し、モデルの訓練の進行状況をユーザーに通知するだけです。
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), loss); Comment(str); ticks = GetTickCount(); } }
モデル訓練サイクルのすべての反復が完了したら、チャート上のコメントブロックを消去し、EAを終了するプロセスを開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", loss); ExpertRemove(); //--- }
これで、提示されたアルゴリズムを実装するためのプログラムの検討が終わりました。訓練済みモデルをテストするためのEAについてはまだ検討していません。訓練サンプルを収集するためのEAと同様の調整を受けています。ただし、訓練されたモデルの実際の品質を評価するために、行動ベクトルにランダムノイズを追加していません。記事で使用したすべてのプログラムの完全なコードは、添付ファイルでご覧いただけます。
3.検証
モデルの訓練とテストは、2023年の最初の5か月間、EURUSDH1で実行されます。いつものように、すべての指標のパラメータがデフォルトで使用されました。モデルの訓練プロセスは非常に時間がかかります。このメソッドの著者らは、スキルの訓練の第1段階で200万回の反復を提案しています。もちろん、より複雑な環境では反復回数を増やすことができます。モデルを訓練する際、訓練データを追加収集して、いくつかのアプローチでこのパスに従いました。
スキルを訓練したら、スケジューラーを微調整して訓練します。このステージでも少なくとも10万回の反復がおこなわれます。また、この段階をいくつかのアプローチで実行することも提案します。まずランダムなスケジューラーモデルを初期化し、それを幅広いデータセットで訓練します。スケジューラー訓練の最初のパスの後、追加の訓練セットを収集します。これには、スケジューラー方策が環境とどのように対話するかの例が含まれます。これにより、方策をより良い方向に調整できるようになります。
訓練中に、利益を生み出すことができるモデルを訓練することができました。グラフでは、バランスラインが明確に上昇傾向にあることがわかります。同時に、いくつかの株式ドローダウンゾーンに気づきました。これは、モデルの追加訓練の必要性を示している可能性があります。私たちは、金融市場が非常に確率的で複雑な環境であることを知っています。したがって、望ましい結果を得るには、より長い期間の訓練が必要になることが予想されます。


結論
この記事では、階層型強化学習の分野で有望な手法である対照的内部統制(CIC)を紹介しました。この手法は、自己制御された内発的報酬に基づくアルゴリズムのファミリーに属します。DIEYNアルゴリズムの原理に基づいて、対照的な訓練を導入することでエージェントの階層的スキルの抽出を改善することを目的としています。
CICの重要な機能の1つは、潜在的な動作の数が非常に多くなる可能性がある複雑な環境でさまざまなスキルを学習できることです。このプロパティは、連続行動空間で問題を解決する分野で特に役立ちます。対照的な訓練を使用すると、エージェントがさまざまなシナリオで効果的に学習できるだけでなく、これらのシナリオから貴重な知識を抽出できるようにガイドできます。
この記事の実践的な部分では、MQL5を使用してアルゴリズムを実装しました。モデルは実際の過去のデータに基づいて訓練およびテストされました。得られた結果は、この方法の潜在的な効率を示唆しています。多数のスキルを訓練するには、エージェントの訓練にも同様のコストが必要です。
リンク
- CIC:Contrastive Intrinsic Control for Unsupervised Skill Discovery
- Representation Learning with Contrastive Predictive Coding
- ニューラルネットワークが簡単に(第43回):報酬関数なしでスキルを習得する
- ニューラルネットワークが簡単に(第44回):ダイナミクスを意識したスキルの習得
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Pretrain.mq5 | EA | Actorスキル訓練EA |
| 3 | Finetune.mq5 | EA | スケジューラーの微調整と訓練EA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13212
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
記事のスクリーンショットにはショートポジション(売り)しか表示されていません。
どうすれば両建てできるようになりますか?Expert Advisorの学習が止まっています。Embedding後にPretrainとFinetuneがチャートから飛んでしまいます。残念です。もう一度最初からやり直すべきでしょうか?
Expert Advisorが学習しなくなった。Embedding後、PretrainとFinetuneがチャートを飛び抜けている。
ログのメッセージは何ですか?
ログメッセージとは?
スモークが復活しました。テスターでリサーチをパスした後、コンピューターがしばらくハングするんだ。だからクラッシュしたんだろう。勉強を続けよう。
スモークハウスは生きている。テスターでリサーチをパスした後、コンピューターがしばらくハングするんだ。おそらく、それが飛び去った理由だろう。私たちは学び続ける。
リサーチに合格すると、例のデータベースが保存される。そして、そのデータベースの容量が大きいと、データベースを処理したりディスクに書き込んだりしている間にコンピュータの動作が遅くなるのを感じることがある。当然ながら、データベースを保存する際にエラーがあると、PretrainとFinetuneは それを読み取ることができず、クラッシュしてしまう。