Força bruta para encontrar padrões (Parte VI): otimização cíclica

Conteúdo
- Introdução
- Complexo
- Novo algoritmo de otimização
- Critério de otimização mais importante
- Busca automática de configurações de negociação
- Conclusão
- Referências
Introdução
Com base em um breve resumo do artigo anterior, posso dizer que isso é apenas uma descrição superficial de todas as funções que introduzi no meu algoritmo. Elas se referem não apenas à automação completa da criação de EAs, mas também a funções importantes como a automação completa do processo de otimização e seleção de resultados com aplicação imediata para negociação automática, ou a criação de EAs mais avançados, que mostrarei mais tarde.
Graças à sinergia dos terminais de negociação, EAs universais e o próprio algoritmo, com capacidades computacionais disponíveis, é possível se livrar completamente do desenvolvimento manual, ou, no pior dos casos, reduzir significativamente a carga de trabalho de possíveis melhorias. Neste artigo, começarei a descrever os aspectos mais importantes dessas inovações.
Complexo
Para mim, o fator mais importante na criação e nas modificações posteriores de tais soluções ao longo do tempo foi entender a possibilidade de proporcionar o máximo de automação das ações rotineiras. As ações rotineiras, neste caso, incluem todo o trabalho opcional humano:
- Geração de ideias.
- Criação de teoria.
- Escrita de código baseado na teoria.
- Correção de código.
- Processo contínuo de reotimização de EAs.
- Processo contínuo de seleção de EAs.
- Manutenção de EAs.
- Trabalho com terminais.
- Experimentos e prática.
- Outros.
Como pode ser visto, a nomenclatura de toda essa rotina é bastante ampla. Eu trato isso exatamente como rotina, porque todas essas coisas, como consegui provar, são totalmente automatizáveis. Eu forneci uma lista geral. Não importa quem você é – um trader algorítmico, um programador ou ambos. Não importa se você sabe programar ou não, mesmo que não, de qualquer forma, você enfrentará, pelo menos, metade dessa lista. Não estou falando sobre os casos em que você comprou um EA no mercado, aplicou-o a um gráfico e relaxou, pressionando um botão. Isso, claro, acontece, mas é extremamente raro.
Entendendo tudo isso, inicialmente tive que automatizar o que é mais óbvio. Eu descrevi conceitualmente toda essa otimização no artigo anterior. No entanto, ao fazer algo assim, você começa a entender como melhorar todo o processo, com base na funcionalidade já implementada. As principais ideias, nesse sentido, para mim foram as seguintes coisas:
- Melhorar o mecanismo de otimização.
- Criar um mecanismo de fusão de EAs (colagem de bots).
- Arquitetura correta dos caminhos de interação de todos os componentes.
Isso é tudo muito resumido. Agora vou descrever mais detalhadamente. Por melhoria da otimização, entendo imediatamente um conjunto de vários fatores. Tudo isso é pensado dentro do paradigma escolhido para a construção de todo o sistema:
- Aceleração da otimização por meio da eliminação de ticks.
- Aceleração da otimização por meio da eliminação do controle da curva de lucro entre os pontos de decisão de negociação.
- Melhoria da qualidade da otimização por meio da introdução de critérios próprios de otimização.
- Maximização da eficiência do período ‘forward’.
Nos recantos do portal, ainda há debates sobre se a otimização é necessária e o que ela traz. Anteriormente, eu tinha uma atitude bastante categórica em relação a esta ação, mais influenciada por certas pessoas que frequentam fóruns e o próprio portal. Agora, essa opinião não me preocupa mais, e eu diria que tudo depende de você saber usar a otimização corretamente, para que você a está usando e como você faz isso. Com a aplicação correta, essa ação fornece o resultado desejado. No geral, verifica-se que esta ação é extremamente útil.
Muitos têm uma aversão à otimização, existem duas razões objetivas para isso:
- Falta de compreensão dos fundamentos (por que, o que e como fazer, como selecionar resultados e tudo relacionado a isso, incluindo a falta de experiência).
- Imperfeições dos algoritmos de otimização.
Na verdade, ambos os fatores se reforçam mutuamente. Para ser justo, devo dizer que o otimizador do MetaTrader 5 é construído impecavelmente do ponto de vista da construção, mas em termos de critérios de otimização e possíveis filtros, ainda há muito trabalho a ser feito. Até agora, toda essa funcionalidade está no nível de uma caixa de areia infantil. Poucos pensam em como alcançar períodos ‘forward’ positivos e, o mais importante, como controlar esse processo. Eu tenho pensado sobre isso há muito tempo, e pode-se dizer que boa parte do meu material é exatamente sobre isso.
Novo algoritmo de otimização
Além dos principais critérios de avaliação conhecidos de qualquer backtest, para uma seleção de resultados mais eficaz e subsequente aplicação das configurações, é possível inventar algumas características combinadas que podem ajudar a aumentar significativamente o valor de qualquer algoritmo. O benefício dessas características é que elas podem acelerar os processos de busca por configurações eficazes. Para isso, criei algo semelhante a um relatório de testador de estratégias, aproximadamente como no MetaTrader:
figura 1

Com essa ferramenta, posso escolher a opção desejada com um simples clique. O clique gera uma configuração que eu posso pegar imediatamente e mover para a pasta específica do terminal, para que os EAs universais a leiam e comecem a negociar com base nela. Além disso, se desejar, posso pressionar o botão de geração do EA, e ele será construído caso eu precise de um EA separado com a configuração incorporada. Também há um gráfico de curva de lucro, que é redesenhado ao selecionar outra opção da tabela.
Vamos entender o que é calculado nesta tabela. Os elementos primários para o cálculo dessas características são os seguintes dados:
- Points: lucro total do backtest em "_Point" do instrumento correspondente.
- Orders: número de ordens totalmente abertas e fechadas (seguidas em estrita ordem, pela regra de "pode haver apenas uma ordem aberta").
- Drawdown: rebaixamento do saldo.
As seguintes características de negociação são consideradas com base nesses valores:
- Math Waiting: expectativa matemática em pontos.
- P Factor: análogo ao fator de lucro normalizado no intervalo [-1 ... 0 ... 1] (meu critério).
- Martingale: indicador de aplicabilidade da martingale (meu critério).
- MPM Complex: indicador composto dos três anteriores (meu critério).
Agora, vamos ver como esses critérios são calculados:
fórmulas 1

Como pode ser visto, todos os critérios que criei são muito simples e, o mais importante, fáceis de entender. Devido ao fato de que o aumento de cada critério indica que o resultado do backtest é melhor do ponto de vista da teoria da probabilidade, torna-se possível multiplicar esses critérios, como fiz no critério "MPM Complex". O indicador geral será mais eficaz na ordenação dos resultados por sua importância, e durante otimizações em massa, permitirá manter mais opções de qualidade e eliminar mais opções de baixa qualidade, respectivamente.
Quero mencionar separadamente que, nesses cálculos, tudo acontece exatamente em pontos. Isso afeta positivamente o processo de otimização. Para os cálculos, são usadas estritamente quantidades primárias positivas, que sempre são calculadas no início, e com base nelas, tudo o mais é calculado. Acho que vale a pena listar essas quantidades primárias que não estão na tabela:
- Points Plus: soma dos lucros de cada ordem lucrativa ou nula em pontos.
- Points Minus: soma dos módulos das perdas de cada ordem perdida em pontos.
- Drawdown: rebaixamento do saldo (calculo de forma própria)
Aqui o mais interessante é como o rebaixamento é calculado. No nosso caso, trata-se do rebaixamento relativo máximo do saldo. Considerando o fato de que meu algoritmo de teste dispensa o monitoramento da curva de capital, os outros tipos de retração não podem ser calculados. No entanto, acho útil mostrar como calculo esse rebaixamento:
figura 2

É determinado de forma muito simples:
- Calculamos o ponto inicial do backtest (início da contagem do primeiro rebaixamento).
- Se a negociação começa com lucro, então movemos esse ponto para cima seguindo o aumento do saldo, até que apareça o primeiro prejuízo (que marca o início do cálculo do rebaixamento).
- Esperamos até que o saldo atinja o nível do ponto de início, após o qual fixamos esse ponto como o novo início de contagem.
- Voltamos ao último segmento de busca de rebaixamento e procuramos o ponto mais baixo nele (a partir do qual a magnitude do rebaixamento é calculado neste segmento).
- Repetimos todo o processo para todo o backtest ou curva de negociação.
É importante também notar que o último ciclo sempre permanecerá inacabado. No entanto, seu rebaixamento também é considerado, apesar de haver uma potencial possibilidade de seu aumento caso o teste continue no futuro. Mas isso não é um detalhe particularmente importante neste caso.
O critério de otimização mais importante
Quero tocar separadamente no filtro mais importante. Na verdade, esse critério é o mais importante na seleção dos resultados da otimização. Esse critério não está disponível na funcionalidade do otimizador do MetaTrader 5, mas posso dizer que é uma grande pena. No entanto, entendendo que ninguém vai me ouvir, quero fornecer material teórico para que todos os interessados possam reproduzir esse algoritmo em seu código. Na realidade, esse critério é multifuncional para qualquer tipo de negociação e funciona para absolutamente todas as curvas de lucro, incluindo apostas esportivas, criptomoedas e tudo o mais que você possa imaginar. O critério é o seguinte:
fórmulas 2

Vamos entender o que está dentro dessa fórmula:
- N — número de posições de negociação totalmente abertas e fechadas durante todo o backtest ou segmento de negociação.
- B(i) — valor da linha de saldo após a respectiva posição fechada "i".
- L(i) — linha reta traçada do zero ao último ponto de saldo (saldo final).
A peculiaridade do cálculo deste indicador é que são necessários dois backtests para seu cálculo. O primeiro backtest calcula o saldo final, e somente após isso é possível realizar o cálculo do indicador correspondente, salvando o valor de cada ponto de saldo, para que não seja necessário realizar cálculos extras. No entanto, de qualquer forma, este cálculo pode ser chamado de re-backtest. Essa fórmula pode ser usada em testadores personalizados que podem ser incorporados aos seus EAs (aqueles que sabem por quê).
É importante notar que este indicador, em geral, pode ser modificado para melhor compreensão. Por exemplo, assim:
fórmulas 3

Do ponto de vista da percepção e compreensão, esta fórmula é mais complexa. Mas, se considerarmos puramente a aplicação prática, tal critério é conveniente porque quanto maior, mais nossa curva de saldo se assemelha a uma linha reta. Eu toquei em questões semelhantes em artigos anteriores, mas não expliquei o significado embutido neles. Então, intuitivamente, acho que muitas pessoas entendem o quê e o porquê, mas nem todas. Para entender, vamos primeiro dar uma olhada na figura a seguir:
figura 3

Nesta figura, é mostrada a linha de saldo e duas curvas: uma relacionada à nossa fórmula (a que é vermelha) e a outra para o próximo critério modificado (fórmulas 11). Mostrarei isso mais adiante, mas agora vamos focar na fórmula, cujo significado estou revelando para você.
Se representarmos nosso backtest como um simples array de pontos com saldos, então podemos considerá-lo como uma amostra estatística e aplicar a ele fórmulas da teoria da probabilidade. A linha reta será considerada o modelo ao qual aspiramos, e a própria curva de lucro o fluxo real de dados que tende para o nosso modelo.
É importante entender que o fator de linearidade indica a confiabilidade de todo o conjunto de critérios de negociação existentes. Por sua vez, uma maior confiabilidade dos dados pode indicar um possível período ‘forward’ mais longo e de maior qualidade (negociação lucrativa no futuro). Falando estritamente, inicialmente deveria ter começado a considerar tais coisas a partir do estudo de variáveis aleatórias, mas me pareceu que essa apresentação simplificaria o aprendizado.
Vamos compor um análogo alternativo do nosso fator de linearidade, considerando possíveis valores atípicos. Para isso, precisaremos da introdução de uma variável aleatória conveniente para nós e sua média para o subsequente cálculo da variância:
fórmulas 4

Para compreensão, deve-se esclarecer que temos "N" posições totalmente abertas e fechadas, que seguem estritamente uma após a outra. Isso significa que temos "N+1" pontos, que conectam esses segmentos da linha de saldo. O ponto zero é comum a todas as linhas, portanto, seus dados distorcerão os resultados em favor da melhoria, assim como o último ponto. Por isso, vamos excluí-los dos cálculos e ficaremos com "N-1" pontos sobre os quais faremos os cálculos.
Foi muito interessante a escolha da expressão para transformar os arrays de valores de duas linhas em uma. Note a seguinte fração:
fórmulas 5

Importante aqui é que, em todos os casos, dividimos tudo pelo saldo final. Assim, convertemos tudo para uma grandeza relativa, o que garante a equivalência das características calculadas para todas as estratégias testadas, sem exceção. A mesma fração presente no critério mais simples do fator de linearidade não está lá por acaso, pois é baseada na mesma consideração. Mas vamos concluir a construção do nosso critério alternativo. Para isso, podemos usar um conceito bem conhecido como variância:
fórmulas 6

A variância é simplesmente a média aritmética do quadrado do desvio da média de toda a amostra. Eu imediatamente substituí nossas variáveis aleatórias, cujas expressões foram definidas anteriormente. Para a curva ideal, o desvio médio é zero, e, consequentemente, a variância dessa amostra também será zero. Com base nesses dados, não é difícil adivinhar que essa variância, devido à sua estrutura a variável aleatória usada ou a amostra (como preferir) pode ser usada como um fator de linearidade alternativo. Além disso, ambos os critérios podem ser usados em conjunto para uma limitação mais eficaz dos parâmetros da amostra, embora, honestamente, eu use apenas o primeiro critério.
E, para ser justo, vamos olhar para um critério semelhante, mais fácil de perceber, que também se baseia no novo fator de linearidade que definimos:
fórmulas 7
![]()
Como você pode ver, ele é idêntico ao critério semelhante baseado no primeiro (fórmulas 2). No entanto, esses dois critérios estão longe de ser o limite do que pode ser inventado. A favor dessa reflexão está o fato óbvio de que esse critério é muito idôneo e mais adequado para modelos ideais, e será extremamente difícil ajustar o Expert Advisor para que haja uma correspondência mais ou menos significativa. Acho que vale a pena listar os fatores negativos que se tornarão óbvios algum tempo após a aplicação dessas fórmulas:
- Redução crítica no número de trades (diminui a confiabilidade dos resultados)
- Descarte do máximo número de cenários eficazes (dependendo da estratégia, nem sempre a curva tende exatamente para uma linha reta)
Essas desvantagens são bastante críticas, pois o objetivo não é descartar boas estratégias, mas, ao contrário, encontrar novos critérios aprimorados, livres dessas desvantagens. Essas desvantagens podem ser completamente ou parcialmente neutralizadas introduzindo várias linhas preferenciais, cada uma das quais pode ser considerada um modelo aceitável ou preferencial. Para entender o novo critério aprimorado, livre dessas desvantagens, basta entender a substituição correspondente:
fórmulas 8

Depois, podemos calcular o fator de correspondência para cada curva da lista:
fórmulas 9

E, de maneira similar, também podemos calcular um critério alternativo, considerando valores atípicos aleatórios, também para cada curva:
fórmulas 10

Após o qual precisamos calcular o seguinte:
fórmulas 11

Aqui introduzo um critério chamado fator da família de curvas. Efetivamente, com essa ação, encontramos simultaneamente a curva mais semelhante à nossa curva de negociação e imediatamente encontramos o fator de correspondência para ela. A curva com o menor fator de correspondência é a mais próxima da situação real. Seu valor é aceito como o valor do critério modificado, e, claro, o cálculo pode ser feito de duas maneiras, dependendo de qual das duas variações preferimos.
Isso é tudo muito bom, mas aqui, como muitos notaram, existem nuances na seleção de tal família de curvas. É possível aderir a várias observações para descrever adequadamente essa família, mas aqui está minha opinião:
- Todas as curvas não devem ter pontos de inflexão (cada ponto intermediário subsequente deve estar estritamente acima do anterior).
- A curva deve ser côncava (a inclinação da curva pode ser constante ou apenas aumentar).
- A concavidade da curva deve ser ajustável (por exemplo, o grau de curvatura deve ser ajustável usando alguma grandeza relativa ou em porcentagem).
- Simplicidade do modelo da curva (o modelo é melhor baseado em modelos gráficos inicialmente simples e compreensíveis).
Como observação à parte, essa é apenas uma variação inicial da família de curvas com a qual comecei, mas é possível criar outras mais abrangentes e que levem em conta todas as configurações desejadas, o que pode eliminar completamente a perda de configurações de qualidade. No futuro, vou abordar esta tarefa, mas por enquanto vou discutir apenas a estratégia inicial da família de curvas côncavas. Consegui criar tal família facilmente, aplicando meus conhecimentos de matemática. Vamos mostrar imediatamente como essa família de curvas acaba parecendo:
figura 4

Na construção de tal família, usei a abstração de uma barra elástica apoiada em suportes verticais. O grau de curvatura dessa barra depende do ponto de aplicação da força e de sua magnitude. Claro, isso apenas lembra tal situação, mas é suficiente para desenvolver um modelo visualmente semelhante. Nesta situação, claro, deve-se determinar primeiro a coordenada do extremo, que deve coincidir com um dos pontos no gráfico do backtest, onde o eixo das abscissas é representado pelos índices dos trades, começando de zero. Eu calculo isso assim:
fórmulas 12

Há dois casos previstos aqui: para "N" par e ímpar. No caso de "N" ser par, não é possível simplesmente dividi-lo por dois, pois o índice deve ser um número inteiro. Foi precisamente esse caso, aliás, que representei na última imagem. Lá, o ponto de aplicação da força está um pouco mais próximo do início. Claro, é possível fazer o oposto, um pouco mais próximo do final, mas isso só será significativo com um pequeno número de trades, como também representei na imagem. Com o aumento do número de trades, isso não terá um papel perceptível para os algoritmos de otimização.
Definindo o valor da deflexão "P" em percentuais e o saldo final do backtest "B", após determinar a coordenada do extremo, pode-se proceder ao cálculo sequencial dos componentes adicionais para a construção de expressões para cada curva da família aceita. Em seguida, precisaremos da inclinação da linha que conecta o início e o fim do backtest:
fórmulas 13

Aliás, uma característica dessas curvas é o fato de que a tangente do ângulo de inclinação da tangente a cada uma das curvas nos pontos com abscissa "N0" é idêntica a "K". Ao construir as fórmulas, requeri essa condição do problema. Isso pode ser visto tanto graficamente na última imagem (imagem 4), e há algumas fórmulas e identidades lá também. Vamos prosseguir. Agora é necessário calcular o seguinte valor:
fórmulas 14

É importante notar aqui que "P" é definido separadamente para cada curva da família. Estritamente falando, são fórmulas para construir uma curva da família. Esses cálculos devem ser repetidos para cada curva da família. Depois, é necessário calcular outro coeficiente importante:
fórmulas 15
![]()
Não é necessário entender profundamente o significado dessas construções. Elas são criadas apenas para simplificar o processo de construção das curvas. Resta calcular o último coeficiente auxiliar:
fórmulas 16

Agora, com base nos dados obtidos, é possível obter a expressão matemática para calcular os pontos da curva construída. No entanto, é necessário esclarecer previamente que a curva não é descrita por uma única fórmula. À esquerda do ponto "N0", uma fórmula funciona, e à direita, outra. Para facilitar o entendimento, pode-se fazer o seguinte:
fórmulas 17
![]()
Agora, você pode ver as fórmulas finais:
fórmulas 18

Além disso, isso pode ser reescrito da seguinte maneira:
fórmulas 19

Estritamente falando, essa função deve ser usada como discreta e auxiliar. No entanto, ela permite calcular valores em "i" fracionários. O que, claro, dificilmente oferece qualquer benefício útil para nós no contexto da tarefa em questão.
Já que estou fornecendo tal matemática, devo também fornecer exemplos de implementação deste algoritmo. Acho que todos estarão interessados em obter um código pronto, que será mais fácil de adaptar aos seus sistemas. Começaremos definindo as variáveis principais e os métodos que simplificarão o cálculo dos valores necessários:
//+------------------------------------------------------------------+ //| Number of lines in the balance model | //+------------------------------------------------------------------+ #define Lines 11 //+------------------------------------------------------------------+ //| Initializing variables | //+------------------------------------------------------------------+ double MaxPercent = 10.0; double BalanceMidK[,Lines]; double Deviations[Lines]; int Segments; double K; //+------------------------------------------------------------------+ //| Method for initializing required variables and arrays | //| Parameters: number of segments and initial balance | //+------------------------------------------------------------------+ void InitLines(int SegmentsInput, double BalanceInput) { Segments = SegmentsInput; K = BalanceInput / Segments; ArrayResize(BalanceMidK,Segments+1); ZeroStartBalances(); ZeroDeviations(); BuildBalances(); } //+------------------------------------------------------------------+ //| Resetting variables for incrementing balances | //+------------------------------------------------------------------+ void ZeroStartBalances() { for (int i = 0; i < Lines; i++ ) { for (int j = 0; j <= Segments; j++) { BalanceMidK[j,i] = 0.0; } } } //+------------------------------------------------------------------+ //| Reset deviations | //+------------------------------------------------------------------+ void ZeroDeviations() { for (int i = 0; i < Lines; i++) { Deviations[i] = -1.0; } }
O código é projetado para reutilização. Após um cálculo subsequente, é possível realizar o cálculo do indicador para outra curva de saldo, após chamar o método "InitLines". Neste método, deve-se fornecer o saldo final do backtest e o número de trades, após o qual podemos começar a construir nossas curvas com base nesses dados:
//+------------------------------------------------------------------+ //| Constructing all balances | //+------------------------------------------------------------------+ void BuildBalances() { int N0 = MathFloor(Segments / 2.0) - Segments / 2.0 == 0 ? Segments / 2 : (int)MathFloor(Segments / 2.0);//calculate first required N0 for (int i = 0; i < Lines; i++) { if (i==0)//very first and straight line { for (int j = 0; j <= Segments; j++) { BalanceMidK[j,i] = K*j; } } else//build curved lines { double ThisP = i * (MaxPercent / 10.0);//calculate current line curvature percentage double KDelta = ( (ThisP /100.0) * K * Segments) / (MathPow(N0,2)/2.0 );//calculation first auxiliary ratio double Psi0 = -KDelta * N0;//calculation second auxiliary ratio double KDelta1 = ((ThisP / 100.0) * K * Segments) / (MathPow(Segments-N0, 2) / 2.0);//calculate last auxiliary ratio //this completes the calculation of auxiliary ratios for a specific line, it is time to construct it for (int j = 0; j <= N0; j++)//construct the first half of the curve { BalanceMidK[j,i] = (K + Psi0 + (KDelta * j) / 2.0) * j; } for (int j = N0; j <= Segments; j++)//construct the second half of the curve { BalanceMidK[j,i] = BalanceMidK[i, N0] + (K + (KDelta1 * (j-N0)) / 2.0) * (j-N0); } } } }
Note que "Lines" define quantas curvas haverá em nossa família. A concavidade aumenta gradualmente de zero (uma linha reta) até "MaxPercent", exatamente como mostrei na imagem correspondente. Depois disso, é possível calcular o desvio para cada uma das curvas e escolher o mínimo:
//+------------------------------------------------------------------+ //| Calculation of the minimum deviation from all lines | //| Parameters: initial balance passed via link | //| Return: minimum deviation | //+------------------------------------------------------------------+ double CalculateMinDeviation(double &OriginalBalance[]) { //define maximum relative deviation for each curve for (int i = 0; i < Lines; i++) { for (int j = 0; j <= Segments; j++) { double CurrentDeviation = OriginalBalance[Segments] ? MathAbs(OriginalBalance[j] - BalanceMidK[j, i]) / OriginalBalance[Segments] : -1.0; if (CurrentDeviation > Deviations[i]) { Deviations[i] = CurrentDeviation; } } } //determine curve with minimum deviation and deviation itself double MinDeviation=0.0; for (int i = 0; i < Lines; i++) { if ( Deviations[i] != -1.0 && MinDeviation == 0.0) { MinDeviation = Deviations[i]; } else if (Deviations[i] != -1.0 && Deviations[i] < MinDeviation) { MinDeviation = Deviations[i]; } } return MinDeviation; }
Deve-se usar assim:
- Definindo o array do saldo original "OriginalBalance".
- Com base nisso, definimos seu comprimento "SegmentsInput" e o saldo final "BalanceInput" e chamamos o método "InitLines".
- Depois disso, construímos as curvas, chamando o método "BuildBalances".
- Como as curvas estão construídas, podemos calcular nosso critério aprimorado da família de curvas "CalculateMinDeviation".
Com isso, o cálculo do critério estará concluído. Eu acho que todos entenderão facilmente como calcular o "Fator da Família de Curvas". Não é necessário trazer isso aqui.
Busca automática de configurações de negociação
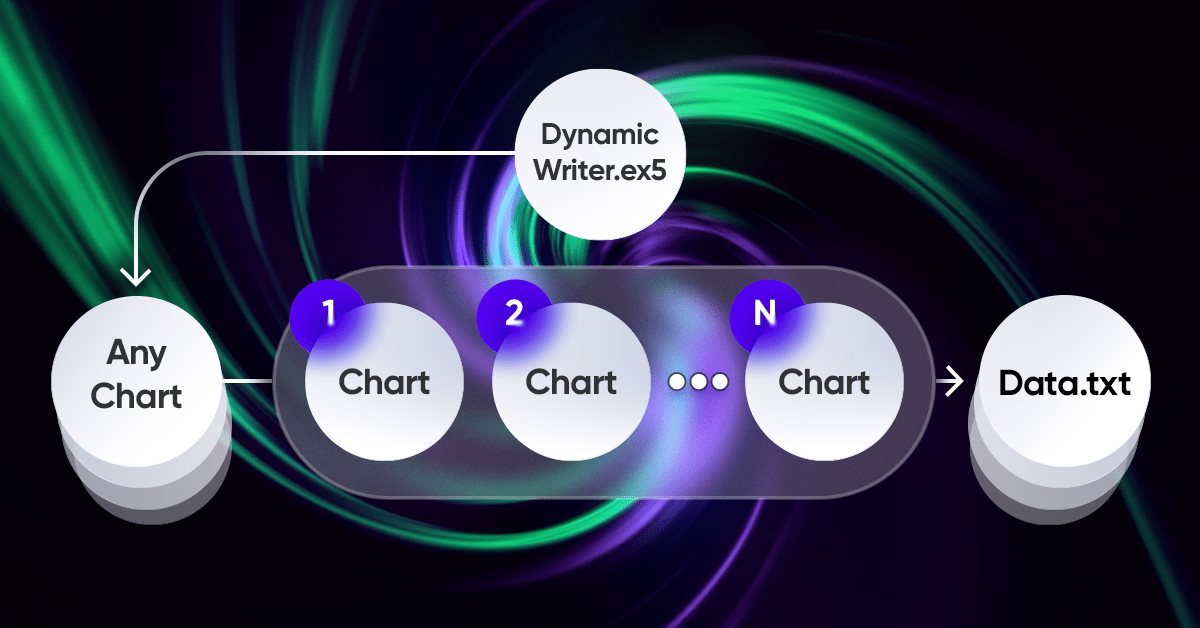
O elemento mais importante de toda a ideia é o sistema de interação entre o terminal e o meu programa. De fato, trata-se de um otimizador cíclico com critérios de otimização avançados, ao qual dediquei toda a seção anterior. Para que todo o sistema funcione, primeiro é necessário uma fonte de cotações, que é um dos terminais MetaTrader 5. Como já mostrei no artigo anterior, as cotações são registradas em um arquivo no formato que me é conveniente. Isso é feito por meio de um Expert Advisor (EA), que opera de uma maneira um tanto quanto peculiar à primeira vista:
. 
Achei bastante interessante e útil aplicar meu esquema único de operação dos EAs. Aqui é apresentada apenas uma demonstração baseada nas tarefas que precisava resolver, mas tudo isso pode ser aplicado também aos Expert Advisors:

A peculiaridade deste esquema é que escolhemos qualquer gráfico à nossa escolha. Este gráfico não será usado como um instrumento de negociação, para evitar duplicação de dados, mas serve apenas como um processador de ticks ou temporizador. E os outros gráficos representam os instrumentos-períodos, cujas cotações precisamos gerar.
O processo de gravação de cotações envolve a seleção aleatória de cotações usando um gerador de números aleatórios. Este processo pode ser otimizado, se necessário. A gravação ocorre em intervalos de tempo definidos usando a seguinte função principal:
//+------------------------------------------------------------------+ //| Function to write data if present | //| Write quotes to file | //+------------------------------------------------------------------+ void WriteDataIfPresent() { // Declare array to store quotes MqlRates rates[]; ArraySetAsSeries(rates, false); // Select a random chart from those we added to the workspace ChartData Chart = SelectAnyChart(); // If the file name string is not empty if (Chart.FileNameString != "") { // Copy quotes and calculate the real number of bars int copied = CopyRates(Chart.SymbolX, Chart.PeriodX, 1, int((YearsE*(365.0*(5.0/7.0)*24*60*60)) / double(PeriodSeconds(Chart.PeriodX))), rates); // Calculate ideal number of bars int ideal = int((YearsE*(365.0*(5.0/7.0)*24*60*60)) / double(PeriodSeconds(Chart.PeriodX))); // Calculate percentage of received data double Percent = 100.0 * copied / ideal; // If the received data is not very different from the desired data, // then we accept them and write them to a file if (Percent >= 95.0) { // Open file (create it if it does not exist, // otherwise, erase all the data it contained) OpenAndWriteStart(rates, Chart, CommonE); WriteAllBars(rates); // Write all data to file WriteEnd(rates); // Add to end CloseFile(); // Close and save data file } else { // If there are much fewer quotes than required for calculation Print("Not enough data"); } } }
A função "WriteDataIfPresent" grava no arquivo informações sobre as cotações do gráfico selecionado, se os dados copiados representarem pelo menos 95% do número ideal de barras, calculado com base nos parâmetros definidos. Se os dados copiados forem inferiores a 95%, a função exibe a mensagem "Dados insuficientes". Se o arquivo com o nome especificado não existir, a função o cria.
Para o funcionamento deste código, é necessário descrever adicionalmente o seguinte:
//+------------------------------------------------------------------+ //| ChartData structure | //| Objective: Storing the necessary chart data | //+------------------------------------------------------------------+ struct ChartData { string FileNameString; string SymbolX; ENUM_TIMEFRAMES PeriodX; }; //+------------------------------------------------------------------+ //| Randomindex function | //| Objective: Get a random number with uniform distribution | //+------------------------------------------------------------------+ int Randomindex(int start, int end) { return start + int((double(MathRand())/32767.0)*double(end-start+1)); } //+------------------------------------------------------------------+ //| SelectAnyChart function | //| Objective: View all charts except current one and select one of | //| them to write quotes | //+------------------------------------------------------------------+ ChartData SelectAnyChart() { ChartData chosenChart; chosenChart.FileNameString = ""; int chartCount = 0; long currentChartId, previousChartId = ChartFirst(); // Calculate number of charts while (currentChartId = ChartNext(previousChartId)) { if(currentChartId < 0) { break; } previousChartId = currentChartId; if (currentChartId != ChartID()) { chartCount++; } } int randomChartIndex = Randomindex(0, chartCount - 1); chartCount = 0; currentChartId = ChartFirst(); previousChartId = currentChartId; // Select random chart while (currentChartId = ChartNext(previousChartId)) { if(currentChartId < 0) { break; } previousChartId = currentChartId; // Fill in selected chart data if (chartCount == randomChartIndex) { chosenChart.SymbolX = ChartSymbol(currentChartId); chosenChart.PeriodX = ChartPeriod(currentChartId); chosenChart.FileNameString = "DataHistory" + " " + chosenChart.SymbolX + " " + IntegerToString(CorrectPeriod(chosenChart.PeriodX)); } if (chartCount > randomChartIndex) { break; } if (currentChartId != ChartID()) { chartCount++; } } return chosenChart; }
Este código é usado para gravar e analisar dados históricos do mercado financeiro (cotações) de várias moedas a partir de diferentes gráficos que podem estar abertos no terminal no momento.
- A estrutura "ChartData" é usada para armazenar dados sobre cada gráfico, incluindo o nome do arquivo, o símbolo (par de moedas) e o intervalo de tempo (timeframe).
- A função "RandomIndex(start, end)" gera um número aleatório entre "start" e "end". Isso é usado para selecionar aleatoriamente um dos gráficos disponíveis.
- "SelectAnyChart()" percorre todos os gráficos abertos e disponíveis, excluindo o atual, e então seleciona aleatoriamente um deles para processamento.
As cotações geradas são automaticamente capturadas pelo programa, após o qual ocorre a busca automática de configurações lucrativas. A automatização de todo o processo é bastante complexa, mas eu tentei resumi-la em uma imagem:
imagem 5

Existem três estados para este algoritmo:
- Desativado.
- Aguardando cotações.
- Ativo.
Se o Expert Advisor para gravação de cotações ainda não gerou nenhum arquivo ou se todas as cotações foram excluídas da pasta especificada, então o algoritmo simplesmente espera a sua aparição e pausa por um tempo. Quanto ao nosso critério aprimorado, que implementei para você no estilo MQL5, ele também é implementado tanto para aplicar força bruta quanto para otimização:
imagem 6

O modo avançado opera precisamente com o fator da família de curvas, enquanto o algoritmo padrão usa apenas o fator de linearidade. Os demais aprimoramentos são extensos demais para caber neste artigo. No próximo artigo, mostrarei meu novo algoritmo de fusão de Expert Advisors, que é baseado em um template universal multimoeda. O template é aplicado a um gráfico, mas processa todos os sistemas de negociação combinados, sem exigir que cada Expert Advisor seja lançado em seu próprio gráfico. Parte de sua funcionalidade foi transferida para este artigo.
Conclusão
As novas possibilidades e ideias no campo da automação do processo de desenvolvimento e otimização de sistemas de negociação são examinadas mais detalhadamente. Os principais avanços incluem o desenvolvimento de um novo algoritmo de otimização, a criação de um mecanismo de sincronização dos terminais e de um otimizador automático, bem como um critério de otimização importante o fator da curva e da família de curvas. Isso permite reduzir o tempo de desenvolvimento e melhorar a qualidade dos resultados obtidos.
Um acréscimo importante também foi a família de curvas côncavas, que representam um modelo de saldo mais realista no contexto de períodos ‘forward’ inverso. O cálculo do fator de adequação de cada curva permite escolher mais precisamente as configurações ótimas para a negociação automática.
Referências
- Força bruta para encontrar padrões (Parte V): uma nova perspectiva
- Força bruta para encontrar padrões (Parte IV): funcionalidade mínima
- Força bruta para encontrar padrões (Parte III): novos horizontes
- Força bruta para encontrar padrões (Parte II): imersão
- Força bruta para encontrar padrões
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/9305
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Você precisa
1) Desenvolver um sistema de simulações, intervalos de confiança e obter a curva como resultado não de um cálculo de TS de negociação como você fez, mas, por exemplo, de 50 simulações de TS em diferentes ambientes, a média dessas 50 simulações para obter como resultado a função de aptidão, que deve ser maximizada/minimizada.
2) Durante a busca da melhor curva (do ponto 1 ) pelo algoritmo de otimização, cada iteração deve ser correlacionada para testes múltiplos.
Há algum exemplo de alguém que tenha usado essa abordagem e a tenha levado a um resultado prático? Pergunta sem zombaria, realmente interessante.
Há algum exemplo de alguém que tenha usado essa abordagem e a tenha levado a um resultado prático? A pergunta é, sem zombaria, realmente interessante.
Eu o fiz e estou aplicando.
Seria interessante ver exemplos concretos. É claro que muitas pessoas simplesmente aplicam (embora com sucesso) e ficam caladas. Mas alguém deve ter descrições detalhadas do que fez, do que obteve e de como continuou negociando.
Seria interessante ver exemplos concretos. É evidente que muitas pessoas simplesmente aplicam (embora com sucesso) e ficam caladas. Mas alguém deveria ter descrições detalhadas do que fizeram, do que receberam e de como continuaram negociando.
Exemplos específicos que você pode ver na ciência e na medicina, como escrevi acima....
O que e como aplicar no mercado pode ser lido nas publicações acima...
Devido ao total analfabetismo dos traders e quase-traders, exemplos de aplicação desses métodos nos mercados não serão vistos em breve no domínio público....
Mas todos esses métodos estão disponíveis e abertos há muitos anos na forma de projetos de código aberto sobre ciência de dados em linguagens normais....
Em uma linguagem normal, tudo isso é escrito em 15 linhas de código.
E o que é a normalidade das linguagens de programação, como ela é definida?
Você sabe em que linguagem o autor do artigo escreveu o código principal de seu programa?
Você acha que a presença de bibliotecas específicas é um sinal de normalidade da linguagem?
Eu gostaria de ver discussões sobre o material do artigo. O autor publicou várias fórmulas para avaliar o desempenho da estratégia, portanto, escreva especificamente sobre suas deficiências, de forma razoável.
Não se sabe se ele se encaixará lá ou não, porque a seleção das regras da estratégia é desconhecida. Não se sabe o que está sob o capô. Talvez existam preditores selecionados por outros métodos.....
O autor não impõe nada, mas fala sobre sua visão e suas realizações, o que é bem-vindo nesse recurso e até mesmo incentivado financeiramente.