
Redes neurais em trading: Aumentando a eficiência do Transformer por meio da redução da nitidez (SAMformer)

Introdução
A previsão multivariada de séries temporais é uma tarefa clássica de aprendizado que consiste em analisar séries temporais para prever tendências futuras com base em informações históricas. E é uma tarefa complexa devido à correlação entre características e às dependências temporais de longo prazo nas séries temporais. Esse problema de aprendizado é amplamente encontrado em aplicações reais nas quais as observações são coletadas de forma sequencial (dados médicos, consumo de energia, preços de ações).
Recentemente, arquiteturas baseadas em Transformer vêm alcançando desempenho revolucionário em tarefas de processamento de linguagem natural e visão computacional. Transformer é especialmente eficaz ao lidar com dados sequenciais, o que naturalmente leva à aplicação dessas soluções em séries temporais. No entanto, o estado atual da previsão de séries temporais multivariadas é dominado por um modelo mais simples baseado em MLP.
Trabalhos recentes sobre o uso do Transformer em dados de séries temporais focam principalmente em implementações eficientes que reduzem o custo quadrático da atenção ou em decompor as séries temporais para melhor refletir os padrões subjacentes. Mas os autores do trabalho "SAMformer: Unlocking the Potential of Transformers in Time Series Forecasting with Sharpness-Aware Minimization and Channel-Wise Attention" destacam o problema de Transformer, que se manifesta na ausência de dados em larga escala.
Na visão computacional e no processamento de linguagem natural, descobriu-se que as matrizes de atenção podem sofrer com entropia ou colapso de posto. Vários métodos foram então propostos para superar esses problemas. No entanto, na previsão de séries temporais, ainda restam dúvidas sobre como treinar arquiteturas Transformer de maneira eficaz sem cair em overfitting. Os autores do estudo mencionado buscam mostrar que, ao eliminar a instabilidade do treinamento, é possível aumentar a eficiência do Transformer na previsão multivariada de longo prazo, contrariando as ideias previamente estabelecidas sobre suas limitações.
1. Algoritmo SAMformer
É considerada uma tarefa de previsão multivariada de longo prazo para uma série temporal de dimensão D e comprimento L (janela de retrospectiva). Os dados brutos são organizados como uma matriz 𝐗 ∈ RD×L. O objetivo é prever os próximos H valores (horizonte de previsão), denotados como 𝐘 ∈ RD×H. Suponha que temos acesso a um conjunto de treinamento que consiste em N observações. Buscamos treinar um modelo de previsão f𝝎: RD×L→RD×L com parâmetros 𝝎, que minimize o erro quadrático médio (MSE) sobre o conjunto de dados de treinamento.
Recentemente, foi demonstrado que os Transformers têm desempenho comparável ao de redes neurais lineares simples, treinadas diretamente para projetar os dados brutos nos valores de previsão. Com o intuito de investigar as causas desse fenômeno, os autores do framework SAMformer analisam um modelo generativo para uma tarefa de regressão artificial, imitando o cenário de previsão de séries temporais. Eles utilizam um modelo linear para gerar uma continuação da série temporal a partir de dados aleatórios e adicionam um pequeno ruído aos resultados obtidos. Dessa forma, foram gerados 15.000 conjuntos de dados brutos e seus respectivos resultados, divididos em 10.000 para o treinamento e 5.000 para a validação do modelo.
Utilizando esse modelo generativo, os autores do SAMformer desenvolvem uma arquitetura Transformer que pode resolver eficientemente o problema de previsão sem complexidade excessiva. Para isso, propõem simplificar o codificador Transformer padrão, mantendo apenas o bloco de Self-Attention e a conexão residual subsequente. Em vez do bloco FeedForward, é usado diretamente um layer linear para prever os dados futuros.
Vale destacar que os autores do framework utilizam atenção por canal, o que simplifica a tarefa e reduz o risco de superparametrização, já que a matriz de atenção torna-se significativamente menor devido ao fato de L>D. Além disso, a atenção por canal é mais adequada, pois a geração de dados segue um processo de identificação.
Para investigar o papel da atenção na resolução do problema, os autores do framework analisam um modelo chamado Random Transformer. Nele, apenas a camada de previsão é otimizada, enquanto todos os parâmetros do bloco Self-Attention são fixados durante o treinamento, com valores aleatórios definidos na inicialização. Isso força o Transformer analisado a atuar efetivamente como um modelo linear. A comparação entre os mínimos locais obtidos por esses dois modelos após a otimização com o método Adam, e a comparação com o modelo Oracle, que corresponde à solução pelo método dos mínimos quadrados, é apresentada na figura abaixo (visualização retirada do artigo original ).
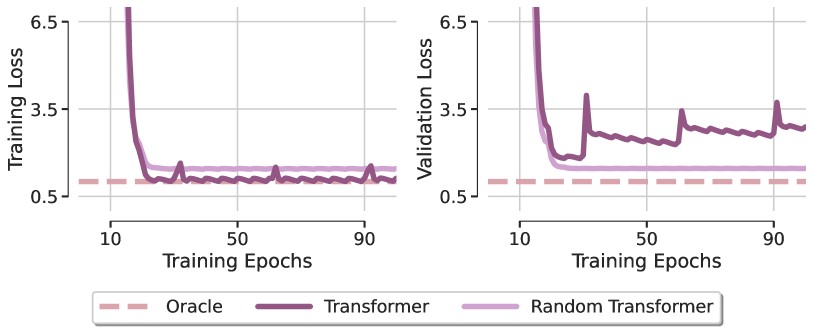
A primeira conclusão surpreendente é que ambos os Transformers não conseguem recuperar a dependência linear da regressão artificial, destacando que a otimização mesmo de uma arquitetura simples com design favorável revela uma clara falta de generalização. Essa observação permanece válida com diferentes otimizadores e taxas de aprendizado. A partir disso, os autores do framework concluem que as fracas capacidades de generalização do Transformer estão principalmente ligadas a problemas na treinabilidade do módulo de atenção.
Para entender melhor esse fenômeno observado, os autores do SAMformer visualizaram as matrizes de atenção em diferentes épocas do treinamento e descobriram que a matriz de atenção se aproxima de uma matriz identidade logo após a primeira época e quase não se altera nas etapas seguintes, especialmente quando o SoftMax amplifica as diferenças nos valores da matriz. Isso revela a ocorrência de um colapso entrópico da atenção com uma matriz de atenção de posto completo, identificada como uma das causas da rigidez no treinamento dos Transformers.
Os autores do SAMformer também identificam uma conexão entre o colapso de entropia e a nitidez da paisagem de perda do Transformer. O Transformer converge para um mínimo mais agudo do que o Random Transformer, apresentando ao mesmo tempo uma entropia significativamente menor (a atenção deste último é fixada na inicialização, mantendo sua entropia constante ao longo de todo o treinamento). Esses padrões patológicos sugerem que o Transformer falha devido ao colapso de entropia e à nitidez da sua função de perda durante o treinamento.
Pesquisas recentes demonstraram que a paisagem de perda dos Transformer é mais aguda quando comparada a outras arquiteturas. Isso pode explicar a instabilidade do treinamento e o baixo desempenho dos Transformer, especialmente ao treinar com conjuntos de dados pequenos.
Buscando uma solução adequada para melhorar a capacidade de generalização e a estabilidade do treinamento, os autores do framework SAMformer investigam dois caminhos. O primeiro propõe o uso de um sistema de minimização com consideração à nitidez, o qual substitui o objetivo do treinamento:
![]()
onde ρ>0 é um hiperparâmetro, e 𝝎 representa o parâmetro do modelo.
O segundo caminho inclui a reparametrização de todas as matrizes de pesos por meio da normalização espectral e de um escalar adicional treinável, chamado σReparam.
Os resultados destacam a convergência bem-sucedida da solução proposta para o resultado desejado. Surpreendentemente, isso é alcançado apenas com o uso do SAM, já que o σReparam não consegue se aproximar de um desempenho ideal, apesar da maximização da entropia da matriz de atenção. Além disso, a nitidez ao utilizar o SAM é vários níveis inferior à do Transformer, enquanto a entropia da atenção gerada pelo SAM permanece próxima à entropia do Transformer base, com um pequeno aumento nas etapas posteriores do treinamento. Isso indica que o colapso de entropia é benigno neste cenário.
Os autores do SAMformer complementam a solução descrita com a normalização reversível de instâncias (RevIN). Isso porque esse método demonstrou sua eficácia no tratamento do deslocamento entre os dados de treinamento e teste em séries temporais. Conforme indicado pelo estudo apresentado acima, a otimização do modelo é feita por meio do SAM, o que leva o modelo a convergir para mínimos locais mais planos. De forma geral, isso resulta em um modelo Transformer reduzido com apenas um codificador, conforme mostrado na figura abaixo (visualização dos autores).
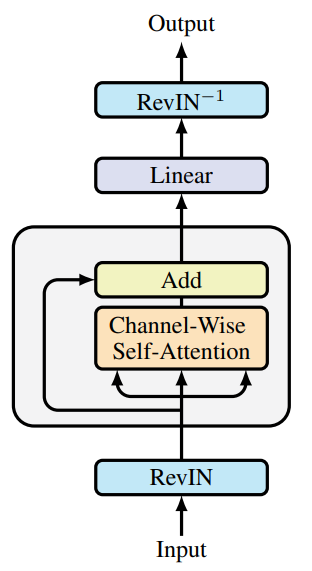
Destacamos que o SAMformer mantém a atenção por canal, representada por uma matriz D×D, ao contrário da atenção espacial (ou temporal), definida por uma matriz L×L usada em outros modelos. Isso traz duas vantagens importantes:
- assegura a invariância à permutação das características, eliminando a necessidade de codificação posicional, que geralmente precede a camada de atenção;
- leva à redução do tempo e da complexidade de memória, já que D≤L na maioria dos conjuntos de dados reais.
2. Implementação com MQL5
Após examinar os aspectos teóricos do framework SAMformer, passamos à implementação das abordagens propostas utilizando MQL5. E aqui é importante definir claramente o que exatamente será implementado em nossos modelos e de que forma. Vamos observar em detalhe o que os autores do framework SAMformer: propõem:
- redução do codificador Transformer ao nível do bloco de Self-Attention com conexão residual;
- atenção por canal;
- normalização reversível;
- otimização com SAM.
A redução do codificador é uma questão interessante, mas na minha opinião, seu principal valor prático está na diminuição da quantidade de parâmetros treináveis do modelo. Afinal, deixando de lado as formalidades, a funcionalidade do modelo não depende da nossa atribuição de certas camadas neurais ao bloco FeedForward do codificador ou ao bloco de previsão, que os autores do framework posicionam após o bloco de atenção.
Para estruturar a atenção por canal, basta transpor os dados brutos antes de enviá-los ao bloco de atenção. E para isso, não é necessário realizar nenhuma modificação.
Já estamos familiarizados com a normalização reversível RevIN. Resta apenas a otimização do modelo pelo método SAM. O SAM funciona buscando parâmetros que estejam em regiões com valores de perda uniformemente baixos.
O algoritmo de otimização SAM opera em várias etapas. Primeiro, com base nos resultados da propagação para frente, obtemos o gradiente do erro no nível dos parâmetros do modelo. Normalizamos os gradientes de erro obtidos e os somamos aos parâmetros atuais, considerando o coeficiente de nitidez. Em seguida, realizamos uma nova propagação para frente e redistribuímos os gradientes de erro. Depois, restauramos a matriz de pesos ao estado anterior, subtraindo o gradiente normalizado que havia sido adicionado. E, por fim, os parâmetros são atualizados utilizando um dos métodos clássicos, como SGD ou Adam. Os autores do framework SAMformer recomendam o uso do Adam.
É importante observar que os autores do método aplicam a normalização dos gradientes de erro em toda a extensão do modelo. Isso é bastante trabalhoso. E, nesse contexto, torna-se mais relevante a questão da redução do número de parâmetros do modelo. A solução evidente é a diminuição dos layers internos e das cabeças de atenção. Foi exatamente isso que os autores do framework SAMformer fizeram.
No nosso caso, decidimos nos afastar um pouco da implementação original, e realizaremos a normalização dos gradientes de erro apenas dentro de uma camada neural individual. Mais ainda: vamos aplicar uma normalização separada dos gradientes para cada grupo de parâmetros que compõem o valor de um único neurônio. E começaremos nossa implementação com a construção de novos kernels no lado do programa OpenCL.
2.1 Complemento ao programa OpenCL
Acredito que você já percebeu que, em nossos trabalhos, usamos com mais frequência dois tipos de camadas neurais: totalmente conectadas e convolucionais. Todos os nossos módulos de atenção são, de uma forma ou de outra, construídos sobre o uso de camadas convolucionais, que empregamos sem sobreposição para análise e transformação de elementos individuais da sequência em análise. Por isso, decidimos estender a funcionalidade justamente dessas duas camadas neurais com a otimização SAM. No lado do programa OpenCL, vamos criar kernels para normalização do gradiente de erro e para criação dos pesos ω+ε.
O primeiro kernel que vamos criar será para a camada totalmente conectada: o CalcEpsilonWeights. Os parâmetros desse kernel incluem ponteiros para 4 buffers de dados e o coeficiente de dispersão da nitidez. Três dos buffers contêm as informações de entrada e um é destinado à gravação dos resultados.
__kernel void CalcEpsilonWeights(__global const float *matrix_w, __global const float *matrix_g, __global const float *matrix_i, __global float *matrix_epsw, const float rho ) { const size_t inp = get_local_id(0); const size_t inputs = get_local_size(0) - 1; const size_t out = get_global_id(1);
O plano é chamar esse kernel em um espaço de tarefas bidimensional, com agrupamento em grupos de trabalho pelo primeiro eixo. No corpo do kernel, identificamos imediatamente o fluxo atual de operações em todas as dimensões do espaço de tarefas.
Em seguida, declaramos um array de dados na memória local do dispositivo para organizar o processo de troca de dados entre os fluxos da mesma grupo de trabalho.
__local float temp[LOCAL_ARRAY_SIZE]; const int ls = min((int)inputs, (int)LOCAL_ARRAY_SIZE);
Na próxima etapa, definiremos o gradiente de erro do elemento analisado como o produto dos elementos correspondentes nos buffers de dados brutos e dos gradientes na saída da camada. O valor obtido será ponderado pelo valor absoluto do parâmetro analisado. Isso permitirá aumentar o peso dos parâmetros que mais contribuem para o resultado da camada.
const int shift_w = out * (inputs + 1) + inp; const float w =IsNaNOrInf(matrix_w[shift_w],0); float grad = fabs(w) * IsNaNOrInf(matrix_g[out],0) * (inputs == inp ? 1.0f : IsNaNOrInf(matrix_i[inp],0));
Depois, precisaremos encontrar a norma L2 dos gradientes de erro obtidos. Para isso, somamos os quadrados dos valores calculados dentro do grupo de trabalho utilizando um array na memória local e dois laços sequenciais, como já fizemos em trabalhos anteriores.
const int local_shift = inp % ls; for(int i = 0; i <= inputs; i += ls) { if(i <= inp && inp < (i + ls)) temp[local_shift] = (i == 0 ? 0 : temp[local_shift]) + IsNaNOrInf(grad * grad,0); barrier(CLK_LOCAL_MEM_FENCE); } //--- int count = ls; do { count = (count + 1) / 2; if(inp < count) temp[inp] += ((inp + count) < inputs ? IsNaNOrInf(temp[inp + count],0) : 0); if(inp + count < inputs) temp[inp + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
A raiz quadrada da soma obtida será a norma procurada dos gradientes. Com ela, encontraremos o valor corrigido do parâmetro.
float norm = sqrt(IsNaNOrInf(temp[0],0)); float epsw = IsNaNOrInf(w * w * grad * rho / (norm + 1.2e-7), w); //--- matrix_epsw[shift_w] = epsw; }
E salvaremos esse valor calculado no elemento correspondente do buffer global de resultados.
De forma semelhante, foi construído o kernel CalcEpsilonWeightsConv, que realiza a correção inicial dos parâmetros da camada convolucional. No entanto, como você sabe, a camada convolucional tem suas particularidades. Ela possui uma quantidade menor de parâmetros, mas cada parâmetro interage com diversos elementos da camada de dados brutos e participa na formação dos valores de vários elementos no buffer de resultados. Portanto, o gradiente de erro de um parâmetro é formado pela soma de suas contribuições provenientes de diversos elementos do buffer de resultados.
A especificidade da camada convolucional também se reflete nos parâmetros do kernel. Aqui, aparecem duas constantes adicionais que definem o tamanho da sequência de entrada e o deslocamento da janela de dados brutos.
__kernel void CalcEpsilonWeightsConv(__global const float *matrix_w, __global const float *matrix_g, __global const float *matrix_i, __global float *matrix_epsw, const int inputs, const float rho, const int step ) { //--- const size_t inp = get_local_id(0); const size_t window_in = get_local_size(0) - 1; const size_t out = get_global_id(1); const size_t window_out = get_global_size(1); const size_t v = get_global_id(2); const size_t variables = get_global_size(2);
Também aumentamos a dimensionalidade do espaço de tarefas para 3. A primeira dimensão corresponde à janela analisada dos dados brutos, ampliada por um elemento de deslocamento. Na segunda dimensão, indicamos o número de filtros convolucionais. A terceira representa o número de sequências independentes nos dados brutos. Como antes, agrupamos os fluxos de operações em grupos de trabalho pela primeira dimensão.
No corpo do kernel, identificamos o fluxo de operações atual em todas as dimensões do espaço de tarefas. Depois, inicializamos um array de dados na memória local do contexto OpenCL para troca de informações dentro do grupo de trabalho.
__local float temp[LOCAL_ARRAY_SIZE]; const int ls = min((int)(window_in + 1), (int)LOCAL_ARRAY_SIZE);
Em seguida, calculamos a quantidade de elementos de cada filtro no buffer de resultados e definimos os deslocamentos nos buffers de dados.
const int shift_w = (out + v * window_out) * (window_in + 1) + inp; const int total = (inputs - window_in + step - 1) / step; const int shift_out = v * total * window_out + out; const int shift_in = v * inputs + inp; const float w = IsNaNOrInf(matrix_w[shift_w], 0);
Aqui mesmo, salvamos em uma variável local o valor atual do parâmetro analisado, o que nos permitirá reduzir a quantidade de acessos à memória global nas operações seguintes.
Na etapa seguinte, vamos reunir o gradiente de erro de todos os elementos do buffer de resultados sobre os quais o parâmetro analisado teve influência.
float grad = 0; for(int t = 0; t < total; t++) { if(inp != window_in && (inp + t * step) >= inputs) break; float g = IsNaNOrInf(matrix_g[t * window_out + shift_out],0); float i = IsNaNOrInf(inp == window_in ? 1.0f : matrix_i[t * step + shift_in],0); grad += IsNaNOrInf(g * i,0); }
Corrigimos esse gradiente pelo valor absoluto do nosso parâmetro.
grad *= fabs(w);
E utilizamos o algoritmo descrito anteriormente, com dois laços sequenciais, para somar os quadrados dos valores obtidos dentro do grupo de trabalho.
const int local_shift = inp % ls; for(int i = 0; i <= inputs; i += ls) { if(i <= inp && inp < (i + ls)) temp[local_shift] = (i == 0 ? 0 : temp[local_shift]) + IsNaNOrInf(grad * grad,0); barrier(CLK_LOCAL_MEM_FENCE); } //--- int count = ls; do { count = (count + 1) / 2; if(inp < count) temp[inp] += ((inp + count) < inputs ? IsNaNOrInf(temp[inp + count],0) : 0); if(inp + count < inputs) temp[inp + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
A raiz quadrada da soma obtida corresponde à norma desejada dos gradientes de erro.
float norm = sqrt(IsNaNOrInf(temp[0],0)); float epsw = IsNaNOrInf(w * w * grad * rho / (norm + 1.2e-7),w); //--- matrix_epsw[shift_w] = epsw; }
Calculamos o valor do parâmetro corrigido e o salvamos no elemento correspondente do buffer de resultados.
Com isso, finalizamos a parte do trabalho no programa OpenCL. O código completo pode ser consultado no anexo.
2.2 Camada totalmente conectada com otimização SAM
Após concluir a parte do programa OpenCL, passamos a trabalhar com nossa biblioteca, onde criaremos o objeto da camada totalmente conectada com funcionalidade de otimização SAM: o CNeuronBaseSAMOCL. A estrutura da nova classe está apresentada abaixo.
class CNeuronBaseSAMOCL : public CNeuronBaseOCL { protected: float fRho; CBufferFloat cWeightsSAM; //--- virtual bool calcEpsilonWeights(CNeuronBaseSAMOCL *NeuronOCL); virtual bool feedForwardSAM(CNeuronBaseSAMOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronBaseSAMOCL(void) {}; ~CNeuronBaseSAMOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, float rho, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronBaseSAMOCL; } virtual int Activation(void) const { return (fRho == 0 ? (int)None : (int)activation); } virtual int getWeightsSAMIndex(void) { return cWeightsSAM.GetIndex(); } //--- virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Como é possível notar na estrutura acima do novo objeto, a funcionalidade principal é herdada da camada totalmente conectada base. Basicamente, trata-se de uma cópia da camada base, na qual reescrevemos o método de atualização dos parâmetros, agora com o funcional SAM de otimização.
Ainda assim, adicionamos o método wrapper calcEpsilonWeights para o kernel de mesmo nome, descrito anteriormente, e fizemos uma cópia do método de propagação para frente, no qual alteramos o buffer de pesos para feedForwardSAM.
Cabe observar que os autores do framework SAMformer inicialmente adicionavam ε aos parâmetros do modelo e depois subtraíam, retornando os parâmetros ao estado original. Nós adotamos uma abordagem um pouco diferente. Armazenamos os parâmetros corrigidos em um buffer separado. Isso nos permitiu eliminar a operação de subtração de ε e, assim, reduzir o tempo total de execução das operações. Mas vamos por partes.
O buffer dos parâmetros corrigidos do modelo foi declarado de forma estática, o que nos permite manter o construtor e o destruidor da classe vazios. A inicialização de todos os objetos declarados e herdados ocorre no método Init.
bool CNeuronBaseSAMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, float rho, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, numNeurons, optimization_type, batch)) return false;
Nos parâmetros desse método, recebemos as constantes principais que definem a arquitetura do objeto que está sendo criado. E no corpo do método, chamamos diretamente o método de mesmo nome da classe pai, no qual é feito o controle dos parâmetros recebidos e a inicialização dos objetos herdados.
Após a execução bem-sucedida do método da classe pai, armazenamos o coeficiente da área de dispersão em uma variável interna.
fRho = fabs(rho); if(fRho == 0 || !Weights) return true;
Em seguida, verificamos o valor do coeficiente de dispersão obtido e a presença da matriz de parâmetros. Se o coeficiente de dispersão for igual a "0" ou se a matriz de parâmetros estiver ausente (ou seja, a camada não possui conexões de saída), encerramos a execução do método com sucesso. Caso contrário, é necessário criar um buffer de parâmetros alternativos. Criamos esse buffer com a mesma estrutura do buffer de parâmetros principais, mas nesta etapa o inicializamos com valores nulos.
if(!cWeightsSAM.BufferInit(Weights.Total(), 0) || !cWeightsSAM.BufferCreate(OpenCL)) return false; //--- return true; }
E assim finalizamos a execução do método.
Com relação aos métodos-wrapper para o enfileiramento dos kernels, recomendo que você os consulte por conta própria. O código está disponível no anexo. Nós agora seguimos para a análise do método de atualização de parâmetros updateInputWeights.
bool CNeuronBaseSAMOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(NeuronOCL.Type() != Type() || fRho == 0) return CNeuronBaseOCL::updateInputWeights(NeuronOCL);
Nos parâmetros do método, como de costume, recebemos um ponteiro para o objeto de dados brutos. E, no corpo do método, verificamos imediatamente a validade do ponteiro recebido. Sem um ponteiro válido para a camada de dados brutos, a continuação da execução do método não é possível, pois isso levaria a erros críticos.
Também verificamos o tipo do objeto de dados brutos, pois nesse caso essa informação é relevante. Além disso, o coeficiente de dispersão deve ser maior que "0". Do contrário, o SAM se reduz a uma camada base de otimização. E, então, chamamos o método correspondente da classe pai.
Após a execução bem-sucedida do bloco de verificação descrito acima, seguimos com as operações específicas do método SAM. E aqui vale lembrar que o algoritmo SAM pressupõe uma propagação completa — tanto a propagação para frente quanto a propagação reversa — com o repasse dos gradientes de erro até os parâmetros do modelo após a adição de ε a esses parâmetros. No entanto, como definido anteriormente, organizamos o algoritmo SAM dentro de uma camada individual. Surge, portanto, uma questão natural: onde obter os valores-alvo para cada camada?
À primeira vista, a resposta parece óbvia — basta somar o resultado final da propagação para frente com o gradiente de erro. Mas há um detalhe. Quando recebemos o gradiente de erro da camada seguinte, ele já foi corrigido pela derivada da função de ativação. Ou seja, uma simples soma dos dados distorceria o resultado. E, nesse ponto, pareceria necessário criar um mecanismo para reverter essa correção do gradiente de erro pela derivada da função de ativação, mas encontramos uma solução mais simples. Reescrevemos o método de retorno da função de ativação, de forma que, quando o coeficiente de dispersão for zero, o método retorne None. Dessa forma, recebemos da camada seguinte o gradiente de erro sem a correção pela função de ativação. Logo, podemos somar o resultado da propagação para frente com o gradiente de erro recebido, e o resultado dessa soma será o alvo do neurônio analisado nesta camada.
if(!SumAndNormilize(Gradient, Output, Gradient, 1, false, 0, 0, 0, 1)) return false;
Em seguida, chamamos o método-wrapper para obter os parâmetros corrigidos do modelo.
if(!calcEpsilonWeights(NeuronOCL)) return false;
E realizamos a propagação para frente utilizando os parâmetros modificados.
if(!feedForwardSAM(NeuronOCL)) return false;
Agora, no buffer de gradientes de erro, temos os valores-alvo, e no buffer de resultados, o vetor para o qual os parâmetros corrigidos nos conduzem. Para determinar a diferença entre esses valores, basta chamar o método da classe pai que calcula a divergência em relação aos resultados-alvo.
float error = 1; if(!calcOutputGradients(Gradient, error)) return false;
Por fim, resta apenas ajustar os parâmetros do modelo considerando o novo gradiente de erro. Para isso, é suficiente invocar o método de mesmo nome da classe pai.
return CNeuronBaseOCL::updateInputWeights(NeuronOCL);
}
Vale comentar brevemente sobre os métodos de manipulação de arquivos. Para economizar espaço em disco, optamos por não salvar o buffer de parâmetros corrigidos cWeightsSAM. Salvar esses dados não teria valor prático, pois o conteúdo desse buffer é relevante apenas durante a execução do método de atualização de parâmetros. E será sobrescrito na próxima chamada do método. Assim, o volume de dados salvos aumentou apenas por um único elemento do tipo float (o coeficiente da área de dispersão).
bool CNeuronBaseSAMOCL::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; if(FileWriteFloat(file_handle, fRho) < INT_VALUE) return false; //--- return true; }
Por outro lado, o buffer cWeightsSAM é necessário para executar a funcionalidade proposta. E o tamanho dele é extremamente importante — deve ser suficiente para armazenar todos os parâmetros da camada atual. Portanto, precisamos restaurá-lo ao carregar um modelo salvo anteriormente. No método de carregamento de dados, começamos executando as operações do método homônimo da classe pai.
bool CNeuronBaseSAMOCL::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false;
Depois, verificamos o fim do arquivo e, se houver dados adicionais, lemos o coeficiente da área de dispersão.
if(FileIsEnding(file_handle)) return false; fRho = FileReadFloat(file_handle);
Em seguida, verificamos se o coeficiente de dispersão é diferente de zero, bem como a existência da matriz de parâmetros (o ponteiro pode estar inválido no caso de a camada neural não possuir conexões de saída).
if(fRho == 0 || !Weights) return true;
Se for encontrado ao menos um desses impedimentos, a otimização dos parâmetros regride aos métodos básicos, e não há necessidade de criar o buffer de parâmetros corrigidos. Portanto, encerramos a execução do método com sucesso.
É importante ressaltar que a falha nessa etapa de verificação é crítica para a otimização SAM, mas não impede o funcionamento do modelo como um todo. Por isso, seguimos com os métodos básicos de otimização.
Caso seja necessário criar o buffer, primeiro limpamos o buffer existente. Optamos conscientemente por não verificar o resultado dessas operações. Afinal, podem ocorrer situações em que, no momento do carregamento dos dados, esse buffer ainda não exista.
cWeightsSAM.BufferFree();
Em seguida, inicializamos o buffer com tamanho suficiente usando valores nulos e criamos sua cópia dentro do contexto OpenCL.
if(!cWeightsSAM.BufferInit(Weights.Total(), 0) || !cWeightsSAM.BufferCreate(OpenCL)) return false; //--- return true; }
Desta vez, monitoramos a execução das operações, pois a realização correta dessas operações é crítica para o funcionamento posterior do modelo. Após a conclusão, encerramos o método retornando um valor lógico com o resultado da execução para o programa que o chamou.
Com isso, finalizamos a análise dos algoritmos de construção dos métodos do objeto da camada totalmente conectada com funcionalidade de otimização SAM, o CNeuronBaseSAMOCL. O código completo dessa classe e de todos os seus métodos pode ser consultado no anexo.
Infelizmente, o espaço da presente matéria está quase esgotado, e ainda não concluímos todo o trabalho. No próximo artigo, daremos continuidade ao que foi iniciado e veremos a implementação da camada convolucional com a funcionalidade SAM. Analisaremos a inserção das tecnologias propostas dentro da arquitetura do Transformer e, naturalmente, testaremos a eficácia das abordagens sugeridas em dados históricos reais.
Considerações finais
O SAMformer oferece uma solução eficaz para os principais desafios enfrentados pelos Transformer na previsão de longo prazo de séries temporais multivariadas, como a complexidade do treinamento e a fraca capacidade de generalização em conjuntos de dados reduzidos. Com uma arquitetura pouco profunda e um mecanismo de otimização com consideração à nitidez, o SAMformer não apenas evita mínimos locais ruins, como também demonstra superioridade em relação aos métodos contemporâneos, mesmo com uma quantidade menor de parâmetros. Os resultados apresentados no artigo original confirmam seu potencial como uma ferramenta versátil para tarefas envolvendo séries temporais.
Na parte prática de nosso artigo, iniciamos a implementação das abordagens propostas utilizando os recursos do MQL5. Mas nosso trabalho ainda está em andamento. E na próxima matéria, avaliaremos o valor prático dessas abordagens para a resolução dos nossos objetivos.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos com o método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento de modelos |
| 4 | StudyEncoder.mq5 | Expert Advisor | EA para treinamento do codificador |
| 5 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrever o estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código para programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16388
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso