
初級から中級へ:配列と文字列(I)

はじめに
ここで提示されるコンテンツは、教育目的のみに使用されることを意図しています。いかなる状況においても、提示された概念を学習し習得する以外の目的でアプリケーションを閲覧することは避けてください。
前回の「初級から中級まで:演算子の優先順位」では、コード内のリファクタリングにおいて注意すべき点について少し触れました。一見正しいように見えても、特定の状況ではまったく予期しない結果を生み出すコードに遭遇することは珍しくありません。この種の問題は、多くの場合、リファクタリングの実装方法に起因しています。一貫した結果を出すコードを書くことは、一見すると簡単そうに思えます。しかし、適切な知識がなければ(前回の記事で示したように)、不適切に実装されたリファクタリングが増えるほど、致命的なバグが生じるリスクが高まります。
適切なリファクタリングについての理論的な部分は非常に退屈で面倒なため、ここでは詳しく説明しません。代わりに、実践的な側面に焦点を当てて進めていきます。ぜひ、サンプルコードを実際に試してみてください。リファクタリングの方法を変えてみたり、制御フローを少しアレンジしてみるのも良いでしょう。
こうした練習は非常に有意義です。というのも、提示された方法とは異なるやり方で同じ結果を得る方法を自分自身で模索することが、学びを深める最良の手段だからです。一見すると時間の無駄に思えるかもしれませんが、これは非常に効果的な学習方法です。添付ファイルには正常に動作するコードが含まれていますので、それと同じ結果を出す別のバージョンを自分で作成してみてください。練習を重ねれば、たとえ最初は未熟なコードであっても、自分だけのソリューションを構築できるようになります。
それでは、本題に入っていきましょう。ここからの内容を理解するには、変数や定数の宣言・初期化・使用方法について、すでにしっかりと理解している必要があります。今回の主な焦点は演算子の使い方ですが、変数や定数の扱いができなければ、解説を十分に理解するのは難しいでしょう。ここでは、いくつかの特殊なデータ型を紹介していきます。できるだけ理論だけに偏らず、実用的な視点から説明を進めていきます。このトピックは、前回の「演算子の優先順位」と並んで、プログラミングの中でもやや難しい分野の一つです。ですが、今回はできるだけわかりやすい角度から取り上げ、理解しやすい形で導入していきます。この基礎を押さえておくことで、今後さらに難易度の高い内容に取り組む際にも役立つでしょう。それでは、始めていきましょう。
配列と文字列
静的型付け言語を扱い始めたばかりのプログラマーにとって、間違いなく最も混乱しやすく、時に挫折の原因ともなるトピックの一つが、配列と文字列です。これは、PythonやJavaScriptのような動的型付け言語では、これらのトピックがほぼ透過的に処理され、プログラマーが定義や構造についてあまり心配せずに使用できるためです。
これに対して、CやC++のような言語では、こうした2つのエンティティが内部的にどう扱われるかによって、このテーマは途端に複雑になります。というのも、CやC++では配列と文字列は明確に別の存在とはされておらず、同じコンテキストの中で、操作の仕方によっては「第3の」あるいは「第4の」エンティティにすら見えてしまう場合があるからです。つまり、初心者にとっては理解するのが難しいテーマです。
しかしMQL5は、C/C++のような静的型付け言語と、PythonやJavaScriptのような動的型付け言語との間にあるような存在です。なぜそう言えるのでしょうか。CやC++では、配列のデータ型が無視できる(少なくとも一部のケースで)こともあり、文字列についても似たような状況が起こります。一方MQL5では、そうした柔軟性は制限されています。少なくとも、ある種の操作を行わない限りは許されません。これはある意味、学習プロセスを単純化してくれる要因でもあります。しかし裏を返せば、CやC++では簡単にできるような操作も、MQL5では難しかったり、不可能だったりする場合があるということです。とはいえ、初心者がMQL5で「手に負えない」ようなコードを書いてしまうリスクは非常に低くなります。CやC++では、ちょっとしたミスが「時限爆弾」のようになり、後で大きな問題を引き起こす可能性があります。
だからこそ、私たちにとっては、MQL5で同じタスクを実行するほうが、CやC++でやるよりも遥かに簡単なのです。私はこの文章を通じて、CやC++で得られる知見をMQL5に翻訳して紹介し、読者の皆さんが高度なプログラミングスキルに到達できるようお手伝いしたいと考えています。
さて、本題に入りましょう。まず明らかにしておきたいのは、「配列と文字列は、ある意味で同じものである」ということです。少なくとも、データがメモリ上にどのように格納されるかという点においてはそうです。より正確に言えば、文字列とは「特殊な形式の配列」にすぎません。「特殊」とされるのは、ある1つの違いがあるからです。それは、文字列が終了地点を示す「マーカー」を持つことです。通常の配列には、そのようなマーカーは存在しません。
理解しやすくするために、他のプログラミング言語と軽く比較してみましょう。たとえば、(MS-DOS時代の)古いBASICをベースにしたような言語では、文字列の最初の文字に「その文字列の長さ」が格納されます。この方法では、文字列内に含まれるデータの長さが明示的に示されるため、あらゆる文字を自由に含めることができます。その最初の「長さ情報」は1バイト以上を占め、画面には表示されません。つまり、ユーザーには見えず、コードの中でしか扱えない情報です。この形式なら、文字列内にどんな文字や数値を入れることも可能ですが、同時に「文字列の最大長」はその最初の長さバイトのサイズに依存します。
一方で、CやC++系の言語では違う方式が取られています。これらの言語では、特殊な文字や値を使って、文字列の「終わり」を示します。実際のところ、CやC++には文字列のためのネイティブなデータ型というものは存在しません。通常は、nullやゼロ値が終端記号として使われます。この終端値が配列内に現れた時点で、文字列の終わりと見なされるのです。この方式では、基本的に使用可能なメモリを最大限に使って長い文字列を作ることができます。しかし同時に、文字列内にnull文字を含めることはできません。
MQL5はCおよびC++をベースにしているため、この論理をそのまま踏襲しています。ただし、CやC++とは異なり、MQL5には「string」という型が存在しています。そのため、常にstring型のまま操作できるとは限らず、場合によっては配列を使ったほうが都合が良いケースも出てきます。もちろん、そのアプローチにも別の問題が発生するかもしれません。幸いなことに、MQL5のライブラリはこれらの課題に対して多くの(単純なものから複雑なものまで)回避策を用意しています。
ここまでなぜ長々と説明してきたかというと、理由は明白です。配列と文字列がどのように構造化されているかを正しく理解していないと、選択肢が大きく制限されてしまい、特定のタスクを実現することができなくなるからです。特に、より高度なプログラミング操作において顕著です。「MQL5ではこれができない、あれができない」という不満を耳にすることは珍しくありません。しかしそうした声の背景には、標準ライブラリが提供する基本機能以上のことを行うために必要な「概念的理解」が欠けている、というケースが多いのです。
誤解のないように言っておきますが、標準ライブラリを使うことは、知識が足りないことを意味するわけではありません。むしろその逆で、しっかりした知識を持っていないと使いこなせないものです。ただ、「配列」や「文字列」などが、実際にはどのように機能しているのかを理解していないと、「できないことが多すぎる」と感じてしまうでしょう。
だからこそ、読者の皆さんに理解しておいてほしいのです。配列は、基本的にどんなデータでも格納できる「汎用的な構造」である一方、文字列は、制限された、そして場合によっては完全に限定された構造体です。何かを作ろうとした時に、配列や文字列が持つ制限を知らなければ、望むものを作ることはできません。配列を扱うのが難しいと感じる一因は、文字列というものが、使われる文字エンコーディングによっては、実質的にucharあるいはushort型の配列にすぎない、という点にあります。しかし「純粋な配列」は、クラスからブール値まで、あらゆる型を持つことができます。これは、初心者にとって確かに混乱を招く要因です。けれども私は、実用的でわかりやすいアプローチを通じて、皆さんがこの混乱を乗り越えられるようにお手伝いしたいと思っています。それでは、文字列から始めましょう。
文字列データ型
変数を文字列として作成または宣言するということは、実質的にコンパイラに「配列を作れ」と伝えているようなものです。ただしこれは、文字列の終わりを示す特別な文字や値を含む、ちょっと特殊な配列です。もう少し深いレベルで見ると、文字列変数を使う際にメモリの確保や解放を手動で行う必要はありません。必要に応じてメモリの量が増減するのは、システム側が自動的に処理してくれるからです。
そのおかげで、私たちは細かいことをあまり気にせずに、さまざまな処理をおこなうことができます。もちろん制限がまったくないわけではありませんが、それについては今は置いておきましょう。今は「何ができるか」に集中しましょう。忘れてはならないのは、本当の意味での習得は、継続的な練習によってのみ得られるということです。ここではほんの触りだけにとどめます。それでは、最初のコードを見てみましょう。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. string sz0 = "Hello world !!!", 07. sz1 = "My first operation with strings...", 08. sz2; 09. 10. sz2 = sz0 + sz1; 11. 12. Print(sz2); 13. } 14. //+------------------------------------------------------------------+
コード01
親愛なる読者の皆さん、よく注意してください。ここでは3つの文字列変数が作成されます。そのうちの2つは作成時に宣言され、初期化されます。3つ目は他の2つの文字列を結合した結果を受け取り、新しい文字列を作成します。12行目では、以下に示すように、結果が端末に出力されるだけです。
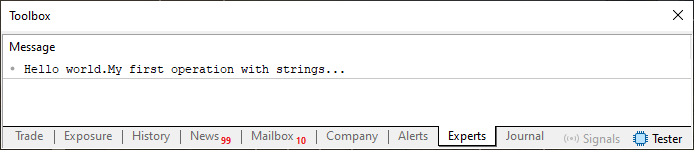
図01
ここで押さえておきたい重要なポイントがあります。それは、10行目で加算(+)演算子を使っているという点です。この演算子は、文字列に対して明確に定義された操作をデフォルトで実行できる、数少ない(あるいは唯一の)演算子のひとつです。今回のケースでは、「文字列同士を連結する」という処理がおこなわれています。ただし、このような「演算子による操作」には注意が必要です。というのも、異なるデータ型を扱う際には、演算子が期待した通りに動作しないことがあるからです。このテーマについては後ほど詳しく解説しますが、現時点では「慣れていないコードを扱うときは特に注意が必要だ」ということを覚えておいてください。
さて、現時点で端末には1行の文が表示されるわけですが、これを複数行に分けて表示したいときはどうすればよいでしょうか。1つの方法は、Print文を2回に分けて書くことです。ですが、文字列の中に直接改行を挿入したい場合には、ある種の特殊文字を使うことで可能になります。
文字列には、特殊文字を埋め込むことができます。MQL5で使えるこうした文字の多くは、CやC++に由来しています。たとえば、特定のポイントで改行改行したい場合には、次のような文字列を使えば実現できます。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. string sz0 = "Hello world !!!", 07. sz1 = "My first operation with strings...", 08. sz2; 09. 10. sz2 = sz0 + "\n" + sz1; 11. 12. Print(sz2); 13. } 14. //+------------------------------------------------------------------+
コード02
ここでは、そうしたマーカーの1つを使った例を示しています。このようなマーカー、たとえば"\n"のようなものは、一般に「エスケープシーケンス」と呼ばれます。少し調べてみると、こうした小さなコード(エスケープシーケンス)がたくさん存在することがわかるでしょう。文字列の中にそれを含めると、出力の結果が変化し、以下のような表示を得ることができます。
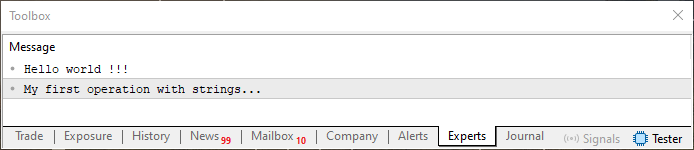
図02
ただし、エスケープシーケンスはそれだけではありません。たとえば、次の例のようにNULLマーカーを使って文字列を途中で切り詰めることもできます。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. string sz0 = "Hello world !!!", 07. sz1 = "My first operation \0with strings...", 08. sz2; 09. 10. sz2 = sz0 + "\n" + sz1; 11. 12. Print(sz2); 13. } 14. //+------------------------------------------------------------------+
コード03
このコード03が実行されると、MetaTrader 5端末に次の出力が表示されます。
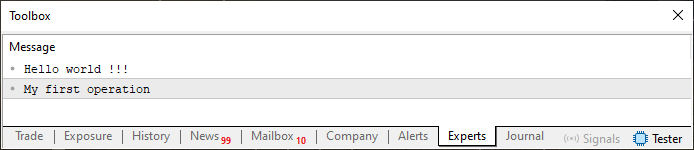
図03
これがいかに簡単でシンプルであるかに注目してください。ですが、それだけではありません。数値を含む文字列を作成することも可能です。こういったケースでは、変換処理をより簡単かつ効率的に行うために、MQL5の標準ライブラリに用意されている関数を利用する必要があります。将来的には、同じ目的で使えるカスタム版の関数の作り方もご紹介するかもしれませんが、それはまた別の機会に。今のところは、MQL5に組み込まれている変換関数を使えば、数値を文字列に変換したり、文字列を数値に戻すことができます。
こうした機能は非常に強力で、特にデータ分析系のシステムを構築する際にはほぼ必須となります。以下は、その簡単な例です。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int i_value = 65538; 07. double d_value = 0.25; 08. color cor = clrRed; 09. string sz0; 10. 11. sz0 = "Color: " + ColorToString(cor) + "\nInteger: " + IntegerToString(i_value) + "\nDouble: " + DoubleToString(d_value); 12. 13. Print(sz0); 14. } 15. //+------------------------------------------------------------------+
コード04
コード04を実行すると、次のような出力が表示されます。
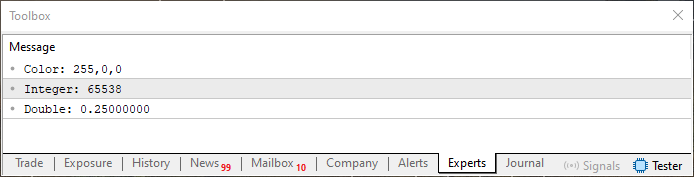
図04
さまざまな情報を含む文字列を作成できたことに注目してください。しかし、場合によっては、構築する文字列が特定のフォーマットに厳密に従う必要があることもあります。それは、扱うデータの性質や、フォーマットに関する要件によるものかもしれません。こういった状況では、これまでに見てきた方法とは少し違ったアプローチが必要になります。そして、これから紹介する内容の性質を踏まえると、ここで一度区切りを入れ、次の話題として分けて扱うのが良いでしょう。その方が、今回学んだことを整理しやすくなり、実際に応用する際にも役立つはずです。
文字列の書式設定
テキストの書式設定というと、多くの人がワードプロセッサを思い浮かべるかもしれません。しかしプログラミングにおけるフォーマットとは、特定の情報が、使用されたり表示されたりする前に、あらかじめ決められた条件を満たす必要があるという意味です。
これらの条件こそが、いわゆる「文字列フォーマット」です。一見すると、それほど難しくなく簡単に実装できそうに見えるかもしれません。実際、この仕組みを使えば、特定の内容を含んだ文字列を比較的簡単に構築することができます。ただし、いくつか注意すべき重要なポイントがあります。たとえば、出力パラメータの構築と使用方法もその1つです。正しく設定すれば、これまでのように文字列を手動で組み立てる必要がなくなり、プログラミング初心者にとっても扱いやすくなります。同時に、出力形式に対して柔軟な制御が可能となり、より厳密な構造を持った文字列を作成できるようになります。同時に、出力のフォーマット方法に関して優れた柔軟性が提供され、正確な構造を持つ文字列を構築できるようになります。
すでにいくつかのコードでPrintFormatプロシージャが使用されているのを見たことがあるかもしれません。この関数を使うと、文字列としてフォーマットされた出力をMetaTrader 5 の端末に表示することができます。しかし、出力を端末に直接送信したくない、あるいはその方法が適さない場合もあります。たとえば、フォーマットされたデータをファイルに保存したり、チャート上のグラフィカルオブジェクト内で利用したりしたいことがあります。そういったケースでは、PrintFormatは必ずしも最適な選択肢ではありません。幸いなことに、MQL5にはこうした用途により適した別の関数が用意されています。StringFormatです。
StringFormat関数はPrintFormatと同じパラメータ構造を使用しますが、出力が端末に表示される代わりに、文字列として返される点が大きく異なります。この特性により、StringFormatはさまざまな状況で非常に便利です。
たとえば、コード04の出力ロジックを応用して、フォーマットされた文字列を生成することができます。この段階では、いくつかのパラメータの扱いがやや分かりづらいかもしれません。そのため、各パラメータについて時間をかけて丁寧に確認することをおすすめします。PrintFormat関数の公式ドキュメントには、各書式指定子の詳細や、希望する文字列形式をどう構築するかが詳しく解説されています。これを踏まえて、コード04を修正し、文字列フォーマットを取り入れた例を以下に示します。これにより、以下のバージョンが実現します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int i_value = 65538; 07. double d_value = 0.25; 08. color cor = clrRed; 09. string sz0; 10. 11. sz0 = StringFormat("Color: %s\nInteger: %d\nDouble : %.2f", ColorToString(cor), i_value, d_value); 12. 13. Print(sz0); 14. } 15. //+------------------------------------------------------------------+
コード05
コード05を実行すると、MetaTrader 5端末に次の図のような結果が表示されます。
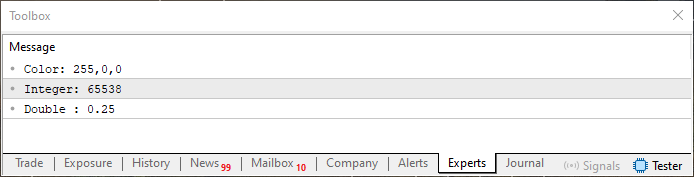
図05
図04と図05の違いを見てみましょう。どちらの例も非常によく似たコードを使用していますが、図05に表示されている情報は、特に11行目の実装によって、コード内で明示的に定義された形式で表示されていることがわかります。もちろん、このようなフォーマットは、今回のケースでは特に必要ないのではと思うかもしれません。しかし、将来的に16進数の値を扱う可能性があることを考えてみてください。多くのプログラムでは、特にビット演算を行う際に、こうした値が使用されます。では、そのような状況で、処理が正しく行われているかを確認するために、16進数の値を視覚的に確認したい場合は、どうすればよいでしょうか。
それは場合によりますが、一般的には、コード05で使用しているようなフォーマット方法が非常に有効です。中には、それ専用のコードを書く価値があると考える人もいるでしょう。ただし、私の考えでは、それは必要性というよりも、個人的な満足感に近いかもしれません。いずれにしても、プログラマーはそれぞれ自分のやり方を選ぶ自由があります。ただ、あなたがまだプログラミングを始めたばかりであれば、標準ライブラリが提供する関数や手続きに従うことをおすすめします。今回のような場合には、StringFormat関数を使って、あとで表示したい値の16進数表現を生成するのが良いでしょう。そのために、引き続きコード05を使いますが、出力を構築するための文字列フォーマットを変更します。幸いなことに、その手順はとても簡単です。11行目を、以下に示すバージョンに置き換えるだけで済みます。
sz0 = StringFormat("Color: 0x%X\nInteger: 0x%X\nDouble : %.2f", cor, i_value, d_value);
この変更したコードを実行すると、次の出力が表示されます。

図06
面白いと思いませんか。しかし、ここでちょっとした問題に直面しました。そしてこれこそが、文字列のフォーマットに関して細部に注意を払う必要があると、先ほどお伝えした理由でもあります。今回の問題は、色の値にあります。ご覧のとおり、その値は16進数形式で表示されています。ただし、図06に示されている値が必ずしも「赤」を表しているとは限りません。実際には、まったく別の色を表している可能性もあります。思い出してください。色の値は通常、RGB形式、あるいは場合によってはARGB形式で表現されます。そのため、単に16進数の値を見ただけでは、それが実際に何を意味しているのかを正確に判断するのは難しいのです。ですが、少しだけコードを工夫すれば、出力をもっと直感的で、人間にとって読みやすい形に変更できます。そのためには、以下のようにコードを変更するだけで十分です。
sz0 = StringFormat("Color: 0x%06X\nInteger: 0x%X\nDouble : %.2f", cor, i_value, d_value);
この新しい変更を加えたコードを実行すると、結果は次のようになります。
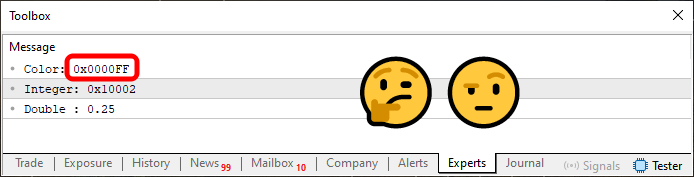
図07
待ってください。これは明らかに赤ではありません。表示されているのは青です。一体何が起きているのでしょうか。原因は、特定のフォーマットに合わせるために、値の前にゼロを追加していることにあるのでしょうか。そのせいで何かがうまくいかなくなっているのでしょうか。それは、ある意味では正しく、ある意味では違います。実際にここで起こっているのは、もう少し微妙な問題です。これをきちんと説明するためには、同じフォーマットの考え方を使いながらも、別の種類の値に適用した別の例を見てみる必要があります。
そこで、変数i_valueの値を変更し、色のときと同じ方法でフォーマットしてみましょう。つまり、表示される値によっては、先頭にゼロが付加されることになります。次の例を見ると、この仕組みがよりはっきりと理解できるはずです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int i_value = 0xF; 07. double d_value = 0.25; 08. color cor = clrRed; 09. string sz0; 10. 11. sz0 = StringFormat("Color :\t0x%06X\t=>\t%s\n" + 12. "Integer:\t0x%06X\t=>\t%d\n" + 13. "Double :\t%.2f", cor, ColorToString(cor), i_value, i_value, d_value); 14. 15. Print(sz0); 16. } 17. //+------------------------------------------------------------------+
コード06
コード06を実行すると、次のような画面が表示されます。
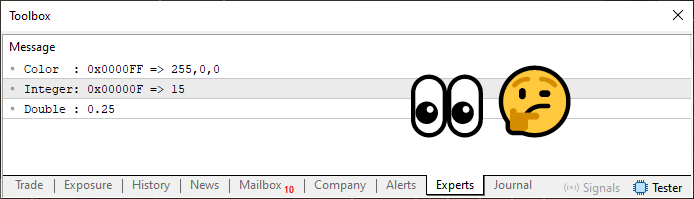
図08
ここでは、私が何を説明しようとしているのかをより理解しやすくするために、出力の構成を工夫しています。コードの11行目と12行目で2つの値を出力しているのは、その表示結果を比較することで、なぜ16進数のカラー値があのような形で表示されるのかを視覚的に示すためです。ご覧のとおり、i_valueの結果は特に問題なさそうに見えます。では、i_valueにさらに大きな数値を設定してみましょう。次のコードバージョンに示されているとおりに変更すると、次の図に示すように、出力形式は変わらず一貫性を保ったまま表示されます。
int i_value = 0xDA09F;

図09
はい、フォーマット自体は問題なく機能しています。ですが、なぜ色の値が16進数で正しく表示されないのでしょうか。その理由は、多くの人が色の値は通常RGB形式で表されると考えがちですが、実際には内部的にBGR形式で保存されているためです。つまり、バイトの並び順が逆なのです。ですので、16進数フィールドに表示される値が一見おかしく見えても、実際には正しいというわけです。では、この出力をより直感的な形式、つまり一般的に馴染みのあるRGBの順序に合わせることはできるのでしょうか。はい、できます。そして、これまでの例で得た知識を活かせば、この調整は非常に簡単におこなうことができます。以下に、その修正を加えたコードを示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int i_value = 0xDA09F; 07. double d_value = 0.25; 08. color cor = clrRoyalBlue; 09. string sz0; 10. 11. sz0 = StringFormat("Color :\t0x%06X\t=>\t%s\n" + 12. "Integer:\t0x%06X\t=>\t%d\n" + 13. "Double :\t%.2f", cor, ColorToString(cor), i_value, i_value, d_value); 14. 15. Print(sz0); 16. PrintFormat("Color value in hexadecimal (RGB format): %s", ColorToStrHex(cor)); 17. } 18. //+------------------------------------------------------------------+ 19. string ColorToStrHex(const color arg) 20. { 21. return StringFormat("0x%02X%02X%02X", (arg & 0xFF), ((arg >> 8) & 0xFF), (arg >> 16) & 0xFF); 22. } 23. //+------------------------------------------------------------------+
コード07
19行目で小さな関数を定義しているのがわかると思います。この関数は、これまでの記事で紹介してきた概念に基づいており、非常にシンプルな内容です。実行すると、この関数は16進数の文字列を返します。ただし、返される値は、色の値を分析する際に一般的に期待されるRGB形式を反映するようになっています。コード07を実行すると、図10に示されているような出力が得られるはずです。
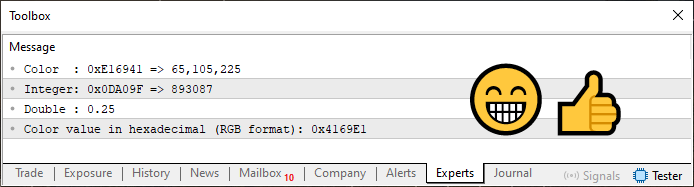
図10
さて、ここでちょっと面白い点があります。図10の最初の行には、色の値が16進数形式で表示されていますが、その値は私たちが想定していたものとは一致していません。しかし、同じ図の最後の行を見てみると、色がRGBとして読み取られていると仮定した場合に、まさに期待していた値が表示されているのがわかります。最初の行にある値は、実際にはバイト順が逆になっているためです。ただし、それを並べ替えれば、期待どおりの形式で表示させることができます。ここで重要な注意点があります。図10の最後の行に表示されている値は、コード07の8行目で定義された実際の色を表しているわけではありません。ここで表示されているフォーマット済みの文字列は、ColorToString関数がどのようにバイト順を入れ替えて、人間にとってわかりやすい表現に変換しているかを示すためのものです。ですから、心配はいりません。視覚的にも論理的にも説明が通るようにするために、色の値をあえて変更しています。
最終的な考察
今回の記事では、一見するとシンプルに思えるかもしれませんが、実は非常に奥が深く、より高度なトピックの第一歩をご紹介しました。もしかすると、今日の内容に少し戸惑いを感じた方もいるかもしれません。しかし、しっかりと時間をかけて内容を振り返り、練習を重ねていけば、ユーザーとのコミュニケーションという観点からも、実用的で強力なアプリケーションを開発できる力が確実に身につきます。
今回扱った内容は、可能性のほんの入り口に過ぎませんが、それでも皆さんが学習やプロジェクトに活用できる材料は十分に揃っています。次回の記事では、さらに一歩踏み込んで、今後の応用にも欠かせない「より高度なフォーマット処理」と「メモリの扱い方」について掘り下げていきます。それまでの間は、添付のファイルを活用しながら、今回学んだ内容をぜひ実践してみてください。それでは、次回の記事でお会いしましょう。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15441
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索