
初級から中級へ:演算子の優先順位

はじめに
ここで提示されるコンテンツは、教育目的のみに使用されることを意図しています。いかなる状況においても、提示された概念を学習し習得する以外の目的でアプリケーションを閲覧することは避けてください。
前回の「初級から中級まで:FOR文」では、FOR文の基本について解説しました。これまでの記事の内容をもとにすれば、かなりのボリュームのMQL5コードを書くことができるでしょう。たとえそれが単純なアプリケーションであっても、多くの人にとっては達成感や楽しさを感じられるものです。
他の多くのプログラマーにとっては、初心者が書いた短いコードスニペットは取るに足らないものに見えるかもしれません。しかし、初心者が自分で問題を解決できたとすれば、それは誇るべき成果です。正直なところ、これまでに説明してきた内容だけでは、スクリプト的なコードしか書けません。それでも、たとえとても単純でユーザーとの対話を必要としないものであっても、自分自身で作り上げたのであれば、それは基本的な知識を実践し始めた証であり、正しい道を進んでいるということです。
さて、次は新しいトピックに進みましょう。この内容を理解することで、より意味のあるコード作成へとさらに踏み込むことができるようになります。今回は演算子について掘り下げていきます。これについては以前にも取り上げましたが、当時の内容は非常に基本的で単純なものでした。今回は、そこからさらに数歩進んだ内容になります。この記事では、演算子の優先順位のルールを実際に使いながら確認し、さらに多くの人にとってやや分かりにくい概念でありながら、非常に多くの場面で有用な三項演算子についても扱います。これは、特定のプログラミングタスクにおいて、時間と労力の両方を節約してくれることがあります。
この記事の内容を理解するための前提条件として、MQL5コードにおける変数の宣言と使用方法を理解している必要があります。この内容は、すでに以前の記事で扱っています。もしこの知識がまだない場合は、この記事を読み進める前にそちらを参照してください。それでは、この記事の最初のトピックから始めましょう。
優先順位ルール
優先順位ルールを理解し、それに慣れることは非常に重要です。このことについては、別の記事でも言及しました。しかしここでは、このトピックをもう少し深く掘り下げていきます。
優先順位のルールに関するドキュメントを参照すると、それを示した表が見つかるでしょう。しかし、多くの人はそのルールの意味や、そこに含まれる情報を正しく理解できていません。もしあなたがその一人だとしても、親愛なる読者の皆さん、恥ずかしがったりためらったりする必要はありません。こうした情報に初めて出会ったときに多少混乱するのは、ごく自然なことです。そもそも、学校では、ここでプログラマーとして応用するような方法で物事を学ぶ機会はほとんどありません。
一部のプログラマーが記述する特定の式の構造は、一見するとわかりにくく感じられるかもしれませんが、技術的には正しい場合が多いのです。たとえその結果が私たちにとって予想外に見える場合としてもです。だからこそ、優先順位ルールを理解することがとても重要なのです。暗記する必要はありません。継続的に使って練習していれば、自然と慣れていくでしょう。ただし、最も重要な点は以下の通りです。
自分のコードを自分で理解できないのであれば、他の人が理解できるはずもありません。
だからこそ、自分が構築しようとしているものを、他の人がどのように受け取るかを常に考えるようにすべきです。では、次のポイントから始めましょう。このトピックの冒頭で述べた表は、上から下へと読んでいきます。上にある演算子ほど、実行時の優先度が高くなります。表の下に進むにつれて、その優先度は徐々に低くなっていきます。
ただし、ここで注意すべき小さな点があります。それを説明するために、以下の図に示した表を見てみましょう。
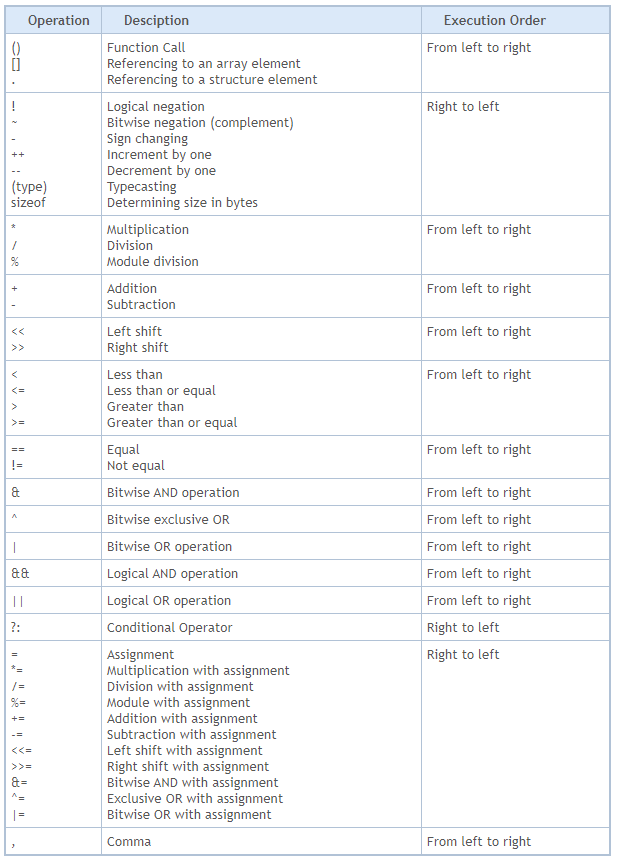
図01
ここでは、演算子が特定の順序でリストされているのがわかります。この順序に注意を払うことは非常に重要です。また、それらがカテゴリごとにグループ化されていることにも気づくでしょう。そして、ここで多くの人が混乱しがちです。というのも、図01に示されたグループ化を理解していなければ、特定のコードに出くわしたときに、その式の結果を予測することができないからです。ですが幸いなことに、このグループ分けは実際には非常にシンプルで、すべての優先順位ルールを暗記しなくても済むようになっています。むしろ、これを理解することで物事がはるかに簡単になります。まず最初にあるのは、参照演算子です。これらは、特定の要素へのアクセス方法を決定するため、すべての他の演算子よりも高い優先順位を持ちます。その直後に登場するのが、型演算子またはバイナリ演算子です。この場合、コードは右から左に読み取られる必要があります。なぜそうなるのかと疑問に思うかもしれませんが、心配はいりません。この点については、すぐ後で詳しく説明します。こうしたケースで、コードをどのように読み解けばよいのかを正確にお伝えします。今の段階では、これは参照演算子とは異なり、左から右には読まれないという点だけ覚えておいてください。
わかりにくいと思われるかもしれません。このあたりで、なぜこんなにややこしくするのかと思っていることでしょう。ですが、これは意味もなく複雑にしているわけではありません、実際にコードとして動作しているところを見れば、すべては理にかなっているのだと分かるはずです。実際に動作しているのを見なければ、精神病院に入ったような気分になるかもしれません。しかし、ほとんどの人にとってより馴染み深い要素が含まれる第3グループに入ると、状況は明確になります。ここには基本的な算術演算子が含まれており、この場合はコードは左から右に読み取られます。このパターンは、図01の残りの部分にも当てはまります。
では、これらすべてが実際にはどう機能するのかを見ていきましょう。そのために、いくつかの非常にシンプルで分かりやすいコードスニペットを使って、単にいくつかの値を出力してみます。ここからが楽しくて簡単な部分です。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char value = 9; 09. 10. PrintX(value); 11. PrintX(++value * 5); 12. PrintX(value); 13. } 14. //+------------------------------------------------------------------+
コード01
ではここで、読者の皆さんにお尋ねします。端末に表示される値は何でしょうか。演算子の優先順位をしっかりと理解していないと、変数(値は9)に定数(値は5)を掛けて、その後に1を加えるから46になるだろう、と考えるかもしれません。しかしそれは間違いです。コード01を実行した実際の結果は、下の図に示すとおり50になります。
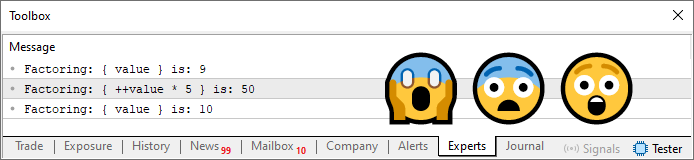
図02
混乱しましたか。それでは、今度はコードのごく小さな部分だけを変更して、もうひとつ小さな実験をしてみましょう。その変更点は、以下に示しています。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char value = 9; 09. 10. PrintX(value); 11. PrintX(value++ * 5); 12. PrintX(value); 13. } 14. //+------------------------------------------------------------------+
コード02
コード02の結果を以下に示します。
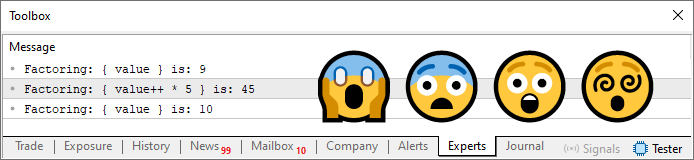
図03
前回の記事で、これからたくさん楽しいことをやると言いました。まだまだ優先順位のルールについて話し続けることもできます。なぜなら、すべてを理解し、もう何でもできると感じるその瞬間でさえ、実際にはようやく立ち上がったばかりであり、まだ最初の一歩を踏み出そうとしている段階に過ぎないということを、d読者の皆さんに明確に示したいからです。
すべてが既知が狂気じみて感じられることは、言われなくてもよく理解しています。おそらく、私は正気ではないのではないかと思われているかもしれません。でも信じてください、親愛なる読者の皆さん。本当の楽しみはここからです。これからもっともっと面白くなっていきます。では、さらに楽しいコードをひとつ見てみましょう。まずは、次のコードから始めましょう。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char v1 = 9, 09. v2 = 5; 10. 11. PrintX(v1); 12. PrintX(v2); 13. PrintX(v1 & 1 * v2); 14. PrintX((v1 & 1) * v2); 15. } 16. //+------------------------------------------------------------------+
コード03
美しいコードです。美しいコードです。特に、ループの中で動作しているときは本当に愉快です。以下は生成される出力です。
図04
さあ、正直に認めましょう。あなたも私と同じように、こういったものを見るのを楽しんでいるのではありませんか。式の中に括弧があるかないかで、結果がどのように変わるかに注目してください。
この種の式を書く際には、実はある種の一般的なルールがあります。厳密な規格や公式な文書に記されているわけではありませんが、プログラマーの間では広く受け入れられているルールです。その内容は次のとおりです。
複雑な式を書くときには、括弧を使って実行の段階を分けるようにすること。他のプログラマーにとって解釈しやすくなるからです。
実際のところ、たとえ結果が明らかであり、標準的な演算子の優先順位に従っていたとしても、括弧を用いて明確に段階を区切ることで、どのような結果を意図しているのかが格段にわかりやすくなります。場合によっては、コンパイラでさえ、あなたが何をしようとしているのか正しく解釈できないことがあります。以下のコードで、その一例をご覧ください。これは、結果がまったく予測できないコードの一例であり、コンパイラですら何をすべきか判断に困るケースです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char v1 = 9, 09. v2 = 5; 10. 11. PrintX(v1); 12. PrintX(v2); 13. PrintX(v1++ & 1 * v2 << 1); 14. PrintX(v1); 15. PrintX(v2); 16. } 17. //+------------------------------------------------------------------+
コード04
この場合、コード04をコンパイルしようとすると、コンパイラは次のような警告を発します。

図05
警告が出ているにもかかわらず、コンパイラはコードの生成を継続していることに注目してください。しかし、ここには重大なリスクがあります。このコードは、特定の状況下では正しい結果を出さない可能性があるのです。したがって、特にコンパイラが式に潜在的な問題があると警告している場合には、このコードを無条件に信頼するのは賢明とは言えません。このような状況では、括弧を使用する必要があります。括弧を使わず、演算子の優先順位のルールだけに従った場合、この具体的なケースで正しい結果が得られるかどうかを確認してみましょう。
そのためにコードを実行すると、結果は以下のとおりです。
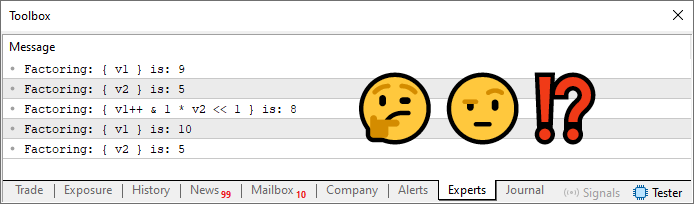
図06
ここで、出力は値8でした。しかし、その値は実際に正しいのでしょうか?これを確かめるには、コードが式をどのように処理したかを手作業で分解して理解する必要があります。このような分析はプログラミングにおいて非常に一般的です。一般に誤解されがちですが、プログラマーは結果を知らずにただコードを書くわけではありません。優秀なプログラマーは常に、自分のコードがどのような結果を生み出すべきかを理解しています。意図した結果を把握せずにコードを書くべきではありません。むしろ、優れたプログラマーは自身の論理をバックテストし、続いてフォワードテストを行います。フォワードテストとは、得られた結果を一つずつ検証していく過程です。こうした徹底的なテストを経て初めて、自分のコードを信頼し始めるものの、完全に信頼することはありません。優れた開発者は常に適度な懐疑心を持ち続けます。その懐疑心を保つ理由については別の記事で解説します。ここではまず、コード04における「8」という結果が正しいかどうかを見てみましょう。
検証するためには、コンパイラがどのように計算を解釈しているかを理解しなければなりません。コンパイラは演算子の優先順位表に従い厳格に処理するため、13行目の計算式を手動で分解して正しさを確認できます。
まず、最も優先順位の高い演算子を特定します。この場合は、変数v1に対する「++」演算子です。ただし、この演算子は右から左へ評価されます。つまり、この演算子は優先順位が変わり、その右側のより優先度の高い演算がすべて完了した後に、v1への影響が適用されます。この例でいうと、その演算子は乗算演算子であり、左シフト演算子やビットAND演算子よりも優先されます。したがって、最初に行われるのは1とv2を掛けることで、その結果は5になります。次に左シフト演算子が適用され、値5が1ビット左にシフトされて新しい値10が生成されます。続いて、v1(値は9)と10の間でビット単位のANDが実行され、その結果は8となります。最後に右側のすべての演算が終わった後、v1の値は1増加します。つまり分解すると、演算結果は8ですが、v1の値は最終的に10になります。
今あなたは、これがとても簡単で、分かりやすいと思っているかもしれません。しかし、本当にそうでしょうか、読者の皆さん。このプロセスがどのように機能するかを本当に理解しているかを見てみましょう。次のコードスニペットの式に挑戦して確かめてみましょう。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char v1 = 9, 09. v2 = 5; 10. 11. PrintX(v1); 12. PrintX(v2); 13. PrintX(++v1 & 1 * v2 << 1); 14. PrintX(v1); 15. PrintX(v2); 16. } 17. //+------------------------------------------------------------------+
コード05
ためらわずに答えてください。もし本当に正しく答えられるなら、優先順位の仕組みを十分に理解しているということです。しかし、少しあなたを困らせるために、結果をお見せしますので、それが正しいか間違っているか教えてください。
このコードを実行したところ、以下の結果が得られました。
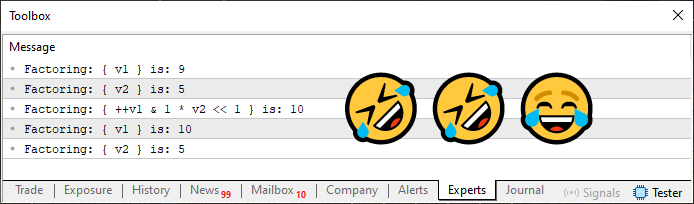
図07
では教えてください。なぜ結果が8ではなく10になったのでしょうか。これは優先順位のルールに理由があります。さて、親愛なる読者の皆さんをあまり困らせるのは嫌なので、なぜ結果が異なるのかをじっくり解説させてください。ただし、そのためには新しいトピックが必要です。一つの記事で頭をパンクさせたくありません。ここでまだ扱うべき重要なトピックがもう一つ残っています。
バックテストとフォワードテスト
親愛なる読者の皆さんにまず理解していただきたいのは、コードを書く前に、そのコードがどのような結果を出すかをあらかじめ把握しておくべきだということです。プログラミングとは、未知の答えを得るためにコードを書くことではなく、むしろ、既に分かっている結果を得るためにコードを書くものです。今回のコード04やコード05に関しても、結果がどうなるかはあらかじめ分かっていました。たとえコンパイラの警告で間違っている可能性が示されていても、予測はできていました。では、どうしてコードを書く前に結果を知ることができるのでしょうか。一見、無意味に思えるかもしれません。実際、多くの人は、まずコードを書いてから結果を見るように言います。しかし、演算子の優先順位を理解すれば、コードを実行して結果が表示される前に答えが分かるのです。
これを明確にするため、添付ファイルに示したコード例を自分で実行してみてください。そうすれば、ここで示している内容を正確に理解し、コードを書く前に答えを知っておくことの重要性を実感できるでしょう。
さて、本当の問題です。図06の答えと図07の答えのどちらが正しいでしょうか。両方とも正しいと言ったらどうでしょう。おそらく、私が正気を失ったと思うでしょう。同じ式で異なる結果が出て、両方正しいことなど、あり得るのでしょうか。しかし、意外にも両方正しいのです。ただし、多くの場合、期待される答えは図07のほうでしょう。一方、図06の結果は、優先順位の誤用や誤解による副作用です。コード04で括弧を使い演算子の順序を明確に指定すれば、結果は図07と同じになります。必要なのは、増分演算子(++)の優先度をわずかに変えるだけです。コード05では増分演算子が変数の前にあるため、乗算よりも優先されます。しかしコード04では演算子が変数の後にあるため、式の残りが評価された後に実行されます。
信じられなければ、試してみましょう。コード04の13行目を次のように変更してください。
PrintX((v1++ & 1) * (v2 << 1));
この変更により、コンパイラは「結果が不確かかもしれない」という警告を出さなくなります。そしてこの簡単な修正を加えたコード04は、図07の結果を返すようになります。これこそがプログラミングの特定の側面が複雑に見える理由です。多くの人は間違った動機でプログラミングを学びますが、本来の目的は、コンピューターに既知の結果を速く正確に出させることです。未知の答えを探す場合、コンピューターの答えは有効な手がかりとなりますが、信用しすぎるのは禁物です。制限はあるものの、既知の値や手動で検証可能な値を使ってコードを十分にテストできれば、ようやく「自分のプログラムはこれやあれを計算できる」と言えるのです。そうなるまでは、バグが潜んでいる可能性が高いでしょう。
では、皆さんにはご自身のペースでこの内容を学び、これまでの話を振り返っていただきたいと思います。ですがこの記事を締める前に、最後にもう一つだけ触れておきたいことがあります。実はまだ取り上げていない最後の演算子があるのです。最後のトピックに進みましょう。
三項演算子
これは私のお気に入りの演算子です。私の記事を追っている方やこのコミュニティの皆さんは、私がこれを頻繁に使っているのを見て少しうんざりしているかもしれません。では、なぜこれが私のお気に入りなのか。理由はシンプルです。IF文を使わずにロジックを組み立てられるからです。IFはプログラミングの基本であり、実行の流れを制御します。しかし、IFが使えない場面でも三項演算子なら使えることが多いのです。私の考えでは、三項演算子は中級者向けのツールです。しっかり他の演算子を理解していないと、十分に活用できません。また、三項演算子の中でのフロー制御の動きも理解しておく必要があります。単独で使われることはほとんどなく、多くの場合は代入演算子や論理演算子と組み合わせて使われます。ですので、今回は読み方だけを説明し、すぐには使いません。
それでは、三項演算子が使える簡単なコード例を見てみましょう。もちろん他にも書き方はありますが、ここでの目的はあくまで教育的なものなので、他の方法があるかどうかは気にせず、コンセプトに集中してください。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char v1 = 9, 09. v2 = 5; 10. 11. PrintX(v1); 12. PrintX(v2); 13. PrintX(v1 * ((v2 & 1) == true ? v2 - 1 : v2 + 1)); 14. PrintX(v2++); 15. PrintX(v1 * ((v2 & 1) == true ? v2 - 1 : v2 + 1)); 16. PrintX(v1); 17. PrintX(v2); 18. } 19. //+------------------------------------------------------------------+
コード06
コード06を実行すると、次の結果が表示されます。
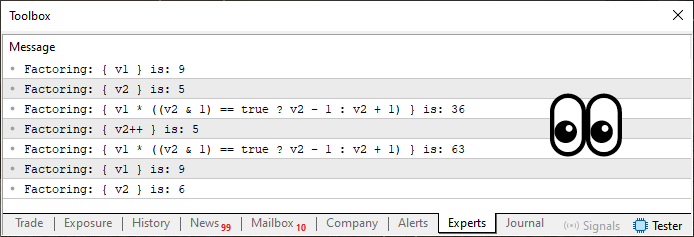
図08
三項演算子は、多くの人にとって、特に初心者には非常に混乱を招きやすいものです。ここで何が起こっているのか、丁寧に説明していきます。ただし、この内容を本当に理解するには、この記事全体をじっくりと時間をかけて読み込むことが必要です。ゆっくりと読み進めて、私が伝えたいことに注意を払ってください。このトピックは内容が濃いため、完全に理解するには時間がかかるかもしれません。
それでは、コード06に戻りましょう。ほとんどの部分は理解しやすいはずです。もちろん、マクロを使っていますが、これを自身のプログラムにどう組み込むかはまだ説明していません。しかし、このマクロ自体は比較的わかりやすいものです。この記事内の他の例でも使われているため、ここでの説明はそれらにも当てはまります。4行目で定義されているマクロは、コード内で使われている内容に基づいて端末へ情報を送るためのものです。では、具体的にはどうするかと言えば、引数を渡します。引数の前にハッシュ記号(#)が付いている場合、コンパイラはその引数をそのまま文字列として表示するように指示されます。これにより、実際に計算されている式や結果の値、場合によっては変数名も一緒に表示できるので、特定の種類のコードのデバッグにとても役立ちます。
しかしこれは話の一部分に過ぎません。ここで本当に重要なのは、13行目と15行目で使われている三項演算子がどのように動いているかという点です。これをわかりやすく説明するために、ほぼ同じ動きをするもう片方の行はひとまず置いておき、13行目だけに注目してみましょう。
では、13行目を三項演算子を使わずに、IF文を使った形に書き換えてみます。三項演算子の説明にIF文を使うのは、三項演算子が本質的にIF文を凝縮したものであり、さらに式として使えるという特徴を持っているからです。つまり、変数や値が通常置かれる場所にそのまま置けるのです。しかし、この類似点があるとはいえ、三項演算子はIF文の代わりにはなりません。三項演算子の中には複雑なコードブロックを含めることはできませんが、IF文ならそれが可能ですし、逆にIF文は値を返す式として使えません。
さて、IF文を使って13行目を書き換えると、次のようになります。
if ((v2 & 1) == true) value = v1 * (v2 - 1); else value = v1 * (v2 + 1); Print("Factoring: { v1 * ((v2 & 1) == true ? v2 - 1 : v2 + 1) } is: ", value);
ここで注意すべき唯一の点は、「value」という変数の値が、技術的には実際には存在しないということです。これは、コンパイラがどのように解釈しているかを説明するために便宜的に使っているだけです。ですので、valueは直接アクセスできない一時的な変数として考えてください。
この考え方を理解すると、コンパイラが三項演算子をどのように解釈しているかがより分かりやすくなります。IF文を使うとコードはずっと読みやすくなることに気づくでしょう。もちろん、三項演算子が本当に必要な場面では、IF文では不便ですが、教育的な目的ではこの形がとても役立ちます。この短い翻訳例で使っているPrint指令も同じで、実際のコード内でマクロが果たす役割を表しています。
一見すると、こうした内容はかなり複雑に見えるかもしれません。特に、先ほども述べた通り、これは私が考えるところの中級レベルの概念だからです。ですので、親愛なる読者の皆さん、焦らずゆっくりと時間をかけて学び、練習してください。ただし、一旦三項演算子が本質的に特殊なIFであることを理解できれば、今後の記事を読み進めるうえで、ずっとスムーズに内容を吸収できるようになるはずです。
最終的な考察
この記事では、少なくとも理論的な観点から見て、プログラミングにおける最も複雑なトピックの一つを紹介し、解説しようと試みました。実際には、演算子というテーマはもっとシンプルで直感的に学べるものです。なぜなら、それぞれの動作や実装がどんな結果を生み出すのかを理解すれば、プログラマーが未知のものを作ろうとしているわけではないことが分かるからです。すべてのプログラムは、私たちが既に答えを知っている質問に答えるために設計されています。しかし、テストや改良を重ねるうちに、アプリケーションは進化し、以前に解決された特定の問題に対してより迅速に答えを出すために使われるようになります。
最後にひとつアドバイスを。さまざまな課題に取り組み、しっかりと練習することを心がけてください。継続的な実践を通じてこそ、各演算子の使い方を本当にマスターできるようになります。理論だけを知っていても十分ではありません。演算子を使いこなすには、理論以上に経験が重要です。さあ、練習を始めましょう。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15440
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索