
多通貨エキスパートアドバイザーの開発(第18回):将来期間を考慮したグループ選択の自動化
はじめに
第7回では、個々の取引戦略インスタンスをグループ化することで、それらが協調して動作した際のパフォーマンス向上を目指しました。インスタンスの選定には、2つのアプローチを用いました。1つ目のアプローチでは、最適化期間全体に基づく結果を用いてグループを構成しました。この方法では、最適化期間内で最も良い成績を収めたインスタンスをグループに含めるようにしました。2つ目のアプローチでは、最適化期間から一部の区間を除外し、その部分には最適化をおこなわずに残しました。そして、その除外区間における成績を基に、グループに含めるインスタンスを選定しました。この方法では、最適化期間中に「そこそこ良好な結果」を示し、かつ除外区間でもほぼ同様の結果を示していたインスタンスを選びました。
結果は次のとおりです。
- 最初の方法が2番目の方法より明らかに優れているという結果は得られませんでした。これは、おそらく比較に用いた履歴期間が短すぎたことが原因でしょう。戦略によっては長期間フラットな推移が続くこともあるため、3か月程度のデータでは評価には不十分です。
- 2番目の方法では、記事で紹介した「類似のパフォーマンスを示すインスタンスをグループ化するアルゴリズム」を用いることで、除外区間における成績が向上することが確認されました。最適化期間全体で成績が最も良いものだけを選定した場合(最初の方法と同様の考え方を短い期間に適用した場合)、グループ全体のパフォーマンスは明らかに悪化しました。
- 両方の方法を組み合わせることも可能です。つまり、異なるアプローチで構成された2つのグループを作成し、それらを統合することも視野に入ります。
第13回では、最適化の第2段階を自動化しました。この段階では、第1段階で得られた取引戦略の個別インスタンスをグループとして選定しました。標準のストラテジーテスターに備わっている遺伝的アルゴリズムを用いたシンプルな探索によってこれを実現しましたが、第6回第6回で検討したようなインスタンスの事前クラスタリングはおこないませんでした。したがって、このとき自動化されたのは、あくまで第1のアプローチによるグループ選定のみです。当時は第2のアプローチに基づく自動化は実現できませんでしたが、今回はこの課題に改めて取り組みます。本稿では、フォワード期間における挙動を考慮しながら、取引戦略の個々のインスタンスを自動的に選定・グループ化する機能の実現を目指します。
パスのマッピング
いつものように、まずは問題を解決するために、現時点で何が揃っていて、何が足りないのかを整理しておきましょう。私たちは、任意の時間間隔にわたって取引戦略の最適化タスクを設定することができます。ここで「タスクを設定する」という言葉は文字どおりの意味です。具体的には、データベースのtasksテーブルに必要なエントリを作成することで実現されます。そのため、たとえば2018年から2022年までの期間で最初に最適化を実行し、次に2023年の期間で別途最適化を実行することも可能です。
しかし、このようなアプローチでは、得られた結果を期待通りに活用することができません。というのも、それぞれの期間における最適化は独立して実行されるため、比較の基準が存在しなくなるからです。つまり、2回目の最適化では、1回目の最適化と同じ入力パラメータの組み合わせが再現されることはありません。これは、私たちが使用している遺伝的アルゴリズムによる最適化にも当てはまります。完全最適化であれば話は別ですが、最適化パラメータの組み合わせが膨大であるため、これまで使用したことはなく、今後も使う可能性は低いでしょう。
したがって、フォワード期間を指定して最適化を実行する必要があります。この場合、テスターはメイン期間と同じ入力パラメータの組み合わせをフォワード期間にも適用して評価をおこないます。ただし、私たちはまだこのフォワード期間付きの自動最適化を実行したことがないため、得られた結果がデータベースにどのように記録されるのかが分かっていません。メイン期間の実行とフォワード期間の実行をデータベース上で明確に区別できるかどうかを確認する必要があります。
もし、メインおよびフォワードの両期間に関するパス情報がデータベースに正しく保存されていることが確認できれば、次のステップに進むことができます。第7回では、得られた結果をExcelで手動分析し、グループ選定をおこないました。しかし、自動化という観点からは、Excelの使用は非効率的です。私たちは、最終的なEAを生成するまでの過程において、データの手作業による操作を極力避けたいと考えています。幸いなことに、Excelで実行していた作業(結果の一部を再計算、さまざまなテスト期間の合格率の比率の計算、各戦略グループの最終スコアの検索と並べ替え)はすべて、データベースへのSQLクエリやPythonスクリプトの実行を通じて、MQL5プログラム内で実現可能です。
これらはすべて、データベースへのSQLクエリやPythonスクリプトの実行を通じて、MQL5プログラム内で実現可能です。選択された銘柄と時間枠のすべての組み合わせについて、同様の処理を実行します。最終的な評価に基づいて並び替えたあと、最上位のグループのみを最終EAに採用します。そして、それらすべての最良グループを統合・正規化することで、最終版のEAが完成します。
実装を始めましょう。まずは発見されたエラーを修正しましょう。
保存エラーの修正
第1段階(取引戦略の単一インスタンスの最適化)を自動化するEAを開発した際には、1つのデータベースしか使用していなかったため、どのデータベースからデータを取得し、どのデータベースに保存するかについて迷うことはありませんでした。しかし、第2段階の最適化では、メインデータベースから必要最小限の情報を抽出した補助用のデータベースが新たに追加されました。この簡略化されたデータベースが、第2段階におけるテストエージェントへの送信対象となっていました。
ただし、データベース操作用の静的クラスを既に実装していた関係で、必要に応じてデータベース名を変更できるという、やや使い勝手の悪い方法を採らざるを得ませんでした。データベース名を変更すると、それ以降のすべての接続メソッド呼び出しでその新しい名前が使用されるようになります。この設計のために、第2段階および第3段階でパス結果を追加する際、 必要な箇所すべてでメインデータベースに切り替えが行われていなかったことが原因で、エラーが発生しました。
この問題を修正するために、各段階のEAおよびプロジェクト自動最適化EAに、メインデータベース名を指定するための追加入力項目を設けました。これによりバグが修正されただけでなく、記事ごとに使用されるデータベースをより明確に分離できるという利点も得られました。たとえば、本稿では最適化タスクの構成を簡素化することにしたため、既存のデータベースを削除せずに、新しいメインデータベースを使用するという選択が可能になりました。
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput string fileName_ = "database683.sqlite"; // - File with the main database
第2段階EA「SimpleVolumesStage2.mq5」のOnInit()関数では、LoadParams()関数の呼び出し内で補助データベースへの接続が行われました。これは、グループ化のために使用される取引戦略の単一インスタンスの入力データを、その補助データベースから取得する必要があるためです。その後、パスの完了時にOnTester()関数が呼び出されます。この関数では、グループの実行結果をメインデータベースに保存する必要がありました。しかし、メインデータベースへの切り替えが行われていなかったため、パスの完全な結果(48列)を、列数がわずか2列しかない補助データベースのテーブルに挿入しようとしてしまいました。
この問題を解決するために、第2段階EA「SimpleVolumesStage2.mq5」のOnInit()関数内に、メインデータベースへの切り替え処理を追加しました。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Load strategy parameter sets string strategiesParams = LoadParams(indexes); // Connect to the main database DB::Connect(fileName_); DB::Close(); ... // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
補助データベースを使用しない第1段階および第3段階の最適化EAでは、EAの新しい入力から取得したデータベース名を、データベース接続メソッドの最初の呼び出しに追加しました。
DB::Connect(fileName_)
もう一つ見つけた別のタイプのエラーは、実行完了後に特定のパスだけを個別に実行しようとした際に発生しました。パス自体は正常に実行されましたが、その結果がデータベースに記録されませんでした。原因は、このように個別に起動された場合、タスクIDが0のままであることです。一方、データベースのpassesテーブルでは、tasksテーブル内の既存タスクのIDと一致する文字列でなければ受け入れられません。
この問題の修正方法としては、タスクIDをEAの入力から取得するようにする(最適化時にはこの方法が使われています)、またはタスクID0のダミータスクをデータベースに追加する、という2つの選択肢が考えられました。最終的には、手動で起動した単一パスが特定の最適化タスクの一部としてカウントされないように、後者のダミータスク追加という方法を採用しました。このダミータスクには、外部キー制約を回避するために既存プロセスの任意のIDを割り当て、さらに自動最適化中にこのタスクが起動されないように、ステータスとして「Done」を設定する必要がありました。
これらの修正を加えたのち、再び本来のメインタスクに戻ることにします。
コードとデータベースの準備
まず、既存のデータベースのコピーを作成し、passes、tasks、jobsに関するデータを削除します。次に、第1段階のデータにフォワード期間の開始日を追加して修正します。stagesテーブルからは第2段階の情報を削除してかまいません。続いて、jobsjテーブルに第1段階用のエントリを1件作成します。このエントリには、通貨ペアと時間足(EURGBP H1)、およびストラテジーテスターのパラメータを指定します。最適化対象は単一のパラメータのみに限定することで、パスの数を減らし、より早く結果を得られるようにします。このジョブに対して、tasksテーブルに複雑な最適化基準を持つタスクを1件追加します。
その後、作成したデータベースをEAの入力パラメータとして指定し、プロジェクト自動最適化EAを起動します。初回の実行後、自動最適化EAが「フォワード期間を使用すべきかどうか」に関する情報をデータベースから取得できていないことが判明し、EAの改良が必要となりました。修正後、データベースから次の最適化タスクを取得する関数のコードは次のようになりました(追加された行は色で強調表示されています)。
//+------------------------------------------------------------------+ //| Get the next optimization task from the queue | //+------------------------------------------------------------------+ ulong GetNextTask(string &setting) { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT s.expert," " s.optimization," " s.from_date," " s.to_date," " s.forward_mode," " s.forward_date," " j.symbol," " j.period," " j.tester_inputs," " t.id_task," " t.optimization_criterion" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status IN ('Queued', 'Processing')" " ORDER BY s.id_stage, j.id_job, t.status LIMIT 1;"; // Open the database if(DB::Connect()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string expert; int optimization; string from_date; string to_date; int forward_mode; string forward_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { setting = StringFormat( "[Tester]\r\n" "Expert=%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=%d\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=%d\r\n" "ForwardDate=%s\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d\r\n" "fileName_=%s\r\n" "%s\r\n", GetProgramPath(row.expert), row.symbol, row.period, row.optimization, row.from_date, row.to_date, row.forward_mode, row.forward_date, row.optimization_criterion, row.id_task, fileName_, row.tester_inputs ); res = row.id_task; } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } return res; }
また、ターミナルEAのルートフォルダを基準とした現在のフォルダから、最適化されたEAのファイルへのパスを取得する関数も追加しました。
//+------------------------------------------------------------------+ //| Getting the path to the file of the optimized EA from the current| //| folders relative to the root folder of terminal EAs | //+------------------------------------------------------------------+ string GetProgramPath(string name) { string path = MQLInfoString(MQL_PROGRAM_PATH); string programName = MQLInfoString(MQL_PROGRAM_NAME) + ".ex5"; string terminalPath = TerminalInfoString(TERMINAL_DATA_PATH) + "\\MQL5\\Experts\\"; path = StringSubstr(path, StringLen(terminalPath), StringLen(path) - (StringLen(terminalPath) + StringLen(programName))); return path + name; }
これにより、データベースのstagesテーブルでは、[ルートEAフォルダ]\MQL5\Experts\を基準としたフォルダ構成を記述せずに、最適化対象のEAファイル名のみを指定できるようになりました。
自動プロジェクト最適化EAのその後の実行では、通常のパス結果とともに、フォワードパスの結果もpassesテーブルに正常に追加されていることが確認されました。しかし、段階が完了した後になると、どのパスがどの期間(メイン期間またはフォワード期間)に対応しているのかを区別するのが困難になります。確かに、「フォワード期間のパスは常に通常のパスの後に追加される」という前提を利用することはできますが、フォワード期間を含む複数の最適化タスクの結果がpassesテーブルに混在するようになると、この前提は成立しなくなります。そこで、通常のパスとフォワードパスを明確に区別できるようにするため、passesテーブルにis_forward列を追加します。さらに、通常の実行パスと最適化として実行されたパスとを区別しやすくするために、is_optimzation列も追加します。
その過程で、ひとつの不正確な点が見つかりました。パス結果のデータを挿入するためのSQLクエリ文字列を作成する際、パス番号を%d指定子で符号付き整数として埋め込んでいました。しかし、パス番号は符号なしのunsigned long型であるため、正しく埋め込むには%I64u指定子を使用する必要があります。
最後に、パスデータを挿入するSQLクエリを生成するコードに、フォワード期間かどうかを判定する関数の値も追加しましょう。
string CTesterHandler::GetInsertQuery(string values, string inputs, ulong pass) { return StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %I64u, %d, %s,\n'%s',\n'%s') RETURNING rowid;", s_idTask, pass, (int) MQLInfoInteger(MQL_FORWARD), values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); }
しかし、これは期待通りには動作しないことが判明しました。その理由は、この関数が「データフレーム収集モード」でメインターミナル上から起動されたEAから呼び出されている点にあります。そのため、MQLInfoInteger(MQL_FORWARD)の呼び出しは常にfalseを返します。
したがって、フォワード期間かどうかの判定は、メインターミナル上のチャートで動作しているコードではなく、テストエージェント上で実行されるコード、すなわちテストパス完了イベントハンドラ内で取得する必要があります。あわせて、最適化かどうかを示すフラグもこの付近で追加されました。
//+------------------------------------------------------------------+ //| Handling completion of tester pass for agent | //+------------------------------------------------------------------+ void CTesterHandler::Tester(double custom, // Custom criteria string params // Description of EA parameters in the current pass ) { ... // Generate a string with pass data data = StringFormat("%d, %d, %s,'%s'", MQLInfoInteger(MQL_OPTIMIZATION), MQLInfoInteger(MQL_FORWARD), data, params); ... }
これらの修正を加えた後、自動最適化EAを再起動すると、ついにpassesテーブルに期待していた形のデータが表示されました。
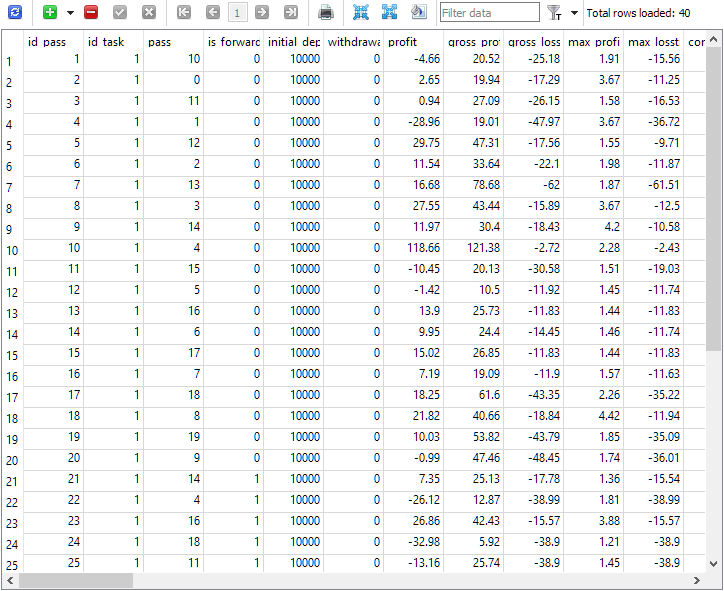
図1:フォワード期間の最適化タスクを完了した後のpassesテーブル
ご覧のとおり、id_task=1の最適化タスクにおいて実行されたパスは合計で40件です。そのうち20件は通常の期間に対するパス(is_forward = 0の最初の20行)であり、残りの20件はフォワード期間に対するパス(is_forward = 1)です。pass列のテスターパス番号は1から20の値を取り、それぞれの番号がちょうど2回ずつ(1回はメイン期間、もう1回はフォワード期間)出現していることが確認できます。
完全な最適化実行に向けた準備
フォワード期間を使用したパスの結果がデータベースに正しく登録されていることを確認できたため、より実運用に近い条件での自動最適化テストを実施します。そのために、クリーンなデータベースに2つの段階を追加します。第1段階では、1つの銘柄・時間足(EURGBP H1)を対象に、2018年から2023年までの期間で取引戦略の単一インスタンスを最適化します。この段階ではフォワード期間は使用されません。第2段階では、第1段階で得られた優秀な単一インスタンスのグループを対象に最適化をおこないます。この段階ではフォワード期間を使用し、2023年全体をその期間として割り当てます。

図2:2段階を含むstagesテーブル
jobsテーブルの各段階に対して、その段階内で実行されるジョブを作成します。このテーブルには、銘柄と期間に加えて、範囲とステップの変化を伴う最適化されたEAの入力が示されています。
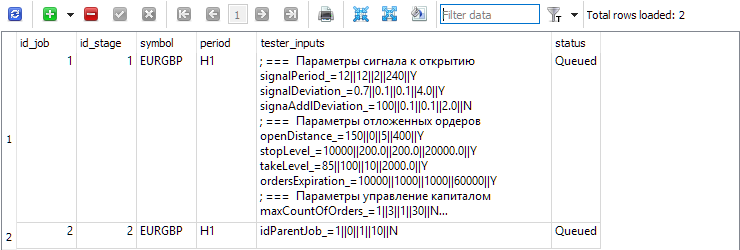
図3: 第1段階と第2段階にそれぞれ2つのジョブがあるjobsテーブル
最初のジョブ(id_job = 1)には、最適化基準(optimization_criterion)の値が異なる複数の最適化タスクを作成します。optimization_criterion = 0 ~ 7のすべての基準を順に使用し、複合基準(optimization_criterion = 7)は最初と最後の2回使用します。2番目のジョブ(id_job = 2)内で実行されるタスクについては、カスタム最適化基準(optimization_criterion = 6)を使用します。
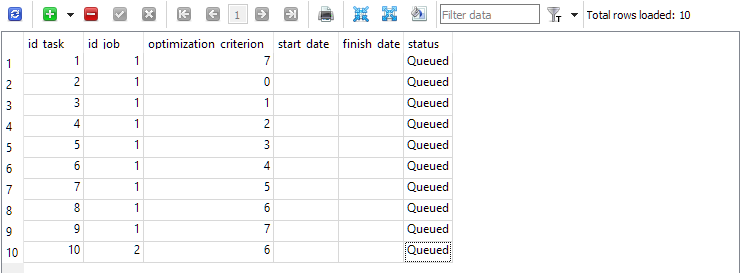
図4:最初のジョブと2番目のジョブのタスクを含むtasksテーブル
任意のターミナルチャートで自動最適化EAを起動し、割り当てられたすべてのタスクが完了するまで待ちます。既存のエージェントを使用した場合、このプロセスには合計で約4時間かかりました。
結果の事前分析
完了した自動最適化では、フォワード期間を使用した最適化タスクは1つだけでした。そのタスクの最適化基準は、与えられたパスに対する標準化された年間平均利益を算出するカスタム基準でした。メイン期間におけるこの基準の値を持つ点群を見てみましょう。
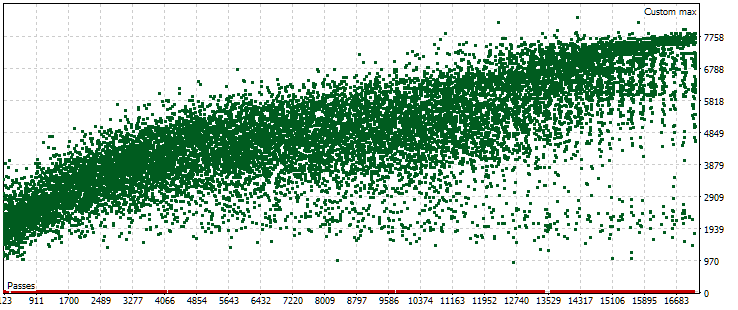
図5:メイン期間における各パスの正規化された平均年間利益の値の点群
グラフから、私たちの基準の値が約1,000米ドルから8,000米ドルの範囲にあることがわかります。0に対応する赤い点は、入力パラメータの単一インスタンスのインデックスの組み合わせが重複し、無効な戦略グループとして扱われるために発生しています。これらのパスからは結果が得られません。後半のパスでは、正規化された平均年間利益が増加する傾向が見られます。平均すると、最良の結果はほぼランダムにパラメータを選択した最初のパスの約2倍に達しています。
続いて、フォワード期間のパス結果の点群を見てみましょう。メインの段階で除外され、不正と判断されたパラメータの組み合わせがあるため、パス数は約17,000から約13,000に減少しています。
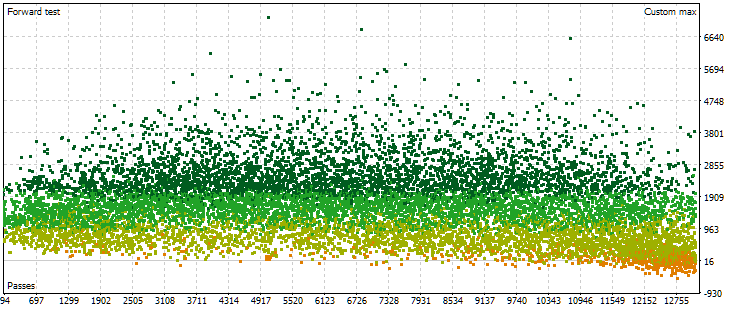
図6:フォワード期間における各パスの正規化された平均年間利益の値の点群
ここでは、点の分布がすでに異なっています。パス番号が増えるにつれて結果が著しく向上する傾向は見られません。むしろ、パス番号が増加するにつれて、最初は結果が初期より高い値に達しますが、その後は逆の傾向に変わります。パス番号がさらに増えると、結果は平均的に減少し始め、番号の右端に近づくほど減少の速度が速くなります。
しかし、これは必ずしも常にこうなるわけではありません。最適化中に反復されるパラメータ範囲の設定が異なる場合、メイン期間とフォワード期間のパスの点群は次のような形になることもあります。
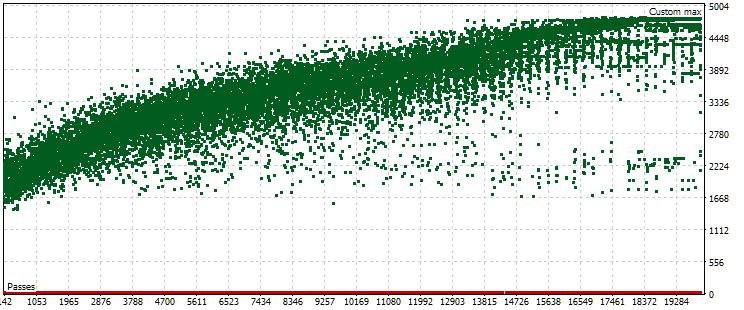
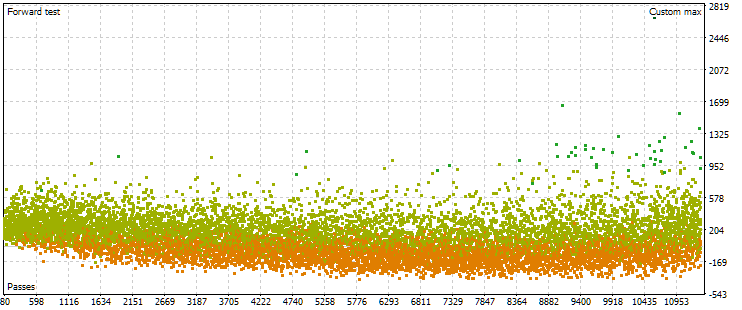
図7:別の最適化設定の場合のメイン期間およびフォワード期間における正規化された平均年間利益の値の点群
ご覧のとおり、メイン期間ではおおむね同様の傾向ですが、基準値の範囲がやや異なり、USD 1,500から5,000となっています。一方で、フォワード期間の点群の様子はまったく異なります。最大値が得られるのは最適化の中盤付近ではなく、終盤に近いパスです。また、フォワード期間の基準値は平均して約10分の1となっており、前回の最適化時の3分の1という差よりも大きくなっています。
直感的には、異なる期間で得られた結果の安定性を高めるには、メイン期間とフォワード期間でほぼ同じような結果を示すグループを選ぶ必要があると思われました。しかし、得られた結果を見ると、この方法で有用なものを得られるか強く疑問を持ちました。特に、フォワード期間での基準値の最大値がメイン期間の平凡な基準値よりも明らかに小さい場合はなおさらです。とはいえ、一度試してみましょう。メイン期間とフォワード期間のパスの中から条件的に「近い」ものを探し、それらのメイン期間、フォワード期間、そして2024年の結果を見てみます。
パスの選択
今後の期間の結果に基づいて最適なグループを選択した方法を思い出してください。 第7回。以下に、若干の調整を加えたアルゴリズムの概要を示します。
- メイン期間とフォワード期間の2つの値の最大ドローダウンを計算して、フォワード期間のパスの正規化された平均年間利益の値を調整してみましょう。OOS_ForwardResultCorrectedの値を取得します。
- 2018年~2022年(メイン期間)と2023年(フォワード期間)の最適化結果の組み合わせ表で、すべてのパラメータについて、メイン期間とフォワード期間における値の比率を計算します。
たとえば、取引件数の場合は TradesRatio=OOS_Trades/IS_Trades、正規化された平均年間利益の場合は ResultRatio = OOS_ForwardResultCorrected / IS_BackResultです。
これらの比率が1に近いほど、2つの期間におけるこれらの指標の値が同一であることを示します。 - これらの関係すべてについて、単一性からの偏差の和を計算してみましょう。この値が、各グループのメイン期間とフォワード期間の成績の差を示す指標となります。
SumDiff = |1 - ResultRatio| + ... + |1 - TradesRatio| -
また、ドローダウンはメイン期間とフォワード期間の各パスで異なる可能性があることを考慮に入れてください。2つの期間から最大ドローダウンを選択し、それを使用して、標準化されたドローダウンの10%を達成するために建てたポジションのサイズに対するスケーリング係数を計算します。
Scale = 10 / MAX(OOS_EquityDD, IS_EquityDD)
-
ここで、SumDiffがScaleほど普及していないセットを選択します。そのためには、最後のパラメータを計算します。
Res = Scale / SumDiff
-
前の手順で計算したRes値ですべてのグループを降順に並べ替えてみましょう。この場合、メイン期間とフォワード期間の成績がより似通っており、両期間のドローダウンが小さかったグループが上位に入ります。
次に、グループの選択を複数回繰り返し、最初に、選択したグループにすでに含まれている取引戦略の単一コピーの数を含むグループを削除することを提案しました。ただし、この手順は単一インスタンスの予備的なクラスタリングに関連し、異なるインデックスが結果が異なるインスタンスに対応するようになります。自動最適化ではまだクラスタリングに到達していないため、この手順はスキップします。
代わりに、各銘柄の異なる時間枠による2番目のレベルのグループ化と、異なる銘柄による3番目のレベルのグループ化を追加できます。
与えられたアルゴリズムを少し修正します。まず、本質的には、比較する結果(特徴量)の数と同じ次元を持つ空間において、2つのパスの結果セットがどれだけ離れているかを理解したいということです。そのために、以前は比較対象の結果の比率からなる座標を持つ点と、すべての座標が1の固定点との距離を、スケーリング係数付きの1次ノルムを用いて計算していました。しかし、これらの比率の中には、1に近いものもあれば、非常に離れたものもあります。後者は、全体的な距離の評価を不当に悪化させる可能性があります。したがって、以前提案された方法の代わりに、通常のユークリッド距離(2次ノルム)を使用することにしましょう。ただし、最初にmin-maxスケーリングを適用してから、このユークリッド距離を計算します。
最終的には、かなり複雑なSQLクエリを書く必要があります(もっと複雑なクエリもあるかもしれませんが)。必要なクエリを作成するプロセスを詳しく見ていきましょう。まずは簡単なクエリから始めて、段階的に複雑にしていきます。一部の結果は一時テーブルに保存し、以降のクエリで使用します。各クエリの後には、その結果がどのようなものかを示します。
したがって、何かを取得するための元データは主にpassesテーブルにあります。本当にそこにあるかどうかを確認し、必要な最適化タスクの枠内で実行されたパスだけをすぐに選択します。今回のケースでは、EURGBP H1の第2段階の最適化に対応するタスク識別子id_taskの値は10でした。したがって、クエリ文ではこの値を使用します。
-- Request 1
SELECT *
FROM passes p0
WHERE p0.id_task = 10;
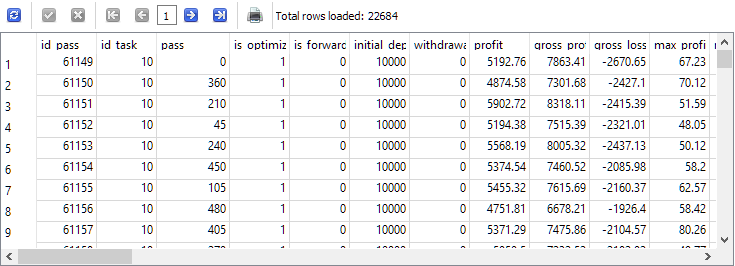
このタスク(id_task=10)に対するpassesテーブルのエントリは、2万2千件以上存在していることが確認できます。
次のステップは、同じテスターのパス番号に対応するデータセットの2つの行、つまり異なる期間(メイン期間とフォワード期間)に対応する行の結果を1つの文字列(行)に結合することです。結果として表示される列の数は一時的に制限し、行の選択が正しくおこなわれているかを確認するために使用できる列のみに絞ります。得られる列には、メイン期間(インサンプル)の列名には接頭辞「I_」を、フォワード期間(アウトオブサンプル)の列名には接頭辞「O_」を付けるというルールに従って名前を付けます。
-- Request 2 SELECT p0.id_pass AS I_id_pass, p0.is_forward AS I_is_forward, p0.custom_ontester AS I_custom_ontester, p1.id_pass AS O_id_pass, p1.is_forward AS O_is_forward, p1.custom_ontester AS O_custom_ontester FROM passes p0 JOIN passes p1 ON p0.pass = p1.pass AND p0.is_forward = 0 AND p1.is_forward = 1 WHERE p0.id_task = 10 AND p1.id_task = 10
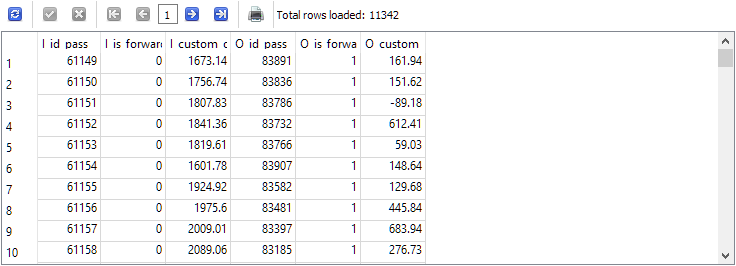
結果として行数はちょうど半分に減りました。つまり、passesテーブルのメイン期間の各パスに対して、フォワード期間のパスがちょうど1つあり、その逆も同様です。
ここで、正規化を実行するための最初のリクエストに戻りましょう。もし正規化を後回しにすると、メイン期間とフォワード期間で同じパラメータに対応する列がすでに分かれて存在しているため、両方の最小値と最大値を同時に計算するのがより困難になります。そこで、まずはいくつかのパラメータに絞って、メイン期間とフォワード期間の結果の「距離」を評価する方法を検討してみましょう。たとえば、まずはcustom_ontester、equity_dd_relative、profit_factorの3つのパラメータで距離を計算する練習をしてみます。
これらのパラメータの値を持つ列を、0から1までの範囲の値を持つ列に変換する必要があります。そのために、ウィンドウ関数を使用して、クエリ内で各列の最小値と最大値を取得します。スケーリングされた値を持つ列には、元の列名に接頭辞「s_」を付けて命名します。 このクエリで返された結果に基づき、CREATE TABLE文を使用して新しいテーブルを作成し、その中にデータを挿入します。
CREATE TABLE ... AS SELECT ... ;
作成され、入力された新しいテーブルの内容を見てみましょう。
-- Request 3
DROP TABLE IF EXISTS t0;
CREATE TABLE t0 AS
SELECT id_pass,
pass,
is_forward,
custom_ontester,
(custom_ontester - MIN(custom_ontester) OVER () ) / (MAX(custom_ontester) OVER () - MIN(custom_ontester) OVER () ) AS s_custom_ontester,
equity_dd_relative,
(equity_dd_relative - MIN(equity_dd_relative) OVER () ) / (MAX(equity_dd_relative) OVER () - MIN(equity_dd_relative) OVER () ) AS s_equity_dd_relative,
profit_factor,
(profit_factor - MIN(profit_factor) OVER () ) / (MAX(profit_factor) OVER () - MIN(profit_factor) OVER () ) AS s_profit_factor
FROM passes
WHERE id_task=10;
SELECT * FROM t0;
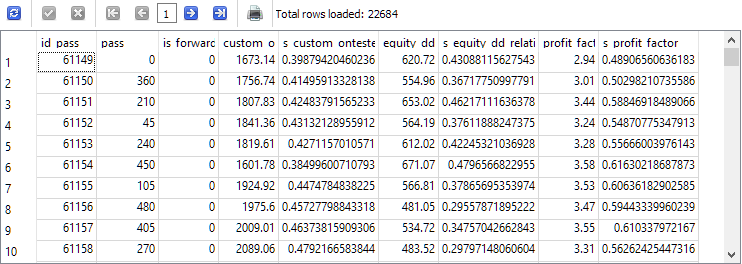
ご覧のとおり、推定された各パラメータの横に、そのパラメータの値が0から1の範囲に縮小された新しい列が表示されています。
それでは、2番目のクエリの内容を少し修正し、passesではなく新しいテーブルt0からデータを取得し、結果を新しいテーブルt1に格納するようにしましょう。ここでは、すでにスケーリングされた値を使用し、利便性のためにそれらを丸めます。また、正規化された利益の値が、メイン期間およびフォワード期間の両方で正の値である行のみを残します。
-- Request 4 DROP TABLE IF EXISTS t1; CREATE TABLE t1 AS SELECT p0.id_pass AS I_id_pass, p0.is_forward AS I_is_forward, ROUND(p0.s_custom_ontester, 4) AS I_custom_ontester, ROUND(p0.s_equity_dd_relative, 4) AS I_equity_dd_relative, ROUND(p0.s_profit_factor, 4) AS I_profit_factor, p1.id_pass AS O_id_pass, p1.is_forward AS O_is_forward, ROUND(p1.s_custom_ontester, 4) AS O_custom_ontester, ROUND(p1.s_equity_dd_relative, 4) AS O_equity_dd_relative, ROUND(p1.s_profit_factor, 4) AS O_profit_factor FROM t0 p0 JOIN t0 p1 ON p0.pass = p1.pass AND p0.is_forward = 0 AND p1.is_forward = 1 AND p0.custom_ontester > 0 AND p1.custom_ontester > 0; SELECT * FROM t1;
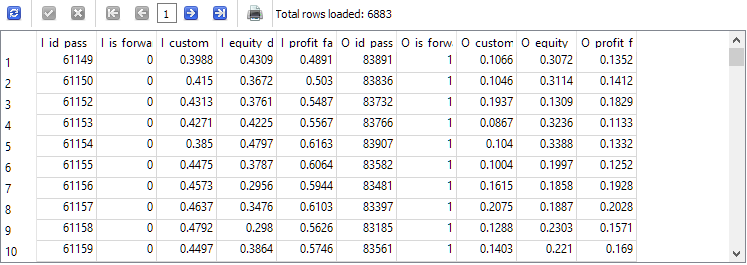
2番目のクエリと比較して行数は約3分の1に削減されましたが、メイン期間とフォワード期間の両方で利益が得られた実行だけが残ります。
ついにクエリ開発プロセスの最終ステップに到達しました。後は、各t1テーブル行のメイン期間とフォワード期間のパラメータの組み合わせ間の距離を計算し、距離の昇順で並べ替えるだけです。
-- Request 5 SELECT ROUND(POW((I_custom_ontester - O_custom_ontester), 2) + POW( (I_equity_dd_relative - O_equity_dd_relative), 2) + POW( (I_profit_factor - O_profit_factor), 2), 4) AS dist, * FROM t1 ORDER BY dist ASC;
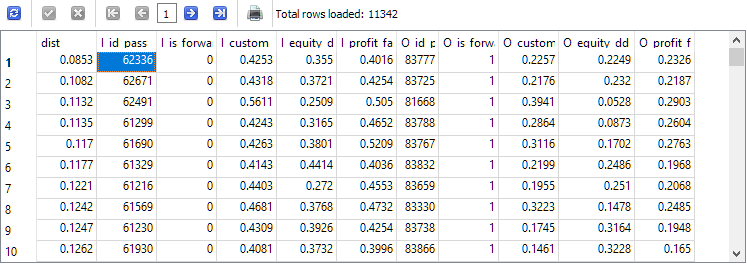
取得された結果の先頭文字列のI_id_passパスIDは、メイン期間とフォワード期間の結果の値の間の距離が最も小さいパスに対応しています。
このパスIDと、メイン期間における正規化された利益が最も高かったパスのIDを取得してみましょう。これらは一致しないため、前回の記事で説明したように、最終的なEA(エキスパートアドバイザー)のためのパラメータライブラリを作成することになります。なお、パラメータセットのライブラリを作成・エクスポートする際に特定のデータベースを指定できるようにするため、前回の記事で追加したファイルに対していくつかの小さな修正を加える必要がありました。
結果
つまり、ライブラリには2つの設定オプションがあります。最初のものは「Best for dist(IS, OS) (2018-2023)」と呼ばれるもので、パラメータ値の距離(メイン期間とフォワード期間の結果の差)が最も小さい最適化パスです。2つ目は「Best on IS (2018–2022)」と呼ばれ、2018年から2022年のメイン期間において正規化された利益が最も高かった最適化パスです。
図8:最終的なEAのライブラリから設定のグループを選択する
最適化に全面的に取り組んだ2018年から2023年の期間におけるこれら2つのグループの結果を見てみましょう。
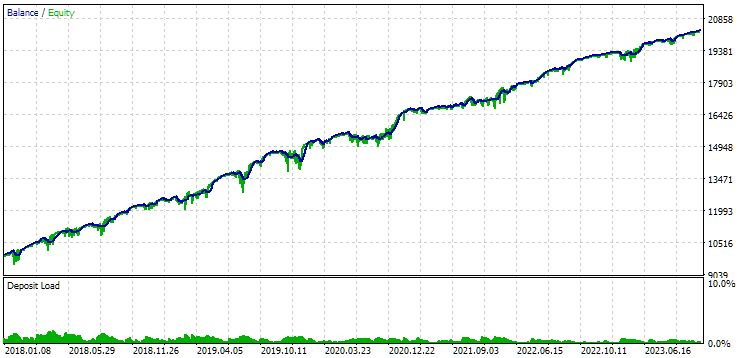
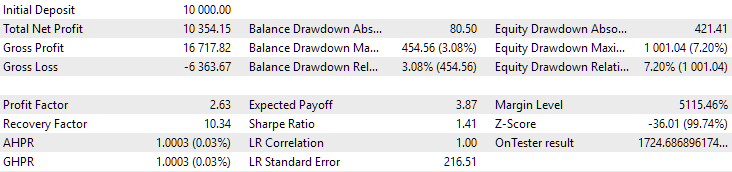
図9:2018年から2023年までの第1グループ(距離別ベスト)の結果
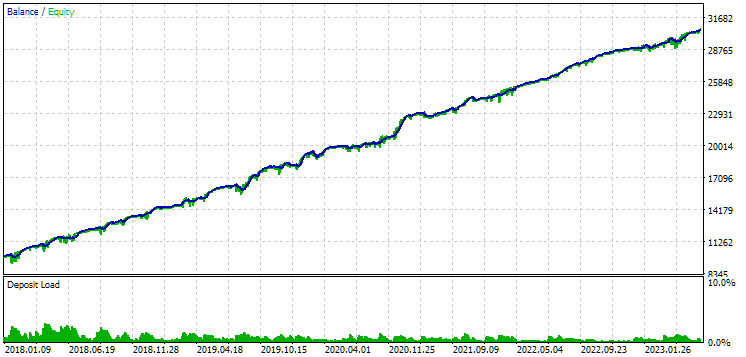
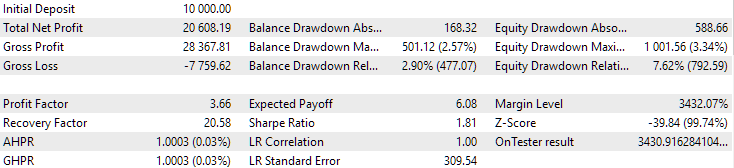
図10:2018年から2023年までの期間における第2グループ(利益面で最高)の結果
この期間において、どちらのグループも良好に正規化されていることが分かります(最大ドローダウンはいずれもUSD 1000)。しかし、1つ目のグループの年間平均利益は、2つ目のグループのおよそ半分にとどまっています(USD 1724対USD 3430)。この段階では、1つ目のグループの利点はまだ明らかになっていません。
それでは次に、最適化には使用されていない2024年(10月以前)の結果を、これら2つのグループについて確認してみましょう。
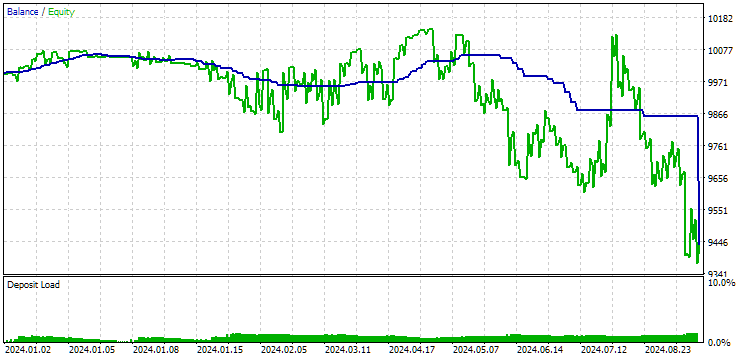
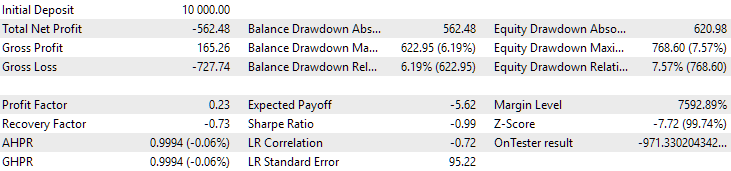
図11:2024年の第1グループ(距離別ベスト)の結果
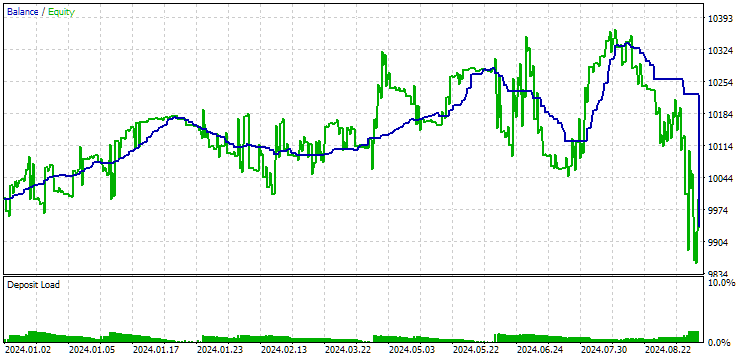
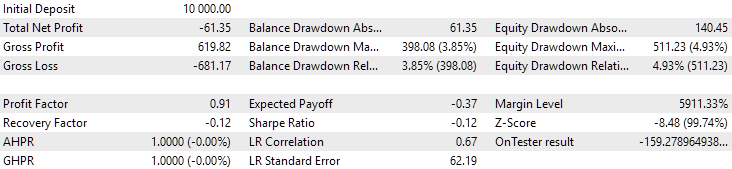
図12:2024年の第2グループ(利益面で最高)の結果
この時点では、どちらの結果もマイナスですが、2つ目のグループの方がまだ良好に見えます。なお、この期間中の最大ドローダウンはいずれの場合も常にUSD 1000未満であったことは注目に値します。
2024年はこの通貨ペアにとって特に成功した年ではなかったため、今度は最適化期間の「後」ではなく「前」の結果を確認してみましょう。幸いなことに期間の選択に余裕があるので、今回はより長い期間、つまり2015年から2017年の3年間を対象とします。
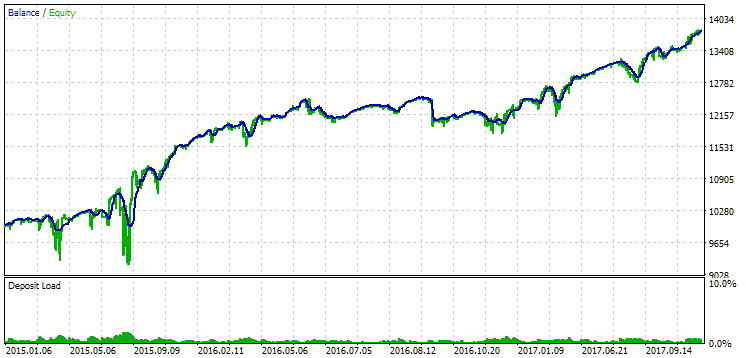
図13:2015年から2017年までの第1グループ(距離別ベスト)の結果
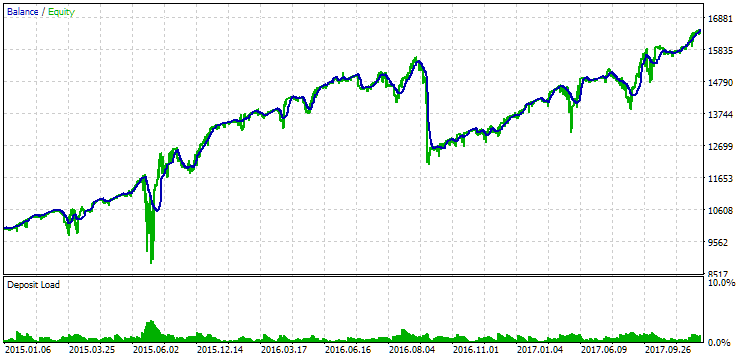
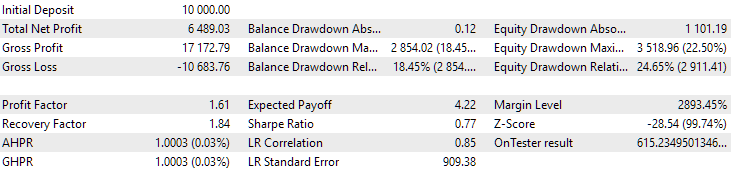
図14:2015年から2017年までの期間における第2グループ(利益面で最高)の結果
この期間中、ドローダウンはすでに許容される計算値を超えていました。最初のバージョンでは約1.5倍、2番目のバージョンでは約3.5倍の大きさでした。この点において、最初のオプションの方がやや優れていると言えます。なぜなら、超過ドローダウンが2番目のオプションに比べて明らかに少なく、全体としてもそれほど大きくないためです。また、最初のバージョンには、2番目のバージョンのようにグラフの中央付近に顕著な落ち込みが見られません。言い換えれば、最初のオプションは、2番目のオプションに比べて、未知の歴史的期間に対する適応性が優れていることを示しています。ただし、正規化された平均年間利益で見ると、これら2つのオプション間の差はそれほど大きくありません(USD 857対USD 615)。残念ながら、未知の期間に対してこの値を事前に計算することはできません。
したがって、この期間においては、最初のオプションの方が依然として優先されるべきです。では、これまでの内容をまとめましょう。
結論
フォワード期間を用いた最適化の第2段階の自動化を実装しました。しかし今回も、明確な利点は確認されませんでした。作業の範囲は当初の予想よりも遥かに広く、想定以上の時間を要しました。その過程で多くの新たな疑問が生まれましたが、それらの多くは今後の課題として残っています。
検証の中で、もしフォワード期間がEAにとって不調な時期と重なった場合には、有効なパラメータの組み合わせを選定するのが困難になる可能性があることが明らかになりました。
また、取引の継続時間が長い場合、メイン期間とフォワード期間の境界で中断されるパスの結果は、連続したパスの結果と大きく異なる場合があります。これは、この形式でフォワード期間を活用することの妥当性に疑問を投げかけます。ここでいう「フォワード期間」とは、将来同等のパフォーマンスが期待できるパラメータを自動的に選択するための手法として用いるものです。
今回は、パスの結果同士の距離を算出するために、シンプルな方法を一つ採用しましたが、より高度な手法を適用することで、結果の精度が向上する可能性もあります。また、複数の銘柄および時間枠に対応したパラメータセットのグループに最適なパスを自動で選択する仕組みについては、まだ実装を開始していません。とはいえ、実装に必要な準備はほぼ整っており、EAからSQLクエリを呼び出すだけで済む段階にまで来ています。。ただし、今後も仕様変更が見込まれるため、本格的な自動化は後日実施する予定です
ご覧いただき、誠にありがとうございました。また近いうちにお会いしましょう。
重要な警告
この記事および連載のこれまでのすべての記事で提示された結果は、過去のテストデータのみに基づいており、将来の利益を保証するものではありません。このプロジェクトでの作業は研究的な性質のものであり、公開された結果はすべて、自己責任で使用されるべきです。
アーカイブ内容
| # | 名前 | バージョン | 詳細 | 最近の変更 |
|---|---|---|---|---|
| MQL5/Experts/Article.15683 | ||||
| 1 | Advisor.mqh | 1.04 | EA基本クラス | 第10回 |
| 2 | Database.mqh | 1.05 | データベースを扱うクラス | 第18回 |
| 3 | database.sqlite.schema.sql | — | データベース構造 | 第18回 |
| 4 | ExpertHistory.mqh | 1.00 | 取引履歴をファイルにエクスポートするクラス | 第16回 |
| 5 | ExportedGroupsLibrary.mqh | — | 戦略グループ名とその初期化文字列の配列をリストした生成されたファイル | 第17回 |
| 6 | Factorable.mqh | 1.01 | 文字列から作成されたオブジェクトの基本クラス | 第10回 |
| 7 | GroupsLibrary.mqh | 1.01 | 選択された戦略グループのライブラリを操作するためのクラス | 第18回 |
| 8 | HistoryReceiverExpert.mq5 | 1.00 | リスクマネージャーとの取引履歴を再生するためのEA | 第16回 |
| 9 | HistoryStrategy.mqh | 1.00 | 取引履歴を再生するための取引戦略のクラス | 第16回 |
| 10 | Interface.mqh | 1.00 | さまざまなオブジェクトを視覚化するための基本クラス | 第4回 |
| 11 | LibraryExport.mq5 | 1.01 | 選択したパスの初期化文字列をライブラリからExportedGroupsLibrary.mqhファイルに保存するEA | 第18回 |
| 12 | Macros.mqh | 1.02 | 配列操作に便利なマクロ | 第16回 |
| 13 | Money.mqh | 1.01 | 基本的なお金の管理クラス | 第12回 |
| 14 | NewBarEvent.mqh | 1.00 | 特定の銘柄の新しいバーを定義するクラス | 第8回 |
| 15 | Optimization.mq5 | 1.02 | 最適化タスクの起動を管理するEA | 第18回 |
| 16 | Receiver.mqh | 1.04 | オープンボリュームを市場ポジションに変換するための基本クラス | 第12回 |
| 17 | SimpleHistoryReceiverExpert.mq5 | 1.00 | 取引履歴を再生するための簡易EA | 第16回 |
| 18 | SimpleVolumesExpert.mq5 | 1.20 | 複数のモデル戦略グループを並列操作するためのEA。パラメータは組み込みのグループライブラリから取得されます。 | 第17回 |
| 19 | SimpleVolumesStage1.mq5 | 1.17 | 取引戦略シングルインスタンス最適化EA(段階1) | 第18回 |
| 20 | SimpleVolumesStage2.mq5 | 1.01 | 取引戦略インスタンスグループ最適化EA(段階2) | 第18回 |
| 21 | SimpleVolumesStage3.mq5 | 1.01 | 生成された標準化された戦略グループを、指定された名前のグループのライブラリに保存するEA。 | 第18回 |
| 22 | SimpleVolumesStrategy.mqh | 1.09 | ティックボリュームを使用した取引戦略のクラス | 第15回 |
| 23 | Strategy.mqh | 1.04 | 取引戦略基本クラス | 第10回 |
| 24 | TesterHandler.mqh | 1.04 | 最適化イベント処理クラス | 第18回 |
| 25 | VirtualAdvisor.mqh | 1.07 | 仮想ポジション(注文)を扱うEAのクラス | 第18回 |
| 26 | VirtualChartOrder.mqh | 1.01 | グラフィカル仮想位置クラス | 第18回 |
| 27 | VirtualFactory.mqh | 1.04 | オブジェクトファクトリクラス | 第16回 |
| 28 | VirtualHistoryAdvisor.mqh | 1.00 | トレード履歴再生EAクラス | 第16回 |
| 29 | VirtualInterface.mqh | 1.00 | EAGUIクラス | 第4回 |
| 30 | VirtualOrder.mqh | 1.04 | 仮想注文とポジションのクラス | 第8回 |
| 31 | VirtualReceiver.mqh | 1.03 | オープンボリュームを市場ポジションに変換するクラス(レシーバー) | 第12回 |
| 32 | VirtualRiskManager.mqh | 1.02 | リスクマネジメントクラス(リスクマネージャー) | 第15回 |
| 33 | VirtualStrategy.mqh | 1.05 | 仮想ポジションを使った取引戦略のクラス | 第15回 |
| 34 | VirtualStrategyGroup.mqh | 1.00 | 取引戦略グループのクラス | 第11回 |
| 35 | VirtualSymbolReceiver.mqh | 1.00 | 銘柄レシーバークラス | 第3回 |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15683
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
新しい記事 多通貨EAトレードの開発(パート18):フォワードの自動グループ選択を考える が掲載されました:
ByYuriy Bykov