
多通貨エキスパートアドバイザーの開発(第20回):自動プロジェクト最適化段階のコンベアの配置(I)
はじめに
本連載では、人間の介入なしで一つのトレーディング戦略のパラメータの良い組み合わせを見つけることができる自動最適化システムを作ろうとしています。これらの組み合わせは最終的に一つのエキスパートアドバイザー(EA)に統合されます。目標は第9回と第11回でより詳しく設定されています。このような検索のプロセス自体は1つのEA(最適化EA)によって制御され、その動作中に保存する必要のあるすべてのデータはメインのデータベースに格納されます。
データベースには、いくつかのクラスのオブジェクトに関する情報を保存するためのテーブルがあります。一部には、固定された値のセットから取ることができるステータスフィールド(QueuedProcessDoneなど)がありますが、すべてのクラスがこのフィールドを使用しているわけではありません。より正確には、現時点では最適化タスク(task)のみで使用されています。私たちの最適化EAは、次に実行するタスクを選択するためにタスクテーブル(tasks)からQueuedのタスクを検索します。各タスクが完了すると、そのステータスはデータベース上でCompletedに変更されます。
次のステップとして、タスクだけでなく、他のすべてのオブジェクト(jobs、stages、projects)のステータスも自動更新されるように実装し、最終的にデータベースに接続せずに独立して動作できる最終EAを取得するまで、必要なすべてのステージを自動的に実行できるように整備してみましょう。
道筋の整理
まず最初に、データベース内でステータスを持つすべてのオブジェクトクラスを詳しく確認し、ステータスを変更するための明確なルールを策定します。これができれば、これらのルールを追加のSQLクエリとして、最適化EAまたはステージEAから呼び出す形で実装することができます。または、特定のデータ変更イベントが発生した際に作動するデータベースのトリガーとして実装することも可能かもしれません。
次に、タスクが完了する順序を決定する方法を合意する必要があります。これまではあまり問題になりませんでした。開発中は毎回新しいデータベースでトレーニングをおこない、プロジェクトのステージ、作業、タスクを完了すべき順序どおりに追加していたからです。しかし、複数のプロジェクトの情報をデータベースに保存したり、新しいプロジェクトを自動で追加したりする場合には、タスクの優先順位の決定方法としてこのやり方に頼ることはできません。そこで、この問題に少し時間をかけて取り組みます。
自動最適化プロジェクトのすべてのタスクを順番に実行するコンベアの動作をテストするために、さらにいくつかの操作を自動化する必要があります。それまではこれらを手動でおこなっていました。たとえば、最適化の第2ステージを完了した後、最終EAで使用するための最良のグループを選択する機会があります。この操作は、第3ステージEAを手動で実行することでおこなっていました。つまり、自動最適化コンベアの外での作業です。このEAの起動パラメータを設定するために、MQL5に関連するサードパーティのデータベースアクセスインターフェイスを使い、第2ステージで最良の結果を出したパスのIDを手動で選択していました。この点についても、何らかの自動化を試みます。
こうした変更をおこなった後、最終的には自動最適化ステージを実行して最終EAを取得する完全なコンベアを作成できることを期待しています。その過程で、作業効率を上げるための他の課題についても検討します。たとえば、第2ステージ以降のEAは、異なるトレーディング戦略でも同じになる可能性があります。これが本当かどうかを確認します。また、小さなプロジェクトを複数作る方が便利か、大規模プロジェクト内にステージや作業を多数作る方が便利かも検討します。
ステータス変更のルール
まず、ステータス変更のルールを定式化することから始めましょう。ご存じの通り、私たちのデータベースにはステータスフィールド(status)を持つ以下のオブジェクトがあります。
- Project:projectsテーブルに保存される1つ以上のステージをまとめるオブジェクト
- Stage:stagesテーブルに保存される1つ以上のジョブをまとめるオブジェクト
- Job:jobsテーブルに保存される1つ以上のタスクをまとめるオブジェクト
- Task:通常は複数のテストパスをまとめ、tasksテーブルに保存される
これら4つのオブジェクトクラスで可能なステータス値は共通で、以下のいずれかです。
- Queued:オブジェクトが処理待ちにキューイングされている
- Process:オブジェクトが処理中である
- Done:オブジェクトの処理が完了した、もしくは未開始である
以下に、プロジェクト自動最適化コンベアの通常サイクルに従った、データベース内オブジェクトのステータス変更ルールを説明します。サイクルは、プロジェクトが最適化のためにキューに入れられる(Queuedステータスが割り当てられる)ことで開始します。
プロジェクトのステータスがQueuedに変更された場合:
- このプロジェクトのすべてのステージのステータスをQueuedに設定する
ステージのステータスがQueuedに変更された場合:
- このステージ内のすべてのジョブのステータスをQueuedに設定する
ジョブのステータスがQueuedに変更された場合:
- のジョブのすべてのタスクのステータスをQueuedに設定する
タスクのステータスがQueuedに変更された場合:
- 開始日と終了日をクリアする
このように、プロジェクトのステータスをQueuedに変更すると、そのプロジェクトのすべてのステージ、ジョブ、タスクのステータスも連鎖的にQueuedに更新されます。これらすべてのオブジェクトは、Optimization.ex5 EAが起動されるまでQueued状態のままです。
起動後、Queuedステータスのタスクが少なくとも1つ存在する必要があります。複数タスクの場合のソート順については後で検討します。タスクのステータスはProcessに変更され、以下の処理がおこなわれます。
タスクのステータスがProcessに変更された場合:
- 開始日を現在時刻に設定
- これまでタスク内でおこなわれたすべてのパスを削除
- このタスクに関連するジョブのステータスをProcessに設定
ジョブのステータスがProcessに変更された場合:
- このジョブに関連するステージのステータスをProcessに設定
ステージのステータスがProcessに変更された場合:
- このステージに関連するプロジェクトのステータスをProcessに設定
以降、プロジェクト内のタスクはステージ単位で順次実行されます。次のタスクが完了するまで、ステータスの変更は発生しません。この時点でタスクのステータスがDoneに変更され、上位オブジェクトに連鎖的に反映される場合があります。
タスクのステータスがDoneに変更された場合:
- 終了日を現在時刻に設定
- このタスクが属するジョブ内のQueuedタスクをすべて取得。存在しなければ、関連ジョブのステータスをDoneに設定
ジョブのステータスがDoneに変更された場合:
- このジョブが属するステージ内のQueuedジョブをすべて取得。存在しなければ、関連ステージのステータスをDoneに設定
ステージのステータスがDoneに変更された場合:
- このステージが属するプロジェクト内のQueuedステージをすべて取得。存在しなければ、関連プロジェクトのステータスをDoneに設定
こうして、最後のステージの最後のジョブの最後のタスクが完了すると、プロジェクト自体もDoneに移行します。
これでステータス変更ルールはすべて定義されました。次のステップとして、これらの動作を実装するデータベーストリガーの作成に進めます。
トリガーの作成
まず、プロジェクトのステータスがQueuedに変更されたときの処理をおこなうトリガーから始めましょう。以下は、その実装方法の一例です。
CREATE TRIGGER upd_project_status_queued AFTER UPDATE OF status ON projects WHEN NEW.status = 'Queued' BEGIN UPDATE stages SET status = 'Queued' WHERE id_project = NEW.id_project; END;
完了後、プロジェクトのステージのステータスもQueuedに変更されます。したがって、ステージ、ジョブ、タスクに対応するトリガーも起動する必要があります。
CREATE TRIGGER upd_stage_status_queued
AFTER UPDATE
ON stages
WHEN NEW.status = 'Queued' AND
OLD.status <> NEW.status
BEGIN
UPDATE jobs
SET status = 'Queued'
WHERE id_stage = NEW.id_stage;
END;
CREATE TRIGGER upd_job_status_queued
AFTER UPDATE OF status
ON jobs
WHEN NEW.status = 'Queued'
BEGIN
UPDATE tasks
SET status = 'Queued'
WHERE id_job = NEW.id_job;
END;
CREATE TRIGGER upd_task_status_queued
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Queued'
BEGIN
UPDATE tasks
SET start_date = NULL,
finish_date = NULL
WHERE id_task = NEW.id_task;
END;
タスクの起動は、以下のトリガーによって処理されます。このトリガーは、タスクの開始日を設定し、前回のタスク実行でのパスデータをクリアし、ジョブのステータスをProcessに更新します。
CREATE TRIGGER upd_task_status_process
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Process'
BEGIN
UPDATE tasks
SET start_date = DATETIME('NOW')
WHERE id_task = NEW.id_task;
DELETE FROM passes
WHERE id_task = NEW.id_task;
UPDATE jobs
SET status = 'Process'
WHERE id_job = NEW.id_job;
END;
次に、このジョブが実行されているステージとプロジェクトのステータスがProcessにカスケードされます。
CREATE TRIGGER upd_job_status_process AFTER UPDATE OF status ON jobs WHEN NEW.status = 'Process' BEGIN UPDATE stages SET status = 'Process' WHERE id_stage = NEW.id_stage; END; CREATE TRIGGER upd_stage_status_process AFTER UPDATE OF status ON stages WHEN NEW.status = 'Process' BEGIN UPDATE projects SET status = 'Process' WHERE id_project = NEW.id_project; END;
タスクのステータスがDoneに更新された、つまりタスクが完了したときに発動するトリガーでは、まずタスクの完了日を更新し、その後(現在のタスクジョブ内で実行待ちの他のタスクが存在するかどうかに応じて)ジョブのステータスをProcessまたはDoneに更新します。
CREATE TRIGGER upd_task_status_done
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Done'
BEGIN
UPDATE tasks
SET finish_date = DATETIME('NOW')
WHERE id_task = NEW.id_task;
UPDATE jobs
SET status = (
SELECT CASE WHEN (
SELECT COUNT( * )
FROM tasks t
WHERE t.status = 'Queued' AND
t.id_job = NEW.id_job
)
= 0 THEN 'Done' ELSE 'Process' END
)
WHERE id_job = NEW.id_job;
END;
ステージとプロジェクトのステータスについても同じことをおこないましょう。
CREATE TRIGGER upd_job_status_done AFTER UPDATE OF status ON jobs WHEN NEW.status = 'Done' BEGIN UPDATE stages SET status = ( SELECT CASE WHEN ( SELECT COUNT( * ) FROM jobs j WHERE j.status = 'Queued' AND j.id_stage = NEW.id_stage ) = 0 THEN 'Done' ELSE 'Process' END ) WHERE id_stage = NEW.id_stage; END; CREATE TRIGGER upd_stage_status_done AFTER UPDATE OF status ON stages WHEN NEW.status = 'Done' BEGIN UPDATE projects SET status = ( SELECT CASE WHEN ( SELECT COUNT( * ) FROM stages s WHERE s.status = 'Queued' AND s.name <> 'Single tester pass' AND s.id_project = NEW.id_project ) = 0 THEN 'Done' ELSE 'Process' END ) WHERE id_project = NEW.id_project; END;
プロジェクト自体にDoneステータスを設定した際に、プロジェクト内のすべてのオブジェクトをDone状態に移行させる機能も提供します。このシナリオは、自動最適化の通常の流れでは必須の操作ではないため、上記のルール一覧には含めていません。このトリガーでは、未実行または実行中のすべてのタスクのステータスをDoneに設定し、それによってプロジェクト内のすべてのジョブとステージにも同じステータスが設定されるようにします。
CREATE TRIGGER upd_project_status_done AFTER UPDATE OF status ON projects WHEN NEW.status = 'Done' BEGIN UPDATE tasks SET status = 'Done' WHERE id_task IN ( SELECT t.id_task FROM tasks t JOIN jobs j ON j.id_job = t.id_job JOIN stages s ON s.id_stage = j.id_stage JOIN projects p ON p.id_project = s.id_project WHERE p.id_project = NEW.id_project AND t.status <> 'Done' ); END;
これらすべてのトリガーが作成されたら、タスクの実行順序を決定する方法を考えてみましょう。
コンベアの整理
これまでデータベースでは、1つのプロジェクトのみを扱ってきましたので、まずこの場合のタスクの実行順序のルールを見ていきます。1つのプロジェクトにおけるタスクの順序を理解できれば、複数プロジェクトを同時に起動した場合のタスク順序についても考えることができます。
同じジョブに属し、最適化の基準が異なるだけの最適化タスクは、順序に関係なく実行できます。異なる基準での遺伝的最適化は、前回の最適化結果を利用しないためです。異なる最適化基準を使用するのは、良好なパラメータ組み合わせの多様性を高めるためです。実際、同じ入力範囲であっても基準が異なる場合、遺伝的最適化は異なる組み合わせに収束することが観察されています。
したがって、タスクテーブルに特別なソート用フィールドを追加する必要はありません。1つのジョブ内でタスクがデータベースに追加された順序、つまりid_taskでソートすることで十分です。
1つのジョブ内にタスクが1つしかない場合、タスクの実行順序はジョブの実行順序に依存します。ジョブは、タスクを異なる銘柄や時間枠の組み合わせにまとめる、または正確には分割するために設計されています。たとえば、3銘柄:EURGBP、EURUSD、GBPUSD、2時間枠:H1、M30、2ステージ:ステージ1、ステージ2の場合、タスクの実行順序として2つの可能性が考えられます。
- 銘柄と時間枠によるグループ化
- EURGBP H1ステージ1
- EURGBP H1ステージ2
- EURGBP M30ステージ1
- EURGBP M30ステージ2
- EURUSD H1ステージ1
- EURUSD H1ステージ2
- EURUSD M30ステージ1
- EURUSD M30ステージ2
- GBPUSD H1ステージ1
- GBPUSD H1ステージ2
- GBPUSD M30ステージ1
- GBPUSD M30ステージ2
- ステージによるグループ化
- ステージ1 EURGBP H1
- ステージ1 EURGBP M30
- ステージ1 EURUSD H1
- ステージ1 EURUSD M30
- ステージ1 GBPUSD H1
- ステージ1 GBPUSD M30
- ステージ2 EURGBP H1
- ステージ2 EURGBP M30
- ステージ2 EURUSD H1
- ステージ2 EURUSD M30
- ステージ2 GBPUSD H1
- ステージ2 GBPUSD M30
1つ目のグループ化方法(銘柄と時間枠でのグループ化)では、第2ステージを完了するごとに、最終EAとして何か完成形を得ることができます。最終EAには、すでに両方のステージの最適化を通過した銘柄と時間枠ごとの単一コピーの取引戦略が含まれます。
2つ目のグループ化方法(ステージでのグループ化)では、第1ステージのすべての作業と、第2ステージの少なくとも1つの作業が完了するまで、最終EAは生成されません。
同じ銘柄と時間枠に対して前段階の結果のみを使用するジョブの場合、両方の方法の間に違いはありません。しかし、少し先を見据えると、第2ステージの結果を異なる銘柄や時間枠で統合する別のステージがあります。このステージはまだ自動最適化ステージとして実装していませんが、ステージEAはすでに用意しており、手動で実行もしました。このステージでは、1つ目のグルーピング方法は適さないため、2つ目の方法を使用します。
なお、もし1つ目の方法を使いたい場合は、シンボルと時間枠ごとに複数のプロジェクトを作成するだけで十分かもしれません。しかし現時点では、その利点は明確ではありません。
1つのステージ内に複数のジョブがある場合、ジョブの実行順序は任意です。異なるステージのジョブの順序は、ステージの優先順序によって決まります。つまり、タスクの場合と同様に、jobsテーブルに特別なソート用フィールドを追加する必要はありません。1つのステージ内でジョブがデータベースに追加された順序、つまりid_jobでソートすれば十分です。
ステージの順序を決定する際も、すでに存在するstagesテーブルのデータを使用できます。最初にid_parent_stage(親ステージ)フィールドを追加しましたが、まだ使用していません。ステージが2つしかない場合は、最初のステージの行を先に作成し、次に2つ目のステージの行を作成すれば順序に問題はありません。しかし、ステージが増え、他のプロジェクトのステージも登場すると、手動で正しい順序を維持するのは難しくなります。
そこで、親ステージが完了した後に子ステージを実行する階層構造を構築することにします。少なくとも1つのステージは親を持たず、階層の最上位に配置される必要があります。次に、tasks、jobs、stagesテーブルのデータを結合し、現在のステージのすべてのタスクを表示するテスト用SQLクエリを作成します。このクエリでは、すべてのフィールドを列の一覧に追加して、可能な限り完全な情報を確認できるようにします。
SELECT t.id_task,
t.optimization_criterion,
t.status AS task_status,
j.id_job,
j.symbol AS job_symbol,
j.period AS job_period,
j.tester_inputs AS job_tester_inputs,
j.status AS job_status,
s.id_stage,
s.name AS stage,
s.expert AS stage_expert,
s.status AS stage_status,
ps.name AS parent_stage,
ps.status AS parent_stage_status,
p.id_project,
p.status AS project_status
FROM tasks t
JOIN
jobs j ON j.id_job = t.id_job
JOIN
stages s ON s.id_stage = j.id_stage
LEFT JOIN
stages ps ON ps.id_stage = s.id_parent_stage
JOIN
projects p ON p.id_project = s.id_project
WHERE t.id_task > 0 AND
t.status IN ('Queued', 'Process') AND
(ps.id_stage IS NULL OR
ps.status = 'Done')
ORDER BY j.id_stage,
j.symbol,
j.period,
t.status,
t.id_task;

図1:現在ステージのタスク取得クエリの結果(あるタスク起動後)
後ほど、別のタスクを取得するために同様のクエリを使用する際には、表示する列数を減らす予定です。それまでは、次のステージ(そのジョブやタスクも含む)が正しく取得できていることを確認しましょう。図1に示されている結果は、id_task=3のタスクが起動された時点のものです。このタスクはid_job=10に属し、さらにid_stage=10のステージに属しています。このステージはFirstと呼ばれ、プロジェクトid_project=1に属しており、親ステージはありません(parent_stage=NULL)。1つのタスクが実行中の場合、そのタスクが属するジョブとプロジェクトの両方にProcessステータスが表示されることが確認できます。一方、id_job=5のジョブはまだタスクが開始されていないため、Queuedステータスのままです。
次に、最初のタスクを完了させてみましょう(テーブルのステータスフィールドを単純にDoneに設定するだけです)。その後、同じクエリを実行した結果を確認します。

図2:現在ステージのタスク取得クエリ結果(実行中タスク完了後)
ご覧の通り、完了したタスクはこのリストから消え、最上行には次に実行可能な別のタスクが表示されています。ここまでの動作は正しいです。次に、このリストの最上位2つのタスクを順に起動して完了させ、さらにid_task=7のタスクを実行のために起動します。

図3:最初のジョブのタスクを完了し、次のタスクを起動した後の現在ステージのタスク取得クエリ結果
id_job=5のジョブはProcessステータスになりました。次に、前回のクエリ結果に表示されている3つのタスクを順に起動して完了させます。それぞれのタスクは完了するごとにクエリ結果から1つずつ消えていきます。最後のタスクが完了した後、再度クエリを実行すると、次の結果が得られます。

図4:現在ステージのタスク取得クエリ結果(第1ステージのすべてのタスク完了後)
クエリ結果には、次のステージに関連するジョブのタスクが含まれるようになりました。id_stage=2は第1ステージの結果をクラスタリングするステージ、id_stage=3は第1ステージで得られた優れた取引戦略の例をグループ化する第2ステージです。この第2ステージではクラスタリングを使用しないため、第1ステージ完了後すぐに実行可能です。そのため、このリストに表示されているのは誤りではありません。両ステージとも親ステージはFirstであり、現在そのステータスはDoneです。
次に、最初の2つのタスクを順に起動して完了させ、再度クエリ結果を確認してみましょう。

図5:タスク取得クエリ結果(クラスタリングステージのすべてのタスク完了後)
結果の最上位には予想通り、第2ステージ(Second)の2つのタスクが表示されていますが、下の2行にはクラスタリング付きの第2ステージ(Second with clustering)のタスクが表示されています。この出現はやや意外ですが、許容される順序と矛盾するものではありません。実際、クラスタリングステージをすでに完了していれば、その結果を使用するステージも実行可能です。クエリ結果に示された2つのステップは互いに独立しているため、順序は問われません。
次に、クエリ結果の最上位タスクを順に選択して、各タスクを起動・完了させます。各ステータス変更後のタスクリストは予想通りに変化し、ジョブやステージのステータスも正しく更新されました。最後のタスクが完了した時点で、クエリ結果は空になり、すべてのステージ・ジョブ・タスクが完了し、プロジェクトはDoneステータスに移行しました。
このクエリを、最適化をおこなうEAに統合していきましょう。
最適化EAの修正
次に、次に実行する最適化タスクのIDを取得するメソッドを変更する必要があります。すでにこの処理をおこなうSQLクエリがありますので、上で作成したクエリをベースに、不要なフィールドを削除してid_taskのみを取得するようにします。また、jobsテーブルの複数フィールド(j.symbol、j.period)でのソートを、j.id_jobに置き換えます。これは、各ジョブがこれらのフィールドに対して1つの値しか持たないためです。最後に、取得する行数を1行に制限します。取得する必要があるのは1行だけです。
GetNextTaskIdメソッドは次のようになります。
//+------------------------------------------------------------------+ //| Get the ID of the next optimization task from the queue | //+------------------------------------------------------------------+ ulong COptimizer::GetNextTaskId() { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT t.id_task" " FROM tasks t " " JOIN " " jobs j ON j.id_job = t.id_job " " JOIN " " stages s ON s.id_stage = j.id_stage " " LEFT JOIN " " stages ps ON ps.id_stage = s.id_parent_stage " " JOIN " " projects p ON p.id_project = s.id_project " " WHERE t.id_task > 0 AND " " t.status IN ('Queued', 'Process') AND " " (ps.id_stage IS NULL OR " " ps.status = 'Done') " " ORDER BY j.id_stage, " " j.id_job, " " t.status, " " t.id_task" " LIMIT 1;"; // ... here we get the query result return res; }
このファイルで作業することにしたので、ついでにもう1つ変更を加えましょう。それは、キュー内のタスク数を取得するメソッドから、ステータスをパラメータとして渡す処理を削除することです。実際、このメソッドはQueuedおよびProcessステータスのタスク数を個別に取得する用途では使われておらず、合計としてのみ使用されます。したがって、TotalTasksメソッドのSQLクエリを修正し、常にこの2つのステータスを持つタスクの合計数を返すように変更し、メソッドのステータス入力も削除します。
//+------------------------------------------------------------------+ //| Get the number of tasks with the specified status | //+------------------------------------------------------------------+ int COptimizer::TotalTasks() { // Result int res = 0; // Request to get the number of tasks with the specified status string query = "SELECT COUNT(*)" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status IN ('Queued', 'Process') " " ORDER BY s.id_stage, j.id_job, t.status LIMIT 1;"; // ... here we get the query result return res; }
現在のフォルダに、Optimizer.mqhファイルの変更内容を保存します。
これらの修正に加えて、いくつかのファイル内で以前のステータス名ProcessingをProcessに置き換える必要があります。これは、上記で統一したステータス名に合わせるためです。
さらに、Pythonプログラムを起動するタスク実行中に発生する可能性のあるエラーに関する情報を取得できるようにすると便利です。現状では、Pythonプログラムが異常終了した場合、最適化EAはタスク完了待ちの段階で停止してしまいます。具体的には、このイベントに関する情報がデータベースに現れるのを待っている状態です。プログラムがエラーで終了すると、タスクステータスをデータベースに更新できないため、コンベアはそのステージで先に進めなくなります。
これまでのところ、この障害を回避する唯一の方法は、タスクに指定されたパラメータでPythonプログラムを手動で再実行し、エラーの原因を解析・修正してから再度プログラムを実行することでした。
SimpleVolumesStage3.mq5の変更
次に、第3ステージの自動化を計画しています。このステージでは、第2ステージの各ジョブ(使用する銘柄や時間枠が異なる)に対して、最終EAに組み込むための最良のパスを選択します。
これまでの第3ステージEAは、第2ステージのパスIDのリストを入力として受け取っており、そのIDをデータベースから手動で選択する必要がありました。それ以外では、このEAは選択されたパスのグループ作成、ドローダウン評価、ライブラリへの保存のみをおこなっていました。第3ステージEAを起動しただけでは最終EAは生成されず、他の複数の操作をおこなう必要がありました。これらの操作の自動化については後で取り組みますが、まずは第3ステージEAの修正に集中します。
パスIDを自動的に選択する方法はいくつかあります。
たとえば、第2ステージの1つのジョブ内で得られたすべてのパスの中から、正規化平均年間利益の指標に基づいて最良のものを選択する方法があります。その1つのパスは、16個の単一取引戦略インスタンスのグループの結果です。最終EAは、複数の単一戦略インスタンスのグループを含む形で作成されます。たとえば、3つの銘柄と2つの時間枠がある場合、第2ステージでは6つのジョブがあります。第3ステージでは、6 * 16 = 96個の単一戦略コピーを含むグループを得ることになります。この方法が最も実装しやすいです。
より複雑な選択方法の例としては、各第2ステージジョブからいくつかの最良パスを選び、選択されたすべてのパスの組み合わせを試す方法があります。これは第2ステージでおこなった方法に非常に似ていますが、今回は16個の単一インスタンスではなく6つのグループから構成します。6つのグループのうち、最初のグループからは第1ジョブの最良パスの1つを、次のグループからは第2ジョブの最良パスの1つを選び、という形で組み合わせます。この方法はより複雑ですが、結果が大幅に向上するとは事前には言えません。
したがって、まずは簡単な方法を実装し、複雑な方法は後回しにします。
このステージではもはやEAパラメータの最適化は必要ありません。今回は単一パスの実行となります。そのため、データベースのステージ設定で、最適化列を0に設定する必要があります。

図6:ステージテーブルの内容
EAコード内で、最適化タスクIDを入力項目に追加し、このEAがコンベア内で起動され、パスの結果を正しくデータベースに保存できるようにします。
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput int idTask_ = 0; // - Optimization task ID sinput string fileName_ = "database911.sqlite"; // - File with the main database input group "::: Selection for the group" input string passes_ = ""; // - Comma-separated pass IDs input group "::: Saving to library" input string groupName_ = ""; // - Group name (if empty - no saving)
pass_パラメータは削除できますが、念のため当面は残しておきます。第2ステージのジョブに対して最良のパスID一覧を取得するSQLクエリを作成しましょう。pass_パラメータが空の場合は、最良パスのIDを取得します。pass_パラメータで特定のIDが渡された場合は、それらを適用します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); CTesterHandler::TesterInit(idTask_, fileName_); // Initialization string with strategy parameter sets string strategiesParams = NULL; // If the connection to the main database is established, if(DB::Connect(fileName_)) { // Form a request to receive passes with the specified IDs string query = (passes_ == "" ? StringFormat("SELECT DISTINCT FIRST_VALUE(p.params) OVER (PARTITION BY p.id_task ORDER BY custom_ontester DESC) AS params " " FROM passes p " " WHERE p.id_task IN (" " SELECT pt.id_task " " FROM tasks t " " JOIN " " jobs j ON j.id_job = t.id_job " " JOIN " " stages s ON s.id_stage = j.id_stage " " JOIN " " jobs pj ON pj.id_stage = s.id_parent_stage " " JOIN " " tasks pt ON pt.id_job = pj.id_job " " WHERE t.id_task = %d " " ) ", idTask_) : StringFormat("SELECT params" " FROM passes " " WHERE id_pass IN (%s);", passes_) ); Print(query); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Structure for reading results struct Row { string params; } row; // For all query result strings, concatenate initialization rows while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } } DB::Close(); } // ... // Successful initialization return(INIT_SUCCEEDED); }
現在のフォルダのSimpleVolumesStage3.mq5ファイルに加えた変更を保存します。
これで第3段階のEAの修正は完了です。データベース内のプロジェクトをQueued状態に移動し、最適化EAを起動しましょう。
最適化コンベアの結果
まだ予定していたすべてのステージを実装していないにもかかわらず、現在ではほぼ完成した最終EAを自動で提供できるツールがすでにあります。第3ステージが完了すると、パラメータライブラリ(strategy_groupsテーブル)に2つのレコードが登録されます。

最初のレコードには、第2ステージで得られた最良のグループをクラスタリングせずに組み合わせたパスのIDが含まれています。2つ目のレコードには、第2ステージで得られた最良のグループをクラスタリングして組み合わせたパスのIDが含まれています。したがって、これらのパスIDに対してpassesテーブルから初期化文字列を取得し、この2つの組み合わせ結果を確認することができます。
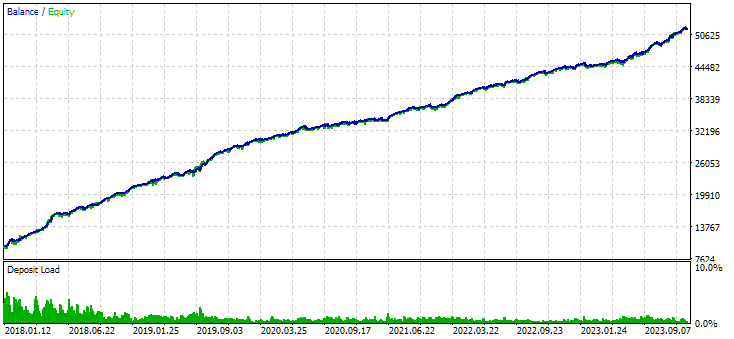
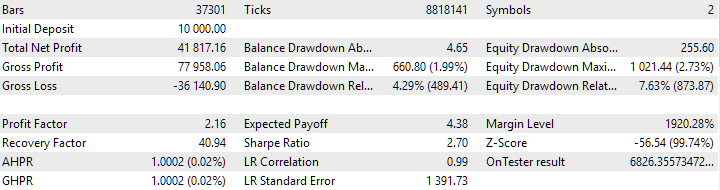
図7:クラスタリングを使用せずに得られたインスタンスの組み合わせグループの結果
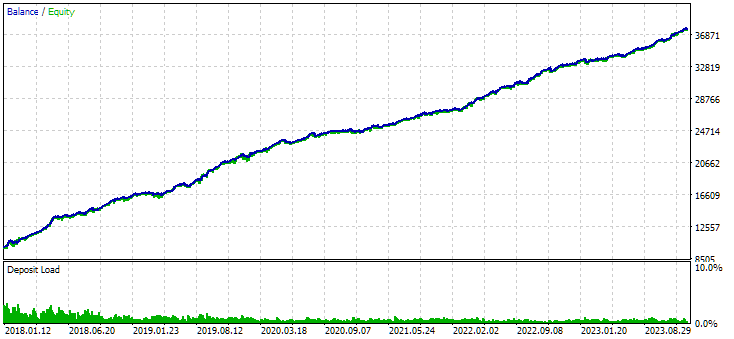
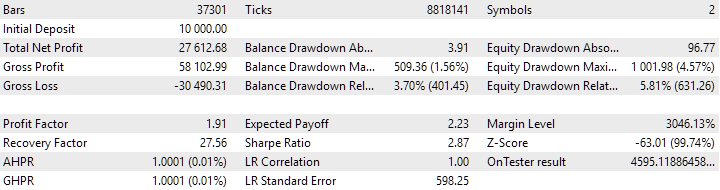
図8:クラスタリングを使用して得られたインスタンスの組み合わせグループの結果
クラスタリングなしのバリエーションのほうが、より高い利益を示しています。しかし、クラスタリングありのバリエーションはシャープレシオが高く、直線性もより優れています。ただし、これらの結果はまだ最終的なものではないため、今回は詳しい分析はおこないません。
次のステップは、最終EAを組み立てるためのステージを追加することです。ライブラリをエクスポートし、データフォルダ内にExportedGroupsLibrary.mqhインクルードファイルを生成する必要があります。その後、このファイルを作業フォルダにコピーします。この操作は、Pythonプログラムを使用するか、DLLからのシステムコピー機能を使って実行できます。最後のステージでは、最終EAをコンパイルし、新しいEAバージョンで端末を起動すれば作業は完了です。
これらの作業を実装するにはかなりの時間が必要となるため、その説明は次回の記事で続けます。
結論
では、これまでに何ができたのかを振り返ってみましょう。自動最適化コンベヤの最初のステージの自動実行を整備し、正しく動作するようにしました。中間結果を確認し、たとえばクラスタリング工程を省くことも、逆に残してクラスタリングなしのオプションを削除することもできます。
このようなツールがあれば、今後の実験を通じて、これまで難しかった問いへの答えを探ることができます。たとえば、第1ステージで異なる入力範囲で最適化をおこなった場合、それらを同じ銘柄と時間枠ごとに別々に組み合わせる方が良いのか、それとも一緒に組み合わせる方が良いのか、といった問題です。
コンベヤにステージを追加することで、徐々により複雑なEAを組み立てることが可能になります。
最後に、部分的な再最適化や、実験による検証を通じた継続的な再最適化の可能性も検討できます。ここでいう再最適化とは、異なる時間範囲での繰り返し最適化のことです。次回その点について詳しく触れます。
ご精読ありがとうございました。またすぐにお会いしましょう。
重要な注意事項
この記事および連載のこれまでのすべての記事で提示された結果は、過去のテストデータのみに基づいており、将来の利益を保証するものではありません。このプロジェクトでの作業は研究的な性質のものであり、公開された結果はすべて、自己責任で使用されるべきです。
アーカイブ内容
| # | 名前 | バージョン | 詳細 | 最近の変更 |
|---|---|---|---|---|
| MQL5/Experts/Article.16134 | ||||
| 1 | Advisor.mqh | 1.04 | EA基本クラス | 第10回 |
| 2 | ClusteringStage1.py | 1.01 | 最適化の第1ステージの結果をクラスタリングするプログラム | 第20回 |
| 3 | Database.mqh | 1.07 | データベースを扱うクラス | 第19回 |
| 4 | database.sqlite.schema.sql | 1.05 | データベース構造 | 第20回 |
| 5 | ExpertHistory.mqh | 1.00 | 取引履歴をファイルにエクスポートするクラス | 第16回 |
| 6 | ExportedGroupsLibrary.mqh | - | 戦略グループ名とその初期化文字列の配列をリストした生成されたファイル | 第17回 |
| 7 | Factorable.mqh | 1.02 | 文字列から作成されたオブジェクトの基本クラス | 第19回 |
| 8 | GroupsLibrary.mqh | 1.01 | 選択された戦略グループのライブラリを操作するためのクラス | 第18回 |
| 9 | HistoryReceiverExpert.mq5 | 1.00 | リスクマネージャーとの取引履歴を再生するためのEA | 第16回 |
| 10 | HistoryStrategy.mqh | 1.00 | 取引履歴を再生するための取引戦略のクラス | 第16回 |
| 11 | Interface.mqh | 1.00 | さまざまなオブジェクトを視覚化するための基本クラス | 第4回 |
| 12 | LibraryExport.mq5 | 1.01 | 選択したパスの初期化文字列をライブラリからExportedGroupsLibrary.mqhファイルに保存するEA | 第18回 |
| 13 | Macros.mqh | 1.02 | 配列操作に便利なマクロ | 第16回 |
| 14 | Money.mqh | 1.01 | 基本的なお金の管理クラス | 第12回 |
| 15 | NewBarEvent.mqh | 1.00 | 特定の銘柄の新しいバーを定義するクラス | 第8回 |
| 16 | Optimization.mq5 | 1.03 | 最適化タスクの起動を管理するEA | 第19回 |
| 17 | Optimizer.mqh | 1.01 | プロジェクト自動最適化マネージャーのクラス | 第20回 |
| 18 | OptimizerTask.mqh | 1.01 | 最適化タスククラス | 第20回 |
| 19 | Receiver.mqh | 1.04 | オープンボリュームを市場ポジションに変換するための基本クラス | 第12回 |
| 20 | SimpleHistoryReceiverExpert.mq5 | 1.00 | 取引履歴を再生するための簡易EA | 第16回 |
| 21 | SimpleVolumesExpert.mq5 | 1.20 | 複数のモデル戦略グループを並列操作するためのEA。パラメータは組み込みのグループライブラリから取得されます。 | 第17回 |
| 22 | SimpleVolumesStage1.mq5 | 1.18 | 取引戦略単一インスタンス最適化EA(第1ステージ) | 第19回 |
| 23 | SimpleVolumesStage2.mq5 | 1.02 | 取引戦略単一インスタンス最適化EA(第2ステージ) | 第19回 |
| 24 | SimpleVolumesStage3.mq5 | 1.02 | 生成された標準化された戦略グループを、指定された名前のグループのライブラリに保存するEA | 第20回 |
| 25 | SimpleVolumesStrategy.mqh | 1.09 | ティックボリュームを使用した取引戦略のクラス | 第15回 |
| 26 | Strategy.mqh | 1.04 | 取引戦略基本クラス | 第10回 |
| 27 | TesterHandler.mqh | 1.05 | 最適化イベント処理クラス | 第19回 |
| 28 | VirtualAdvisor.mqh | 1.07 | 仮想ポジション(注文)を扱うEAのクラス | 第18回 |
| 29 | VirtualChartOrder.mqh | 1.01 | グラフィカル仮想ポジションクラス | 第18回 |
| 30 | VirtualFactory.mqh | 1.04 | オブジェクトファクトリクラス | 第16回 |
| 31 | VirtualHistoryAdvisor.mqh | 1.00 | トレード履歴再生EAクラス | 第16回 |
| 32 | VirtualInterface.mqh | 1.00 | EAGUIクラス | 第4回 |
| 33 | VirtualOrder.mqh | 1.07 | 仮想注文とポジションのクラス | 第19回 |
| 34 | VirtualReceiver.mqh | 1.03 | オープンボリュームを市場ポジションに変換するクラス(レシーバー) | 第12回 |
| 35 | VirtualRiskManager.mqh | 1.02 | リスクマネジメントクラス(リスクマネージャー) | 第15回 |
| 36 | VirtualStrategy.mqh | 1.05 | 仮想ポジションを使った取引戦略のクラス | 第15回 |
| 37 | VirtualStrategyGroup.mqh | 1.00 | 取引戦略グループのクラス | 第11回 |
| 38 | VirtualSymbolReceiver.mqh | 1.00 | 銘柄レシーバークラス | 第3回 |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16134
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
こんにちは、ユーリイ
私はGoogle翻訳を使ってパート20にたどり着きました。 Google翻訳」でググって、ブラウザの新しいタブに置いてください。 右端の検索バーにアイコンが表示されます。 母国語でページを読み込んで、アイコンを押して記事の言語と翻訳する言語を選択してください。 プレスト、私はパート20にいます!完璧な仕事はしてくれませんが、翻訳は99%役に立ちます。
アーカイブソースをエクセルに読み込み、いくつかの列を追加してソートし、コンテンツを並べ替えました。エクセルでの並べ替えに加えて、スプレッドシートを OutLookデータベースに直接インポートすることもできます。
SQLデータベースを確立するための開始記事の特定に困っています。 Simple Volume Stage 1を実行してみましたが、おそらく後戻りして別のSQLデータベースを作成する必要があることを示すフラットラインが得られました。 動作するシステムを得るために必要なプログラムの実行順序の表があると非常に助かります。おそらく、アーカイブ・ソース・テーブルに追加できるだろう。
もうひとつの小さな要望は、インクルード・ファイルの指定に""の代わりに<>オプションを使ってほしいということです。 私はエキスパート・ディレクトリとインクルード・ディレクトリで、#include <!!! と、あなたのシステムを分けて管理しています!MultiCurrencyVirtualAdvisor.mqh>で分けているので、この変更でサブディレクトリ指定/を追加しやすくなります。
ご意見ありがとうございました。
ケープコッダ
こんにちは。
プロジェクト、ステージ、作業、タスクに関する情報をデータベースに入力する方法については、第13、18、19回をご覧ください。これはメイントピックではないので、必要な情報は記事の最後に近いところにあります。例えば、パート18:
あるいはパート19のように:
次回は、補助スクリプトを使ったデータベースの初期充填について説明します。
ライブラリファイルの保存に インクルードフォルダを使用するように変更する計画もあるが、まだその段階には至っていない。
ありがとうございました。
こんにちは、ユーリイ、
次の記事は投稿されましたか?