
ニューラルネットワークが簡単に(第95回):Transformerモデルにおけるメモリ消費の削減

はじめに
2017年にTransformerアーキテクチャが導入されたことで、自然言語処理問題の解決で高い成果を示す 大規模言語モデル(Large Language Models: LLM)が登場しました。自己アテンション(Self-Attention)アプローチの利点はすぐに、機械学習のほぼすべての分野の研究者によって採用されるようになりました。
しかし、その自己回帰的な性質により、Transformerデコーダーは、各タイムステップでKeyとValueのエンティティのロードと保存に必要なメモリ帯域幅によって制限されます(KVキャッシングとして知られている)。このキャッシュは、モデルサイズ、バッチサイズ、コンテキストの長さによって線形にスケールするので、モデルの重みのメモリ使用量を超えることさえあります。
この問題は今に始まったことではありません。それを解決するには、さまざまなアプローチがあります。最も広く使われている方法は、使用するKVヘッドの直接削減を意味します。2019年、論文「Fast Transformer Decoding:One Write-Head is All You Need」の著者は、マルチクエリアテンション(Multi-Query Attention:MQA)アルゴリズムを提案しました。このアルゴリズムでは、1つの層のレベルで、すべてのアテンションヘッドに対して1つのKeyとValueの投影のみを使用します。これにより、KVキャッシュのメモリ消費量が1/ヘッド削減されます。このリソース消費の大幅な削減は、モデルの品質と安定性の低下につながります。
Grouped-Query Attention (GQA)法(論文「GQA:Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints (2023)」で発表)の著者は、複数のKVヘッドを複数のアテンショングループに分離する中間的な解決策を提示しました。GQAを使用した場合のKVキャッシュサイズの削減効率は、グループ/ヘッドに等しくなります。妥当なヘッド数であれば、GQAは様々なテストでベースモデルとほぼ同等の結果を出すことができます。しかし、MQAを使用した場合、KVキャッシュサイズの削減はまだ1/ヘッドに制限されます。用途によっては十分ではないかもしれません。
この制限を超えるために、論文「MLKV:Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding」の著者は、マルチレベルのKeyとValueの共有アルゴリズム (MLKV)を提案しました。彼らはKVの共有をさらに一歩進めています。MLKVはKVヘッドを1つの層のアテンションヘッド間で分割するだけでなく、他の層のアテンションヘッド間でも分割します。KVヘッドは、1つの層のアテンションヘッド群やそれ以降の層のアテンションヘッド群に使用することができます。極端な場合、1つのKVヘッドをすべての層のすべてのアテンションヘッドに使用することができます。この手法の著者は、同じレベルでも異なるレベル間でもグループ化されたQueryとして使用する様々な構成を実験しています。KVヘッドの数が層より少ない構成でもです。本稿で紹介する実験は、これらの構成が性能と達成されたメモリ節約との間で合理的なトレードオフを提供することを示しています。メモリ使用量を元のKVキャッシュサイズの2/層に削減しても、モデルの品質が大幅に低下することはありません。
1. MLKV法
MLKV法は、MQAとGQAのアルゴリズムを論理的に継承したものです。この手法では、KVキャッシュサイズは、単一の自己アテンション層内のアテンションヘッド群によって共有されるKVヘッドの削減により削減されます。完全に予想されるステップは、自己アテンション層間でKeyとValueのエンティティを共有することです。このステップは、アルゴリズムTransformerにおけるFeedForwardブロックの役割に関する最近の研究によって正当化されるかもしれません。指定されたブロックは、異なるレベルの情報を処理するKey-Valueメモリをシミュレートしていると仮定されます。しかし、私たちにとって最も興味深いのは、連続する層のグループが似たようなことを計算するという観察です。より正確には、下位レベルは表面的なパターンを扱い、上位レベルはより意味的な詳細を扱います。したがって、必要な計算をFeedForwardブロックに残したまま、アテンションを層のグループに委ねることができると結論づけることができます。直感的には、KVヘッドは同じようなターゲットを持つ層間で共有できます。
これらのアイデアを発展させ、MLKV法の著者はマルチレベルのKey交換を提供しています。MLKVは、同じ自己アテンション層のQueryアテンションヘッドの間でKVヘッドを共有するだけでなく、他の層のアテンションヘッドの間でも共有します。これにより、TransformerのKVヘッドの総数を減らすことができ、KVキャッシュをさらに小さくすることができます。
MLKVは次のように書くことができます。
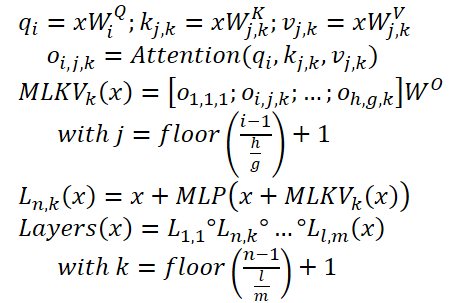
以下は、KVキャッシュサイズ削減方法の比較を著者が視覚化したものです。

この手法の著者がおこなった実験では、メモリと精度の間に明確なトレードオフがあることが示されました。設計者は何を犠牲にするかを選択することになります。さらに、考慮すべき要素がたくさんあります。KVヘッドの数が層数以上の場合は、やはりMLKVではなくGQA/MQAを使用する方が良くなります。この手法の著者は、複数のKVヘッドが複数の層に存在することは、1つの層に複数のKVヘッドが存在することよりも重要であると仮定しています。言い換えれば、まず層レベルのKVヘッドを犠牲にし(GQA/MQA)、次にクロス層(MLKV)を犠牲にすべきです。
KVヘッドの数が層の数より少ない、よりメモリを必要とする状況では、唯一の方法はMLKVです。このデザインソリューションは実行可能です。この手法の著者は、アテンションヘッドを層数の半分以下に減らすと、MLKVがMQAに非常に近い働きをすることを発見しました。つまり、KVキャッシュをMQAが提供する半分のサイズにする必要があれば、比較的簡単な解決策になるはずです。
より低い値が必要な場合は、KVヘッド数を層数の最大6倍まで減らしても、品質が急激に劣化することはありません。それ以下は怪しくなります。
2. MQL5での実装
提案されたアプローチの理論的説明を簡単に説明したので、MQL5を使った実践的な実装に移りましょう。ここでは、MLKV法を実装します。私の考えでは、これはより一般的なアプローチであり、MQAとGQAはMLKVの特殊なケースとして提示できます。
今後の実装で最も切実な問題は、ニューラル層間の情報伝達方法です。この場合、ニューラル層オブジェクト間のデータ交換方法について、既存のアルゴリズムを複雑にしないことにしました。その代わりに、すでに何度も実装しているマルチ層シーケンスブロックを使用します。CNeuronMLMHAttentionOCLを親クラスとして使用します。
2.1 OpenCL側での実装
まず、OpenCLプログラム側のカーネルを準備することから始めましょう。選択された親クラスでは、Query、Key、Valueエンティティの並列生成に1つの連結テンソルを使っていることに注意してください。アテンションのメカニズム全体がこの上に成り立っています。しかし、QueryとKey-Valueで異なるヘッド数を使用し、Key-Valueを別のレベルから使用しているため、2つの別々のテンソルに分割することを考える必要があります。クロスアテンションブロックを構築する際にも、すでに似たようなことをしています。
つまり、既存のコードを利用し、クロスアテンションカーネルのアルゴリズムを少し調整すればいいのです。KVheadsの数を示すもう1つのカーネルパラメータを追加するだけで済みます(コードでは赤で強調表示)。
__kernel void MH2AttentionOut(__global float *q, ///<[in] Matrix of Querys __global float *kv, ///<[in] Matrix of Keys __global float *score, ///<[out] Matrix of Scores __global float *out, ///<[out] Matrix of attention int dimension, ///< Dimension of Key int heads_kv )
カーネル本体では、分析対象のKVヘッドを決定するために、現在のアテンションヘッドをKVヘッドの総数で割った余りを取る必要があります。
const int h_kv = h % heads_kv;
Key-Valueテンソルバッファにシフト調整を追加します。
const int shift_k = 2 * dimension * (k + h_kv); const int shift_v = 2 * dimension * (k + heads_kv + h_kv);
さらなるカーネルコードに変更はありません。同様の編集がバックプロパゲーションカーネルのコードMH2AttentionInsideGradientsにも加えられました。これらのカーネルの完全なコードは添付ファイルにあります。
これでOpenCL側の作業は終了です。メインプログラム側に話を移しましょう。ここではまず、以前に作成したコードの機能を復元する必要があります。なぜなら、上で指定したカーネルに追加のパラメータをつけると、呼び出すときにエラーになるからです。そこで、これらのカーネルへのすべての呼び出しを見つけ、データ転送を新しいパラメータに追加してみましょう。
以前、QueryとKey-Valueで同じ数のゴールを使ったことを思い出してください。
if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_heads_kv, (int)iHeads)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_MH2AttentionInsideGradients, def_k_mh2aig_heads_kv, (int)iHeads)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
2.2 MLKVクラスの作成
プロジェクトを続けましょう。次のステップでは、MLKVアプローチを使って、CNeuronMLMHAttentionMLKV多層アテンションブロッククラスを作成します。先に述べたように、新しいクラスはCNeuronMLMHAttentionOCLクラスの直接の子になります。この新しいクラスの構造を以下に示します。
class CNeuronMLMHAttentionMLKV : public CNeuronMLMHAttentionOCL { protected: uint iLayersToOneKV; uint iHeadsKV; CCollection KV_Tensors; CCollection KV_Weights; CBufferFloat Temp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool AttentionOut(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *scores, CBufferFloat *out); virtual bool AttentionInsideGradients(CBufferFloat *q, CBufferFloat *q_g, CBufferFloat *kv, CBufferFloat *kv_g, CBufferFloat *scores, CBufferFloat *gradient); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronMLMHAttentionMLKV(void) {}; ~CNeuronMLMHAttentionMLKV(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMLMHAttentionMLKV; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
ご覧のように、このクラス構造では、KVヘッドの数(iHeadsKV)とKey-Valueテンソルの更新頻度(iLayersToOneKV)を格納する2つの変数を導入しています。
また、Key-Valueテンソルのストレージコレクションと、その形成のための重み行列(それぞれKV_TensorsとKV_Weights)を追加しました。
さらに、誤差勾配の中間値を記録するTempバッファを追加しました。
クラスメソッド一式はごく標準的なものであり、その目的はすでにお分かりだと思います。これらの詳細については、実施プロセスの中で検討していきます。
すべての内部オブジェクトを静的として宣言するため、クラスのコンストラクタとデストラクタは空のままにできます。すべてのネストされたオブジェクトと変数の初期化はInitメソッドでおこないます。いつものように、このメソッドのパラメータには、必要なオブジェクトを作成するのに必要なすべての情報が含まれています。
bool CNeuronMLMHAttentionMLKV::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
メソッド本体では、すべてのニューラル層の基本クラスCNeuronBaseOCLの関連メソッドを直ちに呼び出します。
直接の親クラスではなく、基盤クラスのオブジェクトにアクセスしていることに注意してください。これは、Query、Key、Valueの各エンティティを2つのテンソルに分離したことに関連しており、一部のデータバッファのサイズが変更されることになります。しかし、この方法では新しいオブジェクトだけでなく、親クラスから継承したオブジェクトも初期化しなければなりません。
基盤クラス初期化メソッドの実行に成功したら、受け取ったクラスパラメータを内部変数に保存します。
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(layers, 1); iHeadsKV = fmax(heads_kv, 1); iLayersToOneKV = fmax(layers_to_one_kv, 1);
次のステップは、作成されるすべてのバッファのサイズを計算することです。
uint num_q = iWindowKey * iHeads * iUnits; //Size of Q tensor uint num_kv = 2 * iWindowKey * iHeadsKV * iUnits; //Size of KV tensor uint q_weights = (iWindow + 1) * iWindowKey * iHeads; //Size of weights' matrix of Q tenzor uint kv_weights = 2 * (iWindow + 1) * iWindowKey * iHeadsKV; //Size of weights' matrix of KV tenzor uint scores = iUnits * iUnits * iHeads; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits; //Size of multi-heads self-attention uint out = iWindow * iUnits; //Size of out tensore uint w0 = (iWindowKey + 1) * iHeads * iWindow; //Size W0 tensor uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
次に、作成されるアテンションブロックの内部層の数に等しい反復回数のループを追加します。
for(uint i = 0; i < iLayers; i++) {
ループの本体では、別の入れ子ループを作り、まずデータを格納するバッファを作ります。ネストされたループの2回目の反復で、対応する誤差勾配を記録するためのバッファを作成します。
CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- Initilize Q tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
ここでは、まずQueryエンティティテンソルを作成します。次に、Key-Valueエンティティの記録用に関連するテンソルを作成します。しかし、後者はループのiLayersToOneKV反復ごとに1回作成されるべきです。
//--- Initilize KV tensor if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Tensors.Add(temp)) return false; }
次に、Transformerアルゴリズムに従って、依存係数行列のテンソル、多頭注目度、およびその圧縮表現を格納するバッファを作成します。
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
次に、FeedForwardブロックバッファを追加します。
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
//--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
FeedForwardブロックの第2層の出力と誤差勾配を格納するバッファを作成する際、まず層番号をチェックすることに注意してください。最後の層のために新しいバッファを作成することはないので、CNeuronMLMHAttentionMLKVクラスの結果と誤差勾配のすでに作成されたバッファへのポインタを保存します。こうして、次の層とデータを交換する際に、不必要なデータのコピーを避けることができます。
中間結果と対応する誤差勾配を格納するバッファを作成した後、クラスの訓練可能なパラメータの行列を格納するバッファを作成します。ここにも十分な数があると言わざるを得ません。まず、Queryエンティティを生成するために、ランダムなパラメータで重み行列を作成し、初期化します。
//--- Initialize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(q_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < q_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
同様の方法でKey-Valueテンソルの生成パラメータを生成します。この場合も、内部層のiLayersToOneKVごとに1回作成されます。
//--- Initialize KV weights if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < kv_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Weights.Add(temp)) return false; }
次に、マルチヘッドアテンションの結果に対する圧縮パラメータを生成します。
//--- Initialize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
そして最後が、FeedForwardブロックのパラメータです。
//--- Initialize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
モデルの訓練過程では、上記のすべてのパラメータのモーメントを記録するためのバッファが必要になります。ネストされたループでこれらのバッファを作成し、その反復回数は選択した最適化手法に依存します。
//--- for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(q_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(kv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Weights.Add(temp)) return false; }
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(w0, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- Initialize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_1, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_2, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } }
アテンションブロックバッファのすべてのコレクションを作成した後、中間値を書き込むために使用するもうひとつの補助バッファを初期化します。
if(!Temp.BufferInit(MathMax(num_kv, out), 0)) return false; if(!Temp.BufferCreate(OpenCL)) return false; //--- return true; }
各ステップにおいて、操作の進行を確実にコントロールします。そしてメソッドの最後には、操作の論理結果を呼び出し元に返します。
AttentionOutメソッドとAttentionInsideGradientsメソッドは、調整したカーネルを実行キューに入れます。しかし、ここではそのアルゴリズムについて詳しく説明しません。任意のカーネルを実行キューに入れるアルゴリズムは変わりません。
- タスクスペースを定義します。
- 必要なパラメータをすべてカーネルに渡します。
- カーネルを実行キューに入れます。
このアルゴリズムのコードは、この連載ですでに何度か説明しています。私たちが修正したオリジナルバージョンのカーネルをキューに入れる方法については、ADAPTメソッドについての記事で説明しました。詳細は添付のコードをご覧ください。
次に、フォワードパスメソッドfeedForwardのアルゴリズムを考えてみましょう。メソッドのパラメータには、前の層のオブジェクトへのポインタを受け取ります。この場合それは入力を提供します。
bool CNeuronMLMHAttentionMLKV::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
メソッド本体では、まず受け取ったポインタの妥当性を確認します。その後、Key-Valueテンソルバッファへのローカルポインタを宣言し、ブロックのすべての内部層を通るループを実行します。
CBufferFloat *kv = NULL; for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(6 * i - 4)); CBufferFloat *q = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, q, iWindow, iWindowKey * iHeads, None)) return false;
ループ本体では、まずQueryエンティティテンソルを生成します。そしてKey-Valueテンソルを生成します。後者は、内部層の反復ごとに生成するのではなく、iLayersToOneKV層ごとに生成することに注意してください。数学的には、この条件の制御は非常に単純です。現在の層のインデックスが、1つのKey-Valueテンソルの層数で余りなく割り切れることを確認します。インデックス0の最初の層では、分割による余りも存在しないことに注意すべきです。
if((i % iLayersToOneKV) == 0) { uint i_kv = i / iLayersToOneKV; kv = KV_Tensors.At(i_kv * 2); if(IsStopped() || !ConvolutionForward(KV_Weights.At(i_kv * (optimization == SGD ? 2 : 3)), inputs, kv, iWindow, 2 * iWindowKey * iHeadsKV, None)) return false; }
生成されたエンティティのバッファへのポインタを、先ほど宣言したローカル変数に保存します。こうすれば、その後のループの繰り返しで簡単にアクセスできます。
必要なエンティティをすべて生成した後、フィードフォワードのクロスアテンション操作を実行します。その結果は、多頭注目の出力バッファに書き込まれます。
//--- Score calculation and Multi-heads attention calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !AttentionOut(q, kv, temp, out)) return false;
出来上がったデータを元データのサイズに圧縮します。
//--- Attention out calculation temp = FF_Tensors.At(i * 6); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9)), out, temp, iWindowKey * iHeads, iWindow, None)) return false;
その後、Transformerアルゴリズムに従い、自己アテンションブロックの演算結果を入力データでまとめ、得られた値を正規化します。
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow, true)) return false;
次にFeedForwardブロックにデータを渡します。
//--- Feed Forward inputs = temp; temp = FF_Tensors.At(i * 6 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), temp, out, 4 * iWindow, iWindow, activation)) return false;
2つのスレッドのデータを再び合計し、正規化します。
//--- Sum and normalize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } //--- return true; }
内部ニューラル層を通るループのすべての反復を成功させた後、演算の論理結果を呼び出し元に返します。
フィードフォワードパスメソッドの実装に続いて、バックプロパゲーションアルゴリズムが構築されます。ここで、訓練データセット上で最大に真の関数を見つけるために、モデルパラメータの最適化をおこないます。ご存知のように、バックプロパゲーションアルゴリズムは2段階で構成されています。まず、誤差勾配をモデルのすべての要素に伝播させ、全体的な結果への影響を考慮します。この機能はcalcInputGradientsメソッドに実装されています。第2段階(メソッドupdateInputWeights)では、反勾配に向けたパラメータの直接最適化をおこないます。
誤差勾配伝搬法calcInputGradientsを使ったバックプロパゲーションアルゴリズムの実装に取りかかります。パラメータとして、このメソッドは前のニューラル層のオブジェクトへのポインタを受け取ります。フィードフォワードパスの間、それは入力データの役割を果たしました。この段階で、メソッド操作の結果を、得られたオブジェクトの誤差勾配バッファに書き込みます。
bool CNeuronMLMHAttentionMLKV::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
メソッド本体では、受け取ったポインタの妥当性を確認します。その後、内部層間で受け渡されるデータバッファへのポインタを格納するために、2つのローカル変数を作成します。
CBufferFloat *out_grad = Gradient;
CBufferFloat *kv_g = KV_Tensors.At(KV_Tensors.Total() - 1);
少し準備作業をした後、内部の神経層に逆ループを作成します。
for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) kv_g = KV_Tensors.At((i / iLayersToOneKV) * 2 + 1);
このループでは、まずKey-Valueエンティティの誤差勾配バッファを変更する必要性を判断します。
これまで見てきたように、MLKV法は、1つのKey-Valueエンティティテンソルが複数の自己アテンションブロックに使われることを意味します。フィードフォワードパスを編成する際、それに対応するメカニズムを実装しました。ここで、適切なKey-Valueレベルへの誤差勾配の伝搬を整理しなければなりません。そしてもちろん、異なるレベルの誤差勾配を合計します。
アルゴリズムの更なる構築は、交差注意オブジェクトにおける誤差勾配伝搬に非常に近いです。まず、後続の層から得られた誤差勾配をFeedForwardブロックを通して伝播させます。
//--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), out_grad, FF_Tensors.At(i * 6 + 1), FF_Tensors.At(i * 6 + 4), 4 * iWindow, iWindow, None)) return false; CBufferFloat *temp = FF_Tensors.At(i * 6 + 3); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), FF_Tensors.At(i * 6 + 4), FF_Tensors.At(i * 6), temp, iWindow, 4 * iWindow, LReLU)) return false;
フィードフォワードパスでは、2つのスレッドからのデータを合計しました。そこで今度は、バックプロパゲーションパスの同じデータスレッドの誤差勾配を合計します。
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false; out_grad = temp;
次のステップでは、得られた誤差勾配をアテンションヘッドに分割します。
//--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 6 : 9)), out_grad, AO_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1), iWindowKey * iHeads, iWindow, None)) return false;
次に、誤差勾配をQuery、Key、Valueエンティティに伝播します。ここでは、アルゴリズムの小さな分岐を整理します。なぜなら、複数の内部層のKey-Valueテンソルの誤差勾配を合計する必要があるからです。誤差勾配分布法を実行する際には、毎回、過去に収集したデータを削除し、新しいデータで上書きします。したがって、最初の呼び出しのときだけ、誤差勾配を直接Key-Valueテンソルバッファに書き込みます。
//--- Passing gradient to query, key and value if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i * 2), QKV_Tensors.At(i * 2 + 1), KV_Tensors.At((i / iLayersToOneKV) * 2), kv_g, S_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1))) return false; }
それ以外の場合は、まず補助バッファに誤差勾配を書き込んでから、得られた値を先に収集した値に加えます。
else { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i * 2), QKV_Tensors.At(i * 2 + 1), KV_Tensors.At((i / iLayersToOneKV) * 2), GetPointer(Temp), S_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1))) return false; if(IsStopped() || !SumAndNormilize(kv_g, GetPointer(Temp), kv_g, iWindowKey, false, 0, 0, 0, 1)) return false; }
次に、誤差勾配を前の層のレベルに渡す必要があります。ここで「前の層」とは、主に内部の前の層を意味します。しかし、最下位のレベルを処理するときは、メソッドのパラメータで受け取ったオブジェクトのバッファに誤差勾配を渡します。
まず、誤差勾配受信オブジェクトへのポインタを定義します。
CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 6 - 1); inp = FF_Tensors.At(i * 6 - 4); }
その後、Queryエンティティから誤差勾配を下ります。
if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, iWindowKey * iHeads, None)) return false;
2つのデータ(Query + "through")の誤差勾配を合計します。
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
上記のアルゴリズムで唯一欠けているのは、KeyとValueのエンティティからの誤差勾配です。覚えているように、これらの実体は内部の各層から形成されるわけではありません。従って、誤差勾配は、その形成に使われたデータにのみ移されます。ただ、1点だけ。先に、Queryエンティティとスルースレッドからのエラーを、入力データのグラデーションバッファに書き込みます。そのため、まず誤差勾配を補助バッファに書き込み、それを以前に収集したデータに追加します。
//--- if((i % iLayersToOneKV) == 0) { if(IsStopped() || !ConvolutionInputGradients(KV_Weights.At(i / iLayersToOneKV * (optimization == SGD ? 2 : 3)), kv_g, inp, GetPointer(Temp), iWindow, 2 * iWindowKey * iHeadsKV, None)) return false; if(IsStopped() || !SumAndNormilize(GetPointer(Temp), temp, temp, iWindow, false, 0, 0, 0, 1)) return false; }
ループ反復の最後に、次のループ反復の演算を実行するために、誤差勾配バッファへのポインタを渡します。
if(i > 0) out_grad = temp; } //--- return true; }
ステップごとに、操作の結果を確認します。そして、ループの反復をすべて成功させた後、メソッド操作の論理結果を呼び出し側プログラムに渡します。
すべての内部オブジェクトと前の層に誤差勾配を伝播させました。次のステップは、モデルのパラメータを調整することです。この機能はupdateInputWeightsメソッドに実装されています。前述した両方のメソッドと同様、パラメータには前の層のオブジェクトへのポインタを受け取ります。
bool CNeuronMLMHAttentionMLKV::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput();
メソッド本体では、受け取ったポインタの妥当性をチェックし、受け取ったオブジェクトの結果バッファへのポインタを直ちにローカル変数に保存します。
次に、すべての内部層を通るループを作成し、モデルのパラメータを更新します。
for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(l * 2 + 1), inputs, (optimization == SGD ? QKV_Weights.At(l * 2 + 1) : QKV_Weights.At(l * 3 + 1)), (optimization == SGD ? NULL : QKV_Weights.At(l * 3 + 2)), iWindow, iWindowKey * iHeads)) return false;
フィードフォワードパス法と同様に、まずクエリテンソルの生成パラメータを調整します。
次に、Key-Valueテンソルの生成パラメータを更新します。繰り返しになりますが、これらのパラメータはループの各反復では調整されないことに注意してください。しかし、一般的なループの中でKey-Valueテンソルのパラメータを調整することで、正しい入力バッファとの同期が容易になり、コードも明快になります。
if(l % iLayersToOneKV == 0) { uint l_kv = l / iLayersToOneKV; if(IsStopped() || !ConvolutuionUpdateWeights(KV_Weights.At(l_kv * (optimization == SGD ? 2 : 3)), KV_Tensors.At(l_kv * 2 + 1), inputs, (optimization == SGD ? KV_Weights.At(l_kv*2 + 1) : KV_Weights.At(l_kv*3 + 1)), (optimization == SGD ? NULL : KV_Weights.At(l_kv * 3 + 2)), iWindow, 2 * iWindowKey * iHeadsKV)) return false; }
自己アテンションブロックには訓練可能なパラメータは含まれていません。しかし、多頭注目の結果を入力データのサイズに圧縮する層では、パラメータが現れます。次のステップでは、これらのパラメータを調整します。
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 6 : 9)), FF_Tensors.At(l * 6 + 3), AO_Tensors.At(l * 2), (optimization == SGD ? FF_Weights.At(l * 6 + 3) : FF_Weights.At(l * 9 + 3)), (optimization == SGD ? NULL : FF_Weights.At(l * 9 + 6)), iWindowKey * iHeads, iWindow)) return false;
あとはFeedForwardブロックのパラメータを調整するだけです。
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 6 : 9) + 1), FF_Tensors.At(l * 6 + 4), FF_Tensors.At(l * 6), (optimization == SGD ? FF_Weights.At(l * 6 + 4) : FF_Weights.At(l * 9 + 4)), (optimization == SGD ? NULL : FF_Weights.At(l * 9 + 7)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 6 : 9) + 2), FF_Tensors.At(l * 6 + 5), FF_Tensors.At(l * 6 + 1), (optimization == SGD ? FF_Weights.At(l * 6 + 5) : FF_Weights.At(l * 9 + 5)), (optimization == SGD ? NULL : FF_Weights.At(l * 9 + 8)), 4 * iWindow, iWindow)) return false;
後続の内部ニューラルループの入力バッファへのポインタを渡し、ループの次の反復に移ります。
inputs = FF_Tensors.At(l * 6 + 2); } //--- return true; }
ループのすべての反復が正常に完了したら、実行された処理の論理結果を呼び出し元に返します。
これで、MLKVメソッドの著者たちによって提案されたアプローチを含む、私たちの新しいアテンションブロッククラスのメソッドの説明は終わりです。このクラスの全コードと全メソッドは添付ファイルにあります。
先に述べたように、MQAとGQAはMLKVの特殊なケースです。作成したクラスを使って、クラス初期化メソッドのパラメータに「layers_to_one_kv=1」を指定すれば、簡単に実装できます。heads_kvパラメータの値がQueryエンティティのアテンションヘッドの数と等しい場合、バニラTransformerが得られます。それ以下の場合はGQAになります。heads_kvが1の場合、MQAの実装になります。
この記事の準備の間に、MLKV (CNeuronMLCrossAttentionMLKV)アプローチを使ってクロスアテンションクラスも作成しました。その構造を以下に示します。
class CNeuronMLCrossAttentionMLKV : public CNeuronMLMHAttentionMLKV { protected: uint iWindowKV; uint iUnitsKV; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); virtual bool AttentionOut(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *scores, CBufferFloat *out); virtual bool AttentionInsideGradients(CBufferFloat *q, CBufferFloat *q_g, CBufferFloat *kv, CBufferFloat *kv_g, CBufferFloat *scores, CBufferFloat *gradient); //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); public: CNeuronMLCrossAttentionMLKV(void) {}; ~CNeuronMLCrossAttentionMLKV(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key,uint heads, uint window_kw, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMLCrossAttentionMLKV; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); };
このクラスは、前述のCNeuronMLMHAttentionMLKVクラスの後継として構築されています。添付ファイルにあるように、私はその方法を少し修正しただけです。
2.3 モデルアーキテクチャ
MLKV法の著者たちによって提案されたアプローチをMQL5に実装しました。さて、学習可能なモデルのアーキテクチャの説明に移りあしょう。最近の多くの記事とは異なり、今日は環境状態エンコーダー(Environment State Encoder)のアーキテクチャーを調整するわけではないことにご注意ください。ActorモデルとCriticモデルのアーキテクチャに新しいオブジェクトを追加します。これらのモデルのアーキテクチャは、CreateDescriptionsメソッドで指定されます。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
パラメータには、モデルのシーケンシャルアーキテクチャを記録するための2つのダイナミックアレイへのポインタを受け取ります。メソッド本体では、受け取ったポインタを確認し、必要であれば新しいオブジェクトインスタンスを生成します。
まず、Actorのアーキテクチャについて説明します。口座状況とポジションをモデルに入力します。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
受信したデータは完全接続層で前処理されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
そして、MLKVアプローチを使って、マルチレベルのクロスアテンションを追加します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); }
この層は、現在の口座の状態と、環境状態エンコーダーから得られた今後の値動きの予測を比較します。
ここでは、Queryには8つのアテンションヘッドを使い、Key-Valueテンソルには2つしか使っていません。
{
int temp[] = {8, 2};
ArrayCopy(descr.heads, temp);
}
合計で9つのネストされた層をブロック内に作成します。新しいKey-Valueテンソルは3層ごとに生成されます。
descr.layers = 9; descr.step = 3;
モデルのパラメータを最適化するために、アダム法を用います。
descr.window_out = 32; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
アテンションブロックの後、データは2つの全結合層で処理されます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
モデルの出力では、Actorの確率的方策を作成し、ある最適値の範囲内での行動を可能にします。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
さらに、周波数領域でのアクションを調整するために、FreDF法のアプローチを使用します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.8f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
同様に、Criticのモデルも作ります。ここでは、口座の状態の代わりに、Actorの方策によって生成された行動のベクトルをモデルに与えます。
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
このデータも全結合層で前処理されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
その後にクロスアテンションブロックが続きます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); } { int temp[] = {8, 2}; ArrayCopy(descr.heads, temp); } descr.window_out = 32; descr.step = 3; descr.layers = 9; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
クロスアテンションブロックでのデータ処理結果は、3つの全結合層を通過します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
モデルの出力では、期待報酬のベクトルが形成されます。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
また、周波数領域の報酬の一貫性を保つためにFreDF層を追加します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.8f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
データを収集し、モデルを訓練するエキスパートアドバイザー(EA)に変更はありません。添付ファイルでそれらの全コードを見ることができます。添付ファイルには、記事で使用されているすべてのプログラムの完全なコードも含まれています。
3.テスト
提案したメソッドを実装したので、研究の最終段階である、提案されたアプローチを実際のデータでテストする段階に移りましょう。
いつものように、モデルを訓練するために、H1時間枠で2023年通年のEURUSDの実際の履歴データを使用します。MetaTrader 5のストラテジーテスターで環境相互作用EAを実行し、訓練データセットのデータを収集します。
最初の立ち上げでは、モデルはランダムなパラメータで初期化されます。その結果、最適とはかけ離れた、完全にランダムな方策が通ることになります。訓練データセットに収益性の高い実行を追加するには、ソースデータの収集時にReal-ORLメソッドのアプローチを使用することを推奨します。
初期訓練データセットを収集した後、まずMetaTrader 5端末のチャート上で「.../MLKV/StudyEncoder.mq5」をリアルタイムで実行し、環境状態エンコーダーを訓練します。このEAは訓練データセットでのみ動作し、値動きの履歴データの依存関係を分析します。実際、取引結果に関係なく、1回パスするだけでも十分に訓練になります。したがって、訓練データセットを更新することなく、予測誤差が減少しなくなるまで状態エンコーダーを訓練します。
ここで注意しなければならないのは、次に訓練されるActorモデルとCriticモデルは、得られた予測値を間接的に使用するということです。最大限の結果を得るためには、環境の状態における現在のトレンドとその強さをエンコーダーの隠れた状態から抽出する必要があります。
環境状態エンコーダーの訓練の過程で望ましい結果が得られたので、Actor方策の訓練とCriticの行動評価の精度の訓練に移ります。モデル訓練の第2段階は反復的です。要は、分析された金融市場環境の変動性が非常に高いということです。エージェントと環境との相互作用の可能なすべてのバリエーションを集めることはできません。そのため、ActorモデルとCriticモデルの訓練を数回繰り返した後、訓練データを収集する追加反復をおこないます。このプロセスによって、以前に収集した訓練データセットに、Actorの現在の方策のある領域における環境との相互作用に関するデータを補足し、それを改良最適化することができるはずです。
そのため、ActorモデルとCriticモデルの訓練を何度か繰り返し、訓練データセットを更新する操作を交互におこないます。このプロセスは、望ましいActor方策が得られるまで何度か繰り返されます。
訓練済みモデルをテストするために、訓練データセットには含まれていない2023年1月からの過去データを使用します。その他のパラメータは、訓練データセットの収集反復からそのまま使用されます。
この記事のためにモデルを訓練する過程で、テストデータセットで利益を生み出すことができる方策を得ることができなかったことを認めなければなりません。これは明らかに、著者たちの原著論文で指摘されたモデルの劣化過程の影響です。
テスト結果を以下に示します。
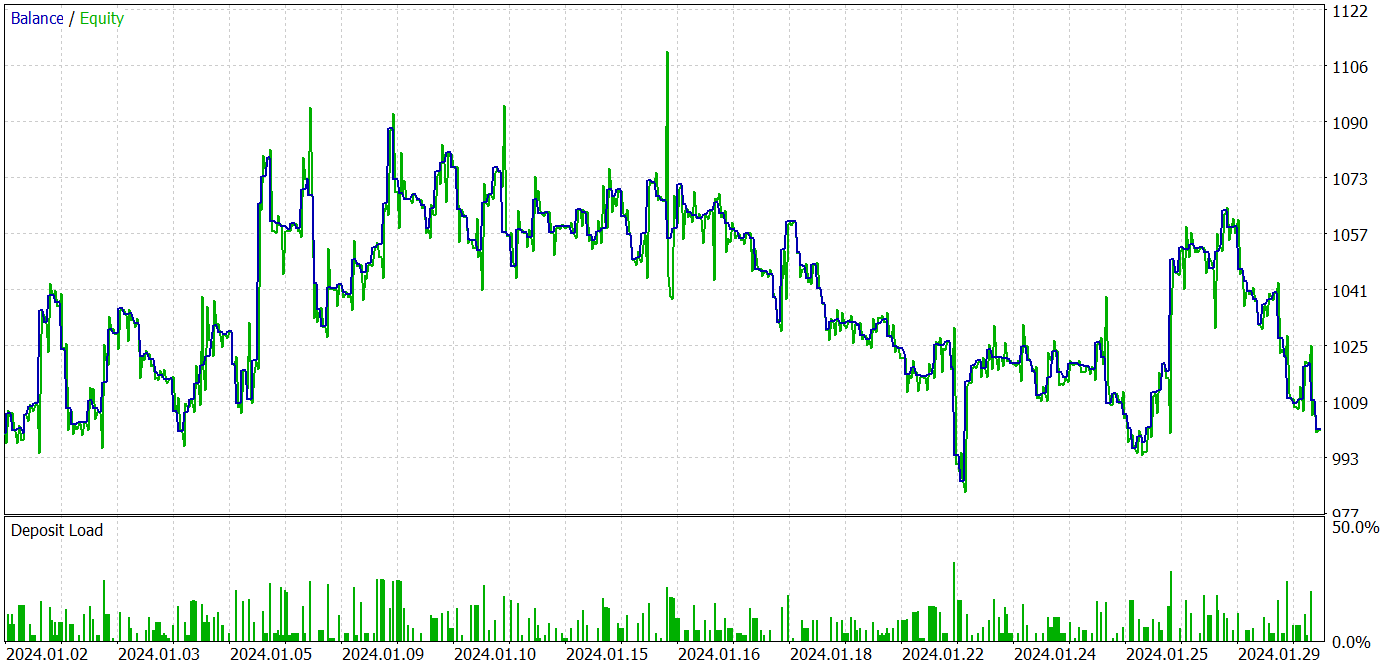
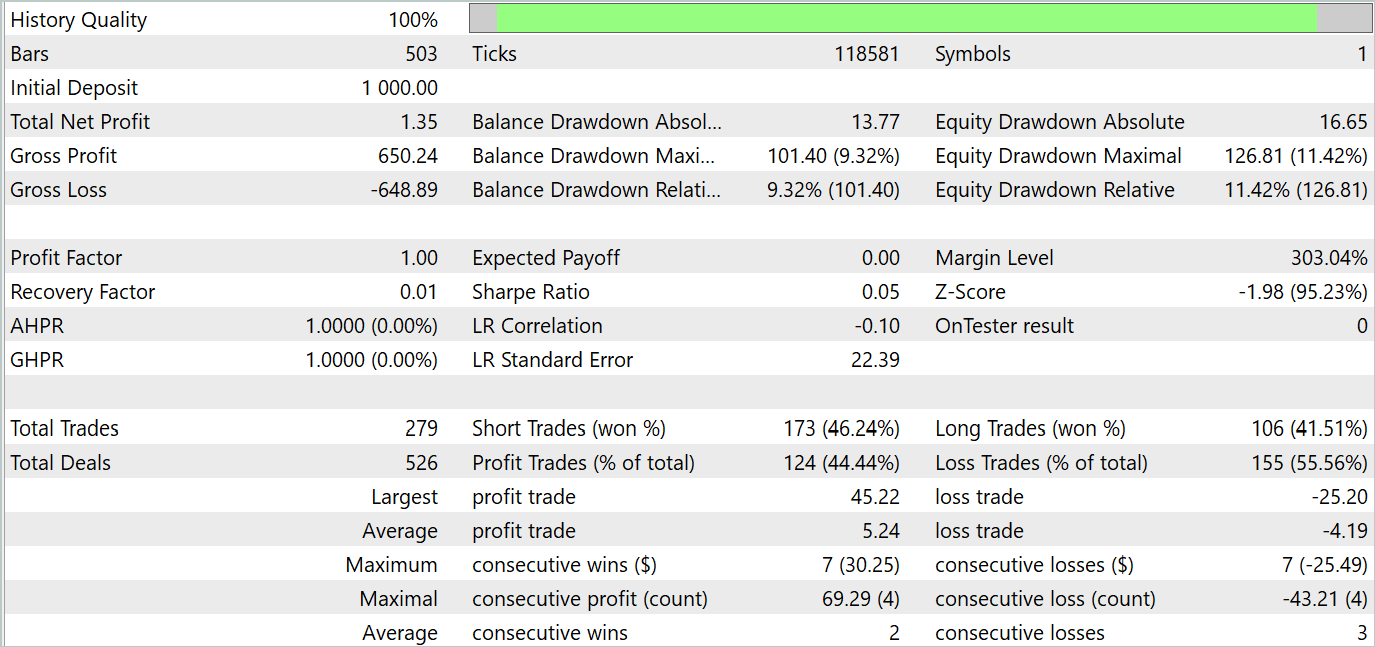
テスト結果によると、「0」に近い新しいデータでは収益性に変動が見られます。全体として、最大利益と平均利益は同様の損失指標よりも高くなります。しかし、44.4%の勝率では、テスト期間中に利益を上げることはできませんでした。
結論
この記事では、MLKV(Multi-Layer Key-Value)という新しい手法を紹介しました。MLKVは、Transformersでより効率的にメモリを使用するための革新的なアプローチです。主なアイデアは、KVキャッシングを複数の層に拡張することで、メモリ使用量を大幅に削減できます。
実用的な部分では、MQL5を使用して提案されたアプローチを実装しました。実際のデータでモデルを訓練し、テストしました。テストでは、提案されたアプローチによってモデルの訓練と運用のコストを大幅に削減できることが示されました。しかし、これはモデルの性能を犠牲にするものです。結論として、私たちはコストとモデルの性能の妥協点を見つけるために、バランスの取れたアプローチを取るべきです。
参照文献
記事で使用されたプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | StudyEncoder.mq5 | EA | エンコーダー訓練EA |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15117
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
また、ネットワークがランダムなシグナルを生成しているのではなく、何かを学習していることにどうやって気づくのだろうか?
アクターの確率的政策は、行動のランダム性をある程度想定している。しかし、学習する過程で、ランダムな値のばらつきの範囲は強く狭められていく。ポイントは、確率的な政策を編成する際に、各行動に対して、平均値と値の広がりの分散という2つのパラメータを学習させるということである。ポリシーを訓練するとき、平均値は最適になり、分散は0になる傾向があります。
エージェントの行動がどの程度ランダムであるかを理解するために、同じポリシーでいくつかのテスト実行を行います。エージェントがランダムなアクションを生成する場合、すべてのパスの結果は大きく異なります。訓練されたポリシーの場合、結果の違いは重要ではありません。
アクターの確率的政策は、行動のランダム性をある程度想定している。しかし、訓練の過程で、ランダムな値の散らばりの範囲は強く狭められる。要は、確率的な方針を編成する際には、各行動に対して、平均値と値の散らばりの分散という2つのパラメータを学習する。ポリシーを訓練するとき、平均値は最適値に、分散は0になる傾向がある。
エージェントのアクションがどの程度ランダムであるかを理解するために、同じポリシーでいくつかのテスト実行を行います。エージェントがランダムなアクションを生成する場合、すべてのパスの結果は大きく異なります。訓練されたポリシーの場合、結果の違いは重要ではありません。
わかった、ありがとう。