
取引におけるニューラルネットワーク:データの局所構造の探索

はじめに
点群におけるオブジェクト検出のタスクは、近年ますます注目を集めています。このタスクの成否は、局所領域の構造に関する情報に大きく依存します。しかしながら、点群はスパースかつ不規則であるため、局所構造が不完全でノイズを含みやすいという課題があります。
従来の畳み込みベースのオブジェクト検出では、固定されたカーネルを用いて、すべての近傍点を一様に処理します。その結果、他のオブジェクトに属する無関係な点やノイズが分析に含まれてしまうことが避けられません。
Transformerは、多様なタスクへの対応力が実証されているモデルです。畳み込みと比較して、自己アテンションメカニズムはノイズの多い点や無関係な点を適応的に除外する能力を持ちます。しかし、従来型のTransformerは、シーケンス内のすべての要素に対して同一の変換を適用するため、中心点から近傍点までの方向性や距離といった空間的関係や局所構造の情報が考慮されません。点の位置が並べ替えられても、TransformerTransformerの出力は変わらないため、オブジェクトの方向性を認識するのが困難になります。これは、価格パターンの検出において特に大きな障害となります。
この課題に対して、論文「SEFormer:Structure Embedding Transformer for 3D Object Detection」の著者は、方向や距離といった局所構造情報を自己アテンションメカニズムに組み込む新たなTransformerアーキテクチャ「Structure-Embedding transFormer (SEFormer)」を提案しました。SEFormerは、異なる方向および距離にある点のValueに対して異なる変換を学習することで、局所空間構造の変化が出力に反映されるように設計されています。これにより、オブジェクトの方向性を高精度で認識することが可能となります。
提案されたSEFormerモジュールに基づいて、この研究では3Dオブジェクト検出用のマルチスケールネットワークを導入します。
1. SEFormerアルゴリズム
畳み込みの局所性と空間的な不変性は、画像データにおける誘導バイアスとよく一致しています。畳み込みのもう一つの重要な利点は、データ内部の構造情報をエンコードできる点です。SEFormerの提案者たちは、畳み込み操作を変換と集約という2つのステップに分解して捉えています。変換ステップでは、各点に対応するカーネルw δを乗算します。その後、これらの値は固定された集約係数α=1を用いて単純に合計されます。畳み込みでは、カーネルの方向や中心からの距離に応じて異なるカーネルが学習されるため、局所空間構造のエンコードが可能となります。しかしながら、集約の段階では、すべての近傍点が等しく扱われる(α =1)ため、空間構造の重み付けが失われがちです。さらに、標準的な畳み込み演算子は静的で剛直なカーネルを使用するため、不規則かつ不完全な点群に対しては、ノイズや無関係な点が特徴量に混入してしまうという課題があります。
畳み込みと比較すると、Transformerの自己アテンションメカニズムは、点群内の不規則な形状やオブジェクト境界の保持において、より効果的な手法を提供します。N個の要素からなる点群𝒑=[ p 1,…, p N ] に対して、Transformerは各点の応答(出力特徴)を次のように計算します。
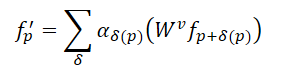
ここでαδは局所近傍における点同士の自己アテンション係数を表し、𝑾vはValue変換を示します。畳み込みにおける静的なα=1と比較して、自己アテンション係数は集約対象の点を適応的に選択することを可能にし、無関係な点の影響を効果的に排除することができます。ただし、Transformerではすべての点に対して同一のValue変換が適用されるため、畳み込みに備わる構造エンコード能力が欠けています。
この点を踏まえ、SEFormerの著者らは、畳み込みはデータ構造をエンコードする能力に優れ、一方でTransformersはその構造を保持するのに適していると考えました。したがって、畳み込みとTransformerの両者の利点を統合する新たな演算子を開発するというシンプルなアイデアに基づき、SEFormerが提案されました。その定式化は以下のようになります。
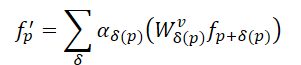
SEFormerと通常のTransformerの主な違いは、ポイント間の相対的な位置に基づいて学習されるValue変換関数にあります。
点群の不規則性を考慮し、SEFormerの著者はPoint Transformerのパラダイムに従い、各Queryポイントの周囲から隣接ポイントを個別にサンプリングし、それらをTransformerに入力する手法を採用しました。本手法では、グリッド補間を用いてキーポイントを生成します。各分析対象ポイントの周囲に、あらかじめ定義されたグリッド上に複数の仮想ポイントが配置されます。グリッド要素間の距離は固定値dに設定されています。
これらの仮想ポイントは、対象の点群内の最近傍点を用いて補間されます。K近傍法(KNN)などの従来のサンプリング手法と比較して、グリッドサンプリングは異なる方向から点を選択できるという利点があり、局所構造をより精密に捉えることが可能です。ただし、グリッド補間では距離dが固定であるため、著者らはサンプリングの柔軟性を高めるためにマルチ半径戦略を導入しました。
SEFormerは、複数のValue変換行列(𝑾v)を格納したメモリプールを構築します。補間されたキーポイントは、元のポイントに対する相対座標に基づいて対応する𝑾vを検索し、それぞれ異なる方法で特徴量変換がおこなわれます。これにより、SEFormerは構造情報のエンコードが可能となり、これは通常のTransformerにはない特徴です。
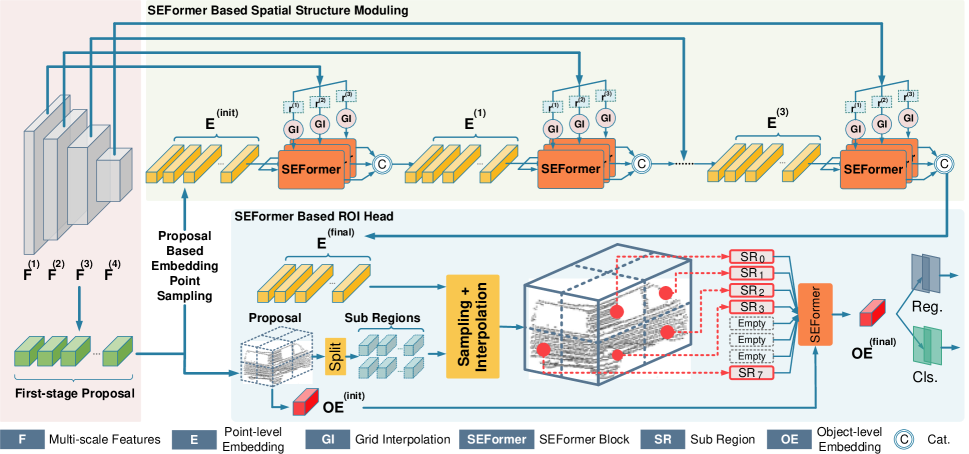
著者が提案するオブジェクト検出モデルでは、まず3D畳み込みに基づくバックボーンを構築し、マルチスケールのボクセル特徴を抽出して初期の提案を生成します。この畳み込みバックボーンは、生の入力データをダウンサンプリング係数が1×、2×、4×、8×の4種類のボクセル特徴量マップに変換し、それぞれ異なる深度で処理します。特徴量抽出後、3DボリュームはZ軸方向に圧縮され、2Dの鳥瞰図(BEV)特徴量マップに変換され、初期の候補オブジェクト予測に用いられます。
続いて、提案された空間モジュレーション構造は、マルチスケール特徴量[𝑭1, 𝑭2, 𝑭3, 𝑭4]を複数の点レベル埋め込み𝑬に集約します。まず、初期埋め込み𝑬initを起点として、各分析対象に対し、最も小さいスケールの特徴マップ𝑭 1からキーポイントを補間します。著者らは異なるグリッド間隔dをm通り用い、それぞれに対応するマルチスケールな特徴量セット𝑭1,1, 𝑭2,1,…, 𝑭m,1を生成します。このマルチ半径戦略により、点群のスパースで不規則な分布への対応力が向上します。次に、m個の並列SEFormerブロックを適用し、それぞれの更新埋め込み𝑬1,1, 𝑬2,1,…, 𝑬m,1を得ます。これらを連結し、バニラTransformerを用いて統一された埋め込み𝑬1に変換します。𝑬1は同様のプロセスを繰り返し、[𝑭2, 𝑭3, 𝑭4]を段階的に統合し、最終的な埋め込み𝑬finalを生成します。これにより、元のボクセル特徴𝑭と比べて、より詳細かつ構造的に豊かな局所表現𝑬finalが得られます。
得られた点レベルの埋め込み𝑬finalに基づき、提案されたモデルヘッドはそれらを複数のオブジェクトレベル埋め込みに集約し、最終的なオブジェクト提案を生成します。具体的には、各初期提案を複数の立方体状サブリージョンに分割し、各サブリージョンに対して周囲の点レベル埋め込みを用いた補間をおこないます。点群がスパースであるため、一部の領域はしばしば空になります。従来手法では、非空領域の特徴を単純に合計するのみでしたが、SEFormerは非空領域と空領域の両方から情報を活用することができます。このように、SEFormerの構造埋め込み能力の向上により、よりリッチなオブジェクトレベルの構造表現が可能となり、精度の高いオブジェクト提案を実現します。
以下に、著者による本手法の可視化図を示します。
2.MQL5での実装
提案されたSEFormer法の理論的側面を確認したうえで、本節では提案手法の解釈に基づいた実装に焦点を当てます。まず、今後構築するモデルのアーキテクチャについて検討します。
初期特徴抽出に関して、SEFormerの著者はボクセルベースの3D畳み込み手法を提案しています。しかしながら、本研究で対象とする単一のバーに対応する特徴量ベクトルには、はるかに多くの属性情報が含まれる可能性があります。そのため、このような畳み込み手法は本タスクには効率的ではないと考えられます。したがって、本研究では以前に用いた、異なるアテンション集中レベルを持つスパースアテンションブロックによる特徴集約手法を引き続き採用することを提案します。
次に注目すべき点は、分析対象ポイントの周囲に「グリッド」を構築する方法です。SEFormerが取り扱う3Dオブジェクト検出タスクでは、データを高さ(Z軸)方向に圧縮することで、平面上(マップ上)でのオブジェクト解析が可能です。しかしながら、ここでのケースではデータの表現が多次元的であり、かつすべての次元が任意のタイミングで重要な役割を果たしうるという特性があります。そのため、いずれかの次元に沿ってデータを圧縮することは現実的ではありません。さらに、高次元空間における「グリッド」の構築は非常に困難であり、次元数が増えるごとに必要なグリッド要素の数は幾何級数的に増加します。このような理由から、本研究では、モデル自身が多次元空間内における最適な重心を学習するアプローチの方が、より実用的かつ効果的であると考えます。
以上を踏まえ、新たなオブジェクトの構築には、既存のCNeuronPointNet2OCLクラスからコア機能を継承する形で、CNeuronSEFormerクラスを新たに設計・実装することを提案します。以下に、このクラスの基本的な構造を示します。
class CNeuronSEFormer : public CNeuronPointNet2OCL { protected: uint iUnits; uint iPoints; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cKeyValue; CArrayInt cScores; CLayer cMHAttentionOut; CLayer cAttentionOut; CLayer cResidual; CLayer cFeedForward; CLayer cCenterPoints; CLayer cFinalAttention; CNeuronMLCrossAttentionMLKV SEOut; CBufferFloat cbTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool AttentionOut(CBufferFloat *q, CBufferFloat *kv, int scores, CBufferFloat *out); virtual bool AttentionInsideGradients(CBufferFloat *q, CBufferFloat *q_g, CBufferFloat *kv, CBufferFloat *kv_g, int scores, CBufferFloat *gradient); //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronSEFormer(void) {}; ~CNeuronSEFormer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, uint center_points, uint center_window, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSEFormer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
上記の構造を見ると、オーバーライド可能なメソッドの一覧や、複数のネストされたオブジェクトがすでに確認できます。これらのコンポーネント名のいくつかはTransformerアーキテクチャを想起させるかもしれませんが、これは偶然ではありません。SEFormer法の提案者は、バニラ版Transformerのアルゴリズムを強化することを目的としていました。しかし、まずは基本的な部分から順を追って説明していきましょう。
本クラス内のすべての内部オブジェクトは静的に宣言されており、そのためコンストラクタおよびデストラクタは空のままにしておくことが可能です。宣言済みのコンポーネントと継承されたコンポーネントの初期化は、Initメソッド内で処理されます。このメソッドの引数には、皆さんご存知の通り、生成されるオブジェクトのアーキテクチャを定義するコア定数が含まれています。
bool CNeuronSEFormer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, uint center_points, uint center_window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronPointNet2OCL::Init(numOutputs, myIndex, open_cl, window, units_count, output, use_tnets, optimization_type, batch)) return false;
すでに馴染みのあるパラメータに加えて、今回は学習可能な重心の数と、その状態を表すベクトルの次元数を新たに導入します。
ここで重要なのは、本ブロックのアーキテクチャが、重心の記述子ベクトルの次元数が、個々のバーを記述するために使用される特徴量の数と異なっていても問題ないように設計されているという点です。
メソッド本体では、まずはこれまでと同様に、パラメータの検証や継承されたコンポーネントの初期化処理を実装している親クラスの対応メソッドを呼び出すことから始めます。ここでは、そのメソッドの実行結果が論理的に正しいかどうかを確認するのみです。
その後、本アルゴリズムの実行時に必要となるいくつかのアーキテクチャパラメータを保存します。
iUnits = units_count; iPoints = MathMax(center_points, 9);
内部オブジェクトの配列として、CLayerオブジェクトを使用しました。正しい操作を有効にするには、OpenCLコンテキストオブジェクトへのポインタを渡します。
cQuery.SetOpenCL(OpenCL); cKey.SetOpenCL(OpenCL); cValue.SetOpenCL(OpenCL); cKeyValue.SetOpenCL(OpenCL); cMHAttentionOut.SetOpenCL(OpenCL); cAttentionOut.SetOpenCL(OpenCL); cResidual.SetOpenCL(OpenCL); cFeedForward.SetOpenCL(OpenCL); cCenterPoints.SetOpenCL(OpenCL); cFinalAttention.SetOpenCL(OpenCL);
重心表現を学習するために、連続する2つの全結合層で構成される小さなMLPを作成します。
//--- Init center points CNeuronBaseOCL *base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(iPoints * center_window * 2, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *buf = base.getOutput(); if(!buf || !buf.BufferInit(1, 1) || !buf.BufferWrite()) return false; if(!cCenterPoints.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base.Init(0, 1, OpenCL, iPoints * center_window * 2, optimization, iBatch)) return false; if(!cCenterPoints.Add(base)) return false;
指定された数の2倍の重心を作成している点にご注意ください。これにより、異なるスケールで構成される2つの重心セットが生成され、異なる解像度のグリッド構造をシミュレートすることができます。
続いて、特徴量スケーリング層の数に応じて内部オブジェクトを初期化するループを構築します。
なお、親クラスでは、2つの異なる注意集中係数を用いて元のデータを集約する仕組みになっていることを思い出してください。したがって、このループも2回の反復を含むことになります。
//--- Inside layers for(int i = 0; i < 2; i++) { //--- Interpolation CNeuronMVCrossAttentionMLKV *cross = new CNeuronMVCrossAttentionMLKV(); if(!cross || !cross.Init(0, i * 12 + 2, OpenCL, center_window, 32, 4, 64, 2, iPoints, iUnits, 2, 2, 2, 1, optimization, iBatch)) return false; if(!cCenterPoints.Add(cross)) return false;
重心の補間には、現在の重心の表現と分析対象の入力データセットを整合させるクロスアテンションブロックを使用します。このプロセスの中核となる考え方は、入力データを最も正確かつ効果的に局所領域に分割できる重心のセットを特定することです。これにより、入力データの構造を学習することを目的としています。
次に、元の著者が提案したSEFormerブロックの構成要素の初期化に進みます。このブロックは、分析対象のポイントの埋め込みに、点群の構造情報を付加することを目的として設計されています。技術的には、すでに点群構造情報で強化された重心に対して、分析対象ポイントからクロスアテンションを適用する形になります。
ここでは、分析されたポイントの埋め込みに基づいて、Queryエンティティを生成するために畳み込み層を使用します。
//--- Query CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, i * 12 + 3, OpenCL, 64, 64, 64, iUnits, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false;
同様の方法でKeyエンティティを生成しますが、ここでは重心の表現を使用します。
//--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, i * 12 + 4, OpenCL, center_window, center_window, 32, iPoints, 2, optimization, iBatch)) return false; if(!cKey.Add(conv)) return false;
Valueエンティティの生成にあたって、SEFormer法の著者は、シーケンス内の各要素に対して個別の変換行列を適用することを提案しています。これに従い、同様の畳み込み層を適用しますが、シーケンス内の要素数は1に設定します。一方で、重心の総数は入力変数のパラメータとして渡されます。この設計により、目的とする処理結果を効率的に得ることが可能となります。
//--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, i * 12 + 5, OpenCL, center_window, center_window, 32, 1, iPoints * 2, optimization, iBatch)) return false; if(!cValue.Add(conv)) return false;
ただし、すべてのカーネルは、Key-Valueエンティティを連結したテンソルに対して動作するよう、クロスアテンションアルゴリズムによって作成されています。したがって、OpenCLプログラムに変更を加えることなく対応するために、指定されたテンソルを単純に連結する処理を追加します。
//--- Key-Value base = new CNeuronBaseOCL(); if(!base || !base.Init(0, i * 12 + 6, OpenCL, iPoints * 2 * 32 * 2, optimization, iBatch)) return false; if(!cKeyValue.Add(base)) return false;
依存係数の行列はOpenCLコンテキスト内でのみ使用され、フィードフォワードパスごとに再計算されます。したがって、メインメモリにこのバッファを作成する意味はありません。そのため、OpenCLコンテキストのメモリ内にのみ作成します。
//--- Score int s = int(iUnits * iPoints * 4); s = OpenCL.AddBuffer(sizeof(float) * s, CL_MEM_READ_WRITE); if(s < 0 || !cScores.Add(s)) return false;
次に、マルチヘッドアテンションデータを記録するための層を作成します。
//--- MH Attention Out base = new CNeuronBaseOCL(); if(!base || !base.Init(0, i * 12 + 7, OpenCL, iUnits * 64, optimization, iBatch)) return false; if(!cMHAttentionOut.Add(base)) return false;
得られた結果をスケーリングするために畳み込み層も追加します。
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, i * 12 + 8, OpenCL, 64, 64, 64, iUnits, 1, optimization, iBatch)) return false; if(!cAttentionOut.Add(conv)) return false;
Transformerアルゴリズムに従って、取得された自己アテンションの結果は元のデータと合計され、正規化されます。
//--- Residual base = new CNeuronBaseOCL(); if(!base || !base.Init(0, i * 12 + 9, OpenCL, iUnits * 64, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false;
次に、FeedForwardブロックの2つの層を追加します。
//--- Feed Forward conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, i * 12 + 10, OpenCL, 64, 64, 256, iUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(LReLU); if(!cFeedForward.Add(conv)) return false; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, i * 12 + 11, OpenCL, 256, 64, 64, iUnits, 1, optimization, iBatch)) return false; if(!cFeedForward.Add(conv)) return false;
そして、残差コミュニケーションを整理するためのオブジェクトを追加します。
//--- Residual base = new CNeuronBaseOCL(); if(!base || !base.Init(0, i * 12 + 12, OpenCL, iUnits * 64, optimization, iBatch)) return false; if(!base.SetGradient(conv.getGradient(), true)) return false; if(!cResidual.Add(base)) return false;
この場合、残差接続層内の勾配誤差バッファをオーバーライドすることに注意してください。これにより、残差層から順方向パスブロックの最終層への勾配誤差データのコピー操作を回避できます。
SEFormerモジュールの締めくくりとして、著者はバニラTransformerの使用を提案しています。しかし、私はシーン認識アテンションモジュールを組み込むことで、より洗練されたアーキテクチャを採用しました。
//--- Final Attention CNeuronMLMHSceneConditionAttention *att = new CNeuronMLMHSceneConditionAttention(); if(!att || !att.Init(0, i * 12 + 13, OpenCL, 64, 16, 4, 2, iUnits, 2, 1, optimization, iBatch)) return false; if(!cFinalAttention.Add(att)) return false; }
この段階で、単一の内部層のすべてのコンポーネントが初期化され、次のループの反復に進みます。
内部層の初期化ループをすべて完了した後、各内部層の出力を個別に利用しない点に注意が必要です。論理的には、それらをひとつのテンソルに連結し、その統合テンソルを親クラスに渡して全体的な点群埋め込みを生成することができます。当然、その前に得られたテンソルを必要な次元にスケーリングする必要があります。しかし今回は別のアプローチを採用し、クロスアテンションブロックを用いて、より大きなスケールの層からの情報で小さなスケールのデータを強化しています。
if(!SEOut.Init(0, 26, OpenCL, 64, 64, 4, 16, 4, iUnits, iUnits, 4, 1, optimization, iBatch)) return false;
メソッドの最後に、一時データ保存用の補助バッファを初期化します。
if(!cbTemp.BufferInit(buf_size, 0) || !cbTemp.BufferCreate(OpenCL)) return false; //--- return true; }
その後、メソッド内で実行された操作の論理結果を呼び出し元プログラムに返します。
この時点で、クラスオブジェクトの初期化メソッドの実装は完了しました。次に、feedForwardメソッド内でフィードフォワードパスアルゴリズムの構築に進みます。ご存知のとおり、このメソッドのパラメータでは、ソースデータオブジェクトへのポインタを受け取ります。
bool CNeuronSEFormer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- CNeuronBaseOCL *neuron = NULL, *q = NULL, *k = NULL, *v = NULL, *kv = NULL;
メソッド本体では、内部オブジェクトへのポインタを一時的に保持するためのローカル変数をいくつか宣言します。続いて、重心の表現を生成します。
//--- Init Points if(bTrain) { neuron = cCenterPoints[1]; if(!neuron || !neuron.FeedForward(cCenterPoints[0])) return false; }
モデルの訓練プロセス中にのみ、重心の表現を生成することに注意してください。運用時には、重心点は静的であるため、各パスで再生成する必要はありません。
次に、内部層を順に処理するループを構築します。
//--- Inside Layers for(int l = 0; l < 2; l++) { //--- Segmentation Inputs if(l > 0 || !cTNetG) { if(!caLocalPointNet[l].FeedForward((l == 0 ? NeuronOCL : GetPointer(caLocalPointNet[l - 1])))) return false; } else { if(!cTurnedG) return false; if(!cTNetG.FeedForward(NeuronOCL)) return false; int window = (int)MathSqrt(cTNetG.Neurons()); if(IsStopped() || !MatMul(NeuronOCL.getOutput(), cTNetG.getOutput(), cTurnedG.getOutput(), NeuronOCL.Neurons() / window, window, window)) return false; if(!caLocalPointNet[0].FeedForward(cTurnedG.AsObject())) return false; }
メソッドの本体では、まずソースデータをセグメント化します(このアルゴリズムは親クラスから継承しています)。続いて、得られたデータを用いて重心を強化します。
//--- Interpolate center points neuron = cCenterPoints[l + 2]; if(!neuron || !neuron.FeedForward(cCenterPoints[l + 1], caLocalPointNet[l].getOutput())) return false;
次に、データ構造をエンコードするアテンションモジュールに進みます。まず、配列から対応する内部層を抽出します。
//--- Structure-Embedding Attention
q = cQuery[l];
k = cKey[l];
v = cValue[l];
kv = cKeyValue[l];
次に、必要なすべてのエンティティを順番に生成します。
//--- Query if(!q || !q.FeedForward(GetPointer(caLocalPointNet[l]))) return false; //--- Key if(!k || !k.FeedForward(cCenterPoints[l + 2])) return false; //--- Value if(!v || !v.FeedForward(cCenterPoints[l + 2])) return false;
KeyとValueの生成結果は、単一のテンソルに連結されます。
if(!kv || !Concat(k.getOutput(), v.getOutput(), kv.getOutput(), 32 * 2, 32 * 2, iPoints)) return false;
その後は、従来のマルチヘッドセルフアテンションメソッドを使用できます。
//--- Multi-Head Attention neuron = cMHAttentionOut[l]; if(!neuron || !AttentionOut(q.getOutput(), kv.getOutput(), cScores[l], neuron.getOutput())) return false;
取得したデータを元のデータのサイズに合わせてスケーリングします。
//--- Scale neuron = cAttentionOut[l]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[l])) return false;
次に、2つの情報ストリームを合計し、結果のデータを正規化します。
//--- Residual q = cResidual[l * 2]; if(!q || !SumAndNormilize(caLocalPointNet[l].getOutput(), neuron.getOutput(), q.getOutput(), 64, true, 0, 0, 0, 1)) return false;
通常のTransformerエンコーダと同様に、FeedForwardブロックを使用し、その後に残差関連付けとデータ正規化をおこないます。
//--- Feed Forward neuron = cFeedForward[l * 2]; if(!neuron || !neuron.FeedForward(q)) return false; neuron = cFeedForward[l * 2 + 1]; if(!neuron || !neuron.FeedForward(cFeedForward[l * 2])) return false; //--- Residual k = cResidual[l * 2 + 1]; if(!k || !SumAndNormilize(q.getOutput(), neuron.getOutput(), k.getOutput(), 64, true, 0, 0, 0, 1)) return false;
得られた結果を、シーンを考慮してアテンションブロックに渡します。そして、ループの次の反復に進みます。
//--- Final Attention neuron = cFinalAttention[l]; if(!neuron || !neuron.FeedForward(k)) return false; }
すべての内部層操作が正常に完了したら、小規模のポイント埋め込みを大規模な情報で強化します。
//--- Cross scale attention if(!SEOut.FeedForward(cFinalAttention[0], neuron.getOutput())) return false;
そして、得られた結果を転送して、分析された点群の大域的な埋め込みを形成します。
//--- Global Point Cloud Embedding if(!CNeuronPointNetOCL::feedForward(SEOut.AsObject())) return false; //--- result return true; }
フィードフォワードパス・メソッドの最後では、操作が正常に実行されたかどうかを示すブール値を呼び出し元のプログラムに返します。
ご覧のとおり、フォワードパスアルゴリズムの実装は、直線的とは程遠い、かなり複雑な情報フロー構造をもたらします。残差接続の使用が見られ、一部のコンポーネントは2つのデータソースに依存しています。さらに、複数の箇所でデータフローが交差しています。当然ながら、このような複雑さは、calcInputGradientsメソッドに実装した逆伝播アルゴリズムの設計にも影響を与えています。
bool CNeuronSEFormer::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
このメソッドは、前の層へのポインタをパラメータとして受け取ります。フォワードパス中、この層は入力データを提供していました。現在は、その入力データがモデルの最終出力に与えた影響に対応する誤差勾配を、この層に逆伝播させる必要があります。
メソッド本体では、受け取ったポインタが無効な場合、その後のすべての処理が無意味になるため、直ちにそのポインタの妥当性を検証します。
また、内部コンポーネントへのポインタを一時的に保持するための局所変数も宣言します。
CNeuronBaseOCL *neuron = NULL, *q = NULL, *k = NULL, *v = NULL, *kv = NULL; CBufferFloat *buf = NULL;
その後、点群の大域埋め込みから内部レイヤーに誤差勾配を伝播します。
//--- Global Point Cloud Embedding if(!CNeuronPointNetOCL::calcInputGradients(SEOut.AsObject())) return false;
フィードフォワードパスでは、親クラスのメソッドを呼び出すことによって最終結果が取得されることに注意してください。したがって、誤差勾配を取得するには、親クラスの対応するメソッドを使用する必要があります。
次に、誤差勾配を異なるスケールのフローに分配します。
//--- Cross scale attention neuron = cFinalAttention[0]; q = cFinalAttention[1]; if(!neuron.calcHiddenGradients(SEOut.AsObject(), q.getOutput(), q.getGradient(), ( ENUM_ACTIVATION)q.Activation())) return false;
次に、内部層を通る逆ループを構成します。
for(int l = 1; l >= 0; l--) { //--- Final Attention neuron = cResidual[l * 2 + 1]; if(!neuron || !neuron.calcHiddenGradients(cFinalAttention[l])) return false;
ここでは、まず誤差勾配を残差接続層のレベルまで伝播します。
内部オブジェクトを初期化するときに、残差接続層の誤差勾配バッファをFeedForwardブロックの層の同様のバッファに置き換えたことを思い出してください。そのため、不要なデータのコピー操作をスキップして、誤差勾配をすぐに下のレベルに渡すことができます。
//--- Feed Forward neuron = cFeedForward[l * 2]; if(!neuron || !neuron.calcHiddenGradients(cFeedForward[l * 2 + 1])) return false;
次に、誤差勾配をアテンションブロックの残差接続層に伝播します。
neuron = cResidual[l * 2]; if(!neuron || !neuron.calcHiddenGradients(cFeedForward[l * 2])) return false;
ここでは、2つの情報ストリームからの誤差勾配を合計し、合計値をアテンションブロックに転送します。
//--- Residual q = cResidual[l * 2 + 1]; k = neuron; neuron = cAttentionOut[l]; if(!neuron || !SumAndNormilize(q.getGradient(), k.getGradient(), neuron.getGradient(), 64, false, 0, 0, 0, 1)) return false;
その後、誤差勾配をアテンションヘッド全体に分散します。
//--- Scale neuron = cMHAttentionOut[l]; if(!neuron || !neuron.calcHiddenGradients(cAttentionOut[l])) return false;
そして、バニラ型Transformerアルゴリズムを使用して、誤差勾配をQuery、Key、Valueエンティティレベルに伝播します。
//--- MH Attention q = cQuery[l]; kv = cKeyValue[l]; k = cKey[l]; v = cValue[l]; if(!AttentionInsideGradients(q.getOutput(), q.getGradient(), kv.getOutput(), kv.getGradient(), cScores[l], neuron.getGradient())) return false;
この操作の結果、Queryのレベルと連結されたKey-Valueテンソルのレベルの2つの誤差勾配テンソルが取得されました。KeyとValueの誤差勾配を、対応する内部層のバッファ全体に分散してみましょう。
if(!DeConcat(k.getGradient(), v.getGradient(), kv.getGradient(), 32 * 2, 32 * 2, iPoints)) return false;
次に、Queryテンソルからの誤差勾配を、元のデータセグメンテーションのレベルまで伝播させることができます。ただし、注意点が1つあります。最後の層では、この操作は特に難しくありません。しかし最初の層では、勾配バッファにすでに後続のセグメンテーションレベルからの誤差情報が格納されており、それを保持する必要があります。したがって、現在の層のインデックスを確認し、必要に応じてデータバッファへのポインタを置き換えます。
if(l == 0) { buf = caLocalPointNet[l].getGradient(); if(!caLocalPointNet[l].SetGradient(GetPointer(cbTemp), false)) return false; }
次に、誤差勾配を伝播します。
if(!caLocalPointNet[l].calcHiddenGradients(q, NULL)) return false;
必要に応じて、2つの情報ストリームのデータを合計し、その後、削除されたポインタをデータバッファに返します。
if(l == 0) { if(!SumAndNormilize(buf, GetPointer(cbTemp), buf, 64, false, 0, 0, 0, 1)) return false; if(!caLocalPointNet[l].SetGradient(buf, false)) return false; }
次に、アテンションブロックの残差接続の誤差勾配を追加します。
neuron = cAttentionOut[l]; //--- Residual if(!SumAndNormilize(caLocalPointNet[l].getGradient(), neuron.getGradient(), caLocalPointNet[l].getGradient(), 64, false, 0, 0, 0, 1)) return false;
次のステップは、誤差勾配を重心レベルに分散することです。ここでは、KeyエンティティとValueエンティティの両方から誤差勾配を分散する必要があります。ここでも、データバッファへのポインタの置換を使用します。
//--- Interpolate Center points neuron = cCenterPoints[l + 2]; if(!neuron) return false; buf = neuron.getGradient(); if(!neuron.SetGradient(GetPointer(cbTemp), false)) return false;
その後、Keyエンティティから最初の誤差勾配を伝播します。
if(!neuron.calcHiddenGradients(k, NULL)) return false;
ただし、それが最初になるのは最後の層の場合のみです。これに対し、最初の層では、すでに次の層の出力に対する影響に基づく誤差勾配の情報がバッファに含まれています。したがって、対象の内部レイヤーのインデックスを確認し、必要に応じて2つの情報ストリームからのデータを統合します。
if(l == 0) { if(!SumAndNormilize(buf, GetPointer(cbTemp), buf, 1, false, 0, 0, 0, 1)) return false; } else { if(!SumAndNormilize(GetPointer(cbTemp), GetPointer(cbTemp), buf, 1, false, 0, 0, 0, 0.5f)) return false; }
同様に、Valueエンティティからの誤差勾配を伝播し、2つの情報ストリームからのデータを要約します。
if(!neuron.calcHiddenGradients(v, NULL)) return false; if(!SumAndNormilize(buf, GetPointer(cbTemp), buf, 1, false, 0, 0, 0, 1)) return false;
その後、以前削除したポインタを誤差勾配バッファに戻します。
if(!neuron.SetGradient(buf, false)) return false;
次に、前の層の重心と現在の層のセグメント化されたデータ間の誤差勾配を分散します。
neuron = cCenterPoints[l + 1]; if(!neuron.calcHiddenGradients(cCenterPoints[l + 2], caLocalPointNet[l].getOutput(), GetPointer(cbTemp), (ENUM_ACTIVATION)caLocalPointNet[l].Activation())) return false;
まさにこの特定の誤差勾配を保持するために、これまで重心層のバッファを上書きしてきました。さらに、データセグメンテーション層の勾配バッファには、関連する情報の大部分がすでに含まれていることにも注意が必要です。したがって、この段階では、誤差勾配を一時的なデータバッファに保存し、2つの情報フローからのデータを統合します。
if(!SumAndNormilize(caLocalPointNet[l].getGradient(), GetPointer(cbTemp), caLocalPointNet[l].getGradient(), 64, false, 0, 0, 0, 1)) return false;
この段階で、新しく宣言されたすべての内部オブジェクト間で誤差勾配が分散されました。しかし、データセグメンテーション層全体に誤差勾配を分散させる必要があります。このアルゴリズムは親クラスのメソッドから完全に流用しています。
//--- Local Net neuron = (l > 0 ? GetPointer(caLocalPointNet[l - 1]) : NeuronOCL); if(l > 0 || !cTNetG) { if(!neuron.calcHiddenGradients(caLocalPointNet[l].AsObject())) return false; } else { if(!cTurnedG) return false; if(!cTurnedG.calcHiddenGradients(caLocalPointNet[l].AsObject())) return false; int window = (int)MathSqrt(cTNetG.Neurons()); if(IsStopped() || !MatMulGrad(neuron.getOutput(), neuron.getGradient(), cTNetG.getOutput(), cTNetG.getGradient(), cTurnedG.getGradient(), neuron.Neurons() / window, window, window)) return false; if(!OrthoganalLoss(cTNetG, true)) return false; //--- CBufferFloat *temp = neuron.getGradient(); neuron.SetGradient(cTurnedG.getGradient(), false); cTurnedG.SetGradient(temp, false); //--- if(!neuron.calcHiddenGradients(cTNetG.AsObject())) return false; if(!SumAndNormilize(neuron.getGradient(), cTurnedG.getGradient(), neuron.getGradient(), 1, false, 0, 0, 0, 1)) return false; } } //--- return true; }
内部層ループのすべての反復が完了した後、メソッドの実行が正常に終了したことを示すブール値を呼び出し元プログラムに返します。
これで、新しいクラスの内部コンポーネントを通じて、フォワードパスおよび勾配伝播のアルゴリズムが実装されました。残るのは、訓練可能なパラメータの更新を担うupdateInputWeightsメソッドの実装です。このケースでは、すべての訓練可能なパラメータがネストされたコンポーネント内にカプセル化されています。したがって、クラスのパラメータを更新するには、各内部オブジェクトにおいて対応するメソッドを順に呼び出すだけで済みます。このアルゴリズムは非常に単純であるため、本メソッドの実装については各自での検討に委ねることを推奨します。
参考までに、CNeuronSEFormerクラスおよびその全メソッドの完全な実装は添付ファイル内に含まれています。また、先ほどこのクラス内でオーバーライド用に宣言したサポートメソッドも、同様にそちらで確認できます。
最後に補足すると、全体のモデルアーキテクチャは前回の記事で紹介したものをほぼ踏襲しており、加えた唯一の変更点は、環境状態エンコーダ内の1つの層を置き換えたことだけです。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSEFormer; { int temp[] = {BarDescr, 8}; // Variables, Center embedding if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {HistoryBars, 27}; // Units, Centers if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.window_out = LatentCount; // Output Dimension descr.step = int(true); // Use input and feature transformation descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
環境との対話やモデルの訓練に使用されるすべてのプログラムについても同様で、前回の記事から完全に引き継がれています。そのため、ここでの説明は省略します。この記事で使用されているすべてのプログラムの完全なコードは添付ファイルに含まれています。
3.テスト
そしてついに、長らく続いた実装作業を終え、本プロセスの最終段階(おそらく最も注目に値するフェーズ)である、モデルの学習および得られたActor方策の実データによる検証に到達しました。
これまでと同様に、モデルの訓練にはEURUSDの実際の履歴データ(H1時間枠、2023年全期間)を使用します。すべてのインジケーターのパラメータはデフォルト値のままとしています。
モデル訓練アルゴリズムと訓練およびテストに用いる各種プログラムは、いずれも過去の記事において導入したものを引き続き使用しています。
訓練済みモデルのテストは、他のすべてのパラメータを変更せずに、2024年1月からの履歴データで実施されました。以下にそのテスト結果を示します。
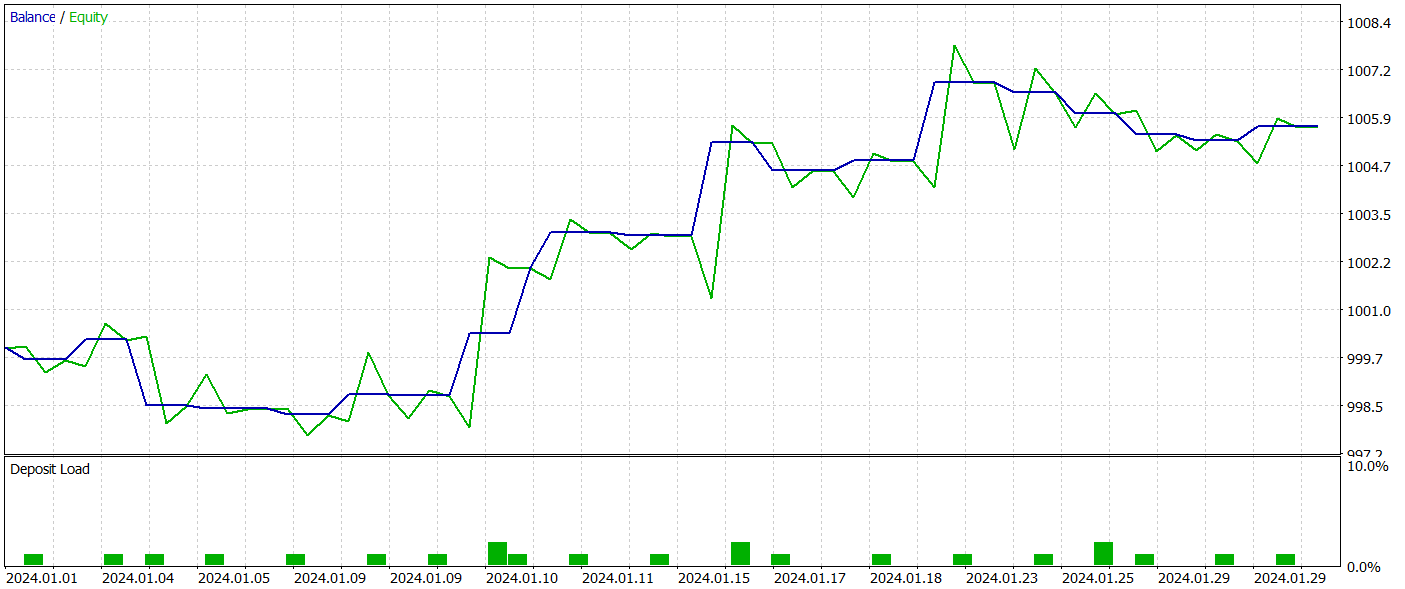
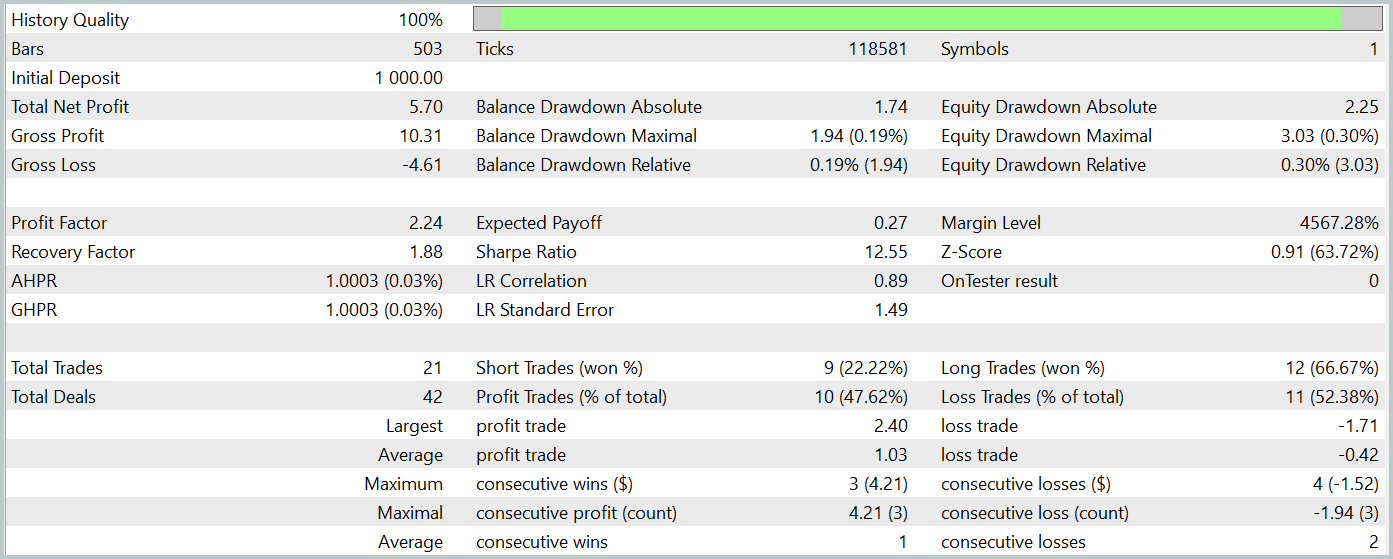
テスト期間中、訓練済みモデルは21件の取引を実行し、47%は利益を出して終了しました。中でも、ロングポジションの収益性が顕著であり、66%が利益となったのに対し、ショートポジションでは22%にとどまりました。この点からも、さらなるモデル訓練の必要性が明らかです。とはいえ、平均的な利益確定取引は、損失取引の2.5倍の利益幅を持っており、結果としてテスト期間全体では総合的な利益を達成することができました。
私の主観的な見解として、本モデルはやや重厚な構造であると感じられました。これは主に、シーン条件付きアテンションメカニズムを導入したことに起因していると考えられます。ただし、類似のアプローチを採用したHyperDet3D法では、より低い計算コストで優れた結果を得ることができました。
もっとも、いずれの場合も取引数およびテスト期間が限られているため、本手法の長期的な有効性について明確な結論を下すことは現時点では困難です。
結論
SEFormer法は点群データの解析に非常に適しており、ノイズの多い環境下においても局所的な依存関係を効果的に捉えることが可能です。これは、正確な予測において重要な要素であり、より精緻な市場変動の予測や意思決定戦略の改善につながる有望な可能性を切り開きます。
この記事の実践部分では、MQL5を使用して提案されたアプローチのビジョンを実装しました。実際の履歴データでモデルを訓練し、テストしました。結果は提案された方法の可能性を示しています。ただし、実際の取引シナリオにモデルを展開する前に、より長い履歴期間にわたってモデルを訓練し、訓練された方策の包括的なテストを実施することが重要です。
参照文献
記事で使用されているプログラム
| # | ファイル名 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15882
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
いい記事だ
ありがとう。