
Нейросети — это просто (Часть 42): Прокрастинация модели, причины и методы решения

Введение
В области обучения с подкреплением моделей нейронных сетей часто сталкиваются с проблемой прокрастинации, когда процесс обучения замедляется или застревает. Прокрастинация модели может иметь серьезные последствия для достижения поставленных целей и требует принятия соответствующих мер для ее преодоления. В данной статье мы рассмотрим основные причины прокрастинации модели и предложим методы их решения.
1. Проблема прокрастинации
Одной из основных причин прокрастинации модели является недостаточное обучающее окружение. Модель может столкнуться с ограниченным доступом к обучающим данным или недостаточными ресурсами. Решение этой проблемы включает создание или обновление набора данных, повышение разнообразия обучающих примеров и добавление дополнительных ресурсов для обучения, таких как вычислительные мощности или предварительно обученные модели для трансферного обучения.
Еще одной причиной прокрастинации модели может быть сложность задачи, которую она должна решать. Или использование алгоритма обучения, требующего большого количества вычислительных ресурсов. В этом случае, решение может состоять в упрощении задачи или алгоритма, оптимизации вычислительных процессов, использовании более эффективных алгоритмов или распределенного обучения.
Модель может прокрастинировать, если ей не хватает мотивации для достижения поставленных целей. Установка четких и релевантных целей для модели, разработка функции вознаграждения, которая стимулирует достижение этих целей, и использование техник усиления, таких как введение наград и штрафов, может помочь решить эту проблему.
Если модель не получает обратной связи или не обновляется на основе новых данных, она может прокрастинировать в своем развитии. Решение заключается в установлении регулярных циклов обновления модели на основе новых данных и обратной связи, а также в разработке механизмов для контроля и мониторинга прогресса обучения.
Важно регулярно оценивать прогресс модели и результаты обучения. Это поможет увидеть достигнутые успехи и обнаружить возможные проблемы или узкие места. Регулярные оценки позволят своевременно внести коррективы в процесс обучения и избежать затягивания задач.
Предоставление модели разнообразных задач и стимулирующей среды может помочь избежать прокрастинации. Вариативность задач поможет сохранить интерес и мотивацию модели, а стимулирующая среда, например, соревнования или игровые элементы, может способствовать активному участию и прогрессу модели.
Прокрастинация модели может быть связана с недостаточным обновлением и улучшением. Важно регулярно анализировать результаты и итеративно улучшать модель на основе обратной связи и новых идей. Постепенное развитие модели и видимый прогресс могут помочь справиться с прокрастинацией.
Создание положительной и поддерживающей обучающей среды для модели является важным аспектом обучения моделей с подкреплением. Исследования показывают, что положительные примеры способствуют более эффективному и направленному обучению модели. Это объясняется тем, что модель находится в поиске наиболее оптимального выбора, и штрафы за неправильные действия приводят к снижению вероятности выбора ошибочных действий. В то же время, положительные награды явно указывают модели на правильность выбора и существенно повышают вероятность повторения таких действий.
Когда модель получает положительную награду за определенное действие, она обратит на него больше внимания и будет склонна повторять это действие в будущем. Этот механизм мотивации помогает модели искать и выявлять наиболее успешные стратегии для достижения поставленных целей.
Наконец, для эффективного решения прокрастинации модели необходимо провести анализ причин, лежащих в ее основе. Идентификация конкретных причин прокрастинации позволит принять целенаправленные меры для их устранения. Это может включать проведение аудита процессов обучения, обнаружение узких мест, проблем с ресурсами или неоптимальных настроек модели.
Учет и адаптация к изменяющимся условиям могут помочь избежать прокрастинации. Периодическое обновление модели на основе новых данных и изменений в задаче обучения поможет ей оставаться актуальной и эффективной. Кроме того, учет факторов, таких как новые требования или ограничения, позволит модели адаптироваться и избежать застоя.
Установление небольших целей и промежуточных этапов может помочь разбить большую задачу на более управляемые и достижимые части. Это поможет модели видеть прогресс и поддерживать мотивацию в процессе обучения.
Для успешного преодоления прокрастинации в модели обучения с подкреплением необходимо использовать разнообразные подходы и стратегии. Этот комплексный подход поможет модели эффективно преодолеть прокрастинацию и достичь наилучших результатов в своем обучении. Путем сочетания различных методов, таких как улучшение обучающей среды, установление ясных целей, регулярная оценка прогресса и использование мотивации, модель сможет преодолеть прокрастинацию и продвигаться вперед к достижению своих обучающих целей.
2. Практические шаги решения
После того, как мы рассмотрели теоретические аспекты проблемы, давайте теперь обратимся к практическому применению этих идей.
В предыдущей статье мы оставили нашу модель с комментарием о необходимости дальнейшего обучения для минимизации убыточных сделок. Однако, в процессе продолжения обучения мы столкнулись с ситуацией, когда советник не совершил ни одной сделки за весь период обучения.
Это явление, называемое "прокрастинацией модели", представляет собой серьезную проблему, которая требует нашего внимания и поиска решений.

2.1. Анализ причин
Для того чтобы преодолеть прокрастинацию модели в обучении с подкреплением, важно начать с анализа текущей ситуации и выявления причин данного явления. Анализ поможет нам понять, почему модель не совершает сделок и что может быть скорректировано для улучшения ее производительности.
Тестирования обученной модели осуществляется с использованием советника "Test.mq5", который осуществляет жадный выбор агента и действия. Важно отметить, что каждый последующий запуск советника с теми же параметрами и периодом тестирования приведет к воспроизведению предыдущего прохода с высокой точностью. Это позволяет нам добавить точки контроля и анализировать работу советника при каждом запуске.
Добавление точек контроля и анализ работы советника при каждом запуске обеспечивает нам большую надежность и уверенность в результате обучения модели с подкреплением. Мы можем лучше понять, как модель применяет свои знания и прогнозы на реальных данных, и делать соответствующие выводы и корректировки для улучшения ее производительности.
Для оценки работы планировщика введем вектор ModelsCount, который будет содержать количество раз, когда каждый агент был выбран. Для этого объявим вектор ModelsCount в блоке глобальных переменных:
vector<float> ModelsCount;
Затем, в функции OnInit, инициализируем данный вектор размером, соответствующим количеству используемых агентов:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- ModelsCount = vector<float>::Zeros(Models); //--- return(INIT_SUCCEEDED); }
В функции OnTick, после каждого прямого прохода планировщика увеличиваем счетчик соответствующего агента в векторе ModelsCount:
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ....... //--- if(!Schedule.feedForward(GetPointer(State1), 12, false)) return; Schedule.getResults(Result); int model = GetAction(Result, 0, 1); ModelsCount[model]++; //--- ........ ........ }
Наконец, при деинициализации советника выведем результаты подсчета в журнал:
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Print(ModelsCount); delete Result; }
Таким образом, мы добавляем функциональность для подсчета количества выборов каждого агента и выводим результаты подсчета в журнал при деинициализации советника. Это позволяет нам оценить работу планировщика и получить информацию о том, как часто каждый агент был выбран в процессе выполнения советника.
После добавления нашей первой точки контроля мы запустили советник в тестере стратегий без изменения параметров и периода тестирования. Полученные результаты подтвердили наши опасения. Мы наблюдаем, что в течение всего тестирования планировщик использовал только одного агента.

Это наблюдение указывает на то, что планировщик может быть предвзят в пользу определенного агента, игнорируя исследование других доступных агентов. Такая предвзятость может затруднить эффективность нашей модели обучения с подкреплением и ограничить ее способность обнаружить более эффективные стратегии.
Чтобы решить эту проблему, нам необходимо исследовать причины, по которым планировщик предпочитает использовать только одного агента.
Продолжая анализировать причины такого поведения модели, мы добавляем две дополнительные точки контроля. Теперь мы сосредоточимся на динамике изменения распределений на выходе моделей в зависимости от изменения состояния окружающей среды. Для этого мы вводим два дополнительных вектора: prev_scheduler и prev_actor. В этих векторах мы будем сохранять результаты предыдущего прямого прохода планировщика и агентов соответственно.
vector<float> prev_scheduler; vector<float> prev_actor;
Это позволит нам сравнить текущие распределения с предыдущими и оценить их изменения. Если мы обнаружим, что распределения значительно меняются с течением времени или в ответ на изменения в окружающей среде, это может указывать на то, что модель может быть слишком чувствительной к изменениям или неустойчивой в своих стратегиях.
Добавление этих векторов в нашу модель позволяет нам получать более подробную информацию о динамике изменения стратегий и распределений, что в свою очередь помогает нам понять причины предпочтения определенного агента и принять меры для решения этой проблемы.
Как и в предыдущем случае, мы инициализируем векторы в методе OnInit, чтобы подготовить их для контроля данных.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- ModelsCount = vector<float>::Zeros(Models); prev_scheduler.Init(Models); prev_actor.Init(Result.Total()); //--- return(INIT_SUCCEEDED); }
Фактический контроль данных осуществляется в методе OnTick.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ........ //--- State1.AssignArray(sState.state); if(!Actor.feedForward(GetPointer(State1), 12, false)) return; Actor.getResults(Result); State1.AddArray(Result); if(!Schedule.feedForward(GetPointer(State1), 12, false)) return; vector<float> temp; Schedule.getResults(Result); Result.GetData(temp); float delta = MathAbs(prev_scheduler - temp).Sum(); int model = GetAction(Result, 0, 1); prev_scheduler = temp; Actor.getResults(Result); Result.GetData(temp); delta = MathAbs(prev_actor - temp).Sum(); prev_actor = temp; ModelsCount[model]++; //--- ........ ........ //--- }
В данном случае мы хотим оценить, как изменение состояния окружающей среды влияет на результат работы модели. В результате этого эксперимента мы ожидаем увидеть уникальное вероятностное распределение на выходе модели для каждой свечи тестовой выборки. То есть мы хотим наблюдать изменение стратегий модели в зависимости от изменения состояния рынка.
Мы не будем выводить результаты анализа в журнал, поскольку это приведет к большому объему информации. Вместо этого мы будем использовать режим отладки для наблюдения за изменением значений. Чтобы уменьшить объем сравниваемых значений, мы будем проверять только суммарное отклонение векторов.
К сожалению, в процессе тестирования мы обнаружили отсутствие отклонений. Это означает, что распределение вероятностей на выходе модели остается практически одинаковым во всех состояниях окружающей среды.
Это наблюдение указывает на то, что модель не адаптируется к изменяющейся среде и не учитывает различия в состояниях рынка. Возможны несколько причин такого поведения модели и различные подходы для их решения:
- Ограниченность обучающего набора данных: Если обучающий набор данных не содержит достаточно разнообразных ситуаций, модель может не научиться адекватно реагировать на новые условия. Решением может быть расширение и разнообразие обучающего набора данных, включая более широкий спектр сценариев и изменяющиеся условия рынка.
- Недостаточное обучение модели: Модель может не получить достаточного количества обучения или не пройти достаточное количество эпох обучения, чтобы адаптироваться к разным условиям среды. В таком случае, увеличение продолжительности обучения или использование дополнительных методов, таких как переобучение (fine-tuning), может помочь модели лучше адаптироваться.
- Недостаточная сложность модели: Модель может быть недостаточно сложной, чтобы улавливать тонкие различия в состояниях среды. В этом случае, увеличение размера и сложности модели, например, добавление дополнительных слоев или увеличение числа нейронов, может помочь ей лучше улавливать и обрабатывать различия в данных.
- Неправильный выбор архитектуры модели: Возможно, текущая архитектура модели не подходит для решения задачи адаптации к изменяющейся среде. В таком случае, пересмотр архитектуры модели может улучшить ее способность адаптироваться к изменениям в среде.
- Неправильная функция вознаграждения: Функция вознаграждения модели может быть недостаточно информативной или не соответствовать требуемым целям. В таком случае, пересмотр функции вознаграждения и учет более релевантных факторов в ней могут помочь модели принимать более умные решения в изменяющейся среде.
Все эти подходы требуют проведения дополнительных экспериментов, тестирования и настройки модели, чтобы достичь более эффективной адаптации к изменяющейся среде и улучшить ее производительность.
Для того чтобы выяснить, где именно в наших моделях теряется информация об изменении состояния системы, мы проведем анализ архитектуры каждого слоя. В режиме отладки мы будем проверять изменение результатов на выходе каждого слоя наших моделей.
Мы начнем с полносвязного слоя CNeuronBaseOCL. В этом слое мы проверим, сохраняется ли информация об изменении состояния системы. Далее, мы проверим слой пакетной нормализации данных CNeuronBatchNormOCL, чтобы убедиться, что он не искажает данные об изменении состояния. Затем мы проанализируем сверточный слой CNeuronConvOCL, чтобы увидеть, как он обрабатывает информацию о изменении состояния системы. И, наконец, мы изучим мульти-модельный полносвязный слой CNeuronMultiModel, чтобы определить, как он учитывает изменение состояния в разных моделях.
Проведение этого анализа поможет нам выявить, на каком уровне архитектуры модели теряется информация об изменении состояния системы и какие слои могут быть подвержены оптимизации или изменению для улучшения производительности модели в адаптации к изменяющейся среде.
Для контроля и отслеживания выходных результатов каждого слоя в модели мы внедряем вектор prev_output в класс CNeuronBaseOCL. Напомним, что этот класс является базовым для всех других классов нейронных слоев, и все остальные слои наследуют его. Путем добавления вектора в тело этого класса мы обеспечиваем его наличие во всех слоях модели.
class CNeuronBaseOCL : public CObject { protected: ........ ........ vector<float> prev_output;
В методе инициализации класса мы установим размер вектора, который будет равен числу нейронов в данном слое.
bool CNeuronBaseOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { ........ ........ //--- prev_output.Init(numNeurons); //--- ........ ........ //--- return true; }
В методе feedForward, который выполняет прямой проход модели, мы добавим точку контроля в конце метода, после завершения всех итераций. Важно отметить, что все операции в этом методе выполняются в контексте OpenCL. Для контроля данных нам необходимо загрузить результаты операций в основную память, но это может занимать значительное время. Ранее мы старались минимизировать эту загрузку, оставив только загрузку результатов работы модели. В текущем случае, загрузка результатов каждого нейронного слоя становится необходимой. Однако, в последующем этот блок кода может быть удален или закомментирован, если не требуется контроль данных.
bool CNeuronBaseOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { ........ ........ //--- vector<float> temp; Output.GetData(temp); float delta=MathAbs(temp-prev_output).Sum(); prev_output=temp; //--- return true; }
Мы также добавляем аналогичный контроль в методы прямого прохода всех анализируемых классов нейронных слоев. Это позволяет нам контролировать значения на выходе каждого слоя и идентифицировать места, где возможно "теряется" изменение состояния системы. Путем добавления соответствующих блоков кода в методы прямого прохода каждого класса слоя, мы можем сохранять и анализировать результаты работы слоя на каждой итерации обучения модели.
Контроль данных осуществляем в режиме отладки.
После анализа результатов, мы обнаружили, что блок предварительной обработки данных, состоящий из слоя исходных данных, слоя пакетной нормализации и двух последовательных блоков сверточного и полносвязного нейронных слоев, не функционирует должным образом. Мы обнаружили, что после второго сверточного слоя модель не реагирует на изменения состояния анализируемой системы.
CNeuronBaseOCL -> CNeuronBatchNormOCL -> CNeuronConvOCL -> CNeuronBaseOCL -> CNeuronConvOCL -> CNeuronBaseOCL
Это наблюдается как в случае агентов, так и в случае планировщика, где мы использовали аналогичный блок предварительной обработки данных. Результаты проверки были идентичны для обоих случаев.
Несмотря на то, что в предыдущих экспериментах такая архитектура давала положительные результаты, в данном случае она оказалась неэффективной. Таким образом, мы сталкиваемся с необходимостью внести изменения в архитектуру используемых моделей.
2.2. Изменение архитектуры моделей
После проведенного анализа мы приходим к выводу о неэффективности текущей архитектуры моделей. Теперь нам предстоит сделать шаг назад и взглянуть на созданную ранее архитектуру с новой точки зрения, чтобы оценить возможные пути ее оптимизации.
В текущей модели мы подаем рыночную ситуацию и состояние нашего счета на вход агентам, которые анализируют ситуацию и предлагают возможные действия. Результат работы агентов мы добавляем к ранее собранным исходным данным и передаем на вход планировщику, который выбирает одного агента для выполнения действия.
А теперь давайте представим инвестиционный отдел, где сотрудники проводят анализ рыночной ситуации и предоставляют результаты своего анализа начальнику отдела. Начальник отдела, имея эти результаты, совмещает их с исходными данными и проводит дополнительный анализ, чтобы выбрать одного агента, чей прогноз совпадает с его собственным. Однако, такой подход может снизить эффективность работы отдела.
При такой организации работы начальнику отдела приходится не только анализировать рыночную ситуацию самостоятельно, но и изучать результаты работы сотрудников. Это добавляет дополнительную нагрузку и не всегда имеет практическую ценность при принятии решений. Попытка предоставить максимально возможную информацию на каждом этапе может привести к упущению основной идеи иерархических моделей, которая заключается в разделении задачи на более мелкие составляющие.
В данном контексте эффективность работы такого отдела, основанного на аналогии с нашей моделью, может быть ниже, чем у самого начальника отдела, так как он должен заниматься не только анализом рыночной ситуации, но и проверкой результатов работы сотрудников, что может быть менее эффективным при принятии решений.
Из представленного сценария становится ясно, что эффективность работы инвестиционного отдела будет повышена, если мы разделим анализ рыночной ситуации между агентами и планировщиком. В данной модели агенты будут специализироваться на анализе рынка, в то время как планировщик будет отвечать за принятие решений на основе прогнозов агентов, без проведения собственного анализа рыночной ситуации.
Агенты будут ответственны за анализ рыночных данных, включая проведение технического и фундаментального анализа. Они будут исследовать и оценивать текущую ситуацию на рынке, выявлять тренды и предлагать возможные варианты действий. Однако, они не будут учитывать состояние счета при проведении своего анализа.
Планировщик, с другой стороны, будет отвечать за риск-менеджмент и принятие решений на основе анализа агентов. Он будет использовать прогнозы и рекомендации, предоставленные агентами, и проводить дополнительный анализ состояния счета и других факторов, связанных с управлением рисками. Основываясь на этой информации, планировщик будет принимать окончательное решение о конкретных действиях в рамках инвестиционной стратегии.
Такое разделение обязанностей позволяет агентам сосредоточиться на анализе рынка без отвлечения на состояние счета, что увеличивает их специализацию и точность прогнозов. Планировщик, в свою очередь, может сосредоточиться на оценке рисков и принятии решений на основе прогнозов агентов, что позволяет ему эффективно управлять портфелем и минимизировать риски.
Такой подход улучшает процесс принятия решений в инвестиционном отделе, поскольку каждый участник команды сосредоточен на своей специализации, что приводит к более точным анализам и прогнозам. Это может повысить эффективность работы нашей модели и привести к принятию более обоснованных и успешных инвестиционных решений.
Учитывая представленную информацию, мы приступим к пересмотру архитектуры нашей модели. В первую очередь, мы проведем изменения в слое исходных данных агента, чтобы он фокусировался исключительно на анализе рыночной ситуации, удалив нейроны, отвечающие за анализ состояния счета.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *scheduler) { //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!critic) { critic = new CArrayObj(); if(!critic) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * 12); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
В блоке предварительной обработки данных мы удалим полносвязные слои. Оставим только слой пакетной нормализации и 2 сверточных слоя.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = prev_count-2; descr.window = 3; descr.step = 1; descr.window_out = 2; prev_count*=descr.window_out; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = (prev_count+1)/2; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Блок принятия решения остаётся без изменений.
Было принято решение изменить архитектуру Критика. Как и ранее, Критик будет анализировать как рыночную ситуацию, так и состояние счета. Это обусловлено тем, что ценность следующего состояния зависит не только от последнего совершенного действия, но также от предыдущих действий, выражающихся в открытых позициях и накопленной прибыли или убытках.
Мы также пришли к выводу, что ценность последующего состояния не должна зависеть от выбранной стратегии. Нашей целью является максимизация потенциальной прибыли, независимо от конкретной стратегии, которую мы используем. С учетом этого, мы внесли некоторые изменения в модель Критика.
Конкретно, мы упростили архитектуру Критика, удалив мультимодельные полносвязные слои. Вместо этого, мы добавили полностью параметризированную модель принятия решений. Это позволяет нам достичь более общего и гибкого подхода, при котором стратегия не оказывает прямого влияния на оценку ценности состояния.
Такое изменение в архитектуре модели Критика помогает нам разделить анализ рыночной ситуации и принятие решений, что упрощает процесс и позволяет сосредоточиться на максимизации прибыли вне зависимости от выбранной стратегии.
Кроме того, мы внесли изменения в блок предварительной обработки данных, аналогичные изменениям в архитектуре агента. Теперь в блоке предварительной обработки данных мы упростили архитектуру, удалив полносвязные слои и оставив только слой пакетной нормализации и два сверточных слоя.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (int)(HistoryBars * 12 + 9); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = prev_count-2; descr.window = 3; descr.step = 1; descr.window_out = 2; prev_count*=descr.window_out; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = (prev_count+1)/2; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 150; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.optimization = ADAM; descr.activation = TANH; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = TANH; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = 4; descr.window_out = 32; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Далее мы провели значительное упрощение архитектуры планировщика. Отказ от анализа рыночной ситуации позволил значительно уменьшить размер слоя исходных данных. В результате мы практически полностью избавились от блока предварительной обработки данных, оставив только слой пакетной нормализации. Мы решили использовать пакетную нормализацию для анализа абсолютных значений состояния счета. В настоящее время мы используем полностью нормализированные значения с выхода модели агентов. В будущем мы можем перейти к относительным значениям состояния счета и отказаться от использования слоя нормализации данных.
В блоке принятия решений мы применили простую модель перцептрона с слоем SoftMax на выходе. Эта модель позволяет нам получить вероятностное распределение по различным Агентам и выбрать наиболее подходящее действие на основе этих вероятностей.
Такое упрощение архитектуры планировщика позволяет нам более эффективно принимать решения, учитывая только результаты анализа агентов. Это сокращает вычислительную сложность и уменьшает зависимость от дополнительных данных.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (9 + 40); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 10; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = 10; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
В процессе обучения модели мы используем три советника, каждый из которых выполняет свою функцию. Чтобы избежать путаницы и уменьшить возможность ошибок, мы приняли решение перенести функцию описания архитектуры модели в файл "Trajectory.mqh", который является частью библиотеки с описанием классов и структур, используемых в нашей модели. Это позволяет нам использовать единую архитектуру моделей во всех советниках и обеспечивает автоматическую синхронизацию изменений в работе всех трех советников.
Строение моделей было изменено, включая разделение потока исходных данных, и это потребовало внесения изменений в структуру описания текущего состояния. Мы выделили отдельный массив для записи состояния счета, чтобы его можно было учитывать при анализе и принятии решений. Это изменение позволяет более эффективно управлять и использовать информацию о состоянии счета в процессе обучения и работы моделей.
struct SState { float state[HistoryBars * 12]; float account[9]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); } };
В результате изменений в структуре модели, нам также пришлось внести изменения в методы работы с файлами. Полный код обновленной структуры и соответствующих методов доступен во вложенном файле для ознакомления.
2.3. Изменения в процессе сбора данных
На следующем этапе мы произвели изменения в процессе сбора данных, который осуществляется в советнике "Research.mq5".
Как уже упоминалось ранее, использование положительных примеров в обучении модели повышает ее эффективность. Поэтому мы внесли ограничение на минимальную доходность сделки для ее сохранения в базе данных примеров. Уровень этой минимальной доходности определяется внешним параметром "ProfitToSave".
Кроме того, для уменьшения случаев длительного удержания позиций, мы ввели внешние параметры ограничения на уровни тейк-профита и стоп-лосса. Значения этих параметров задаются в валюте депозита и позволяют ограничить продолжительность удержания позиции и косвенно контролировать объем открытых позиций.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input double ProfitToSave = 10; input double MoneyTP = 10; input double MoneySL = 5;
Изменение структур хранения данных и архитектуры моделей привело к необходимости внести изменения в операции сбора и подготовки данных для прямого прохода моделей. Как и ранее, мы начинаем сбор данных о рыночном состоянии в массив "state".
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- sState.state[b * 12] = (float)Rates[b].close - open; sState.state[b * 12 + 1] = (float)Rates[b].high - open; sState.state[b * 12 + 2] = (float)Rates[b].low - open; sState.state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; sState.state[b * 12 + 4] = (float)sTime.hour; sState.state[b * 12 + 5] = (float)sTime.day_of_week; sState.state[b * 12 + 6] = (float)sTime.mon; sState.state[b * 12 + 7] = rsi; sState.state[b * 12 + 8] = cci; sState.state[b * 12 + 9] = atr; sState.state[b * 12 + 10] = macd; sState.state[b * 12 + 11] = sign; }
А затем мы сохраняем информацию о состоянии счета в массив "account".
//--- sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); sState.account[2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); sState.account[3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); sState.account[4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } sState.account[5] = (float)buy_value; sState.account[6] = (float)sell_value; sState.account[7] = (float)buy_profit; sState.account[8] = (float)sell_profit;
Для прямого прохода с обновленной архитектурой модели Агентов нам требуется только рыночное состояние из массива "state".
State1.AssignArray(sState.state); if(!Actor.feedForward(GetPointer(State1), 12, false)) return;
Для обеспечения исходными данными прямого прохода Планировщика требуется объединить данные о состоянии счета и результаты прямого прохода модели агентов.
Actor.getResults(Result); State1.AssignArray(sState.account); State1.AddArray(Result); if(!Schedule.feedForward(GetPointer(State1), 12, false)) return;
В результате прямого прохода двух моделей мы выполняем семплирование и выбираем действие. Этот процесс остается неизменным. Однако мы добавляем анализ накопленной прибыли и убытков. Если значение накопленной прибыли или убытков достигает заданных пороговых значений, мы указываем действие закрытия всех позиций.
Важно отметить, что нашей моделью предусмотрено только действие закрытия всех позиций. Поэтому при анализе накопленных прибыли и убытков мы суммируем значение всех позиций, независимо от их направления.
int act = GetAction(Result, Schedule.getSample(), Models); double profit = buy_profit + sell_profit; if(profit >= MoneyTP || profit <= -MathAbs(MoneySL)) act = 2;
Мы также внесли изменения в функцию вознаграждения. Было принято решение исключить влияние изменения эквити, что привело к более разреженному вознаграждению. Однако, мы осознаем, что в процессе торговли на финансовых рынках только изменение баланса несет конечную ценность. Это было учтено при корректировке функции вознаграждения.
С полным кодом всех методов и функций советника можно ознакомиться во вложении.
2.4. Изменения в процессе обучения
Мы также внесли изменения в процесс обучения моделей, с акцентом на параллельном обучении всех моделей и агентов. В частности, мы изменили подход к передаче вознаграждения при обратном проходе. Ранее мы указывали вознаграждение только для выбранного агента, однако теперь мы хотели бы передать целое распределение вознаграждений по всем агентам. Это позволит Планировщику более полно оценить возможное влияние каждого агента и снизить вероятность выбора отдельного агента для всех состояний, что мы наблюдали ранее.
Из теории вероятности мы знаем, что вероятность наступления сложного события равна произведению вероятностей его составляющих. В нашем случае, у нас есть вероятностное распределение выбора агентов и вероятностное распределение выбора действий каждым агентом. В базе примеров у нас также есть конкретные действия и соответствующие им вознаграждения от системы. Чтобы подготовить данные для обратного прохода планировщика, мы умножаем элементы вектора вероятностей выбора агента на элементы вектора вероятностей выбора данного действия каждым агентом.
Для передачи полного вознаграждения планировщику, мы применяем функцию SoftMax для нормализации полученных вероятностей и затем умножаем полученный вектор на внешнее вознаграждение. При этом мы предварительно корректируем внешнее вознаграждение на основе ценности состояния, что позволяет оценить отклонение от оптимальной траектории.
void Train(void) { ........ ........ Actor.getResults(ActorResult); Critic.getResults(CriticResult); State1.AssignArray(Buffer[tr].States[i].account); State1.AddArray(ActorResult); if(!Scheduler.feedForward(GetPointer(State1), 12, false)) return; Scheduler.getResults(SchedulerResult); //--- ulong actions = ActorResult.Size() / Models; matrix<float> temp; temp.Init(1, ActorResult.Size()); temp.Row(ActorResult, 0); temp.Reshape(Models, actions); float reward=(Buffer[tr].Revards[i] - CriticResult.Max())/100; int action=Buffer[tr].Actions[i]; SchedulerResult=SchedulerResult*temp.Col(action); SchedulerResult.Activation(SchedulerResult,AF_SOFTMAX); SchedulerResult = SchedulerResult * reward; Result.AssignArray(SchedulerResult); //--- if(!Scheduler.backProp(GetPointer(Result))) return;
Для обучения Критика мы просто передаем нескорректированное внешнее вознаграждение для соответствующего действия.
CriticResult[action] = Buffer[tr].Revards[i]; Result.AssignArray(CriticResult); //--- if(!Critic.backProp(GetPointer(Result), 0.0f, NULL)) return;
При работе с моделями агентов мы учитываем, что использование любой стратегии может привести как к прибыли, так и к убыткам. В некоторых случаях, после неудачного входа в позицию, важно иметь решимость выйти из нее вовремя и ограничить убытки. Поэтому мы не можем исключить действия с отрицательным вознаграждением полностью, поскольку в некоторых случаях другие действия могут иметь еще больший негативный эффект. То же самое относится и к положительным вознаграждениям.
При подготовке данных для обратного прохода моделей агентов мы просто корректируем результаты последнего прямого прохода с учетом вероятности выбора действия каждым агентом и внешнего вознаграждения от системы. Чтобы сохранить целостность вероятностного распределения для каждого агента, мы нормализуем скорректированное распределение с помощью функции SoftMax.
//--- for(int r = 0; r < Models; r++) { vector<float> row = temp.Row(r); row[action] += row[action] * reward; row.Activation(row, AF_SOFTMAX); temp.Row(row, r); } temp.Reshape(1, ActorResult.Size()); Result.AssignArray(temp.Row(0)); //--- if(!Actor.backProp(GetPointer(Result))) return;
В приложенных файлов можно ознакомиться с полным кодом всех советников, а также их функций, которые используются в работе.
Для начала процесса обучения модели мы запускаем советник "Research.mq5" в режиме оптимизации тестера стратегий, аналогично описанному в статье об алгоритме Go-Explore. Главное отличие здесь заключается в указании минимального уровня доходности прохода, который определяет примеры, сохраняемые в базу данных. Это помогает повысить эффективность обучения модели, так как мы сосредотачиваемся на положительных примерах.
Однако стоит отметить одну важную деталь. Чтобы обеспечить более разнообразное исследование окружающей среды и увеличить охват стратегий поведения, мы можем включить оптимизацию параметров тейк-профита и стоп-лосса в процесс сбора примеров. Это позволяет нашей модели изучить больше различных стратегий и находить оптимальные точки выхода из позиций.

После создания базы примеров мы приступаем к процессу обучения моделей с помощью советника "Study2.mq5". Для этого необходимо присоединить советник к графику выбранного инструмента и указать количество итераций, которое определит, сколько раз параметры модели будут обновляться.
Запуск советника "Study2.mq5" на графике позволяет модели использовать собранные примеры для обучения и настройки своих параметров. В процессе обучения модель будет улучшаться и адаптироваться к рыночной среде, чтобы принимать более точные решения и повысить свою эффективность.
Результаты обучения модели мы проверяем путем одиночного прогона в тестере стратегий советника "Test.mq5". Вполне ожидаемо, что после первой итерации обучения модели её результат будет далек от ожидаемого. Он может быть убыточным.


Или даже генерировать прибыль. Но линия баланса будет далека от наших ожиданий.

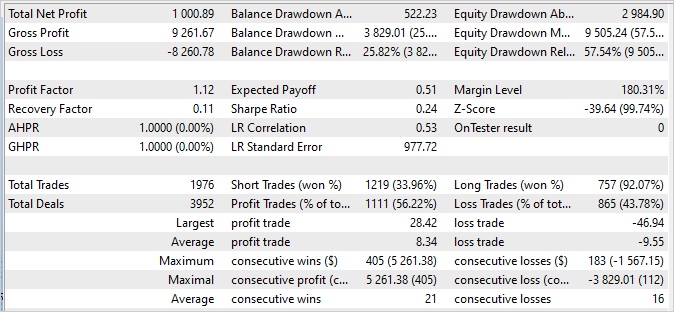
Но при этом мы можем заметить, как наш Планировщик в той или иной степени использует практически все агенты.


Для обнаружения ошибочных действий модели мы добавляем блок сбора информации о посещенных состояниях, совершенных действиях и полученных внешних вознаграждениях в наш тестовый советник "Test.mq5". Этот блок сбора данных аналогичен тому, что используется в советнике для сбора примеров.
Важно отметить, что в тестовом советнике мы используем жадный выбор агента и действия. Это означает, что все совершенные шаги определяются стратегией нашей модели. Поэтому в базу примеров мы добавляем все проходы вне зависимости от их доходности. Включение этих данных в базу примеров позволит нам скорректировать и оптимизировать торговую стратегию нашей модели.
Собирая информацию о посещенных состояниях, действиях и полученных вознаграждениях, мы сможем анализировать производительность модели и определять, какие действия приводят к желательным результатам, а какие - к нежелательным. Эта информация позволит нам улучшить модели эффективность и точность принятия решений при последующих итерациях её обучения.
Дополнительные итерации запуска советника сбора примеров в режиме оптимизации тестера стратегий имеют важное значение для расширения базы положительных примеров и предоставления большего объема данных для обучения нашей модели.
Однако, важно отметить необходимость чередования процессов сбора примеров и обучения модели. Во время сбора примеров мы семплируем действия из распределения вероятностей, сгенерированного моделью. Это означает, что сбор примеров имеет определенную направленность, и новые примеры будут находиться на небольшом расстоянии от жадного выбора действия. Это позволяет более полно исследовать окружающую среду в заданном направлении и обогащать базу примеров полезными данными.
Чередование сбора примеров и обучения модели позволяет модели эффективно использовать новые данные, улучшая свою стратегию на основе полученной информации. При этом, с каждой новой итерацией модель становится все более опытной и адаптированной к требуемому направлению торговли.
3. Тестирование
После нескольких итераций сбора примеров, обучения и тестирования мы достигли модели, которая способна генерировать прибыль на обучающей выборке с профит фактором 114.53. За первые 4 месяца 2023 года, в которые модель была обучена, было совершено 286 сделок. Из них только 16 оказались убыточными. Фактор восстановления на обучающей выборке составил 1.3, что указывает на способность модели быстро восстанавливаться после потерь.
Время удержания открытой позиции было равномерно распределено в диапазоне от 1 до 198 часов, со средним временем удержания составляющим 72 часа 59 минут. Это свидетельствует о том, что модель может принимать решения как на коротких, так и на долгосрочных интервалах времени, в зависимости от текущих рыночных условий.
В целом, эти результаты говорят о том, что модель демонстрирует высокую прибыльность, низкую долю убыточных сделок, способность быстро восстанавливаться и гибкость в выборе времени удержания позиции. Это является положительным подтверждением эффективности модели и ее потенциала для применения в реальных торговых условиях.



Значительно важно отметить, что график баланса за последующие 2 недели, которые не входят в обучающую выборку, демонстрирует стабильность и не имеет значительных отличий от графика на обучающей выборке. Хотя цифры на нем немного ниже, они все же остаются достойными:
- Профит фактор составляет 15.64, что указывает на хорошую прибыльность модели в отношении риска.
- Фактор восстановления составляет 1.07, что свидетельствует о способности модели восстанавливаться после убыточных сделок.
- Из 89 совершенных сделок 80 закрыты с прибылью, что говорит о высокой доле успешных сделок.
Эти результаты подтверждают стабильность и надежность модели на последующих торговых данных. Хотя значения могут немного отличаться от обучающей выборки, они все равно являются впечатляющими и подтверждают потенциал модели для успешной торговли в реальных условиях.


С отчетами тестера стратегий можно ознакомиться во вложении.
Заключение
В данной статье мы рассмотрели проблему прокрастинации модели и предложили эффективные подходы для ее преодоления. Используя алгоритм Scheduled Auxiliary Control, мы разработали подход к обучению моделей для автоматизированной торговли на финансовых рынках.
Мы представили иерархическую архитектуру, состоящую из нескольких моделей, взаимодействующих друг с другом. Каждая модель отвечает за определенные аспекты принятия решений. Такая модульная структура позволяет нам эффективно преодолеть прокрастинацию, разделяя задачу на более мелкие, но взаимосвязанные подзадачи.
Мы также рассмотрели методы сбора примеров, обучения моделей и тестирования, которые позволяют нам эффективно учить модели на реальных данных и адаптироваться к изменяющейся рыночной ситуации. Включение разнообразных стратегий и анализ накопленных прибылей и убытков позволяет нам принимать обоснованные решения и минимизировать риски.
Результаты наших экспериментов показывают, что предложенный подход действительно способен преодолеть прокрастинацию и достичь стабильной и прибыльной торговли. Наши модели демонстрируют высокую прибыльность и стабильность на обучающих и последующих данных, что подтверждает их эффективность в реальных условиях.
В целом, наш подход позволяет моделям эффективно изучать и адаптироваться к рыночной ситуации и принимать обоснованные решения. Дальнейшее развитие и оптимизация этого подхода могут привести к еще более высокой прибыльности и стабильности в автоматизированной торговле на финансовых рынках.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | Study2.mql5 | Советник | Советник обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 5 | FQF.mqh | Библиотека класса | Библиотека класса организации работы полностью параметризированной модели |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
…
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Здравствуйте, Дмитрий. Спасибо за новую работу. Я тоже добивался прямой линии на графике. Теперь понятно, почему. Подскажите пожалуйста, какие результаты Study2 можно считать приемлемыми? Test пока не показывает осмысленных действий, открыл бай и доливает на каждом баре.
Кстати, папку NeuroNet_DNG пришлось перетягивать с прошлого советника. Если вы вносили в нее изменения, то я бьюсь головой об стену.
Последние версии файлов во вложении
Дмитрий здравствуйте. Подскажите а сколько вы тренировали данный советник чтобы он начал совершать хотябы какие-то осмысленные сделки, пусть даже в минус. Просто у меня он либо вообще не пытается торговать, либо открывает кучу сделок и не может пройти весь период в 4 месяца. При этом баланс стоит на месте а эквити плавает. Агентов использует или одного или двух, остальные нули. Начальную выборку пробовал разную.
-от 50$ к примеру 30-40 примеров на начало и потом после каждого прохода Stady2 (100000 по умолчанию), и далее добавлял по 1-2 примера в цикле.
-от 35$ к примеру 130-150 примеров на начало и потом после каждого прохода Stady2 (100000 по умолчанию), и далее добавлял по 1-2 примера в цикле.
- от 50$ с 15 примеров на начало и ничего не добавлял на тренировал Stady2 в 500000 и 2000000 .
При всех вариантах результат один - не работает, не обучается. При том вполне может после к примеру 2-3 миллионов итераций опять ничего не показывать - просто не торговать.
Сколько (в цифрах) его нужно тренировать чтобы он начал открывать и закрывать вообще сделки?
Hello Dmitry! You were a great teacher and mentor!
350668273_1631799953971007_1316803797828649367_n.png (1115×666) (fbcdn.net)After some successful training, I was able to achieve a 99% win rate. However, it only sold trades. no buy trades
Here's a screenshot:
350733414_605596475011106_6366687350579423076_n.png (1909×682) (fbcdn.net)
Дмитрий,
Я слежу за вашими статьями, чтобы узнать как можно больше, так как ваши знания и опыт превосходят мои. После прочтения статьи мне пришло в голову, что, хотя представленная итоговая модель отлично идентифицирует короткие сделки и совершенно неудачна при идентификации длинных сделок, она может быть частью двухуровневого торгового решения.Как вы думаете, можно ли разработать модель для длинных сделок, изменив некоторые допущения, или требуется совершенно новая модель, как, например, Toe Go Explore в статье #39?
Здоровья вам и поддержки в ваших будущих начинаниях