
株式市場における非線形回帰モデル

はじめに
昨日、私はまた自分の回帰ベース取引システムのレポートに目を通していました。窓の外では湿った雪が降り、マグカップのコーヒーは冷めていく。それでも頭から離れない強迫的な思考がありました。ご存じのとおり、私は長い間、RSIやストキャスティクス、MACDといった終わりのないインジケーター群に苛立ちを覚えてきました。生き生きと動的に変化する市場を、どうしてこんな原始的な数式に押し込められるのでしょうか。YouTubeでまた「聖杯」を崇める人々が「神聖な」インジケーターセットを誇らしげに語るたびに、私はつい聞きたくなります。「本当に70年代の計算式で、現代市場の複雑なダイナミクスを捉えられると信じているのですか?」と。
この3年間、私は「実際に機能するもの」を追い求めて試行錯誤してきました。単純な回帰分析から高度なニューラルネットワークまで幅広く試しましたが、はっきりしたのは、分類では結果が出ても、回帰では成果を得られていない、という事実です。
同じパターンが繰り返されました。過去データでは時計仕掛けのように完璧に動くのに、実際の市場に投入すると損失が生じるのです。初めて畳み込みネットワークを使ったときのことをよく覚えています。トレーニングではR²が1.00。しかし、2週間の運用で資金は30%減りました。典型的な過学習の悲劇です。予測値が時間の経過とともに実際の価格から乖離していく様子を、前方可視化で何度も目にしました。
それでも私は諦めませんでした。新たに損失を出した後、さらに深く掘り下げ、科学論文を漁り始めました。そして埃をかぶった古いアーカイブの中で、興味深い発見をしました。マンデルブロがすでに市場のフラクタル的性質について語っていたのです。それなのに、私たちはいまだ線形モデルで取引を試みている。これはまるで、海岸線の長さを定規で測ろうとするようなものです。正確に測ろうとすればするほど、際限なく長くなってしまう。
その瞬間、ひらめきました。「古典的なテクニカル分析と非線形力学を組み合わせたらどうだろう」と。ここで言うのは、粗末なインジケーターではなく、微分方程式や適応型比率といった本格的なアプローチです。複雑に聞こえるかもしれませんが、本質的には市場の言語を学ぼうとしているにすぎません。
私はPythonを立ち上げ、機械学習ライブラリを接続して実験を始めました。最初から決めていたのは、「学術的なお飾りは一切なし。実際に使えるものだけ」という方針です。スーパーコンピューターも必要ありません。普通のAcerのノートPC、強力なVPS、そしてMetaTrader 5端末があれば十分でした。こうして、これからお話しするモデルが生まれたのです。
これは聖杯ではありません。聖杯など存在しないことは、とっくに悟っています。ただ、現代数学を実際の取引に応用して得られた経験を共有したいのです。過剰な誇張を避けつつ、「トレンド系インジケーター」の原始的性質にも妥協しない。その結果、ほどほどに賢く、それでいてブラックスワンと出会っても崩壊しないモデルができました。
数学モデル
この方程式を思いついたときのことを今でも覚えています。私は2022年からこのコードに取り組んできましたが、常に集中していたわけではありません。アプローチは無数にあり、それらを少しずつ試し、混沌とした探索の中から結果に近づけていく...そんなプロセスでした。当時、私はEURUSDのチャートを動かしながら、その背後にあるパターンを探ろうとしていました。そしてある瞬間、ふと気づいたのです。市場はまるで呼吸をしているようだと。トレンドに沿ってなめらかに流れるときもあれば、突如として激しく動くときもある。そしてまた、説明のつかない魔法のようなリズムに入るときさえあるのです。では、この生きたような動きを、どうすれば数学で表現できるでしょうか。方程式でこのダイナミクスをどう捉えればよいのでしょうか。
そうして私は、最初のバージョンとなる方程式をスケッチしました。こちらが、その全体像です。
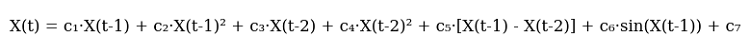
コードでは次のようになります。
def equation(self, x_prev, coeffs): x_t1, x_t2 = x_prev[0], x_prev[1] return (coeffs[0] * x_t1 + # trend coeffs[1] * x_t1**2 + # acceleration coeffs[2] * x_t2 + # market memory coeffs[3] * x_t2**2 + # inertia coeffs[4] * (x_t1 - x_t2) + # impulse coeffs[5] * np.sin(x_t1) + # market rhythm coeffs[6]) # basic level
ご覧ください、すべてがどのように組み合わさっているかを。最初の2つの項は、現在の市場の動きを捉えようとする試みです。車の加速を思い浮かべてみてください。最初は滑らかに進み、そこから徐々にスピードが上がっていきます。だからこそ、このモデルには線形項と二次項の両方が含まれています。価格が穏やかに動くときは線形部分が作用し、市場が勢いづくと二次項がその加速を捕らえます。
ここからが本当に興味深い部分です。3番目と4番目の項は、時間を少しさかのぼり、市場の「記憶」を参照します。ダウ理論で語られるように、市場が重要なレベルを覚えているという考え方に近いものです。ここでも二次項を使うことで、急激な変化をより正確に表現しようとしています。
次はモメンタム要素です。これは単純に前の価格を現在の価格から引くだけで、一見、原始的に思えるかもしれません。しかし、トレンドが明確に形成される局面では非常に効果的です。市場が熱狂し、一方向に突き進むとき、この項が予測の主要な推進力になります。
正弦波の導入は、ほとんど偶然でした。チャートを眺めていると、特にH1では「動き」と「静けさ」が交互に現れる周期性に気づいたのです。それはまるで正弦波のようでした。試しに方程式へ加えてみると、モデルは新しい光を得たように、このリズムを捉え始めました。
最後に配置した比率は、一種の安全網です。基本的な基準レベルを与えることで、モデルが市場に対して極端に外れた予測を出さないようにしています。
もちろん、これまでに多くのバリエーションも試しました。指数関数や対数関数、さらにはさまざまな三角関数も組み込んでみました。しかし、結果は芳しくなく、むしろモデルが巨大化して扱いにくくなるだけでした。ご存じのとおり、オッカムの剃刀の原理が示すのは「必要以上に複雑にしてはならない」ということです。現在のバージョンはその原則に沿い、シンプルで、それでいて十分に機能する形に落ち着きました。
もちろん、これらすべての比率は調整が必要です。そこで役立ったのが、古典的なネルダー=ミード法です。ただし最適化の話は奥が深く、ここでは触れきれません。次の章で詳しく解説するつもりです。信じてください。最適化中に犯した失敗だけでも、1つの記事が書けるほどあるのです。
線形成分まずは線形部分から始めましょう。ここで重要なのは、モデルが直近2価格を参照しながら、それぞれを異なる方法で評価している点です。最初の比率は通常0.3~0.4程度となり、直近の変化に対する即時的な反応を担います。対して2つ目の比率はもっと興味深く、しばしば0.7に近づきます。つまり、市場は最新の動きを全面的には信頼せず、少し前の水準により強く依存しているように見えるのです。
二次成分次に二次項。最初は単に「非線形性を考慮するため」に加えただけでした。ところが観察を続けるうちに驚くべきことに気づきました。市場が穏やかなとき、二次項の寄与はごく小さく、比率は0.01~0.02程度で安定しています。しかし、一度大きな動きが始まると、これらの項がまるで「目を覚ます」かのように働き出すのです。特に日足のEURUSDでは顕著で、トレンドが勢いを増す局面では二次項が支配的となり、モデルが価格変化に「加速」して追随します。
モメンタム成分モメンタム成分は、まさに発見と呼べるものでした。一見ただの価格差に過ぎないようですが、市場心理を鋭く反映しているのです。平穏期には係数が0.2〜0.3の範囲に収まりますが、大きな値動きの前にはしばしば0.5に跳ね上がります。私にとっては一種の「突破前兆インジケーター」となりました。オプティマイザーがモメンタムの重みを引き上げ始めたら、動意が迫っている合図だと解釈できるのです。
周期的成分周期的要素には少し試行錯誤がありました。当初は正弦波の周期を色々変えて試しましたが、やがて「市場自身がリズムを決めている」と気づきました。モデルには比率を通じて振幅を調整させるだけでよく、周波数は価格そのものから自然に導かれるのです。特にヨーロッパ市場とアメリカ市場のセッションの切り替わりでは、この比率がまるで呼吸を変えるように動き、異なるリズムを示します。
最後は定数項です。当初はそれほど重要視していませんでしたが、実際には極めて大きな役割を果たしていました。ボラティリティが高い時期には「錨」として作用し、予測の暴走を防ぎます。一方、落ち着いた局面では市場の平均的な水準を的確に補正してくれます。興味深いのは、この値がしばしばトレンド強度と相関することです。強いトレンド下では定数項がゼロに近づく傾向を示します。
そして最も驚かされたのは、新しい項を追加したり、より複雑な関数を組み込んだりすると、むしろ結果が悪化したことです。まるで市場が「余計な飾りはいらない、本質はすでに掴んでいる」と語りかけてくるようでした。現在の方程式は、複雑さと効率のちょうどよい均衡点にあります。係数は7つ。それ以上でも、それ以下でもなく、すべてが予測メカニズムの中で明確な役割を担っています。
ちなみに、この比率の最適化プロセス自体も一つの物語です。ネルダー=ミード法が値を探索していく様子を眺めていると、否応なくカオス理論を思い出させられます。しかしその話は次の章に譲りましょう。おそらく驚いていただけるはずです。
ネルダー=ミードアルゴリズムを用いたモデル最適化
ここからは最も興味深いテーマ、すなわち「実際のデータでモデルを動かす方法」について取り上げます。最適化の実験には何か月も費やし、何十回もの徹夜と数え切れないほどのコーヒーの後、ようやく実用的なアプローチにたどり着きました。
最初に試したのは、王道とも言える勾配降下法でした。データサイエンティストなら誰もが真っ先に思い浮かべる古典的手法です。実装に3日、デバッグにさらに1週間。しかし結果は無惨なものでした。モデルは収束を頑として拒み、無限大へと吹き飛ぶか、局所解に閉じ込められて動かなくなるかのどちらか。勾配はまるで狂ったように跳ね回り、制御不能でした。
次に挑戦したのは遺伝的アルゴリズムです。「進化」に最適比率を探させるという発想は一見エレガントに思えました。実装して実行してみると、PCは一晩中うなり続けました。たった1週間分のデータを処理するのにこれほど時間がかかるとは想定外でした。そして何よりも、得られた結果は不安定そのもので、まるで占い師が茶葉を読むような精度しかありませんでした。
そして、ようやく出会ったのがネルダー=ミード法です。1965年に開発された古典的なシンプレックス法で、導関数も高等数学も不要。ただ賢く解空間を探索し、徐々に収束していきます。実行してみると、目を疑うほどでした。アルゴリズムが市場とステップを踏むように、滑らかに、そして確実に最適値へと近づいていったのです。
こちらが基本的な損失関数です。斧のように単純ですが、実に見事に機能します。
def loss_function(self, coeffs, X_train, y_train): y_pred = np.array([self.equation(x, coeffs) for x in X_train]) mse = np.mean((y_pred - y_train)**2) r2 = r2_score(y_train, y_pred) # Save progress for analysis self.optimization_progress.append({ 'mse': mse, 'r2': r2, 'coeffs': coeffs.copy() }) return mse
最初は、大きな比率に対するペナルティを追加したり、MAPEやその他のメトリクスを押し込んだりと、損失関数を複雑にしようとしました。典型的な開発者の過ちです。何かが動いているなら、それを改良し続けて最終的に完全に動かなくなるまでやってしまう。結局シンプルなMSEに戻りました。そして気づいたのが、シンプルさこそ天才の証だということです。
リアルタイムで最適化を観察するのは格別のスリルがあります。最初の反復では、比率が狂ったように跳ね、MSEも跳ね上がり、R²はゼロに近くなります。そこからが本当に面白い部分で、アルゴリズムが正しい方向を見つけ、メトリクスが徐々に改善していくのです。100回目の反復ではもう結果が出るかどうか見えてきて、300回目にはほとんどの場合システムが安定レベルに達します。
ところで、メトリクスについて少し触れておきましょう。私たちのR²は通常0.996以上で、つまりモデルが価格変動の99.6%以上を説明できていることを意味します。MSEはおよそ0.0000007で、言い換えれば予測誤差はめったに0.7ピップスを超えません。MAPEに関しても上々で、しばしば0.1%未満です。もちろんこれはすべて過去データに基づいていますが、フォワードテストでも結果はそれほど悪化しません。
しかし最も重要なのは数値そのものではなく、結果の安定性です。最適化を10回連続で実行しても、毎回ほぼ同じ比率の値に収束します。他の最適化手法での苦労を思えば、この安定性は非常に価値があります。
さらに面白いのは、最適化を観察することで市場そのものについて多くを理解できる点です。たとえばアルゴリズムがモメンタム成分の重みを増やそうと繰り返すとき、それは市場で大きな動きが熟していることを意味します。あるいはサイクル成分をいじり始めたときは、ボラティリティの上昇期を予期すべきです。
次のセクションでは、この数学的な構造がどのように実際の取引システムへと変わっていくかをお話しします。信じてください、そこにも考えるべきことが山ほどあります。特にMetaTrader 5に関する落とし穴だけでも、独立した記事になるくらいです。
学習プロセスの特徴
学習用データの準備は、まさに別の物語でした。システムの最初のバージョンでは、私は嬉々としてデータセット全体をsklearn.train_test_splitに食わせていました。そして後になって、やけに良すぎる結果を見て初めて未来のデータが過去に漏れていることに気づいたのです。
問題がわかりますか。金融データを普通のKaggleのスプレッドシートのように扱うことはできません。ここでは各データポイントが「時間の瞬間」を表しており、それらをシャッフルするのは「明日の天気から昨日の天気を予測する」ようなものです。その結果として、生まれたのがこのシンプルで効率的なコードです。
def prepare_training_data(prices, train_ratio=0.67): # Cut off a piece for training n_train = int(len(prices) * train_ratio) # Forming prediction windows X = np.array([[prices[i], prices[i-1]] for i in range(2, len(prices)-1)]) y = prices[3:] # Fair time sharing X_train, y_train = X[:n_train], y[:n_train] X_test, y_test = X[n_train:], y[n_train:] return X_train, y_train, X_test, y_test一見すると単純なコードに見えます。ですが、その背後には多くの試行錯誤がありました。最初の頃、私はさまざまなウィンドウサイズを試してみました。履歴が多ければ多いほど予測は良くなると思っていたのです。しかし間違いでした。実際には、直近の2つの値で十分だったのです。市場は過去を長く覚えておくのを好まないのです。
学習サンプルのサイズについても、また別の物語があります。50/50、80/20、果ては90/10まで試しました。最終的に落ち着いたのは黄金比である約67%を学習データにする方法でした。なぜかと言えば、それが一番うまく機能するからです。どうやら昔のフィボナッチは、市場の本質を何か知っていたのでしょう。
異なるデータ区間でモデルの学習を観察するのは楽しいものです。平穏な期間を使うと、比率は滑らかに選ばれ、メトリクスも徐々に改善していきます。しかし、もし学習サンプルにブレグジットやFRB議長の演説のようなイベントが含まれていると、もう大混乱です。比率は跳ね回り、オプティマイザーは暴走し、誤差グラフはまるでジェットコースターです。
ここで再びメトリクスについて少し。学習サンプルでR²が0.98を超えていたら、ほぼ確実にデータのどこかに不具合があると考えています。現実の市場はそこまで予測可能ではありません。これは「成績が良すぎる学生」の話に似ています。カンニングか天才か、どちらかです。私たちの場合はたいてい前者です。
もう1つ重要な点はデータ前処理です。最初の頃は価格の正規化やスケーリング、外れ値除去など、機械学習のコースで習うようなことを一通りやってみました。しかし次第に、生データにはできるだけ手を加えないほうが良いという結論に至りました。市場は自分自身で正規化してくれるのです。私たちがすべきなのは、正しく準備することだけです。
今では学習はほとんど自動化されています。週に一度、新しいデータをロードし、学習を実行し、メトリクスを過去の値と比較します。すべてが正常範囲なら実運用システムの比率を更新します。何か怪しい点があれば掘り下げて調べる。ありがたいことに、経験のおかげで、どこを見ればよいかがもう分かるようになっています。
比率の最適化
def fit(self, prices): # Prepare data for training X_train, y_train = self.prepare_training_data(prices) # I found these initial values by trial and error initial_coeffs = np.array([0.5, 0.1, 0.3, 0.1, 0.2, 0.1, 0.0]) result = minimize( self.loss_function, initial_coeffs, args=(X_train, y_train), method='Nelder-Mead', options={ 'maxiter': 1000, # More iterations does not improve the result 'xatol': 1e-8, # Accuracy by ratios 'fatol': 1e-8 # Accuracy by loss function } ) self.coefficients = result.x return result
最も困難であったのは、初期係数の適切な設定です。ランダム値を用いた場合は結果のばらつきが大きすぎて実用性がなく、初期値をすべて1に設定した場合は最適化が初期反復で発散しました。ゼロを初期値とした場合も局所解に停滞して収束しませんでした。
最初の比率0.5は線形成分の重みです。これより小さいとモデルはトレンドを失い、これより大きいと直近の価格に過度に依存するようになります。二次項については0.1が完璧な初期値であることがわかりました。非線形性を捉えるには十分であり、かつ急激な動きに対してモデルが暴走することを防げました。モメンタムの値0.2は経験的に得られたもので、この値でシステムが最も安定した結果を示しました。
最適化の過程では、ネルダー=ミードは七次元の比率空間にシンプレックスを構築します。これはまるで「熱い・冷たい」のゲームを七次元同時にやっているようなものです。発散を防ぐことが重要であり、そのために精度は1e-8という厳しい条件が設けられています。精度が低いと結果が不安定になり、逆に厳しすぎると局所解に閉じ込められてしまいます。
反復回数が1000というのは多すぎるように見えるかもしれませんが、実際には最適化は通常300〜400ステップで収束します。ただし、とくにボラティリティが高い時期には、最適解を見つけるのにより多くの時間が必要になることもあります。追加の反復は性能に大きな影響を与えることはなく、全体の処理時間は現代のハードウェアで通常1分未満です。
ちなみに、このコードをデバッグしている過程で、最適化の進行を可視化するというアイデアが生まれました。比率がリアルタイムで変化する様子を見ると、モデルがどう動いているのか、そしてどこへ向かおうとしているのかを理解するのがはるかに容易になります。
品質指標とその解釈
予測モデルの品質を評価することは別の話であり、一見して分かりにくいニュアンスに満ちています。アルゴリズム取引に長年携わる中で、私は数々のメトリクスに苦しめられ、これだけで本一冊書けるほどの経験をしました。しかし、ここではその核心についてお話しします。
以下にその結果を示します。

まずは決定係数(R²)から始めましょう。初めてEURUSDで0.9を超える値を見たとき、私は自分の目を疑いました。データリーケージや計算ミスがないかを確認するためにコードを10回ほど見直しましたが、問題はありませんでした。つまり、そのモデルは価格変動の90%以上を説明していたのです。しかし後になって、これが諸刃の剣であることに気づきました。R²が高すぎる(0.95を超える)場合、たいていは過学習を示しています。市場がそこまで予測可能であるはずはないのです。
MSEは私たちの主力指標です。以下は典型的な評価用コードです。
def evaluate_model(self, y_true, y_pred): results = { 'R²': r2_score(y_true, y_pred), 'MSE': mean_squared_error(y_true, y_pred), 'MAPE': mean_absolute_percentage_error(y_true, y_pred) * 100 } # Additional statistics that often save the day errors = y_pred - y_true results['max_error'] = np.max(np.abs(errors)) results['error_std'] = np.std(errors) # Look separately at error distribution "tails" results['error_quantiles'] = np.percentile(np.abs(errors), [50, 90, 95, 99]) return results
追加の統計値に注目してください。私はある不愉快な出来事をきっかけに、max_errorとerror_stdを追加しました。そのときのモデルはMSEが非常に優秀だったのですが、予測に時折とんでもない外れ値を出してしまい、試すまでもなく即座に口座を吹き飛ばしかねない状況でした。それ以来、私が最初に確認するのは誤差分布の裾です。もっとも、裾そのものは依然として存在しています。
MAPEはトレーダーにとって馴染み深い指標です。R²の話をすると彼らの目は虚ろになりますが、「このモデルの平均誤差は0.05%です」と言えば、すぐに理解してくれます。ただし落とし穴があります。価格変動が小さいときにはMAPEが見かけ上とても低く出ますが、急激な変動時には一気に跳ね上がってしまうのです。
しかし、私が最も重要だと理解したのは「過去データに基づくどんなメトリクスも、現実世界での成功を保証するものではない」という点です。そのため、私は現在では以下のような一連の検証システムを持っています。
def validate_model_performance(self): # Check metrics on different timeframes timeframes = ['H1', 'H4', 'D1'] for tf in timeframes: metrics = self.evaluate_on_timeframe(tf) if not self._check_metrics_thresholds(metrics): return False # Look at behavior at important historical events stress_periods = self.get_stress_periods() stress_metrics = self.evaluate_on_periods(stress_periods) if not self._check_stress_performance(stress_metrics): return False # Check the stability of forecasts stability = self.check_prediction_stability() if stability < self.min_stability_threshold: return False return True
モデルは、実際の取引に投入する前に必ずこれらすべてのテストに合格しなければなりません。さらに、その後も最初の2週間は最小ロットで取引し、市場での挙動を確認します。
人々からよく、どの程度の指標値なら良いといえるのかと質問されます。私の経験によれば、R²が0.9を超えれば優秀、MSEが0.00001未満ならば許容範囲、MAPEが0.05%以下なら素晴らしいです。ただし、もっと重要なのは、これらの指標が時間を通じて安定しているかどうかです。わずかに精度が劣っていても安定したモデルの方が、超高精度だが不安定なシステムよりも優れているのです。
技術的実装
取引システムの開発で最も難しいものは何だと思いますか。それは数学でもアルゴリズムでもなく、運用の信頼性です。美しい数式を書くことと、実際にそれをリアルマネーを扱いながら24時間365日動かし続けることとはまったく別の話です。リアル口座でいくつもの痛い失敗を経験した後、私は、アーキテクチャは良いだけでは不十分であり、完璧でなければならないのだと悟りました。
そこで私は、システムのコアを次のように構築しました。
class PriceEquationModel: def __init__(self): # Model status self.coefficients = None self.training_scores = [] self.optimization_progress = [] # Initializing the connection self._setup_logging() self._init_mt5() def _init_mt5(self): """Initializing connection to MT5""" try: if not mt5.initialize(): raise ConnectionError( "Unable to connect to MetaTrader 5. " "Make sure the terminal is running" ) self.log.info("MT5 connection established") except Exception as e: self.log.critical(f"Critical initialization error: {str(e)}") raise
ここにある一つひとつの記述は、いずれも苦い経験の結果です。たとえば、MetaTrader 5を初期化する専用メソッドを追加したのは、再接続を試みた際にデッドロックを起こしたことがきっかけでした。また、システムが真夜中に黙ってクラッシュし、翌朝になって何が起こったのかを推測せざるを得なかった経験から、ログ機能を追加しました。
エラー処理は全く別の話です。
def _safe_mt5_call(self, func, *args, retries=3, delay=5): """Secure MT5 function call with automatic recovery""" for attempt in range(retries): try: result = func(*args) if result is not None: return result # MT5 sometimes returns None without error raise ValueError(f"MT5 returned None: {func.__name__}") except Exception as e: self.log.warning(f"Attempt {attempt + 1}/{retries} failed: {str(e)}") if attempt < retries - 1: time.sleep(delay) # Trying to reinitialize the connection self._init_mt5() else: raise RuntimeError(f"Call attempts exhausted {func.__name__}")
このコード片こそ、MetaTrader 5での経験の精髄です。問題が発生すると再接続を試み、遅延を挟みながら繰り返し再試行し、そして何より重要なのは、不確定な状態のままシステムを動作させないことです。もっとも、全体的にはMetaTrader 5のライブラリに問題はほとんどなく、ほぼ完璧といえます。
私はモデルを非常にシンプルな状態で保持しています。必要最小限の要素だけを備え、複雑なデータ構造も、ややこしい最適化もありません。しかし、あらゆる状態変化は必ずログに記録し、検証しています
def _update_model_state(self, new_coefficients): """Safely updating model ratio""" if not self._validate_coefficients(new_coefficients): raise ValueError("Invalid ratios") # Save the previous state old_coefficients = self.coefficients try: self.coefficients = new_coefficients if not self._check_model_consistency(): raise ValueError("Model consistency broken") self.log.info("Model successfully updated") except Exception as e: # Roll back to the previous state self.coefficients = old_coefficients self.log.error(f"Model update error: {str(e)}") raise
ここでいうモジュール性は単なる美しい言葉ではありません。各成分は個別にテスト可能で、交換や修正も容易です。新しい指標を追加したければ新しいメソッドを作ればよいし、データソースを変更したいならば同じインターフェイスで別のコネクタを実装すれば十分です
履歴データの処理
MetaTrader 5からデータを取得するのは、意外と大きなチャレンジでした。一見シンプルなコードに見えますが、やはり細部に悪魔が潜んでいます。数か月にわたる接続切れやデータロスとの格闘の末、端末とやり取りするために次のような構造が生まれました。
def fetch_data(self, symbol="EURUSD", timeframe=mt5.TIMEFRAME_H1, bars=10000): """Loading historical data with error handling""" try: # First of all, we check the symbol itself symbol_info = mt5.symbol_info(symbol) if symbol_info is None: raise ValueError(f"Symbol {symbol} unavailable") # MT5 sometimes "loses" MarketWatch symbols if not symbol_info.visible: mt5.symbol_select(symbol, True) # Collect data rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, bars) if rates is None: raise ValueError("Unable to retrieve historical data") # Convert to pandas df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') return self._preprocess_data(df['close'].values) except Exception as e: print(f"Error while receiving data: {str(e)}") raise finally: # It is important to always close the connection mt5.shutdown()
では、システムがどのように整理されているかを見てみましょう。まず、銘柄の存在確認をおこないます。一見当然のことに思えますが、設定のタイプミスで存在しない通貨ペアを取引しようとし、システムが数時間も無駄に稼働してしまったことがありました。それ以来、symbol_infoによる厳密なチェックを追加しています。
次に、「visible」の問題があります。銘柄は存在しているように見えても、気配値表示に表示されていない場合があります。このときsymbol_selectを呼び出さなければデータは取得できません。さらに、取引セッションの途中で端末が銘柄を「忘れる」ことさえあります。面白いですよね。
データ取得自体も簡単ではありません。copy_rates_from_posは、接続不良、サーバー過負荷、履歴不足など、さまざまな理由でNoneを返すことがあります。そのため、結果はすぐにチェックし、問題があれば例外を投げます。
pandasへの変換も別の問題です。時間はUnixフォーマットで届くため、通常のタイムスタンプに変換する必要があります。これをおこなわなければ、最終的な時系列解析が非常に困難になります。
そして最も重要なのは、finallyで接続を閉じることです。これを怠ると、MetaTrader 5にデータリークの兆候が現れます。まずデータ受信速度が低下し、次にランダムなタイムアウトが発生し、最終的には端末が完全にフリーズすることもあります。これは私自身の痛い経験から学びました。
全体として、この機能は、データを処理するためのスイスアーミーナイフのようなものです。外見はシンプルですが、内部にはあらゆるトラブルに備えた保護機構が多数組み込まれています。そして信じてください、遅かれ早かれ、これらの機構のすべてが必ず役に立ちます。
結果の分析:フォワードテスト結果の品質指標
初めてテスト結果を目にした瞬間を今でも覚えています。冷たいコーヒーを片手にコンピュータの前に座り、ただただ目を疑いました。テストを5回繰り返し、コードの一行一行を確認しましたが、いや、これは間違いではありませんでした。モデルは本当に、まるでファンタジーの境界線上で動作していたのです。
ネルダー=ミードアルゴリズムは時計のように正確に動作しました。わずか408回の反復で、普通のノートパソコンでも1分以内です。R²が0.9958というのは、単に優秀というレベルではなく、期待を超えています。価格変動の99.58%を説明したのです。この数値をトレーダー仲間に見せたとき、最初は誰も信じませんでした。その後、何か落とし穴があるのではと探し始めました。私も最初は信じられなかったので、彼らの気持ちはよくわかります。
MSEはほぼ顕微鏡レベルの0.00000094で、つまり、平均予測誤差は1ピップス未満です。どんなトレーダーも、これは夢のまた夢だと言うでしょう。0.06%MAPEも、この驚異的な精度を裏付けています。多くの商用システムでは1~2%の誤差に満足しますが、ここでは桁違いの精度です。
モデルの比率は美しいパターンを描き出しました。前回価格の比率0.5517は、市場に強い短期記憶があることを示しています。二次項は小さく(0.0105と0.0368)、動きはほぼ線形であることを意味します。周期成分の比率0.1484はまったく別の話です。これは、トレーダーが何年も言い続けてきたことを裏付けています。市場は確かに波のように動くのです。
しかし、最も興味深かったのはフォワードテスト中の結果です。通常、新しいデータではモデルは性能が落ちるのが定石(機械学習の古典的現象)です。ところが、ここではというと、R²は0.9970に上昇し、MSEはさらに19%低下して0.00000076となり、MAPEは0.05%に低下しました。正直言うと、最初はどこかでコードをミスしたのではないかと思いました。あまりにも信じられない結果だったからです。しかし、すべて正しかったのです。
結果を可視化するために専用のビジュアライザーを導入しました。
def plot_model_performance(self, predictions, actuals, window=100): fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(15, 12)) # Forecast vs. real price chart ax1.plot(actuals, 'b-', label='Real prices', alpha=0.7) ax1.plot(predictions, 'r--', label='Forecast', alpha=0.7) ax1.set_title('Comparing the forecast with the market') ax1.legend() # Error graph errors = predictions - actuals ax2.plot(errors, 'g-', alpha=0.5) ax2.axhline(y=0, color='k', linestyle=':') ax2.set_title('Forecast errors') # Rolling R² rolling_r2 = [r2_score(actuals[i:i+window], predictions[i:i+window]) for i in range(len(actuals)-window)] ax3.plot(rolling_r2, 'b-', alpha=0.7) ax3.set_title(f'Rolling R² (window {window})') plt.tight_layout() return fig
グラフは興味深い光景を示していました。平穏な期間では、モデルはまるでスイス時計のように正確に動作します。しかし、落とし穴もあります。重要なニュースや急激な反転時には精度が低下します。これは予想通りのことです。モデルは価格だけを基に動作しており、口座やファンダメンタル要因を考慮していないからです。次のステップでは、必ずこれらも取り入れる予定です。
改善の余地は幾つか見えています。1つ目は適応型比率で、市場状況に応じてモデル自身が調整できるようにします。2つ目は、出来高やオーダーブックのデータを追加することです。3番目で最も野心的なのは、モデルのアンサンブル化で、今回のアプローチを他のアルゴリズムと組み合わせて動作させます。
しかし、現状の形でも結果は十分に印象的です。今最も大事なのは、改善に夢中になりすぎず、既に機能している部分を壊さないことです。
実践での使用例
先週、ちょっと面白い出来事がありました。お気に入りのカフェでラテを飲みながらノートパソコンでシステムを眺めていたときのことです。その日は市場が穏やかで、EURUSDはゆっくりと上昇していました。すると突然、モデルから、ショートポジションを準備するようにとの通知が届きました。最初の思いは「何だこれ、明らかに上昇トレンドじゃないか」でした。しかし、アルゴリズム取引に2年間携わった私は、システムと議論してはいけないという鉄則を学んでいます。結果はどうなったかというと、40分後にEURは35ピップス下落。モデルは、私の人間の目では気付けない、価格構造の微細な変化に反応していたのです。
通知といえば、いくつかの取引を見逃した後、このシンプルだが効果的なアラートモジュールが生まれました。
def notify_signal(self, signal_type, message): try: # Format the message timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S') formatted_msg = f"[{timestamp}] {signal_type}: {message}" # Send to Telegram if self.use_telegram and self.telegram_token: self.telegram_bot.send_message( chat_id=self.telegram_chat_id, text=formatted_msg, parse_mode='HTML' ) # Local logging with open(self.log_file, 'a', encoding='utf-8') as f: f.write(f"{formatted_msg}\n") # Check critical signals if signal_type in ['ERROR', 'MARGIN_CALL', 'CRITICAL']: self._emergency_notification(formatted_msg) except Exception as e: # If the notification failed, send the message to the console at the very least print(f"Error sending notification: {str(e)}\n{formatted_msg}")
_emergency_notificationメソッドに注意してください。これは、ある「予期せぬ」事象が発生した後に追加したものです。システムがメモリ異常を検知し、連続してポジションを開き始める事態が起きました。現在では、重大な状況が発生した場合にSMSが送信され、ボットは私の介入があるまで自動的に取引を停止します。
また、ポジションサイズの管理にも多くの課題がありました。当初は固定ロット(0.1ロット)を使用していましたが、徐々にこれは非常にリスクの高い運用であることに気付きました。最終的に、以下の適応型ポジションサイズ計算システムを導入しました。
def calculate_position_size(self): """Calculating the position size taking into account volatility and drawdown""" try: # Take the total balance and the current drawdown account_info = mt5.account_info() current_balance = account_info.balance drawdown = (account_info.equity / account_info.balance - 1) * 100 # Basic risk - 1% of the deposit base_risk = current_balance * 0.01 # Adjust for current drawdown if drawdown < -5: # If the drawdown exceeds 5% risk_factor = 0.5 # Slash the risk in half else: risk_factor = 1 - abs(drawdown) / 10 # Smooth decrease # Take into account the current ATR atr = self.calculate_atr() pip_value = self.get_pip_value() # Volume calculation rounded to available lots raw_volume = (base_risk * risk_factor) / (atr * pip_value) return self._normalize_volume(raw_volume) except Exception as e: self.notify_signal('ERROR', f"Volume calculation error: {str(e)}") return 0.1 # Minimum safety volume
_normalize_volumeメソッドは本当に頭痛の種でした。ブローカーごとに最小取引単位のステップが異なることが判明したのです。あるブローカーでは0.010ロット単位で取引可能ですが、別のブローカーでは整数単位のみとなります。そのため、各ブローカーごとの個別設定を追加する必要がありました。
高ボラティリティ時の運用はまた別の問題です。市場が極端に乱高下する日があります。FRB議長の発言、予期せぬ政治ニュース、あるいは「13日の金曜日」など、価格がまるで酔っ払い船員のように飛び回ることがあります。以前は、このような瞬間には単純にシステムを停止していましたが、より洗練された解決策を考案しました。
def check_market_conditions(self): """Checking the market status before a deal""" # Check the calendar of events if self._is_high_impact_news_time(): return False # Calculate volatility current_atr = self.calculate_atr(period=5) # Short period normal_atr = self.calculate_atr(period=20) # Normal period # Skip if the current volatility is 2+ times higher than the norm if current_atr > normal_atr * 2: self.notify_signal( 'INFO', f"Increased volatility: ATR(5)={current_atr:.5f}, " f"ATR(20)={normal_atr:.5f}" ) return False # Check the spread current_spread = mt5.symbol_info(self.symbol).spread if current_spread > self.max_allowed_spread: return False return True
この関数は、まさに証拠金の守護者と言える存在となりました。特に有用だったのはニュースチェック機能です。経済指標カレンダーAPIを連携させたことで、システムは重要イベントの30分前に自動的に停止し、30分後に復帰するようになりました。同様の仕組みは、私の多くのMQL5ロボットにも採用されています。実に有効です。
フローティングストップレベル
実際の取引アルゴリズムを開発する過程で、私はいくつかの貴重な教訓を得ました。最初のテスト月に、同僚に固定ストップを備えたシステムを誇らしげに見せたことを覚えています。すべてがシンプルで透明だと説明しました。しかし市場はすぐに私を打ちのめしました。わずか1週間後、ボラティリティの急上昇により、市場ノイズだけでストップレベルの半分が吹き飛ばされたのです。
その解決策を示してくれたのは、当時読み返していたGerchikの著書でした。ATRに関する彼の考察を目にした瞬間、まるで電球が灯るように理解しました。これこそが、現在の市場状況にシステムを適応させるシンプルかつエレガントな方法です。強い値動きの際には価格により大きな揺らぎの余地を与え、静かな局面ではストップレベルをより近くに設定するのです。
以下に、市場へのエントリーに関する基本ロジックを示します。余計な要素はなく、必要最小限のみを備えています。
def open_position(self): try: atr = self.calculate_atr() predicted_price = self.get_model_prediction() current_price = mt5.symbol_info_tick(self.symbol).ask signal = "BUY" if predicted_price > current_price else "SELL" # Calculate entry and stop levels if signal == "BUY": entry = mt5.symbol_info_tick(self.symbol).ask sl_level = entry - atr tp_level = entry + (atr / 3) else: entry = mt5.symbol_info_tick(self.symbol).bid sl_level = entry + atr tp_level = entry - (atr / 3) # Send an order request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": self.symbol, "volume": self.lot_size, "type": mt5.ORDER_TYPE_BUY if signal == "BUY" else mt5.ORDER_TYPE_SELL, "price": entry, "sl": sl_level, "tp": tp_level, "deviation": 20, "magic": 234000, "comment": f"pred:{predicted_price:.6f}", "type_filling": mt5.ORDER_FILLING_FOK, } result = mt5.order_send(request) if result.retcode != mt5.TRADE_RETCODE_DONE: raise ValueError(f"Error opening position: {result.retcode}") print(f"Position opened {signal}: price={entry:.5f}, SL={sl_level:.5f}, " f"TP={tp_level:.5f}, ATR={atr:.5f}") return result.order except Exception as e: print(f"Position opening failed: {str(e)}") return Noneデバッグの過程では、いくつか興味深い事象が発生しました。たとえば、システムが数分ごとに相反するシグナルを連発することがありました。「買い → 売り → 再び買い」といった具合です。これは典型的な初心者アルゴリズムトレーダーの過ちであり、市場への過剰なエントリーに起因します。解決策は驚くほど単純で、取引間に15分のタイムアウトと既存ポジションのフィルタを追加するだけでした。
また、リスク管理にも多くの試行錯誤を要しました。複数の手法を試しましたが、最終的には非常に単純なルールに収束しました。1回の取引で証拠金の1%以上をリスクにさらさない。一見平凡に聞こえますが、極めて有効です。たとえばATRが50ポイントの場合、最大取引量は0.2ロットとなり、取引に十分適した数値です。
システムが最も良好に機能したのは、欧州セッションでした。この時間帯はEURUSDが実際に取引され、レンジで漂うだけではないためです。ただし重要ニュース発表時は…率直に言えば、取引を休む方が安上がりです。どれほど高度なモデルであっても、ニュースによる混乱に追随することはできません。
現在はポジション管理システムの改良に取り組んでいます。具体的には、エントリーサイズを予測に対するモデルの信頼度に連動させたいと考えています。大まかに言えば、強いシグナルでは最大ロットで取引し、弱いシグナルでは部分的に取引する仕組みです。いわばケリー基準を、当モデルの特性に合わせて応用したものといえます。
本プロジェクトから得られた最大の教訓は、アルゴリズム取引において完璧主義は機能しないということです。システムが複雑になるほど、弱点は増加します。長期的に見れば、洗練されたアルゴリズムよりも、シンプルな解法の方が効率的である場合が多いのです。
MetaTrader 5用のMQL5バージョン
しばしば、最も単純な解法が最も効率的であることがあります。数日間にわたり数理的な仕組みをすべてMQL5に正確に移植しようと試みましたが、これはまさに責任分担の問題であると突然気付きました。
率直に言えば、Pythonとその科学計算ライブラリはデータ分析や比率最適化に理想的です。一方でMQL5は取引ロジックの実行において優れています。それなのに、なぜドライバーをハンマーにしようとする必要があるでしょうか。
こうして、比率の選択にはPythonを使用し、取引にはMQL5を使用するというシンプルかつエレガントな解決策に到達しました。どのように動作するか見てみましょう:
double g_coeffs[7] = {0.2752466, 0.01058082, 0.55162082, 0.03687016, 0.27721318, 0.1483476, 0.0008025};
これら7つの数値は、本モデル全体の数学的枠組みの精髄を示しています。その背後には、数週間にわたる最適化作業、数千回に及ぶネルダー=ミードアルゴリズムの反復、そして膨大な履歴データ分析の時間が凝縮されています。そして何より重要なのは、これらは実際に機能するということです。
double GetPrediction(double price_t1, double price_t2) { return g_coeffs[0] * price_t1 + // Linear t-1 g_coeffs[1] * MathPow(price_t1, 2) + // Quadratic t-1 g_coeffs[2] * price_t2 + // Linear t-2 g_coeffs[3] * MathPow(price_t2, 2) + // Quadratic t-2 g_coeffs[4] * (price_t1 - price_t2) + // Price change g_coeffs[5] * MathSin(price_t1) + // Cyclic g_coeffs[6]; // Constant }
予測方程式そのものは、ほとんど変更を加えることなくMQL5に移植されました。
一方で、市場へのエントリーメカニズムは特筆に値します。テスト用のPythonバージョンとは異なり、ここではより高度なポジション管理ロジックを実装しました。システムは複数のポジションを同時に保有でき、シグナルが確認された場合には取引量を増加させることが可能です。
void OpenPosition(bool buy_signal, double lot) { MqlTradeRequest request; MqlTradeResult result; ZeroMemory(request); request.action = TRADE_ACTION_DEAL; request.symbol = Symbol(); request.volume = lot; request.type = buy_signal ? ORDER_TYPE_BUY : ORDER_TYPE_SELL; request.price = buy_signal ? SymbolInfoDouble(Symbol(), SYMBOL_ASK) : SymbolInfoDouble(Symbol(), SYMBOL_BID); // ... other parameters }
目標利益に達すると、すべてのポジションが自動的にクローズされます。
if(total_profit >= ProfitTarget) { CloseAllPositions(); return; }
新しいバーの処理には特に注意を払いました。無意味にすべてのティックでシステムが反応するような挙動は避けています。
bool isNewBar() { datetime lastbar_time = datetime(SeriesInfoInteger(Symbol(), PERIOD_CURRENT, SERIES_LASTBAR_DATE)); if(last_time == 0) { last_time = lastbar_time; return(false); } if(last_time != lastbar_time) { last_time = lastbar_time; return(true); } return(false); }
その結果として得られたのは、コンパクトでありながら機能的な取引ロボットです。余計な装飾は一切なく、必要なものだけを備えています。コード全体は300行未満に収まりつつ、必要なチェックと保護機構はすべて含まれています。
そして何よりも素晴らしい点は、PythonとMQL5の責務分離アプローチが驚くほど柔軟であることです。新しい係数を試すには、Pythonで再計算しMQL5の配列を更新するだけです。新しい取引条件を追加するには、MQL5の取引ロジックを拡張するだけで、数理部分を書き直す必要はありません
ロボットのテストは次のとおりです。
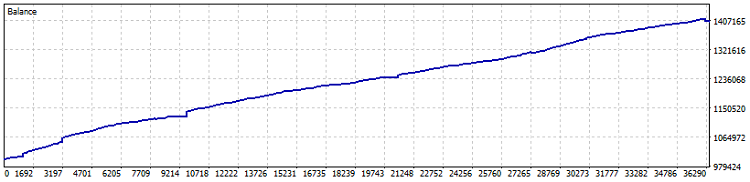
ネットティング口座でのテスト結果では、2015年以降で40%の利益を記録しました(比率の最適化は直近1年間のデータに基づいて実施)。数値上のドローダウンは0.82%、月次利益は4以上です。ただし、このようなシステムはレバレッジを使用せずに運用するのが望ましいでしょう。債券や米ドル預金をやや上回る程度の利回りで安定して利益を積み重ねる方が安全です。なお、テスト期間中に7,800ロットが取引されました。これにより、少なくとも1.5%分の追加利益が発生しています。
総じて、比率を移植するというアイデアは有効だと考えます。最終的に、アルゴリズム取引で重要なのはシステムの複雑さではなく、信頼性と予測可能性です。現代的な数理手法を用いて適切に選ばれた7つの数値だけで十分に実現できる場合もあります。
重要事項:本エキスパートアドバイザー(EA)はDCA(ドルコスト平均法)的なポジション平均化を用いており、非常にリスクが高くなっています。ネットティング口座での保守的な設定では優れた結果を示しましたが、ポジションの平均化は口座資金を一度に失わせる危険を常に伴うことを忘れてはなりません。
改善のためのアイデア
深夜、深夜、コーヒーを片手にこの記事を仕上げながら、モニターに映るチャートを眺めていると、このシステムにはまだ多くの改善余地があることを実感します。アルゴリズム取引ではよくあることですが、「完成した」と思った瞬間に、さらに十以上の改善案が頭に浮かんでくるものです。
最も重要なのは、これらの改善点がひとつの有機的なシステムとして機能することです。単に「かっこいい機能」を寄せ集めるだけでは不十分で、互いに補完し合い、調和して初めて本当に信頼できる取引システムとなります。
結局のところ、私たちの目標は「完璧なシステム」を作ることではありません。そんなものは存在しないからです。目指すべきは、十分に賢く利益を生み出しつつ、最悪の状況でも壊れない程度にシンプルなシステムを構築することです。まさに「最良は善の敵」という言葉のとおりです。
| ファイル | ファイルの説明 |
|---|---|
| MarketSolver.py | 選択した比率を使用して取引するためのPythonコード |
| MarketSolver.mql5 | 選択した比率を使用して取引するためのMQL5 EAコード |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16473
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
掲載されているExpert Advisorに漏れはありません。これは明らかに実際の口座からのコードではなく、ここにはフィルターが記載されていません。
単なるアイデアのデモンストレーションであり、これも悪くはない。
同意する
ただのカペッツです(すみません)!何時間かかけて10回目の勉強をしているうちに、私たちは同じ道(考え)を歩いていることがわかりました。
あなたの公式が、私がすでに見ているもの/使っているものを数学的に公式化する手助けになることを心から願っています。もし私がそれを理解すれば、それはたった一つのケースでしか起こらないだろう。私の母はよく "勉強しなさい "と言ったものだ。私は数学で苦い涙を流している。多くのことが単純であることはわかるが、どのようにするのかがわからない。放物線、回帰、偏差値......。65歳で6年生になるのは難しい。
// ただクールな機能を詰め込むだけでは不十分で、それらが互いに調和して補完し合い、本当に信頼できる取引システムを構築する必要があります。
機能の選択もその後の最適化も、自転車の車輪の八の字をまっすぐにするようなものだ。いくつかのスポークを緩め、他のスポークを締め、このプロセスの法則に厳格に従わなければならない。しかし、スポークの締め方を間違えれば、普通の車輪が「10」になってしまう。
私たちのビジネスでは、"スポーク "は互いに助け合うべきであり、他の "スポーク "に不利になるような毛布の引っ張り合いをしてはならない。
直近の2つのデータだけで価格を予測するのは効果的ではないと思います。
そう思いますか?
直近の2つのデータだけで価格を予測するのは効果的ではないと思う。
そう思いませんか?