
ニューラルネットワークが簡単に(第29部):Advantage Actor-Criticアルゴリズム

内容
はじめに
強化学習の手法を引き続き検討します。前回の記事では、Q学習の報酬関数と方策勾配関数学習の近似方法について説明しました。各方式にはそれぞれ長所と短所があります。モデルの構築や訓練の際に、その長所を最大限に生かせたら最高です。使用するアルゴリズムの欠点を最小限に抑える方法を見つけようとするときはしばしば、既知のさまざまなアルゴリズムや方法からある種のコングロマリットを構築しようとします。今回は、上記の2つのアルゴリズムを組み合わせて、1つのモデル学習方法とする方法であるAdvantage Actor-Criticアルゴリズムについて学びます。
1.先に述べた強化学習手法の利点
アルゴリズムの組み合わせに進む前に、それぞれの特徴や長所と短所を整理しておきましょう。
環境と相互作用するとき、エージェントは環境に影響を与える何らかの行動をとります。外的要因の影響とエージェントの行動により、環境の状態が変化します。状態が変化するたびに、環境はエージェントに何らかの報酬を与えて通知します。この報酬は正の場合も負の場合もあります。報酬の大きさと符号は、エージェントにとって新しい状態が有用であることを示します。エージェントは、報酬がどのように形成されるかを知りません。エージェントの目的は、環境との相互作用の過程で、可能な限り高い報酬を得られるように、そのような行動の実行を学習することです。
まず、報酬関数を近似するアルゴリズムを検討しました(Q学習)。環境のある状態である行動をとった後に、これから得られる報酬を予測する方法を学習させるために、モデルを訓練しました。その後、エージェントは予測された報酬とエージェントの行動方針に基づいて行動をとります。ここでは、原則として貪欲戦略またはɛ貪欲戦略を用います。貪欲戦略に従って、予測される報酬が最も高い行動を選択します。これはエージェントの実用的な運用で最もよく使われます。
2番目のɛ貪欲戦略は、名前だけでなく、貪欲戦略と似ています。また、予測される報酬が最も高い行動を選択することも含まれますが、確率ɛでランダムな行動を許容します。モデルの訓練段階で使用し、環境をよりよく研究することができます。そうしないと、一度正の報酬を得たモデルは、他の選択肢を探さずに、常に同じ行動を繰り返すことになります。この場合、その行動がどれだけ最適だったのか、より高い報酬につながる行動はないのか、知ることができません。しかし、エージェントにはできるだけ環境を探索し、それを最大限に活用してほしいのです。
Q学習法の利点は明白です。モデルは報酬を予測するために訓練されます。それは、私たちが環境から受け取る報酬です。つまり、モデルの演算結果の値と、環境から受け取った基準値には直接的な関係があるのです。この解釈では、学習は教師あり学習法と同様です。モデル訓練時には、標準誤差を損失関数として使用しました。
ここで注意していただきたいのは、以下の点です。訓練済みモデルは,モデルを訓練する際に,環境の類似した状態で特定の行動をとった後にエージェントが環境から受けた割引率を考慮し,セッション終了までの平均的な累積報酬を返します.しかし、環境は新しい状態への具体的な推移に対して報酬を返します。ここでは、エージェントがエピソードを完成させた後にカバーされるギャップを見ることができます。
このアルゴリズムの欠点は、モデルの訓練が複雑になることです。前回は、モデルを訓練するために、ある仕掛けが必要でした。まず、環境の連続した状態は互いに強く相関しています。多くの場合、両者は細かな点で異なるだけです。このようなデータを使って直接学習をおこなうと、現在の状態に合うように常にモデルを再訓練することになります。したがって、モデルはデータを一般化する能力を失ってしまいます。そのため、モデルを訓練するための過去のデータのバッファを作成する必要がありました。モデルの学習時には、過去のデータバッファからランダムに 状態を選択することで、学習時に連続して使用する2つの状態間の相関を低減することが可能となりました。
環境から受け取った報酬の実データでモデルを訓練することで、データの分散が少ないモデルを得ることができます。各状態でモデルが返す値の広がりは、許容範囲内に収まります。これは肯定的な要素です。ただし、環境は特定の遷移ごとに報酬を返し、全期間を通して利益を最大化したいのです。これを計算するためには、エージェントはセッションをすべて完了する必要があります。過去のデータバッファを利用し、将来の報酬を予測するモデルを追加することで、実用化の過程でモデルを追加学習できるアルゴリズムを構築することに成功しました。つまり、学習プロセスは「オンライン」モードで実行されているのですが、その代償として報酬の予測を誤ることになったのです。
2つ目のモデルで将来の報酬を予測しながら、その予測に誤りがあることを十分に認識し、そのリスクを受け入れたのです。しかし、それぞれの誤差はモデルの学習時に考慮され、その後のすべての予測に影響を及ぼしました。こうして、分散は小さいが偏りの大きい結果を予測できるモデルを得ることができました。これは、貪欲な戦略を用いる場合は無視することができます。その際は、最大の報酬を選択するためには他の報酬と比較するだけです。この場合の値の偏りやスケーリングは、行動選択の最終結果には影響しません。

Q学習を使用する場合,モデルは報酬を予測するためにのみに訓練されます。行動を選択するためには、モデル作成段階でエージェントの行動方針(戦略)を指定する必要があります。ただし、貪欲な戦略を使うことで、決定論的な環境でのみうまく機能することができます。これは、確率的戦略を構築する際には全く適用できません。
逆に、方策勾配を用いると,モデル作成段階でエージェントの行動方針(戦略)を決定する必要がありません.この手法によって、エージェントの行動方針を構築することができます。貪欲でも確率的でも大丈夫です。
方策勾配法により訓練したモデルで、環境の各特定状態において、ある行動と別の行動を選択したときに、望ましい結果が得られる確率の分布を返します。
モデル訓練時には、環境から受け取る報酬も利用します。各環境の状態における最適な戦略を選択するために、セッション終了までの累積報酬を使用します。明らかに、モデルの重みを更新するために、エージェントは、セッション全体を通過する必要があります。これがこの手法の最大の短所かもしれません。将来の報酬が分からないので、オンライン訓練モデルを構築することはできません。
同時に、実際の累積報酬を用いることで、予測データの実測値からの偏りの定数誤差を最小にすることができます。これは、将来の報酬の予測値を用いることによるQ学習の問題点でした。
しかし、方策勾配では、期待される報酬ではなく、エージェントが環境のある状態である行動をとったときに望ましい結果が得られる確率分布を予測するように、モデルを訓練します。損失関数として、対数関数を使用します。

誤差の最小化方向を解析的に決定するために、損失関数の導関数を用います。この場合、利便性は対数微分の性質にあります。

損失関数の微分に正の報酬を掛けることで、そのような行動を選択する確率を高めます。また、損失関数の微分に負の報酬を掛ける場合は、重みを逆方向に調整します。これにより、この行動を選択する確率が下がります。そして、報酬値のモジュロは、重みを調整するステップを決定します。
このように、モデルの重み行列を更新する際に、報酬が間接的に利用されます。そのため、実データに対する結果の偏りは小さいが、値の分散がかなり大きいモデルが得られます。

この手法の良い点は、環境を探索することができることです。Q学習とɛ貪欲戦略を用いる場合、研究と開発のバランスをɛを用いて決定し、方策勾配は与えられた分布から行動のサンプリングを用います。
訓練開始当初は、すべての行動の実行確率がほぼ等しくなります。そして、モデルは環境を最大限に研究し、エージェントの行動を等確率で選択します。モデルの訓練過程で、行動の確率分布は変化します。儲かる行動を選ぶ確率は高くなり、儲からない行動を選ぶ確率は低くなります。これにより、モデルが探索する傾向を抑えることができます。バランスは儲かる方にシフトします。
もう一点、ご注目ください。累積報酬を使い、セッションの最後に結果を出すことに重点を置いていて、具体的な各ステップの影響については評価しないということです。このようなアプローチでは、例えば、トレンドの反転を待って採算の合わないポジションを保持するようにエージェントを訓練することができます。あるいは、大量の負けトレードを学習し、その損失を稀に発生する利益トレードでカバーし、高い利益を得ることもできます。なぜなら、モデルはセッション終了時に最終的な利益を受け取り、それをプラスと考えるので、そのような操作の確率が高まるからです。もちろん、環境を探索する手法の能力は、モデルが最適な戦略を見つけるのを助けるはずなので、多くの反復はこの要因を最小化するはずですが、これではモデルの訓練時間が長くなってしまいます。
まとめてみましょう。Q学習モデルでは分散は小さいが偏りが大きくなります。逆に方策勾配では、偏りが小さく、分散が大きいモデルを訓練することができます。必要なのは、分散と偏りを最小限に抑えてモデルを訓練することです。
方策勾配は、個々のステップの影響を考慮することなく、全体的な戦略を構築します。各ステップで最大の利益を得る必要がありますが、これはQ学習で可能です。ベルマン関数のことを考えてください。各ステップで最適な行動を選択することを想定しています。
Q関数近似法を利用するためには、モデル作成段階でエージェントの行動方針を定義する必要があります。しかし、私たちが望むのは環境との相互作用の経験をもとに、モデル自身が戦略を決定することです。もちろん、決定論的な行動戦略に限定されるのも困りものです。これは、方策訓練の手法で実施することができます。
当然ながら、2つの訓練方法を組み合わせることで、最良の結果を得ることができるのです。
2.Advantage actor-criticアルゴリズム
報酬関数近似と方策学習法を組み合わせた最も成功した試みが,Actor-Criticファミリーの手法です。ここでは、Advantage Actor-Criticと呼ばれるアルゴリズムについて紹介します。
Actor-Critic法のファミリーでは、2つのモデルを使用します。モデルの1つであるActorは、エージェントの行動を選択する役割を担っており、方策関数近似法を用いて訓練されます。2つ目のモデルであるCriticは、Q学習法で訓練され、Actorが選択した行動を評価します。
まずすることは、方策モデルでデータのばらつきを減らすことです。方策モデルの損失関数をもう一度見てみましょう。毎回、選択された行動の予測確率の対数を、割引を考慮した累積報酬の大きさに乗算します。予測確率の値は、[0, 1]の範囲で正規化されています。
![]()
分散を小さくするには、累積報酬の値を小さくすればよいのですが、それは全体の結果に対する行動の影響を妨げるものであってはなりません。そして同時に、異なるエージェントの訓練セッションのデータ比較可能性を観察する必要があります。例えば、ある固定した定数やセッション全体の平均報酬を常に差し引くことができます。
![]()
次に、個々の行動の貢献度を評価するためのモデルを訓練できます。累積報酬を取り除き、現在の遷移の報酬だけを訓練に使うという一見単純な考え方は、不快な効果をもたらすことがあります。まず、現在のステップで大きな報酬を得ても、将来も同じように大きな報酬が得られるとは限りません。不利な状態に推移することで、大きな報酬を得ることができるのです。これは「ネズミ捕りの中のチーズ」に例えることができます。
一方、報酬は必ずしも行動によって決まるわけではありません。多くの場合、報酬はエージェントの評価能力よりも環境の状態に依存します。例えば、グローバルトレンドの方向で取引をおこなう場合、エージェントはトレンドに反する修正を待ち、価格が正しい方向に動くのを待つことができます。このため、エージェントが現状を詳細に分析してトレンドを把握する必要はありません。グローバルトレンドを正しく判断するので十分です。この場合、ベストプライスでないポジションに入る可能性が高くなります。詳細な分析により、調整を待って、より良い価格でエントリすることも可能ですが、調整がトレンドの変化に発展した場合の損失のリスクはより高くなります。この場合、ポジションは反転しないため、大きな損失を生むことになります。
したがって、累積報酬をあるベンチマーク結果と比較することが有効です。しかし、この値にアクセスするにはどうしたらよいのでしょうか。そこで使うのが「Critic」です。Actorの仕事を評価するために使用します。
ここでの考え方は、現在の環境の状態を評価するようにCriticモデルを訓練するというものです。これは、セッションが終了するまでにActorが現在の状態から受け取ることができる潜在的な報酬のことです。同時に、Actorは以前の訓練セッションで得た平均以上の報酬を得られる可能性のある行動を選択するよう学習します。そこで、上記の損失関数の式中の定数を状態推定値に置き換えます。
![]()
ここで、V(s)は環境状態評価関数です。
状態推定関数を訓練するために、再び二乗平均平方根誤差を使用します。
![]()
実は、このアルゴリズムを使ったモデル構築には、さまざまなアプローチがあります。ここではActor用とCritic用に2つの別々のニューラルネットワークを使用しますが、多くの場合、2つの出力を持つ1つのニューラルネットワークのアーキテクチャが使用されます。いわゆる「双頭」のニューラルネットワークです。このネットワークのニューラル層の一部は共有されており、初期データの処理を担っています。いくつかの判定層は方向性を分けています。モデル方策を担当するもの(Actor)と、状態を評価する役割を担うもの(Critic)です。ActorもCritic も、同じ状態の環境に対して作用します。したがって、同じ状態認識機能を持つことができます。
また、Advantage Actor-Criticモデルのオンライン訓練の実装もあります。Q学習と同様に、それらの累積報酬を最後の遷移で受け取った報酬の合計に置き換え、割引係数を考慮してその後の状態を評価します。この場合、損失関数は次のようになります。
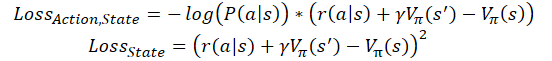
ここでɣは割引率です。
ただし、オンライン訓練にはコストがかかります。このようなモデルは誤差が大きく、訓練が困難です。
3.実装
ここまででこの手法の理論的側面について考察してきましたが、ここからは実践編として、MQL5のツールを使ってモデルの訓練プロセスを構築していきます。このアルゴリズムを実装するために、モデルのアーキテクチャを大幅に変更する必要はありません。2頭身のモデルは作りません。既存の手段を用いて、ActorとCriticという2つのニューラルネットワークを構築します。
また、新しいモデルの完全な訓練はおこないません。代わりに、前々回の記事で紹介した2つのモデルを使用することにします。Criticには、Q学習の記事にあるモデルを使用します。そして、方策勾配記事からのモデルがActorとして機能することになります。
上記で紹介した理論的な内容から若干の逸脱があることをご了承ください。Actorモデルは、検討されたアルゴリズムの要件に完全に適合していますが、今回使用するCriticモデルは、前述の環境状態推定関数とは若干異なります。環境状態の評価は、エージェントがおこなう行動に依存しません。状態の価値は、エージェントがこの状態から得られる最大利益です。先に学習したQ関数によれば、状態のコストは、この関数の結果のベクトルから最大値に等しくなります。ただし、正しいモデル訓練のためには、分析された状態でのエージェントの行動を考慮する必要があります。
では、手法の実装コードを見てみましょう。モデルを訓練するために、Actor_Critic.mq5というEAを作成しましょう。EAでは、過去の記事のテンプレートを使用しています。事前訓練した2つのモデルを使用することにします。モデルは別々に訓練され、別々のファイルに保存されました。そこで、まず、モデルを読み込むためのファイルを定義します。これらの名称は、以前の記事への言及を反映しています。
#define ACTOR Symb.Name()+"_"+EnumToString((ENUM_TIMEFRAMES)Period())+"_REINFORCE" #define CRITIC Symb.Name()+"_"+EnumToString((ENUM_TIMEFRAMES)Period())+"_Q-learning"
2つのモデルには、ニューラルネットワーククラスのインスタンスが2つ必要です。コードを分かりやすくするために、アルゴリズムにおけるモデルの役割に対応した名前を使用することにしましょう。
CNet Actor; CNet Critic;
EA初期化メソッドでは、モデルを読み込んで、すぐに初期データの層の大きさと結果を比較します。モデルをロードする際、比較可能なサンプルでモデルを訓練するため、モデルの比較可能性を評価することができませんが、モデルアーキテクチャの比較可能性を確認する必要があります。特に、ソースデータ層のサイズを確認します。このように、両モデルは同じ状態記述パターンを使って環境の状態を評価していることが確認できます。
次に、両モデルの結果層サイズを確認し、エージェントの可能な行動の離散性を比較することができます。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ................ ................ ................ //--- float temp1, temp2; if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) || !Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false)) return INIT_FAILED; //--- if(!Actor.GetLayerOutput(0, TempData)) return INIT_FAILED; HistoryBars = TempData.Total() / 12; Actor.getResults(TempData); if(TempData.Total() != Actions) return INIT_PARAMETERS_INCORRECT; if(!vActions.Resize(SessionSize) || !vRewards.Resize(SessionSize) || !vProbs.Resize(SessionSize)) return INIT_FAILED; //--- if(!Critic.GetLayerOutput(0, TempData)) return INIT_FAILED; if(HistoryBars != TempData.Total() / 12) return INIT_PARAMETERS_INCORRECT; Critic.getResults(TempData); if(TempData.Total() != Actions) return INIT_PARAMETERS_INCORRECT; //--- ................ ................ ................ //--- return(INIT_SUCCEEDED); }
どのように操作がおこなわれるかのプロセスを制御し、必要なデータを適切な変数に保存することを忘れないでください。特に、1つの分析パターンのローソク足の数を保存します。これは、読み込まれたモデルの初期データ層のサイズに相当します。
訓練アルゴリズムはTrain関数に実装されています。この関数の冒頭で,いつものように訓練サンプルの範囲を決定します.
void Train(void) { //--- MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
履歴データを読み込みます。操作実行結果を必ずご確認ください。
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
読み込んだデータ量を評価し、ローカル変数を用意します。
int total = bars - (int)(HistoryBars + SessionSize+2); //--- CBufferFloat* State; float loss = 0; uint count = 0;
次に、モデルの訓練ループのシステムを整理します。外側のループでは、訓練エポック数をカウントしています。そこで、ループ本体で、セッションの開始点を定義しています。読み込まれた履歴データからランダムに選択されます。この点を選ぶ際、2つの要素が考慮されます。まず、セッションの開始点には、1つのパターンを形成するのに十分な履歴データが先行している必要があります。第2に、セッションの開始点から訓練サンプルの終了点まで、セッションを完了するのに十分な履歴データがある必要があります。
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int error_code; int shift = (int)(fmin(fabs(Math::MathRandomNormal(0, 1, error_code)), 1) * (total) + SessionSize);
過去のデータでモデルを訓練するので、オンライン学習アルゴリズムは実装していません。通常、フルセッションで使用すると、より良い結果が得られます。しかし同時に、市場での仕事は尽きません。そこで、このアルゴリズムを一括して実装しています。セッションのサイズは、データ更新のバッチサイズによって制限されます。この値は、外部パラメータSessionSizeでユーザーが指定します。
次に、セッションの最初の反復のためのネストされたループを作成します。このループの本体で、まず、システム状態記述のパラメータを記録するオブジェクトを作成します。新しいオブジェクトの作成結果を確認することを忘れないでください。
States.Clear(); for(int batch = 0; batch < SessionSize; batch++) { int i = shift - batch; State = new CBufferFloat(); if(!State) { ExpertRemove(); return; }
その後、現在の環境状態のパラメータを保存します。このように、現在のアルゴリズムのステップで分析するためのパターンを準備します。
int r = i + (int)HistoryBars; if(r > bars) { delete State; continue; } for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = r - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) { delete State; continue; } //--- if(!State.Add((float)Rates[bar_t].close - open) || !State.Add((float)Rates[bar_t].high - open) || !State.Add((float)Rates[bar_t].low - open) || !State.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State.Add(sTime.hour) || !State.Add(sTime.day_of_week) || !State.Add(sTime.mon) || !State.Add(rsi) || !State.Add(cci) || !State.Add(atr) || !State.Add(macd) || !State.Add(sign)) { delete State; break; } }
保存されたデータの完全性を確認し、方策モデルのフィードフォワードパスメソッドを呼び出します。
if(IsStopped()) { delete State; ExpertRemove(); return; } if(State.Total() < (int)HistoryBars * 12) { delete State; continue; } if(!Actor.feedForward(GetPointer(State), 12, true)) { delete State; ExpertRemove(); return; }
そして、得られた分布からエージェントの行動をサンプリングします。
Actor.getResults(TempData); int action = GetAction(TempData); if(action < 0) { delete State; ExpertRemove(); return; }
選択した行動に対する報酬を決定します。方策報酬は、前回記事の実験から変わっていません。したがって、この手法の比較可能なテスト結果を得るつもりです。これにより、訓練アルゴリズムの変更がモデルの最終結果に与える影響を、これまでのテストと比較して確認することができます。
double reward = Rates[i - 1].close - Rates[i - 1].open; switch(action) { case 0: if(reward < 0) reward *= -20; else reward *= 1; break; case 1: if(reward > 0) reward *= -20; else reward *= -1; break; default: if(batch == 0) reward = -fabs(reward); else { switch((int)vActions[batch - 1]) { case 0: reward *= -1; break; case 1: break; default: reward = -fabs(reward); break; } } break; }
得られた値をバッファに保存し、後でモデルの重みを更新するために使用します。
if(!States.Add(State)) { delete State; ExpertRemove(); return; } vActions[batch] = (float)action; vRewards[SessionSize - batch - 1] = (float)reward; vProbs[SessionSize - batch - 1] = TempData.At(action); //--- }
これで、セッションに関する情報が収集された最初の入れ子ループの繰り返しが終了しました。すべてのセッションの状態を反復した後、モデルを更新するための完全なデータセットを取得します。
次に、環境の各状態に対する累積割引報酬を計算します。
vectorf rewards = vectorf::Full(SessionSize, 1); rewards = MathAbs(rewards.CumSum() - SessionSize); rewards = (vRewards * MathPow(vectorf::Full(SessionSize, DiscountFactor), rewards)).CumSum(); rewards = rewards / fmax(rewards.Max(), fabs(rewards.Min()));
では、損失関数の値を計算し、最適な結果が得られたらモデルを保存しましょう。
loss = (fmin(count, 9) * loss + (rewards * MathLog(vProbs) * (-1)).Sum() / SessionSize) / fmin(count + 1, 10); count++; float total_reward = vRewards.Sum(); if(BestLoss >= loss) { if(!Actor.Save(ACTOR + ".nnw", loss, 0, 0, Rates[shift - SessionSize].time, false) || !Critic.Save(CRITIC + ".nnw", Critic.getRecentAverageError(), 0, 0, Rates[shift - SessionSize].time, false)) return; BestLoss = loss; }
重み行列を更新する前にモデルを保存することに注意してください。なぜなら、これらは損失関数で推定した結果をモデルが達成したパラメータだからです。行列を更新した後、モデルは更新されたパラメータを受け取るので、次のセッションが完了してから新しいパラメータの結果を見ることになります。
学習エポックの繰り返しの最後に、別の入れ子ループを実装し、モデルパラメータの更新を組織します。ここでは、バッファから環境の状態を取得し、状態を取り除いた状態で両モデルを通過させます。操作の実行を制御することを忘れないでください。
for(int batch = SessionSize - 1; batch >= 0; batch--) { State = States.At(batch); if(!Actor.feedForward(State) || !Critic.feedForward(State)) { ExpertRemove(); return; }
なお、各モデルのフィードフォワードパスの実装は必須です。仮に必要なデータをすべてバッファに保存したとしてもです。実は、バックプロパゲーションのパスの間、訓練アルゴリズムはニューラル・層の計算による中間データを使っています。誤差勾配を正しく分配し、重みを更新するためには、各状態におけるモデルのすべての中間値の完全な連鎖を明確に配置する必要があります。
次に、Criticパラメータを更新します。モデルの更新は、エージェントによって選択された行動にのみ適用されることに注意してください。残りの動作の勾配はゼロとみなします。この理論的な資料との違いは、事前訓練されたQ関数を使用することにより、エージェントが選択した行動に応じて予測される報酬を返すことに起因しています。この手法の著者が提案する状態推定関数の訓練は、実行される動作に依存しないため、そのような詳細な訓練は必要ありません。
Critic.getResults(TempData); float value = TempData.At(TempData.Maximum(0, 3)); if(!TempData.Update((int)vActions[batch], rewards[SessionSize - batch - 1])) { ExpertRemove(); return; } if(!Critic.backProp(TempData)) { ExpertRemove(); return; }
Criticのパラメータ更新に成功したら、同様にActorのパラメータを更新します。前述のように、エージェントが選択した行動を評価するために、分析した環境の状態に対するQ関数の結果ベクトルの最大値を使用します。
if(!TempData.BufferInit(Actions, 0) || !TempData.Update((int)vActions[batch], rewards[SessionSize - batch - 1] - value)) { ExpertRemove(); return; } if(!Actor.backProp(TempData)) { ExpertRemove(); return; } } PrintFormat("Iteration %d, Cummulative reward %.5f, loss %.5f", iter, total_reward, loss); }
モデルパラメータの更新の全反復が完了したら、ユーザーに情報メッセージを表示し、次のエポックに移ります。
モデル訓練の処理は、ユーザーによって先に実行が中断されない限り、すべてのエポックが完了した後に終了します。
Comment(""); //--- ExpertRemove(); }
コメント欄をクリアしてエキスパートアドバイザー(EA)のシャットダウン関数を呼び出すことで、関数の動作が完了します。
EAの全コードは添付ファイルにあります。
4.テスト
EAを作成し、モデルを訓練した後、Advantage Act-Critic法の完全なテストを実施しました。まず、モデルの訓練プロセスを開始します。これは、むしろ前々回の記事のモデルを追加訓練したものです。
訓練は、H1時間枠のEURUSDデータを使用し、過去2年間の履歴を読み込んでおこなわれました。指標はデフォルトのパラメータで使用しました。連載を通して、モデルの訓練パラメータをほとんど変更せずに使用していることがわかります。
以前の記事のモデルを追加で訓練する利点は、以前の記事のテストEAを使って訓練結果を確認できることです。私が使ったのはこれです。モデルの訓練後、追加で訓練した方針モデルを、ストラテジーテスターで「REINFORCE-test.mq5」というEAを前述のモデルを使って起動させました。そのアルゴリズムについては、前回の記事で紹介しました。完全なEAコードは添付ファイルにあります。
以下は、テスト中のEAのバランスのグラフです。テスト中も均等にバランスよく増えているのがわかると思います。なお、モデルは訓練サンプル以外のデータでテストされています。これは、取引システム構築のアプローチに一貫性があることを示しています。モデルのみをテストするために、ストップロスやテイクプロフィットを使用せず、すべての操作を固定最小ロットでおこないました。このようなEAを実際の取引に使用することは、まったくお勧めできません。訓練済みモデルの働きを実証するだけです。

価格チャートでは、負け取引はすぐに決済され、儲かったポジションはしばらく保持されることが分かります。すべての操作は、新しいローソク足が始まるときにおこなわれます。また、反転(フラクタル)ローソク足のほぼ始点でおこなわれるいくつかの取引操作に気づくことができます。

一般的に、テストプロセスにおいて、EAは2.20のプロフィットファクターを示しました。収益性の高い取引の比率は56%を超えました。平均的な利益取引は、平均的な損失取引を70%上回っています。

同時に、このEAはモデルテストにのみ使用されているため、実際の取引に使用しないようご注意ください。まず、EAのテスト期間が短すぎて、実際の取引で使用するかどうかを判断するのに十分ではありません。第二に、このEAには資金管理やリスク管理のためのブロックがありません。取引操作にストップロスやテイクプロフィットがないのは、実際の取引ではあまり推奨されないことです。
結論
今回は、強化学習法の別のアルゴリズムに触れてみました。Advantage actor-criticです。このアルゴリズムは、これまで研究されてきたQ学習と方策勾配を最大限に組み合わせたものである。これにより、モデルの強化学習プロセスで得られる結果を向上させることができます。MQL5を用いて検討したアルゴリズムを構築し、実際の履歴データでモデルを訓練し、テストしました。テスト結果によると、このモデルは利益を生み出す能力を示しており、このモデル訓練アルゴリズムを使って取引システムを構築することが可能であると結論付けることができます。
既存の条件下では、AActor-Criticアルゴリズムのファミリーは、おそらくすべての強化学習法の中で最良の結果をもたらすでしょう。しかし、このモデルを実際の取引に使うには、長い訓練と徹底的なテストが必要です。各種ストレステストを含みます。
参考文献リスト
- 深層強化学習の非同期メソッド
- ニューラルネットワークが簡単に(第26部):強化学習
- ニューラルネットワークが簡単に(第27部):ディープQラーニング(DQN)
- ニューラルネットワークが簡単に(第28部):方策勾配アルゴリズム
記事で使用されているプログラム
| # | 名前 | タイプ | 詳細 |
|---|---|---|---|
| 1 | Actor-Critic.mq5 | EA | モデルを訓練するEA |
| 2 | REINFORCE-test.mq5 | EA | ストラテジーテスターでモデルをテストするためのEA |
| 3 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークモデルを作成するためのライブラリ |
| 4 | NeuroNet.cl | コードベース | ニューラルネットワークモデルを作成するためのOpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/11452
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 相対的活力指数による取引システムの設計方法を学ぶ
相対的活力指数による取引システムの設計方法を学ぶ
 デマーカーによる取引システムの設計方法を学ぶ
デマーカーによる取引システムの設計方法を学ぶ
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
...NeuroNetからNormal libを呼び出すと、なぜかVAE.mqhに到達できないんだ。
だからVAEとNeuronetで直接Normalを呼び出すようにして解決したんだけど、FQFのMathスペースを削除する必要があったんだ:
でも、うまくいったよ:
以下のステートメントを実行すると、EURUSD_PERIOD_H1_REINFORCE.nnw がないため、初期化に失敗しました。
if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) |||)
!!Critic.Load(CRITIC+".nnw",dError,temp1,temp2,dtStudied,false)))
INIT_FAILED を返します;
この問題を解決するには?ありがとうございます。
警告"... hidden method calling ... "の別の解決策
Actor_Critic.mq5の327行目:
非推奨の動作です。hiddenメソッド呼び出しは将来のMQLコンパイラー・バージョンで無効になります:
これは "Maximum(0, 3) "の呼び出しを指しており、これを変更する必要があります:
そのため、この場合は "CArrayFloat:: "を追加してメソッドを指定する必要がある。Maximum()メソッドはCBufferFloatクラスによって上書きされますが、このクラスにはパラメータがありません。
このメソッドには2つのパラメータがあるので、呼び出しは明確であるべきなのだが、コンパイラは私たちに意識してほしいのだ ;-)
以下のステートメントを実行すると、EURUSD_PERIOD_H1_REINFORCE.nnwがないため、初期化に失敗しました。
if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) ||?
!!Critic.Load(CRITIC+".nnw",dError,temp1,temp2,dtStudied,false)))
return INIT_FAILED;
この問題を解決するには?ありがとうございます。
これらの行では、学習されるべきネットワーク構造がロードされています。このEAを開始する前に 、ネットワークを構築し、名前を付けたファイルに保存する必要があります。例えば、記事No.23のモデル構築ツールを使用することができます。
https://www.mql5.com/ja/articles/11273
報酬を計算するコードについて詳しく教えてください。Part 27では、報酬の方針は以下のようになっていますが、上記のコードとは異なります: