
ニューラルネットワークが簡単に(第36回):関係強化学習

はじめに
強化学習の手法を引き続き検討します。以前の記事で、すでにいくつかのアルゴリズムについて説明しましたが、常に畳み込みモデルを使用していました。この理由は簡単です。以前に検討したすべてのアルゴリズムを設計およびテストする際に、さまざまなコンピューターゲームを使用しました。そのため、主にさまざまなコンピューターゲームのレベルの画像をモデルに入力しました。畳み込みモデルは、画像認識とこれらの画像上のオブジェクトの検出に関連するタスクを簡単に解決できます。
コンピューターゲームの画像にはノイズやオブジェクトの歪みはないため、認識タスクが簡素化されます。しかし、実際にはそのような「理想的」な状態はありません。データはさまざまなノイズに満ちています。多くの場合、調査された画像は理想的な期待とはかけ離れています。それらはシーン内で移動でき(畳み込みネットワークはこれを簡単に処理できます)、さまざまな歪みを受ける可能性があります。また、伸ばしたり、圧縮したり、別の角度で表示したりすることもできます。このタスクは、通常の畳み込みモデルでは処理が困難です。
状況によっては、2つ以上のオブジェクトの存在だけでなく、それらの相対的な位置も問題の解決に重要です。非畳み込みモデルを使用してこのような問題を解決することは困難です。しかし、それらは関係モデルによってうまく解決されます。
1.関係強化学習
関係モデルの主な利点は、オブジェクト間の依存関係を構築できることです。これにより、ソースデータの構造化が可能になります。関係モデルは、オブジェクトとイベントがノードとして表されるグラフの形式で表すことができ、関係はオブジェクトとイベント間の依存関係を示します。

グラフを使用することで、オブジェクト間の依存関係の構造を視覚的に構築できます。たとえば、チャネルのブレイクアウトパターンを説明したい場合、チャネルの形成を頂点とするグラフを作成できます。チャネル形成記述は、グラフとして表すこともできます。次に、2つのチャネルブレイクアウトノード(上下の境界線)を作成します。両ノードは前のチャネル形成ノードへの同じリンクを持ちますが、互いに接続されていません。誤ったブレイクアウトの場合にポジションを建てるのを避けるために、価格がチャネル境界にロールバックするのを待つことができます。これらは、チャネルの上下の境界にロールバックするためのさらに2つのノードです。それらは、対応するチャネル境界ブレイクアウトのノードと接続します。ただし、繰り返しになりますが、それらは互いに接続しません。
記述された構造はグラフに適合するため、データとイベントシーケンスの明確な構造が提供されます。連関規則を構築する際にも同様のことを検討しましたが、これは以前に使用した畳み込みネットワークとはほとんど関係がありません。
畳み込みネットワークは、データ内のオブジェクトを識別するために使用されます。モデルを訓練して、いくつかの動きの反転ポイントまたは小さなトレンドを検出できますが、実際には、チャネル形成プロセスは、チャネル内のさまざまな強度のトレンドに合わせて延長できます。ただし、畳み込みモデルは、このような歪みにうまく対処できない場合があります。さらに、畳み込みニューラル層も全結合ニューラル層も、異なるシーケンスを持つ同じオブジェクトで構成される2つの異なるパターンを分離できません。
また、畳み込みニューラルネットワークはオブジェクトを検出することしかできず、オブジェクト間の依存関係を構築できません。したがって、そのような依存関係を学習できる他のアルゴリズムを見つける必要があります。さて、アテンションモデルに戻りましょう。アテンションモデルは、個々のオブジェクトに注意を集中させ、一般的なデータ配列からそれらを抽出できるようにします。
「一般化されたアテンションメカニズム(注意機構)」は、再帰モデルを使用した機械翻訳モデルの効率を改善する取り組みとして、2014年9月に最初に提案されました。アイデアは、元のデータセットを処理するときにエンコーダの隠れ状態を収集する、追加の層を作成することでした。これにより、長期記憶の問題が解決されました。シーケンス要素間の依存関係の分析は、機械翻訳の品質を向上させるのに役立ちました。
機構操作アルゴリズムには、次の反復が含まれていました。
1.エンコーダの隠れ状態を作成し、アテンションブロックに蓄積します。
2.各エンコーダ要素の隠れ状態とデコーダの最後の隠れ状態の間のペアごとの依存関係を評価します。
3.結果のスコアを1つのベクトルに結合し、Softmax関数を使用してそれらを正規化します。
4.エンコーダのすべての隠れ状態に対応するアライメントスコアを掛けて、コンテキストベクトルを計算します。
5.コンテキストベクトルをデコードし、結果の値をデコーダの前の状態と組み合わせます。
文の終わりのシグナルが受信されるまで、すべての反復が繰り返されます。
以下の図は、このソリューションを視覚化しています。

ただし、反復モデルの訓練はかなり時間がかかるプロセスです。そこで、2017年6月に別のバリエーションが「Attention Is All You Need」稿で提案されました。これはTransformerニューラルネットワークの新しいアーキテクチャであり、再帰ブロックを使用せず、新しいセルフアテンション(自己注意、self-attention)アルゴリズムを使用していました。前述のアルゴリズムとは異なり、セルフアテンションは1つのシーケンス内のペアごとの依存関係を分析します。以前の記事で、セルフアテンションアルゴリズムを使用して3種類のニューラル層を作成しました。この記事では、そのうちの1つを使用します。しかし、エキスパートアドバイザー(EA)の実装に進む前に、セルフアテンションアルゴリズムがどのようにグラフ構造を学習できるかを考えてみましょう。

セルフアテンションアルゴリズムの入力では、ソースデータのテンソルが期待されます。このテンソルでは、シーケンスの各要素が特定の数の特徴によって記述されます。このような特徴の数は事前に決定されており、シーケンスのすべての要素に対して固定されています。したがって、初期データテンソルはテーブルとして表示されます。このテーブルの各行は、シーケンスの1つの要素の説明です。各列は1つの特徴に対応します。
使用される特徴は、完全に異なる分布を持つことができます。ある特徴の分布特性は、別の特徴の分布特性とは大きく異なる場合があります。特徴の絶対値とその変更が最終結果に与える影響も、まったく逆になる可能性があります。再帰層の隠れ状態と同様に、データを比較可能な形式にするために、重み行列を使用します。初期データテンソルの各行に重み行列を掛けると、シーケンス要素の記述が特定のd次元の内部埋め込み空間に変換されます。学習プロセスで指定された行列のパラメータを選択すると、シーケンスの要素が最大限に分離可能になり、類似性によってグループ化される値を選択できます。セルフアテンションアルゴリズムでは、このような3つの行列の作成と訓練が可能であることに注意してください。行列を使用すると、3つの異なるソースデータQuery、Key、Valueの埋め込みを形成できます。QueryおよびKeyベクトルの次元は、モデルの作成時に設定されます。Valueベクトルの次元は、ソースデータ内の特徴の数(1つの要素記述ベクトルのサイズ)に対応します。
生成された各埋め込みには、独自の機能上の目的があります。QueryとKeyはシーケンス要素間の相互依存性を定義するために使用されます。Valueは要素から渡される情報を定義します。
シーケンスの要素間の依存係数を見つけるには、Queryテンソルからの各シーケンス要素の埋め込みを、Keyテンソルからのすべての要素の埋め込み(対応する要素の埋め込みを含む)で乗算する必要があります。行列演算を使用する場合、単純にQuery行列に転置されたKey行列を乗算することができます。
![]()
得られた値をKey埋め込み次元の平方根で割り、Query埋め込みシーケンス要素のコンテキストでSoftmax関数を使用して正規化します。この操作の結果、初期データシーケンスの要素間の依存関係の正方行列が得られます。
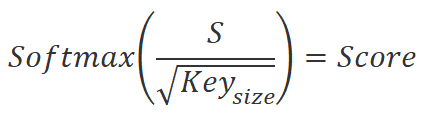
次の2点に注意してください。
- Softmax関数を使用して、0から1の範囲で正規化された依存係数を取得しました。この場合、係数の行方向の合計は1に等しくなります。
- QueryとKeyの埋め込みを作成するために、さまざまな行列を使用しました。これは、ソースデータシーケンスの同じ要素に対して異なる埋め込みが得られたことを意味します。このアプローチにより、最終的に依存係数の非対角行列が得られます。この行列では、依存係数はB要素に対するA要素と、A要素に対するB要素の逆依存係数は異なります。
この行動の目的を思い出しましょう。前述のように、さまざまなオブジェクトとイベント間の依存関係のグラフを作成できるモデルを取得したいと考えています。初期データテンソルの特徴ベクトルを使用して、各オブジェクトまたはイベントを記述します。結果として得られる依存係数の行列は、目的のグラフの表形式の表現です。この行列では、係数のゼロ値は、ソースデータの対応するノード間にリンクがないことを示します。ゼロ以外の値は、1つのノードが別のノードの値に及ぼす重み付けされた影響を決定します。
しかし、セルフアテンションアルゴリズムに戻りましょう。得られた依存係数に、Valueテンソルの対応する埋め込みを掛けます。「重み付けされた」埋め込みの結果の値を合計し、結果のベクトルは、シーケンスの分析された要素のセルフアテンションブロックの出力です。行列演算を使用する場合、単純に行列乗算関数を使用します。依存関係係数の正方行列にValueテンソルを掛けることで、セルフアテンションブロックの結果の目的のテンソルを取得します。
![]()
セルフアテンションアルゴリズムは、単純な1つの注意の頭の場合について上で説明されています。ただし、実際には、主にマルチヘッド注意オプションを使用します。このような実装では、もう1つの次元削減行列が追加されます。連結されたテンソルの次元をすべてのアテンションヘッドからソースデータの次元に減らします。
セルフアテンションアルゴリズムの最後に、アテンションブロックを使用してソースデータテンソルを追加し、結果の値を正規化します。
ご覧のとおり、セルフアテンションブロックの入力と出力のテンソルは同じサイズです。ただし、出力テンソルには正規化された値が含まれているため、結果に大きな影響を与える特徴が最大化されます。逆に、結果やノイズ現象に影響を与えない特徴の値は最小化されます。通常、この効果を高めるために、いくつかの後続のアテンションブロックがモデルで使用されます。
ただし、アテンションブロックは、重要な特徴を見つけるのに役立つだけです。問題の解決策は提供されません。したがって、アテンションブロックの後には意思決定ブロックが続きます。このブロックは、全結合パーセプトロンまたは以前に研究されたアーキテクチャソリューションのいずれかです。
2.MQL5を使用した実装
実装に移ったので、「Deep reinforcement learning with relational inductive biases(関係誘導バイアスによる深層強化学習)」稿のモデルを繰り返さないことに注意してください。提案された開発を使用し、内部好奇心モジュールを使用して関係モジュールをモデルに追加します。前回の記事でこのモデルのコピーを作成しました。前回の記事からEAのコピーを作成し、RLL-Learning.mq5として保存します。
ソースデータ層と結果層を変更せずに訓練しているモデルの内部アーキテクチャを変更する場合、EAアルゴリズムを変更する必要はありません。したがって、EAコードを直接変更することなく、新しいモデルファイルを簡単に作成できます。ただし、以前に公開された記事へのコメントで、NetCreatorツールを使用して作成されたモデルの読み込み中にエラーが発生したというメッセージをよく受け取ります。したがって、この記事では、EAコードのモデルアーキテクチャ記述のコンパイルに戻ることにしました。
もちろん、NetCreatorを使用して必要なモデルを作成することもできますが、この場合、次の点に注意する必要があります。
EAコードでは、モデル名はマクロ置換によって指定されます。したがって、モデルは指定された形式に対応している必要があります。
#define FileName Symb.Name()+"_"+EnumToString(TimeFrame)+"_"+StringSubstr(__FILE__,0,StringFind(__FILE__,".",0))
ファイル名は次のもので構成されます。
- EAが実行されているチャートの銘柄(接頭辞と接尾辞を含む、ターミナルに表示される銘柄完全な名前)
- EAパラメータで指定された時間枠
- 拡張子なしのEAファイル名
上記のコンポーネントはすべてアンダースコアで区切られています。
次の拡張子のいずれかがファイル名に追加されます。
- 訓練中モデルの「nnw」
- フォワードモデルの「fwd」
- 逆モデルの「inv」
作成したモデルのすべてのファイルをターミナルのFilesディレクトリまたはCommon/Filesに保存します。この場合、ファイルのあるディレクトリは、プログラムコードで指定されたcommonフラグと一致する必要があります。commonフラグのtrue値は、Common/Filesディレクトリに対応します。
bool CNet::Load(string file_name, float &error, float &undefine, float &forecast, datetime &time, bool common = true)
ここで、EAのコードに戻りましょう。OnInit関数では、最初に指標を操作するためのクラスを初期化します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED;
次に、以前に準備されたモデルを読み込もうとします。Common/Filesディレクトリからモデルを読み込んでいることに注意してください。このアプローチにより、ストラテジーテスターとリアルタイムの両方で変更を加えることなくEAを使用できます。これは、EAがストラテジーテスターで起動されたときに、ターミナルのFilesディレクトリにアクセスしないためです。セキュリティ上の理由から、ストラテジーテスターはテストエージェントごとに「独自のサンドボックス」を作成します。ただし、各エージェントは共有ファイルリソースであるCommon/Filesディレクトリにはアクセスできます。
//--- if(!StudyNet.Load(FileName + ".icm", true)) if(!StudyNet.Load(FileName + ".nnw", FileName + ".fwd", FileName + ".inv", 6, true)) {
事前訓練済みのモデルの読み込みに失敗した場合は、使用されているモデルのアーキテクチャの説明を作成します。このサブプロセスを別のCreateDescriptionsメソッドに実装しました。ここでは、それを呼び出して、操作の結果を確認します。失敗した場合、不要なオブジェクトを削除し、INIT_FAILEDの結果でEA初期化関数を終了します。
CArrayObj *model = new CArrayObj(); CArrayObj *forward = new CArrayObj(); CArrayObj *inverse = new CArrayObj(); if(!CreateDescriptions(model, forward, inverse)) { delete model; delete forward; delete inverse; return INIT_FAILED; }
必要な3つのモデルすべての記述を正常に作成したら、モデル作成メソッドを呼び出します。操作実行結果を必ずご確認ください。
if(!StudyNet.Create(model, forward, inverse)) { delete model; delete forward; delete inverse; return INIT_FAILED; } StudyNet.SetStateEmbedingLayer(6); delete model; delete forward; delete inverse; }
次に、エンコーダの結果で訓練しているモデルのニューラル層を指定し、不要になった作成済みモデルのアーキテクチャー記述オブジェクトを削除します。
次のステップでは、モデルを訓練モードに切り替え、経験再生バッファのサイズを指定します。
if(!StudyNet.TrainMode(true)) return INIT_FAILED; StudyNet.SetBufferSize(Batch, 10 * Batch);
指標バッファのサイズを設定しましょう。
//--- CBufferFloat* temp; if(!StudyNet.GetLayerOutput(0, temp)) return INIT_FAILED; HistoryBars = (temp.Total() - 9) / 12; delete temp; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
取引操作の実行タイプを指定します。
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- return(INIT_SUCCEEDED); }
これでEAの初期化メソッドは完了です。次に、モデルアーキテクチャの説明を作成するCreateDescriptionsメソッドに進みます。
bool CreateDescriptions(CArrayObj *Description, CArrayObj *Forward, CArrayObj *Inverse)
{
パラメータでは、このメソッドは3つの動的配列へのポインタを受け取り、3つのモデルのアーキテクチャを書き込みます。
- 説明—訓練中のモデル
- フォワードモデル
- 逆モデル
メソッド本体では、受け取ったポインタをすぐに確認します。必要に応じて、新しいオブジェクトインスタンスを作成します。
//--- if(!Description) { Description = new CArrayObj(); if(!Description) return false; } //--- if(!Forward) { Forward = new CArrayObj(); if(!Forward) return false; } //--- if(!Inverse) { Inverse = new CArrayObj(); if(!Inverse) return false; }
操作の実行プロセスを再び制御します。失敗した場合は、falseの結果でメソッドを完了します。
必要なオブジェクトを正常に作成したら、次のサブプロセスに進み、作成するモデルのアーキテクチャを記述します。訓練モデルのアーキテクチャから始めます。モデルアーキテクチャの記述を書き込む動的配列をクリアし、1つのニューラル層記述オブジェクトClayerDescriptionへのポインタを書き込む変数を準備します。
//--- Model
Description.Clear();
CLayerDescription *descr;
いつものように、最初にソースデータのニューラル層を作成します。入力データ層として、活性化関数のない全結合ニューラル層を使用します。モデルに転送される値の数に等しいニューラル層のサイズを指定します。各履歴データローソク足を説明するために、12個の値を転送することに注意してください。これらはローソク足の説明と分析された指標の値です。さらに、口座ステータスとポジションの量を渡します。これにより、さらに9つの値が追加されます。
ニューラル層記述アルゴリズムは、ニューラル層ごとに繰り返されます。これは3つのステップで構成されています。まず、ニューラル層記述オブジェクトの新しいインスタンスを作成します。新しいオブジェクトの作成でエラーが発生した場合、存在しないオブジェクトへのアクセスで重大なエラーが発生する可能性があるため、操作の結果を確認することを忘れないでください。
次に、ニューラル層の記述を設定します。ここで、指定するパラメータの数は、ニューラル層の種類によって異なります。入力データ層では、ニューラル層のタイプ、ニューラル層の要素数、パラメータの最適化タイプ、活性化関数を指定します。
ニューラル層に必要なすべてのパラメータを指定した後、ニューラル層記述オブジェクトへのポインタをモデルアーキテクチャ記述の動的配列に追加します。
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = HistoryBars * 12 * 9; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
ニューラルネットワークの訓練に関する私の経験によると、正規化された初期データを使用すると、学習プロセスがより安定します。訓練および使用中にデータを正規化するために、一括正規化層を使用します。ソースデータ層の直後に作成します。
ここでも、最初にニューラル層記述オブジェクトの新しいインスタンスを作成し、操作の結果を確認します。次に、作成するニューラル層のタイプをdefNeuronBatchNormOCLとして指定します。前のニューラル層のサイズレベルでの要素数と正規化バッチサイズも指定します。その後、ニューラル層の記述のオブジェクトへのポインタをモデルアーキテクチャ記述の動的配列に追加します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
データを正規化した後、前処理ブロックを作成します。ここでは、畳み込みニューラル層を使用して、ソースデータのパターンを見つけます。
前と同じように、ClayerDescriptionニューラル層記述オブジェクトの新しいインスタンスを作成し、defNeuronConvOCLニューラル層タイプを指定し、3要素に等しい分析データのウィンドウを指定し、データウィンドウステップを1に設定します。これらのパラメータを使用すると、1つのフィルター内の要素の数は、前の層のサイズよりも2少なくなります。可能性を最大限に引き出すために、このニューラル層に16個のフィルターを作成しました。フィルターが多すぎるように思えますが、モデルをできるだけ柔軟にしたかったのです。活性化関数としてLeakReLUを使用しました。パラメータを最適化するには、Adamを使用します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count - 2; descr.window = 3; descr.step = 1; descr.window_out = 16; descr.activation = LReLU; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
次のステップは標準ではありません。畳み込み層の後、通常、次元削減のためにサブサンプリング層を使用しました。しかし、今回は時系列で作業します。値に加えて、特徴変更のダイナミクスを追跡する必要があります。これをおこなうために、実験を行い、畳み込み層の後にLSTMブロックを使用することにしました。もちろん、そのサイズは畳み込み層の出力よりも小さくなります。しかし、再帰ブロックのアーキテクチャにより、システムの以前の状態を考慮して次元削減が期待されます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 300; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
より複雑な構造を明らかにするために、畳み込みニューラル層とリカレントニューラル層のブロックを繰り返します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 100; descr.window = 3; descr.step = 3; descr.window_out = 10; descr.activation = LReLU; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 100; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
次に、訓練モデルの関係ブロックに進みます。ここでは、多層マルチヘッドセルフアテンションのブロックを使用します。これをおこなうには、defNeuronMLMHAttentionOCLニューラル層タイプを指定します。初期データシーケンスの要素数は、分析されたローソク足の数と同じになります。この場合、1つのローソク足の説明特徴の数は5になります。
モデル入力と関係ブロックの入力で1つのローソク足を表す符号の数を混同しないでください。関係ブロックの前に、畳み込みニューラル層とリカレントニューラル層によって実行されるデータ前処理があったためです。
Keyのベクトルサイズは16になります。ヘッドの数は64になります。畳み込みニューラルネットワークのフィルターと同様に、現在の市場状況を総合的に分析するために、より多くの注目度を示しました。
このような層を4つ作成します。ただし、このニューラル層の記述を4回保存することはありません。代わりに、layersパラメータを4に設定します。
これまでのすべてのケースと同様に、パラメータの最適化にはAdamメソッドを使用します。この場合、すべての活性化関数はニューラル層構築アルゴリズムによって示されるため、活性化関数を指定しません。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = 20; descr.window = 5; descr.step = 64; descr.window_out = 16; descr.layers = 4; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
モデルアーキテクチャの説明を完了するには、完全にパラメータ化された分位数関数の層を示す必要があります。このニューラル層の説明では、ニューラル層のタイプdefNeuronFQF、アクションスペース、分位数、およびパラメータの最適化方法のみを示します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = 4; descr.window_out = 32; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
これで、訓練モデルのアーキテクチャの記述に関連するサブプロセスは終了です。次に、順モデルと逆モデルが必要です。前回の記事のアーキテクチャを使用します。EAが適切に機能するためには、それらの説明をメソッドに追加する必要があります。記述サブプロセスは、上記のプロセスと同じです。
まず、順モデルアーキテクチャ記述の動的配列をクリアします。次に、ソースデータのニューラル層を追加します。順モデルの場合、入力データ層のサイズは、メインモデルのエンコーダ出力のサイズと可能なエージェントアクションのスペースから連結されたベクトルに等しくなります。
//--- Forward Forward.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 104; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
これに続いて、LReLU活性化関数とAdam最適化法を備えた500要素の全結合ニューラル層が続きます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = LReLU; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
順ブロックの出力では、モデルエンコーダの出力で次の状態を取得することを期待しています。したがって、このモデルは全結合ニューラル層によって完成され、ニューロンの数はモデルエンコーダ出力のベクトルのサイズと等しくなります。活性化関数は使用しません。ここでも、パラメータ最適化手法にAdamを使用します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 100; descr.activation = None; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
逆モデル構築アプローチも同様です。唯一の違いは、2つの後続の状態の連結ベクトルをこのブロックに入力することです。したがって、ソースデータ層のサイズは、モデルエンコーダ出力のサイズの2倍になります。
//--- Inverse Inverse.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 200; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
2番目のニューラル層は、順モデルと同じです。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = LReLU; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
逆モデルの出力で実行されるアクションを期待します。したがって、次のニューラル層のサイズは、可能なエージェントアクションのスペースに等しくなります。この層は活性化関数を使用しません。代わりに次のSoftmax層を使用します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 4; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = 4; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; } //--- return true; }
残りのEAコードは、前回の記事で検討したものと同じです。完全なEAコードと使用されるすべてのライブラリは、添付ファイルで提供されます。
3.検証
モデルは、H1時間枠でEURUSD履歴データを使用して、ストラテジーテスターで訓練およびテストされました。指標はデフォルトのパラメータで使用しました。

モデルの訓練では、ストラテジーテスターでバランスの成長が示されました。平均して2回の利益取引ごとに2回の損失取引がありますが、利益取引の割合は53.7%でした。一般に、平均的な収益性の高い取引は、平均的な損失の取引よりも12.5%高いため、バランスとエクイティのグラフではかなり均等な増加が見られます。利益率は1.31、回収率は2.85です。


結論
この記事では、強化学習の分野における関係アプローチについて説明しました。モデルに関係ブロックを追加し、IntrinsicCuriosityModuleを使用して訓練しました。テスト結果により、モデル訓練に対するこのアプローチの実現可能性が確認されました。これらのモデルは、利益を生み出すことができるEAを作成する際の基礎として使用できます。
提示されたEAは取引操作をおこなうことができますが、実際の取引に使用するにはまだ早いです。EAはあくまで評価用として提示されています。実際の使用に際しては、大幅な改良とあらゆる条件下での総合的なテストが必要です。
参考文献リスト
- Neural Machine Translation by Jointly Learning to Align and Translate
- 注意ベースのニューラル機械翻訳への効果的なアプローチ
- Attention Is All You Need
- Deep reinforcement learning with relational inductive biases
- ニューラルネットワークが簡単に(第8部):アテンションメカニズム
- ニューラルネットワークが簡単に(第10部):Multi-HeadAttention
- ニューラルネットワークが簡単に(第11部):GPTについて
- ニューラルネットワークを簡単に(パート35):内因性好奇心モジュール
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | RRL-learning.mq5 | EA | モデル訓練EA |
| 2 | ICM.mqh | クラスライブラリ | モデル編成クラスライブラリ |
| 3 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 4 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/11876
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
こんにちは、ドミトリー・ギズリク、
素晴らしい記事をありがとう。
助けてください!Ryzen 9 6900hx (APU)を使ってStrategy Testerでトレーニングしようとすると、このようなエラーが出て、EAが取引されません。
どうすればこの問題を解決できますか?
こんにちは、ドミトリー
素晴らしい仕事をありがとう!このチュートリアルは、MQL5プラットフォームのMLに関するネット上のチュートリアルとしては、これまでで最高のものです。
詳細はよく説明されており、新しい学習者にも理解できます。
チュートリアルに従い、Strategy Testerを 実行したところ、以下の画像のように12個のプロセッサが使用可能であるにもかかわらず、1つしか使用されていないようです。
1つだけでなく、すべてのコアをアクティブにする方法はありますか?
OS Windows 11 build 22H2
OpenCL Support 3.0
CPU Intel i5-12400 ghz.html)
GPU Intel UHD Graphic 730 (integrated)
RAM 16gb
メタトレーダーの設定でOpenCLはすでに有効になっています。
詳細なチュートリアルに感謝します!
こんにちは、ドミトリー
素晴らしい仕事をありがとう!これはMQL5プラットフォーム上のMLに関するネット上のこれまでの最高のチュートリアルです。
詳細はよく説明されており、新しい学習者にも理解できます。
チュートリアルに従ってStrategy Testerを実行したところ、以下の画像のように12個のプロセッサが利用可能であるにもかかわらず、私のプロセッサは1つしか使用されていないようです。
1つだけでなく、すべてのコアをアクティブにする方法はありますか?
OS Windows 11 build 22H2
OpenCL Support 3.0
CPU Intel i5-12400 ghz.html)
GPU Intel UHD Graphic 730 (integrated)
RAM 16gb
OpenCL はメタトレーダーの設定ですでに有効になっています。
詳細なチュートリアルに感謝します!
Strategyテスターでは、1つのコアしか使用されていません。これはOpenCLではなく、mqlプログラムで使用されています。OpenCLは、Strategy testerのモニター外のシステムでGPUやCPUコアを使用します。WindowsでOpenCLプログラムのリソース消費を見るには、いくつかの方法があります:
1.MSI AfterburnerやGPU-Zのようなパフォーマンスモニタリングソフトウェアを使用する。MSI AfterburnerやGPU-Zのようなパフォーマンス監視ソフトウェアを使用する。
2.AMD CodeXLやNVIDIA Nsight Visual Studio Editionなどのプロファイラを使用します。これらを使用すると、OpenCL プログラムを分析し、コードのどの部分が最も時間とリソースを消費しているかを表示できます。
3.OpenCL API を使用して統計を収集します。これにより、メモリ使用量やコア性能など、OpenCL リソースの使用に関する情報をプログラムで取得できます。Windows でこの情報を収集するには、Performance Counters for OpenCL(PCPerfCL)ライブラリを使用できます。
4.インテル® VTune Amplifier などのプロファイリング・ツールを使用すると、プログラ ムがプロセッサーやその他のシステム・コンポーネントのリソースをどのように使 用しているかを確認できます。
こんにちは、ディミトリ!
この記事のExpert Advisorを動かすのを手伝ってください。私はそれを動作させるためにすべてを試してみましたが、残念ながらそれは正しく動作しません。
Expert Advisorはテスターで起動し、正常にテストを開始し、秒をカウントダウンし、緑色のバーが表示され、ログにエラーはなく、正常にビデオカードが表示され、選択されます。しかし、ビデオカードの負荷は0%です。まるで何もカウントしていないようだ。CommonFilesには、拡張子がicmとnnwのファイルが2つあり、サイズは1kbです。再度テスターでテストを再開しようとすると、初期化できないと警告が出てテストが始まりません。MT5を再起動し、CommonFilesのこのEAが作成したファイルを削除すると、正常に起動するが、ビデオカードも使用せず、これらの1kbのファイルを再び作成する。
次の記事からNeuroNet.mqhファイルを取り出し(コメントで投稿されたもの)、記事のものと置き換えてみましたが、役に立ちませんでした。テスターで小さな期間(1ヶ月、1週間、2ヶ月など)を選択してみましたが、これも役に立ちませんでした。
どのように開始するのですか?以前の記事のExpert Advisorsは正常に動作し、ビデオカードを正しく使用しています。
次の記事37,38のExpert Advisorにも問題があります。それどころか、テスターでは何の進歩もありませんが、ビデオカードは最大に使用されているため、少なくとも5時間、10時間さえも使用されています。
39のExpert Advisorは問題なく動作した。そこでは1ヶ月以上の履歴を選ぶとデータベースが作成さ れなかったが、1ヶ月を選ぶと正常にデータベースが作成された。他の部分は正常に動作した。
ドミトリー、これは本当に素晴らしい!
私はデータサイエンティストで、時系列データに関する様々な機械学習アルゴリズムの開発に携わっています。これは基礎となる貴重なものです。
あなたの仕事を共有してくれてありがとう。
ビジャン