
ニューラルネットワークが簡単に(第43回):報酬関数なしでスキルを習得する

はじめに
強化学習は、エージェントが環境と相互作用し、報酬関数の形でフィードバックを受け取ることによって、自ら学習することを可能にする強力な機械学習アプローチです。しかし、強化学習における重要な課題のひとつは、エージェントの望ましい行動を形式化する報酬関数を定義する必要性です。
報酬関数の決定は、特に複数の目標が必要なタスクや曖昧な状況においては、複雑な技となります。さらに、タスクによっては報酬関数が明示されておらず、従来の強化学習法の適用が困難な場合もあります。
この記事では、「多様性こそすべて」という概念を紹介します。これは、明示的な報酬関数なしに、モデルにスキルを教えることができるというものです。行動の多様性、環境の探索、環境との相互作用の多様性を最大化することは、エージェントが効果的に行動するように訓練するための重要な要素です。
このアプローチは、報酬関数を用いない学習という新しい視点を提供し、明示的な報酬関数を特定することが困難または不可能な複雑な問題の解決に役立つ可能性があります。
1.「多様性こそすべて」の概念
実生活では、パフォーマーがある機能を果たすためには、一定の知識とスキルが必要とされます。同様に、モデルを訓練する際には、与えられた問題を解決するために必要なスキルを身につけるよう努めます。
強化学習において、モデルを刺激する主な手段は報酬関数です。これによってエージェントは、自分の行動がどれだけ成功したかを理解することができます。しかし、報酬は稀であることが多く、最適解を見つけるにはさらなるアプローチが必要です。モデルの環境探索を促す方法についてはすでにいくつか見てきましたが、必ずしも効果的とは限りません。
伝統的な方法で訓練されたモデルは専門性が狭く、特定の問題しか解決できません。問題の定式化を少し変えるだけで、たとえ既存のスキルが有用であったとしても、モデルの完全な再訓練が必要となります。環境が変わっても同じことが起こります。
この問題に対するひとつの答えとして、複数のブロックからなる階層モデルを使うことが考えられます。このようなモデルでは、スキルごとに別々のモデルを作成し、それらのスキルの使用を管理するスケジューラーを作成します。スケジューラーの訓練によって、以前に訓練されたスキルを使って新しい問題を解決することが可能になります。しかし、新たな問題を解決するためには新たなスキルが必要になる可能性があるため、事前に訓練されたスキルの十分性や質について疑問が生じます。
「多様性こそすべて」という概念は、別々のスキルとスケジューラーを持つ階層モデルの使用を提案しています。エージェントが効果的に学習し適応できるように、最大限の多様な行動と環境の探索に重点を置いています。多様で明確なスキルを教えることで、モデルはより柔軟で適応性が高くなり、状況に応じてさまざまな戦略を使い分けることができるようになります。このアプローチは、明示的な報酬の特定が困難な場合に有効で、モデルは自律的に探索し、新しい解決策を見つけることができるようになります。
この概念の中心的な考え方は、多様性を学習のツールとして活用することです。モデルの行動や振る舞いに多様性を持たせることで、状態空間を探索し、新たな可能性を発見することができます。多様性とは、行き当たりばったりで効果のない行動に限定されるものではなく、さまざまな状況で適用できる、さまざまな有用な戦略を発見することを目的としています。
「多様性こそすべて」という概念は、明らかな報酬関数がなくても、多様性が訓練を成功させる重要な要素であることを暗に示しています。様々なスキルについて訓練されたモデルは、より柔軟で適応性が高くなり、文脈やタスクの要件に応じて異なる戦略を採用できるようになります。
このアプローチは、明示的な報酬関数を決定することが困難であったり、アクセスできなかったりする複雑な問題の解決に応用できる可能性があります。これによってモデルは、環境を独自に探索し、さまざまなスキルや戦略を学び、新たな道筋や解決策を発見することができます。
「多様性こそすべて」という概念の根底にあるもう1つの前提は、モデルの現在の状態は、選択した特定の行動だけでなく、使用したスキルにも依存するという仮定です。つまり、単純に行動と状態を関連付けるのではなく、モデルは特定の状態を特定のスキルに関連付けることを学習します。
概念アルゴリズムは2つの段階からなります。第一に、様々なスキルのガイドなし学習は、特定のタスクに関係なくおこなわれるため、環境を徹底的に探索することができ、エージェントの行動ツールキットを拡大することができます。この後、教師あり強化学習の段階が続き、設定された目標を解決する上でモデルの最大効率を達成することを目的とします。
最初の段階では、スキルモデルを訓練します。モデルの入力は、現在の環境の状態と、適用するために選択された特定のスキルで構成されます。モデルは適切な行動を生成し、それが実行されます。この行動の結果は、環境の新しい状態への移行です。この段階では、この新しい状態にしか興味がなく、外部からの報酬は使いません。
その代わりに、新しい状態に基づいて、前のステップでどのスキルが使われたかを判別しようとする識別器モデルを使います。識別器の結果と、適用されたスキルに対応するワンホットベクトルとの間のクロスエントロピーは、スキルモデルの報酬として機能します。
スキルモデルは、Actor-Criticのような強化学習手法を用いて訓練されます。一方、識別器モデルは古典的な教師あり学習法で訓練されます。
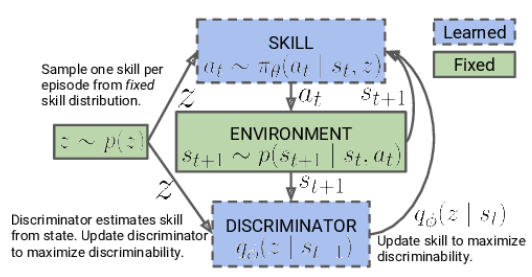
スキルモデルの訓練の最初の段階では、現在の状態に依存しない固定されたスキルの基礎があります。これは、異なる状態における技能とその有用性に関する情報がまだないためです。私たちの仕事は、こうしたスキルを身につけることです。モデルアーキテクチャを開発する際、訓練するスキルの数を決定します。
スキルモデルの訓練プロセスにおいて、エージェントは環境から受け取った情報に基づいて各スキルを能動的に探索し、完成させます。スキルのIDをモデルにランダムに与え、各スキルを独立して学習し、入力できるようにします。
モデルは、学習したスキルIDと現在の環境状態を使用して、実行する適切な行動を決定します。特定のスキルと特定の状態を関連付けて学習し、それぞれのスキルに応じた行動を選択します。
重要なのは、訓練の初期段階では、モデルはスキルや特定の条件下での有用性についての予備知識を持っていないということです。訓練プロセスにおけるスキルと状態の関連性を独自に研究し、決定します。この場合、報酬関数が使用され、使用するスキルに応じてエージェントの行動の多様性を最大限に促進します。
スキルモデルの訓練段階が完了したら、次の段階である教師あり強化学習に移ります。このステップでは、与えられた目標を最大化する、あるいは特定のタスク内で最大の報酬を得ることを目標に、スケジューラーモデルを訓練します。その一方で、固定スキルモデルを使用することで、スケジューラーモデルの訓練プロセスをスピードアップすることができます。
このように、教師なしスキルの完成から始まり、教師あり強化学習で終わるという2段階のアプローチでスキルモデルを訓練することで、モデルは様々なタスクにわたってスキルを独自に学習し、使用することができます。
なお、ここでのアプローチでは、先に説明した階層モデルから階層的な意思決定プロセスを変更しています。以前は複数のエージェントを使い、それぞれが独自のスキルをもっていました。エージェントが行動の選択肢を提案し、スケジューラがその選択肢を評価して最終決定を下します。
今回のアプローチでは、この順序を変更しました。さて、スケジューラーはまず現在の状況を分析し、適切なスキルの選択を決定します。そしてエージェントは、選択されたスキルに基づいて適切な行動を決定します。
スケジューラーが使用するスキルを決定し、エージェントは選択されたスキルに対応する行動を実行します。この変化により、現在の状況に応じて効果的にスキルを管理し、使用することができます。
2.MQL5を使用した実装
では、実践に移りましょう。前回の記事と同様に、モデルの訓練に使用する例のデータベースを作成することから始めます。データ収集は、前回のEAを改良した DIAYNResearch.mq5 EAによっておこなわれます。ただし、現在のアルゴリズムにはいくつかの違いがあります。
最初に行った変更は、モデルのアーキテクチャに関するものです。「多様性こそすべて」という概念から生まれる新たな要求やアイデアを満たすために、アーキテクチャに修正を加えました。
学習プロセスでは3つのモデルを使用します。
- エージェント(スキル)モデル:環境の現状に応じて、さまざまな技術を教え、実行する役割を担っています。
- 状況判断に基づいて意思決定をおこない、タスクを完了するために適切なスキルを選択するスケジューラー:スケジューラーは、スキルモデルと連携し、より高度な意思決定を導きます。
- スキルモデルの訓練中にのみ使用され、リアルタイムでは使用されない識別器:フィードバックを提供し、訓練中の報酬を計算するために使用されます。
ここで重要なのは、スキルモデルとスケジューラーが、産業運営や問題解決に用いられる主要なモデルであるということです。識別器はスキルモデルの訓練を向上させるためにのみ使用され、実際のシステム実行には使用されません。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *scheduler, CArrayObj *discriminator) { //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- if(!discriminator) { scheduler = new CArrayObj(); if(!scheduler) return false; }
「多様性こそすべて」アルゴリズムによれば、エージェントモデル(スキルモデル)には、現在の状態の記述と使用中のスキルの識別子を含む入力データバッファが与えられます。私たちの仕事に関連しては、以下の情報を伝えます。
- 値動きと指標の過去のデータ:このデータは、市場の過去の値動きや各種指標の値に関する情報を提供します。エージェントモデルの意思決定に重要なコンテキストを提供します。
- 現在の口座残高と未決済ポジションに関する情報:このデータには、現在の口座残高、未決済ポジション、ポジションサイズ、その他の財務パラメータに関する情報が含まれます。これらは、エージェントモデルが意思決定をおこなう際に、現在の状況や制約を考慮するのに役立ちます。
- ワンホットスキルIDベクトル:このベクトルは、使用されているスキルのIDを2進数で表したものです。これは、エージェントモデルが与えられた状態で適用すべき特定のスキルを示します。
このような入力を処理するためには、エージェントモデルが最適な意思決定をおこなうために必要な市場環境、財務データ、選択されたスキルに関するすべての必要な情報を取得できるように、十分な大きさのソースデータ層が必要です。
//--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * BarDescr + AccountDescr + NSkills); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
入力データを受け取った後、データ正規化層を作成し、エージェントモデルに渡す前に入力データを処理する重要な役割を果たします。データ正規化層は、異なる初期特徴を同じスケールにすることを可能にします。これにより、データの安定性と一貫性が確保されます。これはエージェントモデルが効果的に機能し、質の高い結果を出すために重要です。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
準備された生データは、畳み込み層のブロックを使って処理することができます。
畳み込み層は、特に画像やシーケンス処理タスクにおいて、深層学習モデルのアーキテクチャにおける重要なコンポーネントです。これにより、ソースデータから空間的および局所的な依存関係を抽出することができます。
「多様性こそすべて」アルゴリズムの場合、畳み込み層を過去の値動きデータと指標に適用して、重要なパターンと傾向を抽出することができます。これは、エージェントが異なる時間ステップ間の関係を把握し、検出されたパターンに基づいて意思決定をおこなうのに役立ちます。
各畳み込み層は、入力データを特定のウィンドウでスキャンする4つのフィルタで構成されます。畳み込み演算を適用した結果は、データの重要な特徴を強調する一連の特徴マップとなります。このような変換により、エージェントモデルは強化学習タスクの文脈でデータの重要な特徴を検出し、考慮することができます。
畳み込み層は、エージェントモデルにデータの意味のある側面を「見る」能力と焦点を当てる能力を与え、これは「多様性こそすべて」の意思決定と行動実行の重要なステップとなります。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
畳み込み層ブロックを通過したデータは、3つの完全連結層からなる決定ブロックで処理されます。完全連結層を介してデータを渡すことで、エージェントモデルは複雑な依存関係を学習し、データの異なる側面間の関係を発見することができます。
決定ブロックの出力は、FQF(Fully Parameterized Quantile Function)を使用します。このモデルは、将来の報酬または目標変数の分布の分位数を推定するために使用されます。これにより、エージェントモデルは平均値の推定値を得るだけでなく、様々な分量を予測することができ、不確実性のモデル化や確率的条件下での意思決定に役立ちます。
完全にパラメータ化されたFQFモデルを意思決定ブロックの出力として使用することで、エージェントモデルはより柔軟で正確な予測をおこなうことができ、「多様性こそすべて」の概念の枠内で最適な行動を選択するために使用することができます。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
スケジューラーモデルは、現在の環境状態を分類し、使用するスキルを決定します。エージェントモデルとは異なり、スケジューラーはデータの前処理に畳み込み層を使用しないシンプルなアーキテクチャを持ち、リソースを節約できます。
スケジューラーの入力データは、スキル識別ベクトル以外はエージェントと同様です。スケジューラーは、過去の値動きデータ、指標、現在の口座状況やポジションに関する情報など、現在の環境状態の説明を受け取ります。
環境状態の分類と使用スキルの決定は、完全連結層とFQFブロックを介してデータを渡すことによって実行されます。結果はSoftMax関数を使って正規化されます。これにより、ある状態が各スキルに属する確率を反映した確率のベクトルが導かれます。
このように、スケジューラーモデルは、現在の環境の状態に基づいて、どのスキルを使うべきかを決定することができます。これはさらに、エージェントモデルが「多様性こそすべて」という概念に従って適切な判断を下し、最適な行動を選択するのに役立ちます。
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NSkills; descr.window_out = 32; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
スキルを多様化させるために、第3のモデルである識別器を使用します。その任務は、エージェントの行動の多様性に貢献する、最も予想外の行動に報酬を与えることです。このモデルの精度は高いレベルでは要求されないので、アーキテクチャをさらに単純化し、FQFブロックを削除することにしました。
識別器アーキテクチャでは、正規化層と完全連結層のみを使用します。これにより、モデルの分類能力を維持しながら、計算リソースを削減することができます。モデルの出力では、 SoftMax関数を使用して、異なるスキルに属する行動の確率を求めます。
//--- Discriminator discriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills; descr.optimization = ADAM; descr.activation = None; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- return true; }
モデルのアーキテクチャを説明した後は、訓練のためのデータ収集プロセスの整理に移りましょう。データ収集の最初の段階では、環境に関する一次情報がないため、エージェントモデルのみを使用します。その代わりに、訓練していないモデルを使っても同等の結果が得られる、ランダムに生成されたスキル識別ベクトルを効果的に使うことができます。これにより、コンピューティングリソースの使用量を大幅に削減することも可能になります。
OnTickメソッドは、データ収集の直接的なプロセスを整理します。メソッドの最初に、新しいバーのオープニングイベントが発生したかどうかを確認し、発生した場合は過去のデータを読み込みます。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
前回と同様に、現在の状態に関する情報を2つの配列に読み込みます。sState構造体の過去のデータ状態の配列と口座状態に関する情報の配列です。
MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- sState.state[b * 12] = (float)Rates[b].close - open; sState.state[b * 12 + 1] = (float)Rates[b].high - open; sState.state[b * 12 + 2] = (float)Rates[b].low - open; sState.state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; sState.state[b * 12 + 4] = (float)sTime.hour; sState.state[b * 12 + 5] = (float)sTime.day_of_week; sState.state[b * 12 + 6] = (float)sTime.mon; sState.state[b * 12 + 7] = rsi; sState.state[b * 12 + 8] = cci; sState.state[b * 12 + 9] = atr; sState.state[b * 12 + 10] = macd; sState.state[b * 12 + 11] = sign; }
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); sState.account[2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); sState.account[3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); sState.account[4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } sState.account[5] = (float)buy_value; sState.account[6] = (float)sell_value; sState.account[7] = (float)buy_profit; sState.account[8] = (float)sell_profit;
その結果得られた構造体は、その後のモデルの訓練のために、例のデータベースに保存されます。ソースデータをエージェントモデルに転送するには、データバッファを作成する必要があります。この場合、まずこのバッファに過去のデータを読み込みます。
State1.AssignArray(sState.state);
口座規模の異なるモデルをより安定的かつ均等に効果的に操作するため、口座状況に関する情報を相対的な単位に変換することにしました。そのために、口座ステータスの指標に変更を加えます。
残高の絶対値の代わりに、残高変化率を使います。これによって、時間の経過に伴う残高の相対的な変化が可能になります。
また、資本指標を株主資本比率に置き換えます。これにより、残高に対する資本の相対的な割合を考慮することができ、異なる勘定科目間でより比較可能な指標となります。
加えて、時系列的な相対的資本の変化を考慮できるよう、株主資本変動比率を追加する予定です。
最後に、口座残高に対する累積取引結果の相対的な大きさを説明するために、残高に対する累積損益比率を導入します。
これらの変更により、さまざまな口座規模を効果的に扱い、相対的な健全性を考慮できる、より汎用性の高いモデルが構築されます。
State1.Add((sState.account[0] - prev_balance) / prev_balance); State1.Add(sState.account[1] / prev_balance); State1.Add((sState.account[1] - prev_equity) / prev_equity); State1.Add(sState.account[3] / 100.0f); State1.Add(sState.account[4] / prev_balance); State1.Add(sState.account[5]); State1.Add(sState.account[6]); State1.Add(sState.account[7] / prev_balance); State1.Add(sState.account[8] / prev_balance);
モデル用のデータ準備の仕上げとして、スキルの識別子となるランダムなワンホットベクトルを作成します。ワンホットベクトルとは、1つの要素だけが1で、残りの要素が0である2値ベクトルです。これにより、モデルは、特定のスキルに対応する要素の値に基づいて、異なるスキルを区別し、識別することができます。
ランダムなワンホットベクトルを生成することで、スキルIDが各データ例で多様かつ明確になります。これは、ここでの「多様性こそすべて」の概念と一致しています。
vector<float> one_hot = vector<float>::Zeros(NSkills); int skill=(int)MathRound(MathRand()/32767.0*(NSkills-1)); one_hot[skill] = 1; State1.AddArray(one_hot);
この段階で、用意された初期データをアクターモデルに転送し、モデルをフォワードパスします。フォワードパスとは、入力データをモデルの層を通過させ、対応する出力値を生成するプロセスです。
フォワードパスを実行した後、Actorモデルによって決定された各行動の確率を表すモデル出力が得られます。実行する行動を選択するために、得られた確率に基づいて可能な行動の1つをサンプリング(確率を考慮してランダムに選択)します。
行動サンプリングによって、Actorは各スキルに応じて可能な限り環境を探索することができます。こうすることで、モデルが取ることのできる行動のバリエーションが増え、同じ行動を選びすぎるのを防ぐことができます。このアプローチは、モデルにより大きな柔軟性を与え、環境のさまざまな状況に適応する能力を提供します。
if(!Actor.feedForward(GetPointer(State1), 1, false)) return; int act = Actor.getSample();
メソッドのその他のコードは、変更なしで以前のEAバージョンから引用しました。すべてのメソッドを含むEAの完全なコードは、添付ファイルにあります。
例のデータベースの収集については、すでに以前の記事で詳しく説明しているので、ここでは繰り返さず、すぐにモデル訓練用EA「DIAYNStudy.mq5」の開発に移ります。ほとんど以前のコードを使用したが、Trainと呼ばれる訓練メソッドに大きな変更を加えました。
このメソッドの著者が提案したオリジナルのアルゴリズムからは少し逸脱しました。私たちのEAでは、スキルモデルとスケジューラーを並行して訓練します。もちろん、「多様性こそすべて」の概念に従って、識別器も一緒に訓練されます。
このように、より持続可能で効果的な結果を得るために、モデルのスキルや行動に多様性を持たせるよう努力しています。
前回同様、モデルの訓練はループの中でおこなわれます。このサイクルの繰り返し回数は、EAの外部パラメータで決定されます。
訓練ループの各反復で、サンプルデータベースからパスと状態をランダムに選択します。状態を選択した後、データ収集EAでおこなわれるのと同様に、値動きと指標に関する過去のデータをデータバッファに読み込みます。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); State1.AssignArray(Buffer[tr].States[i].state);
また、口座状況とポジションのデータも同じデータバッファに追加します。前述したように、このデータを相対的な単位に変換することで、異なる口座規模に対応するモデルのロバスト性を高めています。これにより、モデルにおける口座状況と未決済ポジションの表現を統一し、訓練のための比較可能性を確保することができます。
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State1.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State1.Add(Buffer[tr].States[i].account[1] / PrevBalance); State1.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State1.Add(Buffer[tr].States[i].account[3] / 100.0f); State1.Add(Buffer[tr].States[i].account[4] / PrevBalance); State1.Add(Buffer[tr].States[i].account[5]); State1.Add(Buffer[tr].States[i].account[6]); State1.Add(Buffer[tr].States[i].account[7] / PrevBalance); State1.Add(Buffer[tr].States[i].account[8] / PrevBalance);
準備されたデータはスケジューラーモデルにとって十分なものであり、使用するスキルを決定するためにモデルをフォワードパスすることができます。
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Scheduler.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
スケジューラーモデルをフォワードパスし、確率のベクトルを得た後、ワンホットスキル識別ベクトルを形成します。スキルの選択には、最も高い確率でスキルを選択する貪欲な選択と、確率に基づいてランダムにスキルを選択するサンプリングの2つの選択肢があります。
訓練の段階では、サンプリングを使って環境を最大限に探索することが推奨されます。これにより、モデルはさまざまなスキルを探求し、隠れた能力や最適な戦略を発見することができます。訓練中、サンプリングは特定のスキルへの早すぎる収束を避け、より多様な探索活動を可能にし、より柔軟で適応力のある訓練モデルを促進します。
int skill = Scheduler.getSample(); SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; State1.AddArray(SchedulerResult);
得られたスキル識別ベクトルはソースデータバッファに追加され、エージェントモデルの入力に渡されます。この後、行動を生成するために、エージェントモデルのフォワードパスが実行されます。モデルから得られた確率分布は、行動のサンプリングに使用されます。
確率分布から行動をサンプリングすることで、エージェントモデルは各行動の確率に基づいてさまざまな判断を下すことができます。こうすることで、さまざまな戦略や行動の選択肢を探ることができ、またモデルが特定の行動に早急に固執するのを避けることができます。
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Actor.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } int action = Actor.getSample();
エージェントモデルのフォワードパスを実行した後、識別器モデルのフォワードパスのためのデータバッファの形成に進みます。ここで、システムの次の状態が説明されます。前のステップと同様に、まずは過去のデータをバッファに読み込みます。この場合、これらの指標は使用するモデルやスキルに依存しないので、手間をかけずに例のデータベースからデータバッファに過去のデータをコピーするだけでよくなります。
State1.AssignArray(Buffer[tr].States[i + 1].state);
口座の状態を説明するのは難しくなります。選択した行動と一致することはほとんどないため、サンプルデータベースから単純にデータを取得することはできません。同様に、識別器は入力として受け取った状態を分析し、使用したスキルと比較するため、単純に例のデータベースから行動を代用することはできません。ここにギャップが生じます。
しかし、識別器の出力は報酬関数としてのみ使用されることに注意することが重要です。新しい口座残高の状態を記述するのに高い精度は必要ありません。その代わり、異なる活動間でのデータの比較可能性が必要です。したがって、直前のローソク足のサイズと選択された行動を考慮して、直前の状態から口座の状態値をおおよそ推定することができます。計算に必要なデータはすでに揃っています。
最初の段階では、前の状態から口座データをコピーし、価格が最後のローソク足の値だけ動いたときのロングポジションの利益を計算します。ここでは、ポジションとその方向の具体的な取引量は考慮しません。これらのパラメータについては、後で検討します。
vector<float> account; account.Assign(Buffer[tr].States[i].account); int bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT);
そして、選択した行動に基づいて口座情報を調整します。最も単純なケースは、ポジションを閉じることです。累積損益を当座預金残高に加算するだけです。その結果得られた値は、資本と余剰証拠金の要素に移され、残りの指標はゼロにリセットされます。
取引操作をおこなう際には、対応するポジションを増やす必要があります。すべての取引が最小ロットでおこなわれることを考慮し、対応するポジションのサイズを最小ロット分大きくします。
各方向の累積損益を計算するには、先に計算した1ロットの利益に対応するポジションのサイズを掛けます。ロングポジションの利益は以前に計算されているので、この値を買いポジションの以前の累積利益に加え、売りポジションの利益から差し引きます。口座の総利益は、異なる方向の利益を加算することで得られます。
資本は残高と累積利益の合計として計算されます。
最小ロットの変更は重要ではないため、証拠金指標に変更はありません。
ポジションを保有する場合も、ポジション量を変更することを除いて、アプローチは同様です。
switch(action) { case 0: account[5] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; case 1: account[6] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; case 2: account[0] += account[4]; account[1] = account[0]; account[2] = account[0]; for(bar = 3; bar < AccountDescr; bar++) account[bar] = 0; break; case 3: account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; }
残高状況とポジションのデータを調整した後、データバッファに追加します。この場合、前回と同様、値を相対単位に変換し、識別器モデルを直接通過させます。
PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; State1.Add((account[0] - PrevBalance) / PrevBalance); State1.Add(account[1] / PrevBalance); State1.Add((account[1] - PrevEquity) / PrevEquity); State1.Add(account[3] / 100.0f); State1.Add(account[4] / PrevBalance); State1.Add(account[5]); State1.Add(account[6]); State1.Add(account[7] / PrevBalance); State1.Add(account[8] / PrevBalance); //--- if(!Discriminator.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
識別器のフォワードパスの後、その結果を、エージェントのフォワードパスで使用されたスキルの識別を含むワンホットベクトルと比較します。
Discriminator.getResults(DiscriminatorResult);
Actor.getResults(ActorResult);
ActorResult[action] = DiscriminatorResult.Loss(SchedulerResult, LOSS_CCE);
2つのベクトルを比較して得られたクロスエントロピーの値が、選択された行動に対する報酬として使用されます。この報酬により、エージェントモデルをバックパスし、その重みを更新することで、将来の行動選択を改善することができます。
Result.AssignArray(ActorResult); State1.AddArray(SchedulerResult); if(!Actor.backProp(Result, DiscountFactor, GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
使用されているスキルを表すワンホットIDベクトルは、識別モデルを訓練する際の目標値です。このベクトルをターゲットとして、選択されたスキルに従ってシステムの状態を正しく分類する識別器を訓練します。
Result.AssignArray(SchedulerResult); if(!Discriminator.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
口座残高の変更は、スケジューラーへの報酬としてのみ使用します。この量を正確に計算し、相対値として伝えます。ただし、選択された行動に対してのみ報酬を受け取るエージェントとは異なり、各スキルを選択する確率に基づいて、スケジューラーの報酬をすべてのスキルに分配します。このように、スケジューラーの報酬は、スキルの選択確率に応じて分割されます。
Result.AssignArray(SchedulerResult * ((account[0] - PrevBalance) / PrevBalance)); if(!Scheduler.backProp(Result, DiscountFactor, GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
学習サイクルの各反復が完了すると、学習プロセスに関するデータを含む情報メッセージを生成します。このメッセージは、プロセスを視覚化するためにチャート上に表示されます。そして次の反復練習に移り、訓練プロセスを続けます。
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Discriminator", iter * 100.0 / (double)(Iterations), Discriminator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
訓練プロセスが完了したら、チャートのメッセージをクリーンアップし、以前の情報データを削除します。その後、EAのシャットダウンが開始されます。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Discriminator", Discriminator.getRecentAverageError()); ExpertRemove(); //--- }
添付ファイルには、EAで使用されているすべてのメソッドと関数の完全なコードが含まれています。詳しい情報はこちらをご覧ください。
3.検証
モデルは、2023年の最初の4か月間のH1時間枠のEURUSD商品の過去のデータで訓練されました。訓練の過程で、報酬方策に関連するエージェントモデルの動作に、報酬を無制限に増加させる可能性のある非指摘的なエラーが発見されました。しかし、訓練プロセスは、スケジューラーモデルと識別器モデルの性能によって制御されます。
プロセスの第二の特徴は、スケジューラーの選択と実行される行動の間に直接的な関係がないことです。プランナーの選択は、具体的な行動よりも戦略の選択に大きな影響を与えます。つまり、プランナーが全体的な意思決定アプローチを決定し、具体的な行動はエージェントモデルが現在の状態と選択されたスキルに基づいて選択します。
訓練済みモデルのパフォーマンスをテストするために、2023年5月の最初の2週間のデータを使用しました。これは訓練セットには含まれていませんでしたが、訓練期間にほぼ続きました。このアプローチでは、訓練セットとテストセットの間に時間差がないため、データが比較可能なまま、新しいデータでモデルの性能を評価することができます。
テストには、修正したDIAYNTest.mq5 EAを使用しました。変更されたのは、モデルアーキテクチャに従ったデータ準備アルゴリズムと、ソースデータの準備プロセスのみです。モデルのダイレクトパスの呼び出し順序も変更されました。このプロセスは、例と訓練モデルのデータベースを収集するために、先に説明したEAと同様に構築されます。詳細なEAコードは添付ファイルにあります。


訓練済みモデルをテストした結果、利益率は1.61、回収率は3.21と、わずかな利益が得られました。テスト期間の240バーのうち、モデルは119回の取引をおこない、そのほぼ55%が利益で決済されました。
これらの結果を達成する上で重要な役割を果たしたのが、すべてのスキルの使用を均等に配分するスケジューラーです。行動とスキルの選択に貪欲な戦略が用いられたことは重要です。モデルは、現在の状態に基づいて、最も収益性の高い行動を選択しました。

結論
この記事では、DIAYN(「多様性こそすべて」)メソッドに基づく取引モデルの訓練のアプローチを紹介しました。このメソッドは、特定のタスクに縛られることなく、様々なスキルを持つモデルを訓練することを可能にします。
モデルは、2023年の最初の4ヶ月間のH1時間枠を使用したEURUSD商品の過去のデータで訓練されました。
訓練中、スケジューラーの選択と実行された行動には直接的な関係がないことが明らかになりました。しかし、訓練過程はコントロールされたままであり、収益性の高い取引をおこなうモデルの能力がある程度示されました。
訓練が完了した後、モデルは訓練セットに含まれていない新しいデータでテストされました。テストの結果、利益はわずかで、プロフィットファクターは1.61、リカバリーファクターは3.21でした。しかし、より安定した、より良い結果を得るためには、モデル戦略のさらなる最適化と改善が必要です。
このモデルの重要な点は、すべてのスキルの使用を均等に配分するスケジューラーです。このことは、取引で成果を上げるためには、効果的な意思決定戦略を開発することの重要性を浮き彫りにしています。
一般的に、DIAYN法に基づく取引モデルを訓練するための提示されたアプローチは、自動取引の開発に興味深い展望を提供します。このアプローチをさらに研究改善することで、より効率的で収益性の高い取引モデルが生まれるかもしれません。
参考文献リスト
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Study.mql5 | EA | モデル訓練EA |
| 3 | Test.mq5 | EA | モデルテストEA |
| 4 | 軌道.mqh | クラスライブラリ | システム状態記述構造 |
| 5 | FQF.mqh | クラスライブラリ | 完全にパラメータ化されたモデルの作業を整理するためのクラスライブラリ |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークが作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/12698
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
時間で設定したい場合は、セッション識別のワンホットベクトルを追加し、ソースデータのベクトルと連結することができます。
2つ目のオプションは、ソースデータに時間埋め込みを追加することです。希望する周期で設定できます。トレーディング・セッションであれば、1日単位で設定できます。季節性については、1年に設定できます。