記事「ニューラルネットワークが簡単に(第28部):方策勾配アルゴリズム」についてのディスカッション
 こんにちは。
こんにちは。
ドミトリー、values.AssignとMathRandomNormal関数はどこで手に入りますか?あなたのスクリプトはビルドされておらず、これらの関数がないことを参照しています。VAE.mqhファイルは拒否されます。
こんにちは。
ドミトリー、values.AssignとMathRandomNormal関数はどこで手に入りますか?あなたのスクリプトはビルドされておらず、これらの関数がないことを参照しています。VAE.mqhファイルは拒否されます。
こんにちは、ビクター。
values.Assignについては、ターミナルを更新してみてください。これは最近MQL5に追加された組み込み関数です。 MathRandomNormal is included in the standard library of the terminal and is added in the file "\MQL5\Include\Math\Stat\Normal.mqh".
Dmitry 私は2022年8月5日付けのターミナルバージョン3391(最後の安定版)を持っています。今、私は2022年9月5日からのベータ版3420にアップグレードしようとしました。values.Assignの エラーはなくなりました。しかし、MathRandomNormalの エラーは 消えません。この関数を含むライブラリは、あなたが書かれたようにパス上にあります。しかし、VAE.mqh ファイルではこのライブラリへの参照はありませんが、 NeuroNet.mqhファイルでは次のようにこのライブラリを指定しています:
名前空間 Math
{
<MathStatatNormal.mqh> をインクルードする。
}
しかし、私の組み立て方とは違う。:(
追記:VAE.mqh ファイルに直接ライブラリのパスを指定した 場合。それは可能ですか?NeuroNet.mqh ファイルにライブラリを設定する方法がよくわからないのですが、衝突しませんか?
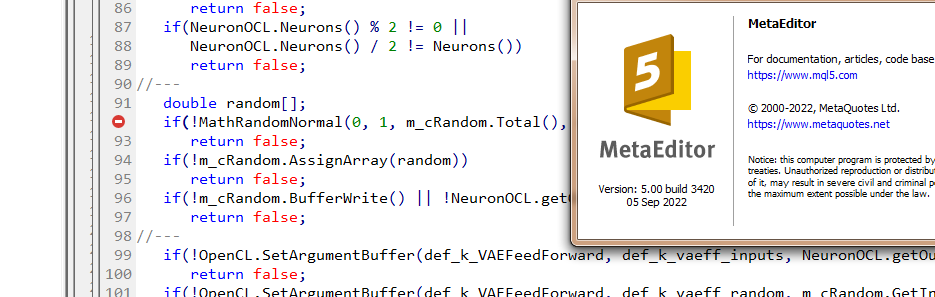
VAE .mqh ファイルに直接#include <MathStatNormal . mqh> 行を追加して みましたが、うまくいきませんでした。コンパイラーはまだ 'MathRandomNormal' - undeclared identifier VAE.mqh 92 8と書いて います。この関数を消してもう一度入力を始めると、この関数が書かれたツールチップが表示されます。これは、私の理解では、VAE.mqh ファイルから見ることができることを示しています。
一般的に、私はvindaの異なる偶数バージョンで別のコンピュータ上で試してみましたが、結果は同じです - 関数が表示されず、コンパイルされません。
ドミトリー、エディタで何か設定を有効にしていますか?
一般的に、私はWindowsの異なるバージョンで別のコンピュータ上でそれを試してみましたが、結果は同じです - それは関数を見ず、コンパイルされません。
ドミトリー、エディターで何か設定を有効にしていますか?
namespace Math" 行をコメントアウトしてみてください。
Dmitry 私は2022年8月5日付けのターミナルバージョン3391(最後の安定版)を持っています。今、私は2022年9月5日からのベータ版3420にアップグレードしようとしました。values.Assignの エラーはなくなりました。しかし、MathRandomNormalの エラーは 消えません。この関数を含むライブラリは、あなたが書いたようにパスにあります。しかし、VAE.mqh ファイルではこのライブラリへの参照はありませんが、 NeuroNet.mqhファイルでは以下のようにこのライブラリを指定しています:
名前空間 Math
{
#インクルード <MathStatatNormal.mqh
}
しかし、これではうまくいかない。:(
追記:VAE.mqh ファイルに直接ライブラリへのパスを指定した 場合。それは可能ですか?NeuroNet.mqh ファイルにライブラリを設定する方法がよくわからないのですが、競合しないのでしょうか?
3445(9月23日付け) - 同じことです。
{kind=link}
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
新しい記事「ニューラルネットワークが簡単に(第28部):方策勾配アルゴリズム」はパブリッシュされました:
強化学習法の研究を続けます。前回は、Deep Q-Learning手法に触れました。この手法では、特定の状況下でとった行動に応じて、これから得られる報酬を予測するようにモデルを訓練します。そして、方策と期待される報酬に応じた行動がとられます。ただし、Q関数を近似的に求めることは必ずしも可能ではありません。その近似が望ましい結果を生み出さないこともあります。このような場合、効用関数ではなく、行動の直接的な方針(戦略)に対して、近似的な手法が適用されます。その1つが方策勾配です。
完全なEAコードは添付ファイルにあります。
最初にテストしたモデルはDQNですが、これは思いがけない驚きを見せてくれます。このモデルは、利益を生み出しました。しかし、実行された取引操作は1つだけで、テスト中はずっとオープンでした。実行された取引の銘柄チャートは以下のとおりです。
銘柄チャートで取引を評価すると、このモデルは全体的なトレンドを明確に認識し、その方向に取引を開始したことが分かります。この取引は利益が出ますが、問題はモデルがこのような取引の決済に間に合うかどうかです。実際、過去2年分の履歴データを使ってモデルを訓練しました。この2年間、分析対象商品はずっと弱気トレンドで推移しています。だからこそ、このモデルが時間内に取引を決済できるかどうかが気になります。
貪欲戦略を用いた場合、方策勾配モデルも同様の結果を得ることができます。強化学習法の勉強を始めた頃、報酬の方針を正しく選択することの重要性を繰り返し強調したことを思い出してください。そこで、報酬方策を実験することにしたのです。特に、負けポジションの長期保有を排除するため、不採算ポジションに対するペナルティーを増やすことにしました。そのため、新しい報酬方策を使って、方策勾配モデルを追加で訓練させました。モデルのハイパーパラメータをいくつか実験した結果、60%の利益率を達成することができました。テストのグラフは以下のとおりです。
作者: Dmitriy Gizlyk