
Desarrollamos un asesor experto multidivisas (Parte 21): Preparación para un experimento importante y optimización del código
Introducción
En la parte anterior, iniciamos el trabajo de puesta a punto del pipeline de optimización automática que nos permita obtener un nuevo asesor experto final considerando los datos de precios acumulados. Sin embargo, aún no hemos llegado a la automatización total, ya que debemos tomar decisiones difíciles sobre la mejor manera de aplicar los pasos finales. Dichas decisiones no son sencillas porque si tomamos la decisión equivocada, tendremos que rehacer muchas cosas. Por eso querríamos ahorrar esfuerzos y tratar de realizar la elección correcta. Y nada ayuda más a tomar decisiones difíciles que..... ¡posponerlas! Sobre todo si podemos permitírnoslo.
Pero procrastinar también puede hacerse de formas diferentes. En lugar de simplemente retrasar el momento de la elección, intentaremos ponernos con otra tarea que parezca permitir la distracción, pero cuya solución pueda en realidad servirnos de ayuda, si no a encontrar el camino correcto, al menos a aumentar la motivación para hacer una elección.
Una pregunta interesante
El escollo en muchos argumentos sobre el uso de la optimización de parámetros es la cuestión de cuánto tiempo pueden usarse los parámetros obtenidos para operar en el periodo futuro manteniendo los principales indicadores de rentabilidad y reducción en los niveles dados. ¿Es posible en general lograrlo?
Aunque a menudo existe la opinión de que no se puede confiar en la repetibilidad de los resultados en pruebas futuras y que es solo cuestión de suerte cuando la estrategia "se rompe", probablemente, casi todos los desarrolladores de estrategias comerciales realmente quieren creer esto, de lo contrario se perdería el sentido de invertir una enorme cantidad de esfuerzo en el desarrollo y las pruebas.
Muchas veces se ha intentado aumentar la confianza en que, tras elegir buenos parámetros, una estrategia puede seguir funcionando bien durante algún tiempo. Hay artículos publicados que tratan de una manera u otra el tema de la selección automática periódica de los mejores parámetros para el comercio de asesores expertos. Por otra parte, podemos mencionar el asesor experto Validate de @fxsaber, que está diseñado para llevar a cabo un experimento muy interesante.
Esta herramienta permite tomar un asesor experto aleatorio (investigado) y, tras elegir un cierto periodo de tiempo (por ejemplo, 3 años), ejecutar el siguiente proceso: el asesor experto investigado se optimizará durante un cierto periodo de tiempo (por ejemplo, 2 meses), y luego, con la mejor configuración, operará en el simulador de estrategias durante un periodo de, por ejemplo, dos semanas. Al final de cada periodo de dos semanas, el asesor experto estudiado optimizará nuevamente los dos meses anteriores y volverá a operar durante otras dos semanas. Esto continuará hasta que se alcance el final del intervalo seleccionado de 3 años.
El resultado será un informe comercial que mostrará cómo habría operado el asesor experto estudiado durante los tres años, si efectivamente se hubiera reoptimizado periódicamente e iniciado con los parámetros actualizados. Está claro que uno puede elegir arbitrariamente dichos intervalos temporales como mejor le parezca. Si algún asesor experto puede mostrar resultados aceptables con dicha sobreoptimización, indicará su mayor potencial de uso en el comercio real.
Sin embargo, esta herramienta tiene una limitación importante: el asesor experto estudiado debe disponer de parámetros de entrada abiertos para realizar la optimización. Si tomamos, por ejemplo, nuestros EAs finales obtenidos en los artículos anteriores combinando muchas instancias individuales, estos no tendrán parámetros de entrada que nos permitan influir en la lógica comercial de la apertura de posiciones. No tendremos en cuenta los parámetros del gestor de capital y del gestor de riesgos, ya que la optimización de sus parámetros, aunque posible, resultará bastante inútil. Después de todo, está claro que si aumentamos el tamaño de las posiciones abiertas, el resultado de la pasada mostrará un beneficio mayor en comparación con el beneficio ya obtenido anteriormente como resultado de la pasada con un tamaño de posición menor.
Por ello, intentaremos implementar algo similar, pero aplicable a nuestros asesores en desarrollo.
Trazando el camino
Básicamente, necesitaremos un script para poblar una base de datos con proyectos casi idénticos. La principal diferencia será únicamente la fecha de inicio y fin del periodo de optimización. La composición de las fases, las actividades de las mismas y las tareas dentro del trabajo pueden ser totalmente iguales. Por consiguiente, todavía resulta posible hacer un asesor de servicio con un pequeño número de parámetros de entrada, entre los que estén la fecha de inicio y la duración del periodo de optimización. Si lo ejecutamos en modo de optimización con la iteración de fechas de inicio, podremos rellenar la base de datos con proyectos similares. Qué otros parámetros tendrá sentido poner en los parámetros de entrada, no está claro todavía, los determinaremos durante el desarrollo.
Completar todas las tareas de optimización, incluso dentro de un mismo proyecto, puede requerir mucho tiempo. Y si tenemos que realizar no uno, sino una docena o más proyectos de este tipo, entonces ya estaremos hablando de tareas que requieren bastante tiempo. Así que tendrá sentido ver si hay algo que podamos hacer para acelerar nuestros asesores de etapas. Para detectar los cuellos de botella que necesitan solución, utilizaremos el perfilador incluido en el MetaEditor.
A continuación, deberemos decidir cómo modelar el trabajo partiendo de las múltiples líneas de inicialización obtenidas (cada proyecto producirá una línea de inicialización del EA final tras completar sus tareas). Lo más probable es que tengamos que crear un nuevo asesor de pruebas específicamente diseñado para este tipo de trabajo. Pero eso es algo que dejaremos probablemente para el próximo artículo.
Primero vamos a optimizar el código de prueba de los asesores expertos, y solo después crearemos un script para rellenar la base de datos.
Optimización del código
Antes de sumergirnos en la implementación de la tarea principal, veamos si hay alguna forma de acelerar el código de los asesores expertos implicados en la optimización automática. Para encontrar posibles cuellos de botella, tomaremos el EA final de la última parte para investigarlo. Este combina 32 instancias de estrategias comerciales individuales (2 símbolos * 1 marco temporal * 16 instancias = 32). Obviamente, esto es mucho menos que el número total estimado de instancias en el EA final, pero durante la optimización tendremos la mayoría absoluta de las pasadas utilizando una instancia (en la primera etapa) o no más de 16 instancias (en la segunda etapa). Por lo tanto, un asesor de prueba de este tipo nos vendrá bastante bien.
Vamos a ejecutar el asesor experto en el modo de perfilado en los datos históricos. Al realizar la ejecución en este modo, una versión especial del asesor experto para la creación de perfiles se compilará automáticamente y se ejecutará en el simulador de estrategias. Vamos a citar la descripción del uso del perfilado de la ayuda:
Para el perfilado, usaremos el método "Sampling". El perfilador pausará el programa MQL (~10 000 veces por segundo) y recogerá estadísticas sobre cuántas veces se ha producido la pausa en una sección concreta del código. Esto incluirá analizar las pilas de llamadas para determinar la "contribución" de cada función al tiempo total de ejecución del código.
"Sampling" es un método ligero y preciso. A diferencia de otros, no realiza ningún cambio en el código analizado que pueda afectar a su velocidad.
El informe de perfilado se presentará en forma de funciones o líneas de programa, para cada una de las cuales se dispondrá de dos lecturas:
- Actividad total de la CPU [unidad de medición, %]: número total de "apariciones" de funciones en la pila de llamadas.
- Actividad de la CPU propia [unidad de medición, %]: número de "pausas" que se han producido directamente dentro de la función especificada. Este contador es el más importante para determinar los cuellos de botella, porque estadísticamente resulta más probable que se produzcan paradas en las partes del programa que requieren más tiempo de la CPU.
Para la métrica se mostrará el número absoluto y el porcentaje del número total.
Esto es lo que hemos obtenido tras completar la pasada:
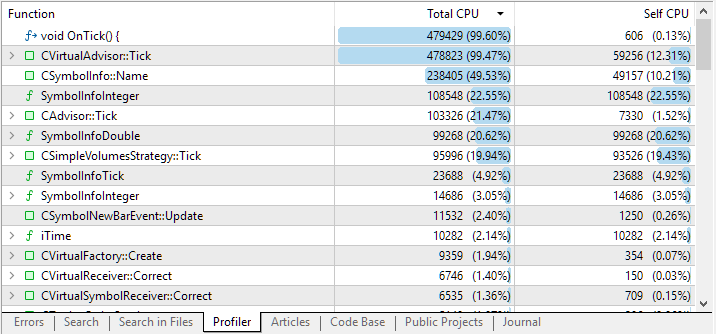
Fig. 1. Resultados del perfilado de código del asesor experto experimental
Por defecto, la lista de resultados de perfilado mostrará las funciones grandes en los niveles superiores. Pero clicando en la línea con el nombre de la función, podremos ver una lista anidada con las funciones que han sido llamadas desde esta función. Esto nos permitirá determinar con mayor precisión qué secciones de código han consumido más tiempo de CPU.
En las dos primeras líneas vemos el manejador OnTick() y el manejador CVirtualAdvisor::Tick() llamado desde él. De hecho, aparte de la inicialización, el EA pasará la mayor parte del tiempo procesando los ticks entrantes. Pero las líneas tercera y cuarta de los resultados plantean preguntas razonables.
¿Por qué tenemos tantas llamadas al método actual de selección del símbolo actual? ¿Por qué se dedica tanto tiempo a obtener algunas propiedades enteras de un símbolo? Vamos a analizar esto.
Tras expandir la línea correspondiente a la llamada del método CSymbolInfo::Name(string name), podemos rastrear que casi todo el tiempo se emplea en su llamada desde la función que comprueba la necesidad de cerrar una posición virtual.
//+------------------------------------------------------------------+ //| Check the need to close by SL, TP or EX | //+------------------------------------------------------------------+ bool CVirtualOrder::CheckClose() { if(IsMarketOrder()) { // If this is a market virtual position, s_symbolInfo.Name(m_symbol); // Select the desired symbol s_symbolInfo.RefreshRates(); // Update information about current prices // ... } return false; }
Este código se escribió hace bastante tiempo. En ese momento, para nosotros era importante que las posiciones virtuales abiertas se tradujeran correctamente en posiciones reales. El cierre de una posición virtual debería haber provocado el cierre inmediato (o casi inmediato) de cierto volumen de posiciones reales. Por consiguiente, esta comprobación deberá realizarse en cada tick y para cada posición virtual abierta.
Para mayor autosuficiencia, dotaremos a cada objeto de la clase CVirtualOrder de su propia instancia de un objeto de la clase CSymbolInfo, a través del cual solicitaremos toda la información necesaria sobre los precios y las especificaciones del instrumento (símbolo) comercial requerido. Así, para 16 instancias de estrategias comerciales que utilicen tres posiciones virtuales cada una, en el array de posiciones virtuales habrá 16*3 = 48 unidades. Si hay varios cientos de instancias de estrategias comerciales en el asesor experto, e incluso utilizando un mayor número de posiciones virtuales, el número de llamadas al método de selección de símbolos aumentará muchas veces. Pero, ¿es necesario?
¿Cuándo es absolutamente necesario llamar al método de selección del nombre del símbolo? Solo si el símbolo de posición virtual ha cambiado. Si no ha cambiado desde el tick anterior, no será necesario llamar a este método de símbolo. Y un símbolo solo puede cambiar al abrir una posición virtual, que o bien no se ha abierto antes o bien ha sido abierta por otro símbolo. Está claro que no ocurre en todos los casos, pero sí con mucha menos frecuencia. Además, en la estrategia modelo usada nunca se produce un cambio de símbolo para una posición virtual en absoluto, porque una instancia de estrategia comercial trabaja con un único símbolo, que será el símbolo para todas las posiciones virtuales de esta instancia de estrategia.
Entonces será posible llevar objetos de la clase CSymbolInfo al nivel de una instancia de estrategia comercial, pero esto puede ser redundante, porque diferentes instancias de estrategia comercial pueden utilizar el mismo símbolo. Así que los llevaremos aún más alto: al nivel global. A este nivel, solo necesitaremos tener tantas instancias de objetos de la clase CSymbolInfo como símbolos diferentes se utilicen en este asesor experto. Cada instancia de CSymbolInfo solo se creará cuando el asesor experto necesite hacer referencia a las propiedades de un nuevo símbolo. Una instancia creada una vez se asignará permanentemente a un símbolo concreto.
Inspirándonos en este ejemplo del manual, crearemos nuestra propia clase CSymbolsMonitor. A diferencia del ejemplo, no crearemos una nueva clase, que, al estar escrita de forma mucho más bella, repetirá esencialmente la funcionalidad de una clase ya existente en la biblioteca estándar. El nuestro actuará como contenedor de varios objetos de la clase CSymbolInfo y se encargará de que por cada símbolo utilizado se cree un objeto de información diferente de esta clase.
Para asegurarnos de que sea accesible desde cualquier parte del código, utilizaremos de nuevo el patrón de diseño Singleton en la implementación. La base de la clase será un array m_symbols[] para almacenar los punteros a los objetos de la clase CSymbolInfo.
//+---------------------------------------------------------------------+ //| Class for obtaining information about trading instruments (symbols) | //+---------------------------------------------------------------------+ class CSymbolsMonitor { protected: // Static pointer to a single class instance static CSymbolsMonitor *s_instance; // Array of information objects for different symbols CSymbolInfo *m_symbols[]; //--- Private methods CSymbolsMonitor() {} // Closed constructor public: ~CSymbolsMonitor(); // Destructor //--- Static methods static CSymbolsMonitor *Instance(); // Singleton - creating and getting a single instance // Tick handling for objects of different symbols void Tick(); // Operator for getting an object with information about a specific symbol CSymbolInfo* operator[](const string &symbol); }; // Initializing a static pointer to a single class instance CSymbolsMonitor *CSymbolsMonitor::s_instance = NULL;
La implementación del método estático de creación de una única instancia de una clase repetirá las implementaciones ya encontradas anteriormente. Y en el destructor colocaremos el ciclo de eliminación de los objetos de información creados.
//+------------------------------------------------------------------+ //| Singleton - creating and getting a single instance | //+------------------------------------------------------------------+ CSymbolsMonitor* CSymbolsMonitor::Instance() { if(!s_instance) { s_instance = new CSymbolsMonitor(); } return s_instance; } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ CSymbolsMonitor::~CSymbolsMonitor() { // Delete all created information objects for symbols FOREACH(m_symbols, if(!!m_symbols[i]) delete m_symbols[i]); }
El método público de procesamiento de ticks ofrecerá actualizaciones periódicas sobre la especificación de los símbolos y las cotizaciones. Es probable que la especificación no cambie con el tiempo, pero por si acaso, nos aseguraremos de actualizarla una vez al día. Las cotizaciones se actualizarán cada minuto, ya que usaremos el modo del asesor experto solo en la apertura de barras de minutos (para que se repitan mejor los resultados de la modelización en el modo OHLC de 1 minuto y el modo de todos los ticks basado en ticks reales).
//+------------------------------------------------------------------+ //| Handle a tick for the array of virtual orders (positions) | //+------------------------------------------------------------------+ void CSymbolsMonitor::Tick() { // Update quotes every minute and specification once a day FOREACH(m_symbols, { if(IsNewBar(m_symbols[i].Name(), PERIOD_D1)) { m_symbols[i].Refresh(); } if(IsNewBar(m_symbols[i].Name(), PERIOD_M1)) { m_symbols[i].RefreshRates(); } }); }
Por último, añadiremos un operador de indexación sobrecargado para obtener el puntero al objeto deseado según el nombre de símbolo dado. Es en este operador donde tendrá lugar la creación automática de nuevos objetos de información para los símbolos a los que no se haya accedido previamente a través de dicho operador.
//+-------------------------------------------------------------------------+ //| Operator for getting an object with information about a specific symbol | //+-------------------------------------------------------------------------+ CSymbolInfo* CSymbolsMonitor::operator[](const string &name) { // Search for the information object for the given symbol in the array int i; SEARCH(m_symbols, m_symbols[i].Name() == name, i); // If found, return it if(i != -1) { return m_symbols[i]; } else { // Otherwise, create a new information object CSymbolInfo *s = new CSymbolInfo(); // Select the desired symbol for it if(s.Name(name)) { // If the selection is successful, update the quotes s.RefreshRates(); // Add to the array of information objects and return it APPEND(m_symbols, s); return s; } else { PrintFormat(__FUNCTION__" | ERROR: can't create symbol with name [%s]", name); } } return NULL; }
Guardaremos el código obtenido en el archivo SymbolsMonitor.mqh en la carpeta actual. Ahora es el turno del código que usará la clase creada.
Modificación de CVirtualAdvisor
En esta clase ya tenemos varios objetos que existen en una única instancia y realizan algunas tareas concretas: receptor de volúmenes de posiciones virtuales, gestor de riesgos, interfaz de información al usuario. Vamos a añadirles también un objeto monitor de símbolos. Más concretamente, vamos a crear un campo de clase que almacenará el puntero al objeto monitor de símbolos:
class CVirtualAdvisor : public CAdvisor { protected: CSymbolsMonitor *m_symbols; // Symbol monitor object CVirtualReceiver *m_receiver; // Receiver object that brings positions to the market CVirtualInterface *m_interface; // Interface object to show the status to the user CVirtualRiskManager *m_riskManager; // Risk manager object ... public: ... };
La creación del objeto monitor de símbolos se iniciará cuando se llame al constructor llamando al método estático CSymbolsMonitor::Instance(), de forma similar a los otros objetos anteriormente mencionados. Y en el destructor añadiremos la eliminación de este objeto.
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualAdvisor::CVirtualAdvisor(string p_params) { ... // If there are no read errors, if(IsValid()) { // Create a strategy group CREATE(CVirtualStrategyGroup, p_group, groupParams); // Initialize the symbol monitor with a static symbol monitor m_symbols = CSymbolsMonitor::Instance(); // Initialize the receiver with the static receiver m_receiver = CVirtualReceiver::Instance(p_magic); // Initialize the interface with the static interface m_interface = CVirtualInterface::Instance(p_magic); ... } } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ void CVirtualAdvisor::~CVirtualAdvisor() { if(!!m_symbols) delete m_symbols; // Remove the symbol monitor if(!!m_receiver) delete m_receiver; // Remove the recipient if(!!m_interface) delete m_interface; // Remove the interface if(!!m_riskManager) delete m_riskManager; // Remove risk manager DestroyNewBar(); // Remove the new bar tracking objects }
En el nuevo manejador de ticks, añadiremos una llamada al método Tick() para el monitor de símbolos. En él se actualizarán las cotizaciones de todos los símbolos usados en el asesor experto:
//+------------------------------------------------------------------+ //| OnTick event handler | //+------------------------------------------------------------------+ void CVirtualAdvisor::Tick(void) { // Define a new bar for all required symbols and timeframes bool isNewBar = UpdateNewBar(); // If there is no new bar anywhere, and we only work on new bars, then exit if(!isNewBar && m_useOnlyNewBar) { return; } // Symbol monitor updates quotes m_symbols.Tick(); // Receiver handles virtual positions m_receiver.Tick(); // Start handling in strategies CAdvisor::Tick(); // Risk manager handles virtual positions m_riskManager.Tick(); // Adjusting market volumes m_receiver.Correct(); // Save status Save(); // Render the interface m_interface.Redraw(); }
Aprovecharemos esta oportunidad para añadir un manejador de eventos ChartEvent a esta clase para futuras referencias. En él se llamará al método homónimo del objeto de interfaz m_interface, que no hace nada en este momento.
Guardaremos los cambios realizados en el archivo VirtualAdvisor.mqh en la carpeta actual.
Modificación de CVirtualOrder
Como ya hemos mencionado, la obtención de información sobre los símbolos se realizará en la clase de posiciones virtuales. Así que empezaremos a hacer cambios con ella, y, en primer lugar, añadiremos a los campos de clase los punteros al monitor (claseCSymbolsMonitor) y al objeto de información para el símbolo (clase CSymbolInfo):
class CVirtualOrder { private: //--- Static fields static ulong s_count; // Counter of all created CVirtualOrder objects CSymbolInfo *m_symbolInfo; // Object for getting symbol properties //--- Related recipient objects and strategies CSymbolsMonitor *m_symbols; CVirtualReceiver *m_receiver; CVirtualStrategy *m_strategy; ... }
La adición de los punteros a la composición de los campos de clase implica que se les deberá asignar punteros a algunos objetos creados. Y si estos objetos se crean dentro de los métodos de los objetos de esta clase, también deberemos ocuparnos de su correcta eliminación.
Luego añadiremos al constructor la inicialización del puntero al monitor de símbolos y el borrado del puntero al objeto de información del símbolo. Para obtener el puntero al monitor de símbolos, llamaremos al método estático CSymbolsMonitor::Instance(). La creación de un único objeto monitor (si no existe un objeto monitor) tendrá lugar en su interior. En el destructor añadiremos el borrado del objeto de información, si es que ha sido creado después de todo y no se ha borrado todavía:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualOrder::CVirtualOrder(CVirtualStrategy *p_strategy) : // Initialization list m_id(++s_count), // New ID = object counter + 1 ... m_point(0) { PrintFormat(__FUNCTION__ + "#%d | CREATED VirtualOrder", m_id); m_symbolInfo = NULL; m_symbols = CSymbolsMonitor::Instance(); } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ CVirtualOrder::~CVirtualOrder() { if(!!m_symbolInfo) delete m_symbolInfo; }
No hemos añadido al constructor la obtención del puntero al objeto de información para el símbolo m_symbolInfo, porque en el momento de llamar al constructor puede que no siempre se sepa exactamente qué símbolo se utilizará en esta posición virtual. Esto solo quedará claro cuando se abra la posición virtual, es decir, cuando se llame al método CVirtualOrder::Open(). En él añadiremos la inicialización del puntero al objeto de información del símbolo:
//+------------------------------------------------------------------+ //| Open a virtual position (order) | //+------------------------------------------------------------------+ bool CVirtualOrder::Open(string symbol, // Symbol ENUM_ORDER_TYPE type, // Type (BUY or SELL) double lot, // Volume double price = 0, // Open price double sl = 0, // StopLoss level (price or points) double tp = 0, // TakeProfit level (price or points) string comment = "", // Comment datetime expiration = 0, // Expiration time bool inPoints = false // Are the SL and TP levels set in points? ) { if(IsOpen()) { // If the position is already open, then do nothing PrintFormat(__FUNCTION__ "#%d | ERROR: Order is opened already!", m_id); return false; } // Get a pointer to the information object for the desired symbol from the symbol monitor m_symbolInfo = m_symbols[symbol]; if(!!m_symbolInfo) { // Actions to open ... return true; } else { ... return false; } }
Ahora, como el monitor de símbolos es el responsable de actualizar la información sobre las cotizaciones de los símbolos, dentro de la clase CVirtualOrder podremos eliminar todas las llamadas a los métodos Name() y RefreshRates() para el objeto de información de propiedades de símbolos m_symbolInfo. Al abrir una posición virtual, m_symbolInfo almacenará el puntero al objeto para el que ya se ha seleccionado el símbolo deseado. Al acompañar una posición virtual previamente abierta en este tick, el método RefreshRates() ya habrá sido llamado una vez por el monitor de símbolos para todos ellos en el método CSymbolsMonitor::Tick().
Vamos a realizar nuevamente el perfilado. La imagen ha cambiado a mejor, pero las llamadas de la función SymbolInfoDouble() todavía tardan un 9%. Una breve búsqueda ha mostrado que estas llamadas resultan necesarias para obtener el valor del spread. Pero podemos sustituir esta operación por el cálculo de la diferencia de precios (Ask - Bid) que ya se han obtenido llamando al método RefreshRates() y no requieren llamadas adicionales a la función SymbolInfoDouble().
Además, hemos introducido cambios en esta clase que no están directamente relacionados con el aumento de la velocidad y no son necesarios para la estrategia de modelización analizada:
- en el manejador CVirtualStrategy::OnOpen() y CVirtualStrategy::OnClose() hemos añadido la transmisión del objeto actual;
- hemos añadido el cálculo del beneficio de las posiciones virtuales cerradas;
- hemos añadido los getters y setters para los niveles de StopLoss y TakeProfit;
- hemos añadido un ticket único asignado al abrir una posición virtual.
Posiblemente, esta biblioteca sufra un rediseño más radical. Por ello, no nos detendremos en la descripción de estos cambios.
Guardaremos los cambios realizados en el archivo VirtualOrder.mqh en la carpeta actual.
Modificación de la estrategia
Para poder usar el monitor de símbolos, también hemos tenido que introducir pequeños cambios en la clase de estrategia comercial. En primer lugar, al igual que en la clase para posiciones virtuales, hemos hecho que el miembro de la clase m_symbolInfo almacene ahora el puntero al objeto en lugar del objeto en sí:
//+------------------------------------------------------------------+ //| Trading strategy using tick volumes | //+------------------------------------------------------------------+ class CSimpleVolumesStrategy : public CVirtualStrategy { protected: ... CSymbolInfo *m_symbolInfo; // Object for getting information about the symbol properties ... public: ... };
Y hemos añadido su inicialización en el constructor:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(string p_params) { ... // Register the event handler for a new bar on the minimum timeframe //IsNewBar(m_symbol, PERIOD_M1); m_symbolInfo = CSymbolsMonitor::Instance()[m_symbol]; ... }
También hemos comentado el registro del nuevo manejador de eventos de la barra, ya que ahora se registrará en el monitor de símbolos.
En segundo lugar, hemos eliminado la actualización de los precios actuales del código de la estrategia (en los métodos de comprobación de la señal de apertura y de apertura de posiciones propiamente dicha), ya que el monitor de símbolos también se encarga de ello.
Guardaremos los cambios realizados en el archivo SimpleVolumesStrategy.mqh en la carpeta actual.
Comprobación de la corrección
Comparemos los resultados de la prueba del asesor experto analizado en el mismo intervalo temporal antes y después de los cambios relacionados con la adición del monitor de símbolos.
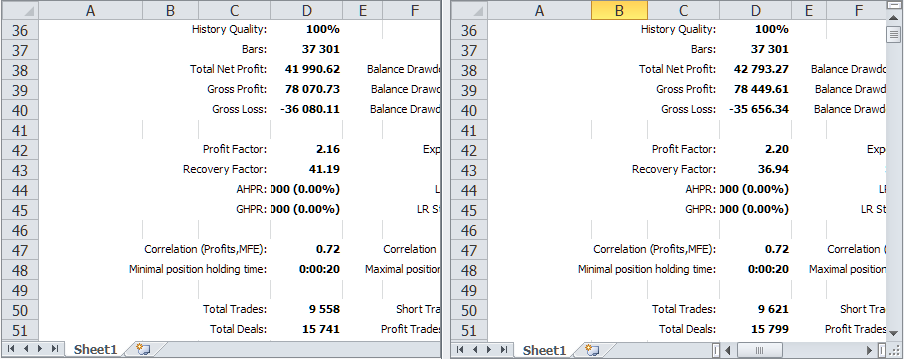
Fig. 2 Comparación de los resultados de la prueba de la versión anterior y la versión actual con el monitor de símbolos
Como puede ver, en líneas generales son iguales, pero existen ligeras diferencias. Para mayor claridad, las mostraremos en forma de tabla.
| Versión | Beneficio | Reducción | Beneficio normalizado |
|---|---|---|---|
| Versión anterior | 41 990.62 | 1 019.49 (0.10%) | 6 867.78 |
| Versión actual | 42 793.27 | 1 158.38 (0.11%) | 6 159.87 |
Si comparamos las primeras operaciones de los informes, observaremos que en la versión anterior hay aperturas de posiciones adicionales que no están presentes en la actual y viceversa. Lo más probable es que esto se deba al hecho de que al iniciar el simulador en el símbolo EURGBP, una nueva barra para EURGBP se produce a las mm:00, mientras que para otro símbolo, por ejemplo GBPUSD, puede producirse tanto a las mm:00 como a las mm:20.
Para eliminar este efecto, añadiremos a la estrategia una comprobación adicional del inicio de una nueva barra:
//+------------------------------------------------------------------+ //| "Tick" event handler function | //+------------------------------------------------------------------+ void CSimpleVolumesStrategy::Tick() override { if(IsNewBar(m_symbol, PERIOD_M1)) { // If their number is less than allowed if(m_ordersTotal < m_maxCountOfOrders) { // Get an open signal int signal = SignalForOpen(); if(signal == 1 /* || m_ordersTotal < 1 */) { // If there is a buy signal, then OpenBuyOrder(); // open the BUY_STOP order } else if(signal == -1) { // If there is a sell signal, then OpenSellOrder(); // open the SELL_STOP order } } } }
Tras esta modificación, los resultados no han hecho sino mejorar. La versión actual ha mostrado la mayor rentabilidad normalizada:
| Versión | Beneficio | Reducción | Beneficio normalizado |
|---|---|---|---|
| Versión anterior | 46 565.39 | 1 079.93 (0.11%) | 7 189.77 |
| Versión actual | 47 897.30 | 1 051.37 (0.10%) | 7 596.31 |
Así que dejaremos las correcciones realizadas y pasaremos a crear el script de rellenado de la base de datos.
Rellenamos la base de datos con proyectos
No vamos a crear un script, sino un asesor experto, pero se comportará como un script. Todo el trabajo se realizará en la función de inicialización, tras lo cual el asesor experto se descargará en el primer tick. Esta implementación nos permitirá ejecutarlo tanto en el gráfico como en el optimizador si queremos obtener múltiples ejecuciones con parámetros que varíen dentro de unos límites especificados.
Como se trata de la primera implementación, no pensaremos de antemano qué composición de parámetros de entrada será más conveniente, sino que intentaremos hacer solo un prototipo mínimo que funcione. Esta será la lista de parámetros:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Database" sinput string fileName_ = "article.16373.db.sqlite"; // - Main database file input group "::: Project parameters" sinput string projectName_ = "SimpleVolumes"; // - Name sinput string projectVersion_ = "1.20"; // - Version sinput string symbols_ = "GBPUSD;EURUSD;EURGBP"; // - Symbols sinput string timeframes_ = "H1;M30;M15"; // - Timeframes input datetime fromDate_ = D'2018-01-01'; // - Start date input datetime toDate_ = D'2023-01-01'; // - End date
Todo está claro con el nombre del proyecto y la versión; luego hay dos parámetros en los que transmitiremos las listas de los símbolos y los marcos temporales separados por punto y coma. Se utilizarán para obtener instancias únicas de la estrategia comercial. Para cada símbolo, se tomarán sucesivamente todos los marcos temporales. Así, si especificáramos tres símbolos y tres marcos temporales en los valores por defecto, se obtendrían nueve instancias únicas.
Cada instancia individual deberá someterse a una primera fase de optimización, en la que se seleccionarán las mejores combinaciones de parámetros solo para ella. Más concretamente, durante el proceso de optimización probaremos muchas combinaciones entre las que podremos seleccionar un cierto número de combinaciones "buenas".
Esta elección se realizará ya en la segunda fase de optimización. Como resultado, tendremos un grupo de varias instancias "buenas" funcionando en un símbolo y un marco temporal determinados. Tras repetir el segundo paso para todas las combinaciones de símbolo y marco temporal, tendremos nueve grupos de instancias únicas para cada combinación.
En el tercer paso, combinaremos estos nueve grupos, obteniendo y almacenando una línea de inicialización en la biblioteca, con la cual podremos crear un asesor experto que incluirá todas las instancias individuales de estos grupos.
Recordemos que el código responsable de la ejecución secuencial de todas las etapas anteriores ya ha sido escrito y puede funcionar si se forman las "instrucciones" necesarias en la base de datos. Antes las añadíamos manualmente a la base de datos. Ahora queremos transferir este procedimiento rutinario al script-asesor que estamos desarrollando.
Los dos parámetros restantes de este asesor experto nos permitirán establecer la fecha de inicio y fin del intervalo de optimización. Las utilizaremos para simular la reoptimización periódica y ver cuánto tiempo después de la reoptimización el asesor experto final negociará con los mismos resultados que en el intervalo de optimización.
Considerando esto, el código de la función de inicialización podría ser algo así:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Connect to the database DB::Connect(fileName_); // Create a project CreateProject(projectName_, projectVersion_, StringFormat("%s - %s", TimeToString(fromDate_, TIME_DATE), TimeToString(toDate_, TIME_DATE) ) ); // Create project stages CreateStages(); // Creating jobs and tasks CreateJobs(); // Queueing the project for execution QueueProject(); // Close the database DB::Close(); // Successful initialization return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Tick handling | //+------------------------------------------------------------------+ void OnTick() { // Since all work is done in OnInit(), delete the EA ExpertRemove(); }
Es decir, crearemos secuencialmente un registro en la tabla de proyectos, luego añadiremos etapas a la tabla de etapas del proyecto y, a continuación, rellenaremos las tablas de trabajos y tareas para cada actividad. Al final pondremos el proyecto en el estado Queued, es decir, en la cola de ejecución. Gracias a los activadores de la base de datos, todos las etapas, actividades y tareas del proyecto pasarán también al estado Queued.
Veamos ahora con más detalle el código de las funciones creadas. La más sencilla será crear un proyecto. Contiene una única consulta SQL para insertar datos y almacenar el identificador de la entrada recién creada en la variable global id_project:
//+------------------------------------------------------------------+ //| Create a project | //+------------------------------------------------------------------+ void CreateProject(string name, string ver, string desc = "") { string query = StringFormat("INSERT INTO projects " " VALUES (NULL,'%s','%s','%s',NULL,'Done') RETURNING rowid;", name, ver, desc); PrintFormat(__FUNCTION__" | %s", query); id_project = DB::Insert(query); }
Como descripción del proyecto, formaremos una línea con la fecha de inicio y fin del intervalo de optimización. Esto nos permitirá distinguir entre proyectos para la misma versión de una estrategia comercial.
La función de creación de etapas será un poco más larga: tendrá que ejecutar tres consultas SQL para crear las tres etapas. Obviamente, podría haber más etapas, pero por ahora nos limitaremos a las tres que se han mencionado un poco antes. Después de crear cada etapa, también recordaremos sus identificadores en las variables globales id_stage1, id_stage2, id_stage3.
//+------------------------------------------------------------------+ //| Create three stages | //+------------------------------------------------------------------+ void CreateStages() { // Stage 1 - single instance optimization string query1 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%s," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project "NULL", // id_parent_stage "First", // name "SimpleVolumesStage1.ex5", // expert "GBPUSD", // symbol "H1", // period 2, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query1); id_stage1 = DB::Insert(query1); // Stage 2 - selection of a good group of single specimens string query2 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%d," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project id_stage1, // id_parent_stage "Second", // name "SimpleVolumesStage2.ex5", // expert "GBPUSD", // symbol "H1", // period 2, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query2); id_stage2 = DB::Insert(query2); // Stage 3 - saving the initialization string of the final EA to the library string query3 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%d," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project id_stage2, // id_parent_stage "Save to library", // name "SimpleVolumesStage3.ex5", // expert "GBPUSD", // symbol "H1", // period 0, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query3); id_stage3 = DB::Insert(query3); }
Para cada etapa, especificaremos un nombre diferente, el ID de la etapa padre y el nombre del asesor de la etapa. Los demás campos de la tabla de etapas serán en su mayoría los mismos para las distintas etapas: intervalo de optimización, depósito inicial, etc.
El trabajo principal recaerá en la función CreateJobs() para crear trabajos y tareas. Cada trabajo se referirá a una combinación de símbolo y marco temporal. Así que primero crearemos los arrays para todos los símbolos y marcos temporales utilizados, que se enumerarán en los parámetros de entrada. Para los marcos temporales, hemos añadido la función StringToTimeframe(), que realizará la conversión del nombre del marco temporal de una línea a un valor de tipo ENUM_TIMEFRAMES.
// Array of symbols for strategies string symbols[]; StringSplit(symbols_, ';', symbols); // Array of timeframes for strategies ENUM_TIMEFRAMES timeframes[]; string sTimeframes[]; StringSplit(timeframes_, ';', sTimeframes); FOREACH(sTimeframes, APPEND(timeframes, StringToTimeframe(sTimeframes[i])));
A continuación, iteraremos todas las combinaciones de símbolos y marcos temporales en un ciclo doble y creamos tres problemas de optimización, cada uno con un criterio personalizado.
// Stage 1 FOREACH(symbols, { for(int j = 0; j < ArraySize(timeframes); j++) { // Use the optimization parameters template for the first stage string params = StringFormat(paramsTemplate1, ""); // Request to create the first stage job for a given symbol and timeframe string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage1, symbols[i], IntegerToString(timeframes[j]), params); ulong id_job = DB::Insert(query); // Add the created job ID to the array APPEND(id_jobs1, id_job); // Create three tasks for this job for(int i = 0; i < 3; i++) { query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 6); DB::Execute(query); } } });
Este número de tareas está condicionado, por una parte, por el hecho de que necesitamos acumular al menos 10 - 20 mil pasadas al optimizar sobre una combinación y, por otra, por el hecho de que no habría tantas como para que el tiempo empleado por la optimización fuera demasiado largo. El criterio de usuario para las tres tareas se elige porque el algoritmo genético para esta estrategia comercial casi siempre converge a diferentes combinaciones de parámetros en diferentes ejecuciones. Por lo tanto, no hay necesidad de usar distintos criterios para diferentes ejecuciones, en cualquier caso, obtendremos una elección lo suficientemente rica de diferentes buenas combinaciones de parámetros de una sola instancia de estrategia.
En el futuro podremos sacar a los parámetros del script el número de tareas y los criterios de optimización utilizados, pero ahora están fijados rígidamente en el código.
Para cada trabajo de la primera etapa, utilizaremos la misma plantilla de parámetros de optimización, que se establecerá en la variable global paramsTemplate1:
// Template of optimization parameters at the first stage string paramsTemplate1 = "; === Open signal parameters\n" "signalPeriod_=212||12||40||240||Y\n" "signalDeviation_=0.1||0.1||0.1||2.0||Y\n" "signaAddlDeviation_=0.8||0.1||0.1||2.0||Y\n" "; === Pending order parameters\n" "openDistance_=10||0||10||250||Y\n" "stopLevel_=16000||200.0||200.0||20000.0||Y\n" "takeLevel_=240||100||10||2000.0||Y\n" "ordersExpiration_=22000||1000||1000||60000||Y\n" "; === Capital management parameters\n" "maxCountOfOrders_=3||3||1||30||N\n";
Los identificadores de los trabajos añadidos los guardaremos en el array id_jobs1, para utilizarlos al crear los trabajos de la segunda etapa.
Para crear los trabajos de la segunda etapa, también utilizaremos la plantilla especificada en la variable global paramsTemplate2, pero ya tendrá una parte modificable:
// Template of optimization parameters for the second stage string paramsTemplate2 = "idParentJob_=%s\n" "useClusters_=false||false||0||true||N\n" "minCustomOntester_=500.0||0.0||0.000000||0.000000||N\n" "minTrades_=40||40||1||400||N\n" "minSharpeRatio_=0.7||0.7||0.070000||7.000000||N\n" "count_=8||8||1||80||N\n";
El valor que viene después de "idParentJob_=" representará el identificador del primer trabajo de etapa, que utilizará una determinada combinación de símbolo y marco temporal. Estos valores nos resultarán desconocidos antes de crear los trabajos de la primera etapa, por lo que se sustituirán en esta plantilla justo antes de que se cree cada trabajo de la segunda etapa a partir del array id_jobs1.
El parámetro count_ de esta plantilla será 8, lo que significa que recopilaremos grupos de ocho instancias únicas de estrategias comerciales. Nuestro asesor experto de segunda etapa nos permitirá establecer este parámetro en un valor de 1 a 16. Así, hemos elegido un valor de 8, igual al número de tareas para un trabajo en la primera fase: ni pocas, ni demasiadas. En el futuro, también podrá incluirse en los parámetros de entrada del script.
// Stage 2 int k = 0; FOREACH(symbols, { for(int j = 0; j < ArraySize(timeframes); j++) { // Use the optimization parameters template for the second stage string params = StringFormat(paramsTemplate2, IntegerToString(id_jobs1[k])); // Request to create a second stage job for a given symbol and timeframe string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage2, symbols[i], IntegerToString(timeframes[j]), params); ulong id_job = DB::Insert(query); // Add the created job ID to the array APPEND(id_jobs2, id_job); k++; // Create one task for this job query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 6); DB::Execute(query); } });
En la segunda fase, solo crearemos un problema de optimización para un único trabajo, ya que, para un ciclo de optimización, se seleccionarán un grupo suficientemente bueno de instancias únicas de la estrategia comercial. Como criterio de optimización, utilizaremos el criterio de usuario.
Los identificadores de los trabajos a añadir también los almacenamos en el array id_jobs2, pero al final resulta no los necesitamos todavía. Estos identificadores pueden resultar útiles a la hora de añadir etapas, por lo que no los eliminaremos.
En el tercer paso, la plantilla de parámetros solo contendrá el nombre del grupo final bajo el que se añadirá a la biblioteca:
// Template of optimization parameters at the third stage string paramsTemplate3 = "groupName_=%s\n" "passes_=";
Así, formaremos el nombre del grupo final a partir del nombre y la versión del proyecto y de la fecha de finalización del intervalo de optimización, y lo sustituiremos en la plantilla utilizada para crear el trabajo de la tercera fase. Como en la tercera etapa es como si reuniéramos los resultados de todas las etapas anteriores, solo se creará un ejemplar del trabajo y la tarea para este trabajo:
// Stage 3 // Use the optimization parameters template for the third stage string params = StringFormat(paramsTemplate3, projectName_ + "_v." + projectVersion_ + "_" + TimeToString(toDate_, TIME_DATE)); // // Request to create a third stage job string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage3, "GBPUSD", "D1", params); ulong id_job = DB::Insert(query); // Create one task for this job query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 0); DB::Execute(query);
Después, solo deberemos cambiar el estado del proyecto para que se ponga en cola de ejecución:
//+------------------------------------------------------------------+ //| Queueing the project for execution | //+------------------------------------------------------------------+ void QueueProject() { string query = StringFormat("UPDATE projects SET status='Queued' WHERE id_project=%d;", id_project); DB::Execute(query); }
Vamos a guardar los cambios realizados en un nuevo archivo CreateProject.mq5 en la carpeta actual.
Una cosa más: Probablemente ya podemos asumir que el esquema de la base de datos será permanente, por lo que podemos integrarlo en la biblioteca. Para ello, hemos creado un archivo db.schema.sql con el esquema de la base de datos como un conjunto de comandos SQL y lo hemos introducido como recurso en el archivo Database.mqh:
// Import sql file for creating DB structure #resource "db.schema.sql" as string dbSchema
También hemos cambiado ligeramente la lógica del método Connect(): si no existe una base de datos con el nombre especificado, se creará automáticamente usando los comandos SQL del archivo cargado como recurso. Al mismo tiempo nos hemos deshecho del método ExecuteFile(), ya que no se utiliza en ninguna otra parte.
Finalmente, estamos en un punto en el que podemos intentar ejecutar el código que hemos escrito.
Rellenando la base de datos
No vamos a generar muchos proyectos a la vez; nos limitaremos a cuatro. Para ello, solo tendremos que colocar cuatro veces el script del asesor experto escrito en cualquier gráfico, estableciendo los parámetros necesarios cada vez. Salvo la fecha final, los valores de todos los parámetros seguirán siendo iguales a los valores por defecto. Y la fecha final la cambiaremos añadiendo un mes más al intervalo de prueba cada vez.
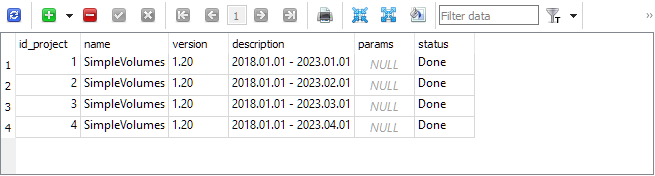
Como resultado, obtendremos aproximadamente el contenido de la base de datos. En la tabla de proyectos, hay cuatro proyectos:
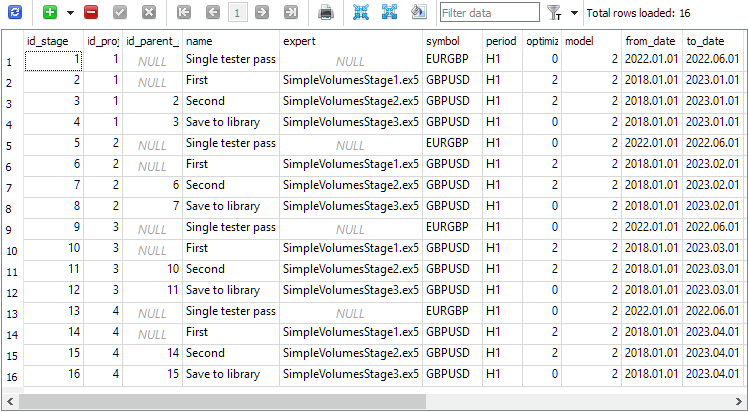
En la tabla de etapas se han creado cuatro etapas para cada proyecto. Durante la creación del proyecto se creará automáticamente un paso adicional denominado "Single tester pass", que se utilizará cuando queramos ejecutar una única estrategia de comprobación fuera del proceso de optimización automática:
En la tabla de trabajos, se han añadido los trabajos correspondientes:
Tras iniciar los proyectos para su ejecución, el resultado se ha obtenido en unos cuatro días. Desde luego, no es poco tiempo, a pesar de los esfuerzos por optimizar el rendimiento. Pero tampoco es tanto como para que no se pueda destacar. Puede verlo en la tabla de la biblioteca strategy_groups:

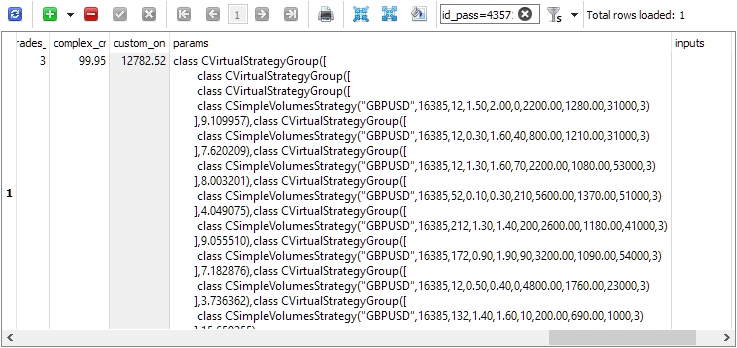
Usando el identificador de pasada id_pass podemos buscar, por ejemplo, la línea de inicialización en la tabla passes:
O podemos sustituir el ID de la pasada como el parámetro de entrada de la tercera etapa del asesor experto SimpleVolumesStage3.ex5 y ejecutarlo en el simulador en el intervalo de tiempo seleccionado:
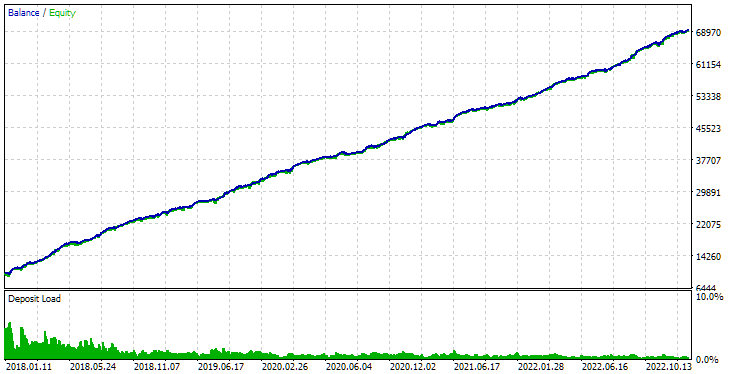
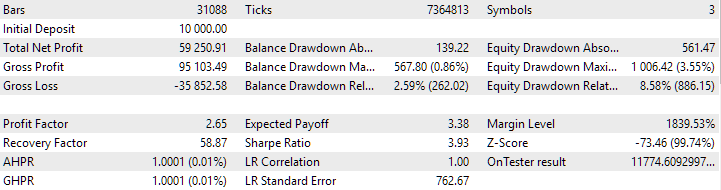
Fig. 3. Resultados de la pasada del asesor experto SimpleVolumesStage3.ex5 con id_pass=876663 en el intervalo 2018.01.01 - 2023.01.01.01
Bueno, por ahora nos detendremos aquí; analizaremos los resultados con más detalle en los artículos siguientes.
Conclusión
Así pues, ahora tenemos la posibilidad de crear automáticamente trabajos para ejecutar un proceso de optimización automática que incluya tres etapas. Esto no es más que un borrador para identificar las áreas preferidas para un mayor desarrollo. Aún no hemos resuelto la cuestión de la fusión o sustitución automática de las líneas finales de inicialización del asesor experto al final de las etapas de cada proyecto.
Pero una cosa es cierta: el orden elegido para las tareas de optimización no es muy bueno. Ahora tendremos que esperar a que todo el trabajo de la primera etapa esté totalmente terminado para poder empezar la segunda. Y del mismo modo, la tercera fase no empezará antes de que se haya completado todo el trabajo de la segunda. Si planeamos implementar de alguna manera el reemplazo "en caliente" de las líneas de inicialización de un asesor experto final que se ejecute continuamente en la cuenta en paralelo con la optimización, podemos hacer que estas actualizaciones sean más pequeñas pero más frecuentes. Quizá esto mejore los resultados, pero sigue siendo solo una hipótesis que hay que probar.
También vale la pena señalar que el script-asesor desarrollado se centra en la creación de proyectos de optimización solo para la estrategia comercial modelo considerada. Para otra estrategia, tendrá que hacer pequeños cambios en el código fuente. Como mínimo, deberá cambiar la plantilla de la línea de parámetros de entrada de la primera etapa de optimización. Todavía no hemos puesto estas plantillas en los parámetros de entrada, ya que no resulta cómodo establecerlas allí directamente. Sin embargo, en el futuro, probablemente desarrollemos algún formato para describir la tarea de creación del proyecto que el script-asesor cargará desde el archivo. Pero eso será en otra ocasión.
Gracias por su atención, ¡hasta pronto!
Advertencia importante
Todos los resultados expuestos en este artículo y en todos los artículos anteriores de la serie se basan únicamente en datos de pruebas históricas y no ofrecen ninguna garantía de lograr beneficios en el futuro. El trabajo de este proyecto es de carácter exploratorio. Todos los resultados publicados pueden ser usados por cualquiera bajo su propia responsabilidad.
Contenido del archivo
| # | Nombre | Versión | Descripción | Cambios recientes |
|---|---|---|---|---|
| MQL5/Experts/Article.16373 | ||||
| 1 | Advisor.mqh | 1.04. | Clase básica del experto | Parte 10 |
| 2 | ClusteringStage1.py | 1.01 | Programa de clusterización de los resultados de la primera etapa de optimización | Parte 20 |
| 3 | CreateProject.mq5 | 1.00 | Script asesor para crear un proyecto con etapas, actividades y tareas de optimización. | Parte 21 |
| 4 | Database.mqh | 1.09 | Clase para trabajar con la base de datos | Parte 21 |
| 5 | db.schema.sql | 1.05 | Esquema de la base de datos | Parte 20 |
| 6 | ExpertHistory.mqh | 1.00 | Clase para exportar la historia de transacciones a un archivo | Parte 16 |
| 7 | ExportedGroupsLibrary.mqh | - | Archivo generado con los nombres de los grupos de estrategias y un array con sus cadenas de inicialización | Parte 17 |
| 8 | Factorable.mqh | 1.02 | Clase básica de objetos creados a partir de una cadena (string) | Parte 19 |
| 9 | GroupsLibrary.mqh | 1.01 | Clase para trabajar con una biblioteca de grupos estratégicos seleccionados | Parte 18 |
| 10 | HistoryReceiverExpert.mq5 | 1.00 | Asesor experto para reproducir la historia de transacciones con el gestor de riesgos | Parte 16 |
| 11 | HistoryStrategy.mqh | 1.00 | Clase de estrategia comercial para reproducir la historia de transacciones | Parte 16 |
| 12 | Interface.mqh | 1.00 | Clase básica de visualización de diversos objetos | Parte 4 |
| 13 | LibraryExport.mq5 | 1.01 | Asesor que guarda las líneas de inicialización de las pasadas seleccionadas de la biblioteca en el archivo ExportedGroupsLibrary.mqh | Parte 18 |
| 14 | Macros.mqh | 1.02 | Macros útiles para operaciones con arrays | Parte 16 |
| 15 | Money.mqh | 1.01 | Clase básica de gestión de capital | Parte 12 |
| 16 | NewBarEvent.mqh | 1.00 | Clase de definición de una nueva barra para un símbolo específico | Parte 8 |
| 17 | Optimization.mq5 | 1.03 | Asesor que gestiona el inicio de las tareas de optimización | Parte 19 |
| 18 | Optimizer.mqh | 1.01 | Clase para el gestor de optimización automática de proyectos | Parte 20 |
| 19 | OptimizerTask.mqh | 1.01 | Clase para la tarea de optimización | Parte 20 |
| 20 | Receiver.mqh | 1.04. | Clase básica de transferencia de volúmenes abiertos a posiciones de mercado | Parte 12 |
| 21 | SimpleHistoryReceiverExpert.mq5 | 1.00 | Asesor experto simplificado para reproducir la historia de transacciones | Parte 16 |
| 22 | SimpleVolumesExpert.mq5 | 1.20 | Asesor experto para el trabajo en paralelo de varios grupos de estrategias modelo. Los parámetros se tomarán de la biblioteca de grupos incorporada. | Parte 17 |
| 23 | SimpleVolumesStage1.mq5 | 1.18 | Asesor experto para optimizar una única instancia de una estrategia comercial (Etapa 1) | Parte 19 |
| 24 | SimpleVolumesStage2.mq5 | 1.02 | Asesor experto para optimizar un grupo de instancias de estrategias comerciales (Etapa 2) | Parte 19 |
| 25 | SimpleVolumesStage3.mq5 | 1.02 | Asesor experto para guardar un grupo normalizado generado de estrategias en la biblioteca de grupos con el nombre especificado. | Parte 20 |
| 26 | SimpleVolumesStrategy.mqh | 1.10 | Clase de estrategia comercial con uso de volúmenes de ticks | Parte 21 |
| 27 | Strategy.mqh | 1.04. | Clase básica de estrategia comercial | Parte 10 |
| 28 | SymbolsMonitor.mqh | 1.00 | Clase de obtención de información sobre instrumentos comerciales (símbolos) | Parte 21 |
| 29 | TesterHandler.mqh | 1.05 | Clase para gestionar los eventos de optimización | Parte 19 |
| 30 | VirtualAdvisor.mqh | 1.08 | Clase de asesor experto para trabajar con posiciones (órdenes) virtuales | Parte 21 |
| 31 | VirtualChartOrder.mqh | 1.01 | Clase de posición virtual gráfica | Parte 18 |
| 32 | VirtualFactory.mqh | 1.04. | Clase de fábrica de objetos | Parte 16 |
| 33 | VirtualHistoryAdvisor.mqh | 1.00 | Clase experta para reproducir la historia de transacciones | Parte 16 |
| 34 | VirtualInterface.mqh | 1.00 | Clase de GUI del asesor | Parte 4 |
| 35 | VirtualOrder.mqh | 1.08 | Clase de órdenes y posiciones virtuales | Parte 21 |
| 36 | VirtualReceiver.mqh | 1.03 | Clase de transferencia de volúmenes abiertos a posiciones de mercado (receptor) | Parte 12 |
| 37 | VirtualRiskManager.mqh | 1.02 | Clase de gestión de riesgos (gestor de riesgos) | Parte 15 |
| 38 | VirtualStrategy.mqh | 1.05 | Clase de estrategia comercial con posiciones virtuales | Parte 15 |
| 39 | VirtualStrategyGroup.mqh | 1.00 | Clase de grupo o grupos de estrategias comerciales | Parte 11 |
| 40 | VirtualSymbolReceiver.mqh | 1.00 | Clase de receptor simbólico | Parte 3 |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16373
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Se ha publicado el artículo Desarrollo de un asesor experto multidivisa (Parte 21): Preparación para un experimento importante y optimización del código:
Autor: Yuriy Bykov
Desafortunadamente, todono es tan simple como nos gustaría . Para poder lanzar elAsesor Experto de la terceraetapa , es necesario especificarlos IDs de los pases obtenidoscomo resultado delasetapas anteriores del pipelinede optimización . Cómo conseguirlos se describe en los artículos.
Entendido. Sin embargo, ya que te has esforzado tanto en describir tu trabajo de una manera más sencilla, sería incluso genial si pudieras crear un videotutorial para enseñar el funcionamiento/optimización del conjunto de EAs que estás creando. Gracias
Entendido. Sin embargo, ya que te has esforzado tanto en describir tu trabajo de una manera más sencilla, sería incluso genial si pudieras crear un videotutorial para enseñar el funcionamiento/optimización del conjunto de EAs que estás creando. Gracias
Hola, gracias por la sugerencia. No puedo prometer que pueda grabar vídeos para los artículos, pero pensaré cómo y de qué forma puedo hacer un vídeo que ayude a los lectores de los artículos.
Hola, gracias por la sugerencia. No puedo prometer que pueda grabar vídeos para los artículos, pero pensaré cómo y de qué forma puedo hacer un vídeo que ayude a los lectores de los artículos.
Gracias. Uno muy sencillo que dure unos segundos será suficiente. Dado que la prueba y optimización de estrategias en MT5 es más compleja de lo que solía ser en MT4, la gente que está en transición a veces lo encuentra difícil. Todo lo que puede hacer es mostrar la configuración exacta que utiliza en la obtención de los resultados que usted está publicando en los artículos.
HI Descargar archivos de la última parte (21) ¿Cómo puedo usuario Este asesor puede u Ayúdame por favor