
Redes neuronales en el trading: Agente con memoria multinivel (Final)

Introducción
En el artículo anterior vimos los fundamentos teóricos del framework FinMem, un agente innovador basado en grandes modelos lingüísticos (LLM). Este framework usa un sistema único de memoria multinivel que permite procesar eficazmente datos de distinta naturaleza y significación temporal.
El módulo de memoria FinMem se divide en dos partes principales:
- Memoria de trabajo: destinada a procesar los datos a corto plazo, como las noticias diarias y las fluctuaciones del mercado.
- Memoria a largo plazo: almacena información con valor a largo plazo, incluidos informes analíticos e investigaciones.
La estructura estratificada de la memoria permite al agente priorizar los datos, centrándose en los más relevantes para las condiciones actuales del mercado. Por ejemplo, los eventos a corto plazo se analizan momentáneamente, mientras que la información con un impacto profundo se almacena para su uso posterior.
El módulo de perfiles de FinMem adapta el trabajo del agente a contextos profesionales y condiciones de mercado específicos. Considerando las preferencias individuales del usuario y su perfil de riesgo, el agente es capaz de optimizar su estrategia, garantizando la máxima eficacia de las operaciones comerciales.
El módulo de toma de decisiones combina los datos actuales y las memorias almacenadas para generar estrategias que tengan en cuenta tanto las tendencias a corto plazo como los patrones a largo plazo. Este enfoque de inspiración cognitiva permite al agente memorizar los eventos clave del mercado y adaptarse a las nuevas señales, lo cual mejora notablemente la precisión y eficacia de las decisiones de inversión.
Los resultados de los experimentos realizados por los autores del framework muestran que FinMem supera a otros modelos de comercio autónomo. Incluso con datos de entrada limitados, el agente muestra un rendimiento sobresaliente en el procesamiento de la información y la formación de estrategias. Su capacidad para gestionar la carga cognitiva le permite analizar de manera simultánea decenas de señales de mercado y destacar las más importantes. El agente estructura las señales según su importancia y toma decisiones informadas incluso con limitaciones de tiempo.
FinMem también tiene una capacidad única para aprender en tiempo real, lo cual lo hace flexible a las cambiantes condiciones del mercado. Esto permite al agente no solo gestionar con éxito las tareas actuales, sino también mejorar sus planteamientos de forma constante, adaptándose a los nuevos datos. FinMem combina principios cognitivos y tecnología avanzada para ofrecer una solución de última generación para hacer frente a unos mercados financieros dinámicos y complejos.
A continuación, le presentamos una visualización del flujo de información del framework FinMem por parte del autor.
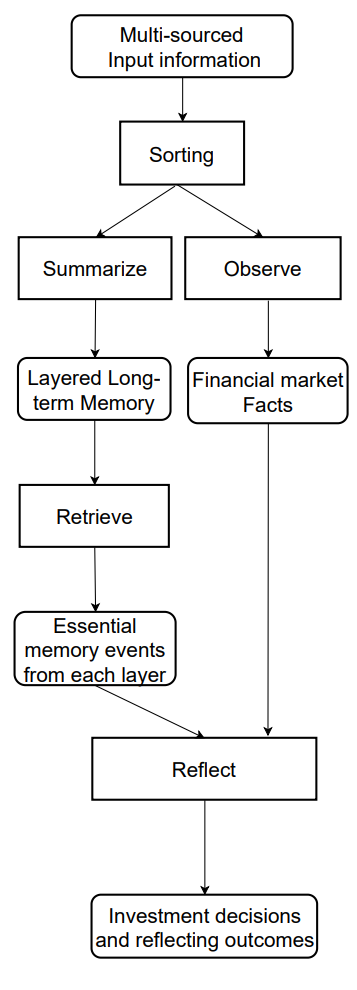
En el artículo anterior, empezamos a aplicar los enfoques propuestos por los autores del framework usando herramientas MQL5. Asimismo, propusimos nuestra propia visión del módulo de memoria multinivel CNeuronMemory, que difiere significativamente de la versión del autor. De hecho, en nuestra implementación del framework FinMem, hemos quitado el gran modelo de lenguaje, que supone un componente clave del concepto original, lo cual ha dejado su huella en todos los componentes del modelo.
A pesar de ello, hemos hecho todo lo posible por reproducir los principales flujos de información del framework. En particular, el objeto CNeuronFinMem se diseñó para mantener un enfoque estratificado del procesamiento de datos. Este mecanismo integra con éxito técnicas de procesamiento de la información a corto plazo y estrategias a largo plazo, ofreciendo un rendimiento estable y predecible en mercados dinámicos.
Creación del framework FinMem
Recordemos que nos detuvimos en la construcción del complejo algoritmo del framework propuesto dentro del objeto CNeuronFinMem, cuya estructura se presenta a continuación.
class CNeuronFinMem : public CNeuronRelativeCrossAttention { protected: CNeuronTransposeOCL cTransposeState; CNeuronMemory cMemory[2]; CNeuronRelativeCrossAttention cCrossMemory; CNeuronRelativeCrossAttention cMemoryToAccount; CNeuronRelativeCrossAttention cActionToAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinMem(void) {}; ~CNeuronFinMem(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint accoiunt_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinMem; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Ya hemos visto cómo se inicializa el objeto, así que ahora pasaremos a la construcción del método feedForward, que toma dos parámetros principales.
El primero es un tensor que supone un conjunto de datos multidimensional que caracteriza el estado del entorno. Contiene diversos datos de mercado, como las cotizaciones actuales y los indicadores técnicos analizados. Este enfoque permite considerar una amplia gama de variables, lo cual ofrece al algoritmo la capacidad de tomar decisiones basadas en análisis complejos.
El segundo parámetro es un vector que contiene información sobre el estado de la cuenta comercial. Incluye el balance actual, los datos sobre pérdidas y ganancias y una marca temporal. Este componente garantiza la disponibilidad de la información actualizada y mantiene la precisión de los cálculos en tiempo real.
bool CNeuronFinMem::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cTransposeState.FeedForward(NeuronOCL)) return false;
Para realizar un análisis exhaustivo del estado del entorno, comenzaremos con el procesamiento de los datos de origen representados como un tensor de un array multidimensional. El procedimiento de transposición permite transformar el array resultante, lo cual ofrece la comodidad de trabajar con diferentes proyecciones para una extracción más detallada de las características clave.
A continuación, las dos proyecciones de los datos de origen se enviarán a módulos de memoria especializados para su análisis en profundidad. El primer módulo está diseñado para estudiar la dinámica temporal de los parámetros de mercado dispuestos en forma de barras, lo cual permitirá registrar e interpretar el complejo comportamiento del instrumento financiero analizado. El segundo módulo se centra en el análisis de secuencias unitarias de una serie temporal multimodal, lo cual permitirá identificar dependencias ocultas entre distintos indicadores y captar sus correlaciones. Esto crea una visión integrada del estado actual del mercado.
Dicha estructura del análisis garantiza un alto nivel de precisión y facilita la adaptación flexible del modelo a los cambios en la dinámica del mercado, lo cual resultará fundamental para lograr decisiones fiables y oportunas en el entorno financiero.
if(!cMemory[0].FeedForward(NeuronOCL) || !cMemory[1].FeedForward(cTransposeState.AsObject())) return false;
La combinación de los resultados del análisis de los dos módulos de memoria se realizará mediante un bloque de atención cruzada que permitirá enriquecer las series temporales multimodales con los resultados del análisis de las secuencias unitarias. Esto mejorará la precisión y exhaustividad de la información obtenida, haciéndola más adecuada para tomar decisiones con conocimiento de causa.
if(!cCrossMemory.FeedForward(cMemory[0].AsObject(), cMemory[1].getOutput())) return false;
A continuación, se investigará el impacto de los cambios del mercado en el balance. Para ello, los resultados del análisis multinivel de la situación del mercado se compararán con el vector del estado de la cuenta actual mediante el módulo de atención cruzada. Este enfoque metodológico permitirá una evaluación más precisa del impacto de los eventos del mercado en los resultados financieros. El análisis permitirá dar cuenta de las complejas relaciones entre los eventos del mercado y los resultados financieros. Esto resulta especialmente importante para la previsión y la gestión de los riesgos.
if(!cMemoryToAccount.FeedForward(cCrossMemory.AsObject(), SecondInput)) return false;
El siguiente paso consistirá en trabajar con el bloque de toma de decisiones operativas. Este trabajo comenzará con una comparación de las acciones recientes del Agente con los beneficios y las pérdidas actuales para determinar sus interdependencias. En esta fase, determinaremos la eficacia de la política utilizada y si es necesario ajustarla. Esto permitirá evitar acciones estándar y aumentará la flexibilidad de la estrategia comercial, lo cual resultará especialmente valioso en entornos de alta volatilidad.
Además, en este paso, el modelo podrá estimar la tolerancia al riesgo para la siguiente operación comercial.
Resulta importante señalar que el tensor de las acciones recientes del Agente supondrá la tercera fuente de datos. Al mismo tiempo, deberemos ser conscientes de las limitaciones del método, que permite el procesamiento de solo dos flujos de información de los datos de origen. Sin embargo, aprovecharemos que el tensor de acciones del Agente se forma a la salida de este objeto y se almacena en su búfer de resultados hasta que se completen las operaciones del siguiente método de pasada directa. Esto nos ofrece la capacidad de llamar a una pasada directa del bloque interno de atención cruzada utilizando el puntero al objeto actual, de forma similar a los módulos de recurrencia.
if(!cActionToAccount.FeedForward(this.AsObject(), SecondInput)) return false;
En esta fase, deberemos asegurarnos de que el tensor de las acciones recientes del Agente se conserve antes de ser rellenado con nuevos datos para garantizar que las operaciones de pasada inversa se realizan correctamente. Para ello, sustituiremos los punteros por los búferes de datos correspondientes, lo cual minimizará el riesgo de pérdida de información.
if(!SwapBuffers(Output, PrevOutput)) return false;
Después, llamaremos al método de la clase padre, cuya tarea consistirá en formar un nuevo tensor de acción del Agente. Este proceso se basará en los resultados de las operaciones analíticas realizadas previamente con el método actual. Esto creará una cadena continua de interacción entre los distintos módulos para mantener un alto nivel de coherencia y pertinencia de los datos.
if(!CNeuronRelativeCrossAttention::feedForward(cActionToAccount.AsObject(), cMemoryToAccount.getOutput())) return false; //--- return true; }
Y finalizaremos el método retornando el resultado lógico de las operaciones al programa que realiza la llamada.
El algoritmo de pasada directa que hemos construido posee una naturaleza no lineal que afectará significativamente al procesamiento de los datos en los métodos de pasada inversa. Esto resulta particularmente evidente en el algoritmo de distribución de gradientes de error implementado en el método calcInputGradients. Para realizar este proceso correctamente, la información deberá procesarse estrictamente según la lógica de la pasada directa, pero en orden inverso. Esto requerirá considerar todas las características únicas de la arquitectura del modelo para garantizar la precisión y coherencia del cálculo.
En los parámetros del método calcInputGradients obtendremos los punteros a los objetos de los dos flujos de datos de origen a los que pasaremos los gradientes de error según la influencia de los datos de origen en el resultado final del modelo.
bool CNeuronFinMem::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondInput || !SecondGradient) return false;
Y en el cuerpo del método comprobaremos inmediatamente la relevancia de los punteros recibidos. De lo contrario, todas las operaciones posteriores carecerán de sentido debido a la imposibilidad de transferir posteriormente sus resultados.
Recordemos que las operaciones de pasada directa se han finalizado llamando al método de la clase padre responsable del procesamiento final. En consecuencia, la distribución del gradiente de error partirá del método homónimo de la clase padre. Su trabajo consistirá en dirigir el gradiente de error a los dos bloques internos de atención cruzada de las líneas troncales de procesamiento paralelo de datos.
if(!CNeuronRelativeCrossAttention::calcInputGradients(cActionToAccount.AsObject(), cMemoryToAccount.getOutput(), cMemoryToAccount.getGradient(), (ENUM_ACTIVATION)cMemoryToAccount.Activation())) return false;
Obsérvese aquí que en una de las líneas troncales de información, hemos utilizado recurrentemente como datos de entrada los resultados de una pasada anterior de nuestro objeto. Esto tendrá el efecto de crear un ciclo continuo en el proceso de pasada inversa que tendremos que romper.
Para realizar correctamente las operaciones de distribución del gradiente de error, primero tendremos que devolver al búfer los resultados del penúltimo valor de la pasada hacia delante, que utilizamos como datos de entrada para el módulo de atención cruzada de la comparación con el resultado financiero obtenido. Esto se logra sustituyendo los punteros a los búferes de datos, lo cual permitirá devolver los datos sin pérdida de información y con un coste mínimo.
if(!SwapBuffers(Output, PrevOutput)) return false;
Además, necesitaremos sustituir el puntero al búfer de gradiente de error de nuestro objeto para no perder los datos obtenidos previamente de la capa posterior. Para ello, utilizaremos cualquier búfer disponible de tamaño suficiente. Obviamente, el tamaño del tensor de descripción del estado del entorno es mucho mayor que el vector de acción del Agente. Esto nos permitirá tomar uno de los búferes de la línea troncal especificada.
CBufferFloat *temp = Gradient; if(!SetGradient(cMemoryToAccount.getPrevOutput(), false)) return false;
Y ahora que hemos conseguido todos los datos necesarios, llamaremos al método de distribución del gradiente de error a través del bloque de atención cruzada para analizar el impacto de las acciones previas del agente en el resultado financiero obtenido.
if(!calcHiddenGradients(cActionToAccount.AsObject(), SecondInput, SecondGradient, SecondActivation)) return false;
Después retornaremos a su estado inicial los punteros a los búferes de datos.
if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
En esta etapa, hemos distribuido el gradiente de error a lo largo de la línea troncal de evaluación de las acciones recientes del Agente. En este caso, además, hemos transmitido los gradientes de error correspondientes a la línea troncal de memoria y al búfer del vector de descripción de la cuenta. Nótese, sin embargo, que los datos del búfer de descripción del estado de la cuenta participan en dos flujos de información: el flujo de memoria y el flujo de acciones del Agente. En este último, ya hemos pasado el gradiente de error. Ahora vamos a determinar la influencia de los datos del estado de la cuenta en el resultado final del modelo a lo largo de la línea troncal de memoria y a sumar los valores obtenidos de los dos flujos de información.
if(!cCrossMemory.calcHiddenGradients(cMemoryToAccount.AsObject(), SecondInput, cMemoryToAccount.getPrevOutput(), SecondActivation)) return false; if(!SumAndNormilize(SecondGradient, cMemoryToAccount.getPrevOutput(), SecondGradient, 1, false, 0, 0, 0, 1)) return false;
A continuación, tendremos que distribuir el gradiente de error a lo largo de la línea troncal de memoria al nivel de los datos de origen de la línea troncal principal según su influencia en el resultado final del modelo. Aquí también tendremos 2 flujos de información de análisis de los datos de origen en diferentes proyecciones. Primero distribuiremos el gradiente de error entre los flujos de información especificados.
if(!cMemory[0].calcHiddenGradients(cCrossMemory.AsObject(), cMemory[1].getOutput(), cMemory[1].getGradient(), (ENUM_ACTIVATION)cMemory[1].Activation())) return false;
Y lo haremos descender al nivel del objeto de transposición de los datos de origen.
if(!cTransposeState.calcHiddenGradients(cMemory[1].AsObject())) return false;
En este punto, solo necesitaremos pasar el gradiente de error al objeto de datos de origen desde las dos líneas troncales de memoria paralela. Primero analizaremos los errores de una línea troncal.
if(!NeuronOCL.calcHiddenGradients(cMemory[0].AsObject())) return false;
Y luego sustituiremos los búferes de datos y pasaremos el gradiente de error por la segunda línea troncal.
temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(cTransposeState.getPrevOutput(), false) || !NeuronOCL.calcHiddenGradients(cTransposeState.AsObject()) || !NeuronOCL.SetGradient(temp, false) || !SumAndNormilize(temp, cTransposeState.getPrevOutput(), temp, iWindow, false, 0, 0, 0, 1)) return false; //--- return true; }
Solo queda sumar los datos de los dos flujos de información y devolver los punteros a los búferes de datos al estado inicial. Después retornaremos el resultado lógico al programa que realiza la llamada y finalizaremos el método.
Con esto concluirá nuestro análisis de los algoritmos para construir los métodos del objeto CNeuronFinMem. Podrá leer el código completo de esta clase y todos sus métodos por sí mismo en el archivo adjunto.
Arquitectura del modelo
Ya hemos completado la implementación de los enfoques del framework FinMem mediante MQL5 dentro del objeto CNeuronFinMem. Esta implementación nos ofrece una funcionalidad básica, así como una base para seguir trabajando con los algoritmos de aprendizaje. El siguiente paso consistirá en integrar el objeto creado en un modelo de Agente entrenado que servirá de núcleo para la toma de decisiones en los sistemas financieros. La arquitectura del modelo entrenado se representará en el método CreateDescriptions.
Cabe señalar que el framework FinMem no se limita solo a soluciones arquitectónicas. También incluye algoritmos de aprendizaje únicos que permiten al modelo adaptarse a los cambios y procesar eficazmente los datos en un entorno financiero complejo. Bueno, volveremos al proceso de aprendizaje un poco más tarde. Lo que nos importa ahora es que solo entrenaremos un modelo, el modelo del Agente.
En los parámetros del método CreateDescriptions, obtendremos el puntero a un array dinámico para registrar la arquitectura del modelo a crear.
bool CreateDescriptions(CArrayObj *&actor) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; }
En el cuerpo del método comprobaremos directamente la relevancia del puntero recibido y, si es necesario, crearemos una nueva instancia del array dinámico.
A continuación, como de costumbre, crearemos un bloque de preprocesamiento para los datos de origen. Este bloque incluirá una capa completamente conectada que admitirá los datos de origen y una capa de normalización por lotes que reducirá la sensibilidad del modelo a los cambios en las escalas de datos y mejorará la estabilidad del entrenamiento. Este enfoque garantizará el funcionamiento eficaz de los componentes posteriores del modelo.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Luego vendrá el bloque framework FinMem, que hemos desarrollado, y que servirá de base para aplicar aspectos clave del procesamiento de datos y la toma de decisiones.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFinMem; //--- Windows { int temp[] = {BarDescr, AccountDescr, 2*NActions}; //Window, Account description, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
En el array windows, especificaremos los 3 tensores de dimensionalidad principales de los datos de origen, a saber, los tensores de descripción de barras individuales, de estado de la cuenta y de acciones del agente. Esta última será simultáneamente la dimensionalidad del vector de resultados del bloque.
Nótese que en este caso hemos especificado que la dimensionalidad del tensor de acciones del Agente es 2 veces la constante correspondiente. Este enfoque nos permitirá introducir los planteamientos estocásticos de la cabeza del Agente. Como es habitual en estos casos, la primera parte indicará los valores medios de las distribuciones, mientras que la segunda indicará la varianza correspondiente. Y a este respecto nos gustaría recordar que al inicializar los objetos de atención cruzada que trabajan con el tensor de acciones del agente, hemos dividido el flujo de datos del flujo principal en 2 vectores iguales. Esto nos permitirá obtener valores coherentes de la media y la varianza correspondiente a la salida del bloque.
La generación de valores dentro de las distribuciones especificadas se realizará mediante la capa de estado latente del autocodificador variacional.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Mientras que la arquitectura del modelo se completará con una capa convolucional que proyectará los valores obtenidos en el rango deseado de acciones del Agente.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- return true; }
Después de ello, solo nos quedará retornar el resultado lógico de las operaciones al programa que realiza la llamada y asegurarnos de que el método funciona.
Programa de entrenamiento
Hemos trabajado mucho para aplicar los enfoques propuestos por los autores del framework FinMem. Y en esta fase, ya disponemos de una arquitectura modelo para procesar eficazmente los datos financieros y adaptarnos a las complejas condiciones del mercado. La peculiaridad del modelo creado es el uso de una memoria multinivel que imitará los procesos cognitivos humanos.
Pero, como ya hemos mencionado, los autores de este framework, además de soluciones arquitectónicas, proponen un algoritmo de entrenamiento de modelos basado en un enfoque multinivel del procesamiento de datos. Esto permite considerar no solo las dependencias lineales, sino también las complejas relaciones no lineales entre parámetros. Durante la fase de entrenamiento, el modelo se expone a una amplia gama de información procedente de múltiples fuentes, lo cual ayuda a crear una visión global del entorno financiero. Esto garantizará la adaptación a las cambiantes condiciones del mercado y aumentará la precisión de las previsiones.
Durante el entrenamiento, al recibir una consulta con datos analizados, el modelo activará dos procesos clave: la observación y la generalización. Así, el sistema observará los marcadores de mercado que incluyan las variaciones diarias del precio del instrumento financiero analizado. Estas etiquetas servirán como indicadores para las acciones "Compra" o "Venta". Esta información permitirá al modelo identificar y priorizar los recuerdos más relevantes, clasificándolos según las puntuaciones de recuperación de cada capa de la memoria a largo plazo.
A su vez, la memoria a largo plazo de FinMem permitirá almacenar datos críticos para el uso futuro de eventos y recuerdos. Estos se procesarán en niveles más profundos de la memoria, lo cual garantizará su almacenamiento a largo plazo. La repetición de las operaciones y las reacciones del mercado reforzarán la pertinencia de la información almacenada, lo cual contribuirá a mejorar continuamente la calidad de las decisiones.
Nuestra anterior decisión de no usar un modelo lingüístico amplio también influirá en el proceso de aprendizaje. No obstante, nos esforzaremos por mantener los enfoques de aprendizaje de los modelos propuestos. En particular, durante el entrenamiento, permitiremos que los modelos miren "hacia el futuro", como hemos hecho al entrenar varios modelos de previsión de movimientos de precios. No obstante, deberemos considerar un pequeño detalle: En este caso, no podremos limitarnos a transmitir la información sobre un próximo movimiento de los precios. El resultado de nuestro modelo generará los parámetros de la operación comercial. Y durante el entrenamiento, necesitaremos transmitir datos similares como retroalimentación (etiquetas de aprendizaje). Por lo tanto, durante el entrenamiento del modelo, basándonos en la información disponible sobre el próximo movimiento de los precios, intentaremos generar una solución comercial casi perfecta.
Le sugiero examinar la aplicación del enfoque propuesto en código. En el marco de este artículo, solo consideraremos el método de entrenamiento directo del modelo Train. El código completo del programa de entrenamiento "...\Experts\FinMem\Study.mq5" se encuentra en el archivo adjunto.
El comienzo del método de entrenamiento del modelo es bastante tradicional: generaremos un vector de probabilidades de selección de trayectorias a partir del búfer de reproducción de experiencias basado en el rendimiento de las pasadas guardadas y declararemos las variables locales necesarias.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); bool Stop = false;
A continuación, organizaremos un ciclo de entrenamiento de modelos. Sin embargo, en este caso utilizaremos modelos de recurrencia sensibles a la secuencia de datos de entrada, lo cual nos llevará a la necesidad de utilizar un sistema de ciclos anidados. Dentro del ciclo exterior, muestrearemos una trayectoria del búfer de reproducción de experiencias y el estado inicial en ella. Y en el ciclo interior iteraremos secuencialmente los estados de la trayectoria seleccionada. El número de iteraciones de entrenamiento y el tamaño del paquete se especificarán en los parámetros externos del programa de entrenamiento.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; } if(!Actor.Clear()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter -= Batch + start - i; break; }
Nótese aquí que, antes de empezar el entrenamiento en cada nueva trayectoria, deberemos borrar la memoria del modelo. Al fin y al cabo, los datos almacenados en él deberán ser pertinentes para la condición del entorno analizado.
En el cuerpo del ciclo anidado, primero extraeremos la descripción del estado del entorno analizado del búfer de reproducción de experiencias y formaremos un vector de descripción del estado de la cuenta.
Aquí debemos señalar que estaremos formando exactamente un vector de descripción del estado de la cuenta. Anteriormente, nos limitábamos a transferir la información del búfer de reproducción de experiencias a este vector, cambiando ligeramente el formato de representación de los datos. En este caso, sin embargo, tendremos que considerar el hecho de que el modelo aprende a analizar el impacto de las acciones recientes del agente en el resultado financiero obtenido. Esto significa que el vector de estado de la cuenta deberá depender de ellas, lo cual no puede conseguirse simplemente transfiriendo información desde el búfer de reproducción de experiencias.
En primer lugar, formaremos los armónicos de la marca temporal del estado del entorno analizado.
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Y obtendremos el vector de las últimas acciones del Agente almacenadas en el búfer del modelo.
//--- Previous Action
Actor.getResults(result);
Aquí calcularemos el rendimiento de esta acción sobre el cambio de precio dentro de la última barra del estado del entorno analizado. Debo admitir que para simplificar el algoritmo se usa el análisis básico. No tendremos en cuenta aspectos como la activación de los niveles de stop loss y take profit, así como las posibles comisiones por operaciones comerciales. Además, se supone que todas las posiciones abiertas anteriormente se han cerrado antes de que se ejecute la última transacción del agente. Este enfoque estará justificado para la estimación superficial de la eficiencia del modelo, pero antes de su uso en el comercio real deberemos considerar detalladamente todas las peculiaridades del mercado y los parámetros relacionados.
Para calcular el rendimiento de la última transacción, simplemente multiplicaremos el cambio de precio por la diferencia en el volumen de las transacciones de compra y venta del vector de acciones recientes del agente.
float profit = float(bState[0] / (_Point * 10) * (result[0] - result[3]));
Recordemos que estamos considerando como cambio de precio la diferencia entre los precios de cierre y apertura. Esto significa que obtendremos un valor positivo para una vela alcista y un valor negativo en caso contrario. La diferencia en el volumen de operaciones comerciales también nos dará un número positivo para las operaciones de compra y un número negativo para las operaciones de venta. Por ello, el producto de los dos valores especificados dará el signo correcto de la operación comercial.
A continuación, tomaremos del búfer de reproducción de experiencias los datos de balance y equidad del estado anterior en el que se suponía que se iba a ejecutar la operación propuesta por el agente en el paso anterior.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1];
Como ya hemos indicado, antes de realizar operaciones, partiremos de la base de que se han cerrado todas las posiciones abiertas anteriormente. Se trata de reequilibrar a un nivel de equidad.
bAccount.Clear(); bAccount.Add((PrevEquity - PrevBalance) / PrevBalance);
La variación de la equidad de la última barra comercial será igual al resultado financiero de la última operación de negociación calculado anteriormente.
bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity);
Comerciaremos únicamente en función de la diferencia del volumen, que se reflejará en los indicadores de las posiciones abiertas.
bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0));
Como consecuencia, especificaremos el resultado financiero solo para una posición abierta.
bAccount.Add((bAccount[3]>0 ? profit / PrevBalance : 0)); bAccount.Add((bAccount[4]>0 ? profit / PrevBalance : 0)); bAccount.Add(0); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Y tras preparar los datos iniciales, realizaremos una pasada directa de nuestro modelo, cuyas operaciones generarán un nuevo vector de acción del Agente.
//--- Feed Forward if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Ahora, para realizar operaciones de pasada inversa, necesitaremos preparar los valores objetivo de la operación "ideal" basándonos en los datos sobre el próximo movimiento del precio. Para ello, recuperaremos los datos para un horizonte de planificación determinado del búfer de reproducción de experiencias.
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break;
Y los reformatearemos en un array.
if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; }
Y, a continuación, cambiaremos el orden de las filas del array para que los datos coincidan con la secuencia cronológica.
for(int i = 0; i < NForecast / 2; i++) { if(!fstate.SwapRows(i, NForecast - i - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
La primera columna de nuestro array de previsiones contendrá la variación del precio de cada barra. Tomaremos la suma acumulada de estos valores, lo cual nos dará la variación total de los precios en cada etapa del periodo de previsión.
target = fstate.Col(0).CumSum();
Nótese aquí que este enfoque no considerará posibles lagunas. Como la probabilidad de que se produzcan estos sucesos es relativamente baja, estamos dispuestos a no tenerlo en cuenta en los experimentos. Pero este enfoque no será aplicable a la hora de preparar decisiones comerciales reales.
La formación posterior del vector de acción objetivo del agente dependerá de la operación anterior. Si en el paso anterior hemos abierto una posición, buscaremos un punto de salida. Vamos a analizar el algoritmo usando como ejemplo una operación de compra. En primer lugar, definiremos el nivel del stop loss fijado y declaremos las variables locales necesarias.
if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0;
A continuación, organizaremos un ciclo de iteración de los valores pronosticados del movimiento del precio con una búsqueda de la posición desencadenante del stop loss actual. Durante la iteración de los valores, fijaremos el valor máximo y mínimo para establecer los nuevos niveles de stop loss y take profit.
for(int i = 0; i < NForecast; i++) { tp = MathMax(tp, target[i] + fstate[i, 1] - fstate[i, 0]); pos = i; if(cur_sl >= target[i] + fstate[i, 2] - fstate[i, 0]) break; sl = MathMin(sl, target[i] + fstate[i, 2] - fstate[i, 0]); }
Si se da un movimiento bajista, se esperará que el valor de take profit permanezca igual a "0", lo cual dará lugar a la formación de un vector cero de acciones del agente. Y como consecuencia, cerraremos todas las posiciones abiertas y esperaremos la apertura de una nueva barra.
Si se espera que el precio suba, se formará un nuevo vector de acciones del agente con una indicación de los valores ajustados de los niveles comerciales.
if(tp > 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.01f); result[1] = tp; result[2] = sl; for(int i = 3; i < NActions; i++) result[i] = 0; bActions.AssignArray(result); } }
El vector de acciones se formará de manera similar al buscar un punto de salida de una operación corta.
else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int i = 0; i < NForecast; i++) { tp = MathMin(tp, target[i] + fstate[i, 2] - fstate[i, 0]); pos = i; if(cur_sl <= target[i] + fstate[i, 1] - fstate[i, 0]) break; sl = MathMax(sl, target[i] + fstate[i, 1] - fstate[i, 0]); } if(tp < 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.01f); result[4] = tp; result[5] = sl; for(int i = 0; i < 3; i++) result[i] = 0; bActions.AssignArray(result); } }
Si no hay ninguna posición abierta, se dará un enfoque ligeramente distinto. En este caso, primero identificaremos la tendencia dominante más próxima.
ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax] > MathAbs(target[argmin])) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin])) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); }
Y el vector de acciones se formará en el marco de esta tendencia, mientras que el volumen de la operación lo especificaremos como el tamaño del lote mínimo por cada 100USD del balance actual.
if(argmin == 0 || argmax < argmin) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong i = 0; i < argmax; i++) { tp = MathMax(tp, target[i] + fstate[i, 1] - fstate[i, 0]); pos = i; if(cur_sl >= target[i] + fstate[i, 2] - fstate[i, 0]) break; sl = MathMin(sl, target[i] + fstate[i, 2] - fstate[i, 0]); } if(tp > 0) { sl = (float)MathMin(MathAbs(sl) / (MaxSL * Point()), 1); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(Buffer[tr].States[i].account[0] / 100 * 0.01); result[1] = tp; result[2] = sl; for(int i = 3; i < NActions; i++) result[i] = 0; bActions.AssignArray(result); } } else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong i = 0; i < argmin; i++) { tp = MathMin(tp, target[i] + fstate[i, 2] - fstate[i, 0]); pos = i; if(cur_sl <= target[i] + fstate[i, 1] - fstate[i, 0]) break; sl = MathMax(sl, target[i] + fstate[i, 1] - fstate[i, 0]); } if(tp < 0) { sl = (float)MathMin(MathAbs(sl) / (MaxSL * Point()), 1); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(Buffer[tr].States[i].account[0] / 100 * 0.01); result[4] = tp; result[5] = sl; for(int i = 0; i < 3; i++) result[i] = 0; bActions.AssignArray(result); } } } } }
Una vez generado un vector de acciones "casi perfectas", realizaremos una pasada inversa de nuestro modelo, minimizando la desviación de las acciones previstas del agente respecto a nuestros valores objetivo.
//--- Actor Policy if(!Actor.backProp(GetPointer(bActions), (CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Ahora solo nos quedará informar al usuario del progreso del proceso de aprendizaje y pasar a la siguiente iteración de nuestro sistema de ciclos.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Y una vez ejecutadas con éxito todas las iteraciones de nuestro sistema de ciclos de entrenamiento de los modelos, borraremos el campo de comentarios del gráfico del instrumento financiero utilizado para informar al usuario. Luego registraremos los resultados del entrenamiento e inicializaremos el proceso de finalización del programa.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
Con esto concluirá la revisión de algoritmos para construir el framework FinMem utilizando herramientas MQL5. Podrá ver el código completo de todos los objetos presentados, sus métodos y los programas utilizados en la preparación del artículo en el archivo adjunto.
Simulación
Los dos últimos artículos han tratado sobre el framework FinMem. En ellos, hemos implementado nuestra visión de los enfoques propuestos por los autores de este framework usando herramientas MQL5. Y ahora nos acercamos a la fase más emocionante: probar la eficacia de las soluciones aplicadas con datos históricos reales.
Cabe destacar que hemos realizado modificaciones significativas en los algoritmos del framework FinMem durante la implementación. Por lo tanto, solo evaluaremos la solución implementada, no el framework original.
El modelo se ha entrenado con datos históricos del par de divisas EURUSD para 2023 utilizando el marco temporal H1. Hemos dejado en los valores por defecto los ajustes de los indicadores analizados por el modelo.
Para la fase inicial de entrenamiento hemos utilizado una muestra de datos generados en estudios anteriores. El algoritmo de aprendizaje implementado con la formación de acciones objetivo del Agente "casi perfectas" permite entrenar el modelo sin actualizar la muestra de entrenamiento. Sin embargo, para abarcar una gama más amplia de estados de la cuenta, le recomendaría añadir actualizaciones periódicas a la muestra de entrenamiento, si es posible.
Tras varios ciclos de entrenamiento, hemos logrado obtener un modelo que muestra una rentabilidad constante tanto en los datos de entrenamiento como en los de prueba. Las pruebas finales se han realizado con los datos históricos de enero de 2024 y con todos los demás parámetros intactos. A continuación le presentamos los resultados de las pruebas.
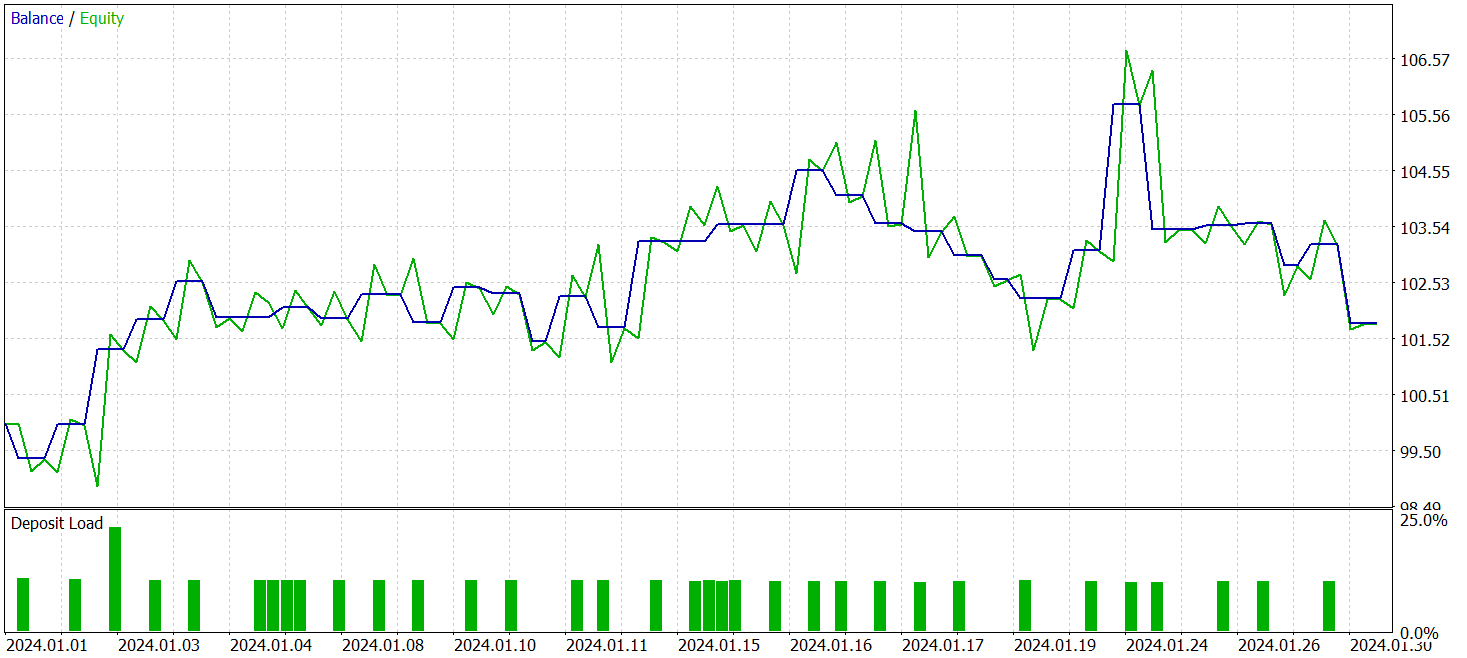
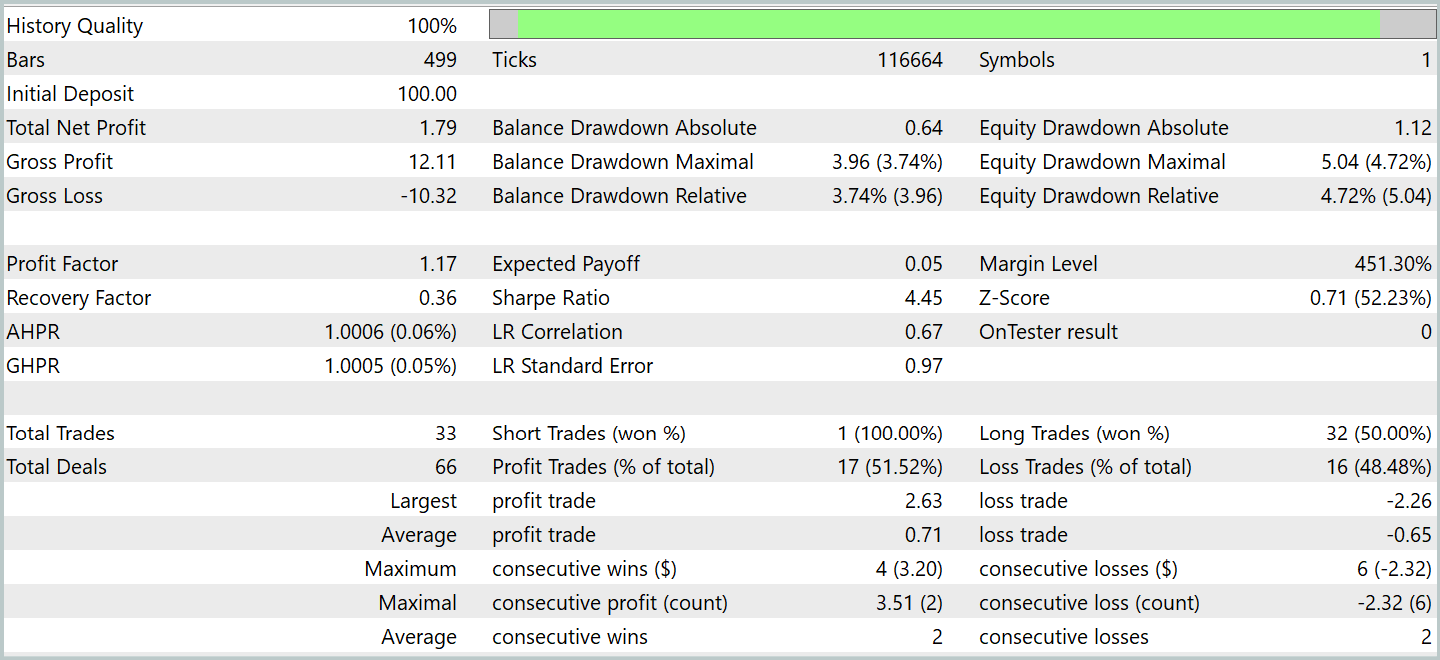
Durante el periodo de prueba, el modelo ha realizado 33 transacciones comerciales y algo más de la mitad de ellas se han cerrado con beneficios. Al mismo tiempo, las posiciones rentables medias y máximas han superado los indicadores similares de las transacciones con pérdidas, permitiendo al modelo demostrar una tendencia hacia el crecimiento equilibrado. Y esto indica el potencial de los enfoques propuestos y la posibilidad de su uso en el comercio real.
Conclusión
Hoy nos hemos familiarizado con el framework FinMem, que supone una nueva etapa en la evolución de los sistemas comerciales autónomos. Este framework combina principios cognitivos y algoritmos modernos basados en grandes modelos lingüísticos. La memoria multinivel y la adaptabilidad en tiempo real permiten al agente tomar decisiones de inversión informadas y precisas, incluso en mercados volátiles.
En la parte práctica del trabajo, hemos implementado nuestra propia interpretación de los enfoques propuestos utilizando el lenguaje de programación MQL5, excluyendo el gran modelo de lenguaje. Los resultados de los experimentos realizados confirman la eficacia de los enfoques propuestos y su aplicabilidad al comercio real. Sin embargo, para poder usar plenamente este modelo en los mercados financieros reales, deberemos llevar a cabo un ajuste y un entrenamiento adicionales del modelo en una muestra de entrenamiento más representativa con pruebas exhaustivas minuciosas.
Enlaces
- FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de la descripción del estado del sistema y la arquitectura del modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16816
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso